Hadoop MapReduce v2 Cookbook, Second Edition (2015)
Chapter 4. Developing Complex Hadoop MapReduce Applications
In this chapter, we will cover the following recipes:
· Choosing appropriate Hadoop data types
· Implementing a custom Hadoop Writable data type
· Implementing a custom Hadoop key type
· Emitting data of different value types from a Mapper
· Choosing a suitable Hadoop InputFormat for your input data format
· Adding support for new input data formats – implementing a custom InputFormat
· Formatting the results of MapReduce computations – using Hadoop OutputFormats
· Writing multiple outputs from a MapReduce computation
· Hadoop intermediate data partitioning
· Secondary sorting – sorting Reduce input values
· Broadcasting and distributing shared resources to tasks in a MapReduce job – Hadoop DistributedCache
· Using Hadoop with legacy applications – Hadoop streaming
· Adding dependencies between MapReduce jobs
· Hadoop counters for reporting custom metrics
Introduction
This chapter introduces you to several advanced Hadoop MapReduce features that will help you to develop highly customized, efficient MapReduce applications.
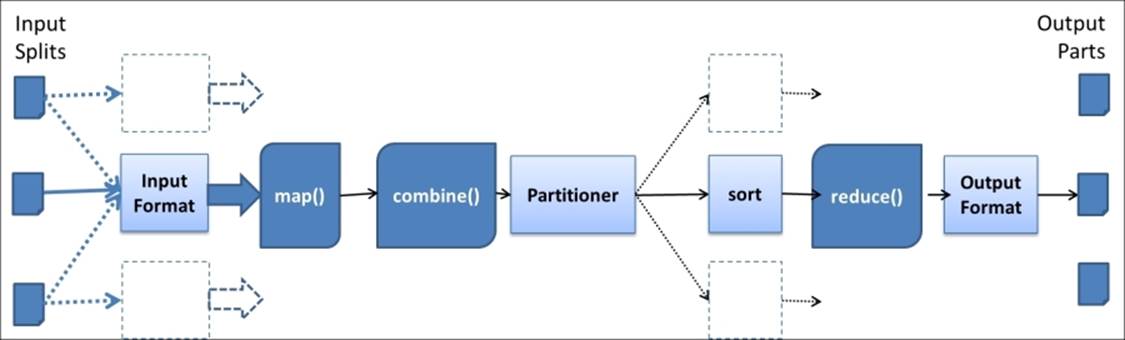
The preceding figure depicts the typical flow of a Hadoop MapReduce computation. The InputFormat reads the input data from HDFS and parses the data to create key-value pair inputs for the map function. InputFormat also performs the logical partitioning of data to create the Map tasks of the computation. A typical MapReduce computation creates a Map task for each input HDFS data block. Hadoop invokes the user provided map function for each of the generated key-value pairs. As mentioned in Chapter 1, Getting Started with Hadoop v2, if provided, the optional combiner step may get invoked with the output data from the map function.
The Partitioner step then partitions the output data of the Map task in order to send them to the respective Reduce tasks. This partitioning is performed using the key field of the Map task output key-value pairs and results in a number of partitions equal to the number of Reduce tasks. Each Reduce task fetches the respective output data partitions from the Map tasks (also known as shuffling) and performs a merge sort of the data based on the key field. Hadoop also groups the input data to the reduce function based on the key field of the data before invoking the reduce function. The output key-value pairs from the Reduce task would get written to the HDFS based on the format specified by the OutputFormat class.
In this chapter, we will explore the different parts of the earlier mentioned high-level flow of a Hadoop MapReduce computation in detail and explore the options and customizations available for each step. First you'll learn the different data types provided by Hadoop and the steps to implement custom data types for Hadoop MapReduce computations. Then we'll walk through the different data InputFormats and OutputFormats provided by Hadoop. Next, we will get a basic understanding of how to add support for new data formats in Hadoop as well as mechanisms for outputting more than one data product from a single MapReduce computation. We will also explore the Map output data partitioning and use that knowledge to introduce secondary sorting of the reduce function input data values.
In addition to the above, we will also discuss other advanced Hadoop features such as using DistributedCache for distributing the data, using Hadoop streaming feature for quick prototyping of Hadoop computations, and using Hadoop counters to report custom metrics for your computations as well as adding job dependencies to manage simple DAG-based workflows of Hadoop MapReduce computations.
Note
Sample code and data
The example code files for this book are available in GitHub at https://github.com/thilg/hcb-v2. The chapter4 folder of the code repository contains the sample source code files for this chapter.
You can download the data for the log processing sample from http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html. You can find a description of the structure of this data from http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html. A small extract of this dataset that can be used for testing is available in the code repository at chapter4/resources.
Sample codes can be compiled by issuing the gradle build command in the chapter4 folder of the code repository. Project files for Eclipse IDE can be generated by running the gradle eclipse command in the main folder of the code repository. Project files for IntelliJ IDEA IDE can be generated by running the gradle idea command in the main folder of the code repository.
Choosing appropriate Hadoop data types
Hadoop uses the Writable interface-based classes as the data types for the MapReduce computations. These data types are used throughout the MapReduce computational flow, starting with reading the input data, transferring intermediate data between Map and Reduce tasks, and finally, when writing the output data. Choosing the appropriate Writable data types for your input, intermediate, and output data can have a large effect on the performance and the programmability of your MapReduce programs.
