Algorithms Third Edition in C++ Part 5. Graph Algorithms (2006)
CHAPTER EIGHTEEN
Graph Search
18.9 Analysis of Graph Algorithms
We have for our consideration a broad variety of graph-processing problems and methods for solving them, so we do not always compare numerous different algorithms for the same problem, as we have in other domains. Still, it is always valuable to gain experience with our algorithms by testing them on real data, or on artificial data that we understand and that have relevant characteristics that we might expect to find in actual applications.
As we discussed briefly in Chapter 2, we seek—ideally—natural input models that have three critical properties:
• They reflect reality to a sufficient extent that we can use them to predict performance.
• They are sufficiently simple that they are amenable to mathematical analysis.
• We can write generators that provide problem instances that we can use to test our algorithms.
With these three components, we can enter into a design-analysis-implementation-test scenario that leads to efficient algorithms for solving practical problems.
For domains such as sorting and searching, we have seen spectacular success along these lines in Parts 3 and 4. We can analyze algorithms, generate random problem instances, and refine implementations to provide extremely efficient programs for use in a host of practical situations. For some other domains that we study, various difficulties can arise. For example, mathematical analysis at the level that we would like is beyond our reach for many geometric problems, and developing an accurate model of the input is a significant challenge for many string-processing algorithms (indeed, doing so is an essential part of the computation). Similarly, graph algorithms take us to a situation where, for many applications, we are on thin ice with respect to all three properties listed in the previous paragraph:
• The mathematical analysis is challenging, and many basic analytic questions remain unanswered.
• There is a huge number of different types of graphs, and we cannot reasonably test our algorithms on all of them.
• Characterizing the types of graphs that arise in practical problems is, for the most part, a poorly understood problem.
Graphs are sufficiently complicated that we often do not fully understand the essential properties of the ones that we see in practice or of the artificial ones that we can perhaps generate and analyze.
The situation is perhaps not as bleak as just described for one primary reason: Many of the graph algorithms that we consider are optimal in the worst case, so predicting performance is a trivial exercise. For example, Program 18.7 finds the bridges after examining each edge and each vertex just once. This cost is the same as the cost of building the graph data structure, and we can confidently predict, for example, that doubling the number of edges will double the running time, no matter what kind of graphs we are processing.
When the running time of an algorithm depends on the structure of the input graph, predictions are much harder to come by. Still, when we need to process huge numbers of huge graphs, we want efficient algorithms for the same reasons that we want them for any other problem domain, and we will continue to pursue the goals of understanding the essential properties of algorithms and applications, striving to identify those methods that can best handle the graphs that might arise in practice.
To illustrate some of these issues, we revisit the study of graph connectivity, a problem that we considered already in Chapter 1 (!). Connectivity in random graphs has fascinated mathematicians for years, and it has been the subject of an extensive literature. That literature is beyond the scope of this book, but it provides a backdrop that validates our use of the problem as the basis for some experimental studies that help us understand the basic algorithms that we use and the types of graphs that we are considering.
For example, growing a graph by adding random edges to a set of initially isolated vertices (essentially, the process behind Program 17.12) is a well-studied process that has served as the basis for
Table 18.1 Connectivity in two random graph models
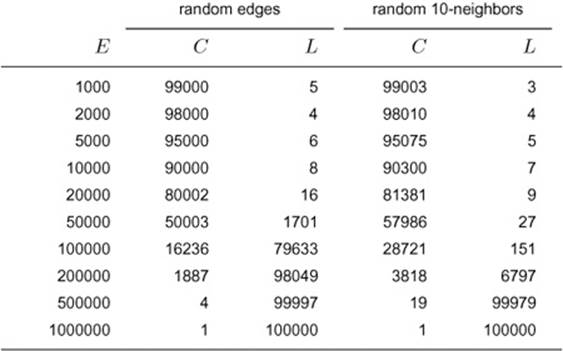
Key:
C number of connected components
L size of largest connected component
This table shows the number of connected components and the size of the largest connected component for 100000-vertex graphs drawn from two different distributions. For the random graph model, these experiments support the well-known fact that the graph is highly likely to consist primarily of one giant component if the average vertex degree is larger than a small constant. The right two columns give experimental results when we restrict the edges to be chosen from those that connect each vertex to just one of 10 specified neighbors.
classical random graph theory. It is well known that, as the number of edges grows, the graph coalesces into just one giant component. The literature on random graphs gives extensive information about the nature of this process. For example,
Property 18.13 If E > ![]() + µV (with µ positive), a random graph with V vertices and E edges consists of a single connected component and an average of less than e−2µ isolated vertices, with probability approaching 1 as V approaches infinity.
