Megan Squire (2015)
Chapter 2. Fundamentals - Formats, Types, and Encodings
A few years ago, I received a very interesting present at my family's annual holiday gift exchange. It was a garde manger kitchen toolset that included a bunch of different knives as well as peelers, scoops, and zesters used to prepare vegetables and fruits. I learned to use each of the tools, and over time, I developed a special fondness for the channel knife and the tomato shark. This chapter is like your introductory data cleaning toolset. We will review:
· File formats, including compression standards
· The fundamentals of data types (including different types of missing data)
· Character encodings
We will need all these fundamentals as we progress to later chapters. Some of the concepts that we'll cover are so basic that you'll encounter them nearly every day, such as compression and file formats. These are so common; they are like a chef's knife. But some of these concepts, like character encodings, are more special-purpose and exotic, like a tomato shark!
File formats
This section describes the different file formats any data scientist is likely to encounter when dealing with data found in the wild—in other words, the kind of data you will not find in those carefully constructed datasets that so many books rely on. Here, we encounter some strategies and limitations to interacting with the most common file formats, and then we review the various compression and archiving formats you are likely to run into.
Text files versus binary files
When collecting data from online sources, you are likely to encounter data in one of these ways:
· The data will be downloadable in a file
· The data will be available via an interactive frontend to a storage system, for example, via a database system with a query interface
· The data will be available through a continuous stream
· The data will be available through an Application Programming Interface (API).
In any case, you may find yourself needing to create data files later on in order to share with others. Therefore, a solid foundation of the various data formats and their strengths and weaknesses is important.
First, we can think of computer files as belonging to two broad groups, commonly called text files and binary files. As all files consist of a sequence of bytes, one right after the other, strictly speaking, all files are binary. But if the bytes in the file are all text characters (for example, letters, numbers, and some control characters such as newlines, carriage returns, or tabs), then we say the file is a text file. In contrast, binary files are those files that contain bytes made up of mostly non-human-readable characters.
Opening and reading files
Text files can be read and written by a program called a text editor. If you try to open a file in a text editor and you can read it successfully (even if you do not understand it), then it is probably a text file. However, if you open the file in a text editor and it just looks like a jumble of garbled characters and weird illegible symbols, then it is probably a binary file.
Binary files are intended to be opened or edited with a particular application, not by a text editor. For example, a Microsoft Excel spreadsheet is intended to be opened and read by Microsoft Excel, and a photograph taken by a digital camera can be read by a graphics program, such as Photoshop or Preview. Sometimes, binary files can be read by multiple compatible software packages, for example, many different graphics programs can read and edit photos and even binary files designed for a proprietary format, such as Microsoft Excel or Microsoft Word files, can be read and edited by compatible software, such as Apache OpenOffice. There are also programs called binary editors, which will let you peek inside a binary file and edit it.
Sometimes, text files are also intended to be read by an application, yet you can still read them in a text editor. For example, web pages and computer source code consist of only text characters and can easily be edited in a text editor, yet they are difficult to understand without some training in the particular format, or layout, of the text itself.
It is usually possible to know what type of file you have even without opening it in an editor. For example, most people look for clues about the file, starting with the file's own name. Three-letter and four-letter file extensions are a common way to indicate the type of file it is. Common extensions that many people know include:
· .xlsx for Excel files, .docx for Word files, .pptx for Powerpoint files
· .png, .jpg, and .gif for image files
· .mp3, .ogg, .wmv, and .mp4 for music and video files
· .txt for text files
There are also several websites that list file extensions and the programs that are affiliated with these particular extensions. One such popular site is fileinfo.com, and Wikipedia also has an alphabetical list of file extensions available athttps://en.wikipedia.org/wiki/List_of_filename_extensions_(alphabetical).
Peeking inside files
If you must open an unknown file to peek inside, there are several command-line options you can use to see the first few bytes of the file.
On OSX or Linux
On an OSX Mac or in Linux, go to your terminal window (on Mac, you can find the standard terminal application available by navigating to Applications | Utilities | Terminal), navigate to the location of your file using a combination of the print working directory (pwd) and change directory (cd) commands, and then use the less command to view the file page by page. Here is what my commands to perform this task looked like:
flossmole2:~ megan$ pwd
/Users/megan
flossmole2:~ megan$ cd Downloads
flossmole2:Downloads megan$ less OlympicAthletes_0.xlsx
"OlympicAthletes_0.xlsx" may be a binary file. See it anyway?
If you are prompted to "view anyway", then the file is binary and you should prepare yourself to see garbled characters. You can type y to see the file or just type n to run in the other direction. The next figure shows you the result of viewing a file called OlympicAthletes_0.xlsx using theless command, as shown in the dialogue. What a mess!
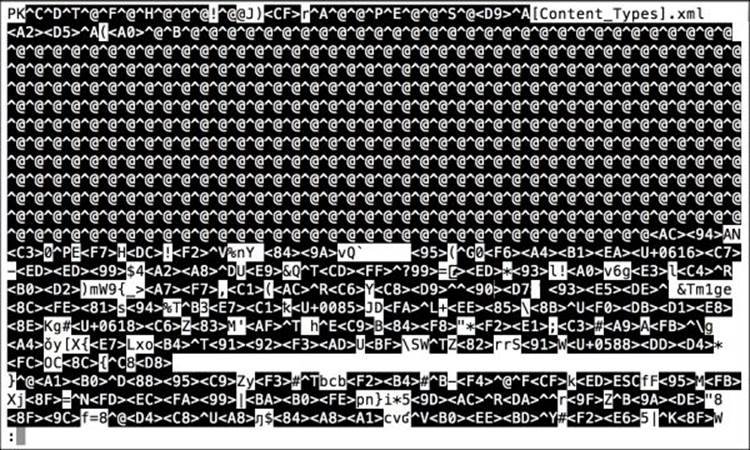
When you are done looking at it, you can type q to quit the less program.
On Windows
Windows has the more program available in its Command Prompt application as well. It works similarly to the less command described earlier (after all, less is more). You can access the Windows Command Prompt with cmd from the Start menu in Windows 7. In Windows 8, navigate toApps | Windows System | Command Prompt. You can use cd and pwd to navigate to your file the same way as we did in the preceding example.
Common formats for text files
In this book, we are mostly concerned with text files rather than binary files. (Some special exceptions include compressed and archived files, which we will cover in the next section, and Excel and PDF files, each of which have their own chapters later in this book.)
The three main types of text files we will be concerned with in this book are:
· The delimited format (structured data)
· The JSON format (semi-structured data)
· The HTML format (unstructured data)
These files differ in layout (they just look different when we read them), and also in terms of how predictable their structures are. In other words, how much of the file is organized and has structured data? And how much of the data in the file is irregular or unstructured? Here, we discuss each of these text file formats individually.
The delimited format
Delimited files are extremely common as a way to share and transfer data. Delimited format files are just text files in which each data attribute (each column) and each instance of the data (each row) are separated by a consistent character symbol. We call the separator characters delimiters. The two most common delimiters are tabs and commas. These two common choices are reflected in the Tab Separated Values (TSV) and Comma Separated Values (CSV) file extensions, respectively. Sometimes, delimited files are also called record-oriented files, as the assumption is that each row represents a record.
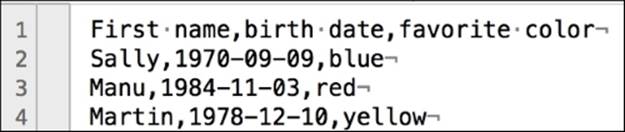
Below are three instances of some data (three rows describing people), with data values separated by commas. The first row lists the names of the columns. This first row is also called the header row, and it has been highlighted in the data to show it more clearly:
First name,birth date,favorite color
Sally,1970-09-09,blue
Manu,1984-11-03,red
Martin,1978-12-10,yellow
Notice that with this example of delimited data, there is no non-data information. Everything is either a row or a data value. And the data is highly structured. Yet, there are still some options that can differentiate one delimited format from another. The first differentiator is how each instance of the data (each row) is separated. Usually at the end of a line, a new line, or a carriage return, or both are used depending on the operating environment in use during the creation of the file.
