C# in Depth (2012)
Part 4. C# 4: Playing nicely with others
Chapter 15. Asynchrony with async/await
This chapter covers
· The fundamental aims of asynchrony
· Writing async methods and delegates
· Compiler transformations for async
· The task-based asynchronous pattern
· Asynchrony in WinRT
Asynchrony has been a thorn in the side of developers for years. It’s been known to be useful as a way of avoiding tying up a thread while waiting for some arbitrary task to complete, but it’s also been a pain in the neck to implement correctly.
Even within the .NET Framework (which is still relatively young in the grand scheme of things), we’ve had three different models to try to make things simpler:
· The BeginFoo / EndFoo approach from .NET 1.x, using IAsyncResult and AsyncCallback to propagate results
· The event-based asynchronous pattern from .NET 2.0, as implemented by BackgroundWorker and WebClient
· The Task Parallel Library (TPL) introduced in .NET 4 and expanded in .NET 4.5
Despite its generally excellent design, writing robust and readable asynchronous code with the TPL was hard. Although the support for parallelism was great, there are some aspects of general asynchrony that are much better fixed in a language instead of purely in libraries.
Async/await will rock your world
The introductory list of topics may make this chapter sound rather dull. It’s an accurate list, but it fails to convey the excitement I feel about this feature. I’ve been playing with async/await for about two years now, and it still makes me feel like a giddy schoolboy. I firmly believe it will do for asynchrony what LINQ did for data handling when C# 3 came out—except that dealing with asynchrony was a far harder problem. To achieve the proper effect, please read this chapter in an overexcited mental voice. Hopefully I’ll infect you with my enthusiasm for the feature along the way.
The main feature of C# 5 builds on the TPL so that you can write synchronous-looking code that uses asynchrony where appropriate. Gone is the spaghetti of callbacks, event subscriptions, and fragmented error handling; instead, asynchronous code expresses its intentions clearly, and in a form that builds on the structures developers are already familiar with. A new language construct allows you to “await” an asynchronous operation. This “awaiting” looks very much like a normal blocking call, in that the rest of your code won’t continue until the operation has completed, but it manages to do this without blocking the currently executing thread. Don’t worry if that statement sounds completely contradictory—all will become clear over the course of the chapter.
The .NET Framework has embraced asynchrony wholeheartedly in version 4.5, exposing asynchronous versions of a great many operations, following a newly documented task-based asynchronous pattern to give a consistent experience across multiple APIs. Additionally, the new Windows Runtime platform[1] used to create Windows Store applications in Windows 8 enforces asynchrony for all long-running (or potentially long-running) operations. In short, the future is asynchronous, and you’d be foolish not to take advantage of the new language features when trying to manage the additional complexity. Even if you’re not using .NET 4.5, Microsoft has created a NuGet package (Microsoft.Bcl.Async) that allows you to use the new features when targeting .NET 4, Silverlight 4 or 5, or Windows Phone 7.5 or 8.
1 This is commonly known as WinRT; it’s not to be confused with Windows RT, which is the version of Windows 8 that runs on ARM processors.
Just to be clear, C# hasn’t become omniscient, guessing where you might want to perform operations concurrently or asynchronously. The compiler is smart, but it doesn’t attempt to remove the inherent complexity of asynchronous execution. You still need to think carefully, but the beauty of C# 5 is that all the tedious and confusing boilerplate code that used to be required has gone. Without the distraction of all the fluff required to make your code asynchronous to start with, you can concentrate on the hard bits.
A word of warning: this topic is reasonably advanced. It has the unfortunate properties of being incredibly important (realistically, even entry-level developers will need to have a passing understanding of it in a few years) but also quite tricky to get your head around to start with. Just as in the rest of this book, I won’t shy away from the complexity—we’ll look at what’s going on in a fair amount of detail.
It’s just possible that I may break your brain a little, hopefully putting it back together again later on. If it all starts sounding a little crazy, don’t worry—it’s not just you; bafflement is an entirely natural reaction. The good news is that when you’re using C# 5, it all makes sense on the surface. It’s only when you try to think of exactly what’s going on behind the scenes that things get tough. Of course, we’ll do exactly that later on—as well as look at how to use the feature effectively.
Let’s make a start.
15.1. Introducing asynchronous functions
So far I’ve claimed that C# 5 makes async easier, but I’ve only given a tiny description of the features involved. Let’s fix that, and then look at an example.
C# 5 introduces the concept of an asynchronous function. This is always either a method or an anonymous function[2] that’s declared with the async modifier, and it can include await expressions. These await expressions are the points where things get interesting from a language perspective: if the value that the expression is awaiting isn’t available yet, the asynchronous function will return immediately, and it will then continue where it left off (in an appropriate thread) when the value becomes available. The natural flow of “don’t execute the next statement until this one has completed” is still maintained, but without blocking.
2 Just as a reminder, an anonymous function is either a lambda expression or an anonymous method.
I’ll break that woolly description down into more concrete terms and behavior later on, but you really need to see an example of it before it’s likely to make any sense.
15.1.1. First encounters of the asynchronous kind
Let’s start with something very simple, but that demonstrates asynchrony in a practical way. We often curse network latency for causing delays in our real applications, but latency does make it easy to show why asynchrony is so important. Take a look at the following listing.
Listing 15.1. Displaying a page length asynchronously
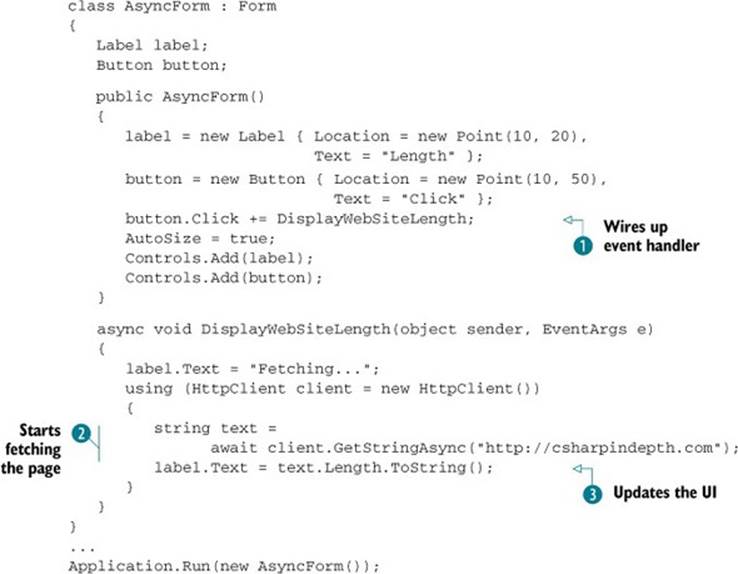
The first part of listing 15.1 simply creates the UI and hooks up an event handler for the button in a straightforward way ![]() . It’s the DisplayWebSiteLength method that’s of interest here. When you click on the button, the text of the book’s home page is fetched
. It’s the DisplayWebSiteLength method that’s of interest here. When you click on the button, the text of the book’s home page is fetched ![]() , and the label is updated to display the HTML length in characters
, and the label is updated to display the HTML length in characters ![]() . The HttpClient is also disposed appropriately, whether the operation succeeds or fails—something that would be all too easy to forget if you were writing similar asynchronous code in C# 4.
. The HttpClient is also disposed appropriately, whether the operation succeeds or fails—something that would be all too easy to forget if you were writing similar asynchronous code in C# 4.
Disposing of tasks
I’m careful to dispose of the -HttpClient when I’m finished using it, but I’m not disposing of the task returned by GetStringAsync, even though Task implements IDisposable. Fortunately, you really don’t need to dispose of tasks in general. The background of this is somewhat complicated, but Stephen Toub explains it in a blog post dedicated to the topic: http://mng.bz/E6L3.
I could have written a smaller example program as a console app, but hopefully listing 15.1 makes a more convincing demo. In particular, if you remove the async and await contextual keywords, change HttpClient to WebClient, and change GetStringAsync to DownloadString, the code will still compile and work...but the UI will freeze while it fetches the contents of the page.[3] If you run the async version (ideally over a slow network connection), you’ll see that the UI is responsive—you can still move the window around while the web page is fetching.
3 HttpClient is in some senses the “new and improved” WebClient—it’s the preferred HTTP API for .NET 4.5 onwards, and it only contains asynchronous operations. If you’re writing a Windows Store app, you don’t even have the option of using WebClient.
Most developers are familiar with the two golden rules of threading in Windows Forms development:
· Don’t perform any time-consuming action on the UI thread.
· Don’t access any UI controls other than on the UI thread.
These are easier to state than to obey. As an exercise, you might want to try a few different ways of creating code similar to listing 15.1without using the new features of C# 5. For this extremely simple example, it’s not actually too bad to use the event-basedWebClient.DownloadStringAsync method, but as soon as more complex flow control (error handling, waiting for multiple pages to complete, and so on) comes into the equation, the “legacy” code quickly becomes hard to maintain, whereas the C# 5 code can be modified in a natural way.
At this point, the DisplayWebSiteLength method feels somewhat magical: you know it does what you need it to, but you have no idea how. Let’s take it apart just a little bit, saving the really gory details for later.
15.1.2. Breaking down the first example
We’ll start by expanding the method very slightly—splitting the call to Http-Client.GetStringAsync from the await expression to highlight the types involved:
async void DisplayWebSiteLength(object sender, EventArgs e)
{
label.Text = "Fetching...";
using (HttpClient client = new HttpClient())
{
Task<string> task =
client.GetStringAsync("http://csharpindepth.com");
string text = await task;
label.Text = text.Length.ToString();
}
}
Notice how the type of task is Task<string>, but the type of the await task expression is just string. In this sense, an await expression performs an “unwrapping” operation—at least when the value being awaited is a Task<TResult>. (You can await other types too, as you’ll see, but Task<TResult> is a good starting point.) That’s one aspect of await that doesn’t seem directly related to asynchrony but makes life easier.
The main purpose of await is to avoid blocking while you wait for time-consuming operations to complete. You may be wondering how this all works in the concrete terms of threading. You’re setting label.Text at both the start and end of the method, so it’s reasonable to assume that both of those statements are executed on the UI thread...and yet you’re clearly not blocking the UI thread while you wait for the web page to download.
The trick is that the method actually returns as soon as you hit the await expression. Up until that point, it executes synchronously on the UI thread, just as any other event handler would. If you put a breakpoint on the first line and hit it in the debugger, you’ll see that the stack trace shows that the button is busy raising its Click event, including the Button.OnClick method. When you reach the await, the code checks whether the result is already available, and if it’s not (which will almost certainly be the case) it schedules a continuation to be executed when the web operation has completed. In this example, the continuation executes the rest of the method, effectively jumping to the end of the await expression, back in the UI thread, just as you want in order to manipulate the UI.
Continuations
A continuation is effectively a callback to be executed when an asynchronous operation (or indeed any Task) has completed. In an async method, the continuation maintains the control state of the method; just as a closure maintains its environment in terms of variables, a continuation remembers where it had got to, so it can continue from there when it’s executed. The Task class has a method specifically for attaching continuations: Task.ContinueWith.
If you then put a breakpoint in the code after the await expression, you’ll see that the stack trace no longer has the Button.OnClick method in it (assuming that the await expression needed to schedule the continuation). That method finished executing long ago. The call stack will now effectively be the bare Windows Forms event loop, with a few layers of async infrastructure on top. The call stack will be very similar to what you’d see if you called Control.Invoke from a background thread in order to update the UI appropriately, but it’s all been done for you. At first it can be unnerving to notice the call stack change dramatically under your feet, but it’s absolutely necessary for asynchrony to be effective.
In case you’re wondering, all of this is handled by the compiler creating a complicated state machine. That’s an implementation detail, and it’s instructive to examine it to get a better grasp of what’s going on, but first we need a more concrete description of what we’re trying to achieve and what the language actually specifies.
15.2. Thinking about asynchrony
If you ask a developer to describe asynchronous execution, chances are they’ll start talking about multithreading. Although that’s an important part of typical uses of asynchrony, it’s not really required for asynchronous execution. To fully appreciate how the async feature of C# 5 works, it’s best to strip away any thoughts of threading and go back to basics.
15.2.1. Fundamentals of asynchronous execution
Asynchrony strikes at the very heart of the execution model that C# developers are familiar with. Consider simple code like this:
Console.WriteLine("First");
Console.WriteLine("Second");
You expect the first call to complete, and then the second call to start. Execution flows from one statement to the next, in order. But an asynchronous execution model doesn’t work that way. Instead, it’s all about continuations. When you start doing something, you tell that operation what you want to happen when that operation has completed. You may have heard (or used) the term callback for the same idea, but that has a broader meaning than the one we’re after here. In the context of asynchrony, I’m using the term to refer to callbacks that preserve the control state of the program—not arbitrary callbacks for other purposes, such as GUI event handlers.
Continuations are naturally represented as delegates in .NET, and they’re typically actions that receive the results of the asynchronous operation. That’s why, to use the asynchronous methods in WebClient prior to C# 5, you would wire up various events to say what code should be executed in the case of success, failure, and so on. The trouble is, creating all those delegates for a complicated sequence of steps ends up being very complicated, even with the benefit of lambda expressions. It’s even worse when you try to make sure that your error handling is correct. (On a good day, I can be reasonably confident that the success paths of handwritten asynchronous code are correct. I’m typically less certain that it reacts the right way on failure.)
Essentially, all that await in C# does is ask the compiler to build a continuation for you. For an idea that can be expressed so simply, however, the consequences for readability and developer sanity are remarkable.
My earlier description of asynchrony was an idealized one. The reality in the task-based asynchronous pattern is slightly different. Instead of the continuation being passed to the asynchronous operation, the asynchronous operation starts and returns a token you can use to provide the continuation later. It represents the ongoing operation, which may have completed before it’s returned to the calling code, or may still be in progress. That token is then used whenever you want to express this idea: “I can’t proceed any further until this operation has completed.” Typically the token is in the form of a Task or Task<TResult>, but it doesn’t have to be.
