Discovering Modern C++. An Intensive Course for Scientists, Engineers, and Programmers(2016)
Chapter 6. Object-Oriented Programming
C++ is a multi-paradigm language, and the paradigm that is most strongly associated with C++ is Object-Oriented Programming (OOP). As a result, we find all these beautiful dog-cat-mouse examples in books and tutorials. Experience shows, however, that most real software packages do not contain such deep class hierarchies as the literature makes us believe.
It is furthermore our experience that generic programming is the superior paradigm in scientific and engineering programming because
• It is more flexible: polymorphism is not limited to sub-classes; and
• It provides better performance: no overhead in function calls.
We will explain this in more detail within this chapter.
On the other hand, inheritance can help us to increase productivity when multiple classes share data and functionality. Accessing inherited data is free of overhead, and even calling inherited methods has no extra cost when they are not virtual.
The great benefit of object-oriented programming is the run-time polymorphism: which implementation of a method is called can be decided at run time. We can even select class types during execution. The before-mentioned overhead of virtual functions is only an issue when very fine-grained methods (like element access) are virtual. Conversely, when we implement only coarse-grained methods (like linear solvers) as virtual, the extra execution cost is negligible.
OOP in combination with generic programming is a very powerful way to provide as a form of reusability that neither of the paradigms can provide on its own (§6.2–§6.6).
6.1 Basic Principles
The basic principles of OOP related to C++ are:
• Abstraction: Classes (Chapter 2) define the attributes and methods of an object. The class can also specify invariants of attributes; e.g., numerator and denominator shall be co-prime in a class for rational numbers. All methods must preserve these invariants.
• Encapsulation denotes the hiding of implementation details. Internal attributes cannot be accessed directly for not violating the invariants but only via the class’s methods. In return, public data members are not internal attributes but part of the class interface.
• Inheritance means that derived classes contain all data and function members of their base class(es).
• Polymorphism is the ability of an identifier to be interpreted depending on context or parameters. We have seen polymorphism in terms of function overloading and template instantiation. In this chapter, we will see another form that is related to inheritance.
– Late Binding is the selection of the actually called function at run time.
We have already discussed abstraction, encapsulation, and some kinds of polymorphism. In this chapter, we will introduce inheritance and the related polymorphism.
To demonstrate the classical usage of OOP, we will use a simple example that has only a tangential relation to science and engineering but allows us to study the C++ features in a comprehensible fashion. Later, we will provide examples from science and introduce more sophisticated class hierarchies.
6.1.1 Base and Derived Classes
![]() c++03/oop_simple.cpp
c++03/oop_simple.cpp
A use case for all kinds of OOP principles is a database of different types of people. We start with a class that will be the basis of all other classes in this section:
class person
{
public:
person() {}
explicit person(const string& name) : name(name) {}
void set_name(const string& n) { name= n; }
string get_name() const { return name; }
void all_info() const
{ cout ![]() "[person] My name is "
"[person] My name is " ![]() name
name ![]() endl; }
endl; }
private:
string name;
};
For the sake of simplicity, we only use one member variable for the name and refrain from splitting it into first, middle, and last names.
Typical OOP classes often contain getter and setter methods for member variables (which some IDEs insert automatically in the class whenever a new variable is added). Nonetheless, introducing a getter and a setter unconditionally for each member is considered bad practice nowadays because it contradicts the idea of encapsulation. Many even consider this an Anti-Pattern since we are directly reading and writing the internal states to perform tasks with the object. Instead the object should provide methods that perform their respective tasks without uncovering internal states.
The method all_info is intended to be Polymorphic in the sense that it depends on the person’s actual class type which information we get about a person.
Our first type of person is student:
class student
: public person
{
public:
student(const string& name, const string& passed)
: person(name), passed(passed) {}
void all_info() const {
cout ![]() "[student] My name is "
"[student] My name is " ![]() get_name()
get_name() ![]() endl;
endl;
cout ![]() "I passed the following grades: "
"I passed the following grades: " ![]() passed
passed ![]() endl;
endl;
}
private:
string passed;
};
The class student is Derived from person. As a consequence, it contains all members of person: both methods and data members; that is, it Inherits them from its base (person). Figure 6–1 shows the public and private members (denoted by +/- respectively) of person andstudent. A student can access them all and a (mere) person only its own. Accordingly, if we added a member to person like a method get_birthday(), it would be added to student as well.
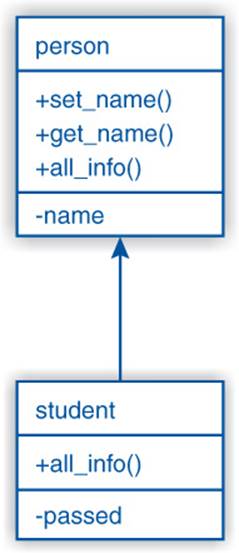
Figure 6–1: Derived class
In other words, a student Is-A person. Therefore, student can be used wherever person can: as an argument, in assignments, etc. Just as in real life, if we allow that a person can open a bank account, so can a student (we’re sorry for all the hard-up students with different experiences). We will later see how this is expressed in C++.
Regarding the visibility of names, the derived class is similar to an inner scope: in addition to the class’s members, we see those of its base class (and their base classes as well). When a derived class contains a variable or function with the same name, those of the base class are hidden, similarly again to a scope. In contrast, we can still access members of the derived class by name qualification like person::all_info. Even a function (overload) with an equal name and a different signature is hidden in the derived class—C++ hides names not signatures. They can be made visible in the derived class with a using declaration like using base::fun. Then those function overloads with a signature different from all overloads in the derived class are accessible without qualification.
When we use our two classes in the following way:
person mark("Mark Markson");
mark.all_info();
student tom("Tom Tomson", "Algebra, Analysis");
tom.all_info();
person p(tom);
person& pr= tom; // or pr(tom) or pr{tom}
person* pp= &tom; // or pp(&tom) or pp{tom}
p.all_info();
pr.all_info();
pp->all_info();
we might be surprised if not disappointed by the result:
[person] My name is Mark Markson
[student] My name is Tom Tomson
I passed the following grades: Algebra, Analysis
[person] My name is Tom Tomson
[person] My name is Tom Tomson
[person] My name is Tom Tomson
Only when the variable has type student do we get the grading information. When we try to handle a student as a regular person, the program compiles and runs but we do not see the additional student information.
Nonetheless, we are allowed to
• Copy a student to a person;
• Refer to a student as a person; and
• Pass a student as a person argument to a function.
More formally phrased: a derived class is a Sub-type of its base class, and wherever the base class is required its derived classes are accepted.
A good way to understand sub- and super-types is to think of sub- and super-sets. A class models a certain set, and a sub-set of this set is modeled by a sub-class that constrains the super-class by invariants. Our person class models all kind of people, and we model groups of people with classes that are sub-classes of person.
