HDInsight Essentials, Second Edition (2015)
Chapter 8. HDInsight 3.1 New Features
The latest HDInsight release is 3.1 and it has several new features. This chapter focuses on key new features that provide significant value to Data Lake customers. The topics covered in this chapter are as follows:
· HBase: A low latency NoSQL database
· Storm: A real-time stream based processing system
· Tez: A high-performance data processing framework
For a complete list of what's new in HDInsight 3.1, visit the webpage at http://azure.microsoft.com/en-us/documentation/articles/hdinsight-component-versioning/.
HBase
HBase is an open source NoSQL database built on Hadoop that provides random, real-time read/write access to Data Lake. HBase is modeled after Google's Bigtable project where data is organized in column-oriented format. The following are the key features of HBase:
· Linear scalability: HBase leverages the cluster and hence is scalable like Hadoop
· Strictly consistent read and writes: HBase is optimized for read performance. For writes, HBase seeks to maintain consistency
· Automatic and configurable sharding: HBase uses row keys to guide data sharding and distribute data throughout the cluster
· Automatic recovery on failure: HBase automatically recovers when a node fails and reassigns the region server that was handling the data to another node
· Low latency queries: HBase provides random and real-time access to data by utilizing memory, bloom filters, and efficient storage mechanisms
HBase positioning in Data Lake and use cases
Let's first understand where HBase fits in the overall Data Lake architecture. HDInsight and Hadoop serve as the long-term data stores and are great for "write once and read many times" type of applications, specifically batch processing. Hadoop is not suited for interactive web applications that require random read/write support. HBase was designed to address these shortcomings of Hadoop and provides a low latency database that can be used for applications. HBase in Azure leverages Azure Blob storage as the underlying storage. The following figure shows the HBase and HDInsight architecture:
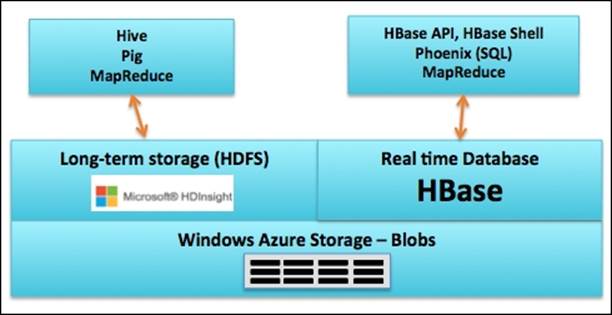
The following are some projects built on HBase:
· Facebook messaging platform switched from MySQL database to HBase for its scalability, performance and data consistency features. For further details, you can refer to https://www.facebook.com/notes/facebook-engineering/the-underlying-technology-of-messages/454991608919.
· Mendeley is a repository for research papers and is fully indexed and searchable. Researchers can read, annotate, and cite as they write new documents. The details about how they use HBase are available at http://www.slideshare.net/danharvey/hbase-at-mendeley.
· Veoh Networks uses HBase to store behavior data for 25 million unique visitors with real-time updates.
