ElasticSearch Cookbook, Second Edition (2015)
Chapter 5. Search, Queries, and Filters
In this chapter, we will cover the following recipes:
· Executing a search
· Sorting results
· Highlighting results
· Executing a scan query
· Suggesting a correct query
· Counting matched results
· Deleting by query
· Matching all the documents
· Querying/filtering for a single term
· Querying/filtering for a multiple term
· Using a prefix query/filter
· Using a Boolean query/filter
· Using a range query/filter
· Using span queries
· Using a match query
· Using an ID query/filter
· Using a has_child query/filter
· Using a top_children query
· Using a has_parent query/filter
· Using a regexp query/filter
· Using a function score query
· Using exists and missing filters
· Using and/or/not filters
· Using a geo bounding box filter
· Using a geo polygon filter
· Using a geo distance filter
· Using a query string query
· Using a template query
Introduction
After you have set the mappings and put the data in the indices, you can search. In this chapter, we will cover the different types of search queries and filters, validating queries, highlighting search results, and limiting fields. This chapter is the core of book: ultimately, everything in ElasticSearch is about serving the query and returning good quality results. To master the search, the user must understand the difference between a query and a filter, how to improve the quality, and how to speedily design more efficient queries. ElasticSearch allows you to use a rich domain specific language (DSL), a syntax language designed for searching, that covers all common needs, from a standard term query to complex Geoshape filtering.
This chapter is divided in two parts: the first part shows some API calls related to searches, and the second part covers the QueryDSL in detail.
All the recipes in this chapter require you to prepare and populate the required indices. In the code bundle available on the PacktPub website (https://www.packtpub.com/big-data-and-business-intelligence/elasticsearch-cookbook) or on GitHub (https://github.com/aparo/elasticsearch-cookbook-second-edition), there are scripts to initialize all the required data.
Executing a search
ElasticSearch was born as a search engine; its main work is to process queries and give results.
In this recipe, we'll see that a search in ElasticSearch is not just limited to matching documents but can also calculate additional information required to improve the search quality.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
To execute a search and view the results, perform the following steps:
1. From the command line, execute a search, as follows:
2. curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search' -d '{"query":{"match_all":{}}}'
In this case, we have used a match_all query which means that all the documents are returned. We'll discuss this kind of query in the Matching all documents recipe in this chapter.
3. The command, if everything is all right, will return the following result:
4. {
5. "took" : 0,
6. "timed_out" : false,
7. "_shards" : {
8. "total" : 5,
9. "successful" : 5,
10. "failed" : 0
11. },
12. "hits" : {
13. "total" : 3,
14. "max_score" : 1.0,
15. "hits" : [ {
16. "_index" : "test-index",
17. "_type" : "test-type",
18. "_id" : "1",
19. "_score" : 1.0, "_source" : {"position": 1, "parsedtext": "Joe Testere nice guy", "name": "Joe Tester", "uuid": "11111"}
20. }, {
21. "_index" : "test-index",
22. "_type" : "test-type",
23. "_id" : "2",
24. "_score" : 1.0, "_source" : {"position": 2, "parsedtext": "Bill Testere nice guy", "name": "Bill Baloney", "uuid": "22222"}
25. }, {
26. "_index" : "test-index",
27. "_type" : "test-type",
28. "_id" : "3",
29. "_score" : 1.0, "_source" : {"position": 3, "parsedtext": "Bill is not\n nice guy", "name": "Bill Clinton", "uuid": "33333"}
30. }]
31. }
}
The result contains a lot of information, as follows:
· took: This is the time, in milliseconds, required to execute the query.
· time_out: This indicates whether a timeout has occurred during the search. This is related to the timeout parameter of the search. If a timeout occurred, you will get partial or no results.
· _shards: This is the status of the shards, which can be divided into the following:
· total: This is the total number of shards.
· successful: This is the number of shards in which the query was successful.
· failed: This is the number of shards in which the query failed, because some error or exception occurred during the query.
· hits: This represents the results and is composed of the following:
· total: This is the total number of documents that match the query.
· max_score: This is the match score of the first document. Usually this is 1 if no match scoring was computed, for example in sorting or filtering.
· hits: This is a list of the result documents.
The result document has a lot of fields that are always available and other fields that depend on the search parameters. The following are the most important fields:
· _index: This is the index that contains the document.
· _type: This is the type of the document.
· _id: This is the ID of the document.
· _source: This is the document's source (the default is returned, but it can be disabled).
· _score: This is the query score of the document.
· sort: These are the values that are used to sort, if the documents are sorted.
· highlight: These are the highlighted segments, if highlighting was requested.
· fields: This denotes some fields can be retrieved without the need to fetch all the source objects.
How it works...
The HTTP method used to execute a search is GET (but POST works too), and the REST URL is:
http://<server>/_search
http://<server>/<index_name(s)>/_search
http://<server>/<index_name(s)>/<type_name(s)>/_search
Multi-indices and types are comma separated. If an index or a type is defined, the search is limited to them only.
One or more aliases can be used as index names.
The core query is usually contained in the body of the GET/POST call, but a lot of options can also be expressed as URI query parameters, as follows:
· q: This is the query string used to perform simple string queries:
· curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?q=uuid:11111'
· df: This is the default field to be used within the query:
· curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?df=uuid&q=11111'
· from (by default, 0): This is the start index of the hits.
· size (by default, 10): This is the number of hits to be returned.
· analyzer: This is the default analyzer to be used.
· default_operator (default, OR): This can be set to AND or OR.
· explain: This allows the user to return information on how the score is calculated:
· curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?q=parsedtext:joe&explain=true'
· fields: This allows you to define fields that must be returned:
· curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?q=parsedtext:joe&fields=name'
· sort (by default, score): This allows you to change the order of the documents. Sort is ascendant by default; if you need to change the order, add desc to the field:
curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?sort=name:desc'
· timeout (not active by default): This defines the timeout for the search. ElasticSearch tries to collect results until the timeout. If a timeout is fired, all the hits accumulated are returned.
· search_type: This defines the search strategy. A reference is available in the online ElasticSearch documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-request-search-type.html.
· track_scores (by default, false): If this is true, it tracks the score and allows it to be returned with the hits. It's used in conjunction with sort, because sorting by default prevents a match score being returned.
· pretty (by default, false): If this is true, the results will be pretty printed.
Generally, the query is contained in the body of the search, a JSON object. The body of the search is the core of ElasticSearch's search functionalities; and the list of search capabilities extends with every release. For the current version (1.4.x) of ElasticSearch, the following parameters are available:
· query: This contains the query to be executed. Later in this chapter, we will see how to create different kinds of queries in order to cover several scenarios.
· from (by default, 0) and size (by default, 10): These allow you to control pagination. from defines the start position of the hits to be returned.
Note
Pagination is applied to the currently returned search results. Firing the same query can lead to different results if a lot of records have the same score or if new document are ingested. If you need to process all the result documents without repetition, you need to execute scan or scroll queries.
· sort: This allows you to change the order of the matched documents. This option is fully covered in the next recipe, Sorting a result.
· post_filter (optional): This allows you to filter out the query results without affecting the facet count. It's usually used to filter by facets values.
· _source (optional): This allows you to control the returned source. It can be disabled (false), partially returned (obj.*), or multiple exclude/include rules. This functionality can be used instead of fields to return values (for a complete coverage, take a look at the ElasticSearch reference at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-request-source-filtering.html).
· fielddata_fields (optional): This allows you to return the field data representation of your field.
· fields (optional): This controls the fields to be returned.
Tip
Returning only the required fields reduces network and memory usage, improving performance.
· facets (optional): This controls the aggregated data that must be computed on the results. Using facets improves the user experience on a search. Facets are deprecated and will be removed from the future versions of ElasticSearch. The aggregation layer covers the functionalities previously managed by facets.
· aggregations or aggs (optional): This controls the aggregation layer for analytics. It will be discussed in Chapter 6, Aggregations.
· index_boost (optional): This allows you to define the per-index boost value. It is used to increase/decrease the score of the results in the boosted indices.
· highlighting (optional): This allows you to define the fields and settings that will be used to calculate a query abstract. (Take a look at the Highlighting results recipe in this chapter.)
· version (by default, false): This adds the version of a document to the results.
· rescore (optional): This allows you to define an extra query to be used in the score to improve the quality of results. The rescore query is executed on the hits that match the first query and the filter.
· min_score (optional): If this is given/set, all the resulting documents that have a score lower than the set value are rejected.
· explain (optional): This parameter returns information on how the TD/IF score is calculated for a particular document.
· script_fields (optional): This defines a script to compute extra fields to be returned with a hit. We'll see ElasticSearch scripting in Chapter 7, Scripting.
· suggest (optional): If this is set, a query and a field returns the most significant terms related to this query. This parameter allows you to implement the Google search-like did you mean functionality. (see the Suggesting a correct query recipe of this chapter)
· search_type (optional): This defines how ElasticSearch should process a query. We'll see the scan query in the Executing a scan query recipe of this chapter.
· scroll (optional): This controls scrolling in the scroll/scan queries. The scroll allows you to have an ElasticSearch equivalent of a DBMS cursor.
There's more...
If you are using sort, pay attention to the tokenized fields. The sort order depends on the lower order token if it is ascendant and on the higher order token if it is descendent. For the preceding example, the results are as follows:
…
"hits" : [ {
"_index" : "test-index",
"_type" : "test-type",
"_id" : "1",
"_score" : null, "_source" : {"position": 1, "parsedtext": "Joe Testere nice guy", "name": "Joe Tester", "uuid": "11111"},
"sort" : [ "tester" ]
}, {
"_index" : "test-index",
"_type" : "test-type",
"_id" : "3",
"_score" : null, "_source" : {"position": 3, "parsedtext": "Bill is not\n nice guy", "name": "Bill Clinton", "uuid": "33333"},
"sort" : [ "clinton" ]
}, {
"_index" : "test-index",
"_type" : "test-type",
"_id" : "2",
"_score" : null, "_source" : {"position": 2, "parsedtext": "Bill Testere nice guy", "name": "Bill Baloney", "uuid": "22222"},
"sort" : [ "bill" ]
}
Note
Two main concepts are important in a search: query and filter. A query means that the matched results are scored using an internal Lucene-scoring algorithm; in a filter, the results are only matched, without scoring. Because a filter doesn't need to compute the score, it is generally faster and can be cached.
To improve the quality of the resulting score, ElasticSearch provides the rescore functionality. This capability allows you to reorder a top number of documents with another query, so it's generally much more expensive, for example, if the query contains a lot of matched queries or scripting. This approach allows you to execute the rescore query only on a small subset of results, reducing the overall computation time and resources.
