High Performance MySQL (2012)
Chapter 13. MySQL in the Cloud
It should be no surprise that many people are running MySQL in the cloud, sometimes at a very large scale. In our experience, most of them are using the Amazon Web Services (AWS) platform: specifically Amazon’s Elastic Compute Cloud (EC2), Elastic Block Store (EBS) volumes, and, to a lesser extent, the Relational Database Service (RDS).
One way to frame the discussion about MySQL in the cloud is to divide it into two rough categories:
IaaS (Infrastructure as a Service)
IaaS is cloud infrastructure for hosting your own MySQL server. You can purchase a virtual server resource in the cloud and use it to install and run your MySQL instance. You can configure MySQL and the operating system as you wish, but you have no access or insight into the underlying physical hardware.
DBaaS (Database as a Service)
MySQL itself is the cloud-managed resource. You receive access credentials to a MySQL server. You can configure some of MySQL’s settings, but you have no access or insight into the underlying operating system or virtual server instance. An example is Amazon RDS running MySQL. Some of these services aren’t really stock MySQL, but they are compatible with the MySQL protocol and query language.
We focus most on the first category: cloud hosting on platforms such as AWS, Rackspace Cloud, and Joyent.[198] There are many good resources for learning how to deploy and manage MySQL and the resources needed to run it, and there are too many platforms for us to cover them all, so we don’t show code samples or discuss operational techniques. Instead, this chapter focuses on the key differences between running MySQL in the cloud versus traditional server deployment, and on the resulting economic and performance characteristics. We assume that you’re familiar with cloud computing. This is not an introduction to the topic; our goal is just to help you avoid some pitfalls you might encounter if you’re not a MySQL-in-the-cloud expert.
In general, MySQL runs fine in the cloud. Running MySQL in the cloud isn’t dramatically different from running MySQL on any other platform, but there are several very important distinctions. You need to be aware of them and design your application and architecture accordingly to get good results. In some circumstances hosting MySQL in the cloud is not a great fit, and sometimes it’s the best thing since sliced bread, but in most cases it’s just another deployment platform.
It is important to understand that the cloud is a deployment platform, not an architecture. Your architecture is influenced by the platform, but the platform and the architecture are distinct. If you confuse the two, you might be more likely to make poor choices that can cause problems in the future. That’s why we’ll spend so much time discussing which differences matter for MySQL in the cloud.
Benefits, Drawbacks, and Myths of the Cloud
Cloud computing has many benefits, few of which are specific to using it with MySQL. There are books written on this topic,[199] and we don’t want to spend too much time on it. But we’ll list a few big items for your consideration, because we’re going to discuss drawbacks in a moment, and we don’t want you to think we’re overly critical of the cloud:
§ The cloud is a way of outsourcing some of your infrastructure so you don’t have to manage it. You don’t have to purchase hardware and develop supply-chain relationships, you don’t have to replace failed hard drives, and so on.
§ The cloud is generally priced pay-as-you-go, converting upfront capital expenses into ongoing operational expenses.
§ The cloud offers increasing value over time as providers deliver new services and lower costs. You don’t have to do anything yourself (such as upgrading your servers) to take advantage of these improvements; you simply have more and better options available to you at a lower cost as time passes.
§ The cloud lets you provision servers and other resources easily, and shut them down when you’re done, without having to dispose of them or reclaim costs by reselling them.
§ The cloud represents a different way of thinking about infrastructure—as resources that are defined by and controlled through APIs—and this allows a lot more automation. You can also get these benefits in a “private cloud.”
Of course, not everything about the cloud is good. Here are some drawbacks that can pose challenges (we’ll list some MySQL-specific drawbacks later in this chapter):
§ Resources are shared and unpredictable, and you can actually get more than you’re paying for. This might sound good, but it can make it difficult to do capacity planning. If you’re getting more than your share of computing resources and you don’t know it there’s a risk that someone else will claim their fair share of resources, bumping your performance back to what it’s supposed to be. In general, it can be difficult to know for certain what you’re supposed to be getting, and most cloud hosting providers don’t provide concrete answers about such questions.
§ There are no guarantees about capacity or availability. You may assume that you can provision new instances, but what if the provider becomes oversubscribed? This happens with many shared resources, and it could happen in the cloud, too.
