Information Management: Strategies for Gaining a Competitive Advantage with Data (2014)
Chapter 10. Operational Big Data
Key-Value, Document, and Column Stores: Hash Tables Reborn
A chapter on key-value stores, which store data paired with its key. Document stores are key-value stores with more robust data type capabilities. These are immensely important for serving any data immediately from a very large dataset. Column stores put some requirements on how NoSQL data is stored in NoSQL.
Keywords
NoSQL; key-value; document stores; column stores; big data
In the mid-2000s, several new-economy Silicon Valley companies were facing data challenges at a scale beyond those of the largest companies in the world. Knowing the exploitation of that data was the essence of their business, and knowing the existing relational technology would be too expensive to scale—if it even could scale to their needs—many companies independently set out to build their own solutions. The commonalities were many among the internal solutions and most reached a similar conclusion about the SQL/relational/transactionally-sound marketplace—it did not have a place in the solutions.
As discussions took place across the Valley, a Meetup was formed to share findings and advance the solutions. That Meetup needed a name and a poll occurred. Jumping on this fact that the solutions had all ignored or banished SQL, the name of “No SQL” was decided on and a movement was begun.
Initially, the movement’s players were adamant that the solutions would rule the enterprise,1 but as initial outreach of this storyline was met with disinterest from enterprises, the “No” came to be known as “NO” as in “Not Only SQL.” I cannot say I like the “No” or “NO” as a label. Any time you name a space something that it is not, it creates issues. Walls form in prospects that believe you are anti- all the software they have in house—and that you will not integrate with it. Prospects also will think of all of the capabilities they have with SQL and believe the “no” solution will not do any of them. This is not true, although there are definitely some capabilities that are not present. Also, the interfaces are so quickly coming close to SQL that it would difficult to imagine the space being named NoSQL today. I’m here to help you with the industry, not create new terms, so let’s talk about NoSQL.
Before we leave semantics, there is a very important term that is very related here. Big data is synonymous with the NoSQL movement because these Valley companies that originated the movement had “big” data challenges. If the data were “small,” they would not have created the space and would have just used relational technology. The literature uses NoSQL and big data synonymously, but really the big data is the data being stored in the NoSQL solutions and what the NoSQL solutions store is, by definition, big data.
This is almost, but not completely, true. Graph databases, discussed in Chapter 12, provide extremely valuable functionality for relationship data—and that data need not be “big.”
When to Yes NoSQL
You may be looking for the quantifiable definition of big data. Again, it’s the workload threshold when relational no longer makes sense—given your unique situation. It’s hard to imagine that under a certain single-digit number of terabytes—unless you have a specialized single-use workload that matches well with the pros of NoSQL and minimizes the cons of NoSQL—that it makes sense.
Many will say that big data/NoSQL2 is a Valley phenomenon and your company does not have a need to get out of the SQL comfort zone. Not so fast. NoSQL enterprise deployments are mostly for net new applications in the business—exactly those applications that have big data needs. It’s a perfect storm of need and solution.
Why Big Data Now?
There are a few trends bringing us into the era of big data.
• Storing Data is Cheaper than Ever
Companies increasingly are feeling liberated by less expensive means for extending the competitive advantages of data exploitation into more voluminous data: clicks, weblogs, and sensor reads of small movements. Factors that are triggering the liberation include past-decade exponential decreases in the cost of all computing resources and an explosion in network bandwidth.
• Sensor Networks
Most people don’t think of their cell phone as part of a “sensor network.” However, their increased ubiquity and web connection are impossible to ignore as data collection mechanisms. One day, we may be able to opt in to contributing our air quality, air pressure, noise level, or other “around me” data to our favorite companies we do business with. Today, we contribute our location, web clicks, and application usage. Cell phones are examples of the growing sensor network, with great adoption in supply chains.
• History Data
Many get into data warehousing entertaining the notion that they will remove data as it becomes old and less useful—perhaps at the 3-year point and perhaps to something as cheap and inaccessible as tape. However, as long as the warehouse is successful enough to make it to that point, the users are inevitably interested in ALL the data and need fast access to all the data. Tiering some of it to lower-cost storage, perhaps some of the big data options—like Hadoop, for example—is possible, but inaccessible, slow tape is not.