The paradox of this picture is that the derived classes may contain additional member variables, and the number of possible objects is larger than that of its super-class. This paradox can be resolved by considering appropriate invariants to model the sub-set properly. For instance, the invariant of the student class would be that no two objects with the same name and different grades exist. This would guarantee that the cardinality of the student set is not larger than that of the person set. Unfortunately, the before-mentioned invariant is hard to verify (even for those languages with automatic invariant check) and must be implicitly established by well-designed program logic.
When we derive from a base class, we can specify how restrictive the access to the members inherited from that class is. In the preceding example we derived publicly so that all inherited members have the same accessibility in the base and derived classes. If we derive a class asprotected, public base class members are protected in the derived class while the others preserve their accessibility. Members of privately derived classes are all private (this form of inheritance is only used in advanced OOP applications). When we do not specify how the base class is accessed, the derivation is by default private when we define a class and public for a struct.
6.1.2 Inheriting Constructors
![]()
![]() c++11/inherit_constructor.cpp
c++11/inherit_constructor.cpp
One method that is not inherited implicitly from the base class is the constructor. Therefore, the following program does not compile:
class person
{
public:
explicit person(const string& name) : name(name) {}
// ...
};
class student
: public person
{}; // No constructor for string defined
int main ()
{
student tom("Tom Tomson"); // Error: no string constructor
}
The class student inherits all methods from person except the string constructor. C++11 allows us to inherit all constructors from a base class with a using declaration:
class student
: public person
{
using person::person;
};
When constructors with the same signature exist in both classes, that from the derived class is preferred.
So far, we have applied three of the four before-mentioned basic principles: encapsulation, inheritance, and sub-typing. But there is still something missing and we will introduce it now.
6.1.3 Virtual Functions and Polymorphic Classes
![]() c++03/oop_virtual.cpp
c++03/oop_virtual.cpp
The full potential of object-oriented programming is only unleashed with virtual functions. Their presence changes the behavior of a class fundamentally, leading to the following:
Definition 6–1 (Polymorphic Types). Classes containing one or more virtual functions are called Polymorphic Types.
We continue with the preceding implementation and only add the attribute virtual to the method all_info():
class person
{
virtual void all_info() const { cout ![]() "My name is "
"My name is " ![]() name
name ![]() endl; }
endl; }
...
};
class student
: public person
{
virtual void all_info() const {
person::all_info(); // call all_info() from person
cout ![]() "I passed the following grades: "
"I passed the following grades: " ![]() passed
passed ![]() endl;
endl;
}
...
};
The double colons :: that we have seen as namespace qualifications (§3.2) can similarly qualify a class from which we call a method. This requires of course that the method is accessible: we cannot call a private method from another class, not even a base class.
Printing the information with the polymorphic class yields a completely different result all of a sudden:
[person] My name is Mark Markson
[student] My name is Tom Tomson
I passed the following grades: Algebra, Analysis
[person] My name is Tom Tomson
[student] My name is Tom Tomson
I passed the following grades: Algebra, Analysis
[student] My name is Tom Tomson
I passed the following grades: Algebra, Analysis
Printing the information on the objects behaves as before. The big difference is getting information on references and pointers to objects: pr.all_info() and pp->all_info(). In this case, the compiler goes through the following steps:
1. What is the static type of pr or pp? That is, how is pr or pp declared?
2. Is there a function named all_info in that class?
3. Can it be accessed? Or is it private?
4. Is it a virtual function? Otherwise just call it.
5. What is the dynamic type of pr or pp? That is, what is the type of the object referred to by pr or pp?
6. Call all_info from that dynamic type.
To realize these dynamic function calls, the compiler maintains Virtual Function Tables (a.k.a. Virtual Method Tables) or Vtables. They contain function pointers through which each virtual method of the actual object is called. The reference pr has the type person& and refers to an object of type student. Through the vtable of pr, the call of all_info() is directed to student::all_info. This indirection over function pointers adds some extra cost to virtual functions which is significant for tiny functions and negligible for sufficiently large functions.
Definition 6–2 (Late Binding and Dynamic Polymorphism). Selecting the executed method during run time is called Late Binding or Dynamic Binding. It also represents Dynamic Polymorphism—as opposed to static polymorphism with templates.
Analogously to the reference pr, the pointer pp points to a student object, and student::all_info is called by late binding for pp->all_info(). We can also introduce a free function spy_on():
void spy_on(const person& p)
{
p.all_info();
}
that provides Tom’s complete information thanks to late binding even when we pass a reference to the base class.
The benefit of dynamic selection is that the code exists only once in the executable no matter for how many sub-classes of person it is called. Another advantage over function templates is that only the declaration (i.e., the signature) must be visible when the function is called but not necessarily the definition (i.e., the implementation). This not only saves significant compile time but also allows us to hide our clever (or dirty) implementation from users.
The only entity originating from Tom that calls person::all_info() is p. p is an object of type person to which we can copy a student object. But when we copy a derived to a base class, we lose all extra data of the derived class and only the data members of the base class are really copied. Likewise, the virtual function calls perform those of the base class (here person::all_info()). That is, a base class object does not behave differently when it is constructed by copy from a derived class: all the extra members are gone and the vtable does not refer to any method from the derived class.
In the same way, passing arguments by value to function:
void glueless(person p)
{
p.all_info();
}
disables late binding and thus impedes calling virtual functions from derived classes. This is a very frequent (not only) beginners’ error in OOP called Slicing. Thus, we must obey the following rule:
Passing Polymorphic Types
Polymorphic types must always be passed by reference or (smart) pointer!
6.1.3.1 Explicit Overriding
![]()
Another popular trap that even advanced programmers fall into from time to time is a slightly different signature in the overridden method, like this:
class person
{
virtual void all_info() const { ... }
};
class student
: public person
{
virtual void all_info() { ... }
};
int main ()
{
student tom("Tom Tomson", "Algebra, Analysis");
person& pr= tom;
pr.all_info();
}
In this example, person::all_info() is not lately bound to person::all_info() because the signatures are different. This difference is admittedly not obvious, starting with the question of what the method’s const qualification has to do with the signature at all. We can think of a member function as having an implicit hidden argument referring to the object itself:
void person::all_info_impl(const person& me= *this) { ... }
Now it becomes clear that the const qualifier of the method qualifies this hidden reference in person::all_info(). The corresponding hidden reference in student::all_info() is not const-qualified and the method is not considered as an override due to the distinct signature. The compiler will not warn us, just taking student::all_info() as new overload. And you can believe us that this little nasty mistake can keep you busy for a while, when classes are large and stored in different files.
