High Performance MySQL (2012)
Chapter 10. Replication
MySQL’s built-in replication is the foundation for building large, high-performance applications on top of MySQL, using the so-called “scale-out” architecture. Replication lets you configure one or more servers as replicas[144] of another server, keeping their data synchronized with the master copy. This is not just useful for high-performance applications—it is also the cornerstone of many strategies for high availability, scalability, disaster recovery, backups, analysis, data warehousing, and many other tasks. In fact, scalability and high availability are related topics, and we’ll be weaving these themes through this chapter and the next two.
In this chapter, we examine all aspects of replication. We begin with an overview of how it works, then look at basic server setup, designing more advanced replication configurations, and managing and optimizing your replicated servers. Although we generally focus a lot on performance in this book, we are equally concerned with correctness and reliability when it comes to replication, so’ll we show you how replication can fail and how to make it work well.
Replication Overview
The basic problem replication solves is keeping one server’s data synchronized with another’s. Many replicas can connect to a single master and stay in sync with it, and a replica can, in turn, act as a master. You can arrange masters and replicas in many different ways.
MySQL supports two kinds of replication: statement-based replication and row-based replication. Statement-based (or “logical”) replication has been available since MySQL 3.23. Row-based replication was added in MySQL 5.1. Both kinds work by recording changes in the master’s binary log[145] and replaying the log on the replica, and both are asynchronous—that is, the replica’s copy of the data isn’t guaranteed to be up-to-date at any given instant. There are no guarantees as to how large the latency on the replica might be. Large queries can make the replica fall seconds, minutes, or even hours behind the master.
MySQL’s replication is mostly backward-compatible. That is, a newer server can usually be a replica of an older server without trouble. However, older versions of the server are often unable to serve as replicas of newer versions: they might not understand new features or SQL syntax the newer server uses, and there might be differences in the file formats replication uses. For example, you can’t replicate from a MySQL 5.1 master to a MySQL 4.0 replica. It’s a good idea to test your replication setup before upgrading from one major or minor version to another, such as from 4.1 to 5.0, or 5.1 to 5.5. Upgrades within a minor version, such as from 5.1.51 to 5.1.58, are usually compatible—read the changelog to find out exactly what changed from version to version.
Replication generally doesn’t add much overhead on the master. It requires binary logging to be enabled on the master, which can have significant overhead, but you need that for proper backups and point-in-time recovery anyway. Aside from binary logging, each attached replica also adds a little load (mostly network I/O) on the master during normal operation. If replicas are reading old binary logs from the master, rather than just following along with the newest events, the overhead can be a lot higher due to the I/O required to read the old logs. This process can also cause some mutex contention that hinders transaction commits. Finally, if you are replicating a very high-throughput workload (say, 5,000 or more transactions per second) to many replicas, the overhead of waking up all the replica threads to send them the events can add up.
Replication is relatively good for scaling reads, which you can direct to a replica, but it’s not a good way to scale writes unless you design it right. Attaching many replicas to a master simply causes the writes to be done many times, once on each replica. The entire system is limited to the number of writes the weakest part can perform.
Replication is also wasteful with more than a few replicas, because it essentially duplicates a lot of data needlessly. For example, a single master with 10 replicas has 11 copies of the same data and duplicates most of the same data in 11 different caches. This is analogous to 11-way RAID 1 at the server level. This is not an economical use of hardware, yet it’s surprisingly common to see this type of replication setup. We discuss ways to alleviate this problem throughout the chapter.
Problems Solved by Replication
Here are some of the more common uses for replication:
Data distribution
MySQL’s replication is usually not very bandwidth-intensive, although, as we’ll see later, the row-based replication introduced in MySQL 5.1 can use much more bandwidth than the more traditional statement-based replication. You can also stop and start it at will. Thus, it’s useful for maintaining a copy of your data in a geographically distant location, such as a different data center. The distant replica can even work with a connection that’s intermittent (intentionally or otherwise). However, if you want your replicas to have very low replication lag, you’ll need a stable, low-latency link.
Load balancing
MySQL replication can help you distribute read queries across several servers, which works very well for read-intensive applications. You can do basic load balancing with a few simple code changes. On a small scale, you can use simplistic approaches such as hardcoded hostnames or round-robin DNS (which points a single hostname to multiple IP addresses). You can also take more sophisticated approaches. Standard load-balancing solutions, such as network load-balancing products, can work well for distributing load among MySQL servers. The Linux Virtual Server (LVS) project also works well. We cover load balancing in Chapter 11.
Backups
Replication is a valuable technique for helping with backups. However, a replica is neither a backup nor a substitute for backups.
High availability and failover
Replication can help avoid making MySQL a single point of failure in your application. A good failover system involving replication can help reduce downtime significantly. We cover failover in Chapter 12.
Testing MySQL upgrades
It’s common practice to set up a replica with an upgraded MySQL version and use it to ensure that your queries work as expected, before upgrading every instance.
How Replication Works
Before we get into the details of setting up replication, let’s look at how MySQL actually replicates data. At a high level, replication is a simple three-part process:
1. The master records changes to its data in its binary log. (These records are called binary log events.)
2. The replica copies the master’s binary log events to its relay log.
3. The replica replays the events in the relay log, applying the changes to its own data.
That’s just the overview—each of those steps is quite complex. Figure 10-1 illustrates replication in more detail.
The first part of the process is binary logging on the master (we’ll show you how to set this up a bit later). Just before each transaction that updates data completes on the master, the master records the changes in its binary log. MySQL writes transactions serially in the binary log, even if the statements in the transactions were interleaved during execution. After writing the events to the binary log, the master tells the storage engine(s) to commit the transactions.
![How MySQL replication worksComment [Baron1]: All figures in this chapter need to be edited to replace “slave” with “replica.”](high.files/image031.jpg)
Figure 10-1. How MySQL replication works
The next step is for the replica to copy the master’s binary log to its own hard drive, into the so-called relay log. To begin, it starts a worker thread, called the I/O slave thread. The I/O thread opens an ordinary client connection to the master, then starts a special binlog dump process (there is no corresponding SQL command). The binlog dump process reads events from the master’s binary log. It doesn’t poll for events. If it catches up to the master, it goes to sleep and waits for the master to signal it when there are new events. The I/O thread writes the events to the replica’s relay log.
WARNING
Prior to MySQL 4.0, replication worked quite differently in many ways. For example, MySQL’s first replication functionality didn’t use a relay log, so replication used only two threads, not three. Most people are running more recent versions of the server, so we won’t mention any further details about very old versions of MySQL in this chapter.
The SQL slave thread handles the last part of the process. This thread reads and replays events from the relay log, thus updating the replica’s data to match the master’s. As long as this thread keeps up with the I/O thread, the relay log usually stays in the operating system’s cache, so relay logs have very low overhead. The events the SQL thread executes can optionally go into the replica’s own binary log, which is useful for scenarios we mention later in this chapter.
Figure 10-1 showed only the two replication threads that run on the replica, but there’s also a thread on the master: like any connection to a MySQL server, the connection that the replica opens to the master starts a thread on the master.
This replication architecture decouples the processes of fetching and replaying events on the replica, which allows them to be asynchronous. That is, the I/O thread can work independently of the SQL thread. It also places constraints on the replication process, the most important of which is that replication is serialized on the replica. This means updates that might have run in parallel (in different threads) on the master cannot be parallelized on the replica, because they’re executed in a single thread. As we’ll see later, this is a performance bottleneck for many workloads. There are some solutions to this, but most users are still subject to the single-threaded constraint.
[144] You might see replicas referred to as “slaves.” We avoid this term wherever possible.
[145] If you’re new to the binary log, you can find more information in Chapter 8, the rest of this chapter, and Chapter 15.
Setting Up Replication
Setting up replication is a fairly simple process in MySQL, but there are many variations on the basic steps, depending on the scenario. The most basic scenario is a freshly installed master and replica. At a high level, the process is as follows:
1. Set up replication accounts on each[146] server.
2. Configure the master and replica.
3. Instruct the replica to connect to and replicate from the master.
This assumes that many default settings will suffice, which is true if you’ve just installed the master and replica and they have the same data (the default mysql database). We show you here how to do each step in turn, assuming your servers are called server1 (IP address 192.168.0.1) andserver2 (IP address 192.168.0.2). We then explain how to initialize a replica from a server that’s already up and running and explore the recommended replication configuration.
Creating Replication Accounts
MySQL has a few special privileges that let the replication processes run. The slave I/O thread, which runs on the replica, makes a TCP/IP connection to the master. This means you must create a user account on the master and give it the proper privileges, so the I/O thread can connect as that user and read the master’s binary log. Here’s how to create that user account, which we’ll call repl:
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.*
-> TO repl@'192.168.0.%' IDENTIFIED BY 'p4ssword',;
We create this user account on both the master and the replica. Note that we restricted the user to the local network, because the replication account has the ability to read all changes to the server, which makes it a privileged account. (Even though it has no ability to SELECT or change data, it can still see some of the data in the binary logs.)
NOTE
The replication user actually needs only the REPLICATION SLAVE privilege on the master and doesn’t really need the REPLICATION CLIENT privilege on either server. So why did we grant these privileges on both servers? We’re keeping things simple, actually. There are two reasons:
§ The account you use to monitor and manage replication will need the REPLICATION CLIENT privilege, and it’s easier to use the same account for both purposes (rather than creating a separate user account for this purpose).
§ If you set up the account on the master and then clone the replica from it, the replica will be set up correctly to act as a master, in case you want the replica and master to switch roles.
Configuring the Master and Replica
The next step is to enable a few settings on the master, which we assume is named server1. You need to enable binary logging and specify a server ID. Enter (or verify the presence of) the following lines in the master’s my.cnf file:
log_bin = mysql-bin
server_id = 10
The exact values are up to you. We’re taking the simplest route here, but you can do something more elaborate.
You must explicitly specify a unique server ID. We chose to use 10 instead of 1, because 1 is the default value a server will typically choose when no value is specified. (This is version-dependent; some MySQL versions just won’t work at all.) Therefore, using 1 can easily cause confusion and conflicts with servers that have no explicit server IDs. A common practice is to use the final octet of the server’s IP address, assuming it doesn’t change and is unique (i.e., the servers belong to only one subnet). You should choose some convention that makes sense to you and follow it.
If binary logging wasn’t already specified in the master’s configuration file, you’ll need to restart MySQL. To verify that the binary log file is created on the master, run SHOW MASTER STATUS and check that you get output similar to the following. MySQL will append some digits to the filename, so you won’t see a file with the exact name you specified:
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 98 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
The replica requires a configuration in its my.cnf file similar to the master, and you’ll also need to restart MySQL on the replica:
log_bin = mysql-bin
server_id = 2
relay_log = /var/lib/mysql/mysql-relay-bin
log_slave_updates = 1
read_only = 1
Several of these options are not technically necessary, and for some we’re just making defaults explicit. In reality, only the server_id parameter is required on a replica, but we enabled log_bin too, and we gave the binary log file an explicit name. By default it is named after the server’s hostname, but that can cause problems if the hostname changes. We are using the same name for the master and replicas to keep things simple, but you can choose differently if you like.
We also added two other optional configuration parameters: relay_log (to specify the location and name of the relay log) and log_slave_updates (to make the replica log the replicated events to its own binary log). The latter option causes extra work for the replicas, but as you’ll see later, we have good reasons for adding these optional settings on every replica.
Some people enable just the binary log and not log_slave_updates, so they can see whether anything, such as a misconfigured application, is modifying data on the replica. If possible, it’s better to use the read_only configuration setting, which prevents anything but specially privileged threads from changing data. (Don’t grant your users more privileges than they need!) However, read_only is often not practical, especially for applications that need to be able to create tables on replicas.
WARNING
Don’t place replication configuration options such as master_host and master_port in the replica’s my.cnf file. This is an old, deprecated way to configure a replica. It can cause problems and has no benefits.
Starting the Replica
The next step is to tell the replica how to connect to the master and begin replaying its binary logs. You should not use the my.cnf file for this; instead, use the CHANGE MASTER TO statement. This statement replaces the corresponding my.cnf settings completely. It also lets you point the replica at a different master in the future, without stopping the server. Here’s the basic statement you’ll need to run on the replica to start replication:
mysql> CHANGE MASTER TO MASTER_HOST='server1',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='p4ssword',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=0;
The MASTER_LOG_POS parameter is set to 0 because this is the beginning of the log. After you run this, you should be able to inspect the output of SHOW SLAVE STATUS and see that the replica’s settings are correct:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 4
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: No
Slave_SQL_Running: No
...omitted...
Seconds_Behind_Master: NULL
The Slave_IO_State, Slave_IO_Running, and Slave_SQL_Running columns show that the replication processes are not running. Astute readers will also notice that the log position is 4 instead of 0. That’s because 0 isn’t really a log position; it just means “at the start of the log file.” MySQL knows that the first event is really at position 4.[147]
To start replication, run the following command:
mysql> START SLAVE;
This command should produce no errors or output. Now inspect SHOW SLAVE STATUS again:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 164
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 164
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...omitted...
Seconds_Behind_Master: 0
Notice that the slave I/O and SQL threads are both running, and Seconds_Behind_Master is no longer NULL (we’ll examine what Seconds_Behind_Master means later). The I/O thread is waiting for an event from the master, which means it has fetched all of the master’s binary logs. The log positions have incremented, which means some events have been fetched and executed (your results will vary). If you make a change on the master, you should see the various file and position settings increment on the replica. You should also see the changes in the databases on the replica!
You will also be able to see the replication threads in the process list on both the master and the replica. On the master, you should see a connection created by the replica’s I/O thread:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 55
User: repl
Host: replica1.webcluster_1:54813
db: NULL
Command: Binlog Dump
Time: 610237
State: Has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
On the replica, you should see two threads. One is the I/O thread, and the other is the SQL thread:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 1
User: system user
Host:
db: NULL
Command: Connect
Time: 611116
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 2
User: system user
Host:
db: NULL
Command: Connect
Time: 33
State: Has read all relay log; waiting for the slave I/O thread to update it
Info: NULL
The sample output we’ve shown comes from servers that have been running for a long time, which is why the I/O thread’s Time column on the master and the replica has a large value. The SQL thread has been idle for 33 seconds on the replica, which means no events have been replayed for 33 seconds.
These processes will always run under the “system user” user account, but the other column values might vary. For example, when the SQL thread is replaying an event on the replica, the Info column will show the query it is executing.
NOTE
If you just want to experiment with MySQL replication, Giuseppe Maxia’s MySQL Sandbox script (http://mysqlsandbox.net) can quickly start a throwaway installation from a freshly downloaded MySQL tarball. It takes just a few keystrokes and about 15 seconds to get a running master and two running replicas:
$ ./set_replication.pl /path/to/mysql-tarball.tar.gz
Initializing a Replica from Another Server
The previous setup instructions assumed that you started the master and replica with the default initial data after a fresh installation, so you implicitly had the same data on both servers and you knew the master’s binary log coordinates. This is not typically the case. You’ll usually have a master that has been up and running for some time, and you’ll want to synchronize a freshly installed replica with the master, even though it doesn’t have the master’s data.
There are several ways to initialize, or “clone,” a replica from another server. These include copying data from the master, cloning a replica from another replica, and starting a replica from a recent backup. You need three things to synchronize a replica with a master:
§ A snapshot of the master’s data at some point in time.
§ The master’s current log file, and the byte offset within that log at the exact point in time you took the snapshot. We refer to these two values as the log file coordinates, because together they identify a binary log position. You can find the master’s log file coordinates with the SHOW MASTER STATUS command.
§ The master’s binary log files from that time to the present.
Here are some ways to clone a replica from another server:
With a cold copy
One of the most basic ways to start a replica is to shut down the master-to-be and copy its files to the replica (see Appendix C for more on how to copy files efficiently). You can then start the master again, which begins a new binary log, and use CHANGE MASTER TO to start the replica at the beginning of that binary log. The disadvantage of this technique is obvious: you need to shut down the master while you make the copy.
With a warm copy
If you use only MyISAM tables, you can use mysqlhotcopy or rsync to copy files while the server is still running. See Chapter 15 for details.
Using mysqldump
If you use only InnoDB tables, you can use the following command to dump everything from the master, load it all into the replica, and change the replica’s coordinates to the corresponding position in the master’s binary log:
$ mysqldump --single-transaction --all-databases --master-data=1--host=server1 \
| mysql --host=server2
The --single-transaction option causes the dump to read the data as it existed at the beginning of the transaction. If you’re not using transactional tables, you can use the --lock-all-tables option to get a consistent dump of all tables.
With a snapshot or backup
As long as you know the corresponding binary log coordinates, you can use a snapshot from the master or a backup to initialize the replica (if you use a backup, this method requires that you’ve kept all of the master’s binary logs since the time of the backup). Just restore the backup or snapshot onto the replica, then use the appropriate binary log coordinates in CHANGE MASTER TO. There’s more detail about this in Chapter 15. You can use LVM snapshots, SAN snapshots, EBS snapshots—any snapshot will do.
With Percona XtraBackup
Percona XtraBackup is an open source hot backup tool we introduced several years ago. It can make backups without blocking the server’s operation, which makes it the cat’s meow for setting up replicas. You can create replicas by cloning the master, or by cloning an existing replica.
We show more details about how to use Percona XtraBackup in Chapter 15, but we’ll mention the relevant bits of functionality here. Just create the backup (either from the master, or from an existing replica), and restore it to the target machine. Then look in the backup for the correct position to start replication:
§ If you took the backup from the new replica’s master, you can start replication from the position mentioned in the xtrabackup_binlog_pos_innodb file.
§ If you took the backup from another replica, you can start replication from the position mentioned in the xtrabackup_slave_info file.
