Learning Ceph (2015)
Chapter 3. Ceph Architecture and Components
In this chapter, we will cover the following topics:
· Ceph storage architecture
· Ceph RADOS
· Ceph Object Storage Device (OSD)
· Ceph monitors (MON)
· librados
· The Ceph block storage
· Ceph Object Gateway
· Ceph MDS and CephFS
Ceph storage architecture
A Ceph storage cluster is made up of several different software daemons. Each of these daemons takes care of unique Ceph functionalities and adds values to its corresponding components. Each of these daemons is separated from the others. This is one of the things that keeps Ceph cluster storage costs down when compared to an enterprise, proprietary black box storage system.
The following diagram briefly highlights the functions of each Ceph component:
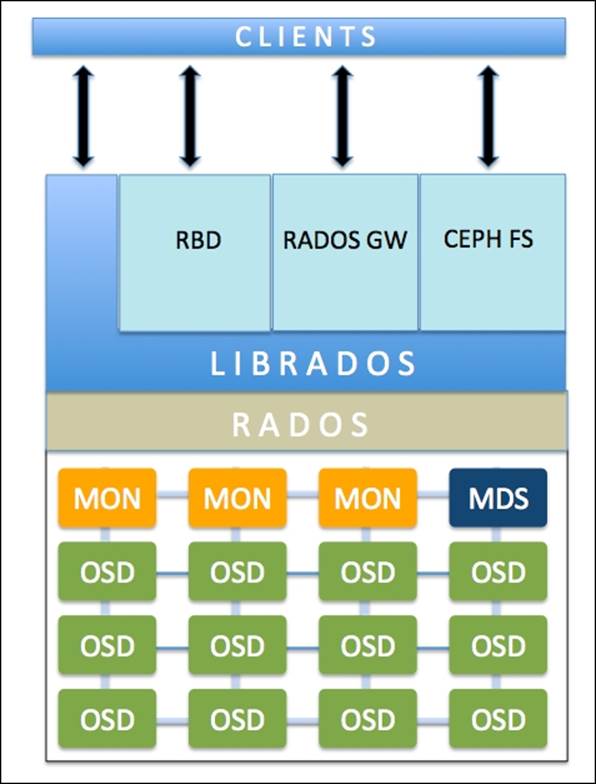
Reliable Autonomic Distributed Object Store (RADOS) is the foundation of the Ceph storage cluster. Everything in Ceph is stored in the form of objects, and the RADOS object store is responsible for storing these objects, irrespective of their data type. The RADOS layer makes sure that data always remains in a consistent state and is reliable. For data consistency, it performs data replication, failure detection, and recovery, as well as data migration and rebalancing across cluster nodes.
As soon as your application issues a write operation to your Ceph cluster, data gets stored in Ceph Object Storage Device (OSD) in the form of objects. This is the only component of a Ceph cluster where actual user data is stored and the same data is retrieved when a client issues a read operation. Usually, one OSD daemon is tied to one physical disk of your cluster. So, in general, the total number of physical disks in your Ceph cluster is the number of OSD daemons working underneath to store user data to each physical disk.
Ceph monitors (MONs) track the health of the entire cluster by keeping a map of the cluster state, which includes OSD, MON, PG, and CRUSH maps. All the cluster nodes report to monitor nodes and share information about every change in their state. A monitor maintains a separate map of information for each component. The monitor does not store actual data; this is the job of OSD.
The librados library is a convenient way to get access to RADOS with the support of the PHP, Ruby, Java, Python, C, and C++ programming languages. It provides a native interface to the Ceph storage cluster, RADOS, and a base for other services such as RBD, RGW, as well as the POSIX interface for CephFS. The librados API supports direct access to RADOS and enables you to create your own interface to the Ceph storage cluster.
Ceph Block Device, formerly known as RADOS block device (RBD), provides block storage, which can be mapped, formatted, and mounted just like any other disk to the server. A Ceph block device is equipped with enterprise storage features such as thin provisioning and snapshots.
Ceph Object Gateway, also known as RADOS gateway (RGW), provides a RESTful API interface, which is compatible with Amazon S3 (Simple Storage Service) and OpenStack Object Storage API (Swift). RGW also supports the multitenancy and OpenStack Keystone authentication services.
Ceph Metadata Server (MDS) keeps track of file hierarchy and stores metadata only for CephFS. A Ceph block device and RADOS gateway do not require metadata, hence they do not need a Ceph MDS daemon. MDS does not serve data directly to clients, thus removing a single point of failure from the system.
Ceph File System (CephFS) offers a POSIX-compliant, distributed filesystem of any size. CephFS relies on Ceph MDS to keep track of file hierarchy, that is, metadata. CephFS is not production ready at the moment, but it's an idle candidate for POC tests. Its development is going at a very fast pace, and we can expect it to be in production ready very soon.
