High Performance MySQL (2012)
Chapter 7. Advanced MySQL Features
MySQL 5.0 and 5.1 introduced many features, such as partitioning and triggers, which are familiar to users with a background in other database servers. The addition of these features attracted many new users to MySQL. However, their performance implications did not really become clear until people began to use them widely. In this chapter we explain what we’ve learned from seeing these features in the real world, beyond what the manuals and reference material have taught us.
Partitioned Tables
A partitioned table is a single logical table that’s composed of multiple physical sub-tables. The partitioning code is really just a wrapper around a set of Handler objects that represent the underlying partitions, and it forwards requests to the storage engine through the Handler objects. Partitioning is a kind of black box that hides the underlying partitions from you at the SQL layer, although you can see them quite easily by looking at the filesystem, where you’ll see the component tables with a hash-delimited naming convention.
The way MySQL implements partitioning—as a wrapper over hidden tables—means that indexes are defined per-partition, rather than being created over the entire table. This is different from Oracle, for example, where indexes and tables can be partitioned in more flexible and complex ways.
MySQL decides which partition holds each row of data based on the PARTITION BY clause that you define for the table. The query optimizer can prune partitions when you execute queries, so the queries don’t examine all partitions—just the ones that hold the data you are looking for.
The primary purpose of partitioning is to act as a coarse form of indexing and data clustering over the table. This can help to eliminate large parts of the table from being accessed, and to store related rows close together.
Partitioning can be very beneficial, especially in specific scenarios:
§ When the table is much too big to fit in memory, or when you have “hot” rows at the end of a table that has lots of historical data.
§ Partitioned data is easier to maintain than nonpartitioned data. For example, it’s easier to discard old data by dropping an entire partition, which you can do quickly. You can also optimize, check, and repair individual partitions.
§ Partitioned data can be distributed physically, enabling the server to use multiple hard drives more efficiently.
§ You can use partitioning to avoid some bottlenecks in specific workloads, such as per-index mutexes with InnoDB or per-inode locking with the ext3 filesystem.
§ If you really need to, you can back up and restore individual partitions, which is very helpful with extremely large datasets.
MySQL’s implementation of partitioning is too complicated to explore in full detail here. We want to concentrate on its performance implications, so we recommend that for the basics you turn to the MySQL manual, which has a lot of material on partitioning. You should read the entire partitioning chapter, and look at the sections on CREATE TABLE, SHOW CREATE TABLE, ALTER TABLE, the INFORMATION_SCHEMA.PARTITIONS table, and EXPLAIN. Partitioning has made the CREATE TABLE and ALTER TABLE commands much more complex.
A few limitations apply to partitioned tables. Here are the most important ones:
§ There’s a limit of 1,024 partitions per table.
§ In MySQL 5.1, the partitioning expression must be an integer or an expression that returns an integer. In MySQL 5.5, you can partition by columns in certain cases.
§ Any primary key or unique index must include all columns in the partitioning expression.
§ You can’t use foreign key constraints.
How Partitioning Works
As we’ve mentioned, partitioned tables have multiple underlying tables, which are represented by Handler objects. You can’t access the partitions directly. Each partition is managed by the storage engine in the normal fashion (all partitions must use the same storage engine), and any indexes defined over the table are actually implemented as identical indexes over each underlying partition. From the storage engine’s point of view, the partitions are just tables; the storage engine doesn’t really know whether a specific table it’s managing is a standalone table or just part of a bigger partitioned table.
Operations on a partitioned table are implemented with the following logical operations:
SELECT queries
When you query a partitioned table, the partitioning layer opens and locks all of the underlying partitions, the query optimizer determines whether any of the partitions can be ignored (pruned), and then the partitioning layer forwards the handler API calls to the storage engine that manages the partitions.
INSERT queries
When you insert a row, the partitioning layer opens and locks all partitions, determines which partition should receive the row, and forwards the row to that partition.
DELETE queries
When you delete a row, the partitioning layer opens and locks all partitions, determines which partition contains the row, and forwards the deletion request to that partition.
UPDATE queries
When you modify a row, the partitioning layer (you guessed it) opens and locks all partitions, determines which partition contains the row, fetches the row, modifies the row and determines which partition should contain the new row, forwards the row with an insertion request to the destination partition, and forwards the deletion request to the source partition.
Some of these operations support pruning. For example, when you delete a row, the server first has to locate it. The server can prune partitions that can’t contain the row if you specify a WHERE clause that matches the partitioning expression. The same applies to UPDATE queries. INSERTqueries are naturally self-pruned; the server looks at the values to be inserted and finds one and only one destination partition.
Although the partitioning layer opens and locks all partitions, this doesn’t mean that the partitions remain locked. A storage engine such as InnoDB, which handles its own locking at the row level, will instruct the partitioning layer to unlock the partitions. This lock-and-unlock cycle is similar to how queries against ordinary InnoDB tables are executed.
We’ll show some examples a bit later that illustrate the cost and consequences of opening and locking every partition when there’s any access to the table.
Types of Partitioning
MySQL supports several types of partitioning. The most common type we’ve seen used is range partitioning, in which each partition is defined to accept a specific range of values for some column or columns, or a function over those columns. For example, here’s a simple way to place each year’s worth of sales into a separate partition:
CREATE TABLE sales (
order_date DATETIME NOT NULL,
-- Other columns omitted
) ENGINE=InnoDB PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN MAXVALUE );
You can use many functions in the partitioning clause. The main requirement is that it must return a nonconstant, deterministic integer. We’re using YEAR() here, but you can also use other functions, such as TO_DAYS(). Partitioning by intervals of time is a common way to work with date-based data, so we’ll return to this example later and see how to optimize it to avoid some of the problems it can cause.
MySQL also supports key, hash, and list partitioning methods, some of which support subpartitions, which we’ve rarely seen used in production. In MySQL 5.5 you can use the RANGE COLUMNS partitioning type, so you can partition by date-based columns directly, without using a function to convert them to an integer. More on that later.
One use of subpartitions we’ve seen was to work around a per-index mutex inside InnoDB on a table designed similarly to our previous example. The partition for the most recent year was modified heavily, which caused a lot of contention on that mutex. Subpartitioning by hash helped chop the data into smaller pieces and alleviated the problem.
Other partitioning techniques we’ve seen include:
§ You can partition by key to help reduce contention on InnoDB mutexes.
§ You can partition by range using a modulo function to create a round-robin table that retains only a desired amount of data. For example, you can partition date-based data by day modulo 7, or simply by day of week, if you want to retain only the most recent days of data.
§ Suppose you have a table with an autoincrementing idprimary key, but you want to partition the data temporally so the “hot” recent data is clustered together. You can’t partition by a timestamp column unless you include it in the primary key, but that defeats the purpose of a primary key. You can partition by an expression such as HASH(id DIV 1000000), which creates a new partition for each million rows inserted. This achieves the goal without requiring you to change the primary key. It has the added benefit that you don’t need to constantly create partitions to hold new ranges of dates, as you’d need to do with range-based partitioning.
How to Use Partitioning
Imagine that you want to run queries over ranges of data from a really huge table that contains many years’ worth of historical metrics in time-series order. You want to run reports on the most recent month, which is about 100 million rows. In a few years this book will be out of date, but let’s pretend that you have hardware from 2012 and your table is 10 terabytes, so it’s much bigger than memory, and you have traditional hard drives, not flash (most SSDs aren’t big enough for this table yet). How can you query this table at all, let alone efficiently?
One thing is sure: you can’t scan the whole table every time you want to query it, because it’s too big. And you don’t want to use an index because of the maintenance cost and space consumption. Depending on the index, you could get a lot of fragmentation and poorly clustered data, which would cause death by a thousand cuts through random I/O. You can sometimes work around this for one or two indexes, but rarely for more. Only two workable options remain: your query must be a sequential scan over a portion of the table, or the desired portion of the table and index must fit entirely in memory.
It’s worth restating this: at very large sizes, B-Tree indexes don’t work. Unless the index covers the query completely, the server needs to look up the full rows in the table, and that causes random I/O a row at a time over a very large space, which will just kill query response times. The cost of maintaining the index (disk space, I/O operations) is also very high. Systems such as Infobright acknowledge this and throw B-Tree indexes out entirely, opting for something coarser-grained but less costly at scale, such as per-block metadata over large blocks of data.
This is what partitioning can accomplish, too. The key is to think about partitioning as a crude form of indexing that has very low overhead and gets you in the neighborhood of the data you want. From there, you can either scan the neighborhood sequentially, or fit the neighborhood in memory and index it. Partitioning has low overhead because there is no data structure that points to rows and must be updated—partitioning doesn’t identify data at the precision of rows, and has no data structure to speak of. Instead, it has an equation that says which partitions can contain which categories of rows.
Let’s look at the two strategies that work at large scale:
Scan the data, don’t index it
You can create tables without indexes and use partitioning as the only mechanism to navigate to the desired kind of rows. As long as you always use a WHERE clause that prunes the query to a small number of partitions, this can be good enough. You’ll need to do the math and decide whether your query response times will be acceptable, of course. The assumption here is that you’re not even trying to fit the data in memory; you assume that anything you query has to be read from disk, and that that data will be replaced soon by some other query, so caching is futile. This strategy is for when you have to access a lot of the table on a regular basis. A caveat: for reasons we’ll explain a bit later, you usually need to limit yourself to a couple of hundred partitions at most.
Index the data, and segregate hot data
If your data is mostly unused except for a “hot” portion, and you can partition so that the hot data is stored in a single partition that is small enough to fit in memory along with its indexes, you can add indexes and write queries to take advantage of them, just as you would with smaller tables.
This isn’t quite all you need to know, because MySQL’s implementation of partitioning has a few pitfalls that can bite. Let’s see what those are and how to avoid them.
What Can Go Wrong
The two partitioning strategies we just suggested are based on two key assumptions: that you can narrow the search by pruning partitions when you query, and that partitioning itself is not very costly. As it turns out, those assumptions are not always valid. Here are a few problems you might encounter:
NULLs can defeat pruning
Partitioning works in a funny way when the result of the partitioning function can be NULL: it treats the first partition as special. Suppose that you PARTITION BY RANGE YEAR(order_date), as in the example we gave earlier. Any row whose order_date is either NULL or not a valid date will be stored in the first partition you define.[92] Now suppose you write a query that ends as follows: WHERE order_date BETWEEN '2012-01-01' AND '2012-01-31'. MySQL will actually check two partitions, not one: it will look at the partition that stores orders from 2012, as well as the first partition in the table. It looks at the first partition because the YEAR() function can return NULL if it receives invalid input, and values that might match the range would be stored as NULL in the first partition. This affects other functions, such as TO_DAYS(), too.[93]
This can be expensive if your first partition is large, especially if you’re using the “scan, don’t index” strategy. Checking two partitions instead of one to find the rows is definitely undesirable. To avoid this, you can define a dummy first partition. That is, we could fix our earlier example by creating a partition such as PARTITION p_nulls VALUES LESS THAN (0). If you don’t put invalid data into your table, that partition will be empty, and although it’ll be checked, it’ll be fast because it’s empty.
This workaround is not necessary in MySQL 5.5, where you can partition by the column itself, instead of a function over the column: PARTITION BY RANGE COLUMNS(order_date). Our earlier example should use that syntax in MySQL 5.5.
Mismatched PARTITION BY and index
If you define an index that doesn’t match the partitioning clause, queries might not be prunable. Suppose you define an index on a and partition by b. Each partition will have its own index, and a lookup on this index will open and check each index tree in every partition. This could be quick if the non-leaf nodes of each index are resident in memory, but it is nevertheless more costly than skipping the index lookups completely. To avoid this problem, you should try to avoid indexing on nonpartitioned columns unless your queries will also include an expression that can help prune out partitions.
This sounds simple enough to avoid, but it can catch you by surprise. For example, suppose a partitioned table ends up being the second table in a join, and the index that’s used for the join isn’t part of the partition clause. Each row in the join will access and search every partition in the second table.
Selecting partitions can be costly
The various types of partitioning are implemented in different ways, so of course their performance is not uniform all the time. In particular, questions such as “Where does this row belong?” or “Where can I find rows matching this query?” can be costly to answer with range partitioning, because the server scans the list of partition definitions to find the right one. This linear search isn’t all that efficient, as it turns out, so the cost grows as the number of partitions grows.
The queries we’ve observed to suffer the worst from this type of overhead are row-by-row inserts. For every row you insert into a table that’s partitioned by range, the server has to scan the list of partitions to select the destination. You can alleviate this problem by limiting how many partitions you define. In practice, a hundred or so works okay for most systems we’ve seen.
Other partition types, such as key and hash partitions, don’t have the same limitation.
Opening and locking partitions can be costly
Opening and locking partitions when a query accesses a partitioned table is another type of per-partition overhead. Opening and locking occur before pruning, so this isn’t a prunable overhead. This type of overhead is independent of the partitioning type and affects all types of statements. It adds an especially noticeable amount of overhead to short operations, such as single-row lookups by primary key. You can avoid high per-statement costs by performing operations in bulk, such as using multirow inserts or LOAD DATA INFILE, deleting ranges of rows instead of one at a time, and so on. And, of course, limit the number of partitions you define.
Maintenance operations can be costly
Some partition maintenance operations are very quick, such as creating or dropping partitions. (Dropping the underlying table might be slow, but that’s another matter.) Other operations, such as REORGANIZE PARTITION, operate similarly to the way ALTER works: by copying rows around. For example, REORGANIZE PARTITION works by creating a new temporary partition, moving rows into it, and deleting the old partition when it’s done.
As you can see, partitioned tables are not a “silver bullet” solution. Here is a sample of some other limitations in the current implementation:
§ All partitions have to use the same storage engine.
§ There are some restrictions on the functions and expressions you can use in a partitioning function.
§ Some storage engines don’t work with partitioning.
§ For MyISAM tables, you can’t use LOAD INDEX INTO CACHE.
§ For MyISAM tables, a partitioned table requires more open file descriptors than a normal table containing the same data. Even though it looks like a single table, as you know, it’s really many tables. As a result, a single table cache entry can create many file descriptors. Therefore, even if you have configured the table cache to protect your server against exceeding the operating system’s per-process file-descriptor limits, partitioned tables can cause you to exceed that limit anyway.
Finally, it’s worth pointing out that older server versions just aren’t as good as newer ones. All software has bugs. Partitioning was introduced in MySQL 5.1, and many partitioning bugs were fixed as late as the 5.1.40s and 5.1.50s. MySQL 5.5 improved partitioning significantly in some common real-world cases. In the upcoming MySQL 5.6 release, there are more improvements, such as ALTER TABLE EXCHANGE PARTITION.
Optimizing Queries
Partitioning introduces new ways to optimize queries (and corresponding pitfalls). The biggest opportunity is that the optimizer can use the partitioning function to prune partitions. As you’d expect from a coarse-grained index, pruning lets queries access much less data than they’d otherwise need to (in the best case).
Thus, it’s very important to specify the partitioned key in the WHERE clause, even if it’s otherwise redundant, so the optimizer can prune unneeded partitions. If you don’t do this, the query execution engine will have to access all partitions in the table, and this can be extremely slow on large tables.
You can use EXPLAIN PARTITIONS to see whether the optimizer is pruning partitions. Let’s return to the sample data from before:
mysql> EXPLAIN PARTITIONS SELECT * FROM sales \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales_by_day
partitions: p_2010,p_2011,p_2012
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3
Extra:
As you can see, the query will access all partitions. Look at the difference when we add a constraint to the WHERE clause:
mysql> EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE day > '2011-01-01'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales_by_day
partitions: p_2011,p_2012
The optimizer is pretty good about pruning; for example, it can convert ranges into lists of discrete values and prune on each item in the list. However, it’s not all-knowing. The following WHERE clause is theoretically prunable, but MySQL can’t prune it:
mysql> EXPLAIN PARTITIONS SELECT * FROM sales_by_day WHERE YEAR(day) = 2010\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales_by_day
partitions: p_2010,p_2011,p_2012
MySQL can prune only on comparisons to the partitioning function’s columns. It cannot prune on the result of an expression, even if the expression is the same as the partitioning function. This is similar to the way that indexed columns must be isolated in the query to make the index usable (see Chapter 5). You can convert the query into an equivalent form, though:
mysql> EXPLAIN PARTITIONS SELECT * FROM sales_by_day
-> WHERE day BETWEEN '2010-01-01' AND '2010-12-31'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales_by_day
partitions: p_2010
Because the WHERE clause now refers directly to the partitioning column, not to an expression, the optimizer can prune out other partitions. The rule of thumb is that even though you can partition by expressions, you must search by column.
