Practical C Programming, 3rd Edition (2011)
Part II. Simple Programming
Chapter 16. Floating Point
1 is equal to 2 for sufficiently large values of 1.
—Anonymous
Computers handle integers very well. The arithmetic is simple, exact, and fast. Floating-point arithmetic is the opposite. Computers do floating-point arithmetic only with great difficulty.
This chapter discusses some of the problems that can occur with floating-point. In order to understand the principles involved in floating-point arithmetic, we have defined a simple decimal floating-point format. We suggest you put aside your computer and work through these problems using pencil and paper so that you can see firsthand the problems and pitfalls that occur.
The format used by computers is very similar to the one defined in this chapter, except that instead of using base 10, computers use base 2, 8, or 16. However, all the problems demonstrated here on paper can occur in a computer.
Floating-Point Format
Floating-point numbers consist of three parts: a sign, a fraction, and an exponent. Our fraction is expressed as a 4-digit decimal. The exponent is a single-decimal digit. So, our format is:
![]()
where:
±
is the sign (plus or minus).
f.fff
is the 4 digit fraction.
±e
is the single-digit exponent with sign.
Zero is +0.000 x 10 +0. We represent these numbers in “E” format: ±0.000 E ±e.
This format is similar to the floating-point format used in many computers. The IEEE has defined a floating-point standard (#754), but not all machines use it.
Table 16-1 shows some typical floating-point numbers.
Table 16-1. Floating-Point Examples
|
Notation |
Number |
|
+1.000E+0 |
1.0 |
|
+3.300E+4 |
33000.0 |
|
-8.223E-3 |
-0.008223 |
|
+0.000E+0 |
0.0 |
The floating-point operations defined in this chapter follow a rigid set of rules. In order to minimize errors, we make use of a guard digit. That is an extra digit added to the end of our fraction during computation. Many computers use a guard digit in their floating-point units.
Floating Addition/Subtraction
To add two numbers like 2.0 and 0.3, you must perform the following steps.
1. Start with the numbers:
2. +2.000E+0 The number is 2.0.
+3.000E-1 The number is 0.3.
3. Add guard digits to both numbers:
4. +2.0000E+0 The number is 2.0.
+3.0000E-1 The number is 0.3.
5. Shift the number with the smallest exponent to the right one digit, and then increment its exponent. Continue until the exponents of the two numbers match:
6. +2.0000E+0 The number is 2.0.
+0.3000E-0 The number is 0.3.
7. Add the two fractions. The result has the same exponent as the two numbers:
8. +2.0000E+0 The number is 2.0.
9. +0.3000E-0 The number is 0.3.
10.__________________________________
+2.3000E+0 The result is 2.3.
11.Normalize the number by shifting it left or right until there is just one non-zero digit to the left of the decimal point. Adjust the exponent accordingly. A number like +0.1234E+0 would be normalized to +1.2340E-1. Because the number +2.3000E+0 is already normalized, we do nothing.
12.Finally, if the guard digit is greater than or equal to 5, round the next digit up; otherwise, truncate the number:
13.+2.3000E+0 Round the last digit.
14._____________________________________
+2.300E+0 The result is 2.3.
For floating-point subtraction, change the sign of the second operand and add.
Multiplication
When we want to multiply two numbers such as 0.12 x 11.0, the following rules apply.
1. Add the guard digit:
2. +1.2000E-1 The number is 0.12.
+1.1000E+1 The number is 11.0.
3. Multiply the two fractions and add the exponents, (1.2 x 1.1 = 1.32) (-1 + 1 = 0):
4. +1.2000E-1 The number is 0.12.
5. +1.1000E+1 The number is 11.0.
6. ___________________________________
+1.3200E+0 The result is 1.32.
7. Normalize the result.
If the guard digit is greater than or equal to 5, round the next digit up. Otherwise, truncate the number:
+1.3200E+0 The number is 1.32.
Notice that in multiplying, you didn’t have to go through all that shifting. The rules for multiplication are a lot shorter than those for addition. Integer multiplication is a lot slower than integer addition. In floating-point arithmetic, multiplication speed is a lot closer to that of addition.
Division
To divide numbers like 100.0 by 30.0, we must perform the following steps.
1. Add the guard digit:
2. +1.0000E+2 The number is 100.0.
+3.0000E+1 The number is 30.0.
3. Divide the fractions and subtract the exponents:
4. +1.0000E+2 The number is 100.0.
5. +3.0000E+1 The number is 30.0.
6. ____________________________________
+0.3333E+1 The result is 3.333.
7. Normalize the result:
+3.3330E+0 The result is 3.333.
8. If the guard digit is greater than or equal to 5, round the next digit up. Otherwise, truncate the number:
+3.333E+0 The result is 3.333.