Provisioning HDInsight HBase cluster
This section describes how to provision an HBase cluster using the Azure portal. Perform the following steps to create a new HDInsight cluster with HBase enabled:
1. Login to Azure management portal and navigate to NEW | DATA SERVICES | HDINSIGHT | HBASE, as shown in the following screenshot:
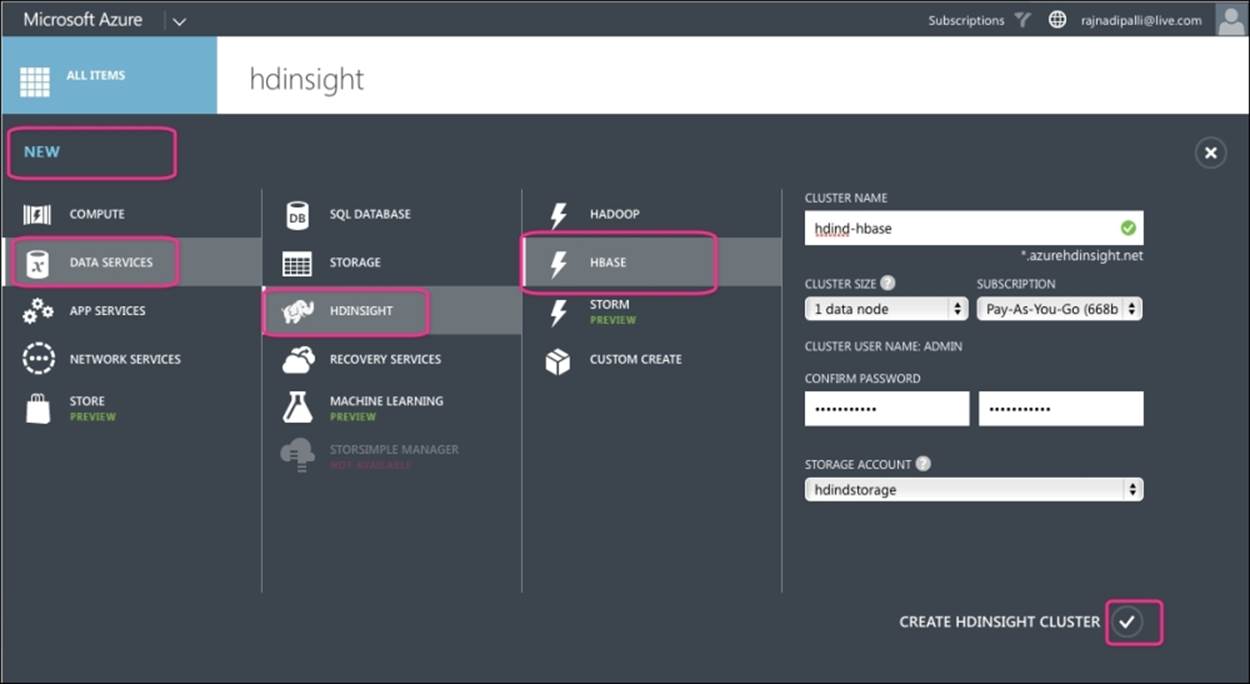
2. Enter the cluster name, cluster size, cluster password, and storage information.
3. Click on the check icon at the bottom-right corner and wait for the cluster to be provisioned.
Creating a sample HBase schema
To use HBase, you will be required to define a set of tables as well as the schemas for all the contained column families. The following section will show you how to create schemas for the airline on-time performance use case.
Designing the airline on-time performance table
An HBase table consists of a row and column like a traditional database table; however, the way it stores data is quite different. Each table must have a primary key and all queries to the table must use the primary key. Each row in the table can have any number of columns grouped together by column families.
Each column family is stored in a separate file and hence HBase is called a columnar database. HBase has a flexible schema that allows any number of columns to be added dynamically within the column families.
Let's take the example of our airline on-time performance data and see how it can be modeled for HBase data store. The row key will be a combination of Date-Carrier-FlightNumber making it easy to query. The following will be the column families:
· Origindetails: This will consist of the origin airport, origin state, departure time, and departure delay columns
· Destinationdetails: This will consist of the destination airport, destination state, arrival time, and arrival delay columns
Connecting to HBase using the HBase shell
The following are the steps to launch the HBase shell:
1. Enable remote desktop (RDP) connection to the new HDInsight cluster provisioned in the previous section using the Configuration tab from Azure management portal.
2. Next, connect to the head node using the RDP application and launch the Hadoop Command Line from the desktop.
3. Next, change the directory to the HBase bin directory; in the current cluster, it is C:\apps\dist\hbase-0.98.0.2.1.6.0-2103-hadoop2\bin.