Ceph RADOS
RADOS (Reliable Autonomic Distributed Object Store) is the heart of the Ceph storage system, which is also referred to as the Ceph storage cluster. RADOS provides all the precious features to Ceph, including distributed object store, high availability, reliablity, no single point of failure, self-healing, self-managing, and so on. As a result, the RADOS layer holds a special importance in the Ceph storage architecture. The data access methods of Ceph, such as RBD, CephFS, RADOSGW, and librados, all operate on top of the RADOS layer.
When the Ceph cluster receives a write request from clients, the CRUSH algorithm calculates the location and decides where the data should be written. This information is then passed to the RADOS layer for further processing. Based on the CRUSH ruleset, RADOS distributes the data to all the cluster nodes in the form of small objects. Finally, these objects are stored on OSDs.
RADOS, when configured with a replication factor of more than one, takes care of data reliability. At the same time, it replicates objects, creates copies, and stores them to a different failure zone, that is, the same object replicas should not reside on the same failure zone. However, for a more customization and higher reliability, you should tune your CRUSH ruleset as per your needs and infrastructure requirements. RADOS guarantees that there will always be more than one copy of an object in a RADOS cluster, provided that you have a sufficient level of replication set.
In addition to storing and replicating objects across the cluster, RADOS also makes sure that the object state is consistent. In case of object inconsistency, recoveries are performed with the remaining object copies. This operation is performed automagically and is user transparent, thus providing self-managing and self-healing capabilities to Ceph. If you do an analysis on Ceph's architectural diagram, you will find that it has two parts, RADOS as the lower part that is totally internal to the Ceph cluster with no direct client interface, and the upper part that has all the client interfaces.
RADOS stores data in the form of objects inside a pool. Take a look at RADOS pools, as follows:
# rados lspools
You will get an output similar to what is shown in the following screenshot:

Check the list of objects in a pool using the following command:
# rados -p metadata ls
Check the cluster utilization with the following command:
# rados df
The output may or may not be similar to what is shown in the following screenshot:

RADOS consists of two core components, OSD and monitors. We will now discuss these components in detail.
Ceph Object Storage Device
Ceph's OSD is one of the most important building blocks of the Ceph storage cluster. It stores the actual data on the physical disk drives of each cluster node in the form of objects. The majority of the work inside a Ceph cluster is done by Ceph OSD daemons. These are the real workhorses which store user data. We will now discuss the roles and responsibilities of a Ceph OSD daemon.
Ceph OSD stores all the client data in the form of objects and serves the same data to clients when they request for it. A Ceph cluster consists of multiple OSDs. For any read or write operation, the client requests for cluster maps from monitors, and after this, they can directly interact with OSDs for I/O operations, without the intervention of a monitor. This makes the data transaction process fast as clients who generate data can directly write to OSD that stores data without any additional layer of data handling. This type of data-storage-and-retrieval mechanism is relatively unique in Ceph as compared to other storage solutions.
The core features of Ceph, including reliability, rebalancing, recovery, and consistency, come with OSD. Based on the configured replication size, Ceph provides reliability by replicating each object several times across cluster nodes, making them highly available and fault tolerant. Each object in OSD has one primary copy and several secondary copies, which are scattered across all other OSDs. Since Ceph is a distributed system and objects are distributed across multiple OSDs, each OSD plays the role of primary OSD for some objects, and at the same time, it becomes the secondary OSD for other objects. The secondary OSD remains under the control of the primary OSD; however, they are capable of becoming the primary OSD. Starting with the Ceph Firefly release (0.80), a new mechanism of data protection known as erasure coding has been added. We will learn erasure coding in detail in the upcoming chapters.
In the event of a disk failure, the Ceph OSD daemon intelligently peers with other OSDs to perform recovery operations. During this time, the secondary OSD holding replica copies of failed objects is promoted to the primary, and at the same time, new secondary object copies are generated during the OSD recovery operation, which is totally transparent to clients. This makes the Ceph cluster reliable and consistent. A typical Ceph cluster deployment creates one OSD daemon for each physical disk in a cluster node, which is a recommended practice. However, OSD supports the flexible deployment of one OSD daemon per disk, per host, or per RAID volume. Majority of the Ceph cluster deployment in a JBOD environment uses one OSD daemon per physical disk.