Rescore, as with every query, is executed at the shard level, so it's automatically distributed.
Tip
The best candidates to be executed in a rescore query are complex queries with a lot of nested options and everything that uses scripting (due to a massive overhead of scripting languages).
The following example will show you how to execute a fast query (Boolean) in the first phase and then rescore it with a match query in the rescore section:
curl -s -XPOST 'localhost:9200/_search' -d '{
"query" : {
"match" : {
"parsedtext" : {
"operator" : "or",
"query" : "nice guy joe",
"type" : "boolean"
}
}
},
"rescore" : {
"window_size" : 100,
"query" : {
"rescore_query" : {
"match" : {
"parsedtext" : {
"query" : "joe nice guy",
"type" : "phrase",
"slop" : 2
}
}
},
"query_weight" : 0.8,
"rescore_query_weight" : 1.5
}
}
}'
The following are the rescore parameters:
· window_size: This controls how many results per shard must be considered in the rescore functionality.
· query_weight (by default, 1.0) and rescore_query_weight (by default, 1.0): These are used to compute the final score using the following formula:
final_score=query_score*query_weight + rescore_score*rescore_query_weight
Tip
If a user wants to only keep the rescore score, he/she can set the query_weight parameter to 0.
See also
· The Executing an aggregation recipe in the next chapter
· The Highlighting results recipe in this chapter
· The Executing a scan query recipe in this chapter
· The Suggesting terms for a query recipe in this chapter
Sorting results
When searching for results, the most common criteria for sorting in ElasticSearch is the relevance to a text query. Sometimes, real-world applications need to control the sorting criteria in typical scenarios, as follows:
· Sorting a user by their last name and first name
· Sorting items by stock symbols and price (ascending and descending)
· Sorting documents by size, file type, source, and so on
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to sort the results, perform the following steps:
1. Add a sort section to your query, as follows:
2. curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{"query":{"match_all":{}},
3. "sort" : [
4. {"price" : {"order" : "asc", "mode" : "avg", "ignore_unmapped":true, "missing":"_last"}},
5. "_score"
6. ]
7. }'
8. The returned result will be similar to this:
9. …,
10. "hits" : {
11. "total" : 3,
12. "max_score" : null,
13. "hits" : [ {
14. "_index" : "test-index",
15. "_type" : "test-type",
16. "_id" : "1",
17. "_score" : null, "_source" :{ … "price":4.0},
18. "sort" : [ 4.0 ]
19. }, {
…
The sorting result is very special: the _score parameter is not computed and an extra field, sort, is created to collect the value used for sorting.
How it works...
The sort parameter can be defined as a list that can contain both simple strings and JSON objects.
The sort string is the name of the field (such as field1, field2, field3, and fields4) that is used to sort, similar to SQL's order by statement.
The JSON object allows you to use the following extra parameters:
· order (asc/desc): This defines whether the order must be considered in the ascending format (which is the default) or the descending format.
· ignore_unmapped (true/false): This allows you to ignore the fields that do not have mappings in them. This option prevents errors during a search due to missing mappings.
· unmapped_type: This defines the type of the sort parameter, if it is missing.
· missing (_last/_first): This defines how to manage a missing value: we can put them at the end (_last) of the results or at the start (_first).
· mode: This defines how to manage multiple value fields. The following are the possible values:
· min: This is the minimum value that is chosen (in the case of multiple prices for an item, it chooses the lower value to be used for the comparison).
· max: This is the maximum value that is chosen.
· sum: Using this, the sort value will be computed as the sum of all the values. This mode is only available on numeric fields.
· avg: This sets the sort value, with which the sort result will be an average of all the values. This mode is only available on numeric fields.
Tip
If you want to add the match score value to the sort list, you must use the special sort field: _score.
If we want to use sorting for a nested object, there are two extra parameters that can be used:
· nested_path: This defines the nested object to be used for sorting. The field defined for sorting will be related to the nested_path parameter. If it is not defined, the sorting field will be related to the document root. For example, if we have an address object nested in a person document, we can sort for the city.name values and use:
· address.city.name: This is used if you want to sort without defining the nested_path.
· city.name: Using this defines a nested_path address.
· nested_filter: This defines a filter that can be used to remove non-matching nested documents from the sorting value extraction. This filter allows a better selection of values to be used for sorting.
Tip
The sorting process requires the sorting fields of all the matched query documents to be fetched in order to be compared. To prevent high memory usage, it's better to sort on numeric fields, and in the case of string sorting, select short text fields processed with an analyzer that don't tokenize the text.
There's more...
There are two special sorting types: geo distance and scripting.
Geo distance sorting uses the distance from a geopoint (location) as a metric to compute the ordering. Check out the following example of sorting:
…
"sort" : [
{
"_geo_distance" : {
"pin.location" : [-70, 40],
"order" : "asc",
"unit" : "km"
}
}
],
…
The earlier example accepts special parameters as follows:
· unit: This defines the unit system (metric in the earlier example) to be used in order to compute the distance.
· distance_type (sloppy_arc/arc/plane): This defines the type of distance to be computed.
The _geo_distance name for the field is mandatory.
The point of reference for the sorting can be defined in several ways, as we already discussed in the Mapping a geo point field recipe in Chapter 3, Managing Mapping.
How to use scripting to sort will be discussed in the Sorting data using scripts recipe in Chapter 7, Scripting, after we introduce the scripting capabilities of ElasticSearch.
See also
· The Mapping a geo point field recipe in Chapter 3, Managing Mapping
· The Sorting data using scripts recipe in Chapter 7, Scripting
Highlighting results
ElasticSearch does a good job of finding matching results in large text documents too. Searching text in very large blocks is very useful, but to improve user experience, it is sometimes necessary to show the abstract to the users, which is a small portion of the text that matches the query. The abstract is a common way to help users understand how the matched document is relevant to them. The highlight functionality in ElasticSearch is designed to do this.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to search and highlight the results, perform the following steps:
1. From the command line, execute a search with a highlight parameter:
2. curl -XGET 'http://127.0.0.1:9200/test-index/_search?pretty=true&from=0&size=10' -d '
3. {
4. "query": {"query_string": {"query": "joe"}},
5. "highlight": {
6. "pre_tags": ["<b>"],
7. "fields": {
8. "parsedtext": {"order": "score"},
9. "name": {"order": "score"}},
10. "post_tags": ["</b>"]
11. }
12. }
13.}'
14. If everything works all right, the command will return the following result:
15.{
16. … truncated …
17. "hits" : {
18. "total" : 1,
19. "max_score" : 0.44194174,
20. "hits" : [ {
21. "_index" : "test-index",
22. "_type" : "test-type",
23. "_id" : "1",
24. "_score" : 0.44194174, "_source" : {"position": 1, "parsedtext": "Joe Testere nice guy", "name": "Joe Tester", "uuid": "11111"},
25. "highlight" : {
26. "name" : [ "<b>Joe</b> Tester" ],
27. "parsedtext" : [ "<b>Joe</b> Testere nice guy" ]
28. }
29. }]
30. }
}
As you can see, in the results, there is a new field called highlight, which contains the highlighted fields along with an array of fragments.
How it works...
When the highlight parameter is passed to the search object, ElasticSearch tries to execute it on the document's results.
The highlighting phase, which is after the document fetching phase, tries to extract the highlight by following these steps:
1. It collects the terms available in the query.
2. It initializes the highlighter with the parameters passed during the query.
3. It extracts the fields we are interested in and tries to load them if they are stored; otherwise they are taken from the source.
4. It executes the query on a single field in order to detect the more relevant parts.
5. It adds the highlighted fragments that are found in the resulting hit.
Using the highlighting functionality is easy, but there are some important factors that you need to pay attention to:
· The field that must be highlighted should be available in one of the forms explained earlier. It must be stored in the source or the term vector.
Note
The ElasticSearch highlighter checks the presence of the data field first as a term vector (the fastest way to execute the highlighting). If the field has no term vectors, it tries to load the field value from the stored fields. If the field is not stored, it loads the JSON source, interprets it, and extracts the data value if it is available. Obviously, the last approach is the slowest and resource-intensive approach.
· If a special analyzer is used in the search, it should be passed to the highlighter as well (this is often managed automatically).
There are several parameters that can be passed to the highlighted object to control the highlighting process, given as follows:
· number_of_fragments (by default, 5): This parameter controls how many fragments are returned. It can be configured globally or for a field.
· fragment_size (by default, 100): This specifies the number of characters that the fragments must contain. It can be configured globally or for a field.
· pre_tags/post_tags: These are a list of tags that can be used to mark the highlighted text.
· tags_schema="styled": This allows you to define the tag schema that marks highlights with different tags in order of importance. This is a helper to reduce the definition of a lot of pre_tags/post_tags.
See also
· The Executing a search recipe in this chapter
Executing a scan query
Every time a query is executed, the results are calculated and returned to the user. In ElasticSearch, there is no deterministic order for the records; pagination on a big block of values can result in inconsistency between the results due to documents being added and deleted, and also between documents with the same score. The scan query tries to resolve these kinds of problems by providing a special cursor that allows you to uniquely iterate all the documents. It's often used to back up documents or reindex them.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script (chapter_05/populate_query.sh) available in the code bundle for this book.
How to do it...
In order to execute a scan query, perform the following steps:
1. From the command line, execute a search of the type scan:
2. curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true&search_type=scan&scroll=10m&size=50' -d '{"query":{"match_all":{}}}'
3. If everything works all right, the command will return a result, as follows:
4. {
5. "_scroll_id" : "c2Nhbjs1OzQ1Mzp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ1Njp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ1Nzp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ1NDp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ1NTp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzE7dG90YWxfaGl0czozOw==",
6. "took" : 1,
7. "timed_out" : false,
8. "_shards" : {
9. "total" : 5,
10. "successful" : 5,
11. "failed" : 0
12. },
13. "hits" : {
14. "total" : 3,
15. "max_score" : 0.0,
16. "hits" : [ ]
}
The result is composed of the following parameters:
· scroll_id: This is the value to be used to scroll records.
· took: This is the time required to execute the query.
· timed_out: This is used to notify whether the query, if any query has, timed out.
· _shards: This gives information about the status of shards during the query.
· hits: This gives the total hits. The hits other than the total are available when you scroll.
Using the scroll_id parameter, you can use the scroll IDs to get the results:
curl -XGET 'localhost:9200/_search/scroll?scroll=10m' -d 'c2Nhbjs1OzQ2Mzp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ2Njp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ2Nzp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ2NDp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzQ2NTp4d1Ftcng0NlNCYUpVOXh4c0ZiYll3OzE7dG90YWxfaGl0czozOw=='
17. The result should be similar to this:
18.{
19. "_scroll_id" : "c2NhbjswOzE7dG90YWxfaGl0czozOw==",
20. "took" : 20,
21. "timed_out" : false,
22. "_shards" : {
23. "total" : 5,
24. "successful" : 0,
25. "failed" : 5
26. },
27. "hits" : {
28. "total" : 3,
29. "max_score" : 0.0,
…}
How it works...
