Information Management: Strategies for Gaining a Competitive Advantage with Data (2014)
Chapter 2. Relational Theory In Practice
A technical look at the relational theory, so the reader can keep in mind its advantages as the information management technology community continues to expand elsewhere. A review of the current usual landscape of data warehouses, data marts, and specialized marts like multidimensional databases and their lasting value in the information ecosystem.
Keywords
business intelligence; data warehousing; relational theory; database management systems; database; database theory; relational data; data warehouse; SQL
Over 40 years ago, E. F. Codd of IBM published definitive papers on the relational database model. IBM and Oracle embraced the model early and developed commercial database systems (DBMS) that utilized the relational model.
Relational Theory
The relational theory is quite extensive with its own set of lingo about what is eventually implemented in the DBMS1 as a table and accessed with a form of Structured Query Language (SQL). Note that a table is not part of the relational theory, but it is the physical implementation of the relational theory—specifically the construct known as the relation. It is not necessary to fully understand the relational theory to be an expert information manager, but there is one concept about it that must be understood and that is referential integrity.
This simply means that tables are connected by keys and there can be no “orphan” records in any table. If the Customer table doesn’t have customer number “123,” the Order table should not record a customer number of “123.” If the Product table doesn’t have product code “XYZ,” the Order table should not record a product code of “XYZ.” This implies some ordering that is necessary for the loads and inserts into the tables. Primarily, the concept is in place to protect the tables from unwanted data. In DBMS, this function can be turned on or off.
All tables are keyed by a column or set of columns that must contain unique values.
If referential integrity is turned off, it may be for performance (referential integrity causes some overhead), in which case you would want to ensure your processes don’t allow non-integrant data into the tables such as products sold that are not in the product table or trucks loaded that are not in the truck table. The function could also be turned off because processes have data loads in an order that would knowingly cause non-integrant data that will eventually become integrant. However, just allowing non-integrant data to come in without doing something about it would probably cause many problems for the system.
More detail on this is unnecessary now, but the point is that the referential integrity concept demonstrates some of the true value of the relational theory. There are numerous other concepts about which decisions must be made with any DBMS implementation. There are also numerous other DBMS objects that support the table.
The names vary from DBMS to DBMS, but I’m talking about tablespaces, databases, storage groups, indexes (explained below), synonyms, aliases, views, keys, schemas, etc. These are some of the tools of the trade for the database administrator (DBA). However, as far as the relational theory goes, it is all about the table—rows and columns.
The DBMS has been the centerpiece of information technology for 30 years. It is not going away anytime soon, either. Enterprises are absolutely bound to tables in DBMS.2 Enterprises have anywhere from 50% to 90% of their data in tables and, if the criteria was data under management, it would easily be over 90% for most enterprises.
Hadoop (Chapter 11) and NoSQL databases (Chapter 10) will change this dynamic somewhat. However, the most important data in enterprises is, and will be, in DBMS. Certainly, the most important data per capita (i.e., per terabyte) in an enterprise is DBMS data.
For the data options presented in this book, here is how the DBMS is involved:
1. Data Warehouse (Chapter 6) – Implemented on DBMS
2. Cubes or Multidimensional Databases (later in this chapter) – Not exactly DBMS, but are conceptually similar
3. Data Warehouse Appliances (Chapter 6) – DBMS bundled on specialized hardware
4. Data Appliances like HANA and Exadata (Chapter 6) – DBMS bundled on specialized hardware
5. Columnar databases (Chapter 5) – DBMS with a different orientation to the data
6. Master Data Management (Chapter 7) – Implemented on DBMS
7. Data Stream Processing (Chapter 8) – Data layer option is not relevant as Data Stream Processing is not storing data
8. Data Virtualization (Chapter 9) – works with DBMS and non-DBMS data
9. Hadoop (Chapter 11) – Hadoop is not DBMS
10. NoSQL (Chapter 10) – NoSQL databases are not DBMS
11. Graph Databases (Chapter 12) – Graph databases are not DBMS
In addition, the operational side of a business,3 which is not extensively covered in this book except for profound changes happening there like Master Data Management, Data Stream Processing, and NoSQL systems, is mostly run on DBMS.
