Data Science For Dummies (2016)
Part 2
Using Data Science to Extract Meaning from Your Data
IN THIS PART …
Master the basics behind machine learning approaches.
Explore the importance of math and statistics for data science.
Work with clustering and instance-based learning algorithms.
Examine how Internet-of-things analytics are revolutionizing the world.
Chapter 4
Machine Learning: Learning from Data with Your Machine
IN THIS CHAPTER
![]() Understanding the machine learning process
Understanding the machine learning process
![]() Exploring machine learning styles and algorithms
Exploring machine learning styles and algorithms
![]() Overviewing algorithms, deep learning, and Apache Spark
Overviewing algorithms, deep learning, and Apache Spark
If you’ve been watching any news lately, there’s no doubt that you’ve heard of something called machine learning. It’s often referenced when reporters are covering stories on some new and amazing invention from artificial intelligence. In this chapter, you dip your toes into the area called machine learning, and in Chapter 8, you get a view on how machine learning works within this new world of artificial intelligence inventions.
Defining Machine Learning and Its Processes
Machine learning is the practice of applying algorithmic models to data, in an iterative manner, so that your computer discovers hidden patterns or trends that you can use to make predictions. It’s also called algorithmic learning.Machine learning has a vast and ever-expanding assortment of use cases, including
· Real-time Internet advertising
· Internet marketing personalization
· Internet search
· Spam filtering
· Recommendation engines
· Natural language processing and sentiment analysis
· Automatic facial recognition
· Customer churn prediction
· Credit score modeling
· Survival analysis for mechanical equipment
Walking through the steps of the machine learning process
Three main steps are involved in machine learning: setting up, learning, and application. Setting up involves acquiring data, preprocessing it, feature selection (the process of selecting the most appropriate variables for the task at hand), and breaking the data into training and test datasets. You use the training data to train the model, and the test data to test the accuracy of the model’s predictions. The learning step involves model experimentation, training, building, and testing. The application step involves model deployment and prediction.
 A good rule of thumb when breaking data into test and training sets is to apply random sampling to take two-thirds of the original dataset to use as data to train the model. Use the remaining one-third of the data as test data, for evaluating the model’s predictions.
A good rule of thumb when breaking data into test and training sets is to apply random sampling to take two-thirds of the original dataset to use as data to train the model. Use the remaining one-third of the data as test data, for evaluating the model’s predictions.
Getting familiar with machine learning terms
Before getting too deep into a discussion on machine learning methods, you need to know about the sometimes confusing vocabulary associated with the field. Because machine learning is an offshoot of both traditional statistics and computer science, it has adopted terms from both fields and added a few of its own. Here is what you need to know:
· Instance: The same as a row (in a data table), an observation (in statistics), and a data point. Machine learning practitioners are also known to call an instance a case.
· Feature: The same as a column or field (in a data table) and a variable (in statistics). In regression methods, a feature is also called an independent variable (IV).
· Target variable: The same as a predictant or dependent variable (DV) in statistics.
In machine learning, feature selection is a somewhat straightforward process for selecting appropriate variables; for feature engineering, you need substantial domain expertise and strong data science skills to manually design input variables from the underlying dataset. You use feature engineering in cases where your model needs a better representation of the problem being solved than is available in the raw dataset.
Considering Learning Styles
There are three main styles within machine learning: supervised, unsupervised, and semisupervised. Supervised and unsupervised methods are behind most modern machine learning applications, and semisupervised learning is an up-and-coming star.
Learning with supervised algorithms
Supervised learning algorithms require that input data has labeled features. These algorithms learn from known features of that data to produce an output model that successfully predicts labels for new incoming, unlabeled data points. You use supervised learning when you have a labeled dataset composed of historical values that are good predictors of future events. Use cases include survival analysis and fraud detection, among others. Logistic regression is a type of supervised learning algorithm, and you can read more on that topic in the next section.
Learning with unsupervised algorithms
Unsupervised learning algorithms accept unlabeled data and attempt to group observations into categories based on underlying similarities in input features, as shown in Figure 4-1. Principal component analysis, k-means clustering, and singular value decomposition are all examples of unsupervised machine learning algorithms. Popular use cases include recommendation engines, facial recognition systems, and customer segmentation.
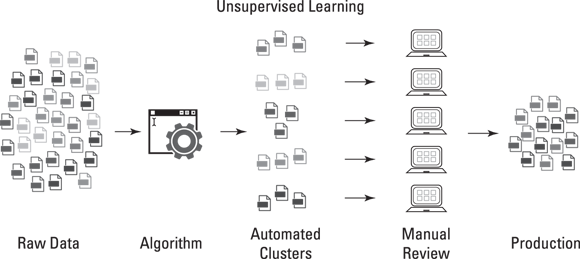
FIGURE 4-1: Unsupervised machine learning breaks down unlabeled data into subgroups.
