Megan Squire (2015)
Chapter 6. Cleaning Data in PDF Files
In the last chapter, we discovered different ways of separating the data we want from the data we do not want. We imagined that the data cleaning process was a little like making chicken stock, in which our goal was to keep the broth but strain out the bones. But what happens if the data we want is not so easily distinguishable from the data we do not want?
Consider a fine, older wine with considerable sediment. At first glance, we might not be able to see the sediment suspended in the liquid. But after the wine spends some time in a decanter, the sediment falls to the bottom, and we are able to pour out a cleaner, more aromatic wine. A simple strainer would not have been able to separate the wine from the sediment in this case—a special-purpose tool would have been needed.
In this chapter, we will experiment with several data decanters to extract all the good stuff hidden inside inscrutable PDF files. We will explore the following topics:
· What PDF files are for and why it is difficult to extract data from them
· How to copy and paste from PDF files, and what to do when this does not work
· How to shrink a PDF file by saving only the pages that we need
· How to extract text and numbers from a PDF file using the tools inside a Python package called pdfMiner
· How to extract tabular data from within a PDF file using a browser-based Java application called Tabula
· How to use the full, paid version of Adobe Acrobat to extract a table of data
Why is cleaning PDF files difficult?
Files saved in Portable Document Format (PDF) are a little more complicated than the text files we have looked at so far in this book. PDF is a binary format that was invented by Adobe Systems, which later evolved into an open standard so that multiple applications could create PDF versions of their documents. The purpose of a PDF file is to provide a way of viewing the text and graphics in a document independent of the software that did the original layout.
In the early 1990s, the heyday of desktop publishing, each graphic design software package had a different proprietary format for its files, and the packages were quite expensive. In those days, in order to view a document created in Word, Pagemaker, or Quark, you would have to open the document using the same software that had created it. This was especially problematic in the early days of the Web, since there were not many available techniques in HTML to create sophisticated layouts, but people still wanted to share files with each other. PDF was meant to be a vendor-neutral layout format. Adobe made its Acrobat Reader software free for anyone to download, and subsequently the PDF format became widely used.
Note
Here is a fun fact about the early days of Acrobat Reader. The words click here when entered into Google search engine still bring up Adobe's Acrobat PDF Reader download website as the first result, and have done so for years. This is because so many websites distribute PDF files along with a message saying something like, "To view this file you must have Acrobat Reader installed. Click here to download it." Since Google's search algorithm uses the link text to learn what sites go with what keywords, the keyword click here is now associated with Adobe Acrobat's download site.
PDF is still used to make vendor- and application-neutral versions of files that have layouts that are more complicated than what could be achieved with plain text. For example, viewing the same document in the various versions of Microsoft Word still sometimes causes documents with lots of embedded tables, styles, images, forms, and fonts to look different from one another. This can be due to a number of factors, such as differences in operating systems or versions of the installed Word software itself. Even with applications that are intended to be compatible between software packages or versions, subtle differences can result in incompatibilities. PDF was created to solve some of this.
Right away we can tell that PDF is going to be more difficult to deal with than a text file, because it is a binary format, and because it has embedded fonts, images, and so on. So most of the tools in our trusty data cleaning toolbox, such as text editors and command-line tools (less) are largely useless with PDF files. Fortunately there are still a few tricks we can use to get the data out of a PDF file.
Try simple solutions first – copying
Suppose that on your way to decant your bottle of fine red wine, you spill the bottle on the floor. Your first thought might be that this is a complete disaster and you will have to replace the whole carpet. But before you start ripping out the entire floor, it is probably worth trying to clean the mess with an old bartender's trick: club soda and a damp cloth. In this section, we outline a few things to try first, before getting involved in an expensive file renovation project. They might not work, but they are worth a try.
Our experimental file
Let's practice cleaning PDF data by using a real PDF file. We also do not want this experiment to be too easy, so let's choose a very complicated file. Suppose we are interested in pulling the data out of a file we found on the Pew Research Center's website called "Is College Worth It?". Published in 2011, this PDF file is 159 pages long and contains numerous data tables showing various ways of measuring if attaining a college education in the United States is worth the investment. We would like to find a way to quickly extract the data within these numerous tables so that we can run some additional statistics on it. For example, here is what one of the tables in the report looks like:

This table is fairly complicated. It only has six columns and eight rows, but several of the rows take up two lines, and the header row text is only shown on five of the columns.
