High Performance MySQL (2012)
Chapter 12. High Availability
This chapter covers the third of our little trio of topics: replication, scalability, and high availability. At the end of the day, high availability really means “less downtime.” Unfortunately, high availability is frequently conflated with related concepts such as redundancy, protection against data loss, and load balancing. We hope that the preceding two chapters have set the stage for a clear understanding of high availability. However, this chapter can’t be singularly focused; like the others in the trio, it must synthesize a few related topics.
What Is High Availability?
High availability is actually a bit of a mythical beast. It’s usually expressed as a percentage, which is a hint in itself: there is no absolute high availability, only relatively higher availability. 100% availability is simply impossible. The “nines” rule of availability is the most common way to express an availability goal. As you probably know, “five nines” means 99.999% uptime, which is just over five minutes of downtime per year. That’s pretty impressive for most applications, although some achieve even more nines than that.
Applications have vastly different availability needs. Before you set your heart on a certain uptime goal, ask yourself what you really need to achieve. Each increment of availability usually costs far more than the previous one; the ratio of availability to effort and cost is nonlinear. How much uptime you need usually depends on how much you can afford. The trick with high availability is to balance the cost of downtime against the cost of reducing downtime. Put another way, if you have to spend a lot of money to achieve better uptime, but the increased uptime earns you only a little more money, it might not be worth it. In general, making an application highly available is difficult and expensive past a certain point, so we advise setting realistic goals and avoiding overengineering. Fortunately, the effort required to build two or three nines of uptime might not be that high, depending on the application.
Sometimes people define availability as the portion of time that a service is running. We think the definition should also include whether the application is serving requests with good performance. There are many ways that a server can be running but not really available. A common case is just after a MySQL server is restarted. It could take many hours for a big server to warm up enough to serve queries with acceptable response times, even if the server receives only a small portion of its normal traffic.
A related consideration is whether you’ll lose any data, even if your application doesn’t go offline. If a server has a truly catastrophic failure, you might lose at least some data, such as the last few transactions that were written to the (now lost) binary log and didn’t make it to a replica’s relay log. Can you tolerate this? Most applications can; the alternatives are usually expensive, complex, or have some performance overhead. For example, you can use synchronous replication, or place the binary log on a device that’s replicated by DRBD so you won’t lose it even if the server fails completely. (You can still lose power to the whole data center, though.)
A smart application architecture can often reduce your availability needs, at least for part of the system, and thus make high availability easier to achieve. Separating critical and noncritical parts of your application can save you a lot of work and money, because it’s much easier to improve availability for a smaller system. You can identify high-priority risks by calculating your “risk exposure,” which is the probability of failure multiplied by the cost of failure. A simple spreadsheet of risks—with columns for the probability, the cost, and the exposure—can help you prioritize your efforts.
In the previous chapter we examined how to achieve better scalability by avoiding the causes of poor scalability. We’ll take a similar approach here, because we believe that availability is best understood by studying its opposite: downtime. Let’s begin by discussing why downtime happens.
What Causes Downtime?
We’ve heard it said that the main cause of downtime in database servers is badly written SQL queries, but is that really true? In 2009 we decided to analyze our database of customer incidents and determine what really causes downtime, and how to prevent it.[186] Although the results affirmed some of what we already believed, they contradicted other beliefs, and we learned a lot.
We first categorized the downtime incidents by the way they manifested, rather than by cause. Broadly speaking, what we call the “operating environment” was the leading place that downtime appeared, with about 35% of incidents landing in this category. The operating environment is the set of systems and resources that support the database server, such as the operating system, disks, and network. Performance problems were a close runner-up, with about another 35% of the downtime-causing incidents. Replication followed that, accounting for 20% of the incidents; and the last 10% were down to various types of data loss or corruption, plus a few miscellaneous problems.
After we categorized the incidents by type, we identified the causes of the incidents. Here are a few highlights:
§ Within the operating environment, the most prevalent problem by a large margin was running out of disk space.
§ The biggest cause of downtime in the performance problem category was indeed bad SQL execution, although badly written queries were not always to blame; many problems were caused by server bugs or misbehavior, for example.
§ Bad schema and indexing design were the next most common performance problems.
§ Replication problems were usually caused by differences in data between the master and replica.
§ Data loss issues were usually caused by DROP TABLE, and were always combined with a lack of usable backups.
Notice that replication—one of the tactics people use to try to improve uptime—often causes downtime. That’s usually because it’s used incorrectly, but even so, it illustrates a common theme: many high-availability tactics can and do backfire. We’ll see this again later.
Now that we know the broad categories of downtime and where to point the finger of blame, we’ll get into specifics of how to achieve high availability.
[186] We wrote a lengthy white paper with the full analysis of our customers’ downtime-causing incidents, and followed it with another on how to prevent downtime, including detailed checklists of activities you can schedule periodically. There wasn’t room to include all the details in this book, but you can find both white papers on Percona’s website (http://www.percona.com).
Achieving High Availability
High availability is achieved by two practices, which should go hand-in-hand. First, try to reduce downtime by preventing the causes of downtime. Many of them are easily preventable with steps such as proper configuration, monitoring, and policies or safeguards to avoid human error. Second, try to ensure that when downtime happens, you can recover quickly. The usual tactic is building redundancy and failover capability into systems. These two dimensions of high availability can be measured by two corresponding metrics: mean time between failures (MTBF) and mean time to recovery (MTTR). Some organizations track these metrics carefully.
The second activity—quick recovery through redundancy—is unfortunately what seems to get the most attention, but the return on investment from prevention efforts can be quite high. Let’s explore prevention a bit.