In order to be used as a value data type of a MapReduce computation, a data type must implement the org.apache.hadoop.io.Writable interface. The Writable interface defines how Hadoop should serialize and de-serialize the values when transmitting and storing the data. In order to be used as a key data type of a MapReduce computation, a data type must implement the org.apache.hadoop.io.WritableComparable<T> interface. In addition to the functionality of the Writable interface, the WritableComparable interface further defines how to compare the key instances of this type with each other for sorting purposes.
Note
Hadoop's Writable versus Java's Serializable
Hadoop's Writable-based serialization framework provides a more efficient and customized serialization and representation of the data for MapReduce programs than using the general-purpose Java's native serialization framework. As opposed to Java's serialization, Hadoop's Writable framework does not write the type name with each object expecting all the clients of the serialized data to be aware of the types used in the serialized data. Omitting the type names makes the serialization process faster and results in compact, random accessible serialized data formats that can be easily interpreted by non-Java clients. Hadoop's Writable-based serialization also has the ability to reduce the object-creation overhead by reusing the Writable objects, which is not possible with Java's native serialization framework.
How to do it...
The following steps show you how to configure the input and output data types of your Hadoop MapReduce application:
1. Specify the data types for the input (key: LongWritable, value: Text) and output (key: Text, value: IntWritable) key-value pairs of your Mapper using the generic-type variables:
2. public class SampleMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
3.
4. public void map(LongWritable key, Text value,
5. Context context) … {
6. …… }
}
7. Specify the data types for the input (key: Text, value: IntWritable) and output (key: Text, value: IntWritable) key-value pairs of your Reducer using the generic-type variables. The Reducer's input key-value pair data types should match the Mapper's output key-value pairs.
8. public class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
9.
10. public void reduce(Text key,
11. Iterable<IntWritable> values, Context context) {
12. …… }
}
13. Specify the output data types of the MapReduce computation using the Job object as shown in the following code snippet. These data types will serve as the output types for both the Reducer and the Mapper, unless you specifically configure the Mapper output types as in step 4.
14.Job job = new Job(..);
15.….
16.job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
17. Optionally, you can configure the different data types for the Mapper's output key-value pairs using the following steps, when your Mapper and Reducer have different data types for the output key-value pairs.
18.job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
There's more...
Hadoop provides several primitive data types such as IntWritable, LongWritable, BooleanWritable, FloatWritable, and ByteWritable, which are the Writable versions of their respective Java primitive data types. We can use these types as both the key types as well as the value types.
The following are several more Hadoop built-in data types that we can use as both the key as well as the value types:
· Text: This stores UTF8 text
· BytesWritable: This stores a sequence of bytes
· VIntWritable and VLongWritable: These store variable length integer and long values
· NullWritable: This is a zero-length Writable type that can be used when you don't want to use a key or value type
The following Hadoop built-in collection data types can only be used as value types:
· ArrayWritable: This stores an array of values belonging to a Writable type. To use ArrayWritable type as the value type of a Reducer's input, you need to create a subclass of ArrayWritable to specify the type of the Writable values stored in it.
· public class LongArrayWritable extends ArrayWritable {
· public LongArrayWritable() {
· super(LongWritable.class);
· }
}
· TwoDArrayWritable: This stores a matrix of values belonging to the same Writable type. To use the TwoDArrayWritable type as the value type of a Reducer's input, you need to specify the type of the stored values by creating a subclass of the TwoDArrayWritable type similar to the ArrayWritable type.
· public class LongTwoDArrayWritable extends TwoDArrayWritable {
· public LongTwoDArrayWritable() {
· super(LongWritable.class);
· }
}
· MapWritable: This stores a map of key-value pairs. Keys and values should be of the Writable data types. You can use the MapWritable function as follows. However, you should be aware that the serialization of MapWritable adds a slight performance penalty due to the inclusion of the class names of each object stored in the map.
· MapWritable valueMap = new MapWritable();
valueMap.put(new IntWritable(1),new Text("test"));
· SortedMapWritable: This stores a sorted map of key-value pairs. Keys should implement the WritableComparable interface. Usage of SortedMapWritable is similar to the MapWritable function.
See also
· The Implementing a custom Hadoop Writable data type recipe
· The Implementing a custom Hadoop key type recipe
Implementing a custom Hadoop Writable data type
There can be use cases where none of the inbuilt data types match your requirement or a custom data type optimized for your use case may perform better than a Hadoop built-in data type. In such scenarios, we can easily write a custom Writable data type by implementing the org.apache.hadoop.io.Writable interface to define the serialization format of your data type. The Writable interface-based types can be used as value types in Hadoop MapReduce computations.
In this recipe, we implement a sample Hadoop Writable data type for HTTP server log entries. For the purpose of this sample, we consider that a log entry consists of the five fields: request host, timestamp, request URL, response size, and the HTTP status code. The following is a sample log entry:
192.168.0.2 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245
You can download a sample HTTP server log dataset from ftp://ita.ee.lbl.gov/traces/NASA_access_log_Jul95.gz.
How to do it...
The following are the steps to implement a custom Hadoop Writable data type for the HTTP server log entries:
1. Write a new LogWritable class implementing the org.apache.hadoop.io.Writable interface:
2. public class LogWritable implements Writable{
3.