We can easily protect ourselves against such trouble with the attribute override added to C++11:
class student
: public person
{
virtual void all_info() override { ... }
};
Here the programmer declares that this function overrides a virtual function of the base class (with the exact same signature). If there is no such function, the compiler will complain:1
1. Messages have been reformatted to fit on the page.
...: error: 'all_info' marked 'override' but doesn't override
any member functions
virtual void all_info() override {
^
...: warning: 'student::all_info' hides overloaded virtual fct.
...: note: hidden overloaded virtual function 'person::all_info'
declared here: different qualifiers (const vs none)
virtual void all_info() const { ... }
^
Here, we also get the hint from clang that the qualifiers are different. Using override for non-virtual functions is an error:
...: error: only virtual member fct. can be marked 'override'
void all_info() override {
^~~~~~~~~
override does not add exciting new functionality to our software, but it can save us from tediously searching for slips of the pen (keyboard). It is advisable to use override everywhere, unless backward compatibility is needed. The word is quickly typed (especially with auto-completion) and renders our programs more reliable. It also communicates our intentions to other programmers or even to ourselves after not having looked at the code for some years.
Another new attribute in C++11 is final. It declares that a virtual member function cannot be overridden. This allows the compiler to replace certain indirect vtable calls with direct function calls. Unfortunately, we have no experience so far with how much final actually accelerates a virtual function. However, we can also use final to protect against surprising behavior of function overriding. Even entire classes can be declared final to prevent somebody from deriving from them.
Compared to each other, override is a statement regarding the super-classes while final refers to sub-classes. Both are contextual keywords; i.e., they are only reserved in a certain context: as qualifiers of member functions. Everywhere else the words could be freely used, for instance, as variable names. However, it is advisable to refrain from doing this for the sake of clarity.
6.1.3.2 Abstract Classes
So far we have looked only at examples where a virtual function was defined in a base class and then expanded in derived classes. Sometimes we find ourselves in a situation where we have an ensemble of classes with a common function and need a common super-class to select the classes dynamically. For instance, in Section 6.4, we will introduce solvers that provide the same interface: a solve function. To select them at run time, they need to share a super-class with a solve function. However, there is no universal solve algorithm that we can override later. For that purpose, we need a new feature to state: “I have a virtual function in this class without implementation; this will come later in sub-classes.”
Definition 6–3 (Pure Virtual Function and Abstract Class). A virtual function is a Pure Virtual Function when it is declared with = 0. A class containing a pure virtual function is called an Abstract Class.
![]() c++11/oop_abstract.cpp
c++11/oop_abstract.cpp
To be more specific, we expand our person example with an abstract super-class creature:
class creature
{
virtual void all_info() const= 0; // pure virtual
};
class person
: public creature
{ ... };
int main ()
{
creature some_beast; // Error: abstract class
person mark("Mark Markson");
mark.all_info();
}
The creation of a creature object fails with a message like this:
...: error: variable type 'creature' is an abstract class
creature some_biest;
^
...: note: unimplemented pure method 'all_info' in 'creature'
virtual void all_info() const= 0;
^
The object mark behaves as before when we override all_info so that person contains no pure virtual functions.
Abstract classes can be considered as interfaces: we can declare references and pointers thereof but no objects. Note that C++ allows us to mix pure and regular virtual functions. Objects of sub-classes can only be built2 when all pure virtual functions are overridden.
2. We refrain here from the term Instantiation to avoid confusion. The term is used in Java for saying that an object is built from a class (whereas some authors even call objects specific classes). In C++, instantiation almost always names the process of creating a specific class/function from a class/function template. We have occasionally seen the term “class instantiation” for the creation of an object from a class but this is not common terminology and we refrain from it.
Side note to Java programmers: In Java, all member functions are by nature virtual (i.e., methods cannot be non-virtual3). Java provides the language feature interface where methods are only declared but not defined (unless they have the attribute default which allows for an implementation). This corresponds to a C++ class where all methods are pure virtual.
3. However, declaring them final enables the compiler to remove the overhead of late binding.
Large projects often establish multiple levels of abstraction:
• Interface: no implementations;
• Abstract class: default implementations;
• Specific classes.
This helps to keep a clear mental picture for an elaborate class system.
6.1.4 Functors via Inheritance
In Section 3.8, we discussed functors and mentioned that they can be implemented in terms of inheritance as well. Now, we keep our promise. First we need a common base class for all functors to be realized:
struct functor_base
{
virtual double operator() (double x) const= 0;
};
This base class can be abstract since it only serves us as an interface, for instance, to pass a functor to finite_difference evaluation:
double finite_difference(functor_base const& f,
double x, double h)
{
return (f(x+h) - f(x)) / h;
}
Evidently, all functors to be differentiated must be derived from functor_base, for instance:
class para_sin_plus_cos
: public functor_base
{
public:
para_sin_plus_cos(double p) : alpha(p) {}
virtual double operator() (double x) const override
{
return sin(alpha * x) + cos(x);
}
private:
double alpha;
};
We reimplemented para_sin_plus_cos so that we can approximate the derivative of sin(αx) + cos x with finite differences:
para_sin_plus_cos sin_1 (1.0);
cout ![]() finite_difference( sin_1, 1., 0.001 )
finite_difference( sin_1, 1., 0.001 ) ![]() endl;
endl;
double df1= finite_difference(para_sin_plus_cos(2.), 1., 0.001),
df0= finite_difference(para_sin_plus_cos(2.), 0., 0.001);
The object-oriented approach allows us as well to realize functions with states. If we like, we could also implement the finite differences as OOP functors and combine them similarly as the generic functors.
The disadvantages of the OOP approach are:
• Performance: operator() is always called as a virtual function.
• Applicability: Only classes that are derived from functor_base are allowed as arguments. A template parameter allows for traditional functions and any kind of functors including those from Section 3.8.
Thus, functors should be implemented whenever possible with the generic approach from Section 3.8. Only when functions are selected at run time does the use of inheritance provide a benefit.
6.2 Removing Redundancy
By using inheritance and implicit up-casting, we can avoid the implementation of redundant member and free functions. The fact that classes are implicitly casted to super-classes allows us to implement common functionality once and reuse it in all derived classes. Say we have several matrix classes (dense, compressed, banded, triangle, . . . ) that share member functions like num_rows and num_cols.4 Those can be easily outsourced into a common super-class—including the corresponding data members:
4. The terminology used is from MTL4.
class base_matrix
{
public:
base_matrix(size_t nr, size_t nc) : nr(nr), nc(nc) {}
size_t num_rows() const { return nr; }
size_t num_cols() const { return nc; }
private:
size_t nr, nc;
};
class dense_matrix
: public base_matrix
{ ... };
class compressed_matrix
: public base_matrix
{ ... };
class banded_matrix
: public base_matrix
{ ... };
...
All matrix types now provide the member functions from base_matrix by inheritance. Having the common implementations in one place not only saves typing but also ensures that modifications apply in all relevant classes at once. This is not an issue in this toy example (especially as there is not much to change anyway), but keeping all redundant code snippets consistent becomes pretty laborious in large projects.