+ µV (with µ positive), a random graph with V vertices and E edges consists of a single connected component and an average of less than e−2µ isolated vertices, with probability approaching 1 as V approaches infinity.
Figure 18.30 Connectivity in random graphs
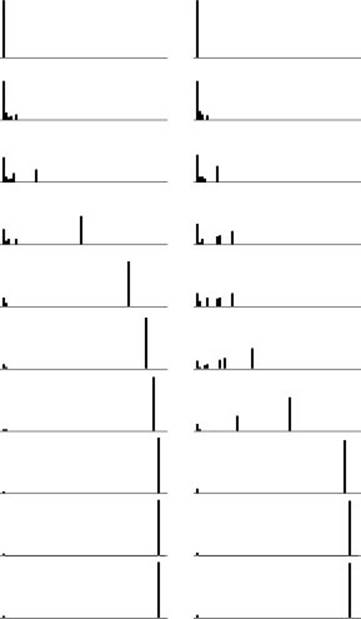
This figures show the evolution of two types of random graphs at 10 equal increments as a total of 2E edges are added to initially empty graphs. Each plot is a histogram of the number of vertices in components of size 1 through V − 1 (left to right). We start out with all vertices in components of size 1 and end with nearly all vertices in a giant component. The plot at left is for a standard random graph: the giant component forms quickly, and all other components are small. The plot at right is for a random neighbor graph: components of various sizes persist for a longer time.
Proof: This fact was established by seminal work of Erdös and Renyi in 1960. The proof is beyond the scope of this book (see reference section).•
This property tells us that we can expect large nonsparse random graphs to be connected. For example, if V > 1000 and E > 10V, then µ > ![]() > 6.5 and the average number of vertices not in the giant component is (almost surely) less than e−13<. 000003. If we generate a million random 1000-vertex graphs of density greater than 10, we might get a few with a single isolated vertex, but the rest will all be connected.
> 6.5 and the average number of vertices not in the giant component is (almost surely) less than e−13<. 000003. If we generate a million random 1000-vertex graphs of density greater than 10, we might get a few with a single isolated vertex, but the rest will all be connected.
Figure 18.30 compares random graphs with random neighbor graphs, where we allow only edges that connect vertices whose indices are within a small constant of one another. The neighbor-graph model yields graphs that are evidently substantially different in character from random graphs. We eventually get a giant component, but it appears suddenly, when two large components merge.
Table 18.2 shows that these structural differences between random graphs and neighbor graphs persist for V and E in ranges of practical interest. Such structural differences certainly may be reflected in the performance of our algorithms.
Table 18.3 gives empirical results for the cost of finding the number of connected components in a random graph, using various algorithms. Although the algorithms perhaps are not subject to direct comparison for this specific task because they are designed to handle different tasks, these experiments do validate a subset of the general conclusions that we have drawn.
First, it is plain from the table that we should not use the adjacency-matrix representation for large sparse graphs (and cannot use it for huge ones), not just because the cost of initializing the matrix is prohibitive, but also because the algorithm inspects every entry in the matrix, so its running time is proportional to the size (V2) of the matrix rather than to the number of 1s in it (E). The table shows, for example, that it takes about as long to process a graph that contains 1000 edges as it does to process one that contains 100000 edges when we are using an adjacency matrix.