Improving Mean Time Between Failures
You can avoid a lot of downtime with a little due diligence. When we categorized downtime incidents and attributed them to root causes, we also identified ways they could have been prevented. We found that most downtime incidents can be averted through an overall common-sense approach to managing systems. The following suggestions are selected from the guidelines in the white paper we wrote detailing the results of our analysis:
§ Test your recovery tools and procedures, including restores from backups.
§ Follow the principle of least privilege.
§ Keep your systems clean and neat.
§ Use good naming and organization conventions to avoid confusion, such as whether servers are for development or production use.
§ Upgrade your database server on a prudent schedule to keep it current.
§ Test carefully with a tool such as pt-upgrade from Percona Toolkit before upgrading.
§ Use InnoDB, configure it properly, and ensure that it is set as the default storage engine and the server cannot start if it is disabled.
§ Make sure the basic server settings are configured properly.
§ Disable DNS with skip_name_resolve.
§ Disable the query cache unless it has proven beneficial.
§ Avoid complexity, such as replication filters and triggers, unless absolutely needed.
§ Monitor important components and functions, especially critical items such as disk space and RAID volume status, but avoid false positives by alerting only on conditions that reliably indicate problems.
§ Record as many historical metrics as possible about server status and performance, and keep them forever if you can.
§ Test replication integrity on a regular basis.
§ Make replicas read-only, and don’t let replication start automatically.
§ Perform regular query reviews.
§ Archive and purge unneeded data.
§ Reserve some space in filesystems. In GNU/Linux, you can use the –m option to reserve space in the filesystem itself. You can also leave space free in your LVM volume group. Or, perhaps simplest of all, just create a large dummy file that you can delete if the filesystem becomes completely full.[187]
§ Make a habit of reviewing and managing system changes and status and performance information.
We found that lapses in system change management were the most important overall reason for downtime incidents. Typical mistakes include careless upgrades, failing to upgrade at all and encountering bugs, pushing schema or query changes to production without testing them, and failing to plan for things such as reaching the limits of disk capacity. Another leading cause of problems is lack of due diligence, such as neglecting to verify that backups are restorable. Finally, people generally monitor the wrong things about MySQL. Alerts on metrics such as cache hit ratios, which don’t indicate a real problem and create lots of false positives, cause the monitoring system to be regarded as unhelpful, so people ignore alerts. Sometimes the monitoring system fails and nobody even notices, leading to tough questions from the boss later on, such as “Why didn’t Nagios alert us about the disk being full?”
Improving Mean Time to Recovery
As we mentioned, it can be tempting to focus exclusively on reducing recovery time to achieve high availability. In fact, sometimes people go even further and focus on only one aspect of reducing recovery time: preventing complete system failure by building redundancy into systems and avoiding single points of failure.
It is very important to invest in quick recovery time, and a good system architecture that provides redundancy and failover capabilities is a key part of that, but achieving high availability is not solely a technical problem. There is a large human and organizational component. Organizations and individuals vary in their level of maturity and capability to avoid and recover from downtime incidents.
Your people are your most important high-availability asset, so good procedures for recovery are vital. Skilled, adaptable, and well-trained staff members, supported by well-documented and well-tested procedures for dealing with emergencies, can contribute greatly to quick recovery from downtime. Trusting solely to tools and systems is usually a mistake, because they don’t understand nuanced situations, and they sometimes do what would usually be the right thing, but is utterly catastrophic in your case.
Reviewing downtime incidents can be very helpful in improving organizational learning, to help avoid similar incidents in the future. Beware, however, of overvaluing practices such as “after-action reviews” or “post-mortems.” Hindsight is badly distorted, and the desire to find a single root cause tends to impair judgment.[188] Many popular approaches, such as the “Five Whys” approach, can be applied badly, causing people to focus their attention on finding a single scapegoat. It’s difficult to look back at a situation we’ve resolved and understand the real causes, and there are always multiple causes. As a result, while after-action reviews can be beneficial, you should take the conclusions with a grain of salt. Even our own recommendations, based as they are on lengthy studies of the causes and preventions of downtime, are just opinions.
This bears repeating: all downtime incidents are caused by multiple failures in combination, and thus they could have been averted by the proper functioning of a single safeguard. The entire chain must be broken, not merely a single link. For example, people who ask us for help with data recovery are usually suffering both from a loss of data (storage failure, DBA mistake, etc.) and a lack of usable backups.
With that said, most people and organizations are not guilty of overdoing it when it comes to investigating and trying to prevent or hasten recovery from failures. Instead, they can be prone to focusing on technical measures—especially the cool ones, such as clustered systems and redundant architectures. There is a place for this, but keep in mind that systems are fallible, too. In fact, one of the tools we mentioned in the second edition of this book, the MMM replication manager, has fallen out of our favor because it turns out that it might cause even more downtime than it prevents. You probably aren’t surprised that a set of Perl scripts can go haywire, but even extremely expensive and elaborate systems fail in catastrophic ways—yes, even the SAN that cost you a king’s ransom. We’ve seen a lot of SAN failures.
[187] It’s 100% cross-platform-compatible!
[188] Two refutations of common wisdom for further reading: Richard Cook’s paper entitled “How Complex Systems Fail” (http://www.ctlab.org/documents/How%20Complex%20Systems%20Fail.pdf) and Malcolm Gladwell’s essay on the Challenger space shuttle disaster, in his book What the Dog Saw (Little, Brown).
Avoiding Single Points of Failure
Finding and eliminating single points of failure in your system, combined with a mechanism to switch to using a spare component, is one way of improving availability by reducing recovery time (MTTR). If you’re clever, you can sometimes reduce the recovery time to effectively zero, though this is rather difficult in the general case. (Even very impressive technologies such as expensive load balancers cause some delay while they notice problems and respond to them.)
Think through your application and try to identify any single points of failure. Is it a hard drive, a server, a switch or router, or the power for one rack? Are your machines all in one data center, or are your “redundant” data centers provided by the same company? Any point in your system that isn’t redundant is a single point of failure. Other common single points of failure, depending on your point of view, are reliance on services such as DNS, a single network provider,[189] a single cloud “availability zone,” and a single power grid.
