HDInsight Essentials, Second Edition (2015)
Chapter 9. Strategy for a Successful Data Lake Implementation
The Data Lake vision and promise is to transform the vast amount of big data into real insights that help drive fact-based decisions. We are now witnessing this dream being realized in several enterprises across multiple industries such as fashion, food, retail, banks, and others. While there are a few success stories, there are a significant number of organizations that have the new platform stuck in development or proof of concept stage and are unable to move to production.
In this chapter, I will share the approaches to ensure a successful big data project. The topics covered in this chapter are as follows:
· Challenges on building a production Data Lake
· The success path for a sustainable production Data Lake
· Architectural considerations
· Online resources
Challenges on building a production Data Lake
Most organizations start with a short proof of concept (POC) that demonstrates the value of big data and the Hadoop ecosystem. These are primarily executed from a research perspective with specific datasets and goals and are generally successful.
After the proof of technology (POT) readout is when management has the following key questions that block further progress:
· Do we have the development skills to handle this technology on a large scale?
· How do we integrate this Hadoop Data Lake with current systems?
· How do we secure data in Hadoop and meet compliance requirements?
· Can the current operations team manage this in production?
These are tough questions and require people, process, and technology to transition so that the organization can leap forward to a modern Data Lake architecture. In the next section, we will review a few key steps for a successful Data Lake implementation.
The success path for a production Data Lake
For a successful production Data Lake transition, there are three key steps:
· Identify the big data problem
· Conduct a successful proof of technology
· Form a Data Lake Center of Excellence
Let's review each of these steps in detail.
Identifying the big data problem
A big data solution should not be considered as a hammer looking for a nail but a solution for a real business problem. The first step for a Data Lake journey is to evaluate your current state architecture and business needs to see whether there is a real big data problem. It is possible that some of your current systems are better suited for handling your business requirements than a new Data Lake.
To give you some ideas, the following are the top use cases of a Hadoop-based Data Lake and might be relevant to your organization:
· ETL offload: Hadoop MapReduce provides a low cost alternative for the traditional batch-oriented extract-transform-load. Offloading this to Hadoop will free up your data warehouse to perform high-value functions such as analytics and reporting.
· Active data archival: Data archival solutions for a typical relational database have been the magnetic tapes that are typically stored offsite and takes days to restore. With a Data Lake based on HDFS, data can be archived onto low cost commodity hardware and can always be available for queries and hence "active archive".
· Log analytics: A modern Data Lake based on Hadoop is well-suited for analyzing server logs that are useful to manage applications and to detect security breaches.
· Advanced analytics: A Data Lake built on top of Hadoop empowers data scientists to explore and create insights straight from unstructured data without the need for complex and expensive data preparation. This unprecedented flexibility opens new possibilities for agile analytics.
While these are some common patterns, there might be several other use cases that pertain to your business, which current systems are unable to keep up with, such as the data volume or business demand, and they could be candidates for the modern Data Lake. It is also advisable to have a priority of your business use cases based on impact and return on investment. Ensure that you capture and document executive and business buy-in for future traceability.
For example, the multinational company GE conducted a study on the business value of the Industrial Internet and found that 1 percent reduction in system inefficiencies in healthcare will translate to $63 billion of savings over a 15-year period. This study built a great business case for GE management to invest in big data infrastructure and initiatives. The following figure shows the potential business value of the investment:

Proof of technology for Data Lake
After you have identified a set of use cases that demonstrate potential business value, the next step is to conduct a short proof of technology (POT) with a limited set of those use cases. This should be time bound with specific success criteria. The following should be in your proof of technology plan:
· POT objectives: This should include the dataset for POT, sample data, desired aggregates, integrations, and success criteria
· Infrastructure considerations: This should include the factors such as will this architecture scale, be available, meet the SLAs as data grows, and will it be manageable?
· Timeline and Resources: This should have the start and end dates with resources identified
· POT readout: POT should have a closure date with a readout to the stakeholders
A successful POT will provide management support to proceed with a larger production scale rollout.
