Hadoop MapReduce v2 Cookbook, Second Edition (2015)
Chapter 9. Classifications, Recommendations, and Finding Relationships
In this chapter, we will cover:
· Performing content-based recommendations
· Classification using the naïve Bayes classifier
· Assigning advertisements to keywords using the Adwords balance algorithm
Introduction
This chapter discusses how we can use Hadoop for more complex use cases like classifying a dataset and making recommendations.
The following are a few instances of some such scenarios:
· Making product recommendations to users either based on similarities between products (for example, if a user liked a book about history, he/she might like another book on the same subject) or on user behavior patterns (for example, if two users are similar, they might like books the other has read)
· Clustering a dataset to identify similar entities; for example, identifying users with similar interests
· Classifying data into several groups based on historical data
In this recipe, we will apply these and other techniques using MapReduce. For recipes in this chapter, we will use the Amazon product co-purchasing network metadata dataset available at http://snap.stanford.edu/data/amazon-meta.html.
Note
The contents of this chapter are based on Chapter 8, Classifications, Recommendations, and Finding Relationships, of the previous edition of this book, Hadoop MapReduce Cookbook. That chapter was contributed by the co-author Srinath Perera.
Tip
Sample code
The sample code and data files for this book are available in GitHub at https://github.com/thilg/hcb-v2. The chapter9 folder of the code repository contains the sample source code files for this chapter. Sample codes can be compiled and built by issuing the gradle build command in the chapter9 folder of the code repository. The project files for Eclipse IDE can be generated by running the gradle eclipse command in the main folder of the code repository. The project files for IntelliJ IDEA IDE can be generated by running the gradle idea command in the main folder of the code repository.
Performing content-based recommendations
Recommendations are suggestions to someone about things that might be interesting to him. For example, you would recommend a good book to a friend who you know has similar interests as you. We often find use cases for recommendations in online retail. For example, when you browse a product, Amazon suggests other products also bought by users who bought that particular item.
An online retail site such as Amazon has a very large collection of items. Although books are found under several categories, often each category has too many to browse one after the other. Recommendations make the user's life easier by helping him find the best product for his tastes, and at the same time increase sales.
There are many ways to make recommendations:
· Content-based recommendations: One could use information about the product to identify similar products. For instance, you could use categories, content similarities, and so on, to identify products that are similar and recommend them to users who have already bought a particular product.
· Collaborative filtering: The other option is to use user behavior to identify similarities between products. For example, if the same user gave a high rating to two products, there is some similarity between those two products.
This recipe uses a dataset collected from Amazon about products to make content-based recommendations. In the dataset, each product has a list of similar items which is provided to the user, predetermined by Amazon. In this recipe, we will use that data to make recommendations.
How to do it...
1. Download the dataset from the Amazon product co-purchasing network metadata available at http://snap.stanford.edu/data/amazon-meta.html and unzip it. We call this directory as DATA_DIR.
Upload the data to HDFS by running the following commands. If the data directory is already there, clean it up.
$ hdfs dfs -mkdir data
$ hdfs dfs -mkdir data/input1
$ hdfs dfs -put <DATA_DIR>/amazon-meta.txt data/input1
2. Compile the source by running the gradle build command from the chapter9 directory of the source repository and obtain the hcb-c9-samples.jar file.
3. Run the most frequent user finder MapReduce job using the following command:
4. $ hadoop jar hcb-c9-samples.jar \
5. chapter9.MostFrequentUserFinder \
6. data/input1 data/output1
7. Read the results by running the following command:
8. $ hdfs dfs -cat data/output1/*
9. You will see that the MapReduce job has extracted the purchase data from each customer, and the results will look like the following:
10.customerID=A1002VY75YRZYF,review=ASIN=0375812253#title=Really Useful Engines (Railway Series)#salesrank=623218#group=Book #rating=4#similar=0434804622|0434804614|0434804630|0679894780|0375827439|,review=ASIN=B000002BMD#title=EverythingMustGo#salesrank=77939#group=Music#rating=4#similar=B00000J5ZX|B000024J5H|B00005AWNW|B000025KKX|B000008I2Z
11. Run the recommendation MapReduce job using the following command:
12.$ hadoop jar hcb-c9-samples.jar \
13.chapter9.ContentBasedRecommendation \
14.data/output1 data/output2
15. Read the results by running the following command:
16.$ hdfs dfs -cat data/output2/*
You will see that it will print the results as follows. Each line of the result contains the customer ID and a list of product recommendations for that customer.