The optimizer is smart enough to prune partitions during query processing, too. For example, if a partitioned table is the second table in a join, and the join condition is the partitioned key, MySQL will search for matching rows only in the relevant partitions. (EXPLAIN won’t show the partition pruning, because it happens at runtime, not at query optimization time.)
Merge Tables
Merge tables are sort of an earlier, simpler kind of partitioning with different restrictions and fewer optimizations. Whereas partitioning enforces the abstraction rigorously, denying access to the underlying partitions and permitting you to reference only the partitioned table, merge tables let you access the underlying tables separately from the merge table. And whereas partitioning is more integrated with the query optimizer and is the way of the future, merge tables are quasi-deprecated and might even be removed someday.
Like partitioned tables, merge tables are wrappers around underlying MyISAM tables with the same structure. Although you can think of merge tables as an older, more limited version of partitioning, they actually provide some features you can’t get with partitions.[94]
The merge table is really just a container that holds the real tables. You specify which tables to include with a special UNION syntax to CREATE TABLE. Here’s an example that demonstrates many aspects of merge tables:
mysql> CREATE TABLE t1(a INT NOT NULL PRIMARY KEY)ENGINE=MyISAM;
mysql> CREATE TABLE t2(a INT NOT NULL PRIMARY KEY)ENGINE=MyISAM;
mysql> INSERT INTO t1(a) VALUES(1),(2);
mysql> INSERT INTO t2(a) VALUES(1),(2);
mysql> CREATE TABLE mrg(a INT NOT NULL PRIMARY KEY)
-> ENGINE=MERGE UNION=(t1, t2) INSERT_METHOD=LAST;
mysql> SELECT a FROM mrg;
+------+
| a |
+------+
| 1 |
| 1 |
| 2 |
| 2 |
+------+
Notice that the underlying tables have exactly the same number and types of columns, and that all indexes that exist on the merge table also exist on the underlying tables. These are requirements when creating a merge table. Notice also that there’s a primary key on the sole column of each table, yet the resulting merge table has duplicate rows. This is one of the limitations of merge tables: each table inside the merge behaves normally, but the merge table doesn’t enforce constraints over the entire set of tables.
The INSERT_METHOD=LAST instruction to the table tells MySQL to send all INSERT statements to the last table in the merge. Specifying FIRST or LAST is the only control you have over where rows inserted into the merge table are placed (you can still insert into the underlying tables directly, though). Partitioned tables give more control over where data is stored.
The results of an INSERT are visible in both the merge table and the underlying table:
mysql> INSERT INTO mrg(a) VALUES(3);
mysql> SELECT a FROM t2;
+---+
| a |
+---+
| 1 |
| 2 |
| 3 |
+---+
Merge tables have some other interesting features and limitations, such as what happens when you drop a merge table or one of its underlying tables. Dropping a merge table leaves its “child” tables untouched, but dropping one of the child tables has a different effect, which is operating system–specific. On GNU/Linux, for example, the underlying table’s file descriptor stays open and the table continues to exist, but only via the merge table:
mysql> DROP TABLE t1, t2;
mysql> SELECT a FROM mrg;
+------+
| a |
+------+
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |
+------+
A variety of other limitations and special behaviors exist. Here are some aspects of merge tables you should keep in mind:
§ The CREATE statement that creates a merge table doesn’t check that the underlying tables are compatible. If the underlying tables are defined slightly differently, MySQL might create a merge table that it can’t use later. Also, if you alter one of the underlying tables after creating a valid merge table, it will stop working and you’ll see this error: “ERROR 1168 (HY000): Unable to open underlying table which is differently defined or of non-MyISAM type or doesn’t exist.”
§ REPLACE doesn’t work at all on a merge table, and AUTO_INCREMENT won’t work as you might expect. We’ll let you read the manual for the details.
§ Queries that access a merge table access every underlying table. This can make single-row key lookups relatively slow, compared to a lookup in a single table. Therefore, it’s a good idea to limit the number of underlying tables in a merge table, especially if it is the second or later table in a join. The less data you access with each operation, the more important the cost of accessing each table becomes, relative to the entire operation. Here are a few things to keep in mind when planning how to use merge tables:
§ Range lookups are less affected by the overhead of accessing all the underlying tables than individual item lookups.
§ Table scans are just as fast on merge tables as they are on normal tables.
§ Unique key and primary key lookups stop as soon as they succeed. In this case, the server accesses the underlying merge tables one at a time until the lookup finds a value, and then it accesses no further tables.
§ The underlying tables are read in the order specified in the CREATE TABLE statement. If you frequently need data in a specific order, you can exploit this to make the merge-sorting operation faster.
Because merge tables don’t hide the underlying MyISAM tables, they offer some features that partitions don’t as of MySQL 5.5:
§ A MyISAM table can be a member of many merge tables.
§ You can copy underlying tables between servers by copying the .frm, .MYI, and .MYD files.
§ You can add more tables to a merge collection easily; just alter the merge definition.
§ You can create temporary merge tables that include only the data you want, such as data from a specific time period, which you can’t do with partitions.
§ You can remove a table from the merge if you want to back it up, restore it, alter it, repair it, or perform other operations on it. You can then add it back when you’re done.
§ You can use myisampack to compress some or all of the underlying tables.
In contrast, a partitioned table’s partitions are hidden by the MySQL server and are accessible only through the partitioned table.
[92] This happens even if order_date is not nullable, because you can store a value that’s not a valid date.
[93] This is a bug from the user’s point of view, but a feature from the server developer’s point of view.
[94] Some people call these features “foot-guns.”
Views
Views were added in MySQL 5.0. A view is a virtual table that doesn’t store any data itself. Instead, the data “in” the table is derived from a SQL query that MySQL runs when you access the view. MySQL treats a view exactly like a table for many purposes, and views and tables share the same namespace in MySQL; however, MySQL doesn’t treat them identically. For example, you can’t have triggers on views, and you can’t drop a view with the DROP TABLE command.
This book does not explain how to create or use views; you can read the MySQL manual for that. We’ll focus on how views are implemented and how they interact with the query optimizer, so you can understand how to get good performance from them. We use the world sample database to demonstrate how views work:
mysql> CREATE VIEW Oceania AS
-> SELECT * FROM Country WHERE Continent = 'Oceania'
-> WITH CHECK OPTION;
The easiest way for the server to implement a view is to execute its SELECT statement and place the result into a temporary table. It can then refer to the temporary table where the view’s name appears in the query. To see how this would work, consider the following query:
mysql> SELECT Code, Name FROM Oceania WHERE Name = 'Australia';
Here’s how the server might execute it as a temporary table. The temporary table’s name is for demonstration purposes only:
mysql> CREATE TEMPORARY TABLE TMP_Oceania_123 AS
-> SELECT * FROM Country WHERE Continent = 'Oceania';
mysql> SELECT Code, Name FROM TMP_Oceania_123 WHERE Name = 'Australia';
There are obvious performance and query optimization problems with this approach. A better way to implement views is to rewrite a query that refers to the view, merging the view’s SQL with the query’s SQL. The following example shows how the query might look after MySQL has merged it into the view definition:
mysql> SELECT Code, Name FROM Country
-> WHERE Continent = 'Oceania' AND Name = 'Australia';
MySQL can use both methods. It calls the two algorithms MERGE and TEMPTABLE,[95] and it tries to use the MERGE algorithm when possible. MySQL can even merge nested view definitions when a view is based upon another view. You can see the results of the query rewrite with EXPLAIN EXTENDED, followed by SHOW WARNINGS.
If a view uses the TEMPTABLE algorithm, EXPLAIN will usually show it as a DERIVED table. Figure 7-1 illustrates the two implementations.
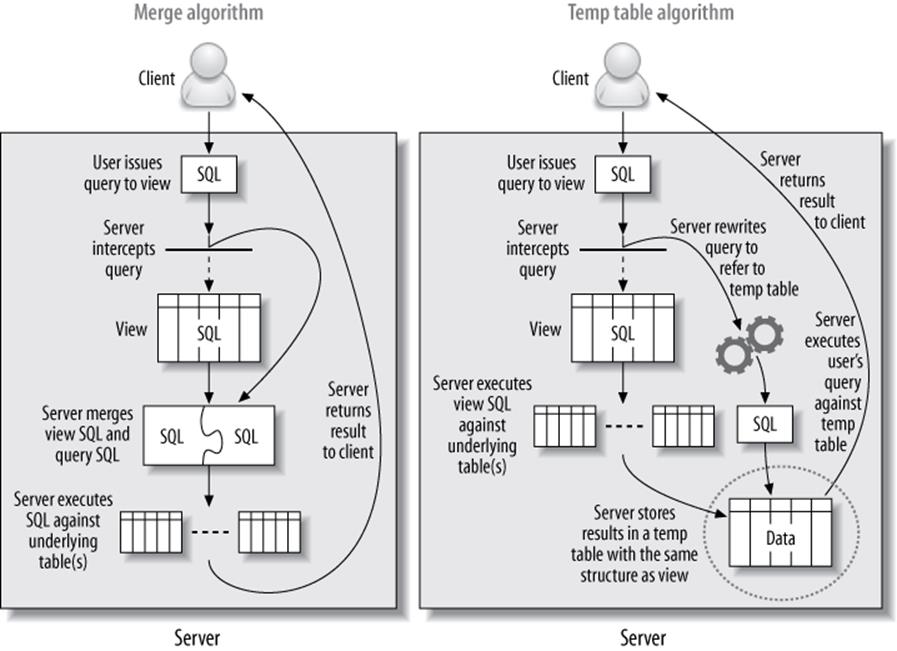
Figure 7-1. Two implementations of views
MySQL uses TEMPTABLE when the view definition contains GROUP BY, DISTINCT, aggregate functions, UNION, subqueries, or any other construct that doesn’t preserve a one-to-one relationship between the rows in the underlying base tables and the rows returned from the view. This is not a complete list, and it might change in the future. If you want to know whether a view will use MERGE or TEMPTABLE, you can EXPLAIN a trivial SELECT query against the view:
mysql> EXPLAIN SELECT * FROM<view_name>;
+----+-------------+
| id | select_type |
+----+-------------+
| 1 | PRIMARY |
| 2 | DERIVED |
+----+-------------+
The presence of a SELECT type of DERIVED select type indicates that the view will use the TEMPTABLE algorithm. Beware, though: if the underlying derived table is expensive to produce, EXPLAIN can be quite costly and slow to execute in MySQL 5.5 and older versions, because it will actually execute and materialize the derived table.
The algorithm is a property of the view and is not influenced by the type of query that is executed against the view. For example, suppose you create a trivial view and explicitly specify the TEMPTABLE algorithm:
CREATE ALGORITHM=TEMPTABLE VIEW v1 AS SELECT * FROM sakila.actor;
The SQL inside the view doesn’t inherently require a temporary table, but the view will always use one, no matter what type of query you execute against it.
Updatable Views
An updatable view lets you update the underlying base tables via the view. As long as specific conditions hold, you can UPDATE, DELETE, and even INSERT into a view as you would with a normal table. For example, the following is a valid operation:
mysql> UPDATE Oceania SET Population = Population * 1.1 WHERE Name = 'Australia';
A view is not updatable if it contains GROUP BY, UNION, an aggregate function, or any of a few other exceptions. A query that changes data might contain a join, but the columns to be changed must all be in a single table. Any view that uses the TEMPTABLE algorithm is not updatable.
The CHECK OPTION clause, which we included when we created the view in the previous section, ensures that any rows changed through the view continue to match the view’s WHERE clause after the change. So, we can’t change the Continent column, nor can we insert a row that has a different Continent. Either would cause the server to report an error:
mysql> UPDATE Oceania SET Continent = 'Atlantis';
ERROR 1369 (HY000): CHECK OPTION failed 'world.Oceania'
Some database products allow INSTEAD OF triggers on views so you can define exactly what happens when a statement tries to modify a view’s data, but MySQL does not support triggers on views.
Performance Implications of Views
Most people don’t think of using views to improve performance, but in some cases they can actually enhance performance in MySQL. You can also use them to aid other performance improvements. For example, refactoring a schema in stages with views can let some code continue working while you change the tables it accesses.
You can use views to implement column privileges without the overhead of actually creating those privileges:
CREATE VIEW public.employeeinfo AS
SELECT firstname, lastname -- but not socialsecuritynumber
FROM private.employeeinfo;
GRANT SELECT ON public.* TO public_user;
You can also sometimes use pseudotemporary views to good effect. You can’t actually create a truly temporary view that persists only for your current connection, but you can create a view under a special name, perhaps in a database reserved for it, that you know you can drop later. You can then use the view in the FROM clause, much the same way you’d use a subquery in the FROM clause. The two approaches are theoretically the same, but MySQL has a different codebase for views, so performance can vary. Here’s an example:
-- Assuming 1234 is the result of CONNECTION_ID()
CREATE VIEW temp.cost_per_day_1234 AS
SELECT DATE(ts) AS day, sum(cost) AS cost
FROM logs.cost
GROUP BY day;
SELECT c.day, c.cost, s.sales
FROM temp.cost_per_day_1234 AS c
INNER JOIN sales.sales_per_day AS s USING(day);
DROP VIEW temp.cost_per_day_1234;
Note that we’ve used the connection ID as a unique suffix to avoid name clashes. This approach can make it easier to clean up in the event that the application crashes and doesn’t drop the temporary view. See Missing Temporary Tables for more about this technique.
Views that use the TEMPTABLE algorithm can perform very badly (although they might still perform better than an equivalent query that doesn’t use a view). MySQL executes them as a recursive step in optimizing the outer query, before the outer query is even fully optimized, so they don’t get a lot of the optimizations you might be used to from other database products. The query that builds the temporary table doesn’t get WHERE conditions pushed down from the outer query, and the temporary table does not have any indexes.[96] Here’s an example, again using thetemp.cost_per_day_1234 view:
mysql> SELECT c.day, c.cost, s.sales
-> FROM temp.cost_per_day_1234 AS c
-> INNER JOIN sales.sales_per_day AS s USING(day)
-> WHERE day BETWEEN '2007-01-01' AND '2007-01-31';
What really happens in this query is that the server executes the view and places the result into a temporary table, then joins the sales_per_day table against this temporary table. The BETWEEN restriction in the WHERE clause is not “pushed into” the view, so the view will create a result set for all dates in the table, not just the one month desired. The temporary table also lacks any indexes. In this example, this isn’t a problem: the server will place the temporary table first in the join order, so the join can use the index on the sales_per_day table. However, if we were joining two such views against each other, the join would not be optimized with any indexes.
Views introduce some issues that aren’t MySQL-specific. Views might trick developers into thinking they’re simple, when in fact they’re very complicated under the hood. A developer who doesn’t understand the underlying complexity might think nothing of repeatedly querying what looks like a table but is in fact an expensive view. We’ve seen cases where an apparently simple query produced hundreds of lines of EXPLAIN output because one or more of the “tables” it referenced was actually a view that referred to many other tables and views.
You should always measure carefully if you’re trying to use views to improve performance. Even MERGE views add overhead, and it’s hard to predict how a view will impact performance. Views actually use a different execution path within the MySQL optimizer, one that isn’t tested as widely and might still have bugs or problems. For that reason, views don’t seem quite as mature as we’d like. For example, we’ve seen cases where complex views under high concurrency caused the query optimizer to spend a lot of time in the planning and statistics stages of the query, even causing server-wide stalls, which we solved by replacing the view with the equivalent SQL. This indicates that views—even those using the MERGE algorithm—don’t always have an optimal implementation.
Limitations of Views
MySQL does not support the materialized views that you might be used to if you’ve worked with other database servers. (A materialized view generally stores its results in an invisible table behind the scenes, with periodic updates to refresh the invisible table from the source data.) MySQL also doesn’t support indexed views. You can emulate materialized and/or indexed views by building cache and summary tables, however. You use Justin Swanhart’s Flexviews tool for this purpose; see Chapter 4 for more.