Using InnoDB Hot Backup or MySQL Enterprise Backup, both covered in Chapter 15, is another good way to initialize a replica.
From another replica
You can use any of the snapshot or copy techniques just mentioned to clone one replica from another. However, if you use mysqldump, the --master-data option doesn’t work.
Also, instead of using SHOW MASTER STATUS to get the master’s binary log coordinates, you’ll need to use SHOW SLAVE STATUS to find the position at which the replica was executing on the master when you snapshotted it.
The biggest disadvantage of cloning one replica from another is that if your replica has become out of sync with the master, you’ll be cloning bad data.
WARNING
Don’t use LOAD DATA FROM MASTER or LOAD TABLE FROM MASTER! They are obsolete, slow, and very dangerous. They also work only with MyISAM.
No matter what technique you choose, get comfortable with it, and document or script it. You will probably be doing it more than once, and you need to be able to do it in a pinch if something goes wrong.
Recommended Replication Configuration
There are many replication parameters, and most of them have at least some effect on data safety and performance. We explain later which rules to break and when. In this section, we show a recommended, “safe” replication configuration that minimizes the opportunities for problems.
The most important setting for binary logging on the master is sync_binlog:
sync_binlog=1
This makes MySQL synchronize the binary log’s contents to disk each time it commits a transaction, so you don’t lose log events if there’s a crash. If you disable this option, the server will do a little less work, but binary log entries could be corrupted or missing after a server crash. On a replica that doesn’t need to act as a master, this option creates unnecessary overhead. It applies only to the binary log, not to the relay log.
We also recommend using InnoDB if you can’t tolerate corrupt tables after a crash. MyISAM is fine if table corruption isn’t a big deal, but MyISAM tables are likely to be in an inconsistent state after a replica server crashes. Chances are good that a statement will have been incompletely applied to one or more tables, and the data will be inconsistent even after you’ve repaired the tables.
If you use InnoDB, we strongly recommend setting the following options on the master:
innodb_flush_logs_at_trx_commit=1 # Flush every log write
innodb_support_xa=1 # MySQL 5.0 and newer only
innodb_safe_binlog # MySQL 4.1 only, roughly equivalent to
# innodb_support_xa
These are the default settings in MySQL 5.0 and newer. We also recommend specifying a binary log base name explicitly, to create uniform binary log names on all servers and prevent changes in binary log names if the server’s hostname changes. You might not think that it’s a problem to have binary logs named after the server’s hostname automatically, but our experience is that it causes a lot of trouble when moving data between servers, cloning new replicas, and restoring backups, and in lots of other ways you wouldn’t expect. To avoid this, specify an argument to thelog_bin option, optionally with an absolute path, but certainly with the base name (as shown earlier in this chapter):
log_bin=/var/lib/mysql/mysql-bin # Good; specifies a path and base name
#log_bin # Bad; base name will be server’s hostname
On the replica, we also recommend enabling the following configuration options. We also recommend using an absolute path for the relay log location:
relay_log=/path/to/logs/relay-bin
skip_slave_start
read_only
The relay_log option prevents hostname-based relay log file names, which avoids the same problems we mentioned earlier that can happen on the master, and giving the absolute path to the logs avoids bugs in various versions of MySQL that can cause the relay logs to be created in an unexpected location. The skip_slave_start option will prevent the replica from starting automatically after a crash, which can give you a chance to repair a server if it has problems. If the replica starts automatically after a crash and is in an inconsistent state, it might cause so much additional corruption that you’ll have to throw away its data and start fresh.
The read_only option prevents most users from changing non-temporary tables. The exceptions are the replication SQL thread and threads with the SUPER privilege. This is one of the many reasons you should try to avoid giving your normal accounts the SUPER privilege.
Even if you’ve enabled all the options we’ve suggested, a replica can easily break after a crash, because the relay logs and master.info file aren’t crash-safe. They’re not even flushed to disk by default, and there’s no configuration option to control that behavior until MySQL 5.5. You should enable those options if you’re using MySQL 5.5 and if you don’t mind the performance overhead of the extra fsync() calls:
sync_master_info = 1
sync_relay_log = 1
sync_relay_log_info = 1
If a replica is very far behind its master, the slave I/O thread can write many relay logs. The replication SQL thread will remove them as soon as it finishes replaying them (you can change this with the relay_log_purge option), but if it is running far behind, the I/O thread could actually fill up the disk. The solution to this problem is the relay_log_space_limit configuration variable. If the total size of all the relay logs grows larger than this variable’s size, the I/O thread will stop and wait for the SQL thread to free up some more disk space.
Although this sounds nice, it can actually be a hidden problem. If the replica hasn’t fetched all the relay logs from the master, those logs might be lost forever if the master crashes. And this option has had some bugs in the past, and seems to be uncommonly used, so the risk of bugs is higher when you use it. Unless you’re worried about disk space, it’s probably a good idea to let the replica use as much space as it needs for relay logs. That’s why we haven’t included the relay_log_space_limit setting in our recommended configuration.
[146] This isn’t strictly necessary, but it’s something we recommend; we’ll explain later.
[147] Actually, as you can see in the earlier output from SHOW MASTER STATUS, it’s really at position 98. The master and s/slave/replica/ will work that out together once the s/slave/replica/ connects to the master, which hasn’t yet happened.
Replication Under the Hood
Now that we’ve explained some replication basics, let’s dive deeper into it. Let’s take a look at how replication really works, see what strengths and weaknesses it has as a result, and examine some more advanced replication configuration options.
Statement-Based Replication
MySQL 5.0 and earlier support only statement-based replication (also called logical replication). This is unusual in the database world. Statement-based replication works by recording the query that changed the data on the master. When the replica reads the event from the relay log and executes it, it is reexecuting the actual SQL query that the master executed. This arrangement has both benefits and drawbacks.
The most obvious benefit is that it’s fairly simple to implement. Simply logging and replaying any statement that changes data will, in theory, keep the replica in sync with the master. Another benefit of statement-based replication is that the binary log events tend to be reasonably compact. So, relatively speaking, statement-based replication doesn’t use a lot of bandwidth—a query that updates gigabytes of data might use only a few dozen bytes in the binary log. Also, the mysqlbinlog tool, which we mention throughout the chapter, is most convenient to use with statement-based logging.
In practice, however, statement-based replication is not as simple as it might seem, because many changes on the master can depend on factors besides just the query text. For example, the statements will execute at slightly—or possibly greatly—different times on the master and replica. As a result, MySQL’s binary log format includes more than just the query text; it also transmits several bits of metadata, such as the current timestamp. Even so, there are some statements that MySQL can’t replicate correctly, such as queries that use the CURRENT_USER() function. Stored routines and triggers are also problematic with statement-based replication.
Another issue with statement-based replication is that the modifications must be serializable. This requires more locking—sometimes significantly more. Not all storage engines work with statement-based replication, although those provided with the official MySQL server distribution up to and including MySQL 5.5 do.
You can find a complete list of statement-based replication’s limitations in the MySQL manual’s chapter on replication.
Row-Based Replication
MySQL 5.1 added support for row-based replication, which records the actual data changes in the binary log and is more similar to how most other database products implement replication. This scheme has several advantages and drawbacks of its own. The biggest advantages are that MySQL can replicate every statement correctly, and some statements can be replicated much more efficiently.
NOTE
Row-based logging is not backward-compatible. The mysqlbinlog utility distributed with MySQL 5.1 can read binary logs that contain events logged in row-based format (they are not human-readable, but the MySQL server can interpret them). However, versions of mysqlbinlog from earlier MySQL distributions will fail to recognize such log events and will exit with an error upon encountering them.
MySQL can replicate some changes more efficiently using row-based replication, because the replica doesn’t have to replay the queries that changed the rows on the master. Replaying some queries can be very expensive. For example, here’s a query that summarizes data from a very large table into a smaller table:
mysql> INSERT INTO summary_table(col1, col2, sum_col3)
-> SELECT col1, col2, sum(col3)
-> FROM enormous_table
-> GROUP BY col1, col2;
Imagine that there are only three unique combinations of col1 and col2 in the enormous_table table. This query will scan many rows in the source table but will result in only three rows in the destination table. Replicating this event as a statement will make the replica repeat all that work just to generate a few rows, but replicating it with row-based replication will be trivially cheap on the replica. In this case, row-based replication is much more efficient.
On the other hand, the following event is much cheaper to replicate with statement-based replication:
mysql> UPDATE enormous_table SET col1 = 0;
Using row-based replication for this query would be very expensive because it changes every row: every row would have to be written to the binary log, making the binary log event extremely large. This would place more load on the master during both logging and replication, and the slower logging might reduce concurrency.
Because neither format is perfect for every situation, MySQL can switch between statement-based and row-based replication dynamically. By default, it uses statement-based replication, but when it detects an event that cannot be replicated correctly with a statement, it switches to row-based replication. You can also control the format as needed by setting the binlog_format session variable.
It’s harder to do point-in-time recovery with a binary log that has events in row-based format, but not impossible. A log server can be helpful—more on that later.
Statement-Based or Row-Based: Which Is Better?
We’ve mentioned advantages and disadvantages for both replication formats. Which is better in practice?
In theory, row-based replication is probably better all-around, and in practice it generally works fine for most people. But its implementation is new enough that it hasn’t had years of little special-case behaviors baked in to support all the operational needs of MySQL administrators, and as a result it’s still a nonstarter for some people. Here’s a more complete discussion of the benefits and drawbacks of each format to help you decide which is more suitable for your needs:
Statement-based replication advantages
Logical replication works in more cases when the schema is different on the master and the replica. For example, it can be made to work in more cases where the tables have different but compatible data types, different column orders, and so on. This makes it easier to perform schema changes on a replica and then promote it to master, reducing downtime. Statement-based replication generally permits more operational flexibility.
The replication-applying process in statement-based replication is normal SQL execution, by and large. This means that all changes on the server are taking place through a well-understood mechanism, and it’s easy to inspect and determine what is happening if something isn’t working as expected.
Statement-based replication disadvantages
The list of things that can’t be replicated correctly through statement-based logging is so large that any given installation is likely to run into at least one of them. In particular, there were tons of bugs affecting replication of stored procedures, triggers, and so on in the 5.0 and 5.1 series of the server—so many that the way these are replicated was actually changed around a couple of times in attempts to make it work better. Bottom line: if you’re using triggers or stored procedures, don’t use statement-based replication unless you’re watching like a hawk to make sure you don’t run into problems.
There are also lots of problems with temporary tables, mixtures of storage engines, specific SQL constructs, nondeterministic statements, and so on. These range from annoying to show-stopping.
Row-based replication advantages
There are a lot fewer cases that don’t work in row-based replication. It works correctly with all SQL constructs, with triggers, with stored procedures, and so on. It generally only fails when you’re trying to do something clever such as schema changes on the replica.
It also creates opportunities for reduced locking, because it doesn’t require such strong serialization to be repeatable.
Row-based replication works by logging the data that’s changed, so the binary log is a record of what has actually changed on the master. You don’t have to look at a statement and guess whether it changed any data. Thus, in some ways you actually know more about what’s changed in your server, and you have a better record of the changes. Also, in some cases the row-based binary logs record what the data used to be, so they can potentially be more useful for some kinds of data recovery efforts.
Row-based replication can be less CPU-intensive in many cases, due to the lack of a need to plan and execute queries in the same way that statement-based replication does.
Finally, row-based replication can help you find and solve data inconsistencies more quickly in some cases. For example, statement-based replication won’t fail if you update a row on the master and it doesn’t exist on the replica, but row-based replication will throw an error and stop.
Row-based replication disadvantages
The statement isn’t included in the log event, so it can be tough to figure out what SQL was executed. This is important in many cases, in addition to knowing the row changes. (This will probably be fixed in a future version of MySQL.)
Replication changes are applied on replicas in a completely different manner—it isn’t SQL being executed. In fact, the process of applying row-based changes is pretty much a black box with no visibility into what the server is doing, and it’s not well documented or explained, so when things don’t work right, it can be tough to troubleshoot. As an example, if the replica chooses an inefficient way to find rows to change, you can’t observe that.
If you have multiple levels of replication servers, and all are configured for row-based logging, a statement that you execute while your session-level @@binlog_format variable is set to STATEMENT will be logged as a statement on the server where it originates, but then the first-level replicas might relay the event in row-based format to further replicas in the chain. That is, your desired statement-based logging will get switched back to row-based logging as it propagates through the replication topology.
Row-based logging can’t handle some things that statement-based logging can, such as schema changes on replicas.
Replication will sometimes halt in cases where statement-based replication would continue, such as when the replica is missing a row that’s supposed to be changed. This could be regarded as a good thing. In any case, it is configurable with the slave_exec_mode option.
Many of these disadvantages are being lifted as time passes, but at the time of writing, they are still true in most production deployments.
Replication Files
Let’s take a look at some of the files replication uses. You already know about the binary log and the relay log, but there are several other files, too. Where MySQL places them depends mostly on your configuration settings. Different MySQL versions place them in different directories by default. You can probably find them either in the data directory or in the directory that contains the server’s .pid file (possibly /var/run/mysqld/ on Unix-like systems). Here they are:
mysql-bin.index
A server that has binary logging enabled will also have a file named the same as the binary logs, but with a .index suffix. This file keeps track of the binary log files that exist on disk. It is not an index in the sense of a table’s index; rather, each line in the file contains the filename of a binary log file.
You might be tempted to think that this file is redundant and can be deleted (after all, MySQL could just look at the disk to find its files), but don’t. MySQL relies on this index file, and it will not recognize a binary log file unless it’s mentioned here.
mysql-relay-bin.index
This file serves the same purpose for the relay logs as the binary log index file does for the binary logs.
master.info
This file contains the information a replica needs to connect to its master. The format is plain text (one value per line) and varies between MySQL versions. Don’t delete it, or your replica will not know how to connect to its master after it restarts. This file contains the replication user’s password, in plain text, so you might want to restrict its permissions.
relay-log.info
This file contains the replica’s current binary log and relay log coordinates (i.e., the replica’s position on the master). Don’t delete this either, or the replica will forget where it was replicating from after a restart and might try to replay statements it has already executed.
These files are a rather crude way of recording MySQL’s replication and logging state. Unfortunately, they are not written synchronously, so if your server loses power and the files haven’t yet been flushed to disk, they can be inaccurate when the server restarts. This is improved in MySQL 5.5, as mentioned previously.
The .index files interact with another setting, expire_logs_days, which specifies how MySQL should purge expired binary logs. If the mysql-bin.index files mention files that don’t exist on disk, automatic purging will not work in some MySQL versions; in fact, even the PURGE MASTER LOGS statement won’t work. The solution to this problem is generally to use the MySQL server to manage the binary logs, so it doesn’t get confused. (That is, you shouldn’t use rm to purge files yourself.)
You need to implement some sort of log purging strategy explicitly, either with expire_logs_days or another means, or MySQL will fill up the disk with binary logs. You should consider your backup policy when you do this.
Sending Replication Events to Other Replicas
The log_slave_updates option lets you use a replica as a master of other replicas. It instructs MySQL to write the events the replication SQL thread executes into its own binary log, which its own replicas can then retrieve and execute. Figure 10-2 illustrates this.
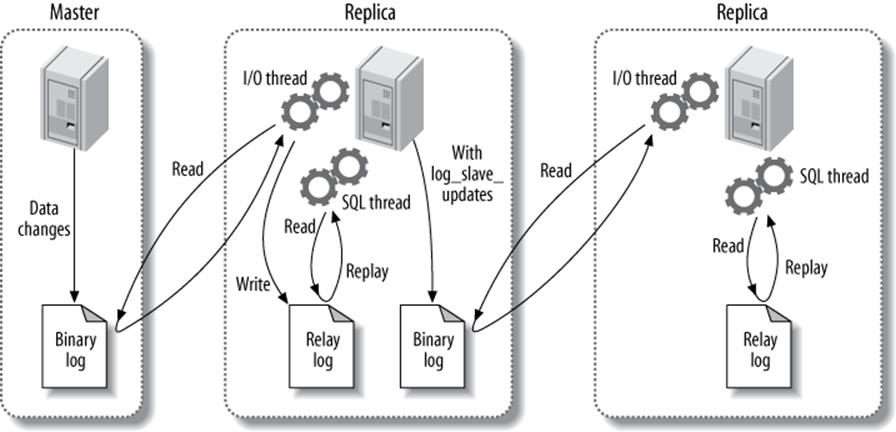
Figure 10-2. Passing on a replication event to further replicas
In this scenario, a change on the master causes an event to be written to its binary log. The first replica then fetches and executes the event. At this point, the event’s life would normally be over, but because log_slave_updates is enabled, the replica writes it to its binary log instead. Now the second replica can retrieve the event into its own relay log and execute it. This configuration means that changes on the original master can propagate to replicas that are not attached to it directly. We prefer setting log_slave_updates by default because it lets you connect a replica without having to restart the server.
When the first replica writes a binary log event from the master into its own binary log, that event will almost certainly be at a different position in the log from its position on the master—that is, it could be in a different log file or at a different numerical position within the log file. This means you can’t assume all servers that are at the same logical point in replication will have the same log coordinates. As we’ll see later, this makes it quite complicated to do some tasks, such as changing replicas to a different master or promoting a replica to be the master.