4. private Text userIP, timestamp, request;
5. private IntWritable responseSize, status;
6.
7. public LogWritable() {
8. this.userIP = new Text();
9. this.timestamp= new Text();
10. this.request = new Text();
11. this.responseSize = new IntWritable();
12. this.status = new IntWritable();
13. }
14. public void readFields(DataInput in) throws IOException {
15. userIP.readFields(in);
16. timestamp.readFields(in);
17. request.readFields(in);
18. responseSize.readFields(in);
19. status.readFields(in);
20. }
21.
22. public void write(DataOutput out) throws IOException {
23. userIP.write(out);
24. timestamp.write(out);
25. request.write(out);
26. responseSize.write(out);
27. status.write(out);
28. }
29.
30.……… // getters and setters for the fields
}
31. Use the new LogWritable type as a value type in your MapReduce computation. In the following example, we use the LogWritable type as the Map output value type:
32.public class LogProcessorMap extends Mapper<LongWritable,
33.Text, Text, LogWritable> {
34.….
35.}
36.
37.public class LogProcessorReduce extends Reducer<Text,
38.LogWritable, Text, IntWritable> {
39.
40. public void reduce(Text key,
41. Iterable<LogWritable> values, Context context) {
42. …… }
}
43. Configure the output types of the job accordingly.
44.Job job = ……
45.….
46.job.setOutputKeyClass(Text.class);
47.job.setOutputValueClass(IntWritable.class);
48.job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LogWritable.class);
How it works...
The Writable interface consists of the two methods, readFields() and write(). Inside the readFields() method, we de-serialize the input data and populate the fields of the Writable object.
public void readFields(DataInput in) throws IOException {
userIP.readFields(in);
timestamp.readFields(in);
request.readFields(in);
responseSize.readFields(in);
status.readFields(in);
}
In the preceding example, we use the Writable types as the fields of our custom Writable type and use the readFields() method of the fields for de-serializing the data from the DataInput object. It is also possible to use Java primitive data types as the fields of theWritable type and to use the corresponding read methods of the DataInput object to read the values from the underlying stream as done in the following code snippet:
int responseSize = in.readInt();
String userIP = in.readUTF();
Inside the write() method, we write the fields of the Writable object to the underlying stream.
public void write(DataOutput out) throws IOException {
userIP.write(out);
timestamp.write(out);
request.write(out);
responseSize.write(out);
status.write(out);
}
In case you are using Java primitive data types as the fields of the Writable object, then you can use the corresponding write methods of the DataOutput object to write the values to the underlying stream as follows:
out.writeInt(responseSize);
out.writeUTF(userIP);
There's more...
Please be cautious about the following issues when implementing your custom Writable data type:
· In case you are adding a custom constructor to your custom Writable class, make sure to retain the default empty constructor.
· TextOutputFormat uses the toString() method to serialize the key and value types. In case you are using the TextOutputFormat to serialize the instances of your custom Writable type, make sure to have a meaningful toString() implementation for your customWritable data type.
· While reading the input data, Hadoop may reuse an instance of the Writable class repeatedly. You should not rely on the existing state of the object when populating it inside the readFields() method.
See also
The Implementing a custom Hadoop key type recipe.
Implementing a custom Hadoop key type
The instances of Hadoop MapReduce key types should have the ability to compare against each other for sorting purposes. In order to be used as a key type in a MapReduce computation, a Hadoop Writable data type should implement theorg.apache.hadoop.io.WritableComparable<T> interface. The WritableComparable interface extends the org.apache.hadoop.io.Writable interface and adds the compareTo() method to perform the comparisons.
In this recipe, we modify the LogWritable data type of the Implementing a custom Hadoop Writable data type recipe to implement the WritableComparable interface.
How to do it...
The following are the steps to implement a custom Hadoop WritableComparable data type for the HTTP server log entries, which uses the request hostname and timestamp for comparison.
1. Modify the LogWritable class to implement the org.apache.hadoop.io.WritableComparable interface:
2. public class LogWritable implements
3. WritableComparable<LogWritable> {
4.
5. private Text userIP, timestamp, request;
6. private IntWritable responseSize, status;
7.
8. public LogWritable() {
9. this.userIP = new Text();
10. this.timestamp= new Text();
11. this.request = new Text();
12. this.responseSize = new IntWritable();
13. this.status = new IntWritable();
14. }
15.
16. public void readFields(DataInput in) throws IOException {
17. userIP.readFields(in);
18. timestamp.readFields(in);
19. request.readFields(in);
20. responseSize.readFields(in);
21. status.readFields(in);
22. }
23.
24. public void write(DataOutput out) throws IOException {
25. userIP.write(out);
26. timestamp.write(out);
27. request.write(out);
28. responseSize.write(out);
29. status.write(out);
30. }
31.
32. public int compareTo(LogWritable o) {
33. if (userIP.compareTo(o.userIP)==0){
34. return (timestamp.compareTo(o.timestamp));
35. }else return (userIP.compareTo(o.userIP);
36. }
37.
38. public boolean equals(Object o) {
39. if (o instanceof LogWritable) {
40. LogWritable other = (LogWritable) o;
41. return userIP.equals(other.userIP) && timestamp.equals(other.timestamp);
42. }
43. return false;
44. }
45.
