Programming in C (Fourth Edition) (2015)
9. Character Strings
Now, you are ready to take a look at character strings in more detail. Data manipulation is the single-most important function your programs will perform. Numbers, in their various data formats, only cover half the story. You also need to deal with words, characters, and alphanumeric combinations of the two. Although the C language does not have a string data type like many other languages, you’ve already seen that a combination of the char data type and arrays can cover what you need. In addition, there are both library functions as well as routines you can write to manipulate string data. This chapter covers the basics, including
![]() Understanding character arrays
Understanding character arrays
![]() Employing variable-length character arrays
Employing variable-length character arrays
![]() Using escape characters
Using escape characters
![]() Adding character arrays to structures
Adding character arrays to structures
![]() Performing data operations on strings
Performing data operations on strings
Revisiting the Basics of Strings
You were first introduced to character strings in Chapter 2, “Compiling and Running Your First Program,” when you wrote your first C program. In the statement
printf ("Programming in C is fun.\n");
the argument that is passed to the printf() function is the character string
"Programming in C is fun.\n"
The double quotation marks are used to delimit the character string, which can contain any combinations of letters, numbers, or special characters, other than a double quotation mark. But as you shall see shortly, it is even possible to include a double quotation mark inside a character string.
When introduced to the data type char, you learned that a variable that is declared to be of this type can contain only a single character. To assign a single character to such a variable, the character is enclosed within a pair of single quotation marks. Thus, the assignment
plusSign = '+';
has the effect of assigning the character '+' to the variable plusSign, assuming it has been appropriately declared. In addition, you learned that there is a distinction made between the single quotation and double quotation marks, and that if plusSign is declared to be of type char, then the statement
plusSign = "+";
is incorrect. Be certain you remember that single quotation and double quotation marks are used to create two different types of constants in C.
Arrays of Characters
If you want to be able to deal with variables that can hold more than a single character1, this is precisely where the array of characters comes into play.
1. Recall that the type wchar_t can be used for representing so-called wide characters, but that’s for handling a single character from an international character set. The discussion here is about storing sequences of multiple characters.
In Program 6.6, you defined an array of characters called word as follows:
char word [] = { 'H', 'e', 'l', 'l', 'o', '!' };
Remembering that in the absence of a particular array size, the C compiler automatically computes the number of elements in the array based upon the number of initializers, this statement reserves space in memory for exactly six characters, as shown in Figure 9.1.

Figure 9.1 The array word in memory.
To print out the contents of the array word, you ran through each element in the array and displayed it using the %c format characters.
With this technique, you can begin to build an assortment of useful functions for dealing with character strings. Some of the more commonly performed operations on character strings include combining two character strings together (concatenation), copying one character string to another, extracting a portion of a character string (substring), and determining if two character strings are equal (that is, if they contain the same characters). Take the first mentioned operation, concatenation, and develop a function to perform this task. You can define a call to your concat()function as follows:
concat (result, str1, n1, str2, n2);
where str1 and str2 represent the two character arrays that are to be concatenated and n1 and n2 represent the number of characters in the respective arrays. This makes the function flexible enough so that you can concatenate two character arrays of arbitrary length. The argumentresult represents the character array that is to be the destination of the concatenated character arrays str1 followed by str2. See Program 9.1.
Program 9.1 Concatenating Character Arrays
// Function to concatenate two character arrays
#include <stdio.h>
void concat (char result[], const char str1[], int n1,
const char str2[], int n2)
{
int i, j;
// copy str1 to result
for ( i = 0; i < n1; ++i )
result[i] = str1[i];
// copy str2 to result
for ( j = 0; j < n2; ++j )
result[n1 + j] = str2[j];
}
int main (void)
{
void concat (char result[], const char str1[], int n1,
const char str2[], int n2);
const char s1[5] = { 'T', 'e', 's', 't', ' '};
const char s2[6] = { 'w', 'o', 'r', 'k', 's', '.' };
char s3[11];
int i;
concat (s3, s1, 5, s2, 6);
for ( i = 0; i < 11; ++i )
printf ("%c", s3[i]);
printf ("\n");
return 0;
}
Program 9.1 Output
Test works.
The first for loop inside the concat() function copies the characters from the str1 array into the result array. This loop is executed n1 times, which is the number of characters contained inside the str1 array.
The second for loop copies str2 into the result array. Because str1 was n1 characters long, copying into result begins at result[n1]—the position immediately following the one occupied by the last character of str1. After this for loop is done, the result array contains the n1+n2 characters representing str2 concatenated to the end of str1.
Inside the main() routine, two const character arrays, s1 and s2, are defined. The first array is initialized to the characters 'T', 'e', 's', 't', and ' '. This last character represents a blank space and is a perfectly valid character constant. The second array is initially set to the characters 'w', 'o', 'r', 'k', 's', and '.'. A third character array, s3, is defined with enough space to hold s1 concatenated to s2, or 11 characters. It is not declared as a const array because its contents will be changed.
The function call
concat (s3, s1, 5, s2, 6);
calls the concat() function to concatenate the character arrays s1 and s2, with the destination array s3. The arguments 5 and 6 are passed to the function to indicate the number of characters in s1 and s2, respectively.
After the concat() function has completed execution and returns to main(), a for loop is set up to display the results of the function call. The 11 elements of s3 are displayed, and as you can see from the program’s output, the concat() function seems to be working properly. In the preceding program example, it is assumed that the first argument to the concat() function—the result array—contains enough space to hold the resulting concatenated character arrays. Failure to do so can produce unpredictable results when the program is run.
Variable-Length Character Strings
You can adopt a similar approach to that used by the concat() function for defining other functions to deal with character arrays. That is, you can develop a set of routines, each of which has as its arguments one or more character arrays plus the number of characters contained in each such array. Unfortunately, after working with these functions for a while, you will find that it gets a bit tedious trying to keep track of the number of characters contained in each character array that you are using in your program—especially if you are using your arrays to store character strings of varying sizes. What you need is a method for dealing with character arrays without having to worry about precisely how many characters you have stored in them.
There is such a method, and it is based upon the idea of placing a special character at the end of every character string. In this manner, the function can then determine for itself when it has reached the end of a character string after it encounters this special character. By developing all of your functions to deal with character strings in this fashion, you can eliminate the need to specify the number of characters that are contained inside a character string.
In the C language, the special character that is used to signal the end of a string is known as the null character and is written as '\0'. So, the statement
const char word [] = { 'H', 'e', 'l', 'l', 'o', '!', '\0' };
defines a character array called word that contains seven characters, the last of which is the null character. (Recall that the backslash character [\] is a special character in the C language and does not count as a separate character; therefore, '\0' represents a single character in C.) The array word is depicted in Figure 9.2.

Figure 9.2 The array word with a terminating null character.
To begin with an illustration of how these variable-length character strings are used, write a function that counts the number of characters in a character string, as shown in Program 9.2. Call the function stringLength() and have it take as its argument a character array that is terminated by the null character. The function determines the number of characters in the array and returns this value back to the calling routine. Define the number of characters in the array as the number of characters up to, but not including, the terminating null character. So, the function call
stringLength (characterString)
should return the value 3 if characterString is defined as follows:
char characterString[] = { 'c', 'a', 't', '\0' };
Program 9.2 Counting the Characters in a String
// Function to count the number of characters in a string
#include <stdio.h>
int stringLength (const char string[])
{
int count = 0;
while ( string[count] != '\0' )
++count;
return count;
}
int main (void)
{
int stringLength (const char string[]);
const char word1[] = { 'a', 's', 't', 'e', 'r', '\0' };
const char word2[] = { 'a', 't', '\0' };
const char word3[] = { 'a', 'w', 'e', '\0' };
printf ("%i %i %i\n", stringLength (word1),
stringLength (word2), stringLength (word3));
return 0;
}
Program 9.2 Output
5 2 3
The stringLength() function declares its argument as a const array of characters because it is not making any changes to the array, merely counting its size.
