Hadoop MapReduce v2 Cookbook, Second Edition (2015)
Chapter 10. Mass Text Data Processing
In this chapter, we will cover the following topics:
· Data preprocessing (extract, clean, and format conversion) using Hadoop streaming and Python
· De-duplicating data using Hadoop streaming
· Loading large datasets to an Apache HBase data store – importtsv and bulkload
· Creating TF and TF-IDF vectors for the text data
· Clustering text data using Apache Mahout
· Topic discovery using Latent Dirichlet Allocation (LDA)
· Document classification using Mahout Naive Bayes Classifier
Introduction
Hadoop MapReduce together with the supportive set of projects makes it a good framework of choice to process large text datasets and to perform extract-transform-load (ETL) type operations.
In this chapter, we'll be exploring how to use Hadoop streaming to perform data preprocessing operations such as data extraction, format conversion, and de-duplication. We'll also use HBase as the data store to store the data and will explore mechanisms to perform large bulk data loads to HBase with minimal overhead. Finally, we'll look into performing text analytics using the Apache Mahout algorithms.
We will be using the following sample dataset for the recipes in this chapter:
· 20 Newsgroups dataset available at http://qwone.com/~jason/20Newsgroups. This dataset contains approximately 20,000 newsgroup documents originally collected by Ken Lang.
Tip
Sample code
The example code files for this book are available in GitHub at https://github.com/thilg/hcb-v2. The chapter10 folder of the code repository contains the sample code for this chapter.
Data preprocessing using Hadoop streaming and Python
Data preprocessing is an important and often required component in data analytics. Data preprocessing becomes even more important when consuming unstructured text data generated from multiple different sources. Data preprocessing steps include operations such as cleaning the data, extracting important features from data, removing duplicate items from the datasets, converting data formats, and many more.
Hadoop MapReduce provides an ideal environment to perform these tasks in parallel when processing massive datasets. Apart from using Java MapReduce programs or Pig scripts or Hive scripts to preprocess the data, Hadoop also contains several other tools and features that are useful in performing these data preprocessing operations. One such feature is the InputFormats, which provides us with the ability to support custom data formats by implementing custom InputFormats. Another feature is the Hadoop streaming support, which allows us to use our favorite scripting languages to perform the actual data cleansing and extraction, while Hadoop will parallelize the computation to hundreds of compute and storage resources.
In this recipe, we are going to use Hadoop streaming with a Python script-based Mapper to perform data extraction and format conversion.
Getting ready
· Check whether Python is already installed on the Hadoop worker nodes. If not, install Python on all the Hadoop worker nodes.
How to do it...
The following steps show how to clean and extract data from the 20news dataset and store the data as a tab-separated file:
1. Download and extract the 20news dataset from http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz:
2. $ wget http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz
3. $ tar –xzf 20news-19997.tar.gz
4. Upload the extracted data to the HDFS. In order to save the compute time and resources, you can use only a subset of the dataset:
5. $ hdfs dfs -mkdir 20news-all
6. $ hdfs dfs –put <extracted_folder> 20news-all
7. Extract the resource package for this chapter and locate the MailPreProcessor.py Python script.
8. Locate the hadoop-streaming.jar JAR file of the Hadoop installation in your machine. Run the following Hadoop streaming command using that JAR. /usr/lib/hadoop-mapreduce/ is the hadoop-streaming JAR file's location for the Bigtop-based Hadoop installations:
9. $ hadoop jar \
10./usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
11.-input 20news-all/*/* \
12.-output 20news-cleaned \
13.-mapper MailPreProcessor.py \
14.-file MailPreProcessor.py
15. Inspect the results using the following command:
16.> hdfs dfs –cat 20news-cleaned/part-* | more
How it works...
Hadoop uses the default TextInputFormat as the input specification for the previous computation. Usage of the TextInputFormat generates a Map task for each file in the input dataset and generates a Map input record for each line. Hadoop streaming provides the input to the Map application through the standard input:
line = sys.stdin.readline();
while line:
….
if (doneHeaders):
list.append( line )
elif line.find( "Message-ID:" ) != -1:
messageID = line[ len("Message-ID:"):]
….
elif line == "":
doneHeaders = True
line = sys.stdin.readline();
The preceding Python code reads the input lines from the standard input until it reaches the end of the file. We parse the headers of the newsgroup file till we encounter the empty line that demarcates the headers from the message contents. The message content will be read in to a list line by line:
value = ' '.join( list )
value = fromAddress + "\t" ……"\t" + value
print '%s\t%s' % (messageID, value)
The preceding code segment merges the message content to a single string and constructs the output value of the streaming application as a tab-delimited set of selected headers, followed by the message content. The output key value is the Message-ID header extracted from the input file. The output is written to the standard output by using a tab to delimit the key and the value.