The scan query is interpreted as a standard search. This kind of search is designed to iterate on a large set of results, so the score and the order are not computed.
During the query phase, every shard stores the state of the IDs in the memory until a timeout.
A scan query can be processed in two steps, as follows:
1. The first part of the preceding example code executes a query and returns a scroll_id value, which can be used to fetch the results.
2. The second part of the preceding example code executes the document scrolling. You iterate the second step, getting the new scroll_id value, in order to fetch other documents.
Tip
If you need to iterate on a big set of records, a scan query must be used; otherwise you might have duplicated results.
A scan query is similar to every executed standard query, but there are two special parameters that must be passed in the query string:
· search_type=scan: This informs ElasticSearch to execute a scan query.
· scroll=(your timeout): This allows you to define how long the hits should live. The time can be expressed in seconds using the s postfix (such as, 5s, 10s, and 15s) or in minutes using the m postfix (that is 5m, 10m). If you are using a long timeout, you must ensure that your nodes have a lot of RAM in order to keep the resulting ID live. This parameter is mandatory.
Note
Size is also special as it is treated per shard, meaning that if you have a size equal to 10 and 5 shards, each scroll will return 50 documents.
See also
· The Executing a Search recipe in this chapter
Suggesting a correct query
It's very common for users to commit typing errors or to require suggestions for the words they are writing. These issues are solved by ElasticSearch with the suggest functionality.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to suggest relevant terms by query, perform the following steps:
1. From the command line, execute a suggest call:
2. curl -XGET 'http://127.0.0.1:9200/test-index/_suggest?pretty=true' -d ' {
3. "suggest1" : {
4. "text" : "we find tester",
5. "term" : {
6. "field" : "parsedtext"
7. }
8. }
9. }'
10. This result will be returned by ElasticSearch if everything works all right:
11.{
12. "_shards": {
13. "failed": 0,
14. "successful": 5,
15. "total": 5
16. },
17. "suggest1": [
18. {
19. "length": 2,
20. "offset": 0,
21. "options": [],
22. "text": "we"
23. },
24. {
25. "length": 4,
26. "offset": 3,
27. "options": [],
28. "text": "find"
29. },
30. {
31. "length": 6,
32. "offset": 8,
33. "options": [
34. {
35. "freq": 2,
36. "score": 0.8333333,
37. "text": "testere"
38. }
39. ],
40. "text": "tester"
41. }
42. ]
}
The preceding result is composed of the following:
· The shard's status at the time of the query.
· The list of tokens with their available candidates.
How it works...
The suggest API call works by collecting term statistics on all the index shards. Using Lucene field statistics, it is possible to detect the correct or complete term.
The HTTP method used to execute a suggestion is GET (but POST also works). The URLs for the REST endpoints are:
http://<server>/_suggest
http://<server>/<index_name(s)>/_suggest
Tip
This call can be also embedded in the standard search API call.
There are two types of suggesters: the term suggester and the phrase suggester.
The terms suggester is the simpler form of suggester. It only requires the text and the field to work. It also allows you to set a lot of parameters, for example: the minimum size for a word, how to sort results, the suggester strategy, and so on. A complete reference is available on the ElasticSearch website.
The phrase suggester is able to keep relationships between terms that it needs to suggest. The phrase suggester is less efficient than the term suggester, but it provides better results.
The suggest API is a new feature, so parameters and options can change between releases; New suggesters can also be added via plugins.
See also
· The Executing a Search recipe in this chapter
· The phrase suggester's online documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-suggesters-phrase.html
· The completion suggester's online documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-suggesters-completion.html
· The context suggester's online documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/suggester-context.html
Counting matched results
It is often required to return only the count of the matched results and not the results themselves. The advantages of using a count request is the performance it offers and reduced resource usage, as a standard search call also returns hits count.
A lot of scenarios involve counting, as follows:
· To return the number of, for example, posts for a blog or comments for a post.
· To validate that some items are available. Are there posts? Are there comments?
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a counting query, perform the following steps:
1. From the command line, execute a count query:
2. curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_count?pretty=true' -d '{"query":{"match_all":{}}}'
3. The following result should be returned by ElasticSearch if everything works all right:
4. {
5. "count" : 3,
6. "_shards" : {
7. "total" : 5,
8. "successful" : 5,
9. "failed" : 0
10. }
}
The result is composed of the count result (a long type value) and the shard's status at the time of the query.
How it works...
The query is interpreted as it is done for searching. The count is processed and distributed in all the shards, in which it's mapped in a low-level Lucene count call. With every hit, a shard returns a count that is aggregated and returned to the user.
Note
In ElasticSearch, it is faster to count than search. If results are not required, it's good practice to use it.
The HTTP method to execute a count is GET (but POST works too). The URL examples for the REST endpoints are:
http://<server>/_count
http://<server>/<index_name(s)>/_count
http://<server>/<index_name(s)>/<type_name(s)>/_count
Multi-indices and types are comma separated. If an index or a type is defined, the search is limited to them only. An alias can be used as the index name.
Typically, a body is used to express a query, but for a simple query, q (the query argument) can be used. Take the following code as an example:
curl -XGET 'http://127.0.0.1:9200/test-index/test-type/_count?q=uuid:11111'
Note
Counts can also be requested from a normal search call by configuring the search_type parameter to count. More details are available in the ElasticSearch documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-request-search-type.html.
See also
· The Executing a search recipe in this chapter
Deleting by query
In the Deleting a document recipe from Chapter 4, Basic Operations, we saw how to delete a document(). A document can be deleted very quickly, but it requires you to know the document ID.
ElasticSearch provides a call to delete all the documents that match a query.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script (chapter_05/populate_query.sh) available in the code bundle for this book.
How to do it...
In order to execute a DELETE by query, perform the following steps:
1. Using the command line, execute a query, as follows:
2. curl -XDELETE 'http://127.0.0.1:9200/test-index/test-type/_query?pretty=true' -d '{"query":{"match_all":{}}}'
3. The following result should be returned by ElasticSearch, if everything works all right:
4. {
5. "_indices" : {
6. "test-index" : {
7. "_shards" : {
8. "total" : 5,
9. "successful" : 5,
10. "failed" : 0
11. }
12. }
13. }
}
14. The result is composed of the shard's status at the time of the DELETE query.
How it works...
The query is interpreted in the same way as it is done for searching. The DELETE query is processed and distributed to all the shards.
Note
When you want to remove all the documents without deleting the mapping, using a DELETE query along with a match all query allows you to clean your mapping of all the documents. This call is analogous to the truncate table syntax of the SQL language.
The HTTP method to execute a DELETE query is DELETE, and the URL examples for the REST endpoints are:
http://<server>/_query
http://<server>/<index_name(s)>/_query
http://<server>/<index_name(s)>/<type_name(s)>/_query
Multiple indices and types are comma separated. If an index or a type is defined, the search is limited only to them. An alias can be used as the index name.
Typically, a body is used to express a query, but for a simple query, q (the query argument) can be used, as follows:
curl -XDELETE 'http://127.0.0.1:9200/test-index/test-type/_query?q=uuid:11111'
See also
· The Executing a Search recipe in this chapter
Matching all the documents
One of the most used queries, usually in conjunction with a filter, is the match all query. This kind of query allows you to return all the documents.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a match_all query, perform the following steps:
1. From the command line, execute the query:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{"query":{"match_all":{}}}'
3. The following result should be returned by ElasticSearch if everything works all right:
4. {
5. "took" : 52,
6. "timed_out" : false,
7. "_shards" : {
8. "total" : 5,
9. "successful" : 5,
10. "failed" : 0
11. },
12. "hits" : {
13. "total" : 3,
14. "max_score" : 1.0,
15. "hits" : [{
16. "_index" : "test-index",
17. "_type" : "test-type",
18. "_id" : "1",
19. "_score" : 1.0, "_source" : {"position": 1, "parsedtext": "Joe Testere nice guy", "name": "Joe Tester", "uuid": "11111"}
20. }, {
21. "_index" : "test-index",
22. "_type" : "test-type",
23. "_id" : "2",
24. "_score" : 1.0, "_source" : {"position": 2, "parsedtext": "Bill Testere nice guy", "name": "Bill Baloney", "uuid": "22222"}
25. }, {
26. "_index" : "test-index",
27. "_type" : "test-type",
28. "_id" : "3",
29. "_score" : 1.0, "_source" : {"position": 3, "parsedtext": "Bill is not\n nice guy", "name": "Bill Clinton", "uuid": "33333"}
30. }]
31. }
}
The result is a standard query result, as we have seen in the Executing a Search recipe in this chapter.
How it works...
The match_all query is one of the most commonly used query types. It's fast because it doesn't require the score calculus (it's wrapped in a Lucene ConstantScoreQuery query).
The match_all query is often used in conjunction with a filter in a filter query, as follows:
curl -XPOST "http://localhost:9200/test-index/test-type/_search" -d'
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"term": {
"myfield": "myterm"
}
}
}
}
}'
Tip
If no query is defined in the search object, the default query will be a match_query query.
See also
· The Executing a search recipe in this chapter
Querying/filtering for a single term
Searching or filtering for a particular term is frequently done. A term query and filter work with exact values and are generally very fast.
The term query/filter can be compared to the equals "=" query in the SQL world (for the fields that are not tokenized).
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a term query/filter, perform the following steps:
1. Execute a term query from the command line:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "term": {
5. "uuid": "33333"
6. }
7. }
8. }'
9. The following result should be returned by ElasticSearch if everything works all right:
10.{
11. "took" : 58,
12. "timed_out" : false,
13. "_shards" : {
14. "total" : 5,
15. "successful" : 5,
16. "failed" : 0
17. },
18. "hits" : {
19. "total" : 1,
20. "max_score" : 0.30685282,
21. "hits" : [ {
22. "_index" : "test-index",
23. "_type" : "test-type",
24. "_id" : "3",
25. "_score" : 0.30685282, "_source" : {"position": 3, "parsedtext": "Bill is not\n nice guy", "name": "Bill Clinton", "uuid": "33333"}
26. } ]
27. }
}
The result is a standard query result, as we have seen in the Executing a Search recipe in this chapter.