Unless you’ve taken care to give each server a unique server ID, configuring a replica in this manner can cause subtle errors and might even cause replication to complain and stop. One of the more common questions about replication configuration is why one needs to specify the server ID. Shouldn’t MySQL be able to replicate statements without knowing where they originated? Why does MySQL care whether the server ID is globally unique? The answer to this question lies in how MySQL prevents an infinite loop in replication. When the replication SQL thread reads the relay log, it discards any event whose server ID matches its own. This breaks infinite loops in replication. Preventing infinite loops is important for some of the more useful replication topologies, such as master-master replication.[148]
NOTE
If you’re having trouble getting replication set up, the server ID is one of the things you should check. It’s not enough to just inspect the @@server_id variable. It has a default value, but replication won’t work unless it’s explicitly set, either in my.cnf or via a SET command. If you use a SET command, be sure you update the configuration file too, or your settings won’t survive a server restart.
Replication Filters
Replication filtering options let you replicate just part of a server’s data, which is much less of a good thing than you might think. There are two kinds of replication filters: those that filter events out of the binary log on the master, and those that filter events coming from the relay log on the replica. Figure 10-3 illustrates the two types.
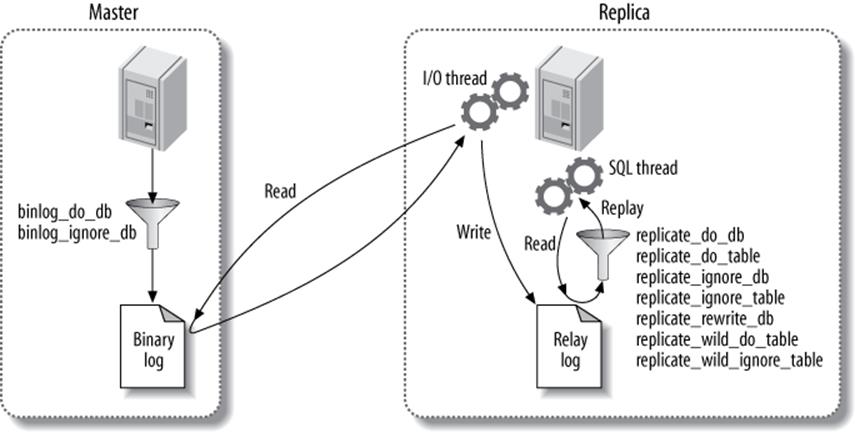
Figure 10-3. Replication filtering options
The options that control binary log filtering are binlog_do_db and binlog_ignore_db. You should not enable these, as we’ll explain in a moment, unless you think you’ll enjoy explaining to your boss why the data is gone permanently and can’t be recovered.
On the replica, the replicate_* options filter events as the replication SQL thread reads them from the relay log. You can replicate or ignore one or more databases, rewrite one database to another database, and replicate or ignore tables based on LIKE pattern matching syntax.
The most important thing to understand about these options is that the *_do_db and *_ignore_db options, both on the master and on the replica, do not work as you might expect. You might think they filter on the object’s database name, but they actually filter on the current default database.[149] That is, if you execute the following statements on the master:
mysql> USE test;
mysql> DELETE FROM sakila.film;
the *_do_db and *_ignore_db parameters will filter the DELETE statement on test, not on sakila. This is not usually what you want, and it can cause the wrong statements to be replicated or ignored. The *_do_db and *_ignore_db parameters have uses, but they’re limited and rare, and you should be very careful with them. If you use these parameters, it’s very easy to for replication to get out of sync or fail.
WARNING
The binlog_do_db and binlog_ignore_db options don’t just have the potential to break replication; they also make it impossible to do point-in-time recovery from a backup. For most situations, you should never use them. They can cause endless grief. We show some alternative ways to filter replication with Blackhole tables later in this chapter.
In general, replication filters are a problem waiting to happen. For example, suppose you want to prevent privilege changes from propagating to replicas, a fairly common goal. (The desire to do this should probably tip you off that you’re doing something wrong; there are probably other ways to accomplish your real goal.) Replication filters on the system tables will certainly prevent GRANT statements from replicating, but they will prevent events and routines from replicating, too. Such unforeseen consequences are a reason to be careful with filters. It might be a better idea to prevent specific statements from being replicated, usually with SET SQL_LOG_BIN=0, though that practice has its own hazards. In general, you should use replication filters very carefully, and only if you really need them, because they make it so easy to break replication and cause problems that will manifest when it’s least convenient, such as during disaster recovery.
The filtering options are well documented in the MySQL manual, so we won’t repeat the details here.
[148] Statements running around in infinite loops are also one of the many joys of multi-server ring replication topologies, which we’ll show later. Avoid ring replication like the plague.
[149] If you’re using statement-based replication, that is. If you’re using row-based replication, they don’t behave quite the same (another good reason to stay away from them).
Replication Topologies
You can set up MySQL replication for almost any configuration of masters and replicas, with the limitation that a given MySQL replica instance can have only one master. Many complex topologies are possible, but even the simple ones can be very flexible. A single topology can have many different uses. The variety of ways you can use replication could easily fill its own book.
We’ve already seen how to set up a master with a single replica. In this section, we look at some other common topologies and discuss their strengths and limitations. As we go, remember these basic rules:
§ A MySQL replica instance can have only one master.
§ Every replica must have a unique server ID.
§ A master can have many replicas (or, correspondingly, a replica can have many siblings).
§ A replica can propagate changes from its master, and be the master of other replicas, if you enable log_slave_updates.
Master and Multiple Replicas
Aside from the basic two-server master-replica setup we’ve already mentioned, this is the simplest replication topology. In fact, it’s just as simple as the basic setup, because the replicas don’t interact with each other;[150] they each connect only to the master. Figure 10-4 shows this arrangement.
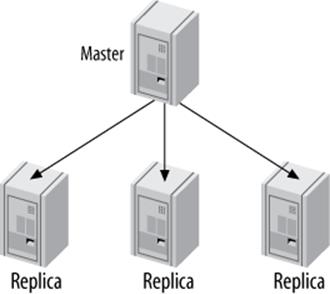
Figure 10-4. A master with multiple replicas
This configuration is most useful when you have few writes and many reads. You can spread reads across any number of replicas, up to the point where the replicas put too much load on the master or network bandwidth from the master to the replicas becomes a problem. You can set up many replicas at once, or add replicas as you need them, using the same steps we showed earlier in this chapter.
Although this is a very simple topology, it is flexible enough to fill many needs. Here are just a few ideas:
§ Use different replicas for different roles (for example, add different indexes or use different storage engines).
§ Set up one of the replicas as a standby master, with no traffic other than replication.
§ Put one of the replicas in a remote data center for disaster recovery.
§ Time-delay one or more of the replicas for disaster recovery.
§ Use one of the replicas for backups, for training, or as a development or staging server.
One of the reasons this topology is popular is that it avoids many of the complexities that come with other configurations. Here’s an example: it’s easy to compare one replica to another in terms of binary log positions on the master, because they’ll all be the same. In other words, if you stop all the replicas at the same logical point in replication, they’ll all be reading from the same physical position in the master’s logs. This is a nice property that simplifies many administrative tasks, such as promoting a replica to be the master.
This property holds only among “sibling” replicas. It’s more complicated to compare log positions between servers that aren’t in a direct master-replica or sibling relationship. Many of the topologies we mention later, such as tree replication or distribution masters, make it harder to figure out where in the logical sequence of events a replica is really replicating.
Master-Master in Active-Active Mode
Master-master replication (also known as dual-master or bidirectional replication) involves two servers, each configured as both a master and a replica of the other—in other words, a pair of co-masters. Figure 10-5 shows the setup.
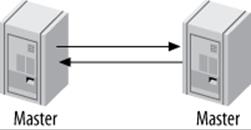
Figure 10-5. Master-master replication
MYSQL DOES NOT SUPPORT MULTISOURCE REPLICATION
We use the term multisource replication very specifically to describe the scenario where there is a replica with more than one master. Regardless of what you might have been told, MySQL (unlike some other database servers) does not support the configuration illustrated in Figure 10-6 at present. However, we show you some ways to emulate multisource replication later in this chapter.
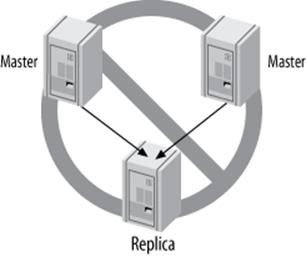
FIGURE 10-6. MYSQL DOES NOT SUPPORT MULTISOURCE REPLICATION
Master-master replication in active-active mode has uses, but they’re generally special-purpose. One possible use is for geographically separated offices, where each office needs its own locally writable copy of data.
The biggest problem with such a configuration is how to handle conflicting changes. The list of possible problems caused by having two writable co-masters is very long. Problems usually show up when a query changes the same row simultaneously on both servers or inserts into a table with an AUTO_INCREMENT column at the same time on both servers.[151]
MySQL 5.0 added some replication features that make this type of replication setup slightly less of a foot-gun: the auto_increment_increment and auto_increment_offset settings. These settings let servers autogenerate nonconflicting values for INSERT queries. However, allowing writes to both masters is still extremely dangerous. Updates that happen in a different order on the two machines can still cause the data to silently become out of sync. For example, imagine you have a single-column, single-row table containing the value 1. Now suppose these two statements execute simultaneously:
§ On the first co-master:
mysql> UPDATE tbl SET col=col + 1;
§ On the second:
mysql> UPDATE tbl SET col=col * 2;
The result? One server has the value 4, and the other has the value 3. And yet, there are no replication errors at all.
Data getting out of sync is only the beginning. What if normal replication stops with an error, but applications keep writing to both servers? You can’t just clone one of the servers from the other, because each of them will have changes that you need to copy to the other. Solving this problem is likely to be very hard. Consider yourself warned!
If you set up a master-master active-active configuration carefully, perhaps with well-partitioned data and privileges, and if you really know what you’re doing, you can avoid some of these problems.[152] However, it’s hard to do well, and there’s almost always a better way to achieve what you need.
In general, allowing writes on both servers causes way more trouble than it’s worth. However, an active-passive configuration is very useful indeed, as you’ll see in the next section.
Master-Master in Active-Passive Mode
There’s a variation on master-master replication that avoids the pitfalls we just discussed and is, in fact, a very powerful way to design fault-tolerant and highly available systems. The main difference is that one of the servers is a read-only “passive” server, as shown in Figure 10-7.
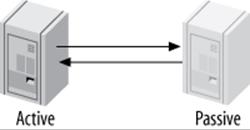
Figure 10-7. Master-master replication in active-passive mode
This configuration lets you swap the active and passive server roles back and forth very easily, because the servers’ configurations are symmetrical. This makes failover and failback easy. It also lets you perform maintenance, optimize tables, upgrade your operating system (or application, or hardware), and do other tasks without any downtime.
For example, running an ALTER TABLE statement locks the entire table, blocking reads and writes to it. This can take a long time and disrupt service. However, the master-master configuration lets you stop the replication threads on the active server (so it doesn’t process any updates from the passive server), alter the table on the passive server, switch the roles, and restart replication on the formerly active server.[153] That server then reads its relay log and executes the same ALTER TABLE statement. Again, this might take a long time, but it doesn’t matter because the server isn’t serving any live queries.
The active-passive master-master topology lets you sidestep many other problems and limitations in MySQL. There are some toolsets to help with this type of operational task, too.
Let’s see how to configure a master-master pair. Perform these steps on both servers, so they end up with symmetrical configurations:
1. Ensure that the servers have exactly the same data.
2. Enable binary logging, choose unique server IDs, and add replication accounts.
3. Enable logging replica updates. This is crucial for failover and failback, as we’ll see later.
4. Optionally configure the passive server to be read-only to prevent changes that might conflict with changes on the active server.
5. Start each server’s MySQL instance.
6. Configure each server as a replica of the other, beginning with the newly created binary log.
Now let’s trace what happens when there’s a change to the active server. The change gets written to its binary log and flows through replication to the passive server’s relay log. The passive server executes the query and writes the event to its own binary log, because you enabledlog_slave_updates. The active server then ignores the event, because the server ID in the event matches its own. See the section Changing Masters to learn how to switch roles.
Setting up an active-passive master-master topology is a little like creating a hot spare in some ways, except that you can use the “spare” to boost performance. You can use it for read queries, backups, “offline” maintenance, upgrades, and so on—things you can’t do with a true hot spare. However, you cannot use it to gain better write performance than you can get with a single server (more about that later).
As we discuss more scenarios and uses for replication, we’ll come back to this configuration. It is a very important and common replication topology.
Master-Master with Replicas
A related configuration is to add one or more replicas to each co-master, as shown in Figure 10-8.
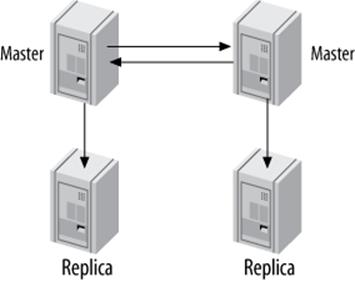
Figure 10-8. Master-master topology with replicas
The advantage of this configuration is extra redundancy. In a geographically distributed replication topology, it removes the single point of failure at each site. You can also offload read-intensive queries to the replicas, as usual.
If you’re using a master-master topology locally for fast failover, this configuration is still useful. Promoting one of the replicas to replace a failed master is possible, although it’s a little more complex. The same is true of moving one of the replicas to point to a different master. The added complexity is an important consideration.
Ring Replication
The dual-master configuration is really just a special case[154] of the ring replication configuration, shown in Figure 10-9. A ring has three or more masters. Each server is a replica of the server before it in the ring, and a master of the server after it. This topology is also called circular replication.
Rings don’t have some of the key benefits of a master-master setup, such as symmetrical configuration and easy failover. They also depend completely on every node in the ring being available, which greatly increases the probability of the entire system failing. And if you remove one of the nodes from the ring, any replication events that originated at that node can go into an infinite loop: they’ll cycle forever through the chain of servers, because the only server that will filter out an event based on its server ID is the server that created it. In general, rings are brittle and best avoided, no matter how clever you are.
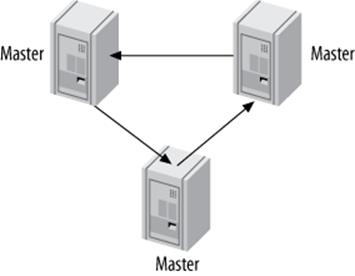
Figure 10-9. A replication ring topology
You can mitigate some of the risk of a ring replication setup by adding replicas to provide redundancy at each site, as shown in Figure 10-10. This merely protects against the risk of a server failing, though. A loss of power or any other problem that affects any connection between the sites will still break the entire ring.
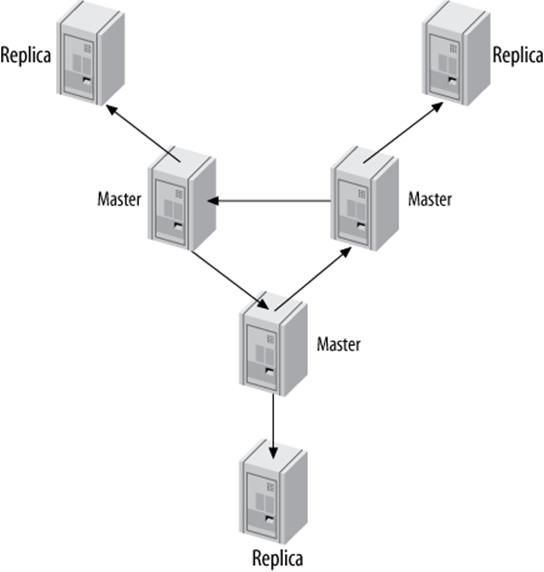
Figure 10-10. A replication ring with additional replicas at each site
Master, Distribution Master, and Replicas
We’ve mentioned that replicas can place quite a load on the master if there are enough of them. Each replica creates a new thread on the master, which executes the special binlog dump command. This command reads the data from the binary log and sends it to the replica. The work is repeated for each replica; they don’t share the resources required for a binlog dump.
If there are many replicas and there’s a particularly large binary log event, such as a huge LOAD DATA INFILE, the master’s load can go up significantly. The master might even run out of memory and crash because of all the replicas requesting the same huge event at the same time. On the other hand, if the replicas are all requesting different binlog events that aren’t in the filesystem cache anymore, that can cause a lot of disk seeks, which might also interfere with the master’s performance and cause mutex contention.
For this reason, if you need many replicas, it’s often a good idea to remove the load from the master and use a distribution master. A distribution master is a replica whose only purpose is to read and serve the binary logs from the master. Many replicas can connect to the distribution master, which insulates the original master from the load. To remove the work of actually executing the queries on the distribution master, you can change its tables to the Blackhole storage engine, as shown in Figure 10-11.
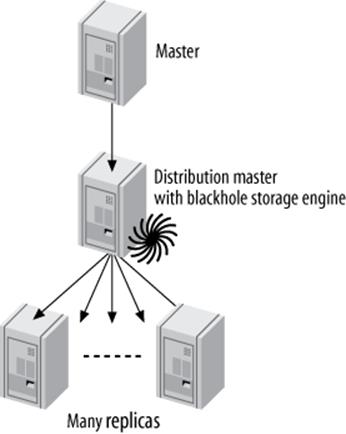
Figure 10-11. A master, a distribution master, and many replicas
It’s hard to say exactly how many replicas a master can handle before it needs a distribution master. As a very rough rule of thumb, if your master is running near its full capacity, you might not want to put more than about 10 replicas on it. If there’s very little write activity, or you’re replicating only a fraction of the tables, the master can probably serve many more replicas. Additionally, you don’t have to limit yourself to just one distribution master. You can use several if you need to replicate to a really large number of replicas, or you can even use a pyramid of distribution masters. In some cases it also helps to set slave_compressed_protocol, to save some bandwidth on the master. This is most helpful for cross–data center replication.
You can also use the distribution master for other purposes, such as applying filters and rewrite rules to the binary log events. This is much more efficient than repeating the logging, rewriting, and filtering on each replica.
