Better Business Decisions from Data: Statistical Analysis for Professional Success (2014)
Part VI. Forecasts
Chapter 18. Forecasting from Known Distributions
Why Does the Phone Never Stop Ringing?
The normal distribution has featured prominently in previous chapters because it is found to appropriately describe the data obtained in numerous situations. If there is good reason to believe in advance that the normal distribution will apply, then predictions can be made regarding future observations. Many other distributions are found to apply in certain circumstances, and, in a similar way, these can provide useful estimates of future outcomes. This chapter describes several of the commonly used distributions and gives examples of their use in forecasting.
Uniform Distribution
Forecasting from a uniform distribution is a trivial procedure, but it is worth considering it briefly to outline the steps involved. The score obtained from the throw of a fair die follows a uniform distribution. Each score from 1 to 6 has an equal probability of occurring. Figure 18-1 shows the distribution. The total area within the distribution is 1.0. If we wish to know what the probability is of obtaining a 1 or a 2, we add the areas within these two blocks. Thus the probability is 1/6 + 1/6 = 1/3.
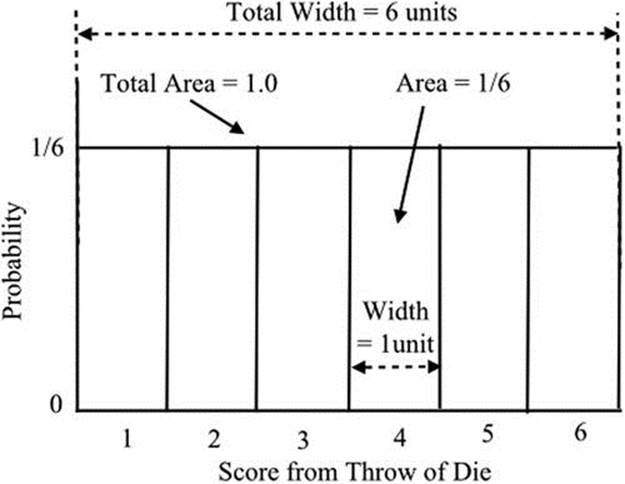
Figure 18-1. A uniform distribution
This is all very simple, but it does put us in a good position to see what happens when we consider non-uniform distributions.
Normal Distribution
You have seen that the normal distribution is a continuous symmetrical distribution with a central peak positioned at the mean value. The standard normal distribution has the central mean located at zero; the standard deviation, which controls the width of the distribution, has a value of unity. You also saw that the distribution describes the spread of data in many real situations, where there is a driving influence to render all the data the same but random errors from different and often unknown sources create a spread in the data.
Heights of people and their other physical dimensions—such as arm length, leg length, and so on—would be expected to be normally distributed. Manufacturers and retailers of clothing need information regarding future demand for clothes of different sizes. If the mean height and standard deviation of army recruits, for example, is known from past records, it is possible to forecast the likely future situation and ensure that uniforms are available in appropriate sizes.
Suppose the mean height of recruits is 174 cm and the standard deviation is 7 cm. We wish to know the proportion of recruits with heights between 180 cm and 184 cm. This represents a vertical strip on the normal distribution (Figure 18-2), the area of the strip indicating the probability of values between these limits being encountered. We have to convert our values to standard values so that we can use the published tables of the normal distribution, and we do this by calculating Z-scores, as we did in Chapter 10. For each of our limits, 180 cm and 184 cm, Z is equal to the difference between the limit and the mean value, divided by the standard deviation. For 180 cm, Z is 0.857; and for 184 cm, Z is 1.43. In effect, the Z-score expresses each limit in terms of the number of standard deviations it lies from the mean value.