The execution flow in an asynchronous method in C# 5 typically follows these lines:
1. Do some work.
2. Start an asynchronous operation, and remember the token it returns.
3. Possibly do some more work. (Often you can’t make any further progress until the asynchronous operation has completed, in which case this step is empty.)
4. Wait for the asynchronous operation to complete (via the token).
5. Do some more work.
6. Finish.
If you didn’t care about exactly what the “wait” part meant, you could do all of this in C# 4. If you’re happy to block until the asynchronous operation completes, the token will normally provide you some way of doing so. For a Task, you could just call Wait(). At that point though, you’re taking up a valuable resource (a thread) and not doing any useful work. It’s a little like phoning for a delivery pizza, and then standing at the front door until it arrives. What you really want to do is get on with something else, ignoring the pizza until it arrives. That’s where await comes in.
When you “wait” for an asynchronous operation, you’re really saying, “I’ve gone as far as I can go for now. Keep going when the operation has completed.” But if you’re not going to block the thread, what can you do? Very simply, you can return right then and there. You’ll continue asynchronously yourself. And if you want your caller to know when your asynchronous method has completed, you’ll pass a token back to them, which they can block on if they want, or (more likely) use with another continuation. Often you’ll end up with a whole stack of asynchronous methods calling each other—it’s almost as if you go into an “async mode” for a section of code. There’s nothing in the language that states that it has to be done that way, but the fact that the same code that consumes asynchronous operations also behaves as an asynchronous operation certainly encourages it.
Synchronization contexts
Earlier I mentioned that one of the golden rules of UI code is that you mustn’t update the user interface unless you’re on the right thread. In the “check the web page length” example (listing 15.1) you need to ensure that the code after the await expression executes on the UI thread. Asynchronous functions get back to the right thread using SynchronizationContext—a class that’s existed since .NET 2.0 and is used by other components such as BackgroundWorker. A SynchronizationContext generalizes the idea of executing a delegate “on an appropriate thread”; its Post (asynchronous) and Send (synchronous) messages are similar to Control .BeginInvoke and Control.Invoke in Windows Forms.
Different execution environments use different contexts; for example, one context may let any thread from the thread pool execute the action it’s given. There’s more contextual information around than just the synchronization context, but if you start wondering how asynchronous methods manage to execute exactly where you want them to, bear this sidebar in mind.
For more information on SynchronizationContext, read Stephen Cleary’s MSDN magazine article on the topic (http://mng.bz/5cDw). In particular, pay careful attention if you’re an ASP.NET developer: the ASP.NET context can easily trap unwary developers into creating deadlocks within code that looks fine.
With the theory out of the way, let’s take a closer look at the concrete details of asynchronous methods. Asynchronous anonymous functions fit into the same mental model, but it’s much easier to talk about asynchronous methods.
15.2.2. Modeling asynchronous methods
I find it very useful to think about asynchronous methods as shown in figure 15.1.
Figure 15.1. Async model
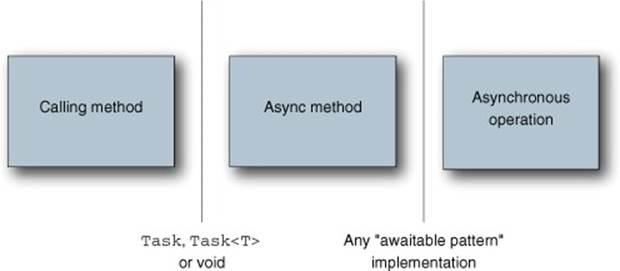
Here you have three blocks of code (the methods) and two boundaries (the method return types). As a very simple example, you might have code like this:
static async Task<int> GetPageLengthAsync(string url)
{
using (HttpClient client = new HttpClient())
{
Task<string> fetchTextTask = client.GetStringAsync(url);
int length = (await fetchTextTask).Length;
return length;
}
}
static void PrintPageLength()
{
Task<int> lengthTask =
GetPageLengthAsync("http://csharpindepth.com");
Console.WriteLine(lengthTask.Result);
}
The five parts of figure 15.1 correspond to the preceding code like this:
· The calling method is PrintPageLength.
· The async method is GetPageLengthAsync.
· The asynchronous operation is HttpClient.GetStringAsync.
· The boundary between the calling method and the async method is Task<int>.
· The boundary between the async method and the asynchronous operation is Task<string>.
We’re mainly interested in the async method itself, but I’ve included the other methods so you can see how they all interact. In particular, you definitely need to know about the valid types at the method boundaries.
I’ll refer to these blocks and boundaries repeatedly in the rest of this chapter, so keep figure 15.1 in mind as you read on.
15.3. Syntax and semantics
We’re finally ready to look at how to write async methods and how they’ll behave. There’s a lot to cover here, as “what you can do” and “what happens when you do it” blend together to a large extent.
There are only two new pieces of syntax: async is a modifier used when declaring an asynchronous method, and await expressions consume asynchronous operations. But following how information is transferred between different parts of your program gets complicated really quickly, especially when you have to consider what happens when things go wrong. I’ve tried to separate out the different aspects, but your code will be dealing with everything at once. If you find yourself asking, “But what about...?” while reading this section, keep reading—chances are your question will be dealt with soon.
Let’s start with the method declaration itself—that’s the easiest bit...
15.3.1. Declaring an async method
The syntax for an async method declaration is exactly the same as for any other method, except it has to include the async contextual keyword. This can appear anywhere before the return type. All of these are valid:
public static async Task<int> FooAsync() { ... }
public async static Task<int> FooAsync() { ... }
async public Task<int> FooAsync() { ... }
public async virtual Task<int> FooAsync() { ... }
My personal preference is to keep the async modifier just before the return type, but there’s no reason you shouldn’t come up with your own convention. As ever, discuss it with your team and try to be consistent within one code base.
Now, the async contextual keyword has a dirty secret: the language designers didn’t really need to include it at all. Just as the compiler goes into a sort of “iterator block mode” when you try to use yield return or yield break in a method with a suitable return type, the compiler couldhave just spotted the use of await inside a method and used that to go into “async mode.” But I’m personally pleased that async is required, as it makes it much easier to read code written using asynchronous methods. It sets your expectations immediately, so you’re actively looking forawait expressions—and you can actively look for any blocking calls that should be turned into an async call and an await expression.
The fact that the async modifier has no representation[4] in the generated code is important, though. As far as the calling method is concerned, it’s just a normal method, possibly returning a task. You can change an existing method (with an appropriate signature) to use async, or you could go in the other direction—it’s a compatible change in terms of both source and binary.
4 Well, sort of. In practice there is an attribute applied, as you’ll see later, but it’s not part of the signature of the method, and it can be ignored as far as humans are concerned. It’s really used to help tools identify where the “real” code has gone.
15.3.2. Return types from async methods
Communication between the caller and the async method is effectively in terms of the value returned. Asynchronous functions are limited to the following return types:
· void
· Task
· Task<TResult> (for some type TResult, which could itself be a type parameter)
The .NET 4 Task and Task<TResult> types both represent an operation that may not have completed yet; Task<TResult> derives from Task. The difference between the two is essentially that Task<TResult> represents an operation that returns a value of type T, whereas Task need not produce a result at all. It’s still useful to return a Task, though, as it allows the caller to attach their own continuations to the returned task, detect when the task has failed or completed, and so on. In some senses, you can think of Task as being like a Task<void> type, if such a thing were valid.
The ability to return void from an async method is designed for compatibility with event handlers. For example, you might have a UI button click handler like this:
private async void LoadStockPrice(object sender, EventArgs e)
{
string ticker = tickerInput.Text;
decimal price = await stockPriceService.FetchPriceAsync(ticker);
priceDisplay.Text = price.ToString("c");
}
This is an asynchronous method, but the calling code (the button OnClick method or whatever piece of framework code is raising the event) doesn’t really care. It doesn’t need to know when you’ve really finished handling the event—when you’ve loaded the stock price and updated the UI. It just calls the event handler it’s been given. The fact that the code generated by the compiler will end up with a state machine attaching a continuation to whatever is returned by FetchPriceAsync is effectively an implementation detail.
You can subscribe to an event with the preceding method as if it were any other event handler:
loadStockPriceButton.Click += LoadStockPrice;
After all (and yes, I’m laboring this deliberately), it’s just a normal method as far as calling code is concerned. It has a void return type and parameters of type object and EventArgs, which makes it suitable as the action for an EventHandler delegate instance.
Event subscription is pretty much the only time I’d recommend returning void from an asynchronous method. Any other time you don’t need to return a specific value, it’s best to declare the method to return Task. That way, the caller is able to await the operation completing, detect failures, and so on.
One additional restriction around the signature of an async method: none of the parameters can use the out or ref modifiers. This makes sense as those modifiers are for communicating information back to the calling code; because some of the async method may not have run by the time control returns to the caller, the value of the by-reference parameter might not have been set. Indeed, it could get stranger than that: imagine passing a local variable as an argument for a ref parameter—the async method could end up trying to set that variable after the calling method had already completed. It doesn’t make a lot of sense to try to do this, so the compiler prohibits it.
Once you’ve declared the method, you can start writing the body and awaiting other asynchronous operations.
15.3.3. The awaitable pattern
An async method can basically contain almost anything a regular C# method can contain, plus await expressions. You can use all kinds of control flow—loops, exceptions, using statements, anything. The code will behave just as normal. The only interesting bits are what awaitexpressions do and how return values are propagated.
Restrictions on await
Just like yield return, there are restrictions around where you can use await expressions. You can’t use them in catch or finally blocks, non-async anonymous functions,[5] the body of a lock statement, or unsafe code.
5 Lambda expressions and anonymous methods that aren’t declared with async—so any anonymous function declaration that would have been valid C# 4. You’ll see async anonymous functions in section 15.4.
These restrictions are for your safety—particularly the restriction around locks. If you ever find yourself wanting to hold a lock while an asynchronous operation completes, you should redesign your code. Don’t work around the compiler restriction by calling Monitor.TryEnter andMonitor.Exit manually with a try/finally block—change your code so you don’t need the lock during the operation. If this is really, really awkward in your situation, consider using SemaphoreSlim instead, with its WaitAsync method.
An await expression is very simple—it’s just await before another expression. But there are limits on what you can await, of course. Just as a reminder, we’re talking about the second boundary from figure 15.1—how the async method interacts with another asynchronous operation. Informally, you can only await something that describes an asynchronous operation. In other words, something that provides you with the means of
· Telling whether or not it’s already finished
· Attaching a continuation if it hasn’t finished
· Getting the result, which may be a return value but at least is an indication of success or failure
You might expect this to be expressed via interfaces, but it’s (mostly) not. There’s only one interface involved, and it just covers the “attaching a continuation” part. Even that is very simple—and you’ll almost never need to deal with it directly. It’s in theSystem.Runtime.CompilerServices namespace and looks like this:
// Real interface in System.Runtime.CompilerServices
public interface INotifyCompletion
{
void OnCompleted(Action continuation);
}
The bulk of the work is expressed via patterns, a bit like foreach and LINQ queries. To make the shape of the pattern clearer, I’ll briefly present it as if there were interfaces involved, but there really aren’t. I’ll cover reality in a moment. Let’s have a look at the imaginary interfaces:
// Warning: these don't really exist
// Imaginary interfaces for asynchronous operations returning values
public interface IAwaitable<T>
{
IAwaiter<T> GetAwaiter();
}
public interface IAwaiter<T> : INotifyCompletion
{
bool IsCompleted { get; }
T GetResult();
// Inherited from INotifyCompletion
// void OnCompleted(Action continuation);
}
// Imaginary interfaces for "void" asynchronous operations
public interface IAwaitable
{
IAwaiter GetAwaiter();
}
public interface IAwaiter : INotifyCompletion
{
bool IsCompleted { get; }
void GetResult();
// Inherited from INotifyCompletion
// void OnCompleted(Action continuation);
}
These probably remind you of IEnumerable<T> and IEnumerator<T>. In order to iterate over a collection in a foreach loop, the compiler generates code that calls GetEnumerator() first, and then uses MoveNext() and Current. Likewise, in async methods, whenever you write anawait expression, the compiler will generate code that first calls GetAwaiter(), and then uses the members of the awaiter to await the result appropriately.
The C# compiler does require the awaiter to implement INotifyCompletion. This is primarily for efficiency reasons; some prerelease versions of the compiler didn’t have the interface at all.
All the other members are checked by the compiler just by signature. Importantly, the GetAwaiter() method itself doesn’t have to be a normal instance method. It can be an extension method on whatever you want to use an await expression with. The IsCompleted and GetResultmembers have to be real members of whatever type is returned from GetAwaiter(), but they don’t have to be public—they just need to be accessible to the code containing the await expression.
The preceding text describes what’s required for an expression to be used as the target of the await keyword, but the whole expression itself also has an interesting type: if the GetResult() returns void, then the overall type of the await expression is nothing—the await expression has to be a standalone statement. Otherwise, the overall type is the same as the return type of GetResult().
For example, Task<TResult>.GetAwaiter() returns a TaskAwaiter<TResult>, which has a GetResult() method returning TResult. (No surprise there, hopefully.) The rule about the type of the await expression is what allows us to write this:
using (var client = new HttpClient())
{
Task<string> task = client.GetStringAsync(...);
string result = await task;
}
Compare that with the static Task.Yield() method, which returns a YieldAwaitable. That, in turn, has a GetAwaiter() method returning a YieldAwaitable.YieldAwaiter, which has a GetResult method returning void. That means you can only use it like this:
await Task.Yield();
Or if you really wanted to split things up—odd though it would be:
YieldAwaitable yielder = Task.Yield();
await yielder;
The await expression here doesn’t return a value of any kind, so you can’t assign it to a variable, or pass it as a method argument, or do anything else you might with expressions classified as values.
One important point to note is that because both Task and Task<TResult> implement the awaitable pattern, you can call one async method from another, and so on:
public async Task<int> FooAsync()
{
string bar = await BarAsync();
// Obviously this would usually be more complicated...
return bar.Length;
}
public async Task<string> BarAsync()
{
// Some async code that could call more async methods...