The Ceph OSD filesystem
Ceph OSD consists of a physical disk drive, the Linux filesystem on top of it, and the Ceph OSD service. The Linux filesystem is significant to the Ceph OSD daemon as it supports extended attributes (XATTRs). These filesystems' extended attributes provide internal information about the object state, snapshot, metadata, and ACL to the Ceph OSD daemon, which helps in data management. Have a look at the following diagram:
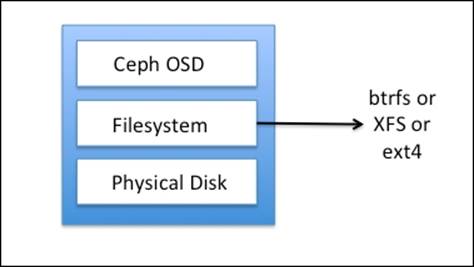
Ceph OSD operates on top of a physical disk drive having a valid Linux partition. The Linux partition can be either Btrfs (B-tree file system), XFS, or ext4. The filesystem selection is one of the major criteria for performance benchmarking of your Ceph cluster. With respect to Ceph, these filesystems differ from each other in various ways:
· Btrfs: The OSD, with the Btrfs filesystem underneath, delivers the best performance as compared to XFS and ext4 filesystem-based OSDs. One of the major advantages of using Btrfs is its support to copy-on-write and writable snapshots, which are very advantageous when it comes to VM provisioning and cloning. It also supports transparent compression and pervasive checksums, and incorporates multidevice management in a filesystem. Btrfs also supports efficient XATTRs and inline data for small files, provides integrated volume management that is SSD aware, and has the demanding feature of online fsck. However, despite these new features, Btrfs is currently not production ready, but it's a good candidate for test deployment.
· XFS: It is a reliable, mature, and very stable filesystem, and hence, it is recommended for production usage in Ceph clusters. As Btrfs is not production ready, XFS is the most-used filesystem in Ceph storage and is recommended for OSDs. However, XFS stands at a lower side as compared to Btrfs. XFS has performance issues in metadata scaling. Also, XFS is a journaling filesystem, that is, each time a client sends data to write to a Ceph cluster, it is first written to a journaling space and then to an XFS filesystem. This increases the overhead of writing the same data twice, and thus makes XFS perform slower as compared to Btrfs, which does not uses journals.
· Ext4: The fourth extended filesystem is also a journaling filesystem that is a production-ready filesystem for Ceph OSD; however, it's not as popular as XFS. From a performance point of view, the ext4 filesystem is not at par with Btrfs.
Ceph OSD makes use of the extended attributes of the underlying filesystem for various forms of internal object states and metadata. XATTRs allow storing additional information related to objects in the form of xattr_name and xattr_value, and thus provide a way of tagging objects with more metadata information. The ext4 filesystem does not provide sufficient capacity for XATTRs due to limits on the number of bytes stored as XATTRs, thus making it less popular among filesystem choices. On the other hand, Btrfs and XFS have a relatively large limit for XATTRs.
The Ceph OSD journal
Ceph uses journaling filesystems such as Btrfs and XFS for OSD. Before committing data to a backing store, Ceph first writes the data to a separate storage area called journal, which is a small buffer-sized partition either on the same or a separate spinning disk as OSD, on a separate SSD disk or partition, or even as a file on a filesystem. In this mechanism, Ceph writes everything first to journal, and then to the backing storage as shown in following diagram:
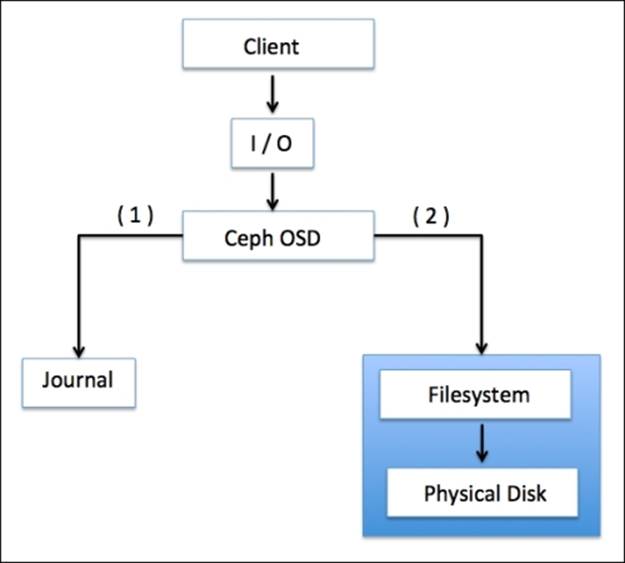
A journal lasts through backing store syncs, running every five seconds, by default. 10 GB is the common size of the journal, but the bigger the partition, the better it is. Ceph uses journals for speed and consistency. The journal allows Ceph OSD to do small writes quickly; a random write is first written in a sequential pattern on journals, and then flushed to a filesystem. This gives filesystems enough time to merge writes to disk. Relatively high performance improvements have been seen when journals are created on SSD disk partition. In such a scenario, all the client writes are written to superfast SSD journals, and then flushed to spinning disks.