§ Virtualized and shared resources can be harder to troubleshoot, especially because you don’t have access to the underlying physical hardware to inspect and measure what’s happening. For example, we’ve seen systems where iostat claimed that the I/O was fine or vmstat showed that the CPU was fine, and yet when we actually measured the time elapsed to complete tasks, the resources were clearly overloaded by something else on the system. If you run into performance problems on a cloud platform, it is even more important than usual to measure carefully. If you’re not good at this, you might not be able to identify whether the underlying system is just performing badly, or whether you’ve done something that’s causing the application to make unreasonable demands on the system.
We can summarize the above points by saying that there is reduced transparency and control over performance, availability, and capacity in the cloud. Finally, here are a few cloud myths to keep in mind:
The cloud is inherently more scalable
Applications, their architectures, and the organizations that manage them are scalable (or not). The cloud isn’t inherently scalable just because it’s a cloud, and choosing a scalable platform doesn’t automatically make your application scalable. It’s true that if the cloud hosting provider isn’t oversubscribed, there are resources that you can purchase on demand, but availability of resources when you need them is only one aspect of scalability.
The cloud automatically improves or even guarantees uptime
Individual cloud-hosted servers are actually more likely to fail or have outages, in general, than well-designed dedicated infrastructure. Many people don’t realize this, however. For example, one person wrote “we are upgrading our infrastructure to a cloud-based system to give us 100% uptime and scalability.” This was just after AWS had suffered two huge outages that affected large portions of its user base. A good architect can design reliable systems with unreliable components, but in general a more reliable infrastructure contributes to higher availability. (There’s no such thing as 100% uptime, of course.)
On the other hand, by subscribing to a cloud computing service, you’re buying a platform that was built by experts. They have taken care of a lot of low-level things for you, and that means you can focus on higher-level tasks. If you build your own platform and you’re not an expert on all those minutiae, you’re likely to make some beginner’s mistakes, which will probably cause some downtime sooner or later. In this way, cloud computing can help you improve your uptime.
The cloud is the only thing that provides [insert benefit here]
Actually, many of the benefits of the cloud are inherited from the technologies used to build cloud platforms and can be obtained with or without the cloud.[200] With properly managed virtualization and capacity planning, for example, you can spin up a new machine as easily and quickly as you can in any cloud. You don’t need the cloud for this.
The cloud is a silver bullet
It might seem absurd that anyone would actually say this, but some do. There is no such thing.
Cloud computing provides unique benefits, to be sure, and over time we will develop a greater shared understanding of what those are and when they’re useful. One thing is certain: this is all new, and any predictions we make now are unlikely to age well. We’ll take the safe course in this book and leave the rest of this topic to in-person discussions.
[198] OK, OK, we admit it. Amazon Web Services is the cloud. This chapter is mostly about AWS.
[199] See George Reese’s Cloud Application Architectures (O’Reilly).
[200] We’re not saying it would be easy or cheap. We’re just saying that the cloud isn’t the only place you can get these benefits.
The Economics of MySQL in the Cloud
Cloud hosting can certainly be more economical than traditional server deployment in some cases. In our experience, cloud hosting is a great match for a lot of prototype-phase businesses, or businesses who are perpetually spinning out new concepts and essentially running them through a feasibility trial-by-fire. Mobile app developers and game developers come to mind immediately. The market for these technologies is exploding with the spread of mobile computing, and it’s a fast-paced world. In many cases, success comes through factors that are out of the developer’s control, such as word-of-mouth referrals or timing that coincides with important world events.
We have helped many companies build mobile, social networking, and gaming applications in the cloud. One strategy many of them use is to develop and release applications as quickly and cheaply as possible. If an application happens to catch on, the company will invest resources into making it work at a larger scale; otherwise, they’ll terminate it quickly. Some companies build and release such applications in lifecycles as short as a few weeks. In such an environment, cloud hosting is a no-brainer.
If you’re a small-scale company, you probably can’t afford your own data center with enough hardware to meet the scaling curve of a virally popular Facebook application. We’ve also helped scale some of the largest Facebook applications ever built, and it can be astonishing how fast they can grow—sometimes, it seems, faster than some managed hosting companies can rack servers. But even worse, the growth of these apps is completely unpredictable; they could just as easily fail to get more than a handful of users. We’ve worked on such applications both in datacenters and in the cloud. If you’re a small company, the cloud can help you hedge against the risk that you’ll need to scale larger and faster than your capital can support up front.