Inside the stringLength() function, the variable count is defined and its value set to 0. The program then enters a while loop to sequence through the string array until the null character is reached. When the function finally hits upon this character, signaling the end of the character string, the while loop is exited and the value of count is returned. This value represents the number of characters in the string, excluding the null character. You might want to trace through the operation of this loop on a small character array to verify that the value of countwhen the loop is exited is in fact equal to the number of characters in the array, excluding the null character.
In the main() routine, three character arrays, word1, word2, and word3, are defined. The printf() function call displays the results of calling the stringLength() function for each of these three character arrays.
Initializing and Displaying Character Strings
Now, it is time to go back to the concat() function developed in Program 9.1 and rewrite it to work with variable-length character strings. Obviously, the function must be changed somewhat because you no longer want to pass as arguments the number of characters in the two arrays. The function now takes only three arguments: the two character arrays to be concatenated and the character array in which to place the result.
Before delving into this program, you should first learn about two nice features that C provides for dealing with character strings.
The first feature involves the initialization of character arrays. C permits a character array to be initialized by simply specifying a constant character string rather than a list of individual characters. So, for example, the statement
char word[] = { "Hello!" };
can be used to set up an array of characters called word with the initial characters ’H’, ’e’, ’l’, ’l’, ’o’, ’!’, and ’\0’, respectively. You can also omit the braces when initializing character arrays in this manner. So, the statement
char word[] = "Hello!";
is perfectly valid. Either statement is equivalent to the statement
char word[] = { 'H', 'e', 'l', 'l', 'o', '!', '\0' };
If you’re explicitly specifying the size of the array, make certain you leave enough space for the terminating null character. So, in
char word[7] = { "Hello!" };
the compiler has enough room in the array to place the terminating null character. However, in
char word[6] = { "Hello!" };
the compiler can’t fit a terminating null character at the end of the array, and so it doesn’t put one there (and it doesn’t complain about it either).
In general, wherever they appear in your program, character-string constants in the C language are automatically terminated by the null character. This fact helps functions such as printf() determine when the end of a character string has been reached. So, in the call
printf ("Programming in C is fun.\n");
the null character is automatically placed after the newline character in the character string, thereby enabling the printf() function to determine when it has reached the end of the format string.
The other feature to be mentioned here involves the display of character strings. The special format characters %s inside a printf() format string can be used to display an array of characters that is terminated by the null character. So, if word is a null-terminated array of characters, theprintf() call
printf ("%s\n", word);
can be used to display the entire contents of the word array at the terminal. The printf() function assumes when it encounters the %s format characters that the corresponding argument is a character string that is terminated by a null character.
The two features just described were incorporated into the main() routine of Program 9.3, which illustrates your revised concat() function. Because you are no longer passing the number of characters in each string as arguments to the function, the function must determine when the end of each string is reached by testing for the null character. Also, when str1 is copied into the result array, you want to be certain not to also copy the null character because this ends the string in the result array right there. You do need, however, to place a null character into theresult array after str2 has been copied so as to signal the end of the newly created string.
Program 9.3 Concatenating Character Strings
#include <stdio.h>
int main (void)
{
void concat (char result[], const char str1[], const char str2[]);
const char s1[] = { "Test " };
const char s2[] = { "works." };
char s3[20];
concat (s3, s1, s2);
printf ("%s\n", s3);
return 0;
}
// Function to concatenate two character strings
void concat (char result[], const char str1[], const char str2[])
{
int i, j;
// copy str1 to result
for ( i = 0; str1[i] != '\0'; ++i )
result[i] = str1[i];
// copy str2 to result
for ( j = 0; str2[j] != '\0'; ++j )
result[i + j] = str2[j];
// Terminate the concatenated string with a null character
result [i + j] = '\0';
}
Program 9.3 Output
Test works.
In the first for loop of the concat() function, the characters contained inside str1 are copied into the result array until the null character is reached. Because the for loop terminates as soon as the null character is matched, it does not get copied into the result array.
In the second loop, the characters from str2 are copied into the result array directly after the final character from str1. This loop makes use of the fact that when the previous for loop finished execution, the value of i was equal to the number of characters in str1, excluding the null character. Therefore, the assignment statement
result[i + j] = str2[j];
is used to copy the characters from str2 into the proper locations of result.
After the second loop is completed, the concat() function puts a null character at the end of the string. Study the function to ensure that you understand the use of i and j. Many program errors when dealing with character strings involve the use of an index number that is off by 1 in either direction.
Remember, to reference the first character of an array, an index number of 0 is used. In addition, if a character array string contains n characters, excluding the null byte, then string[n − 1] references the last (nonnull) character in the string, whereas string[n] references the null character. Furthermore, string must be defined to contain at least n + 1 characters, bearing in mind that the null character occupies a location in the array.
Returning to the program, the main() routine defines two char arrays, s1 and s2, and sets their values using the new initialization technique previously described. The array s3 is defined to contain 20 characters, thus ensuring that sufficient space is reserved for the concatenated character string and saving you from the trouble of having to precisely calculate its size.
The concat function is then called with the three strings s1, s2, and s3 as arguments. The result, as contained in s3 after the concat function returns, is displayed using the %s format characters. Although s3 is defined to contain 20 characters, the printf() function only displays characters from the array up to the null character.
Testing Two Character Strings for Equality
You cannot directly test two strings to see if they are equal with a statement such as
if ( string1 == string2 )
...
because the equality operator can only be applied to simple variable types, such as floats, ints, or chars, and not to more sophisticated types, such as structures or arrays.
To determine if two strings are equal, you must explicitly compare the two character strings character by character. If you reach the end of both character strings at the same time, and if all of the characters up to that point are identical, the two strings are equal; otherwise, they are not.
It might be a good idea to develop a function that can be used to compare two character strings, as shown in Program 9.4. You can call the function equalStrings() and have it take as arguments the two character strings to be compared. Because you are only interested in determining whether the two character strings are equal, you can have the function return a bool value of true (or nonzero) if the two strings are identical, and false (or zero) if they are not. In this way, the function can be used directly inside test statements, such as in
if ( equalStrings (string1, string2) )
...
Program 9.4 Testing Strings for Equality
// Function to determine if two strings are equal
#include <stdio.h>
#include <stdbool.h>
bool equalStrings (const char s1[], const char s2[])
{
int i = 0;
bool areEqual;
while ( s1[i] == s2 [i] &&
s1[i] != '\0' && s2[i] != '\0' )
++i;
if ( s1[i] == '\0' && s2[i] == '\0' )
areEqual = true;
else
areEqual = false;
return areEqual;
}
int main (void)
{
bool equalStrings (const char s1[], const char s2[]);
const char stra[] = "string compare test";
const char strb[] = "string";
printf ("%i\n", equalStrings (stra, strb));
printf ("%i\n", equalStrings (stra, stra));
printf ("%i\n", equalStrings (strb, "string"));
return 0;
}
Program 9.4 Output
0
1
1
The equalStrings() function uses a while loop to sequence through the character strings s1 and s2. The loop is executed so long as the two character strings are equal (s1[i] == s2[i]) and so long as the end of either string is not reached (s1[i] != '\0' && s2[i] != '\0'). The variable i, which is used as the index number for both arrays, is incremented each time through the while loop.
The if statement that executes after the while loop has terminated determines if you have simultaneously reached the end of both strings s1 and s2. You could have used the statement
if ( s1[i] == s2[i] )
...
instead to achieve the same results. If you are at the end of both strings, the strings must be identical, in which case areEqual is set to true and returned to the calling routine. Otherwise, the strings are not identical and areEqual is set to false and returned.
In main(), two character arrays stra and strb are set up and assigned the indicated initial values. The first call to the equalStrings() function passes these two character arrays as arguments. Because these two strings are not equal, the function correctly returns a value of false,or 0.