You can’t always eliminate single points of failure. Making a component redundant might not be possible because of some limitation you can’t work around, such as a geographic, budgetary, or timing constraint. Try to understand all of the components that affect availability, take a balanced view of the risks, and work on the biggest ones first. Some people work hard to build software that can handle any kind of hardware failure, but bugs in this kind of software can cause more downtime than it saves. Some people build “unsinkable” systems with all kinds of redundancy, but they forget that the data center can lose power or connectivity. Or maybe they completely forget about the possibility of malicious attackers or programmer mistakes that delete or corrupt data—a careless DROP TABLE can cause downtime, too.
Adding redundancy to your system can take two forms: adding spare capacity and duplicating components. It’s actually quite easy to add spare capacity—you can use any of the techniques we mention throughout this chapter or the previous one. One way to increase availability is to create a cluster or pool of servers and add a load-balancing solution. If one server fails, the other servers take over its load. Some people underutilize components intentionally, because it leaves much more “headroom” to handle performance problems caused either by increased load or by component failures.
For many purposes, you will need to duplicate components and have a standby ready to take over if the main component fails. A duplicated component can be as simple as a spare network card, router, or hard drive—whatever you think is most likely to fail. Duplicating entire MySQL servers is a little harder, because a server is useless without its data. That means you must ensure that your standby servers have access to the primary server’s data. Shared or replicated storage is one popular way to accomplish this. But is it really a high-availability architecture? Let’s dig in and see.
Shared Storage or Replicated Disk
Shared storage is a way to decouple your database server and its storage, usually with a SAN. With shared storage, the server mounts the filesystem and operates normally. If the server dies, a standby server can mount the same filesystem, perform any necessary recovery operations, and start MySQL on the failed server’s data. This process is logically no different from fixing the failed server, except that it’s faster because the standby server is already booted and ready to go. Filesystem checks, InnoDB recovery, and warmup[190] are the biggest delays you’re likely to encounter once failover is initiated, but failure detection itself can take quite a long time in many setups, too.
Shared storage has two advantages: it helps avoid data loss from the failure of any component other than the storage, and it makes it possible to build redundancy in the non-storage components. As a result, it’s a strategy for helping to reduce availability requirements in some parts of the system, making it easier to achieve high availability by concentrating your efforts on a smaller set of components. But the shared storage itself is still a single point of failure. If it goes down, the whole system goes down, and although SANs are generally very well engineered, they can and do fail, sometimes spectacularly. Even SANs that are themselves redundant can fail.
WHAT ABOUT ACTIVE-ACTIVE ACCESS TO SHARED STORAGE?
What about running many servers in active-active mode on a SAN, NAS, or clustered filesystem? MySQL can’t do that. It is not designed to synchronize its access to data with other MySQL instances, so you can’t fire up multiple instances of MySQL working on the same data. (Technically you could, if you used MyISAM on read-only static data, but we’ve never seen a real use for that.)
A storage engine for MySQL called ScaleDB operates through an API with a shared-storage architecture underneath, but we have neither evaluated it nor seen it in production use. It’s in beta at the time of writing.
Shared storage has its risks. If a failure such as a MySQL crash corrupts your data files, that might prevent the standby server from recovering. We highly recommend using InnoDB or another robust ACID storage engine with shared storage. A crash will almost certainly corrupt MyISAM tables, and repairing them can take a long time and result in lost rows. We also strongly recommend a journaling filesystem with shared storage. We’ve seen cases of severe, unrecoverable corruption with a nonjournaling filesystem and a SAN. (It was the filesystem’s fault, not the SAN’s.)
A replicated disk is another way to achieve the same ends as a SAN. The type of disk replication most commonly used for MySQL is DRBD (http://www.drbd.org), in combination with tools from the Linux-HA project (more on this later).
DRBD is synchronous, block-level replication implemented as a Linux kernel module. It copies every block from a primary device over a network card to another server’s block device (the secondary device), and writes it there before committing the block on the primary device.[191] Because writes must complete on the secondary DRBD device before the writes on the primary are considered complete, the secondary device must perform at least as well as the primary, or it will limit write performance on the primary. Also, if you’re using DRBD disk replication to have an interchangeable standby in the event that the primary fails, the standby server’s hardware should match the primary server’s. And a good RAID controller with a battery-backed write cache is all but mandatory with DRBD; performance will be very poor without it.
If the active server fails, you can promote the secondary device to be the primary. Because DRBD replicates the disk at the block layer, however, the filesystem can become inconsistent. This means it’s essential to use a journaling filesystem for fast recovery. Once recovery is complete, MySQL will need to run its own recovery as well. If the first server recovers, it resyncs its device with the new primary device and assumes the secondary role.
In terms of how you actually implement failover, DRBD is similar to a SAN: you have a hot standby machine, and you begin serving from the same data as the failed machine. The biggest difference is that it is replicated storage—not shared storage—so with DRBD you’re serving a replicated copy of the data, while with a SAN you’re serving the same data from the same physical device as the failed machine. In other words, replicated disks create data redundancy, so neither the storage nor the data itself is a single point of failure. In both cases, the MySQL server’s caches will be empty when you start it on the standby machine. In contrast, a replica’s caches are likely to be at least partially warmed up.
DRBD has some nice features and capabilities that can prevent problems common to clustering software. An example is split-brain syndrome, which occurs when two nodes promote themselves to primary simultaneously. You can configure DRBD so it won’t let this happen. However, DRBD isn’t a perfect solution for every need. Let’s take a look at its drawbacks:
§ DRBD’s failover is not subsecond. It will generally require at least a few seconds to promote the secondary device to primary, not including any necessary filesystem and MySQL recovery.