46. public int hashCode()
47. {
48. Return userIP.hashCode();
49. }
50. ……… // getters and setters for the fields
}
51. You can use the LogWritable type as either a key type or a value type in your MapReduce computation. In the following example, we use the LogWritable type as the Map output key type:
52.public class LogProcessorMap extends Mapper<LongWritable,
53.Text, LogWritable, IntWritable> {
54.…
55.}
56.
57.public class LogProcessorReduce extends Reducer<LogWritable,
58.IntWritable, Text, IntWritable> {
59.
60.public void reduce(LogWritablekey,
61.Iterable<IntWritable> values, Context context) {
62. …… }
}
63. Configure the output types of the job accordingly.
64.Job job = ……
65.…
66.job.setOutputKeyClass(Text.class);
67.job.setOutputValueClass(IntWritable.class);
68.job.setMapOutputKeyClass(LogWritable.class);
job.setMapOutputValueClass(IntWritable.class);
How it works...
The WritableComparable interface introduces the compareTo() method in addition to the readFields() and write() methods of the Writable interface. The compareTo() method should return a negative integer, zero, or a positive integer, if this object is less than, equal to, or greater than the object being compared to it respectively. In the LogWritable implementation, we consider the objects equal if both user's IP addresses and the timestamps are the same. If the objects are not equal, we decide the sort order, first based on the user IP address and then based on the timestamp.
public int compareTo(LogWritable o) {
if (userIP.compareTo(o.userIP)==0){
return (timestamp.compareTo(o.timestamp));
}else return (userIP.compareTo(o.userIP);
}
Hadoop uses HashPartitioner as the default partitioner implementation to calculate the distribution of the intermediate data to the Reducers. HashPartitioner requires the hashCode() method of the key objects to satisfy the following two properties:
· Provide the same hash value across different JVM instances
· Provide a uniform distribution of hash values
Hence, you must implement a stable hashCode() method for your custom Hadoop key types satisfying both the earlier-mentioned requirements. In the LogWritable implementation, we use the hash code of the request hostname/IP address as the hash code of theLogWritable instance. This ensures that the intermediate LogWritable data will be partitioned based on the request hostname/IP address.
public int hashCode()
{
return userIP.hashCode();
}
See also
The Implementing a custom Hadoop Writable data type recipe.
Emitting data of different value types from a Mapper
Emitting data products belonging to multiple value types from a Mapper is useful when performing Reducer-side joins as well as when we need to avoid the complexity of having multiple MapReduce computations to summarize different types of properties in a dataset. However, Hadoop Reducers do not allow multiple input value types. In these scenarios, we can use the GenericWritable class to wrap multiple value instances belonging to different data types.
In this recipe, we reuse the HTTP server log entry analyzing the sample of the Implementing a custom Hadoop Writable data type recipe. However, instead of using a custom data type, in the current recipe, we output multiple value types from the Mapper. This sample aggregates the total number of bytes served from the web server to a particular host and also outputs a tab-separated list of URLs requested by the particular host. We use IntWritable to output the number of bytes from the Mapper and Text to output the request URL.
How to do it...
The following steps show how to implement a Hadoop GenericWritable data type that can wrap instances of either IntWritable or Text data types:
1. Write a class extending the org.apache.hadoop.io.GenericWritable class. Implement the getTypes() method to return an array of the Writable classes that you will be using. If you are adding a custom constructor, make sure to add a parameter-less default constructor as well.
2. public class MultiValueWritable extends GenericWritable {
3.
4. private static Class[] CLASSES = new Class[]{
5. IntWritable.class,
6. Text.class
7. };
8.
9. public MultiValueWritable(){
10. }
11.
12. public MultiValueWritable(Writable value){
13. set(value);
14. }
15.
16. protected Class[] getTypes() {
17. return CLASSES;
18. }
}
19. Set MultiValueWritable as the output value type of the Mapper. Wrap the output Writable values of the Mapper with instances of the MultiValueWritable class.
20.public class LogProcessorMap extends
21. Mapper<Object, Text, Text, MultiValueWritable> {
22. private Text userHostText = new Text();
23. private Text requestText = new Text();
24. private IntWritable responseSize = new IntWritable();
25.
26. public void map(Object key, Text value,
27. Context context)…{
28. ……// parse the value (log entry) using a regex.
29. userHostText.set(userHost);
30. requestText.set(request);
31. bytesWritable.set(responseSize);
32.
33. context.write(userHostText,
34. new MultiValueWritable(requestText));
35. context.write(userHostText,
36. new MultiValueWritable(responseSize));
37. }
}
38. Set the Reducer input value type as MultiValueWritable. Implement the reduce() method to handle multiple value types.
39.public class LogProcessorReduce extends
40. Reducer<Text,MultiValueWritable,Text,Text> {
41. private Text result = new Text();
42.
43. public void reduce(Text key, Iterable<MultiValueWritable>values, Context context)…{
44. int sum = 0;
45. StringBuilder requests = new StringBuilder();
46. for (MultiValueWritable multiValueWritable : values) {
47. Writable writable = multiValueWritable.get();
48. if (writable instanceof IntWritable){
49. sum += ((IntWritable)writable).get();
50. }else{
51. requests.append(((Text)writable).toString());
52. requests.append("\t");
53. }
54. }
55. result.set(sum + "\t"+requests);
56. context.write(key, result);
57. }
}
58. Set MultiValueWritable as the Map output value class of this computation:
59. Job job = …
job.setMapOutputValueClass(MultiValueWritable.class);
How it works...
