Adaptive Code via C#. Agile coding with design patterns and SOLID principles (2014)
Chapter 6. Hashes and Message Authentication
In Chapter 5, we discussed primitives for symmetric encryption. Some of those primitives were capable of providing two of the most important security goals: secrecy and message integrity. There are occasions where secrecy may not be important in the slightest, but you'd still like to ensure that messages are not modified as they go over the Internet. In such cases, you can use a symmetric primitive such as CWC mode, which allows you to authenticate data without encrypting any of it. Alternatively, you can consider using a standalone message authentication code (MAC).
This chapter focuses on MACs, and it also covers two types of one-way hash functions: cryptographic hash functions and "universal" hash functions. Cryptographic hash functions are used in public key cryptography and are a popular component to use in a MAC (you can also use block ciphers), but universal hash functions turn out to be a much better foundation for a secure MAC.
WARNING
Many of the recipes in this chapter are too low-level for general-purpose use. We recommend that you first try to find what you need in Chapter 9; the recipes there are more generally applicable. If you do use these recipes, please be careful, read all our warnings, and consider using the higher-level constructs we suggest.
6.1. Understanding the Basics of Hashes and MACs
Problem
You would like to understand the basic concepts behind hash functions as used in cryptography and message authentication codes (MACs).
Solution
See Section 6.1.3. Be sure to note the possible attacks on these constructs, and how to thwart them.
Discussion
One common thread running through the three types of primitives described in this chapter is that they take an arbitrary amount of data as an input, and produce a fixed-size output. The output is always identical given the exact same inputs (where inputs may include keys, nonces, and text). In addition, in each case, given random inputs, every output is (just about) equally likely.
Types of primitives
These are the three types of primitives:
Message authentication codes
MACs are hash functions that take a message and a secret key (and possibly a nonce) as input, and produce an output that cannot, in practice, be forged without possessing the secret key. This output is often called a tag . There are many ways to build a secure MAC, and there are several good MACs available, including OMAC, CMAC, and HMAC.
Cryptographic hash functions
These functions are the simplest of the primitives we'll discuss (even though they are difficult to use securely). They simply take an input string and produce a fixed-size output string (often called a hash value or message digest ). Given the output string, there should be no way to determine the input string other than guessing (a dictionary attack). Traditional algorithms include SHA1 and MD5, but you can use algorithms based on block ciphers (and, indeed, you can get more assurance from a block cipher-based construction). Cryptographic hash functions generally are not secure on their own. They are securely used in public key cryptography, and are used as a component in a type of MAC called HMAC.
Universal hash functions
These are keyed hash functions with specific mathematical properties that can also be used as MACs, despite the fact that they're not cryptographically secure. It turns out that if you take the output of a keyed universal hash function, and combine it with seemingly random bits in particular ways (such as encrypting the result with a block cipher), the result has incredibly good security properties. Or, if you are willing to use one-time keys that are securely generated, you don't have to use encryption at all! Dan Bernstein's hash127 is an example of a fast, freely available universal hash function. Most people don't use universal hash functions directly. They're usually used under the hood in a MAC. For example, CMAC uses a hash127-like function as its foundation.
Generally, you should prefer an encryption mode like CWC that provides both encryption and message integrity to one of these constructions. Using a MAC, you can get message integrity without encryption, which is sometimes useful.
MACs aren't useful for software distribution, because the key itself must remain secret and can't be public knowledge. Another limitation is that if there are two parties in the system, Alice and Bob, Alice cannot prove that Bob sent a message by showing the MAC value sent by Bob (i.e., non-repudiation). The problem is that Alice and Bob share a key; Alice could have forged the message and produced the correct MAC value. Digital signature schemes (discussed in Chapter 7) can circumvent these problems, but they have limitations of their own—the primary one is efficiency.
Attacks against one-way constructs
There are numerous classes of problems that you need to worry about when you're using a cryptographic hash function or a MAC. Generally, if an attacker can find collisions for a hash function (two inputs that give the same output), that can be turned into a real attack.
The most basic collision attack is this: given a known hash function {input, output} pair, somehow produce another input that gives the same output. To see how this can be a real attack, consider a public key-based digital signature scheme where the message to "sign" gets cryptographically hashed, and the hash gets encrypted with the private key of the signer. In such a scenario, anyone who has the associated public key can validate the signature, and no one can forge it. (We'll discuss such schemes further in Chapter 7.)
Suppose that an attacker sees the message being signed. From that, he can determine the hash value computed. If he can find another message that gives the same hash value, he can claim that a different message is being signed from the one that actually was. For example, an attacker could get someone to sign a benign document, then substitute a contract that is beneficial to the attacker.
Of course, we assume that if an attacker has a way to force collisions in a reasonably efficient manner, he can force the second plaintext to be a message of his choice, more or less. (This isn't always the case, but it is generally a good assumption, particularly because it applies for the most basic brute-force attacks.)
To illustrate, let's say that an attacker uses a hash function that is cryptographically strong but outputs only a 16-bit hash. Given a message and a digest, an attacker should be able to generate a collision after generating, on average, 32,768 messages. An attacker could identify 16 places where a one-bit change could be made without significantly changing the content (e.g., 16 places where you could put an extra space after a period, or refrain from doing so).
If the attacker can control both messages, collisions are far easier to find. For example, if an attacker can give the target a message of his choosing and get the target to sign it, there is an attack that will find a collision after 256 attempts, on average.
The basic idea is to take two model documents, one that the target will sign, and one that the attacker would like the target to sign. Then, vary a few places in each of those, and generate hashes of each document.
The difference between these two attacks is that it's statistically a lot easier to find a collision when you don't have to find a collision for a particular message.
This is canonically illustrated with something called the birthday paradox. The common analogy involves finding people with the same birthday. If you're in a room of 253 people, the odds are just about even that one of them will share your birthday. Surprisingly to some, if there are a mere 23 people in a room, the odds of finding two people with the same birth date is also a bit over 50 percent.
In both cases, we've got a better than 50% chance after checking 253 pairs of people. The difference is that in the first scenario, a fixed person must always be a part of the pairings, which seriously reduces the number of possible combinations of people we can consider. For this reason, the situation where an attacker can find a collision between any two messages is called a birthday attack .
When a birthday attack applies, the maximum bit strength of a hash function is half the length of the hash function's output (the digest size). Also, birthday attacks are often possible when people think they're not. That is, the attacker doesn't need to be able to control both messages for a birthday attack to apply.
For example, let's say that the target hashes a series of messages. An attacker can precompute a series of hashes and wait for one of the messages to give the same hash. That's the same problem, even though the attacker doesn't control the messages the target processes.
Generally, the only reliable way to thwart birthday attacks is to use a per-message nonce, which is typically done only with MAC constructs. Indeed, many MAC constructs have built-in facilities for this. We discuss how to use a nonce with a hash function in Recipe 6.8, and we discuss how to use one with MACs that aren't built to use one in Recipe 6.12.
Another problem that occurs with every practical cryptographic hash function is that they are susceptible to length extension attacks . That is, if you have a message and a hash value associated with that message, you can easily construct a new message and hash value by extending the original message.
The MACs we recommend in this chapter avoid length-extension problems and other attack vectors against hash functions.[1] We discuss how to thwart length extension problems when using a hash function outside the context of a MAC in Recipe 6.7.
See Also
Recipe 6.7, Recipe 6.8, Recipe 6.12
[1] While most of the MACs we recommend are based on block ciphers, if a MAC isn't carefully designed, it will still be susceptible to the attacks we describe in this section, even if it's built on a block cipher.
6.2. Deciding Whether to Support Multiple Message Digests or MACs
Problem
You need to figure out whether to support multiple algorithms in your system.
Solution
The simple answer is that there is no right answer, as we discuss next.
Discussion
Clearly, if you need to support multiple algorithms for standards compliance or legacy support, you should do so. Beyond that, there are two schools of thought. The first school recommends that you support multiple algorithms in order to allow users to pick their favorite. The other benefit of this approach is that if an algorithm turns out to be seriously broken, supporting multiple algorithms can make it easier for users to switch. The second school of thought points out that the reality is if an algorithm is broken, many users will never switch, so that's not a good reason for providing options. Moreover, by supporting multiple algorithms, you risk adding additional complexity to your application, and that can be detrimental. In addition, if there are multiple interoperating implementations of a protocol you're creating, often other developers will implement only their own preferred algorithms, potentially leading to major interoperability problems.
We personally prefer picking a single algorithm that will do a good enough job of meeting the needs of all users. That way, the application is simpler to comprehend, and there are no interoperability issues. If you choose well-regarded algorithms, the hope is that there won't be a break that actually impacts end users. However, if there is such a break, you should make the algorithm easy to replace. Because cryptographic hash functions and MACs tend to have standard interfaces, that is usually easy to do.
Besides dedicated hash algorithms such as SHA1 (Secure Hash Algorithm 1) and MD5 (Message Digest 5 from Ron Rivest), there are several constructs for turning a block cipher into a cryptographic hash function. One advantage of such a construct is that block ciphers are a better-studied construct than hash functions. In addition, needing fewer cryptographic algorithms for an application can be important when pushing cryptography into hardware.
One disadvantage of turning a block cipher into a hash function is speed. As we'll show in Recipe 6.3, dedicated cryptographic hash constructs tend to be faster than those based on block ciphers.
In addition, all hash-from-cipher constructs assume that any cipher used will resist related-key attacks, a type of attack that has not seen much mainstream study. Because cryptographic hash functions aren't that well studied either, it's hard to say which of these types of hash constructs is better.
It is clear that if you're looking for message authentication, a good universal MAC solution is better than anything based on a cryptographic hash function, because such constructs tend to have incredibly good, provable security properties, and they tend to be faster than traditional MACs. Unfortunately, they're not often useful outside the context of message authentication.
See Also
Recipe 6.3
6.3. Choosing a Cryptographic Hash Algorithm
Problem
You need to use a hash algorithm for some purpose (often as a parameter to a MAC), and you want to understand the important concerns so you can determine which algorithm best suits your needs.
Solution
Security requirements should be your utmost concern. SHA1 is a generally a good compromise for those in need of efficiency. We recommend that you do not use the popular favorite MD5, particularly in new applications.
Note that outside the context of a well-designed MAC, it is difficult to use a cryptographic hash function securely, as we discuss in Recipe 6.5 through Recipe 6.8.
Discussion
A secure message digest function (or one-way hash function) should have the following properties:
One-wayness
If given an arbitrary hash value, it should be computationally infeasible to find a plaintext value that generated that hash value.
Noncorrelation
It should also be computationally infeasible to find out anything about the original plaintext value; the input bits and output bits should not be correlated.
Weak collision resistance
If given a plaintext value and the corresponding hash value, it should be computationally infeasible to find a second plaintext value that gives the same hash value.
Strong collision resistance
It should be computationally infeasible to find two arbitrary inputs that give the same hash value.
Partial collision resistance
It should be computationally infeasible to find two arbitrary inputs that give two hashes that differ only by a few bits. The difficulty of finding partial collisions of size n should, in the worst case, be about as difficult as brute-forcing a symmetric key of length n/2.
Unfortunately, there are cryptographic hash functions that have been found to be broken with regard to one or more of the above properties. MD4 is one example that is still in use today, despite its insecurity. MD5 is worrisome as well. No full break of MD5 has been published, but there is a well-known problem with a very significant component of MD5, resulting in very low trust in the security of MD5. Most cryptographers recommend against using it in any new applications. In addition, because MD5 was broken a long time ago, in 1995, it's a strong possibility that a government or some other entity has a full break that is not being shared.
For the time being, it's not unreasonable to use MD5 in legacy applications and in some applications where the ability to break MD5 buys little to nothing (don't try to be the judge of this yourself!), but do realize that you might need to replace MD5 entirely in the short term.
The strength of a good hash function differs depending on the circumstances of its use. When given a known hash value, finding an input that produces that hash value should have no attack much better than brute force. In that case, the effective strength of the hash algorithm will usually be related to the length of the algorithm's output. That is, the strength of a strong hash algorithm against such an attack should be roughly equivalent to the strength of an excellent block cipher with keys of that length.
However, hash algorithms are much better at protecting against attacks against the one-wayness of the function than they are at protecting against attacks on the strong collision resistance. Basically, if the application in question requires the strong collision resistance property, the algorithm will generally have its effective strength halved in terms of number of bits. That is, SHA1, which has a 160-bit output, would have the equivalent of 80 bits of security, when this property is required.
It can be quite difficult to determine whether an application that uses hash functions really does need the strong collision resistance property. Basically, it is best to assume that you always need it, then figure out if your design somehow provides it. Generally, that will be the case if you use a hash function in a component of a MAC that requires a nonce, and not true otherwise (however, see Recipe 6.8).
As a result, you should consider MD5 to have, at best, 64 bits of strength. In fact, considering the weaknesses inherent in MD5, you should assume that, in practice, MD5's strength is less than that. 64 bits of security is on the borderline of what is breakable. (It may or may not be possible for entities with enough resources to brute-force 64 bits in a reasonable time frame.)
Table 6-1 lists popular cryptographic hash functions and compares important properties of those functions. Note that the two MDC-2 constructs we detail are covered by patent restrictions until August 28, 2004, but everything else in this list is widely believed to be patent-free.