28. Execute a term filter from the command line:
29.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
30. "query": {
31. "filtered": {
32. "filter": {
33. "term": {
34. "uuid": "33333"
35. }
36. },
37. "query": {
38. "match_all": {}
39. }
40. }
41. }
42.}'
43. This is the result:
44.{
45. "took" : 4,
46. "timed_out" : false,
47. "_shards" : {
48. "total" : 5,
49. "successful" : 5,
50. "failed" : 0
51. },
52. "hits" : {
53. "total" : 1,
54. "max_score" : 1.0,
55. "hits" : [ {
56. "_index" : "test-index",
57. "_type" : "test-type",
58. "_id" : "3",
59. "_score" : 1.0, "_source" : {"position": 3, "parsedtext": "Bill is not\n nice guy", "name": "Bill Clinton", "uuid": "33333"}
60. } ]
61. }
}
How it works...
Lucene, due to its inverted index, is one of the fastest engines to search for a term/value in a field.
Every field that is indexed in Lucene is converted in a fast search structure for its particular type:
· The text is split into tokens if it is analyzed or saved as a single token
· Numeric fields are converted into their fastest binary representations
· Date and Date-time fields are converted into binary forms
In ElasticSearch, all these conversions are automatically managed. The search for a term, independent of the value, is archived by ElasticSearch using the correct format for the field.
Internally, during a term query execution, all the documents matching the term are collected and then sorted by their scores (the scoring depends on the Lucene similarity algorithm chosen). The term filter follows the same approach, but because it doesn't require the score step, it's much faster.
If we take a look at the results of the previous searches, for the term query, the hit has 0.30685282 as the score and the filter has 1.0. The time required to score a sample if it is very small is not so relevant, but if you have thousands or millions of documents, it takes a lot more time.
Tip
If the score is not important, use the term filter.
A filter is preferred to query when the score is not important, for example, in the following scenarios:
· Filtering permissions
· Filtering numerical values
· Filtering ranges
Tip
In a filtered query, the filter is applied first, narrowing down the number of documents to be matched against the query, and then the query is applied.
There's more...
Matching a term is the basic function of Lucene and ElasticSearch. In order to correctly use a query/filter, you need to pay attention to how the field is indexed.
As we saw in Chapter 3, Managing Mapping, the terms of an indexed field depend on the analyzer that is used to index it. In order to better understand this concept, in the following table, there is a representation of a phrase that depends on several analyzers. Take the phrase: Peter's house is big, as an example:
|
Mapping index |
Analyzer |
Tokens |
|
no |
(No index) |
(No tokens) |
|
not_analyzed |
KeywordAnalyzer |
[Peter's house is big] |
|
analyzed |
StandardAnalyzer |
[peter, s, house, is, big] |
The common pitfalls in searching are related to misunderstanding the analyzer/mapping configuration.
The KeywordAnalyzer analyzer, which is used as a default for the not_analyzed field, saves the text without any changes as a single token.
The StandardAnalyzer analyzer, the default for the analyzed field, tokenizes on whitespaces and punctuation; and every token is converted to lowercase. You should use the same analyzer that is used in indexing to analyze the query (the default settings). In the preceding example, if the phrase is analyzed with the StandardAnalyzer analyzer, you cannot search for the term Peter, but you have to search for peter, because the StandardAnalyzer analyzer executes a lowercasing on the terms.
Tip
When the same field requires one or more search strategies, you need to use the fields property using the different analyzers that you need.
See also
· The Executing a search recipe in this chapter
Querying/filtering for multiple terms
The previous type of search works very well if you need to search for a single term. If you want to search for multiple terms, you can do that in two ways: using an AND/OR filter or using the multiple term query.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a terms query/filter, perform the following steps:
1. Execute a terms query from the command line:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "terms": {
5. "uuid": ["33333", "32222"]
6. }
7. }
8. }'
The result returned by ElasticSearch is the same as in the previous recipe.
9. If you want to use the terms query in a filter, this is how the query should look:
10.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
11. "query": {
12. "filtered": {
13. "filter": {
14. "terms": {
15. "uuid": ["33333", "32222"]
16. }
17. },
18. "query": {
19. "match_all": {}
20. }
21. }
22. }
23.}'
How it works…
The terms query/filter is related to the preceding type of query. It extends the term query to support multiple values.
This call is very useful because the concept of filtering on multiple values is very common. In traditional SQL, this operation is achieved with the in keyword in the where clause:
Select * from *** where color in ("red", "green")
In the preceding examples, the query searches for uuid with the values 33333 or 22222.
The terms query/filter is not merely a helper for the term matching function, but it also allows you to define extra parameters in order to control the query 'margin-left:18.0pt;text-indent:-18.0pt;line-height: normal'>· minimum_match/minimum_should_match: This parameter controls the number of matched terms that are required to validate the query. For example, the following query matches all the documents where the color fields have at least two values from a list of red, blue, and white:
· "terms": {
· "color": ["red", "blue", "white"],
· "minimum_should_match":2
}
· disable_coord: With this parameter, a Boolean function indicates whether the coord query must be enabled or disabled. The coord query is a query option that is used for better scoring by overlapping the match in Lucene. For more details, visithttp://lucene.apache.org/core/4_0_0/core/org/apache/lucene/search/similarities/Similarity.html.
· boost: This parameter is the standard query boost value used to modify the query weight.
The term filter is very powerful, as it allows you to define the strategy that must be used in order to filter terms. The strategies are passed in the execution parameter, and the following parameters are currently available:
· plain (default): This parameter works as a terms query. It generates a bit set with the terms, and is evaluated. This strategy cannot be automatically cached.
· bool: This parameter generates a term query for every term and then creates a Boolean filter to be used in order to filter terms. This approach allows you to reuse the term filters required for the Boolean filtering, which increases the performance if the subterm filters are reused.
· and: This parameter is similar to the bool parameter, but the term filter's subqueries are wrapped in an AND filter.
· or: This parameter is also similar to the bool parameter, but the term filter's subqueries are wrapped in an OR filter.
There's more...
Because term filtering is very powerful, in order to increase performance the terms can be fetched by other documents during the query. This is a very common scenario. Take, for example, a user that contains a list of the groups it is associated with, and you want to filter the documents that can only be seen by some groups. This is how the pseudo code should be:
curl -XGET localhost:9200/my-index/document/_search?pretty=true -d '{
"query" : {
"filtered" : {
"query":{"match_all":{}},
"filter" : {
"terms" : {
"can_see_groups" : {
"index" : "my-index",
"type" : "user",
"id" : "1bw71LaxSzSp_zV6NB_YGg",
"path" : "groups"
}
}
}
}
}
}'
In the preceding example, the list of groups is fetched at runtime from a document (which is always identified by an index, type, and ID) and the path (field) that contains the values to be put in it. This pattern is similar to the one used in SQL:
select * from xxx where can_see_group in (select groups from user where user_id='1bw71LaxSzSp_zV6NB_YGg')
Generally, NoSQL data stores do not support joins, so the data must be optimized to search using de-normalization or other techniques. ElasticSearch does not provide the join as in SQL, but it provides similar alternatives, as follows:
· Child/parent queries
· Nested queries
· Term filter with external document term fetching
See also
· The Executing a search recipe in this chapter
· The Querying/filtering for term recipe in this chapter
· The Using a Boolean query/filter recipe in this chapter
· The Using and/or/not filters recipe in this chapter
Using a prefix query/filter
The prefix query/filter is used when only the starting part of a term is known. It allows you to complete truncated or partial terms.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a prefix query/filter, perform the following steps:
1. Execute a prefix query from the command line:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "prefix": {
5. "uuid": "333"
6. }
7. }
8. }'
9. The result returned by ElasticSearch is the same as in the previous recipe.
10. If you want to use the prefix query in a filter, this is how the query should look:
11.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
12. "query": {
13. "filtered": {
14. "filter": {
15. "prefix": {
16. "uuid": "333"
17. }
18. },
19. "query": {
20. "match_all": {}
21. }
22. }
23. }
24.}'
How it works…
When a prefix query/filter is executed, Lucene has a special method to skip to terms that start with a common prefix, so the execution of a prefix query is very fast.
The prefix query/filter is used, in general, in scenarios where term completion is required, as follows:
· Name completion
· Code completion
· On-type completion
When designing a tree structure in ElasticSearch, if the ID of the item is designed to contain the hierarchic relation, it can speed up application filtering a lot. The following table, for example, shows the ID and the corresponding elements:
|
ID |
Element |
|
001 |
Fruit |
|
00102 |
Apple |
|
0010201 |
Green apple |
|
0010202 |
Red apple |
|
00103 |
Melon |
|
0010301 |
White melon |
|
002 |
Vegetables |
In the preceding example, we have structured IDs that contain information about the tree structure, which allows you to create queries, as follows:
· Filter by all fruit:
"prefix": {"fruit_id": "001" }
· Filter by all apple types:
"prefix": {"fruit_id": "001002" }
· Filter by all vegetables:
"prefix": {"fruit_id": "002" }
If the preceding structure is compared to a standard SQL parent_id table in a very large dataset, the reduction in join and the fast search performance of Lucene can filter the results in a few milliseconds, compared to a few seconds/minutes.
Tip
Structuring the data in the correct way can provide an impressive performance boost!
See also
· The Querying/filtering for terms recipe in this chapter
Using a Boolean query/filter
Every person who uses a search engine has at some point in time used the syntax with minus (-) and plus (+) to include or exclude some query terms. The Boolean query/filter allows you to programmatically define a query to include, exclude, or optionally include terms (should) in the query.
This kind of query/filter is one of the most important ones, because it allows you to aggregate a lot of simple queries/filters, which we will see in this chapter, to build a big complex query.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a Boolean query/filter, perform the following steps:
1. Execute a Boolean query using the command line:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "bool" : {
5. "must" : {
6. "term" : { "parsedtext" : "joe" }
7. },
8. "must_not" : {
9. "range" : {
10. "position" : { "from" : 10, "to" : 20 }
11. }
12. },
13. "should" : [
14. {
15. "term" : { "uuid" : "11111" }
16. },
17. {
18. "term" : { "uuid" : "22222" }
19. }
20. ],
21. "minimum_number_should_match" : 1,
22. "boost" : 1.0
23. }
24. }
25.}'
26. The result returned by ElasticSearch is similar to the result from the previous recipes, but in this case, it should return just one record (ID: 1).
27. If you want to use a Boolean filter, use the following query:
28.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
29. "query": {
30. "filtered": {
31. "filter": {
32. "bool" : {
33. "must" : {
34. "term" : { "parsedtext" : "joe" }
35. },
36. "must_not" : {
37. "range" : {
38. "position" : { "from" : 10, "to" : 20 }
39. }
40. },
41. "should" : [
42. {
43. "term" : { "uuid" : "11111" }
44. },
45. {
46. "term" : { "uuid" : "22222" }
47. }
48. ]
49. }
50. },
51. "query": {
52. "match_all": {}
53. }
54. }
55. }
56.}'
How it works…
The Boolean query/filter is often one of the more frequently used ones because it allows you to compose a big query using a lot of simple ones. It must have one of these three parts:
· must: This is a list of the queries/filters that must be satisfied. All the must queries must be verified to return hits. It can be seen as an AND filter with all its subqueries.