Free functions can be reused in the same manner, for instance:
inline size_t num_rows(const base_matrix& A)
{ return A.num_rows(); }
inline size_t num_cols(const base_matrix& A)
{ return A.num_cols(); }
inline size_t size(const base_matrix& A)
{ return A.num_rows() * A.num_cols(); }
These free functions can be called for all matrices derived from base_matrix thanks to implicit up-casting. This form of common base class functionality does not cost run time.
We can also consider the implicit up-cast of free functions’ arguments as a special case of a more general concept: the is-a relation; for instance, compressed_matrix is-a base_matrix and we can pass a compressed_matrix value to every function that expects abase_matrix.
6.3 Multiple Inheritance
C++ provides multiple inheritance which we will illustrate now with some examples.
6.3.1 Multiple Parents
![]() c++11/oop_multi0.cpp
c++11/oop_multi0.cpp
A class can be derived from multiple super-classes. For more figurative descriptions and for a less clumsy discussion of base classes’ base classes we occasionally use the terms parents and grandparents which are intuitively understood. With two parents, the class hierarchy looks like a V (and with many like a bouquet). The members of the sub-class are the union of all super-class members. This bears the danger of ambiguities:
class student
{
virtual void all_info() const {
cout ![]() "[student] My name is "
"[student] My name is " ![]() name
name ![]() endl;
endl;
cout ![]() " I passed the following grades: "
" I passed the following grades: " ![]() passed
passed ![]() endl;
endl;
}
...
};
class mathematician
{
virtual void all_info() const {
cout ![]() "[mathman] My name is "
"[mathman] My name is " ![]() name
name ![]() endl;
endl;
cout ![]() " I proved: "
" I proved: " ![]() proved
proved ![]() endl;
endl;
}
...
};
class math_student
: public student, public mathematician
{
// all_info not defined -> ambiguously inherited
};
int main ()
{
math_student bob("Robert Robson", "Algebra", "Fermat's Last Theorem");
bob.all_info();
}
math_student inherits all_info from student and from mathematician and there is no priority for one or another. The only way to disambiguate all_info for math_student is to define the method in the class math_student appropriately.
This ambiguity allows us to illustrate a subtlety of C++ that we should be aware of. public, protected, and private modify accessibility, not visibility. This becomes painfully clear when we try to disambiguate member functions by inheriting one or more super-classes asprivate or protected:
class student { ... };
class mathematician { ... };
class math_student
: public student, private mathematician
{ ... };
Now the methods of student are public and those of mathematician private. Calling math_student::all_info we hope to see now the output of student::all_info. Instead we get two error messages: first that math_student::all_info is ambiguous and in addition that mathematician::all_info is inaccessible.
6.3.2 Common Grandparents
It is not rare that multiple base classes share their base classes as well. In the previous section, mathematician and student had no super-classes. From the sections before, it would be more natural to derive them both from person. Depicting this inheritance configuration builds a diamond shape as in Figure 6–2. We will implement this in two slightly different ways.
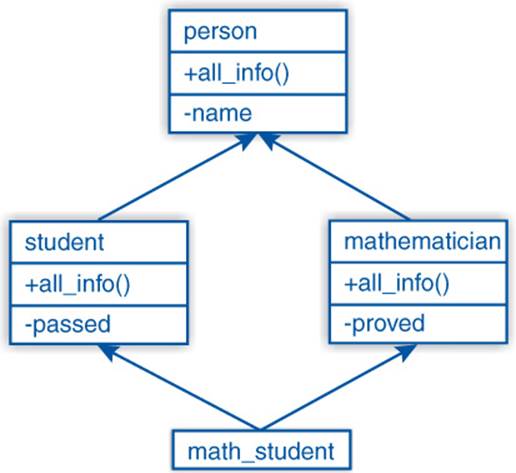
Figure 6–2: Diamond-shaped class hierarchy
6.3.2.1 Redundancy and Ambiguity
![]() c++11/oop_multi1.cpp
c++11/oop_multi1.cpp
First, we implement the classes in a straightforward way:
class person { ... } // as before
class student { ... } // as before
class mathematician
: public person
{
public:
mathematician(const string& name, const string& proved)
: person(name), proved(proved) {}
virtual void all_info() const override {
person::all_info();
cout ![]() " I proved: "
" I proved: " ![]() proved
proved ![]() endl;
endl;
}
private:
string proved;
};
class math_student
: public student, public mathematician
{
public:
math_student(const string& name, const string& passed,
const string& proved)
: student(name, passed), mathematician(name, proved) {}
virtual void all_info() const override {
student::all_info();
mathematician::all_info();
}
};
int main ()
{
math_student bob("Robert Robson", "Algebra", "Fermat's Last Theorem");
bob.all_info();
}
The program works properly except for the redundant name information:
[student] My name is Robert Robson
I passed the following grades: Algebra
[person] My name is Robert Robson
I proved: Fermat's Last Theorem
You as reader now have two choices: accept this sub-optimal method and keep reading or jump to Exercise 6.7.1 and try to solve it on your own.
As a consequence of deriving person twice, this code is
• Redundant: The name is stored twice as illustrated in Figure 6–3.
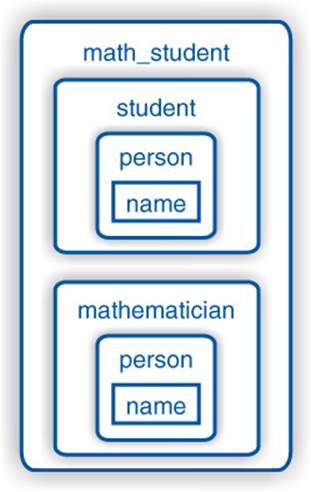
Figure 6–3: Memory layout of math_student
• Error-prone: The two values of name can be inconsistent.
• Ambiguous: when accessing person::name in math_student.
![]() c++11/oop_multi2.cpp
c++11/oop_multi2.cpp
To illustrate the before-mentioned ambiguity, we call person::all_info within math_student:
class math_student : ...
{
virtual void all_info() const override {
person::all_info();
}
};
This causes the following (reformatted) complaint:
...: error: ambiguous conversion from derived class
'const math_student' to base class 'person':
class math_student -> class student -> class person
class math_student -> class mathematician -> class person
person::all_info();
^~~~~~~~~
with clang 3.4. We will of course encounter the same problem with every function or data member of super-classes inherited via multiple paths.
6.3.2.2 Virtual Base Classes
![]() c++11/oop_multi3.cpp
c++11/oop_multi3.cpp
Virtual Base Classes allow us to store members in common super-classes only once and thus help overcome related problems. However, it requires a basic understanding of the internal implementation to not introduce new problems. In the following example, we just denote person as avirtual base class:
class person { ... };
class student
: public virtual person
{ ... };
class mathematician
: public virtual person
{ ... };
class math_student
: public student, public mathematician
{
public:
math_student(const string& name, const string& passed, const string&
proved) : student(name, passed), mathematician(name, proved) {}
...