Seeing invisible characters
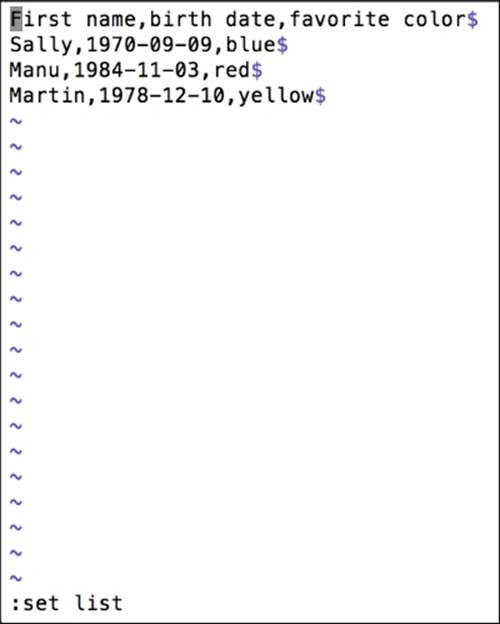
In the preceding example, the new line or carriage return is invisible. How do you see the invisible characters? We will read the same file in Text Wrangler on a Mac (similar full-featured editors such as Notepad++ are available for Windows), where we can use the Show invisibles option (located by navigating to View | Text Display).
Another way to view the invisible characters is to use vi (a command-line text editor) on a Linux system or in the Terminal window on a Mac (this is not available on a Windows machine, by default). The process to view the invisible characters in a file using vi is as follows:
1. First, use the command:
vi <filename>
2. Then, type : to enter the vi edit mode.
3. Then, type set list and press Enter to view the invisible characters.
The following screenshot shows the end-of-line characters that are revealed by set list in vi, showing line termination symbol $.
Enclosing values to trap errant characters
Another important option with delimited files is what character to use to enclose each value being separated. For example, comma-separated values are great unless you have numeric values with commas as the thousands separator. Consider the following example, where the salaries were given commas as their thousands separator, but commas are also the delimiter:
First name,birth date,favorite color,salary
Sally,1971-09-16,light blue,129,000
Manu,1984-11-03,red,159,960
Martin,1978-12-10,yellow,76,888
How can this be fixed at the point of file creation? Well, we have two options:
· Option 1: The person creating the delimited file would need to remove the commas in the final column before creating this table (in other words, no commas in salary amounts)
· Option 2: The person creating this file would need to use an additional symbol to enclose the data values themselves.
If option 2 is chosen, typically, a double quote separator is then added to enclose data values. So, 129,000 on the first line would become "129,000".
Escaping characters
What if the data itself has quotation marks in it? What if Sally's favorite color were listed and shown as light "Carolina" blue? Take a look:
First name,birth date,favorite color,salary
"Sally","1971-09-16","light "Carolina" blue","129,000"
"Manu","1984-11-03","red","159,960"
"Martin","1978-12-10","yellow","76,888"
Internal quotation marks will have to be escaped through the use of another special character, the backslash \:
First name,birth date,favorite color,salary
"Sally","1971-09-16","light \"Carolina\" blue","129,000"
"Manu","1984-11-03","red","159,960"
"Martin","1978-12-10","yellow","76,888"
Tip
Or, we could try encapsulating with a single quote instead of double quotes, but then we might have issues with possessives such as "it's" or names such as O'Malley. There's always something!
Delimited files are very convenient in that they are easy to understand and easy to access in a simple text editor. However, as we have seen, they also require a bit of planning in advance in order to ensure that the data values are truly separated properly and everything is formatted the way it was intended.
If you find yourself the unlucky recipient of a file with delimiting errors such as the preceding ones, we'll give you some tricks and tips in Chapter 3, Workhorses of Clean Data – Spreadsheets and Text Editors, for how to clean them up.
The JSON format
JavaScript Object Notation (JSON), pronounced JAY-sahn, is one of the more popular formats for what is sometimes called semi-structured data. Contrary to the implications in its name, JSON is not dependent upon JavaScript to be useful. The name refers to the fact that it was designed to serialize JavaScript objects.
A collection of data can be called semi-structured when its data values are labeled, but their order does not matter, and in fact, some of the data values may even be missing. A JSON file is just a collection of attribute-value pairs, such as this:
{
"firstName": "Sally",
"birthDate": "1971-09-16",
"faveColor": "light\"Carolina\" blue",
"salary":129000
}
The attributes are on the left-hand side of the colon, and the values are on the right-hand side. Each attribute is separated by a comma. The entire entity is enclosed in curly braces.
A few things about JSON are similar to delimited files, and a few things are different. First, string values must be double-quoted, and therefore, any double quotes internal to a string must be escaped with a backslash. (The escape character \ , when used as a regular character, must also be escaped!)
In JSON, commas cannot be included in numeric values unless the values are treated as strings and properly quoted. (Be careful when stringifying numbers, though—are you sure you want to do that? Then, refer to the Data types section in this chapter, which can help you with these issues.)
{
"firstName": "Sally",
"birthDate": "1971-09-16",
"faveColor": "light\"Carolina\" blue",
"salary": "129,000"
}
Multivalue attributes are acceptable, as are hierarchical values (neither of these are available very easily with delimited files). Here is an example of a JSON file with a multivalue attribute for pet and a hierarchy of data for jobTitle. Note that we've moved the salary data inside this new jobhierarchy:
{
"firstName": "Sally",
"birthDate": "1971-09-16",
"faveColor": "light\"Carolina\" blue",
"pet":
[
{
"type": "dog",
"name": "Fido"
},
{
"type": "dog",
"name": "Lucky"
}
],
"job": {
"jobTitle": "Data Scientist",
"company": "Data Wizards, Inc.",
"salary":129000
}
}
Experimenting with JSON
JSON is an extremely popular choice of data exchange format because of its extensibility, simplicity, and its support for multivalue attributes, missing attributes, and nested attributes / hierarchies of attributes. The increasing popularity of APIs for distributing datasets has also contributed to JSON's usefulness.
To see an example of how an API uses a search term to produce a dataset encoded in JSON, we can experiment with the iTunes API. iTunes is a music service run by Apple. Anyone can query the iTunes service for details about songs, artists, and albums. Search terms can be appended onto the iTunes API URL as follows:
https://itunes.apple.com/search?term=the+growlers
In this URL, everything after the = sign is a search term. In this case, I searched for a band I like, called The Growlers. Note that there is a + sign to represent the space character, as URLs do not allow spaces.
The iTunes API returns 50 results from its music database for my search keywords. The entire set is formatted as a JSON object. As with all JSON objects, it is formatted as a collection of name-value pairs. The JSON returned in this example appears very long, because there are 50 results returned, but each result is actually very simplistic—there are no multivalue attributes or even any hierarchical data in the iTunes data shown in this URL.
Note
For more details on how to use the iTunes API, visit the Apple iTunes developer documentation at https://www.apple.com/itunes/affiliates/resources/documentation/itunes-store-web-service-search-api.html.
The HTML format
HTML files, or web page files, are another type of text file that often have a lot of juicy data in them. How many times have you seen an interesting table, or list of information on a website, and wanted to save the data? Sometimes, copying and pasting works to try to create a delimited file from the web page, but most of the time, copying and pasting does not work effectively. HTML files can be terribly messy and thus, are a potentially painful way to extract data. For this reason, sometimes, we refer to web files as unstructured data. Even though web pages may have some HTML tags that could be used to attempt a delimiting type of pattern-based organization of data, they don't always. And there is also a lot of room for error in how these various HTML tags are applied, both across different websites and even within the same website.
The following figure shows just a small portion of the http://weather.com website. Even though there are pictures and colors and other non-text things in this screenshot, at its base level, this web page is written in HTML, and if we want to pull text data out of this page, we can do that.