When comparing speeds, times were measured in x86 cycles per byte processed (lower numbers are better), though results will vary slightly from place to place. Implementations used for speed testing were either the default OpenSSL implementation (when available); the implementation in this book using OpenSSL versions of the underlying cryptographic primitives; or, when neither of those two were available, a reference implementation from the Web (in particular, for the last three SHA algorithms). In many cases, implementations of each algorithm exist that are more efficient, but we believe that our testing strategy should give you a reasonable idea of relative speeds between algorithms.
Table 6-1. Cryptographic hash functions and their properties
|
Algorithm |
Digest size |
Security confidence |
Small message speed (64 bytes), in cycles per byte[2] |
Large message speed (8K), in cycles per byte |
Uses block cipher |
|
Davies-Meyer-AES-128 |
128 bits (same length as cipher block size) |
Good |
46.7 cpb |
57.8 cpb |
Yes |
|
MD2 |
128 bits |
Good to low |
392 cpb |
184 cpb |
No |
|
MD4 |
128 bits |
Insecure |
32 cpb |
5.8 cpb |
No |
|
MD5 |
128 bits |
Very low, may be insecure |
40.9 cpb |
7.7 cpb |
No |
|
MDC-2-AES-128 |
256 bits |
Very high |
93 cpb |
116 cpb |
Yes |
|
MDC-2-DES |
128 bits |
Good |
444 cpb |
444 cpb |
Yes |
|
RIPEMD-160 |
160 bits |
High |
62.2 cpb |
20.6 cpb |
No |
|
SHA1 |
160 bits |
High |
53 cpb |
15.9 cpb |
No |
|
SHA-256 |
256 bits |
Very high |
119 cpb |
116 cpb |
No |
|
SHA-384 |
384 bits |
Very high |
171 cpb |
166 cpb |
No |
|
SHA-512 |
512 bits |
Very high |
171 cpb |
166 cpb |
No |
|
[2] All timing values are best cases based on our empirical testing, and assume that the data being processed is already in cache. Do not expect that you'll quite be able to match these speeds in practice. |
|||||
Let's look briefly at the pros and cons of using these functions.
Davies-Meyer
This function is one way of turning block ciphers into one-way hash functions (Matyas-Meyer-Oseas is a similar technique that is also commonly seen). This technique does not thwart birthday attacks without additional measures, and it's therefore an inappropriate construct to use with most block ciphers because most ciphers have 64-bit blocks. AES is a good choice for this construct, though 64 bits of resistance to birthday attacks is somewhat liberal. While we believe this to be adequate for the time being, it's good to be forward-thinking and require something with at least 80 bits of resistance against a birthday attack. If you use Davies-Meyer with a nonce, it offers sufficient security. We show how to implement Davies-Meyer in Recipe 6.15.
MD2
MD2 (Message Digest 2 from Ron Rivest[3]) isn't used in many situations. It is optimized for 16-bit platforms and runs slowly everywhere else. It also hasn't seen much scrutiny, has an internal structure now known to be weak, and has a small digest size. For these reasons, we strongly suggest that you use other alternatives if at all possible.
MD4, MD5
As we mentioned, MD4 (Message Digest 4 from Ron Rivest) is still used in some applications, but it is quite broken and should not be used, while MD5 should be avoided as well, because its internal structure is known to be quite weak. This doesn't necessarily amount to a practical attack, but cryptographers do not recommend the algorithm for new applications because there probably is a practical attack waiting to be found.
MDC-2
MDC-2 is a way of improving Matyas-Meyer-Oseas to give an output that offers twice as many bits of security (i.e., the digest is two blocks wide). This clearly imposes a speed hit over Matyas-Meyer-Oseas, but it avoids the need for a nonce. Generally, when people say "MDC-2," they're talking about a DES-based implementation. We show how to implement MDC-2-AES in Recipe 6.16.
RIPEMD-160, SHA1
RIPEMD-160 and SHA1 are both well-regarded hash functions with reasonable performance characteristics. SHA1 is a bit more widely used, partially because it is faster, and partially because the National Institute of Standards and Technology (NIST) has standardized it. While there is no known attack better than a birthday attack against either of these algorithms, RIPEMD-160 is generally regarded as having a somewhat more conservative design, but SHA1 has seen more study.
SHA-256, SHA-384, SHA-512
After the announcement of AES, NIST moved to standardize hash algorithms that, when considering the birthday attack, offer comparable levels of security to AES-128, AES-192, and AES-256. The result was SHA-256, SHA-384, and SHA-512. SHA-384 is merely SHA-512 with a truncated digest value, and it therefore isn't very interesting in and of itself.
These algorithms are designed in a very conservative manner, and therefore their speed is closer to that expected from a block cipher than that expected from a traditional cryptographic message digest function. Clearly, if birthday-style attacks are not an issue (usually due to proper use of nonce), then AES-256 and SHA-256 offer equivalent security margins, making SHA-384 and SHA-512 overkill. In such a scenario, SHA1 is an excellent algorithm to pair with AES-128. In practice, a nonce is a good idea, and we therefore recommend AES-128 and SHA1 when you want to use a block cipher and a separate message digest algorithm. Note also that performance numbers for SHA-384 and SHA-512 would improve on a platform with native 64-bit operations.
The cryptographic hash function constructs based on block ciphers not only tend to run more slowly than dedicated functions, but also they rely on assumptions that are a bit unusual. In particular, these constructions demand that the underlying cipher resist related-key attacks, which are relatively unstudied compared with traditional attacks. On the other hand, dedicated hash functions have received a whole lot less scrutiny from the cryptanalysts in the world—assuming that SHA1 acts like a pseudo-random function (or close to it) is about as dicey.
In practice, if you really need to use a one-way hash function, we believe that SHA1 is suitable for almost all needs, particularly if you are savvy about thwarting birthday attacks and collision attacks on the block cipher (see Recipe 5.3). If you're using AES with 128-bit keys, SHA1 makes a reasonable pairing. However, if you ever feel the need to use stronger key sizes (which is quite unnecessary for the foreseeable future), you should also switch to SHA-256.
See Also
Recipe 5.3, Recipe 6.5-Recipe 6.8, Recipe 6.15, Recipe 6.16
[3] MD1 was never public, nor was MD3.
6.4. Choosing a Message Authentication Code
Problem
You need to use a MAC (which yields a tag that can only be computed correctly on a piece of data by an entity with a particular secret key), and you want to understand the important concerns so you can determine which algorithm best suits your needs.
Solution
In most cases, instead of using a standalone MAC, we recommend that you use a dual-use mode that provides both authentication and encryption all at once (such as CWC mode, discussed in Recipe 5.10). Dual-use modes can also be used for authentication when encryption is not required.
If a dual-use mode does not suit your needs, the best solution depends on your particular requirements. In general, HMAC is a popular and well-supported alternative based on hash functions (it's good for compatibility), and OMAC is a good solution based on a block cipher (which we see as a strong advantage). If you care about maximizing efficiency, a hash127-based MAC is a reasonable solution (though it has some limitations, so CMAC may be better in such cases; see Recipe 6.13 and Recipe 6.14).
We recommend against using RMAC and UMAC, for reasons discussed in the following section.
Discussion
WARNING
Do not use the same key for encryption that you use in a MAC. See Recipe 4.11 for how to overcome this restriction.
As with hash functions, there are a large number of available algorithms for performing message authentication, each with its own advantages and drawbacks. Besides algorithms designed explicitly for message authentication, some encryption modes such as CWC provide message authentication as a side effect. (See Recipe 5.4 for an overview of several such modes, and Recipe 6.10 for a discussion of CWC.) Such dual-use modes are designed for general-purpose needs, and they are high-level enough that it is far more difficult to use these modes in an insecure manner than regular cryptography.
Table 6-2 lists interesting message authentication functions, all with provable security properties assuming the security of the underlying primitive upon which they were based. This table also compares important properties of those functions. When comparing speeds, we used an x86-based machine and unoptimized implementations for testing. Results will vary depending on platform and other operating conditions. Speeds are measured in cycles per byte; lower numbers are better.
Table 6-2. MACs and their properties
|
MAC |
Built upon |
Small message speed (64 bytes)[4] |
Large message speed (8K) |
Appropriate for hardware |
Patent restric-tions |
Parallel-izable |
|
CMAC |
A universal hash and AES |
~18 cpb |
~18 cpb |
Yes |
No |
Yes |
|
HMAC-SHA1 |
Message digest function |
90 cpb |
20 cpb |
Yes |
No |
No |
|
MAC127 |
hash127 + AES |
~6 cpb |
~6 cpb |
Yes |
No |
Yes |
|
OMAC1 |
AES |
29.5 cpb |
37 cpb |
Yes |
No |
No |
|
OMAC2 |
AES |
29.5 cpb |
37 cpb |
Yes |
No |
No |
|
PMAC-AES |
Block cipher |
72 cpb |
70 cpb |
Yes |
Yes |
Yes |
|
RMAC |
Block cipher |
89 cpb |
80 cpb |
Yes |
No |
No |
|
UMAC32 |
UHASH and AES |
19 cpb |
cpb |
No |
No |
Yes |
|
XMACC-SHA1 |
Any cipher or MD function |
162 cpb |
29 cpb |
Yes |
Yes |
Yes |
|
[4] All timing values are best cases based on our empirical testing, and assume that the data being processed is already in cache. Do not expect that you'll quite be able to match these speeds in practice. |
||||||
Note that our considerations for comparing MACs are different from our considerations for comparing cryptographic hash functions. First, all of the MACs we discuss provide a reasonable amount of assurance, assuming that the underlying construct is secure (though MACs without nonces do not resist the birthday attack without additional work; see Recipe 6.12). Second, all of the cryptographic hash functions we discussed are suitable for hardware, patent-free, and not parallelizable.
Let's look briefly at the pros and cons of using these functions.
CMAC
CMAC is the MAC portion of the CWC encryption mode, which can be used in a standalone fashion. It's built upon a universal hash function that can be made to run very fast, especially in hardware. CMAC is discussed in Recipe 6.14.
HMAC
HMAC, discussed in Recipe 6.10, is a widely used MAC, largely because it was one of the first MAC constructs with provable security—even though the other MACs on this list also have provable security (and the proofs for those other MACs tend to be based on somewhat more favorable assumptions). HMAC is fairly fast, largely because it performs only two cryptographic operations, both hashes. One of the hashes is constant time; and the other takes time proportional to the length of the input, but it doesn't have the large overhead block ciphers typically do as a result of hash functions having a very large block size internally (usually 64 bytes).
HMAC is designed to take a one-way hash function with an arbitrary input and a key to produce a fixed-sized digest. Therefore, it cannot use block ciphers, unless you use a construction to turn a block cipher into a strong hash function, which will significantly slow down HMAC. If you want to use a block cipher to MAC (which we recommend), we strongly recommend that you use another alternative. Note that HMAC does not use a nonce by default, making HMAC vulnerable to capture replay attacks (and theoretically vulnerable to a birthday attack). Additional effort can thwart such attacks, as shown in Recipe 6.12.
MAC127
MAC127 is a MAC we define in Recipe 6.14 that is based on Dan Bernstein's hash127. This MAC is very similar to CMAC, but it runs faster in software. It's the fastest MAC in software that we would actually recommend using.
OMAC1, OMAC2
OMAC1 and OMAC2, which we discuss in Recipe 6.11, are MACs built upon AES. They are almost identical to each other, working by running the block cipher in CBC mode and performing a bit of additional magic at the end. These are "fixed" versions of a well-known MAC called CBC-MAC. CBC-MAC, without the kinds of modifications OMAC1 and OMAC2 make, was insecure unless all messages MAC'd with it were exactly the same size. The OMAC algorithms are a nice, general-purpose pair of MACs for when you want to keep your system simple, with only one cryptographic primitive. What's more, if you use an OMAC with AES in CTR mode, you need only have an implementation of the AES encryption operation (which is quite different code from the decryption operation). There is little practical difference between OMAC1 and OMAC2, although they both give different outputs. OMAC1 is slightly preferable, as it has a very slight speed advantage. Neither OMAC1 nor OMAC2 takes a nonce. As of this writing, NIST is expected to standardize OMAC1.
PMAC
PMAC is also parallelizable, but it is protected by patent. We won't discuss this MAC further because there are reasonable free alternatives.
RMAC
RMAC is another MAC built upon a block cipher. It works by running the block cipher in CBC mode and performing a bit of additional magic at the end. This is a mode created by NIST, but cryptographers have found theoretical problems with it under certain conditions;[5] thus, we do not recommend it for any use.
UMAC32
On many platforms, UMAC is the reigning speed champion for MACs implemented in software. The version of UMAC timed for Table 6-2 uses 64-bit tags, which are sufficient for most applications, if a bit liberal. That size is sufficient because tags generally need to have security for only a fraction of a second, assuming some resistance to capture replay attacks. 64 bits of strength should easily last years. The 128-bit version generally does a bit better than half the speed of the 64-bit version. Nevertheless, although there are a few things out there using UMAC, we don't recommend it. The algorithm is complex enough that, as of this writing, the reference implementation of UMAC apparently has never been validated. In addition, interoperability with UMAC is exceptionally difficult because there are many different parameters that can be tweaked.
XMACC
XMACC can be built from a large variety of cryptographic primitives. It provides good performance characteristics, and it is fully parallelizable. Unfortunately, it is patented, and for this reason we won't discuss it further in this book.