A10003PM9DTGHQ [0446611867, 0446613436, 0446608955, 0446606812, 0446691798, 0446611867, 0446613436, 0446608955, 0446606812, 0446691798]
How it works...
The following listing shows an entry for one product from the dataset. Here, each data entry includes an ID, title, categorization, items similar to this item, and information about users who have reviewed the item. In this example, we assume that the customer who has reviewed the item has bought the item.
Id: 13
ASIN: 0313230269
title: Clockwork Worlds : Mechanized Environments in SF (Contributions to the Study of Science Fiction and Fantasy)
group: Book
salesrank: 2895088
similar: 2 1559360968 1559361247
categories: 3
|Books[283155]|Subjects[1000]|Literature & Fiction[17]|History & Criticism[10204]|Criticism & Theory[10207]|General[10213]
|Books[283155]|Subjects[1000]|Science Fiction & Fantasy[25]|Fantasy[16190]|History & Criticism[16203]
|Books[283155]|Subjects[1000]|Science Fiction & Fantasy[25]|Science Fiction[16272]|History & Criticism[16288]
reviews: total: 2 downloaded: 2 avg rating: 5
2002-8-5 cutomer: A14OJS0VWMOSWO rating: 5 votes: 2 helpful: 1
2003-3-21 cutomer: A2C27IQUH9N1Z rating: 5 votes: 4 helpful: 4
We have written a Hadoop InputFormat to parse the Amazon product data; the data format works similar to the format we have written in the Simple analytics using MapReduce recipe of Chapter 5, Analytics. The source files,src/chapter9/amazondata/AmazonDataReader.java and src/chapter9/amazondata/AmazonDataFormat.java, contain the code for the Amazon data formatter.
The Amazon data formatter will parse the dataset and emit the data about each Amazon product as key-value pairs to the map function. Data about each Amazon product is represented as a string, and the AmazonCustomer.java class includes code to parse and write out the data about Amazon customers.
This recipe includes two MapReduce computations. The source for these tasks can be found from src/chapter9/MostFrequentUserFinder.java and src/chapter9/ ContentBasedRecommendation.java. The Map task of the first MapReduce job receives data about each product in the log file as a different key-value pair.
When the Map task receives the product data, it emits the customer ID as the key and product information as the value for each customer who has bought the product.
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
List<AmazonCustomer> customerList = AmazonCustomer.parseAItemLine(value.toString());
for(AmazonCustomer customer: customerList){
context.write(new Text(customer.customerID),
new Text(customer.toString()));
}
}
Then, Hadoop collects all values for the key and invokes the Reducer once for each key. There will be a reduce function invocation for each customer, and each of those invocations will receive all products that have been bought by a customer. The Reducer emits the list of items bought by each customer, thus building a customer profile. Each of the items contains a list of similar items as well. In order to limit the size of the dataset, the Reducer will emit only the details of a customer who has bought more than five products.
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
AmazonCustomer customer = new AmazonCustomer();
customer.customerID = key.toString();
for(Text value: values){
Set<ItemData> itemsBought =new AmazonCustomer(
value.toString()).itemsBought;
for(ItemData itemData: itemsBrought){
customer.itemsBought.add(itemData);
}
}
if(customer.itemsBought.size() > 5){
context.write(
new IntWritable(customer.itemsBrought.size()),
new Text(customer.toString()));
}
}
The second MapReduce job uses the data generated from the first MapReduce task to make recommendations for each customer. The Map task receives data about each customer as the input, and the MapReduce job makes recommendations using the following three steps:
1. Each product (item) data from Amazon includes items similar to that item. Given a customer, the map function creates a list of all similar items for each item that customer has bought.