Form a Data Lake Center of Excellence
Organizations should not stop at a successful POT. If the management sees value in the Data Lake architecture, then they should next set up a Center of Excellence (COE). A new core team should be formed that champions the technology, process, and governance of the Data Lake. The following are the benefits of building such a COE:
· A unified Data Lake instead of potential silos based on business units resulting in lower total cost of ownership and avoiding redundancy
· Consistent process and tools for ingestion, organization, and extraction to and from the Data Lake
· Talented pool of resources for addressing big data solutions
· Operational and development efficiencies
The following figure shows the four key subteams required to form a Data Lake COE:
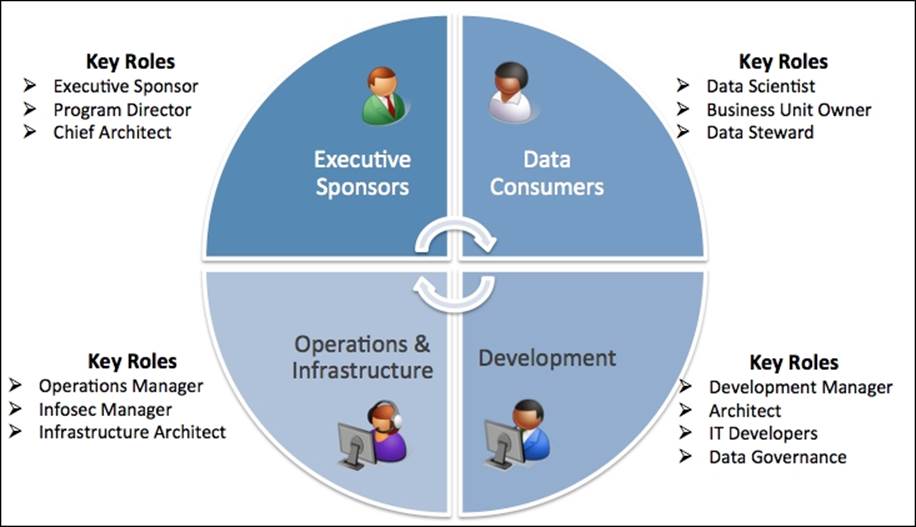
Let's review the responsibilities for each of the quarters of the preceding COE:
Executive sponsors
This group is the key for keeping the Data Lake initiative alive and consists of the following roles and responsibilities:
· Visionary director/vice president: This person believes in big data and is committed by funding the initiative.
· Program director: This person overlooks all the projects on boarding and consuming Data Lake.
· Chief technology architect: This person is responsible for the overall Data Lake architecture design and implementation that supports business strategy. He/she is also responsible for approving tools, technology, and frameworks, which form the foundation of a Data Lake.
Data Lake consumers
This group identifies the business problems that are appropriate for a Data Lake and has the following key roles and responsibilities:
· Line of business owners: They can identify use cases that are fit for the Data Lake and provide real return on investment to the organization
· Data scientists: They can demonstrate the real value of the information in the Data Lake using pattern detections, regression analysis, and other data mining techniques
Development
This group is the lifeline for the Data Lake responsible for actual delivery and has the following key roles and responsibilities:
· Development manager: This person manages delivery and builds the right talent pool for a successful implementation based on direction from the chief architect
· Solution architects: They design and implement solutions for specific projects within the timeframe
· IT developers: They build the applications using a common framework and tools
· Data governance team: This team defines and overlooks policies to ensure data quality and integrity of the Data Lake
Operations and infrastructure
This group ensures that the lights are always on for the Data Lake and has the following key roles and responsibilities:
· Operations manager: This person is responsible for the Data Lake availability, including the core platform and the applications built on top of it by meeting the business service level agreements (SLA)
· Information security (Infosec) manager: This person is responsible for protecting the organization's assets and ensures that the right folks have access to the right data
· Infrastructure architect: This person is responsible for the hardware and software strategy to keep up with the SLA and growth demands for a Data Lake
An organization that plans, forms, and integrates these various teams will reap the benefits for a successful Data Lake program that can scale to the business needs.