If you use Blackhole tables on the distribution master, it will be able to serve more replicas than it could otherwise. The distribution master will execute the queries, but the queries will be extremely cheap, because the Blackhole tables will not have any data. The drawback of Blackhole tables is that they have bugs, such as forgetting to put autoincrementing IDs into their binary logs in some circumstances, so be very careful with Blackhole tables if you use them.[155]
A common question is how to ensure that all tables on the distribution master use the Blackhole storage engine. What if someone creates a new table on the master and specifies a different storage engine? Indeed, the same issue arises whenever you want to use a different storage engine on a replica. The usual solution is to set the server’s storage_engine option:
storage_engine = blackhole
This will affect only CREATE TABLE statements that don’t specify a storage engine explicitly. If you have an existing application that you can’t control, this topology might be fragile. You can disable InnoDB and make tables fall back to MyISAM with the skip_innodb option, but you can’t disable the MyISAM or Memory engines.
The other major drawback is the difficulty of replacing the master with one of the (ultimate) replicas. It’s hard to promote one of the replicas into its place, because the intermediate master ensures that they will almost always have different binary log coordinates than the original master does.[156]
Tree or Pyramid
If you’re replicating a master to a very large number of replicas—whether you’re distributing data geographically or just trying to build in more read capacity—it can be more manageable to use a pyramid design, as illustrated in Figure 10-12.
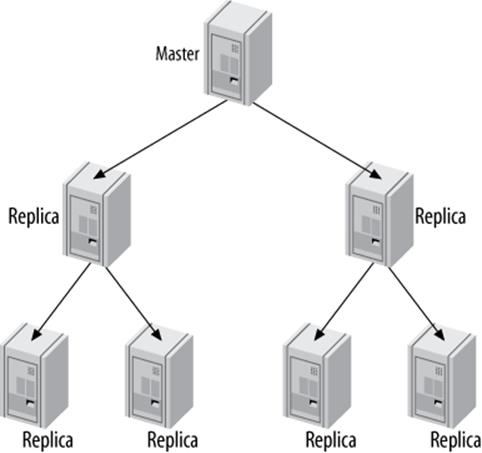
Figure 10-12. A pyramid replication topology
The advantage of this design is that it eases the load on the master, just as the distribution master did in the previous section. The disadvantage is that any failure in an intermediate level will affect multiple servers, which wouldn’t happen if the replicas were each attached to the master directly. Also, the more intermediate levels you have, the harder and more complicated it is to handle failures.
Custom Replication Solutions
MySQL replication is flexible enough that you can often design a custom solution for your application’s needs. You’ll typically use some combination of filtering, distribution, and replicating to different storage engines. You can also use “hacks,” such as replicating to and from servers that use the Blackhole storage engine (as discussed earlier in this chapter). Your design can be as elaborate as you want. The biggest limitations are what you can monitor and administer reasonably and what resource constraints you have (network bandwidth, CPU power, etc.).
Selective replication
To take advantage of locality of reference and keep your working set in memory for reads, you can replicate a small amount of data to each of many replicas. If each replica has a fraction of the master’s data and you direct reads to the replicas, you can make much better use of the memory on each replica. Each replica will also have only a fraction of the master’s write load, so the master can become more powerful without making the replicas fall behind.
This scenario is similar in some respects to the horizontal data partitioning we’ll talk more about in the next chapter, but it has the advantage that one server still hosts all the data—the master. This means you never have to look on more than one server for the data needed for a write query, and if you have read queries that need data that doesn’t all exist on any single replica server, you have the option of doing those reads on the master instead. Even if you can’t do all reads on the replicas, you should be able to move many of them off the master.
The simplest way to do this is to partition the data into different databases on the master, and then replicate each database to a different replica server. For example, if you want to replicate data for each department in your company to a different replica, you can create databases called sales,marketing, procurement, and so on. Each replica should then have a replicate_wild_do_table configuration option that limits its data to the given database. Here’s the configuration option for the sales database:
replicate_wild_do_table = sales.%
Filtering with a distribution master is also useful. For example, if you want to replicate just part of a heavily loaded server across a slow or very expensive network, you can use a local distribution master with Blackhole tables and filtering rules. The distribution master can have replication filters that remove undesired entries from its logs. This can help avoid dangerous logging settings on the master, and it doesn’t require you to transfer all the logs across the network to the remote replicas.
Separating functions
Many applications have a mixture of online transaction processing (OLTP) and online analytical processing (OLAP) queries. OLTP queries tend to be short and transactional. OLAP queries are usually large and slow and don’t require absolutely up-to-date data. The two types of queries also place very different stresses on the server. Thus, they perform best on servers that are configured differently and perhaps even use different storage engines and hardware.
A common solution to this problem is to replicate the OLTP server’s data to replicas specifically designed for the OLAP workload. These replicas can have different hardware, configurations, indexes, and/or storage engines. If you dedicate a replica to OLAP queries, you might also be able to tolerate more replication lag or otherwise degraded quality of service on that replica. That might mean you can use it for tasks that would result in unacceptable performance on a nondedicated replica, such as executing very long-running queries.
No special replication setup is required, although you might choose to omit some of the data from the master if you’ll achieve significant savings by not having it on the replica. Filtering out even a small amount of data with replication filters on the relay log might help reduce I/O and cache activity.
Data archiving
You can archive data on a replica server—that is, keep it on the replica but remove it from the master—by running delete queries on the master and ensuring that those queries don’t execute on the replica. There are two common ways to do this: one is to selectively disable binary logging on the master, and the other is to use replicate_ignore_db rules on the replica. (Yes, both are dangerous.)
The first method requires executing SET SQL_LOG_BIN=0 in the process that purges the data on the master, then purging the data. This has the advantage of not requiring any special replication configuration on the replica, and because the statements aren’t even logged to the master’s binary log, it’s slightly more efficient there too. The main disadvantage is that you won’t be able to use the binary log on the master for auditing or point-in-time recovery anymore, because it won’t contain every modification made to the master’s data. It also requires the SUPER privilege.
The second technique is to USE a certain database on the master before executing the statements that purge the data. For example, you can create a database named purge, and then specify replicate_ignore_db=purge in the replica’s my.cnf file and restart the server. The replica will ignore statements that USE this database. This approach doesn’t have the first technique’s weaknesses, but it has the (minor) drawback of making the replica fetch binary log events it doesn’t need. There’s also a potential for someone to mistakenly execute non-purge queries in the purgedatabase, thus causing the replica not to replay events you want it to.
Percona Toolkit’s pt-archiver tool supports both methods.
NOTE
A third option is to use binlog_ignore_db to filter out replication events, but as we stated earlier, we consider this too dangerous.
Using replicas for full-text searches
Many applications require a combination of transactions and full-text searches. However, at the time of writing only MyISAM tables offer built-in full-text search capabilities, and MyISAM doesn’t support transactions. (There’s a laboratory preview of InnoDB full-text search in MySQL 5.6, but it isn’t GA yet.) A common workaround is to configure a replica for full-text searches by changing the storage engine for certain tables to MyISAM on the replica. You can then add full-text indexes and perform full-text search queries on the replica. This avoids potential replication problems with transactional and nontransactional storage engines in the same query on the master, and it relieves the master of the extra work of maintaining the full-text indexes.
Read-only replicas
Many organizations prefer replicas to be read-only, so unintended changes don’t break replication. You can achieve this with the read_only configuration variable. It disables most writes: the exceptions are the replica processes, users who have the SUPER privilege, and temporary tables. This is perfect as long as you don’t give the SUPER privilege to ordinary users, which you shouldn’t do anyway.
Emulating multisource replication
MySQL does not currently support multisource replication (i.e., a replica with more than one master). However, you can emulate this topology by changing a replica to point at different masters in turn. For example, you can point the replica at master A and let it run for a while, then point it at master B for a while, and then switch it back to master A again. How well this will work depends on your data and how much work the two masters will cause the single replica to do. If your masters are relatively lightly loaded and their updates won’t conflict at all, it might work very well.
You’ll need to do a little work to keep track of the binary log coordinates for each master. You also might want to ensure that the replica’s I/O thread doesn’t fetch more data than you intend it to execute on each cycle; otherwise, you could increase the network traffic and load on the master significantly by fetching and throwing away a lot of data on each cycle.
You can also emulate multisource replication using master-master (or ring) replication and the Blackhole storage engine with a replica, as depicted in Figure 10-13.
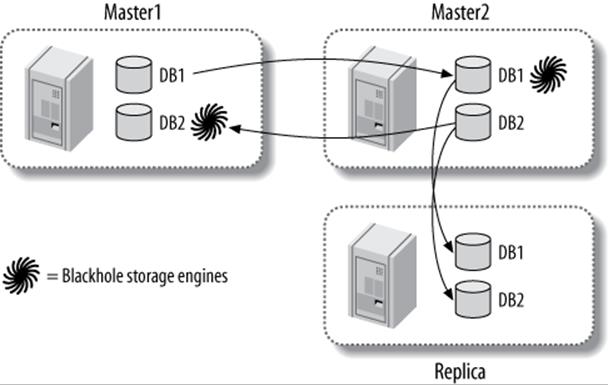
Figure 10-13. Emulating multisource replication with dual masters and the Blackhole storage engine
In this configuration, the two masters each contain their own data. They each also contain the tables from the other master, but use the Blackhole storage engine to avoid actually storing the data in those tables. A replica is attached to one of the co-masters—it doesn’t matter which one. This replica does not use the Blackhole storage engine at all, so it is effectively a replica of both masters.
In fact, it’s not really necessary to use a master-master topology to achieve this. You can simply replicate from server1 to server2 to the replica. If server2 uses the Blackhole storage engine for tables replicated from server1, it will not contain any data from server1, as shown inFigure 10-14.
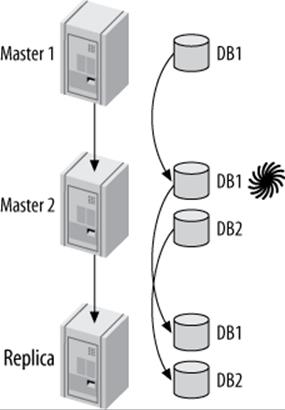
Figure 10-14. Another way to emulate multisource replication
Either of these configurations can suffer from the usual problems, such as conflicting updates and CREATE TABLE statements that explicitly specify a storage engine.
Another option is to use Continuent’s Tungsten Replicator, which we’ll discuss later in this chapter.
Creating a log server
One of the things you can do with MySQL replication is create a “log server” with no data, whose only purpose is to make it easy to replay and/or filter binary log events. As you’ll see later in this chapter, this is very useful for restarting replication after crashes. It’s also useful for point-in-time recovery, which we discuss in Chapter 15.
Imagine you have a set of binary logs or relay logs—perhaps from a backup, perhaps from a server that crashed—and you want to replay the events in them. You could use mysqlbinlog to extract the events, but it’s more convenient and efficient to just set up a MySQL instance without any data and let it think the binary logs are its own. You can use the MySQL Sandbox script available at http://mysqlsandbox.net to create the log server if you’ll need it only temporarily. The log server does not need any data because it won’t be executing the logs—it will only be serving the logs to other servers. (It does need to have a replication user, however.)
Let’s take a look at how this technique works (we show some applications for it later). Suppose the logs are called somelog-bin.000001, somelog-bin.000002, and so on. Place these files into your log server’s binary log directory. We’ll assume it’s /var/log/mysql. Then, before you start the log server, edit its my.cnf file as follows:
log_bin = /var/log/mysql/somelog-bin
log_bin_index = /var/log/mysql/somelog-bin.index
The server doesn’t automatically discover log files, so you’ll also need to update the server’s log index file. The following command will accomplish this on Unix-like systems:[157]
# /bin/ls −1 /var/log/mysql/somelog-bin.[0-9]* > /var/log/mysql/somelog-bin.index
Make sure the user account under which MySQL runs can read and write the log index file. Now you can start your log server and verify that it sees the log files with SHOW MASTER LOGS.
Why is a log server better than using mysqlbinlog for recovery? For several reasons:
§ Replication is a means of applying binary logs that’s been tested by millions of users and is known to work. The mysqlbinlog tool isn’t guaranteed to work in the same way as replication and might not reproduce the changes from the binary log faithfully.
§ It’s faster because it eliminates the need to extract statements from the log and pipe them into mysql.
§ You can see the progress easily.
§ You can work with errors easily. For example, you can skip statements that fail to replicate.
§ You can filter replication events easily.
§ Sometimes mysqlbinlog might not be able to read the binary log, because of changes to the logging format.
[150] This isn’t technically true. If they have duplicate server IDs, they’ll get into a catfight and kick each other off the master repeatedly.
[151] Actually, these problems usually show up at 3am on a weekend, and we’ve seen them take months to resolve.
[152] Some, but not all—we can play devil’s advocate and show you flaws in just about any setup you can imagine.
[153] You can also disable binary logging temporarily with SET SQL_LOG_BIN=0, instead of stopping replication. Some commands, such as OPTIMIZE TABLE, also support a LOCAL or NO_WRITE_TO_BINLOG option that prevents logging. This can allow you to choose your timing more precisely, rather than just letting the ALTER happen when it occurs in the replication stream.
[154] A slightly more sane special case, we might add.
[155] See MySQL bugs 35178 and 62829 for starters. In general, anytime you use a nonstandard storage engine or feature, it can be a good idea to look for open and closed bugs affecting it.
[156] You can use Percona Toolkit’s pt-heartbeat to create a crude global transaction ID to help with this. It makes it much easier to find binary log positions on various servers, because the heartbeat table itself has the approximate binary log positions in it.
[157] We use /bin/ls explicitly to avoid invoking common aliases that add terminal escape codes for coloring.
Replication and Capacity Planning
Writes are usually the replication bottleneck, and it’s hard to scale writes with replication. You need to make sure you do the math right when you plan how much capacity replicas will add to your system overall. It’s easy to make mistakes where replication is concerned.
For example, imagine your workload is 20% writes and 80% reads. To make the math easy, let’s grossly oversimplify and assume the following are true:
§ Read and write queries involve an identical amount of work.
§ All servers are exactly equal and have a capacity of exactly 1,000 queries per second.
§ Replicas and masters have the same performance characteristics.
§ You can move all read queries to the replicas.
If you currently have one server handling 1,000 queries per second, how many replicas will you need to add so that you can handle twice your current load and move all read queries to the replicas?
It might seem that you could add two replicas and split the 1,600 reads between them. However, don’t forget that your write workload has also increased to 400 queries per second, and this cannot be divided between the master and replicas. Each replica must perform 400 writes per second. That means each replica is 40% busy with writes and can serve only 600 reads per second. Thus, you’ll need not two but three replicas to handle twice the traffic.
What if your traffic doubles again? There will be 800 writes per second, so the master will still be able to keep up. But the replicas will each be 80% busy with writes too, so you’ll need 16 replicas to handle the 3,200 reads per second. And if the traffic increases just a little more, it will be too much for the master.
This is far from linear scalability: you need 17 times as many servers to handle 4 times as many queries. This illustrates that you quickly reach a point of diminishing returns when adding replicas to a single master. And this is even with our unrealistic assumptions, which ignore, for example, the fact that single-threaded statement-based replication usually causes replicas to have lower capacity than the master. A real replication setup is likely to perform even worse than our theoretical one.
Why Replication Doesn’t Help Scale Writes
The fundamental problem with the poor server-to-capacity ratio we just discussed is that you cannot distribute the writes equally among the machines, as you can with the reads. Another way to say this is that replication scales reads, but it doesn’t scale writes.
You might wonder whether there’s a way to add write capacity with replication. The answer is no—not even a little. Partitioning your data, which we cover in the next chapter, is the only way you can scale writes.
Some readers might have thought about using a master-master topology (see Master-Master in Active-Active Mode) and writing to both masters. This configuration can handle slightly more writes as compared to a master-replicas topology, because you can share the serialization penalty equally between the two servers. If you do 50% of the writes on each server, only the 50% that execute via replication from the other server must be serialized. In theory, that’s better than doing 100% of the writes in parallel on one machine (the master) and 100% of the writes serially on the other machine (the replica).
This might seem attractive. However, such a configuration still can’t handle as many writes as a single server. A server whose write workload is 50% serialized is slower than a single server that can do all its writes in parallel.
That’s why this tactic does not scale writes. It’s only a way to share the serialized-write disadvantage over two servers, so the “weakest link in the chain” isn’t quite so weak. It provides only a relatively small improvement over an active-passive setup, adding a lot of risk for a small gain—and it generally won’t benefit you anyway, as we explain in the next section.
When Will Replicas Begin to Lag?
A common question about replicas is how to predict when they won’t be able to keep up with the changes coming from the master. It can be hard to tell the difference between a replica that’s at 5% of its capacity and one that’s at 95%. However, it’s possible to get at least a little advance warning of impending saturation and estimate replication capacity.
The first thing you should do is watch for spikes of lag. If you have graphs of replication lag, you should notice little bumps in the graphs as the replica begins to encounter short periods where there’s more work and it can’t keep up. As the workload gets closer to consuming the replica’s capacity, you’ll see these bumps get higher and wider. The front side of the bump will generally have a consistent angle, but the back side, when the replica is catching up after lagging behind, will become a gentler and gentler slope. The presence of these bumps, and growth in them, is a warning sign that you’re approaching your limits.
To predict what’s going to happen at some point in the future, deliberately delay a replica, and then see how fast it can catch up. The goal is to explicitly see how steep the back side of that slope is. If you stop a replica for an hour, then start it and it catches up in one hour, it is running at half of its capacity. That is, if you stop it at noon and restart it at 1:00, and it’s caught up again at 2:00, it has applied all of the changes from 12:00 to 2:00 in an hour, so it went at double speed.