The GenericWritable implementations should extend org.apache.hadoop.io.GenericWritable and should specify a set of the Writable value types to wrap, by returning an array of CLASSES from the getTypes() method. The GenericWritable implementations serialize and de-serialize the data using the index to this array of classes.
private static Class[] CLASSES = new Class[]{
IntWritable.class,
Text.class
};
protected Class[] getTypes() {
return CLASSES;
}
In the Mapper, you wrap each of your values with instances of the GenericWritable implementation:
private Text requestText = new Text();
context.write(userHostText,new MultiValueWritable(requestText));
The Reducer implementation has to take care of the different value types manually.
if (writable instanceof IntWritable){
sum += ((IntWritable)writable).get();
}else{
requests.append(((Text)writable).toString());
requests.append("\t");
}
There's more...
org.apache.hadoop.io.ObjectWritable is another class that can be used to achieve the same objective as GenericWritable. The ObjectWritable class can handle Java primitive types, strings, and arrays without the need of a Writable wrapper. However, Hadoop serializes the ObjectWritable instances by writing the class name of the instance with each serialized entry, making it inefficient compared to a GenericWritable class-based implementation.
See also
The Implementing a custom Hadoop Writable data type recipe.
Choosing a suitable Hadoop InputFormat for your input data format
Hadoop supports processing of many different formats and types of data through InputFormat. The InputFormat of a Hadoop MapReduce computation generates the key-value pair inputs for the Mappers by parsing the input data. InputFormat also performs the splitting of the input data into logical partitions, essentially determining the number of Map tasks of a MapReduce computation and indirectly deciding the execution location of the Map tasks. Hadoop generates a Map task for each logical data partition and invokes the respective Mappers with the key-value pairs of the logical splits as the input.
How to do it...
The following steps show you how to use FileInputFormat based KeyValueTextInputFormat as InputFormat for a Hadoop MapReduce computation:
1. In this example, we are going to specify the KeyValueTextInputFormat as InputFormat for a Hadoop MapReduce computation using the Job object as follows:
2. Configuration conf = new Configuration();
3. Job job = new Job(conf, "log-analysis");
4. ……
job.SetInputFormatClass(KeyValueTextInputFormat.class)
5. Set the input paths to the job:
FileInputFormat.setInputPaths(job, new Path(inputPath));
How it works...
KeyValueTextInputFormat is an input format for plain text files, which generates a key-value record for each line of the input text files. Each line of the input data is broken into a key (text) and value (text) pair using a delimiter character. The default delimiter is the tab character. If a line does not contain the delimiter, the whole line will be treated as the key and the value will be empty. We can specify a custom delimiter by setting a property in the job's configuration object as follows, where we use the comma character as the delimiter between the key and value.
conf.set("key.value.separator.in.input.line", ",");
KeyValueTextInputFormat is based on FileInputFormat, which is the base class for the file-based InputFormats. Hence, we specify the input path to the MapReduce computation using the setInputPaths() method of the FileInputFormat class. We have to perform this step when using any InputFormat that is based on the FileInputFormat class.
FileInputFormat.setInputPaths(job, new Path(inputPath));
We can provide multiple HDFS input paths to a MapReduce computation by providing a comma-separated list of paths. You can also use the addInputPath() static method of the FileInputFormat class to add additional input paths to a computation.
public static void setInputPaths(JobConf conf,Path... inputPaths)
public static void addInputPath(JobConf conf, Path path)
There's more...
Make sure that your Mapper input data types match the data types generated by InputFormat used by the MapReduce computation.
The following are some of the InputFormat implementations that Hadoop provides to support several common data formats:
· TextInputFormat: This is used for plain text files. TextInputFormat generates a key-value record for each line of the input text files. For each line, the key (LongWritable) is the byte offset of the line in the file and the value (Text) is the line of text. TextInputFormat is the default InputFormat of Hadoop.
· NLineInputFormat: This is used for plain text files. NLineInputFormat splits the input files into logical splits of fixed numbers of lines. We can use NLineInputFormat when we want our Map tasks to receive a fixed number of lines as the input. The key (LongWritable) and value (Text) records are generated for each line in the split similar to the TextInputFormat class. By default, NLineInputFormat creates a logical split (and a Map task) per line. The number of lines per split (or key-value records per Map task) can be specified as follows. NLineInputFormat generates a key-value record for each line of the input text files.
NLineInputFormat.setNumLinesPerSplit(job,50);
· SequenceFileInputFormat: This is used for Hadoop SequenceFile input data. Hadoop SequenceFiles store the data as binary key-value pairs and support data compression. SequenceFileInputFormat is useful when using the result of a previous MapReducecomputation in SequenceFile format as the input of a MapReduce computation. The following are its subclasses:
· SequenceFileAsBinaryInputFormat: This is a subclass of the SequenceInputFormat class that presents the key (BytesWritable) and the value (BytesWritable) pairs in raw binary format.
· SequenceFileAsTextInputFormat: This is a subclass of the SequenceInputFormat class that presents the key (Text) and the value (Text) pairs as strings.