Another potentially great use for the cloud is to run noncritical infrastructure, such as integration environments, testbeds for deployment, and evaluations. Suppose your deployment lifecycle is two weeks long. Do you test a deployment every hour of every day, or do you test when you’re toward the end of the sprint? Many users need staging and deployment test environments only occasionally. Cloud hosting can help save money in such cases.
Here are two ways we use the cloud ourselves. The first is as part of our interviewing process for technical staff members, where we ask them to solve some real problems. We spin up some “broken” machines with Amazon Machine Images (AMIs) that we created for this purpose, and we ask candidates to log in and perform a variety of tasks on the servers. We don’t have to open up access to our own network, and it’s unbeatably cheap. Another way we’ve used cloud hosting is for staging and development servers for new projects. One such project ran on a staging server in the cloud for months and generated a total bill of less than a dollar! There’s no way we could do that on our own infrastructure. Just sending an email to our system administrator asking for a staging server would take more than a dollar’s worth of time.
On the other hand, cloud hosting can be more expensive over the long term. You should take the time to do the math yourself, if you’re in it for the long haul. This will require benchmarking and a full accounting of total cost of ownership (TCO), as well as some guesswork about what future innovations will bring both in cloud computing and in commodity hardware. To get to the heart of the matter and incorporate all the relevant details, you need to boil everything down to a single number: business transactions per dollar. Things change quickly, so we leave this as an exercise for the reader.
MySQL Scaling and HA in the Cloud
As we noted earlier, MySQL doesn’t automatically become more scalable in the cloud. In fact, the less powerful machines that are available force you to use horizontal scaling strategies much earlier. And cloud-hosted servers are less reliable and predictable than dedicated hardware, so achieving high availability requires more creativity.
By and large, though, there aren’t many differences between scaling MySQL in the cloud and scaling MySQL elsewhere. The biggest difference is the ability to provision servers on demand. However, there are some limitations that make scaling and high availability a bit harder, at least in some cloud environments. For example, in the AWS cloud platform, you can’t use the equivalent of virtual IP addresses to perform fast atomic failover. The limited control over resources like this simply means you have to use other approaches, such as proxies. (ScaleBase is one that could be worth looking into.)
The other siren call of the cloud is the dream of auto-scaling—that is, spinning up more instances in response to increased demand, and shutting them down again when demand reduces. Although this is feasible with stateless parts of the stack such as web servers, it’s very hard to do with the database server, because it is stateful. For special cases, such as read-mostly applications, you can get a limited form of auto-scaling by adding replicas,[201] but this is not a one-size-fits-all solution. In practice, although many applications use auto-scaling in the web tier, MySQL isn’t natively capable of running across a shared-nothing cluster of servers that all assume peer roles. You could do it with a sharded architecture that automatically reshards and grows or shrinks,[202] but MySQL itself just isn’t able to auto-scale.
In fact, as it’s typically the main or only stateful and persistent component of an application, it’s pretty common for people to move an application into the cloud because of the benefits it offers for everything but the database—web servers, job queue servers, caches, etc.—and MySQL just has to go where everything else goes.
The database isn’t the center of the world, after all. If the benefits to the rest of the application outweigh the additional cost and effort required to make MySQL work as needed, then it’s not a question of whether it will happen, but how. To answer this, it’s helpful to understand the additional challenges you might face in the cloud. These typically center around the resources available to the database server.
[201] A popular open source service for auto-scaling MySQL replication in the cloud is Scalr (http://scalr.net).
[202] This is what computer scientists like to call a “non-trivial challenge.”
The Four Fundamental Resources
MySQL needs four fundamental resources to do its work: CPU cycles, memory, I/O, and the network. These four resources have characteristic and important differences in most cloud platforms. One helpful way to approach decisions about hosting MySQL in the cloud is to examine these differences and their implications for MySQL:
§ CPUs are generally fewer and slower. The largest standard EC2 instances at the time of writing offer eight virtual CPU cores. The virtual CPUs EC2 offers are effectively slower than top-end CPUs (see our benchmarks a bit later in the chapter for the subtleties). This is probably fairly typical of most cloud hosting, although there will be variations. EC2 offers instances with more CPU resources, but they have lower maximum memory sizes. At the time of writing, commodity servers offer dozens of CPU cores—and even more, if you count hardware threads.[203]
§ Memory size is limited. The largest EC2 instances currently offer 68.4 GB of memory. In contrast, commodity servers are available with 512 GB to 1 TB of memory.