Finally, in Percona Server and MariaDB you can measure the replication utilization directly. Enable the userstat server variable, and then you’ll be able to do the following:
mysql> SELECT * FROM INFORMATION_SCHEMA.USER_STATISTICS
-> WHERE USER='#mysql_system#'\G
*************************** 1. row ***************************
USER: #mysql_system#
TOTAL_CONNECTIONS: 1
CONCURRENT_CONNECTIONS: 2
CONNECTED_TIME: 46188
BUSY_TIME: 719
ROWS_FETCHED: 0
ROWS_UPDATED: 1882292
SELECT_COMMANDS: 0
UPDATE_COMMANDS: 580431
OTHER_COMMANDS: 338857
COMMIT_TRANSACTIONS: 1016571
ROLLBACK_TRANSACTIONS: 0
You can compare the BUSY_TIME to one-half of the CONNECTED_TIME (because there are two replication threads on the replica) to see how much of the time the replication thread was actively processing statements.[158] In our example, the replica is using around 3% of its capacity. This doesn’t mean it won’t have occasional spikes of lag—if the master executes a change that takes 10 minutes to complete, it’s likely that the replica will lag by about the same amount of time while applying the change—but it’s a good indication that the replica will be able to recover from any spikes it experiences.
Plan to Underutilize
Intentionally underutilizing your servers can be a smart and cost-effective way to build a large application, especially when you use replication. Servers that have spare capacity can tolerate surges better, have more power to handle slow queries and maintenance jobs (such as OPTIMIZE TABLE operations), and will be better able to keep up in replication.
Trying to reduce the replication penalty a little by writing to both nodes in a master-master topology is typically a false economy. You should usually load the master-master pair less than 50% with reads, because if you add more load, there won’t be enough capacity if one of the servers fails. If both servers can handle the load by themselves, you probably won’t need to worry much about the single-threaded replication penalty.
Building in excess capacity is also one of the best ways to achieve high availability, although there are other ways, such as running your application in “degraded” mode when there’s a failure. Chapter 12 covers this in more detail.
[158] If the replication threads are always running, you can just use the server’s uptime instead of half the CONNECTED_TIME.
Replication Administration and Maintenance
Setting up replication probably isn’t something you’ll do constantly, unless you have many servers. But once it’s in place, monitoring and administering your replication topology will be a regular job, no matter how many servers you have.
You should try to automate this work as much as possible. You might not need to write your own tools for this purpose, though: in Chapter 16, we discuss several productivity tools for MySQL, many of which have built-in replication monitoring capabilities or plugins.
Monitoring Replication
Replication increases the complexity of MySQL monitoring. Although replication actually happens on both the master and the replica, most of the work is done on the replica, and that is where the most common problems occur. Are all the replicas working? Has any replica had errors? How far behind is the slowest replica? MySQL provides most of the information you need to answer these questions, but automating the monitoring process and making replication robust is left up to you.
On the master, you can use the SHOW MASTER STATUS command to see the master’s current binary log position and configuration (see the section Configuring the Master and Replica). You can also ask the master which binary logs exist on disk:
mysql> SHOW MASTER LOGS;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000220 | 425605 |
| mysql-bin.000221 | 1134128 |
| mysql-bin.000222 | 13653 |
| mysql-bin.000223 | 13634 |
+------------------+-----------+
This information is useful in determining what parameters to give the PURGE MASTER LOGS command. You can also view replication events in the binary log with the SHOW BINLOG EVENTS command. For example, after running the previous command, we created a table on an otherwise unused server. Because we knew this was the only statement that changed any data, we knew the statement’s offset in the binary log was 13634, so we were able to view it as follows:
mysql> SHOW BINLOG EVENTS IN 'mysql-bin.000223' FROM 13634\G
*************************** 1. row ***************************
Log_name: mysql-bin.000223
Pos: 13634
Event_type: Query
Server_id: 1
End_log_pos: 13723
Info: use `test`; CREATE TABLE test.t(a int)
Measuring Replication Lag
One of the most common things you’ll need to monitor is how far behind the master a replica is running. Although the Seconds_behind_master column in SHOW SLAVE STATUS theoretically shows the replica’s lag, in fact it’s not always accurate, for a variety of reasons:
§ The replica calculates Seconds_behind_master by comparing the server’s current timestamp to the timestamp recorded in the binary log event, so the replica can’t even report its lag unless it is processing a query.
§ The replica will usually report NULL if the replication processes aren’t running.
§ Some errors (for example, mismatched max_allowed_packet settings between the master and replica, or an unstable network) can break replication and/or stop the replication threads, but Seconds_behind_master will report 0 rather than indicating an error.
§ The replica sometimes can’t calculate the lag even if the replication processes are running. If this happens, the replica might report either 0 or NULL.
§ A very long transaction can cause the reported lag to fluctuate. For example, if you have a transaction that updates data, stays open for an hour, and then commits, the update will go into the binary log an hour after it actually happened. When the replica processes the statement, it will temporarily report that it is an hour behind the master, and then it will jump back to zero seconds behind.
§ If a distribution master is falling behind and has replicas of its own that are caught up with it, the replicas will report that they are zero seconds behind, even if there is lag relative to the ultimate master.
The solution to these problems is to ignore Seconds_behind_master and monitor replica lag with something you can observe and measure directly. The best solution is a heartbeat record, which is a timestamp that you update once per second on the master. To calculate the lag, you can simply subtract the heartbeat from the current timestamp on the replica. This method is immune to all the problems we just mentioned, and it has the added benefit of creating a handy timestamp that shows to what point in time the replica’s data is current. The pt-heartbeat script, included in Percona Toolkit, is the most popular implementation of a replication heartbeat.
A heartbeat has other benefits, too. The replication heartbeat records in the binary log are useful for many purposes, such as disaster recovery in otherwise hard-to-solve scenarios.
None of the lag metrics we just mentioned gives a sense of how long it will take for a replica to actually catch up to the master. This depends upon many factors, such as how powerful the replica is and how many write queries the master continues to process. See the section When Will Replicas Begin to Lag? for more on that topic.
Determining Whether Replicas Are Consistent with the Master
In a perfect world, a replica would always be an exact copy of its master. But in the real world, errors in replication can cause the replica’s data to “drift” out of sync with the master’s. Even if there are apparently no errors, replicas can still get out of sync because of MySQL features that don’t replicate correctly, bugs in MySQL, network corruption, crashes, ungraceful shutdowns, or other failures.[159]
Our experience is that this is the rule, not the exception, which means checking your replicas for consistency with their masters should probably be a routine task. This is especially important if you use replication for backups, because you don’t want to take backups from a corrupted replica.
MySQL has no built-in method of determining whether one server has the same data as another server. It does provide some building blocks for checksumming tables and data, such as CHECKSUM TABLE. However, it’s nontrivial to compare a replica to its master while replication is working.
Percona Toolkit has a tool called pt-table-checksum that solves this and several other problems. The tool’s main feature is that it can verify that a replica’s data is in sync with its master’s data. It works by running INSERT ... SELECT queries on the master.
These queries checksum the data and insert the results into a table. The statements flow through replication and execute again on the replica. You can then compare the results on the master to the results on the replica and see whether the data differs. Because this process works through replication, it gives consistent results without the need to lock tables on both servers simultaneously.
A typical way to use the tool is to run it on the master, with parameters similar to the following:
$ pt-table-checksum --replicate=test.checksum <master_host>
This command checksums all tables and inserts the results into the test.checksum table. After the queries have executed on the replicas, a simple query can check each replica for differences from the master. pt-table-checksum can discover the server’s replicas, run the query on each replica, and output the results automatically. At the time of this writing, pt-table-checksum is the only tool that can reliably compare a replica’s data to its master’s.
Resyncing a Replica from the Master
You’ll probably have to deal with an out-of-sync replica more than once in your career. Perhaps you used the checksum technique and found differences; perhaps you know that the replica skipped a query or that someone changed the data on the replica.
The traditional advice for fixing an out-of-sync replica is to stop it and reclone it from the master. If an inconsistent replica is a critical problem, you should probably stop it and remove it from production as soon as you find it. You can then reclone the replica or restore it from a backup.
The drawback to this approach is the inconvenience factor, especially if you have a lot of data. If you can find out which data is different, you can probably do it more efficiently than by recloning the entire server. And if the inconsistency you discovered isn’t critical, you might be able to leave the replica online and resync only the affected data.
The simplest fix is to dump and reload only the affected data with mysqldump. This can work very well if your data isn’t changing while you do it. You can simply lock the table on the master, dump the table, wait for the replica to catch up to the master, and then import the table on the replica. (You need to wait for the replica to catch up so you don’t introduce more inconsistencies in other tables, such as those that might be updated in joins against the out-of-sync table.)
Although this works acceptably for many scenarios, it’s often impossible to do on a busy server. It also has the disadvantage of changing the replica’s data outside of replication. Changing a replica’s data through replication (by making changes on the master) is usually the safest technique, because it avoids nasty race conditions and other surprises. If the table is very large or network bandwidth is limited, dumping and reloading is also prohibitively expensive. What if only every thousandth row in a million-row table is different? Dumping and reloading the whole table is wasteful in this case.
pt-table-sync is another tool from Percona Toolkit that solves some of these problems. It can find and resolve differences between tables efficiently. It can also operate through replication, resynchronizing the replica by executing queries on the master, so there are no race conditions. It integrates with the checksum table created by pt-table-checksum, so it can operate only on chunks of tables that are known to differ. It doesn’t work in all scenarios, though: it requires that replication is running in order to sync a master and replica correctly, so it won’t work when there’s a replication error. pt-table-sync is designed to be efficient, but it still might be impractical for extremely large data sizes. Comparing a terabyte of data on the master and the replica inevitably causes extra work for both servers. Still, for those cases where it works, it can save you a great deal of time and effort.
Changing Masters
Sooner or later, you’ll need to point a replica at a new master. Maybe you’re rotating servers for an upgrade, maybe there was a failure and you need to promote a replica to be the master, or maybe you’re just reallocating capacity. Regardless of the reason, you have to inform the replica about its new master.
When the process is planned, it’s easy (or at least easier than it is in a crisis). You simply need to issue the CHANGE MASTER TO command on the replica, using the appropriate values. Most of the values are optional; you can specify just the ones you’re changing. The replica will discard its current configuration and relay logs and begin replicating from the new master. It will also update the master.info file with the new parameters, so the change will persist across a replica restart.
The hardest part of this process is figuring out the desired position on the new master, so the replica begins at the same logical position at which it stopped on the old master.
Promoting a replica to a master is a little harder. There are two basic scenarios for replacing a master with one of its replicas. The first is when it’s a planned promotion; the second is when it’s unplanned.
Planned promotions
Promoting a replica to a master is conceptually simple. Briefly, here are the steps involved:
1. Stop writes to the old master.
2. Optionally let its replicas catch up in replication (this makes the subsequent steps simpler).
3. Configure a replica to be the new master.
4. Point replicas and write traffic to the new master, then enable writes on it.
The devil is in the details, however. Several scenarios are possible, depending on your replication topology. For example, the steps are slightly different in a master-master topology than in a master-replica setup.
In more depth, here are the steps you’ll probably need to take for most setups:
1. Stop all writes on the current master. If possible, you might even want to force all client programs (not replication connections) to quit. It helps if you’ve built your client programs with a “do not run” flag you can set. If you use virtual IP addresses, you can simply shut off the virtual IP and then kill all client connections to close their open transactions.
2. Optionally stop all write activity on the master with FLUSH TABLES WITH READ LOCK. You can also set the master to be read-only with the read_only option. From this point on, you should forbid any writes to the soon-to-be-replaced master, because once it’s no longer a master, writing to it means losing data! Note, however, that setting read_only doesn’t prevent existing transactions from committing. For a stronger guarantee, kill all open transactions; this will really stop all writes.
3. Choose one of the replicas to be the new master, and ensure it is completely caught up in replication (i.e., let it finish executing all the relay logs it has fetched from the old master).
4. Optionally verify that the new master contains the same data as the old master.
5. Execute STOP SLAVE on the new master.
6. Execute CHANGE MASTER TO MASTER_HOST='' followed by RESET SLAVE on the new master, to make it disconnect from the old master and discard the connection information in its master.info file. (This will not work correctly if connection information is specified in my.cnf, which is one reason we recommend you don’t put it there.)
7. Note the new master’s binary log coordinates with SHOW MASTER STATUS.
8. Make sure all other replicas are caught up.
9. Shut down the old master.
10.In MySQL 5.1 and newer, activate events on the new master if necessary.
11.Let clients connect to the new master.
12.Issue a CHANGE MASTER TO command on each replica, pointing it to the new master. Use the binary log coordinates you gathered from SHOW MASTER STATUS.
NOTE
When you promote a replica to a master, be sure to remove from it any replica-specific databases, tables, and privileges. You also need to change any replica-specific configuration parameters, such as a relaxed innodb_flush_log_at_trx_commit option. Likewise, if you demote a master to a replica, be sure to reconfigure it as needed.
If you configure your masters and replicas identically, you won’t need to change anything.
Unplanned promotions
If the master crashes and you have to promote a replica to replace it, the process might not be as easy. If there’s only one replica, you just use the replica. But if there’s more than one, you’ll have to do a few extra steps to promote a replica to be the new master.
There’s also the added problem of potentially lost replication events. It’s possible that some updates that have happened on the master will not yet have been replicated to any of its replicas. It’s even possible that a statement was executed and then rolled back on the master, but not rolled back on the replica—so the replica could actually be ahead of the master’s logical replication position.[160] If you can recover the master’s data at some point, you might be able to retrieve the lost statements and apply them manually.
In all of the following steps, be sure to use the Master_Log_File and Read_Master_Log_Pos values in your calculations. Here is the procedure to promote a replica in a master-and-replicas topology:
1. Determine which replica has the most up-to-date data. Check the output of SHOW SLAVE STATUS on each replica and choose the one whose Master_Log_File/Read_Master_Log_Pos coordinates are newest.
2. Let all replicas finish executing the relay logs they fetched from the old master before it crashed. If you change a replica’s master before it’s done executing the relay log, it will throw away the remaining log events and you won’t know where it stopped.
3. Perform steps 5–7 from the list in the preceding section.
4. Compare every replica’s Master_Log_File/Read_Master_Log_Pos coordinates to those of the new master.
5. Perform steps 10–12 from the list in the preceding section.
We’re assuming you have log_bin and log_slave_updates enabled on all your replicas, as we advised you to do in the beginning of this chapter. Enabling this logging lets you recover all replicas to a consistent point in time, which you can’t reliably do otherwise.
Locating the desired log positions
If any replica isn’t at the same position as the new master, you’ll have to find the position in the new master’s binary logs corresponding to the last event that replica executed, and use it for CHANGE MASTER TO. You can use the mysqlbinlog tool to examine the last query the replica executed and find that same query in the new master’s binary log. A little math can often help, too.
To illustrate this, let’s assume that log events have increasing ID numbers and that the most up-to-date replica—the new master—had just retrieved event 100 when the old master crashed. Now let’s assume that there are two more replicas, replica2 and replica3; replica2 had retrieved event 99, and replica3 had retrieved event 98. If you point both replicas at the new master’s current binary log position, they will begin replicating event 101, so they’ll be out of sync. However, as long as the new master’s binary log was enabled with log_slave_updates, you can find events 99 and 100 in the new master’s binary log, so you can bring the replicas back to a consistent state.
Because of server restarts, different configurations, log rotations, or FLUSH LOGS commands, the same events can exist at different byte offsets in different servers. Finding the events can be slow and tedious, but it’s usually not hard. Just examine the last event executed on each replica by running mysqlbinlog on the replica’s binary log or relay log. Then find the same query in the new master’s binary log, also with mysqlbinlog; it will print the byte offset of the query, and you can use this offset in the CHANGE MASTER TO query.[161]
You can make the process faster by subtracting the byte offsets at which the new master and the replica stopped, which tells you the difference in their byte positions. If you then subtract this value from the new master’s current binary log position, chances are the desired query will be at that position. You just need to verify that it is, and you’ve found the position at which you need to start the replica.
Let’s look at a concrete example. Suppose server1 is the master of server2 and server3, and it crashes. According to Master_Log_File/Read_Master_Log_Pos in SHOW SLAVE STATUS, server2 has managed to replicate all the events that were in server1’s binary log, butserver3 isn’t as up-to-date. Figure 10-15 illustrates this scenario (the log events and byte offsets are for demonstration purposes only).
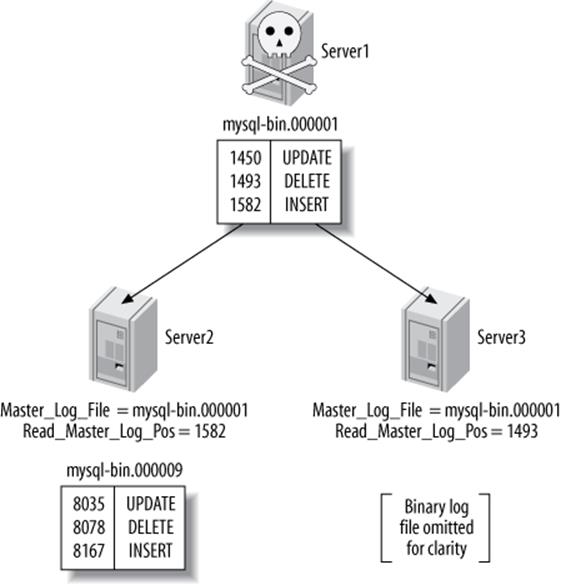
Figure 10-15. When server1 crashed, server2 was caught up, but server3 was behind in replication
As Figure 10-15 illustrates, we can be sure that server2 has replicated all the events in the master’s binary log because its Master_Log_File and Read_Master_Log_Pos match the last positions on server1. Therefore, we can promote server2 to be the new master and makeserver3 a replica of it.