§ It’s expensive, because you must run it in active-passive mode. The hot standby server’s replicated device is not usable for any other tasks while it’s in passive mode. Whether this is really a shortcoming depends on your point of view. If you want truly high availability and can’t tolerate degraded service when there’s a failure, you can’t place more than one machine’s worth of load on any two machines, because if you did, you wouldn’t be able to handle the load if one of them failed. You can use the standby server for something else, such as a replica, but you’ll still waste some resources.
§ It’s practically unusable for MyISAM tables, because they take too long to check and repair. MyISAM is not a good choice for any installation that requires high availability; use InnoDB or another storage engine that allows quick, reliable recovery instead.
§ It does not replace backups. If your data becomes corrupt on disk due to malicious interference, mistakes, bugs, or hardware failures, DRBD will not help: the replicated data will be a perfect copy of the corrupted original. You need backups (or time-delayed MySQL replication) to protect against these problems.
§ It introduces some overhead for writes. How much overhead? It’s popular to cite a percentage, but that’s not a good metric. Instead you need to understand that writes suffer added latency due to the network round-trip and the remote server’s storage, and this is relatively larger for small writes. Although the added network latency might only be about 0.3 ms, which seems small relative to the 4 ms–10 ms latency of an actual I/O on local disk, it’s about three or four times the latency you should expect from a good RAID controller’s write cache. The most common reason for the server to become slower with DRBD is that MySQL with InnoDB in full durability mode does a lot of short writes and fsync() calls that will be slowed greatly by DRBD.[192]
Our favorite way to use DRBD is to replicate only the device that holds the binary logs. If the active node fails, you can start a log server on the passive node and use the recovered binary logs to bring all of the failed master’s replicas up to the latest binary log position. You can then choose one of the replicas and promote it to master, replacing the failed system.
In the final analysis, shared storage and replicated disks aren’t as much of a high-availability (low-downtime) solution as they are a way to keep your data safe. As long as you have your data, you can recover from failures, with a lower MTTR than not being able to recover. (Even a long recovery time is still faster than no recovery at all.) However, as compared to architectures that permit the standby server to be up and running all the time, most shared storage or replicated disk architectures will increase the MTTR. There are two ways to have standbys up and running: standard MySQL replication, which we discussed in Chapter 10, and synchronous replication, which is the topic of our next section.
Synchronous MySQL Replication
In synchronous replication, a transaction cannot complete on the master until it commits on one or more replica servers. This accomplishes two goals: no committed transactions are lost if a server crashes, and there is at least one other server with a “live” copy of the data. Most synchronous replication architectures run in active-active mode. That means every server is a candidate for failover at any time, making high availability through redundancy much simpler.
MySQL itself does not offer synchronous replication at the time of this writing,[193] but there are two MySQL-based clustering solutions that do support it. You should also review Chapter 10, Chapter 11, and Chapter 13 for discussions of other products, such as Continuent Tungsten and Clustrix, that might be of interest.
MySQL Cluster
The first place to look for synchronous replication in MySQL is MySQL Cluster (NDB Cluster). It has synchronous active-active replication between all nodes. That means you can write to any node; they’re all equally capable of serving reads and writes. Every row is stored redundantly, so you can lose a node without losing data, and the cluster remains functional. Although MySQL Cluster still isn’t a complete solution for every type of application, as we mentioned in the previous chapter, it has been improved rapidly in recent releases and now has a huge list of new features and characteristics: disk storage for nonindexed data, online scaling by adding data nodes, ndbinfo tables for managing the cluster, scripts for provisioning and managing the cluster, multithreaded operation, push-down joins (now called adaptive query localization), the ability to handle BLOBs and tables with many columns, centralized user management, and NoSQL access through the NDB API as well as the memcached protocol. Upcoming releases will include the ability to run in eventual-consistency mode, with per-transaction conflict detection and resolution across a WAN, for active-active replication between datacenters. In short, MySQL Cluster is an impressive piece of technology.
There are also at least two providers of add-on products to simplify cluster deployment and management: Oracle support contracts for MySQL Cluster include its MySQL Cluster Manager product, and Severalnines offers a Cluster Control product (http://www.severalnines.com). This product is also capable of helping deploy and manage replication clusters.
Percona XtraDB Cluster
Percona XtraDB Cluster is a relatively new technology that adds synchronous replication and clustering capabilities to the XtraDB (InnoDB) storage engine itself, rather than through a new storage engine or an external server. It is built on Galera,[194] a library that replicates writes across nodes in a cluster. Like MySQL Cluster, Percona XtraDB Cluster offers synchronous multi-master replication,[195] with true write-anywhere capabilities. Also like MySQL Cluster, it can provide high availability as well as guarantee zero data loss (durability, the D in ACID) when a node fails, and of course nodes can fail without causing the whole cluster to fail.
The underlying technology, Galera, uses a technique called write-set replication. Write sets are actually encoded as row-based binary log events for the purpose of transmitting them between nodes and updating the other nodes in the cluster, though the binary log is not required to be enabled.
Percona XtraDB Cluster is very fast. Cross-node replication can actually be faster than not clustering, because writing to remote RAM is faster than writing to the local disk in full durability mode. You have the option of relaxing durability on each node for performance, if you wish, and relying on the presence of multiple nodes with copies of the data for durability. NDB operates on the same principle. The cluster’s durability as a whole is not reduced; only the local durability is reduced. In addition, it supports parallel (multithreaded) replication at the row level, so multiple CPU cores can be used to apply write sets. These characteristics combine to make Percona XtraDB Cluster attractive in cloud computing environments, where disks and CPUs are usually slower than normal.