· DBInputFormat: This supports reading the input data for MapReduce computation from a SQL table. DBInputFormat uses the record number as the key (LongWritable) and the query result record as the value (DBWritable).
See also
The Adding support for new input data formats – implementing a custom InputFormat recipe
Adding support for new input data formats – implementing a custom InputFormat
Hadoop enables us to implement and specify custom InputFormat implementations for our MapReduce computations. We can implement custom InputFormat implementations to gain more control over the input data as well as to support proprietary or application-specific input data file formats as inputs to Hadoop MapReduce computations. An InputFormat implementation should extend the org.apache.hadoop.mapreduce.InputFormat<K,V> abstract class overriding the createRecordReader() and getSplits() methods.
In this recipe, we implement an InputFormat and a RecordReader for the HTTP log files. This InputFormat will generate LongWritable instances as keys and LogWritable instances as the values.
How to do it...
The following are the steps to implement a custom InputFormat for the HTTP server log files based on the FileInputFormat class:
1. LogFileInputFormat operates on the data in HDFS files. Hence, we implement the LogFileInputFormat subclass extending the FileInputFormat class:
2. public class LogFileInputFormat extends FileInputFormat<LongWritable, LogWritable>{
3.
4. public RecordReader<LongWritable, LogWritable>createRecordReader(InputSplit arg0,TaskAttemptContext arg1) throws …… {
5. return new LogFileRecordReader();
6. }
7.
}
8. Implement the LogFileRecordReader class:
9. public class LogFileRecordReader extends RecordReader<LongWritable, LogWritable>{
10.
11. LineRecordReader lineReader;
12. LogWritable value;
13.
14. public void initialize(InputSplit inputSplit, TaskAttemptContext attempt)…{
15. lineReader = new LineRecordReader();
16. lineReader.initialize(inputSplit, attempt);
17. }
18.
19. public boolean nextKeyValue() throws IOException, ..{
20. if (!lineReader.nextKeyValue()){
21. return false;
22. }
23.
24. String line =lineReader.getCurrentValue().toString();
25. ……………//Extract the fields from 'line' using a regex
26.
27. value = new LogWritable(userIP, timestamp, request,
28. status, bytes);
29. return true;
30. }
31.
32. public LongWritable getCurrentKey() throws..{
33. return lineReader.getCurrentKey();
34. }
35.
36. public LogWritable getCurrentValue() throws ..{
37. return value;
38. }
39.
40. public float getProgress() throws IOException ..{
41. return lineReader.getProgress();
42. }
43.
44. public void close() throws IOException {
45. lineReader.close();
46. }
}
47. Specify LogFileInputFormat as InputFormat for the MapReduce computation using the Job object as follows. Specify the input paths for the computations using the underlying FileInputFormat.
48.Job job = ……
49.……
50.job.setInputFormatClass(LogFileInputFormat.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
51. Make sure the Mappers of the computation use LongWritable as the input key type and LogWritable as the input value type:
52.public class LogProcessorMap extendsMapper<LongWritable, LogWritable, Text, IntWritable>{
53. public void map(LongWritable key, LogWritable value, Context context) throws ……{
54. ………}
}
How it works...
LogFileInputFormat extends FileInputFormat, which provides a generic splitting mechanism for HDFS-file based InputFormat. We override the createRecordReader() method in LogFileInputFormat to provide an instance of our custom RecordReader implementation,LogFileRecordReader. Optionally, we can also override the isSplitable() method of the FileInputFormat class to control whether the input files are split-up to logical partitions or used as whole files.
Public RecordReader<LongWritable, LogWritable>createRecordReader(InputSplit arg0,TaskAttemptContext arg1) throws …… {
return new LogFileRecordReader();
}
The LogFileRecordReader class extends the org.apache.hadoop.mapreduce.RecordReader<K,V> abstract class and uses LineRecordReader internally to perform the basic parsing of the input data. LineRecordReader reads lines of text from the input data:
lineReader = new LineRecordReader();
lineReader.initialize(inputSplit, attempt);
We perform custom parsing of the log entries of the input data in the nextKeyValue() method. We use a regular expression to extract the fields out of the HTTP service log entry and populate an instance of the LogWritable class using those fields.
public boolean nextKeyValue() throws IOException, ..{
if (!lineReader.nextKeyValue())
return false;
String line = lineReader.getCurrentValue().toString();
……………//Extract the fields from 'line' using a regex
value = new LogWritable(userIP, timestamp, request, status, bytes);
return true;
}
There's more...
We can perform custom splitting of input data by overriding the getSplits() method of the InputFormat class. The getSplits() method should return a list of InputSplit objects. An InputSplit object represents a logical partition of the input data and will be assigned to a single Map task. InputSplit classes extend the InputSplit abstract class and should override the getLocations() and getLength() methods. The getLength() method should provide the length of the split and the getLocations() method should provide a list of nodes where the data represented by this split is physically stored. Hadoop uses a list of data local nodes for Map task scheduling. The FileInputFormat class we use in the preceding example uses the org.apache.hadoop.mapreduce.lib.input.FileSplit as the InputSplitimplementations.
You can write InputFormat implementations for non-HDFS data as well. The org.apache.hadoop.mapreduce.lib.db.DBInputFormat is one example of InputFormat.DBInputFormat supports reading the input data from a SQL table.