There's more...
We can generate the output of the preceding computation in the Hadoop SequenceFile format by specifying SequenceFileOutputFormat as the OutputFormat of the streaming computations:
$ hadoop jar \
/usr/lib/Hadoop-mapreduce/hadoop-streaming.jar \
-input 20news-all/*/* \
-output 20news-cleaned \
-mapper MailPreProcessor.py \
-file MailPreProcessor.py \
-outputformat \
org.apache.hadoop.mapred.SequenceFileOutputFormat \
-file MailPreProcessor.py
It is a good practice to store the data as SequenceFiles (or other Hadoop binary file formats such as Avro) after the first pass of the input data because SequenceFiles takes up less space and supports compression. You can use hdfs dfs -text <path_to_sequencefile> to output the contents of a SequenceFile to text:
$ hdfs dfs –text 20news-seq/part-* | more
However, for the preceding command to work, any Writable classes that are used in the SequenceFile should be available in the Hadoop classpath.
See also
· Refer to the Using Hadoop with legacy applications - Hadoop streaming and Adding support for new input data formats - implementing a custom InputFormat recipes of Chapter 4, Developing Complex Hadoop MapReduce Applications.
De-duplicating data using Hadoop streaming
Often, the datasets contain duplicate items that need to be eliminated to ensure the accuracy of the results. In this recipe, we use Hadoop to remove the duplicate mail records in the 20news dataset. These duplicate records are due to the users cross-posting the same message to multiple newsboards.
Getting ready
· Make sure Python is installed on your Hadoop compute nodes.
How to do it...
The following steps show how to remove duplicate mails due to cross-posting across the lists, from the 20news dataset:
1. Download and extract the 20news dataset from http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz:
2. $ wget http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz
3. $ tar –xzf 20news-19997.tar.gz
4. Upload the extracted data to the HDFS. In order to save the compute time and resources, you can use only a subset of the dataset:
5. $ hdfs dfs -mkdir 20news-all
6. $ hdfs dfs –put <extracted_folder> 20news-all
7. We are going to use the MailPreProcessor.py Python script from the previous recipe, Data preprocessing using Hadoop streaming and Python as the Mapper. Locate the MailPreProcessorReduce.py file in the source repository of this chapter.
8. Execute the following command:
9. $ hadoop jar \
10./usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
11.-input 20news-all/*/* \
12.-output 20news-dedup\
13.-mapper MailPreProcessor.py \
14.-reducer MailPreProcessorReduce.py \
15.-file MailPreProcessor.py\
16.-file MailPreProcessorReduce.py
17. Inspect the results using the following command:
18.$ hdfs dfs –cat 20news-dedup/part-00000 | more
How it works...
The Mapper Python script outputs the MessageID as the key. We use the MessageID to identify the duplicated messages that are a result of cross-posting across different newsgroups.
Hadoop streaming provides the Reducer input records of each key group line by line to the streaming reducer application through the standard input. However, Hadoop streaming does not have a mechanism to distinguish a new key-value group. The streaming reducer applications need to keep track of the input key to identify new groups when Hadoop starts to feed records of a new Key to the process. Since we output the Mapper results using the MessageID, the Reducer input gets grouped by the MessageID. Any group with more than one value (aka a message) per MessageID contains duplicates. In the following script, we use only the first value (message) of the record group and discard the others, which are the duplicate messages:
#!/usr/bin/env python
import sys;
currentKey = ""
for line in sys.stdin:
line = line.strip()
key, value = line.split('\t',1)
if currentKey == key :
continue
print '%s\t%s' % (key, value)
See also
· The Using Hadoop with legacy applications – Hadoop streaming recipe of Chapter 4, Developing Complex Hadoop MapReduce Applications and the Data preprocessing using Hadoop streaming and Python recipe of this chapter.