Using SSDs as journals for OSD absorb spikes in your workload. However, if journals are slower than your backing store, it will be a limiting factor on your cluster performance. As per the recommendation, you should not exceed OSD to journal ratio of 4 to 5 OSDs per journal disk when using external SSDs for journals. Exceeding the OSD count per journal disk might create performance bottlenecks for your cluster. Also, if your journal disk that hosts multiple OSDs running on XFS or ext4 filesystems fails, you will lose your OSD and its data.
This is where Btrfs takes the advantage; in case of journal failure in a Btrfs-based filesystem, it will go back in time, causing minimal or no data loss. Btrfs is a copy-on-write filesystem, that is, if the content of a block is changed, the changed block is written separately, thus preserving the old block. In case of journal disasters, data remains available since the old content is still available. For more information on Btrfs, visit https://btrfs.wiki.kernel.org.
Till now, we discussed using physical disk drives for Ceph OSD; however, Ceph cluster deployments also use RAID underneath for OSD. We do not recommend you to use RAID underneath your Ceph storage cluster due to several reasons, which are listed as follows:
· Doing RAID and then replication on top of it is a pain. Ceph, by default, performs internal replication for data protection; doing RAID on the same replicated data will not provide any benefit. It will eventually add an additional layer of data protection and increase complexity. In a RAID group, if you lose a disk, the recovery operation will require an additional spare disk of the same type before it can even start. Next, we have to wait for a whole drive worth of data to be written on a new disk. Resilvering a RAID volume takes a huge amount of time as well as degrades performance as compared to a distributed replication method. So, you should not do RAID with replication. However, if your system has a RAID controller, you should use each disk drive as RAID 0.
· For data protection, Ceph relies on replication instead of RAID. The benefit is that replication does not require a free disk or the same capacity of disk drive in the event of disk failure of the storage system. It uses a cluster network for recovery of failed data from the other nodes. During the recovery operation, based on your replication level and placement groups, almost all the cluster nodes participate in data recovery, which makes the recovery operation complete faster as there are a higher number of disks participating in the recovery process.
· There can be a performance impact on a Ceph cluster with RAID as random I/O operations on RAID 5 and 6 are pretty slow.
Note
There are scenarios where RAID can be useful. For example, if you have a lot more physical disks per host and have to run a daemon for each, you can think of creating a RAID volume by collecting some disks and then running an OSD on top of the RAID volume. This will decrease your OSD count as compared to a physical disk count.
For example, if you have a fat node of 64 physical disks with a low system memory of 24 GB, a recommended OSD configuration will require 128 GB of system memory (2 GB per physical disk) for 64 physical disk machines. Since you do not have enough system resources for OSD, you can consider creating RAID groups for your physical disks (six RAID groups with 10 physical disks per RAID group and four spare), and then running OSD for these six RAID groups. In this way, you will require 12 GB of memory approximately, which is available.
The downside of this kind of setup is that if any OSD fails, you will lose all the 10 disks of data (the entire RAID group), which will be a big risk. Hence, if possible, try to avoid using RAID groups underneath OSD.
OSD commands
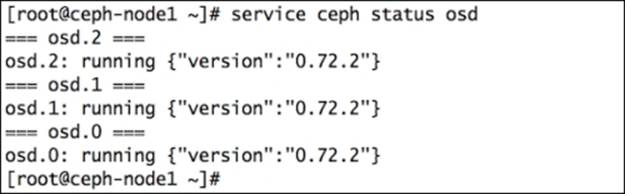
The following is the command to check the OSD status for a single node:
# service ceph status osd
The following is the command to check the OSD status for an entire cluster. Keep in mind that in order to monitor entire cluster OSDs from a single node, the ceph.conf file must have information of all the OSDs with their host name. You would need to update theceph.conf file to achieve this. This concept has been explained in later chapters.