Learning with reinforcement
Reinforcement learning (or semisupervised learning) is a behavior-based learning model. It is based on a mechanic similar to how humans and animals learn. The model is given “rewards” based on how it behaves, and it subsequently learns to maximize the sum of its rewards by adapting the decisions it makes to earn as many rewards as possible. Reinforcement learning is an up-and-coming concept in data science.
Seeing What You Can Do
Whether you’re just getting familiar with the algorithms that are involved in machine learning or you’re looking to find out more about what’s happening in cutting-edge machine learning advancements, this section has something for you. First I give you an overview of machine learning algorithms, broken down by function, and then I describe more about the advanced areas of machine learning that are embodied by deep learning and Apache Spark.
Selecting algorithms based on function
When you need to choose a class of machine learning algorithms, it’s helpful to consider each model class based on its functionality. For the most part, algorithmic functionality falls into the categories shown in Figure 4-2.
· Regression algorithm: You can use this type of algorithm to model relationships between features in a dataset. You can read more on linear and logistic regression methods and ordinary least squares in Chapter 5.
· Association rule learning algorithm: This type of algorithm is a rule-based set of methods that you can use to discover associations between features in a dataset.
· Instance-based algorithm: If you want to use observations in your dataset to classify new observations based on similarity, you can use this type. To model with instances, you can use methods like k-nearest neighbor classification, covered in Chapter 7.
· Regularizing algorithm: You can use regularization to introduce added information as a means by which to prevent model overfitting or to solve an ill-posed problem.
· Naïve Bayes method: If you want to predict the likelihood of an event occurring based on some evidence in your data, you can use this method, based on classification and regression. Naïve Bayes is covered in Chapter 5.
· Decision tree: A tree structure is useful as a decision-support tool. You can use it to build models that predict for potential fallouts that are associated with any given decision.
· Clustering algorithm: You can use this type of unsupervised machine learning method to uncover subgroups within an unlabeled dataset. Both k-means clustering and hierarchical clustering are covered in Chapter 6.
· Dimension reduction method: If you’re looking for a method to use as a filter to remove redundant information, noise, and outliers from your data, consider dimension reduction techniques such as factor analysis and principal component analysis. These topics are covered in Chapter 5.
· Neural network: A neural network mimics how the brain solves problems, by using a layer of interconnected neural units as a means by which to learn, and infer rules, from observational data. It’s often used in image recognition and computer vision applications.
Imagine that you’re deciding whether you should go to the beach. You never go to the beach if it’s raining, and you don’t like going if it’s colder than 75 degrees (Fahrenheit) outside. These are the two inputs for your decision. Your preference to not go to the beach when it’s raining is a lot stronger than your preference to not go to the beach when it is colder than 75 degrees, so you weight these two inputs accordingly. For any given instance where you decide whether you’re going to the beach, you consider these two criteria, add up the result, and then decide whether to go. If you decide to go, your decision threshold has been satisfied. If you decide not to go, your decision threshold was not satisfied. This is a simplistic analogy for how neural networks work.
Now, for a more technical definition. The simplest type of neural network is the Perceptron. It accepts more than one input, weights them, adds them up on a processor layer, and then, based on the activation function and the threshold you set for it, outputs a result. An activation function is a mathematical function that transforms inputs into an output signal. The processor layer is called a hidden layer. A neural network is a layer of connected Perceptrons that all work together as a unit to accept inputs and return outputs that signal whether some criteria is met. A key feature of neural nets is that they are self-learning — in other words, they adapt, learn, and optimize per changes in input data. Figure 4-3 is a schematic layout that depicts how a Perceptron is structured.
· Deep learning method: This method incorporates traditional neural networks in successive layers to offer deep-layer training for generating predictive outputs. I tell you more about this topic in the next section.
· Ensemble algorithm: You can use ensemble algorithms to combine machine learning approaches to achieve results that are better than would be available from any single machine learning method on its own.