MySQL’s implementation of views also has a few annoyances. For example, MySQL doesn’t preserve your original view SQL, so if you ever try to edit a view by executing SHOW CREATE VIEW and changing the resulting SQL, you’re in for a nasty surprise. The query will be expanded to the fully canonicalized and quoted internal format, without the benefit of formatting, comments, and indenting.
If you need to edit a view and you’ve lost the pretty-printed query you originally used to create it, you can find it in the last line of the view’s .frm file. If you have the FILE privilege and the .frm file is readable by all users, you can even load the file’s contents through SQL with theLOAD_FILE() function. A little string manipulation can retrieve your original code intact, thanks to Roland Bouman’s creativity:
mysql> SELECT
-> REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
-> REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
-> SUBSTRING_INDEX(LOAD_FILE('/var/lib/mysql/world/Oceania.frm'),
-> '\nsource=', −1),
-> '\\_','\_'), '\\%','\%'), '\\\\','\\'), '\\Z','\Z'), '\\t','\t'),
-> '\\r','\r'), '\\n','\n'), '\\b','\b'), '\\\"','\"'), '\\\'','\''),
-> '\\0','\0')
-> AS source;
+-------------------------------------------------------------------------+
| source |
+-------------------------------------------------------------------------+
| SELECT * FROM Country WHERE continent = 'Oceania'
WITH CHECK OPTION
|
+-------------------------------------------------------------------------+
[95] That’s “temp table,” not “can be tempted.” MySQL’s views don’t fast for 40 days and nights in the wilderness, either.
[96] This will be improved in MySQL 5.6, which is unreleased at the time of writing.
Foreign Key Constraints
InnoDB is currently the only bundled storage engine that supports foreign keys in MySQL, limiting your choice of storage engines if you require them (PBXT has foreign keys, too).
Foreign keys aren’t free. They typically require the server to do a lookup in another table every time you change some data. Although InnoDB requires an index to make this operation faster, this doesn’t eliminate the impact of these checks. It can even result in a very large index with virtually zero selectivity. For example, suppose you have a status column in a huge table and you want to constrain the status to valid values, but there are only three such values. The extra index required can add significantly to the table’s total size—even if the column itself is small, and especially if the primary key is large—and is useless for anything but the foreign key checks.
Still, foreign keys can actually improve performance in some cases. If you must guarantee that two related tables have consistent data, it can be more efficient to let the server perform this check than to do it in your application. Foreign keys are also useful for cascading deletes or updates, although they do operate row by row, so they’re slower than multitable deletes or batch operations.
Foreign keys cause your query to “reach into” other tables, which means acquiring locks. If you insert a row into a child table, for example, the foreign key constraint will cause InnoDB to check for a corresponding value in the parent. It must also lock the row in the parent, to ensure it doesn’t get deleted before the transaction completes. This can cause unexpected lock waits and even deadlocks on tables you’re not touching directly. Such problems can be very unintuitive and frustrating to debug.
You can sometimes use triggers instead of foreign keys. Foreign keys tend to outperform triggers for tasks such as cascading updates, but a foreign key that’s just used as a constraint, as in our status example, can be more efficiently rewritten as a trigger with an explicit list of allowable values. (You can also just use an ENUM data type.)
Instead of using foreign keys as constraints, it’s often a good idea to constrain the values in the application. Foreign keys can add significant overhead. We don’t have any benchmarks to share, but we have seen many cases where server profiling revealed that foreign key constraint checks were the performance problem, and removing the foreign keys improved performance greatly.
Storing Code Inside MySQL
MySQL lets you store code inside the server in the form of triggers, stored procedures, and stored functions. In MySQL 5.1, you can also store code in periodic jobs called events. Stored procedures and stored functions are collectively known as “stored routines.”
All four types of stored code use a special extended SQL language that contains procedural structures such as loops and conditionals.[97] The biggest difference between the types of stored code is the context in which they operate—that is, their inputs and outputs. Stored procedures and stored functions can accept parameters and return results, but triggers and events do not.
In principle, stored code is a good way to share and reuse code. Giuseppe Maxia and others have created a library of useful general-purpose stored routines at http://mysql-sr-lib.sourceforge.net. However, it’s hard to reuse stored routines from other database systems, because most have their own language (the exception is DB2, which has a fairly similar language based on the same standard).[98]
We focus more on the performance implications of stored code than on how to write it. Guy Harrison and Steven Feuerstein’s MySQL Stored Procedure Programming (O’Reilly) might be useful if you plan to write stored procedures in MySQL.
It’s easy to find both advocates and opponents of stored code. Without taking sides, we’ll list some of the pros and cons of using it in MySQL. First, the advantages:
§ It runs where the data is, so you can save bandwidth and reduce latency by running tasks on the database server.
§ It’s a form of code reuse. It can help centralize business rules, which can enforce consistent behavior and provide more safety and peace of mind.
§ It can ease release policies and maintenance.
§ It can provide some security advantages and a way to control privileges more finely. A common example is a stored procedure for funds transfer at a bank: the procedure transfers the money within a transaction and logs the entire operation for auditing. You can let applications call the stored procedure without granting access to the underlying tables.
§ The server caches stored procedure execution plans, which lowers the overhead of repeated calls.
§ Because it’s stored in the server and can be deployed, backed up, and maintained with the server, stored code is well suited for maintenance jobs. It doesn’t have any external dependencies, such as Perl libraries or other software that you might not want to place on the server.
§ It enables division of labor between application programmers and database programmers. It can be preferable for a database expert to write the stored procedures, as not every application programmer is good at writing efficient SQL queries.
Disadvantages include the following:
§ MySQL doesn’t provide good developing and debugging tools, so it’s harder to write stored code in MySQL than it is in some other database servers.
§ The language is slow and primitive compared to application languages. The number of functions you can use is limited, and it’s hard to do complex string manipulations and write intricate logic.
§ Stored code can actually add complexity to deploying your application. Instead of just application code and database schema changes, you’ll need to deploy code that’s stored inside the server, too.
§ Because stored routines are stored with the database, they can create a security vulnerability. Having nonstandard cryptographic functions inside a stored routine, for example, will not protect your data if the database is compromised. If the cryptographic function were in the code, the attacker would have to compromise both the code and the database.
§ Storing routines moves the load to the database server, which is typically harder to scale and more expensive than application or web servers.
§ MySQL doesn’t give you much control over the resources stored code can allocate, so a mistake can bring down the server.
§ MySQL’s implementation of stored code is pretty limited—execution plan caches are per-connection, cursors are materialized as temporary tables, there’s very limited ability to raise and catch errors prior to MySQL 5.5, and so on. (We mention the limitations of various features as we describe them.) In general, MySQL’s stored routine language is nowhere near as capable as T-SQL or PL/SQL.
§ It’s hard to profile code with stored procedures in MySQL. It’s difficult to analyze the slow query log when it just shows CALL XYZ('A'), because you have to go and find that procedure and look at the statements inside it. (This is configurable in Percona Server.)
§ It doesn’t play well with statement-based binary logging or replication. There are so many “gotchas” that you probably should not use stored code with statement-based logging unless you are very knowledgeable and strict about checking it for potential problems.
That’s a long list of drawbacks—what does this all mean in the real world? Here’s an example where we’ve seen the use of stored code backfire in real life: in one instance, using them to create an API for the application to access the database. This resulted in all access to the database—even trivial primary-key row lookups—going through CALL queries, which reduced performance by about a factor of five.
Ultimately, stored code is a way to hide complexity, which simplifies development but can be very bad for performance and add a lot of potential hazards with replication and other server features. When you’re thinking about using stored code, you should ask yourself where you want your business logic to live: in application code, or in the database? Both approaches are popular. You just need to be aware that you’re placing logic into the database when you use stored code.
Stored Procedures and Functions
MySQL’s architecture and query optimizer place some limits on how you can use stored routines and how efficient they can be. The following restrictions apply at the time of this writing:
§ The optimizer doesn’t use the DETERMINISTIC modifier in stored functions to optimize away multiple calls within a single query.
§ The optimizer cannot estimate how much it will cost to execute a stored function.
§ Each connection has its own stored procedure execution plan cache. If many connections call the same procedure, they’ll waste resources caching the same execution plan over and over. (If you use connection pooling or persistent connections, the execution plan cache can have a longer useful life.)
§ Stored routines and replication are a tricky combination. You might not want to replicate the call to the routine. Instead, you might want to replicate the exact changes made to your dataset. Row-based replication, introduced in MySQL 5.1, helps alleviate this problem. If binary logging is enabled in MySQL 5.0, the server will insist that you either define all stored procedures as DETERMINISTIC or enable the elaborately named server option log_bin_trust_function_creators.
We usually prefer to keep stored routines small and simple. We like to perform complex logic outside the database in a procedural language, which is more expressive and versatile. It can also give you access to more computational resources and potentially to different forms of caching.
However, stored procedures can be much faster for certain types of operations—especially when a single stored procedure call with a loop inside it can replace many small queries. If a query is small enough, the overhead of parsing and network communication becomes a significant fraction of the overall work required to execute it. To illustrate this, we created a simple stored procedure that inserts a specified number of rows into a table. Here’s the procedure’s code:
1 DROP PROCEDURE IF EXISTS insert_many_rows;
2
3 delimiter //
4
5 CREATE PROCEDURE insert_many_rows (IN loops INT)
6 BEGIN
7 DECLARE v1 INT;
8 SET v1=loops;
9 WHILE v1 > 0 DO
10 INSERT INTO test_table values(NULL,0,
11 'qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt',
12 'qqqqqqqqqqwwwwwwwwwweeeeeeeeeerrrrrrrrrrtttttttttt');
13 SET v1 = v1 - 1;
14 END WHILE;
15 END;
16 //
17
18 delimiter ;
We then benchmarked how quickly this stored procedure could insert a million rows into a table, as compared to inserting one row at a time via a client application. The table structure and hardware we used doesn’t really matter—what is important is the relative speed of the different approaches. Just for fun, we also measured how long the same queries took to execute when we connected through a MySQL Proxy. To keep things simple, we ran the entire benchmark on a single server, including the client application and the MySQL Proxy instance. Table 7-1 shows the results.
Table 7-1. Total time to insert one million rows one at a time
|
Method |
Total time |
|
Stored procedure |
101 sec |
|
Client application |
279 sec |
|
Client application with MySQL Proxy |
307 sec |
The stored procedure is much faster, mostly because it avoids the overhead of network communication, parsing, optimizing, and so on.
We show a typical stored procedure for maintenance jobs later in this chapter.
Triggers
Triggers let you execute code when there’s an INSERT, UPDATE, or DELETE statement. You can direct MySQL to activate triggers before and/or after the triggering statement executes. They cannot return values, but they can read and/or change the data that the triggering statement changes. Thus, you can use triggers to enforce constraints or business logic that you’d otherwise need to write in client code.
Triggers can simplify application logic and improve performance, because they save round-trips between the client and the server. They can also be helpful for automatically updating denormalized and summary tables. For example, the Sakila sample database uses them to maintain thefilm_text table.
MySQL’s trigger implementation is very limited. If you’re used to relying on triggers extensively in another database product, you shouldn’t assume they will work the same way in MySQL. In particular:
§ You can have only one trigger per table for each event (in other words, you can’t have two triggers that fire AFTER INSERT).
§ MySQL supports only row-level triggers—that is, triggers always operate FOR EACH ROW rather than for the statement as a whole. This is a much less efficient way to process large datasets.
The following universal cautions about triggers apply in MySQL, too:
§ They can obscure what your server is really doing, because a simple statement can make the server perform a lot of “invisible” work. For example, if a trigger updates a related table, it can double the number of rows a statement affects.
§ Triggers can be hard to debug, and it’s often difficult to analyze performance bottlenecks when triggers are involved.
§ Triggers can cause nonobvious deadlocks and lock waits. If a trigger fails the original query will fail, and if you’re not aware the trigger exists, it can be hard to decipher the error code.
In terms of performance, the most severe limitation in MySQL’s trigger implementation is the FOR EACH ROW design. This sometimes makes it impractical to use triggers for maintaining summary and cache tables, because they might be too slow. The main reason to use triggers instead of a periodic bulk update is that they keep your data consistent at all times.
Triggers also might not guarantee atomicity. For example, a trigger that updates a MyISAM table cannot be rolled back if there’s an error in the statement that fires it. It is possible for a trigger to cause an error, too. Suppose you attach an AFTER UPDATE trigger to a MyISAM table and use it to update another MyISAM table. If the trigger has an error that causes the second table’s update to fail, the first table’s update will not be rolled back.
Triggers on InnoDB tables all operate within the same transaction, so the actions they take will be atomic, together with the statement that fired them. However, if you’re using a trigger with InnoDB to check another table’s data when validating a constraint, be careful about MVCC, as you can get incorrect results if you’re not careful. For example, suppose you want to emulate foreign keys, but you don’t want to use InnoDB’s foreign keys. You can write a BEFORE INSERT trigger that verifies the existence of a matching record in another table, but if you don’t use SELECT FOR UPDATE in the trigger when reading from the other table, concurrent updates to that table can cause incorrect results.
We don’t mean to scare you away from triggers. On the contrary, they can be useful, particularly for constraints, system maintenance tasks, and keeping denormalized data up-to-date.
You can also use triggers to log changes to rows. This can be handy for custom-built replication setups where you want to disconnect systems, make data changes, and then merge the changes back together. A simple example is a group of users who take laptops onto a job site. Their changes need to be synchronized to a master database, and then the master data needs to be copied back to the individual laptops. Accomplishing this requires two-way synchronization. Triggers are a good way to build such systems. Each laptop can use triggers to log every data modification to tables that indicate which rows have been changed. The custom synchronization tool can then apply these changes to the master database. Finally, ordinary MySQL replication can sync the laptops with the master, which will have the changes from all the laptops. However, you need to be very careful with triggers that insert rows into other tables that have autoincrementing primary keys. This doesn’t play well with statement-based replication, as the autoincrement values are likely to be different on replicas.
Sometimes you can work around the FOR EACH ROW limitation. Roland Bouman found that ROW_COUNT() always reports 1 inside a trigger, except for the first row of a BEFORE trigger. You can use this to prevent a trigger’s code from executing for every row affected and run it only once per statement. It’s not the same as a per-statement trigger, but it is a useful technique for emulating a per-statement BEFORE trigger in some cases. This behavior might actually be a bug that will get fixed at some point, so you should use it with care and verify that it still works when you upgrade your server. Here’s a sample of how to use this hack:
CREATE TRIGGER fake_statement_trigger
BEFORE INSERT ON sometable
FOR EACH ROW
BEGIN
DECLARE v_row_count INT DEFAULT ROW_COUNT();
IF v_row_count <> 1 THEN
-- Your code here
END IF;
END;
Events
Events are a new form of stored code in MySQL 5.1. They are akin to cron jobs but are completely internal to the MySQL server. You can create events that execute SQL code once at a specific time, or frequently at a specified interval. The usual practice is to wrap the complex SQL in a stored procedure, so the event merely needs to perform a CALL.
Events are initiated by a separate event scheduler thread, because they have nothing to do with connections. They accept no inputs and return no values—there’s no connection for them to get inputs from or return values to. You can see the commands they execute in the server log, if it’s enabled, but it can be hard to tell that those commands were executed from an event. You can also look in the INFORMATION_SCHEMA.EVENTS table to see an event’s status, such as the last time it was executed.
Similar considerations to those that apply to stored procedures apply to events. First, you are giving the server additional work to do. The event overhead itself is minimal, but the SQL it calls can have a potentially serious impact on performance. Further, events can cause the same types of problems with statement-based replication that other stored code can cause. Good uses for events include periodic maintenance tasks, rebuilding cache and summary tables to emulate materialized views, or saving status values for monitoring and diagnostics.
The following example creates an event that will run a stored procedure for a specific database, once a week (we’ll show you how to create this stored procedure later):
CREATE EVENT optimize_somedb ON SCHEDULE EVERY 1 WEEK
DO
CALL optimize_tables('somedb');
You can specify whether events should be replicated. In some cases this is appropriate, whereas in others it’s not. Take the previous example, for instance: you probably want to run the OPTIMIZE TABLE operation on all replicas, but keep in mind that it could impact overall server performance (with table locks, for instance) if all replicas were to execute this operation at the same time.