Tip
The complete report can be found at the PewResearch website at http://www.pewsocialtrends.org/2011/05/15/is-college-worth-it/, and the particular file we are using is labeled Complete Report: http://www.pewsocialtrends.org/files/2011/05/higher-ed-report.pdf.
Step one – try copying out the data we want
The data we will experiment on in this example is found on page 149 of the PDF file (labeled page 143 in their document). If we open the file in a PDF viewer, such as Preview on Mac OSX, and attempt to select just the data in the table, we already see that some strange things are happening. For example, even though we did not mean to select the page number (143); it got selected anyway. This does not bode well for our experiment, but let's continue. Copy the data out by using Command-C or select Edit | Copy.

How text looks when selected in this PDF from within Preview
Step two – try pasting the copied data into a text editor
The following screenshot shows how the copied text looks when it is pasted into Text Wrangler, our text editor:

Clearly, this data is not in any sensible order after copying and pasting it. The page number is included, the numbers are horizontal instead of vertical, and the column headers are out of order. Even some of the numbers have been combined; for example, the final row contains the numbers 4,4,3,2; but in the pasted version, this becomes a single number 4432. It would probably take longer to clean up this data manually at this point than it would have taken just to retype the original table. We can conclude that with this particular PDF file, we are going to have to take stronger measures to clean it.
Tip
We should note at this point that the other areas of this PDF file do clean up nicely. For example, the Preface, a text-only section located on page 3 of the file, copies out just fine using the preceding technique. With this file, it is only the actual tabular data that is a problem. You should experiment with all parts of a PDF file—including text and tabular data—before deciding on an extraction technique.
Step three – make a smaller version of the file
Our copying and pasting procedures have not worked, so we have resigned ourselves to the fact that we are going to need to prepare for more invasive measures. Perhaps if we are not interested in extracting data from all 159 pages of this PDF file, we can identify just the area of the PDF that we want to operate on, and save that section to a separate file.
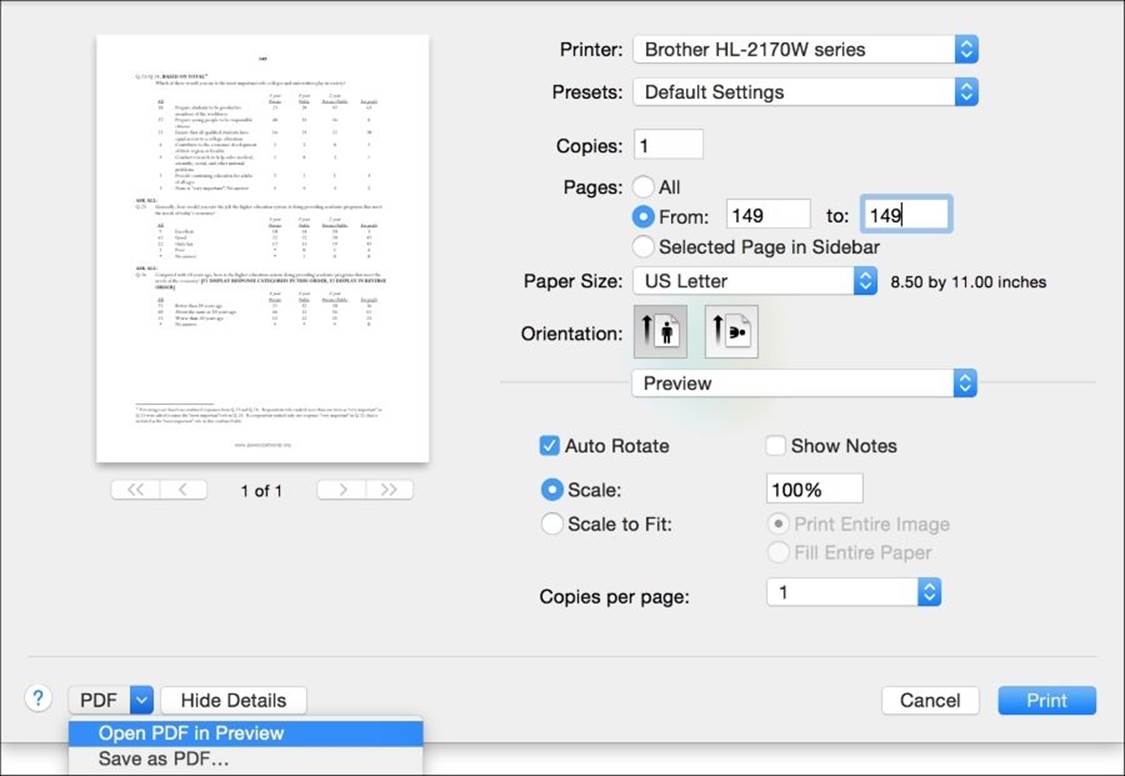
To do this in Preview on MacOSX, launch the File | Print… dialog box. In the Pages area, we will enter the range of pages we actually want to copy. For the purpose of this experiment, we are only interested in page 149; so enter 149 in both the From: and to: boxes as shown in the following screenshot.