Loading large datasets to an Apache HBase data store – importtsv and bulkload
The Apache HBase data store is very useful when storing large-scale data in a semi-structured manner, so that it can be used for further processing using Hadoop MapReduce programs or to provide a random access data storage for client applications. In this recipe, we are going to import a large text dataset to HBase using the importtsv and bulkload tools.
Getting ready
1. Install and deploy Apache HBase in your Hadoop cluster.
2. Make sure Python is installed in your Hadoop compute nodes.
How to do it…
The following steps show you how to load the TSV (tab-separated value) converted 20news dataset in to an HBase table:
1. Follow the Data preprocessing using Hadoop streaming and Python recipe to perform the preprocessing of data for this recipe. We assume that the output of the following step 4 of that recipe is stored in an HDFS folder named "20news-cleaned":
2. $ hadoop jar \
3. /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
4. -input 20news-all/*/* \
5. -output 20news-cleaned \
6. -mapper MailPreProcessor.py \
7. -file MailPreProcessor.py
8. Start the HBase shell:
9. $ hbase shell
10. Create a table named 20news-data by executing the following command in the HBase shell. Older versions of the importtsv (used in the next step) command can handle only a single column family. Hence, we are using only a single column family when creating the HBase table:
11.hbase(main):001:0> create '20news-data','h'
12. Execute the following command to import the preprocessed data to the HBase table created earlier:
13.$ hbase \
14. org.apache.hadoop.hbase.mapreduce.ImportTsv \
15. -Dimporttsv.columns=HBASE_ROW_KEY,h:from,h:group,h:subj,h:msg \
16. 20news-data 20news-cleaned
17. Start the HBase Shell and use the count and scan commands of the HBase shell to verify the contents of the table:
18.hbase(main):010:0> count '20news-data'
19. 12xxx row(s) in 0.0250 seconds
20.
21.hbase(main):010:0> scan '20news-data', {LIMIT => 10}
22. ROW COLUMN+CELL
23. <1993Apr29.103624.1383@cronkite.ocis.te column=h:c1, timestamp=1354028803355, value= katop@astro.ocis.temple.edu (Chris Katopis)>
24. <1993Apr29.103624.1383@cronkite.ocis.te column=h:c2, timestamp=1354028803355, value= sci.electronics
25.......
The following are the steps to load the 20news dataset to an HBase table using the bulkload feature:
1. Follow steps 1 to 3, but create the table with a different name:
2. hbase(main):001:0> create '20news-bulk','h'
3. Use the following command to generate an HBase bulkload datafile:
4. $ hbase \
5. org.apache.hadoop.hbase.mapreduce.ImportTsv \
6. -Dimporttsv.columns=HBASE_ROW_KEY,h:from,h:group,h:subj,h:msg\
7. -Dimporttsv.bulk.output=hbaseloaddir \
8. 20news-bulk–source 20news-cleaned
9. List the files to verify that the bulkload datafiles are generated:
10.$ hadoop fs -ls 20news-bulk-source
11.......
12.drwxr-xr-x - thilina supergroup 0 2014-04-27 10:06 /user/thilina/20news-bulk-source/h
13.
14.$ hadoop fs -ls 20news-bulk-source/h
15.-rw-r--r-- 1 thilina supergroup 19110 2014-04-27 10:06 /user/thilina/20news-bulk-source/h/4796511868534757870
16. The following command loads the data to the HBase table by moving the output files to the correct location:
17.$ hbase \
18. org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \
19. 20news-bulk-source 20news-bulk
20.......
21.14/04/27 10:10:00 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://127.0.0.1:9000/user/thilina/20news-bulk-source/h/4796511868534757870 first= <1993Apr29.103624.1383@cronkite.ocis.temple.edu>last= <stephens.736002130@ngis>
22.......
23. Start the HBase Shell and use the count and scan commands of the HBase shell to verify the contents of the table:
24.hbase(main):010:0> count '20news-bulk'
25.hbase(main):010:0> scan '20news-bulk', {LIMIT => 10}
How it works...