Finally, if a periodic event can take a long time to complete, it might be possible for the event to fire again while its earlier execution is still running. MySQL doesn’t protect against this, so you’ll have to write your own mutual exclusivity code. You can use GET_LOCK() to make sure that only one event runs at a time:
CREATE EVENT optimize_somedb ON SCHEDULE EVERY 1 WEEK
DO
BEGIN
DECLARE CONTINUE HANLDER FOR SQLEXCEPTION
BEGIN END;
IF GET_LOCK('somedb', 0) THEN
DO CALL optimize_tables('somedb');
END IF;
DO RELEASE_LOCK('somedb');
END
The “dummy” continue handler ensures that the event will release the lock, even if the stored procedure throws an exception.
Although events are dissociated from connections, they are still associated with threads. There’s a main event scheduler thread, which you must enable in your server’s configuration file or with a SET command:
mysql> SET GLOBAL event_scheduler := 1;
When enabled, this thread executes events on the schedule specified in the event. You can watch the server’s error log for information about event execution.
Although the event scheduler is single-threaded, events can run concurrently. The server will create a new process each time an event executes. Within the event’s code, a call to CONNECTION_ID() will return a unique value, as usual—even though there is no “connection” per se. (The return value of CONNECTION_ID() is really just the thread ID.) The process and thread will live only for the duration of the event’s execution. You can see it in SHOW PROCESSLIST by looking at the Command column, which will appear as “Connect”.
Although the process necessarily creates a thread to actually execute, the thread is destroyed at the end of event execution, not placed into the thread cache, and the Threads_created status counter is not incremented.
Preserving Comments in Stored Code
Stored procedures, stored functions, triggers, and events can all have significant amounts of code, and it’s useful to add comments. But the comments might not be stored inside the server, because the command-line client can strip them out. (This “feature” of the command-line client can be a nuisance, but c’est la vie.)
A useful trick for preserving comments in your stored code is to use version-specific comments, which the server sees as potentially executable code (i.e., code to be executed only if the server’s version number is that high or higher). The server and client programs know these aren’t ordinary comments, so they won’t discard them. To prevent the “code” from being executed, you can just use a very high version number, such as 99999. Let’s add some documentation to our trigger example to demystify what it does:
CREATE TRIGGER fake_statement_trigger
BEFORE INSERT ON sometable
FOR EACH ROW
BEGIN
DECLARE v_row_count INT DEFAULT ROW_COUNT();
/*!99999 ROW_COUNT() is 1 except for the first row, so this executes
only once per statement. */
IF v_row_count <> 1 THEN
-- Your code here
END IF;
END;
[97] The language is a subset of SQL/PSM, the Persistent Stored Modules part of the SQL standard. It is defined in ISO/IEC 9075-4:2003 (E).
[98] There are also some porting utilities, such as the tsql2mysql project (http://sourceforge.net/projects/tsql2mysql) for porting from Microsoft SQL Server.
Cursors
MySQL provides read-only, forward-only server-side cursors that you can use only from within a MySQL stored procedure or the low-level client API. MySQL’s cursors are read-only because they iterate over temporary tables rather than the tables where the data originated. They let you iterate over query results row by row and fetch each row into variables for further processing. A stored procedure can have multiple cursors open at once, and you can “nest” cursors in loops.
MySQL’s cursor design holds some snares for the unwary. Because they’re implemented with temporary tables, they can give developers a false sense of efficiency. The most important thing to know is that a cursor executes the entire query when you open it. Consider the following procedure:
1 CREATE PROCEDURE bad_cursor()
2 BEGIN
3 DECLARE film_id INT;
4 DECLARE f CURSOR FOR SELECT film_id FROM sakila.film;
5 OPEN f;
6 FETCH f INTO film_id;
7 CLOSE f;
8 END
This example shows that you can close a cursor before iterating through all of its results. A developer used to Oracle or Microsoft SQL Server might see nothing wrong with this procedure, but in MySQL it causes a lot of unnecessary work. Profiling this procedure with SHOW STATUS shows that it does 1,000 index reads and 1,000 inserts. That’s because there are 1,000 rows in sakila.film. All 1,000 reads and writes occur when line 5 executes, before line 6 executes.
The moral of the story is that if you close a cursor that fetches data from a large result set early, you won’t actually save work. If you need only a few rows, use LIMIT.
Cursors can cause MySQL to perform extra I/O operations too, and they can be very slow. Because in-memory temporary tables do not support the BLOB and TEXT types, MySQL has to create an on-disk temporary table for cursors over results that include these types. Even when that’s not the case, if the temporary table is larger than tmp_table_size, MySQL will create it on disk.
MySQL doesn’t support client-side cursors, but the client API has functions that emulate client-side cursors by fetching the entire result into memory. This is really no different from putting the result in an array in your application and manipulating it there. See Chapter 6 for more on the performance implications of fetching the entire result into client-side memory.
Prepared Statements
MySQL 4.1 and newer support server-side prepared statements that use an enhanced binary client/server protocol to send data efficiently between the client and server. You can access the prepared statement functionality through a programming library that supports the new protocol, such as the MySQL C API. The MySQL Connector/J and MySQL Connector/NET libraries provide the same capability to Java and .NET, respectively. There’s also a SQL interface to prepared statements, which we discuss later (it’s confusing).
When you create a prepared statement, the client library sends the server a prototype of the actual query you want to use. The server parses and processes this “skeleton” query, stores a structure representing the partially optimized query, and returns a statement handle to the client. The client library can execute the query repeatedly by specifying the statement handle.
Prepared statements can have parameters, which are question-mark placeholders for values that you can specify when you execute them. For example, you might prepare the following query:
INSERT INTO tbl(col1, col2, col3) VALUES (?, ?, ?);
You could then execute this query by sending the statement handle to the server, with values for each of the question-mark placeholders. You can repeat this as many times as desired. Exactly how you send the statement handle to the server will depend on your programming language. One way is to use the MySQL connectors for Java and .NET. Many client libraries that link to the MySQL C libraries also provide some interface to the binary protocol; you should read the documentation for your chosen MySQL API.
Using prepared statements can be more efficient than executing a query repeatedly, for several reasons:
§ The server has to parse the query only once.
§ The server has to perform some query optimization steps only once, as it caches a partial query execution plan.
§ Sending parameters via the binary protocol is more efficient than sending them as ASCII text. For example, a DATE value can be sent in just 3 bytes, instead of the 10 bytes required in ASCII. The biggest savings are for BLOB and TEXT values, which can be sent to the server in chunks rather than as a single huge piece of data. The binary protocol therefore helps save memory on the client, as well as reducing network traffic and the overhead of converting between the data’s native storage format and the non-binary protocol’s format.
§ Only the parameters—not the entire query text—need to be sent for each execution, which reduces network traffic.
§ MySQL stores the parameters directly into buffers on the server, which eliminates the need for the server to copy values around in memory.
Prepared statements can also help with security. There is no need to escape or quote values in the application, which is more convenient and reduces vulnerability to SQL injection or other attacks. (You should never trust user input, even when you’re using prepared statements.)
You can use the binary protocol only with prepared statements. Issuing queries through the normal mysql_query() API function will not use the binary protocol. Many client libraries let you “prepare” statements with question-mark placeholders and then specify the values for each execution, but these libraries are often only emulating the prepare-execute cycle in client-side code and are actually sending each query, as text with parameters replaced by values, to the server with mysql_query().
Prepared Statement Optimization
MySQL caches partial query execution plans for prepared statements, but some optimizations depend on the actual values that are bound to each parameter and therefore can’t be precomputed and cached. The optimizations can be separated into three types, based on when they must be performed. The following list applies at the time of this writing:
At preparation time
The server parses the query text, eliminates negations, and rewrites subqueries.
At first execution
The server simplifies nested joins and converts OUTER JOINs to INNER JOINs where possible.
At every execution
The server does the following:
§ Prunes partitions
§ Eliminates COUNT(), MIN(), and MAX() where possible
§ Removes constant subexpressions
§ Detects constant tables
§ Propagates equalities
§ Analyzes and optimizes ref, range, and index_merge access methods
§ Optimizes the join order
See Chapter 6 for more information on these optimizations. Even though some of them are theoretically possible to do only once, they are still performed as noted above.
The SQL Interface to Prepared Statements
A SQL interface to prepared statements is available in MySQL 4.1 and newer. It lets you instruct the server to create and execute prepared statements, but doesn’t use the binary protocol. Here’s an example of how to use a prepared statement through SQL:
mysql> SET @sql := 'SELECT actor_id, first_name, last_name
-> FROM sakila.actor WHERE first_name = ?';
mysql> PREPARE stmt_fetch_actor FROM @sql;
mysql> SET @actor_name := 'Penelope';
mysql> EXECUTE stmt_fetch_actor USING @actor_name;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 1 | PENELOPE | GUINESS |
| 54 | PENELOPE | PINKETT |
| 104 | PENELOPE | CRONYN |
| 120 | PENELOPE | MONROE |
+----------+------------+-----------+
mysql> DEALLOCATE PREPARE stmt_fetch_actor;
When the server receives these statements, it translates them into the same operations that would have been invoked by the client library. This means that you don’t have to use the special binary protocol to create and execute prepared statements.
As you can see, the syntax is a little awkward compared to just typing the SELECT statement directly. So what’s the advantage of using a prepared statement this way?
The main use case is for stored procedures. In MySQL 5.0, you can use prepared statements in stored procedures, and the syntax is similar to the SQL interface. This means you can build and execute “dynamic SQL” in stored procedures by concatenating strings, which makes stored procedures much more flexible. For example, here’s a sample stored procedure that can call OPTIMIZE TABLE on each table in a specified database:
DROP PROCEDURE IF EXISTS optimize_tables;
DELIMITER //
CREATE PROCEDURE optimize_tables(db_name VARCHAR(64))
BEGIN
DECLARE t VARCHAR(64);
DECLARE done INT DEFAULT 0;
DECLARE c CURSOR FOR
SELECT table_name FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = db_name AND TABLE_TYPE = 'BASE TABLE';
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN c;
tables_loop: LOOP
FETCH c INTO t;
IF done THEN
LEAVE tables_loop;
END IF;
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END LOOP;
CLOSE c;
END//
DELIMITER ;
You can use this stored procedure as follows:
mysql> CALL optimize_tables('sakila');
Another way to write the loop in the procedure is as follows:
REPEAT
FETCH c INTO t;
IF NOT done THEN
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
UNTIL done END REPEAT;
There is an important difference between the two loop constructs: REPEAT checks the loop condition twice for each loop. This probably won’t cause a big performance problem in this example because we’re merely checking an integer’s value, but with more complex checks it could be costly.
Concatenating strings to refer to tables and databases is a good use for the SQL interface to prepared statements, because it lets you write statements that won’t work with parameters. You can’t parameterize database and table names because they are identifiers. Another scenario is dynamically setting a LIMIT clause, which you can’t specify with a parameter either.
The SQL interface is useful for testing a prepared statement by hand, but it’s otherwise not all that useful outside of stored procedures. Because the interface is through SQL, it doesn’t use the binary protocol, and it doesn’t really reduce network traffic because you have to issue extra queries to set the variables when there are parameters. You can benefit from using this interface in special cases, such as when preparing an enormous string of SQL that you’ll execute many times without parameters.
Limitations of Prepared Statements
Prepared statements have a few limitations and caveats:
§ Prepared statements are local to a connection, so another connection cannot use the same handle. For the same reason, a client that disconnects and reconnects loses the statements. (Connection pooling or persistent connections can alleviate this problem.)
§ Prepared statements cannot use the query cache in MySQL versions prior to 5.1.
§ It’s not always more efficient to use prepared statements. If you use a prepared statement only once, you might spend more time preparing it than you would just executing it as normal SQL. Preparing a statement also requires two extra round-trips to the server (to use prepared statements properly, you should deallocate them after use).
§ You cannot currently use a prepared statement inside a stored function (but you can use prepared statements inside stored procedures).
§ You can accidentally “leak” a prepared statement by forgetting to deallocate it. This can consume a lot of resources on the server. Also, because there is a single global limit on the number of prepared statements, a mistake such as this can interfere with other connections’ use of prepared statements.
§ Some operations, such as BEGIN, cannot be performed in prepared statements.
Probably the biggest limitation of prepared statements, however, is that it’s so easy to get confused about what they are and how they work. Sometimes it’s very hard to explain the difference between these three kinds of prepared statements:
Client-side emulated
The client driver accepts a string with placeholders, then substitutes the parameters into the SQL and sends the resulting query to the server.
Server-side
The driver sends a string with placeholders to the server with a special binary protocol, receives back a statement identifier, then executes the statement over the binary protocol by specifying the identifier and the parameters.
SQL interface
The client sends a string with placeholders to the server as a PREPARE SQL statement, sets SQL variables to parameter values, and finally executes the statement with an EXECUTE SQL statement. All of this happens via the normal textual protocol.
User-Defined Functions
MySQL has supported user-defined functions (UDFs) since ancient times. Unlike stored functions, which are written in SQL, you can write UDFs in any programming language that supports C calling conventions.
UDFs must be compiled and then dynamically linked with the server, making them platform-specific and giving you a lot of power. UDFs can be very fast and can access a large range of functionality in the operating system and available libraries. SQL stored functions are good for simple operations, such as calculating the great-circle distance between two points on the globe, but if you want to send network packets, you need a UDF. Also, while you can’t currently build aggregate functions in SQL stored functions, you can do this easily with a UDF.
With great power comes great responsibility. A mistake in your UDF can crash your whole server, corrupt the server’s memory and/or your data, and generally wreak all the havoc that any misbehaving C code can potentially cause.
NOTE
Unlike stored functions written in SQL, UDFs cannot currently read and write tables—at least, not in the same transactional context as the statement that calls them. This means they’re more helpful for pure computation, or interaction with the outside world. MySQL is gaining more and more possibilities for interaction with resources outside of the server. The functions Brian Aker and Patrick Galbraith have created to communicate with memcached (http://tangent.org/586/Memcached_Functions_for_MySQL.html) are a good example of how this can be done with UDFs.
If you use UDFs, check carefully for changes between MySQL versions when you upgrade, because they might need to be recompiled or even changed to work correctly with the new MySQL server. Also make sure your UDFs are absolutely thread-safe, because they execute within the MySQL server process, which is a pure multithreaded environment.
There are good libraries of prebuilt UDFs for MySQL, and many good examples of how to implement your own. The biggest repository of UDFs is at http://www.mysqludf.org.
The following is the code for the NOW_USEC() UDF we’ll use to measure replication speed in Chapter 10:
#include <my_global.h>
#include <my_sys.h>
#include <mysql.h>
#include <stdio.h>
#include <sys/time.h>
#include <time.h>
#include <unistd.h>
extern "C" {
my_bool now_usec_init(UDF_INIT *initid, UDF_ARGS *args, char *message);
char *now_usec(
UDF_INIT *initid,
UDF_ARGS *args,
char *result,
unsigned long *length,
char *is_null,
char *error);
}
my_bool now_usec_init(UDF_INIT *initid, UDF_ARGS *args, char *message) {
return 0;
}
char *now_usec(UDF_INIT *initid, UDF_ARGS *args, char *result,
unsigned long *length, char *is_null, char *error) {
struct timeval tv;
struct tm* ptm;
char time_string[20]; /* e.g. "2006-04-27 17:10:52" */
char *usec_time_string = result;
time_t t;
/* Obtain the time of day, and convert it to a tm struct. */
gettimeofday (&tv, NULL);
t = (time_t)tv.tv_sec;
ptm = localtime (&t);
/* Format the date and time, down to a single second. */
strftime (time_string, sizeof (time_string), "%Y-%m-%d %H:%M:%S", ptm);
/* Print the formatted time, in seconds, followed by a decimal point
* and the microseconds. */
sprintf(usec_time_string, "%s.%06ld\n", time_string, tv.tv_usec);
*length = 26;
return(usec_time_string);
}
For one example of a user-defined function at work solving a thorny problem, see the case studies in the previous chapter. We’ve also written UDFs that ship with the Percona Toolkit for checksumming data efficiently so you can test your replication integrity at lower cost, and one for preprocessing text before indexing it with Sphinx for searching. UDFs can be very powerful.
Plugins
In addition to UDFs, MySQL supports a variety of other plugins. They can add their own command-line options and status variables, provide INFORMATION_SCHEMA tables, run as daemons, and much more. In MySQL 5.1 and newer, the server has many more plugin APIs than it did previously, and the server can now be extended in many ways without altering its source code. Here is a short list:
Procedure plugins
Procedure plugins can post-process a result set. This is an ancient type of plugin, similar to UDFs, that most people aren’t even aware of and never consider using. The built-in PROCEDURE ANALYSE is an example.