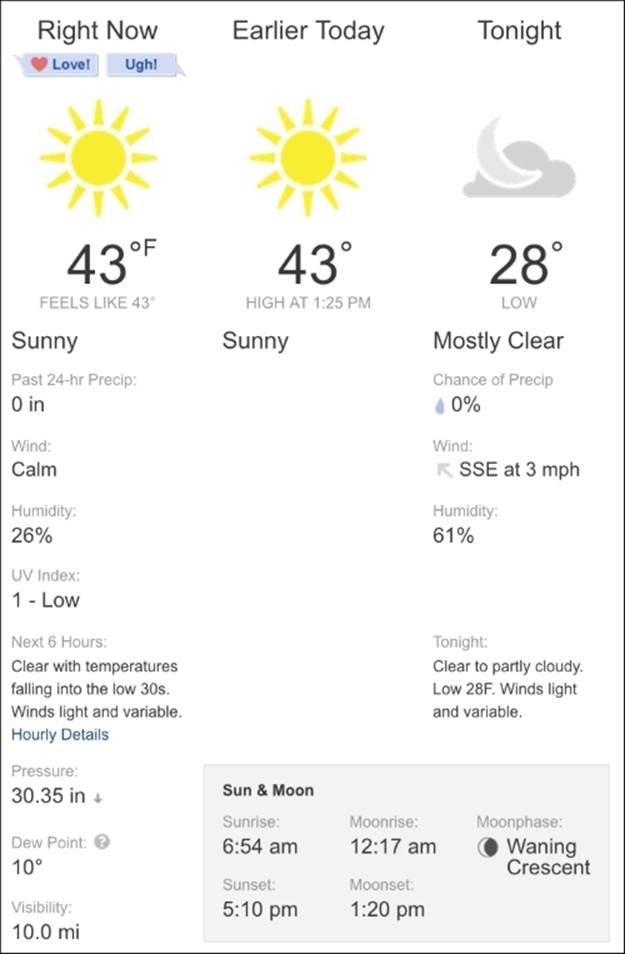
If we view the HTML source for the web page, we can locate a few lines of the nearly 1,000 lines of HTML code that comprise the data and layout instructions for the browser to show that particular weather table:

Unstructured indeed! Of course, it is technically possible to pull the data value 43 (for the temperature in Fahrenheit) from this page, but it's not going to be a fun process, and we have no guarantee that our method to do that will be the same tomorrow or the day after that, ashttp://weather.com could change the source code for the site at any moment. Nonetheless, there is a ton of data on the Web, so in Chapter 5, Collecting and Cleaning Data from the Web, we cover a few strategies to extract data from web-based, unstructured files.
Archiving and compression
When is a text file also a binary file? When it's been compressed or archived, of course. What are archiving and compression? In this section, we'll learn what file archives and compressed files are, how archiving and compression work, and the various standards for each.
This is an important section as a lot of real-world data (especially, delimited data) will be compressed when you find it out in the real world. What are the most common compression formats that you as a data scientist are likely to run into? We will definitely find the answer to this question. You might also want to compress your data when you share it with others. How can you figure out which compression method is the best choice?
Archive files
An archive file is simply a single file that contains many files inside it. The files inside can be either text or binary or a mixture of both. Archive files are created by a special program that takes a list of files and changes them into a single file. Of course, the archive files are created in such a way that they can be expanded back into many files.
tar
The most common archived files that you are likely to encounter when doing data science work are so-called Tape ARchive (TAR) files, created using the tar program and usually given a .tar extension. Their original purpose was to create archives of magnetic tapes.
The tar program is available on Unix-like operating systems, and we can access it in the Mac OSX Terminal as well.
To create a tar file, you simply instruct the tar program which files you want included and what the output file name should be. (Program option c is used to indicate that we're creating a new archive file, and option v prints the filenames as they are extracted. The f option lets us specify the name of the output file.)
tar cvf fileArchive.tar reallyBigFile.csv anotherBigFile.csv
To "untar" a file (or expand it into the full listing of all the files), you just direct the tar program to the file you want expanded. The x letter in xvf stands for eXtract:
tar xvf fileArchive.tar
So, a .tar archive file includes multiple files, but how many and what are the files? You'll want to make sure that before you start extracting files, you have enough available disk space and that the files are really what you wanted to begin with. The t option in the tar command will show a list of the files inside a tar file:
tar –tf fileArchive.tar
There are many more archive programs apart from tar, but some of the interesting ones (for example, the built-in archiving ZIP compressor on OSX and the various ZIP and RAR utilities on Windows) also perform compression on the files, in addition to archiving, so we should probably discuss this concept next.
Compressed files
Compressed files are those files that have been made smaller so that they will take up less space. Smaller files mean less storage space on the disk and a faster transfer time if the file needs to be shared over the network. In the case of data files, like the ones we are interested in, the assumption is that the compressed file can be easily uncompressed back to the original.
How to compress files
There are numerous ways of creating compressed files, and which one you choose will depend on the operating system you are using and what compression software you have installed. On OSX, for example, any file or folder (or group) can easily be compressed by selecting it in Finder, right-clicking on it, and choosing Compress from the menu. This action will create a compressed (.zip extension) file in the same directory as the original file. This is shown in the following image:
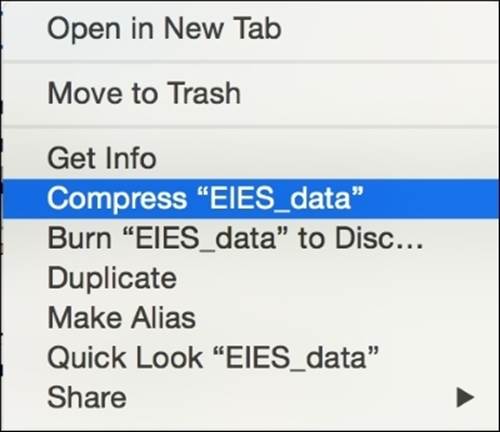
How to uncompress files
The collection step of the data science process will often include downloading compressed files. These might be delimited text files, such as the ones we described earlier in this chapter, or they might be files containing multiple types of data files, such as spreadsheets or SQL commands used to build a database.
In any case, uncompressing a file returns the data to a state where we can use it to accomplish our goals. How do we know which program to use to uncompress the file? The first and biggest clue is the file's extension. This is a key tip-off as to what compression program created the file. Knowing how to uncompress the file is dependent on knowing how it was compressed.
In Windows, you can see the installed program that is associated with your file extension by right-clicking on the file and choosing Properties. Then, look for the Open With option to see which program Windows thinks will uncompress the file.
The remainder of this section will outline how to use command-line programs on OSX or a Linux system.
Compression with zip, gzip, and bzip2
zip, gzip and bzip2 are the most common compression programs. Their uncompression partners are called Unzip, Gunzip, and Bunzip2, respectively.
The following table shows a sample command-line for compressing and uncompressing in each of these programs.
|
Compress |
Uncompress |
|
|
Zip |
zip filename.csv filename.zip |
unzip filename.zip |
|
gzip |
gzip filename.csv filename.gz |
gunzip filename.gz |
|
bzip2 |
bzip2 filename.csv filename.bz2 |
bunzip2 filename.bz2 |
Sometimes, you will see a file that includes both a .tar and a .gz extension or a .bz2 extension like this: somefile.tar.gz. Other combinations that are common include: .tgz and .tbz2, as in somefile.tgz. These are files that have been tarred (archived) first and then compressed using gzip or bzip2. The reason for this is that gzip and bzip2 are not archiving programs; they are only compressors. Therefore, they can only compress a single file (or file archive) at a time. As tar's job is to make multiple files into single files, these programs are found together very often.
The tar program even has a built-in option that will gzip or bzip2 a file immediately after tarring it. To gzip the newly created .tar file, we can simply add z to the preceding tar command, and modify the filename:
tar cvzf fileArchive.tar.gz reallyBigFile.csv anotherBigFile.csv
Or, you can do this in two steps:
tar cvf fileArchive.tar reallyBigFile.csv anotherBigFile.csv
gzip fileArchive.tar
This sequence of commands will create the fileArchive.tar.gz file:
To uncompress a tar.gz file, use two steps:
gunzip fileArchive.tar.gz
tar xvf fileArchive.tar
These steps also work for bzip2 files:
tar cvjf fileArchive.tar.bz2 reallyBigFile.csv anotherBigFile.csv
To uncompress a tar.bz2 file, use two steps:
bunzip2 fileArchive.tar.bz
tar xvf fileArchive.tar
Compression options
When compressing and uncompressing, there are many other options you should take into consideration in order to make your data cleaning job easier:
· Do you want to compress a file and also keep the original? By default, most compression and archiving programs will remove the original file. If you want to keep the original file and also create a compressed version of it, you can usually specify this.
· Do you want to add new files to an existing compressed file? There are options for this in most archiving and compression programs. Sometimes, this is called updating or replacing.
· Do you want to encrypt the compressed file and require a password to open it? Many compression programs provide an option for this.
· When uncompressing, do you want to overwrite files in the directory with the same name? Look for a force option.
Depending on which compression software you are using and what its options are, you can use many of these options to make the job of dealing with files easier. This is especially true with large files—either large in size or large in number!
Which compression program should I use?
The concepts in this section on archiving and compression are widely applicable for any operating system and any type of compressed data files. Most of the time, we will be downloading compressed files from somewhere, and our main concern will be uncompressing these files efficiently.
However, what if you are creating compressed files yourself? What if you need to uncompress a data file, clean it, then recompress it and send it to a coworker? Or what if you are given a choice of files to download, each in a different compression format: zip, bz2, or gz? Which format should you choose?
Assuming that we are in an operating environment that allows you to work with multiple compression types, there are a few rules of thumb for what the various strengths and weaknesses of the different compression types are.
