Algorithms Third Edition in C++ Part 5. Graph Algorithms (2006)
CHAPTER SEVENTEEN
Graph Properties and Types
17.5 Variations, Extensions, and Costs
In this section, we describe a number of options for improving the graph representations discussed in Sections 17.3 and 17.4. The topics fall into one of three categories. First, the basic adjacency-matrix and adjacency-lists mechanisms extend readily to allow us to represent other types of graphs. In the relevant chapters, we consider these extensions in detail and give examples; here, we look at them briefly. Second, we discuss graph ADT designs with more features than our basic one and implementations that use more advanced data structures to efficiently implement them. Third, we discuss our general approach to addressing graph-processing tasks, by developing task-specific classes that use the basic graph ADT.
Our implementations in Programs 17.7 and 17.9 build digraphs if the call to the constructor includes a second argument with value true. We represent each edge just once, as illustrated in Figure 17.11. An edge v-w in a digraph is represented by a 1 in the entry in row v and column w in the adjacency matrix or by the appearance of w on v’s adjacency list in the adjacency-lists representation. These representations are simpler than the corresponding representations that we have been considering for undirected graphs, but the asymmetry makes digraphs more complicated combinatorial objects than undirected graphs, as we see in Chapter 19. For example, the standard adjacency-lists representation gives no direct way to find all edges coming into a vertex in a digraph, so we would need to choose a different representation if that operation needs to be supported.
Figure 17.11 Digraph representations
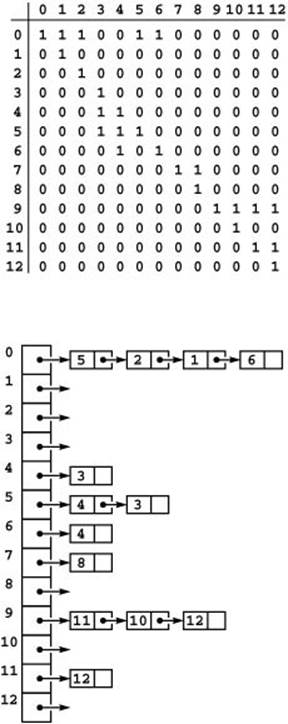
The adjacency-matrix and adjacency-lists representations of a digraph have only one representation of each edge, as illustrated in the adjacency-matrix (top) and adjacency-lists (bottom) representation of the set of edges in Figure 17.1 interpreted as a digraph (see Figure 17.6, top).
For weighted graphs and networks, we fill the adjacency matrix with structures containing information about edges (including their presence or absence) instead of Boolean values; in the adjacency-lists representation, we include this information in adjacency-list elements.
It is often necessary to associate still more information with the vertices or edges of a graph, to allow that graph to model more complicated objects. We can associate extra information with each edge by extending the Edge type in Program 17.1 as appropriate, then using instances of that type in the adjacency matrix, or in the list nodes in the adjacency lists. Or, since vertex names are integers between 0 and V − 1, we can use vertex-indexed vectors to associate extra information for vertices, perhaps using an appropriate ADT. We consider ADTs of this sort in Chapters 20 through22. Alternatively, we could use a separate symbol-table ADT to associate extra information with each vertex and edge (see Exercise 17.48 and Program 17.15).
To handle various specialized graph-processing problems, we often define classes that contain specialized auxiliary data structures related to the graph. The most common such data structure is a vertex-indexed vector, as we saw already in Chapter 1, where we used vertex-indexed vectors to answer connectivity queries. We use vertex-indexed vectors in numerous implementations throughout the book.