The second call to the equalStrings() function passes the string stra twice. The function correctly returns a true value to indicate that the two strings are equal, as verified by the program’s output.
The third call to the equalStrings() function is a bit more interesting. As you can see from this example, you can pass a constant character string to a function that is expecting an array of characters as an argument. In Chapter 10, “Pointers,” you see how this works. TheequalStrings() function compares the character string contained in strb to the character string "string" and returns true to indicate that the two strings are equal.
Inputting Character Strings
By now, you are used to the idea of displaying a character string using the %s format characters. But what about reading in a character string from your window (or your “terminal window”)? Well, on your system, there are several library functions that you can use to input character strings. The scanf() function can be used with the %s format characters to read in a string of characters up to a blank space, tab character, or the end of the line, whichever occurs first. So, the statements
char string[81];
scanf ("%s", string);
have the effect of reading in a character string typed into your terminal window and storing it inside the character array string. Note that unlike previous scanf() calls, in the case of reading strings, the & is not placed before the array name (the reason for this is also explained in Chapter 10).
If the preceding scanf() call is executed, and the following characters are entered:
Gravity
the string "Gravity" is read in by the scanf() function and is stored inside the string array. If the following line of text is typed instead:
iTunes playlist
just the string "iTunes" is stored inside the string array because the blank space after the word scanf() terminates the string. If the scanf() call is executed again, this time the string "playlist" is stored inside the string array because the scanf() function always continues scanning from the most recent character that was read in.
The scanf() function automatically terminates the string that is read in with a null character. So, execution of the preceding scanf() call with the line of text
abcdefghijklmnopqrstuvwxyz
causes the entire lowercase alphabet to be stored in the first 26 locations of the string array, with string[26] automatically set to the null character.
If s1, s2, and s3 are defined to be character arrays of appropriate sizes, execution of the statement
scanf ("%s%s%s", s1, s2, s3);
with the line of text
mobile app development
results in the assignment of the string "mobile" to s1, "app" to s2, and "development" to s3. If the following line of text is typed instead:
tablet computer
it results in the assignment of the string "tablet" to s1, and "computer" to s2. Because no further characters appear on the line, the scanf() function then waits for more input to be entered.
In Program 9.5, scanf() is used to read three character strings.
Program 9.5 Reading Strings with scanf()
// Program to illustrate the %s scanf format characters
#include <stdio.h>
int main (void)
{
char s1[81], s2[81], s3[81];
printf ("Enter text:\n");
scanf ("%s%s%s", s1, s2, s3);
printf ("\ns1 = %s\ns2 = %s\ns3 = %s\n", s1, s2, s3);
return 0;
}
Program 9.5 Output
Enter text:
smart phoneapps
s1 = smart
s2 = phone
s3 = apps
In the preceding program, the scanf() function is called to read in three character strings: s1, s2, and s3. Because the first line of text contains only two character strings—where the definition of a character string to scanf() is a sequence of characters up to a space, tab, or the end of the line—the program waits for more text to be entered. After this is done, the printf() call is used to verify that the strings "smart", "phone", and "apps" are correctly stored inside the string arrays s1, s2, and s3, respectively.
If you type in more than 80 consecutive characters to the preceding program without pressing the spacebar, the tab key, or the Enter (or Return) key, scanf() overflows one of the character arrays. This might cause the program to terminate abnormally or cause unpredictable things to happen. Unfortunately, scanf() has no way of knowing how large your character arrays are. When handed a %s format, it simply continues to read and store characters until one of the noted terminator characters is reached.
If you place a number after the % in the scanf format string, this tells scanf the maximum number of characters to read. So, if you used the following scanf call:
scanf ("%80s%80s%80s", s1, s2, s3);
instead of the one shown in Program 9.5, scanf knows that no more than 80 characters are to be read and stored into either s1, s2, or s3. (You still have to leave room for the terminating null character that scanf stores at the end of the array. That’s why %80s is used instead of %81s.)
Single-Character Input
The standard library provides several functions for the express purposes of reading and writing single characters and entire character strings. A function called getchar() can be used to read in a single character from the terminal. Repeated calls to the getchar() function return successive single characters from the input. When the end of the line is reached, the function returns the newline character '\n'. So, if the characters “abc” are typed, followed immediately by the Enter (or Return) key, the first call to the getchar() function returns the character 'a', the second call returns the character 'b', the third call returns 'c', and the fourth call returns the newline character '\n'. A fifth call to this function causes the program to wait for more input to be entered from the terminal.
You might be wondering why you need the getchar() function when you already know how to read in a single character with the %c format characters of the scanf() function. Using the scanf() function for this purpose is a perfectly valid approach; however, the getchar()function is a more direct approach because its sole purpose is for reading in single characters, and, therefore, it does not require any arguments. The function returns a single character that might be assigned to a variable or used as desired by the program.
In many text-processing applications, you need to read in an entire line of text. This line of text is frequently stored in a single place—generally called a “buffer”—where it is processed further. Using the scanf() call with the %s format characters does not work in such a case because the string is terminated as soon as a space is encountered in the input.
Also available from the function library is a function called gets(). The sole purpose of this function—you guessed it—is to read in a single line of text. As an interesting program exercise, Program 9.6 shows how a function similar to the gets() function—called readLine() here—can be developed using the getchar() function. The function takes a single argument: a character array in which the line of text is to be stored. Characters read from the terminal window up to, but not including, the newline character are stored in this array by the function.
Program 9.6 Reading Lines of Data
#include <stdio.h>
int main (void)
{
int i;
char line[81];
void readLine (char buffer[]);
for ( i = 0; i < 3; ++i )
{
readLine (line);
printf ("%s\n\n", line);
}
return 0;
}
// Function to read a line of text from the terminal
void readLine (char buffer[])
{
char character;
int i = 0;
do
{
character = getchar ();
buffer[i] = character;
++i;
}
while ( character != '\n' );
buffer[i - 1] = '\0';
}
Program 9.6 Output
This is a sample line of text.
This is a sample line of text.
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
runtime library routines
runtime library routines
The do loop in the readLine() function is used to build up the input line inside the character array buffer. Each character that is returned by the getchar() function is stored in the next location of the array. When the newline character is reached—signaling the end of the line—the loop is exited. The null character is then stored inside the array to terminate the character string, replacing the newline character that was stored there the last time that the loop was executed. The index number i − 1 indexes the correct position in the array because the index number was incremented one extra time inside the loop the last time it was executed.
The main() routine defines a character array called line with enough space reserved to hold 81 characters. This ensures that an entire line (80 characters has historically been used as the line length of a “standard terminal”) plus the null character can be stored inside the array. However, even in windows that display 80 or fewer characters per line, you are still in danger of overflowing the array if you continue typing past the end of the line without pressing the Enter (or Return) key. It is a good idea to extend the readLine() function to accept as a second argument the size of the buffer. In this way, the function can ensure that the capacity of the buffer is not exceeded.
Another good idea for this program is to improve the user interactivity by adding a prompt line that informs the user what the program is looking for. Adding the following line before the do...while loop in the readline() function makes things more clear for the program’s user:
printf("Enter a line of text, up to 80 characters. Hit enter when done:\n");
A line like this can also specify the format you are looking for in a data point, like a dollar sign ($) before a money amount, or a colon (:) between the hours and minutes of a time entry. Cues like this are another way to minimize data-entry errors.
The program then enters a for loop, which simply calls the readLine() function three times. Each time that this function is called, a new line of text is read from the terminal. This line is simply echoed back at the terminal to verify proper operation of the function. After the third line of text has been displayed, execution of Program 9.6 is complete.
For your next program example (see Program 9.7), consider a practical text-processing application: counting the number of words in a portion of text. This program develops a function called countWords(), which takes as its argument a character string and which returns the number of words contained in that string. For the sake of simplicity, assume here that a word is defined as a sequence of one or more alphabetic characters. The function can scan the character string for the occurrence of the first alphabetic character and considers all subsequent characters up to the first nonalphabetic character as part of the same word. Then, the function can continue scanning the string for the next alphabetic character, which identifies the start of a new word.