4. Next, to launch the HBase shell, type in hbase shell, which will get you to the HBase prompt.
Creating an HBase table
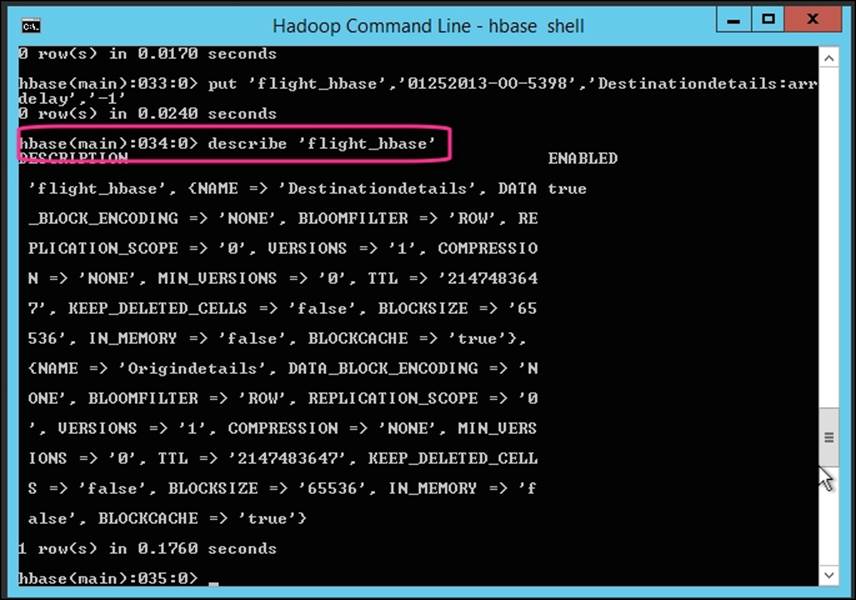
The following commands will create a new table, flight_hbase, and describe the structure of the table:
hbase> create 'flight_hbase','Origindetails','Destinationdetails'
hbase> describe 'flight_hbase'
The following screenshot shows the results of the describe command:
Loading data to the HBase table
The following commands will insert records to the flight_hbase table:
put 'flight_hbase','01272013-UA-1499','Origindetails:originairportabr','IAH'
put 'flight_hbase','01272013-UA-1499','Origindetails:originstateabr','TX'
put 'flight_hbase','01272013-UA-1499','Origindetails:deptime','1858'
put 'flight_hbase','01272013-UA-1499','Origindetails:depdelay','-3'
put 'flight_hbase','01272013-UA-1499','Destinationdetails:destairportabr','MSP'
put 'flight_hbase','01272013-UA-1499','Destinationdetails:deststateabr','MN'
put 'flight_hbase','01272013-UA-1499','Destinationdetails:arrtime','132'
put 'flight_hbase','01272013-UA-1499','Destinationdetails:arrdelay','-27'
Querying data from the HBase table
To query the table data, the HBase shell has two options: scan that gets all the records and get that can be used to query a specific row based on the row key. The following are the commands:
scan 'flight_hbase'
get 'flight_hbase', '01272013-UA-1499'
HBase additional information
In this section about HBase, we reviewed how to provision an HDInsight HBase cluster, create a table, insert data, and retrieve data from HBase using HBase shell. To get additional information about HDInsight and HBase, review the web page athttp://azure.microsoft.com/en-us/documentation/articles/hdinsight-hbase-overview/.
Storm
Apache Storm is a scalable, fault-tolerant, distributed, real-time computation system. Storm makes it easy to reliably process streams of data. Storm has many use cases: real-time analytics, online machine learning, continuous computation, ETL, and others. Storm can process over 1 million tuples per second per node. The following are the key features of Storm:
· Real-time computation
· Guarantees data will be processed
· Scalable
· Fault tolerant
Note
At the time this book was authored, Storm is a preview feature in Azure HDInsight.
Storm positioning in Data Lake
Hadoop and MapReduce provide a great batch processing capability. HBase provides the low latency store. Storm provides low latency transformation so that real-time processing can be performed on the raw data.