• Syndicated Data
The third-party data marketplace, discussed in Chapter 7, is booming and dispensing data to the enterprise in many cases as much as, or more than, the enterprise generates internally. This potentially significant additional avenue of interesting data can dramatically expand enterprise information.
Not all of these trends directly correlate to the need for a NoSQL solution, but they are making enterprise information “bigger.”
• Ability to Utilize the Data
Just as successful data warehouses result in user need for all the data they’ve ever seen in the data warehouse, likewise high-end analysts (sometimes referred to as Data Scientists) are finding business uses for all data—including data types they have never utilized before—which usually falls into the big data category.
There are many other aspects of NoSQL that define its best workload other than cheaply storing a large amount of data.
Achieving high availability cheaply would be another important consideration.
Data model flexibility, defined later in the chapter, would be another good indicator that NoSQL is a correct categorization for the workload.
In general, it is the sensor data, full webclick data, social data, and related offshoots, such as those attributed later in the chapter to certain of the models, that make for the best fit in NoSQL stores. Enterprises have mostly been force-fitting snapshots and summaries of this data into relational databases for years and now it’s time to realize the full potential of big data.
NoSQL Attributes
Open Source
Most of the NoSQL movement has an open source component. While most of the players in enterprise decision making are familiar with open source, it remains an enigma in the enterprise itself. Certainly, being able to take on software with an open source origin in the enterprise is a requirement for taking on NoSQL and, consequently, a requirement for success in IT today.
Many NoSQL companies have high triage with the open source software they support, in addition to the support and related software they add on to that software. Still, the support model is not the same as enterprise “closed source” software. An enterprise can make it passable, even excellent, with effort, but will likely find a new set of challenges given the abstraction of support from software owner (the “community” in open source) to a third-party company.
Data Models
NoSQL solutions do not require, or accept, a preplanned data model whereby every record has the same fields and each field of a table has to be accounted for in each record. Though there can be strong similarities3 from record to record, there is no “carryover” from one record to the next and each field is encoded with JavaScript Object Notation.
(JSON) or Extensible Markup Language (XML)—according to the solution’s architecture. A record may look like:
• Book: “War and Peace”: Author: “Tolstoy”
This is what is meant by unstructured data- Data of varying forms loaded without a set schema.4
Abstact Programming in Relational Databases
Many attempt to simulate the data model flexibility in a relational system through abstract programming techniques.
1. “Dummy” fields like COLUMN32, COLUMN33, COLUMN34, etc. that are usually large VARCHARs and accept the variable fields of the record
2. Heavy use of subtypes and supertypes in tables
3. Storing column names in fields
4. “Code tables” with a code numbering system that spans codes
These techniques may make sense in relational systems if other factors are involved that make relational best for the workload. However, if a flexible data model is a primary consideration in the workload, consider a NoSQL solution.
Scale Out
It has long been a truism that to achieve scaling to higher and higher levels,5 it is less expensive to do it with smaller machines than larger machines. In the early days of computing, as systems began to tackle scaling challenges with larger machines, the costs took off exponentially. Machines were getting much more complex. A 10-terabyte system could cost not 10 times a 1-terabyte system, but nearly 100 times. If you wanted to store 10 terabytes, you paid the price. This is scale up.
NoSQL solutions found a way to multiply that 1-terabyte system 10 times: at 10, not 100, times the cost. The key is the divide and conquer, exemplified by MapReduce, discussed later in the chapter. By dividing the programming across a single data set spread over many machines, NoSQL is able to keep the costs down and the scale up (I mean out!).
The following sections are also traits of NoSQL solutions that are dissimilar to relational databases. However, their nature could differ from NoSQL solution to NoSQL solution. I advise you get your solution into the right category first, then make sure the solution adheres to the characteristics of these traits that are needed by the application.