· must_not: This is a list of the queries/filters that must not be matched. It can be seen as a NOT filter of an AND query.
· should: This is a list of the queries that can be verified. The value of the minimum number of queries that must be verified is controlled by the minimum_number_should_match parameter (by default, 1).
Note
The Boolean filter is faster than a group of AND/OR/NOT queries because it is optimized to execute fast Boolean bitwise operations on a document's bitmap results.
See also
· The Querying/filtering for Terms recipe in this chapter
Using a range query/filter
Searching/filtering by range is a very common scenario in a real-world application. The following are a few standard cases:
· Filtering by a numeric value range (such as price, size, age, and so on)
· Filtering by date (for example, the events of 03/07/12 can be a range query, from 03/07/12 00:00:00 and 03/07/12 24:59:59)
· Filtering by term range (for example, terms from A to D)
Getting ready
You need a working ElasticSearch cluster, an index named test (see Chapter 4, Basic Operations, to create an index named test), and basic knowledge of JSON.
How to do it...
In order to execute a range query/filter, perform the following steps:
· Consider the previous example's data, which contains a position integer field. This can be used to execute a query in order to filter positions between 3 and 5, as follows:
· curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
· "query": {
· "filtered": {
· "filter": {
· "range" : {
· "position" : {
· "from" : 3,
· "to" : 4,
· "include_lower" : true,
· "include_upper" : false
· }
· }
· },
· "query": {
· "match_all": {}
· }
· }
· }
· }'
How it works...
A range query is used because scoring results can cover several interesting scenarios, as follows:
· Items with high availability in stocks should be presented first
· New items should be highlighted
· Most bought item should be highlighted
The range filter is very useful for numeric values, as the earlier example shows. The parameters that a range query/filter will accept are:
· from (optional): This is the start value for the range
· to (optional): This is the end value for the range
· include_in_lower (optional, by default true): This parameter includes the start value in the range
· include_in_upper (optional, by default true): This parameter includes the end value in the range
In a range filter, other helper parameters are available to simplify a search:
· gt (greater than): This parameter has the same functionality as the from parameter and the include_in_lower field when set to false
· gte (greater than or equal to): This parameter has the same functionality to set the from parameter and the include_in_lower field to true
· lt (lesser than): This parameter has the same functionality to set the to parameter and the include_in_lower field to false
· lte (lesser than or equal to): This parameter has the same functionality to set the to parameter and the include_in_lower field to false
There's more...
In ElasticSearch, a range query/filter covers several types of SQL queries, such as <, <=, >, and >= on numeric values.
In ElasticSearch, because date-time fields are managed internally as numeric fields, it's possible to use range queries/filters for date values. If the field is a date field, every value in the range query is automatically converted to a numeric value. For example, if you need to filter the documents of this year, this is how the range fragment will be:
"range" : {
"timestamp" : {
"from" : "2014-01-01",
"to" : "2015-01-01",
"include_lower" : true,
"include_upper" : false
}
}
Using span queries
The big difference between standard databases (SQL as well as many NoSQL databases, such as MongoDB, Riak, or CouchDB) and ElasticSearch is the number of facilities to express text queries.
The SpanQuery family is a group of queries that control a sequence of text tokens via their positions. Standard queries and filters don't take into account the positional presence of text tokens.
Span queries allow you to define several kinds of queries:
· The exact phrase query
· The exact fragment query (such as, Take off, give up)
· A partial exact phrase with a slop, that is, other tokens between the searched terms (such as the man with slop 2 can also match the strong man, the old wise man, and so on)
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute span queries, perform the following steps:
1. The main element in span queries is the span_term term whose usage is similar to the term of a standard query. One or more span_term can be aggregated to formulate a span query. The span_first query defines a query in which the span_term must match in the first token or ones near it. Take the following code as an example:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "span_first" : {
5. "match" : {
6. "span_term" : { "parsedtext" : "joe" }
7. },
8. "end" : 5
9. }
10. }
11.}'
12. The span_or query is used to define multiple values in a span query. This is very handy for a simple synonym search:
13.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
14. "query": {
15. "span_or" : {
16. "clauses" : [
17. { "span_term" : { "parsedtext" : "nice" } },
18. { "span_term" : { "parsedtext" : "cool" } },
19. { "span_term" : { "parsedtext" : "wonderful"}
20. ]
21. }
22. }
23.}'
The list of clauses is the core of the span_or query, because it contains the span terms that should match.
24. Similar to the span_or query, there is a span_multi query, which wraps multiple term queries such as prefixes and wildcards, as follows:
25.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
26. "query": {
27. "span_multi":{
28. "match":{
29. "prefix" : { "parsedtext" : { "value" : "jo" } }
30. }
31. }
32. }
33.}'
34. All these kinds of queries can be used to create the span_near query that allows you to control the token sequence of the query:
35.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
36. "query": {
37. "span_near" : {
38. "clauses" : [
39. { "span_term" : { "parsedtext" : "nice" } },
40. { "span_term" : { "parsedtext" : "joe" } },
41. { "span_term" : { "parsedtext" : "guy" } }
42. ],
43. "slop" : 3,
44. "in_order" : false,
45. "collect_payloads" : false
46. }
47. }
48.}'
How it works...
Lucene provides the span queries available in ElasticSearch. The base span query is span_term, which works exactly the same as the term query. The goal of this span query is to match an exact term (field plus text). It's possible to compose and formulate the other kind of span queries.
Note
The main use of a span query is for a proximity search: to search terms that are close to each other.
A span_first function is used in a span_term query to match a term that must be in the first position. If the end parameter (integer) is defined, it extends the first token that matches the passed value.
One of the most powerful span queries is the span_or query, which allows you to define multiple terms in the same position. It covers several scenarios, as follows:
· Multiple names
· Synonyms
· Several verbal forms
The span_or query does not have the counterpart span_and query function, as it does not have any meaning, because span queries are merely positional.
If the number of terms that must be passed to a span_or query function is huge, it can sometimes be reduced with a span_multi query using a prefix or wildcard. This approach allows you to make matches. For example, for the terms play, playing, plays, player,players and so on, a prefix query with play must be used.
The other most powerful span query is span_near, which allows you to define whether a list of span queries (clauses) needs to be matched in a sequence or not. The following parameters can be passed to this span query:
· in_order (by default, true): This parameter defines that the term that is matched in the clauses must be executed in an order. If you define two span_near queries with two span terms to match joe and black, you will not be able to match the text black joe if thein_order parameter is true.
· slop (by default, 0): This parameter defines the distance between the terms that must match the clauses.
Tip
By setting slop to 0 and the in_order parameter to true, you will be creating an exact phrase match.
A span near (span_near) query and slop can be used to create a phrase match that can have some terms that are not known. For example, consider matching an expression such as the house. If you need to execute an exact match, you need to write a similar query:
{
"query": {
"span_near" : {
"clauses" : [
{ "span_term" : { "parsedtext" : "the" } },
{ "span_term" : { "parsedtext" : "house" } }
],
"slop" : 0,
"in_order" : true
}
}
}
Now, if you have, for example, an adjective between the article and house (such as the wonderful house, the big house, and so on), the previous query will never match them. To achieve this goal, slop must be set to 1.
Usually, slop is set to 1, 2, or 3. High values have no meaning.
See also
· The Using a match query recipe in this chapter
Using a match query
ElasticSearch provides a helper to build complex span queries that depend on simple preconfigured settings. This helper is called a match query.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a match query, perform the following steps:
1. The standard usage of a match query simply requires the field name and the query text:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "match" : {
5. "parsedtext" : {
6. "field": "nice guy",
7. "operator": "and"
8. }
9. }
10. }
11.}'
12. If you need to execute the same query as a phrase query, the type of match changes in the match_phrase function:
13.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
14. "query": {
15. "match_phrase" : {
16. "parsedtext" : "nice guy"
17. }
18. }
19.}'
20. An extension of the previous query used in text completion or the search as you type functionality is the match_phrase_prefix function:
21.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
22. "query": {
23. "match_phrase_prefix" : {
24. "parsedtext" : "nice gu"
25. }
26. }
27.}'
How it works...
The match query aggregates several frequently used query types that cover standard query scenarios. The standard match query creates a Boolean query that can be controlled by these parameters:
· operator (by default, OR): This parameter defines how to store and process terms. If it's set to OR, all the terms are converted to a Boolean query with all the terms in should clauses. If it's set to AND, the terms will build a list of must clauses.
· analyzer (by default, it is based on mapping or it is set in the search setup): This parameter allows you to override the default analyzer of the field.
· fuzziness: This parameter allows you to define fuzzy term searches (see the Using QueryString query recipe in this chapter). In relation to this parameter, the prefix_length and max_expansion parameters are available.
· zero_terms_query (can be none/all, but by default, it is none): This parameter allows you to define a tokenizer filter that removes all the terms from the query. The default behavior is to return nothing or all of the documents. This is the case when you build an English query search for the the or a terms that could match all the documents.
· cutoff_frequency: This parameter allows you to handle dynamic stopwords (very common terms in text) at runtime. During query execution, terms over the cutoff_frequency value are considered to be stopwords. This approach is very useful because it allows you to convert a general query to a domain-specific query, because the terms to skip depend on the text statistic. The correct value must be defined empirically.
The Boolean query created from the match query is very handy, but it suffers some of the common problems related to Boolean queries, such as term position. If the term position matters, you need to use another family of match queries, such as the match_phrasequery. The match_phrase type in a match query builds long span queries from the query text. The parameters that can be used to improve the quality of the phrase query are the analyzers for text processing, and the slop parameter controls the distance between terms (see the Using Span queries recipe in this chapter).