The MailPreProcessor.py Python script extracts a selected set of data fields from the newsboard message and outputs them as a tab-separated dataset:
value = fromAddress + "\t" + newsgroup
+"\t" + subject +"\t" + value
print '%s\t%s' % (messageID, value)
We import the tab-separated dataset generated by the Streaming MapReduce computations to HBase using the importtsv tool. The importtsv tool requires the data to have no other tab characters except for the tab characters that separate the data fields. Hence, we remove any tab characters that may be present in the input data by using the following snippet of the Python script:
line = line.strip()
line = re.sub('\t',' ',line)
The importtsv tool supports the loading of data into HBase directly using the Put operations as well as by generating the HBase internal HFiles as well. The following command loads the data to HBase directly using the Put operations. Our generated dataset contains a Key and four fields in the values. We specify the data fields to the table column name mapping for the dataset using the -Dimporttsv.columns parameter. This mapping consists of listing the respective table column names in the order of the tab-separated data fields in the input dataset:
$ hbase \
org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.columns=<data field to table column mappings> \
<HBase tablename> <HDFS input directory>
We can use the following command to generate HBase HFiles for the dataset. These HFiles can be directly loaded to HBase without going through the HBase APIs, thereby reducing the amount of CPU and network resources needed:
$ hbase \
org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.columns=<filed to column mappings> \
-Dimporttsv.bulk.output=<path for hfile output> \
<HBase tablename> <HDFS input directory>
These generated HFiles can be loaded into HBase tables by simply moving the files to the right location. This moving can be performed by using the completebulkload command:
$ hbase \org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \
<HDFS path for hfiles> <table name>
There's more...
You can use the importtsv tool that has datasets with other data-filed separator characters as well by specifying the '-Dimporttsv.separator' parameter. The following is an example of using a comma as the separator character to import a comma-separated dataset in to an HBase table:
$ hbase \
org.apache.hadoop.hbase.mapreduce.ImportTsv \
'-Dimporttsv.separator=,' \
-Dimporttsv.columns=<data field to table column mappings> \
<HBase tablename> <HDFS input directory>
Look out for Bad Lines in the MapReduce job console output or in the Hadoop monitoring console. One reason for Bad Lines is to have unwanted delimiter characters. The Python script we used in the data-cleaning step removes any extra tabs in the message:
14/03/27 00:38:10 INFO mapred.JobClient: ImportTsv
14/03/27 00:38:10 INFO mapred.JobClient: Bad Lines=2
Data de-duplication using HBase
HBase supports the storing of multiple versions of column values for each record. When querying, HBase returns the latest version of values, unless we specifically mention a time period. This feature of HBase can be used to perform automatic de-duplication by making sure we use the same RowKey for duplicate values. In our 20news example, we use MessageID as the RowKey for the records, ensuring duplicate messages will appear as different versions of the same data record.
HBase allows us to configure the maximum or minimum number of versions per column family. Setting the maximum number of versions to a low value will reduce the data usage by discarding the old versions. Refer tohttp://hbase.apache.org/book/schema.versions.html for more information on setting the maximum or minimum number of versions.
See also
· The Running MapReduce jobs on HBase recipe of Chapter 7, Hadoop Ecosystem II – Pig, HBase, Mahout, and Sqoop.
· Refer to http://hbase.apache.org/book/ops_mgt.html#importtsv for more information on the ImportTsv command.
Creating TF and TF-IDF vectors for the text data
Most of the text analysis data-mining algorithms operate on vector data. We can use a vector space model to represent text data as a set of vectors. For example, we can build a vector space model by taking the set of all terms that appear in the dataset and by assigning an index to each term in the term set. The number of terms in the term set is the dimensionality of the resulting vectors, and each dimension of the vector corresponds to a term. For each document, the vector contains the number of occurrences of each term at the index location assigned to that particular term. This creates the vector space model using term frequencies in each document, which is similar to the result of the computation we performed in the Generating an inverted index using Hadoop MapReducerecipe of Chapter 8, Searching and Indexing.