2. Then, the map function removes any item that the customer has already bought from the similar items list.
3. Finally, the map function selects ten items as recommendations.
4. public void map(Object key, Text value, Context context)
5. throws IOException, InterruptedException {
6. AmazonCustomer amazonCustomer =
7. new AmazonCustomer(value.toString()
8. .replaceAll("[0-9]+\\s+", ""));
9.
10. List<String> recommendations = new ArrayList<String>();
11. for (ItemData itemData : amazonCustomer.itemsBrought) {
12. recommendations.addAll(itemData.similarItems);
13. }
14.
15. for (ItemData itemData : amazonCustomer.itemsBrought) {
16. recommendations.remove(itemData.itemID);
17. }
18.
19. ArrayList<String> finalRecommendations =
20. new ArrayList<String>();
21. for (int i = 0;
22. i < Math.min(10, recommendations.size());i++) {
23. finalRecommendations.add(recommendations.get(i));
24. }
25. context.write(new Text(amazonCustomer.customerID),
26. new Text(finalRecommendations.toString()));
}
There's more...
You can learn more about content-based recommendations from Chapter 9, Recommendation Systems, of the book, Mining of Massive Datasets, Cambridge University Press, by Anand Rajaraman and Jeffrey David Ullman.
Apache Mahout, introduced in Chapter 7, Hadoop Ecosystem II –Pig, HBase, Mahout, and Sqoop, and used in Chapter 10, Mass Text Data Processing, contains several recommendation implementations. The following articles will give you information on using user-based and item-based recommenders in Mahout:
· https://mahout.apache.org/users/recommender/userbased-5-minutes.html
· https://mahout.apache.org/users/recommender/intro-itembased-hadoop.html
Classification using the naïve Bayes classifier
A classifier assigns inputs into one of the N classes based on some properties (also known as features) of inputs. Classifiers have widespread applications, such as e-mail spam filtering, finding the most promising products, selecting customers for closer interactions, and taking decisions in machine learning situations. Let's explore how to implement a classifier using a large dataset. For instance, a spam filter will assign each e-mail to one of the two clusters: spam mail or not spam mail.
There are many classification algorithms. One of the simplest, but effective, algorithm is the naïve Bayesian classifier that uses the Bayes theorem involving conditional probability.
In this recipe, we will also focus on the Amazon metadata dataset as before. We will look at several features of a product, such as the number of reviews received, positive ratings, and known similar items to identify a product with potential to be within the first 10,000 sales rank. We will use the naïve Bayesian classifier for this classification.
Note
You can learn more about the naïve Bayer classifier at http://en.wikipedia.org/wiki/Naive_Bayes_classifier.
How to do it...
1. Download the dataset from the Amazon product co-purchasing network metadata available at http://snap.stanford.edu/data/amazon-meta.html and unzip it. We will call this directory DATA_DIR.
2. Upload the data to HDFS by running the following commands. If the data directory is already there, clean it up.
3. $ hdfs dfs -mkdir data
4. $ hdfs dfs -mkdir data/input1
5. $ hdfs dfs -put <DATA_DIR>/amazon-meta.txt data/input1
6. Compile the source by running the gradle build command from the chapter9 directory of the source repository and obtain the hcb-c9-samples.jar file.
7. Run the MapReduce job using the following command:
8. $ hadoop jar hcb-c9-samples.jar \
9. chapter9.NaiveBayesProductClassifier \
10.data/input1 data/output5
11. Read the results by running the following command:
12.$ hdfs dfs -cat data/output5/*
13. You will see that it will print the following results. You can use these values with the Bayes classifier to classify the inputs:
14.postiveReviews>30 0.635593220338983
15.reviewCount>60 0.62890625
16.similarItemCount>150 0.5720620842572062
How it works...