If the last term is partially complete and you want to provide your users with the query while writing functionality, the phrase type can be set to match_phrase_prefix. This type builds a span near query in which the last clause is a span prefix term. This functionality is often used for typeahead widgets, as shown in the following screenshot:
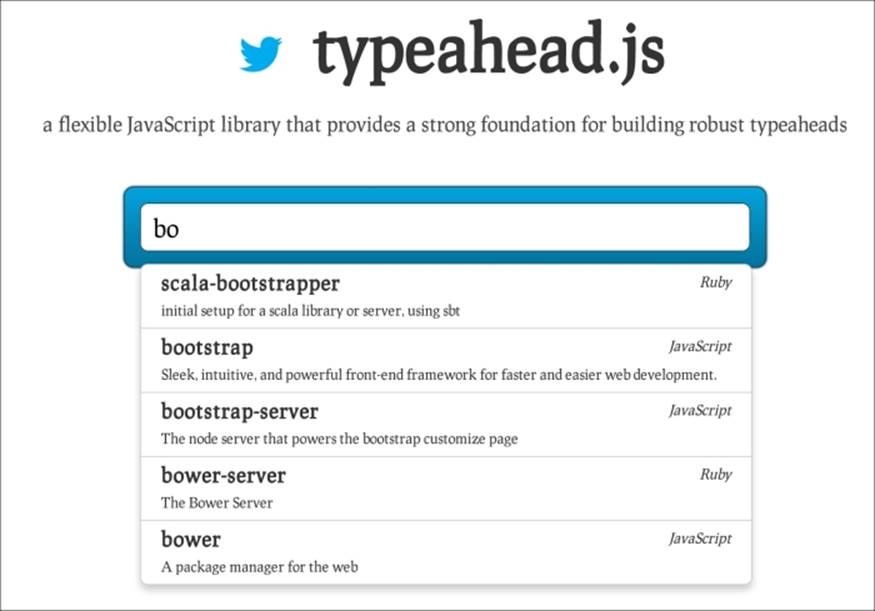
The match query is a very useful query type or, as I have previously defined, it helps to build several common queries internally.
See also
· The Using Span queries recipe in this chapter
· The Using Boolean query/filter recipe in this chapter
· The Using Prefix query/filter recipe in this chapter
Using an ID query/filter
The ID query/filter allows you to match documents by their IDs.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute ID queries/filters, perform the following steps:
1. The ID query to fetch IDs 1, 2, 3 of the type test-type is in this form:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "ids" : {
5. "type" : "test-type",
6. "values" : ["1", "2", "3"]
7. }
8. }
9. }'
10. The same query can be converted to a filter query, similar to this one:
11.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
12. "query": {
13. "filtered": {
14. "filter": {
15. "ids" : {
16. "type" : "test-type",
17. "values" : ["1", "2", "3"]
18. }
19. },
20. "query": {
21. "match_all": {}
22. }
23. }
24. }
25.}'
How it works...
Querying/filtering by ID is a fast operation because IDs are often cached in-memory for a fast lookup.
The following parameters are used in this query/filter:
· ids (required): This parameter is a list of the IDs that must be matched.
· type (optional): This parameter is a string or a list of strings that defines the types in which to search. If it is not defined, then the type is taken from the URL of the call.
Note
ElasticSearch internally stores the ID of a document in a special field called the _uid field composed of the type#id parameter. A _uid field is unique to an index.
Usually, the standard way to use an ID query/filter is to select documents. This query allows you to fetch documents without knowing the shard that contains the documents.
Documents are stored in shards based on a hash on their IDs. If a parent ID or a routing is defined, they are used to choose other shards. In these cases, the only way to fetch the document by knowing its ID is to use the ID query/filter.
If you need to fetch multiple IDs and there are no routing changes (due to the parent_id or routing parameter at index time), it's better not to use this kind of query, but to use the GET/Multi-GET API calls in order to get documents, as they are much faster and also work in real time.
See also
· The Getting a document recipe in Chapter 4, Basic Operations
· The Speeding up GET operations (multi GET) recipe in Chapter 4, Basic Operations
Using a has_child query/filter
ElasticSearch does not only support simple documents, but it also lets you define a hierarchy based on parent and children. The has_child query allows you to query for the parent documents of which children match some queries.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute the has_child queries/filters, perform the following steps:
1. Search for the parents, test-type, for which the children, test-type2, have a term in the field value as value1. We can create this kind of query as follows:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "has_child" : {
5. "type" : "test-type2",
6. "query" : {
7. "term" : {
8. "value" : "value1"
9. }
10. }
11. }
12. }
13.}'
14. If scoring is not important for performances, it's better to reformulate the query as a filter in this way:
15.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
16. "query": {
17. "filtered": {
18. "filter": {
19. "has_child" : {
20. "type" : "test-type2",
21. "query" : {
22. "term" : {
23. "value" : "value1"
24. }
25. }
26. }
27. },
28. "query": {
29. "match_all": {}
30. }
31. }
32. }
33.}'
How it works...
This kind of query works by returning parent documents whose children match the query. The query executed on children can be of any type. The prerequisite for this kind of query is that the children must be correctly indexed in the shard of their parent.
Internally, this kind of query is a query executed on the children, and all the IDs of the children are used to filter the parent. A system must have enough memory to store the child IDs.
The parameters that are used to control this process are:
· type: This is the type of the children, which is part of the same index as the parent.
· query: This is the query that can be executed for selecting the children. For achieving this any kind of query can be used.
· score_mode (by default, none; the available values are max, sum, avg, and none): This parameter, if defined, allows you to aggregate the children's scores with the parent scores.
· min_children and max_children (optional): This is the minimum/maximum number of children required to match the parent document.
In ElasticSearch, a document must have only one parent, because the parent ID is used to choose the shard to put the children in.
Note
When working with child documents, it is important to remember that they must be stored in the same shard as their parents. So, special precautions must be taken to fetch, modify, and delete them if the parent (ID) is unknown. It's a good practice to store theparent_id parameter as a field of the child.
As the parent-child relationship can be considered similar to a foreign key of standard SQL, there are some limitations due the distributed nature of ElasticSearch, as follows:
· There must be a parent for the type.
· The join part of child/parent is done in a shard and not distributed on all the clusters, in order to reduce networking and increase its performance.
See also
· The Indexing a document recipe in Chapter 4, Basic Operations
Using a top_children query
In the previous recipe, the has_child query consumes a huge amount of memory because it requires you to fetch all child IDs. To bypass this limitation in huge data contexts, the top_children query allows you to fetch only the top child results. This scenario is very common: think of a blog with the latest 10 comments.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute the top_children query, perform the following steps:
· Search the test-type parent of which the test-type2 top child has a term in the field value as value1. We can create a query, as follows:
· curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
· "query": {
· "top_children" : {
· "type" : "test-type2",
· "query" : {
· "term" : {
· "value" : "value1"
· }
· },
· "score" : "max",
· "factor" : 5,
· "incremental_factor" : 2
· }
· }
· }'
How it works...
This kind of query works by returning parent documents whose children match the query. The query executed on the children can be of any type.
Internally, this kind of query is a query executed on the children, and then the top IDs of the children are used to filter the parent. If the number of child IDs is not enough, other IDs are fetched.
The following parameters are used to control this process:
· type: This parameter denotes the type of the children. This type is a part of the same index as the parent.
· query: This parameter is a query that can be executed in order to select the children. Any kind of query can be used.
· score (max/ sum/ avg): This parameter allows you to control the chosen score in order to select the children.
· factor (by default, 5): This parameter is the multiplicative factor used to fetch the children. Because one parent can have a lot of children and the parent_id ID required for a query is a set of the returned children, you need to fetch more parent_id IDs from the children to be sure that you have the correct number of resulting hits. With a factor of 5 and 10 result hits required, about 50 child IDs must be fetched.
· incremental_factor: (by default, 2): This parameter is the multiplicative factor to be used if there are not enough child documents fetched by the first query. The equation that controls the number of fetched children is:
desired_hits * factor * incremental_factor
See also
· The Indexing a document recipe in Chapter 4, Basic Operations
· The Using a has_child query/filter recipe in this chapter
Using a has_parent query/filter
In the previous recipes, we have seen the has_child query. ElasticSearch provides a query to search child documents based on the parent query: the has_parent query.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute the has_parent query/filter, perform the following steps:
1. Search for the test-type2 children of which the test-type parents have a term joe in the parsedtext field. Create the query as follows:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type2/_search?pretty=true' -d '{
3. "query": {
4. "has_parent" : {
5. "type" : "test-type",
6. "query" : {
7. "term" : {
8. "parsedtext" : "joe"
9. }
10. }
11. }
12. }
13.}'
14. If scoring is not important, then it's better to reformulate the query as a filter in this way:
15.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type2/_search?pretty=true' -d '{
16. "query": {
17. "filtered": {
18. "filter": {
19. "has_parent" : {
20. "type" : "test-type",
21. "query" : {
22. "term" : {
23. "parsedtext" : "joe"
24. }
25. }
26. }
27. },
28. "query": {
29. "match_all": {}
30. }
31. }
32.}'
How it works...
This kind of query works by returning child documents whose parent matches the parent query.
Internally, this subquery is executed on the parents, and all the IDs of the matching parents are used to filter the children. A system must have enough memory to store all the parent IDs.
The following parameters are used to control this process:
· type: This parameter suggests the type of the parent.
· query: This is the query that can be executed to select the parents. Any kind of query can be used.
· score_type (by default, none; the available values are none and score): Using this parameter with the default configuration none, ElasticSearch ignores the scores for the parent document, which reduces memory usage and increases performance. If it's set toscore, the parent's query score is aggregated with the children's score.
See also
· The Indexing a document recipe in Chapter 4, Basic Operations
Using a regexp query/filter
In the previous recipes, we saw different term queries (terms, fuzzy, and prefix). Another powerful terms query is the regexp (regular expression) query.
Getting ready
You will need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute a regexp query/filter, perform the following steps:
1. Execute a regexp term query from the command line:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. = "regexp": {
5. "parsedtext": {
6. "value": "j.*",
7. "flags" : "INTERSECTION|COMPLEMENT|EMPTY"
8. }
9. }
10. }
11.}'
12. If scoring is not important, it's better to reformulate the query as a filter in this way:
13.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
14. "query": {
15. "filtered": {
16. "filter": {
17. "regexp": {
18. "parsedtext": "j.*"
19. }
20. },
21. "query": {
22. "match_all": {}
23. }
24. }
25. }
26.}'
How it works...
The regexp query/filter executes the regular expression against all the terms of the documents. Internally, Lucene compiles the regular expression in an automaton to improve performance, so, the performance of this query/filter is generally not very fast, as the performance depends on the regular expression used.
To speed up the regexp query/filter, a good approach is to have a regular expression that doesn't start with a wildcard.
The following parameters are used to control this process:
· boost (by default, 1.0): These are the values used to boost the score for the regexp query.
· flags: This is a list of one or more flags pipe (|) delimited. These flags are available:
· ALL: This flag enables all optional regexp syntax
· ANYSTRING: This flag enables any string (@)
· AUTOMATON: This flag enables the named automata (<identifier>)
· COMPLEMENT: This flag enables the complement (~)
· EMPTY: This flag enables an empty language (#)
· INTERSECTION: This flag enables intersection (&)
· INTERVAL: This flag enables numerical intervals (<n-m>)
· NONE: This flag enables no optional regexp syntax
Tip
To avoid poor performance in a search, don't execute regex starting with .*.