Sharding
Sharding is a partitioning pattern for the NoSQL age. It’s a partitioning pattern that places each partition in potentially separate servers—potentially all over the world. This scale out works well for supporting people all over the world accessing different parts of the data set with performance. If you are taking an order for someone in Dallas, for example, that order can be placed in the Southwest U.S. data center.
A shard is managed by a single server. Based on the replication schema, the shard is most likely replicated twice on other shards. Shards can be set up to split automatically when they get too large or they can be more directed. Auto-sharding takes a load off of the programming, which would otherwise not only have to manage the placement of data, but also the application code’s data retrieval.
Consistency
ACID (see box) is essential for guaranteeing 100% accuracy when you have many rows spanning many tables in a single operation. The operation should succeed or fail completely and concurrent operations are isolated so partial updates do not commit.
Most NoSQL solutions do not have full ACID compliance like a relational system does. This inhibits its abilities to do critical financial transactions. Each record will be consistent, but transactions are usually guaranteed to be “eventually consistent” which means changes to data could be staggered to the queries of that data for a short period of time.6 Some queries are looking at “old” data while some may be looking at “new” data. Consider the business model behind the application to determine the fit of the consistency model of the solution. The trade-off for this downside is improved performance and scalability.
No vendor has been able to articulate the risk of the lack of full ACID compliance of a NoSQL solution. Also, I know of no one who has experienced some sort of transaction, and hence business, failure as a result of overcommitting transactions to NoSQL. Still, it IS theoretically possible that a transaction could fail unless full ACID is guaranteed and, for that reason, critical money matters should not be committed (pun) to NoSQL.
What is ACID?
• Atomicity – full transactions pass or fail
• Consistency – database in valid state after each transaction
• Isolation – transactions do not interfere with one another
• Durability – transactions remain committed no matter what (e.g., crashes)
Though the most important component of ACID is atomicity, the more complex component is consistency. Consistency may be tunable by the NoSQL database administrator. By tuning the replication factor and the number of nodes that will respond to a write, the system can follow a more or less “write tolerant” profile. Not only writes, but also the replication, can have this inconsistency window. The effect of replication on consistency can be profound. Consistency can often be tuned on a session basis.
Commodity Components
“Commodity” is a class of hardware and does not refer to your old Tandy 1000s, TRS-80s, Burroughs B2500s, and the like. It is, however, an unspecialized level of computer, somewhere in the mid-single digit thousands of dollars that can be effectively used in NoSQL systems. The scale-out architectures are built to utilize this class of computer.
MapReduce
The idea of MapReduce has been around quite a while. Lisp Systems had the same concept decades ago, but Google effectively revived it as the primary access mechanism for NoSQL systems. The idea is to take a large problem and divide it into locally processed subproblems. As much of a query as possible will be processed in the node where the data is held. That part of the query is the same for all nodes. That is called the Map function. The same homogeneity is true for the Reduce step, which follows the Map step and the movement of the data within the nodes to where it can be effectively utilized.
Both the Map and the Reduce are programmed using Java (primarily). While many organizations have attempted to marginalize or eliminate programming from their shop for internal “system integrator” types who can install and customize software, with NoSQL, you need to bring those skills back!
Sample MapReduce Code: Find Out How Many Times Each Account Was Accessed In The Last 10 Years7
map(key, value)
{
// key=byte offset in log file
// value=a line in the log file
if (value is an account access audit log)
{
account number=parse account from value
output key=account number, value=1
}
}
reduce(key, list of values)
{
// key=account number
// list of values {1,1,1,1……}
for each value
count=count+value
output key, count
}
7Credit: Java Code Geeks http://www.javacodegeeks.com/2011/05/mapreduce-soft-introduction.html
Each Map and Reduce also specifies how much parallelism across the nodes, potentially thousands, there will be. MapReduce runs in batch and always completely scans all the nodes, being careful to avoid reading the same data twice due to the replication. The replication factor is usually three, so figure the scans are reading slightly more than 1/3 of the nodes with every MapReduce job.
Cloud Computing
While not required, the volume and unpredicatability of the data selected for NoSQL make the cloud an ideal place to store the data. Cloud computing will be covered in detail in Chapter 13, but breaking into NoSQL often means breaking into the cloud—two ideals worth achieving.