Some of the factors we use when making a compression decision are:
· The speed of compressing and uncompressing
· The compression ratio (how much smaller did the file get?)
· The interoperability of the compression solution (can my audience easily decompress this file?)
Rules of thumb
Gzip is faster to compress and decompress, and it is readily available on every OSX and Linux machine. However, some Windows users will not have a gunzip program readily available.
Bzip2 makes smaller files than gzip and zip, but it takes longer to do so. It is widespread on OSX and Linux. Windows users will probably struggle to handle bzip2 files if they have not already installed special software.
Zip is readily available on Linux, OSX, and Windows, and its speed to compress and decompress is not terrible. However, it does not create very favorable compression ratios (other compressors make smaller files). Still, its ubiquity and relative speed (compared to bzip2, for example) are strong points in its favor.
RAR is a widely available archiving and compression solution for Windows; however, its availability for OSX and Linux requires special software, and its compression speed is not as good as some of the other solutions.
Ultimately, you will have to decide on a compression standard based on the particular project you are working on and the needs of your audience or user, whether that is yourself, a customer, or a client.
Data types, nulls, and encodings
This section provides an overview of the most common data types that data scientists must deal with on a regular basis and some of the variations between these types. We also talk about converting between data types and how to safely convert without losing information (or at least understanding the risks beforehand).
This section also covers the mysterious world of empties, nulls, and blanks. We explore the various types of missing data and describe how missing data can negatively affect results of data analysis. We will compare choices and trade-offs for handling the missing data and some of the pros and cons of each method.
As much of our data will be stored as strings, we will learn to identify different character encodings and some of the common formats you will encounter with real-world data. We will learn how to identify character encoding problems and how to determine the proper type of character encoding for a particular dataset. We will write some Python code to convert from one encoding scheme to another. We will also cover the limitations of this strategy.
Data types
Whether we are cleaning data stored in a text file, a database system, or in some other format, we will start to recognize the same types of data make an appearance over and over: numbers of various kinds, dates, times, characters, strings of characters, and more. The upcoming sections describe a few of the most common data types, along with some examples of each.
Numeric data
In this section, we will discover that there are many ways to store a number, and some of them are easier to clean and manage than others. Still, numbers are fairly straightforward compared to strings and dates, so we will start with these before moving on to trickier data types.
Integers
Integers, or whole numbers, can be positive or negative, and just like the name implies, they do not have decimal points or fractions. Depending on what kind of storage system the integers are stored in, for example, in a Database Management System (DBMS), we may also have additional information about how large an integer can be stored as well as whether it is allowed to be signed (positive or negative values) or only unsigned (all positive values).
Numbers with decimals
In our data cleaning work, numbers with a fractional component—such as prices, averages, measurements, and the like—are typically expressed using a decimal point (rather than a numerator/denominator). Sometimes, the particular storage system in place also has rules specifying the number of digits that are allowed to come after the decimal point (scale) as well as the total number of digits allowed in the number (precision). For example, we say that the number 34.984 has a precision of 3 and a scale of 5.
Different data storage systems will also allow for different types of decimal numbers. For example, a DBMS may allow us to declare whether we will be storing floating-point numbers, decimal numbers, and currency/money numbers at the time we set up our database. Each of these will act slightly differently—in math problems, for instance. We will need to read the guidance provided by the DBMS for each data type and stay on top of changes. Many times, the DBMS provider will change the specifications for a particular data type because of memory concerns or the like.
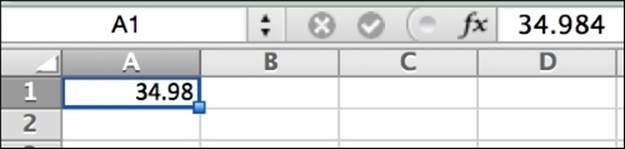
Spreadsheet applications, on the other hand, unlike DBMS applications, are designed to display data in addition to just storing it. Therefore, we may actually be able to store a number in one format and display it in another. This can cause some confusion if formatting has been applied to data cells in a spreadsheet. The following figure shows an example of some decimal display properties being set for a cell. The formula bar shows the full number 34.984, but the cell shows that the number appears to have been rounded down.
Tip
In many locations around the world, the comma character separates the decimal from the nondecimal portion of a number rather than a dot or period character. This is a good reminder that it is always worth inspecting the localization settings of the system you are on and making sure that they match the expectations of the data you are working with. For example, in OSX, there is a Language & Region dialogue located in the Systems Preferences menu. From here, you can change your localization settings if you need to.
Unlike in a DBMS, a raw text file has no options to specify the size or expectations of a number field, and unlike a spreadsheet, the text file has no display options for a given data value either. If a text file shows a value of 34.98, then that may be all we know about that number.
When numbers are not numeric
Numeric data is first and foremost comprised of sequences of digits 0-9 and, sometimes, a decimal point. But a key point about true numeric data is that it is primarily designed to have calculations performed on it. We should choose numeric storage for our data when we expect to be able todo math on a data value, when we expect to compare one value to another numerically, or when we want items to be sorted in numeric order. In these cases, the data values need to be stored as numbers. Consider the following list of numbers sorted by their number value, low to high:
· 1
· 10
· 11
· 123
· 245
· 1016
Now, consider the same list sorted as if they are text values in an address field:
· 1 Elm Lane
· 10 Pine Cir.
· 1016 Pine Cir.
· 11 Front St.
· 123 Main St.
· 245 Oak Ave.
Telephone numbers and postal codes (and house numbers in street addresses as in the previous example) are often comprised of numeric digits, but when we think of them as data values, do they have more in common with text or with numeric data? Do we plan to add them, subtract them, or take their averages or standard deviations? If not, they may more appropriately be stored as text values.
Dates and time
You are probably familiar with many different ways of writing the same date, and you probably have some that you prefer over others. For instance, here are a few common ways of writing the same date:
· 11-23-14
· 11-23-2014
· 23-11-2014
· 2014-11-23
· 23-Nov-14
· November 23, 2014
· 23 November 2014
· Nov. 23, 2014
Regardless of our preference for writing dates, a complete date is made up of three parts: month, day, and year. Any date should be able to be parsed into these component parts. Areas of confusion with dates are usually in two areas: lack of clarity about the month signifier and a day signifier for numbers below 12, and confusion about specifying years. For example, if we only see "11-23", we can assume November 23, as there is no month abbreviated "23", but what year is it? If we see a date of "11-12", is that the 12th of November or the 11th of December? And in what year? Does a year of 38 signify 1938 or 2038?
Most DBMSes have a particular way you should import data if you have specified it as a date, and if you export data, you will get it back in that date format too. However, these systems also have many functions that you can apply to reformat dates or pull out just the pieces you want. For example, MySQL has many interesting date functions that allow us to pull out just the month or day, as well as more complicated functions that allow us to find out what week in the year a particular date falls in or what day of the week it was. For example, the following SQL counts the messages in the Enron dataset from Chapter 1, Why Do You Need Clean Data?, that were sent on May 12 each year, and it also prints the day of the week:
SELECT YEAR(date) AS yr, DAYOFWEEK(date) AS day, COUNT(mid) FROM message WHERE MONTHNAME(date) = "May" AND DAY(date) = 12
GROUP BY yr, day
ORDER BY yr ASC;
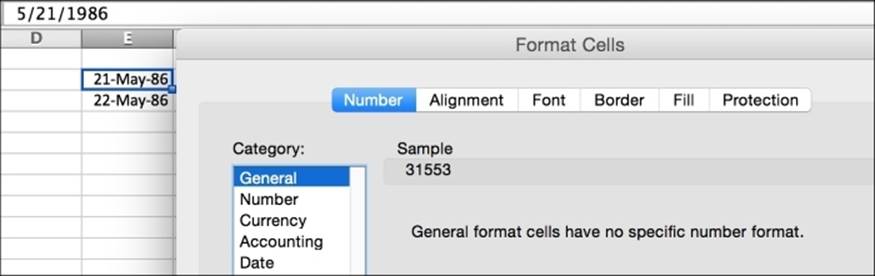
Some spreadsheet programs, such as Excel, internally store dates as numbers but then allow the user to display the values in any format that they like using either built-in or custom formats. Excel stores a given date value as a fractional number of days since Dec 31, 1899. You can see the internal representation of a date in Excel by entering a date and asking for General formatting, as shown in the following figure. Excel stores May 21, 1986 as 31553.
So, when you convert back and forth between different formats, switching the slashes to dashes, or swapping the order of months and days, Excel is just applying a different look to the date as you see it, but underneath, its internal representation of the date value has not changed.