It is essential to understand relational theory, as it is essential to understand how tables are implemented in DBMS. If someone were to give me an hour to describe the relational theory—the backbone of this huge percentage of enterprise data, data under management, and important data—I would quickly take the discussion to the physical implementation of the table. From this knowledge base, so much can be understood that will generate better utilized and better performing DBMS.4 It will also help draw the comparison to NoSQL systems later.
So, let’s go. This will be some of the more technical content of the book. Hang in there. Again, there absolutely is some technical material that one needs to know in order to be an excellent information manager or strategist.
The Data Page
A relational database is a file system. It’s not a file system in the vernacular of how we refer to pre-DBMS file systems, but it is a file. It’s a file that has a repeating pattern in the data. Most data in a DBMS is in table page or index page5 representation and each has different patterns.
The table page’s pattern repeats according to the specified size of all pages in the file, typically anywhere from 2,048 (2 k) to 32,768 (32 k) bytes. After a few overhead pages, the pages are data pages and this is what we need to focus on.
For simplicity, I’ll use 4,096 bytes (4 k) as the chosen page size for the file and we’ll assume that there is only one table in the file. This is not unusual.
The data page (figure 2.1) has 3 sections.6 The first section is the page header. It is of fixed length and contains various meta information about what’s going on in the page. One of the most important pieces of information is where the first free space is on the page. More on that in a moment.
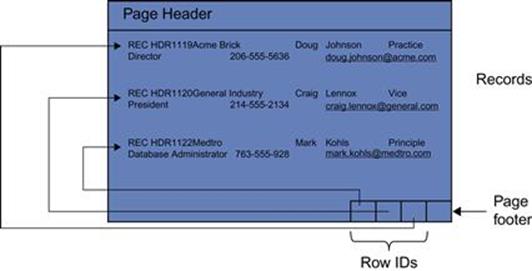
FIGURE 2.1 Relational Data Page Layout.
Next comes the exciting part of the data page—the records. Each record has a few bytes of a record header followed by the value of every column of the table for that record. Columns are ordered in the same way for every record and every record has every column. The data manager (component of the DBMS that does the page navigation for inserts, updates, deletes, and reads) knows where every column begins because the byte count for each column is stored in the catalog.
In figure 2.1, we have customer number, company name, first name, last name, title, phone number, and email columns.
The third column of the record after an integer (4 bytes) and a 25-byte character always starts at the beginning of the record plus bytes for the record header plus 29.
This all holds true as long as the columns are fixed length. There are variable length columns where the length of the column is actually stored just in front of the column’s value. The number of bytes may be 1 or 2 bytes according to the maximum length of the variable length column, but let’s say it is 2 bytes. That’s 2 bytes stored for the column plus, of course, the actual value, itself.
The data manager will have to read those length bytes to know where all columns following this column start. This presents some additional overhead, which is why a rule of thumb is to store the variable length columns at the end of the record.7
Columns that may be null (no value) will have a byte8 prepended to the value that will have 2 values possible—one representing the column is null (in which case, the value is ignored), the other representing that the column is not null (in which case, the value is good and will be read). The data manager will, naturally, understand this additional byte is part of the column length and use it when calculating offsets to column starts.9
Finally, a hugely important aspect of the DBMS is the row identifiers or row IDs (RIDs). These are bytes (the number of which is dependent on page size, but I’ll use 2 bytes per row ID) that start from the end of the page and are allocated backwards within the page as records are added to the page. There is one row ID per record on the page and it contains the offset from the beginning of the page to where that record (record header) begins. The number of row IDs equals the number of records on the page.
The offset from the beginning of the file to the beginning of a data page is going to be the sum of:
• The number of “overhead” pages at the beginning of the file, typically 1–3, times the page size
• The page number minus one times the page size
For example, to get to the 100th page of a table where the page size is 4 k and there are 2 overhead pages, the data manager will start at the beginning of the file and advance:
• 4 k times 2 for the overhead pages
• 4 k times 99 to get to the start of the 100th page
The number of records a page can hold primarily depends on the size of the record versus the size of the page. If the records are really small, however, the number of row IDs could actually be exhausted before the space is fully utilized. In figure 2.1, we see that there are 3 records on this page.