Program 9.7 Counting Words
// Function to determine if a character is alphabetic
#include <stdio.h>
#include <stdbool.h>
bool alphabetic (const char c)
{
if ( (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') )
return true;
else
return false;
}
/* Function to count the number of words in a string */
int countWords (const char string[])
{
int i, wordCount = 0;
bool lookingForWord = true, alphabetic (const char c);
for ( i = 0; string[i] != '\0'; ++i )
if ( alphabetic(string[i]) )
{
if ( lookingForWord )
{
++wordCount;
lookingForWord = false;
}
}
else
lookingForWord = true;
return wordCount;
}
int main (void)
{
const char text1[] = "Well, here goes.";
const char text2[] = "And here we go... again.";
int countWords (const char string[]);
printf ("%s - words = %i\n", text1, countWords (text1));
printf ("%s - words = %i\n", text2, countWords (text2));
return 0;
}
Program 9.7 Output
Well, here goes. - words = 3
And here we go... again. - words = 5
The alphabetic() function is straightforward enough—it simply tests the value of the character passed to it to determine if it is either a lowercase or uppercase letter. If it is either, the function returns true, indicating that the character is alphabetic; otherwise, the function returnsfalse.
The countWords() function is not as straightforward. The integer variable i is used as an index number to sequence through each character in the string. The integer variable lookingForWord is used as a flag to indicate whether you are currently in the process of looking for the start of a new word. At the beginning of the execution of the function, you obviously are looking for the start of a new word, so this flag is set to true. The local variable wordCount is used for the obvious purpose of counting the number of words in the character string.
For each character inside the character string, a call to the alphabetic() function is made to determine whether the character is alphabetic. If the character is alphabetic, the lookingForWord flag is tested to determine if you are in the process of looking for a new word. If you are, the value of wordCount is incremented by 1, and the lookingForWord flag is set to false, indicating that you are no longer looking for the start of a new word.
If the character is alphabetic and the lookingForWord flag is false, this means that you are currently scanning inside a word. In such a case, the for loop is continued with the next character in the string.
If the character is not alphabetic—meaning either that you have reached the end of a word or that you have still not found the beginning of the next word—the flag lookingForWord is set to true (even though it might already be true).
When all of the characters inside the character string have been examined, the function returns the value of wordCount to indicate the number of words that were found in the character string.
It is helpful to present a table of the values of the various variables in the countWords function to see how the algorithm works. Table 9.1 shows such a table, with the first call to the countWords function from the preceding program as an example. The first line of Table 9.1 shows the initial value of the variables wordCount and lookingForWord before the for loop is entered. Subsequent lines depict the values of the indicated variables each time through the for loop. So, the second line of the table shows that the value of wordCount has been set to 1 and thelookingForWord flag set to false (0) after the first time through the loop (after the 'W' has been processed). The last line of the table shows the final values of the variables when the end of the string is reached. You should spend some time studying this table, verifying the values of the indicated variables against the logic of the countWords() function. After this has been accomplished, you should then feel comfortable with the algorithm that is used by the function to count the number of words in a string.
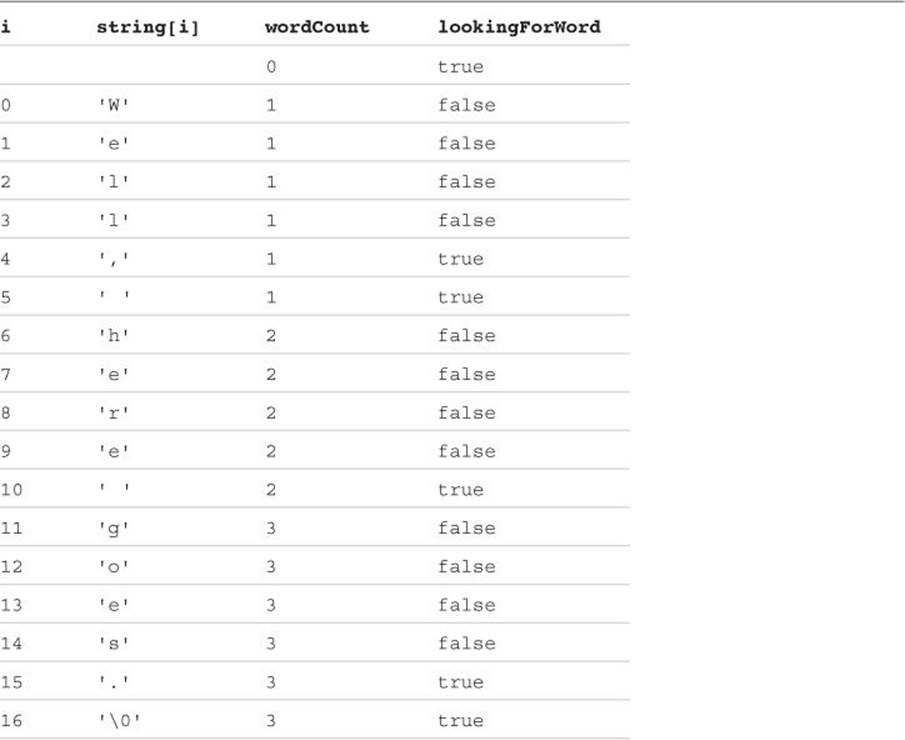
Table 9.1 Execution of the countWords() Function
The Null String
Now consider a slightly more practical example of the use of the countWords() function. This time, you make use of your readLine() function to allow the user to type in multiple lines of text. The program then counts the total number of words in the text and displays the result.
To make the program more flexible, you do not limit or specify the number of lines of text that are entered. Therefore, you must have a way for the user to “tell” the program when he is done entering text. One way to do this is to have the user simply press the Enter (or Return) key an extra time after the last line of text has been entered. When the readLine() function is called to read in such a line, the function immediately encounters the newline character and, as a result, stores the null character as the first (and only) character in the buffer. Your program can check for this special case and can know that the last line of text has been entered after a line containing no characters has been read.
A character string that contains no characters other than the null character has a special name in the C language; it is called the null string. When you think about it, the use of the null string is still perfectly consistent with all of the functions that you have defined so far in this chapter. ThestringLength() function correctly returns 0 as the size of the null string; your concat() function also properly concatenates “nothing” onto the end of another string; even your equalStrings() function works correctly if either or both strings are null (and in the latter case, the function correctly calls these strings equal).
Always remember that the null string does, in fact, have a character in it, albeit a null one.
Sometimes, it becomes desirable to set the value of a character string to the null string. In C, the null string is denoted by an adjacent pair of double quotation marks. So, the statement
char buffer[100] = "";
defines a character array called buffer and sets its value to the null string. Note that the character string "" is not the same as the character string " " because the second string contains a single blank character. (If you are doubtful, send both strings to the equalStrings() function and see what result comes back.)
Program 9.8 uses the readLine(), alphabetic(), and countWords() functions from previous programs..
Program 9.8 Counting Words in a Piece of Text
#include <stdio.h>
#include <stdbool.h>
bool alphabetic (const char c)
{
if ( (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') )
return true;
else
return false;
}
void readLine (char buffer[])
{
char character;
int i = 0;
do
{
character = getchar ();
buffer[i] = character;
++i;
}
while ( character != '\n' );
buffer[i - 1] = '\0';
}
int countWords (const char string[])
{
int i, wordCount = 0;
bool lookingForWord = true, alphabetic (const char c);
for ( i = 0; string[i] != '\0'; ++i )
if ( alphabetic(string[i]) )
{
if ( lookingForWord )
{
++wordCount;
lookingForWord = false;
}
}
else
lookingForWord = true;
return wordCount;
}
int main (void)
{
char text[81];
int totalWords = 0;
int countWords (const char string[]);
void readLine (char buffer[]);
bool endOfText = false;
printf ("Type in your text.\n");
printf ("When you are done, press 'RETURN'.\n\n");
while ( ! endOfText )
{
readLine (text);
if ( text[0] == '\0' )
endOfText = true;
else
totalWords += countWords (text);
}
printf ("\nThere are %i words in the above text.\n", totalWords);
return 0;
}
Program 9.8 Output
Type in your text.