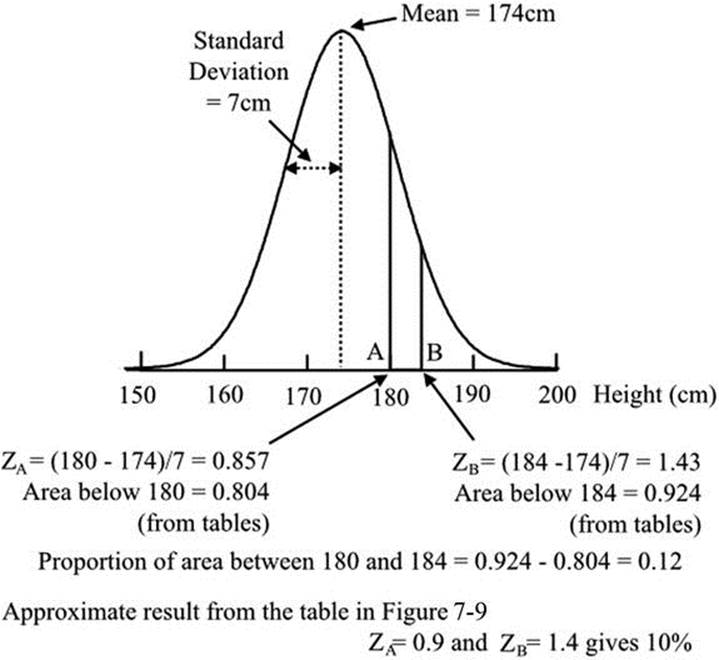
Figure 18-2. Use of the normal distribution to predict the proportion of army recruits within a height range
Referring Z to the tables gives the required area—i.e., the probability—and the difference between the two areas, derived from the two limits, gives the proportion of recruits. The calculation is shown in Figure 18-2 and gives the result that 12% of recruits are expected to be within our selected range. An approximate value can be obtained more easily by using Figure 7-9. Entering A = 0.9 (for a Z of 0.857) and B = 1.4 (for a Z of 1.43) gives a probability of 10%, which is approximately correct.
Binomial Distribution
The binomial distribution was described in Chapter 11. Here we will recall its features and show how it may be used in forecasting. The distribution describes the probability of observing a particular event when there are only two possible outcomes. Thus, if we have a series of yes or no answers to a question, the distribution describes the expected number of yes (or no) answers, given knowledge of the average number of yes (or no) answers in the population. If we toss a coin a number of times, the distribution shows the probability of obtaining a given number of heads or tails.
If the population proportion is known from theoretical considerations (as in our coin-tossing example) or has been estimated from a previously obtained large sample, we can use this to predict the characteristics of subsequent samples. If the samples are large, the binomial distribution can be approximated by the normal distribution, and we can proceed as in the previous section. For the Z-score, we take the difference between our sample proportion and the population proportion, and divide it by the standard deviation. The standard deviation of a binomial distribution is the square root of the variance, the variance being np(1 – p), as you have seen previously, where n is the number of data in the sample and p is the population proportion.
If the sample is small, however, and the population proportion not approximately a half, the binomial distribution is skewed, as shown in Figure 11-1, and we have to proceed differently. To illustrate the procedure, consider the throwing of a die a small number of times. We will look at the probability of throwing a 3, so the two possible results are 3 or not 3. When we throw the die once, the probability of getting a 3 is 1/6 and the probability of not getting a 3 is 5/6. This is illustrated by the tree diagram in Figure 18-3, which will assist you in appreciating the results of further throws of the die. If we throw the die twice, the probability of two 3s is 1/36, the probability of one 3 is 10/36, and the probability of zero 3s is 25/36, making the total probability 36/36 (i.e., 1). Figure 18-3 includes the results of throwing the die three times and, additionally, shows the binomial distribution for each of the three stages. It is possible to calculate the results for any number of throws in this manner, but the calculations become tedious; it is customary to obtain the results by consulting published tables of the binomial distribution.