The vectors can be seen as follows:
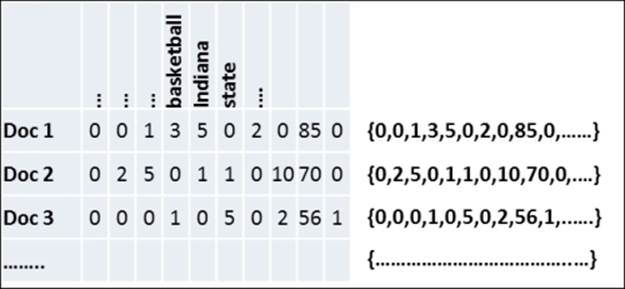
The term frequencies and the resulting document vectors
However, creating vectors using the preceding term count model gives a lot of weight to the terms that occur frequently across many documents (for example, the, is, a, are, was, who, and so on), although these frequent terms have a very minimal contribution when it comes to defining the meaning of a document. The Term frequency-inverse document frequency (TF-IDF) model solves this issue by utilizing the inverted document frequencies (IDF) to scale the term frequencies (TF). IDF is typically calculated by first counting the number of documents (DF) the term appears in, inversing it (1/DF) and normalizing it by multiplying with the number of documents and using the logarithm of the resultant value as shown roughly by the following equation:
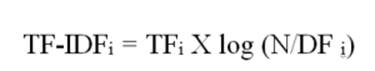
In this recipe, we'll create TF-IDF vectors from a text dataset using a built-in utility tool of Apache Mahout.
Getting ready
Install Apache Mahout in your machine using your Hadoop distribution or install the latest Apache Mahout version manually.
How to do it…
The following steps show you how to build a vector model of the 20news dataset:
1. Download and extract the 20news dataset from http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz:
2. $ wget http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz
3. $ tar –xzf 20news-19997.tar.gz
4. Upload the extracted data to the HDFS. In order to save the compute time and resources, you may use only a subset of the dataset:
5. $ hdfs dfs -mkdir 20news-all
6. $ hdfs dfs –put <extracted_folder> 20news-all
7. Go to MAHOUT_HOME. Generate the Hadoop sequence files from the uploaded text data:
8. $ mahout seqdirectory -i 20news-all -o 20news-seq
9. Generate TF and TF-IDF sparse vector models from the text data in the sequence files:
10.$ mahout seq2sparse -i 20news-seq -o 20news-vector
The preceding command launches a series of MapReduce computations. Wait for the completion of these computations:

11. Check the output directory using the following command. The tfidf-vectors folder contains the TF-IDF model vectors, the tf-vectors folder contains the term count model vectors, and the dictionary.file-0 contains the term to term-index mapping:
12.$ hdfs dfs -ls 20news-vector
13.
14.Found 7 items
15.drwxr-xr-x - u supergroup 0 2012-11-27 16:53 /user/u/20news-vector /df-count
16.-rw-r--r-- 1 u supergroup 7627 2012-11-27 16:51 /user/u/20news-vector/dictionary.file-0
17.-rw-r--r-- 1 u supergroup 8053 2012-11-27 16:53 /user/u/20news-vector/frequency.file-0
18.drwxr-xr-x - u supergroup 0 2012-11-27 16:52 /user/u/20news-vector/tf-vectors
19.drwxr-xr-x - u supergroup 0 2012-11-27 16:54 /user/u/20news-vector/tfidf-vectors
20.drwxr-xr-x - u supergroup 0 2012-11-27 16:50 /user/u/20news-vector/tokenized-documents
21.drwxr-xr-x - u supergroup 0 2012-11-27 16:51 /user/u/20news-vector/wordcount
22. Optionally, you can use the following command to dump the TF-IDF vectors as text. The key is the filename and the contents of the vectors are in the format <term index>:<TF-IDF value>:
23.$ mahout seqdumper -i 20news-vector/tfidf-vectors/part-r-00000
24.