# service ceph -a status osd
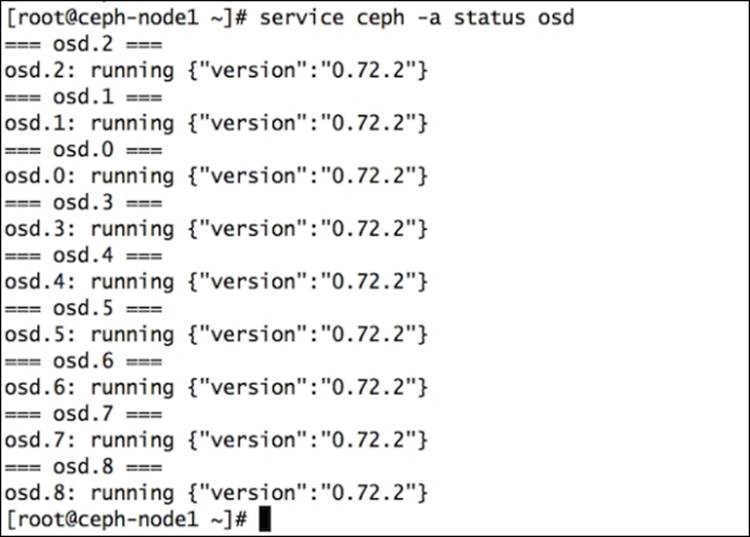
The following is the command to check OSD ID:
# ceph osd ls
The following is the command to check an OSD map and state:
# ceph osd stat
The following is the command to check an OSD tree:
# ceph osd tree
Ceph monitors
As the name suggests, Ceph monitors are responsible for monitoring the health of the entire cluster. These are daemons that maintain the cluster membership state by storing critical cluster information, the state of peer nodes, and cluster configuration information. The Ceph monitor performs its tasks by maintaining a master copy of a cluster. The cluster map includes the monitor, OSD, PG, CRUSH, and MDS maps. All these maps are collectively known as a cluster map. Let's have a quick look at the functionality of each map:
· Monitor map: This holds end-to-end information about a monitor node, which includes the Ceph cluster ID, monitor hostname, and IP address with port number. It also stores the current epoch for map creation and the last-changed information. You can check your cluster's monitor map by executing:
· # ceph mon dump
· OSD map: This stores some common fields such as the cluster ID; epoch for OSD map creation and last-changed information; and information related to pools such as pool names, pool ID, type, replication level, and placement groups. It also stores OSD information such as count, state, weight, last clean interval, and OSD host information. You can check your cluster's OSD maps by executing:
· # ceph osd dump
· PG map: This holds the in-placement group version, time stamp, last OSD map epoch, full ratio, and near full ratio information. It also keeps track of each placement group ID, object count, state, state stamp, up and acting OSD sets, and finally, the scrub details. To check your cluster PG map, execute:
· # ceph pg dump
· CRUSH map: This holds information of your cluster's storage devices, failure domain hierarchy, and the rules defined for the failure domain when storing data. To check your cluster CRUSH map, execute the following command:
· # ceph osd crush dump
· MDS map: This stores information of the current MDS map epoch, map creation and modification time, data and metadata pool ID, cluster MDS count, and MDS state. To check your cluster MDS map, execute:
· # ceph mds dump
Ceph monitor does not store and serve data to clients, rather, it serves updated cluster maps to clients as well as other cluster nodes. Clients and other cluster nodes periodically check with monitors for the most recent copies of cluster maps.
Monitors are lightweight daemons that usually do not require a huge amount of system resources. A low-cost, entry-level server with a fair amount of CPU, memory, and a gigabit Ethernet is enough for most of the scenarios. A monitor node should have enough disk space to store cluster logs, including OSD, MDS, and monitor logs. A regular healthy cluster generates logs under few MB to some GB; however, storage requirements for logs increase when the verbosity/debugging level is increased for a cluster. Several GB of disk space might be required to store logs.
Note
It is important to make sure that a system disk should not be filled up, otherwise clusters might run into problems. A scheduled log rotation policy as well as regular filesystem utilization monitoring is recommended, especially for the nodes hosting monitors as increasing the debugging verbosity might lead to generate huge logs with an average rate of 1 GB per hour.
A typical Ceph cluster consists of more than one monitor node. A multimonitored Ceph architecture develops quorum and provides consensus for distributed decision-making in clusters by using the Paxos algorithm. The monitor count in your cluster should be an odd number; the bare minimum requirement is one monitor node, and the recommended count is three. Since a monitor operates in quorum, more than half of the total monitor nodes should always be available to prevent split-brain problems that are seen by other systems. This is why odd numbers of monitors are recommended. Out of all the cluster monitors, one of them operates as the leader. The other monitor nodes are entitled to become leaders if the leader monitor is unavailable. A production cluster must have at least three monitor nodes to provide high availability.

The preceding output demonstrates ceph-node1 as our initial monitor and cluster leader. The output also explains the quorum status and other monitor details.
If you have budget constraints or are hosting a small Ceph cluster, the monitor daemons can run on the same nodes as OSD. However, the recommendation for such a scenario is to use more CPU, memory, and a larger system disk to store monitor logs if you plan to serve monitor and OSD services from a single common node.
For enterprise production environments, the recommendation is to use dedicated monitor nodes. If you lose the OSD node, you can still be able to connect to your Ceph cluster if enough monitors run on separate machines. The physical racking layout should also be considered during your cluster-planning phase. You should scatter your monitor nodes throughout all the failure domains you have, for example, different switches, power supplies, and physical racks. If you have multiple data centers in a single high-speed network, your monitor nodes should belong to different data centers.