Overflow and Underflow
There are limits to the size of the number that a computer can handle. What are the results of the following calculation?
9.000E+9 x 9.000E+9
Multiplying it out, we get:
8.1 x 10+19
However, we are limited to a single-digit exponent, too small to hold 19. This example illustrates overflow (sometimes called exponent overflow). Some computers generate a trap when this overflow occurs, thus interrupting the program and causing an error message to be printed. Other computers are not so nice and generate a wrong answer (like 8.100E+9). Computers that follow the IEEE floating-point standard generate a special value called +Infinity.
Underflow occurs when the numbers become too small for the computer to handle. For example:
1.000E-9 x 1.000E-9
The result is:
1.0 x 10 -18
Because -18 is too small to fit into one digit, we have underflow.
Roundoff Error
Floating-point arithmetic is not exact. Everyone knows that 1+1 is 2, but did you know that 1/3 + 1/3 does not equal 2/3?
This result can be shown by the following floating-point calculations:
2/3 as floating-point is 6.667E-1.
1/3 as floating-point is 3.333-1.
+3.333E-1
+3.333E-1
+6.666E-1 or 0.6666
which is not:
+6.667E-1
Every computer has a similar problem with its floating point. For example, the number 0.2 has no exact representation in binary floating-point.
Floating-point arithmetic should never be used for money. Because we are used to dealing with dollars and cents, you might be tempted to define the amount of $1.98 as:
float amount = 1.98;
However, the more calculations you do with floating-point arithmetic, the bigger the roundoff error. Banks, credit card companies, and the IRS tend to be very fussy about money. Giving the IRS a check that’s almost right is not going to make them happy. Money should be stored as an integer number of pennies.
Accuracy
How many digits of the fraction are accurate? At first glance you might be tempted to say all four digits. Those of you who have read the previous section on roundoff error might be tempted to change your answer to three.
The answer is: the accuracy depends on the calculation. Certain operations, like subtracting two numbers that are close to each other, generate inexact results. For example, consider the following equation:
1 - 1/3 - 1/3 - 1/3
1.000E+0
- 3.333E-1
- 3.333E-1
- 3.333E-1
or:
1.000E+0
- 0.333E+0
- 0.333E+0
- 0.333E+0
_____________________
0.0010E+0 or 1.000E-3
The correct answer is 0.000E+0 and we got 1.000E-3. The very first digit of the fraction is wrong. This error is an example of the problem called “roundoff error” that can occur during floating-point operations.
Minimizing Roundoff Error
There are many techniques for minimizing roundoff error. Guard digits have already been discussed. Another trick is to use double instead of float. This solution gives you approximately twice the accuracy as well as an enormously greater range. It also pushes away the minimization problem twice as far. But roundoff errors still can creep in.
Advanced techniques for limiting the problems caused by floating point can be found in books on numerical analysis. They are beyond the scope of this text. The purpose of this chapter is to give you some idea of the sort of problems that can be encountered.
Floating-point by its very nature is not exact. People tend to think of computers as very accurate machines. They can be, but they also can give wildly wrong results. You should be aware of the places where errors can slip into your program.
Determining Accuracy
There is a simple way of determining how accurate your floating point is (for simple calculations). The method used in the following program is to add 1.0+0.1, 1.0+0.01, 1.0+0.001, and so on until the second number gets so small that it makes no difference in the result.
The C language specifies that all floating-point numbers are to be done in double. This method means that the expression:
float number1, number2;
. . .
while (number1 + number2 != number1)
is equivalent to:
while (double(number1) + double(number2) != double(number1))
When using the 1+0.001 trick, the automatic conversion of float to double may give a distorted picture of the accuracy of your machine. (In one case, 84 bits of accuracy were reported for a 32-bit format.) Example 16-1 computes both the accuracy of floating-point numbers as used in equations and floating-point numbers as stored in memory. Note the trick used to determine the accuracy of the floating-point numbers in storage.
Example 16-1. float/float.c
#include <stdio.h>
int main()
{
/* two numbers to work with */
float number1, number2;
float result; /* result of calculation */
int counter; /* loop counter and accuracy check */
number1 = 1.0;
number2 = 1.0;
counter = 0;
while (number1 + number2 != number1) {
++counter;
number2 = number2 / 10.0;
}
printf("%2d digits accuracy in calculations\n", counter);
number2 = 1.0;
counter = 0;
while (1) {
result = number1 + number2;
if (result == number1)
break;
++counter;
number2 = number2 / 10.0;
}
printf("%2d digits accuracy in storage\n", counter);
return (0);
}
Running this on a Sun-3/50 with a MC68881 floating-point chip, we get:
20 digits accuracy in calculations
8 digits accuracy in storage
This program gives only an approximation of the floating-point precision arithmetic. A more precise definition can be found in the standard include file float.h.