The classifier uses the following features as indicators that the product can fall within the first 10,000 products:
· Number of reviews for a given product
· Number of positive reviews for a given product
· Number of similar items for a given product
We first run the MapReduce task to calculate the following probabilities, and then we will use those with the preceding formula to classify a given product:
· P1: Probability that a given item is within the first 10,000 products if it has more than 60 reviews
· P2: Probability that a given item is within the first 10,000 products if it has more than 30 positive reviews
· P3: Probability that a given item is within the first 10,000 products if it has more than 150 similar items
You can find the source for the classifier in the file, src/chapter9/ NaiveBayesProductClassifier.java. The Mapper function looks like this:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
List<AmazonCustomer> customerList = AmazonCustomer.parseAItemLine(value.toString());
int salesRank = -1;
int reviewCount = 0;
int postiveReviews = 0;
int similarItemCount = 0;
for (AmazonCustomer customer : customerList) {
ItemData itemData = customer.itemsBrought.iterator().next();
reviewCount++;
if (itemData.rating > 3) {
postiveReviews++;
}
similarItemCount = similarItemCount +
itemData.similarItems.size();
if (salesRank == -1) {
salesRank = itemData.salesrank;
}
}
boolean isInFirst10k = (salesRank <= 10000);
context.write(new Text("total"),
new BooleanWritable(isInFirst10k));
if (reviewCount > 60) {
context.write(new Text("reviewCount>60"),
new BooleanWritable(isInFirst10k));
}
if (postiveReviews > 30) {
context.write(new Text("postiveReviews>30"),
new BooleanWritable(isInFirst10k));
}
if (similarItemCount > 150) {
context.write(new Text("similarItemCount>150"),
new BooleanWritable(isInFirst10k));
}
}
The Mapper function walks though each product and evaluates its features. If the feature evaluates as true, it emits the feature name as the key and whether the product is within the first 10,000 products as the value.
MapReduce invokes the Reducer once for each feature. Then, each Reduce job receives all values for which the feature is true, and it calculates the probability that the product is within the first 10,000 products in the sales rank, given the feature is true.
public void reduce(Text key, Iterable<BooleanWritable> values, Context context) throws IOException,
InterruptedException {
int total = 0;
int matches = 0;
for (BooleanWritable value : values) {
total++;
if (value.get()) {
matches++;
}
}
context.write(new Text(key), new DoubleWritable((double) matches / total));
}
Given a product, we will examine and decide the following:
· Does it have more than 60 reviews?
· Does it have more than 30 positive reviews?
· Does it have more than 150 similar items?
We can decide the probabilities of events A, B, and C and we can calculate the probability of the given item being within the top 10,000 products using the Bayes theorem. The following code implements this logic:
public static boolean classifyItem(int similarItemCount, int reviewCount, int postiveReviews){
double reviewCountGT60 = 0.8;
double postiveReviewsGT30 = 0.9;
double similarItemCountGT150 = 0.7;
double a , b, c;
if (reviewCount > 60) {
a = reviewCountGT60;
}else{
a= 1 - reviewCountGT60;
}
if (postiveReviews > 30) {
b = postiveReviewsGT30;
}else{
b = 1- postiveReviewsGT30;
}
if (similarItemCount > 150) {
c = similarItemCountGT150;
}else{
c = 1- similarItemCountGT150;
}
double p = a*b*c/ (a*b*c + (1-a)*(1-b)*(1-c));
return p > 0.5;
}
When you run the classifier testing logic, it will load the data generated by the MapReduce job and classify 1,000 randomly selected products.