But what parameters should we use in the CHANGE MASTER TO command on server3? This is where we need to do a little math and investigation. server3 stopped at offset 1493, which is 89 bytes behind offset 1582, the last command server2 executed. server2 is currently writing to position 8167 in its binary log. 8167 – 89 = 8078, so in theory we need to point server3 at that offset in server2’s logs. It’s a good idea to investigate the log events around this position and verify that server2 really has the right events at that offset in its logs, though. It might have something else there because of a data update that happened only on server2, for example.
Assuming that the events are the same upon inspection, the following command will switch server3 to be a replica of server2:
server2> CHANGE MASTER TO MASTER_HOST="server2", MASTER_LOG_FILE="mysql-bin.000009",
MASTER_LOG_POS=8078;
What if server1 had actually finished executing and logging one more event, beyond offset 1582, when it crashed? Because server2 had read and executed only up to offset 1582, you might have lost one event forever. However, if the old master’s disk isn’t damaged, you can still recover the missing event from its binary log with mysqlbinlog or with a log server.
If you need to recover missing events from the old master, we recommend that you do so after you promote the new master, but before you let clients connect to it. This way, you won’t have to execute the missing events on every replica; replication will take care of that for you. If the failed master is totally unavailable, however, you might have to wait and do this work later.
A variation on this procedure is to use a reliable way to store the master’s binary log files, such as a SAN or a distributed replicated block device (DRBD). Even if the master has a complete failure, you’ll still have its binary log files. You can set up a log server, point the replicas to it, and then let them all catch up to the point at which the master failed. This makes it trivial to promote one of the replicas to be a new master—it’s essentially the same process we showed for a planned promotion. We discuss these storage options further in the next chapter.
WARNING
When you promote a replica to master, don’t change its server ID to match the old master’s. If you do, you won’t be able to use a log server to replay events from the old master. This is one of many reasons it’s a good idea to treat server IDs as fixed.
Switching Roles in a Master-Master Configuration
One of the advantages of master-master replication is that you can switch the active and passive roles easily, because of the symmetrical configuration. In this section, we show you how to accomplish the switch.
When switching the roles in a master-master configuration, the most important thing is to ensure that only one of the co-masters is written to at any time. If writes from one master are interleaved with writes from the other, the writes can conflict. In other words, the passive server must not receive any binary log events from the active server after the roles are switched. You can guarantee this doesn’t happen by ensuring that the passive server’s replication SQL thread is caught up to the active server before you make it writable.
The following steps switch the roles without danger of conflicting updates:
1. Stop all writes on the active server.
2. Execute SET GLOBAL read_only = 1 on the active server, and set the read_only option in its configuration file for safety in case of a restart. Remember, this won’t stop users with the SUPER privilege from making changes. If you want to prevent changes from all users, useFLUSH TABLES WITH READ LOCK. If you don’t do this, you must kill all client connections to make sure there are no long-running statements or uncommitted transactions.
3. Execute SHOW MASTER STATUS on the active server and note the binary log coordinates.
4. Execute SELECT MASTER_POS_WAIT() on the passive server with the active server’s binary log coordinates. This command will block until the replication processes catch up to the active server.
5. Execute SET GLOBAL read_only = 0 on the passive server, thus making it the active server.
6. Reconfigure your applications to write to the newly active server.
Depending on your application’s configuration, you might need to do other tasks as well, including changing the IP addresses on the two servers. We discuss this in the following chapters.
[159] If you’re using a nontransactional storage engine, shutting down the server without first running STOP SLAVE is ungraceful.
[160] This really is possible, even though MySQL doesn’t log any events until the transaction commits. See “Mixing Transactional and Nontransactional Tables” on page 498 for the details. Another scenario where this can happen is when the master crashes and recovers, but it didn’t have innodb_flush_log_at_trx_commit set to 1, so it loses some changes.
[161] As mentioned earlier, heartbeat records from pt-heartbeat can be a great help in figuring out approximately where in a binary log you should be looking for your event.
Replication Problems and Solutions
Breaking MySQL’s replication isn’t hard. The simple implementation that makes it easy to set up also means there are many ways to stop, confuse, and otherwise disrupt it. This section shows common problems, how they manifest themselves, and how you can solve or even prevent them.
Errors Caused by Data Corruption or Loss
For a variety of reasons, MySQL replication is not very resilient to crashes, power outages, and corruption caused by disk, memory, or network errors. You’ll almost certainly have to restart replication at some point due to one of these problems.
Most of the problems you’ll have with replication after an unexpected shutdown stem from one of the servers not flushing something to disk. Here are the issues you might encounter in the event of an unexpected shutdown:
Unexpected master shutdown
If the master isn’t configured with sync_binlog, it might not have flushed its last several binary log events to disk before crashing. The replication I/O thread may, therefore, have been in the middle of reading from an event that never made it to disk. When the master restarts, the replica will reconnect and try to read that event again, but the master will respond by telling it that there’s no such binlog offset. The binlog dump process is typically almost instantaneous, so this is not uncommon.
The solution to this problem is to instruct the replica to begin reading from the beginning of the next binary log. However, some log events will have been lost permanently, so you will need to use Percona Toolkit’s pt-table-checksum tool to check the server for inconsistencies so you can fix them. This loss of data could have been prevented by configuring the master with sync_binlog.
Even if you’ve configured sync_binlog, MyISAM data can still get corrupted when there’s a crash, and InnoDB transactions can be lost (but data won’t be corrupted) if innodb_flush_logs_at_trx_commit is not set to 1.
Unexpected replica shutdown
When the replica restarts after an unplanned shutdown, it reads its master.info file to determine where it stopped replicating. Unfortunately, this file is not synchronized to disk, so the information it contains is likely to be wrong. The replica will probably try to reexecute a few binary log events, which could cause some unique index violations. Unless you can determine where the replica really stopped, which is unlikely, you’ll have no choice but to skip the errors that result. The pt-slave-restart tool, part of Percona Toolkit, can help you with this.
If you use all InnoDB tables, you can look at the MySQL error log after restarting the replica. The InnoDB recovery process prints the binary log coordinates up to the point where it recovered, and you can use them to determine where to point the replica on the master. Percona Server offers a feature to automatically extract this information during the recovery process and update the master.info file for you, essentially making the replication coordinates transactional on the replica. MySQL 5.5 also offers options to control how the master.info and other files are synced to disk, helping reduce these problems.
In addition to data losses resulting from MySQL being shut down uncleanly, it’s not uncommon for binary logs or relay logs to be corrupted on disk. The following are some of the more common scenarios:
Binary logs corrupted on the master
If the binary log is corrupted on the master, you’ll have no choice but to try to skip the corrupted portion. You can run FLUSH LOGS on the master so it starts a new log file and point the replica at the beginning of the new log, or you can try to find the end of the bad region. Sometimes you can use SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 to skip a single corrupt event. If there is more than one corrupt event, just repeat the process until they’ve all been skipped. If there’s a lot of corruption, though, you might not be able to do that; corrupt event headers can prevent the server from being able to find the next event. In that case you might have to do some manual work to find the next good event.
Relay logs corrupted on the replica
If the master’s binary logs are intact, you can use CHANGE MASTER TO to discard and refetch the corrupt relay logs. Just point the replica at the same position from which it’s currently replicating (Relay_Master_Log_File/Exec_Master_Log_Pos). This will cause it to throw away any relay logs on disk. MySQL 5.5 has some improvements in this regard: it can refetch relay logs automatically after a crash.
Binary log out of sync with the InnoDB transaction log
If the master crashes, InnoDB might record a transaction as committed even if it didn’t get written to the binary log on disk. There’s no way to recover the missing transaction, unless it’s in a replica’s relay log. You can prevent this with the sync_binlog parameter in MySQL 5.0, or thesync_binlog and safe_binlog parameters in MySQL 4.1.
When a binary log is corrupt, how much data you can recover depends on the type of corruption. There are several common types:
Bytes changed, but the event is still valid SQL
Unfortunately, MySQL cannot even detect this type of corruption. This is why it can be a good idea to routinely check that your replicas have the right data. This might be fixed in a future version of MySQL.
Bytes changed and the event is invalid SQL
You might be able to extract the event with mysqlbinlog and see garbled data, such as the following:
UPDATE tbl SET col?????????????????
Try to find the beginning of the next event, which you can do by adding the offset and length, and print it. You might be able to skip just this event.
Bytes omitted and/or the event’s length is wrong
In this case, mysqlbinlog will sometimes exit with an error or crash because it can’t read the event and can’t find the beginning of the next event.
Several events corrupted or were overwritten, or offsets have shifted and the next event starts at the wrong offset
Again, mysqlbinlog will not be much use.
When the corruption is bad enough that mysqlbinlog can’t read the log events, you’ll have to resort to some hex editing or other tedious techniques to find the boundaries between log events. This usually isn’t hard to do, because recognizable markers separate the events.
Here’s an example. First, let’s look at log event offsets for a sample log, as reported by mysqlbinlog:
$ mysqlbinlog mysql-bin.000113 | egrep '^# at '
# at 4
# at 98
# at 185
# at 277
# at 369
# at 447
A simple way to find offsets in the log is to compare the offsets to the output of the following strings command:
$ strings -n 2 -t d mysql-bin.000113
1 binpC'G
25 5.0.38-Ubuntu_0ubuntu1.1-log
99 C'G
146 std
156 test
161 create table test(a int)
186 C'G
233 std
243 test
248 insert into test(a) values(1)
278 C'G
325 std
335 test
340 insert into test(a) values(2)
370 C'G
417 std
427 test
432 drop table test
448 D'G
474 mysql-bin.000114
There’s a pretty recognizable pattern that should allow you to locate the beginnings of events. Notice that the strings that end with ’G are located one byte after the beginning of the log event. They are part of the fixed-length log event header.
The exact value will vary from server to server, so your results will vary depending on the server whose log you’re examining. With a little sleuthing, though, you should be able to find the pattern in your binary log and determine the next intact log event’s offset. You can then try to skip past the bad event(s) with the --start-position argument to mysqlbinlog, or use the MASTER_LOG_POS parameter to CHANGE MASTER TO.
Using Nontransactional Tables
If all goes well, statement-based replication usually works fine with nontransactional tables. However, if there’s an error in an update to a nontransactional table, such as the statement being killed before it is complete, the master and replica will end up with different data.
For example, suppose you’re updating a MyISAM table with 100 rows. If the statement updates 50 of the rows and then someone kills it, what happens? Half of the rows will have been changed, but not the other half. Replication is bound to get out of sync as a result, because the statement will replay on the replica and change all 100 rows. (MySQL will then notice that the statement caused an error on the master but not the replica, and replication will stop with an error.)
If you’re using MyISAM tables, be sure to run STOP SLAVE before stopping the MySQL server, or the shutdown will kill any running queries (including any incomplete update statements). Transactional storage engines don’t have this problem. If you’re using transactional tables, the failed update will be rolled back on the master and not logged to the binary log.
Mixing Transactional and Nontransactional Tables
When you use a transactional storage engine, MySQL doesn’t log the statements you execute to the binary log until the transactions commit. Thus, if a transaction is rolled back, MySQL won’t log the statements, so they won’t get replayed on the replica.
However, if you mix transactional and nontransactional tables and there’s a rollback, MySQL will be able to roll back the changes to the transactional tables, but the nontransactional ones will be changed permanently. As long as there are no errors, such as an update being killed partway through execution, this is not a problem: instead of just not logging the statements, MySQL logs the statements and then logs a ROLLBACK statement to the binary log. The result is that the same statements execute on the replica, and all is well. It’s a little less efficient, because the replica must do some work and then throw it away, but the replica will theoretically still be in sync with the master.
So far, so good. The problem is when the replica has a deadlock that didn’t happen on the master. The tables that use a transactional storage engine will roll back on the replica, but the replica won’t be able to roll back the nontransactional tables. As a result, the replica’s data will be different from the master’s.
The only way to prevent this problem is to avoid mixing transactional and nontransactional tables. If you do encounter the problem, the only way to fix it is to skip the error on the replica and resync the involved tables.
Row-based replication does not suffer from this problem. Row-based replication logs changes to rows, not SQL statements. If a statement changes some rows in a MyISAM table and an InnoDB table and then deadlocks on the master and rolls back the InnoDB table, the changes to the MyISAM table will still be logged to the binary log and replayed on the replica.
Nondeterministic Statements
Any statement that changes data in a nondeterministic way can cause a replica’s data to become different from its master’s when using statement-based replication. For example, an UPDATE with a LIMIT relies on the order in which the statement finds rows in the table. Unless the order is guaranteed to be the same on the master and the replica—for example, if the rows are ordered by primary key—the statement might change different rows on the two servers. Such problems can be subtle and difficult to notice, so some people make a policy of never using LIMIT with any statement that changes data. Another surprising source of nondeterministic behavior is a REPLACE or INSERT IGNORE on a table with more than one unique index—the server might choose a different “winner” on the master than on the replica.
Watch out for statements that involve INFORMATION_SCHEMA tables, too. These can easily differ between the master and the replica, so the results might vary as well. Finally, be aware that most server variables, such as @@server_id and @@hostname, will not replicate correctly before MySQL 5.1.
Row-based replication does not have these limitations.
Different Storage Engines on the Master and Replica
It’s often handy to have different storage engines on a replica, as we’ve mentioned throughout this chapter. However, in some circumstances, statement-based replication might produce different results on a replica with different storage engines than the master. For example, nondeterministic statements (such as the ones mentioned in the previous section) are more likely to cause problems if the storage engines on the master and the replica differ.
If you find that your replica’s data is falling out of sync with the master in specific tables, you should examine the storage engines used on both servers, as well as the queries that update those tables.
Data Changes on the Replica
Statement-based replication relies upon the replica having the same data as the master, so you should not make or allow any changes on the replica (using the read_only configuration variable accomplishes this nicely). Consider the following statement:
mysql> INSERT INTO table1 SELECT * FROM table2;
If table2 contains different data on the replica, table1 will end up with different data, too. In other words, data differences tend to propagate from table to table. This happens with all types of queries, not just INSERT ... SELECT queries. There are two possible outcomes: you’ll get an error such as a duplicate index violation on the replica, or you won’t get any error at all. Getting an error is a blessing, because at least it alerts you that your data isn’t the same on the replica. Invisibly different data can silently wreak all kinds of havoc.
The only solution to this problem is to resync the data from the master.
Nonunique Server IDs
This is one of the more elusive problems you might encounter with replication. If you accidentally configure two replicas with the same server ID, they might seem to work just fine if you’re not watching closely. But if you watch their error logs, or watch the master with innotop, you’ll notice something very odd.
On the master, you’ll see only one of the two replicas connected at any time. (Usually, all replicas are connected and replicating all the time.) On the replica, you’ll see frequent disconnect and reconnect error messages in the error log, but no mention of a misconfigured server ID.
Depending on the MySQL version, the replicas might replicate correctly but slowly, or they might not actually replicate correctly—any given replica might miss binary log events, or even repeat them, causing duplicate key errors (or silent data corruption). You can also cause problems on the master because of the increased load from the replicas fighting amongst themselves. And if replicas are fighting each other badly enough, the error logs can grow enormous in a very short time.
The only solution to this problem is to be careful when setting up your replicas. You might find it helpful to create a master list of replica-to–server ID mappings so that you don’t lose track of which ID belongs to each replica.[162] If your replicas live entirely within one network subnet, you can choose unique IDs by using the last octet of each machine’s IP address.
Undefined Server IDs
If you don’t define the server ID in the my.cnf file, MySQL will appear to set up replication with CHANGE MASTER TO but will not let you start the replica:
mysql> START SLAVE;
ERROR 1200 (HY000): The server is not configured as slave; fix in config file or with
CHANGE MASTER TO
This error is especially confusing if you’ve just used CHANGE MASTER TO and verified your settings with SHOW SLAVE STATUS. You might get a value from SELECT @@server_id, but it’s just a default. You have to set the value explicitly.
Dependencies on Nonreplicated Data
If you have databases or tables on the master that don’t exist on the replica, or vice versa, it’s quite easy to accidentally break replication. Suppose there’s a scratch database on the master that doesn’t exist on the replica. If any data updates on the master refer to a table in this database, replication will break when the replica tries to replay the updates. Similarly, if you create a table on the master and it already exists on the replica, replication will break.
There’s no way around this problem. The only way to prevent it is to avoid creating tables on the master that don’t exist on the replica.
How does such a table get created? There are many possible ways, and some are harder to prevent than others. For example, suppose you originally created a scratch database on the replica that didn’t exist on the master, and then you switched the master and replica for some reason. When you did this, you might have forgotten to remove the scratch database and its privileges. Now someone might connect to the new master and run a query in that database, or a periodic job might discover the tables and run OPTIMIZE TABLE on each of them.
This is one of the things to keep in mind when promoting a replica to master, or when deciding how to configure replicas. Anything that makes replicas different from masters, or vice versa, is a potential future problem.
Missing Temporary Tables
Temporary tables are handy for some uses, but unfortunately they’re incompatible with statement-based replication. If a replica crashes, or if you shut it down, any temporary tables the replica thread was using disappear. When you restart the replica, any further statements that refer to the missing temporary tables will fail.
There’s no safe way to use temporary tables on the master with statement-based replication. Many people love temporary tables dearly, so it can be hard to convince them of this, but it’s true.[163] No matter how briefly they exist, temporary tables make it difficult to stop and start replicas and to recover from crashes. This is true even if you use them only within a single transaction. (It’s slightly less problematic to use temporary tables on a replica, where they can be convenient, but if the replica is itself a master, the problem still exists.)