};
and get the following output that might surprise some of us:
[student] My name is
I passed the following grades: Algebra
I proved: Fermat's Last Theorem
We lost the value of name despite both student and mathematician calling the person constructor which initializes name. To understand this behavior, we need to know how C++ handles virtual base classes. We know that it is a derived class’s responsibility to call the base-class constructor (or else the compiler will generate a call to the default constructor). However, we have only one copy of the person base class. Figure 6–4 illustrates the new memory layout: mathematician and student do not contain the person data any longer but only refer to a common object that is part of the most derived class: math_student.
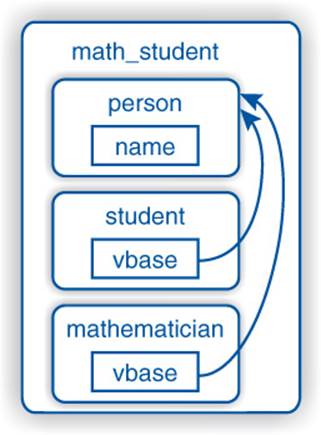
Figure 6–4: math_student’s memory with virtual base classes
When creating a student object, its constructor must call the person constructor. And likewise when we create a mathematician object, its constructor will call the person constructor. Now we create a math_student object. The math_student constructor must call the constructors of both mathematician and student. But we know that those constructors should both call the person constructor and thus the shared person part would be constructed twice.
To prevent that, it has been defined that in the case of virtual base classes, it is the responsibility of the Most Derived Class (in our case: math_student) to call the shared base-class constructor (in our case: person). In return, the person constructor calls in mathematicianand student are disabled when they are indirectly called from a derived class.
![]() c++11/oop_multi4.cpp
c++11/oop_multi4.cpp
With this in mind, we modify our constructors accordingly:
class student
: public virtual person
{
protected:
student(const string& passed) : passed(passed) {}
...
};
class mathematician
: public virtual person
{
protected:
mathematician(const string& proved) : proved(proved) {}
...
};
class math_student
: public student, public mathematician
{
public:
math_student(const string& name, const string& passed, const string&
proved) : person(name), student(passed), mathematician(proved) {}
virtual void all_info() const override {
student::all_info();
mathematician::my_infos();
}
};
Now, math_student initializes person explicitly to set the name there. The two intermediate classes student and mathematician are refactored to distinguish between inclusive and exclusive member treatment:
• The inclusive handling incorporates the methods from person: the two-argument constructor and all_info. These methods are public and (primarily) intended for student and mathematician objects.
• The exclusive handling deals only with members of the class itself: the one-argument constructor and my_infos. These methods are protected and thus available in sub-classes only.
The example shows that all three access modifiers are needed:
• private: for data members that will only be accessed within the class;
• protected: for methods needed by sub-classes that will not be used for their own objects; and
• public: for methods intended for objects of the class.
After laying the foundations of the OOP techniques, we will apply them now in a scientific context.
6.4 Dynamic Selection by Sub-typing
![]() c++11/solver_selection_example.cpp
c++11/solver_selection_example.cpp
The dynamic solver selection can be realized with a switch like this:
#include <iostream>
#include <cstdlib>
class matrix {};
class vector {};
void cg(const matrix& A, const vector& b, vector& x);
void bicg(const matrix& A, const vector& b, vector& x);
int main (int argc, char* argv[])
{
matrix A;
vector b, x;
int solver_choice= argc >= 2 ? std::atoi(argv[1]) : 0;
switch (solver_choice) {
case 0: cg(A, b, x); break;
case 1: bicg(A, b, x); break;
...
}
}
This works but it is not scalable with respect to source code complexity. When we call the solver with other vectors and matrices somewhere else, we must copy the whole switch-case-block for each argument combination. This can be avoided by encapsulating the block into a function and calling this function with different arguments.
The situation becomes much more elaborate when multiple arguments are selected dynamically. For a linear solver, we want to choose the left and right preconditioners (diagonal, ILU, IC, etc.). Then we need nested switch as shown in Section A.8. So we can dynamically select our function objects without OOP, but we have to accept the combinatorial explosion over the parameter space: solvers, left and right preconditioners. If we add a new solver or preconditioner, we will need to expand this monstrous selection block in multiple places.
An elegant solution for our solvers and preconditioners is to use abstract classes as interfaces and derived classes with the specific solvers:
struct solver
{
virtual void operator()( ... )= 0;
virtual ∼solver() {}
};
// potentially templatize
struct cg_solver : solver
{
virtual void operator()( ... ) override { cg(A, b, x); }
};
struct bicg_solver : solver
{
virtual void operator()( ... ) override { bicg(A, b, x); }
};
In our application, we can define a (smart) pointer of the interface type solver and assign it to the desired solver:
![]()
unique_ptr<solver> my_solver;
switch (solver_choice) {
case 0: my_solver= unique_ptr<cg_solver>(new cg_solver);
break;
case 1: my_solver= unique_ptr<bicg_solver>(new bicg_solver);
break;
...
}
This technique is thoroughly discussed in the design patterns book [14] as the Factory pattern. The factory can also be implemented with raw pointers in C++03.
The construction of the unique_ptr is somewhat cumbersome. C++14 introduces the convenience function make_unique that makes this situation really more convenient:
![]()
unique_ptr<solver> my_solver;
switch (solver_choice) {
case 0: my_solver= make_unique<cg_solver>(); break;
case 1: my_solver= make_unique<bicg_solver>(); break;
}
It is a good exercise to implement your own make_unique as suggested in Exercise 3.11.13.
Once our polymorphic pointer is initialized, it is straightforward to call our dynamically selected solver:
(*my_solver)(A, b, x);
The parentheses here mean that we dereference a function pointer and call the referenced function. Without the parentheses, we would (unsuccessfully) try to call the function pointer as a function and dereference its result.
The full power of the factory approach becomes evident when multiple functions are dynamically selected. Then we can avoid the combinatorial explosion shown before. The polymorphic function pointers allow us to decouple the respective selections and to decompose the task into a sequence of factories and a single call with the pointers:
struct pc
{
virtual void operator()( ... )= 0;
virtual ~pc() {}
};
struct solver { ... };
// Solver factory
// Left Preconditioner factory
// Right Preconditioner factory
(*my_solver)(A, b, x, *left, *right );
Now, we have linear code complexity in the factories and a single statement for the function call opposed to the cubic code complexity in the huge selection block.
In our example, we implemented a common super-class. We can also deal with solver classes and functions without a common base class by using std::function. This allows us to realize more general factories. Nonetheless, it is based on the same techniques: virtual functions and pointers to polymorphic classes. A backward-compatible alternative in C++03 is boost::function.