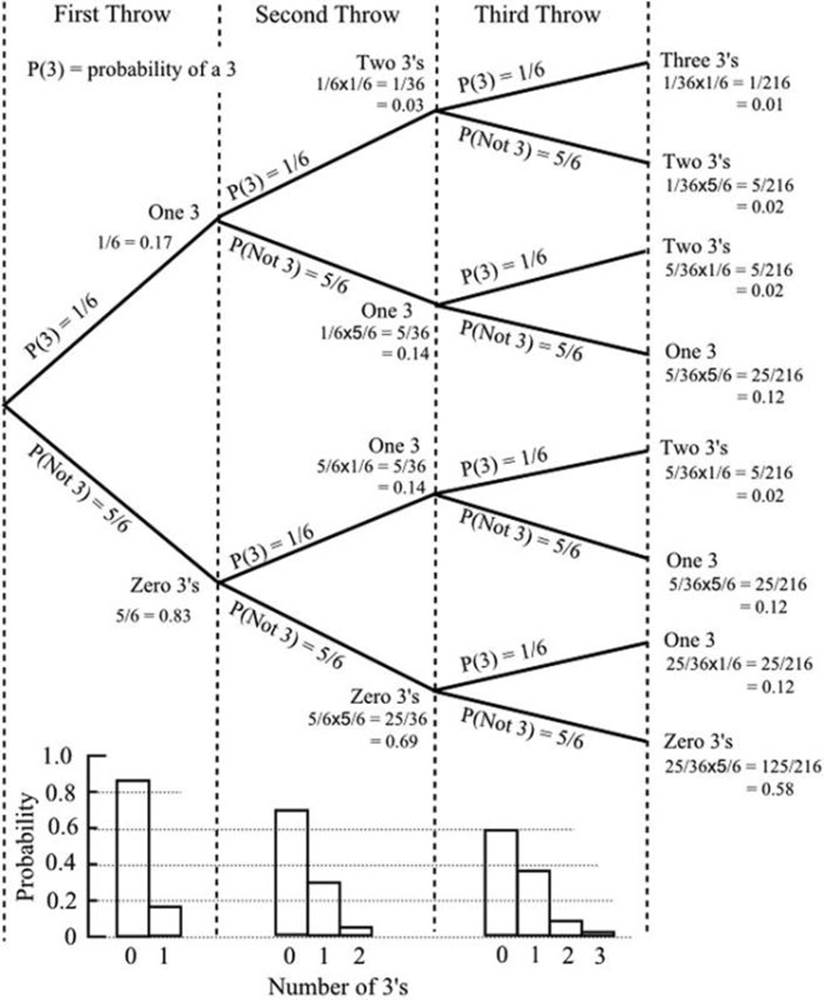
Figure 18-3. Tree diagram showing the probability of obtaining a number of 3s in several throws of a die
A practical situation would be in applying the knowledge that 5% of cars on the road have no registration. This will have been obtained from records or from a large sample. The police may then wish to consider stopping a number of cars at random to check for any that are unregistered. The probability of, for example, 1, 2, or 3 cars having no registration, in a random sample of 20 cars, can be calculated using the same procedure that we used in the throwing of a die. For a sample size of 20 and a proportion of unregistered cars of 0.05, tables of the binomial distribution give the following probabilities.
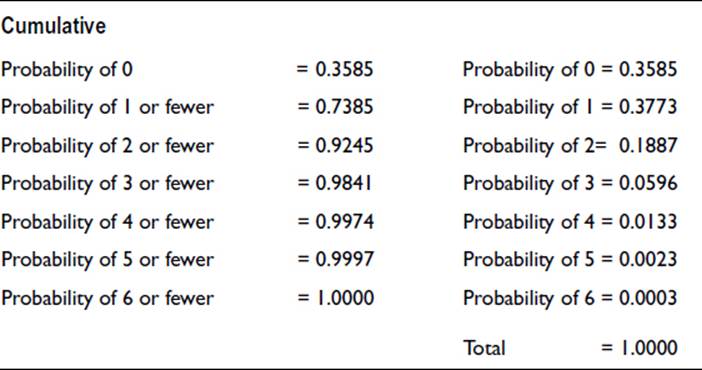
The probability of there being no unregistered cars in the sample is 36%, and this provides a useful guide for the proposed sampling arrangement. It may be decided, for example, that a larger sample size should be adopted to increase the probability of detecting at least one unregistered car. The results are shown in Figure 18-4 as a probability distribution. Note that tables of the binomial distribution give cumulative probabilities. The probabilities for individual numbers, shown in the final column above, are obtained by subtracting adjacent cumulative values. Thus, the probability of 2 unregistered cars is the difference between the probability of 2 or fewer and the probability of 1 or fewer.