The cluster implements autoincrementing keys with auto_increment_offset and auto_increment_increment so that nodes won’t generate conflicting values. Locking is generally the same as it is in standard InnoDB. It uses optimistic concurrency control. Changes are serialized and transmitted between nodes at transaction commit, with a certification process so that if there is a conflicting update, someone has to lose. As a result, if many nodes are changing the same rows simultaneously, there can be lots of deadlocks and rollbacks.
Percona XtraDB Cluster provides high availability by keeping the nodes online as long as they form a quorum. If nodes discover that they are not part of a quorum, they are ejected from the cluster, and they must resync before joining the cluster again. As a result, the cluster can’t handle split-brain scenarios; it will stop if that happens. When a node fails in a two-node cluster, the remaining node isn’t a quorum and will stop functioning, so in practice you need at least three nodes to have a high-availability cluster.
Percona XtraDB Cluster has lots of benefits:
§ It provides transparent clustering based on InnoDB, so there’s no need to move to another technology such as NDB, which is a whole different beast to learn and administer.
§ It provides real high availability, with all nodes equal and ready for reads and writes at all times. In contrast, MySQL’s built-in asynchronous or semisynchronous replication must have one master, can’t guarantee that your data is replicated, and can’t guarantee that replicas are up-to-date and ready for reads or to be promoted to master.
§ It protects you against data loss when a node fails. In fact, because all nodes have all the data, you can lose every node but one and still not lose the data (even if the cluster has a split brain and stops working). This is different from NDB, where the data is partitioned across node groups and some data can be lost if all servers in a node group are lost.
§ Replicas cannot fall behind, because write sets are propagated to and certified on every node in the cluster before the transaction commits.
§ Because it uses row-based log events to apply changes to replicas, applying write sets can be less expensive than generating them, just as with normal row-based replication. This, combined with multithreaded application of write sets, can make its replication more scalable than MySQL replication.
Of course, we need to mention its drawbacks, too:
§ It’s new. There isn’t a huge body of experience with its strengths, weaknesses, and appropriate use cases.
§ The whole cluster performs writes as slowly as the weakest node. Thus, all nodes need similar hardware, and if one node slows down (e.g., because the RAID card does a battery-learn cycle), all of them slow down. If one node has probability P of being slow to accept writes, a three-node cluster has probability 3P of being slow.
§ It isn’t as space-efficient as NDB, because every node has all the data, not just a portion. On the other hand, it is based on Percona XtraDB (which is an enhanced version of InnoDB), so it doesn’t have NDB’s limitations regarding on-disk data.
§ It currently disallows some operational tricks that are possible with asynchronous replication, such as making schema changes offline on a replica and promoting it to be master so you can repeat the changes on other nodes offline. The current alternative is to use a technique such as Percona Toolkit’s online schema change tool. Rolling schema upgrades are nearly ready for release at the time of writing, however.
§ Adding a new node to a cluster requires copying data to it, plus the ability to keep up with ongoing writes, so a big cluster with lots of writes could be hard to grow. This will put a practical limit on the cluster’s data size. We aren’t sure how large this is, but a pessimistic estimate is that it could be as low as 100 GB or so. It could be much larger; time and experience will tell.
§ The replication protocol seems to be somewhat sensitive to network hiccups at the time of writing, and that can cause nodes to stop themselves and drop out of the cluster, so we recommend a high-performance network with good redundancy. If you don’t have a reliable network, you might end up adding nodes back to the cluster too often. This requires a resynchronization of the data. At the time of writing, incremental state transfer to avoid a full copy of the dataset is almost ready to use, so this should not be as much of a problem in the future. It’s also possible to configure Galera to be more tolerant of network timeouts (at the cost of delayed failure detection), and more reliable algorithms are planned for future releases.
§ If you aren’t watching carefully, your cluster could grow too big to restart nodes that fail, just as backups can get too big to restore in a reasonable amount of time if you don’t practice it routinely. We need more practical experience to know how this will work in reality.
§ Because of the cross-node communication required at transaction commit, writes will get slower, and deadlocks and rollbacks will get more frequent, as you add nodes to the cluster. (See the previous chapter for more on why this happens.)
Both Percona XtraDB Cluster and Galera are still early in their lifecycles and are changing and improving rapidly. At the time of writing, we can point to recent or forthcoming improvements to quorum behavior, security, synchronicity, memory management, state transfer, and a host of other things. You will also be able to take nodes offline for operations such as rolling schema changes in the future.
Replication-Based Redundancy
Replication managers are tools that attempt to use standard MySQL replication as a building block for redundancy.[196] Although it is possible to improve availability with replication, there is a “glass ceiling” that blocks MySQL’s current asynchronous and semisynchronous replication from achieving what can be done with true synchronous replication. You can’t guarantee instantaneous failover and zero data loss, nor can you treat all nodes as identical.
Replication managers typically monitor and manage three things: the communication between the application and MySQL, the health of the MySQL servers, and replication relationships between MySQL servers. They either alter the configuration of load balancing or move virtual IP addresses as necessary to make the application connect to the proper servers, and they manipulate replication to elect a server as the writable node in the pseudo-cluster. In principle, it’s not complicated: just make sure that writes are never directed to a server that’s not ready for writes, and make sure to get replication coordinates right when promoting a replica to master status.
This sounds workable in theory, but our experience has been that it doesn’t always work so well in practice. It’s too bad, really, because it would sometimes be nice to have a lightweight set of tools to help recover from common failures and get a little bit higher availability on the cheap. Unfortunately, we don’t know of any good toolset that accomplishes this reliably at the time of writing. We’ll mention two replication managers in a moment,[197] but one is new and the other has a lot of issues.
We’ve also seen many people try to write their own replication managers. They usually fall into the same traps that have snared others before them. It’s not a great idea to roll your own. Coaxing good behavior from asynchronous components with oodles of failure modes you’ve never personally experienced, many of which simply cannot be understood and handled appropriately by a program, is very hard, and it’s riddled with opportunities to lose data. In fact, a machine can begin with a situation that could be fixed by a skilled human, and make it much worse by doing the wrong thing.