}
This ability to compose asynchronous operations is one of the aspects of the async feature that really makes it shine. Once you’re in an async mode, it’s very easy to stay there, writing code that flows very naturally.
But I’m getting ahead of myself. I’ve described what the compiler needs in order for you to await something, but not what it actually does.
15.3.4. The flow of await expressions
One of the most curious aspects of the async feature in C# 5 is how await can be simultaneously intuitive and extremely confusing. If you don’t think too hard about it, it’s really simple. If you just accept that it will do what you want, without really defining exactly what you want to start with, you’ll probably be fine...at least until something goes wrong.
Once you start trying to work out exactly what must be going on to achieve the desired effect, things become a bit trickier. Given that you’re reading a book with “In Depth” in the title, I’ll assume you want to know about these details. In the long run, I promise it will allow you to use awaitwith more confidence, and use it more effectively.
Even so, I urge you to try to develop the ability to read asynchronous code on two different levels, depending on your context: when you don’t need to think about the individual steps listed here, let them breeze past you. Read the code almost as if it were synchronous, just taking note of where the code waits asynchronously for some operation or other to complete. Then, when you get stuck on some thorny problem where the code isn’t behaving as you expect it to, you can switch into the more forensic mode, working out which threads will be involved where, and what the call stack will be at any point in time. (I’m not saying this will be simple, but understanding the machinery will at least make it more feasible.)
Expanding complex expressions
Let’s start by simplifying things a bit. Sometimes await is used with the result of a method call or occasionally a property, like this:[6]
6 This example is slightly contrived, as you would normally use a using statement for the HttpClient, but I hope you’ll forgive me for not disposing resources just this once.
string pageText = await new HttpClient().GetStringAsync(url);
This makes it look as if await can modify the meaning of the whole expression. The truth is that await just operates on a single value. The preceding line is equivalent to this:
Task<string> task = new HttpClient().GetStringAsync(url);
string pageText = await task;
Similarly, the result of an await expression can be used as a method argument or within some other expression. Again, it helps if you can separate out the await-specific part from everything else.
Imagine you have two methods, GetHourlyRateAsync() and GetHoursWorkedAsync(), returning a Task<decimal> and a Task<int>, respectively. You might have this complicated statement:
AddPayment(await employee.GetHourlyRateAsync() *
await timeSheet.GetHoursWorkedAsync(employee.Id));
The normal rules of C# expression evaluation apply, and the left operand of the * operator has to be completely evaluated before the right operand is evaluated, so the preceding statement can be expanded as follows:
Task<decimal> hourlyRateTask = employee.GetHourlyRateAsync();
decimal hourlyRate = await hourlyRateTask;
Task<int> hoursWorkedTask = timeSheet.GetHoursWorkedAsync(employee.Id);
int hoursWorked = await hoursWorkedTask;
AddPayment(hourlyRate * hoursWorked);
This expansion reveals a potential inefficiency in the original statement—you could introduce parallelism into this code by starting both tasks (calling both Get...Async methods) before awaiting either of them.
For the moment, the more useful result is that you only need to examine the behavior of await in the context of a value. Even if that value originally came from a method call, you can ignore that method call for the purpose of talking about asynchrony.
Visible behavior
When execution reaches the await expression, there are two possibilities—either the asynchronous operation you’re awaiting has already completed, or it hasn’t.
If the operation has already completed, the execution flow is really simple—it keeps going. If the operation failed and it’s captured an exception to represent that failure, the exception is thrown. Otherwise, any result from the operation is obtained—for example, extracting the string from aTask<string>—and you move on to the next part of the program. All of this is done without any thread context switching or attaching continuations to anything.
You might be wondering why an operation that completes immediately would be represented with asynchrony in the first place. It’s a little bit like calling the Count() method on a sequence in LINQ: in the general case you may need to iterate over every item in the sequence, but in some situations (such as when the sequence turns out to be a List<T>) there’s an easy optimization available. It’s useful to have a single abstraction that covers both scenarios, but without paying an execution-time price. As a real-world example in the asynchronous API case, consider reading asynchronously from a stream associated with a file on disk. All the data you want to read may already have been fetched from disk into memory, perhaps as part of previous ReadAsync call request, so it makes sense to use it immediately, without going through all the other async machinery.
The more interesting scenario is where the asynchronous operation is still ongoing. In this case, the method waits asynchronously for the operation to complete, and then continues in an appropriate context. This “asynchronous waiting” really means the method isn’t executing at all. A continuation is attached to the asynchronous operation, and the method returns. It’s up to the asynchronous operation to make sure that the method resumes on the right thread—typically either a thread-pool thread (where it doesn’t matter which thread is used) or the UI thread where that makes sense.
From the developer’s point of view, this feels like the method is just paused while the asynchronous operation completes. The compiler makes sure that all the local variables used within the method have the same values as they did before the continuation—just as it does with iterator blocks.
I’ve attempted to capture this flow in figure 15.2, although classic flowcharts weren’t really designed with asynchronous behavior in mind.
Figure 15.2. User-visible model of await handling
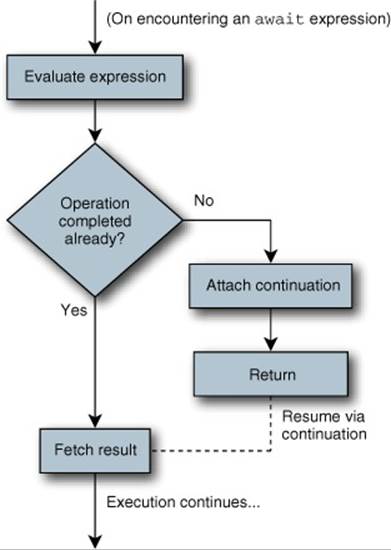
You could think of the dotted line as being another line coming into the top of the flowchart as an alternative. Note that I’m assuming the target of the await expression has a result. If you’re just awaiting a plain Task or something similar, “fetch result” really means “check the operation completed successfully.”
It’s worth stopping to think briefly about what it means to “return” from an asynchronous method. Again, there are two possibilities:
· This is the first await expression you’ve actually had to wait for, so you still have the original caller somewhere in your stack. (Remember that until you really need to wait, the method executes synchronously.)
· You’ve already awaited something else, so you’re in a continuation that has been called by something. Your call stack will almost certainly have changed very significantly from the one you’d have seen when you first entered the method.
In the first case, you’ll usually end up returning a Task or Task<T> to the caller. Obviously you don’t have the actual result of the method yet—even if there’s no value to return as such, you don’t know whether the method will complete without exceptions. Because of this, the task you’ll be returning has to be an uncompleted one.
In the latter case, the “something” calling you back depends on your context. For example, in a Windows Forms UI, if you started your async method on the UI thread and didn’t deliberately switch away from it, the whole method would execute on the UI thread. For the first part of the method, you’ll be in some event handler or other—whatever kicked off the async method. Later on, however, you’d be called back by the message pump pretty directly, as if you were using Control.BeginInvoke(continuation). Here, the calling code—whether it’s the Windows Forms message pump, part of the thread pool machinery, or something else—doesn’t care about your task.
Note that until you hit the first truly asynchronous await expression, the method executes entirely synchronously. Calling an asynchronous method is not like firing up a new task in a separate thread, and it’s up to you to make sure that you always write async methods so they return quickly. Admittedly, it depends on the context in which you’re writing code, but you should generally avoid performing long-running work in an async method. Separate it out into another method that you can create a Task for.
The use of awaitable pattern members
Now that you understand what you need to achieve, it’s reasonably easy to see how the members of the awaitable pattern are used. Figure 15.3 is really just the same as figure 15.2, but fleshed out to include the calls to the pattern.
Figure 15.3. Await handling via the awaitable pattern
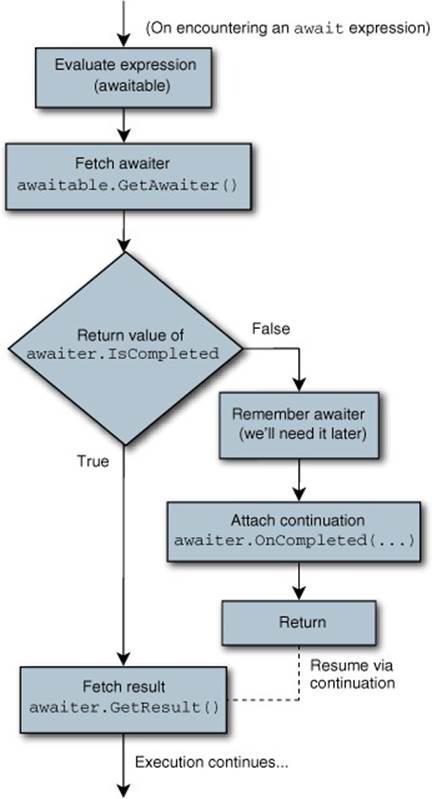
When it’s written like this, you might be wondering what all the fuss is about—why is it worth having language support at all? Attaching a continuation is more complex than you might imagine, though. In very simple cases, when the control flow is entirely linear (do some work, await something, do some more work, await something else), it’s pretty easy to imagine what the continuation might look like as a lambda expression, even if it wouldn’t be very pleasant. As soon as the code contains loops or conditions, however, and you want to keep the code within one method, life becomes very much more complicated. It’s here that the benefits of C# 5 really kick in. Although you could argue that the compiler is just applying syntactic sugar, there’s an enormous difference in readability between manually creating the continuations and getting the compiler to do so for you.
Unlike simple transformations, such as automatically implemented properties, the code generated by the compiler is quite different from what you’d probably write by hand, even when the async method itself is almost trivial. We’ll look at a little bit of this transformation in a later section, but you can already see some of the “man behind the curtain”—hopefully async methods are feeling a little less mysterious now.
I’ve already described the limitations on async method return types, and you’ve seen how an await expression unwraps asynchronous operation results via the GetResult() method, but I haven’t talked about the link between the two, or how you can return values from async methods.
15.3.5. Returning from an async method
You’ve already seen an example that returned data, but let’s look at it again, this time focusing on the return aspect alone:
static async Task<int> GetPageLengthAsync(string url)
{
using (HttpClient client = new HttpClient())
{
Task<string> fetchTextTask = client.GetStringAsync(url);
int length = (await fetchTextTask).Length;
return length;
}
}
You can see that the type of length is int, but the return type of the method is Task<int>. The generated code takes care of the wrapping for you, so that the caller gets a Task<int>, which will eventually have the value returned from the method when it completes. A method returning just Task is like a normal void method—it doesn’t need a return statement at all, and any return statements it does have must be simply return; rather than trying to specify a value. In either case, the task will also propagate any exception thrown within the async method.
Hopefully by now you should have a good intuition about why this wrapping is necessary: you’re almost certainly returning to the caller before you hit the return statement, and you’ve got to propagate the information to that caller somehow. A Task<T> (often known as a future in computer science) is the promise of a value—or an exception—at a later time.
Just as with normal execution flow, if the return statement occurs within the scope of a try block that has an associated finally block (including when all of this happens due to a using statement), the expression used to compute the return value is evaluated immediately, but it doesn’t become the result of the task until everything has been cleaned up. This means that if the finally block throws an exception, you don’t get a task that both succeeds and fails—the whole thing will fail.
To reiterate a point I made earlier, it’s the combination of automatic wrapping and unwrapping that makes the async feature work so well with composition. You can think of this as being a bit like LINQ: you write operations on each element of a sequence in LINQ, and the wrapping and unwrapping means you can apply those operations to sequences and get sequences back. In an async world, you rarely need to explicitly handle a task—instead you await the task to consume it, and produce a result task automatically as part of the mechanism of the async method.
15.3.6. Exceptions
Of course, things don’t always work smoothly, and the idiomatic way of representing failures in .NET is via exceptions. Like returning a value to the caller, exception handling requires extra support from the language. When you want to throw an exception, the original caller of the async method may not be on the stack; and when you await an asynchronous operation that’s failed, it may well not have executed on the same thread, so you need a way of marshaling the failure across. If you think of failure as just another kind of result, it makes sense that exceptions and return values are handled similarly.
In this section we’ll look at how exceptions cross over both of the boundaries in figure 15.1. Let’s start with the boundary between the async method and the asynchronous operation it’s awaiting.
Unwrapping exceptions when awaiting
Just as the GetResult() method of an awaiter is meant to fetch the return value if there is one, it’s also responsible for propagating any exceptions from the asynchronous operation back to the method. This isn’t quite as simple as it sounds, because in an asynchronous world a single Taskcan represent multiple operations, leading to multiple failures. Although other awaitable pattern implementations are available, it’s worth considering Task specifically, as it’s the type you’re likely to be awaiting for the vast majority of the time.
Task indicates exceptions in a number of ways:
· The Status of a task becomes Faulted when the asynchronous operation has failed (and IsFaulted returns true).
· The Exception property returns an AggregateException containing all the (potentially multiple) exceptions that caused the task to fail, or null if the task isn’t faulted.
· The Wait() method will throw an AggregateException if the task ends up in a faulted state.
· The Result property of Task<T> (which also waits for completion) will likewise throw an AggregateException.
Additionally, tasks support the idea of cancellation, via CancellationTokenSource and CancellationToken. If a task is canceled, the Wait() method and Result properties will throw an AggregateException containing an OperationCanceledException (in practice, aTaskCanceledException, which derives from OperationCanceledException), but the status becomes Canceled instead of Faulted.
When you await a task, if it’s either faulted or canceled, an exception will be thrown—but not the AggregateException. Instead, for convenience (in most cases), the first exception within the AggregateException is thrown. In most cases, this is really what you want. It’s in the spirit of the async feature to allow you to write asynchronous code that looks very much like the synchronous code you’d otherwise write. For example, consider something like this:
async Task<string> FetchFirstSuccessfulAsync(IEnumerable<string> urls)
{
// TODO: Validate that we've actually got some URLs...
foreach (string url in urls)
{
try
{
using (var client = new HttpClient())
{
return await client.GetStringAsync(url);
}
}
catch (WebException exception)
{
// TODO: Logging, update statistics etc.