![]()
C++ forbids virtual template functions (they would render the compiler implementation very complicated: potentially infinite vtables). However, class templates can contain virtual functions. This enables generic programming with virtual functions by type parameterization of the entire class instead of parameterizing single methods.
6.5 Conversion
Conversion is a topic not only related to OOP, but we could not discuss it comprehensively without having introduced base and derived classes before. Vice versa, looking at castings between related classes solidifies the understanding of inheritance.
C++ is a strongly typed language. The type of each object (variable or constant) is defined at compile time and cannot be changed during execution.5 We can think of an object as
5. In contrast, Python variables have no fixed type and are actually merely names referring to some object. In an assignment, the variable just refers to another object and adopts the new object’s type.
• Bits in memory, and
• A type that gives those bits a meaning.
For several casts, the compiler just looks differently on the bits in memory: either with another interpretation of the bits or with other access rights (e.g., const versus non-const). Other casts actually create new objects.
In C++, there are four different cast operators:
• static_cast
• dynamic_cast
• const_cast
• reinterpret_cast
C as its linguistic root knows only one casting operator: ( type ) expr. This single operator is difficult to understand because it can trigger a cascade of transformations to create an object of the target type: for instance, converting a const pointer to int into a non-const pointer to char.
In contrast, the C++ casts only change one aspect of the type at a time. Another disadvantage of C-style casts is that they are hard to find in code (see also [45, Chapter 95]), whereas the C++ casts are easy to discover: just search for _cast. C++ still allows this old-style casting but all C++ experts agree on discouraging its use.
C Casts
Do not use C-style casts.
In this section, we will show the different cast operators and discuss the pros and cons of different casts in different contexts.
6.5.1 Casting between Base and Derived Classes
C++ offers a static and a dynamic cast between classes of a hierarchy.
6.5.1.1 Casting Up
![]() c++03/up_down_cast_example.cpp
c++03/up_down_cast_example.cpp
Casting up, i.e., from a derived to a base class, is always possible when there are no ambiguities. It can even be performed implicitly like we did in the function spy_on:
void spy_on(const person& p);
spy_on(tom); // Upcast student -> person
spy_on accepts all sub-classes of person without the need for explicit conversion. Thus, we can pass student tom as an argument. To discuss conversions between classes in a diamond-shaped hierarchy, we introduce some single-letter class names for brevity:
struct A
{
virtual void f(){}
virtual ~A(){}
int ma;
};
struct B : A { float mb; int fb() { return 3; } };
struct C : A {};
struct D : B, C {};
We add the following unary functions:
void f(A a) { /* ... */ } // Not polymorphic -> slicing!
void g(A& a) { /* ... */ }
void h(A* a) { /* ... */ }
An object of type B can be passed to all three functions:
B b;
f(b); // Slices!
g(b);
h(&b);
In all three cases, the object b is implicitly converted to an object of type A. However, function f is not polymorphic because it slices object b as discussed in Section 6.1.3. Up-casting only fails when the base class is ambiguous. In the current example, we cannot up-cast from D to A:
D d;
A ad(d); // Error: ambiguous
because the compiler does not know whether the base class A from B or from C is meant. We can clarify this situation with an explicit intermediate up-cast:
A ad(B(d));
Or we can share A between B and C with virtual bases:
struct B : virtual A { ... };
struct C : virtual A {};
Now, the members of A exist only once in D. This is usually the best solution for multiple inheritance in most cases because we save memory and do not risk inconsistent replication of A.
6.5.1.2 Casting Down
Down-casting is the conversion of a pointer/reference to a sub-type pointer/reference. When the actually referred-to object is not of that sub-type, the behavior is undefined. Thus, this cast should be used with utter care and only when absolutely necessary.
Recall that we passed an object of type B to a reference and a pointer of type A& respectively A*:
void g(A& a) { ... }
void h(A* a) { ... }
B b;
g(b);
h(&b);
Within g and h we cannot access members of B (i.e., mb and fb()) despite the fact that the referred object b is of type B. Being sure that the respective function parameter a refers to an object of type B, we can down-cast a to B& or B* respectively and then access mb and fb().
Before we introduce a down-cast in our program, we should ask ourselves the following questions:
• How do we assure that the argument passed to the function is really an object of the derived class? For instance, with extra arguments or with run-time tests?
• What can we do if the object cannot be down-casted?
• Should we write a function for the derived class instead?
• Why do we not overload the function for the base and the derived type? This is definitively a much cleaner design and always feasible.
• Last but not least, can we redesign our classes such that our task can be accomplished with the late binding of virtual functions?
If after answering all these questions we honestly still believe we need a down-cast, we must then decide which down-cast we apply. There are two forms:
• static_cast, which is fast and unsafe; and
• dynamic_cast, which is safe at some extra cost and only available for polymorphic types.
As the name suggests, static_cast only checks compile-time information. This means in the context of down-casting whether the target type is derived from the source type. We can, for instance, cast a, the function argument of g, to type B& and are then able to call a method of class B:
void g(A& a)
{
B& bref= static_cast<B&>(a);
std::cout ![]() "fb returns "
"fb returns " ![]() bref.fb()
bref.fb() ![]() "\n";
"\n";
}
The compiler verifies that B is a sub-class of A and accepts our implementation. When the argument a refers to an object that is not of type B (or a sub-type thereof), the program behavior is undefined—the most likely result being a crash.
In our diamond-shaped example, we can also down-cast pointers from B to D. To this end, we declare pointers of type B* that are allowed to refer to objects of sub-class D:
B *bbp= new B, *bdp= new D;
The compiler accepts a down-cast to D* for both pointers:
dbp= static_cast<D*>(bbp); // erroneous downcast performed
ddp= static_cast<D*>(bdp); // correct downcast (but not checked)
Since no run-time checks are performed, it is our responsibility as programmers to only refer to objects of the right type. bbp points to an object of type B, and when we dereference the pointer, we risk data corruption and program crashes. In this small example, a smart compiler might detect the erroneous down-cast by static analysis and emit a warning. In general, it is not always possible to back-trace the actual type referenced by a pointer, especially as it can be selected at run time:
B *bxp= (argc > 1) ? new B : new D;
In Section 6.6, we will see an interesting application of a static down-cast that is safe since type information is provided as a template argument.
dynamic_cast performs a run-time test whether the actually casted object has the target type or a sub-type thereof. It can only be applied on polymorphic types (classes that define or inherit one or more virtual functions, §6.1):
D* dbp= dynamic_cast<D*>(bbp); // Error: cannot downcast to D
D* ddp= dynamic_cast<D*>(bdp); // Okay: bdp points to a D object
When the cast cannot be performed, a null pointer is returned so that the programmer can eventually react to the failed down-cast. Incorrect down-casts of references throw exceptions of type std::bad_cast and can be handled in a try-catch-block. These checks are realized with Run-Time Type Information (RTTI) and take a little extra time.