The first replication manager we want to mention is MMM (http://mysql-mmm.org). The authors of this book don’t all agree on how suitable this toolkit is for production deployment (although the original author of the toolkit has opined that it’s not trustworthy). Some of us think it can be helpful in some cases in manual-failover mode, and others would rather never use it in any mode. It is certain, however, that many of our customers who use it in automatic-failover mode have a lot of serious issues with it. It can take healthy servers offline, send writes to the wrong place, and move replicas to the wrong coordinates. Chaos sometimes ensues.
The other tool, which is rather new, is Yoshinori Matsunobu’s MHA toolkit (http://code.google.com/p/mysql-master-ha/). It is similar to MMM in that it is a set of scripts to build a pseudo-cluster with some of the same general techniques, but it is not a complete replacement; it doesn’t attempt to do as many things, and it relies on Pacemaker to move virtual IP addresses. One major difference is that it has a test suite, which should prevent some of the problems MMM has encountered. Other than this, we don’t have a strong opinion on the toolkit yet. We haven’t talked with anyone other than Yoshinori who is using it in production, and we haven’t used it ourselves.
Replication-based redundancy is ultimately a mixed blessing. The candidate use case is when availability is much more important than consistency or zero-data-loss guarantees. For example, some people don’t really make any money from their site’s functionality, only from its availability. Who cares if there’s a failure and the site loses a few comments on a photo or something? As long as the ad revenue keeps rolling in, the cost of truly high availability might not be worth it. But sticking with the “best effort” high availability you can build with replication carries the potential for serious downtime that can be extremely laborious to fix. It’s a pretty big gamble, and one that’s probably too risky for all but the most blasé (or expert) of users.
The problem is, many users don’t know how to self-qualify and assess whether Replication Roulette is suitable for them. There are two reasons for this. First, they don’t see the glass ceiling, and they mistakenly believe that a set of virtual IP addresses, replication, and management scripts can deliver “real” high availability. Second, they underestimate the complexity of the technology, and therefore the severity of the failures that can happen and the difficulty of recovering from them. As a result, sometimes people think they can live with replication-based redundancy, but they might later wish that they’d chosen a simpler system with stronger guarantees.
Other types of replication, such as DRBD or a SAN, have their flaws, too—please don’t think we are promoting them as bulletproof and saying that MySQL replication is a mess, because that’s not our intention. You can write poor-quality failover scripts for DRBD just easily as you can for MySQL replication. The main difference is that MySQL replication is a lot more complex, with a lot more nuances, and it doesn’t prevent you from doing bad things.
[189] Feeling paranoid? Check that your redundant network connections are really connected to different Internet backbones, and make sure they aren’t physically cabled on the same street or strung on the same poles, so they won’t get cut by the same backhoe or hit by the same car.
[190] Percona Server offers a feature to restore the buffer pool to its saved state after a restart, and this works fine with shared storage. This can reduce warmup time by hours or days. MySQL 5.6 will have a similar feature.
[191] You can actually adjust the level of synchronization for DRDB. You can set it to be asynchronous, to wait until the remote device receives the data, or to block until the remote device writes the data to disk. Also, it is strongly recommended that you dedicate a network card to DRBD.
[192] On the other hand, large sequential writes are a different story. The added latency introduced by DRBD practically vanishes, but throughput limitations will come into play. A decent RAID array should give you 200 to 500 MB/second of sequential write throughput, well above what a GigE network can achieve.
[193] There is support for semisynchronous replication in MySQL 5.5; see Chapter 10.
[194] The Galera technology is developed by Codership Oy (http://www.codership.com) and is available as a patch for standard MySQL and InnoDB. Percona XtraDB Cluster includes a modified version of that patchset, as well as other features and functionality. Percona XtraDB Cluster is a Galera-based solution that’s ready to use out of the box.
[195] You can also use it in a master-replica configuration by writing to just one node, but there’s no difference in the cluster configuration for this mode of operation.
[196] We’re being careful to avoid confusion in this section. Redundancy is not the same thing as high availability.
[197] We’re also working on a solution that’s based on Pacemaker and the Linux-HA stack, but it’s not ready to mention in this book. This footnote will self-destruct in 10..9..8..
Failover and Failback
Redundancy is great, but it actually doesn’t buy you anything except the opportunity to recover from a failure. (Heck, you can get that with backups.) Redundancy doesn’t increase availability or reduce downtime one whit. High availability is built on top of redundancy, through the process offailover. When a component fails and there is redundancy, you can stop using the failed piece and start using its redundant standby instead. The combination of redundancy and failover can enable you to recover more quickly, and as you know, reducing MTTR reduces downtime and improves availability.
Before we continue, we should talk about a few terms. We use “failover” consistently; some people use “fallback” as a synonym. Sometimes people also say “switchover” to denote a switch that’s planned instead of a response to a failure. Po-tay-toe, po-tah-toe. We also use the term“failback” to indicate the reverse of failover. If you have failback capability, failover can be a two-way process: when server A fails and server B replaces it, you can repair server A and fail back to it.
Failover is good for more than just recovery from failures. You can also do planned failovers to reduce downtime (improve availability) for events such as upgrades, schema changes, application modifications, or scheduled maintenance.
You need to identify how fast failover needs to be, but you also need to know how quickly you have to replace the failed component after a failover. Until you restore the system’s depleted standby capacity, you have less redundancy and you’re exposed to extra risk. Thus, having a standby doesn’t eliminate the need for timely replacement of failed components. How quickly can you build a new standby server, install its operating system, and give it a fresh copy of your data? Do you have enough standby machines? You might need more than one.