}
}
throw new WebException("No URLs succeeded");
}
For the moment, ignore the fact that you’re losing all the original exceptions, and that you’re fetching all the pages sequentially. The point I’m trying to make is that catching WebException is what you’d expect here—you’re trying an asynchronous operation with an HttpClient, and if something fails it’ll throw a WebException. You want to catch and handle that...right? That certainly feels like what you’d want to do—but, of course, GetStringAsync() can’t throw a WebException for an error such as the server timing out because the method only starts the operation. All it can do is return a task that is faulted containing a WebException. If you simply called Wait() on the task, an AggregateException would be thrown, containing the WebException within it. The task awaiter’s GetResult method just throws the WebException instead, and it’s caught in the preceding code.
Of course, this can lose information. If there are multiple exceptions in a faulted task, GetResult can only throw one of them, and it arbitrarily uses the first. You might want to rewrite the preceding code so that on failure, the caller can catch an AggregateException and examine all the causes of the failure. Importantly, some framework methods such as Task.WhenAll() do exactly this—WhenAll() is a method that will asynchronously wait for multiple tasks (specified in the method call) to complete. If any of them fails, the result is a failure that will contain the exceptions from all the faulted tasks. But if you just await the task returned by WhenAll(), you’ll only see the first exception.
Fortunately, it doesn’t take very much work to fix this. You can use your knowledge of the awaitable pattern and write an extension method on Task<T> to create a special awaitable that will throw the original AggregateException from a task. The full code is a little unwieldy for the printed page, but the gist of it is shown in the following listing.
Listing 15.2. Rewrapping multiple exceptions from task failures

You’d probably want a similar approach for Task<T>, using return task.Result; in GetResult() instead of calling Wait(). The important point is that you delegate to the task’s normal awaiter for the bits you don’t want to handle yourself ![]() , but sidestep the usual behavior ofGetResult(), which is where the exception unwrapping takes place. By the time GetResult is called, you know that the task is in a terminal state, so the Wait() call
, but sidestep the usual behavior ofGetResult(), which is where the exception unwrapping takes place. By the time GetResult is called, you know that the task is in a terminal state, so the Wait() call ![]() will complete immediately—this doesn’t violate the asynchrony you’re trying to achieve.
will complete immediately—this doesn’t violate the asynchrony you’re trying to achieve.
To use the code, you just need to call the extension method and await the result, as shown next.
Listing 15.3. Catching multiple exceptions as AggregateException
private async static Task CatchMultipleExceptions()
{
Task task1 = Task.Run(() => { throw new Exception("Message 1");
});
Task task2 = Task.Run(() => { throw new Exception("Message 2");
});
try
{
await Task.WhenAll(task1, task2).WithAggregatedExceptions();
}
catch (AggregateException e)
{
Console.WriteLine("Caught {0} exceptions: {1}",
e.InnerExceptions.Count,
string.Join(", ",
e.InnerExceptions.Select(x => x.Message)));
}
}
WithAggregatedExceptions() returns your custom awaitable; GetAwaiter() from that, in turn, supplies the custom awaiter, which supports the operations the C# compiler requires to await the result. Note that you could have coalesced the awaitable and the awaiter—there’s nothing to say they have to be different types—but it feels a little cleaner to separate them.
Here’s the output of listing 15.3:
Caught 2 exceptions: Message 1, Message 2
It’s relatively rare that you’ll want to do this—sufficiently rare that Microsoft didn’t include any support for it in the framework—but it’s worth knowing about this option.
That’s all you need to know about exception handling for the second boundary, at least for now. But what about the first boundary, between the async method and the caller?
Wrapping exceptions when throwing
You may well be able to predict what’s coming here: async methods never throw exceptions directly when called. Instead, for async methods returning Task or Task<T>, any exceptions thrown within the method (including those propagated up from other operations, whether synchronous or asynchronous) are simply transferred to the task, as you’ve already seen. If the caller waits on the task directly, they’ll get an AggregateException containing the exception, but if the caller uses await instead, the exception will be unwrapped from the task. Async methods that returnvoid will report the exception to the original SynchronizationContext—how that handles it is up to the context.[7]
7 We’ll discuss contexts in more detail in section 15.6.4.
Unless you really care about the wrapping and unwrapping for a particular context, you can just catch the exception the nested async method has thrown. The following listing demonstrates how familiar this feels:
Listing 15.4. Handling asynchronous exceptions in a familiar style
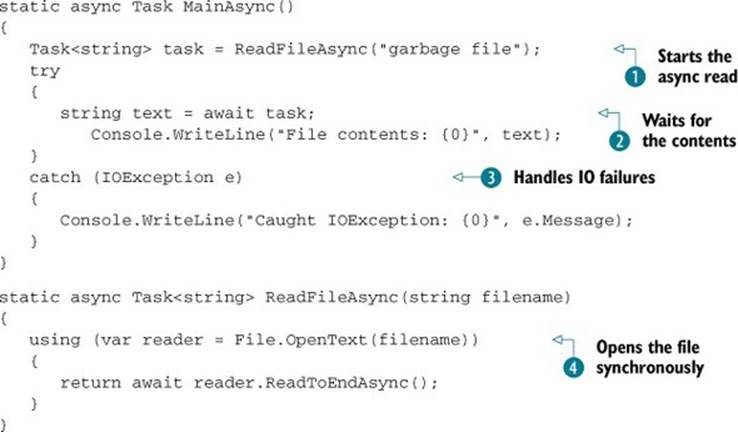
Here you’ll get an IOException in the File.OpenText call ![]() (unless you create a file called “garbage file”), but you’d see the same execution path if the task returned by ReadToEndAsync failed. Within MainAsync, the call to ReadFileAsync
(unless you create a file called “garbage file”), but you’d see the same execution path if the task returned by ReadToEndAsync failed. Within MainAsync, the call to ReadFileAsync ![]() happens before you enter the tryblock, but it’s only when you await the task
happens before you enter the tryblock, but it’s only when you await the task ![]() that the exception is seen by the caller and caught by the catch block
that the exception is seen by the caller and caught by the catch block ![]() , just like with the WebException example earlier. Again, it behaves in a very familiar way—except perhaps for the timing of the exception.
, just like with the WebException example earlier. Again, it behaves in a very familiar way—except perhaps for the timing of the exception.
Just like iterator blocks, this is a bit of a pain in terms of argument validation. Suppose you want to do some work in an async method after validating that the parameters don’t have null values. If you validate the parameters as you would in a normal synchronous code, the caller won’t have any indication of the problem until the task is awaited. The following listing gives an example of this.
Listing 15.5. Broken argument validation in an async method

Listing 15.5 outputs Fetched the task before it fails. The exception has actually been thrown synchronously before that output is written, as there are no await expressions before the validation ![]() , but the calling code won’t see it until it awaits the returned task
, but the calling code won’t see it until it awaits the returned task ![]() . Generally, for argument validation that can sensibly be done up front without taking a long time (or incurring other asynchronous operations), it would be better if the failure were reported immediately, before the system can get itself into further trouble. As an example of this,HttpClient.GetStringAsync will throw an exception immediately if you pass it a null reference.
. Generally, for argument validation that can sensibly be done up front without taking a long time (or incurring other asynchronous operations), it would be better if the failure were reported immediately, before the system can get itself into further trouble. As an example of this,HttpClient.GetStringAsync will throw an exception immediately if you pass it a null reference.
There are two approaches to forcing the exception to be thrown “eagerly” in C# 5. The first is to split the argument validation from the implementation, in the same way you did for iterator blocks in listing 6.9. The following listing shows a fixed version of ComputeLengthAsync.
Listing 15.6. Splitting argument validation from async implementation
static Task<int> ComputeLengthAsync(string text)
{
if (text == null)
{
throw new ArgumentNullException("text");
}
return ComputeLengthAsyncImpl(text);
}
static async Task<int> ComputeLengthAsyncImpl(string text)
{
await Task.Delay(500); // Simulate real asynchronous work
return text.Length;
}
In listing 15.6, ComputeLengthAsync itself isn’t an asynchronous method as far as the language is concerned—it doesn’t have the async modifier. It executes using the normal execution flow, so if the argument validation at the start of the method throws an exception, it really throws an exception. If that passes, however, the task returned is the one created by the ComputeLengthAsyncImpl method, which is where the real work occurs. In a more real-world scenario, ComputeLengthAsync would probably be a public or internal method, and ComputeLengthAsyncImplshould be private, because it assumes that the argument validation has already been performed.
The other approach to eager validation is to use asynchronous anonymous functions—we’ll revisit this example when we look at those in section 15.4.
There’s one other kind of exception that’s handled differently within asynchronous methods: cancellation.
Handling cancellation
The Task Parallel Library (TPL) introduced a uniform cancellation model into .NET 4 using two types: CancellationTokenSource and CancellationToken. The idea is that you can create a CancellationTokenSource, and then ask it for a CancellationToken, which is passed to an asynchronous operation. You can only perform the cancellation on the source, but that is reflected to the token. (This means you can pass out the same token to multiple operations and not worry about them interfering with each other.) There are various ways of using the cancellation token, but the most idiomatic approach is to call ThrowIfCancellationRequested, which will throw OperationCanceledException if the token has been canceled and do nothing otherwise. The same exception is thrown by synchronous calls (such as Task.Wait) if they’re canceled.
How this interacts with asynchronous methods is undocumented in the C# 5 specification. According to the specification, if an asynchronous method body throws any exception, the task returned by the method will be in a faulted state. The exact meaning of “faulted” is implementation-specific, but in reality if an asynchronous method throws an OperationCanceledException (or a derived exception type, such as TaskCanceledException), the returned task will end up with a status of Canceled. The following listing proves that it really is an exception that causes the task to be canceled.
Listing 15.7. Creating a canceled task by throwing OperationCanceledException
static async Task ThrowCancellationException()
{
throw new OperationCanceledException();
}
...
Task task = ThrowCancellationException();
Console.WriteLine(task.Status);
This outputs Canceled rather than the Faulted you might expect from the specification. If you Wait() on the task, or ask for its result (in the case of a Task<T>), the exception is still thrown within an AggregateException, so it’s not like you need to explicitly start checking for cancellation on every task you use.
Off to the races?
You might be wondering if there’s a race condition in listing 15.7. After all, you’re calling an asynchronous method and then immediately expecting the status to be fixed. If you were actually starting a new thread, that would be dangerous...but you’re not. Remember that before the firstawait expression, an asynchronous method runs synchronously—it still performs result and exception wrapping, but the fact that it’s in an asynchronous method does not necessarily mean there are any more threads involved. The ThrowCancellationException method doesn’t contain any await expressions, so the whole method (all one line of it) runs synchronously; you know that you’ll have a result by the time it returns. Visual Studio actually warns you about an asynchronous method without any await expressions in it, but in this case it’s exactly what you want.
Importantly, if you await an operation that’s canceled, the original OperationCanceledException is thrown. This means that unless you take any direct action, the task returned from the asynchronous method will also be canceled—cancellation is propagated in a natural fashion.
The following listing gives a slightly more realistic example of task cancellation.
Listing 15.8. Cancellation of an async method via a canceled delay

Here you start an asynchronous operation ![]() that simply calls into Task.Delay to simulate real work
that simply calls into Task.Delay to simulate real work ![]() , but provides a cancellation token. This time, you really do have multiple threads involved: when it hits the await expression, control returns to the calling method, at which point you ask the cancellation token to be canceled in 1 second
, but provides a cancellation token. This time, you really do have multiple threads involved: when it hits the await expression, control returns to the calling method, at which point you ask the cancellation token to be canceled in 1 second ![]() . You then wait (synchronously) for the task to finish
. You then wait (synchronously) for the task to finish ![]() , fully expecting it to end with an exception. Finally, you show the status of the task
, fully expecting it to end with an exception. Finally, you show the status of the task ![]() .
.
The output of 15.8 looks like this:
Waiting for 30 seconds...
Initial status: WaitingForActivation
Caught System.Threading.Tasks.TaskCanceledException: A task was canceled.
Final status: Canceled
You can think of this in terms of cancellation being transitive by default: if operation A is waiting for operation B, and operation B is canceled, then you regard operation A as being canceled too.
Of course, you don’t have to leave it that way. You could have caught the OperationCanceledException in the DelayFor30Seconds method and either continued to do something else, or returned immediately, or even thrown a different exception. Again, the async feature isn’t removing control; it’s just giving you useful default behavior.
Careful where you run this!
Listing 15.8 works fine in a console application, or when called from a thread-pool thread, but if you execute it on a Windows Forms UI thread (or any other single-thread synchronization context), it will deadlock. Can you see why? Think about which thread the DelayFor-30Secondsmethod will try to return to when the delayed task completes, and then think about which thread the task.Wait() call is running on. This is a relatively simple example, but the same type of mistake has caused problems for several developers when they first started out with asynchronous code. Fundamentally, the problem is in using the Wait() method call, or the Result property, both of which will block until the relevant task completes. I’m not saying you shouldn’t use them, but you should think very carefully any time you do use them. You should usually be usingawait to asynchronously wait for the results of tasks instead.
That pretty much covers the behavior of asynchronous methods. It’s likely that most of your use of the async feature in C# 5 will be via asynchronous methods, but they do have a close sibling...
15.4. Asynchronous anonymous functions
I won’t spend much time on asynchronous anonymous functions. As you’d probably expect, they’re a combination of two features: anonymous functions (lambda expressions and anonymous methods) and asynchronous functions (code that can include await expressions). Basically, they allow you to create delegates[8] that represent asynchronous operations. Everything you’ve learned so far about asynchronous methods applies to asynchronous anonymous functions too.