25.……
26.Key class: class org.apache.hadoop.io.Text Value Class: class org.apache.mahout.math.VectorWritable
27.Key: /54492: Value: {225:3.374729871749878,400:1.5389964580535889,321:1.0,324:2.386294364929199,326:2.386294364929199,315:1.0,144:2.0986123085021973,11:1.0870113372802734,187:2.652313232421875,134:2.386294364929199,132:2.0986123085021973,......}
28.……
How it works…
Hadoop SequenceFiles store the data as binary key-value pairs and support data compression. Mahout's seqdirectory command converts the text files into a Hadoop SequenceFile by using the filename of the text file as the key and the contents of the text file asthe value. The seqdirectory command stores all the text contents in a single SequenceFile. However, it's possible for us to specify a chunk size to control the actual storage of the SequenceFile data blocks in the HDFS. The following are a selected set of options for the seqdirectory command:
mahout seqdirectory –i <HDFS path to text files> -o <HDFS output directory for sequence file>
-ow If present, overwrite the output directory
-chunk <chunk size> In MegaBytes. Defaults to 64mb
-prefix <key prefix> The prefix to be prepended to the key
The seq2sparse command is an Apache Mahout tool that supports the generation of sparse vectors from SequenceFiles that contain text data. It supports the generation of both TF as well as TF-IDF vector models. This command executes as a series of MapReduce computations. The following are a selected set of options for the seq2sparse command:
mahout seq2sparse -i <HDFS path to the text sequence file> -o <HDFS output directory>
-wt {tf|tfidf}
-chunk <max dictionary chunk size in mb to keep in memory>
--minSupport <minimum support>
--minDF <minimum document frequency>
--maxDFPercent <MAX PERCENTAGE OF DOCS FOR DF
The minSupport command is the minimum frequency for the word to be considered as a feature. minDF is the minimum number of documents the word needs to be in. maxDFPercent is the maximum value of the expression (document frequency of a word/total number of document) in order for that word to be considered as a good feature in the document. This helps remove high-frequency features such as stop words.
You can use the Mahout seqdumper command to dump the contents of a SequenceFile that uses the Mahout writable data types as plain text:
mahout seqdumper -i <HDFS path to the sequence file>
-o <output directory>
--count Output only the number of key value pairs.
--numItems Max number of key value pairs to output
--facets Output the counts per key.
See also
· The Generating an inverted index using Hadoop MapReduce recipe of Chapter 9, Classifications, Recommendations, and Finding Relationships.
· Refer to the Mahout documentation on creating vectors from text data at https://cwiki.apache.org/confluence/display/MAHOUT/Creating+Vectors+from+Text.
Clustering text data using Apache Mahout
Clustering plays an integral role in data-mining computations. Clustering groups together similar items of a dataset using one or more features of the data items based on the use case. Document clustering is used in many text-mining operations such as document organization, topic identification, information presentation, and so on. Document clustering shares many of the mechanisms and algorithms with traditional data clustering mechanisms. However, document clustering has its unique challenges when it comes to determining the features to use for clustering and when building vector space models to represent the text documents.
The Running K-means with Mahout recipe of Chapter 7, Hadoop Ecosystem II – Pig, HBase, Mahout, and Sqoop focuses on using Mahout KMeansClustering to cluster a statistics data. The Clustering an Amazon sales dataset recipe of Chapter 8, Classifications, Recommendations, and Finding Relationships of the previous edition of this book focuses on using clustering to identify customers with similar interests. These two recipes provide a more in-depth understanding of using Clustering algorithms in general. This recipe focuses on exploring two of the several clustering algorithms available in Apache Mahout for document clustering.
Getting ready
· Install Apache Mahout in your machine using your Hadoop distribution or install the latest Apache Mahout version manually in your machine.
How to do it...
The following steps use the Apache Mahout KmeansClustering algorithm to cluster the 20news dataset:
1. Refer to the Creating TF and TF-IDF vectors for the text data recipe in this chapter and generate TF-IDF vectors for the 20news dataset. We assume the TF-IDF vectors are in the 20news-vector/tfidf-vectors folder of HDFS.
2. Execute the following command to run the Mahout KMeansClustering computation:
3. $ mahout kmeans \
4. --input 20news-vector/tfidf-vectors \
5. --clusters 20news-seed/clusters
6. --output 20news-km-clusters\
7. --distanceMeasure \
8. org.apache.mahout.common.distance.SquaredEuclideanDistanceMeasure-k 10 --maxIter 20 --clustering
9. Execute the following command to convert the clusters to text:
10.$ mahout clusterdump \
11. -i 20news-km-clusters/clusters-*-final\
12. -o 20news-clusters-dump \
13. -d 20news-vector/dictionary.file-0 \
14. -dt sequencefile \
15. --pointsDir 20news-km-clusters/clusteredPoints
16.
17.$ cat 20news-clusters-dump
How it works...
The following code shows the usage of the Mahout KMeans algorithm:
mahout kmeans
--input <tfidf vector input>
--clusters <seed clusters>
--output <HDFS path for output>
--distanceMeasure <distance measure>-k <number of clusters>--maxIter <maximum number of iterations>--clustering
Mahout will generate random seed clusters when an empty HDFS directory path is given to the --clusters option. Mahout supports several different distance calculation methods such as Euclidean, Cosine, and Manhattan.