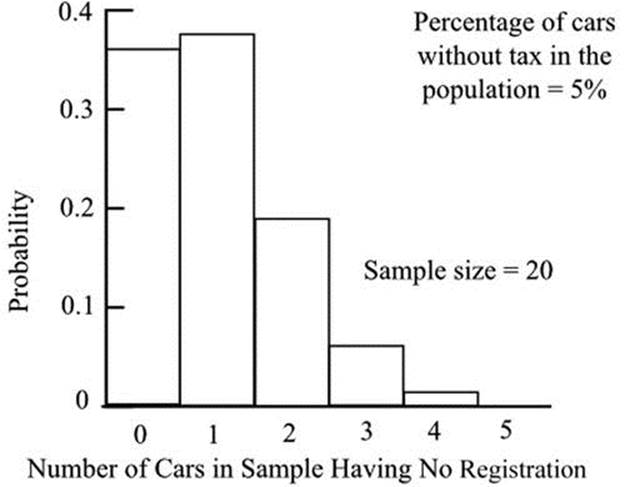
Figure 18-4. Binomial probability distribution of the number of unregistered cars in a sample of twenty
Instead of asking for the probability of a particular number of cars not having registration, we could ask how many unregistered cars, on average, we expect to find in a sample of 20. This is given by the expectation, which is equal to np, where n is the number in the sample (20) and p is the proportion (0.05). The expectation is therefore 1, a result that we might well have deduced at the outset.
Poisson Distribution
The Poisson distribution is relevant when we are dealing with events that are randomly scattered either in time or in space. The number of road accidents in a given period of time and the number of goals scored in a soccer match are examples of random events distributed in time. The number of defective links in a length of chain and the number of misprints on each page of a book are examples of random events distributed in space.
The best estimate of the population mean for a Poisson distribution is the sample mean, and the best estimate of the population variance is the sample variance. The variance of a Poisson distribution, surprisingly perhaps, is equal to the mean. When the mean value is large, the distribution approximates to the normal distribution, which can then be used for forecasting. If, for example, we knew that the mean number of telephone calls received by a switchboard per day is 200, we could proceed as in Chapter 10 by calculating Z-scores. Thus we could determine the probability of receiving as few as 100 calls in a day, say, or as many as 300.
If, however, our concern was with the likely variation within shorter time periods, the mean number of calls would be small. The Poisson distribution departs seriously from the normal distribution when the mean is small, becoming extremely skewed. It is then necessary to consult tables to obtain the required probabilities. We might, for example, staying with our telephone calls, be interested in the number of calls received in each five-minute period, to reveal the extent to which callers might be kept waiting.
Suppose the mean number of calls in a five-minute period is 2.5. From tables of the Poisson distribution, we can read off the cumulative probabilities of various numbers of calls arriving in a five-minute period. Thus:
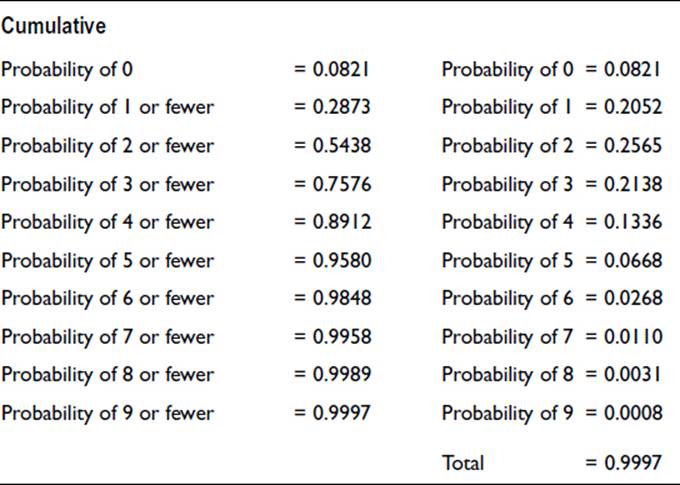
The probability of a particular number of calls, shown in the final column, is obtained by subtracting adjacent cumulative values. Thus the probability of two calls is the difference between the probability of 2 or fewer and the probability of 1 or fewer. The probability distribution is shown inFigure 18-5.

Figure 18-5. Poisson probability of the number of telephone calls in a five-minute period
Exponential Distribution
The exponential (negative exponential, to be precise) distribution is related to the Poisson distribution. Again, it concerns random events distributed in time or space, but the times or distances between successive events are recorded rather than the number of events in a given extent of time or space. If instead of recording the number of telephone calls arriving in each given time interval, as we did in the previous section, we recorded the time between each pair of successive telephone calls, then the data would consist of numerical values distributed according to the exponential distribution. The exponential distribution is continuous, whereas the Poisson distribution is discrete, and it is extremely skewed having a maximum probability at zero. As with the Poisson distribution, the variance is equal to the mean.