As an example, suppose that we wish to know whether a vertex v in a graph is isolated. Is v of degree 0? For the adjacency-lists representation, we can find this information immediately, simply by checking whether adj[v] is null. But for the adjacency-matrix representation, we need to check all V entries in the row or column corresponding to v to know that each one is not connected to any other vertex; and for the vector-of-edges representation, we have no better approach than to check all E edges to see whether there are any that involve v. We need to enable clients to avoid these potentially time-consuming computations. As discussed in Section 17.2 one way to do so is to define a client ADT for the problem, such as the example in Program 17.11. This implementation, after preprocessing the graph in time proportional to the size of its representation, allows clients to find the degree of any
Program 17.11 Vertex-degrees class implementation
This class provides a way for clients to learn the degree of any given vertex in a GRAPH in constant time, after linear-time preprocessing in the constructor. The implementation is based on maintaining a vertex-indexed vector of vertex degrees as a private data member and overloading [] as a public function member. We initialize all entries to 0, then process all edges in the graph, incrementing the appropriate entry for each edge.
We use classes like this one throughout the book to develop object-oriented implementations of graph-processing functions as clients of class GRAPH.
template <class Graph> class DEGREE
{ const Graph &G;
vector <int> degree;
public:
DEGREE(const Graph &G) : G(G), degree(G.V(), 0)
{
for (int v = 0; v < G.V(); v++)
{ typename Graph::adjIterator A(G, v);
for (int w = A.beg(); !A.end(); w = A.nxt())
degree[v]++;
}
}
int operator[](int v) const
{ return degree[v]; }
};
vertex in constant time. That is no improvement if the client needs the degree of just one vertex, but it represents a substantial savings for clients that need to know the degrees of many vertices. Such a substantial performance differential for such a simple problem is typical in graph processing.
For each of the graph-processing tasks that we consider in this book, we encapsulate solutions in classes like this one, with private data and function members and public function members specific to the task. Clients create objects whose member functions do the graph processing. This approach amounts to extending the graph ADT interface by defining a cooperating set of classes. Any set of such classes defines a graph-processing interface, but each encapsulates its own private data and function members.
There are many other ways to build upon an interface in C++. One way to proceed is to simply add public function members (and whatever private data and function members we might need) to the basic GRAPH ADT definition. While this approach has all of the virtues extolled in Chapter 4, it also has some serious drawbacks, because the world of graph-processing is significantly more expansive than the kinds of basic data structures that are the subject of Chapter 4. Chief among these drawbacks are the following:
• There are many more graph-processing functions to implement than we can accurately define in a single interface.
• Simple graph-processing tasks have to use the same interface needed by complicated tasks.
• One member function can access a data member intended for use by another member function, contrary to encapsulation principles that we would like to follow.
Interfaces of this kind have come to be known as fat interfaces. In a book filled with graph-processing algorithms, an interface of this sort would be fat indeed.
Another approach is to use inheritance to define various types of graphs that provide clients with various sets of graph-processing tasks. Comparing the intricacies of this approach with the simpler approach that we use is a worthwhile exercise in the study of software engineering, but would take us still further afield from the subject of graph-processing algorithms, our main focus.
Table 17.1 shows the dependence of the cost of various simple graph-processing operations on the representation that we use. This table is worth examining before we consider the implementation of more complicated operations; it will help you to develop an intuition for the difficulty of various primitive operations. Most of the costs listed follow immediately from inspecting the code, with the exception of the bottom row, which we consider in detail at the end of this section.
In several cases, we can modify the representation to make simple operations more efficient, although we have to take care that doing so does not increase costs for other simple operations. For example, the entry for adjacency-matrix destroy is an artifact of our vector-of-vectors
Table 17.1 Worst-case cost of graph-processing operations
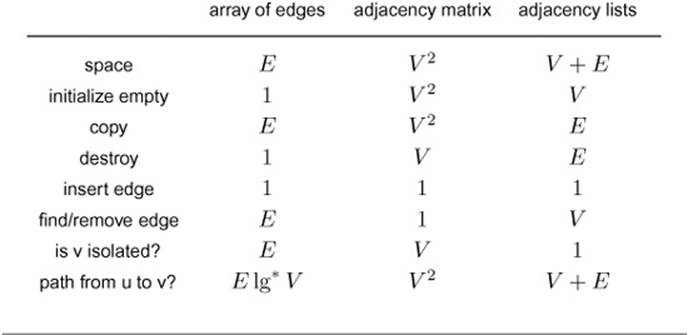
The performance characteristics of basic graph-processing ADT operations for different graph representations vary widely, even for simple tasks, as indicated in this table of the worst-case costs (all within a constant factor for large V and E ). These costs are for the simple implementations we have described in previous sections; various modifications that affect the costs are described in the text of this section.