Failover comes in many flavors. We’ve already discussed several of them, because load balancing and failover are similar in many ways, and the line between them is a bit fuzzy. In general, we think a full failover solution, at a minimum, needs to be able to monitor and automatically replace a component. This should ideally be transparent to the application. Load balancing need not provide this capability.
In the Unix world, failover is often accomplished with the tools provided by the High Availability Linux project (http://linux-ha.org), which run on many Unix-like operating systems, not just Linux. The Linux-HA stack has become significantly more featureful in the last few years. Today most people think of Pacemaker as the main component in the stack. Pacemaker replaces the older heartbeat tool. Various other tools accomplish IP takeover and load-balancing functionality. You can combine them with DRBD and/or LVS.
The most important part of failover is failback. If you can’t switch back and forth between servers at will, failover is a dead end and only postpones downtime. This is why we like symmetrical replication topologies, such as the dual-master configuration, and we dislike ring replication with three or more co-masters. If the configuration is symmetrical, failover and failback are the same operation in opposite directions. (It’s worth mentioning that DRBD has built-in failback capabilities.)
In some applications, it’s critical that failover and failback be as fast and atomic as possible. Even when it’s not critical, it’s still a good idea not to rely on things that are out of your control, such as DNS changes or application configuration files. Some of the worst problems don’t show up until a system becomes larger, when issues such as forced application restarts and the need for atomicity rear their heads.
Because load balancing and failover are closely related, and the same piece of hardware or software often serves both purposes, we suggest that any load-balancing technique you choose should provide failover capabilities as well. This is the real reason we suggested you avoid DNS or code changes for load balancing. If you use these strategies for load balancing, you’ll create extra work: you’ll have to rewrite the affected code later when you need high availability.
The following sections discuss some common failover techniques. You can perform these manually, or use tools to accomplish them.
Promoting a Replica or Switching Roles
Promoting a replica to master, or switching the active and passive roles in a master-master replication setup, is an important part of many failover strategies for MySQL. See Chapter 10 for detailed explanations of how to accomplish this manually. As mentioned earlier in this chapter, we aren’t aware of any automated tools that always do the right thing in all situations—or at least, none that we’ll put our reputations behind.
Depending on your workload, you shouldn’t assume that you can fail over to a passive replica instantly. Replicas replay the master’s writes, but if you’re not also using them for reads, they will not be warmed up to serve the production workload. If you want a replica to be ready for read traffic, you have to continuously “train” it, either by letting it participate in the production workload or by mirroring production read queries onto it. We’ve sometimes done this by sniffing TCP traffic, filtering out everything but SELECT queries, and replaying those against the replica. Percona Toolkit has tools that can help with this.
Virtual IP Addresses or IP Takeover
You can assign a logical IP address to a MySQL instance that you expect to perform certain services. If the MySQL instance fails, you can move the IP address to a different MySQL server. This is essentially the same approach we wrote about in the previous chapter, except that now we’re using it for failover instead of load balancing.
The benefit of this approach is its transparency for the application. It will abort existing connections, but it doesn’t require you to change your application’s configuration. It is also sometimes possible to move the IP address atomically, so all applications see the change at the same time. This can be especially important when a server is “flapping” between available and unavailable states.
The downsides are as follows:
§ You need to either define all IP addresses on the same network segment, or use network bridging.
§ Changing the IP address requires root access to the system.
§ Sometimes you need to update address resolution protocol (ARP) caches. Some network devices might cache ARP entries for too long, and might not instantly switch an IP address to a different MAC address. We’ve seen lots of cases where network hardware or other components decide not to cooperate, and thus the various parts of the system don’t agree on where the IP address really lives.
§ You need to make sure the network hardware supports fast IP takeover. Some hardware requires MAC address cloning for this to work properly.
§ It’s possible for a server to keep its IP address even though it’s not fully functional, so you might need to physically shut it down or disconnect it from the network. This is known by the lovely acronym of STONITH: “shoot the other node in the head.” It’s also called “fencing,” which is a more delicate and official-sounding name.
Floating IP addresses and IP takeover can work well for failover between machines that are local to each other—that is, on the same subnet. In the end, however, you need to be aware that this isn’t always a bulletproof strategy, depending on your network hardware and so on.
WAITING FOR CHANGES TO PROPAGATE
Often, when you define redundancy on one layer, you have to wait for a lower layer to actually carry out a change. Earlier in this chapter, we pointed out that changing servers through DNS is a weak solution because DNS is slow to propagate changes. Changing IP addresses gives you more control, but IP addresses on a LAN also depend on a lower layer—ARP—to propagate changes.
Middleman Solutions
You can use proxies, port forwarding, network address translation (NAT), and hardware load balancers for failover and failback. They’re nice because unlike other solutions that tend to introduce uncertainty (do all of the system components really agree on which one is the master database? can it be changed instantaneously and atomically?), they’re a central authority that controls connections between the application and the database. However, they do introduce a single point of failure themselves, and you’ll need to make them redundant to avoid that problem.
One of the nice things you can do with such a solution is make a remote data center appear to be on the same network as your application. This lets you use techniques such as floating IP addresses to make your application begin communicating with an entirely different data center. You can configure each application server in each data center to connect through its own middleman, each of which routes traffic to the machines in the active data center. Figure 12-1 illustrates this configuration.