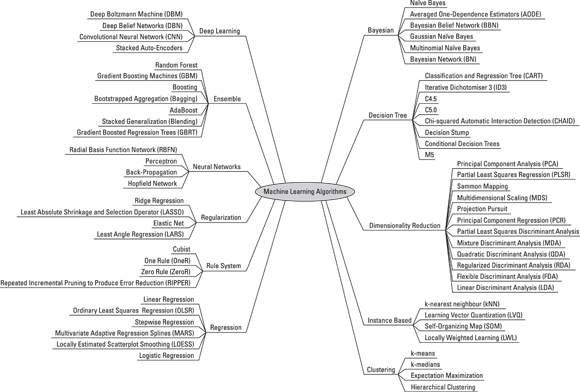
FIGURE 4-2: Machine learning algorithms can be broken down by function.
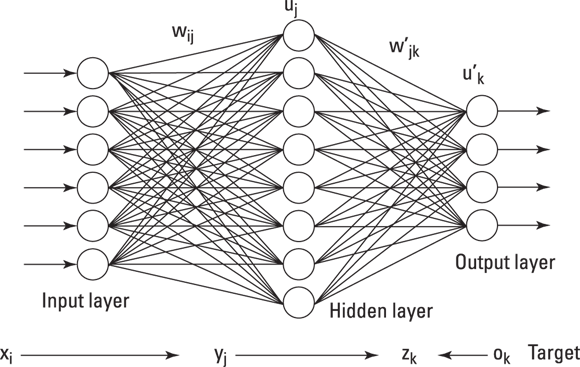
FIGURE 4-3: Neural networks are connected layers of artificial neural units.
If you use Gmail, you must be enjoying its autoreply functionality. You know — the three 1-line messages from which you can choose an autoreply to a message someone sent you? Well, this autoreply functionality within Gmail is called SmartReply, and it is built on deep learning algorithms. Another innovation built on deep learning is Facebook DeepFace, the Facebook feature that automatically recognizes and suggests tags for the people who appear in your Facebook photos. Figure 4-4 is a schematic layout that depicts how a deep learning network is structured.
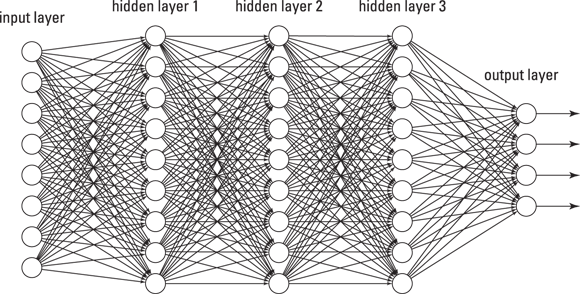
FIGURE 4-4: A deep learning network is a neural network with more than one hidden layer.
Deep learning is a machine learning method that uses hierarchical neural networks to learn from data in an iterative and adaptive manner. It’s an ideal approach for learning patterns from unlabeled and unstructured data. It’s essentially the same concept as the neural network, except that deep learning algorithms have two or more hidden layers. In fact, computer vision applications have been known to implement more than 150 hidden layers in a single deep neural network. The more hidden layers there are, the more complex a decision the algorithm can make.
Using Spark to generate real-time big data analytics
Apache Spark is an in-memory distributed computing application that you can use to deploy machine learning algorithms on big data sources in near - real-time, to generate analytics from streaming big data sources. Because it processes data in microbatches, with 3-second cycle times, you can use it to significantly decrease time-to-insight in cases where time is of the essence. It sits on top of the HDFS and acts a secondary processing framework, to be used in parallel with the large-scale batch processing work that’s done by MapReduce. Spark is composed of the following submodules:
· Spark SQL: You use this module to work with and query structured data using Spark. Within Spark, you can query data using Spark’s built-in SQL package: SparkSQL. You can also query structured data using Hive, but then you’d use the HiveQL language and run the queries using the Spark processing engine.
· GraphX: The GraphX library is how you store and process network data from within Spark.
· Streaming: The Streaming module is where the big data processing takes place. This module basically breaks a continuously streaming data source into much smaller data streams, called Dstreams — or discreet data streams. Because the Dstreams are small, these batch cycles can be completed within three seconds, which is why it’s called microbatch processing.
· MLlib: The MLlib submodule is where you analyze data, generate statistics, and deploy machine learning algorithms from within the Spark environment. MLlib has APIs for Java, Scala, Python, and R. The MLlib module allows you to build machine learning models in Python or R but pull data directly from the HDFS (rather than via an intermediary repository). This helps reduce the reliance that data scientists sometimes have on data engineers. Furthermore, computations are known to be 100 times faster when processed in-memory using Spark as opposed to the standard MapReduce framework.
You can deploy Spark on-premise by downloading the open-source framework from the Apache Spark website: http://spark.apache.org/downloads.html. Another option is to run Spark on the cloud via the Apache Databricks service https://databricks.com.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.