All in all, we personally prefer MAC127 or CMAC. When you want to avoid using a nonce, OMAC1 is an excellent choice.
See Also
Recipe 4.11, Recipe 5.4, Recipe 5.10, Recipe 6.9 through Recipe 6.14
[5] In particular, RMAC makes more assumptions about the underlying block cipher than other MACs need to make. The extra assumptions are a bit unreasonable, because they require the block cipher to resist related-key attacks, which are not well studied.
6.5. Incrementally Hashing Data
Problem
You want to use a hash function to process data incrementally, returning a result when the last of the data is finally available.
Solution
Most hash functions use a standard interface for operation, following these steps:
1. The user creates a "context" object to hold intermediate state.
2. The context object gets initialized.
3. The context is "updated" by passing in the data to be hashed.
4. When the data is updated, "finalization" returns the output of the cryptographic hash function.
Discussion
WARNING
Hash functions are not secure by themselves—not for a password system, not for message authentication, not for anything! If you do need a hash function by itself, be sure to at least protect against length extension attacks, as described in Recipe 6.7 and Recipe 6.8.
Libraries with cryptographic hash functions tend to support incremental operation using a standard structure. In fact, this structure is standardized for cryptographic hardware APIs in PKCS (Public Key Cryptography Standard) #11. There are four steps:
1. Allocate a context object. The context object holds the internal state of the hash until data processing is complete. The type can be specific to the hash function, or it can be a single type that works for all hash functions in a library (such as the EVP_MD_CTX type in the OpenSSL library orHCRYPTHASH in Microsoft's CryptoAPI).
2. Initialize the context object, resetting internal parameters of the hash function. Generally, this function takes no arguments other than a pointer to the context object, unless you're using a generic API, in which case you will need to specify which hash algorithm to use.
3. "Update" the context object by passing in data to be hashed and the associated length of that input. The results of the hash will be dependent on the order of the data you pass, but you can pass in all the partial data you wish. That is, calling the update routine with the string "he" then "llo" would produce the same results as calling it once with the string "hello". The update function generally takes the context object, the data to process, and the associated length of that data as arguments.
4. "Finalize" the context object and produce the message digest. Most APIs take as arguments the context object and a buffer into which the message digest is placed.
The OpenSSL API has both a single generic interface to all its hash functions and a separate API for each hash function. Here's an example using the SHA1 API:
#include <stdio.h>
#include <string.h>
#include <openssl/sha.h>
int main(int argc, char *argv[ ]) {
int i;
SHA_CTX ctx;
unsigned char result[SHA_DIGEST_LENGTH]; /* SHA1 has a 20-byte digest. */
unsigned char *s1 = "Testing";
unsigned char *s2 = "...1...2...3...";
SHA1_Init(&ctx);
SHA1_Update(&ctx, s1, strlen(s1));
SHA1_Update(&ctx, s2, strlen(s2));
/* Yes, the context object is last. */
SHA1_Final(result, &ctx);
printf("SHA1(\"%s%s\") = ", s1, s2);
for (i = 0; i < SHA_DIGEST_LENGTH; i++) printf("%02x", result[i]);
printf("\n");
return 0;
}
Every hash function that OpenSSL supports has a similar API. In addition, every such function has an "all-in-one" API that allows you to combine the work of calls for initialization, updating, and finalization, obviating the need for a context object:
unsigned char *SHA1(unsigned char *in, unsigned long len, unsigned char *out);
This function returns a pointer to the out argument.
Both the incremental API and the all-in-one API are very standard, even beyond OpenSSL. The reference versions of most hash algorithms look incredibly similar. In fact, Microsoft's CryptoAPI for Windows provides a very similar API. Any of the Microsoft CSPs provide implementations of MD2, MD5, and SHA1. The following code is the CryptoAPI version of the OpenSSL code presented previously:
#include <windows.h>
#include <wincrypt.h>
#include <stdio.h>
int main(int argc, char *argv[ ]) {
BYTE *pbData;
DWORD cbData = sizeof(DWORD), cbHashSize, i;
HCRYPTHASH hSHA1;
HCRYPTPROV hProvider;
unsigned char *s1 = "Testing";
unsigned char *s2 = "...1...2...3...";
CryptAcquireContext(&hProvider, 0, MS_DEF_PROV, PROV_RSA_FULL, 0);
CryptCreateHash(hProvider, CALG_SHA1, 0, 0, &hSHA1);
CryptHashData(hSHA1, s1, strlen(s1), 0);
CryptHashData(hSHA1, s2, strlen(s2), 0);
CryptGetHashParam(hSHA1, HP_HASHSIZE, (BYTE *)&cbHashSize, &cbData, 0);
pbData = (BYTE *)LocalAlloc(LMEM_FIXED, cbHashSize);
CryptGetHashParam(hSHA1, HP_HASHVAL, pbData, &cbHashSize, 0);
CryptDestroyHash(hSHA1);
CryptReleaseContext(hProvider, 0);
printf("SHA1(\"%s%s\") = ", s1, s2);
for (i = 0; i < cbHashSize; i++) printf("%02x", pbData[i]);
printf("\n");
LocalFree(pbData);
return 0;
}
The preferred API for accessing hash functions from OpenSSL, though, is the EVP API, which provides a generic API to all of the hash functions OpenSSL supports. The following code does the same thing as the first example with the EVP interface instead of the SHA1 interface:
#include <stdio.h>
#include <string.h>
#include <openssl/evp.h>
int main(int argc, char *argv[ ]) {
int i, ol;
EVP_MD_CTX ctx;
unsigned char result[EVP_MAX_MD_SIZE]; /* enough for any hash function */
unsigned char *s1 = "Testing";
unsigned char *s2 = "...1...2...3...";
/* Note the extra parameter */
EVP_DigestInit(&ctx, EVP_sha1( ));
EVP_DigestUpdate(&ctx, s1, strlen(s1));
EVP_DigestUpdate(&ctx, s2, strlen(s2));
/* Here, the context object is first. Notice the pointer to the output length */
EVP_DigestFinal(&ctx, result, &ol);
printf("SHA1(\"%s%s\") = ", s1, s2);
for (i = 0; i < ol; i++) printf("%02x", result[i]);
printf("\n");
return 0;
}
Note particularly that EVP_DigestFinal( ) requires you to pass in a pointer to an integer, into which the output length is stored. You should use this value in your computations instead of hardcoding SHA1's digest size, under the assumption that you might someday have to replace crypto algorithms in a hurry, in which case the digest size may change. For that reason, allocate EVP_MAX_MD_SIZE bytes for any buffer into which you store a message digest, even if some of that space may go unused.
Alternatively, if you'd like to allocate a buffer of the correct size for output dynamically (which is a good idea if you're space-constrained, because if SHA-512 is ever added to OpenSSL, EVP_MAX_MD_SIZE will become 512 bits), you can use the function EVP_MD_CTX_size( ) , which takes a context object and returns the size of the digest. For example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <openssl/evp.h>
int main(int argc, char *argv[ ]) {
int i, ol;
EVP_MD_CTX ctx;
unsigned char *result;
unsigned char *s1 = "Testing";
unsigned char *s2 = "...1...2...3...";
EVP_DigestInit(&ctx, EVP_sha1( ));
EVP_DigestUpdate(&ctx, s1, strlen(s1));
EVP_DigestUpdate(&ctx, s2, strlen(s2));
if (!(result = (unsigned char *)malloc(EVP_MD_CTX_block_size(&ctx))))abort();
EVP_DigestFinal(&ctx, result, &ol);
printf("SHA1(\"%s%s\") = ", s1, s2);
for (i = 0; i < ol; i++) printf("%02x", result[i]);
printf("\n");
free(result);
return 0;
}
The OpenSSL library supports only two cryptographic hash functions that we recommend, SHA1 and RIPEMD-160. It also supports MD2, MD4, MD5, and MDC-2-DES. MDC-2-DES is reasonable, but it is slow and provides only 64 bits of resistance to birthday attacks, whereas we recommend a minimum baseline of 80 bits of security. As an alternative, you could initialize the hash function with a nonce, as discussed in Recipe 6.8.
Nonetheless, Table 6-3 contains a summary of the necessary information on each hash function to use both the EVP and hash-specific APIs with OpenSSL.
Table 6-3. OpenSSL-supported hash functions
|
Message digest function |
EVP function to specify MD |
Context type for MD-specific API |
Prefix for MD-specific API calls (i.e., XXX_Init, ...) |
Include file for MD-specific API |
|
MD2 |
EVP_md2() |
MD2_CTX |
MD2 |
openssl/md2.h |
|
MD4 |
EVP_md4() |
MD4_CTX |
MD4 |
openssl/md4.h |
|
MD5 |
EVP_md5() |
MD5_CTX |
MD5 |
openssl/md5.h |
|
MDC-2-DES |
EVP_mdc2() |
MDC2_CTX |
MDC2 |
openssl/mdc2.h |
|
RIPEMD-160 |
EVP_ripemd160() |
RIPEMD160_CTX |
RIPEMD160 |
openssl/ripemd.h |
|
SHA1 |
EVP_sha1() |
SHA_CTX |
SHA1 |
openssl/sha.h |
Of course, you may want to use an off-the-shelf hash function that isn't supported by either OpenSSL or CryptoAPI—for example, SHA-256, SHA-384, or SHA-512. Aaron Gifford has produced a good, free library with implementations of these functions and released it under a BSD-style license. It is available from http://www.aarongifford.com/computers/sha.html.
That library exports an API that should look very familiar:
SHA256_Init(SHA256_CTX *ctx);
SHA256_Update(SHA256_CTX *ctx, unsigned char *data, size_t inlen);
SHA256_Final(unsigned char out[SHA256_DIGEST_LENGTH], SHA256_CTX *ctx);
SHA384_Init(SHA384_CTX *ctx);
SHA384_Update(SHA384_CTX *ctx, unsigned char *data, size_t inlen);
SHA384_Final(unsigned char out[SHA384_DIGEST_LENGTH], SHA384_CTX *ctx);
SHA512_Init(SHA512_CTX *ctx);
SHA512_Update(SHA512_CTX *ctx, unsigned char *data, size_t inlen);
SHA512_Final(unsigned char out[SHA512_DIGEST_LENGTH], SHA512_CTX *ctx);
All of the previous functions are prototyped in the sha2.h header file.
See Also
Implementations of SHA-256 and SHA-512 from Aaron Gifford: http://www.aarongifford.com/computers/sha.html
Recipe 6.7, Recipe 6.8
6.6. Hashing a Single String
Problem
You have a single string of data that you would like to hash, and you don't like the complexity of the incremental interface.
Solution
Use an "all-in-one" interface, if available, or write your own wrapper, as shown in Section 6.6.3.
Discussion
WARNING
Hash functions are not secure by themselves—not for a password system, not for message authentication, not for anything! If you do need a hash function by itself, be sure to at least protect against length extension attacks, as described in Recipe 6.7.
Complexity can certainly get you in trouble, and a simpler API can be better. While not every API provides a single function that can perform a cryptographic hash, many of them do. For example, OpenSSL provides an all-in-one API for each of the message digest algorithms it supports:
unsigned char *MD2(unsigned char *in, unsigned long n, unsigned char *md);
unsigned char *MD4(unsigned char *in, unsigned long n, unsigned char *md);
unsigned char *MD5(const unsigned char *in, unsigned long n, unsigned char *md);
unsigned char *MDC2(const unsigned char *in, unsigned long n, unsigned char *md);
unsigned char *RIPEMD160(const unsigned char *in, unsigned long n,
unsigned char *md);
unsigned char *SHA1(const unsigned char *in, unsigned long n, unsigned char *md);
APIs in this style are commonly seen, even outside the context of OpenSSL. Note that these functions require you to pass in a buffer into which the digest is placed, but they also return a pointer to that same buffer.
OpenSSL does not provide an all-in-one API for calculating message digests with the EVP interface. However, here's a simple wrapper that even allocates its result with malloc( ):
#include <stdio.h>
#include <stdlib.h>
#include <openssl/evp.h>
/* Returns 0 when malloc() fails. */
unsigned char *spc_digest_message(EVP_MD *type, unsigned char *in,
unsigned long n, unsigned int *outlen) {
EVP_MD_CTX ctx;
unsigned char *ret;
EVP_DigestInit(&ctx, type);
EVP_DigestUpdate(&ctx, in, n);
if (!(ret = (unsigned char *)malloc(EVP_MD_CTX_size(&ctx))) return 0;
EVP_DigestFinal(&ctx, ret, outlen);
return ret;
}
Here's a simple example that uses the previous wrapper:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <openssl/evp.h>
int main(int argc, char *argv[ ]) {
int i;
unsigned int ol;
unsigned char *s = "Testing...1...2...3...";
unsigned char *r;
r = spc_digest_message(EVP_sha1( ), s, strlen(s), &ol);
printf("SHA1(\"%s\") = ", s);
for (i = 0; i < ol; i++) printf("%02x", r[i]);
printf("\n");
free(r);
return 0;
}
Such a wrapper can be adapted easily to any incremental hashing API, simply by changing the names of the functions and the underlying data type, and removing the first argument of the wrapper if it is not necessary. Here is the same wrapper implemented using Microsoft's CryptoAPI:
#include <windows.h>
#include <wincrypt.h>
BYTE *SpcDigestMessage(ALG_ID Algid, BYTE *pbIn, DWORD cbIn, DWORD *cbOut) {
BYTE *pbOut;
DWORD cbData = sizeof(DWORD);
HCRYPTHASH hHash;
HCRYPTPROV hProvider;
CryptAcquireContext(&hProvider, 0, MS_DEF_PROV, PROV_RSA_FULL, 0);
CryptCreateHash(hProvider, Algid, 0, 0, &hHash);
CryptHashData(hHash, pbIn, cbIn, 0);
CryptGetHashParam(hHash, HP_HASHSIZE, (BYTE *)cbOut, &cbData, 0);
pbOut = (BYTE *)LocalAlloc(LMEM_FIXED, *cbOut);
CryptGetHashParam(hHash, HP_HASHVAL, pbOut, cbOut, 0);
CryptDestroyHash(hHash);
CryptReleaseContext(hProvider, 0);
return pbOut;
}
See Also
Recipe 6.7
6.7. Using a Cryptographic Hash
Problem
You need to use a cryptographic hash function outside the context of a MAC, and you want to avoid length-extension attacks, which are quite often possible.