allocation scheme for two-dimensional matrices (see Section 3.7). It is not difficult to reduce this cost to be constant (see Exercise 17.25). On the other hand, if graph edges are sufficiently complex structures that the matrix entries are pointers, then to destroy an adjacency matrix would take time proportional to V2.
Because of their frequent use in typical applications, we consider the find edge and remove edge operations in detail. In particular, we need a find edge operation to be able to remove or disallow parallel edges. As we saw in Section 17.3, these operations are trivial if we are using an adjacency-matrix representation—we need only to check or set a matrix entry that we can index directly. But how can we implement these operations efficiently in the adjacency-lists representation? In C++, we could use the STL; here we describe underlying mechanisms, to gain perspective on efficiency issues. One approach is described next, and another is described in Exercise 17.50. Both approaches are based on symbol-table implementations. If we use, for example, dynamic hash table implementations (see Section 14.5), both approaches take space proportional to Eandallowustoperform either operation in constant time (on the average, amortized).
Specifically, to implement find edge when we are using adjacency lists, we could use an auxiliary symbol table for the edges. We can assign an edge v-w the integer key v*V+w and use an STL map or any of the symbol-table implementations from Part 4. (For undirected graphs, we might assign the same key to v-w and w-v.) We can insert each edge into the symbol table, after first checking whether it has already been inserted. We can choose either to disallow parallel edges (see Exercise 17.49) or to maintain duplicate records in the symbol table for parallel edges (seeExercise 17.50). In the present context, our main interest in this technique is that it provides a constant-time find edge implementation for adjacency lists.
To be able to remove edges, we need a pointer in the symbol-table record for each edge that refers to its representation in the adjacency-lists structure. But even this information is not sufficient to allow us to remove the edge in constant time unless the lists are doubly linked (see Section 3.4). Furthermore, in undirected graphs, it is not sufficient to remove the node from the adjacency list, because each edge appears on two different adjacency lists. One solution to this difficulty is to put both pointers in the symbol table; another is to link together the two list nodes that correspond to a particular edge (see Exercise 17.46). With either of these solutions, we can remove an edge in constant time.
Removing vertices is more expensive. In the adjacency-matrix representation, we essentially need to remove a row and a column from the matrix, which is not much less expensive than starting over again with a smaller matrix (although that cost can be amortized using the same mechanism as for dynamic hash tables). If we are using an adjacency-lists representation, we see immediately that it is not sufficient to remove nodes from the vertex’s adjacency list, because each node on the adjacency list specifies another vertex whose adjacency list we must search to remove the other node that represents the same edge. We need the extra links to support constant-time edge removal as described in the previous paragraph if we are to remove a vertex in time proportional to V.
We omit implementations of these operations here because they are straightforward programming exercises using basic techniques from Part 1, because the STL provides implementations that we could use, because maintaining complex structures with multiple pointers per node is not justified in typical applications that involve static graphs, and because we wish to avoid getting bogged down in layers of abstraction or in low-level details of maintaining multiple pointers when implementing graph-processing algorithms that do not otherwise use them. In Chapter 22, we do consider implementations of a similar structure that play an essential role in the powerful general algorithms that we consider in that chapter.
For clarity in describing and developing implementations of algorithms of interest, we use the simplest appropriate representation. Generally, we strive to use data structures that are directly relevant to the task at hand. Many programmers practice this kind of minimalism as a matter of course, knowing that maintaining the integrity of a data structure with multiple disparate components can be a challenging task, indeed.