The following is the usage of the Mahout clusterdump command:
mahout clusterdump -i <HDFS path to clusters>-o <local path for text output>
-d <dictionary mapping for the vector data points>
-dt <dictionary file type (sequencefile or text)>
--pointsDir <directory containing the input vectors to clusters mapping>
See also
· The Running K-means with Mahout recipe of Chapter 7, Hadoop Ecosystem II – Pig, HBase, Mahout, and Sqoop.
Topic discovery using Latent Dirichlet Allocation (LDA)
We can use Latent Dirichlet Allocation (LDA) to cluster a given set of words into topics and a set of documents into combinations of topics. LDA is useful when identifying the meaning of a document or a word based on the context, without solely depending on the number of words or the exact words. LDA is a step away from raw text matching and towards semantic analysis. LDA can be used to identify the intent and to resolve ambiguous words in a system such as a search engine. Some other example use cases of LDA are identifying influential Twitter users for particular topics and Twahpic (http://twahpic.cloudapp.net) application uses LDA to identify topics used on Twitter.
LDA uses the TF vector space model as opposed to the TF-IDF model as it needs to consider the co-occurrence and correlation of words.
Getting ready
Install Apache Mahout in your machine using your Hadoop distribution, or install the latest Apache Mahout version manually.
How to do it…
The following steps show you how to run the Mahout LDA algorithm on a subset of the 20news dataset:
1. Download and extract the 20news dataset from http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz:
2. $ wget http://qwone.com/~jason/20Newsgroups/20news-19997.tar.gz
3. $ tar –xzf 20news-19997.tar.gz
4. Upload the extracted data to the HDFS. In order to save the compute time and resources, you may use only a subset of the dataset:
5. $ hdfs dfs -mkdir 20news-all
6. $ hdfs dfs –put <extracted_folder> 20news-all
7. Generate sequence files from the uploaded text data:
8. $ mahout seqdirectory -i 20news-all -o 20news-seq
9. Generate a sparse vector from the text data in the sequence files:
10.$ mahout seq2sparse \
11.–i 20news-seq -o 20news-tf \
12.-wt tf -a org.apache.lucene.analysis.WhitespaceAnalyzer
13. Convert the TF vectors from SequenceFile<Text, VectorWritable> to SequenceFile<IntWritable,Text>:
14.$ mahout rowid -i 20news-tf/tf-vectors -o 20news-tf-int
15. Run the following command to perform the LDA computation:
16.$ mahout cvb \
17.-i 20news-tf-int/matrix -o lda-out \
18.-k 10 -x 20 \
19.-dict 20news-tf/dictionary.file-0 \
20.-dt lda-topics \
21.-mt lda-topic-model
22. Dump and inspect the results of the LDA computation:
23.$ mahout seqdumper -i lda-topics/part-m-00000
24.
25.Input Path: lda-topics5/part-m-00000
26.Key class: class org.apache.hadoop.io.IntWritable Value Class: class org.apache.mahout.math.VectorWritable
27.Key: 0: Value: {0:0.12492744375758073,1:0.03875953927132082,2:0.1228639250669511,3:0.15074522974495433,4:0.10512715697420276,5:0.10130565323653766,6:0.061169131590630275,7:0.14501579630233746,8:0.07872957132697946,9:0.07135655272850545}
28......
29. Join the output vectors with the dictionary mapping of term-to-term indexes:
30.$ mahout vectordump \
31.-i lda-topics/part-m-00000 \
32.--dictionary 20news-tf/dictionary.file-0 \
33.--vectorSize 10 -dt sequencefile
34.
35.......
36.
37.{"Fluxgate:0.12492744375758073,&:0.03875953927132082,(140.220.1.1):0.1228639250669511,(Babak:0.15074522974495433,(Bill:0.10512715697420276,(Gerrit:0.10130565323653766,(Michael:0.061169131590630275,(Scott:0.14501579630233746,(Usenet:0.07872957132697946,(continued):0.07135655272850545}
38.{"Fluxgate:0.13130952097888746,&:0.05207587369196414,(140.220.1.1):0.12533225607394424,(Babak:0.08607740024552457,(Bill:0.20218284543514245,(Gerrit:0.07318295757631627,(Michael:0.08766888242201039,(Scott:0.08858421220476514,(Usenet:0.09201906604666685,(continued):0.06156698532477829}
39........