In general, DBAs have been increasing page sizes for analytic workloads over the years. Some shops understand why and other shops do not. The primary reason is that the bottleneck is I/O and we need our DBMS to, when it finally gets to the point of doing an I/O, grab as much information as is reasonably possible at that point. Since the page is the usual unit of I/O, this means the page sizes are getting bigger. I’ll have more on this in Chapter 5 on columnar databases, where I talk about how they tackle this problem.
NewSQL
Products in the NewSQL category are an implementation of relational SQL in scale out (described in Chapter 10); in-memory (described in Chapter 6) architectures, which provide relational database functions for high performance, high throughput transactional workloads, such as storing capital market data feeds, placing financial trades, absorbing entire record streams in telecommunications, supporting online gaming, and supporting digital exchanges.
A newly allocated table’s data pages will have no records and the first usable space is just after the page header. Once records begin to fill on the page, the usable space begins to shrink and the starting point for the next record advances. The page header contains where this starting point is to help the data manager place records. Simple enough, but what about when a record is deleted?
Deletions create “holes” on the page. The data page changes very little physically except noting the record is invalid. Holes get chained together on the page. If a record has turned into a hole, there is a pointer to the next hole in the record header. If the data manager wants to use this page to place a record to, for example, force ordering of data in the table (as in the use of a “clustering” index), it will do a “mini-reorg” of the page to collapse the holes and create more available space. You see, it is the order of the records in the row IDs that count (in terms of the records being “in order”), not the physical ordering of the records on the page.
If you are forcing a customer number ordering on the table, the customer numbers could get jumbled on the page, but the row IDs will surely be pointing to records with increasing customer numbers.
These DBMS are extremely math-driven. By doing microsecond calculations, the DBMS gets the I/O where it needs to get to retrieve the record. It’s off the disk as binary, translated to hexadecimal, and on to the ASCII that we appreciate! This is, in a nutshell, how the data page works. The other large chunk of DBMS space is for indexes.
Indexes
Indexes take single or multiple columns out of a table into a different physical structure, where the values are kept in order regardless of the ordering of the table. This is a structure where “random access” is possible because of the ordering. There are also structure pages (called “nonleaf”) that help guide the DBMS in understanding on what index pages certain values are. The DBMS will traverse these structure pages to get to the “leaf” pages, which is where the index entries are.
Index entries are comprised of the key plus the RID(s)10 for where the “rest of the record” is in the table. For example, if there were an index on company name, an entry might be:
ACME BRICK|100-1
This means the company name of “ACME BRICK” can be found on page 100, row ID 1. For SELECT * WHERE COMPANYNAME=“ACME BRICK”, it would be much more efficient to look this up quickly in the index and then go to page 100 in the table to get the other fields for the result set (as opposed to reading every table entry to see if it’s for ACME BRICK).
That’s the beauty of the index. There are many kinds of indexes and the navigation patterns differ according to kind, but they are mostly for one purpose—performance.11 The DBMS’s optimizer works with the index structures to determine the most appropriate “path” to take within the data to accomplish what is necessary.
Optimizers are pretty smart. Most use an estimated cost basis approach and will forge the lowest cost path for the query. While all these machinations can seem to work fine “behind the scenes,” DBMSs benefit tremendously from excellent database administrators (DBAs). Without some knowledge of their work or points of communication, enterprises are hostages to their DBAs, as well as undervaluing them.
Multidimensional Databases
Multidimensional databases (MDBs), or cubes, are specialized structures that support very fast access to summarized data. The information data store associated with multidimensional access is often overshadowed by the robust data access speed and financial calculation capabilities. However, as additional structures that need to be maintained, the multidimensional databases create storage and processing overhead for the organization.
The data access paradigm is simple:
1. What do you want to see?
2. What do you want to see it by?
3. What parameters do you want to put on the dimensions?
For example:
1. I want to see sales
2. I want to see sales by state
3. I want to limit the result set to the Southwest region (from the geographic dimension)
Cube access is referred to as online analytical processing (OLAP) access. Specifically, the cube implements the multidimensional form of OLAP access, or MOLAP access. ROLAP, for relational OLAP, refers to the utilization of the data access paradigm upon a relational (not a cube) structure. ROLAP is just glorified SQL. Since I’m advocating the primary continuance of a ton of DBMS and SQL in the enterprise, I’ll just lump ROLAP into SQL use. ROLAP is not a platform like MOLAP is.