Figure 18-6(a) shows the exponential distribution of the time between successive telephone calls received, on the assumption of a mean time between calls of 2 minutes. This is equivalent to the rate of arrival of 2.5 calls in 5 minutes, which was used in the illustration of the Poisson distribution in the previous section. Because the time axis is continuous and not discrete, probabilities are obtained by evaluating areas under the curve. This was the procedure you saw to be necessary when using the normal distribution. Available tables, of course, remove the need for the rather complicated calculations.
In Figure 18-6(b), the cumulative probability is shown. You can see that shorter time intervals between calls are much more likely than longer time intervals. The probability of the interval being less than one minute is almost 40%. Nearly two thirds of calls are spaced at less than two minutes, though two minutes is the mean spacing.
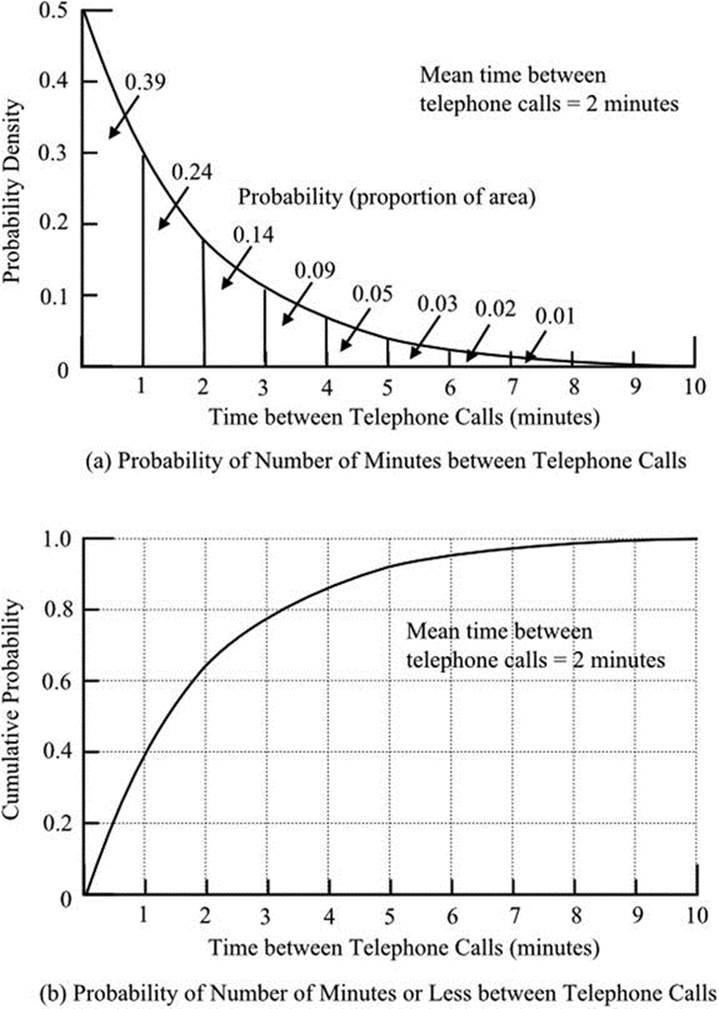
Figure 18-6. Negative exponential distribution showing the likely spacing of telephone calls
Geometric Distribution
The geometric distribution is relevant in situations where a number of attempts are made before success is achieved. Many games and sports, for example, are based on minimizing the number of attempts to hit a target or to throw a six. As with the binomial distribution, it is possible to construct the geometric distribution by combining probabilities. We can illustrate this by considering the achievement of a six when throwing a die.
Because the chance of throwing a six is 1/6, this is the chance of achieving success on the first throw. If success is not achieved until the second throw, the first throw must have been not a six, which has a probability of 5/6. The second throw yields a six with a probability of 1/6. The combined probability—that is, the probability of success at the second attempt—is 5/6 × 1/6 = 5/36. This is the application of the “and” rule: a not-6 and a 6. If success is not achieved until the third throw, we have to combine two not-6s with a final 6. Thus the probability is 5/6 × 5/6 × 1/6 = 25/216. These probabilities can be seen in the tree diagram of Figure 18-3, which we used in discussing the binomial distribution. Notice that the probability decreases as we consider each subsequent throw. The probability of success at each throw remains constant, of course, at the value of 1/6; but success at later throws requires failure at the preceding throws, and these failures involve a probability of occurrence.