If replication stops because the replica can’t find a temporary table after a restart, there are really only a couple of things to do: you can skip the errors that occur, or you can manually create a table that has the same name and structure as the now-vanished temporary table. Either way, your data will likely become different on the replica if any write queries refer to the temporary table.
It’s not as hard as it seems to eliminate temporary tables. The two most useful properties of temporary tables are as follows:
§ They’re visible only to the connection that created them, so they don’t conflict with other connections’ temporary tables of the same names.
§ They go away when the connection closes, so you don’t have to remove them explicitly.
You can emulate these properties easily by reserving a database exclusively for pseudotemporary tables, where you’ll create permanent tables instead. You just have to choose unique names for them. Fortunately, that’s pretty easy to do: simply append the connection ID to the table name. For example, where you used to execute CREATE TEMPORARY TABLE top_users(...), now you can execute CREATE TABLE temp.top_users_1234(...), where 1234 is the value returned by CONNECTION_ID(). After your application is done with the pseudotemporary table, you can either drop it or let a cleanup process remove it instead. Having the connection ID in the table name makes it easy to determine which tables are not in use anymore—you can get a list of active connections from SHOW PROCESSLIST and compare it to the connection IDs in the table names.[164]
Using real tables instead of temporary tables has other benefits, too. For example, it makes it easier to debug your applications, because you can see the data the applications are manipulating from another connection. If you used a temporary table, you wouldn’t be able to do that as easily.
Real tables do have some overhead temporary tables don’t, however: it’s slower to create them because the .frm files associated with these tables must be synced to disk. You can disable the sync_frm option to speed this up, but it’s more dangerous.
If you do use temporary tables, you should ensure that the Slave_open_temp_tables status variable is 0 before shutting down a replica. If it’s not 0, you’re likely to have problems restarting the replica. The proper procedure is to run STOP SLAVE, examine the variable, and only then shut down the replica. If you examine the variable before stopping the replica processes, you’re risking a race condition.
Not Replicating All Updates
If you misuse SET SQL_LOG_BIN=0 or don’t understand the replication filtering rules, your replica might not execute some updates that have taken place on the master. Sometimes you want this for archiving purposes, but it’s usually accidental and has bad consequences.
For example, suppose you have a replicate_do_db rule to replicate only the sakila database to one of your replicas. If you execute the following commands on the master, the replica’s data will become different from the data on the master:
mysql> USE test;
mysql> UPDATE sakila.actor ...
Other types of statements can even cause replication to fail with an error because of nonreplicated dependencies.
Lock Contention Caused by InnoDB Locking Selects
InnoDB’s SELECT statements are normally nonlocking, but in certain cases they do acquire locks. In particular, INSERT ... SELECT locks all the rows it reads from the source table by default when using statement-based replication. MySQL needs the locks to ensure that the statement produces the same result on the replica when it executes there. In effect, the locks serialize the statement on the master, which matches how the replica will execute it.
You might encounter lock contention, blocking, and lock wait timeouts because of this design. One way to alleviate the problems is not to hold a transaction open longer than needed, so the locks cause less blocking. You can release the locks by committing the transaction as soon as possible on the master.
It can also help to keep your statements short, by breaking up large statements into several smaller ones. This is a very effective way to reduce lock contention, and even when it’s hard to do, it’s often worth it. (It’s quite simple with the pt-archiver tool in Percona Toolkit.)
Another workaround is to replace INSERT ... SELECT statements with a combination of SELECT INTO OUTFILE followed by LOAD DATA INFILE on the master. This is fast and doesn’t require locking. It is admittedly a hack, but it’s sometimes useful anyway. The biggest issues are choosing a unique name for the output file, which must not already exist, and cleaning up the output file when you’re done with it. You can use the CONNECTION_ID() technique we just discussed to ensure that the filename is unique, and you can use a periodic job (crontab on Unix,scheduled tasks on Windows) to purge unused output files after the connections that created them are finished with them.
You might be tempted to try to disable the locks instead of using these workarounds. There is a way to do so, but it’s not a good idea for most scenarios, because it makes it possible for your replica to fall silently out of sync with the master. It also makes the binary log useless for recovering a server. If, however, you decide that the risks are worth the benefits, the configuration change that accomplishes this is as follows:
# THIS IS NOT SAFE!
innodb_locks_unsafe_for_binlog = 1
This allows a statement’s results to depend on data it doesn’t lock. If a second statement modifies that data and then commits before the first statement, the two statements might not produce the same results when you replay the binary log. This is true both for replication and for point-in-time recovery.
To see how locking reads prevent chaos, imagine you have two tables: one without rows, and one whose single row has the value 99. Two transactions update the data. Transaction 1 inserts the second table’s contents into the first table, and transaction 2 updates the second (source) table, as depicted in Figure 10-16.
Figure 10-16. Two transactions update data, with shared locks to serialize the updates
Step 2 in this sequence of events is very important. In it, transaction 2 tries to update the source table, which requires it to place an exclusive (write) lock on the rows it wants to update. An exclusive lock is incompatible with any other lock, including the shared lock transaction 1 has placed on that row, so transaction 2 is forced to wait until transaction 1 commits. The transactions are serialized in the binary log in the order they committed, so replaying these transactions in binary log (commit) order will give the same results.
On the other hand, if transaction 1 doesn’t place a shared lock on the rows it reads for the INSERT, no such guarantee exists. Study Figure 10-17, which shows a possible sequence of events without the lock.
The absence of locks allows the transactions to be written to the binary log in an order that will produce different results when that log is replayed, as you can see in the illustration. MySQL logs transaction 2 first, so it will affect transaction 1’s results on the replica. This didn’t happen on the master. As a result, the replica will contain different data than the master.
We strongly suggest that you leave the innodb_locks_unsafe_for_binlog configuration variable set to 0 in most situations. Row-based replication avoids this whole scenario, of course, by logging actual data changes instead of statements.
Figure 10-17. Two transactions update data, but without a shared lock to serialize the updates
Writing to Both Masters in Master-Master Replication
Writing to both masters is a terrible idea. If you’re trying to make it safe to write to both masters at the same time, some of the problems have solutions, but not all. It takes an expert with a lot of battle scars to know the difference.
In MySQL 5.0, two server configuration variables help address the problem of conflicting AUTO_INCREMENT primary keys. The variables are auto_increment_increment and auto_increment_offset. You can use them to “stagger” the numbers the servers generate, so they interleave rather than collide.
However, this doesn’t solve all the problems you’ll have with two writable masters; it solves only the autoincrement problem, which probably accounts for just a small subset of the conflicting writes you’re likely to have. In fact, it actually adds several new problems:
§ It makes it harder to move servers around in the replication topology.
§ It wastes key space by potentially introducing gaps between numbers.
§ It doesn’t help unless all your tables have AUTO_INCREMENT primary keys, and it’s not always a good idea to use AUTO_INCREMENT primary keys universally.
You can generate your own nonconflicting primary key values. One way is to create a multicolumn primary key and use the server ID for the first column. This works well, but it makes your primary keys larger, which has a compound effect on secondary keys in InnoDB.
You can also use a single-column primary key, and use the “high bits” of the integer to store the server ID. A simple left-shift (or multiplication) and addition can accomplish this. For example, if you’re using the 8 most significant bits of an unsigned BIGINT (64-bit) column to hold the server ID, you can insert the value 11 on server 15 as follows:
mysql> INSERT INTO test(pk_col, ...) VALUES( (15 << 56) + 11, ...);
If you convert the result to base 2 and pad it out to 64 bits wide, the effect is easier to see:
mysql> SELECT LPAD(CONV(pk_col, 10, 2), 64, '0') FROM test;
+------------------------------------------------------------------+
| LPAD(CONV(pk_col, 10, 2), 64, '0') |
+------------------------------------------------------------------+
| 0000111100000000000000000000000000000000000000000000000000001011 |
+------------------------------------------------------------------+
The problem with this method is that you need an external way to generate key values, because AUTO_INCREMENT can’t do it for you. Don’t use @@server_id in place of the constant value 15 in the INSERT, because you’ll get a different result on the replica.
You can also turn to pseudorandom values using a function such as MD5() or UUID(), but these can be bad for performance—they’re big, and they’re essentially random, which is bad for InnoDB in particular. (Don’t use UUID() unless you generate the values in the application, becauseUUID() doesn’t replicate correctly with statement-based replication.)
It’s a hard problem to solve, and we usually recommend redesigning your application so that you have only one writable master instead. Who’d have guessed it?
Excessive Replication Lag
Replication lag is a frequent problem. No matter what, it’s a good idea to design your applications to tolerate some lag on the replicas. If the system can’t function with lagging replicas, replication might not be the correct architecture for your application. However, there are some steps you can take to help replicas keep up with the master.
The single-threaded nature of MySQL replication means it’s relatively inefficient on the replica. Even a fast replica with lots of disks, CPUs, and memory can easily fall behind a master, because the replica’s single thread usually uses only one CPU and disk efficiently. In fact, each replica typically needs to be at least as powerful as the master.
Locking on the replicas is also a problem. Other queries running on a replica might acquire locks that block the replication thread. Because replication is single-threaded, the replication thread won’t be able to do other work while it waits.
Replication tends to fall behind in two ways: spikes of lag followed by catching up, or staying steadily behind. The former pattern is usually caused by single queries that run for a long time, but the latter can crop up even when there are no long queries.
Unfortunately, at present it’s not as easy as we’d like to find out whether a replica is close to its capacity, as discussed earlier in this chapter. If your load were perfectly uniform at all times, your replicas would perform nearly as well at 99% capacity as at 10% capacity and when they reached 100% capacity they’d abruptly begin to fall behind. In reality, the load is unlikely to be steady, so when a replica is close to its write capacity you’ll probably see increased replication lag during times of peak load.
Logging queries on a replica and using a log analysis tool to see what’s really slow is one of the best things to do when replicas can’t keep up. Don’t rely on your instincts about what’s slow, and don’t base your opinion on how queries perform on the master, because replicas and masters have very different performance profiles. The best way to do this analysis is to enable the slow query log on a replica for a while, and then analyze it with pt-query-digest as discussed in Chapter 3. The standard MySQL slow query log can log queries the replication thread executes in MySQL 5.1 and newer, if you enable the log_slow_slave_statements option, so you can see which queries are slow when they’re replicated. Percona Server and MariaDB let you enable and disable this without restarting the server.
There’s not much you can tweak or tune on a replica that can’t keep up, aside from buying faster disks and CPUs (solid-state drives can help tremendously; see Chapter 9 for details). Most of the options involve disabling some things that cause extra work on the replica to try to reduce its load. One easy change is to configure InnoDB to flush changes to disk less frequently, so transactions commit more quickly. You can accomplish this by setting innodb_flush_log_at_trx_commit to 2. You can also disable binary logging on the replica, setinnodb_locks_unsafe_for_binlog to 1, and set delay_key_write to ALL for MyISAM. These settings trade safety for speed, though. If you promote a replica to be a master, make sure to reset these settings to safe values.
Don’t duplicate the expensive part of writes
Rearchitecting your application and/or optimizing your queries is often the best way to help the replicas keep up. Try to minimize the amount of work that has to be duplicated through your system. Any write that’s expensive on the master will be replayed on every replica. If you can move the work off the master onto a replica, only one of the replicas will have to do the work. You can then push the write results back up to the master, for example, with LOAD DATA INFILE.
Here’s an example. Suppose you have a very large table that you summarize into a smaller table for frequent processing:
mysql> REPLACE INTO main_db.summary_table (col1, col2, ...)
-> SELECT col1, sum(col2, ...)
-> FROM main_db.enormous_table GROUP BY col1;
If you perform that operation on the master, every replica will have to repeat the enormous GROUP BY query. If you do enough of this, the replicas will not be able to keep up. Moving the number crunching to one of the replicas can help. On the replica, perhaps in a special database reserved for the purpose of avoiding conflicts with the data being replicated from the master, you can run the following:
mysql> REPLACE INTO summary_db.summary_table (col1, col2, ...)
-> SELECT col1, sum(col2, ...)
-> FROM main_db.enormous_table GROUP BY col1;
Now you can use SELECT INTO OUTFILE, followed by LOAD DATA INFILE on the master, to move the results back up to the master. Voilà—the duplicated work is reduced to a simple LOAD DATA INFILE. If you have N replicas, you have just saved N – 1 enormous GROUP BY queries.
The problem with this strategy is dealing with stale data. Sometimes it’s hard to get consistent results by reading on the replica and writing on the master (a problem we address in detail in the following chapters). If it’s hard to do the read on the replica, you can simplify and still save your replicas a lot of work. If you separate the REPLACE and SELECT parts of the query, you can fetch the results into your application and then insert them back into the master. First, perform the following query on the master:
mysql> SELECT col1, sum(col2, ...) FROM main_db.enormous_table GROUP BY col1;
You can then insert the results back into the summary table by repeating the following query for every row in the result set:
mysql> REPLACE INTO main_db.summary_table (col1, col2, ...) VALUES (?, ?, ...);
Again, you’ve spared the replicas from the large GROUP BY portion of the query; separating the SELECT from the REPLACE means that the SELECT part of the query isn’t replayed on every replica.
This general strategy—saving the replicas from the expensive portion of a write—can help in many cases where you have queries whose results are expensive to calculate but cheap to handle once they’ve been calculated.
Do writes in parallel outside of replication
Another tactic for avoiding excessive lag on the replicas is to circumvent replication. Any writes you do on the master must be serialized on the replica, so it makes sense to think of “serialized writes” as a scarce resource. Do all your writes need to flow from the master to the replica? How can you reserve your replica’s limited serialized write capacity for the writes that really need to be done via replication?
Thinking of it in this light might help you prioritize writes. In particular, if you can identify some writes that are easy to do outside of replication, you can parallelize writes that would otherwise claim precious write capacity on the replica.
One great example is data archiving, which we discussed earlier in this chapter. OLTP archiving queries are often simple single-row operations. If you’re just moving unneeded rows from one table to another, there might be no reason these writes have to be replicated to replicas. Instead, you can disable binary logging for the archiving statements, and then run separate but identical archiving processes on the master and replicas.
It might sound crazy to copy the data to another server yourself instead of letting replication do it, but it can actually make sense for some applications. This is especially true if an application is the only source of updates to a certain set of tables. Replication bottlenecks often center around a small set of tables, and if you can handle just those tables outside of replication, you might be able to speed it up significantly.
Prime the cache for the replication thread
If you have the right kind of workload, you might benefit from parallelizing I/O on replicas by prefetching data into memory. This technique is not well known, for good reason. Most people should not use it, because it won’t work unless you have the right workload characteristics and hardware configuration. The other types of changes we’ve just been discussing are usually far better options, and there are lots more ways to apply them than you might think. However, we know of a small handful of large applications that benefit from prefetching data from disk.
There are two workable implementations for this. One idea is to use a program that reads slightly ahead of the replica’s SQL thread in the relay logs and executes the queries as SELECT statements. This causes the server to fetch some of the data from the disk into memory, so when the replica’s SQL thread executes the statement from the relay log, it doesn’t need to wait for data to be fetched from disk. In effect, the SELECT parallelizes I/O that the replica SQL thread must normally do serially. While one statement is changing data, the next statement’s data is being fetched from disk into memory.
The following conditions might indicate that prefetching will work:
§ The replication SQL thread is I/O-bound, but the replica server isn’t I/O-bound overall. A completely I/O-bound server won’t benefit from prefetching, because it won’t have any idle hard drives to do the work.
§ The replica has a lot of disk drives—perhaps eight or more drives per replica.
§ You use the InnoDB storage engine, and the working set is much too large to fit in memory.
An example workload that benefits from prefetching is one with a lot of widely scattered single-row UPDATE statements, which are typically high-concurrency on the master. DELETE statements might also benefit from this approach, but INSERT statements are less likely to—especially when rows are inserted sequentially—because the end of the index will already be “hot” from previous inserts.
If a table has many indexes, it might not be possible to prefetch all the data the statement will modify. The UPDATE statement might modify every index, but the SELECT will typically read only the primary key and one secondary index, in the best case. The UPDATE will still need to fetch other indexes for modification. That decreases how effective this tactic can be on tables with many indexes.
This technique is not a silver bullet. There are many reasons why it might not work for you or might even cause more problems. You should attempt it only if you know your hardware and operating system well. We know some people for whom this approach increased replication speed by 300% to 400%, but we’ve tried it ourselves many times and found it usually doesn’t work. Getting the parameters right is important, but there isn’t always a right combination of parameters.
The mk-slave-prefetch tool, which is part of Maatkit, is one implementation of the ideas we’ve described in this section. It has a lot of sophisticated features to try to work in as many cases as possible, but the drawback is that it has a lot of complexity and requires a lot of expertise to use. Another is Anders Karlsson’s slavereadahead tool, available from http://sourceforge.net/projects/slavereadahead/.
Another technique entirely, which is under development at the time of writing, is internal to InnoDB. It puts transactions into a special mode that causes InnoDB to “fake” updates, so a process can execute these fake updates and then the replication thread can do the real updates quickly. This is something we’re developing in Percona Server specifically for a very popular Internet-scale web application. Check on the status of this, because it’s bound to have changed by the time this book is published.
If you’re considering this technique, we think you would be well advised to get qualified advice from an expert who’s familiar with when it works and what other options are available. This is best reserved as a last-resort measure for when all else fails.