Second, it is also plain from Table 18.3 that the cost of allocating memory for the list nodes is significant when we build adjacency lists for large sparse graphs. The cost of building the lists is more than five
Table 18.2 Empirical study of graph-search algorithms
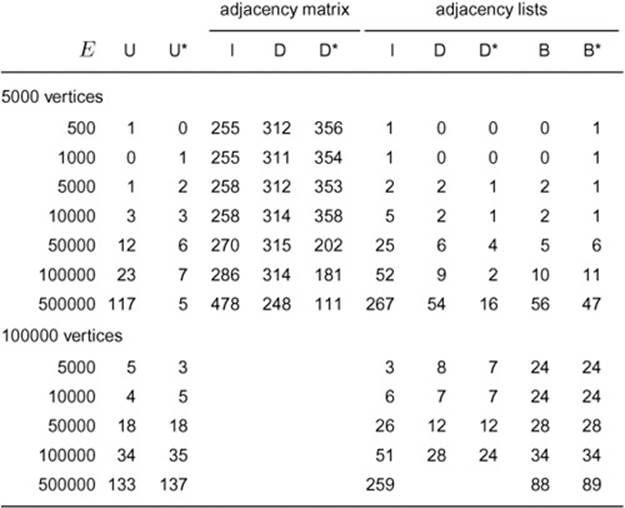
Key:
U weighted quick union with halving (Program 1.4)
I initial construction of the graph representation
D recursive DFS (Program 18.3)
B BFS (Program 18.9)
* exit when graph is found to be fully connected
This table shows relative timings for various algorithms for the task of determining the number of connected components (and the size of the largest one) for graphs with various numbers of vertices and edges. As expected, algorithms that use the adjacency-matrix representation are slow for sparse graphs but competitive for dense graphs. For this specialized task, the union-find algorithms that we considered in Chapter 1 are the fastest, because they build a data structure tailored to solve the problem and do not need otherwise to represent the graph. Once the data structure representing the graph has been built, however, DFS and BFS are faster and more flexible. Adding a test to stop when the graph is known to consist of a single connected component significantly speeds up DFS and union-find (but not BFS) for dense graphs.
times the cost of traversing them. In the typical situation where we are going to perform numerous searches of various types after building the graph, this cost is acceptable. Otherwise, we might consider alternate implementations to reduce this cost.
Third, the absence of numbers in the DFS columns for large sparse graphs is significant. These graphs cause excessive recursion depth, which (eventually) cause the program to crash. If we want to use DFS on such graphs, we need to use the nonrecursive version that we discussed in Section 18.7.
Fourth, the table shows that the union-find–based method from Chapter 1 is faster than DFS or BFS, primarily because it does not have to represent the entire graph. Without such a representation, however, we cannot answer simple queries such as “Is there an edge connecting v and w?” so union-find–based methods are not suitable if we want to do more than what they are designed to do (answer “Is there a path between v and w?” queries intermixed with adding edges). Once the internal representation of the graph has been built, it is not worthwhile to implement a union-find algorithm just to determine whether it is connected, because DFS or BFS can provide the answer about as quickly.
When we run empirical tests that lead to tables of this sort, various anomalies might require further explanation. For example, on many computers, the cache architecture and other features of the memory system might have dramatic impact on performance for large graphs. Improving performance in critical applications may require detailed knowledge of the machine architecture in addition to all the factors that we are considering.
Careful study of these tables will reveal more properties of these algorithms than we are able to address. Our aim is not to do an exhaustive comparison but to illustrate that, despite the many challenges that we face when we compare graph algorithms, we can and should run empirical studies and make use of any available analytic results, both to get a feeling for the algorithms’ important characteristics and to predict performance.
Exercises
• 18.72 Do an empirical study culminating in a table like Table 18.2 for the problem of determining whether or not a graph is bipartite (two-colorable).
18.73 Do an empirical study culminating in a table like Table 18.2 for the problem of determining whether or not a graph is biconnected.
• 18.74 Do an empirical study to find the expected size of the second largest connected component in sparse graphs of various sizes, drawn from various graph models (see Exercises 17.64–76).
18.75 Write a program that produces plots like those in Figure 18.30, and test it on graphs of various sizes, drawn from various graph models (see Exercises 17.64–76).
• 18.76 Modify your program from Exercise 18.75 to produce similar histograms for the sizes of edge-connected components.
••18.77 The numbers in the tables in this section are results for only one sample. We might wish to prepare a similar table where we run 1000 experiments for each entry and give the sample mean and standard deviation, but we probably could not include nearly as many entries. Would this approach be a better use of computer time? Defend your answer.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.