How it works…
The Mahout CVB version of LDA implements the Collapse Variable Bayesian inference algorithm using an iterative MapReduce approach:
mahout cvb \
-i 20news-tf-int/matrix \
-o lda-out -k 10 -x 20 \
-dict 20news-tf/dictionary.file-0 \
-dt lda-topics \
-mt lda-topic-model
The -i parameter provides the input path, while the -o parameter provides the path to store the output. The -k parameter specifies the number of topics to learn and –x specifies the maximum number of iterations for the computation. The -dict parameter points to the dictionary that contains the mapping of terms to term-indexes. The path given in the –dt parameter stores the training topic distribution. The path given in –mt is used as a temporary location to store the intermediate models.
All the command-line options of the cvb command can be queried by invoking the help option as follows:
mahout cvb --help
Setting the number of topics to a very small value brings out extremely high-level topics. A large number of topics produces more descriptive topics but takes longer to process. The maxDFPercent option can be used to remove common words, thereby speeding up the processing.
See also
· A Collapsed Variational Bayesian Inference Algorithm for Latent Dirichlet Allocation by Y.W. Teh, D. Newman, and M. Welling. In NIPS, volume 19, 2006 which can be found at http://www.gatsby.ucl.ac.uk/~ywteh/research/inference/nips2006.pdf.
Document classification using Mahout Naive Bayes Classifier
Classification assigns documents or data items to an already known set of classes with already known properties. Document classification or categorization is used when we need to assign documents to one or more categories. This is a frequent use case in information retrieval as well as library science.
The Classification using the naïve Bayes classifier recipe in Chapter 9, Classifications, Recommendations, and Finding Relationships provides a more detailed description about classification use cases, and also gives you an overview of using the Naive Bayes classifier algorithm. This recipe focuses on highlighting the classification support in Apache Mahout for text documents.
Getting ready
· Install Apache Mahout in your machine using your Hadoop distribution, or install the latest Apache Mahout version manually.
How to do it...
The following steps use the Apache Mahout Naive Bayes algorithm to cluster the 20news dataset:
1. Refer to the Creating TF and TF-IDF vectors for the text data recipe in this chapter and generate TF-IDF vectors for the 20news dataset. We assume that the TF-IDF vectors are in the 20news-vector/tfidf-vectors folder of the HDFS.
2. Split the data into training and test datasets:
3. $ mahout split \
4. -i 20news-vectors/tfidf-vectors \
5. --trainingOutput /20news-train-vectors \
6. --testOutput /20news-test-vectors \
7. --randomSelectionPct 40 \
8. --overwrite --sequenceFiles
9. Train the Naive Bayes model:
10.$ mahout trainnb \
11. -i 20news-train-vectors -el \
12. -o model \
13. -li labelindex
14. Test the classification on the test dataset:
15.$ mahout testnb \
16. -i 20news-train-vectors \
17. -m model \
18. -l labelindex \
19. -o 20news-testing
How it works...
Mahout's split command can be used to split a dataset into a training dataset and a test dataset. This command works with text datasets as well as with Hadoop SequenceFile datasets. The following is the usage of the Mahout data-splitting command. You can use the --help option with the split command to print out all the options:
mahout split \
-i <input data directory> \
--trainingOutput <HDFS path to store the training dataset> \
--testOutput <HDFS path to store the test dataset> \
--randomSelectionPct <percentage to be selected as test data> \
--sequenceFiles
The sequenceFiles option specifies that the input dataset is in Hadoop SequenceFiles.
The following is the usage of the Mahout Naive Bayes classifier training command. The --el option informs Mahout to extract the labels from the input dataset:
mahout trainnb \
-i <HDFS path to the training data set> \
-el \
-o <HDFS path to store the trained classifier model> \
-li <Path to store the label index> \
The following is the usage of the Mahout Naive Bayes classifier testing command:
mahout testnb \
-i <HDFS path to the test data set>
-m <HDFS path to the classifier model>\
-l <Path to the label index> \
-o <path to store the test result>
See also
· The Classification using the naïve Bayes classifier recipe of Chapter 9, Classifications, Recommendations, and Finding Relationships
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.