Daemon plugins
Daemon plugins run as a process within MySQL and can perform tasks such as listening on network ports or executing periodic jobs. An example is the HandlerSocket plugin included with Percona Server. It opens network ports and accepts a simple protocol that lets you access InnoDB tables through the Handler interface without using SQL, which makes it a high-performance NoSQL interface into the server.
INFORMATION_SCHEMA plugins
These plugins can provide arbitrary INFORMATION_SCHEMA tables.
Full-text parser plugins
These plugins provide a way to intercept the processes of reading and breaking a document into words for indexing, so you can do things such as indexing PDF documents given their filenames. You can also make it a part of the matching process during query execution.
Audit plugins
Audit plugins receive events at defined points in query execution, so they can be used (for example) as a way to log what happens in the server.
Authentication plugins
Authentication plugins can work on the client or the server side to extend the range of authentication mechanisms available to the server, including PAM and LDAP authentication, for example.
For more details, see the MySQL manual, or read the book MySQL 5.1 Plugin Development by Sergei Golubchik and Andrew Hutchings (Packt). If you need a plugin and don’t know how to write one, many service providers have competent staff who can help you, including Monty Program, Open Query, Percona, and SkySQL.
Character Sets and Collations
A character set is a mapping from binary encodings to a defined set of symbols; you can think of it as how to represent a particular alphabet in bits. A collation is a set of sorting rules for a character set. In MySQL 4.1 and later, every character-based value can have a character set and a collation.[99] MySQL’s support for character sets and collations is very full-featured, but it can add complexity, and in some cases it has a performance cost. (By the way, Drizzle discards it all and makes everything UTF-8, period.)
This section explains the settings and functionality you’ll need for most situations. If you need to know the more esoteric details, you should consult the MySQL manual.
How MySQL Uses Character Sets
Character sets can have several collations, and each character set has a default collation. Collations belong to a particular character set and cannot be used with any other. You use a character set and a collation together, so we’ll refer to them collectively as a character set from now on.
MySQL has a variety of options that control character sets. The options and the character sets are easy to confuse, so keep this distinction in mind: only character-based values can truly “have” a character set. Everything else is just a setting that specifies which character set to use for comparisons and other operations. A character-based value can be the value stored in a column, a literal in a query, the result of an expression, a user variable, and so on.
MySQL’s settings can be divided into two classes: defaults for creating objects, and settings that control how the server and the client communicate.
Defaults for creating objects
MySQL has a default character set and collation for the server, for each database, and for each table. These form a hierarchy of defaults that influences the character set that’s used when you create a column. That, in turn, tells the server what character set to use for values you store in the column.
At each level in the hierarchy, you can either specify a character set explicitly or let the server use the applicable default:
§ When you create a database, it inherits from the server-wide character_set_server setting.
§ When you create a table, it inherits from the database.
§ When you create a column, it inherits from the table.
Remember, columns are the only place MySQL stores values, so the higher levels in the hierarchy are only defaults. A table’s default character set doesn’t affect values stored in the tables; it just tells MySQL which character set to use when you create a column without specifying a character set explicitly.
Settings for client/server communication
When the server and the client communicate with each other, they might send data back and forth in different character sets. The server will translate as needed:
§ The server assumes the client is sending statements in the character set specified by character_set_client.
§ After the server receives a statement from the client, it translates it into the character set specified by character_set_connection. It also uses this setting to determine how to convert numbers into strings.
§ When the server returns results or error messages back to the client, it translates them into character_set_result.
Figure 7-2 illustrates this process.

Figure 7-2. Client and server character sets
You can use the SET NAMES statement and/or the SET CHARACTER SET statement to change these three settings as needed. However, note that this command affects only the server’s settings. The client program and the client API also need to be set correctly to avoid communication problems with the server.
Suppose you open a client connection with latin1 (the default character set, unless you’ve used mysql_options() to change it) and then use SET NAMES utf8 to tell the server to assume the client is sending data in UTF-8. You’ve created a character set mismatch, which can cause errors and even security problems. You should set the client’s character set and use mysql_real_escape_string() when escaping values. In PHP, you can change the client’s character set with mysql_set_charset().
How MySQL compares values
When MySQL compares two values with different character sets, it must convert them to the same character set for the comparison. If the character sets aren’t compatible, this can cause an error, such as “ERROR 1267 (HY000): Illegal mix of collations.” In this case, you’ll generally need to use the CONVERT() function explicitly to force one of the values into a character set that’s compatible with the other. MySQL 5.0 and newer often do this conversion implicitly, so this error is more common in MySQL 4.1.
MySQL also assigns a coercibility to values. This determines the priority of a value’s character set and influences which value MySQL will convert implicitly. You can use the CHARSET(), COLLATION(), and COERCIBILITY() functions to help debug errors related to character sets and collations.
You can use introducers and collate clauses to specify the character set and/or collation for literal values in your SQL statements. For example, the following statement uses an introducer (preceded by an underscore) to specify the utf8 character set, and a collate clause to specify a binary collation:
mysql> SELECT _utf8 'hello world' COLLATE utf8_bin;
+--------------------------------------+
| _utf8 'hello world' COLLATE utf8_bin |
+--------------------------------------+
| hello world |
+--------------------------------------+
Special-case behaviors
MySQL’s character set behavior holds a few surprises. Here are some things you should watch out for:
The magical character_set_database setting
The character_set_database setting defaults to the default database’s setting. As you change your default database, it will change too. If you connect to the server without a default database, it defaults to character_set_server.
LOAD DATA INFILE
LOAD DATA INFILE interprets incoming data according to the current setting of character_set_database. MySQL versions 5.0 and newer accept an optional CHARACTER SET clause in the LOAD DATA INFILE statement, but you shouldn’t rely on this. We’ve found that the best way to get reliable results is to USE the desired database, execute SET NAMES to select a character set, and only then load the data. MySQL interprets all the loaded data as having the same character set, regardless of the character sets specified for the destination columns.
SELECT INTO OUTFILE
MySQL writes all data from SELECT INTO OUTFILE without converting it. There is currently no way to specify a character set for the data without wrapping each column in a CONVERT() function.
Embedded escape sequences
The MySQL server interprets escape sequences in statements according to character_set_client, even when there’s an introducer or collate clause. This is because the parser interprets the escape sequences in literal values. The parser is not collation-aware—as far as it is concerned, an introducer isn’t an instruction, it’s just a token.
Choosing a Character Set and Collation
MySQL 4.1 and later support a large range of character sets and collations, including support for multibyte characters with the UTF-8 encoding of the Unicode character set (MySQL supports a three-byte subset of full UTF-8 that can store most characters in most languages). You can see the supported character sets with the SHOW CHARACTER SET and SHOW COLLATION commands.
KEEP IT SIMPLE
A mixture of character sets in your database can be a real mess. Incompatible character sets tend to be terribly confusing. They might even work fine until certain characters appear in your data, at which point you’ll start getting problems in all sorts of operations (such as joins between tables). You can solve the errors only by using ALTER TABLE to convert columns to compatible character sets, or casting values to the desired character set with introducers and collate clauses in your SQL statements.
For sanity’s sake, it’s best to choose sensible defaults on the server level, and perhaps on the database level. Then you can deal with special exceptions on a case-by-case basis, probably at the column level.
The most common choices for collations are whether letters should sort in a case-sensitive or case-insensitive manner, or according to the encoding’s binary value. The collation names generally end with _cs, _ci, or _bin, so you can tell which is which easily. The difference between case-sensitive and binary collations is that binary collations sort according to the byte values of the characters, whereas case-sensitive collations might have complex sorting rules such as those regarding multiple characters in languages like German.
When you specify a character set explicitly, you don’t have to name both a character set and a collation. If you omit one or both, MySQL fills in the missing pieces from the applicable default. Table 7-2 shows how MySQL decides which character set and collation to use.
Table 7-2. How MySQL determines character set and collation defaults
|
If you specify |
Resulting character set |
Resulting collation |
|
Both character set and collation |
As specified |
As specified |
|
Character set only |
As specified |
Character set’s default collation |
|
Collation only |
Character set to which collation belongs |
As specified |
|
Neither |
Applicable default |
Applicable default |
The following commands show how to create a database, table, and column with explicitly specified character sets and collations:
CREATE DATABASE d CHARSET latin1;
CREATE TABLE d.t(
col1 CHAR(1),
col2 CHAR(1) CHARSET utf8,
col3 CHAR(1) COLLATE latin1_bin
) DEFAULT CHARSET=cp1251;
The resulting table’s columns have the following collations:
mysql> SHOW FULL COLUMNS FROM d.t;
+------+---------+-------------------+
|Field | Type | Collation |
+------+---------+-------------------+
|col1 | char(1) | cp1251_general_ci |
|col2 | char(1) | utf8_general_ci |
|col3 | char(1) | latin1_bin |
+------+---------+-------------------+
How Character Sets and Collations Affect Queries
Some character sets might require more CPU operations, consume more memory and storage space, or even defeat indexing. Therefore, you should choose character sets and collations carefully.
Converting between character sets or collations can add overhead for some operations. For example, the sakila.film table has an index on the title column, which can speed up ORDER BY queries:
mysql> EXPLAIN SELECT title, release_year FROM sakila.film ORDER BY title\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: index
possible_keys: NULL
key: idx_title
key_len: 767
ref: NULL
rows: 953
Extra:
However, the server can use the index for sorting only if it’s sorted by the same collation as the one the query specifies. The index is sorted by the column’s collation, which in this case is utf8_general_ci. If you want the results ordered by another collation, the server will have to do a filesort:
mysql> EXPLAIN SELECT title, release_year
-> FROM sakila.film ORDER BY title COLLATE utf8_bin\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 953
Extra: Using filesort
In addition to accommodating your connection’s default character set and any preferences you specify explicitly in queries, MySQL has to convert character sets so that it can compare them when they’re not the same. For example, if you join two tables on character columns that don’t have the same character set, MySQL has to convert one of them. This conversion can make it impossible to use an index, because it is just like a function enclosing the column. If you’re not sure whether something like this is happening, you can use EXPLAIN EXTENDED followed by SHOW WARNINGS to look at the query from the server’s point of view. You’ll see character sets in the query and you can often tell if something is being translated between character sets.
The UTF-8 multibyte character set stores each character in a varying number of bytes (between one and three). MySQL uses fixed-size buffers internally for many string operations, so it must allocate enough space to accommodate the maximum possible length. For example, a CHAR(10)encoded with UTF-8 requires 30 bytes to store, even if the actual string contains no so-called “wide” characters. Variable-length fields (VARCHAR, TEXT) do not suffer from this on disk, but in-memory temporary tables used for processing and sorting queries will always allocate the maximum length needed.
In multibyte character sets, a character is no longer the same as a byte. Consequently, MySQL has separate LENGTH() and CHAR_LENGTH() functions, which don’t return the same results on multibyte characters. When you’re working with multibyte character sets, be sure to use theCHAR_LENGTH() function when you want to count characters (e.g., when you’re doing SUBSTRING() operations). The same caution holds for multibyte characters in application languages.
Another possible surprise is index limitations. If you index a UTF-8 column, MySQL has to assume each character can take up to three bytes, so the usual length restrictions are suddenly shortened by a factor of three:
mysql> CREATE TABLE big_string(str VARCHAR(500), KEY(str)) DEFAULT CHARSET=utf8;
Query OK, 0 rows affected, 1 warning (0.06 sec)
mysql> SHOW WARNINGS;
+---------+------+---------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------+
| Warning | 1071 | Specified key was too long; max key length is 999 bytes |
+---------+------+---------------------------------------------------------+
Notice that MySQL shortened the index to a 333-character prefix automatically:
mysql> SHOW CREATE TABLE big_string\G
*************************** 1. row ***************************
Table: big_string
Create Table: CREATE TABLE `big_string` (
`str` varchar(500) default NULL,
KEY `str` (`str`(333))
) ENGINE=MyISAM DEFAULT CHARSET=utf8
If you didn’t notice the warning and check the table definition, you might not have spotted that the index was created on only a prefix of the column. This will have side effects such as disabling covering indexes.
Some people recommend that you just use UTF-8 globally to “make your life simpler.” However, this is not necessarily a good idea if you care about performance. Many applications don’t need to use UTF-8 at all, and depending on your data, UTF-8 can use much more storage space on disk.
When deciding on a character set, it’s important to consider the kind of data you will store. For example, if you store mostly English text UTF-8 will add practically no storage penalty, because most characters in the English language fit in one byte in UTF-8. On the other hand, you might see a big difference if you store non-Latin languages such as Russian or Arabic. An application that needs to store only Arabic could use the cp1256 character set, which can represent all Arabic characters in one byte. But if the application needs to store many different languages and you choose UTF-8 instead, the very same Arabic characters will use more space. Likewise, if you convert a column from a national character set to UTF-8, you can increase the required storage space dramatically. If you’re using InnoDB, you might increase the data size to the point that the values don’t fit on the page and require external storage, which can cause a lot of wasted storage space and fragmentation.
Sometimes you don’t need to use a character set at all. Character sets are mostly useful for case-insensitive comparison, sorting, and string operations that need to be character-aware, such as SUBSTRING(). If you don’t need the database server to be aware of characters, you can store anything you want in BINARY columns, including UTF-8 data. If you do this, you can also add a column that tells you what character set you used to encode the data. Although this is an approach some people have used for a long time, it does require you to be more careful. It can cause hard-to-catch mistakes, such as errors with SUBSTRING() and LENGTH(), if you forget that a byte is not necessarily a character. We recommend you avoid this practice if possible.
[99] MySQL 4.0 and earlier used a global setting for the entire server, and you could choose from among several 8-bit character sets.
Full-Text Searching
Most of the queries you’ll write will probably have WHERE clauses that compare values for equality, filter out ranges of rows, and so on. However, you might also need to perform keyword searches, which are based on relevance instead of comparing values to each other. Full-text search systems are designed for this purpose.
Full-text searches require a special query syntax. They can work with or without indexes, but indexes can speed up the matching. The indexes used for full-text searches have a special structure to help find documents that contain the desired keywords.
You might not know it, but you’re already familiar with at least one type of full-text search system: Internet search engines. Although they operate at a massive scale and don’t usually have a relational database for a backend, the principles are similar.
Full-text searching lets you search character-based content (CHAR, VARCHAR, and TEXT columns), and it supports both natural-language and Boolean searching. The full-text search implementation has a number of restrictions and limitations[100] and is quite complicated, but it’s still widely used because it’s included with the server and is adequate for many applications. In this section, we take a general look at how to use it and how to design for performance with full-text searching.
In standard MySQL, only the MyISAM storage engine supports full-text indexing at the time of writing, though there is a lab preview of InnoDB full-text search available for the unreleased MySQL 5.6, and there are third-party storage engines for full-text search, such as Groonga.
The fact that only MyISAM supports full-text search is a serious limitation that makes it a nonstarter for most applications, because it’s just too painful to deal with table-level locking, data corruption, and crash recovery. In most cases you should simply use another solution, such as Sphinx, Lucene, Solr, Groonga, Xapian, or Senna, or wait for MySQL 5.6 to be released and use InnoDB. Still, if using MyISAM is acceptable for your application, read on.
A MyISAM full-text index operates on a full-text collection, which is made up of one or more character columns from a single table. In effect, MySQL builds the index by concatenating the columns in the collection and indexing them as one long string of text.
A MyISAM full-text index is a special type of B-Tree index with two levels. The first level holds keywords. Then, for each keyword, the second level holds a list of associated document pointers that point to full-text collections that contain that keyword. The index doesn’t contain every word in the collection. It prunes it as follows:
§ A list of stopwords weeds out “noise” words by preventing them from being indexed. The stopword list is based on common English usage by default, but you can use the ft_stopword_file option to replace it with a list from an external file.
§ The index ignores words unless they’re longer than ft_min_word_len characters and shorter than ft_max_word_len characters.
Full-text indexes don’t store information about which column in the collection a keyword occurs in, so if you need to search on different combinations of columns, you will need to create several indexes.