8 In case you were wondering, you can’t use asynchronous anonymous functions to create expression trees.
You create an asynchronous anonymous function just like any other anonymous method or lambda expression, just with the async modifier at the start. Here’s an example:
Func<Task> lambda = async () => await Task.Delay(1000);
Func<Task<int>> anonMethod = async delegate()
{
Console.WriteLine("Started");
await Task.Delay(1000);
Console.WriteLine("Finished");
return 10;
};
The delegate you create has to have a signature with a return type of void, Task, or Task<T>, just as with an asynchronous method. You can capture variables, as with other anonymous functions, and add parameters. Also, the asynchronous operation doesn’t start until the delegate is invoked, and multiple invocations create multiple operations. Delegate invocation really does start the operation though; just as before, it’s not awaiting that starts an operation, and you don’t have to use await with the result of an asynchronous anonymous function at all.
The following listing shows a slightly fuller (although still pointless) example.
Listing 15.9. Creating and calling an asynchronous function using a lambda expression
Func<int, Task<int>> function = async x =>
{
Console.WriteLine("Starting... x={0}", x);
await Task.Delay(x * 1000);
Console.WriteLine("Finished... x={0}", x);
return x * 2;
};
Task<int> first = function(5);
Task<int> second = function(3);
Console.WriteLine("First result: {0}", first.Result);
Console.WriteLine("Second result: {0}", second.Result);
I’ve deliberately chosen the values here so that the second operation completes quicker than the first. But because you wait for the first to finish before printing the results (using the Result property, which blocks until the task has completed—again, be careful where you run this!), the output looks like this:
Starting... x=5
Starting... x=3
Finished... x=3
Finished... x=5
First result: 10
Second result: 6
Again, this is exactly the same as if you’d put the asynchronous code into an asynchronous method.
I find it hard to get terribly excited about asynchronous anonymous functions, but they have their uses. Although you can’t include them in LINQ query expressions, there are still cases where you might want to perform data transformations asynchronously. You just need to think about the whole process in a slightly different way.
We’ll come back to that idea when we discuss composition, but first I want to show you one area where they really are very useful indeed. I promised earlier that I’d show another way of performing eager argument validation at the start of an asynchronous method. You’ll remember that we wanted to check a parameter value for nullity before launching into the main operation. The following listing is a single method that achieves the same result as the split implementation in listing 15.6.
Listing 15.10. Argument validation using an async anonymous function

You’ll note that this isn’t an asynchronous method. If it were, the exception would be wrapped up in a task instead of being thrown immediately. You still want to return a task though, so after the validation ![]() , you just wrap the work up in an asynchronous anonymous function
, you just wrap the work up in an asynchronous anonymous function ![]() , call the delegate
, call the delegate ![]() , and return the result.
, and return the result.
While this is still a little bit ugly, it’s cleaner than having to split the method in two. There’s a performance penalty to be aware of though: this extra wrapping doesn’t come for free. In most cases that’s fine, but if you’re writing a library that may be used in performance-critical work, you should check the cost in your actual scenario before deciding which approach to use.
VB superiority?
In version 11, Visual Basic finally gained the iterator block support that C# has had since version 2. The delay has allowed the team to reflect on C#’s shortcomings though—the Visual Basic implementation allows anonymous iterator functions, permitting the same kind of in-method split between eager and deferred execution. The feature hasn’t (yet) been added to C#...
You’ve now seen pretty much all there is in terms of the async feature in C# 5. For the remainder of the chapter, we’ll dig into some implementation details and then look at how to get the most out of the feature. All of this will assume that you’re reasonably comfortable with everything that’s gone before—if you haven’t tried any of the sample code yet (or ideally your own experimental code), now would be a great time to do so. Even if you think you understand the theory, it’s well worth playing with async and await to really get the feeling of what it’s like to program asynchrony in a somewhat-synchronous style.
15.5. Implementation details: compiler transformation
I vividly remember the evening of October 28, 2010. Anders Hejlsberg was presenting async/await at PDC, and shortly before his talk started, an avalanche of downloadable material was made available—including a draft of the changes to the C# specification, a CTP (Community Technology Preview) of the C# 5 compiler, and the slides Anders was presenting. At one point I was watching the talk live and skimming through the slides while the CTP installed. By the time Anders had finished, I was writing async code and trying things out.
In the next few weeks, I started taking bits apart—looking at exactly what code the compiler was generating, trying to write my own simplistic implementation of the library that came with the CTP, and generally poking at it from every angle. As new versions came out, I worked out what had changed and became more and more comfortable with what was going on behind the scenes. The more I saw, the more I appreciated how much boilerplate code the compiler is happy to write on our behalf. It’s like looking at a beautiful flower under a microscope: the beauty is still there to be admired, but there’s so much more to it than can be seen at first glance.
Not everyone is like me, of course. If you just want to rely on the behavior I’ve already described, and simply trust that the compiler will do the right thing, that’s absolutely fine. Alternatively, you won’t miss out on anything if you skip this section for now and come back to it at a later date—none of the rest of the chapter relies on it. It’s unlikely that you’ll ever have to debug your code down to the level that we’ll look at here...but I believe this section will give you more insight into how the whole feature hangs together. The awaitable pattern certainly makes a lot more sense once you’ve looked at the generated code, and you’ll see some of the types that the framework provides to help the compiler. Some of the scariest details are only present due to optimization; the design and implementation are very carefully tuned to avoid unnecessary heap allocations and context switches, for example.
As a rough approximation, we’ll pretend the C# compiler performs a transformation from “C# code using async/await” to “C# code without using async/await.” In reality, the internals of the compiler aren’t available to us, and it’s more than likely that this transformation occurs at a lower level than C#. Certainly the generated IL can’t always be expressed in non-async C#, as C# has tighter restrictions around flow control than IL does. But it’s simpler for us to think of it as C#, in terms of how the jigsaw of code fits together.
The generated code is somewhat like an onion, with layers of complexity. We’ll start from the very outside, working our way in toward the tricky bit—await expressions and the dance of awaiters and continuations.
15.5.1. Overview of the generated code
Still with me? Let’s get started. I won’t go into all the depth I could here—that could fill hundreds of pages—but I’ll give you enough background to understand the overall structure, and then you can either read the various blog posts I’ve written over the past couple of years for more intricate detail, or simply write some asynchronous code and decompile it. Also, I’ll only cover asynchronous methods—that will include all the interesting machinery, and you won’t need to deal with the extra layer of indirection that asynchronous anonymous functions present.
Warning, brave traveler—here be implementation details!
This section documents some aspects of the implementation found in the Microsoft C# 5 compiler, released with .NET 4.5. A few details changed pretty substantially between CTP versions and in the beta, and they may well change again in the future. But I think it unlikely that the fundamental ideas will change much though. If you understand enough of this section to be comfortable that there’s no magic involved, just really clever compiler-generated code, you should be able to take any future changes to the details in your stride.
As I’ve mentioned a couple of times, the implementation (both in this approximation and in the code generated by the real compiler) is basically in the form of a state machine. The compiler will generate a private nested struct to represent the asynchronous method, and it must also include a method with the same signature as the one you’ve declared. I call this the skeleton method—there’s not much to it, but everything else hangs off it.
The skeleton method needs to create the state machine, make it perform a single step (where a step is whatever code executes before the first genuinely waiting await expression), and then return a task to represent the state machine’s progress. (Don’t forget that until you hit the first awaitexpression that actually needs to wait, execution is synchronous.) After that, the method’s job is done—the state machine looks after everything else, and continuations attached to other asynchronous operations simply tell the state machine to perform another step. The state machine signals when it’s reached the end by giving the appropriate result to the task that was returned earlier. Figure 15.4 shows a flow diagram of this, as best I can represent it.
Figure 15.4. Flowchart of generated code
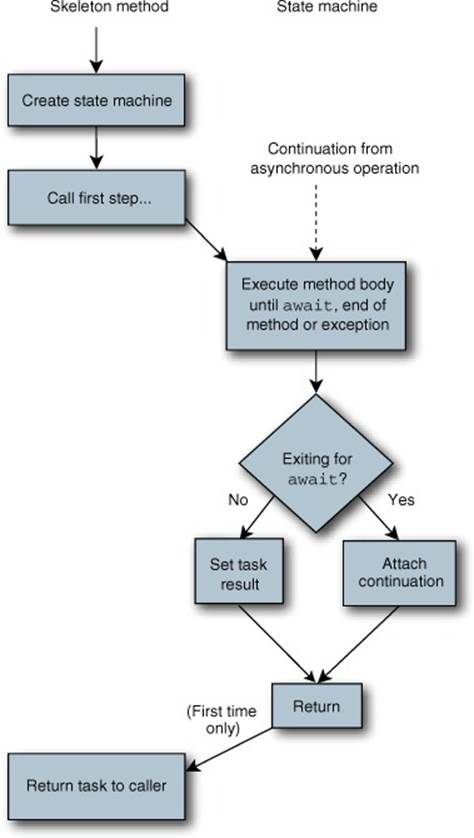
Of course the “execute method body” step only starts from the beginning of the method the first time it’s called, from the skeleton method. After that, each time you get to that block, it’s via a continuation, at which point execution effectively continues from where it left off.
We now have two things to look at: the skeleton method and the state machine. For most of the remainder of this section, I’ll use a single sample asynchronous method, shown in the following listing.
Listing 15.11. Simple async method to demonstrate compiler transformations
static async Task<int> SumCharactersAsync(IEnumerable<char> text)
{
int total = 0;
foreach (char ch in text)
{
int unicode = ch;
await Task.Delay(unicode);
total += unicode;
}
await Task.Yield();
return total;
}
Listing 15.11 doesn’t do anything useful, but we’re really just interested in the control flow. It’s worth noting a few points before we start:
· The method has a parameter (text).
· It contains a loop that you effectively need to jump back into when the continuation executes.
· It has two await expressions of different types: Task.Delay returns a Task, but Task.Yield() returns a YieldAwaitable.
· It has obvious local variables (total, ch, and unicode) that you’ll need to keep track of across calls.
· It has an implicit local variable created by calling text.GetEnumerator().
· It returns a value at the end of the method.
The original version of this code had text as a string parameter, but the C# compiler knows about iterating over strings in an efficient way, using the Length property and the indexer, which made the decompiled code more complicated.
I won’t present the complete decompiled code, although it’s in the downloadable source. In the next few sections we’ll look at a few of the most important parts. You won’t see exactly this code if you decompile the code yourself; I’ve renamed variables and types so they’re rather more legible, but it’s effectively the same code.
Let’s start off with the simplest bit—the skeleton method.
15.5.2. Structure of the skeleton method
Although the code in the skeleton method is simple, it offers some hints about the state machine’s responsibilities. The skeleton method generated for listing 15.11 looks like this:
[DebuggerStepThrough]
[AsyncStateMachine(typeof(DemoStateMachine))]
static Task<int> SumCharactersAsync(IEnumerable<char> text)
{
var machine = new DemoStateMachine();
machine.text = text;
machine.builder = AsyncTaskMethodBuilder<int>.Create();
machine.state = -1;
machine.builder.Start(ref machine);
return machine.builder.Task;
}
The AsyncStateMachineAttribute type is just one of the new attributes introduced for async. It’s really for the benefit of tools—you’re unlikely to ever need to consume it yourself, and you shouldn’t start decorating your own methods with it.
You can see three of the fields of the state machine already:
· One for the parameter (text). Obviously there are as many fields here as there are parameters.
· One for an AsyncTaskMethodBuilder<int>. This struct is effectively responsible for tying the state machine and the skeleton method together. There’s a nongeneric equivalent for methods returning just Task and an AsyncVoidMethodBuilder structure for methods returningvoid.
· One for state, starting off with a value of -1. The initial value is always -1, and we’ll take a look at what various possible values mean later.
Given that the state machine is a struct, and AsyncTaskMethodBuilder<int> is a struct, you haven’t knowingly performed any heap allocation yet. It’s entirely possible for the various calls you’re making to have done so for you, of course, but it’s worth noting that the code tries to avoid them as far as possible. The nature of asynchrony means that if any await expressions need to really wait, you’ll need a lot of these values on the heap, but the code makes sure that they’re only boxed when they need to be. All of this is an implementation detail, just like the heap and the stack are implementation details, but in order for async to be practical in as many situations as possible, the teams involved in Microsoft have worked closely to reduce allocations to the bare minimum.
The machine.builder.Start(ref machine) call is an interesting one. The use of pass-by-reference here allows you to avoid creating a copy of the state machine (and thus a copy of the builder)—this is for both performance and correctness. The compiler would really like to treat both the state machine and the builder as classes, so ref is used liberally throughout the code. In order to use interfaces, various methods take the builder (or awaiter) as a parameter using a generic type parameter that’s constrained to implement an interface (such as IAsyncStateMachine for the state machine). That allows the members of the interface to be called without any boxing being required. The action of the method is simple to describe—it makes the state machine take the first step, synchronously, returning only when the method has either completed or reached a point where it needs to wait for an asynchronous operation.
Once that first step has completed, the skeleton method asks the builder for the task to return. The state machine uses the builder to set results or exceptions when it finishes.
15.5.3. Structure of the state machine
The overall structure of the state machine is pretty straightforward. It always implements the IAsyncStateMachine interface (introduced in .NET 4.5) using explicit interface implementation. The two methods declared by that interface (MoveNext and SetStateMachine) are the only two methods it contains. It also has a bunch of fields—some private, some public.
For example, this is the collapsed declaration of the state machine for listing 15.11:

In this example I’ve split the fields up into various sections. You’ve already seen that the text field ![]() representing the original parameter is set by the skeleton method, along with the builder and state fields, which are common infrastructure shared by all state machines.
representing the original parameter is set by the skeleton method, along with the builder and state fields, which are common infrastructure shared by all state machines.
Each local variable also has its own field ![]() , as you need to preserve the values across invocations of the MoveNext() method. Sometimes there are local variables that are only ever used between two particular await expressions, and don’t really need to be preserved in fields, but in my experience the current implementation always hoists them up to be fields anyway. Aside from anything else, this improves the debugging experience, as you wouldn’t generally expect local variables to lose their values, even if there’s nothing in the code that uses them any further.