As with the exponential distribution, to which it is related, the geometric distribution is extremely skewed, having a maximum probability at the first attempt. The geometric distribution is discrete, whereas the exponential distribution, as you saw, is continuous.
As a practical example, consider a door-to-door salesman. It is known from company records that the probability of making a sale at a house is 1/10. This is sufficient information for the following list to be constructed:

The distribution is shown in Figure 18-7(a) as far as the tenth call. The distribution continues indefinitely: the salesman, poor fellow, may never get a sale, but the probability of not getting a sale after a large number of calls is very small.
The cumulative values, which are shown in Figure 18-7(b), are probably of more interest to the salesman and to his company. These show the probability of a sale at the first call, or the second call, or the third call, and so on. The cumulative values approach the value of one as the number of calls increases, reflecting the fact that the probability of a sale increases with the number of calls and would become a certainty given an infinite number of calls.
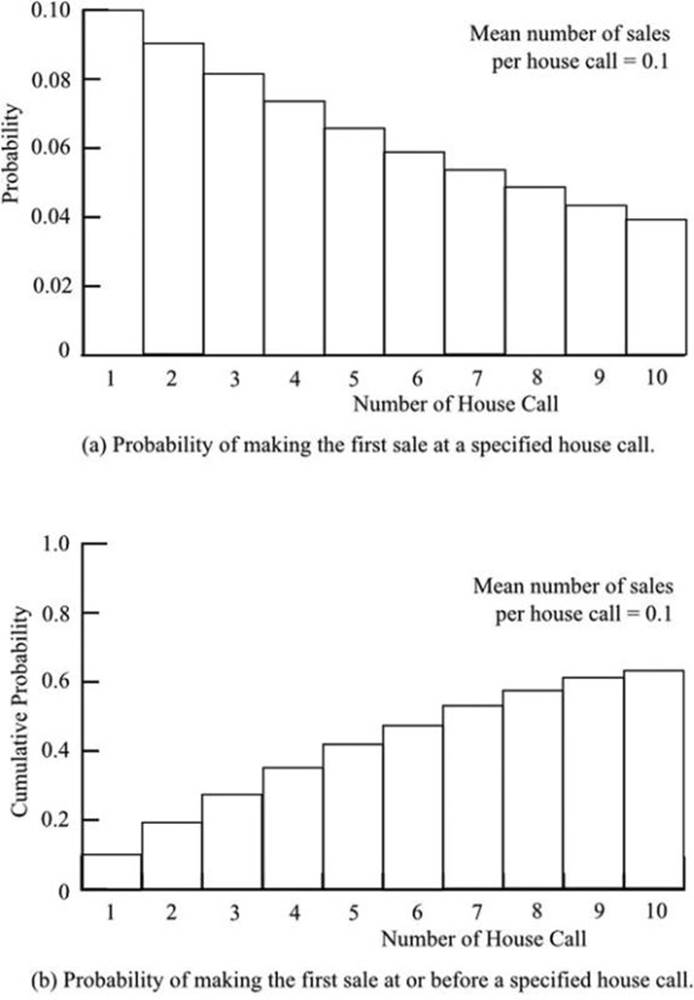
Figure 18-7. Geometric distribution of the first success in a sequence of house calls
Weibull Distribution
The Weibull distribution is a continuous distribution having a complex mathematical description. A shape parameter within the definition can take a range of values to give different forms of distribution. In one form the distribution is identical to the exponential distribution, while in another it approximates to the normal distribution.
The distribution is particularly useful in describing data that is positively skewed, having a peak at low values and tailing away to few but distant large values. Failure of components—for example, ball bearings—frequently follows this kind of distribution. Other applications include manufacturing and delivery times, and meteorological data such as wind-speed distributions. Extreme value theory, which deals with the low probabilities of unusual events—such as major floods, wildfires, freak waves, and large incomes—makes use of the Weibull distribution.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.