Let's consider our airline on-time performance use case. In the previous chapters, we saw how to ingest, transform, and analyze historical data using batch processing. With Storm, we can now process real-time feeds and analyze both historical and real time at the same time. The following figure shows the data flow from source to analysis:
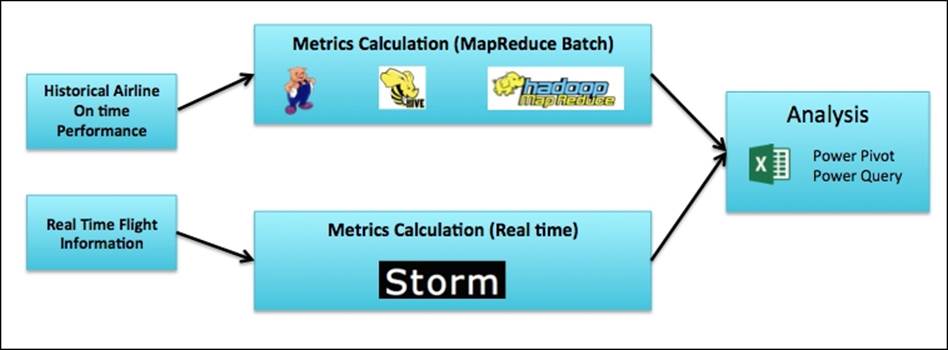
Storm key concepts
A Storm cluster is similar to a Hadoop cluster and has a master and several worker nodes. In a Storm cluster, "topologies" run similar to "MapReduce" that runs on a Hadoop cluster. One key difference is that a MapReduce job does eventually finish but a Storm topology is always running and processing messages.
The master/head node of Storm is called Nimbus and is responsible for distributing code around the various worker nodes, which is similar to YARN ResourceManager. HDInsight provides two Nimbus nodes so that there is no single point of failure for the Storm cluster. Each worker node runs a supervisor that is responsible for starting worker processes on the node.
A topology is a graph of computation where each node contains the processing logic and the links between nodes, which dictate how data is transferred between the nodes. A topology is distributed across several worker processes and will continue to run unless you stop it.
To build a topology, we need to start with a stream, which is an unbounded sequence of tuples. For example, a stream of Twitter feeds. A spout is a source of streams. For example, a spout might connect to Twitter API and emit a stream of tweets. A bolt can consume a number of input streams, process, and emit new streams.
This network of spouts and bolts are packaged into a topology. The following figure shows a sample topology:
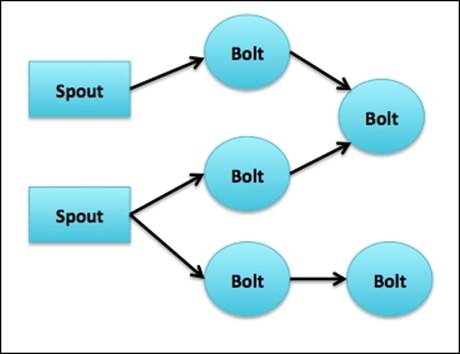
Provisioning HDInsight Storm cluster
This section describes how to provision an HDInsight Storm cluster using Azure portal. Perform the following steps to create a new HDInsight cluster with Storm:
1. Login to Azure management portal and navigate to NEW | DATA SERVICES | HDINSIGHT | STORM, as shown in the following screenshot:
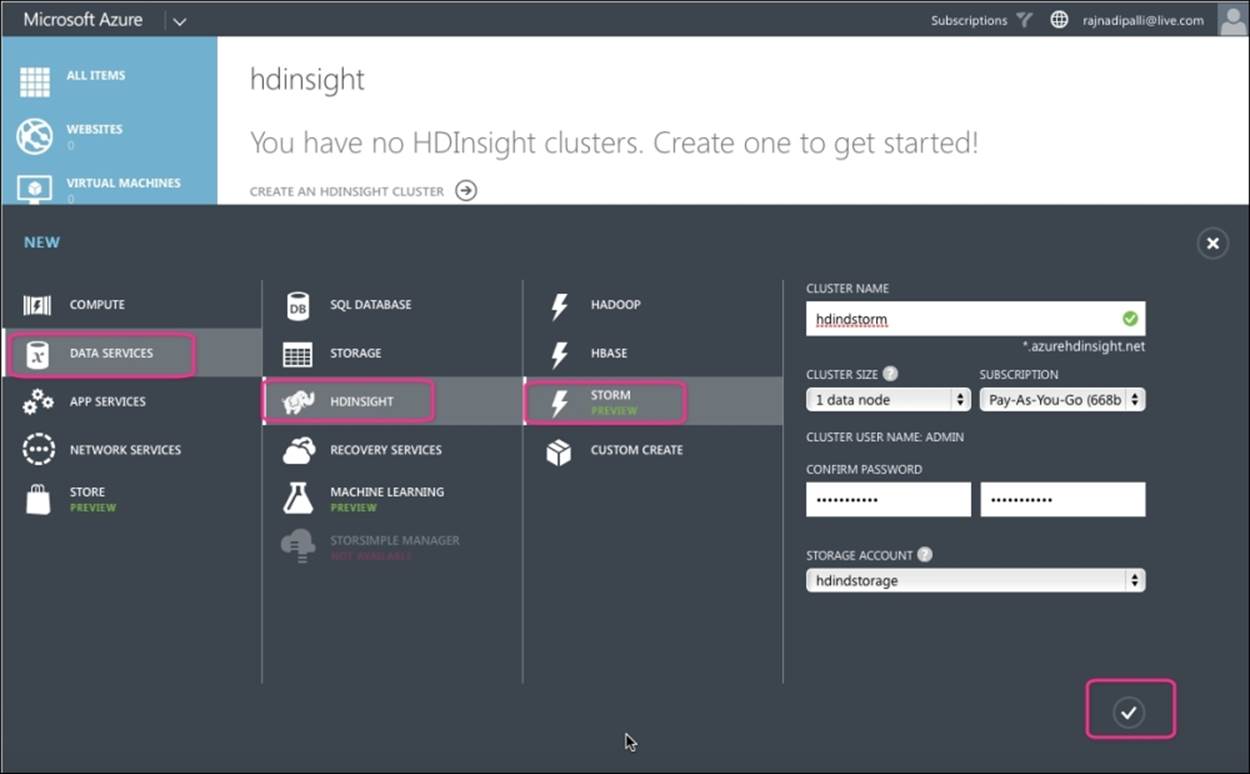
2. Enter the cluster name, cluster size, cluster password, and storage information.
3. Click on the check icon at the bottom-right corner and wait for the cluster to be provisioned.
Running a sample Storm topology
In this section, we will review how to run a sample Storm topology that is preinstalled with HDInsight.
Connecting to Storm using Storm shell
The following are the steps to launch the Storm shell:
1. Enable remote desktop (RDP) connection to the new HDInsight cluster provisioned in the previous section using the Configuration tab from Azure management portal.
2. Next, connect to the head node using the RDP application and launch the Hadoop Command Line from the desktop.
3. Click on the Storm Command Line shortcut from the desktop.
4. Navigate to the bin directory and then you can list the commands by typing the word storm without any parameters. The following is a screenshot of the various options seen after you type this command:
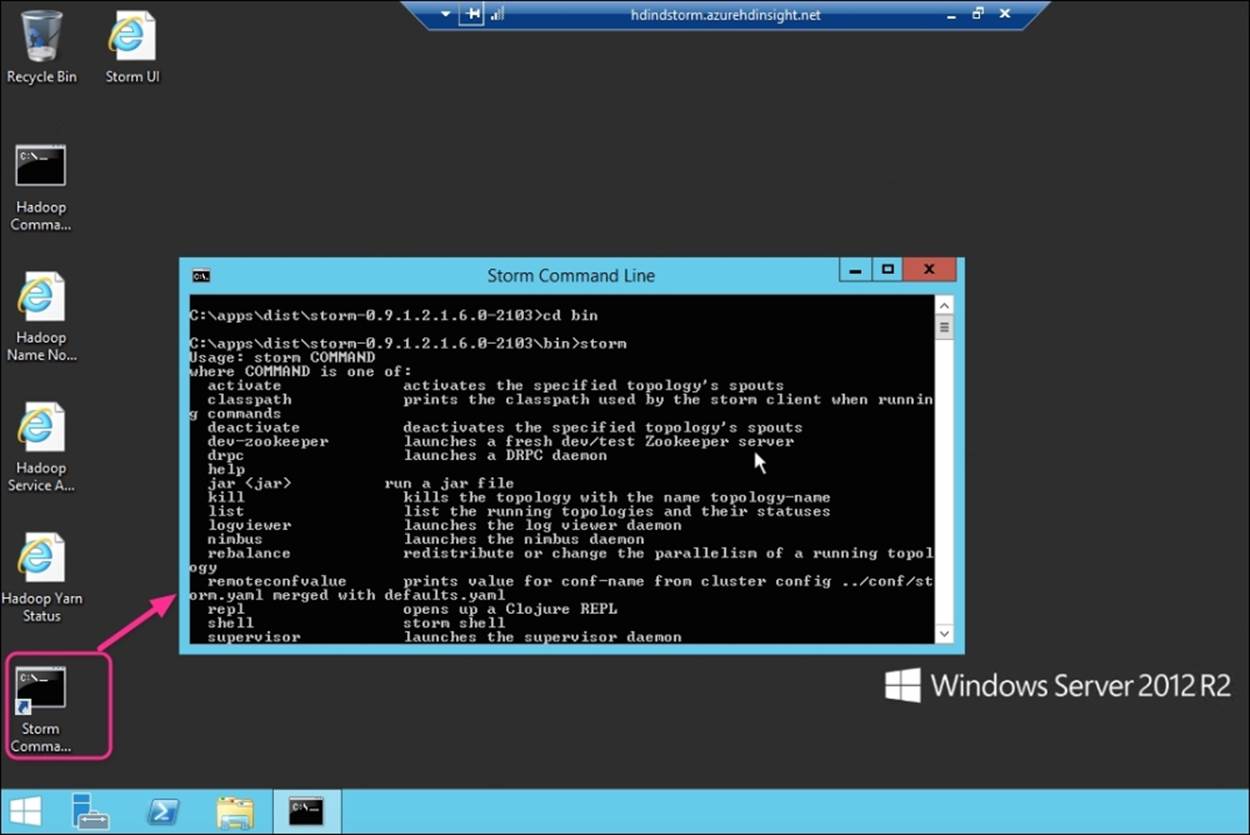
Running the Storm Wordcount topology
HDInsight comes packaged with a working example of Storm, which is the basic Wordcount example. To start this Storm topology, enter the following commands from the Storm Command Line.
C:\apps\dist\storm-0.9.1.2.1.6.0-2013\bin>storm jar ..\contrib\storm-starter\storm-starter-0.9.1.2.1.6.0-2103-jar-with-dependencies.jar storm.starter.WordCountTopology wordcount