, as you need to preserve the values across invocations of the MoveNext() method. Sometimes there are local variables that are only ever used between two particular await expressions, and don’t really need to be preserved in fields, but in my experience the current implementation always hoists them up to be fields anyway. Aside from anything else, this improves the debugging experience, as you wouldn’t generally expect local variables to lose their values, even if there’s nothing in the code that uses them any further.
There’s a single field for each type of awaiter used in the asynchronous method if they’re value types, and one field for all awaiters that are reference types (in terms of their compile-time type). In this case, you’ve got two await expressions that use two different types of awaiter structures, so you’ve got two fields ![]() . If the second await expression had also used a TaskAwaiter, or if TaskAwaiter and YieldAwaiter were both classes, you’d just have a single field. Only one awaiter can ever be live at a time, so it doesn’t matter that you can only store one value at a time. You have to propagate awaiters across await expressions so that once the operation has finished, you can get the result.
. If the second await expression had also used a TaskAwaiter, or if TaskAwaiter and YieldAwaiter were both classes, you’d just have a single field. Only one awaiter can ever be live at a time, so it doesn’t matter that you can only store one value at a time. You have to propagate awaiters across await expressions so that once the operation has finished, you can get the result.
Out of the common infrastructure fields ![]() , you’ve already seen state and builder. Just as a reminder, state is used to keep track of where you’ve got to, so the continuation can get to the right point in the code. builder is used for various things, including creating a Task or Task<T>for the skeleton method to return—a task that will then be populated with the right result when the asynchronous method finishes. The stack field is a little more arcane—it’s used when an await expression occurs as part of a statement that needs to keep track of some extra state that isn’t represented by normal local variables. You’ll see an example of that in section 15.5.6—it’s not used in the state machine generated for listing 15.11.
, you’ve already seen state and builder. Just as a reminder, state is used to keep track of where you’ve got to, so the continuation can get to the right point in the code. builder is used for various things, including creating a Task or Task<T>for the skeleton method to return—a task that will then be populated with the right result when the asynchronous method finishes. The stack field is a little more arcane—it’s used when an await expression occurs as part of a statement that needs to keep track of some extra state that isn’t represented by normal local variables. You’ll see an example of that in section 15.5.6—it’s not used in the state machine generated for listing 15.11.
The MoveNext() method is where all the compiler smarts really come into play, but before I describe that, we’ll take a very quick look at SetStateMachine. It has the same implementation in every state machine, and it looks like this:
void IAsyncStateMachine.SetStateMachine(IAsyncStateMachine machine)
{
builder.SetStateMachine(machine);
}
In brief, this method is used to allow a boxed copy of the state machine to have a reference to itself, within the builder. I won’t go into the details of how all the boxing is managed—all you need to understand is that the state machine is boxed where necessary, and the various aspects of the async machinery ensure that after boxing, the single boxed copy is used consistently. This is really important, as we’re talking about a mutable value type (shudder!). If some changes were applied to one copy of the state machine, and some changes were applied to another copy, the whole thing would fall apart very quickly.
If you want to think of it another way—and this will be important if you ever start really thinking about how the instance variables of the state machine are propagated—the state machine is a struct to avoid unnecessary heap allocations early on, but most of the code tries to act like it’s really a class. The reference juggling around SetStateMachine makes it all work.
Right...now we’ve got everything in place except for the actual code that was in the asynchronous method. Let’s dive into MoveNext().
15.5.4. One entry point to rule them all
If you ever decompile an async method—and I really hope you will—you’ll see that the MoveNext() method in the state machine gets very long, very fast, mostly as a function of how many await expressions you have. It contains all the logic in the original method, and the delicate ballet required to handle all the state transitions,[9] and some wrapper code to handle the overall result or exception.
9 It really does feel like a dance, with intricate steps that have to be performed at exactly the right time and place.
When writing asynchronous code by hand, you’d typically put continuations into separate methods: start in one method, then continue in another, and maybe finish in a third. But that makes it hard to handle flow control, such as loops, and it’s unnecessary for the C# compiler. It’s not like the readability of the generated code matters. The state machine has a single entry point, MoveNext(), which is used from the start and for the continuations for all await expressions. Each time MoveNext() is called, the state machine works out where in the method to get to via the statefield. This is either the logical starting point of the method or the end of an await expression, when you’re ready to evaluate the result. Each state machine is executed only once. Effectively there’s a switch statement based on state, with different cases corresponding to goto statements with different labels.
The MoveNext() method typically looks something like this:
void IStateMachine.MoveNext()
{
// For an asynchronous method declared to return Task<int>
int result;
try
{
bool doFinallyBodies = true;
switch (state)
{
// Code to jump to the right place...
}
// Main body of the method
}
catch (Exception e)
{
state = -2;
builder.SetException(e);
return;
}
state = -2;
builder.SetResult(result);
}
The initial state is always -1, and that’s also the state when the method is executing your code (as opposed to being paused while awaiting). Any non-negative states indicate the target of a continuation. The state machine ends up in state -2 when it’s completed. In state machines created in debug configurations, you’ll see reference to a state of -3—it’s never expected that you’ll actually end up in that state. It’s there to avoid having a degenerate switch statement, which would result in a poorer debugging experience.
The result variable is set during the course of the method, at the point where the original async method had a return statement. This is then used in the builder .SetResult() call, when you reach the logical end of the method. Even the nongeneric AsyncTaskMethodBuilder andAsyncVoidMethodBuilder types have SetResult() methods; the former communicates the fact that the method has completed to the task returned from the skeleton method, and the latter signals completion to the original SynchronizationContext. (Exceptions are propagated to the original SynchronizationContext in the same way. It’s a rather dirtier way of keeping track of what’s going on, but it provides a solution for situations where you really must have void methods.)
The doFinallyBodies variable is used to work out whether any finally blocks in the original code (including implicit ones from using or foreach statements) should be executed when execution leaves the scope of a try block. Conceptually, you only want to execute a finallyblock when you leave the try block in a normal way. If you’re just returning from the method early having attached a continuation to an awaiter, the method is logically “paused” so you don’t want to execute the finally block. Any finally blocks would appear within the Main body of the method section of code, along with the associated try block.
Most of the body of the method is recognizable in terms of the original async method. Admittedly, you need to get used to all the local variables now appearing as instance variables in the state machine, but that’s not too hard. The tricky bits are all around await expressions—as you might expect.
15.5.5. Control around await expressions
Just as a reminder, any await expression represents a fork in terms of possible execution paths. First the awaiter is fetched for the asynchronous operation being awaited, and then its IsCompleted property is checked. If that returns true, you can get the results immediately and continue. Otherwise, you need to do the following:
· Remember the awaiter for later
· Update the state to indicate where to continue from
· Attach a continuation to the awaiter
· Return from MoveNext(), ensuring that any finally blocks are not executed
Then, when the continuation is called, you need to jump to the right point, retrieve the awaiter, and reset your state before continuing.
As an example, the first await expression in listing 15.11 looks like this:
await Task.Delay(unicode);
The generated code looks like this:
TaskAwaiter localTaskAwaiter = Task.Delay(unicode).GetAwaiter();
if (localTaskAwaiter.IsCompleted)
{
goto DemoAwaitCompletion;
}
state = 0;
taskAwaiter = localTaskAwaiter;
builder.AwaitUnsafeOnCompleted(ref localTaskAwaiter, ref this);
doFinallyBodies = false;
return;
DemoAwaitContinuation:
localTaskAwaiter = taskAwaiter;
taskAwaiter = default(TaskAwaiter);
state = -1;
DemoAwaitCompletion:
localTaskAwaiter.GetResult();
localTaskAwaiter = default(TaskAwaiter);
If you’d been awaiting an operation that returned a value—for example assigning the result of await client.GetStringAsync(...) using an HttpClient—the GetResult() call near the end would be where you’d get the value.
The AwaitUnsafeOnCompleted method attaches the continuation to the awaiter, and the switch statement at the start of the MoveNext() method would ensure that when MoveNext() executes again, control passes to DemoAwaitContinuation.
AwaitOnCompleted vs. AwaitUnsafeOnCompleted
Earlier, I showed you a notional set of interfaces, where IAwaiter<T> extended INotifyCompletion with its OnCompleted method. There’s also an ICriticalNotifyCompletion interface, with an UnsafeOnCompleted method. The state machine callsbuilder.AwaitUnsafeOnCompleted for awaiters that implement ICriticalNotifyCompletion, or builder.AwaitOnCompleted for awaiters that only implement INotifyCompletion. We’ll look at the differences between these two calls in section 15.6.4 when we discuss how the awaitable pattern interacts with contexts.
Note that the compiler wipes both the local and instance variables for the awaiter, so that it can be garbage-collected where appropriate.
Once you can identify a block like this as corresponding to a single await expression, the generated code really isn’t too bad to read in decompiled form. There may be more goto statements (and corresponding labels) than you’d expect, due to CLR restrictions, but getting your head round the await pattern is the biggest hump in understanding, in my experience.
There’s one thing I still need to explain—the mysterious stack variable in the state machine...
15.5.6. Keeping track of a stack
When you think of a stack frame, you probably think about the local variables you’ve declared in the method. Sure, you may be aware of some hidden local variables like the iterator for a foreach loop, but that’s not all that goes on the stack...at least logically.[10] In various situations, there are intermediate expressions that can’t be used until some other expressions are evaluated. The simplest examples of these are binary operations like addition, and method invocations.
10 As Eric Lippert is fond of saying, the stack is an implementation detail—some variables you might expect to go on the stack actually end up on the heap, and some variables may end up only existing in registers. For the purposes of this section, we’re just talking about what logically happens on the stack.
As a trivial example, consider this line:
var x = y * z;
In stack-based pseudocode, that’s something like this:
push y
push z
multiply
store x
Now suppose you have an await expression in there:
var x = y * await z;
You need to evaluate y and store it somewhere before you await z, but you might well end up returning from the MoveNext() method immediately, so you need a logical stack to store y on. When the continuation executes, you can restore the value and perform the multiplication. In this case, the compiler can assign the value of y to the stack instance variable. This does involve boxing, but it means you get to use a single variable.
That’s a simple example. Imagine you had something where multiple values needed to be stored, like this:
Console.WriteLine("{0}: {1}", x, await task);
You need both the format string and the value of x on your logical stack. This time, the compiler creates a Tuple<string, int> containing the two values, and stores that reference in stack. Like the awaiter, you only ever need a single logical stack at a time, so it’s fine to always use the same variable.[11] In the continuation, the individual arguments can be fetched from the tuple and used in the method call. The downloadable source code contains a complete decompilation of this sample, with both of the preceding statements (LogicalStack.cs andLogicalStackDecompiled.cs).
11 Admittedly there are times when the compiler could be smarter about the type of the variable, or avoid including one at all if it’s never needed, but all of that may be added in a later version, as a further optimization.
The second statement ends up using code like this:
string localArg0 = "{0} {1}";
int localArg1 = x;
localAwaiter = task.GetAwaiter();
if (localAwaiter.IsCompleted)
{
goto SecondAwaitCompletion;
}
var localTuple = new Tuple<string, int>(localArg0, localArg1);
stack = localTuple;
state = 1;
awaiter = localAwaiter;
builder.AwaitUnsafeOnCompleted(ref awaiter, ref this);
doFinallyBodies = false;
return;
SecondAwaitContinuation:
localTuple = (Tuple<string, int>) stack;
localArg0 = localTuple.Item1;
localArg1 = localTuple.Item2;
stack = null;
localAwaiter = awaiter;
awaiter = default(TaskAwaiter<int>);
state = -1;
SecondAwaitCompletion:
int localArg2 = localAwaiter.GetResult();
Console.WriteLine(localArg0, localArg1, localArg2); // Bold
The bold lines here are the ones involving elements of the logical stack.
At this point, we’ve probably gone as far as we need to—if you’ve made it this far successfully, you know more about the details of what’s going on under the hood than 99 percent of developers are ever likely to. It’s fine if you didn’t quite follow everything first time through—if your experience is anything like mine has been when reading the code of these state machines, you’ll want to wait a little while, and then come back to it.
15.5.7. Finding out more
Want even more details? Crack out a decompiler. I’d urge you to use very small programs to investigate what the compiler does—it’s very easy to get lost in a maze of twisty little continuations, all alike, if you write anything nontrivial. You may need to reduce the level of optimization the decompiler performs in order to get it to show you a fairly close-to-the-metal view of the code, rather than an interpretation. After all, a perfect decompiler would just reproduce your async functions, which would defeat the whole purpose of the exercise!
The code that the compiler generates can’t always be decompiled into valid C#. There’s always the problem of it deliberately using unspeakable names for both variables and types, but more important, there are some cases where valid IL has no direct equivalent in C#. For example, in IL it’s legitimate to branch to an instruction that’s within a loop—after all, IL doesn’t even have the concept of a loop, as such. In C#, you can’t goto a label within a loop from outside the loop, so such an instruction can’t be represented entirely correctly. Even the C# compiler can’t have it all its own way: IL still has some restrictions on jump targets, so you’ll often find the compiler has to go through a series of jumps to get to the right place.
Similarly, I’ve seen some decompilers get a little confused as to the exact ordering of assignment statements around the logical stack, occasionally moving the assignment of the temporary variables (localArg0 and localArg1, for example) to the wrong side of the IsCompleted check. I believe this is due to the code not being quite like the normal output of the C# compiler. It’s not too bad when you know what to look for, but it does mean that occasionally you’ll probably end up dropping down to IL.
15.6. Using async/await effectively
I’ve shown you how asynchronous functions behave, and what they look like behind the scenes. You’re now an expert at asynchronous programming, right? Obviously not.[12] Like many aspects of programming, there’s a lot to be said for experience... and very few people have had a great deal of experience with asynchronous functions so far. While I can’t give you experience, I can provide some hints and tips that should make your life slightly easier.
12 Of course, you might be an expert at asynchronous programming, but just reading this chapter won’t have done that for you.