§ I/O performance is limited in throughput, latency, and consistency. There are two options for storage in the AWS cloud.
The first is using EBS volumes, which are like a cloud SAN. The best practice in the AWS cloud is to build servers on RAID 10 volumes over EBS. However, EBS is a shared resource, as is the network connection between the EC2 server and the EBS server. Latency can be high and unpredictable, even under moderate throughput demands. We’ve measured I/O latency to EBS devices well into the tenths of seconds. In comparison, directly attached commodity hard drives respond in single-digit milliseconds, and flash devices are orders of magnitude faster even than hard drives. On the other hand, EBS volumes have a lot of nice features, such as integration with other AWS services, fast snapshots, and so on.
The second storage option is the instance’s local storage. Each EC2 server has some amount of local storage, which is actually attached to the underlying server. It can offer more consistent performance than EBS,[204] but it does not persist when the instance is stopped. The ephemeral nature of the local storage makes it unsuitable for most database server use cases.
§ Network performance is usually decent, although it is a shared resource and can be variable. Although you can get faster and more consistent network performance in commodity hardware, the CPU, RAM, and I/O tend to be the first bottlenecks, and we haven’t had problems with network performance in the AWS cloud.
As you can see, three of the four fundamental resources are limited in the AWS cloud, in some cases significantly so. In general, the underlying resources aren’t as powerful as what’s available in commodity hardware. We’ll discuss the precise consequences of this in the next section.
[203] Commodity hardware still offers more power than MySQL can use effectively in terms of CPU, RAM, and I/O, so it’s not completely fair to compare the cloud with the biggest horsepower available outside the cloud.
[204] Local storage is not actually allocated to the instance until it is written, causing a first-write penalty for each block that is written. The trick to avoiding this penalty is to use dd to write the device full of data.
MySQL Performance in Cloud Hosting
In general, MySQL performance on cloud hosting platforms such as AWS isn’t as good as you can get elsewhere, due to weaker CPU, memory, and I/O performance. This varies from cloud platform to cloud platform, but it is still generally true.[205] However, cloud hosting might still be a high-enough performance platform for your needs, and it’s better for some needs than for others.
It shouldn’t surprise you that with weaker resources to run the database, you can’t make MySQL run as fast when you host it in the cloud. What might surprise you is that you might not be able to make it run as fast as you can on similarly sized physical hardware. For example, if you have a server with 8 CPU cores, 16 GB of memory, and a midlevel RAID array, you might assume that you can get about the same performance from an EC2 instance with 8 EC2 compute units, 15 GB of memory, and a handful of EBS volumes. That’s not guaranteed, however. The EC2 instance’s performance is likely to be more variable than that of your physical hardware, especially because it’s not one of the super-large instances and is therefore presumably sharing resources with other instances on the same physical hardware.
Variability is a really big deal. MySQL, and InnoDB in particular, doesn’t like variable performance—especially not variable I/O performance. I/O operations can acquire mutex locks inside the server, and when these last too long they can cause pileups that manifest as many “stuck” processes, inexplicably long-running queries, and spikes in status variables such as Threads_running or Threads_connected.
The practical result of inconsistent or unpredictable performance is that queueing becomes more severe. Queueing is a natural consequence of variability in response times and inter-arrival times, and there is an entire branch of mathematics devoted to the study of queueing. All computers are networks of queueing systems, and requests for resources must wait if the desired resource (CPU, I/O, network, etc.) is busy. When resource performance is more variable, requests overlap more often, and they experience more queueing. As a result, it’s a bit harder to achieve high concurrency or consistently low response times in most cloud computing platforms. We have a lot of experience observing these limitations on the EC2 platform. In our experience, the most concurrency you can expect from MySQL on the largest instance sizes is a Threads_running count of 8 to 12 on typical web OLTP workloads. Anything beyond that, and performance tends to become unacceptable, as a rule of thumb.