This also means you can’t instruct a MATCH AGAINST clause to regard words from a particular column as more important than words from other columns. This is a common requirement when building search engines for websites. For example, you might want search results to appear first when the keywords appear in an item’s title. If you need this, you’ll have to write more complicated queries. (We show an example later.)
Natural-Language Full-Text Searches
A natural-language search query determines each document’s relevance to the query. Relevance is based on the number of matched words and the frequency with which they occur in the document. Words that are less common in the entire index make a match more relevant. In contrast, extremely common words aren’t worth searching for at all. A natural-language full-text search excludes words that exist in more than 50% of the rows in the table, even if they’re not in the stopword list.[101]
The syntax of a full-text search is a little different from other types of queries. You tell MySQL to do full-text matching with MATCH AGAINST in the WHERE clause. Let’s look at an example. In the standard Sakila sample database, the film_text table has a full-text index on the title anddescription columns:
mysql> SHOW INDEX FROM sakila.film_text;
+-----------+-----------------------+-------------+------------+
| Table | Key_name | Column_name | Index_type |
+-----------+-----------------------+-------------+------------+
| ...
| film_text | idx_title_description | title | FULLTEXT |
| film_text | idx_title_description | description | FULLTEXT |
+-----------+-----------------------+-------------+------------+
Here’s an example natural-language full-text search query:
mysql> SELECT film_id, title, RIGHT(description, 25),
-> MATCH(title, description) AGAINST('factory casualties') AS relevance
-> FROM sakila.film_text
-> WHERE MATCH(title, description) AGAINST('factory casualties');
+---------+-----------------------+---------------------------+-----------------+
| film_id | title | RIGHT(description, 25) | relevance |
+---------+-----------------------+---------------------------+-----------------+
| 831 | SPIRITED CASUALTIES | a Car in A Baloon Factory | 8.4692449569702 |
| 126 | CASUALTIES ENCINO | Face a Boy in A Monastery | 5.2615661621094 |
| 193 | CROSSROADS CASUALTIES | a Composer in The Outback | 5.2072987556458 |
| 369 | GOODFELLAS SALUTE | d Cow in A Baloon Factory | 3.1522686481476 |
| 451 | IGBY MAKER | a Dog in A Baloon Factory | 3.1522686481476 |
MySQL performed the full-text search by breaking the search string into words and matching each of them against the title and description fields, which are combined in the full-text collection upon which the index is built. Notice that only one of the results contains both words, and that the three results that contain “casualties” (there are only three in the entire table) are listed first. That’s because the index sorts the results by decreasing relevance.
NOTE
Unlike with normal queries, the results of full-text searches are automatically ordered by relevance. MySQL cannot use an index for sorting when you perform a full-text search. Therefore, you shouldn’t specify an ORDER BY clause if you want to avoid a filesort.
The MATCH() function actually returns the relevance as a floating-point number, as you can see from our example. You can use this to filter by relevance or to present the relevance in a user interface. There is no extra overhead from specifying the MATCH() function twice; MySQL recognizes they are the same and does the operation only once. However, if you put the MATCH() function in an ORDER BY clause, MySQL will use a filesort to order the results.
You have to specify the columns in the MATCH() clause exactly as they’re specified in a full-text index, or MySQL can’t use the index. This is because the index doesn’t record in which column a keyword appeared.
This also means you can’t use a full-text search to specify that a keyword should appear in a particular column of the index, as we mentioned previously. However, there’s a workaround: you can do custom sorting with several full-text indexes on different combinations of columns to compute the desired ranking. Suppose we want the title column to be more important. We can add another index on this column, as follows:
mysql> ALTER TABLE film_text ADD FULLTEXT KEY(title) ;
Now we can make the title twice as important for purposes of ranking:
mysql> SELECT film_id, RIGHT(description, 25),
-> ROUND(MATCH(title, description) AGAINST('factory casualties'), 3)
-> AS full_rel,
-> ROUND(MATCH(title) AGAINST('factory casualties'), 3) AS title_rel
-> FROM sakila.film_text
-> WHERE MATCH(title, description) AGAINST('factory casualties')
-> ORDER BY (2 * MATCH(title) AGAINST('factory casualties'))
-> + MATCH(title, description) AGAINST('factory casualties') DESC;
+---------+---------------------------+----------+-----------+
| film_id | RIGHT(description, 25) | full_rel | title_rel |
+---------+-------------- ------------+----------+-----------+
| 831 | a Car in A Baloon Factory | 8.469 | 5.676 |
| 126 | Face a Boy in A Monastery | 5.262 | 5.676 |
| 299 | jack in The Sahara Desert | 3.056 | 6.751 |
| 193 | a Composer in The Outback | 5.207 | 5.676 |
| 369 | d Cow in A Baloon Factory | 3.152 | 0.000 |
| 451 | a Dog in A Baloon Factory | 3.152 | 0.000 |
| 595 | a Cat in A Baloon Factory | 3.152 | 0.000 |
| 649 | nizer in A Baloon Factory | 3.152 | 0.000 |
However, this is usually an inefficient approach because it causes filesorts.
Boolean Full-Text Searches
In Boolean searches, the query itself specifies the relative relevance of each word in a match. Boolean searches use the stopword list to filter out noise words, but the requirement that search terms be longer than ft_min_word_len characters and shorter than ft_max_word_len characters is disabled.[102] The results are unsorted.
When constructing a Boolean search query, you can use prefixes to modify the relative ranking of each keyword in the search string. The most commonly used modifiers are shown in Table 7-3.
Table 7-3. Common modifiers for Boolean full-text searches
|
Example |
Meaning |
|
dinosaur |
Rows containing “dinosaur” rank higher. |
|
~dinosaur |
Rows containing “dinosaur” rank lower. |
|
+dinosaur |
Rows must contain “dinosaur”. |
|
-dinosaur |
Rows must not contain “dinosaur”. |
|
dino* |
Rows containing words that begin with “dino” rank higher. |
You can also use other operators, such as parentheses for grouping. You can construct complex searches in this way.
As an example, let’s again search the sakila.film_text table for films that contain both “factory” and “casualties.” A natural-language search returns results that match either or both of these terms, as we saw before. If we use a Boolean search, however, we can insist that both must appear:
mysql> SELECT film_id, title, RIGHT(description, 25)
-> FROM sakila.film_text
-> WHERE MATCH(title, description)
-> AGAINST('+factory +casualties' IN BOOLEAN MODE);
+---------+---------------------+---------------------------+
| film_id | title | RIGHT(description, 25) |
+---------+---------------------+---------------------------+
| 831 | SPIRITED CASUALTIES | a Car in A Baloon Factory |
+---------+---------------------+---------------------------+
You can also do a phrase search by quoting multiple words, which requires them to appear exactly as specified:
mysql> SELECT film_id, title, RIGHT(description, 25)
-> FROM sakila.film_text
-> WHERE MATCH(title, description)
-> AGAINST('"spirited casualties"' IN BOOLEAN MODE);
+---------+---------------------+---------------------------+
| film_id | title | RIGHT(description, 25) |
+---------+---------------------+---------------------------+
| 831 | SPIRITED CASUALTIES | a Car in A Baloon Factory |
+---------+---------------------+---------------------------+
Phrase searches tend to be quite slow. The full-text index alone can’t answer a query like this one, because it doesn’t record where words are located relative to each other in the original full-text collection. Consequently, the server actually has to look inside the rows to do a phrase search.
To execute such a search, the server will find all documents that contain both “spirited” and “casualties.” It will then fetch the rows from which the documents were built, and check for the exact phrase in the collection. Because it uses the full-text index to find the initial list of documents that match, you might think this will be very fast—much faster than an equivalent LIKE operation. In fact, it is very fast, as long as the words in the phrase aren’t common and not many results are returned from the full-text index to the Boolean matcher. If the words in the phrase are common,LIKE can actually be much faster, because it fetches rows sequentially instead of in quasirandom index order, and it doesn’t need to read a full-text index.
A Boolean full-text search doesn’t actually require a full-text index to work, although it does require the MyISAM storage engine. It will use a full-text index if there is one, but if there isn’t, it will just scan the entire table. You can even use a Boolean full-text search on columns from multiple tables, such as the results of a join. In all of these cases, though, it will be slow.
Full-Text Changes in MySQL 5.1
MySQL 5.1 introduced quite a few changes related to full-text searching. These include performance improvements and the ability to build pluggable parsers that can enhance the built-in capabilities. For example, plugin can change the way indexing works. They can split text into words more flexibly than the defaults (you can specify that “C++” is a single word, for example), do preprocessing, index different content types (such as PDF), or do custom word stemming. The plugins can also influence the way searches work—for example, by stemming search terms.
Full-Text Tradeoffs and Workarounds
MySQL’s implementation of full-text searching has several design limitations. These can be contraindications for specific purposes, but there are also many ways to work around them.
For example, there is only one form of relevance ranking in MySQL’s full-text indexing: frequency. The index doesn’t record the indexed word’s position in the string, so proximity doesn’t contribute to relevance. Although that’s fine for many purposes—especially for small amounts of data—it might not be what you need, and MySQL’s full-text indexing doesn’t give you the flexibility to choose a different ranking algorithm. (It doesn’t even store the data you’d need for proximity-based ranking.)
Size is another issue. MySQL’s full-text indexing performs well when the index fits in memory, but if the index is not in memory it can be very slow, especially when the fields are large. When you’re using phrase searches, the data and indexes must both fit in memory for good performance. Compared to other index types, it can be very expensive to insert, update, or delete rows in a full-text index:
§ Modifying a piece of text with 100 words requires not 1 but up to 100 index operations.
§ The field length doesn’t usually affect other index types much, but with full-text indexing, text with 3 words and text with 10,000 words will have performance profiles that differ by orders of magnitude.
§ Full-text search indexes are also much more prone to fragmentation, and you might find you need to use OPTIMIZE TABLE more frequently.
Full-text indexes affect how the server optimizes queries, too. Index choice, WHERE clauses, and ORDER BY all work differently from how you might expect:
§ If there’s a full-text index and the query has a MATCH AGAINST clause that can use it, MySQL will use the full-text index to process the query. It will not compare the full-text index to the other indexes that might be used for the query. Some of these other indexes might actually be better for the query, but MySQL will not consider them.
§ The full-text search index can perform only full-text matches. Any other criteria in the query, such as WHERE clauses, must be applied after MySQL reads the row from the table. This is different from the behavior of other types of indexes, which can be used to check several parts of aWHERE clause at once.
§ Full-text indexes don’t store the actual text they index. Thus, you can never use a full-text index as a covering index.
§ Full-text indexes cannot be used for any type of sorting, other than sorting by relevance in natural-language mode. If you need to sort by something other than relevance, MySQL will use a filesort.
Let’s see how these constraints affect queries. Suppose you have a million documents, with an ordinary index on the document’s author and a full-text index on the content. You want to do a full-text search on the document content, but only for author 123. You might write the query as follows:
... WHERE MATCH(content) AGAINST ('High Performance MySQL')
AND author = 123;
However, this query will be very inefficient. MySQL will search all one million documents first, because it prefers the full-text index. It will then apply the WHERE clause to restrict the results to the given author, but this filtering operation won’t be able to use the index on the author.
One workaround is to include the author IDs in the full-text index. You can choose a prefix that’s very unlikely to appear in the text, then append the author’s ID to it, and include this “word” in a filters column that’s maintained separately (perhaps by a trigger).
You can then extend the full-text index to include the filters column and rewrite the query as follows:
... WHERE MATCH(content, filters)
AGAINST ('High Performance MySQL +author_id_123' IN BOOLEAN MODE);
This might be more efficient if the author ID is very selective, because MySQL will be able to narrow the list of documents very quickly by searching the full-text index for “author_id_123”. If it’s not selective, though, the performance might be worse. Be careful with this approach.
Sometimes you can use full-text indexes for bounding-box searches. For instance, if you want to restrict searches to a range of coordinates (for geographically constrained searches), you can encode the coordinates into the full-text collection. Suppose the coordinates for a given row are X=123 and Y=456. You can interleave the coordinates with the most significant digits first, as in XY142536, and place them in a column that is included in the full-text index. Now if you want to limit searches to, for example, a rectangle bounded by X between 100 and 199 and Y between 400 and 499, you can add “+XY14*” to the search query. This can be faster than filtering with a WHERE clause.
A technique that sometimes works well with full-text indexes, especially for paginated displays, is to select a list of primary keys by a full-text query and cache the results. When the application is ready to render some results, it can issue another query that fetches the desired rows by their IDs. This second query can include more complicated criteria or joins that need to use other indexes to work well.
Even though only MyISAM supports full-text indexes, if you need to use InnoDB or another storage engine instead, you can replicate your tables to a server that uses the MyISAM storage engine, then use the replica to serve full-text queries. If you don’t want to serve some queries from a different server, you can partition a table vertically by breaking it into two, keeping textual columns separate from the rest of the data.
You can also duplicate some columns into a table that’s full-text indexed. You can see this strategy in action in the sakila.film_text table, which is maintained with triggers. Yet another alternative is to use an external full-text engine, such as Lucene or Sphinx. You can read more about Sphinx in Appendix F.
GROUP BY queries with full-text searches can be performance killers, again because the full-text query typically finds a lot of matches; these cause random disk I/O, followed by a temporary table or filesort for the grouping. Because such queries are often just looking for the top items per group, a good optimization is to sample the results instead of trying for complete accuracy. For example, select the first 1,000 rows into a temporary table, then return the top result per group from that.
Full-Text Configuration and Optimization
Regular maintenance of your full-text indexes is one of the most important things you can do to enhance performance. The double-B-Tree structure of full-text indexes, combined with the large number of keywords in typical documents, means they suffer from fragmentation much more than normal indexes. You might need to use OPTIMIZE TABLE frequently to defragment the indexes. If your server is I/O-bound, it might be much faster to just drop and recreate the full-text indexes periodically.
A server that must perform well for full-text searches needs key buffers that are large enough to hold the full-text indexes, because they work much better when they’re in memory. You can use dedicated key buffers to make sure other indexes don’t flush your full-text indexes from the key buffer. See Chapter 8 for more details on MyISAM key buffers.
It’s also important to provide a good stopword list. The defaults will work well for English prose, but they might not be good for other languages or for specialized texts, such as technical documents. For example, if you’re indexing a document about MySQL, you might want “mysql” to be a stopword, because it’s too common to be helpful.
You can often improve performance by skipping short words. The length is configurable with the ft_min_word_len parameter. Increasing the default value will skip more words, making your index smaller and faster, but less accurate. Also bear in mind that for special purposes, you might need very short words. For example, a full-text search of consumer electronics products for the query “cd player” is likely to produce lots of irrelevant results unless short words are allowed in the index. A user searching for “cd player” won’t want to see MP3 and DVD players in the results, but if the minimum word length is the default four characters, the search will actually be for just “player,” so all types of players will be returned.
The stopword list and the minimum word length can improve search speeds by keeping some words out of the index, but the search quality can suffer as a result. The right balance is application-dependent. If you need good performance and good-quality results, you’ll have to customize both parameters for your application. It’s a good idea to build in some logging and then investigate common searches, uncommon searches, searches that don’t return results, and searches that return a lot of results. You can gain insight about your users and your searchable content this way, and then use that insight to improve performance and the quality of your search results.
NOTE
Be aware that if you change the minimum word length, you’ll have to rebuild the index with OPTIMIZE TABLE for the change to take effect. A related parameter is ft_max_word_len, which is mainly a safeguard to avoid indexing very long keywords.
If you’re importing a lot of data into a server and you want full-text indexing on some columns, disable the full-text indexes before the import with DISABLE KEYS and enable them afterward with ENABLE KEYS. This is usually much faster because of the high cost of updating the index for each row inserted, and you’ll get a defragmented index as a bonus.
For large datasets, you might need to manually partition the data across many nodes and search them in parallel. This is a difficult task, and you might be better off using an external full-text search engine, such as Lucene or Sphinx. Our experience shows they can have orders of magnitude better performance.
[100] In MySQL 5.1, you can use full-text parser plugins to extend full-text search. Still, you might find that MySQL’s full-text limitations make it impractical or impossible to use for your application. We discuss using Sphinx as an external full-text search engine in Appendix F.
[101] A common mistake during testing is to put a few rows of sample data into a full-text search index, only to find that no queries match. The problem is that every word appears in more than half the rows.