Solution
A good way to thwart length-extension attacks is to run the hash function twice, once over the message, and once over the output of the first hash. This does not protect against birthday attacks, which probably aren't a major problem in most situations. If you need to protect against those attacks as well, use the advice in Recipe 6.8 on the first hash operation.
Discussion
WARNING
Hash functions are not secure by themselves—not for a password system, not for message authentication, not for anything!
Because all of the commonly used cryptographic hash functions break a message into blocks that get processed in an iterative fashion, it's often possible to extend the message and at the same time extend the associated hash, even if some sort of "secret" data was processed at the start of a message.
It's easy to get rid of this kind of problem at the application level. When you need a cryptographic hash, don't use SHA1 or something similar directly. Instead, write a wrapper that hashes the message with your cryptographic hash function, then takes that output and hashes it as well, returning the result.
For example, here's a wrapper for the all-in-one SHA1 interface discussed in Recipe 6.6:
#define SPC_SHA1_DGST_LEN (20)
/* Include anything else you need. */
void spc_extended_sha1(unsigned char *message, unsigned long n,unsigned char *md) {
unsigned char tmp[SPC_SHA1_DGST_LEN];
SHA1(message, n, tmp);
SHA1(tmp, sizeof(tmp), md);
}
Note that this solution does not protect against birthday attacks. When using SHA1, birthday attacks are generally considered totally impractical. However, to be conservative, you can use a nonce to protect against such attacks, as discussed in Recipe 6.8.
See Also
Recipe 6.6, Recipe 6.8
6.8. Using a Nonce to Protect Against Birthday Attacks
Problem
You want to harden a hash function against birthday attacks instead of switching to an algorithm with a longer digest.
Solution
Use a nonce or salt before and after your message (preferably a securely generated random salt), padding the nonce to the internal block size of the hash function.
Discussion
WARNING
Hash functions are not secure by themselves—not for a password system, not for message authentication, not for anything! If you do need a hash function by itself, be sure to at least protect against length extension attacks, as described in Recipe 6.7.
In most cases, when using a nonce or salt with a hash function, where the nonce is as large as the output length of the hash function, you double the effective strength of the hash function in circumstances where a birthday attack would apply. Even smaller nonces help improve security.
To ensure the best security, we strongly recommend that you follow these steps:
1. Select a nonce using a well-seeded cryptographic random number generator (see Chapter 11). If you're going to have multiple messages to process, select a random portion that is common to all messages (at least 64 bits) and use a counter for the rest. (The counter should be big enough to handle any possible number of messages. Here we also recommend dedicating at least 64 bits.)
2. Determine the internal block length of the hash function (discussed later in this section).
3. Pad the nonce to the internal block length by adding as many zero-bytes as necessary.
4. Add the padded nonce to both the beginning and the end of the message.
5. Hash, creating a value V.
6. Hash V to get the final output. This final step protects against length-extension attacks, as discussed in Recipe 6.7.
One thing that you need to be sure to avoid is a situation in which the attacker can control the nonce value. A nonce works well only if it cannot be reused. If an attacker can control the nonce, he can generally guarantee it gets reused, in which case problems like the birthday attack still apply.
In cases where having a nonce that the attacker can't control isn't appropriate, you can probably live with birthday attacks if you're using SHA1 or better. To protect against other attacks without using a nonce, see Recipe 6.7.
All hash functions have a compression function as an element. The size to which that function compresses is the internal block size of the function, and it is usually larger than the actual digest value. For hash functions based on block ciphers, the internal block size is the output length of the hash function (and the compression function is usually built around XOR'ing multiple pieces of block-sized data). Table 6-4 lists the internal block sizes of common message digest functions not based on block ciphers.
Table 6-4. Internal block sizes of common message digest functions
|
Algorithm |
Digest size |
Internal block size |
|
MD2 |
128 bits |
16 bytes (128 bits) |
|
MD4 |
128 bits |
64 bytes (512 bits) |
|
MD5 |
128 bits |
64 bytes (512 bits) |
|
RIPEMD-160 |
160 bits |
64 bytes (512 bits) |
|
SHA1 |
160 bits |
64 bytes (512 bits) |
|
SHA-256 |
256 bits |
64 bytes (512 bits) |
|
SHA-384 |
384 bits |
128 bytes (1,024 bits) |
|
SHA-512 |
512 bits |
128 bytes (1,024 bits) |
Here's a pair of functions that do all-in-one wrapping of the OpenSSL EVP message digest interface:
#include <openssl/evp.h>
#include <openssl/rand.h>
#include <string.h>
unsigned char *spc_create_nonced_digest(EVP_MD *type, unsigned char *in,
unsigned long n, unsigned int *outlen) {
int bsz, dlen;
EVP_MD_CTX ctx;
unsigned char *pad, *ret;
EVP_DigestInit(&ctx, type);
dlen = EVP_MD_CTX_size(&ctx);
if (!(ret = (unsigned char *)malloc(dlen * 2))) return 0;
RAND_bytes(ret, dlen);
EVP_DigestUpdate(&ctx, ret, dlen);
bsz = EVP_MD_CTX_block_size(&ctx);
if (!(pad = (unsigned char *)malloc(bsz - dlen))) {
free(ret);
return 0;
}
memset(pad, 0, bsz - dlen);
EVP_DigestUpdate(&ctx, pad, bsz - dlen);
EVP_DigestUpdate(&ctx, in, n);
EVP_DigestUpdate(&ctx, ret, dlen);
EVP_DigestUpdate(&ctx, pad, bsz - dlen);
free(pad);
EVP_DigestFinal(&ctx, ret + dlen, outlen);
*outlen *= 2;
return ret;
}
int spc_verify_nonced_digest(EVP_MD *type, unsigned char *in, unsigned long n,
unsigned char *toverify) {
int dlen, outlen, bsz, i;
EVP_MD_CTX ctx;
unsigned char *pad, *vfy;
EVP_DigestInit(&ctx, type);
bsz = EVP_MD_CTX_block_size(&ctx);
dlen = EVP_MD_CTX_size(&ctx);
EVP_DigestUpdate(&ctx, toverify, dlen);
if (!(pad = (unsigned char *)malloc(bsz - dlen))) return 0;
memset(pad, 0, bsz - dlen);
EVP_DigestUpdate(&ctx, pad, bsz - dlen);
EVP_DigestUpdate(&ctx, in, n);
EVP_DigestUpdate(&ctx, toverify, dlen);
EVP_DigestUpdate(&ctx, pad, bsz - dlen);
free(pad);
if (!(vfy = (unsigned char *)malloc(dlen))) return 0;
EVP_DigestFinal(&ctx, vfy, &outlen);
in += dlen;
for (i = 0; i < dlen; i++)
if (vfy[i] != toverify[i + dlen]) {
free(vfy);
return 0;
}
free(vfy);
return 1;
}
The first function, spc_create_nonced_digest( ), automatically selects a nonce from the OpenSSL random number generator and returns twice the digest size in output, where the first digest-sized block is the nonce and the second is the hash. The second function, spc_verify_nonced_digest( ), takes data consisting of a nonce concatenated with a hash value, and returns 1 if the hash validates, and 0 otherwise.
Two macros can make extracting the nonce and the hash easier:
#include <stdio.h>
#include <string.h>
#include <openssl/evp.h>
/* Here, l is the output length of spc_create_nonced_digest( ) */
#define spc_extract_nonce(l, s) (s)
#define spc_extract_digest(l, s) ((s)+((l) / 2))
Here's a sample program using this API:
int main(int argc, char *argv[ ]) {
unsigned int i, ol;
unsigned char *s = "Testing hashes with nonces.";
unsigned char *dgst, *nonce, *ret;
ret = spc_create_nonced_digest(EVP_sha1( ), s, strlen(s), &ol);
nonce = spc_extract_nonce(ol, ret);
dgst = spc_extract_digest(ol, ret);
printf("Nonce = ");
for(i = 0; i < ol / 2; i++)
printf("%02x", nonce[i]);
printf("\nSHA1-Nonced(Nonce, \"%s\") = \n\t", s);
for(i = 0; i < ol / 2; i++)
printf("%02x", dgst[i]);
printf("\n");
if (spc_verify_nonced_digest(EVP_sha1( ), s, strlen(s), ret))
printf("Recalculation verified integrity.\n");
else
printf("Recalculation FAILED to match.\n");
return 0;
}
See Also
Recipe 6.7
6.9. Checking Message Integrity
Problem
You want to provide integrity for messages in such a way that people with a secret key can verify that the message has not changed since the integrity value (often called a tag) was first calculated.
Solution
Use a message integrity check. As with hash functions, there are somewhat standard interfaces, particularly an incremental interface.
Discussion
Libraries that support MACs tend to support incremental operation using a standard structure, very similar to that used by hash functions:
1. Allocate and key a context object. The context object holds the internal state of the MAC until data processing is complete. The type of the context object can be specific to the MAC, or there can be a single type that works for all hash functions in a library. OpenSSL supports only one MAC and has only the associated context type. The key can be reused numerous times without reallocating. Often, you will need to specify the underlying algorithm you are using for your MAC.
2. Reset the context object, setting the internal parameters of the MAC to their initial state so that another message's authentication tag can be calculated. Many MACs accept a nonce, and this is where you would pass that in. This is often combined with the "init" call when the algorithm does not take a nonce, such as with OMAC and HMAC.
3. "Update" the context object by passing in data to be authenticated and the associated length of that input. The results of the MAC'ing process will be dependent on the order of the data that you pass, but you can pass in all the partial data you wish. That is, calling the update routine with the strings "he" then "llo" would produce the same results as calling it once with the string "hello". The update function generally takes as arguments the context object, the data to process, and the associated length of that data.
4. "Finalize" the context object and produce the authentication tag. Most APIs will generally take as arguments the context object and a buffer into which the message digest is placed.
Often, you may have a block cipher or a hash function that you'd like to turn into a MAC, but no associated code comes with the cryptographic primitive. Alternately, you might use a library such as OpenSSL or CryptoAPI that provides very narrow choices. For this reason, the next several recipes provide implementations of MACs we recommend for general-purpose use, particularly OMAC, CMAC, and HMAC.
SECURITY RECOMMENDATIONS FOR MACS
MACs are not quite as low-level as cryptographic hash functions. Yet they are still fairly low-level constructs, and there are some common pitfalls associated with them. We discuss these elsewhere in the book, but here's a summary of steps you should take to defend yourself against common problems:
§ Don't use the same MAC key as an encryption key. If you'd like to have a system with a single key, key your MAC and encryption separately, using the technique from Recipe 4.11.
§ Use a securely generated, randomly chosen key for your MAC, not something hardcoded or otherwise predictable!
§ Be sure to read Recipe 6.18 on how to use a MAC and encryption together securely, as it can be difficult to do.
§ Use an always-increasing nonce, and use this to actively thwart capture replay attacks. Do this even if the MAC doesn't have built-in support for nonces. (See Recipe 6.21 for information on how to thwart capture replay attacks, and Recipe 6.12 for using a nonce with MACs that don't have direct support for them.)
§ It is of vital importance that any parties computing a MAC agree on exactly what data is to be processed. To that end, it pays to get very detailed in specifying the content of messages, including any fields you have and how they are encoded before the MAC is computed. Any encoding should be unambiguous.
Some MAC interfaces may not remove key material from memory when done. Be sure to check the particular implementation you're using.
OpenSSL provides only a single MAC implementation, HMAC, while CryptoAPI supports both CBC-MAC and HMAC. Neither quite follows the API outlined in this recipe, though they stray in different ways. OpenSSL performs the reset operation the same way as the initialization operation (you just pass in 0 in place of the key and the algorithm arguments). CryptoAPI does not allow resetting the context object, and instead requires that a completely new context object be created.
OMAC and HMAC do not take a nonce by default. See Recipe 6.12 to see how to use these algorithms with a nonce. To see how to use the incremental HMAC interface in OpenSSL and CryptoAPI, see Recipe 6.10. CryptoAPI does not have an all-in-one interface, but instead requires use of its incremental API.