See also
· Read the official documentation for Regexp queries at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html
· The Querying/filtering for terms recipe in this chapter
Using a function score query
This kind of query is one of the most powerful queries available, because it allows extensive customization. The function score query allows you to define a function that controls the score of the documents that are returned by a query.
Generally, these functions are CPU-intensive and executing them on a large dataset requires a lot of memory, but computing them in a small subset can significantly improve the search quality.
These are the common scenarios used for this query:
· Creating a custom score function (for example with the decay function)
· Creating a custom boost factor, for example, based on another field (such as boosting a document by its distance from a point)
· Creating a custom filter score function, for example based on scripting ElasticSearch capabilities
· Ordering the documents randomly
Getting ready
You need a working ElasticSearch cluster and an index populated with the script (chapter_05/populate_query.sh) available in the code bundle for this book.
How to do it...
In order to execute a function score query, perform the following steps:
1. Execute a function score query using the following command line:
2. curl -XPOST 'localhost:9200/_search?pretty' -d '{
3. "query": {
4. "function_score": {
5. "query": {
6. "query_string": {
7. "query": "bill"
8. }
9. },
10. "functions": [{
11. "linear": {
12. "position": {
13. "origin": "0",
14. "scale": "20"
15. }
16. }
17. }],
18. "score_mode": "multiply"
19. }
20. }
21.}'
We execute a query to search for bill, and we score the result with the linear function on the position field.
22. This is how the result should look:
23.{
24. …truncated…
25. "hits" : {
26. "total" : 2,
27. "max_score" : 0.41984466,
28. "hits" : [ {
29. "_index" : "test-index",
30. "_type" : "test-type",
31. "_id" : "2",
32. "_score" : 0.41984466,
33. "_source":{"position": 2, …truncated…}
34. }, {
35. "_index" : "test-index",
36. "_type" : "test-type",
37. "_id" : "3",
38. "_score" : 0.12544023,
39. "_source":{"position": 3, …truncated… }
40. } ]
41. }
}
How it works...
The function score query is probably the most complex query type to master due to the natural complexity of the mathematical algorithm involved in the scoring.
The following is the generic full form of the function score query:
"function_score": {
"(query|filter)": {},
"boost": "boost for the whole query",
"functions": [
{
"filter": {},
"FUNCTION": {}
},
{
"FUNCTION": {}
}
],
"max_boost": number,
"boost_mode": "(multiply|replace|)",
"score_mode": "(multiply|max|)",
"script_score": {},
"random_score": {"seed ": number}
}
These are the parameters that exist in the preceding code:
· query or filter (optional, by default the match_all query): This is the query/filter used to match the required documents.
· boost (by default, 1.0): This is the boost that is to be applied to the whole query.
· functions: This is a list of the functions used to score the queries. In a simple case, use only one function. In the function object, a filter can be provided to apply the function only to a subset of documents, because the filter is applied first.
· max_boost (by default, java FLT_MAX): This sets the maximum allowed value for the boost score.
· boost_mode (by default, multiply): This parameter defines how the function score is combined with the query score. These are the possible values:
· multiply (default): The query score and function score is multiplied using this parameter
· replace: By using this value, only the function score is used, while the query score is ignored
· sum: Using this, the query score and function score are added
· avg: This value is the average between the query score and the function score
· max: This is the maximum value of the query score and the function score
· min: This is the minimum value of the query score and the function score
· score_mode (by default, multiply): This parameter defines how the resulting function scores (when multiple functions are defined) are combined. These are the possible values:
· multiply: The scores are multiplied
· sum: The scores are added together
· avg: The scores are averaged
· first: The filter is applied to the first function that has a match
· max: The maximum score is used
· min: The minimum score is used
· script_score (optional): This parameter allows you to define a script score function that is to be used in order to compute the score (ElasticSearch scripting will be discussed in Chapter 7, Scripting). This parameter is very useful to implement simple script algorithms. The original score value is in the _score function scope. This allows you to define similar algorithms, as follows:
· "script_score": {
· "params": {
· "param1": 2,
· "param2": 3.1
· },
· "script": "_score * doc['my_numeric_field'].value / pow(param1, param2)"
}
· random_score (optional): This parameter allows you to randomly score the documents. It is very useful to retrieve records randomly.
ElasticSearch provides native support for the most common scoring decay distribution algorithms, as follows:
· Linear: This algorithm is used to linearly distribute the scores based on a distance from a value
· Exponential (exp): This algorithm is used for the exponential decay function
· Gaussian (gauss): This algorithm is used for the Gaussian decay function
Choosing the correct function distribution depends on the context and data distribution.
See also
· Chapter 7, Scripting, to learn more about scripting
· The official ElasticSearch documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html
· Blog posts at http://jontai.me/blog/2013/01/advanced-scoring-in-elasticsearch/ and https://www.found.no/foundation/function-scoring/
Using exists and missing filters
One of the main characteristics of ElasticSearch is its schema-less indexing capability. Records in ElasticSearch can have missing values. To manage them, two kinds of filters are supported:
· Exists filter: This checks whether a field exists in a document
· Missing filter: This checks whether a field is missing
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute existing and missing filters, perform the following steps:
1. To search all the test-type documents that have a field called parsedtext, this will be the query:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "filtered": {
5. "filter": {
6. "exists": {
7. "field":"parsedtext"
8. }
9. },
10. "query": {
11. "match_all": {}
12. }
13. }
14. }
15.}'
16. To search all the test-type documents that do not have a field called parsedtext, this is how the query should look:
17.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
18. "query": {
19. "filtered": {
20. "filter": {
21. "missing": {
22. "field":"parsedtext"
23. }
24. },
25. "query": {
26. "match_all": {}
27. }
28. }
29. }
30.}'
How it works...
The exists and missing filters take only a field parameter, which contains the name of the field to be checked.
If you use simple fields, there are no pitfalls, but if you are using a single embedded object or a list of these objects, you need to use a subobject field, due to the way in which ElasticSearch/Lucene works.
The following example helps you understand how ElasticSearch maps JSON objects to Lucene documents internally. Take the example of the following JSON document:
{
"name":"Paul",
"address":{
"city":"Sydney",
"street":"Opera House Road",
"number":"44"
}
}
ElasticSearch will internally index the document, as shown here:
name:paul
address.city:Sydney
address.street:Opera House Road
address.number:44
As you can see, there is no indexed field named address, so the existing filter on the term address fails. To match documents with an address, you must search for a subfield (such as, address.city).
Using and/or/not filters
When building complex queries, some typical Boolean operation filters are required, as they allow you to construct complex filter relations as in the traditional relational database world.
Any query DSL cannot be completed if there is no and, or, or not filter.
Getting ready
You need a working ElasticSearch cluster and an index populated with the script chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
In order to execute and/or/not filters, perform the following steps:
1. Search for documents with parsedtext equal to joe and uuid equal to 11111 in this way:
2. curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
3. "query": {
4. "filtered": {
5. "filter": {
6. "and": [
7. {
8. "term": {
9. "parsedtext":"joe"
10. }
11. },
12. {
13. "term": {
14. "uuid":"11111"
15. }
16. }
17. ]
18. },
19. "query": {
20. "match_all": {}
21. }
22. }
23. }
24.}'
25. Search for documents with uuid equal to 11111 or 22222 with a similar query:
26.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
27. "query": {
28. "filtered": {
29. "filter": {
30. "or": [
31. {
32. "term": {
33. "uuid":"11111"
34. }
35. },
36. {
37. "term": {
38. "uuid":"22222"
39. }
40. }
41. ]
42. },
43. "query": {
44. "match_all": {}
45. }
46. }
47. }
48.}'
49. Search for documents with uuid not equal to 11111 using this query:
50.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search' -d '{
51. "query": {
52. "filtered": {
53. "filter": {
54. "not": {
55. "term": {
56. "uuid":"11111"
57. }
58. }
59. },
60. "query": {
61. "match_all": {}
62. }
63. }
64. }
65.}'
How it works...
The Boolean operator filters are the simplest filters available in ElasticSearch. The and and or queries accept a list of subfilters that can be used. This kind of Boolean operator filters are very fast, as in Lucene they are converted to very efficient bitwise operations on document IDs.
Also, the not filter is as fast as the Boolean operators, but it requires only a single filter to be negated.
From a user's point of view, you can consider these fields as traditional numerical group operations, as follows:
· and: In this operation, the documents that match all the subfilters are returned
· or: In this operation, the documents that match a least one of the subfields are returned
· not: In this operation, the documents that don't match the subfield are returned
Note
For performance reasons, a Boolean filter is faster than a bulk of and/or/not filters.
Using a geo bounding box filter
One of the most common operations in geolocalization is searching for a box (square).
Getting ready
You need a working ElasticSearch cluster and an index populated with the GeoScript chapter_05/geo/populate_geo.sh, available in the code bundle for this book.
How to do it...
A search to filter documents related to a bounding box (40.03, 72.0) and (40.717, 70.99) can be done with a similar query:
curl -XGET http://127.0.0.1:9200/test-mindex/_search?pretty -d '{
"query": {
"filtered": {
"filter": {
"geo_bounding_box": {
"pin.location": {
"bottom_right": {
"lat": 40.03,
"lon": 72.0
},
"top_left": {
"lat": 40.717,
"lon": 70.99
}
}
}
},
"query": {
"match_all": {}
}
}
}
}'
How it works...
ElasticSearch has a lot of optimization options to search for a box shape. The latitude and longitude are indexed for a fast range check, so this kind of filter is executed really quickly.
The parameters required to execute a geo_bounding_box filter are the top_left and bottom_right geo-points.
It's possible to use several representations of a geo-point, as described in the Mapping a geo point field recipe in Chapter 3, Managing Mapping.
See also
· The Mapping a geo point field recipe in Chapter 3, Managing Mapping
Using a geo polygon filter
The previous recipe, Using a geo bounding box filter, shows you how to filter on a square section, which is the most common case. ElasticSearch provides a way to filter user-defined polygonal shapes via the geo_polygon filter. This filter is useful if the filter is based on a country/region/district shape.
Getting ready
You need a working ElasticSearch cluster and an index populated with the GeoScript chapter_05/geo/populate_geo.sh, available in the code bundle for this book.
How to do it...
Search for documents in which pin.location is part of a triangle (a shape made up of three geopoints), as follows:
curl -XGET http://127.0.0.1:9200/test-mindex/_search?pretty -d '{
"query": {
"filtered": {
"filter": {
"geo_polygon" {
"pin.location": {
"points": [
{
"lat": 50,
"lon": -30
},
{
"lat": 30,
"lon": -80
},
{
"lat": 80,
"lon": -90
}
]
}
}
},
"query": {
"match_all": {}
}
}
}
}'
How it works...