Why does Excel need a fractional number to store the date since 1899? Isn't the number of days a whole number? It turns out that the fraction part is the way Excel stores time.
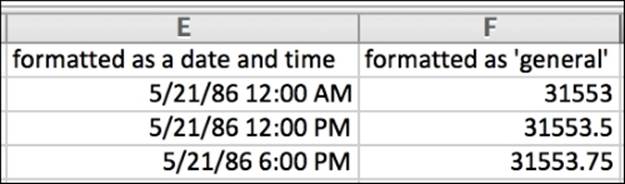
In the preceding figure, we can see how an internal date of 31553 is mapped to midnight, but 31553.5 (halfway through the day) is noon, and 31553.75 is 6 p.m. The greater precision we add to the decimal points, the greater time specificity we will get in the internal representation.
But not all data storage systems store dates and time as fractions, and they do not all start at the same spot. Some systems store dates and time as a number of seconds since the Unix epoch (00:00:00, January 1, 1970, universal time), and a negative number is used to store time before the epoch.
Both DBMS and spreadsheet applications allow for some date math, just like with numbers. In both types of systems, there are functions that allow dates to be subtracted to find a difference, or other calculations, such as adding a number of weeks to a day and getting a new day value.
Strings
Strings represent sequences of any character data, including alphabetic letters, numbers, spaces and punctuation, characters in hundreds of languages, and all kinds of special purpose symbols. Strings are very flexible, and this makes them the most common way to store data. Plus, as they can store nearly any other type of data (not necessarily efficiently), strings become the lowest common denominator to communicate data or move it from one system to another.
As with numeric data, the storage mechanism we are using at the moment may have some guidelines we are expected to use with strings. For example, a DBMS or spreadsheet may require that we state in advance what size we expect our strings to be or what types of characters we are expecting. Character encoding is an interesting and important area on its own, so we have a whole section on it coming up later in this chapter.
Or, there may be guidelines for the size of the data we are allowed to work with in a particular environment. In the world of databases, there are fixed and variable width character columns, which are designed to hold shorter strings, and some DBMS vendors have designed a text type that is intended to hold longer strings.
Note
Generically, many data scientists extend this terminology. As string data gets bigger and more unwieldy, it is referred to as text data, and its analysis becomes text analysis or text mining.
String (or text) data can be found in any of the file formats we talked about earlier in the chapter (delimited files, JSON, or web pages) and can be stored in or accessed by many of the storage solutions we talked about (APIs, DBMS, spreadsheets, and flat files). But no matter what the storage and delivery mechanism, it seems as though strings are most often discussed in same breath as big, messy, unstructured data. An Excel expert will be unfazed if asked to parse out the pieces of a few hundred street addresses or sort a few thousand book titles into categories. No statistician or programmer is going to blink if asked to count the character frequency in a word list. But when string manipulation turns into "extract the source code found embedded in 90 million e-mail messages written in Russian" or "calculate the lexical diversity of the entire contents of the Stack Overflow website", things get a lot more interesting.
Other data types
Numbers, dates/times, and strings are the big three data types, but there are many other types of exotic data that we will run into depending on what environment we are working in. Here is a quick rundown of some of the more interesting ones:
· Sets/enums: If your data seems to only have a few choices for possible data values, you may be looking at a set or enumerated (enum) type. An example of enumerated data might be the set of possible final grades in a college course: {A, A-, B+, B, B-, C+, C, C-, D+, D, D-, F, W}.
· Booleans: If your data is limited to one of just two selections, and they evaluate to 0/1 or true/false, you may be looking at Boolean data. A database column called package_shipped might have values of either yes or no, indicating whether a package has been shipped out.
· Blobs (binary large objects): If your data is binary, for example, you are storing the actual bytes for a picture file (not just the link to it) or the actual bytes for an mp3 music file, then you are probably looking at blob data.
Converting between data types
Conversions between data types are an inevitable part of the cleaning job. You may be given string data, but you know that you need to perform math on it, so you wish to store it as a number. You may be given a date string in one format but you want it in a different date format. Before we go any further, though, we need to discuss a potential problem with conversions.
Data loss
There is a risk of losing data when converting from one data type to another. Usually, this happens when the target data type is not capable of storing as much detail as the original data type. Sometimes, we are not upset by data loss (in fact, there may even be times when a cleaning procedure will warrant some intentional loss), but if we are not expecting the data loss, it can be devastating. Risk factors include:
· Converting between different sizes of the same data type: Suppose you have a string column that is 200 characters long and you decide to move the data to a column that is only 100 characters long. Any data that exceeds 100 characters might be chopped off or truncated. This can also happen when switching between different sizes of numeric columns, for example, when going from big integers to regular integers or from regular integers to tiny integers.
· Converting between different levels of precision: Suppose you have a list of decimal numbers that are precise to four digits, and then you convert them to two digits of precision, or even worse, to integers. Each number will be rounded off or truncated, and you will lose the precision that you had.
Strategies for conversion
There are many strategies to handle data type conversions, and which one you use depends on where the data is being stored at the moment. We are going to cover two of the most common ways in which we encounter data type conversions in the data science cleaning process.
The first strategy, SQL-based manipulation, will apply if we have data in a database. We can use database functions, available in nearly every database system, to slice and dice the data into a different format, suitable for either exporting as a query result or for storing in another column.
The second strategy, file-based manipulation, comes into play when we have been given a flat file of data—for example, a spreadsheet or JSON file—and we need to manipulate the data types in some way after reading them out of the file.
Type conversion at the SQL level
Here, we will walk through a few common cases when SQL can be used to manipulate data types.
Example one – parsing MySQL date into a formatted string
For this example, we will return to the Enron e-mail dataset we used in Chapter 1, Why Do You Need Clean Data?. As with the previous example, we are going to look in the message table, where we have been using the date column, which is stored as a datetime MySQL data type. Suppose we want to print a full date with spelled-out months (as opposed to numbers) and even the day of the week and time of day. How can we best achieve this?
For the record with the message ID (mid) of 52, we have:
2000-01-21 04:51:00
We want is this:
4:51am, Friday, January 21, 2000
· Option 1: Use concat() and individual date and time functions, as shown in the following code sample. The weakness of this option is that the a.m./p.m. is not printed easily:
· SELECT concat(hour(date),
· ':',
· minute(date),
· ', ',
· dayname(date),
· ', ',
· monthname(date),
· ' ',
· day(date),
· ', ',
· year(date))
· FROM message WHERE mid=52;
Result:
4:51, Friday, January 21, 2000
If we decided that we really wanted the a.m./p.m., we could use an if statement that tests the hour and prints "a.m". if the hour is less than 12 and "pm" otherwise:
SELECT concat(
concat(hour(date),
':',
minute(date)),
if(hour(date)<12,'am','pm'),
concat(
', ',
dayname(date),
', ',
monthname(date),
' ',
day(date),
', ',
year(date)
)
)
FROM message
WHERE mid=52;
Result:
4:51am Friday, January 21, 2000
Tip
MySQL date and time functions, such as day() and year(), are described in their documentation: http://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html, and their string functions, such as concat(), can be found here: http://dev.mysql.com/doc/refman/5.7/en/string-functions.html. Other database management systems will have similar versions of these functions.
· Option 2: Use the more sophisticated date_format() MySQL function. This function takes a series of string specifiers for how you want the date to be formatted. There is a very long list of these specifiers in the MySQL documentation. A completed example to convert the date into our desired format is shown in the following code:
· SELECT date_format(date, '%l:%i%p, %W, %M %e, %Y')
· FROM message
· WHERE mid=52;
Result:
4:51AM, Friday, January 21, 2000
This is pretty close to what we said we wanted, and it is much shorter than Option 1. The only difference is that the a.m./p.m. is capitalized. If we really want it lowercased, we can do this:
SELECT concat(
date_format(date, '%l:%i'),
lower(date_format(date,'%p ')),
date_format(date,'%W, %M %e, %Y')
)
FROM message
WHERE mid=52;
Result:
4:51am, Friday, January 21, 2000
Example two – converting a string into MySQL's date type
For this example, let's look at a new table in the Enron schema: the table called referenceinfo. This table shows the messages to which the other messages refer. For example, the first entry in that table, with a rfid 2, contains the text of the e-mail to which message 79 refers. The column is a string, and its data looks like this (in part):
> From: Le Vine, Debi> Sent: Thursday, August 17, 2000 6:29 PM> To: ISO Market Participants> Subject: Request for Bids - Contract for Generation Under Gas> Curtailment Conditions>> Attached is a Request for Bids to supply the California ISO with> Generation
This is a very messy string! Let's take on the job of extracting the date shown on the top line and converting it into a MySQL date type, suitable for inserting into another table or for performing some date math.