When you are done, press 'RETURN'.
Wendy glanced up at the ceiling where the mound of lasagna loomedlike a mottled mountain range. Within seconds, she was crowned withricotta ringlets and a tomato sauce tiara. Bits of beef formed meatymoles on her forehead. After the second thud, her culinary coronationwas complete.Return
There are 48 words in the above text.
The line labeled Return indicates the pressing of the Enter or Return key.
The endOfText variable is used as a flag to indicate when the end of the input text has been reached. The while loop is executed as long as this flag is false. Inside this loop, the program calls the readLine() function to read a line of text. The if statement then tests the input line that is stored inside the text array to see if just the Enter (or Return) key was pressed. If so, then the buffer contains the null string, in which case the endOfText flag is set to true to signal that all of the text has been entered.
If the buffer does contain some text, the countWords() function is called to count the number of words in the text array. The value that is returned by this function is added into the value of totalWords, which contains the cumulative number of words from all lines of text entered thus far.
After the while loop is exited, the program displays the value of totalWords, along with some informative text.
It might seem that the preceding program does not help to reduce your work efforts much because you still have to manually enter all of the text at the terminal. But as you will see in Chapter 15, “Input and Output Operations in C,” this same program can also be used to count the number of words contained in a file stored on a disk, for example. So, an author using a computer system for the preparation of a manuscript might find this program extremely valuable as it can be used to quickly determine the number of words contained in the manuscript (assuming the file is stored as a normal text file and not in some word processor format like Microsoft Word).
Escape Characters
As alluded to previously, the backslash character has a special significance that extends beyond its use in forming the newline and null characters. Just as the backslash and the letter n, when used in combination, cause subsequent printing to begin on a new line, so can other characters be combined with the backslash character to perform special functions. These various backslash characters, often referred to as escape characters, are summarized in Table 9.2.
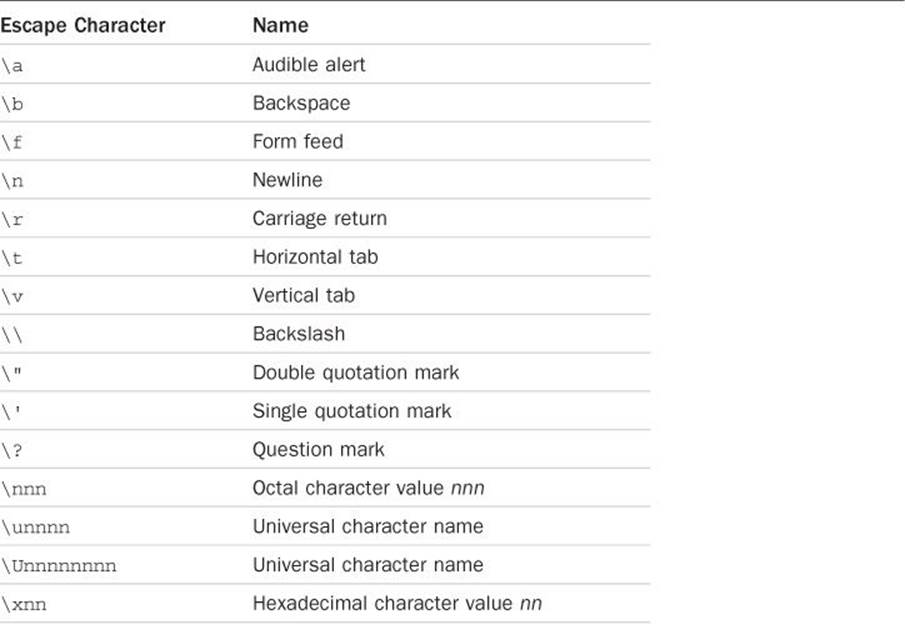
Table 9.2 Escape Characters
The first seven characters listed in Table 9.2 perform the indicated function on most output devices when they are displayed. The audible alert character, \a, sounds a “bell.” So, the printf() call
printf ("\aSYSTEM SHUT DOWN IN 5 MINUTES!!\n");
sounds an alert and displays the indicated message.
Including the backspace character '\b' inside a character string causes the terminal to backspace one character at the point at which the character appears in the string, provided that it is supported. Similarly, the function call
printf ("%i\t%i\t%i\n", a, b, c);
displays the value of a, space over to the next tab setting (typically set to every eight columns by default), displays the value of b, space over to the next tab setting, and then displays the value of c. The horizontal tab character is particularly useful for lining up data in columns.
To include the backslash character itself inside a character string, two backslash characters are necessary, so the printf() call
printf ("\\t is the horizontal tab character.\n");
displays the following:
\t is the horizontal tab character.
Note that because the \\ is encountered first in the string, a tab is not displayed in this case.
To include a double quotation character inside a character string, it must be preceded by a backslash. So, the printf() call
printf ("\"Hello,\" he said.\n");
results in the display of the message
"Hello," he said.
To assign a single quotation character to a character variable, the backslash character must be placed before the quotation mark. If c is declared to be a variable of type char, the statement
c = '\'';
assigns a single quotation character to c.
The backslash character, followed immediately by a ?, is used to represent a ? character. This is sometimes necessary when dealing with trigraphs in non-ASCII character sets. For more details, consult Appendix A, “C Language Summary.”
The final four entries in Table 9.2 enable any character to be included in a character string. In the escape character '\nnn', nnn is a one- to three-digit octal number. In the escape character '\xnn', nn is a hexadecimal number. These numbers represent the internal code of the character. This enables characters that might not be directly available from the keyboard to be coded into a character string. For example, to include an ASCII escape character, which has the value octal 33, you could include the sequence \033 or \x1b inside your string.
The null character '\0' is a special case of the escape character sequence described in the preceding paragraph. It represents the character that has a value of 0. In fact, because the value of the null character is 0, this knowledge is frequently used by programmers in tests and loops dealing with variable-length character strings. For example, the loop to count the length of a character string in the function stringLength() from Program 9.2 can also be equivalently coded as follows:
while ( string[count] )
++count;
The value of string[count] is nonzero until the null character is reached, at which point the while loop is exited.
It should once again be pointed out that these escape characters are only considered a single character inside a string. So, the character string "\033\"Hello\"\n" actually consists of nine characters (not counting the terminating null): the character '\033', the double quotation character'\"', the five characters in the word Hello, the double quotation character once again, and the newline character. Try passing the preceding character string to the stringLength() function to verify that nine is indeed the number of characters in the string (again, excluding the terminating null).
A universal character name is formed by the characters \u followed by four hexadecimal numbers or the characters \U followed by eight hexadecimal numbers. It is used for specifying characters from extended character sets; that is, character sets that require more than the standard eight bits for internal representation. The universal character name escape sequence can be used to form identifier names from extended character sets, as well as to specify 16-bit and 32-bit characters inside wide character string and character string constants. For more information, refer toAppendix A.
More on Constant Strings
If you place a backslash character at the very end of the line and follow it immediately by a carriage return, it tells the C compiler to ignore the end of the line. This line continuation technique is used primarily for continuing long constant character strings onto the next line and, as you see inChapter 12, “The Preprocessor,” for continuing a macro definition onto the next line.