Monitor commands
To check the monitor service status, run the following command:
# service ceph status mon
There are multiple ways to check the monitor status, such as:
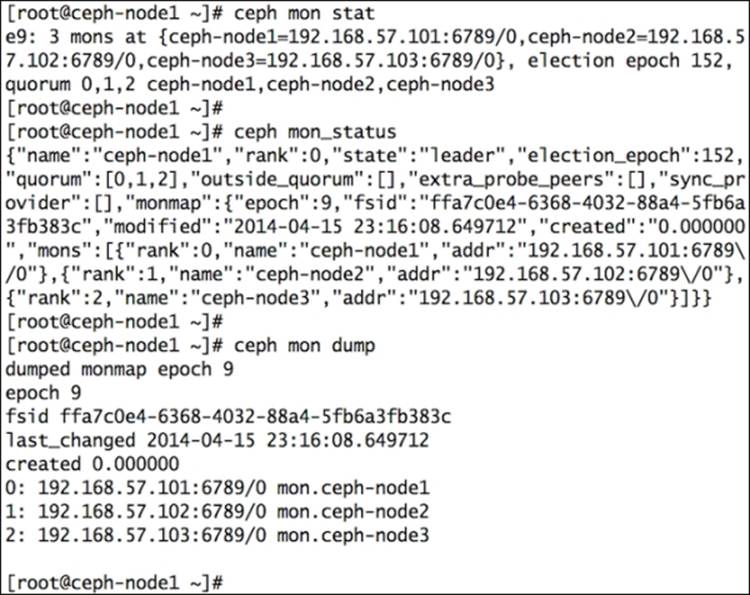
# ceph mon stat
# ceph mon_status
# ceph mon dump
Have a look at the following screenshot:
librados
librados is a native C library that allows applications to work directly with RADOS, bypassing other interface layers to interact with the Ceph cluster. librados is a library for RADOS, which offers rich API support, granting applications to do direct and parallel access to clusters, with no HTTP overhead. Applications can extend their native protocols to get access to RADOS by linking with librados. Similar libraries are available to extend support to C++, Java, Python, Ruby, and PHP. librados serves as the base for other service interfaces that are built on top of the librados native interface, which includes the Ceph block device, Ceph filesystem, and Ceph RADOS gateway. librados provides rich API subsets, efficiently storing key/value inside an object. API supports atomic-single-objecttransaction by updating data, key, and attributes together. Interclient communication is supported via objects.
Direct interaction with RADOS clusters via the librados library drastically improves application performance, reliability, and efficiency. librados offers a very powerful library set, which can provide added advantages to Platform-as-a-Service and Software-as-a-Service cloud solutions.
The Ceph block storage
Block storage is one of the most common formats to store data in an enterprise environment. The Ceph block device is also known as RADOS block device (RBD); it provides block storage solutions to physical hypervisors as well as virtual machines. The Ceph RBD driver has been integrated with the Linux mainline kernel (2.6.39 and higher) and supported by QEMU/KVM, allowing access to a Ceph block device seamlessly.
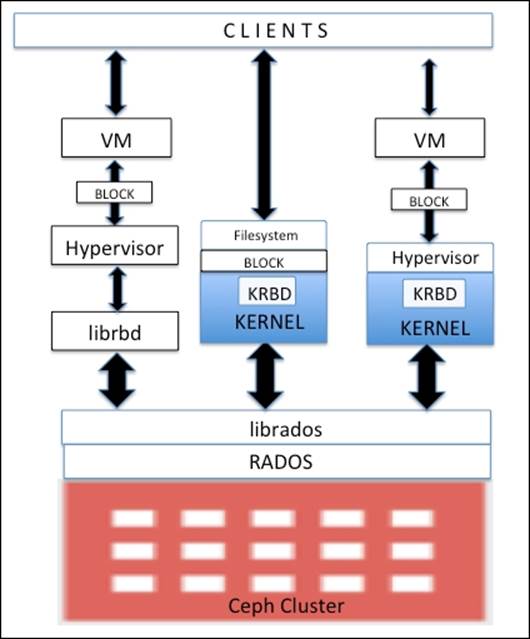
Linux hosts extended full support to Kernel RBD (KRBD) and maps Ceph block devices using librados. RADOS then stores Ceph block device objects across clusters in a distributed pattern. Once a Ceph block device is mapped to a Linux host, it can either be used as a RAW partition or can be labelled with a filesystem followed by mounting.