To do this, we will use the built-in str_to_date()MySQL function. This function is a bit like date_format() that we saw earlier, except that it's backwards. Here is a working example that will look for the word Sent: and extract the following characters up to the > symbol and then turn these characters into a real MySQL datetime data type:
SELECT
str_to_date(
substring_index(
substring_index(reference,'>',3),
'Sent: ',
-1
),
'%W,%M %e, %Y %h:%i %p'
)
FROM referenceinfo
WHERE mid=79;
Result:
2000-08-17 18:29:00
Now we have a datetime value that is ready for inserting into a new MySQL column or for performing more date functions or calculations on it.
Example three – casting or converting MySQL string data to a decimal number
In this example, let's consider how to convert numbers hiding inside a text column into a format suitable for calculations.
Suppose we were interested in extracting the price for a barrel of oil (abbreviated bbl) from some e-mail messages sent to Enron from a mailing list. We could write a query such that every time we see the /bbl string in an e-mail message from a certain sender, we look for the preceding dollar sign and extract the attached numeric value as a decimal number.
Here is a sample snippet from an e-mail message in the Enron message table with a message ID (mid) of 270516, showing how the number looks inside the string:
March had slipped by 51 cts at the same time to trade at $18.47/bbl.
The MySQL command to perform this string extraction and conversion to a decimal is as follows:
SELECT convert(
substring_index(
substring(
body,
locate('$',body)+1
),
'/bbl',
1
),
decimal(4,2)
) as price
FROM message
WHERE body LIKE "%$%" AND body LIKE "%/bbl%" AND sender = 'energybulletin@platts.com';
The WHERE clause restrictions are added so that we make sure we are only getting messages that have bbl oil prices in them.
The convert() function is similar to cast() in MySQL. Most modern database systems will have a way of converting data types into numbers like this.
Type conversion at the file level
In this section, we will show some common cases when data types will need to be manipulated at the file level.
Tip
This material really only applies to file types where there is an implicit typing structure, for example, spreadsheets and semi-structured data like JSON. We have no examples here that use delimited (text-only) flat files, as in a text file, all data is text data!
Example one – type detection and converting in Excel
You may be familiar with type converting in Excel and similar spreadsheet applications via the cell formatting menu options. The typical procedure involves selecting the cells you want to change and using the drop-down menu located on the ribbon.
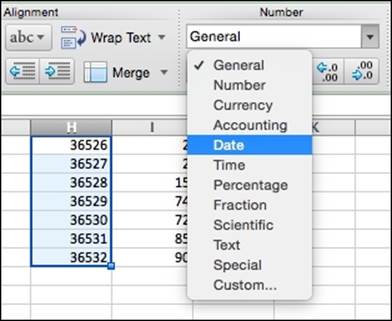
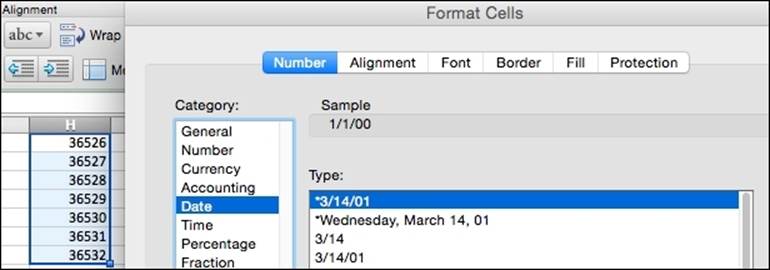
Or, if that does not offer enough options, there is also the Format Cells dialogue, located in the format menu, which offers more granular control over the output of the conversion process.
The lesser-known istext() and isnumber() functions may also be useful in formatting data in Excel.
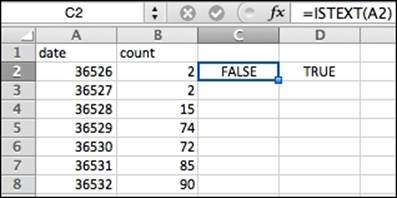
These functions can be applied to any cell, and they return TRUE or FALSE depending on whether the data is text or not, or in the case of isnumber(), whether the number is really a number or not. Paired with a feature like conditional formatting, these two formulas can help you locate bad values or incorrectly typed values in small amounts of data.
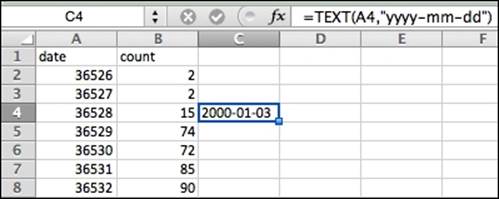
Excel also has a few simple functions for manipulating strings into other data types, other than using the menus. The following figure shows the TEXT() function being used to convert a numeric date to a string version of that date in the yyyy-mm-dd format. In the formula bar, we type=TEXT(A4,"yyyy-mm-dd"), and the 36528 number is converted into 2000-01-03. The date string now appears in the format we specified.
Example two – type converting in JSON
JSON, as a semi-structured text-based format, does not offer a lot of options in the way of formatting and data types. Recall from the JSON description earlier in this chapter that JSON objects are constructed as name-value pairs. The only options for formatting the value part of a name-value pair are a text string, a number, or a list. While it is possible to build JSON objects by hand—for example, by typing them out in a text editor—usually, we build JSON objects programmatically, either by exporting JSON from a database or by writing a small program to convert a flat text file into JSON.
What happens if our program that is designed to generate JSON is flawed? Suppose the program gives us strings instead of numbers. This happens occasionally and it can have unintended consequences for any program designed to consume JSON. The following is an example showing some simple PHP code that is designed to generate JSON, which will later be read into D3 to build a graph.
The PHP code to generate a JSON representation of a dataset from a database is straightforward. The sample code, as shown in the following example, connects to the Enron database, builds a query, runs the query, puts each part of the query result into an array, and then encodes the array values as JSON name-value pairs. Here is the code to build a list of dates and counts, just like the dates and counts we used in Chapter 1, Why Do You Need Clean Data?:
<?php
// connect to db
$dbc = mysqli_connect('localhost','username','password','enron')
or die('Error connecting to database!' . mysqli_error());
// the same sample count-by-date query from chapter 1
$select_query = "SELECT date(date) AS dateSent, count(mid) AS numMsg FROM message GROUP BY 1 ORDER BY 1";
$select_result = mysqli_query($dbc, $select_query);
// die if the query failed
if (!$select_result)
die ("SELECT failed! [$select_query]" . mysqli_error());
// build a new array, suitable for json printing
$counts = array();
while($row = mysqli_fetch_array($select_result))
{
array_push($counts, array('dateSent' => $row['dateSent'], 'numMsg' => $row['numMsg']));
}
echo json_encode($counts);
?>
Tip
Note that the json_encode() function requires PHP version 5.3 or higher, and this example relies on the same working Enron database that we built in Chapter 1, Why Do You Need Clean Data?.
The problem here is that the result is stringified—PHP has placed the numeric values for numMsg in quotation marks, which in JSON means string values:
[
{"dateSent":"0001-05-30","numMsg":"2"},
{"dateSent":"0001-06-18","numMsg":"1"}
]
To nudge the PHP function to be really careful about numeric values and not just assume that everything is a string, we will need to specifically convert the values to numbers before printing them to the screen. Simply change the way we call json_encode() so that it looks like this:
echo json_encode($counts, JSON_NUMERIC_CHECK);
Now the JSON result includes actual numbers for numMsg:
[
{"dateSent":"0001-05-30","numMsg":2},
{"dateSent":"0001-06-18","numMsg":1}
]
PHP includes similar functions for converting big integers to strings as well. This can be useful when you have extremely large numbers but you need them to be stored as string data for some reason, for example, when storing session values or Facebook or Twitter user ID values.
If we do not control the PHP code that is generating the JSON output—for example, if we are accessing the JSON via an API and we don't have any control over its generation—then we'll have to perform a conversion after the JSON has already been built. In this case, we need to ask our D3 JavaScript code to coerce the strings into numbers using a + operator on that data value. In this example, we have read the JSON output and are preparing to build a graph. The numMsg value has been coerced from a string to a number:
d3.json("counts.json", function(d) {
return {
dateSent: d.dateSent,
numMsg: +d.numMsg
};
}, function(error, rows) {
console.log(rows);
});
If a null falls in a forest…
In this section, we are going to dip our chef's ladle into the mysterious stew of zeroes, empties, and nulls.