We might also consider alternate implementations that modify the basic data structures in a performance-tuning process to save space or time, particularly when processing huge graphs (or huge numbers of small graphs). For example, we can dramatically improve the performance of algorithms that process huge static graphs represented with adjacency lists by stripping down the representation to use vectors of varying length instead of linked lists to represent the set of vertices incident on each vertex. With this technique, we can ultimately represent a graph with just 2Eintegers less than V and V integers less than V2 (see Exercises 17.52 and 17.54). Such representations are attractive for processing huge static graphs.
The algorithms that we consider adapt readily to all the variations that we have discussed in this section, because they are based on a few high-level abstract operations such as “perform the following operation for each edge adjacent to vertex v” that are supported by our basic ADT.
In some instances, our algorithm-design decisions depend on certain properties of the representation. Working at a higher level of abstraction might obscure our knowledge of that dependence. If we know that one representation would lead to poor performance but another would not, we would be taking an unnecessary risk were we to consider the algorithm at the wrong level of abstraction. As usual, our goal is to craft implementations such that we can make precise statements about performance. For this reason, though both implement the basic graph ADT, we retain separate DenseGRAPH and SparseMultiGRAPH types for the adjacency-matrix and adjacency-lists representations, respectively, to emphasize that clients can use these implementations as appropriate to suit the task at hand.
All of the operations that we have considered so far are simple, albeit necessary, data-processing functions; and the bottom line of the discussion in this section is that basic algorithms and data structures from Parts 1 through 3 are effective for handling them. As we develop more sophisticated graph-processing algorithms, we face more diffi-cult challenges in finding the best implementations for specific practical problems. To illustrate this point, we consider the last row in Table 17.1, which gives the costs of determining whether there is a path connecting two given vertices.
In the worst case, the simple path-finding algorithm in Section 17.7 examines all E edges in the graph (as do several other methods that we consider in Chapter 18). The entries in the center and right column on the bottom row in Table 17.1 indicate, respectively, that the algorithm may examine all V2 entries in an adjacency-matrix representation, and all V list heads and all E nodes on the lists in an adjacency-lists representation. These facts imply that the algorithm’s running time is linear in the size of the graph representation, but they also exhibit two anomalies: The worst-case running time is not linear in the number of edges in the graph if we are using an adjacency-matrix representation for a sparse graph or either representation for an extremely sparse graph (one with a huge number of isolated vertices). To avoid repeatedly considering these anomalies, we assume throughout that the size of the representation that we use is proportional to the number of edges in the graph. This point is moot in the majority of applications because they involve huge sparse graphs and thus require an adjacency-lists representation.
The left column on the bottom row in Table 17.1 derives from the use of the union-find algorithms in Chapter 1 (see Exercise 17.15). This method is attractive because it only requires space proportional to V, but has the drawback that it cannot exhibit the path. This entry highlights the importance of completely and precisely specifying graph-processing problems.
Even after taking all of these factors into consideration, one of the most significant challenges that we face when developing practical graph-processing algorithms is assessing the extent to which the results of worst-case performance analyses, such as those in Table 17.1, over-estimate time and space needs for processing graphs that we encounter in practice. Most of the literature on graph algorithms describes performance in terms of such worst-case guarantees, and, while this information is helpful in identifying algorithms that can have unacceptably poor performance, it may not shed much light on which of several simple, direct programs may be most suitable for a given application. This situation is exacerbated by the difficulty of developing useful models of average-case performance for graph algorithms, leaving us with (perhaps unreliable) benchmark testing and (perhaps overly conservative) worst-case performance guarantees to work with. For example, the graph-search methods that we discuss in Chapter 18 are all effective linear-time algorithms for finding a path between two given vertices, but their performance characteristics differ markedly, depending both upon the graph being processed and its representation. When using graph-processing algorithms in practice, we constantly fight this disparity between the worst-case performance guarantees that we can prove and the actual performance characteristics that we can expect. This theme will recur throughout the book.