As I write this, the teams who know the most about asynchronous programming using C# 5 are the ones within Microsoft, who have lived and breathed it during development and received feedback from beta testers and the like. To that end, I thoroughly recommend the Parallel Programming Team’s blog (http://blogs.msdn.com/b/pfxteam/), which has a lot more advice than I have room to give here.
Of course, that doesn’t mean I don’t have some suggestions...
15.6.1. The task-based asynchronous pattern
One of the benefits of the asynchronous function feature in C# 5 is that it gives a consistent approach to asynchrony. But that could easily be undermined if everyone came up with their own ways of using it—how to name asynchronous methods, how exceptions should be raised, and the like. Microsoft has addressed this by publishing the Task-based Asynchronous Pattern (TAP)—a set of conventions for everyone to follow. It’s available as a standalone document (http://mng.bz/B68W) or on MSDN as separate pages (http://mng.bz/4N39).
Of course, Microsoft has also been following this—.NET 4.5 contains a huge number of asynchronous APIs for all kinds of scenarios. Just like with normal .NET conventions for naming, type design, and the like, if you follow the same conventions as the rest of the framework, other developers will find your code much easier to work with.
The TAP is very readable, and it’s only 38 pages long—I strongly advise you to read the full document. In the rest of this section, I’ll cover what I consider to be the most important parts.
Asynchronous methods should end with the suffix Async—GetAuthenticationTokenAsync, FetchUserPortfolioAsync, and so on. In the .NET Framework this has already caused some collisions—WebClient already had methods such as DownloadStringAsync following the event-based asynchronous pattern, which is why the new TAP-based methods have the slightly ugly names of DownloadStringTaskAsync, UploadDataTaskAsync, and the like. TaskAsync is the recommended suffix if you have your own naming collisions, too. Where the asynchrony is obvious, the suffix can be dropped entirely—Task.Delay and Task.WhenAll are examples of this. As a general rule, if the entire business of the method is asynchrony, rather than achieving some business goal, it’s probably safe to drop the suffix.
TAP methods generally return Task or Task<T>—again, there are exceptions such as Task.Yield, where the awaitable pattern comes in, but these should be few and far between. Importantly, the task returned from a TAP method should be hot. In other words, the operation it represents should already be in progress—the caller shouldn’t need to start it manually. For most developers, this probably sounds obvious, but there are other platforms where the convention is to create a cold task that doesn’t start until you explicitly ask it to—a little bit like an iterator block in C#. In particular, F# follows this convention, and it’s also something you need to consider in Reactive Extensions (Rx).
There are generally four overloads to consider providing when you create an asynchronous method. All would take the same basic parameters, but they’d provide different options in terms of both progress reporting and cancellation. Suppose you were considering developing an asynchronous method that would be logically equivalent to a synchronous method like this:
Employee LoadEmployeeById(string id)
Following TAP conventions, you could provide any or all of these:
// NOTE TO PRODUCTION: Please consult with Jon on formatting.
Do not abbreviate!
Task<Employee> LoadEmployeeById(string id)
Task<Employee> LoadEmployeeById(string id, CancellationToken cancellationToken)
Task<Employee> LoadEmployeeById(string id, IProgress<int> progress)
Task<Employee> LoadEmployeeById(string id,
CancellationToken cancellationToken, IProgress<int> progress)
Here the IProgress<int> could be an IProgress<T> for any type T that’s appropriate to use for progress reporting. For example, if your asynchronous method found a collection of records and then processed them one by one, you could accept an IProgress<Tuple<int, int>>, which could report both the number of reports processed so far and the number of reports in total.
I’d avoid trying to shoehorn progress reporting into operations where it really doesn’t make sense. Cancellation is generally easier to support, because so many framework methods support it. If your asynchronous method basically consists of performing several other asynchronous operations (possibly with dependencies), you may find it’s easier to just accept a cancellation token and pass it downstream.
Asynchronous operations should check for usage errors—typically invalid arguments—synchronously. This is slightly awkward, but it can be implemented either using a split method, as shown in section 15.3.6, or with a single method using an anonymous asynchronous function, as shown insection 15.4. Although it’s tempting to validate arguments lazily, you’ll curse yourself when you’re trying to address a failure that’s harder to diagnose than it needs to be.
IO-based operations—where you’re handing off a job to either a disk or another computer—are great candidates for asynchrony, with no obvious downside. CPU-bound tasks are less so. It’s easy to offload some work onto the thread pool, and even easier in .NET 4.5 than it was before, thanks to the Task.Run method, but doing so within library code would be making assumptions on behalf of the caller. Different callers may well have different requirements; if you just expose a synchronous method, you give the caller the flexibility to work in the most appropriate fashion. They can either start a new task if they need to, or call it synchronously if they’re happy for the current thread to be busy executing the method for some time.
Tasks that are a mixture of waiting for results from other systems and then processing them in a potentially time-consuming manner are trickier. Although I think hard-and-fast guidelines are unlikely to be helpful, it’s important to document the behavior. If you’re going to end up taking a lot of CPU in the caller’s context, you should make that very clear.
Another option is to avoid using the caller’s context, using the Task.ConfigureAwait method. This method currently only has a single parameter, continueOnCapturedContext, although for clarity it’s worth using a named argument to specify it. The method returns an implementation of the awaitable pattern. When the argument is true, the awaitable behaves exactly as normal, so if the async method is called on a UI thread, for example, the continuation after the await expression will still execute on the UI thread. That’s handy if you want to access UI elements. If you don’t have any special requirements, however, you can specify false for the argument, in which case the continuation will usually execute in the same context that the original operation completed.[13]
13 Usually, but not always. The details aren’t explicitly documented, but there are times when you really don’t want to execute in the same context. You should consider ConfigureAwait(false) to be saying, “I don’t mind where the continuation executes,” rather than explicitly attaching it to a specific context.
For a mixed workload that fetches some data, processes it, and then saves it to a database, you might have code like this:
public static async Task<int> ProcessRecords()
{
List<Record> records = await FetchRecordsAsync()
.ConfigureAwait(continueOnCapturedContext: false);
// ... record handling here ...
await SaveResultsAsync(results)
.ConfigureAwait(continueOnCapturedContext: false);
// Let the caller know how many records were processed
return records.Count;
}
Most of this method is likely to execute on a thread from the thread pool; this is exactly what you want, as you’re not doing anything that requires execution in the original thread. (The jargon for this is that the operation doesn’t have any thread affinity.) This doesn’t affect the caller, however; if an async UI method awaits the result of calling ProcessRecords, that async method will still continue on the UI thread. It’s only the code within ProcessRecords that’s declaring that it doesn’t care about its execution context.
Arguably, you don’t really need to call ConfigureAwait on the second await expression here, as there’s so little work remaining, but in general you should use it on every await expression, and it’s a good idea to get into the habit of doing so consistently. If you want to give the caller flexibility about the context in which the method executes, you could potentially make this a parameter to the asynchronous method.
Note that ConfigureAwait only affects the synchronization part of the execution context. Other aspects such as impersonation are propagated regardless, as you’ll see in section 15.6.4.
TPL Dataflow
Although TAP is just a set of conventions and some examples, Microsoft has also made a separate library called “TPL Dataflow,” which is available to provide higher-level building blocks for specific scenarios, particularly those that can be modeled using producer/consumer patterns. The simplest way to get started is probably via the NuGet package (Microsoft .Tpl.Dataflow). It’s free to use, and there’s lots of guidance around it. Even if you don’t use it directly, it’s worth looking at, just to get more of a feeling for how parallel programs can be designed.
Even without any extra libraries, you can still build elegant asynchronous code following normal design principles, and one of the most important aspects of that is composition.
15.6.2. Composing async operations
One of the things I love most about the asynchrony in C# 5 is the way it composes so naturally. This manifests itself in two different ways. Most obviously, asynchronous methods return tasks and typically involve calling other methods that return tasks. Those could be direct asynchronous operations (the bottom of the chain, so to speak) or just more asynchronous methods. All the wrapping and unwrapping required to turn results into tasks and vice versa is handled by the compiler.
The other form of composition is the way that you can create operation-neutral building blocks to govern how tasks are handled. These building blocks don’t need to know anything about what the tasks are doing—they stay purely at the abstraction level of Task<T>. They’re a little bit like the LINQ operators, but they work on tasks instead of sequences. Some building blocks are built into the framework, but you can write your own.
Collecting results in a single call
As an example, let’s consider the task of fetching lots of URLs. In section 15.3.6 you did this one at a time, stopping as soon as you were successful. Suppose this time you want to launch the requests in parallel, and then log the result for each URL. Remembering that asynchronous methods return already-running tasks, you can start a task for each URL fairly easily:
var tasks = urls.Select(async url =>
{
using (var client = new HttpClient())
{
return await client.GetStringAsync(url);
}
}).ToList();
Note that the ToList() is required in order to materialize the LINQ query. This ensures that you start each task once and only once—otherwise each time you iterated over tasks, you’d start another set of fetches. (The code would be even simpler if you didn’t care about disposing of theHttpClient, but even with that wrinkle, it’s not too bad.)
The TPL provides a method Task.WhenAll that combines the results of lots of tasks, each providing a single result, into a single task with multiple results. The signature of the overload you’ll use looks like this:
static Task<TResult[]> WhenAll<TResult>(IEnumerable<Task<TResult>> tasks)
That’s a fearsome-looking declaration, but the purpose of the method is quite simple when you start to use it. You’ve got a List<Task<string>>, so you can write this:
string[] results = await Task.WhenAll(tasks);
That will wait until all the tasks have finished and gather the results together into an array. This is one of those occasions where if several tasks throw exceptions, only the first will be thrown immediately, but you can always iterate over the tasks to work out which ones have failed and why, or use the WithAggregatedExceptions extension method shown in listing 15.2.
If you only care about the first request to come back, there’s another method called Task.WhenAny that doesn’t wait for the first successful task completion; it just waits for the first task to reach a terminal state.
In this case, you may want something a little different. It might be more useful to report all the results as they come in.
Collecting results as they arrive
Although Task.WhenAll was an example of a transformational building block that’s built into .NET, the next example shows how you can build your own methods in a similar way. The TAP documentation gives some very similar sample code, creating a method called Interleaved, and we’ll look at a slightly alternative version.
The idea of listing 15.12 is to allow you to pass in a sequence of input tasks, and the method will return a sequence of output tasks. The results of the tasks in the two sequences will be the same, but with one crucial difference: the output tasks will complete in the order they’re provided, so you can await them one at a time and know you’ll get the results as soon as they’re available. Now, this may sound like magic—it does to me—so let’s look at the code and see how it works.
Listing 15.12. Transforming a task sequence into a new collection in completion order
public static IEnumerable<Task<T>> InCompletionOrder<T>
(this IEnumerable<Task<T>> source)
{
var inputs = source.ToList();
var boxes = inputs.Select(x => new TaskCompletionSource<T>())
.ToList();
int currentIndex = -1;
foreach (var task in inputs)
{
task.ContinueWith(completed =>
{
var nextBox = boxes[Interlocked.Increment(ref currentIndex)];
PropagateResult(completed, nextBox);
}, TaskContinuationOptions.ExecuteSynchronously);
}
return boxes.Select(box => box.Task);
}
Listing 15.12 relies on a very important type in the TPL—TaskCompletionSource<T>. This type allows you to create a Task with no result yet, and then provide a result (or an exception) later on. This is built on the same underlying infrastructure that AsyncTaskMethodBuilder<T>uses to provide a Task for an asynchronous method to return, allowing the task to be populated with the result when the method body completes.
To explain the slightly curious variable names, I often think of tasks as being like cardboard boxes, with the promise that at some point they’ll have a value inside (or a fault). A TaskCompletionSource<T> is like a box with a hole in the back—you can give it to someone and then sneakily poke the value through the hole later on.[14]
14 Any resemblance to quantum physics is purely coincidental, and I won’t be held responsible for any experiments involving Task<Cat>. That’s exactly what the PropagateResult method does—it’s not terribly interesting, so I’ve omitted it here, but basically it propagates the result of a completed Task<T> into a TaskCompletionSource<T>. If the original task completes normally, the return value is copied into the task completion source. If the original task faults, the exception is copied into the task completion source. If the original task was canceled, the task completion source is canceled.
The really clever part here (and I take no credit for this—the suggestion was emailed to me) is that when this method runs, it doesn’t know which TaskCompletionSource<T> will correspond with which input task. Instead, it simply attaches the same continuation to each task, and that continuation says, “Find the next TaskCompletionSource<T> (by atomically incrementing a counter) and propagate the result.” In other words, the boxes are filled in the output order as the original tasks complete.
Figure 15.5 shows three input tasks and the corresponding output tasks returned by the method. The output tasks complete in the returned order, even though the input tasks complete in a different order.
Figure 15.5. Visualization of ordering
With this wonderful extension method in place, you can then write the following code, which takes a collection of URLs, launches requests for each of them in parallel, writes out each page length as it completes, and returns the total length.
Listing 15.13. Displaying page lengths as the data is returned
static async Task<int> ShowPageLengthsAsync(params string[] urls)
{
var tasks = urls.Select(async url =>
{
using (var client = new HttpClient())
{
return await client.GetStringAsync(url);
}
}).ToList();
int total = 0;
foreach (var task in tasks.InCompletionOrder())
{
string page = await task;
Console.WriteLine("Got page length {0}", page.Length);
total += page.Length;
}
return total;
}
There are two slight issues with listing15.13:
· As soon as one task fails, the whole asynchronous operation fails with no indication of the remaining results. That may be okay, or you may want to make sure that you log every failure. (Unlike in .NET 4, letting task exceptions go unobserved won’t bring down the process by default, but you should at least think about what you want to happen to other tasks.)
· You lose track of which page went with which URL.
Both of these are reasonably easily fixed with a little bit more code, and they might even suggest further reusable building blocks. The point of showing these examples wasn’t to examine the individual requirements—it was to open your mind to the possibilities provided by composition.