From the roots, Ceph has been tightly integrated with cloud platforms such as OpenStack. For Cinder and Glance, which are volume and image programs for OpenStack, Ceph provides its block device backend to store virtual machine volumes and OS images. These images and volumes are thin provisioned. Only the changed objects needed to be stored; this helps in a significant amount of storage space, saving for OpenStack.
The copy-on-write and instant cloning features of Ceph help OpenStack to spin hundreds of virtual machine instances in less time. RBD also supports snapshots, thus quickly saving the state of virtual machine, which can be further cloned to produce the same type of virtual machines and used for point-in-time restores. Ceph acts as a common backend for virtual machines, and thus helps in virtual machine migration since all the machines can access a Ceph storage cluster. Virtualization containers such as QEMU, KVM, and XEN can be configured to boot virtual machines from volumes stored in a Ceph cluster.
RBD makes use of librbd libraries to leverage the benefits of RADOS and provides reliable, fully distributed, and object-based block storage. When a client writes data to RBD, librbd libraries map data blocks into objects to store them in Ceph clusters, strip these data objects, and replicate them across the cluster, thus providing improved performance and reliability. RBD on top of the RADOS layer supports efficient updates to objects. Clients can perform write, append, or truncate operations on existing objects. This makes RBD the optimal solution for virtual machine volumes and supports frequent writes to their virtual disks.
Ceph RBD is stealing the show and replacing expensive SAN storage solutions by providing enterprise class features such as thin provisioning, copy-on-write snapshots and clones, revertible read-only snapshots, and support to cloud platforms such as OpenStack and CloudStack. In the upcoming chapters, we will learn more about the Ceph block device.
Ceph Object Gateway
Ceph Object Gateway, also known as RADOS gateway, is a proxy that converts HTTP requests to RADOS requests and vice versa, providing RESTful object storage, which is S3 and Swift compatible. Ceph Object Storage uses the Ceph Object Gateway daemon (radosgw) to interact with librgw and the Ceph cluster, librados. It is implemented as a FastCGI module using libfcgi, and can be used with any FastCGI-capable web server. Ceph Object Store supports three interfaces:
· S3 compatible: This provides an Amazon S3 RESTful API-compatible interface to Ceph storage clusters.
· Swift compatible: This provides an OpenStack Swift API-compatible interface to Ceph storage clusters. Ceph Object Gateway can be used as a replacement for Swift in an OpenStack cluster.
· Admin API: This supports the administration of your Ceph cluster over HTTP RESTful API.
The following diagram shows different access methods that uses RADOS gateway and librados for object storage.
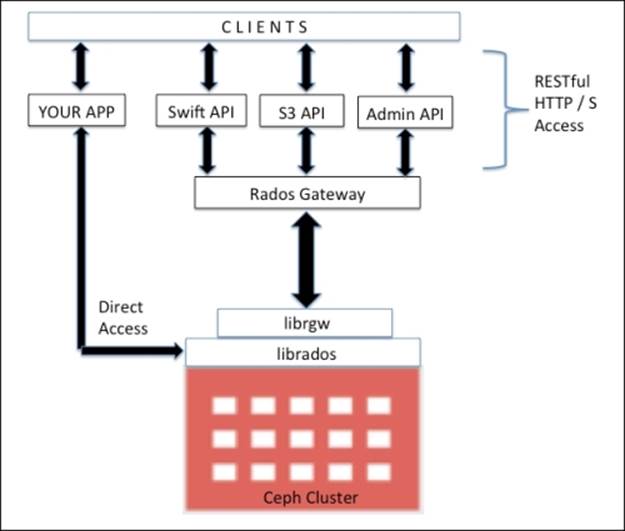
Ceph Object Gateway has its own user management. Both S3 and Swift API share a common namespace inside a Ceph cluster, so you can write data from one API and retrieve it from another. For quick processing, it can use memory to effectively cache metadata. You can also use more than one gateway and keep them under a load balancer to efficiently manage the load on your object storage. Performance improvements are taken care of by striping large REST objects over smaller RADOS objects. Apart from S3 and Swift API, your application can be made to bypass the RADOS gateway and get direct parallel access to librados, that is, to the Ceph cluster. This can be used effectively in custom enterprise applications that require extreme performances from a storage point of view by removing additional layers. Ceph allows direct access to its cluster; this makes it superior to other storage solutions that are rigid and have limited interfaces.
Ceph MDS
Ceph MDS stands for Metadata Server and is required only for a Ceph filesystem (CephFS) and other storage method blocks; object-based storage does not require MDS services. Ceph MDS operates as a daemon, which allows a client to mount a POSIX filesystem of any size. MDS does not serve any data directly to a client; data serving is done by OSD. MDS provides a shared coherent filesystem with a smart caching layer; hence, drastically reducing reads and writes. MDS extends its benefits towards dynamic subtree partitioning and single MDS for a piece of metadata. It is dynamic in nature; daemons can join and leave, and takeover of failed nodes is quick.