Architectural considerations
A modern Data Lake based on Hadoop is now mainstream technology and is used in several public sectors and enterprises; however, the ecosystem is still evolving and new tools and projects are released every quarter. In the next few sections, I will highlight the key architectural considerations to ensure that your Data Lake is well-planned and extensible for years to come.
Extensible and modular
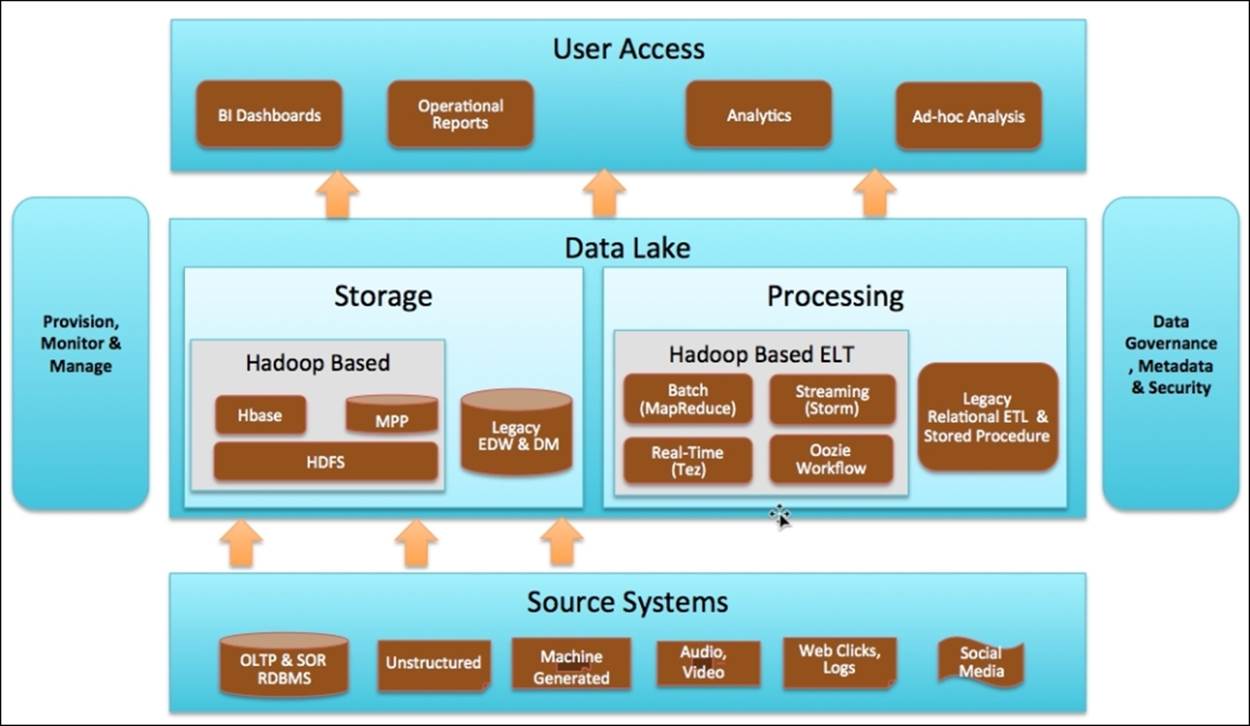
In Chapter 2, Enterprise Data Lake using HDInsight, we looked into the reference architecture for the next generation Data Lake, as shown in the following figure. Use this architecture to design and build reusable components and well-defined interfaces between each layer, which allows a pluggable model. Let's take an example for the processing layer if you start with Pig as your ELT and later decide to switch to a newer technology such as Spark; this change will be contained within the Processing layer of the stack and will not impact the other layers as long as the interface agreements between the layers are maintained.