Then from the PDF dropdown box at the bottom, select Open PDF in Preview. You will see your single-page PDF in a new window. From here, we can save this as a new file and give it a new name, such as report149.pdf or the like.
Another technique to try – pdfMiner
Now that we have a smaller file to experiment with, let's try some programmatic solutions to extract the text and see if we fare any better. pdfMiner is a Python package with two embedded tools to operate on PDF files. We are particularly interested in experimenting with one of these tools, a command-line program called pdf2txt that is designed to extract text from within a PDF document. Maybe this will be able to help us get those tables of numbers out of the file correctly.
Step one – install pdfMiner
Launch the Canopy Python environment. From the Canopy Terminal Window, run the following command:
pip install pdfminer
This will install the entire pdfMiner package and all its associated command-line tools.
Tip
The documentation for pdfMiner and the two tools that come with it, pdf2txt and dumpPDF, is located at http://www.unixuser.org/~euske/python/pdfminer/.
Step two – pull text from the PDF file
We can extract all text from a PDF file using the command-line tool called pdf2txt.py. To do this, use the Canopy Terminal and navigate to the directory where the file is located. The basic format of the command is pdf2txt.py <filename>. If you have a larger file that has multiple pages (or you did not already break the PDF into smaller ones), you can also run pdf2txt.py –p149 <filename> to specify that you only want page 149.
Just as with the preceding copy-and-paste experiment, we will try this technique not only on the tables located on page 149, but also on the Preface on page 3. To extract just the text from page 3, we run the following command:
pdf2txt.py –p3 pewReport.pdf
After running this command, the extracted preface of the Pew Research report appears in our command-line window:

To save this text to a file called pewPreface.txt, we can simply add a redirect to our command line as follows:
pdf2txt.py –p3 pewReport.pdf > pewPreface.txt
But what about those troublesome data tables located on page 149? What happens when we use pdf2txt on those? We can run the following command:
pdf2txt.py pewReport149.pdf
The results are slightly better than copy and paste, but not by much. The actual data output section is shown in the following screenshot. The column headers and data are mixed together, and the data from different columns are shown out of order.
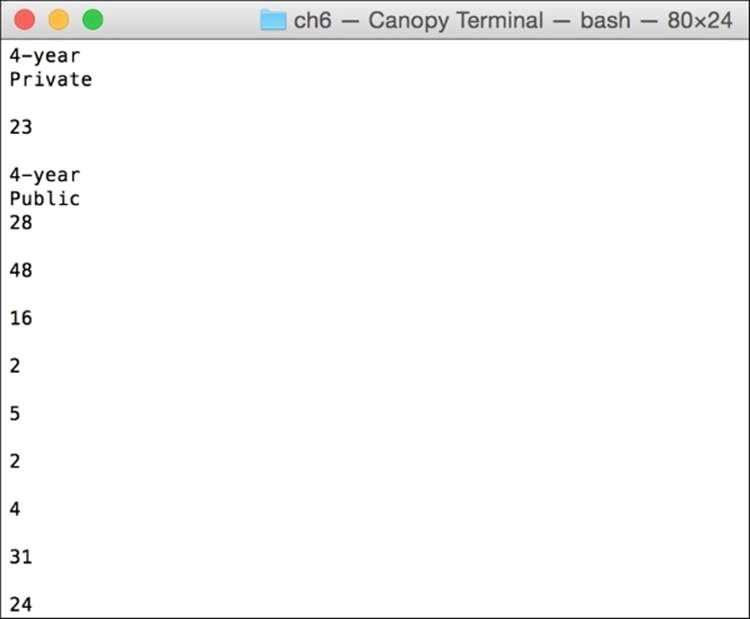
We will have to declare the tabular data extraction portion of this experiment a failure, though pdfMiner worked reasonably well on line-by-line text-only extraction.
Note
Remember that your success with each of these tools may vary. Much of it depends on the particular characteristics of the original PDF file.
It looks like we chose a very tricky PDF for this example, but let's not get disheartened. Instead, we will move on to another tool and see how we fare with it.