Without the line continuation character, your C compiler generates an error message if you attempt to initialize a character string across multiple lines; for example:
char letters[] =
{ "abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ" };
By placing a backslash character at the end of each line to be continued, a character string constant can be written over multiple lines:
char letters[] =
{ "abcdefghijklmnopqrstuvwxyz\
ABCDEFGHIJKLMNOPQRSTUVWXYZ" };
It is necessary to begin the continuation of the character string constant at the beginning of the next line because, otherwise, the leading blank spaces on the line get stored in the character string. The preceding statement, therefore, has the net result of defining the character array lettersand of initializing its elements to the character string
"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
Another way to break up long character strings is to divide them into two or more adjacent strings. Adjacent strings are constant strings separated by zero or more spaces, tabs, or newlines. The compiler automatically concatenates adjacent strings together. Therefore, writing the strings
"one" "two" "three"
is syntactically equivalent to writing the single string
"onetwothree"
So, the letters array can also be set to the letters of the alphabet by writing
char letters[] =
{ "abcdefghijklmnopqrstuvwxyz"
"ABCDEFGHIJKLMNOPQRSTUVWXYZ" };
Finally, the three printf() calls
printf ("Programming in C is fun\n");
printf ("Programming" " in C is fun\n");
printf ("Programming" " in C" " is fun\n");
all pass a single argument to printf() because the compiler concatenates the strings together in the second and third calls.
Character Strings, Structures, and Arrays
You can combine the basic elements of the C programming language to form very powerful programming constructs in many ways. In Chapter 8, “Working with Structures,” for example, you saw how you could easily define an array of structures. Program 9.9 further illustrates the notion of arrays of structures, combined with the variable-length character string.
Suppose you want to write a computer program that acts like a dictionary. If you had such a program, you could use it whenever you came across a word whose meaning was not clear. You could type the word into the program, and the program could then automatically “look up” the word inside the dictionary and tell you its definition.
If you contemplate developing such a program, one of the first thoughts that comes to mind is the representation of the word and its definition inside the computer. Obviously, because the word and its definition are logically related, the notion of a structure comes immediately to mind. You can define a structure called entry, for example, to hold the word and its definition:
struct entry
{
char word[15];
char definition[50];
};
In the preceding structure definition, you have defined enough space for a 14-letter word (remember, you are dealing with variable-length character strings, so you need to leave room for the null character) plus a 49-character definition. The following is an example of a variable defined to be of type struct entry that is initialized to contain the word “blob” and its definition.
struct entry word1 = { "blob", "an amorphous mass" };
Because you want to provide for many words inside your dictionary, it seems logical to define an array of entry structures, such as in
struct entry dictionary[100];
which allows for a dictionary of 100 words. Obviously, this is far from sufficient if you are interested in setting up an English language dictionary, which requires at least 100,000 entries to be of any value. In that case, you would probably adopt a more sophisticated approach, one that would typically involve storing the dictionary on the computer’s disk, as opposed to storing its entire contents in memory.
Having defined the structure of your dictionary, you should now think a bit about its organization. Most dictionaries are organized alphabetically. It makes sense to organize yours the same way. For now, assume that this is because it makes the dictionary easier to read. Later, you see the real motivation for such an organization.
Now, it’s time to think about the development of the program. It is convenient to define a function to look up a word inside the dictionary. If the word is found, the function could return the entry number of the word inside the dictionary; otherwise, the function could return −1 to indicate that the word was not found in the dictionary. So, a typical call to this function, which you can call lookup(), might appear as follows:
entry = lookup (dictionary, word, entries);
In this case, the lookup() function searches dictionary for the word as contained in the character string word. The third argument, entries, represents the number of entries in the dictionary. The function searches the dictionary for the specified word and returns the entry number in the dictionary if the word is found, or returns −1 if the word is not found.
In Program 9.9, the lookup() function uses the equalStrings() function defined in Program 9.4 to determine if the specified word matches an entry in the dictionary.
Program 9.9 Using the Dictionary Lookup Program
// Program to use the dictionary lookup program
#include <stdio.h>
#include <stdbool.h>
struct entry
{
char word[15];
char definition[50];
};
bool equalStrings (const char s1[], const char s2[])
{
int i = 0;
bool areEqual;
while ( s1[i] == s2 [i] &&
s1[i] != '\0' && s2[i] != '\0' )
++i;
if ( s1[i] == '\0' && s2[i] == '\0' )
areEqual = true;
else
areEqual = false;
return areEqual;
}
// function to look up a word inside a dictionary
int lookup (const struct entry dictionary[], const char search[],
const int entries)
{
int i;
bool equalStrings (const char s1[], const char s2[]);
for ( i = 0; i < entries; ++i )
if ( equalStrings (search, dictionary[i].word) )
return i;
return -1;
}
int main (void)
{
const struct entry dictionary[100] =
{ { "aardvark", "a burrowing African mammal" },
{ "abyss", "a bottomless pit" },
{ "acumen", "mentally sharp; keen" },
{ "addle", "to become confused" },
{ "aerie", "a high nest" },
{ "affix", "to append; attach" },
{ "agar", "a jelly made from seaweed" },
{ "ahoy", "a nautical call of greeting" },
{ "aigrette", "an ornamental cluster of feathers" },
{ "ajar", "partially opened" } };
char word[10];
int entries = 10;
int entry;
int lookup (const struct entry dictionary[], const char search[],
const int entries);
printf ("Enter word: ");
scanf ("%14s", word);
entry = lookup (dictionary, word, entries);
if ( entry != -1 )
printf ("%s\n", dictionary[entry].definition);
else
printf ("Sorry, the word %s is not in my dictionary.\n", word);
return 0;
}
Program 9.9 Output
Enter word: agar
a jelly made from seaweed
Program 9.9 Output (Rerun)
Enter word: accede
Sorry, the word accede is not in my dictionary.
The lookup() function sequences through each entry in the dictionary. For each such entry, the function calls the equalStrings() function to determine if the character string search matches the word member of the particular dictionary entry. If it does match, the function returns the value of the variable i, which is the entry number of the word that was found in the dictionary. The function is exited immediately upon execution of the return statement, despite the fact that the function is in the middle of executing a for loop.
If the lookup() function exhausts all the entries in the dictionary without finding a match, the return statement after the for loop is executed to return the “not found” indication (−1) back to the caller.
A Better Search Method
The method used by the lookup() function to search for a particular word in the dictionary is straightforward enough; the function simply performs a sequential search through all the entries in the dictionary until either a match is made or the end of the dictionary is reached. For a small-sized dictionary like the one in your program, this approach is perfectly fine. However, if you start dealing with large dictionaries containing hundreds or perhaps even thousands of entries, this approach might no longer be sufficient because of the time it takes to sequentially search through all of the entries. The time required can be considerable—even though considerable in this case could mean only a fraction of a second. One of the prime considerations that must be given to any sort of information retrieval program is that of speed. Because the searching process is one that is so frequently used in computer applications, much attention has been given by computer scientists to developing efficient algorithms for searching (about as much attention as has been given to the process of sorting).
You can make use of the fact that your dictionary is in alphabetical order to develop a more efficient lookup() function. The first obvious optimization that comes to mind is in the case that the word you are looking for does not exist in the dictionary. You can make your lookup()function “intelligent” enough to recognize when it has gone too far in its search. For example, if you look up the word “active” in the dictionary defined in Program 9.9, as soon as you reach the word “acumen,” you can conclude that “active” is not there because, if it was, it would have appeared in the dictionary before the word “acumen.”
As was mentioned, the preceding optimization strategy does help to reduce your search time somewhat, but only when a particular word is not present in the dictionary. What you are really looking for is an algorithm that reduces the search time in most cases, not just in one particular case. Such an algorithm exists under the name of the binary search.
The strategy behind the binary search is relatively simple to understand. To illustrate how this algorithm works, take an analogous situation of a simple guessing game. Suppose I pick a number from 1 to 99 and then tell you to try to guess the number in the fewest number of guesses. For each guess that you make, I can tell you if you are too low, too high, or if your guess is correct. After a few tries at the game, you will probably realize that a good way to narrow in on the answer is by using a halving process. For example, if you take 50 as your first guess, an answer of either “too high” or “too low” narrows the possibilities down from 100 to 49. If the answer was “too high,” the number must be from 1 to 49, inclusive; if the answer was “too low,” the number must be from 51 to 99, inclusive.