Up until now, I have not even mentioned the 800-pound gorilla of big data that is Hadoop. I will defer that to its own chapter 11, but all of the NoSQL origins, common attributes (open source, model flexibility, scale out), and those attributes that differ from solution-to-solution—but most likely differ from a relational solution (sharding, concurrency, JSON, MapReduce, HTTP Based Interface)—are present with Hadoop.
While a Hadoop file system is the gathering place for transactional big data for analytics and long-term storage, numerous other forms of NoSQL are available and one or more could be needed for a modern enterprise although for quite different purposes. These NoSQL stores primarily serve an operational purpose—with some exceptions noted. They support the new class of “webscale” applications in which usage, and hence data, can expand and contract quickly like an accordion.
Much non-Hadoop NoSQL support is heavily intertwined with the application and supported by the application teams and not necessarily the information management team. It might be tempting to select from these solutions without giving much “enterprise” thought to the matter. However, an organization with one webscale application usually could soon have several. It would be advantageous to have skills around a single multipurpose NoSQL solution, especially within a NoSQL categorization.
All of the categories later in the chapter support thousands of concurrent users needing their data in real time—a pulsating system of vibrant activity made possible with recent advances in internet and network capabilities. Without NoSQL, many of the applications in use today that were “invented” in the last decade would not have access to the data they need to exist.
NoSQL Categorization
These categories of NoSQL beyond Hadoop are mostly key-value in nature. They do not have proper data models, but instead store the key (column name in relational vernacular) followed by the value for each column. We refer to this as a “hash table.” Like Hadoop, this allows each record (“aggregate”) to be constituted quite differently, although often the records will be similar. As we’ll see, the similar/dissimilar nature of the records is a determining factor for the category.
The emerging NoSQL space has had many entrants and quite possibly quite a few more already than can survive for very long. It is important to categorize the vendor products as I have done here. In technical spaces in this book with durations of at least a few years—namely all but the NoSQL group—the analyst and user communities have pushed vendors into appropriate categories.
NoSQL has not hit this threshold yet, so the vendors still largely abhor the categorizations in an attempt to keep all their cards on the table. Even Hadoop distributors can be loose in their marketing, bleeding over into these other NoSQL categories. Look beyond vendor self-categorization. It’s usually less that the product defines a supercategory or defies categorization than it is that the product fits one category.
These are good categories to learn about so you can make the proper categorization, put the wares into the correct category, and make the correct selection.
Value Per Capita
The “value per capita” (e.g., value per terabyte) of big data is going to be less than the value per capita of data that is stored in a relational solution. Nonetheless, if that value exceeds the cost, that data should come under management as well. Over time, we may find that the aggregate value of managed big data exceeds that of relational data.
Key-Value Stores
Key-value stores have little to no understanding of the value part of the key. It is simply a blob, keyed by a unique identifier which serves a “primary key” function. This key is used for get, put, and delete. You can also search inside the value, although the performance may be suboptimal. The application consuming the record will need to know what to do with the blob/value.
Key-value stores are effectively used for keeping track of everything related to the new class of web, console, and mobile applications that are run simultaneously by thousands of users, sometimes sharing sessions, as in games. The value is the full session or game–state information with every session having a unique key.
Key-value stores are also used for shopping carts, which can persist over time. User Preferences are similar from a data perspective and stored in key-value stores. Both seek to create availability of the information from any platform (browser, console) at any time.
Many companies are taking advantage of NoSQL stores to personalize and optimize the web experience for their current web presence(s) without regard to the product the company produces.
The commonality in these uses is that the primary use of this data is the need to look up the full session information at once and to do so by a single key.
Key-value stores are prominent today, but with a few additional features they can become a document store or a column store. As a result, this may be a dying category. Some products have migrated categories. However, when records are simple and lack strong commonality of look, a key-value store may be all you need.