Most libraries also provide an all-in-one interface to the MACs they provide. For example, the HMAC all-in-one function for OpenSSL looks like this:
unsigned char *HMAC(const EVP_MD *evp_md, const void *key, int key_len,
const unsigned char *msg, int msglen, unsigned char *tag,
unsigned int *tag_len);
There is some variation in all-in-one APIs. Some are single-pass, like the OpenSSL API described in this section. Others have a separate initialization step and a context object, so that you do not need to specify the underlying cryptographic primitive and rekey every single time you want to use the MAC. That is, such interfaces automatically call functions for resetting, updating, and finalization for you.
See Also
Recipe 4.11, Recipe 6.10, Recipe 6.12, Recipe 6.18, Recipe 6.21
6.10. Using HMAC
Problem
You want to provide message authentication using HMAC.
Solution
If you are using OpenSSL, you can use the HMAC API:
/* The incremental interface */
void HMAC_Init(HMAC_CTX *ctx, const void *key, int len, const EVP_MD *md);
void HMAC_Update(HMAC_CTX *ctx, const unsigned char *data, int len);
void HMAC_Final(HMAC_CTX *ctx, unsigned char *tag, unsigned int *tag_len);
/* HMAC_cleanup erases the key material from memory. */
void HMAC_cleanup(HMAC_CTX *ctx);
/* The all-in-one interface. */
unsigned char *HMAC(const EVP_MD *evp_md, const void *key, int key_len,
const unsigned char *msg, int msglen, unsigned char *tag,
unsigned int *tag_len);
If you are using CryptoAPI, you can use the CryptCreateHash( ) , CryptHashData( ) , CryptGetHashParam( ) , CryptSetHashParam( ) , and CryptDestroyHash( ) functions:
BOOL WINAPI CryptCreateHash(HCRYPTPROV hProv, ALG_ID Algid, HCRYPTKEY hKey,
DWORD dwFlags, HCRYPTHASH *phHash);
BOOL WINAPI CryptHashData(HCRYPTHASH hHash, BYTE *pbData, DWORD cbData,
DWORD dwFlags);
BOOL WINAPI CryptGetHashParam(HCRYPTHASH hHash, DWORD dwParam, BYTE *pbData,
DWORD *pcbData, DWORD dwFlags);
BOOL WINAPI CryptSetHashParam(HCRYPTHASH hHash, DWORD dwParam, BYTE *pbData,
DWORD dwFlags);
BOOL WINAPI CryptDestroyHash(HCRYPTHASH hHash);
Otherwise, you can use the HMAC implementation provided with this recipe in combination with any cryptographic hash function you have handy.
Discussion
TIP
Be sure to look at our generic recommendations for using a MAC (Recipe 6.9).
Here's an example of using OpenSSL's incremental interface to hash two messages using SHA1:
#include <stdio.h>
#include <openssl/hmac.h>
void spc_incremental_hmac(unsigned char *key, size_t keylen) {
int i;
HMAC_CTX ctx;
unsigned int len;
unsigned char out[20];
HMAC_Init(&ctx, key, keylen, EVP_sha1( ));
HMAC_Update(&ctx, "fred", 4);
HMAC_Final(&ctx, out, &len);
for (i = 0; i < len; i++) printf("%02x", out[i]);
printf("\n");
HMAC_Init(&ctx, 0, 0, 0);
HMAC_Update(&ctx, "fred", 4);
HMAC_Final(&ctx, out, &len);
for (i = 0; i < len; i++) printf("%02x", out[i]);
printf("\n");
HMAC_cleanup(&ctx); /* Remove key from memory */
}
To reset the HMAC context object, we call HMAC_Init( ) , passing in zeros (NULLs) in place of the key, key length, and digest type to use. The NULL argument when initializing in OpenSSL generally means "I'm not supplying this value right now; use what you already have."
The following example shows an implementation of the same code provided for OpenSSL, this time using CryptoAPI (with the exception of resetting the context, because CryptoAPI actually requires a new one to be created). This implementation requires the use of the code in Recipe 5.26 to convert raw key data into an HCRYPTKEY object as required by CryptCreateHash( ) . Note the difference in the arguments required between spc_incremental_hmac( ) as implemented for OpenSSL, and SpcIncrementalHMAC( ) as implemented for CryptoAPI. The latter requires an additional argument that specifies the encryption algorithm for the key. Although the information is never really used, CryptoAPI insists on tying an encryption algorithm to key data. In general, CALG_RC4 should work fine for arbitrary key data (the value will effectively be ignored).
#include <windows.h>
#include <wincrypt.h>
#include <stdio.h>
void SpcIncrementalHMAC(BYTE *pbKey, DWORD cbKey, ALG_ID Algid) {
BYTE out[20];
DWORD cbData = sizeof(out), i;
HCRYPTKEY hKey;
HMAC_INFO HMACInfo;
HCRYPTHASH hHash;
HCRYPTPROV hProvider;
hProvider = SpcGetExportableContext( );
hKey = SpcImportKeyData(hProvider, Algid, pbKey, cbKey);
CryptCreateHash(hProvider, CALG_HMAC, hKey, 0, &hHash);
HMACInfo.HashAlgid = CALG_SHA1;
HMACInfo.pbInnerString = HMACInfo.pbOuterString = 0;
HMACInfo.cbInnerString = HMACInfo.cbOuterString = 0;
CryptSetHashParam(hHash, HP_HMAC_INFO, (BYTE *)&HMACInfo, 0);
CryptHashData(hHash, (BYTE *)"fred", 4, 0);
CryptGetHashParam(hHash, HP_HASHVAL, out, &cbData, 0);
for (i = 0; i < cbData; i++) printf("%02x", out[i]);
printf("\n");
CryptDestroyHash(hHash);
CryptDestroyKey(hKey);
CryptReleaseContext(hProvider, 0);
}
If you aren't using OpenSSL or CryptoAPI, but you have a hash function that you'd like to use with HMAC, you can use the following HMAC implementation:
#include <stdlib.h>
#include <string.h>
typedef struct {
DGST_CTX mdctx;
unsigned char inner[DGST_BLK_SZ];
unsigned char outer[DGST_BLK_SZ];
} SPC_HMAC_CTX;
void SPC_HMAC_Init(SPC_HMAC_CTX *ctx, unsigned char *key, size_t klen) {
int i;
unsigned char dk[DGST_OUT_SZ];
DGST_Init(&(ctx->mdctx));
memset(ctx->inner, 0x36, DGST_BLK_SZ);
memset(ctx->outer, 0x5c, DGST_BLK_SZ);
if (klen <= DGST_BLK_SZ) {
for (i = 0; i < klen; i++) {
ctx->inner[i] ^= key[i];
ctx->outer[i] ^= key[i];
}
} else {
DGST_Update(&(ctx->mdctx), key, klen);
DGST_Final(dk, &(ctx->mdctx));
DGST_Reset(&(ctx->mdctx));
for (i = 0; i < DGST_OUT_SZ; i++) {
ctx->inner[i] ^= dk[i];
ctx->outer[i] ^= dk[i];
}
}
DGST_Update(&(ctx->mdctx), ctx->inner, DGST_BLK_SZ);
}
void SPC_HMAC_Reset(SPC_HMAC_CTX *ctx) {
DGST_Reset(&(ctx->mdctx));
DGST_Update(&(ctx->mdctx), ctx->inner, DGST_BLK_SZ);
}
void SPC_HMAC_Update(SPC_HMAC_CTX *ctx, unsigned char *m, size_t l) {
DGST_Update(&(ctx->mdctx), m, l);
}
void SPC_HMAC_Final(unsigned char *tag, SPC_HMAC_CTX *ctx) {
unsigned char is[DGST_OUT_SZ];
DGST_Final(is, &(ctx->mdctx));
DGST_Reset(&(ctx->mdctx));
DGST_Update(&(ctx->mdctx), ctx->outer, DGST_BLK_SZ);
DGST_Update(&(ctx->mdctx), is, DGST_OUT_SZ);
DGST_Final(tag, &(ctx->mdctx));
}
void SPC_HMAC_Cleanup(SPC_HMAC_CTX *ctx) {
volatile char *p = ctx->inner;
volatile char *q = ctx->outer;
int i;
for (i = 0; i < DGST_BLK_SZ; i++) *p++ = *q++ = 0;
}
The previous code does require a particular interface to a hash function interface. First, it requires two constants: DGST_BLK_SZ, which is the internal block size of the underlying hash function (see Recipe 6.3), and DGST_OUT_SZ, which is the size of the resulting message digest. Second, it requires a context type for the message digest, which you should typedef to DGST_CTX. Finally, it requires an incremental interface to the hash function:
void DGST_Init(DGST_CTX *ctx);
void DGST_Reset(DGST_CTX *ctx);
void DGST_Update(DGST_CTX *ctx, unsigned char *m, size_t len);
void DGST_Final(unsigned char *tag. DGST_CTX *ctx);
Some hash function implementations won't have an explicit reset implementation, in which case you can implement the reset functionality by calling DGST_Init( ) again.
Even though OpenSSL already has an HMAC implementation, here is an example of binding the previous HMAC implementation to OpenSSL's SHA1 implementation:
typedef SHA_CTX DGST_CTX;
#define DGST_BLK_SZ 64
#define DGST_OUT_SZ 20
#define DGST_Init(x) SHA1_Init(x)
#define DGST_Reset(x) DGST_Init(x)
#define DGST_Update(x, m, l) SHA1_Update(x, m, l)
#define DGST_Final(o, x) SHA1_Final(o, x)
See Also
Recipe 5.26, Recipe 6.3, Recipe 6.4, Recipe 6.9
6.11. Using OMAC (a Simple Block Cipher-Based MAC)
Problem
You want to use a simple MAC based on a block cipher, such as AES.
Solution
Use the OMAC implementation provided in Section 6.11.3.
Discussion
TIP
Be sure to look at our generic recommendations for using a MAC (see Recipe 6.9).
OMAC is a straightforward message authentication algorithm based on the CBC-encryption mode. It fixes some security problems with the naïve implementation of a MAC from CBC mode (CBC-MAC). In particular, that MAC is susceptible to length-extension attacks, similar to the ones we consider for cryptographic hash functions in Recipe 6.7.
OMAC has been explicitly specified for AES, and it is easy to adapt to any 128-bit block cipher. It is possible, but a bit more work, to get it working with ciphers with 64-bit blocks. In this section, we only cover using OMAC with AES.
The basic idea behind using CBC mode as a MAC is to encrypt a message in CBC mode and throw away everything except the very last block of output. That's not generally secure, though. It only works when all messages you might possibly process are a particular size.
Besides OMAC, there are several MACs that try to fix the CBC-MAC problem, including XCBC-MAC, TMAC, and RMAC:
RMAC
RMAC (the R stands for randomized) has security issues in the general case, and is not favored by the cryptographic community.[6]
XCBC-MAC
XCBC-MAC (eXtended CBC-MAC) is the foundation for TMAC and OMAC, but it uses three different keys.
TMAC
TMAC uses two keys (thus the T in the name).
OMAC is the first good CBC-MAC derivative that uses a single key. OMAC works the same way CBC-MAC does until the last block, where it XORs the state with an additional value before encrypting. That additional value is derived from the result of encrypting all zeros, and it can be performed at key setup time. That is, the additional value is key-dependent, not message-dependent.
OMAC is actually the name of a family of MAC algorithms. There are two concrete versions, OMAC1 and OMAC2, which are slightly different but equally secure. OMAC1 is slightly preferable because its key setup can be done a few cycles more quickly than OMAC2's key setup. NIST is expected to standardize on OMAC1.
First, we provide an incremental API for using OMAC. This code requires linking against an AES implementation, and also that the macros developed in Recipe 5.5 be defined (they bridge the API of your AES implementation with this book's API). The secure memory function spc_memset( )from Recipe 13.2 is also required.
To use this API, you must instantiate an SPC_OMAC_CTX object and pass it to the various API functions. To initialize the context, call either spc_omac1_init( ) or spc_omac2_init( ) , depending on whether you want to use OMAC1 or OMAC2. The initialization functions always return success unless the key length is invalid, in which case they return 0. Successful initialization is indicated by a return value of 1.
int spc_omac1_init(SPC_OMAC_CTX *ctx, unsigned char *key, int keylen);
int spc_omac2_init(SPC_OMAC_CTX *ctx, unsigned char *key, int keylen);
These functions have the following arguments:
ctx
Context object to be initialized.
key
Block cipher key.
keylen
Length of the key in bytes. The length of the key must be 16, 24, or 32 bytes; any other key length is invalid.
Once initialized, spc_omac_update( ) can be used to process data. Note that the only differences between OMAC1 and OMAC2 in this implementation are handled at key setup time, so they both use the same functions for updating and finalization. Multiple calls to spc_omac_update( ) act just like making a single call where all of the data was concatenated together. Here is its signature:
void spc_omac_update(SPC_OMAC_CTX *ctx, unsigned char *in, size_t il);
This function has the following arguments:
ctx
Context object to use for the current message.
in
Buffer that contains the data to be processed.
il
Length of the data buffer to be processed in bytes.
To obtain the output of the MAC operation, call spc_omac_final( ) , which has the following signature:
int spc_omac_final(SPC_OMAC_CTX *ctx, unsigned char *out);
This function has the following arguments:
ctx
Context object to be finalized.
out
Buffer into which the output will be placed. This buffer must be at least 16 bytes in size. No more than 16 bytes will ever be written to it.