You can now repeat the halving process with the remaining 49 numbers. So if the first answer was “too low,” the next guess should be halfway between 51 and 99, which is 75. This process can be continued until you finally narrow in on the answer. On the average, this procedure takes far less time to arrive at the answer than any other search method.
The preceding discussion describes precisely how the binary search algorithm works. The following provides a formal description of the algorithm. In this algorithm, you are looking for an element x inside an array M, which contains n elements. The algorithm assumes that the array M is sorted in ascending order.
Binary Search Algorithm
Step 1: Set low to 0, high to n − 1.
Step 2: If low > high, x does not exist in M and the algorithm terminates.
Step 3: Set mid to (low + high) / 2.
Step 4: If M[mid] < x, set low to mid + 1 and go to step 2.
Step 5: If M[mid] > x, set high to mid − 1 and go to step 2.
Step 6: M[mid] equals x and the algorithm terminates.
The division performed in step 3 is an integer division, so if low is 0 and high is 49, the value of mid is 24.
Now that you have the algorithm for performing a binary search, you can rewrite your lookup() function to use this new search strategy. Because the binary search must be able to determine if one value is less than, greater than, or equal to another value, you might want to replace yourequalStrings() function with another function that makes this type of determination for two character strings. Call the function compareStrings() and have it return the value −1 if the first string is lexicographically less than the second string, 0 if the two strings are equal, and 1 if the first string is lexicographically greater than the second string. So, the function call
compareStrings ("alpha", "altered")
returns the value −1 because the first string is lexicographically less than the second string (think of this to mean that the first string occurs before the second string in a dictionary). And, the function call
compareStrings ("zioty", "yucca");
returns the value 1 because “zioty” is lexicographically greater than “yucca.”
In Program 9.10, the new compareStrings() function is presented. The lookup function now uses the binary search method to scan through the dictionary. The main() routine remains unchanged from the previous program.
Program 9.10 Modifying the Dictionary Lookup Using Binary Search
// Dictionary lookup program
#include <stdio.h>
struct entry
{
char word[15];
char definition[50];
};
// Function to compare two character strings
int compareStrings (const char s1[], const char s2[])
{
int i = 0, answer;
while ( s1[i] == s2[i] && s1[i] != '\0'&& s2[i] != '\0' )
++i;
if ( s1[i] < s2[i] )
answer = -1; /* s1 < s2 */
else if ( s1[i] == s2[i] )
answer = 0; /* s1 == s2 */
else
answer = 1; /* s1 > s2 */
return answer;
}
// Function to look up a word inside a dictionary
int lookup (const struct entry dictionary[], const char search[],
const int entries)
{
int low = 0;
int high = entries - 1;
int mid, result;
int compareStrings (const char s1[], const char s2[]);
while ( low <= high )
{
mid = (low + high) / 2;
result = compareStrings (dictionary[mid].word, search);
if ( result == -1 )
low = mid + 1;
else if ( result == 1 )
high = mid - 1;
else
return mid; /* found it */
}
return -1; /* not found */
}
int main (void)
{
const struct entry dictionary[100] =
{ { "aardvark", "a burrowing African mammal" },
{ "abyss", "a bottomless pit" },
{ "acumen", "mentally sharp; keen" },
{ "addle", "to become confused" },
{ "aerie", "a high nest" },
{ "affix", "to append; attach" },
{ "agar", "a jelly made from seaweed" },
{ "ahoy", "a nautical call of greeting" },
{ "aigrette", "an ornamental cluster of feathers" },
{ "ajar", "partially opened" } };
int entries = 10;
char word[15];
int entry;
int lookup (const struct entry dictionary[], const char search[],
const int entries);
printf ("Enter word: ");
scanf ("%14s", word);
entry = lookup (dictionary, word, entries);
if ( entry != -1 )
printf ("%s\n", dictionary[entry].definition);
else
printf ("Sorry, the word %s is not in my dictionary.\n", word);
return 0;
}
Program 9.10 Output
Enter word: aigrette
an ornamental cluster of feathers
Program 9.10 Output (Rerun)
Enter word: acerb
Sorry, that word is not in my dictionary.
The compareStrings() function is identical to the equalStrings() function up through the end of the while loop. When the while loop is exited, the function analyzes the two characters that resulted in the termination of the while loop. If s1[i] is less than s2[i], s1 must be lexicographically less than s2. In such a case, −1 is returned. If s1[i] is equal to s2[i], the two strings are equal so 0 is returned. If neither is true, s1 must be lexicographically greater than s2, in which case 1 is returned.
The lookup() function defines int variables low and high and assigns them initial values defined by the binary search algorithm. The while loop executes as long as low does not exceed high. Inside the loop, the value mid is calculated by adding low and high and dividing the result by 2. The compareStrings() function is then called with the word contained in dictionary[mid] and the word you are searching for as arguments. The returned value is assigned to the variable result.
If compareStrings() returns a value of −1—indicating that dictionary[mid].word is less than search—lookup() sets the value of low to mid + 1. If compareStrings() returns 1—indicating that dictionary[mid].search is greater than search—lookup()sets the value of high to mid − 1. If neither −1 nor 1 is returned, the two strings must be equal, and, in that case, lookup() returns the value of mid, which is the entry number of the word in the dictionary.
If low eventually exceeds high, the word is not in the dictionary. In that case, lookup() returns −1 to indicate this “not found” condition.
Character Operations
Character variables and constants are frequently used in relational and arithmetic expressions. To properly use characters in such situations, it is necessary for you to understand how they are handled by the C compiler.
Whenever a character constant or variable is used in an expression in C, it is automatically converted to, and subsequently treated as, an integer value.
In Chapter 5, “Making Decisions,” you saw how the expression
c >= 'a' && c <= 'z'
could be used to determine if the character variable c contained a lowercase letter. As mentioned there, such an expression could be used on systems that used an ASCII character representation because the lowercase letters are represented sequentially in ASCII, with no other characters in-between. The first part of the preceding expression, which compares the value of c against the value of the character constant 'a', is actually comparing the value of c against the internal representation of the character 'a'. In ASCII, the character 'a' has the value 97, the character 'b'has the value 98, and so on. Therefore, the expression c >= 'a' is TRUE (nonzero) for any lowercase character contained in c because it has a value that is greater than or equal to 97. However, because there are characters other than the lowercase letters whose ASCII values are greater than 97 (such as the open and close braces), the test must be bounded on the other end to ensure that the result of the expression is TRUE for lowercase characters only. For this reason, c is compared against the character 'z', which, in ASCII, has the value 122.
Because comparing the value of c against the characters 'a' and 'z' in the preceding expression actually compares c to the numerical representations of 'a' and 'z', the expression
c >= 97 && c <= 122
could be equivalently used to determine if c is a lowercase letter. The first expression is preferred, however, because it does not require the knowledge of the specific numerical values of the characters 'a' and 'z', and because its intentions are less obscure.
The printf() call
printf ("%i\n", c);
can be used to print out the value that is used to internally represent the character stored inside c. If your system uses ASCII, the statement
printf ("%i\n", 'a');
displays 97, for example.
Try to predict what the following two statements would produce:
c = 'a' + 1;
printf ("%c\n", c);
Because the value of 'a' is 97 in ASCII, the effect of the first statement is to assign the value 98 to the character variable c. Because this value represents the character 'b' in ASCII, this is the character that is displayed by the printf() call.