Third choice – Tabula
Tabula is a Java-based program to extract data within tables in PDF files. We will download the Tabula software and put it to work on the tricky tables in our page 149 file.
Step one – download Tabula
Tabula is available to be downloaded from its website at http://tabula.technology/. The site includes some simple download instructions.
Tip
On Mac OSX version 10.10.1, I had to download the legacy Java 6 application before I was able to run Tabula. The process was straightforward and required only following the on-screen instructions.
Step two – run Tabula
Launch Tabula from inside the downloaded .zip archive. On the Mac, the Tabula application file is called simply Tabula.app. You can copy this to your Applications folder if you like.
When Tabula starts, it launches a tab or window within your default web browser at the address http://127.0.0.1:8080/. The initial action portion of the screen looks like this:
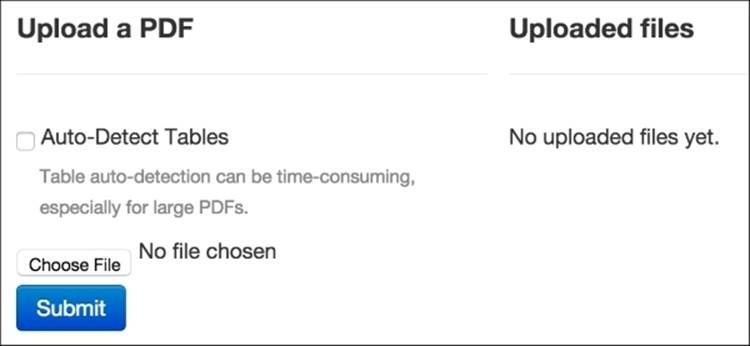
The warning that auto-detecting tables takes a long time is true. For the single-page perResearch149.pdf file, with three tables in it, table auto-detection took two full minutes and resulted in an error message about an incorrectly formatted PDF file.
Step three – direct Tabula to extract the data
Once Tabula reads in the file, it is time to direct it where the tables are. Using your mouse cursor, select the table you are interested in. I drew a box around the entire first table.
Tabula took about 30 seconds to read in the table, and the results are shown as follows:
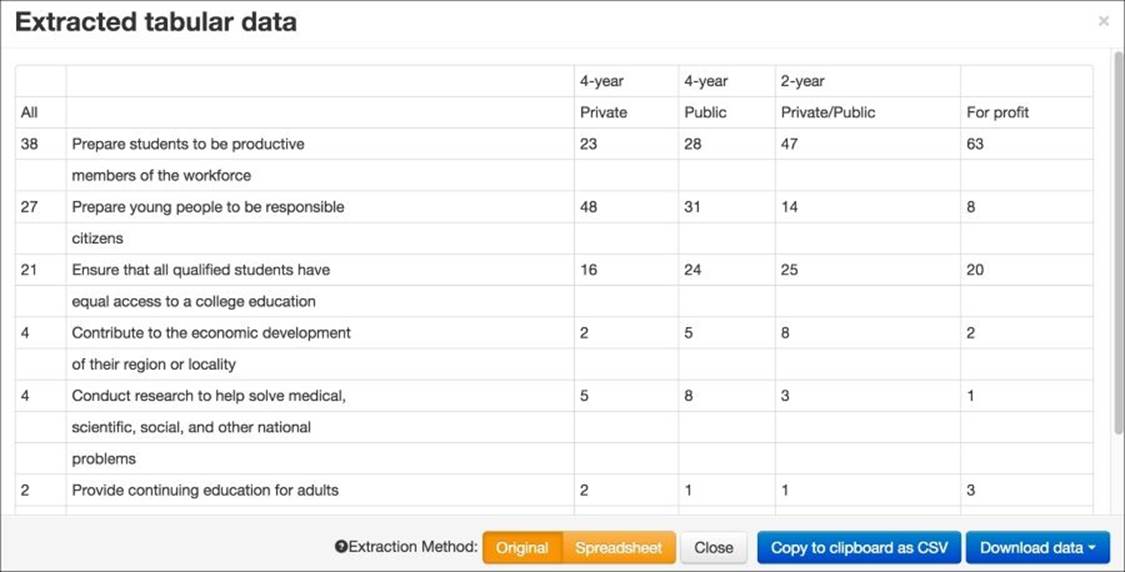
Compared to the way the data was read with copy and paste and pdf2txt, this data looks great. But if you are not happy with the way Tabula reads in the table, you can repeat this process by clearing your selection and redrawing the rectangle.