Advanced background information: dynamic_cast is implemented under the hood as a virtual function. Therefore, it is only available when the user has made a class polymorphic by defining at least one virtual function. Otherwise, all classes would incur the cost of a vtable. Polymorphic functions have these anyway, so the cost of the dynamic_cast is one extra pointer in the vtable.
6.5.1.3 Cross-Casting
An interesting feature of dynamic_cast is casting across from B to C when the referenced object’s type is a derived class of both types:
C* cdp= dynamic_cast<C*>(bdp); // Okay: B -> C with D object
Likewise, we could cross-cast from student to mathematician.
Static cross-casting from B to C:
cdp= static_cast<C*>(bdp); // Error: neither sub- nor super-class
is not allowed because C is neither a base nor a derived class of B. It can be casted indirectly via D:
cdp= static_cast<C*>(static_cast<D*>(bdp)); // B -> D -> C
Here again it is the programmer’s responsibility to determine whether the addressed object can really be casted this way.
6.5.1.4 Comparing Static and Dynamic Cast
Dynamic casting is safer but slower then static casting due the run-time check of the referenced object’s type. Static casting allows for casting up and down with the programmer being responsible that the referenced objects are handled correctly.
Table 6-1 summarizes the differences between the two forms of casting:
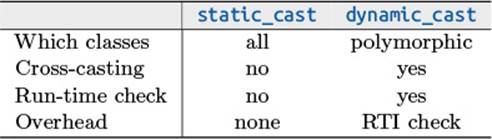
Table 6–1: Static versus Dynamic Cast
6.5.2 const-Cast
const_cast adds or removes the attributes const and/or volatile. The keyword volatile informs the compiler that a variable can be modified from somewhere else. For instance, certain memory entries are set by hardware, and we must be aware of this when we write drivers for this hardware. Those memory entries cannot be cached or held in registers and must be read each time from main memory. In scientific and high-level engineering software, externally modified variables are less frequent and we therefore refrain from discussing volatile further in this book.
Both const and volatile can be added implicitly. Removing the volatile attribute of an object that is really volatile leads to undefined behavior since inconsistent values may exist in caches and registers. Conversely, the volatile attribute can only be removed fromvolatile-qualified pointers and references when they refer to a non-volatile object.
Removing the const attribute invalidates all corresponding const qualifiers on the entire call stack and thus increases the debugging effort tremendously when data is accidentally overwritten. Sadly enough, it is sometimes necessary to do so when dealing with old-style libraries which are often lacking appropriate const qualifiers.
6.5.3 Reinterpretation Cast
This is the most aggressive form of casting and is not used in this book. It takes an object’s memory location and interprets its bits as if the object had another type. This allows us, for instance, to change a single bit in a floating-point number by casting it to a bit chain. reinterpret_castis more important for programming hardware drivers than for advanced flux solvers. Needless to say, it is one of the most efficient ways to undermine the portability of our applications. If you really have to use it, incorporate it in platform-dependent conditional compilation and test your code excessively.
6.5.4 Function-Style Conversion
Constructors can be used to convert values: if a type T has a constructor for arguments of type U, we can create an object of type T from an object of type U:
U u;
T t(u);
or better:
U u;
T t{u}; // C++11
Therefore, it makes sense to use the constructor notation for converting values. Let’s reuse our example with different matrix types. Assume we have a function for dense matrices and want to apply it to a compressed matrix:
struct dense_matrix
{ ... };
struct compressed_matrix
{ ... };
void f(const dense_matrix&) {}
int main ()
{
compressed_matrix A;
f(dense_matrix(A));
}
Here we take the compressed_matrix A and create a dense_matrix out of it. This requires either
• A constructor in dense_matrix that accepts a compressed_matrix; or
• A conversion operator in compressed_matrix to dense_matrix.
These methods look like this:
struct compressed_matrix; // forward decl. needed in constructor
struct dense_matrix
{
dense_matrix() = default;
dense_matrix(const compressed_matrix& A) { ... }
};
struct compressed_matrix
{
operator dense_matrix() { dense_matrix A; ... return A; }
};
When both exist, the constructor is preferred. With this class implementation, we can also call f with implicit conversion:
int main ()
{
compressed_matrix A;
f(A);
}
In this case, the conversion operator is prioritized over the constructor. Note that the implicit conversion does not work with an explicit constructor or conversion operator. explicit conversion operators were introduced in C++11.
![]()
The danger of this notation is that it behaves like a C cast with an intrinsic target type, i.e.:
long(x); // corresponds to
(long)x;
This allows us to write evil code like
double d= 3.0;
double const* const dp= &d;
long l= long(dp); // OUCH!!! All bets are off!
Here we converted a const pointer to const double into a long! Although we seemingly asked to create a new value, a const_cast and a reinterpret_cast were performed. Needless to say, the value of l is rather meaningless and so are all values depending on it.
Note that the following initialization:
long l(dp); // Error: cannot initialize long with pointer
does not compile. Neither does the braced initialization:
long l{dp}; // Same Error (C++11)
This leads us to another notation:
l= long{dp}; // Error: failed initialization (C++11)
With curly braces, we always initialize a new value and even impede narrowing. static_cast allows for narrowing but refuses as well a conversion from a pointer to a number:
l= static_cast<long>(dp); // Error: pointer -> long
For those reasons, Bjarne Stroustrup advises the use of T{u} Tu for well-behaved construction and named casts like static_cast for other conversions.
6.5.5 Implicit Conversions
The rules of implicit conversion are not trivial. The good news is that we get along most of the time with knowing the most important rules and can usually be agnostic to their priorities. A complete list, for instance, can be found in the “C++ Reference” [7]. Table 6–2 gives an overview of the most important conversions.

Table 6–2: Implicit Conversion
Numeric types can be converted in different ways. First, integral types can be promoted, i.e., expanded with 0s or sign bits.6 In addition, every intrinsic numeric type can be converted to every other numeric type when needed for matching function argument types. For the new initialization techniques in C++11, only conversion steps are allowed that do not lose accuracy (i.e., no narrowing). Without the narrowing rules, even conversion between floating-point and bool is allowed with the intermediate conversion to int. All conversions between user types that can be expressed in function style (§6.5.4) are also performed implicitly when the enabling constructor or conversion operator is not declared explicit. Needless to say, the usage of implicit conversions should not be overdone. Which conversion should be expressed explicitly and where we can rely on the implicit rules is an important design decision for which no general rule exists.
6. Promotion is not a conversion in the purest sense of language laws.
6.6 CRTP
This section describes the Curiously Recurring Template Pattern (CRTP). It combines template programming very efficiently with inheritance. The term is sometimes confused with the Barton-Nackman Trick that is based on CRTP and was introduced by John Barton and Lee Nackman [4].