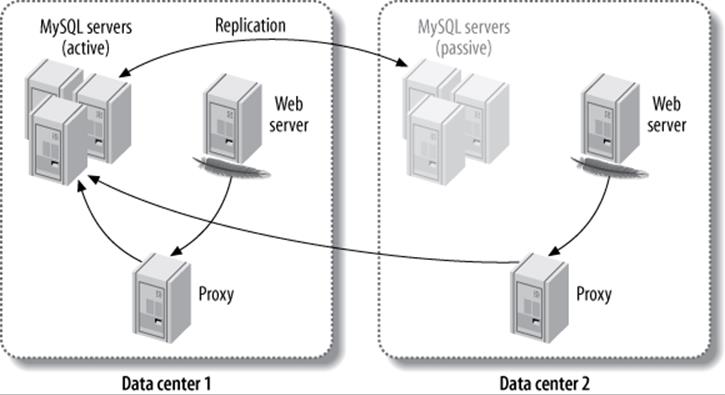
Figure 12-1. Using a middleman to route MySQL connections across data centers
If the active data center’s MySQL installation fails entirely, the middleman can route the traffic to the pool of servers in the other data center, and the application never needs to know the difference.
The major disadvantage of this configuration is the high latency between the Apache server in one data center and the MySQL servers in the other data center. To alleviate this problem, you can run the web server in redirect mode. This will redirect traffic to the data center that houses the pool of active MySQL servers. You can also achieve this with an HTTP proxy.
Figure 12-1 shows a proxy as the means of connecting to the MySQL servers, but you can combine this approach with many middleman architectures, such as LVS and hardware load balancers.
Handling Failover in the Application
Sometimes it’s easier or more flexible to let the application handle failover. For example, if the application experiences an error that isn’t normally detected by an outside observer, such as an error message indicating database corruption, it can handle the failover process itself.
Although integrating the failover process into the application might seem attractive, it tends not to work as well as you might think it will. Most applications have many components, such as cron jobs, configuration files, and scripts written in different programming languages. Integrating failover into the application can therefore become unwieldy, especially as the application grows and becomes more complicated.
However, it’s a good idea to build monitoring into your application and let it initiate the failover process if it needs to. The application should also be able to manage the user experience, by degrading functionality and showing appropriate messages to the user.
Summary
You can achieve high availability by reducing downtime, which you should attack from two directions: increasing time between failures (MTBF), and reducing time to recover from failures (MTTR).
To increase time between failures, try to prevent them. Sadly, when you’re preventing failures it can feel like you’re not doing very much, so preventive efforts are often neglected. We mentioned the highlights of how to prevent downtime on MySQL systems; for the long-winded details, see our white papers, available on http://www.percona.com. And do try to learn from your downtime, but beware of placing root cause analysis and post-mortems on a pedestal.
Shortening recovery time can get complex and expensive. On the simple and easy side, you can monitor so that you notice problems more quickly, and record lots of metrics to help diagnose the problems. As a bonus, these can sometimes be used to spot problems before they become downtime. Monitor and alert selectively to avoid noise, but record status and performance metrics eagerly.
Another tactic for shortening recovery time is to build redundancy into the system, and make the system capable of failover so you can switch between redundant components when one fails. Unfortunately, redundancy makes systems really complicated. Now things are no longer centralized; they’re distributed, and that means coordination and synchronization and CAP theorems and Byzantine Generals and all that messy stuff. This is why systems like NDB Cluster are both hard to build and hard to make general-purpose enough to serve everyone’s workloads. But the situation is improving, and maybe by the fourth edition we’ll be able to sing the praises of one or more clustered databases.
This chapter and the previous two have covered topics that are often lumped together: replication, scalability, and high availability. We’ve attempted to consider them as separately as possible, because it is helpful to be clear on the differences between these topics. So how are these three chapters related?
People generally want three things from their databases as their applications grow:
§ They want to be able to add capacity to serve increasing load without sacrificing performance.
§ They want protection against losing a committed transaction.
§ They want the applications to remain online and servicing transactions so they keep making money.
To accomplish this combination of goals, people usually start by adding redundancy. That, combined with a failover mechanism, provides high availability through minimizing MTTR. The redundancy also adds spare capacity to serve more load.
Of course, you have to duplicate the data too, not just the resources. This can help prevent losing the data when you lose a server, which adds durability. The only way to duplicate data is to replicate it somehow. Unfortunately, data duplication introduces the possibility of inconsistency. Dealing with that requires coordination and communication between nodes. This adds extra overhead to the system; that’s why systems are more or less scalable.
Duplication also requires more resources (more hard drives, more RAM, etc.), which adds cost. One way to reduce both the resource consumption and the overhead of maintaining consistency is to partition (shard) the data and distribute each shard only to certain systems. This reduces the number of times the data is duplicated and decouples data redundancy from resource redundancy.
So, although one thing leads to the next, again we’re really talking about a group of related concepts and practices to address a set of goals. They’re not just different ways of talking about the same thing.
In the end, you need to choose a strategy that makes sense for you and your application. Deciding on a full end-to-end high-availability strategy is not something you should tackle with simple rules of thumb, but perhaps we can help by giving broad-brush guidelines.
To achieve very short downtimes, you need redundant servers that are ready to take over the application’s workload instantly. They must be online and processing queries all the time, not just standing by, so they are “warmed up” and ready to go. If you want strong guarantees, you need a clustering product such as MySQL Cluster, Percona XtraDB Cluster, or Clustrix. If you can tolerate a bit more slack in the failover process, standard replication can be quite a good alternative. Be cautious about using automatic failover mechanisms; they can wreck your data if they don’t get it right.
If you don’t care as much about the failover time but you want to avoid data loss, you need some kind of strongly guaranteed data redundancy—i.e., synchronous replication. At the storage layer, you can do it on the cheap with DRBD, or on the other end of the cost spectrum you can get two SANs that have synchronous replication between them. Alternatively, you can replicate the data at the database layer instead, with a technology such as MySQL Cluster, Percona XtraDB Cluster, or Clustrix. You can also use middleware such as Tungsten Replicator. If you don’t need strong protection and you want to keep things as simple as possible, normal asynchronous or semisynchronous replication might be a good option at a reasonable cost.
Or you could just put your application into the cloud. Why not? Won’t that instantly make it highly available and infinitely scalable? Let’s find out.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.