See also
The Choosing a suitable Hadoop InputFormat for your input data format recipe.
Formatting the results of MapReduce computations – using Hadoop OutputFormats
Often the output of your MapReduce computation will be consumed by other applications. Hence, it is important to store the result of a MapReduce computation in a format that can be consumed efficiently by the target application. It is also important to store and organize the data in a location that is efficiently accessible by your target application. We can use Hadoop OutputFormat interface to define the data storage format, data storage location, and the organization of the output data of a MapReduce computation. An OutputFormat prepares the output location and provides a RecordWriter implementation to perform the actual serialization and storage of data.
Hadoop uses the org.apache.hadoop.mapreduce.lib.output.TextOutputFormat<K,V> abstract class as the default OutputFormat for the MapReduce computations. TextOutputFormat writes the records of the output data to plain text files in HDFS using a separate line for each record. TextOutputFormat uses the tab character to delimit between the key and the value of a record. TextOutputFormat extends FileOutputFormat, which is the base class for all file-based output formats.
How to do it...
The following steps show you how to use the FileOutputFormat based SequenceFileOutputFormat as the OutputFormat for a Hadoop MapReduce computation.
1. In this example, we are going to specify the org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat<K,V> as the OutputFormat for a Hadoop MapReduce computation using the Job object as follows:
2. Job job = ……
3. ……
job.setOutputFormatClass(SequenceFileOutputFormat.class)
4. Set the output paths to the job:
FileOutputFormat.setOutputPath(job, new Path(outputPath));
How it works...
SequenceFileOutputFormat serializes the data to Hadoop SequenceFiles. Hadoop SequenceFiles store the data as binary key-value pairs and support data compression. SequenceFiles are efficient specially for storing non-text data. We can use the SequenceFiles to store the result of a MapReduce computation, if the output of the MapReduce computation is going to be the input of another Hadoop MapReduce computation.
SequenceFileOutputFormat is based on the FileOutputFormat, which is the base class for the file-based OutputFormat. Hence, we specify the output path to the MapReduce computation using the setOutputPath() method of the FileOutputFormat. We have to perform this step when using any OutputFormat that is based on the FileOutputFormat.
FileOutputFormat.setOutputPath(job, new Path(outputPath));
There's more...
You can implement custom OutputFormat classes to write the output of your MapReduce computations in a proprietary or custom data format and/or to store the result in a storage other than HDFS by extending the org.apache.hadoop.mapreduce.OutputFormat<K,V>abstract class. In case your OutputFormat implementation stores the data in a filesystem, you can extend from the FileOutputFormat class to make your life easier.
Writing multiple outputs from a MapReduce computation
We can use the MultipleOutputs feature of Hadoop to emit multiple outputs from a MapReduce computation. This feature is useful when we want to write different outputs to different files and also when we need to output an additional output in addition to the main output of a job. The MultipleOutputs feature allows us to specify a different OutputFormat for each output as well.
How to do it...
The following steps show you how to use the MultipleOutputs feature to output two different datasets from a Hadoop MapReduce computation:
1. Configure and name the multiple outputs using the Hadoop driver program:
2. Job job = Job.getInstance(getConf(), "log-analysis");
3. …
4. FileOutputFormat.setOutputPath(job, new Path(outputPath));
5. MultipleOutputs.addNamedOutput(job, "responsesizes", TextOutputFormat.class,Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "timestamps", TextOutputFormat.class,Text.class, Text.class);
6. Write data to the different named outputs from the reduce function:
7. public class LogProcessorReduce …{
8. private MultipleOutputs mos;
9.
10. protected void setup(Context context) .. {
11. mos = new MultipleOutputs(context);
12. }
13.
14. public void reduce(Text key, … {
15. …
16. mos.write("timestamps", key, val.getTimestamp());
17. …
18. mos.write("responsesizes", key, result);
19. }
}
20. Close all the opened outputs by adding the following to the cleanup function of the Reduce task:
21.@Override
22. public void cleanup(Context context) throws IOException,
23. InterruptedException {
24. mos.close();
}
25. Output filenames will be in the format namedoutput-r-xxxxx for each output type written. For the current sample, example output filenames would be responsesizes-r-00000 and timestamps-r-00000.
How it works...
We first add the named outputs to the job in the driver program using the following static method of the MultipleOutputs class:
public static addNamedOutput(Job job, String namedOutput, Class<? extends OutputFormat> outputFormatClass, Class<?> keyClass, Class<?> valueClass)
Then we initialize the MultipleOutputs feature in the setup method of the Reduce task as follows:
protected void setup(Context context) .. {
mos = new MultipleOutputs(context);
}
We can write the different outputs using the names we defined in the driver program using the following method of the MultipleOutputs class:
public <K,V> void write (String namedOutput, K key, V value)
You can directly write to an output path without defining the named outputs using the following method of the MultipleOutputs. This output will use the OutputFormat defined for the job to format the output.
public void write(KEYOUT key, VALUEOUT value,
String baseOutputPath)
Finally, we make sure to close all the outputs from the cleanup method of the Reduce task using the close method of the MultipleOutputs class. This should be done to avoid loss of any data written to the different outputs.
public void close()
Using multiple input data types and multiple Mapper implementations in a single MapReduce application
We can use the MultipleInputs feature of Hadoop to run a MapReduce job with multiple input paths, while specifying a different InputFormat and (optionally) a Mapper for each path. Hadoop will route the outputs of the different Mappers to the instances of the single Reducer implementation of the MapReduce computation. Multiple inputs with different InputFormats are useful when we want to process multiple datasets with the same meaning but different InputFormats (comma-delimited dataset and tab-delimited dataset).