The following are the other considerations while building components of the stack:
· Use of frameworks: As far as possible, use an existing framework instead of a custom-built framework, as this helps with long-term maintenance of the component.
· Reusable components: Every component that is designed should be implemented with a configuration that will improve the chances for reusability.
· Scalable: HDInsight and Hadoop are meant to scale and hence any application that is built for the Data Lake should be designed to scale and should be planned to be distributed.
· Support agile development: Agile-based development is the preferred approach for most organizations. This model allows natural evolution of components with features that get added incrementally at each sprint with an engaged end user, therebyimproving the chance of adoption.
Metadata-driven solution
For each component, a metadata-driven solution will help development and streamline operations. The following are a few examples of how a metadata-driven design will help the Data Lake development and operations:
· For all data sources, consider a metadata of database names, table names, file patterns, and frequency of ingestion. This can be used to build an automated registration process for onboarding new providers and also help the operations team prepare to troubleshoot ingestion issues.
· For all workflows that need to transform data in the Data Lake, consider a listing of workflows, workflow type batch or streaming, script location (MapReduce/Hive/Pig), parameters, scheduling, and logging. This will help developers manage and reuse code wherever applicable.
· For all scheduled extracts from the Data Lake, consider a metadata repository that has all the target system information such as FTP site/database name, credential if required, frequency, and contact information. This can be used to automate extraction processes and notify owners in case of an outage or impact to their process.
Integration strategy
Plan and build a good integration strategy for both upstream and downstream systems. Typical implementations involve an edge node that is dedicated for receiving files and ingests to HDInsight. For sending data out of HDInsight, you can set up scheduled workflows to export data out of the cluster to the external system or have the downstream system query HDFS via Hive/Pig.
Security
Hadoop has POSIX style filesystem security with three roles: users, groups, and others, and read/write/execute for each role. This allows the basic filesystem security that can be used to manage access by functional users defined per application. Hadoop does integrate with Kerberos for network-based authentication. If your data has personal identifiable information (PII), you can consider masking and/or tokenization to ensure that the information is protected.
Online resources
HDInsight has several resources available online for both beginners and advanced users. Here are some useful websites and blogs that will help you in building a modern Data Lake based on HDInsight:
|
URL |
Description |
|
http://azure.microsoft.com/en-us/documentation/articles/hdinsight-learn-map/ |
This is an HDInsight documentation with learning map-based on the following categories: · Managing cluster · Uploading data · Developing and running jobs · Real-world scenarios · Latest release notes |
|
http://azure.microsoft.com/en-us/documentation/services/hdinsight/ |
This is an HDInsight documentation with tutorials, videos, forums, and downloads |
|
http://feedback.azure.com/forums/217335-hdinsight |
This website has feedback from customers/developers and you can vote for topics to influence the product roadmap |
|
http://anindita9.wordpress.com/ |
Anindita Basak has regular updates on features and use cases on big data, machine learning, and analytics on Azure |
|
https://www.facebook.com/MicrosoftBigData |
This is a Facebook account that provides the latest updates on HDInsight |
|
http://blogs.msdn.com/b/cindygross/ |
This is Cindy Gross' blog, which has several examples on using HDInsight and BI |
|
https://github.com/Azure/azure-content |
This is a repository of sample code from various contributors on Azure, which you can further filter to articles related to HDInsight |
|
http://hortonworks.com/hdp/ |
This is the Hortonworks Data Platform, which is the underlying platform for HDInsight and it has great information for building a modern data architecture |
Summary
To gain a competitive edge over their peers, organizations are looking for technologies such as HDInsight to provide breakthrough insights from the vast amount of structured and unstructured data. While the promise and value of a modern Data Lake is clear, the journey requires proper planning of people, process, and technology. A key success factor is to build a Big Data Center of Excellence that can champion the cause and execute with skilled resource delivering solutions for real business problems.
These are exciting times for all of us working with big data and we have the opportunity to make a big difference leveraging the next generation Data Lake platform. Good luck on your journey!
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.