Interleaved isn’t the only example in the TAP white paper—it’s got lots of ideas, with sample code to help you.
15.6.3. Unit testing asynchronous code
I’m slightly nervous about even starting to write this section. At the moment, I don’t believe that the community has enough experience to come up with definitive answers about how to test asynchronous code. I’m sure there will be some missteps along the way, and no doubt several competing approaches will be explored. The important point is that, just like synchronous code, if you design for testability from the start, you can unit test asynchronous code effectively.
Injecting asynchrony safely
In this section I’ll present an approach for situations where you’re able to control the asynchronous operations that your own asynchronous code depends on. It doesn’t try to address the difficulties of testing code that uses HttpClient and similarly tricky-to-fake types, but that’s nothing new—if you have dependencies that are hard to use in tests, you’ll always face problems.
Suppose you want to test the “magic ordering” code from the previous section. You want to be able to create tasks that’ll complete in a specified order, and (in at least some tests) make sure you can perform assertions in between task completions. Additionally, you’d like to do all of this without any other threads getting involved—you want as much control and predictability as possible. In essence, you want to be able to control time.
My solution to this is to essentially fake out time by using a TimeMachine class that provides a way of advancing time programmatically with scheduled tasks that complete in particular ways at specific times. Combine this with a SynchronizationContext that’s effectively a manually pumped version of the familiar Windows Forms message pump, and you get a pretty reasonable test harness. I won’t show all of the framework code used to host this, as it’s a little too long and relatively dull, but it’s all in the sample code. I’ll show a couple of tests though.
Let’s start off with the overall success case: if you program three tasks to complete at times 1, 2, and 3, and call InCompletionOrder with those tasks in a different order, you should still get the results in order:
[TestMethod]
public void TasksCompleteInOrder()
{
var tardis = new TimeMachine();
var task1 = tardis.ScheduleSuccess(1, "t1");
var task2 = tardis.ScheduleSuccess(2, "t2");
var task3 = tardis.ScheduleSuccess(3, "t3");
var tasksOutOfOrder = new[] { task2, task3, task1 };
tardis.ExecuteInContext(advancer =>
{
var inOrder = tasksOutOfOrder.InCompletionOrder().ToList();
advancer.AdvanceTo(3);
Assert.AreEqual("t1", inOrder[0].Result);
Assert.AreEqual("t2", inOrder[1].Result);
Assert.AreEqual("t3", inOrder[2].Result);
});
}
The ExecuteInContext method temporarily replaces the current thread’s SynchronizationContext with a ManuallyPumpedSynchronizationContext (also in the sample code) and then provides an advancer to the delegate specified by the method argument. That advancer can be used to advance time by specific amounts, with tasks completing (and executing continuations) at the appropriate times. In this test you just fast-forward until they’ve all completed.
Here’s a second test that demonstrates that you can control time in a more fine-grained way:
// Omitted setup steps, which are the same as the previous test.
tardis.ExecuteInContext(advancer =>
{
var inOrder = tasksOutOfOrder.InCompletionOrder().ToList();
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[0].Status);
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[1].Status);
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[2].Status);
advancer.Advance();
Assert.AreEqual(TaskStatus.RanToCompletion, inOrder[0].Status);
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[1].Status);
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[2].Status);
advancer.Advance();
Assert.AreEqual(TaskStatus.RanToCompletion, inOrder[1].Status);
Assert.AreEqual(TaskStatus.WaitingForActivation, inOrder[2].Status);
advancer.Advance();
Assert.AreEqual(TaskStatus.RanToCompletion, inOrder[2].Status);
});
Here you can see the output tasks completing in the right order.
You may be wondering why the times here are just integers—you may have expected DateTime and TimeSpan to get involved. This is deliberate—the only timeline you really have is the artificial one set up by the time machine, and the only interesting points in time are the ones where tasks complete.
Of course, the method you’re testing is slightly unusual here in two ways:
· It’s not actually implemented with async.
· It’s given tasks directly as arguments.
If you were testing a more business-focused async method, you’d quite possibly schedule all the results for your dependencies, advance time to complete them all, and then check the result of the returned task. You’d have to be able to provide your production code with fakes in the normal way—the only difference that asynchrony makes here is that instead of using stubs or mocks to return the direct results of calls, you’d ask them to return the tasks produced by the TimeMachine. All the normal benefits of inversion of control still apply—you just need a way of creating appropriate tasks.
This single idea clearly isn’t going to be a panacea, but I hope it’s at least persuaded you of the possibility of unit testing asynchronous code without arbitrary calls to Thread.Sleep and the constant risk of test flakiness.
Running asynchronous tests
The tests in the previous section are entirely synchronous. You don’t use async or await within the tests themselves at all. When you’re using the TimeMachine class for all your tests, that’s fairly reasonable, but in other cases you may want to write test methods decorated with async.
You can do so easily:
[Test] // NUnit TestAttribute
public async void BadTestMethod()
{
// Code using await
}
This will compile against any normal test framework...but it may not do what you expect. In particular, you may end up with all your tests being started in parallel, and quite possibly “finishing” before they get around to asserting anything.
As it happens, NUnit supports asynchronous tests as of version 2.6.2, and the preceding method would work due to some cleverness in the implementation, but if you tried to run it against earlier versions, the test would start and then complete, as far as the test runner was concerned, as soon as it hit the first “slow” await. Any failures later in the method would end up being reported to the test’s SynchronizationContext, which may not be expecting it.
For test frameworks that support asynchronous tests, a much better approach is to make those tests return Task, like this:
[Test]
public async Task GoodTestMethod()
{
// Code using await
}
Now it’s much easier for the test framework to know when your tests have completed, and to check for failure. It has the additional benefit that test frameworks that don’t support asynchronous tests may not even try to run them, instead reporting a warning, which is far better than running the tests incorrectly. As I write this, the latest versions of NUnit, xUnit, and Visual Studio Unit Testing Framework (also known informally as MS Test) all support asynchronous tests—other frameworks may do so too. Please check the specific framework and version you want to use before starting to write such tests.
You should also be careful of the possibility of deadlocks. Unlike with the time machine tests in the previous section, you probably don’t want all the continuations executing on a single thread, unless that thread is also pumping as a UI thread would. Sometimes you control all the tasks involved and can reason your way into using a single-threaded context...other times you need to be rather more careful and may well want multiple threads able to fire continuations, as long as your test code doesn’t execute in parallel with itself. I’d be nervous of this for unit tests, but if you’re using the same sort of framework for functional tests, integration tests, or even production probing, you’ll typically want your tests to be running against real tasks rather than the fakes provided by the time machine.
I’m confident that over time the community will develop some great tools to help us test more and more of our code. I’m convinced that a significant proportion of future code will be naturally asynchronous, and I’m utterly certain that I don’t want to be writing such code without tests. We’re nearly finished with asynchrony now, but I did promise earlier that I’d come back to that interesting AwaitUnsafeOnCompleted method call in the generated code.
15.6.4. The awaitable pattern redux
In section 15.3.3 I showed some imaginary interfaces that give the right basic idea about the awaitable pattern. Even when I explained that this wasn’t quite reality, I fudged it a little bit. Unless you’re implementing the awaitable pattern itself or looking closely at the decompiled code, you don’t really need to know about the fudging, but if you’ve gotten this far, you probably want to know everything.
The genuine interface I mentioned earlier was INotifyCompletion, which looks like this:
public interface INotifyCompletion
{
void OnCompleted(Action continuation);
}
There’s another interface that extends this, however—still in the System.Runtime .CompilerServices namespace:
public interface ICriticalNotifyCompletion : INotifyCompletion
{
void UnsafeOnCompleted(Action continuation);
}
All the reasoning behind these two interfaces has context at its heart. I’ve mentioned SynchronizationContext a number of times already in this chapter, and you may well have come across it before; it’s a synchronization context that allows calls to be marshaled onto an appropriate thread, whether that’s a specific thread pool, or a single UI thread, or whatever is required. It’s not the only context involved though. There are plenty of them—SecurityContext, LogicalCallContext, and HostExecutionContext, for example. The granddaddy of them all, however, is ExecutionContext. It acts as a container for all the other contexts, and it’s what we’ll focus on in this section.
It’s very important that the ExecutionContext flows across await points; you don’t want to come back to your asynchronous method when a task has completed, only to find that you’ve forgotten which user you’re impersonating, for example. In order to flow the context, it needs to becaptured when you attach the continuation, and then restored when the continuation is executed. This is achieved through the ExecutionContext.Capture and ExecutionContext.Run methods, respectively.
There are two pieces of code that can perform this capture/restore pair: the awaiter, and the AsyncTaskMethodBuilder<T> class (along with its siblings). You might expect that you could just decide one way or the other, and leave it at that. But various other trade-offs come into play. It’s easy to forget to flow the execution context in the awaiter, so it makes sense to implement it once in the method-builder code. On the other hand, your awaiter will be directly accessible to any code using it, so you wouldn’t want to expose a possible security flaw by relying on all callers using the compiler-generated code...suggesting that it should be in the awaiter code. But equally, you wouldn’t want to capture and restore the context twice, redundantly. How can we resolve this dichotomy?
We’ve already seen the answer: use two different interfaces with subtly different meanings. If you implement the awaitable pattern, your OnCompleted method (which is mandatory) should flow the execution context. If you choose to implement ICriticalNotifyCompletion, yourUnsafeOnCompleted method should not flow the execution context...and should be decorated with the [SecurityCritical] attribute to prevent untrusted code from calling it. The method builders are trusted, of course, and they flow the context, so all is well—partially trusted callers can still use your awaiter efficiently, but would-be attackers won’t be able to sidestep context flow.
I’ve deliberately kept this section fairly brief; I find the whole topic of contexts somewhat confusing, and there are even more complexities I haven’t touched on. If you’re implementing your own awaiter without delegating to an existing one (and you probably won’t need to), you should definitely read Stephen Toub’s “ExecutionContext vs SynchronizationContext” blog post (http://mng.bz/Ye65) for more details.
15.6.5. Asynchronous operations in WinRT
Windows 8 has introduced the Windows Store to the application ecosystem—and alongside it, WinRT. I go into a little more detail about WinRT in appendix C, but it’s designed to be a modern, object-oriented, unmanaged environment. In many ways, it’s the new Win32. Some of the familiar .NET types aren’t available in WinRT, and even those that are available have mostly been stripped of blocking calls related to IO.
Types that still live in the CLR generally expose asynchronous operations via Task<T> as you’ve already seen, but that type doesn’t exist within WinRT itself. Instead, there are a bunch of interfaces, all of which extend one core IAsyncInfo interface:
· IAsyncAction
· IAsyncActionWithProgress<TProgress>
· IAsyncOperation<TResult>
· IAsyncOperationWithProgress<TResult, TProgress>
You can think of the difference between the Action types and the Operation types as being similar to the difference between Task and Task<T>, or between Action and Func: an Action has no return value, whereas an Operation does. The WithProgress versions build progress reporting into the single type, rather than requiring method overloads with IProgress<T> as per the TAP.
The details of these interfaces are beyond the scope of this book, but there are plenty of resources available explaining them. I suggest you start with Stephen Toub’s Windows 8 “Diving deep with WinRT and await” blog post (http://mng.bz/F1TF).
In terms of handling these interfaces from C# 5, there are a few important points:
· The GetAwaiter extension methods allow you to await actions and operations directly.
· The AsTask extension methods allow you to view an action or operation as a task, with support for cancellation tokens and progress reporting via IProgress<T>.
· The AsAsyncOperation and AsAsyncAction extension methods go in the opposite direction, taking a task and returning a WinRT-friendly wrapper.
All of these are provided by the System.WindowsRuntimeSystemExtensions class, in the System.Runtime.WindowsRuntime.dll assembly.
Once again you’ve seen the value of the awaitable pattern. The C# compiler really doesn’t care that it’s calling an extension method in order to await the asynchronous operation. It’s just another awaitable type. Most of the time you’re likely to be able to leave an asynchronous operation in its native type and await it as normal. It’s nice to have the flexibility to treat a WinRT asynchronous operation as a more familiar Task<T> for more complex scenarios though.
Another option for running code in the WinRT model of asynchrony is to use the Run method in the System.Runtime.InteropServices.WindowsRuntime.AsyncInfo class. Using this is cleaner than calling Task.Run(...).AsAsyncOperation if you need to hand anIAsyncOperation (or IAsyncAction) to some other code.
Asynchrony really isn’t optional when writing WinRT applications. A lot of the time, the platform won’t give you the option of writing synchronous code for IO. Of course, you can do all the work yourself, but using the features of C# 5 makes WinRT significantly simpler to use. I’m sure it’s no coincidence that the language gained asynchrony at roughly the same time WinRT was released. Microsoft isn’t just dipping its toe in the water here; this is how you will write Windows Store applications in C#.
15.7. Summary
I hope that the more complicated, deep-dive sections of this chapter haven’t obscured the elegance of the asynchronous features of C# 5. The ability to write efficient asynchronous code in a more familiar execution model is a huge step forward, and I believe it will be transformative—once it’s well understood. It’s been my experience when giving presentations about async that many developers get easily confused by the feature the first time they see and use it. That’s entirely understandable, but please don’t let that put you off. Hopefully this chapter will help to answer at least some of your questions as you go along, but there’s a wealth of documentation out there, and plenty of people ready to help on Stack Overflow, of course.
Speaking of other resources, I should emphasize that I’ve mostly tried to cover the language aspects of asynchrony here, in keeping with the rest of the book. There’s much more to asynchronous development than just knowing those language features, though, and I urge you to read everything you can about TPL. Even if you can’t use C# 5 yet, if you’re using .NET 4 you can start using Task<T> as a clean model for asynchronous operations. Whenever you’re tempted to reach for a raw Thread method, think about whether TPL might provide a higher abstraction to let you achieve the same goal more simply.
To sum up: async functions in C# 5 rock. That’s not quite all there is to look at though. There are a couple of tiny features that I really ought to cover before wrapping up this edition...
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.