Exercises
• 17.39 Develop an adjacency-matrix representation for dense multigraphs, and provide an ADT implementation for Program 17.1 that uses it.
• 17.40 Why not use a direct representation for graphs (a data structure that models the graph exactly, with vertex objects that contain adjacency lists with references to the vertices)?
• 17.41 Why does Program 17.11 not increment both deg[v] and deg[w] when it discovers that w is adjacent to v?
• 17.42 Add to the graph class that uses adjacency matrices (Program 17.7) a vertex-indexed vector that holds the degree of each vertex. Add a public member function degree that returns the degree of a given vertex.
17.43 Do Exercise 17.42 for the adjacency-lists representation.
• 17.44 Add a row to Table 17.1 for the problem of determining the number of isolated vertices in a graph. Support your answer with function implementations for each of the three representations.
• 17.45 Give a row to add to Table 17.1 for the problem of determining whether a given digraph has a vertex with indegree V and outdegree 0. Support your answer with function implementations for each of the three representations. Note: Your entry for the adjacency-matrix representation should be V.
17.46 Use doubly-linked adjacency lists with cross links as described in the text to implement a constant-time remove edge function remove for the graph ADT implementation that uses adjacency lists (Program 17.9).
17.47 Add a remove vertex function remove to the doubly-linked adjacency-lists graph class described in the previous exercise.
• 17.48 Modify your solution to Exercise 17.16 to use a dynamic hash table, as described in the text, such that insert edge and remove edge take constant amortized time.
17.49 Add to the graph class that uses adjacency lists (Program 17.9) a symbol table to ignore duplicate edges, so that it represents graphs instead of multigraphs. Use dynamic hashing for your symbol-table implementation so that your implementation uses space proportional to E and can insert, find, and remove edges in constant time (on the average, amortized).
17.50 Develop a multigraph class based on a vector-of-symbol-tables representation (with one symbol table for each vertex, which contains its list of adjacent edges). Use dynamic hashing for your symbol-table implementation so that your implementation uses space proportional to E and can insert, find, and remove edges in constant time (on the average, amortized).
17.51 Develop a graph ADT intended for static graphs, based upon a constructor that takes a vector of edges as an argument and uses the basic graph ADT to build a graph. (Such an implementation might be useful for performance comparisons with the implementations described inExercises 17.52 through 17.55.)
17.52 Develop an implementation for the constructor described in Exercise 17.51 that uses a compact representation based on the following data structures:
struct node { int cnt; vector <int> edges; };
struct graph { int V; int E; vector <node> adj; };
A graph is a vertex count, an edge count, and a vector of vertices. A vertex contains an edge count and a vector with one vertex index corresponding to each adjacent edge.
• 17.53 Add to your solution to Exercise 17.52 a function that eliminates self-loops and parallel edges, as in Exercise 17.34.
• 17.54 Develop an implementation for the static-graph ADT described in Exercise 17.51 that uses just two vectors to represent the graph: one vector of E vertices, and another of V indices or pointers into the first vector. Implement io::show for this representation.
• 17.55 Add to your solution to Exercise 17.54 a function that eliminates self-loops and parallel edges, as in Exercise 17.34.
17.56 Develop a graph ADT interface that associates (x, y) coordinates with each vertex, so that you can work with graph drawings. Include functions drawV and drawE to draw a vertex and to draw an edge, respectively.
17.57 Write a client program that uses your interface from Exercise 17.56 to produce drawings of edges that are being added to a small graph.
17.58 Develop an implementation of your interface from Exercise 17.56 that produces a PostScript program with drawings as output (see Section 4.3).
17.59 Find an appropriate graphics interface that allows you to develop an implementation of your interface from Exercise 17.56 that directly draws graphs in a window on your display.
• 17.60 Extend your solution to Exercises 17.56 and 17.59 to include functions to erase vertices and edges and to draw them in different styles, so that you can write client programs that provide dynamic graphical animations of graph algorithms in operation
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.