MDS is the only component of Ceph that is not production ready; current metadata servers are not currently scale only, and one MDS is supported as of now. A lot of Q&A work is going on to make it production ready; we can expect some news very soon.
MDS does not store local data, which is quite useful in some scenarios. If an MDS daemon dies, we can start it up again on any system that has cluster access. A metadata server's daemons are configured as active and passive. The primary MDS node becomes active, and the rest will go into standby. In the event of a primary MDS failure, the second node takes charge and is promoted to active. For even faster recovery, you can specify that a standby node should follow one of your active nodes, which will keep the same data in memory to prepopulate the cache.
Deploying MDS for your Ceph cluster
To configure Ceph MDS for a Ceph filesystem, you should have a running Ceph cluster. In the previous chapter, we deployed a Ceph cluster. We will use the same cluster for MDS deployment. MDS configuration is relatively simple to configure:
1. Use ceph-deploy from the ceph-node1 machine to configure MDS:
2. # ceph-deploy mds create ceph-node2
3. Check the status of your Ceph cluster and look for an mdsmap entry. You will see your newly configured MDS node:
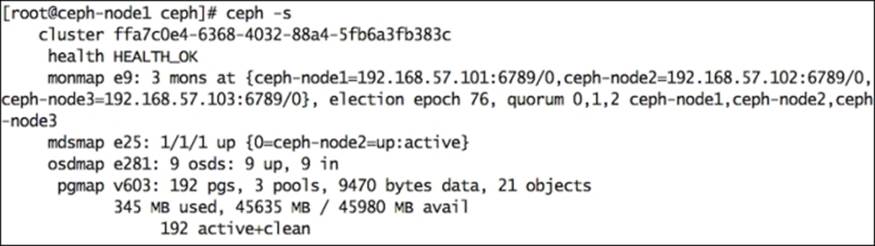
The Ceph filesystem
CephFS provides a POSIX-compliant filesystem on top of RADOS. It uses the MDS daemon, which manages its metadata and keeps it separated from the data, which helps in reduced complexity and improves reliability. CephFS inherits features from RADOS and provides dynamic rebalancing for data.
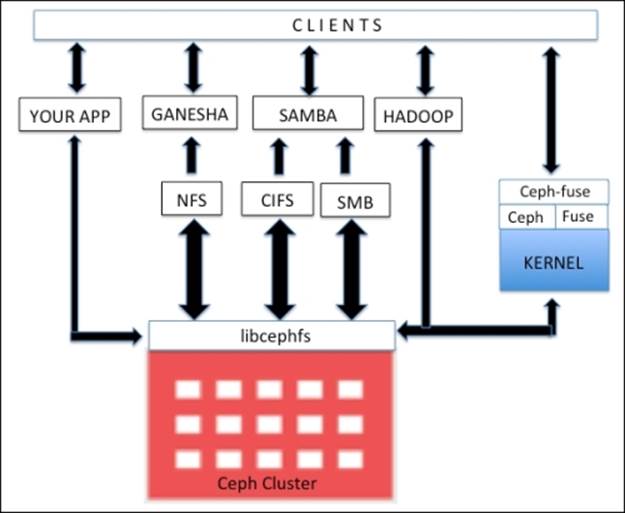
libcephfs libraries play an important role in supporting its multiple client implementations. It has native Linux kernel driver support, thus clients can use native filesystem mounting using the mount command. It has a tight integration with SAMBA and support for CIFS and SMB. CephFS extends its support to filesystems in userspace (FUSE) using the cephfuse modules. It also allows direct application interaction, with the RADOS cluster using libcephfs libraries.
CephFS is getting popular as a replacement for Hadoop HDFS. HDFS has a single name node, which impacts its scalability and creates a single point of failure. Unlike HDFS, CephFS can be implemented over multiple MDSes in an active-active state, thus making it highly scalable and high performing with no single point of failure. In the upcoming chapters, we will focus on implementing CephFS.
Summary
From the ground, Ceph has been designed to behave as a powerful unified storage solution featuring Ceph Block Device, Ceph Object Storage, and a Ceph filesystem from a single Ceph cluster. During the cluster formation, Ceph makes use of components such as monitors, OSD, and MDS, which are fault tolerant, highly scalable, and high performing. Ceph uses a unique approach to store data on to physical disks. Any type of data, whether it's from Ceph Block Device, an object store, or a filesystem, is chopped in the form of small objects, and then stored to a dynamically calculated data storage location. Monitor maps maintain the information and keep cluster nodes and clients updated with it. This mechanism makes Ceph stand out from the crowd and deliver highly scalable, reliable, and high-performing storage solutions.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.