Once this topology starts, there is no message on the command line as it is running in the background.
Monitoring status of the Wordcount topology
For the sample Wordcount topology that we started in the previous step, HDInsight provides a web page to show the status. Perform the following steps to get to the logs of the topology:
1. From the remote desktop, double-click on the Storm UI shortcut provided on the desktop; this will bring up the Storm UI main dashboard. Next, under the Topology summary section, click on the wordcount link, which will show the details of that specific topology:

2. Next, under the Spouts (All time) section, click on the spout link, which will show the details of that specific spout, as shown in the following screenshot:
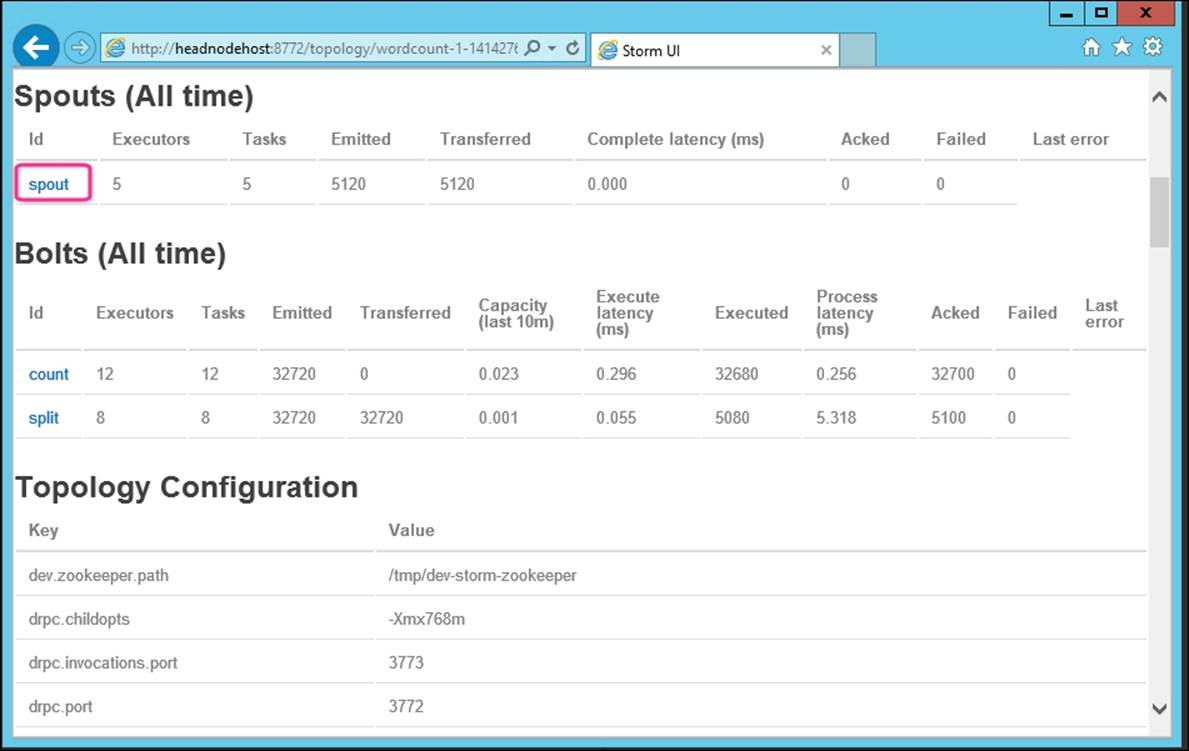
3. Next, from the Spout details page, scroll to the Executors (All time) section and click on one of the ports, as shown in the following screenshot:
4. After you click on the executor link, you will see the log information from the spout. In this Wordcount sample, the spouts emits sentences such as "snow white and the seven dwarfs", which are then split into words by a bolt, and then counted by another bolt. These sentences will keep changing based on what the spout emits. The following is a screenshot of the log:

Additional information on Storm
Storm can consume data from services such as Azure Service Bus queues and Event Hubs. Additionally, it can also integrate with Apache Kafka, which is a high-throughput distributed messaging system. For further information on Storm and Kafka, you can visit the following websites:
· http://kafka.apache.org/
· http://azure.microsoft.com/en-us/documentation/articles/hdinsight-storm-overview/