What is the difference between these? Well, as I mentioned stew, consider this illustration first. Imagine you have a top-of-the-line stove in your fancy chef's kitchen, and on that stove, you are going to prepare a pot of thick, hearty stew. Your sous chef asks you, "How much stew is in the pot?". Take a look at these options:
1. At the beginning of the day, you observe that there is no pot on the stove. The question "how much stew is in the pot?" is unanswerable. There is no pot! The answer is not a positive value, it is not a zero value, and it is not even empty. The value is NULL.
2. A few hours later, after much cleaning and chopping, you look in the pot and see three liters of delicious stew. Great; you now have an answer to the question. In this case, our answer is a data value of 3.
3. After the lunch rush, you look in the pot again and discover that there is no more stew. Every last drop has been sold. You looked, you measured, and you found the answer to "how much stew is in the pot?" is a zero value. You send the pot to be washed at the sink.
4. Just before the evening meal, you grab the clean pot from the sink. As you walk across the kitchen, the sous chef asks, "What's in the pot?" Currently, the pot is empty. There is nothing in the pot. Note that the answer is not zero, because the question he asked was not a numeric one. The answer is also not NULL because we DO have a pot, and we DID look inside it, but there was just no answer.
Different data and programming environments (DBMS, storage systems, and programming languages) treat these zero, empty, and NULL concepts slightly differently. Not all of them clearly distinguish between all four cases. Therefore, this chapter is written somewhat generically, and when examples are given, we try to point out which environment we are applying them to. It is important to be aware of what you mean in each environment when you say that something is null, empty, or zero. And when you see these values in real-world datasets, it is important to be clear about what you can (and cannot) assume about each.
Tip
A special caveat for those dealing with Oracle databases: empty, blank, and NULL are different in Oracle when compared to many other systems. Proceed with caution through this section and consult your database documentation for details specific to Oracle.
Zero
First things first. Of the zeroes, empties, and NULLs, the easiest to deal with is the zero value. Zero is a measurable quantity and has meaning in a numeric system. We can sort zeroes (they come before 1, 2, 3…), and we can compare other numbers to zero using the handy number line (-2, -1, 0, 1, 2, 3…). We can also perform math on zeroes (except for division by zero, which is always awkward).
As a legitimate value, zero works best as numeric data. A string value of zero does not make much sense as it would end up just needing to be interpreted as 0, or the character of 0, which is probably not really the spirit of what we intended.
Empties
Empties are a bit more tricky to work with than zeroes, but they make a lot of sense in some cases, for instance, when working with strings. For example, suppose we have an attribute called middle name. Well, I have no middle name so I would always like to leave this field empty. (Fun fact: my mother still tells the story of how my Kindergarten graduation certificate shows a middle name that I made up on the spot, too shy to admit to my teacher that I lacked a middle name.) Filling in a space or a hyphen (or making up something) for a value that is truly empty does not make a lot of sense. Space is not the same thing as empty. The correct value in the case of an empty string may, in fact, be "empty".
In a CSV or delimited file, an empty value can look like this—here, we have emptied out the favorite color values for the second two records:
First name,birth date,favorite color,salary
"Sally","1971-09-16","light blue",129000
"Manu","1984-11-03","",159960
"Martin","1978-12-10","",76888
In an INSERT database, for example, to put the Manu record into a MySQL system, we would use some code like this:
INSERT INTO people (firstName, birthdate, faveoriteColor, salary) VALUES ("Manu","1984-11-03","",159960);
Sometimes, semi-structured data formats, such as JSON, will allow a blank object and blank strings. Consider this example:
{
"firstName": "Sally",
"birthDate": "1971-09-16",
"faveColor": "",
"pet": [],
"job": {
"jobTitle": "Data Scientist",
"company": "Data Wizards, Inc.",
"salary":129000
}
}
Here, we have taken away Sally's pets and made her favorite color an empty string.
Blanks
Be aware that " " (two double quotes with a space in between, sometimes called a blank but more appropriately called a space) is not necessarily the same thing as "" (two double quotes right next to each other, sometimes also called a blank but more appropriately called empty). Consider the difference between these two MySQL INSERT statements:
-- this SQL has an empty for Sally's favoriteColor and a space for Frank's
INSERT INTO people (firstName, birthdate, faveoriteColor, salary)
VALUES ("Sally","1971-09-16","",129000),
("Frank","1975-10-23"," ",76000);
In addition to spaces, other invisible characters that sometimes get accidentally interpreted as empty or blank include tabs and carriage returns / line feeds. Be careful of these, and when in doubt, use some of the tricks introduced earlier in this chapter to uncover invisible characters.
Null
I know that if you look up null in the dictionary, it might say that it means zero. But do not be fooled. In computing, we have a whole host of special definitions for NULL. To us, NULL is not nothing; in fact, it is the absence of even nothing.
How is this different than empty? First, empty can be equal to empty, as the length of the empty string will be 0. So, we can imagine a value existing, against which we can perform comparisons. However, NULL cannot be equal to NULL, and NOT NULL will not be equal to NOT NULL either. I have heard it suggested that we should all repeat as a mantra that NULL is not equal to anything, even itself.
We use NULL when we legitimately want no entry of any kind for the data value. We do not even want to put the pot on the stove!
Why is the middle name example "empty" and not NULL?
Good question. Recall from the stew pot analogy that if we ask the question and the answer is empty, it is different from never getting an answer (NULL). If you asked me what my middle name was and I told you I did not have one, then the data value is empty. But if you just do not know whether I have a middle name or not, then the data value is NULL.
Is it ever useful to clean data using a zero instead of an empty or null?
Maybe. Remember in the e-mail example from Chapter 1, Why Do You Need Clean Data?, when we discussed adding missing dates to our line graph and how the various spreadsheet programs automatically filled in a count of zero when creating a line graph with missing dates? Even though we had not counted the e-mails on those dates, our graphs interpolated the missing values as if they were zeroes. Are we OK with this? Well, it depends. If we can confirm the fact that the e-mail system was live and working on these dates, and we are confident that we have the full collection of e-mails sent, then the count for these dates could truly be inferred to be zero. However, in the case of the Enron e-mails we were using in Chapter 1, Why Do You Need Clean Data?, we were pretty sure that was not the case.
Another case where it might be useful to store a zero-type data instead of empty is when we have a dummy date or only part of a date, for example, if you know the month and year, but not the day, and you have to insert data into a full date column. Filling in 2014-11-00 might be the way to go in that instance. But you should, of course, document this action (refer to the Communicating about data cleaning section in Chapter 1, Why Do You Need Clean Data?) because what you did and why is probably not going to be obvious to you looking at this data six months from now!
Character encodings
In the olden days of computing, every string value had to be constructed from only 128 different symbols. This early encoding system, called American Standard Code for Information Exchange (ASCII), was largely based on the English alphabet, and it was set in stone. The 128 characters included a-z, A-Z, 0-9, some punctuation and spaces, as well as some now-useless Teletype codes. In our data science kitchen, using this type of encoding system today would be like cooking a frozen dinner. Yes, it is cheap, but it also lacks variety and nutrition, and you really cannot expect to serve it to a guest.
In the early 1990s, a variable length encoding system, now called UTF-8, was proposed and standardized. This variable length scheme allows many more natural language symbols to be encoded properly as well as all the mathematical symbols and provides plenty of room to grow in the future. (The list of all these symbols is called Unicode. The encoding for the Unicode symbols is called UTF-8.) There is also now a UTF-16 encoding, where each character takes a minimum of two bytes to encode. At the time of writing this, UTF-8 is the predominant encoding for the Web.
For our purposes in this book, we are mostly concerned with what to do with data that exists in one encoding and must be cleaned by converting it to another encoding. Some example scenarios where this could be relevant include:
· You have a MySQL database that has been created using a simple encoding (such as one of the 256-bit Latin-1 character sets that are the default on MySQL), and which stores UTF-8 data as Latin-1, but you would now like to convert the entire table to UTF-8.
· You have a Python 2.7 program that uses functions designed for ASCII but must now handle UTF-8 files or strings.
In this section, we will work through a few basic examples based on these scenarios. There are many more equally likely situations where you will encounter character encoding issues, but this will be a starting point.
Example one – finding multibyte characters in MySQL data
Suppose we have a column of data and we are curious about how many values in that column actually have multibyte encoding. Characters that appear as a single character but take multiple bytes to encode can be discovered by comparing their length in bytes (using the length() function) to their length in characters (using the char_length() function).