6.6.1 A Simple Example
![]() c++03/crtp_simple_example.cpp
c++03/crtp_simple_example.cpp
We will explain this new technique with a simple example. Assume we have a class named point containing an equality operator:
class point
{
public:
point(int x, int y) : x(x), y(y) {}
bool operator==(const point& that) const
{ return x == that.x && y == that.y; }
private:
int x, y;
};
We can program the inequality by using common sense or by applying de Morgan’s law:
bool operator!=(const point& that) const
{ return x != that.x || y != that.y; }
Or we can simplify our life and just negate the result of the equality:
bool operator!=(const point& that) const
{ return !(*this == that); }
Our compilers are so sophisticated, they can certainly handle de Morgan’s law perfectly after inlining. Negating the equality operator this way is a correct implementation of the inequality operator of every type (with an equality operator). We could copy-and-paste this code snippet and just replace the type of the argument each time.
Alternatively, we can write a class like this:
template <typename T>
struct inequality
{
bool operator!=(const T& that) const
{ return !(static_cast<const T&>(*this) == that); }
};
and derive from it:
class point : public inequality<point> { ... };
This class definition establishes a mutual dependency:
• point is derived from inequality, and
• inequality is parameterized with point.
These classes can be compiled despite their mutual dependency because member functions of template classes (like inequality) are not compiled until they are called. We can check that operator!= works:
point p1(3, 4), p2(3, 5);
cout ![]() "p1 != p2 is "
"p1 != p2 is " ![]() boolalpha
boolalpha ![]() (p1 != p2)
(p1 != p2) ![]() '\n';
'\n';
But what really happens when we call p1 != p2?
1. The compiler searches for operator!= in class point → without success.
2. The compiler looks for operator!= in the base class inequality<point> → with success.
3. The this pointer refers to the object of type inequality<point> being part of a point object.
4. Both types are completely known and we can statically down-cast the this pointer to point*.
5. Since we know that the this pointer of inequality<point> is an up-casted this pointer to point it is safe to down-cast it to its original type.
6. The equality operator of point is called and instantiated (if not done before).
Every class U with an equality operator can be derived from inequality<U> in the same manner. A collection of such CRTP templates for operator defaults is provided by Boost.Operators from Jeremy Siek and David Abrahams.
6.6.2 A Reusable Access Operator
![]() c++11/matrix_crtp_example.cpp
c++11/matrix_crtp_example.cpp
The CRTP idiom allows us to tackle a problem mentioned earlier (§2.6.4): accessing multidimensional data structures with the bracket operator with a reusable implementation. At the time we did not know the necessary language features, especially templates and inheritance. Now we do and will apply this knowledge to realize two bracket operator calls by one of a binary call operator, i.e., evaluate A[i][j] as A(i, j).
Say we have a matrix type going by the elegant name some_matrix whose operator() accesses aij. For consistency with the vector notation, we prefer bracket operators. Those accept only one argument, and we therefore need a proxy that represents the access to a matrix row. This proxy provides in turn a bracket operator for accessing a column in the corresponding row, i.e., yields an element of the matrix:
class some_matrix; // Forward declaration
class simple_bracket_proxy
{
public:
simple_bracket_proxy(matrix& A, size_t r) : A(A), r(r) {}
double& operator[](size_t c){ return A(r, c); } // Error
private:
matrix& A;
size_t r;
};
class some_matrix
{
// ...
double& operator()(size_t r, size_t c) { ... }
simple_bracket_proxy operator[](size_t r)
{
return simple_bracket_proxy(*this, r);
}
};
The idea is that A[i] returns a proxy p referring to A and containing i. Calling A[i][j] corresponds to p[j] which in turn should call A(i, j). Unfortunately, this code does not compile. When we call some_matrix::operator() insimple_bracket_proxy::operator[], the type some_matrix is only declared but not fully defined. Switching the two class definitions would only reverse the dependency and lead to more uncompilable code. The problem in this proxy implementation is that we need two complete types that depend on each other.
This is an interesting aspect of templates: they allow us to break mutual dependencies thanks to their postponed code generation. Adding template parameters to the proxy removes the dependency:
template <typename Matrix, typename Result>
class bracket_proxy
{
public:
bracket_proxy(Matrix& A, size_t r) : A(A), r(r) {}
Result& operator[](size_t c){ return A(r, c); }
private:
Matrix& A;
size_t r;
};
class some_matrix
{
// ...
bracket_proxy<some_matrix, double> operator[](size_t r)
{
return bracket_proxy<some_matrix, double>(*this, r);
}
};
Finally, we can write A[i][j] and have it performed internally in terms of the two-argument operator(). Now we can write many matrix classes with entirely different implementations of operator(), and all of them can deploy bracket_proxy in exactly the same manner.
Once we have implemented several matrix classes, we realize that the operator[] looks quite the same in all matrix classes: just returning a proxy with the matrix reference and the row argument. We can add another CRTP class for implementing this bracket operator just once:
![]()
template <typename Matrix, typename Result>
class bracket_proxy { ... };
template <typename Matrix, typename Result>
class crtp_matrix
{
using const_proxy= bracket_proxy<const Matrix, const Result>;
public:
bracket_proxy<Matrix, Result> operator[](size_t r)
{
return {static_cast<Matrix&>(*this), r};
}
const_proxy operator[](size_t r) const
{
return {static_cast<const Matrix&>(*this), r};
}
};
class matrix
: public crtp_matrix<matrix, double>
{
// ...
};
Note that the C++11 features are just used for brevity; we can implement this code as well in C++03 with little more verbosity. This CRTP matrix class can provide the bracket operator for every matrix class with a two-argument application operator. In a full-fledged linear-algebra package, however, we need to pay attention to which matrices are mutable and whether references or values are returned. These distinctions can be safely handled with meta-programming techniques from Chapter 5.
Although the proxy approach creates an extra object, our benchmarks have shown that the usage of the bracket operator is as fast as that of the application operator. Apparently, sophisticated reference forwarding in modern compilers can eliminate the actual creation of proxies.
6.7 Exercises
6.7.1 Non-redundant Diamond Shape
Implement the diamond shape from Section 6.3.2 such that the name is only printed once. Distinguish in derived classes between all_info() and my_infos() and call the two functions appropriately.
6.7.2 Inheritance Vector Class
Revise the vector example from Chapter 2. Introduce the base class vector_expression for size and operator(). Make vector inherit from this base class. Then make a class ones that is a vector of all ones and also inherits from vector_expression.
6.7.3 Clone Function
Write a CRTP class for a member function named clone() that copies the current object—like the Java function clone (http://en.wikipedia.org/wiki/Clone_%28Java_method%29). Consider that the return type of the function must be the one of the cloned object.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.