Algorithms Third Edition in C++ Part 5. Graph Algorithms (2006)
CHAPTER SEVENTEEN
Graph Properties and Types
17.4 Adjacency-Lists Representation
The standard representation that is preferred for graphs that are not dense is called the adjacency-lists representation, where we keep track of all the vertices connected to each vertex on a linked list that is associated with that vertex. We maintain a vector of lists so that, given a vertex, we can immediately access its list; we use linked lists so that we can add new edges in constant time.
Program 17.9 is an implementation of the ADT interface in Program 17.1 that is based on this approach, and Figure 17.10 depicts an example. To add an edge connecting v and w to this representation of the graph, we add w to v’s adjacency list and v to w’s adjacency list. In this way, we still can add new edges in constant time, but the total amount of space that we use is proportional to the number of vertices plus the number of edges (as opposed to the number of vertices squared, for the adjacency-matrix representation). For undirected graphs, we again represent each edge in two different places: an edge connecting v and w is represented as nodes on both adjacency lists. It is important to include both; otherwise, we could not answer efficiently simple questions such as, “Which vertices are adjacent to vertex v?” Program 17.10 implements the iterator that answers this question for clients, in time proportional to the number of such vertices.
The implementation in Programs 17.9 and 17.10 is a low-level one. An alternative is to use the STL list to implement each linked list (see Exercise 17.30). The disadvantage of doing so is that STL list implementations need to support many more operations than we need and therefore typically carry extra overhead that might affect the performance of all of our algorithms (see Exercise 17.31). Indeed, all of our graph algorithms use the Graph ADT interface, so this implementation is an appropriate place to encapuslate all the low-level operations and concentrate on efficiency without affecting our other code. Another advantage of using the linked-list representation is that it provides a concrete basis for understanding the performance characteristics of our implementations.
But an important factor to consider is that the linked-list–based implementation in Programs 17.9 and 17.10 is incomplete, because it lacks a destructor and a copy constructor. For many applications, this defect could lead to unexpected results or severe performance problems.
Figure 17.10 Adjacency-lists data structure
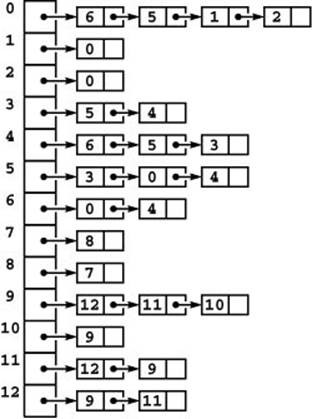
This figure depicts a representation of the graph in Figure 17.1 as an array of linked lists. The space used is proportional to the number of nodes plus the number of edges. To find the indices of the vertices connected to a given vertex v, we look at the v th position in an array, which contains a pointer to a linked list containing one node for each vertex connected to v. The order in which the nodes appear on the lists depends on the method that we use to construct the lists.
Program 17.9 Graph ADT implementation (adjacency lists)
This implementation of the interface in Program 17.1 uses a vector of linked lists, one corresponding to each vertex. It is equivalent to the representation of Program 3.15, where an edge v-w is represented by a node for w on list v and a node for v on list w.
Implementations of remove and edge are left for exercises, as are the copy constructor and the destructor. The insert code keeps insertion time constant by not checking for duplicate edges, and the total amount of space used is proportional to V + E; hence, this representation is most suitable for sparse multigraphs.
Clients may use typedef to make this type equivalent to GRAPH or use SparseMultiGRAPH explicitly.

Program 17.10 Iterator for adjacency-lists representation
This implementation of the iterator for Program 17.9 maintains a link t to traverse the linked list associated with vertex v. A call to beg() followed by a sequence of calls to nxt() (checking that end() is false before each call) gives a sequence of the vertices adjacent to v in G.
class SparseMultiGRAPH::adjIterator
{ const SparseMultiGRAPH &G;
int v;
link t;
public:
adjIterator(const SparseMultiGRAPH &G, int v) :
G(G), v(v) {t=0;}
int beg()
{ t = G.adj[v]; return t ? t->v : -1; }
int nxt()
{ if (t) t = t->next; return t ? t->v : -1; }
bool end()
{ return t == 0; }
};
These functions are direct extensions of those in the first-class queue implementation of Program 4.22 (see Exercise 17.29). We assume throughout the book that SparseMultiGRAPH objects have them. Using the STL list instead of low-level singly-linked lists has the distinct advantage that this extra code is unnecessary because a proper destructor and copy constructor are automatically defined. For example, DenseGRAPH objects built by Program 17.7 are properly destroyed and copied in client programs that manipulate them, because they are built from STL objects.