Here is the code implementing OMAC:
#include <stdlib.h>
typedef struct {
SPC_KEY_SCHED ks;
int ix;
unsigned char iv[SPC_BLOCK_SZ];
unsigned char c1[SPC_BLOCK_SZ]; /* L * u */
unsigned char c2[SPC_BLOCK_SZ]; /* L / u */
} SPC_OMAC_CTX;
int spc_omac1_init(SPC_OMAC_CTX *ctx, unsigned char *key, int keylen) {
int condition, i;
unsigned char L[SPC_BLOCK_SZ] = {0,};
if (keylen != 16 && keylen != 24 && keylen != 32) return 0;
SPC_ENCRYPT_INIT(&(ctx->ks), key, keylen);
SPC_DO_ENCRYPT(&(ctx->ks), L, L);
spc_memset(ctx->iv, 0, SPC_BLOCK_SZ);
ctx->ix = 0;
/* Compute L * u */
condition = L[0] & 0x80;
ctx->c1[0] = L[0] << 1;
for (i = 1; i < SPC_BLOCK_SZ; i++) {
ctx->c1[i - 1] |= L[i] >> 7;
ctx->c1[i] = L[i] << 1;
}
if (condition) ctx->c1[SPC_BLOCK_SZ - 1] ^= 0x87;
/* Compute L * u * u */
condition = ctx->c1[0] & 0x80;
ctx->c2[0] = ctx->c1[0] << 1;
for (i = 1; i < SPC_BLOCK_SZ; i++) {
ctx->c2[i - 1] |= ctx->c1[i] >> 7;
ctx->c2[i] = ctx->c1[i] << 1;
}
if (condition) ctx->c2[SPC_BLOCK_SZ - 1] ^= 0x87;
spc_memset(L, 0, SPC_BLOCK_SZ);
return 1;
}
int spc_omac2_init(SPC_OMAC_CTX *ctx, unsigned char *key, int keylen) {
int condition, i;
unsigned char L[SPC_BLOCK_SZ] = {0,};
if (keylen != 16 && keylen != 24 && keylen != 32) return 0;
SPC_ENCRYPT_INIT(&(ctx->ks), key, keylen);
SPC_DO_ENCRYPT(&(ctx->ks), L, L);
spc_memset(ctx->iv, 0, SPC_BLOCK_SZ);
ctx->ix = 0;
/* Compute L * u, storing it in c1 */
condition = L[0] >> 7;
ctx->c1[0] = L[0] << 1;
for (i = 1; i < SPC_BLOCK_SZ; i++) {
ctx->c1[i - 1] |= L[i] >> 7;
ctx->c1[i] = L[i] << 1;
}
if (condition) ctx->c1[SPC_BLOCK_SZ - 1] ^= 0x87;
/* Compute L * u ^ -1, storing it in c2 */
condition = L[SPC_BLOCK_SZ - 1] & 0x01;
i = SPC_BLOCK_SZ;
while (--i) ctx->c2[i] = (L[i] >> 1) | (L[i - 1] << 7);
ctx->c2[0] = L[0] >> 1;
L[0] >>= 1;
if (condition) {
ctx->c2[0] ^= 0x80;
ctx->c2[SPC_BLOCK_SZ - 1] ^= 0x43;
}
spc_memset(L, 0, SPC_BLOCK_SZ);
return 1;
}
void spc_omac_update(SPC_OMAC_CTX *ctx, unsigned char *in, size_t il) {
int i;
if (il < SPC_BLOCK_SZ - ctx->ix) {
while (il--) ctx->iv[ctx->ix++] ^= *in++;
return;
}
if (ctx->ix) {
while (ctx->ix < SPC_BLOCK_SZ) --il, ctx->iv[ctx->ix++] ^= *in;
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, ctx->iv);
}
while (il > SPC_BLOCK_SZ) {
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((unsigned int *)(ctx->iv))[i] ^= ((unsigned int *)in)[i];
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, ctx->iv);
in += SPC_BLOCK_SZ;
il -= SPC_BLOCK_SZ;
}
for (i = 0; i < il; i++) ctx->iv[i] ^= in[i];
ctx->ix = il;
}
int spc_omac_final(SPC_OMAC_CTX *ctx, unsigned char *out) {
int i;
if (ctx->ix != SPC_BLOCK_SZ) {
ctx->iv[ctx->ix] ^= 0x80;
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)ctx->iv)[i] ^= ((int *)ctx->c2)[i];
} else {
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)ctx->iv)[i] ^= ((int *)ctx->c1)[i];
}
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, out);
return 1;
}
For those interested in the algorithm itself, note that we precompute two special values at key setup time, both of which are derived from the value we get from encrypting the all-zero data block. Each precomputed value is computed by using a 128-bit shift and a conditional XOR. The last block of data is padded, if necessary, and XOR'd with one of these two values, depending on its length.
Here is an all-in-one wrapper to OMAC, exporting both OMAC1 and OMAC2:
int SPC_OMAC1(unsigned char key[ ], int keylen, unsigned char in[ ], size_t l,
unsigned char out[16]) {
SPC_OMAC_CTX c;
if (!spc_omac1_init(&c, key, keylen)) return 0;
spc_omac_update(&c, in, l);
spc_omac_final(&c, out);
return 1;
}
int SPC_OMAC2(unsigned char key[ ], int keylen, unsigned char in[ ], size_t l,
unsigned char out[16]) {
SPC_OMAC_CTX c;
if (!spc_omac2_init(&c, key, keylen)) return 0;
spc_omac_update(&c, in, l);
spc_omac_final(&c, out);
return 1;
}
See Also
Recipe 5.5, Recipe 6.7, Recipe 6.9, Recipe 13.2
[6] Most importantly, RMAC requires the underlying block cipher to protect against related-key attacks, where other constructs do not. Related-key attacks are not well studied, so it's best to prefer constructs that can avoid them when possible.
6.12. Using HMAC or OMAC with a Nonce
Problem
You want to use HMAC or OMAC, but improve its resistance to birthday attacks and capture replay attacks.
Solution
Use an ever-incrementing nonce that is concatenated to your message.
Discussion
TIP
Be sure to actually test the nonce when validating the nonce value, so as to thwart capture replay attacks. (See Recipe 6.21.)
If you're using an off-the-shelf HMAC implementation, such as OpenSSL's or CryptoAPI's, you can easily concatenate your nonce to the beginning of your message.
You should use a nonce that's at least half as large as your key size, if not larger. Ultimately, we would recommend that any nonce contain a message counter that is 64 bits (it can be smaller if you're 100% sure you'll never use every counter value) and a random portion that is at least 64 bits. The random portion can generally be chosen per session instead of per message.
Here's a simple wrapper that provides a nonced all-in-one version of OMAC1, using the implementation from Recipe 6.11 and a 16-byte nonce:
void spc_OMAC1_nonced(unsigned char key[ ], int keylen, unsigned char in[ ],
size_t l, unsigned char nonce[16], unsigned char out[16]) {
SPC_OMAC_CTX c;
if (!spc_omac1_init(&c, key, keylen)) abort( );
spc_omac_update(&c, nonce, 16);
spc_omac_update(&c, in, l);
spc_omac_final(&c, out);
}
See Also
Recipe 6.11, Recipe 6.21
6.13. Using a MAC That's Reasonably Fast in Software and Hardware
Problem
You want to use a MAC that is fast in both software and hardware.
Solution
Use CMAC. It is available from http://www.zork.org/cmac/.
Discussion
TIP
Be sure to look at our generic recommendations for using a MAC (see Recipe 6.9).
CMAC is the message-integrity component of the CWC encryption mode. It is based on a universal hash function that is similar to hash127. It requires an 11-byte nonce per message. The Zork implementation has the following API:
int cmac_init(cmac_t *ctx, unsigned char key[16]);
void cmac_mac(cmac_t *ctx, unsigned char *msg, u_int32 msglen,
unsigned char nonce[11], unsigned char output[16]);
void cmac_cleanup(cmac_t *ctx);
void cmac_update(cmac_t *ctx, unsigned char *msg, u_int32 msglen);
void cmac_final(cmac_t *ctx, unsigned char nonce[11], unsigned char output[16]);
The cmac_t type keeps track of state and needs to be initialized only when you key the algorithm. You can then make messages interchangeably using the all-in-one API or the incremental API.
The all-in-one API consists of the cmac_mac( ) function. It takes an entire message and a nonce as arguments and produces a 16-byte output. If you want to use the incremental API, cmac_update( ) is used to pass in part of the message, and cmac_final( ) is used to set the nonce and get the resulting tag. The cmac_cleanup( ) function securely erases the context object.
To use the CMAC API, just copy the cmac.h and cmac.c files, and compile and link against cmac.c.
See Also
§ The CMAC home page: http://www.zork.org/cmac/
§ Recipe 6.9
6.14. Using a MAC That's Optimized for Software Speed
Problem
You want to use the MAC that is fastest in software.
Solution
Use a MAC based on Dan Bernstein's hash127, as discussed in the next section. The hash127 library is available from http://cr.yp.to.
Discussion
TIP
Be sure to look at our generic recommendations for using a MAC (see Recipe 6.9).
The hash127 algorithm is a universal hash function that can be turned into a secure MAC using AES. It is available from Dan Bernstein's web page: http://cr.yp.to/hash127.html. Follow the directions on how to install the hash127 library. Once the library is compiled, just include the directory containing hash127.h in your include path and link against hash127.a.
TIP
Unfortunately, at the time of this writing, the hash127 implementation has not been ported to Windows. Aside from differences in inline assembler syntax between GCC and Microsoft Visual C++, some constants used in the implementation overflow Microsoft Visual C++'s internal token buffer. When a port becomes available, we will update the book's web site with the relevant information.
The way to use hash127 as a MAC is to hash the message you want to authenticate (the hash function takes a key and a nonce as inputs, as well as the message), then encrypt the result of the hash function using AES.
In this recipe, we present an all-in-one MAC API based on hash127, which we call MAC127. This construction first hashes a message using hash127, then uses two constant-time postprocessing operations based on AES. The postprocessing operations give this MAC excellent provable security under strong assumptions.
When initializing the MAC, a 16-byte key is turned into three 16-byte keys by AES-encrypting three constant values. The first two derived keys are AES keys, used for postprocessing. The third derived key is the hash key (though the hash127 algorithm will actually ignore one bit of this key).
Note that Bernstein's hash127 interface has some practical limitations:
§ The entire message must be present at the time hash127( ) is called. That is, there's no incremental interface. If you need a fast incremental MAC, use CMAC (discussed in Recipe 6.13) instead.
§ The API takes an array of 32-bit values as input, meaning that it cannot accept an arbitrary character string.
However, we can encode the leftover bytes of input in the last parameter passed to hash127( ). Bernstein expects the last parameter to be used for additional per-message keying material. We're not required to use that parameter for keying material (i.e., our construction is still a secure MAC). Instead, we encode any leftover bytes, then unambiguously encode the length of the message.
To postprocess, we encrypt the hash output with one AES key, encrypt the nonce with the other AES key, then XOR the two ciphertexts together. This gives us provable security with good assumptions, plus the additional benefits of a nonce (see Recipe 6.12).
The core MAC127 data type is SPC_MAC127_CTX. There are only two functions: one to initialize a context, and one to MAC a message. The initialization function has the following signature:
void spc_mac127_init(SPC_MAC127_CTX *ctx, unsigned char *key);
This function has the following arguments:
ctx
Context object that holds key material so that several messages may be MAC'd with a single key.
key
Buffer that contains a 16-byte key.
To MAC a message, we use the function spc_mac127( ) :
void spc_mac127(SPC_MAC127_CTX *ctx, unsigned char *m, size_t l,
unsigned char *nonce, unsigned char *out);
This function has the following arguments:
ctx
Context object to be used to perform the MAC.
m
Buffer that contains the message to be authenticated.
l
Length of the message buffer in octets.
nonce
Buffer that contains a 16-byte value that must not be repeated.
out
Buffer into which the output will be placed. It must be at least 16 bytes in size. No more than 16 bytes will ever be written to it.