Note that we said “typical web OLTP workloads.” Not all workloads respond in the same way to the limitations of cloud platforms. It turns out that there are actually some workloads that perform just fine in the cloud, and some that suffer especially badly. Let’s take a look at what those are:
§ Workloads that need high concurrency, as we just discussed, don’t tend to be as well suited to cloud computing. The same is true of applications that demand extremely fast response times. The reason boils down to the limited number and speed of the virtual CPUs. Every query runs on a single CPU inside MySQL, so query response time is limited by the raw speed of the CPU. If you want fast response times, you need fast CPUs. To support higher concurrency, you need more of them. It’s true that MySQL and InnoDB don’t provide great bang for the buck on many dozens of CPU cores, but they generally scale well out to at least 24 cores these days, and that’s more than you can usually get in the cloud.
§ Workloads that require a lot of I/O don’t tend to perform all that well in the cloud. When I/O is slow and variable, things grind to a halt fairly quickly. On the other hand, if your workload doesn’t demand a lot of I/O, either in throughput (operations per second) or bandwidth (bytes per second), MySQL can hum along quite nicely.
The preceding points really follow from the weaknesses of CPU and I/O resources in the cloud. What can you do about them? There’s not much you can do about CPU limitations. If you don’t have enough, you don’t have enough. However, I/O is different. I/O is really the interchange between two kinds of memory: volatile memory (RAM) and persistent memory (disk, EBS, or what have you). As a result, MySQL’s I/O demands can be influenced by how much memory the system has. With enough memory, reads can be served from caches, reducing the I/O needed for both reads and writes. Writes can generally be buffered in memory too, and multiple writes to the same bits of memory can be combined and then persisted with a single I/O operation.
That’s where the limitations on memory come into the picture. With enough memory to hold the working set of data,[206] I/O demands can be reduced significantly for certain workloads. Larger EC2 instance sizes also offer better network performance, which further helps I/O to EBS volumes. But if your working set is too big to fit into the largest instances available, I/O demands escalate and things start to block and stall, as discussed earlier. The largest high-memory instance sizes in EC2 have enough memory to serve many workloads quite nicely. However, you should be aware that warmup time can be very long; more on that topic later in this section.
What types of workloads can’t be fixed by adding more memory? Regardless of buffering, some write-heavy workloads simply require more I/O than you can expect from many cloud computing platforms. If you’re executing many transactions per second, for example, that will demand a lot of I/O operations per second to ensure durability, and you can only get so much throughput from systems such as EBS. Likewise, if you’re pushing a lot of data into the database, you might exceed the available bandwidth.
You might think that you can improve your I/O performance by striping and mirroring EBS volumes with RAID. That does help, up to a point. The problem is that as you add more EBS volumes, you actually increase the likelihood that one of them is going to be performing badly at any given point in time, and due to the way I/O works inside of InnoDB, the weakest link is often the bottleneck for the whole system. In practice, we’ve tried RAID 10 sets of 10 and 20 EBS volumes, and the 20-volume RAID had more problems with stalls than the 10-volume one did. When we measured the I/O performance of the underlying block devices, it was clear that only one or two of the EBS volumes was performing slowly, and yet the whole server suffered.
You can change the application and server to reduce the I/O demands, too. Careful logical and physical database design (schema and indexing) goes a long way toward reducing I/O needs, as does application and query optimization. These are the most powerful levers you can apply to reducing I/O. Some workloads, such as insert-heavy workloads, can be helped by judicious use of partitioning to concentrate the I/O on a single partition whose indexes fit in memory. You can relax durability, for example by setting innodb_flush_logs_at_trx_commit=2 andsync_binlog=0, or moving the InnoDB transaction logs and binary logs off the EBS volumes and onto the local drives (though this is risky). But the harder you try to squeeze a little bit extra from the server, the more complexity (and thus cost) you inevitably add.
You can also upgrade your MySQL server software. Newer versions of MySQL and InnoDB (recent versions of MySQL 5.1 with the InnoDB plugin, or MySQL 5.5 and newer) offer significantly better I/O performance and fewer internal bottlenecks, and will suffer from stalls and pileups much less than the older code in early 5.1 and previous versions. Percona Server can offer even more benefits in certain workloads. For example, Percona Server’s feature to warm up the buffer pool quickly after a restart is enormously helpful in getting a server back up and running quickly, especially if the I/O performance is not great and the server relies on an in-memory workload. This is one of the scenarios we’ve been discussing as a candidate for good performance in the cloud, where servers tend to fail more often than on-premise hardware. Percona Server can reduce warmup times from hours or even days to just minutes. At the time of writing, a similar warmup feature is available in a MySQL 5.6 development milestone release.