By contrast to Program 17.7, Program 17.9 builds multigraphs, because it does not remove parallel edges. Checking for duplicate edges in the adjacency-lists structure would necessitate searching through the lists and could take time proportional to V. Similarly, Program 17.9 does not include an implementation of the remove edge operation or the edge existence test. Adding implementations for these functions is an easy exercise (see Exercise 17.28), but each operation might take time proportional to V, to search through the lists for the nodes that represent the edges. These costs make the basic adjacency-lists representation unsuitable for applications involving huge graphs where parallel edges cannot be tolerated, or applications involving heavy use of remove edge or of edge existence tests. In Section 17.5, we discuss adjacency-list implementations that support constant-time remove edge and edge existence operations.
When a graph’s vertex names are not integers, then (as with adjacency matrices) two different programs might associate vertex names with the integers from 0 to V − 1 in two different ways, leading to two different adjacency-list structures (see, for example, Program 17.15). We cannot expect to be able to tell whether two different structures represent the same graph because of the difficulty of the graph isomorphism problem.
Moreover, with adjacency lists, there are numerous representations of a given graph even for a given vertex numbering. No matter in what order the edges appear on the adjacency lists, the adjacency-list structure represents the same graph (see Exercise 17.33). This characteristic of adjacency lists is important to know because the order in which edges appear on the adjacency lists affects, in turn, the order in which edges are processed by algorithms. That is, the adjacency-list structure determines how our various algorithms see the graph. Although an algorithm should produce a correct answer no matter how the edges are ordered on the adjacency lists, it might get to that answer by different sequences of computations for different orderings. If an algorithm does not need to examine all the graph’s edges, this effect might affect the time that it takes. And, if there is more than one correct answer, different input orderings might lead to different output results.
The primary advantage of the adjacency-lists representation over the adjacency-matrix representation is that it always uses space proportional to E + V, as opposed to V2 in the adjacency matrix. The primary disadvantage is that testing for the existence of specific edges can take time proportional to V, as opposed to constant time in the adjacency matrix. These differences trace, essentially, to the difference between using linked lists and vectors to represent the set of vertices incident on each vertex.
Thus, we see again that an understanding of the basic properties of linked data structures and vectors is critical if we are to develop efficient graph ADT implementations. Our interest in these performance differences is that we want to avoid implementations that are inappropriately inefficient under unexpected circumstances when a wide range of operations is to be demanded of the ADT. In Section 17.5, we discuss the application of basic data structures to realize many of the theoretical benefits of both structures. Nonetheless, Program 17.9 is a simple implementation with the essential characteristics that we need to learn efficient algorithms for processing sparse graphs.
Exercises
• 17.27 Show, in the style of Figure 17.10, the adjacency-lists structure produced when you use Program 17.9 to insert the edges in the graph
3-7 1-4 7-8 0-5 5-2 3-8 2-9 0-6 4-9 2-6 6-4
(in that order) into an initially empty graph.
17.28 Provide implementations of remove and edge for the adjacency-lists graph class (Program 17.9 ). Note: Duplicates may be present, but it suffices to remove any edge connecting the specified vertices.
17.29 Add a copy constructor and a destructor to the adjacency-lists graph class (Program 17.9 ). Hint: See Program 4.22.
• 17.30 Modify the implementation of SparseMultiGRAPH Programs 17.9 and 17.10 to use an STL list instead of a linked list for each adjacency list.
17.31 Run empirical tests to compare your SparseMultiGRAPH implementation of Exercise 17.30 with the implementation in the text. For a well-chosen set of values for V, compare running times for a client program that builds complete graphs with V vertices, then extracts the edges using Program 17.2.
• 17.32 Give a simple example of an adjacency-lists graph representation that could not have been built by repeated insertion of edges by Program 17.9.
17.33 How many different adjacency-lists representations represent the same graph as the one depicted in Figure 17.10?
• 17.34 Add a public member function declaration to the graph ADT (Pro-gram 17.1) that removes self-loops and parallel edges. Provide the trivial implementation of this function for the adjacency-matrix–based class (Pro-gram 17.7), and provide an implementation of the function for the adjacency-list–based class (Program 17.9) that uses time proportional to E and extra space proportional to V.
17.35 Write a version of Program 17.9 that disallows parallel edges (by scanning through the adjacency list to avoid adding a duplicate entry on each edge insertion) and self-loops. Compare your implementation with the implementation described in Exercise 17.34. Which is better for static graphs?Note: See Exercise 17.49 for an efficient implementation.
17.36 Write a client of the graph ADT that returns the result of removing self-loops, parallel edges, and degree-0 (isolated) vertices from a given graph. Note: The running time of your program should be linear in the size of the graph representation.
• 17.37 Write a client of the graph ADT that returns the result of removing self-loops, collapsing paths that consist solely of degree-2 vertices from a given graph. Specifically, every degree-2 vertex in a graph with no parallel edges appears on some path u-…-w where u and w are either equal or not of degree 2. Replace any such path with u-w, and then remove all unused degree-2 vertices as in Exercise 17.36. Note: This operation may introduce self-loops and parallel edges, but it preserves the degrees of vertices that are not removed.
• 17.38 Give a (multi)graph that could result from applying the transformation described in Exercise 17.37 on the sample graph in Figure 17.1.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.