Back to multidimensional databases, they are what I call “hyperdimensional.” The logical model is dimensional, but the physical rendering is fully denormalized so there are no “joins.” Like a data warehouse, they are built from source data. The point that must be made is that these structures grow (and build times grow) tremendously with every column added. The data access layer hides the complex underlying multidimensional structure.
This structure includes all the columns of the source tables physically “pre-joined,” such that there are no joins in the data access. The rows are then compressed and indexed within the MDB so it is able to do random access.
If a query is paired well with the MDB (i.e., query asks for the columns of the MDB—no more and no less), the MDB will outperform the relational database, potentially by an order of magnitude. This is the promise that many reach for in MDBs. However, most of the time growing cubes and, therefore, growing the load cycle and the storage, is far too tempting. The temptation to think that because some queries perform well, the MDB will be adopted for all queries, can be too much to resist. One client of mine began rebuilding “the cube” on Fridays at 5:00 pm and half of the time, it was not complete by Monday at 9:00 am.
Beware of multidimensional hell.
Multidimensional databases (MDB) are a “last resort” when a highly tuned relational database will not give the performance that is required. MDBs can be quickly built to support a single query or just a few queries, but there often is a high price for this approach.
Since many multidimensional databases land in companies as a result of coming in with packaged software, it must also be said that if the overall package provides a true return on investment—versus the alternative of building the package functionality in the shop—then that is another valid reason for a multidimensional database.
If you do have MDBs, ensure that the maintenance (cycles, storage) is well understood. MDBs can support workloads that are well-defined and understood. Otherwise, tread lightly.
RDBMS Platforms
A DBMS, technically, is software and not a platform. I’ll talk here about some various hardware that the DBMS might reside upon. Together, DBMS and hardware make a platform for data. In this chapter, I will avoid the pre-bundled data warehouse appliance and data appliance and stick with advisement for the many cases where the DBMS and hardware are separate and you, or your vendor, are putting DBMS onto hardware, like Legos, to create your platform.
Most major DBMSs are a far cry from the early days. They have innovated along with the demand. They have grown in their capabilities and continue to grow. They have not, however, obviated, in any way, the need for appliances, stream processing, master data management, or the growing NoSQL movement. Chapters 10–12 will talk about their workloads. The information management pot has only swelled with these advances.
One of the major areas of focus is not in DBMS features, but in where the DBMS stores its data.
The decision point is the allocation and juxtaposition of storage across hard disk drives (HDD) and flash-based solid state drives (SSD), the accompanying allocation of memory, and the associated partitioning strategy (hot/cold)12 within the data. Throw in the compression strategy, also key to a successful DBMS architecture, and—as long as cost matters (per capita costs are falling, but data is growing)—you have a complex architecture that cannot be perfect.
The issue of HDD v. SSD v. Memory comes down to cost versus performance: dollars per GB v. pennies per GB for vastly different read rate performance. The cost of more than 40% to SSD or Memory is prohibitive to most workloads. However, there are many other factors to consider as well, including durability, start-up performance, write performance, CPU utilization, sound, heat, and encryption.
Teradata machines, for example, automatically determine what is hot and cold and allocate data based on usage. As Dan Graham, General Manager Enterprise Systems at Teradata, put it: “DBAs can’t keep up with the random thoughts of users” so hard or fixed “allocating” data to hot/cold is not a good approach. Get a system that learns and allocates. Business “dimensional” data—like customers, products, stores, etc.—tend to be very hot and therefore stay in the hot option, but, again, this is based on actual usage.
All of this doesn’t help to determine how much and what percentage of overall space to make HDD, SSD, and Memory. On an average system, it ends up being between 50 and 70 percent HDD. It’s based on workload (if migrating) or anticipated workload (for new systems) and an attempt to get “most” of the I/Os on SSD and Memory.
Memory is certainly a huge factor in allocating budget to need. A strong memory component can mitigate the value of SSD when it comes to reads, but may produce inconsistent response times. Transactional databases will move to more memory-based solutions faster than analytical workloads due to the variability of performance with memory.
In-memory capabilities will be the corporate standard for the future, especially for traditional databases, where disk I/O is the bottleneck. In-memory based systems do not have disk I/O. Access to databases in main memory is up to 10,000 times faster than access from storage drives. Near-future blade servers will have up to 500 gigabytes of RAM. Already, systems are being sold with up to 50 terabytes of main memory. Compression techniques can make this effectively 10x–20x that size in data.