Tip
The following example uses the MyISAM version of the MySQL World database that is available as part of the MySQL documentation at http://dev.mysql.com/doc/index-other.html
By default, the MyISAM version of the MySQL World test database uses the latin1_swedish_ci character encoding. So, if we run a query on a country name that has a special character in it, we might see something like the following for Côte d'Ivoire:
SELECT Name, length(Name)
FROM Country
WHERE Code='CIV';
This shows the length of 15 for the country, and the name of the country Côte d'Ivoire is encoded as CÙte dÃIvoire. There are several other entries in various columns that are encoded strangely as well. To fix this, we can change the default collation of the name column to utf8 with the following SQL command:
ALTER TABLE Country CHANGE Name `Name` CHAR(52) CHARACTER SET utf8 COLLATE utf8_general_ci
NOT NULL DEFAULT '';
Now we can empty the table and insert the 239 Country rows again:
TRUNCATE Country;
Now we have Country names that use UTF-8 encoding. We can test to see whether any of the countries are using a multibyte character representation for their name now by running the following SQL:
SELECT * FROM Country WHERE length(Name) != char_length(Name);
It shows that the Côte d'Ivoire and the French island Réunion both have multibyte character representations.
Here is another example if you do not have access to the world dataset, or in fact, any dataset at all. You can run a comparison of multibyte characters as a MySQL select command:
SELECT length('私は、データを愛し'), char_length('私は、データを愛し');
In this example, the Japanese characters have a length of 27 but a character length of 9.
This technique is used when we want to test the character set of our data—maybe you have too many rows to look one at a time, and you simply want a SQL statement that can show you all the multibyte entries at once so that you can make a plan for how to clean them. This command shows us the data that currently has a multibyte format.
Example two – finding the UTF-8 and Latin-1 equivalents of Unicode characters stored in MySQL
The following code will use the convert() function and the RLIKE operator to print the UTF-8 equivalent of Unicode strings that have been saved to MySQL using Latin-1. This is useful if you have multibyte data that has been stored in Latin-1 encoded text columns in MySQL, an unfortunately common occurrence as Latin-1 is still the default (as of MySQL 5).
This code uses the publicly available and widely used Movielens database of movies and their reviews. The entire movielens dataset is widely available on many websites, including from the original project site: http://grouplens.org/datasets/movielens/. Another SQL-friendly link is here:https://github.com/ankane/movielens.sql. To make it easier to work through these examples, the CREATE and INSERT statements for just a small subset of the relevant rows have been made available on the author's GitHub site for this book:https://github.com/megansquire/datacleaning/blob/master/ch2movies.sql. This way, if you prefer, you can simply create this one table using that code and work through the following example.
SELECT convert(
convert(title USING BINARY) USING latin1 ) AS 'latin1 version',
convert(
convert(title USING BINARY) USING utf8
) AS 'utf8 version'
FROM movies WHERE convert(title USING BINARY)
RLIKE concat(
'[', unhex('80'), '-', unhex('FF'), ']'
);
The following screenshot shows the results for the first three movies after running this command in phpMyAdmin on the Latin-1 encoded title column in the movies table within the Movielens database:

Note
Any advice for converting an existing database to UTF-8?
Because of the ubiquity of UTF-8 on the Web and its importance in accurately conveying information written in natural languages from around the world, we strongly recommend that you create new databases in a UTF-8 encoding scheme. It will be far easier to start off in a UTF-8 encoding than not.
However, if you have the tables already created in a non-UTF-8 encoding, but they are not yet populated with data, you will have to alter the table to a UTF-8 encoding and change the character set of each column to a UTF-8 encoding. Then, you will be ready to insert UTF-8 data.
The hardest case is when you have a large amount of data already in a non-UTF-8 encoding, and you want to convert it in place in the database. In this case, you have some planning to do. You'll have to take a different approach depending on whether you can get away with running commands on a few tables and/or a few columns or whether you have a very long list of columns and tables to adjust. In planning this conversion, you should consult the documentation specific to your database system. For example, when performing MySQL conversions, there are solutions that use either the mysqldump utility or those that use a combination of SELECT, convert(), and INSERT. You will have to determine which of these is right for your database system.
Example three – handling UTF-8 encoding at the file level
Sometimes, you will need to adjust your code to deal with UTF-8 data at file level. Imagine a simple program designed to collect and print web content. If the majority of web content is now UTF-8 encoded, then our program internals need to be ready to handle that. Unfortunately, many programming languages still need a little bit of coaxing in order to handle UTF-8 encoded data cleanly. Consider the following example of a Python 2.7 program designed to connect to Twitter using its API and write 10 tweets to a file:
import twitter
import sys
####################
def oauth_login():
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
OAUTH_TOKEN = ''
OAUTH_TOKEN_SECRET = ''
auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET,
CONSUMER_KEY, CONSUMER_SECRET)
twitter_api = twitter.Twitter(auth=auth)
return twitter_api
###################
twitter_api = oauth_login()
codeword = 'DataCleaning'
twitter_stream = twitter.TwitterStream(auth=twitter_api.auth)
stream = twitter_stream.statuses.filter(track=codeword)
f = open('outfile.txt','wb')
counter = 0
max_tweets = 10
for tweet in stream:
print counter, "-", tweet['text'][0:10]
f.write(tweet['text'])
f.write('\n')
counter += 1
if counter >= max_tweets:
f.close()
sys.exit()
Tip
If you are worried about setting up Twitter authentication in order to get the keys and tokens used in this script, do not worry. You can either work your way through the simple setup procedure at https://dev.twitter.com/apps/new, or we have a much longer, in-depth example of Twitter mining in Chapter 10, Twitter Project. In that chapter, we walk through the entire setup of a Twitter developer account and go over the tweet collection procedure in much more detail.
This little program finds 10 recent tweets that use the keyword DataCleaning. (I chose this keyword because I recently posted several tweets full of emojis and UTF-8 characters using this hashtag, I was pretty sure it would quickly generate some nice results characters within the first 10 tweets.) However, asking Python to save these tweets to a file using this code results in the following error message:
UnicodeEncodeError: 'ascii' codec can't encode character u'\u00c9' in position 72: ordinal not in range(128)
The issue is that open() is not prepared to handle UTF-8 characters. We have two choices for a fix: strip out UTF-8 characters or change the way we write files.
Option one – strip out the UTF-8 characters
If we take this route, we need to understand that by stripping out characters, we have lost data that could be meaningful. As we discussed earlier in this chapter, data loss is generally an undesirable thing. Still, if we did want to strip these characters, we could make the following changes to the original for loop:
for tweet in stream:
encoded_tweet = tweet['text'].encode('ascii','ignore')
print counter, "-", encoded_tweet[0:10]
f.write(encoded_tweet)
This new code changes an original tweet written in Icelandic like this:
Ég elska gögn
To this:
g elska ggn
For text analysis purposes, this sentence no longer makes any sense as g and ggn are not words. This is probably not our best option for cleaning the character encoding of these tweets.
Option two – write the file in a way that can handle UTF-8 characters
Another option is to just use the codecs or io libraries, which allow UTF-8 encoding to be specified at the time the file is opened. Add an import codec line at the top of the file, and then change the line where you open the file like this:
f = codecs.open('outfile.txt', 'a+', 'utf-8')
The a+ parameter states we want to append the data to the file if it has already been created.
Another option is to include the io library at the top of your program and then use its version of open(), which can be passed a particular encoding, as follows:
f= io.open('outfile.txt', 'a+', encoding='utf8')
Note
Can we just use Python 3? Why are you still using 2.7?
It is true that Python 3 handles UTF-8 encodings more easily than Python 2.7. Feel free to use Python 3 if the rest of your development environment can handle it. In my world, I prefer to use Enthought Canopy to work in data analysis and data mining and to teach my students. Many distributions of Python—Enthought included—are written for 2.7 and will not be moved to Python 3 for quite some time. The reason for this is that Python 3 made some major changes to the internals of the language (for example, in supporting UTF-8 encodings naturally, as we just discussed), and this means that there were a lot of important and useful packages that still have to be rewritten to work with it. This rewriting process takes a long time. For more on this issue, visit https://wiki.python.org/moin/Python2orPython3
Summary
This chapter covered a whirlwind of fundamental topics that we will need in order to clean data in the rest of this book. Some of the techniques we learned here were simple, and some were exotic. We learned about file formats, compression, data types, and character encodings at both the file level and database level. In the next chapter, we will tackle two more workhorses of clean data: the spreadsheet and the text editor.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.