[102] Full-text indexes won’t even contain words that are too short or too long, but that’s a different matter. Here we refer to the fact that the server won’t strip words from the search phrase if they’re too short or too long, which it normally does as part of the query optimization process.
Distributed (XA) Transactions
Whereas storage engine (see Transactions) transactions give ACID properties inside the storage engine, a distributed (XA) transaction is a higher-level transaction that can extend some ACID properties outside the storage engine—and even outside the database—with a two-phase commit. MySQL 5.0 and newer have partial support for XA transactions.
An XA transaction requires a transaction coordinator, which asks all participants to prepare to commit (phase one). When the coordinator receives a “ready” from all participants, it tells them all to go ahead and commit. This is phase two. MySQL can act as a participant in XA transactions, but not as a coordinator.
There are actually two kinds of XA transactions in MySQL. The MySQL server can participate in an externally managed distributed transaction, but it also uses XA internally to coordinate storage engines and binary logging.
Internal XA Transactions
The reason for MySQL’s internal use of XA transactions is the architectural separation between the server and the storage engines. Storage engines are completely independent from and unaware of each other, so any cross-engine transaction is distributed by nature and requires a third party to coordinate it. That third party is the MySQL server. Were it not for XA transactions, for example, a cross-engine transaction commit would require sequentially asking each engine involved to commit. That would introduce the possibility of a crash after one engine had committed but before another did, which would break the rules of transactions (recall that transactions are supposed to be all-or-nothing operations).
If you consider the binary log to be a “storage engine” for log events, you can see why XA transactions are necessary even when only a single transactional engine is involved. Synchronizing a storage engine commit with “committing” an event to the binary log is a distributed transaction, because the server—not the storage engine—handles the binary log.
XA currently creates a performance dilemma. It has broken InnoDB’s support for group commit (a technique that can commit several transactions with a single I/O operation) since MySQL 5.0, so it causes many more fsync() calls than it should.[103] It also causes each transaction to require a binary log sync if binary logs are enabled and requires two InnoDB transaction log flushes per commit instead of one. In other words, if you want the binary log to be safely synchronized with your transactions, each transaction will require a total of at least three fsync() calls. The only way to prevent this is to disable the binary log and set innodb_support_xa to 0.[104]
These settings are unsafe and incompatible with replication. Replication requires binary logging and XA support, and in addition—to be as safe as possible—you need sync_binlog set to 1, so the storage engine and the binary log are synchronized. (The XA support is worthless otherwise, because the binary log might not be “committed” to disk.) This is one of the reasons we strongly recommend using a RAID controller with a battery-backed write cache: the cache can speed up the extra fsync() calls and restore performance.
The next chapter goes into more detail on how to configure transaction logging and binary logging.
External XA Transactions
MySQL can participate in, but not manage, external distributed transactions. It doesn’t support the full XA specification. For example, the XA specification allows connections to be joined in a single transaction, but that’s not possible in MySQL at this time.
External XA transactions are even more expensive than internal ones, due to the added latency and the greater likelihood of a participant failing. Using XA over a WAN, or even over the Internet, is a common trap because of unpredictable network performance. It’s generally best to avoid XA transactions when there’s an unpredictable component, such as a slow network or a user who might not click the “Save” button for a long time. Anything that delays the commit has a heavy cost, because it’s causing delays not just on one system, but potentially on many.
You can design high-performance distributed transactions in other ways, though. For instance, you can insert and queue data locally, then distribute it atomically in a much smaller, faster transaction. You can also use MySQL replication to ship data from one place to another. We’ve found that some applications that use distributed transactions really don’t need to use them at all.
That said, XA transactions can be a useful way to synchronize data between servers. This method works well when you can’t use replication for some reason, or when the updates are not performance-critical.
[103] At the time of writing, a lot of work has gone into fixing the group commit problem, and there are at least three competing implementations. It remains to be seen which one ends up in the official MySQL source code that most people will use, or which version it will be fixed in. The version available in MariaDB and Percona Server appears to be a good solution.
[104] A common misconception is that innodb_support_xa is only needed if you use XA transactions. This is incorrect: it controls the internal XA transactions between the storage engine and the binary log, and if you value your data, you need this setting to be enabled.
The MySQL Query Cache
Many database products can cache query execution plans, so the server can skip the SQL parsing and optimization stages for repeated queries. MySQL can do this in some circumstances, but it also has a different type of cache (known as the query cache) that stores complete result sets forSELECT statements. This section focuses on that cache.
The MySQL query cache holds the exact bits that a completed query returned to the client. When a query cache hit occurs, the server can simply return the stored results immediately, skipping the parsing, optimization, and execution steps.
The query cache keeps track of which tables a query uses, and if any of those tables changes, it invalidates the cache entry. This coarse invalidation policy might seem inefficient, because the changes made to the tables might not affect the results stored in the cache, but it’s a simple approach with low overhead, which is important on a busy system.
The query cache is designed to be completely transparent to the application. The application does not need to know whether MySQL returned data from the cache or actually executed the query. The result should be the same either way. In other words, the query cache doesn’t change semantics; the server appears to behave the same way with it enabled or disabled.[105]
As servers have gotten larger and more powerful, the query cache has unfortunately proven not to be a very scalable part of MySQL. It is effectively a single point of contention for the whole server, and it can cause severe stalls on multicore servers. Although we’ll go into quite a bit of detail about how to configure it, we think that the best approach is actually to disable it by default, and configure a small query cache (no more than a few dozen megabytes) only if it’s very beneficial. We’ll explain later how to determine if the query cache is likely to be beneficial for your workload.
How MySQL Checks for a Cache Hit
The way MySQL checks for a cache hit is simple: the cache is a lookup table. The lookup key is a hash of the query text itself, the current database, the client protocol version, and a handful of other things that might affect the actual bytes in the query’s result.
MySQL does not parse, “normalize,” or parameterize a statement when it checks for a cache hit; it uses the statement and other bits of data exactly as the client sends them. Any difference in character case, spacing, or comments—any difference at all—will prevent a query from matching a previously cached version.[106] This is something to keep in mind while writing queries. Using consistent formatting and style is a good habit anyway, but in this case it can even make your system faster.
Another caching consideration is that the query cache will not store a result unless the query that generated it was deterministic. Thus, any query that contains a nondeterministic function, such as NOW() or CURRENT_DATE(), will not be cached. Similarly, functions such asCURRENT_USER() or CONNECTION_ID() might vary when executed by different users, thereby preventing a cache hit. In fact, the query cache does not work for queries that refer to user-defined functions, stored functions, user variables, temporary tables, tables in the mysql database, or any table that has a column-level privilege. (For a list of everything that makes a query uncacheable, see the MySQL manual.)
We’ve heard statements such as “MySQL doesn’t check the cache if the query contains a nondeterministic function.” This is incorrect. MySQL cannot know whether a query contains a nondeterministic function unless it parses the query, and the cache lookup happens before parsing. The server performs a case-insensitive check to verify that the query begins with the letters SEL, but that’s all.
However, it is correct to say “The server will find no results in the cache if the query contains a function such as NOW(),” because even if the server executed the same query earlier, it will not have cached the results. MySQL marks a query as uncacheable as soon as it notices a construct that forbids caching, and the results generated by such a query are not stored.
A useful technique to enable the caching of queries that refer to the current date is to include the date as a literal value, instead of using a function. For example:
... DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) -- Not cacheable!
... DATE_SUB('2007-07-14’, INTERVAL 1 DAY) -- Cacheable
Because the query cache works at the level of a complete SELECT statement when the server first receives it from the client connection, identical queries made inside a subquery or view cannot use the query cache, and neither can queries in stored procedures. Prepared statements also cannot use the query cache in versions prior to MySQL 5.1.
MySQL’s query cache can sometimes improve performance, but there are a few issues you should be aware of when using it. First, enabling the query cache adds some overhead for both reads and writes:
§ Read queries must check the cache before beginning.
§ If the query is cacheable and isn’t in the cache yet, there’s some overhead due to storing the result after generating it.
§ There’s overhead for write queries, which must invalidate the cache entries for queries that use tables they change. Invalidation can be very costly if the cache is fragmented and/or large (has many cached queries, or is configured to use a large amount of memory).
The query cache can still be a net gain. However, as we explain later, the extra overhead can add up, especially in combination with contention caused by queries trying to lock the cache to perform operations on it.
For InnoDB users, another problem is that transactions limit the query cache’s usefulness. When a statement inside a transaction modifies a table, the server invalidates any cached queries that refer to the table, even though InnoDB’s multiversioning might hide the transaction’s changes from other statements. The table is also globally uncacheable until the transaction commits, so no further queries against that table—whether inside or outside the transaction—can be cached until the transaction commits. Long-running transactions can, therefore, increase the number of query cache misses.
Invalidation can become a very serious problem with a large query cache. If there are many queries in the cache, the invalidation can take a long time and cause the entire system to stall while it works. This is because there’s a single global lock on the query cache, which will block all queries that need to access it. Accessing happens both when checking for a hit and when checking whether there are any queries to invalidate. Chapter 3 includes a real case study that shows excessive query cache invalidation overhead.
How the Cache Uses Memory
MySQL stores the query cache completely in memory, so you need to understand how it uses memory before you can configure it correctly. The cache stores more than just query results in its memory. It’s a lot like a filesystem in some ways: it keeps structures that help it figure out which memory in its pool is free, mappings between tables and query results, query text, and the query results.
Aside from some basic housekeeping structures, which require about 40 KB, the query cache’s memory pool is available to be used in variable-sized blocks. Every block knows what type it is, how large it is, and how much data it contains, and it holds pointers to the next and previous logical and physical blocks. Blocks can be of several types: they can store cache results, lists of tables used by a query, query text, and so on. However, the different types of blocks are treated in much the same way, so there’s no need to distinguish among them for purposes of configuring the query cache.
When the server starts, it initializes the memory for the query cache. The memory pool is initially a single free block. This block is as large as the entire amount of memory the cache is configured to use, minus the housekeeping structures.
When the server caches a query’s results, it reserves a block from its memory pool to store those results. This block must be a minimum of query_cache_min_res_unit bytes, though it might be larger if the server knows it is storing a larger result. Unfortunately, the server cannot choose a block of precisely the right size, because it makes its initial choice before the result set is complete. The server does not build the entire result set in memory and then send it—it’s much more efficient to send each row as it’s generated. Consequently, when it begins caching the result set, the server has no way of knowing how large it will eventually be.
Assigning blocks is a relatively slow process, because it requires the server to look at its lists of free blocks to find one that’s big enough. Therefore, the server tries to minimize the number of times it performs this task. When it needs to cache a result set, it chooses a block of at least the minimum size (possibly larger, for reasons too complex to explain) and begins placing the results in that block. If the block becomes full while there is still data left to store, the server reserves a new block—again of at least the minimum size—and continues storing the data in that block. When the result is finished, if there is space left in the last block the server trims it to size and merges the leftover space into the adjacent free block. Figure 7-3 illustrates this process.[107]
Figure 7-3. How the query cache allocates blocks to store a result
When we say the server “reserves a block,” we don’t mean it is asking the operating system to allocate memory with malloc() or a similar call. It does that only once, when it creates the query cache. What we mean is that the server is examining its list of blocks and either choosing the best place to put a new block or, if necessary, removing the oldest cached query to make room. In other words, the MySQL server manages its own memory; it does not rely on the operating system to do it.
So far, this is all pretty straightforward. However, the picture can become quite a bit more complicated than it appeared in Figure 7-3. Let’s suppose the average result is quite small, and the server is sending results to two client connections simultaneously. Trimming the results can leave a free block that’s smaller than query_cache_min_res_unit and cannot be used for storing future cache results. The block allocation might end up looking something like Figure 7-4.
Figure 7-4. Fragmentation caused by storing results in the query cache
Trimming the first result to size left a gap between the two results—a block too small to use for storing a different query result. The appearance of such gaps is called fragmentation, and it’s a classic problem in memory and filesystem allocation. Fragmentation can happen for a number of reasons, including cache invalidations, which can leave blocks that are too small to reuse later.
When the Query Cache Is Helpful
Caching queries isn’t automatically more efficient than not caching them. Caching takes work, and the query cache results in a net gain only if the savings are greater than the overhead. This will depend on your server’s workload.
In theory, you can tell whether the cache is helpful by comparing the amount of work the server has to do with the cache enabled and disabled. With the cache disabled, each read query has to execute and return its results, and each write query has to execute. With the cache enabled, each read query has to first check the cache and then either return the stored result or, if there isn’t one, execute, generate the result, store it, and return it. Each write query has to execute and then check whether there are any cached queries that must be invalidated.
Although this might sound straightforward, it’s not—it’s hard to calculate or predict the query cache’s benefit. You must also take into account external factors. For example, the query cache can reduce the amount of time required to produce a query’s result, but not the time it takes to send the result to the client program, which might be the dominating factor.
In addition, MySQL provides no good way to determine how beneficial the query cache is for individual queries,[108] because the counters in SHOW STATUS are aggregated over the whole workload. But the average behavior usually isn’t really interesting. For example, you might have one slow query that becomes much faster with the help of the query cache, even though it makes everything else a little bit slower or even makes the server slower on average. Is this what you want? It might actually be the right thing to do, if the queries that get faster are ones to which users are very sensitive and the others aren’t so important. This would be a good candidate for selective use of the cache with the SQL_CACHE directive.
The type of query that benefits most from caching is one whose result is expensive to generate but doesn’t take up much space in the cache, so it’s cheap to store, return to the client, and invalidate. Aggregate queries, such as small COUNT() results from large tables, fit into this category. However, some other types of queries might be worth caching, too. As a rule of thumb, you can consider the query cache if your workload is dominated by complex SELECT queries, such as multitable joins with ORDER BY and LIMIT clauses, which produce small result sets. You should have very few UPDATE, DELETE, and INSERT queries in comparison to these complex SELECT queries.
One of the ways to tell if you are benefiting from the query cache is to examine the query cache hit rate. This is the number of queries that are served from the cache instead of being executed by the server. When the server receives a SELECT statement, it increments either the Qcache_hitsor the Com_select status variable, depending on whether the query was cached. Thus, the query cache hit rate is given by the formula Qcache_hits / (Qcache_hits+Com_select).
Unfortunately, the cache hit rate isn’t easy to interpret. What’s a good cache hit rate? It depends. Even a 30% hit rate can be very helpful, because the work saved by not executing queries could be much more (per query) than the overhead of invalidating entries and storing results in the cache. It is also important to know which queries are cached. If the cache hits represent the most expensive queries, even a low hit rate could save work for the server. So there is no simple rule that tells you whether the query cache hit rate is good or not.
Any SELECT query that MySQL doesn’t serve from the cache is a cache miss. A cache miss can occur for any of the following reasons:
§ The query is not cacheable, either because it contains a nondeterministic construct (such as CURRENT_DATE) or because its result set is too large to store. Both types of uncacheable queries increment the Qcache_not_cached status variable.
§ The server has never seen the query before, so it never had a chance to cache its result.
§ The query’s result was previously cached, but the server removed it. This can happen because there wasn’t enough memory to keep it, because someone instructed the server to remove it, or because it was invalidated (more on invalidations in a moment).
If your server has a lot of cache misses but very few uncacheable queries, one of the following must be true:
§ The query cache is not warmed up yet. That is, the server hasn’t had a chance to fill the cache with result sets.
§ The server is seeing queries it hasn’t seen before. If you don’t have a lot of repeated queries, this can happen even after the cache is warmed up.
§ There are a lot of cache invalidations.
Cache invalidations can happen because of fragmentation, insufficient memory, or data modifications. If you have allocated enough memory to the cache and configured the query_cache_min_res_unit value properly, most cache invalidations should be due to data modifications. You can see how many queries have modified data by examining the Com_* status variables (Com_update, Com_delete, and so forth), and you can check the Qcache_lowmem_prunes variable to see how many queries have been invalidated due to low memory.
It’s a good idea to consider the overhead of invalidation separately from the hit rate. As an extreme example, suppose you have one table that gets all the reads and has a 100% query cache hit rate, and another table that gets only updates. If you simply calculate the hit rate from the status variables, you will see a 100% hit rate. However, the query cache can still be inefficient, because it will slow down the update queries. All update queries will have to check whether any of the queries in the query cache need to be invalidated as a result of their modifications, but since the answer will always be “no,” this is wasted work. You might not spot a problem such as this unless you check the number of uncacheable queries as well as the hit rate.