Assigning advertisements to keywords using the Adwords balance algorithm
Advertisements have become a major medium of revenue for the Web. It is a billion dollar business and is the source for revenue of most leading companies in Silicon Valley. Further, it has made it possible for companies such as Google, Facebook, Yahoo!, and Twitter to run their main services for free while collecting their revenue through advertisements.
Adwords lets people bid for keywords. For example, advertiser A can bid for the keyword, Hadoop Support, for $2 and provide a maximum budget of $100. Advertiser B can bid for the keyword, Hadoop Support, for $1.50 and provide a maximum budget of $200. When a user searches for a document with the given keywords, the system will choose one or more advertisements among the bids for these keywords. Advertisers will pay only if a user clicks on the advertisement.
The goal is to select advertisements such that they will maximize revenue. There are several factors in play when designing such a solution:
· We want to show advertisements that are more likely to be clicked often, as often times only clicks, not showing the advertisement, will get us money. We measure this as the fraction of times an advertisement was clicked as opposed to the number of times it was shown. We call this click-through rate for a keyword.
· We want to show advertisements belonging to advertisers with higher budgets as opposed to those with lower budgets.
In this recipe, we will implement a simplified version of the Adwords balance algorithm that can be used in such situations. For simplicity, we will assume that advertisers only bid on single words. Also, since we cannot find a real bid dataset, we will generate a sample bid dataset. Have a look at the following figure:
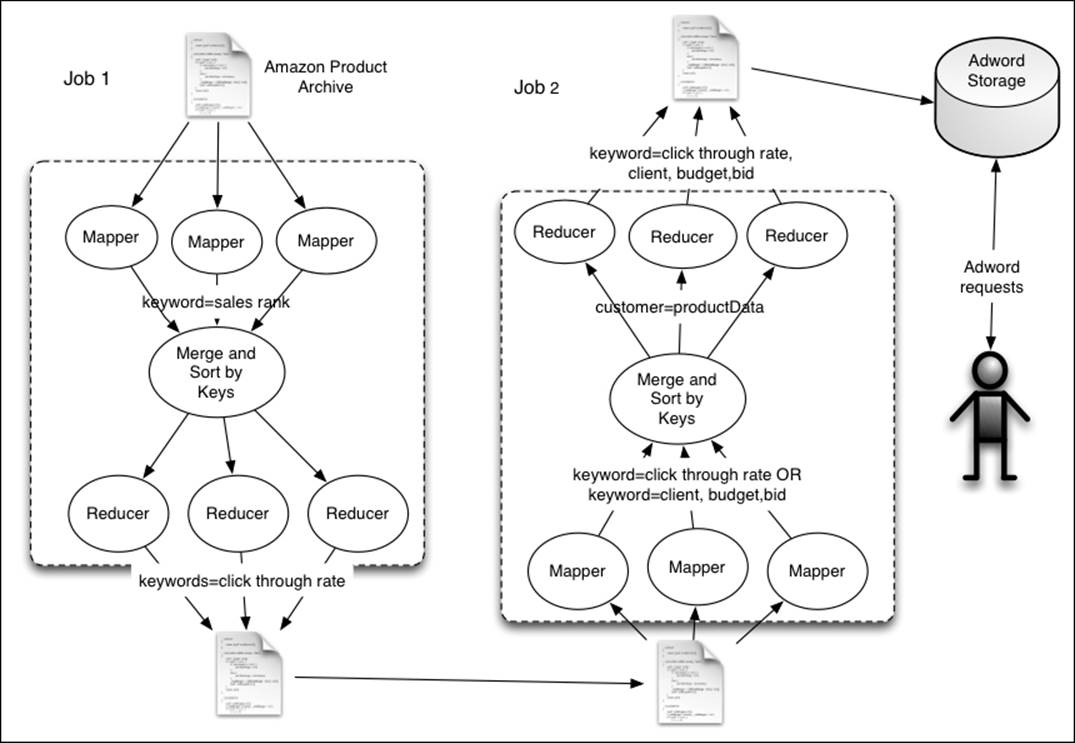
Assume that you are to support keyword-based advertisements using the Amazon dataset. The recipe will work as follows:
1. The first MapReduce job will approximate the click-through rate of the keyword using the Amazon sales index. Here, we assume that keywords that are found in the title of products with higher sales rank will have better click-through rates.