Step four – copy the data out
We can use the Download Data button within Tabula to save the data to a friendlier file format, such as CSV or TSV. As we know from our work in previous chapters, these are formats that can be cleaned, if necessary, in a spreadsheet or text editor. Right on cue, we are ready for our next step.
Step five – more cleaning
Open the CSV file in Excel or a text editor and take a look at it. At this stage, we have had a lot of failures in getting this PDF data extracted, so it is very tempting to just quit now. However, if you have made it this far in a book about data cleaning, you can probably guess that this data could be made even cleaner. Here are some simple data cleaning tasks that we know how to do already from earlier chapters:
1. We can combine all the two-line text cells into a single cell. For example, in column B, many of the phrases take up more than one row. Prepare students to be productive and members of the workforce should be in one cell as a single phrase. The same is true for the headers in Rows 1 and 2 (4-year and Private should be in a single cell). To clean this in Excel, create a new column between columns B and C. Use the concatenate() function to join B3:B4, B5:B6, and so on. Use Paste-Special to add the new concatenated values into a new column. Then remove the two columns you no longer need. Do the same for rows 1 and 2.
2. Remove blank lines between rows.
When these procedures are finished, the data looks like this:

Tip
Tabula might seem like a lot of work compared to cutting and pasting data or running a simple command-line tool. That is true, unless your PDF file turns out to be finicky like this one was. Remember that specialty tools are there for a reason—but do not use them unless you really need them. Start with a simple solution first and only proceed to a more difficult tool when you really need it.
When all else fails – the fourth technique
Adobe Systems sells a paid, commercial version of their Acrobat software that has some additional features above and beyond just allowing you to read PDF files. With the full version of Acrobat, you can create complex PDF files and manipulate existing files in various ways. One of the features that is relevant here is the Export Selection As… option found within Acrobat.
To get started using this feature, launch Acrobat and use the File Open dialog to open the PDF file. Within the file, navigate to the table holding the data you want to export. The following screenshot shows how to select the data from the page 149 PDF we have been operating on. Use your mouse to select the data, then right-click and choose Export Selection As…
At this point, Acrobat will ask you how you want the data exported. CSV is one of the choices. Excel Workbook (.xlsx) would also be a fine choice if you are sure you will not want to also edit the file in a text editor. Since I know that Excel can also open CSV files, I decided to save my file in that format so I would have the most flexibility between editing in Excel and my text editor.
After choosing the format for the file, we will be prompted for a filename and location for where to save the file. When we launch the resulting file, either in a text editor or in Excel, we can see that it looks a lot like the Tabula version we saw in the previous section. Here is how our CSV file will look when opened in Excel:
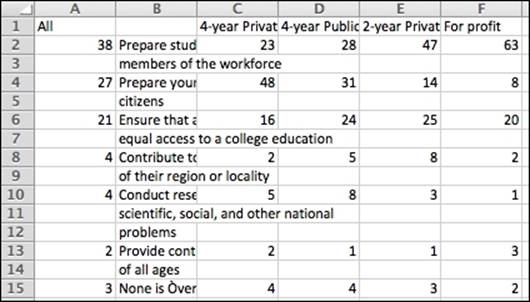
At this point, we can use the exact same cleaning routine we used with the Tabula data, where we concatenated the B2:B3 cells into a single cell and then removed the empty rows.
Summary
The goal of this chapter was to learn how to export data out of a PDF file. Like sediment in a fine wine, the data in PDF files can appear at first to be very difficult to separate. Unlike decanting wine, however, which is a very passive process, separating PDF data took a lot of trial and error. We learned four ways of working with PDF files to clean data: copying and pasting, pdfMiner, Tabula, and Acrobat export. Each of these tools has certain strengths and weaknesses:
· Copying and pasting costs nothing and takes very little work, but is not as effective with complicated tables.
· pdfMiner/Pdf2txt is also free, and as a command-line tool, it could be automated. It also works on large amounts of data. But like copying and pasting, it is easily confused by certain types of tables.
· Tabula takes some work to set up, and since it is a product undergoing development, it does occasionally give strange warnings. It is also a little slower than the other options. However, its output is very clean, even with complicated tables.
· Acrobat gives similar output to Tabula, but with almost no setup and very little effort. It is a paid product.
By the end, we had a clean dataset that was ready for analysis or long-term storage.
In the next chapter, we will focus on data that has been placed into long-term storage in a Relational Database Management System (RDBMS). We will learn about the challenges of cleaning data stored this way, as well as some of the common data anomalies and how to fix them.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.