SAP BusinessObjects introduced in-memory databases in 2006 and is the first major vendor to deliver in-memory technology for BI applications. There are currently many database systems that primarily rely on main memory for computer data storage13 and few that would claim to be absent any in-memory capabilities or a roadmap with near-term strong in-memory capabilities.
Also, many architectures have flash memory on their SSD. Apples-to-apples comparisons are hard to come by, but there is experience, knowledge and references that serve as guideposts. Every situation is different. Please call us at (214) 514–1444 if you want to discuss yours.
Use of Solid State Drives
A few systems that very effectively utilize SSD are part of this growing movement and are likely to have their descendants relevant for a long time, including: Fusion-io, IBM’s XIV, and Violin Memory.
Fusion-io
Fusion-io is a computer hardware and software systems company based in Cottonwood Heights, Utah, that designs and manufactures what it calls a new memory tier based on NAND Flash memory technology. Its chief scientist is Steve Wozniak. Fusion-io technology primarily sells through partnerships.
IBM’s project Quicksilver, based on Fusion-io technology, showed that solid-state technology in 2008 could deliver the fastest performance of its time: 1 million Input/Output Operations Per Second.
IBM XIV
IBM XIV Storage System Gen3’s SSD caching option is being designed to provide up to terabytes of fast read cache to support up to a 90% reduction in I/O latency for random read workloads.
Violin Memory
Violin Memory is based in Mountain View, California, and designs and manufactures enterprise flash memory arrays that combine Toshiba NAND flash, DRAM, distributed processing, and software to create solutions like network-attached storage (NAS), local clusters, and QFabric data centers from Juniper Networks.
It’s DRAM-based rack-mounted SSD.
Violin was refounded and recapitalized by Don Basile, ex-CEO of Fusion-io. He brought a few members of his previous team, and Violin Memory is now considered the leading flash memory array vendor in the industry.
Current configurations are either 16 Terabytes of SLC flash or 32 Terabytes of MLC.
Keep an eye on the QR Code for developments in DBMS use of SSD and memory-based systems.
Action Plan
1. Inventory your use of relational databases to see how prominent they are in the environment
2. Inventory your collective knowledge of relational databases to understand if you have the skills to optimize this important data store
3. Inventory your multidimensional databases and reduce your overcommitment to this platform
4. Stop any mindset that favors MDBs as the default way to access enterprise data
5. Move your most important, real-time requirements to a DMBS with a strong in-memory component
6. Only procure new DBMS platforms that well utilize SSD
7. Deploy DBMS with 20%–40% SSD
8. Consider NewSQL to replace underperforming relational transactional systems and for new transactional systems with high performance and high throughput requirements
www.mcknightcg.com/bookch2
1We could easily put an “R” in front of DBMS to indicate relational and distinguish it from other forms of DBMS like Object DBMS (OODBMS), Network DBMS, and Hierarchical DBMS. Since I’m not recommending any of the other DBMS, or referring to them outside of this chapter, I will stick with DBMS for RDBMS.
2Most prominently, DB2, Microsoft SQL Server, Oracle, Teradata, and MySQL
3Many of these systems are known as ERP for Enterprise Resource Planning.
4For a longer treatment of developing a personal knowledge base, see Chapter 5: “How to Stay Current: Technology and Skills” in my first book: McKnight, William. 90 Days to Success in Consulting. Cengage Learning PTR, 2009.
5Indexes contain ordered, selective columns of the table and provide smaller, alternative structures for queries to use. They also “point” to where the “rest of the record” is in the table structure. Depending on the indexing strategy, even though indexes are subsets of the table data, all columns can be indexed and columns can be indexed multiple times.
6In addition to a small “page footer” which acts like a check digit.
7Although some DBMS group the VARCHARs at the end of the record automatically.
8A bit would do, but everything is done on a byte boundary.
9Some DBMS group multiple null bytes into one byte.
10Why the “(s)”? Because, in nonunique indexes (most indexes are nonunique), multiple records can have the same value for the key (e.g., multiple records for ACME BRICK company name).
11Although some index types also force table order or uniqueness among the values.
12data temperature.
13or solely rely on memory for the storage, such as HANA from SAP.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.