2. Then, we will run a Java program to generate a bid dataset.
3. Now, the second MapReduce task will group bids for the same product together and create an output that can be used by an advertisement assignment program.
4. Finally, we will use an advertisement assignment program to assign keywords to advertisers. We will use the following formula to implement the Adword balance algorithm. The formula assigns priority based on the fraction of unspent budget of each advertiser, bid value, and click-through rate:
Measure = bid value * click-through rate * (1-e^(-1*current budget/ initial budget))
How to do it...
1. Download the dataset from the Amazon product co-purchasing network metadata available from http://snap.stanford.edu/data/amazon-meta.html and unzip it. We will call this directory DATA_DIR.
2. Upload the data to HDFS by running the following commands. If data directory is already there, clean it up.
3. $ hdfs dfs -mkdir data
4. $ hdfs dfs -mkdir data/input1
5. $ hdfs dfs -put <DATA_DIR>/amazon-meta.txt data/input1
6. Compile the source by running the gradle build command from the chapter9 directory of the source repository and obtain the hcb-c9-samples.jar file.
7. Run the MapReduce job using the following command:
8. $ hadoop jar hcb-c9-samples.jar \
9. chapter9.adwords.ClickRateApproximator \
10.data/input1 data/output6
11. Download the results to your computer by running the following command:
12.$ hdfs dfs -get data/output6/part-r-* clickrate.data
13. You will see that it will print the following results. You may use these values with the Bayes classifier to classify the inputs:
14.keyword:(Annals 74
15.keyword:(Audio 153
16.keyword:(BET 95
17.keyword:(Beat 98
18.keyword:(Beginners) 429
19.keyword:(Beginning 110
20. Generate a bid dataset by running the following command. You can find the results in a biddata.data file.
21.$ java -cp hcb-c9-samples.jar \
22. chapter9.adwords.AdwordsBidGenerator \
23. clickrate.data
24. Create a directory called data/input2 and upload the bid dataset and results from the earlier MapReduce task to the data/input2 directory of HDFS with the following command:
25.$ hdfs dfs -put clickrate.data data/input2
26.$ hdfs dfs -put biddata.data data/input2
27. Run the second MapReduce job as follows:
28.$ hadoop jar hcb-c9-samples.jar \
29. chapter9.adwords.AdwordsBalanceAlgorithmDataGenerator \
30. data/input2 data/output7
31. Download the results to your computer by running the following command:
32.$ hdfs dfs -get data/output7/part-r-* adwords.data
33. Inspect the results:
34.(Animated client23,773.0,5.0,97.0|
35.(Animated) client33,310.0,8.0,90.0|
36.(Annals client76,443.0,13.0,74.0|
37.client51,1951.0,4.0,74.0|
38.(Beginners) client86, 210.0,6.0,429.0|
39. client6,236.0,5.0,429.0|
40.(Beginning client31,23.0,10.0,110.0|
41. Perform matches for random sets of keywords by running the following command:
42.$ java jar hcb-c9-samples.jar \
43. chapter9.adwords.AdwordsAssigner adwords.data
How it works...
As we discussed, this recipe consists of two MapReduce jobs. You can find the source for the first MapReduce job from the file, src/chapter9/adwords/ClickRateApproximator.java.
The Mapper function parses the Amazon dataset using the Amazon data format, and for each word in each product title, it emits the word and the sales ranks of that product. The function looks something like this:
public void map(Object key, Text value, Context context) {
......