Here is our implementation of MAC127:
#include <stdlib.h>
#ifndef WIN32
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#else
#include <windows.h>
#include <winsock.h>
#endif
#include <hash127.h>
typedef struct {
struct hash127 hctx;
SPC_KEY_SCHED ekey;
SPC_KEY_SCHED nkey;
} SPC_MAC127_CTX;
void spc_mac127_init(SPC_MAC127_CTX *ctx, unsigned char key[16]) {
int i;
unsigned char pt[16] = {0, };
volatile int32 hk[4];
volatile unsigned char ek[16], nk[16];
SPC_ENCRYPT_INIT(&(ctx->ekey), key, 16);
SPC_DO_ENCRYPT(&(ctx->ekey), pt, (unsigned char *)ek);
pt[15] = 1;
SPC_DO_ENCRYPT(&(ctx->ekey), pt, (unsigned char *)nk);
pt[15] = 2;
SPC_DO_ENCRYPT(&(ctx->ekey), pt, (unsigned char *)hk);
SPC_ENCRYPT_INIT(&(ctx->ekey), (unsigned char *)ek, 16);
SPC_ENCRYPT_INIT(&(ctx->nkey), (unsigned char *)nk, 16);
hk[0] = htonl(hk[0]);
hk[1] = htonl(hk[1]);
hk[2] = htonl(hk[2]);
hk[3] = htonl(hk[3]);
hash127_expand(&(ctx->hctx), (int32 *)hk);
hk[0] = hk[1] = hk[2] = hk[3] = 0;
for (i = 0; i < 16; i++) ek[i] = nk[i] = 0;
}
void spc_mac127(SPC_MAC127_CTX *c, unsigned char *msg, size_t mlen,
unsigned char nonce[16], unsigned char out[16]) {
int i, r = mlen % 4; /* leftover bytes to stick into final block */
int32 x[4] = {0,};
for (i = 0; i <r; i++) ((unsigned char *)x)[i] = msg[mlen - r + i];
x[3] = (int32)mlen;
hash127_little((int32 *)out, (int32 *)msg, mlen / 4, &(c->hctx), x);
x[0] = htonl(*(int *)out);
x[1] = htonl(*(int *)(out + 4));
x[2] = htonl(*(int *)(out + 8));
x[3] = htonl(*(int *)(out + 12));
SPC_DO_ENCRYPT(&(c->ekey), out, out);
SPC_DO_ENCRYPT(&(c->nkey), nonce, (unsigned char *)x);
((int32 *)out)[0] ^= x[0];
((int32 *)out)[1] ^= x[1];
((int32 *)out)[2] ^= x[2];
((int32 *)out)[3] ^= x[3];
}
See Also
§ hash127 home page: http://cr.yp.to/hash127.html
§ Recipe 6.9, Recipe 6.12, Recipe 6.13
6.15. Constructing a Hash Function from a Block Cipher
Problem
You're in an environment in which you'd like to use a hash function, but you would prefer to use one based on a block cipher. This might be because you have only a block cipher available, or because you would like to minimize security assumptions in your system.
Solution
There are several good algorithms for doing this. We present one, Davies-Meyer, where the digest size is the same as the block length of the underlying cipher. With 64-bit block ciphers, Davies-Meyer does not offer sufficient security unless you add a nonce, in which case it is barely sufficient. Even with AES-128, without a nonce, Davies-Meyer is somewhat liberal when you consider birthday attacks.
Unfortunately, there is only one well-known scheme worth using for converting a block cipher into a hash function that outputs twice the block length (MDC-2), and it is patented at the time of this writing. However, those patent issues will go away by August 28, 2004. MDC-2 is covered inRecipe 6.16.
Note that such constructs assume that block ciphers resist related-key attacks. See Recipe 6.3 for a general comparison of such constructs compared to dedicated constructs like SHA1.
Discussion
WARNING
Hash functions do not provide security in and of themselves! If you need to perform message integrity checking, use a MAC instead.
The Davies-Meyer hash function uses the message to hash as key material for the block cipher. The input is padded, strengthened, and broken into blocks based on the key length, each block used as a key to encrypt a single value. Essentially, the message is broken into a series of keys.
With Davies-Meyer, the first value encrypted is an initialization vector (IV) that is usually agreed upon in advance. You may treat it as a nonce instead, however, which we strongly recommend. (The nonce is then as big as the block size of the cipher.) The result of encryption is XOR'd with the IV, then used as a new IV. This is repeated until all keys are exhausted, resulting in the hash output. See Figure 6-1 for a visual description of one pass of Davies-Meyer.
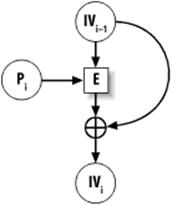
Figure 6-1. The Davies-Meyer construct
Traditionally, hash functions pad by appending a bit with a value of 1, then however many zeros are necessary to align to the next block of input. Input is typically strengthened by adding a block of data to the end that encodes the message length. Nonetheless, such strengthening does not protect against length-extension attacks. (To prevent against those, see Recipe 6.7.)
Matyas-Meyer-Oseas is a similar construction that is preferable in that the plaintext itself is not used as the key to a block cipher (this could make related-key attacks on Davies-Meyer easier); we'll present that as a component when we show how to implement MDC-2 in Recipe 6.16.
Here is an example API for using Davies-Meyer wihtout a nonce:
void spc_dm_init(SPC_DM_CTX *c);
void spc_dm_update(SPC_DM_CTX *c, unsigned char *msg, size_t len);
void spc_dm_final(SPC_DM_CTX *c, unsigned char out[SPC_BLOCK_SZ]);
The following is an implementation using AES-128. This code requires linking against an AES implementation, and it also requires that the macros developed in Recipe 5.5 be defined (they bridge the API of your AES implementation with this book's API).
#include <stdlib.h>
#include <string.h>
#ifndef WIN32
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#else
#include <windows.h>
#include <winsock.h>
#endif
#define SPC_KEY_SZ 16
typedef struct {
unsigned char h[SPC_BLOCK_SZ];
unsigned char b[SPC_KEY_SZ];
size_t ix;
size_t tl;
} SPC_DM_CTX;
void spc_dm_init(SPC_DM_CTX *c) {
memset(c->h, 0x52, SPC_BLOCK_SZ);
c->ix = 0;
c->tl = 0;
}
static void spc_dm_once(SPC_DM_CTX *c, unsigned char b[SPC_KEY_SZ]) {
int i;
SPC_KEY_SCHED ks;
unsigned char tmp[SPC_BLOCK_SZ];
SPC_ENCRYPT_INIT(&ks, b, SPC_KEY_SZ);
SPC_DO_ENCRYPT(&ks, c->h, tmp);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)c->h)[i] ^= ((int *)tmp)[i];
}
void spc_dm_update(SPC_DM_CTX *c, unsigned char *t, size_t l) {
c->tl += l; /* if c->tl < l: abort */
while (c->ix && l) {
c->b[c->ix++] = *t++;
l--;
if (!(c->ix %= SPC_KEY_SZ)) spc_dm_once(c, c->b);
}
while (l > SPC_KEY_SZ) {
spc_dm_once(c, t);
t += SPC_KEY_SZ;
l -= SPC_KEY_SZ;
}
c->ix = l;
for (l = 0; l < c->ix; l++) c->b[l] = *t++;
}
void spc_dm_final(SPC_DM_CTX *c, unsigned char output[SPC_BLOCK_SZ]) {
int i;
c->b[c->ix++] = 0x80;
while (c->ix < SPC_KEY_SZ) c->b[c->ix++] = 0;
spc_dm_once(c, c->b);
memset(c->b, 0, SPC_KEY_SZ - sizeof(size_t));
c->tl = htonl(c->tl);
for (i = 0; i < sizeof(size_t); i++)
c->b[SPC_KEY_SZ - sizeof(size_t) + i] = ((unsigned char *)(&c->tl))[i];
spc_dm_once(c, c->b);
memcpy(output, c->h, SPC_BLOCK_SZ);
}
See Also
Recipe 5.5, Recipe 6.3, Recipe 6.7, Recipe 6.16
6.16. Using a Block Cipher to Build a Full-Strength Hash Function
Problem
Given a block cipher, you want to produce a one-way hash function, where finding collisions should always be as hard as inverting the block cipher.
Solution
Use MDC-2, which is a construction that turns a block cipher into a hash function using two Matyas-Meyer-Oseas hashes and a bit of postprocessing.
Discussion
WARNING
Hash functions do not provide security in and of themselves! If you need to perform message integrity checking, use a MAC instead.
The MDC-2 message digest construction turns an arbitrary block cipher into a one-way hash function. It's different from Davies-Meyer and Matyas-Meyer-Oseas in that the output of the hash function is twice the block length of the cipher. It is also protected by patent until August 28, 2004.
However, MDC-2 does use two instances of Matyas-Meyer-Oseas as components in its construction. Matyas-Meyer-Oseas hashes block by block and uses the internal state as a key used to encrypt each block of input. The resulting ciphertext is XOR'd with the block of input, and the output of that operation becomes the new internal state. The output of the hash function is the final internal state (though if the block size is not equal to the key size, it may need to be expanded, usually by repeating the value). The initial value of the internal state can be any arbitrary constant. SeeFigure 6-2 for a depiction of how one block of the message is treated.
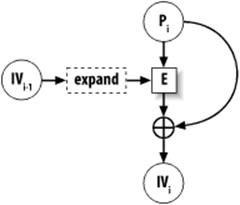
Figure 6-2. The Mayas-Meyer-Oseas construct
An issue with Matyas-Meyer-Oseas is that the cipher block size can be smaller than the key size, so you might need to expand the internal state somehow before using it to encrypt. Simply duplicating part of the key is sufficient. In the code we provide with this recipe, though, we'll assume that you want to use AES with 128-bit keys. Because the block size of AES is also 128 bits, there doesn't need to be an expansion operation.
MDC-2 is based on Matyas-Meyer-Oseas. There are two internal states instead of one, and each is initialized with a different value. Each block of input is copied, and the two copies go through one round of Matyas-Meyer-Oseas separately. Then, before the next block of input is processed, the two internal states are shuffled a bit; the lower halves of the two states are swapped. This is all illustrated for one block of the message in Figure 6-3.
Figure 6-3. The MDC-2 construct
Clearly, input needs to be padded to the block size of the cipher. We do this internally to our implementation by adding a 1 bit to the end of the input, then as many zeros as are necessary to make the resulting string block-aligned.
One important thing to note about MDC-2 (as well as Matyas-Meyer-Oseas) is that there are ways to extend a message to get the same hash as a result, unless you do something to improve the function. The typical solution is to use MD-strengthening, which involves adding to the end of the input a block that encodes the length of the input. We do that in the code presented later in this section.
Our API allows for incremental processing of messages, which means that there is a context object. The type for our context object is named SPC_MDC2_CTX. As with other hash functions presented in this chapter, the incremental API has three operations: initialization, updating (where data is processed), and finalization (where the resulting hash is output).
The initialization function has the following signature:
void spc_mdc2_init(SPC_MDC2_CTX *c);
All this function does is set internal state to the correct starting values.
Processing data is actually done by the following updating function:
void spc_mdc2_update(SPC_MDC2_CTX *c, unsigned char *t, size_t l);
This function hashes l bytes located at memory address t into the context c.
The result is obtained with the following finalization function:
void spc_mdc2_final(SPC_MDC2_CTX *c, unsigned char *output);
The output argument is always a pointer to a buffer that is twice the block size of the cipher being used. In the case of AES, the output buffer should be 32 bytes.
Following is our implementation of MDC-2, which is intended for use with AES-128. Remember: if you want to use this for other AES key sizes or for ciphers where the key size is different from the block size, you will need to perform some sort of key expansion before callingSPC_ENCRYPT_INIT( ). Of course, you'll also have to change that call to SPC_ENCRYPT_INIT( ) to pass in the desired key length.
#include <stdlib.h>
#include <string.h>
#ifndef WIN32
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#else
#include <windows.h>
#include <winsock.h>
#endif
/* This implementation only works when the block size is equal to the key size */
typedef struct {
unsigned char h1[SPC_BLOCK_SZ];
unsigned char h2[SPC_BLOCK_SZ];
unsigned char bf[SPC_BLOCK_SZ];
size_t ix;
size_t tl;
} SPC_MDC2_CTX;
void spc_mdc2_init(SPC_MDC2_CTX *c) {
memset(c->h1, 0x52, SPC_BLOCK_SZ);
memset(c->h2, 0x25, SPC_BLOCK_SZ);
c->ix = 0;
c->tl = 0;
}
static void spc_mdc2_oneblock(SPC_MDC2_CTX *c, unsigned char bl[SPC_BLOCK_SZ]) {
int i, j;
SPC_KEY_SCHED ks1, ks2;
SPC_ENCRYPT_INIT(&ks1, c->h1, SPC_BLOCK_SZ);
SPC_ENCRYPT_INIT(&ks2, c->h2, SPC_BLOCK_SZ);
SPC_DO_ENCRYPT(&ks1, bl, c->h1);
SPC_DO_ENCRYPT(&ks2, bl, c->h2);
j = SPC_BLOCK_SZ / (sizeof(int) * 2);
for (i = 0; i < SPC_BLOCK_SZ / (sizeof(int) * 2); i++) {
((int *)c->h1)[i] ^= ((int *)bl)[i];
((int *)c->h2)[i] ^= ((int *)bl)[i];
((int *)c->h1)[i + j] ^= ((int *)bl)[i + j];
((int *)c->h2)[i + j] ^= ((int *)bl)[i + j];
/* Now swap the lower halves using XOR. */
((int *)c->h1)[i + j] ^= ((int *)c->h2)[i + j];
((int *)c->h2)[i + j] ^= ((int *)c->h1)[i + j];
((int *)c->h1)[i + j] ^= ((int *)c->h2)[i + j];
}
}
void spc_mdc2_update(SPC_MDC2_CTX *c, unsigned char *t, size_t l) {
c->tl += l; /* if c->tl < l: abort */
while (c->ix && l) {
c->bf[c->ix++] = *t++;
l--;
if (!(c->ix %= SPC_BLOCK_SZ))
spc_mdc2_oneblock(c, c->bf);
}
while (l > SPC_BLOCK_SZ) {
spc_mdc2_oneblock(c, t);
t += SPC_BLOCK_SZ;
l -= SPC_BLOCK_SZ;
}
c->ix = l;
for (l = 0; l < c->ix; l++)
c->bf[l] = *t++;
}
void spc_mdc2_final(SPC_MDC2_CTX *c, unsigned char output[SPC_BLOCK_SZ * 2]) {
int i;
c->bf[c->ix++] = 0x80;
while (c->ix < SPC_BLOCK_SZ)
c->bf[c->ix++] = 0;
spc_mdc2_oneblock(c, c->bf);
memset(c->bf, 0, SPC_BLOCK_SZ - sizeof(size_t));
c->tl = htonl(c->tl);
for (i = 0; i < sizeof(size_t); i++)
c->bf[SPC_BLOCK_SZ - sizeof(size_t) + i] = ((unsigned char *)(&c->tl))[i];
spc_mdc2_oneblock(c, c->bf);
memcpy(output, c->h1, SPC_BLOCK_SZ);
memcpy(output+SPC_BLOCK_SZ, c->h2, SPC_BLOCK_SZ);
}
6.17. Using Smaller MAC Tags
Problem
You want to trade off security for smaller authentication tags.