Ultimately, though, a growing application will reach a point where you have to shard the database to stay in the cloud. We really like to avoid sharding when we can, but if you only have so much horsepower, at some point you have to either go elsewhere (leave the cloud), or break things up into smaller pieces whose demands don’t exceed the capacity of the virtual hardware that’s available. You can generally count on having to shard when your working set doesn’t fit in memory anymore, meaning a working set size of around 50 GB to 60 GB on the largest EC2 instances. In contrast, we have lots of experience running multi-terabyte databases on physical hardware. You have to shard much earlier in the cloud.
Benchmarks for MySQL in the Cloud
We performed some benchmarks to illustrate MySQL’s performance in the AWS cloud environment. It’s virtually impossible to get consistent and reproducible benchmarks in the cloud when a lot of I/O is needed, so we chose an in-memory workload that measures essentially everything except I/O. We used Percona Server version 5.5.16 with a 4 GB buffer pool to run the standard SysBench read-only benchmark on 10 million rows of data. This allowed us to compare results across a variety of instance sizes. We omitted the high-CPU instances because they actually have less CPU power than the m2.4xlarge instance does, and we included a Cisco server as a point of reference. The Cisco machine is fairly powerful but aging a bit, with dual Intel Xeon X5670 Nehalem CPUs at 2.93 GHz. Each CPU has six cores with two hardware threads on each, which the operating system sees as 24 CPUs overall. Figure 13-1 shows the results.
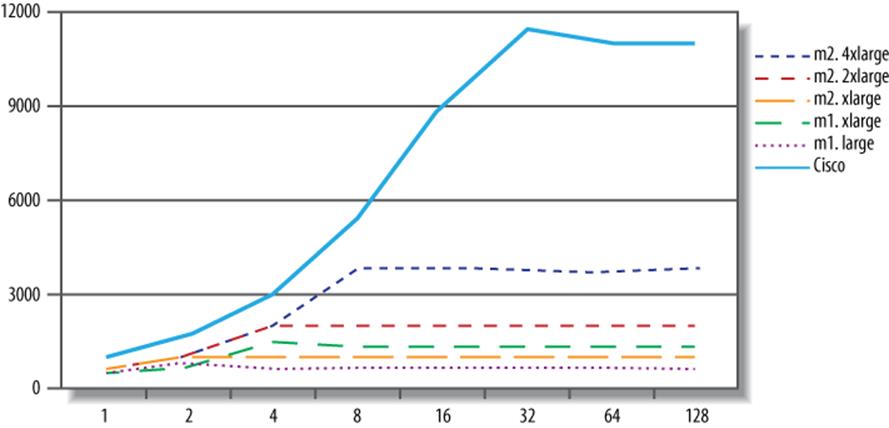
Figure 13-1. SysBench read-only benchmarks for MySQL in the AWS cloud
The results should not be surprising, given the workload and the hardware. For example, the largest EC2 instance tops out at eight threads, because it has eight CPU cores. (A read/write workload would spend some of its time off-CPU doing I/O, so we would be able to achieve more than eight threads of effective concurrency.) This chart might lead you to assume that the Cisco’s advantage is in CPU power, which is what we thought. So we benchmarked raw CPU performance to find out, using SysBench’s prime-number benchmark. Figure 13-2 shows the results.