String[] tokens = itemData.title.split("\\s");
for(String token: tokens){
if(token.length() > 3){
context.write(new Text(token), new IntWritable(itemData.salesrank));
}
}
}
Then, the MapReduce framework sorts the emitted key-value pairs by key and invokes the Reducer once for each key. As shown here, the reducer calculates an approximation for click rate using sales ranks emitted against the key:
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
double clickrate = 0;
for(IntWritable val: values){
if(val.get() > 1){
clickrate = clickrate + 1000/Math.log(val.get());
}else{
clickrate = clickrate + 1000;
}
}
context.write(new Text("keyword:" +key.toString()),
new IntWritable((int)clickrate));
}
There is no publicly available bid dataset. Therefore, we will generate a random bid dataset for our recipe using the AdwordsBidGenerator program. It will read the keywords generated by the preceding recipe and generate a random bid dataset.
Then, we will use the second MapReduce job to merge the bid dataset with the click-through rate and generate a dataset that has bid information sorted against the keyword. You can find the source for the second MapReduce task from the file,src/chapter9/adwords/AdwordsBalanceAlgorithmDataGenerator.java. The Mapper function looks like this:
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] keyVal = value.toString().split("\\s");
if (keyVal[0].startsWith("keyword:")) {
context.write(
new Text(keyVal[0].replace("keyword:", "")),
new Text(keyVal[1]));
} else if (keyVal[0].startsWith("client")) {
List<String[]> bids = new ArrayList<String[]>();
double budget = 0;
String clientid = keyVal[0];
String[] tokens = keyVal[1].split(",");
for (String token : tokens) {
String[] kp = token.split("=");
if (kp[0].equals("budget")) {
budget = Double.parseDouble(kp[1]);
} else if (kp[0].equals("bid")) {
String[] bidData = kp[1].split("\\|");
bids.add(bidData);
}
}
for (String[] bid : bids) {
String keyword = bid[0];
String bidValue = bid[1];
Double.parseDouble(bidValue);
context.write(new Text(keyword),
new Text(new StringBuffer()
.append(clientid).append(",")
.append(budget).append(",")
.append(bidValue).toString()));
}
}
}
The Mapper function reads both, the bid dataset and click-through rate dataset and emits both types of data against the keyword. Then, each Reducer receives all bids and the associated click-through data for each keyword. Next, the reducer merges the data and emits a list of bids against each keyword.
public void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
String clientid = null;
String budget = null;
String bid = null;
String clickRate = null;
List<String> bids = new ArrayList<String>();
for (Text val : values) {
if (val.toString().indexOf(",") > 0) {
bids.add(val.toString());
} else {
clickRate = val.toString();
}
}
StringBuffer buf = new StringBuffer();
for (String bidData : bids) {
String[] vals = bidData.split(",");
clientid = vals[0];
budget = vals[1];
bid = vals[2];
buf.append(clientid).append(",")
.append(budget).append(",")
.append(Double.valueOf(bid)).append(",")
.append(Math.max(1, Double.valueOf(clickRate)));
buf.append("|");
}
if (bids.size() > 0) {
context.write(key, new Text(buf.toString()));
}
}
Finally, the Adwords assigner loads the bid data and stores it against keywords to memory. Given a keyword, the Adwords assigner finds the bid that has the maximum value for the following equation and selects a bid among all the bids for advertisement:
Measure = bid value * click-through rate * (1-e^(-1*current budget/ initial budget))
There's more...
The preceding recipe assumes that the Adwords assigner can load all the data into memory to make advertisement assignment decisions. In reality, these computations are handled by large clusters making real-time decisions combining streaming technologies such as Apache Storm and high-throughput databases such as HBase, due to the millisecond level response times and the large datasets required by advertisement bidding systems.
This recipe assumes that users only bid for single words. However, to support multiple keyword bids, we would need to combine the click-through rates, and the rest of the algorithm can proceed as earlier.
More information about online advertisement can be found in the book, Mining of Massive Datasets, Cambridge University Press, by Anand Rajaraman and Jeffrey David Ullman.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.