The geo polygon filter allows you to define your own shape with a list of geo-points so that ElasticSearch can filter the documents that are in the polygon.
It can be considered an extension of the geo bounding box for a generic polygonal form.
See also
· The Mapping a geo point field recipe in Chapter 3, Managing Mapping
· The Using a geo bounding box filter recipe in this chapter
Using geo distance filter
When you are working with geolocations, one of the most common tasks is to filter results based on their distance from a location. This scenario covers the following common site requirements:
· Finding the nearest restaurant in a 20 km distance
· Finding your nearest friends in a 10 km range
The geo_distance filter is used to achieve this goal.
Getting ready
You need a working ElasticSearch cluster and an index populated with the GeoScript chapter_05/geo/populate_geo.sh, available in the code bundle for this book.
How to do it...
Search for documents in which the pin.location is 200 km away from latitude 40, longitude 70, as follows:
curl -XGET 'http://127.0.0.1:9200/test-mindex/_search?pretty' -d '{
"query": {
"filtered": {
"filter": {
"geo_distance": {
"pin.location": {
"lat": 40,
"lon": 70
},
"distance": "200km",
"optimize_bbox": "memory"
}
},
"query": {
"match_all": {}
}
}
}
}'
How it works...
As discussed in the Mapping a geo point Field recipe in Chapter 3, Managing Mapping, there are several ways to define a geo point, and it is internally saved in an optimized way so that it can be searched.
The distance filter executes a distance calculation between a given geo-point and the points in the documents, returning hits that satisfy the distance requirement.
These parameters control the distance filter:
· The field and the point of reference to be used in order to calculate the distance. In the preceding example, we have pin.location and (40,70).
· distance: This parameter defines the distance to be considered. It is usually expressed as a string by a number plus a unit.
· unit (optional): This parameter can be the unit of the distance value if the distance is defined as a number. These are the valid values:
· in or inch
· yd or yards
· m or miles
· km or kilometers
· m or meters
· mm or millimeters
· cm or centimeters
· distance_type (by default, sloppy_arc; the valid choices are arc/sloppy_arc/plane): This parameter defines the type of algorithm used to calculate the distance.
· optimize_bbox: This parameter defines that you first need to filter with a bounding box in order to improve performance. This kind of optimization removes a lot of document evaluations, limiting the check to values that match a square. These are the valid values for this parameter:
· memory (default): This parameter does the memory check.
· indexed: This parameter checks using the indexing values. It only works if the latitude and longitude are indexed.
· none: This parameter disables bounding box optimization.
There's more...
There's a range version of this filter too that allows you to filter by range. The geo_distance_range filter works as a standard range filter (see the Using a range query/filter recipe in this chapter), in which the range is defined in the from and to parameters. For example, the preceding code can be converted into a range without the from part, as follows:
curl -XGET 'http://127.0.0.1:9200/test-mindex/_search?pretty' -d '{
"query": {
"filtered": {
"filter": {
"geo_distance_range": {
"pin.location": {
"lat": 40,
"lon": 70
},
"to": "200km",
"optimize_bbox": "memory"
}
},
"query": {
"match_all": {}
}
}
}
}'
See also
· The Mapping a geo point field recipe in Chapter 3, Managing Mapping
· The Using a range query/filter in this chapter
Using a QueryString query
In the previous recipes, we saw several types of query that use text to match the results. The QueryString query is a special type of query that allows you to define complex queries by mixing field rules.
It uses the Lucene query parser in order to parse text to complex queries.
Getting ready
You need a working ElasticSearch cluster and an index populated with the GeoScript chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
We want to retrieve all the documents that match parsedtext, joe, or bill, with a price between 4 and 6.
To execute this QueryString query, this is how the code will look:
curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d ' {
"query": {
"query_string": {
"default_field": "parsedtext",
"query": "(bill OR joe) AND price:[4 TO 6]"
}
}
}'
The search will return three results.
How it works...
The QueryString query is one of the most powerful types of queries. The only required field is query, which contains the query that must be parsed with the Lucene query parser (http://lucene.apache.org/core/4_10_2/queryparser/org/apache/lucene/queryparser/classic/package-summary.html).
The Lucene query parser is able to analyze complex query syntax and convert it to many of the query types that we have seen in the previous recipes.
These are the optional parameters that can be passed to the QueryString query:
· default_field (by default, _all): This defines the default field to be used for querying. It can also be set at the index level, defining the index.query.default_field index property.
· fields: This defines a list of fields to be used during querying and replaces the default_field field. The fields parameter also allows you to use wildcards as values (such as, city.*).
· default_operator (by default, OR; the available values are AND and OR): This is the default operator to be used for text in a query parameter.
· analyzer: This is the analyzer that must be used for the query string.
· allow_leading_wildcard (by default, true): This parameter allows the use of the * and ? wildcards as the first character. Using similar wildcards leads to performance penalties.
· lowercase_expanded_terms (by default, true): This controls whether all expansion terms (generated by fuzzy, range, wildcard, and prefix) must be lowercased.
· enable_position_increments (by default, true): This enables the position increment in queries. For every query token, the positional value is incremented by 1.
· fuzzy_max_expansions (by default, 50): This controls the number of terms to be used in a fuzzy term expansion.
· fuzziness (by default, AUTO): This sets the fuzziness value for fuzzy queries.
· fuzzy_prefix_length (by default, 0): This sets the prefix length for fuzzy queries.
· phrase_slop (by default, 0): This sets the default slop (the number of optional terms that can be present in the middle of given terms) for phrases. If it is set to zero, the query will be an exact phrase match.
· boost (by default, 1.0): This defines the boost value of the query.
· analyze_wildcard (by default, false): This enables the processing of the wildcard terms in the query.
· auto_generate_phrase_queries (by default, false): This enables the autogeneration of phrase queries from the query string.
· minimum_should_match: This controls how many should clauses should be verified to match the result. The value can be an integer (such as, 3), a percentage (such as, 40%), or a combination of both.
· lenient (by default, false): If set to true, the parser will ignore all format-based failures (such as date conversion from text to number).
· locale (by default, ROOT): This is the locale used for string conversion.
There's more...
The query parser is very powerful and can support a wide range of complex queries. These are the most common cases:
· field:text: This parameter is used to match a field that contains some text. It's mapped on a term query/filter.
· field:(term1 OR term2): This parameter is used to match some terms in OR. It's mapped on a term query/filter.
· field:"text": This parameter is used for a exact text match. It's mapped on a match query.
· _exists_:field: This parameter is used to match documents that have a field. It's mapped on an exists filter.
· _missing_:field: This parameter is used to match documents that don't have a field. It's mapped on a missing filter.
· field:[start TO end]: This parameter is used to match a range from the start value to the end value. The start and end values can be terms, numbers, or valid date-time values. The start and end values are included in the range. If you want to exclude a range, you must replace the [] delimiters with {}.
· field:/regex/: This parameter is used to match regular expressions.
The query parser also supports a text modifier, which is used to manipulate the text functionalities. These are the most commonly used text modifiers:
· Fuzziness using the text~ form: The default fuzziness value is 2, which allows the Damerau–Levenshtein edit-distance algorithm to be used (http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance).
· Wildcards with ?: This replaces a single character or * to replace zero or more characters (such as b?ll or bi* to match bill).
· Proximity search "term1 term2"~3: This allows you to match phrase terms with a defined slop (such as, "my umbrella"~3 matches "my green umbrella", "my new umbrella", and so on).
See also
· The Lucene official query parser syntax reference at http://lucene.apache.org/core/4_10_2/queryparser/org/apache/lucene/queryparser/classic/package-summary.html.
· The official ElasticSearch documentation about the query string query at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html.
Using a template query
ElasticSearch provides the capability to provide a template and some parameters to fill it. This functionality is very useful because it allows you to manage query templates stored in the server's filesystem or in the .scripts index, allowing you to change them without changing your application code.
Getting ready
You need a working ElasticSearch cluster and an index populated with the GeoScript chapter_05/populate_query.sh, available in the code bundle for this book.
How to do it...
The Template query is composed of two components: the query and the parameters that must be filled in. We can execute a template query in several ways.
To execute an embedded template query, use the following code:
curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search?pretty=true' -d '{
"query": {
"template": {
"query": {
"term": {
"uuid": "{{value}}"
}
},
"params": {
"value": "22222"
}
}
}
}'
If you want to use an indexed stored template, perform the following steps:
1. Store the template in the .scripts index:
2. curl -XPOST 'http://127.0.0.1:9200/_search/template/myTemplate' -d '
3. {
4. "template": {
5. "query": {
6. "term": {
7. "uuid": "{{value}}"
8. }
9. }
10. }
11.}'
12. Now, call the template with the following code:
13.curl -XPOST 'http://127.0.0.1:9200/test-index/test-type/_search/template?pretty=true' -d '{
14. "template": {
15. "id": "myTemplate"
16. },
17. "params": {
18. "value": "22222"
19. }
20.}'
How it works...
A template query is composed of two components:
· A template, that can be any query object that is supported by ElasticSearch. The template uses the mustache (http://mustache.github.io/) syntax, a very common syntax to express templates.
· An optional dictionary of parameters to be used in order to fill the template.
When the search query is called, the template is loaded, populated with the parameter data, and executed as a normal query.
The template query is a shortcut to use the same query with different values.
Typically, the template is generated by executing the query in the standard way and then adding parameters, if required, when templating it. The template query also allows you to define the template as a string, but the user must pay attention to escaping it (see the official documentation at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-template-query.html for escaping templates). It allows you to remove the query execution from the application code and put it in the filesystem or indices.
There's more...
The template query can retrieve a previously stored template from the disk (it must be stored in the config/scripts directory with the .mustache extension) or from the .scripts special index.
The search template can be managed in ElasticSearch via the special end points, /_search/template. These are the special endpoints:
· To store a template:
· curl -XPOST 'http://127.0.0.1:9200/_search/template/<template_name>' -d <template_body>
· To retrieve a template:
· curl -XGET 'http://127.0.0.1:9200/_search/template/<template_name>'
· To delete a template:
· curl -XDELETE 'http://127.0.0.1:9200/_search/template/<template_name>'
Note
The indexed templates and scripts are stored in the .script index. This is a normal index and can be managed as a standard data index.
See also
· The official mustache documentation at http://mustache.github.io/
· The official ElasticSearch documentation about search templates at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-template.html
· The official ElasticSearch documentation about query templates at http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-template-query.html
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.