Oversized Packets from the Master
Another hard-to-trace problem in replication can occur when the master’s max_allowed_packet size doesn’t match the replica’s. In this case, the master can log a packet the replica considers oversized, and when the replica retrieves that binary log event, it might suffer from a variety of problems. These include an endless loop of errors and retries, or corruption in the relay log.
Limited Replication Bandwidth
If you’re replicating over limited bandwidth, you can enable the slave_compressed_protocol option on the replica (available in MySQL 4.0 and newer). When the replica connects to the master, it will request a compressed connection—the same compression any MySQL client connection can use. The compression engine used is zlib, and our tests show it can compress some textual data to roughly a third of its original size. The trade-off is that extra CPU time is required to compress the data on the master and decompress it on the replica.
If you have a slow link with a master on one side and many replicas on the other side, you might want to colocate a distribution master with the replicas. That way only one server connects to the master over the slow link, reducing the bandwidth load on the link and the CPU load on the master.
No Disk Space
Replication can indeed fill up your disks with binary logs, relay logs, or temporary files, especially if you do a lot of LOAD DATA INFILE queries on the master and have log_slave_updates enabled on the replica. The more a replica falls behind, the more disk space it is likely to use for relay logs that have been retrieved from the master but not yet executed. You can prevent these errors by monitoring disk usage and setting the relay_log_space configuration variable.
Replication Limitations
MySQL replication can fail or get out of sync, with or without errors, just because of its inherent limitations. A fairly large list of SQL functions and programming practices simply won’t replicate reliably (we’ve mentioned many of them in this chapter). It’s hard to ensure that none of these finds a way into your production code, especially if your application or team is large.[165]
Another issue is bugs in the server. We don’t want to sound negative, but many major versions of the MySQL server have historically had bugs in replication, especially in the first releases of the major version. New features, such as stored procedures, have usually caused more problems.
For most users, this is not a reason to avoid new features. It’s just a reason to test carefully, especially when you upgrade your application or MySQL. Monitoring is also important; you need to know when something causes a problem.
MySQL replication is complicated, and the more complicated your application is, the more careful you need to be. However, if you learn how to work with it, it works quite well.
[162] Perhaps you’d like to store it in a database table? We’re only half joking... you can add a unique index on the ID column.
[163] We’ve had people stubbornly try all sorts of ways to work around this, but there is no way to make temporary tables safe for statement-based replication. Period. No matter what you’re thinking of, we’ve proven it won’t work.
[164] pt-find—yet another tool in the Percona Toolkit—can remove pseudotemporary tables easily with the --connection-id and --server-id options.
[165] Alas, MySQL doesn’t have a forbid_operations_unsafe_for_replication option. In recent versions, however, it does warn pretty vigorously about some unsafe things, and even refuses certain ones.
How Fast Is Replication?
A common question about replication is “How fast is it?” The short answer is that it runs as quickly as MySQL can copy the events from the master and replay them, with very little overhead. If you have a slow network and very large binary log events, the delay between binary logging and execution on the replica might be perceptible. If your queries take a long time to run and you have a fast network, you can generally expect the query time on the replica to contribute more to the time it takes to replicate an event.
A more complete answer requires measuring every step of the process and deciding which steps will take the most time in your application. Some readers might care only that there’s usually very little delay between logging events on the master and copying them to the replica’s relay log. For those who would like more details, we did a quick experiment.
We elaborated on the process described in the first edition of this book, and methods used by Giuseppe Maxia,[166] to measure replication speed with high precision. We built a nondeterministic UDF that returns the system time to microsecond precision (see User-Defined Functions for the source code):
mysql> SELECT NOW_USEC()
+----------------------------+
| NOW_USEC() |
+----------------------------+
| 2007-10-23 10:41:10.743917 |
+----------------------------+
This lets us measure replication speed by inserting the value of NOW_USEC() into a table on the master, then comparing it to the value on the replica.
We measured the delay by setting up two instances of MySQL on the same server to avoid inaccuracies caused by the clock. We configured one instance as a replica of the other, then ran the following queries on the master instance:
mysql> CREATE TABLE test.lag_test(
-> id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> now_usec VARCHAR(26) NOT NULL
-> );
mysql> INSERT INTO test.lag_test(now_usec) VALUES( NOW_USEC() );
We used a VARCHAR column because MySQL’s built-in time types can’t store times with subsecond resolution (although some of its time functions can do subsecond calculations). All that remained was to compare the difference between the replica and the master. We decided to use a Federated table to help.[167] On the replica, we ran:
mysql> CREATE TABLE test.master_val (
-> id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> now_usec VARCHAR(26) NOT NULL
-> ) ENGINE=FEDERATED
-> CONNECTION='mysql://user:pass@127.0.0.1/test/lag_test',;
A simple join and the TIMESTAMPDIFF() function show the microseconds of lag between the time the query executed on the master and on the replica:
mysql> SELECT m.id, TIMESTAMPDIFF(FRAC_SECOND, m.now_usec, s.now_usec) AS usec_lag
-> FROM test.lag_test as s
-> INNER JOIN test.master_val AS m USING(id);
+----+----------+
| id | usec_lag |
+----+----------+
| 1 | 476 |
+----+----------+
We inserted 1,000 rows into the master with a Perl script, with a 10-millisecond delay between row insertions to prevent the master and replica instances from fighting each other for CPU time. We then built a temporary table containing the lag of each event:
mysql> CREATE TABLE test.lag AS
> SELECT TIMESTAMPDIFF(FRAC_SECOND, m.now_usec, s.now_usec) AS lag
-> FROM test.master_val AS m
-> INNER JOIN test.lag_test as s USING(id);
Next, we grouped the results by lag time to see what the most frequent lag times were:
mysql> SELECT ROUND(lag / 1000000.0, 4) * 1000 AS msec_lag, COUNT(*)
-> FROM lag
-> GROUP BY msec_lag
-> ORDER BY msec_lag;
+----------+----------+
| msec_lag | COUNT(*) |
+----------+----------+
| 0.1000 | 392 |
| 0.2000 | 468 |
| 0.3000 | 75 |
| 0.4000 | 32 |
| 0.5000 | 15 |
| 0.6000 | 9 |
| 0.7000 | 2 |
| 1.3000 | 2 |
| 1.4000 | 1 |
| 1.8000 | 1 |
| 4.6000 | 1 |
| 6.6000 | 1 |
| 24.3000 | 1 |
+----------+----------+
The results show that most small queries take less than 0.3 milliseconds to replicate, from execution time on the master to execution time on the replica.
The part of replication this doesn’t measure is how soon an event arrives at the replica after being logged to the binary log on the master. It would be nice to know this, because the sooner the replica receives the log event, the better. If the replica has received the event, it can provide a copy if the master crashes.
Although our measurements don’t show exactly how long this part of the process takes, in theory it should be extremely fast (i.e., bounded only by the network speed). The MySQL binlog dump process does not poll the master for events, which would be inefficient and slow. Instead, the master notifies the replica of events. Reading a binary log event from the master is a blocking network call that begins sending data practically instantaneously after the master logs the event. Thus, it’s probably safe to say the event will reach the replica as quickly as the replication thread can wake up and the network can transfer the data.
[166] See http://datacharmer.blogspot.com/2006/04/measuring-replication-speed.html.
[167] By the way, this is the only time that some of the authors have used the Federated engine.
Advanced Features in MySQL Replication
Oracle released significant enhancements to replication in MySQL 5.5, and many more are in development milestone releases, to be included in MySQL 5.6. Some of these make replication more robust, others add multithreaded (parallel) replication apply to alleviate the current single-threaded bottleneck, and still others add advanced features for more flexibility and control. We won’t speculate much on functionality that isn’t in a GA release, but there are a few things we want to mention about MySQL 5.5’s enhancements.
The first is semisynchronous replication. Based on work that Google did several years ago, this is probably the biggest change to replication since MySQL 5.1 introduced row-based replication. It helps you ensure that your replicas actually have a copy of the master’s data, so there is less potential for data loss in the event of a complete loss of the master server.
Semisynchronous replication adds a delay to the commit process: when you commit a transaction, the binary log events must be transmitted to at least one connected replica before the client connection receives notification that the query has completed. This delay is added after the master commits the transaction to its disks. As such, it really just adds latency to the clients so that they can’t push a bunch of transactions into the master faster than it can send them to replicas.
There are some common misconceptions about semisynchronous replication. Here’s what it doesn’t do:
§ It does not block the commit on the master until the replicas have acknowledged receipt. The commit completes on the master, and only the client’s notification of the commit is delayed.
§ It does not block the client until the replicas have applied the transaction. They acknowledge after receiving the transaction, not after applying it.
§ It isn’t bulletproof. If replicas don’t acknowledge receipt, it’ll time out and revert to “normal” asynchronous replication mode.
Still, it is a very useful tool to help ensure that replicas really do provide greater redundancy and durability.
In terms of performance, semisynchronous replication adds a bit of latency to commits from the client’s point of view. There is a slight delay due to the network transfer time, the time needed to write and sync data to the replica’s disk (if so configured), and the network time for the acknowledgment. It sounds like this might add up, but in tests it has proven to be barely measurable, probably because the latency is hidden by other causes of latency. Giuseppe Maxia found about a 200-microsecond performance penalty per commit.[168] The overhead will be more noticeable with extremely small transactions, as you might expect.
In fact, semisynchronous replication can actually give you enough flexibility to improve performance in some cases, by making it safer to relax sync_binlog on the master. Writing to remote memory (a replica’s acknowledgment) is faster than writing to the local disk (syncing on commit).Henrik Ingo ran some benchmarks that showed about a twofold performance improvement when he used semisynchronous replication instead of insisting on strong durability on the master.[169] There’s no such thing as absolute durability in any system—just higher and higher levels of it—and it looks like semisynchronous replication could be a lower-cost way to raise a system’s data durability than some of the alternatives.
In addition to semisynchronous replication, MySQL 5.5 also sports replication heartbeats, which help replicas stay in touch with the master and avoid silent disconnections. If there’s a dropped network connection, the replica will notice the lack of a heartbeat. There’s an improved ability to deal with differing data types between master and replica when row-based replication is used, and there are several options to configure how replication metadata files are actually synced to disk and how relay logs are treated after a crash, reducing some of the opportunities for problems after a replica crashes and recovers.
That said, we haven’t yet seen wide production deployment of any of MySQL 5.5’s improvements to replication, so there is certainly more to learn.
Aside from the above, here’s a quick rundown of improvements in the works, either in MySQL or in third-party branches such as Percona Server and MariaDB:
§ Oracle has many improvements in MySQL 5.6 lab builds and development milestone releases:
§ Transactional replication state—no more metadata files to get out of sync on a crash. (Percona Server and MariaDB have had this for a while in a different form.)
§ Binary log event checksums to help detect corrupted events in a relay log.
§ Time-delayed replication to replace Percona Toolkit’s pt-slave-delay tool.
§ Row-based binary log events can contain the original SQL executed on the master.
§ Multi-threaded replication apply (parallelized replication).
§ MySQL 5.6, Percona Server, Facebook’s patches, and MariaDB have three different fixes for the group commit problems introduced in MySQL 5.0.
[168] See http://datacharmer.blogspot.com/2011/05/price-of-safe-data-benchmarking-semi.html.
[169] See http://openlife.cc/blogs/2011/may/drbd-and-semi-sync-shootout-large-server.
Other Replication Technologies
Built-in replication isn’t the only way to replicate your data from one server to another, although it probably is the best for most purposes. (In contrast to PostgreSQL, MySQL doesn’t have a wide variety of add-on replication options, probably because built-in replication was added early in the product’s life.)
We’ve brushed elbows with a few of the add-on technologies for MySQL replication, such as Oracle GoldenGate, but we’re really not familiar enough with most of them to write much about them. There are two that we want to mention, however. The first is Percona XtraDB Cluster’s synchronous replication, which we’ll discuss in Chapter 12 because it fits better into a chapter on high availability. The second is Continuent’s Tungsten Replicator (http://code.google.com/p/tungsten-replicator/).
Tungsten is an open source middleware replication product written in Java. It has similarities to Oracle GoldenGate and seems poised to gain a lot of sophisticated features in future releases. At the time of writing, it already offers features such as replicating data between servers, sharding data automatically, applying changes in parallel on replicas (multithreaded replication), promoting a replica if a master fails, cross-platform replication, and multisource replication (many sources replicating to a single destination). It is the open source version of the Tungsten Enterprise database clustering suite, which is commercial software from Continuent.
Tungsten also implements multimaster clusters, where writes can be directed to any server in the cluster. A generic implementation of this architecture requires conflict detection and/or resolution. This is very hard, and it isn’t always what is needed. Instead, Tungsten provides a slightly limited implementation wherein not all data is writable on all nodes; instead, each node is tagged as the system of record for specific bits of data. This means that, for example,the Seattle office can own and write to its data, which is replicated to Houston and Baltimore. In Houston and Baltimore, the data is available locally for low-latency reads, but Tungsten prevents it from being written to, so conflicting updates are not possible. Houston and Baltimore can update their own data, of course, which is also replicated to each of the other locations. This “system of record” approach solves a need that people frequently try to satisfy with MySQL’s built-in replication in a ring, which, as we’ve discussed, is far from safe or robust.
Tungsten Replicator doesn’t just plug into or manage MySQL replication; it replaces it. It captures data changes on servers by reading their binary logs, but that’s where the built-in MySQL functionality stops and Tungsten Replicator takes over. It reads the binary logs and extracts the transactions, then executes them on the replicas.
This process has a richer feature set than MySQL replication does. In particular, Tungsten Replicator was the first to offer parallel replication apply for MySQL. We haven’t seen it in production yet, but it’s claimed to offer up to a threefold improvement in replication speed, depending on the workload characteristics. This seems credible to us, based on the architecture and what we know of the product.
Here are some things we like about Tungsten Replicator:
§ It provides built-in data consistency checking. Enough said.
§ It offers a plugin capability so you can write your own custom functionality. MySQL’s replication source code is very hard to understand and harder to modify. Even very talented programmers have introduced bugs into the server when’ve they tried to modify the replication code. It’s nice to have an option to change replication without changing the MySQL replication code.
§ There are global transaction IDs, which enable you to figure out the state of servers relative to each other without trying to match up binary log names and offsets.
§ It’s a good high-availability solution, with the ability to promote a replica to be the master quickly.
§ It supports heterogeneous replication (between MySQL and PostgreSQL or MySQL and Oracle, for example).
§ It supports replication between MySQL versions in cases where MySQL’s replication isn’t backward-compatible. This is very nice for certain upgrade scenarios, where you might not otherwise be able to create a workable rollback scenario in case the upgrade doesn’t go well, or you’d have to upgrade servers in an order you’d prefer not to.
§ The parallel replication design is a good match for sharded or multitenant applications.
§ Java applications can transparently write to masters and read from replicas.
§ It’s a lot simpler and easier to set up and administer than it used to be, thanks in large part to Giuseppe Maxia’s diligent work as QA Director.
And here are some drawbacks:
§ It’s arguably more complex than built-in MySQL replication, with more moving parts to set up and administer. It is middleware, after all.
§ It’s one more thing to learn and understand in your application stack.
§ It’s not as lightweight as built-in MySQL replication and doesn’t have as good performance. Single-threaded replication is slower than MySQL’s single-threaded replication.
§ It’s not as widely tested and deployed as MySQL replication, so the risk of bugs and problems is higher.
All in all, we’re happy that Tungsten Replicator is available and is under active development, with new features and functionality being released steadily. It’s nice to have an alternative to built-in replication, making MySQL suitable for more use cases and flexible enough to satisfy requirements that MySQL replication will probably never meet.
Summary
MySQL replication is the Swiss Army Knife of MySQL’s built-in capabilities, and it increases MySQL’s range of functionality and usefulness dramatically. It is probably one of the key reasons why MySQL became so popular so quickly, in fact.
Although replication has many limitations and caveats, it turns out that most of them are relatively unimportant or easy for most users to avoid. Many of the drawbacks are simply special-case behaviors of advanced features that most people won’t use, but which are very helpful for the minority of users who need them.
Because replication offers such important and complex functionality, the server itself doesn’t offer every bell and whistle that you’ll need to configure, monitor, administer, and optimize it. Third-party tools can be a tremendous help. We’re biased, but we think the most notable tools for improving your life with replication are bound to be Percona Toolkit and Percona XtraBackup. Before you use any other tools, we advise you to inspect their test suites. If they don’t have formal, automated test suites, think hard before trusting them with your data.
When it comes to replication, your motto should be K.I.S.S.[170] Don’t do anything fancy, such as using replication rings, Blackhole tables, or replication filters, unless you really need to. Use replication simply to mirror an entire copy of your data, including all privileges. Keeping your replicas identical to the master in every way will help you avoid many problems.
Speaking of keeping replicas identical to the master, here’s a short list of important things to do when you use replication:
§ Use Percona Toolkit’s pt-table-checksum to verify that replicas are true copies of the master.
§ Monitor replication to ensure that it’s running and isn’t lagging behind the master.
§ Understand the asynchronous nature of replication, and design your application to avoid or tolerate reading stale data from replicas.
§ Don’t write to more than one server in a replication topology. Configure replicas as read-only, and lock down privileges to prevent changes to data.
§ Enable sanity and safety settings as described in this chapter.
As we’ll discuss in Chapter 12, replication failure is one of the most common reasons for MySQL downtime. To avoid problems with replication, read that chapter, and try to put its suggestions into practice. You should also read the replication section of the MySQL manual thoroughly, and learn how replication works and how to administer it. If you like reading, the book MySQL High Availability by Charles Bell et al. (O’Reilly) also has useful information about replication internals. But you still need to read the manual!
[170] Keep It Simple, Schwartz! Some of us think that’s what K.I.S.S. means, anyway.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.