Although adding one to a character constant hardly seems practical, the preceding example gives way to an important technique that is used to convert the characters '0' through '9' into their corresponding numerical values 0 through 9. Recall that the character '0' is not the same as the integer 0, the character '1' is not the same as the integer 1, and so on. In fact, the character '0' has the numerical value 48 in ASCII, which is what is displayed by the following printf() call:
printf ("%i\n", '0');
Suppose the character variable c contains one of the characters '0' through ’9' and that you want to convert this value into the corresponding integer 0 through 9. Because the digits of virtually all character sets are represented by sequential integer values, you can easily convert c into its integer equivalent by subtracting the character constant '0' from it. Therefore, if i is defined as an integer variable, the statement
i = c - '0';
has the effect of converting the character digit contained in c into its equivalent integer value. Suppose c contained the character '5', which, in ASCII, is the number 53. The ASCII value of '0' is 48, so execution of the preceding statement results in the integer subtraction of 48 from 53, which results in the integer value 5 being assigned to i. On a machine that uses a character set other than ASCII, the same result would most likely be obtained, even though the internal representations of '5' and '0' might differ.
The preceding technique can be extended to convert a character string consisting of digits into its equivalent numerical representation. This has been done in Program 9.11 in which a function called strToInt() is presented to convert the character string passed as its argument into an integer value. The function ends its scan of the character string after a non-digit character is encountered and returns the result back to the calling routine. It is assumed that an int variable is large enough to hold the value of the converted number.
Program 9.11 Converting a String to its Integer Equivalent
// Function to convert a string to an integer
#include <stdio.h>
int strToInt (const char string[])
{
int i, intValue, result = 0;
for ( i = 0; string[i] >= '0' && string[i] <= '9'; ++i )
{
intValue = string[i] - '0';
result = result * 10 + intValue;
}
return result;
}
int main (void)
{
int strToInt (const char string[]);
printf ("%i\n", strToInt("245"));
printf ("%i\n", strToInt("100") + 25);
printf ("%i\n", strToInt("13x5"));
return 0;
}
Program 9.11 Output
245
125
13
The for loop is executed as long as the character contained in string[i] is a digit character. Each time through the loop, the character contained in string[i] is converted into its equivalent integer value and is then added into the value of result multiplied by 10. To see how this technique works, consider execution of this loop when the function is called with the character string "245" as an argument: The first time through the loop, intValue is assigned the value of string[0] − '0'. Because string[0] contains the character '2', this results in the value2 being assigned to intValue. Because the value of result is 0 the first time through the loop, multiplying it by 10 produces 0, which is added to intValue and stored back in result. So, by the end of the first pass through the loop, result contains the value 2.
The second time through the loop, intValue is set equal to 4, as calculated by subtracting '0' from '4'. Multiplying result by 10 produces 20, which is added to the value of intValue, producing 24 as the value stored in result.
The third time through the loop, intValue is equal to '5' − '0', or 5, which is added into the value of result multiplied by 10 (240). Thus, the value 245 is the value of result after the loop has been executed for the third time.
Upon encountering the terminating null character, the for loop is exited and the value of result, 245, is returned to the calling routine.
The strToInt() function could be improved in two ways. First, it doesn’t handle negative numbers. Second, it doesn’t let you know whether the string contained any valid digit characters at all. For example, strToInt ("xxx") returns 0. These improvements are left as an exercise.
This discussion concludes this chapter on character strings. As you can see, C provides capabilities that enable character strings to be efficiently and easily manipulated. The library actually contains a wide variety of library functions for performing operations on strings. For example, it offers the function strlen() to calculate the length of a character string; strcmp() to compare two strings; strcat() to concatenate two strings; strcpy() to copy one string to another; atoi() to convert a string to an integer; and isupper(), islower(), isalpha(), andisdigit() to test whether a character is uppercase, lowercase, alphabetic, or a digit. A good exercise is to rewrite the examples from this chapter to make use of these routines. Consult Appendix B, “The Standard C Library,” which lists many of the functions available from the library.
Exercises
1. Type in and run the 11 programs presented in this chapter. Compare the output produced by each program with the output presented after each program in the text.
2. Why could you have replaced the while statement of the equalStrings() function of Program 9.4 with the statement
while ( s1[i] == s2[i] && s1[i] != '\0' )
to achieve the same results?
3. The countWords() function from Programs 9.7 and 9.8 incorrectly counts a word that contains an apostrophe as two separate words. Modify this function to correctly handle this situation. Also, extend the function to count a sequence of positive or negative numbers, including any embedded commas and periods, as a single word.
4. Write a function called substring() to extract a portion of a character string. The function should be called as follows:
substring (source, start, count, result);
where source is the character string from which you are extracting the substring, start is an index number into source indicating the first character of the substring, count is the number of characters to be extracted from the source string, and result is an array of characters that is to contain the extracted substring. For example, the call
substring ("character", 4, 3, result);
extracts the substring "act" (three characters starting with character number 4) from the string "character" and places the result in result.
Be certain the function inserts a null character at the end of the substring in the result array. Also, have the function check that the requested number of characters does, in fact, exist in the string. If this is not the case, have the function end the substring when it reaches the end of the source string. So, for example, a call such as
substring ("two words", 4, 20, result);
should just place the string “words” inside the result array, even though 20 characters were requested by the call.
5. Write a function called findString() to determine if one character string exists inside another string. The first argument to the function should be the character string that is to be searched and the second argument is the string you are interested in finding. If the function finds the specified string, have it return the location in the source string where the string was found. If the function does not find the string, have it return −1. So, for example, the call
index = findString ("a chatterbox", "hat");
searches the string "a chatterbox" for the string "hat". Because "hat" does exist inside the source string, the function returns 3 to indicate the starting position inside the source string where "hat" was found.
6. Write a function called removeString() to remove a specified number of characters from a character string. The function should take three arguments: the source string, the starting index number in the source string, and the number of characters to remove. So, if the character array text contains the string "the wrong son", the call
removeString (text, 4, 6);
has the effect of removing the characters “wrong” (the word “wrong” plus the space that follows) from the array text. The resulting string inside text is then "the son".
7. Write a function called insertString() to insert one character string into another string. The arguments to the function should consist of the source string, the string to be inserted, and the position in the source string where the string is to be inserted. So, the call
insertString (text, "per", 10);
with text as originally defined in the previous exercise, results in the character string "per" being inserted inside text, beginning at text[10]. Therefore, the character string "the wrong person" is stored inside the text array after the function returned.
8. Using the findString(), removeString(), and insertString() functions from preceding exercises, write a function called replaceString() that takes three character string arguments as follows
replaceString (source, s1, s2);
and that replaces s1 inside source with the character string s2. The function should call the findString() function to locate s1 inside source, then call the removeString() function to remove s1 from source, and finally call the insertString() function to insert s2 into source at the proper location.
So, the function call
replaceString (text, "1", "one");
replaces the first occurrence of the character string "1" inside the character string text, if it exists, with the string "one". Similarly, the function call
replaceString (text, "*", "");
has the effect of removing the first asterisk inside the text array because the replacement string is the null string.
9. You can extend even further the usefulness of the replaceString() function from the preceding exercise if you have it return a value that indicates whether the replacement succeeded, which means that the string to be replaced was found inside the source string. So, if the function returns true if the replacement succeeds and false if it does not, the loop
do
stillFound = replaceString (text, " ", "");
while ( stillFound );
could be used to remove all blank spaces from text, for example.
Incorporate this change into the replaceString() function and try it with various character strings to ensure that it works properly.
10. Write a function called dictionarySort() that sorts a dictionary, as defined in Programs 9.9 and 9.10, into alphabetical order.
11. Extend the strToInt() function from Program 9.11 so that if the first character of the string is a minus sign, the value that follows is taken as a negative number.
12. Write a function called strToFloat() that converts a character string into a floating-point value. Have the function accept an optional leading minus sign. So, the call
strToFloat ("-867.6921");
should return the value −867.6921.
13. If c is a lowercase character, the expression
c – 'a' + 'A'
produces the uppercase equivalent of c, assuming an ASCII character set.
Write a function called uppercase() that converts all lowercase characters in a string into their uppercase equivalents.
14. Write a function called intToStr() that converts an integer value into a character string. Be certain the function handles negative integers properly.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.