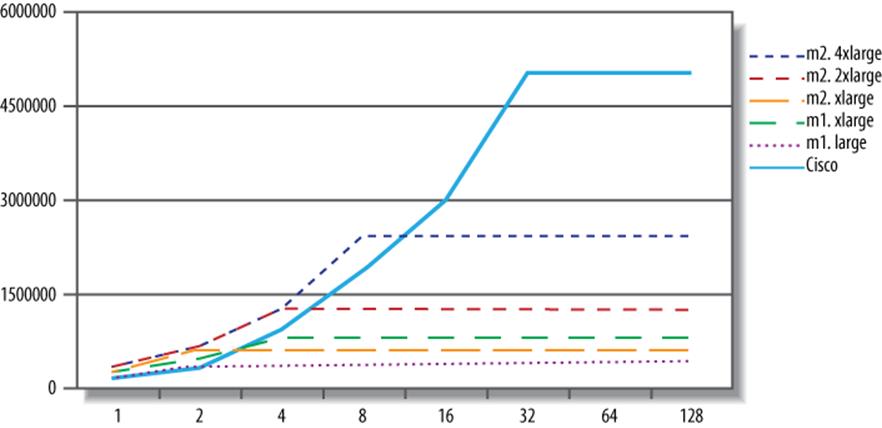
Figure 13-2. SysBench CPU prime-number benchmarks for AWS servers
The Cisco server has lower per-CPU performance than the EC2 servers. Surprised? We were a bit surprised ourselves. The prime-number benchmark is essentially raw CPU instructions, and as such, it shouldn’t have a noticeable virtualization overhead or much memory traffic. Thus, the explanation for our results is probably as follows: the Cisco server’s CPUs are a couple of years old, and are slower than the EC2 servers. But for more complex tasks such as running a database server, the overhead of virtualization places the EC2 servers at a disadvantage. It’s not always easy to distinguish between slow CPUs, slow memory access, and virtualization overhead, but in this instance the differences seem a bit clearer.
[205] If you believe http://www.xkcd.com/908/, then obviously all clouds have the same weaknesses. We’re just sayin’.
[206] See Chapter 9 for a definition of the working set and a discussion of how it influences I/O demands.
MySQL Database as a Service (DBaaS)
Installing MySQL on a cloud-hosted server isn’t the only option for using MySQL in the cloud. More and more companies are offering the database itself as a cloud resource, dubbing it Database as a Service (DBaaS, or sometimes DaaS). This means that you can get a database in the cloud somewhere and leave the actual running of the service to others. Although we’ve spent most of our time examining IaaS in this chapter, the IaaS market is rapidly becoming commoditized, and we expect that in the future a lot of emphasis will shift to DBaaS instead. There are several DBaaS providers at the time of writing.
Amazon RDS
We’ve seen much more deployment on Amazon’s Relational Database Service (RDS) than any of the other DBaaS offerings. Amazon RDS isn’t just a MySQL-compatible service; it actually is MySQL, so it’s completely compatible with your own MySQL server[207] and can serve as a drop-in replacement. We can’t say for sure, but like most people we believe that RDS is hosted on an EC2 machine backed by EBS volumes—Amazon has not officially confirmed the underlying technologies, but when you get to know RDS well, it seems pretty obvious that it’s just MySQL, EC2, and EBS.
Amazon does all the system administration for you. You don’t have access to the EC2 machine; you have access credentials to log into MySQL, and that’s it. You can create databases, insert data, and so on. You’re not locked in; if you want to, you can export the data and move it elsewhere, and you can create volume snapshots and mount them on other machines, too.
RDS comes with some restrictions to keep you from inspecting or interfering with Amazon’s management of the server or the host instance. There are some privilege restrictions, for example. You can’t use SELECT INTO OUTFILE, FILE(), LOAD DATA INFILE, or any other method of accessing the server’s filesystem through MySQL. You can’t do anything related to replication, and you can’t escalate your privileges to grant yourself these rights, either. Amazon has taken measures such as placing triggers on the system tables to prevent that. And as part of the terms of service, you agree not to try to get around these limitations.
The MySQL version installed is slightly modified to prevent you from meddling with the server, but otherwise it seems to be stock MySQL as you know it. We benchmarked RDS against EBS and EC2 and found nothing beyond the variations we’d expect from the platform. That is, it looks like Amazon hasn’t done any performance enhancements to the server.
RDS can offer few compelling benefits, depending on your circumstances:
§ You can leave the system administration work and even much of the database administration work to Amazon. For example, they handle replication for you and ensure you don’t mess it up.
§ Depending on your cost structure and staffing resources, RDS can be inexpensive compared to the alternatives.
§ The restrictions can be seen as a good thing: Amazon takes away the loaded gun you might otherwise use to shoot yourself in the foot.
However, it does have some potential drawbacks:
§ Because you can’t access the server, you can’t tell what’s going on in the operating system. For example, you can’t measure I/O response time or CPU utilization. Amazon does provide this through another of its services, CloudWatch. It gives detailed enough metrics to troubleshoot many performance problems, but sometimes you need the raw data to know exactly what’s happening. (You can’t use functions such as FILE() to access /proc/diskstats, either.)