Solution
Truncate the least significant bytes of the MAC, but make sure to retain adequate security.
Discussion
Normal software environments should not have a need for smaller MACs because space is not at a premium. However, if you're working in a space-constrained embedded environment, it's acceptable to truncate MAC tags if space is a requirement. Note that doing so will not reduce computation costs. In addition, keep in mind that security goes down as the tag size decreases, particularly if you are not using a nonce (or are using a small nonce).
6.18. Making Encryption and Message Integrity Work Together
Problem
You need to encrypt data and ensure the integrity of your data at the same time.
Solution
Use either an encryption mode that performs both encryption and message integrity checking, such as CWC mode, or encrypt data with one secret key and use a second key to MAC the encrypted data.
Discussion
Unbelievably, many subtle things can go wrong when you try to perform encryption and message integrity checking in tandem. This is part of the reason encryption modes such as CWC and CCM are starting to appear, both of which perform encryption and message integrity checking together, and they are still secure (such modes are compared in Recipe 5.4, and CWC is discussed in Recipe 5.10). However, if you're not willing to use one of those encryption modes, follow these guidelines to ensure security:
§ Use two separate keys, one for encryption and one for MAC'ing.
§ Encrypt first, then MAC the ciphertext.
We recommend encrypting, then MAC'ing the ciphertext (the encrypt-then-authenticate paradigm; see Figure 6-4) because other approaches aren't always secure.
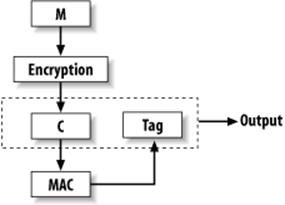
Figure 6-4. The encrypt-then-authenticate paradigm
For example, if you're using a stream-based mode such as CTR (discussed in Recipe 5.9), or if you're using CBC mode (Recipe 5.6), you will still have a good design if you use a MAC to authenticate the plaintext, then encrypt both the plaintext and the MAC tag (the authenticate-then-encrypt paradigm; see Figure 6-5). But if you fail to encrypt the MAC tag (this is actually called the authenticate-and-encrypt paradigm, because the two operations could happen in parallel with the same results; see Figure 6-6), or if you use an encryption mode with bad security properties (such as ECB mode), you might have something significant to worry about.
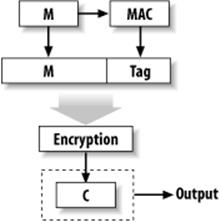
Figure 6-5. The authenticate-then-encrypt paradigm
Another advantage of encrypting first is that if you're careful, your servers can reject bogus messages before decrypting them, which can help improve resistance to denial of service attacks. We consider this of minor interest at best.
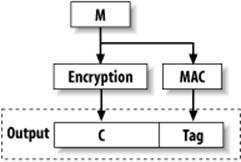
Figure 6-6. The authenticate-and-encrypt paradigm
The one significant reason you might want to encrypt first is to give extra protection for message authentication, assuming your MAC is cryptographically broken. The hope is that if the privacy component isn't broken, the MAC may still be secure, which may or may not be the case, depending on the nature of the attack.
In practice, if you're using a well-designed system—a dual-use scheme such as CWC mode—the correct functioning of authentication and encryption both assume the correct functioning of an underlying cipher such as AES. If this is broken, we consider all bets to be off anyway!
See Also
Recipe 5.4, Recipe 5.6, Recipe 5.9
6.19. Making Your Own MAC
Problem
You do not want to use an off-the-shelf MAC; you would prefer just to use a hash function.
Solution
Don't do it.
Discussion
Many things can go wrong, and there's really no reason not to use one of the excellent existing solutions. Nonetheless, some people believe they can do message authentication in a straightforward manner using a hash function, and they believe they would be better off doing this than using an off-the-shelf solution. Basically, they think they can do something less complex and faster with just a hash function. Other people think that creating some sort of "encryption with redundancy" scheme is a good idea, even though many such schemes are known to be bad.
OMAC, HMAC, CMAC, and MAC127, which we compare in Recipe 6.4, are all simple and efficient, and there are proofs that those constructions are secure with some reasonable assumptions. Will that be the case for anything you put together manually?
See Also
Recipe 6.4
6.20. Encrypting with a Hash Function
Problem
You want to encrypt with a hash function, possibly because you want only a single cryptographic primitive and to use a hash function instead of a block cipher.
Solution
Use a hash-based MAC in counter mode.
Discussion
TIP
Use a separate key from the one you use to authenticate, and don't forget to use the MAC for message authentication as well!
You can turn any MAC into a stream cipher essentially by using the MAC in counter (CTR) mode. You should not use a hash function by itself, because it's difficult to ensure that you're doing so securely. Basically, if you have a MAC built on a hash function that is known to be a secure MAC, it will be secure for encryption in CTR mode.
There is no point in using any MAC that uses a block cipher in any way, such as OMAC, CMAC, or MAC127 (see Recipe 6.4 for a discussion of MAC solutions). Instead, just use the underlying block cipher in CTR mode, which will produce the same results. This recipe should be used only when you don't want to use a block cipher.
Using a MAC in CTR mode is easy. As illustrated in Figure 6-7, key it, then use it to "MAC" a nonce concatenated with a counter. XOR the results with the plaintext.
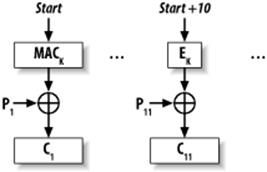
Figure 6-7. Encrypting with a MAC in counter mode
For example, here's a function that encrypts a stream of data using the HMAC-SHA1 implementation from Recipe 6.10:
#include <stdlib.h>
#include <string.h>
#define NONCE_LEN 16
#define CTR_LEN 16
#define MAC_OUT_SZ 20
unsigned char *spc_MAC_encrypt(unsigned char *in, size_t len, unsigned char *key,
int keylen, unsigned char *nonce) {
/* We're using a 128-bit nonce and a 128-bit counter, packed into one variable */
int i;
size_t blks;
SPC_HMAC_CTX ctx;
unsigned char ctr[NONCE_LEN + CTR_LEN];
unsigned char keystream[MAC_OUT_SZ];
unsigned char *out;
if (!(out = (unsigned char *)malloc(len))) abort( );
SPC_HMAC_Init(&ctx, key, keylen);
memcpy(ctr, nonce, NONCE_LEN);
memset(ctr + NONCE_LEN, 0, CTR_LEN);
blks = len / MAC_OUT_SZ;
while (blks--) {
SPC_HMAC_Reset(&ctx);
SPC_HMAC_Update(&ctx, ctr, sizeof(ctr));
SPC_HMAC_Final(out, &ctx);
i = NONCE_LEN + CTR_LEN;
/* Increment the counter. */
while (i-- != NONCE_LEN)
if (++ctr[i]) break;
for (i = 0; i < MAC_OUT_SZ; i++) *out++ = *in++ ^ keystream[i];
}
if (len % MAC_OUT_SZ) {
SPC_HMAC_Reset(&ctx);
SPC_HMAC_Update(&ctx, ctr, sizeof(ctr));
SPC_HMAC_Final(out, &ctx);
for (i = 0; i < len % MAC_OUT_SZ; i++) *out++ = *in++ ^ keystream[i];
}
return out;
}
Note that this code is not optimized; it works on individual characters to avoid potential endian-ness problems.
See Also
Recipe 6.4, Recipe 6.10
6.21. Securely Authenticating a MAC (Thwarting Capture Replay Attacks)
Problem
You are using a MAC, and you need to make sure that when you get a message, you properly validate the MAC.
Solution
If you're using an ever-increasing nonce (which we strongly recommend), check to make sure that the nonce associated with the message is indeed larger than the last one. Then, of course, recalculate the MAC and check against the transmitted MAC.
Discussion
The following is an example of validating a MAC using the OMAC1 implementation in Recipe 6.11, along with AES-128. We nonce the MAC by using a 16-byte nonce as the first block of input, as discussed in Recipe 6.12. Note that we expect you to be MAC'ing the ciphertext, as discussed in Recipe 6.18.
#include <stdlib.h>
#include <string.h>
/* last_nonce must be a pointer to a NULL on first invocation. */
int spc_omac1_validate(unsigned char *ct, size_t ctlen, unsigned char sent_nonce[16],
unsigned char *sent_tag, unsigned char *k,
unsigned char **last_nonce) {
int i;
SPC_OMAC_CTX c;
unsigned char calc_tag[16]; /* Maximum tag size for OMAC. */
spc_omac1_init(&c, k, 16);
if (*last_nonce) {
for (i = 0; i < 16; i++)
if (sent_nonce[i] > (*last_nonce)[i]) goto nonce_okay;
return 0; /* Nonce is equal to or less than last nonce. */
}
nonce_okay:
spc_omac_update(&c, sent_nonce, 16);
spc_omac_update(&c, ct, ctlen);
spc_omac_final(&c, calc_tag);
for (i = 0; i < 16; i++)
if (calc_tag[i] != sent_tag[i]) return 0;
if (sent_nonce) {
if (!*last_nonce) *last_nonce = (unsigned char *)malloc(16);
if (!*last_nonce) abort(); /* Consider an exception instead. */
memcpy(*last_nonce, sent_nonce, 16);
}
return 1;
}
This code requires you to pass in a char ** to track the last nonce that was received. You're expected to allocate your own char *, set it to NULL, and pass in the address of that char *. The validate function will update that memory with the last valid nonce it saw, so that it can check the new nonce against the last nonce to make sure it got bigger. The function will return 1 if the MAC validates; otherwise, it will return 0.
See Also
Recipe 6.11, Recipe 6.12, Recipe 6.18
6.22. Parallelizing MACs
Problem
You want to use a MAC, but parallelize the computation.
Solution
Run multiple MACs at the same time, then MAC the resulting tags together (and in order) to yield one tag.
Discussion
If you want to perform message authentication in parallel, you can do so with a variation of interleaving (which we discussed for block ciphers in Recipe 5.12 through Recipe 5.14) Basically, you can run multiple MACs keyed separately at the same time and divide up the data stream between those MACs. For example, you might run two MACs in parallel and alternate sending 64 bytes to each MAC.
The problem with doing this is that your two MAC's authentication values need to be tied together; otherwise, someone could rearrange the two halves of your stream. For example, if you were to MAC this message:
ABCDEFGHIJKL
where MAC 1 processed the first six characters, yielding tag A, and MAC 2 processed the final six, yielding tag B, an attacker could rearrange the message to be:
GHIJKLABCDEF
and report the tags in the reverse order. Authentication would not detect the change. To solve this problem, once all the MACs are reported, MAC all the resulting tags to create a composite MAC. Alternatively, you could take the last MAC context and add in the MAC values for the other contexts before generating the tag, as illustrated in Figure 6-8.
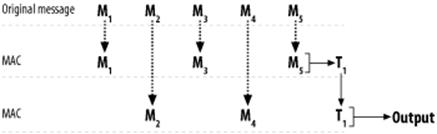
Figure 6-8. Properly interleaving MACs
If your MAC accepts a nonce, you can use the same key for each context, as long as you never reuse a {key, nonce} pair.
Here's a simple sequential example that runs two OMAC1 contexts, alternating every 512 bytes, that produces a single resulting tag of 16 bytes. It uses the OMAC1 implementation from Recipe 6.11.
#include <stddef.h>
#define INTERLEAVE_SIZE 512
unsigned char *spc_double_mac(unsigned char *text, size_t len,
unsigned char key[16]) {
SPC_OMAC_CTX ctx1, ctx2;
unsigned char *out = (unsigned char *)malloc(16);
unsigned char tmp[16];
if (!out) abort(); /* Consider throwing an exception instead. */
spc_omac1_init(&ctx1, key, 16);
spc_omac1_init(&ctx2, key, 16);
while (len > 2 * INTERLEAVE_SIZE) {
spc_omac_update(ctx1, text, INTERLEAVE_SIZE);
spc_omac_update(ctx2, text + INTERLEAVE_SIZE, INTERLEAVE_SIZE);
text += 2 * INTERLEAVE_SIZE;
len -= 2 * INTERLEAVE_SIZE;
}
if (len > INTERLEAVE_SIZE) {
spc_omac_update(ctx1, text, INTERLEAVE_SIZE);
spc_omac_update(ctx2, text + INTERLEAVE_SIZE, len - INTERLEAVE_SIZE);
} else spc_omac_update(ctx1, text, len);
spc_omac_final(ctx1, tmp);
spc_omac_update(ctx2, tmp, sizeof(tmp));
spc_omac_final(ctx2, out);
return out;
}
See Also
Recipe 5.11, Recipe 6.12 through Recipe 6.14
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.