Precision and Speed
A variable of type double has about twice the precision of a normal float variable. Most people assume that double-precision arithmetic takes longer than single- precision arithmetic. This statement is not always true. Remember that C requires that all the arithmetic must be done in double.
For the equation:
float answer, number1, number2;
answer = number1 + number2;
C must perform the following steps:
1. Convert number1 from single to double precision.
2. Convert number2 from single to double precision.
3. Double-precision add.
4. Convert result into single-precision arithmetic and store in answer.
If the variables were of type double, C would only have to perform these steps:
1. Carry out a double-precision add.
2. Store result in answer.
As you can see, the second form is a lot simpler, requiring three fewer conversions. In some cases, converting a program from single-precision arithmetic to double- precision arithmetic makes it run faster.
Many computers, including the PC and Sun series machines, have a floating-point processor that does all the floating-point arithmetic. Actual tests using the Motorola 68881 floating-point chip (which is used in the Sun/3) as well as the floating-point on the PC show that single-precision and double-precision run at the same speed.
Power Series
Many trigonometry functions are computed using a power series. For example, the series for sine is:
Equation 16-0.
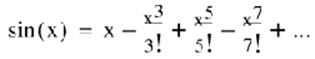
The question is: how many terms do we need to get 4-digit accuracy? Table 16-2 contains the terms for the sin(/2).
Table 16-2. Terms for the sin(/2)
|
Term |
Value |
Total |
|
|
1 |
x |
1.571E+0 |
|
|
2 |
|
6.462E-1 |
9.248E-1 |
|
3 |
|
7.974E-2 |
1.005E+0 |
|
4 |
|
4.686E-3 |
9.998E-1 |
|
5 |
|
1.606E-4 |
1.000E+0 |
|
6 |
|
3.604E-6 |
1.000E+0 |
From this, we conclude that five terms are needed. However, if we try to compute the sin(), we get the values in Table 16-3.
Table 16-3. Terms for the sin()
|
Term |
Value |
Total |
|
|
1 |
x |
3.142E+0 |
|
|
2 |
|
5.170E+0 |
-2.028E+0 |
|
3 |
|
2.552E-0 |
5.241E-1 |
|
4 |
|
5.998E-1 |
-7.570E-2 |
|
5 |
|
8.224E-2 |
6.542E-3 |
|
6 |
|
7.381E-3 |
-8.388E-4 |
|
7 |
|
4.671E-4 |
-3.717E-4 |
|
8 |
|
2.196E-5 |
-3.937E-4 |
|
9 |
|
7.970E-7 |
-3.929E-4 |
|
10 |
|
2.300E-8 |
-3.929E-4 |
needs nine terms. So different angles require a different number of terms. (A program for computing the sine to four-digit accuracy showing intermediate terms is included in Appendix D.)
Compiler designers face a dilemma when it comes to designing a sine function. If they know ahead of time the number of terms to use, they can optimize their algorithms for that number of terms. However, they lose accuracy for some angles. So a compromise must be struck between speed and accuracy.
Don’t assume that because the number came from the computer, it is accurate. The library functions can generate bad answers—especially when you work with excessively large or small values. Most of the time, you will not have any problems with these functions, but you should be aware of their limitations.
Finally there is the question of what is sin(1000000)? Our floating-point format is good for only four digits. The sine function is cyclical. That is, sin(0) = sin(2) = sin(4). ... So sin(1000000) is the same as sin(1000000 mod 2).
Note that our floating-point format is good to only four digits, so sin(1000000) is actually sin(1000000 + 1000). Because 1000 is bigger than 2, the error renders meaningless the result of the sine.
HOW HOT IS IT?
I attended a physics class at Caltech that was taught by two professors. One was giving a lecture on the sun when he said, “... and the mean temperature of the inside of the sun is 13,000,000 to 25,000,000 degrees.” At this point, the other instructor broke in and asked “Is that Celsius or Kelvin (absolute zero or Celsius-273)?”
The lecturer turned to the board for a minute, then said, “What’s the difference?” The moral of the story is that when your calculations have a possible error of 12,000,000, a difference of 273 doesn’t mean very much.
Programming Exercises
Exercise 16-1: Write a program that uses strings to represent floating-point numbers in the format used in this chapter. A typical string might look like "+1.333E+2". The program should have functions to read, write, add, subtract, multiply, and divide floating-point numbers.
Exercise 16-2: Create a set of functions to handle fixed-point numbers. A fixed- point number has a constant (fixed) number of digits to the right of the decimal point.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.