§ You can’t get the full slow query log file. You can direct MySQL to log slow queries to a CSV logging table, but this isn’t as good. It consumes a lot more server resources, and it doesn’t give high-resolution query response times. This makes it a bit harder to profile and troubleshoot SQL.
§ If you want the latest and greatest, or some performance enhancements such as those you could get with Percona Server, you’re out of luck. RDS doesn’t offer them.
§ You must rely on Amazon’s support team to resolve some problems that you might otherwise be able to fix yourself. For example, suppose queries hang, or your server crashes due to data corruption. You can either wait for Amazon to work on it, or you can take matters into your own hands. But to do the latter, you have to take the data elsewhere; you can’t access the instance itself to fix it. You have to spend extra time and pay for additional resources if you want to do this. This isn’t just theoretical; we’ve gotten lots of support requests for help with things that really require access to the system to troubleshoot, and aren’t really solvable for RDS users as a result.
In terms of performance, as we said, RDS is pretty comparable to a large high-memory EC2 instance with EBS storage and stock MySQL. You can squeeze a little more performance out of the AWS cloud if you use EC2 and EBS directly and install and tweak a higher-performance version of MySQL, such as Percona Server, but it won’t be an order-of-magnitude difference. With that in mind, it makes sense to base your decision to use RDS on your business needs, not on performance. If you really need performance that badly, you should not use the AWS cloud at all.
Other DBaaS Solutions
Amazon RDS isn’t the only DBaaS game in town for MySQL users. There are also services such as FathomDB (http://fathomdb.com) and Xeround (http://xeround.com). We don’t have enough firsthand experience to recommend any of them, though, because we haven’t had any production deployments on these services. From the limited public information on FathomDB, it appears to be similar to Amazon RDS, although it is available on the Rackspace cloud as well as the AWS cloud. It is in private beta at the time of writing.
Xeround is quite different: it is a distributed cluster of servers, fronted by MySQL with a proprietary storage engine. It seems to have at least some minor incompatibilities with or differences from stock MySQL, but it only recently became generally available (GA), so it’s too early to judge it. The storage engine appears to communicate with a clustered backend system that might bear similarities to NDB Cluster. It has the added benefit of resharding automatically to add and subtract nodes (dynamic scaling) as the workload increases and decreases.
There are many other DBaaS services, and new ones are announced pretty frequently. Anything we write about this will be outdated by the time you read it, so we’ll let you research the landscape yourself.
[207] Unless you’re using an alternative storage engine or some other nonstandard modification to MySQL.
Summary
There are at least two mainstream ways to use MySQL in the cloud: install it on cloud servers, or use a DBaaS offering. MySQL runs just fine in cloud hosting, but the limitations of the cloud environment usually result in sharding much earlier than is necessary outside the cloud. And cloud servers that appear comparable to your existing physical hardware are likely to provide reduced performance and quality of service.
Sometimes it seems that people are saying, “The cloud is the answer; what is the question?” That is one extreme, but people who are fervent believers that the cloud is a silver bullet are likely to have corresponding problems. Three of the four fundamental resources the database needs (CPU, memory, and disk) can be significantly weaker and/or less effective in the cloud, and that has a direct impact on MySQL performance.
Nevertheless, MySQL runs great in the cloud for lots of workloads. In general, you’ll be fine if you can fit your working set in memory, and if you don’t generate a higher write workload than your cloud-based I/O can handle. With careful design and architecture, and by choosing the correct version of MySQL and configuring it properly, you can match your database’s workload and capabilities to the cloud’s strengths. Still, MySQL isn’t a cloud database by nature; that is, it can’t really use all of the benefits cloud computing theoretically offers, such as auto-scaling. Alternative technologies such as Xeround are attempting to address these shortcomings.
We’ve talked a lot about the shortcomings of the cloud, which might give you the impression that we’re anti-cloud. We’re not. It’s just that we’re trying to focus on MySQL, instead of listing all of the benefits of cloud computing, which would not be much different from anything you’d read elsewhere. We’re trying to point out what’s different, and what you really need to know, about running MySQL in the cloud.
The biggest successes we’ve seen in the cloud have been when decisions are motivated by business reasons. Even if the cost per business transaction is higher in the cloud over the long term, other factors, such as increased flexibility, reduced upfront costs, reduced time to market, and reduced risk, can be more important. And the benefits to the non-MySQL parts of your application could far outweigh any disadvantages you experience with MySQL.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.