Keep in mind document stores and column stores are also key-value in the sense of how data is stored—as a hash table. However, their additional capabilities earn them a separate categorization. These capabilities, discussed in their respective sections later in the chapter, also highlight some of the workloads you do not want to use a key-value store for: those involving relationships amongst data, complexity of data, or the need to operate on multiple keys/records at once.
Document Stores
Document stores are specialized key-value stores. As the name implies, the model is particularly good at storing and retrieving actual documents. However, the term “document” actually is the document store’s term for the record.
Documents can be nested. In addition to key-value stores, document stores add the ability to store lists, arrays, and sets. It is an excellent model when fields have a variable number of values (e.g., addresses, “likes,” phone numbers, cart items) according to the record. Of course, that number could be zero for a given record. And unlike key-value stores, the value part of the field can be queried. The entire document/record does not need to be retrieved by the key. It is good when more granular data than full records is required.
Document stores tend to be excellent for logging online events of different types when those events can have varying characteristics. They work well as pseudo content management systems that support website content. Due to the ability to manipulate at a granular level, document stores are good for real-time analytics that change dynamically, which the application can take advantage of immediately.
Column Stores
A column store is a key-value store that is conceptually similar to the column database I talked about in Chapter 5, whereby each column’s values (or set grouping of columns) are stored independently. Column stores somewhat defy the idea that each record is independently crafted with no forced schema. In column stores, defined column families MUST exist in each record. This makes the column store ideal for semi-structured data in which there is some commonality, as well as differences, record to record. Column families would be comprised of columns that have similar access characteristics.
Column stores are ideal for application state information across a side variety of users. Blogging, with its similar columns for each record, are also semi-structured, as are some content management systems.
Given the “modeling” (still light by relational standards!) that is done for column stores, for data that is still relatively unknown, column stores may prove to be too restrictive. However, when the query pattern is by subsets of the entire record, the added ability to create column families makes the column store attractive.
NoSQL in the Enterprise
The NoSQL community can rapidly accelerate its progress in the enterprise by:
1. Making reasonable recommendations for NoSQL use
2. Communicating and educating
3. Documenting the expected record profiles (data model)
4. Helping IT with their agile, cloud, and open source knowledge and adoption – nonstarters for NoSQL projects
5. Developing ROI around their projects
6. Developing strategies early for integration with enterprise data
7. Making NoSQL ware easier to use and fitting it into frameworks
8. Tackling softer issues of these projects, like program and data governance
NoSQL Solution Checklist
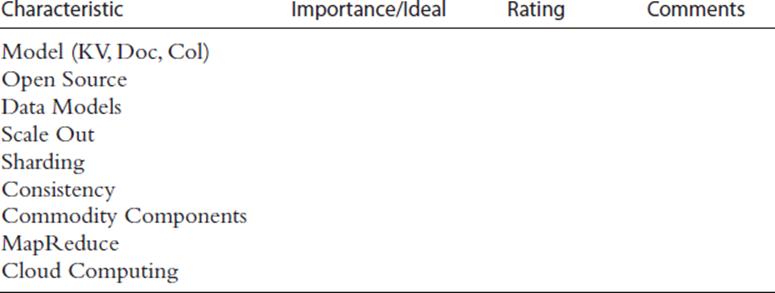
Action Plan
• As a prerequisite to NoSQL deployments, get comfortable with open source technology, develop a cloud computing strategy (Chapter 13), and adopt an agile methodology (Chapter 16)
• Determine what you are doing with available sensor, social, and webclick data today; possibly more could be captured with NoSQL adoption
• Likewise, determine if any source data is not being captured because of limitations of relational technology
• When web applications are being considered or are in development, put the appropriate NoSQL technology (key-value, document, or column store) on the proverbial table
www.mcknightcg.com/bookch10
1This mindset still exists out there
2I’ll call it NoSQL from this point forward in the book
3the level of similarities will help drive a NoSQL categorization decision—the column store being particularly good for a high level of similarity from record to record
4“Give me your tired, your poor, Your huddled masses…” of data
5I’ll use levels of data as an example, but scale also refers to the computing done with the data
6frequently within tens or hundreds of milliseconds
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.