A server that handles a balanced blend of writes and cacheable reads on the same tables also might not benefit much from the query cache. The writes will constantly invalidate cached results, while at the same time the cacheable reads will constantly insert new results into the cache. These will be beneficial only if they are subsequently served from the cache.
If a cached result is invalidated before the server receives the same SELECT statement again, storing it was a waste of time and memory. Examine the relative sizes of Com_select and Qcache_inserts to see whether this is happening. If nearly every SELECT is a cache miss (thus incrementing Com_select) and subsequently stores its result into the cache, Qcache_inserts will be nearly as large as Com_select. Thus, you’d like Qcache_inserts to be much smaller than Com_select, at least when the cache is properly warmed up. However, this is still a hard-to-interpret ratio because of the subtleties of what’s happening inside the cache and the server.
As you’ve seen, the hit rate and the insert-to-select rate are not good guides. It’s really best to measure and calculate how much the cache could help your workload. But if you want, you can look at a different ratio, the hit-to-insert ratio. That indicates the size of Qcache_hits relative toQcache_inserts. As a rough rule of thumb, a hit-to-insert ratio of 3:1 or better might be worth considering for average quick queries, but it’s much better to have 10:1 or higher. If you aren’t achieving this level of benefit from your query cache, it’s probably better to disable it, unless you have done the math and determined that two things are true for your server: hits are way cheaper than misses, and query cache contention isn’t a problem.
Every application has a finite potential cache size, even if there are no write queries. The potential cache size is the amount of memory required to store every possible cacheable query the application will ever issue. In theory, this is an extremely large number for most applications. In practice, many applications have a much smaller usable cache size than you might expect, because of the number of invalidations. Even if you make the query cache very large, it will never fill up more than the potential cache size.
You should monitor how much of the query cache your server actually uses. If it doesn’t use as much memory as you’ve given it, make it smaller. If memory restrictions are causing excessive invalidations you can try making it bigger, but as mentioned previously, it can be dangerous to exceed a few dozen megabytes. (This depends on your hardware and workload.)
You also have to balance the query cache with the other server caches, such as the InnoDB buffer pool or the MyISAM key cache. It’s not possible to just give a ratio or a simple formula for this, because the right balance depends on the application.
The best way to know how beneficial the query cache really is is to measure how long queries take to execute with and without the cache, if possible. Percona Server’s extended slow query log can report whether a query was a cache hit or not. If the query cache isn’t saving you a significant amount of time, it’s probably best to try disabling it.
How to Configure and Maintain the Query Cache
Once you understand how the query cache works, it’s easy to configure. It has only a few moving parts:
query_cache_type
Whether the query cache is enabled. Possible values are OFF, ON, or DEMAND, where the latter means that only queries containing the SQL_CACHE modifier are eligible for caching. This is both a session-level and a global variable. (See Chapter 8 for details on session and global variables.)
query_cache_size
The total memory to allocate to the query cache, in bytes. This must be a multiple of 1,024 bytes, so MySQL might use a slightly different value than the one you specify.
query_cache_min_res_unit
The minimum size when allocating a block. We explained this setting previously; it’s discussed further in the next section.
query_cache_limit
The largest result set that MySQL will cache. Queries whose results are larger than this setting will not be cached. Remember that the server caches results as it generates them, so it doesn’t know in advance when a result will be too large to cache. If the result exceeds the specified limit, MySQL will increment the Qcache_not_cached status variable and discard the results cached so far. If you know this happens a lot, you can add the SQL_NO_CACHE hint to queries you don’t want to incur this overhead.
query_cache_wlock_invalidate
Whether to serve cached results that refer to tables other connections have locked. The default value is OFF, which makes the query cache change the server’s semantics because it lets you read cached data from a table another connection has locked, which you wouldn’t normally be able to do. Changing it to ON will keep you from reading this data, but it might increase lock waits. This really doesn’t matter for most applications, so the default is generally fine.
In principle, configuring the cache is pretty simple, but understanding the effects of your changes is more complicated. In the following sections, we’ll try to help you make good decisions.
Reducing fragmentation
There’s no way to avoid all fragmentation, but choosing your query_cache_min_res_unit value carefully can help you avoid wasting a lot of memory in the query cache. The trick is to balance the size of each new block against the number of allocations the server has to do while storing results. If you make this value too small, the server will waste less memory, but it will have to allocate blocks more frequently, which is more work for the server. If you make it too large, you’ll get too much fragmentation. The trade-off is wasting memory versus using more CPU cycles during allocation.
The best setting varies with the size of your typical query result. You can see the average size of the queries in the cache by dividing the memory used (approximately query_cache_size — Qcache_free_memory) by the Qcache_queries_in_cache status variable. If you have a mixture of large and small results, you might not be able to choose a size that avoids fragmentation while also avoiding too many allocations. However, you might have reason to believe that it’s not beneficial to cache the larger results (this is frequently true). You can keep large results from being cached by lowering the value of the query_cache_limit variable, which can sometimes help achieve a better balance between fragmentation and the overhead of storing results in the cache.
You can detect query cache fragmentation by examining the Qcache_free_blocks status variable, which shows you how many blocks in the query cache are of type FREE. In the final configuration shown in Figure 7-4, there are two free blocks. The worst possible fragmentation is when there’s a slightly-too-small free block between every pair of blocks used to store data, so every other block is a free block. Thus, if Qcache_free_blocks approaches Qcache_total_blocks / 2, your query cache is severely fragmented. If the Qcache_lowmem_prunes status variable is increasing and you have a lot of free blocks, fragmentation is causing queries to be deleted from the cache prematurely.
You can defragment the query cache with FLUSH QUERY CACHE. This command compacts the query cache by moving all blocks “upward” and removing the free space between them, leaving a single free block at the bottom. Contrary to its name, it does not remove queries from the cache; that’s what RESET QUERY CACHE does. FLUSH QUERY CACHE blocks access to the query cache while it runs, which effectively locks the whole server, so be very careful with it. One rule of thumb for query cache sizing is to keep it small enough that the stalls caused by FLUSH QUERY CACHE are acceptably short.
Improving query cache usage
If your query cache isn’t fragmented but you’re still not getting a good hit rate, you might have given it too little memory. If the server can’t find any free blocks that are large enough to use for a new block, it must “prune” some queries from the cache.
When the server prunes cache entries, it increments the Qcache_lowmem_prunes status variable. If this value increases rapidly, there are two possible causes:
§ If there are many free blocks, fragmentation is the likely culprit (see the previous section).
§ If there are few free blocks, it might mean that your workload can use a larger cache size than you’re giving it. You can see the amount of unused memory in the cache by examining Qcache_free_memory.
If there are many free blocks, fragmentation is low, there are few prunes due to low memory, and the hit rate is still low, your workload probably won’t benefit much from the query cache. Something is keeping it from being used. If you have a lot of updates, that’s probably the culprit; it’s also possible that your queries are not cacheable.
If you’ve measured the cache hit ratio and you’re still not sure whether the server is benefiting from the query cache, you can disable it and monitor performance, then reenable it and see how performance changes. To disable the query cache, set query_cache_size to 0. (Changingquery_cache_type globally won’t affect connections that are already open, and it won’t return the memory to the server.) You can also benchmark, but it’s sometimes tricky to get a realistic combination of cached queries, uncached queries, and updates.
Figure 7-5 shows a flowchart with a basic example of the process you can use to analyze and configure your server’s query cache.
InnoDB and the Query Cache
InnoDB interacts with the query cache in a more complex way than other storage engines, because of its implementation of MVCC. In MySQL 4.0 the query cache is disabled entirely within transactions, but in MySQL 4.1 and newer InnoDB indicates to the server, on a per-table basis, whether a transaction can access the query cache. It controls access to the query cache for both reads (retrieving results from the cache) and writes (saving results to the cache).
Figure 7-5. How to analyze and configure the query cache
The factors that determine access are the transaction ID and whether there are any locks on the table. Each table in InnoDB’s in-memory data dictionary has an associated transaction ID counter. Transactions whose IDs are less than the counter value are forbidden to read from or write to the query cache for queries that involve that table.
Any locks on a table also make queries that access it uncacheable. For example, if a transaction performs a SELECT FOR UPDATE query on a table, no other transactions will be able to read from or write to the query cache for queries involving that table until the locks are released.
When a transaction commits, InnoDB updates the counters for the tables upon which the transaction has locks. A lock is a rough heuristic for determining whether the transaction has modified a table; it is possible for a transaction to lock rows in a table and not update them, but it is not possible for it to modify the table’s contents without acquiring any locks. InnoDB sets each table’s counter to the system’s transaction ID, which is the maximum transaction ID in existence.
This has the following consequences:
§ The table’s counter is an absolute lower bound on which transactions can use the query cache. If the system’s transaction ID is 5 and a transaction acquires locks on rows in a table and then commits, transactions 1 through 4 can never read from or write to the query cache for queries involving that table again.
§ The table’s counter is updated not to the transaction ID of the transaction that locked rows in it, but to the system’s transaction ID. As a result, transactions that lock rows in tables might find themselves blocked from reading from or writing to the query cache for queries involving that table in the future.
Query cache storage, retrieval, and invalidation are handled at the server level, and InnoDB cannot bypass or delay this. However, InnoDB can tell the server explicitly to invalidate queries that involve specific tables. This is necessary when a foreign key constraint, such as ON DELETE CASCADE, alters the contents of a table that isn’t mentioned in a query.
In principle, InnoDB’s MVCC architecture could let queries be served from the cache when modifications to a table don’t affect the consistent read view other transactions see. However, implementing this would be complex. InnoDB’s algorithm takes some shortcuts for simplicity, at the cost of locking transactions out of the query cache when this might not really be necessary.
General Query Cache Optimizations
Many schema, query, and application design decisions affect the query cache. In addition to what we discussed in the previous sections, here are some points to keep in mind:
§ Having multiple smaller tables instead of one huge one can help the query cache. This design effectively makes the invalidation strategy work at a finer level of granularity. Don’t let this unduly influence your schema design, though, as other factors can easily outweigh the benefit.
§ It’s more efficient to batch writes than to do them singly, because this method invalidates cached cache entries only once. (Be careful not to delay and batch so much that the invalidations caused by the writes will stall the server for too long, however.)
§ We’ve noticed that the server can stall for a long time while invalidating entries in or pruning a very large query cache. A possible solution is to not make query_cache_size very large, but in some cases you simply have to disable it altogether, because nothing is small enough.
§ You cannot control the query cache on a per-database or per-table basis, but you can include or exclude individual queries with the SQL_CACHE and SQL_NO_CACHE modifiers in the SELECT statement. You can also enable or disable the query cache on a per-connection basis by setting the session-level query_cache_type server variable to the appropriate value.
§ For a write-heavy application, disabling the query cache completely might improve performance. Doing so eliminates the overhead of caching queries that would be invalidated soon anyway. Remember to set query_cache_size to 0 when you disable it, so it doesn’t consume any memory.
§ Disabling the query cache might be beneficial for a read-heavy application, too, because of contention on the single query cache mutex. If you need good performance at high concurrency, be sure to validate it with high-concurrency tests, because enabling the query cache and testing at low concurrency can be very misleading.
If you want to avoid the query cache for most queries, but you know that some will benefit significantly from caching, you can set the global query_cache_type to DEMAND and then add the SQL_CACHE hint to those queries you want to cache. Although this requires you to do more work, it gives you very fine-grained control over the cache. Conversely, if you want to cache most queries and exclude just a few, you can add SQL_NO_CACHE to them.
Alternatives to the Query Cache
The MySQL query cache works on the principle that the fastest query is the one you don’t have to execute, but you still have to issue the query, and the server still needs to do a little bit of work. What if you really didn’t have to talk to the database server at all for particular queries? Client-side caching can help ease the workload on your MySQL server even more. We explain caching more in Chapter 14.
[105] The query cache actually does change semantics in one subtle way: by default, a query can still be served from the cache when one of the tables to which it refers is locked with LOCK TABLES. You can disable this with the query_cache_wlock_invalidate variable.
[106] Percona Server is an exception to this rule; it can strip comments from queries before comparing them to the query cache. This feature is needed because it’s a common, and good, practice to insert comments into queries with additional information about the process that invoked them. The PHP instrumentation software that we discussed in Chapter 3 relies on this, for example.
[107] We’ve simplified the diagrams in this section for the purposes of illustration. The server really reserves query cache blocks in a more complicated fashion than we’ve shown here. If you’re interested in how it works, the comments at the top of sql/sql_cache.cc in the server’s source code explain it very clearly.
[108] The enhanced “slow query log” in Percona Server and MariaDB reveals whether individual queries were cache hits.
Summary
This chapter has been more of a potpourri of different topics than some of the previous chapters were. We’ll wrap up by revisiting some of the most important points from each topic:
Partitioned tables
Partitioning is a kind of cheap, coarse indexing that works at large scale. For best results, either forget about indexing and plan to full-scan selected partitions, or make sure that only one partition is hot and it fits in memory, including its indexes. Stick to about 150 or fewer partitions per table, watch out for subtleties that defeat pruning, and monitor the per-row and per-query overhead of partitioning.
Views
Views can be useful for abstracting underlying tables and complex queries. Beware of views that use temporary tables, though, because they don’t push your WHERE clauses down to the underlying queries; nor do they have indexes themselves, so you can’t query them efficiently in a join. Using views as conveniences is probably the best approach.
Foreign keys
Foreign key constraints push constraints into the server, where they can be more efficient. However, they can also add complexity, extra indexing overhead, and interactions between tables that cause more locking and contention. We think foreign keys are a nice-to-have feature for ensuring system integrity, but they’re a luxury for applications that need extremely high performance; most people don’t use them when performance is a concern, preferring instead to trust the application code.
Stored routines
MySQL’s implementation of stored procedures, triggers, stored functions, and events is quite frankly pretty unimpressive. There are also a lot of problems with statement-based replication. Use these features when they can save you a lot of network round-trips—in such cases, you can get much better performance by cutting out costly latency. You can also use them for the usual reasons (centralizing business logic, enforcing privileges, and so on), but this just doesn’t work as well in MySQL as it does in the bigger, more complex and mature database servers.
Prepared statements
Prepared statements are useful when a large portion of the cost of executing statements is from transferring statements across the network, parsing the SQL, and optimizing the SQL. If you’ll repeat the same statement many times, you can save on these costs by using prepared statements because they’re parsed once, there is some execution plan caching, and the binary protocol is more efficient than the ordinary text-based protocol.
Plugins
Plugins are written in C or C++ and let you extend the functionality of the server in many ways. They’re very powerful, and we’ve written many UDFs and plugins for various purposes when the problem is best solved inside the server in native code.
Character sets
A character set is a mapping between byte values and characters, and a collation is the sort order of the characters. Most people use either the latin1 (the default, suitable for English and some European languages) or UTF-8 character sets. If you use UTF-8, beware of temporary tables and buffers: the server allocates three bytes per character, so you can use a lot of disk and memory space if you’re not careful. Be very careful to make character sets and character set configuration options match, from the client-side connections all the way through, or you’ll cause conversions that defeat indexing.
Full-text searching
Only MyISAM supports full-text indexes at the time of writing, though it looks like InnoDB will offer this capability when MySQL 5.6 is released. MyISAM is basically unusable for large-scale full-text searching due to locking and lack of crash resilience, and we generally help people set up and use Sphinx instead.
XA transactions
Most people don’t use XA transactions with MySQL. However, don’t disable innodb_support_xa unless you know what you are doing. It is not, as many people think, unnecessary if you don’t do explicit XA transactions. It is used for coordinating InnoDB and the binary log so crash recovery will work correctly.
The query cache
The query cache prevents queries from being reexecuted if the stored result of an exactly identical query is already cached. Our experience with the query cache in high-load environments has been peppered with server lockups and stalls. If you use the query cache, don’t make it very large, and use it only if you know it’s highly beneficial. How can you know that? The best way is to use Percona Server’s extended query logging facilities and a little math. Barring that, you can look at the cache hit ratio (not always helpful), the select-to-insert ratio (also hard to interpret), or the hit-to-insert ratio (a bit more meaningful). In the final analysis, the query cache is convenient because it’s transparent and doesn’t require any additional coding on your part, but if you need a highly efficient cache for high performance, you’re better off looking atmemcached or another external solution. More on this in Chapter 14.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.