· http://azure.microsoft.com/en-us/documentation/articles/hdinsight-storm-sensor-data-analysis/
· http://azure.microsoft.com/en-us/documentation/articles/hdinsight-hadoop-storm-scpdotnet-csharp-develop-streaming-data-processing-application/
Apache Tez
Apache Tez is an extensible framework for YARN-based high-performance data processing applications. Projects such as Hive and Pig can leverage this framework for improved performance and faster response times and they can be used for interactive needs.
HDInsight 3.1 is capable of running Hive queries using Tez, which provides substantial performance improvements over MapReduce. By default, Tez is not enabled for Hive and can be enabled, as shown in the following code snippet:
set hive.execution_engine=tez;
select flightyear, flightquarter, flightmonth ,
regexp_replace(uniquecarrier,"\"","") as airlinecarrier, avg(depdelay) as avgdepdelay
from airline_otp_refined
group by flightyear, flightquarter, flightmonth ,
regexp_replace(uniquecarrier,"\"","");
Summary
The Hadoop ecosystem and HDInsight platform are constantly evolving and new components are being added with every release that enable new use cases and improved experience for data consumers. In this chapter, we reviewed HBase, Storm, and Tez. HBase provides a low latency database that currently powers applications such as Facebook messaging. Storm provides real-time data processing capabilities and complements the batch processing with MapReduce. Tez is the next generation MapReduce-like framework built on top of YARN projects such as Hive and Pig can be leveraged for improved performance.
In the next chapter, we will review the tips and architectural considerations for starting a new Data Lake initiative.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.