We can use the following addInputPath static method of the MutlipleInputs class to add the input paths and the respective InputFormats to the MapReduce computation:
Public static void addInputPath(Job job, Path path, Class<?extendsInputFormat>inputFormatClass)
The following is an example usage of the preceding method:
MultipleInputs.addInputPath(job, path1, CSVInputFormat.class);
MultipleInputs.addInputPath(job, path1, TabInputFormat.class);
Multiple inputs feature with the ability to specify different Mapper implementations and InputFormats is useful when performing a Reduce-side join of two or more datasets:
public static void addInputPath(JobConfconf,Path path,
Class<?extendsInputFormat>inputFormatClass,
Class<?extends Mapper>mapperClass)
The following is an example of using multiple inputs with different InputFormats and different Mapper implementations:
MultipleInputs.addInputPath(job, accessLogPath, TextInputFormat.class, AccessLogMapper.class);
MultipleInputs.addInputPath(job, userDataPath, TextInputFormat.class, UserDataMapper.class);
See also
The Adding support for new input data formats – implementing a custom InputFormat recipe.
Hadoop intermediate data partitioning
Hadoop MapReduce partitions the intermediate data generated by the Map tasks across the Reduce tasks of the computations. A proper partitioning function ensuring balanced load for each Reduce task is crucial to the performance of MapReduce computations. Partitioning can also be used to group together related sets of records to specific reduce tasks, where you want certain outputs to be processed or grouped together. The figure in the Introduction section of this chapter depicts where the partitioning fits into the overall MapReduce computation flow.
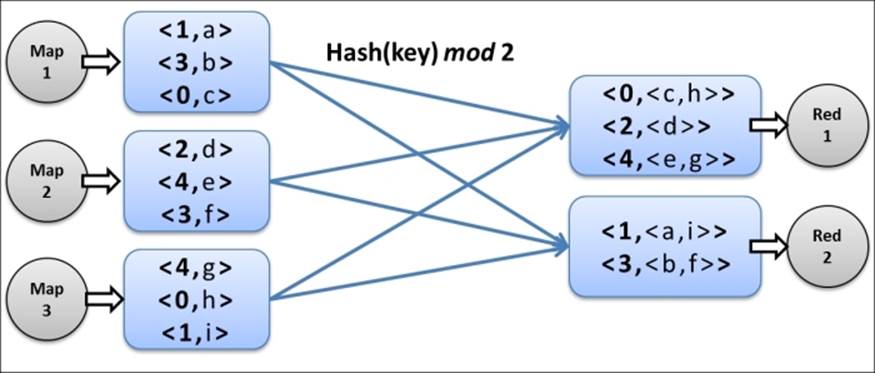
Hadoop partitions the intermediate data based on the key space of the intermediate data and decides which Reduce task will receive which intermediate record. The sorted set of keys and their values of a partition would be the input for a Reduce task. In Hadoop, the total number of partitions should be equal to the number of Reduce tasks for the MapReduce computation. Hadoop partitioners should extend the org.apache.hadoop.mapreduce.Partitioner<KEY,VALUE> abstract class. Hadoop usesorg.apache.hadoop.mapreduce.lib.partition.HashPartitioner as the default partitioner for the MapReduce computations. HashPartitioner partitions the keys based on their hashcode(), using the formula key.hashcode() mod r, where r is the number of Reduce tasks. The following diagram illustrates HashPartitioner for a computation with two Reduce tasks:
There can be scenarios where our computations logic would require or can be better implemented using an application's specific data-partitioning schema. In this recipe, we implement a custom partitioner for our HTTP log processing application, which partitions the keys (IP addresses) based on their geographic regions.
How to do it...
The following steps show you how to implement a custom partitioner that partitions the intermediate data based on the location of the request IP address or the hostname:
1. Implement the IPBasedPartitioner class extending the Partitioner abstract class:
2. public class IPBasedPartitioner extends Partitioner<Text, IntWritable>{
3.
4. public int getPartition(Text ipAddress,
5. IntWritable value, int numPartitions) {
6. String region = getGeoLocation(ipAddress);
7.
8. if (region!=null){
9. return ((region.hashCode() & Integer.MAX_VALUE) % numPartitions);
10. }
11. return 0;
12. }
}
13. Set the Partitioner class parameter in the Job object:
14.Job job = ……
15.……
job.setPartitionerClass(IPBasedPartitioner.class);
How it works...
In the preceding example, we perform the partitioning of the intermediate data, such that the requests from the same geographic region will be sent to the same Reducer instance. The getGeoLocation() method returns the geographic location of the given IP address. We omit the implementation details of the getGeoLocation() method as it's not essential for the understanding of this example. We then obtain the hashCode() method of the geographic location and perform a modulo operation to choose the Reducer bucket for the request.
There's more...
TotalOrderPartitioner and KeyFieldPartitioner are two of the several built-in partitioner implementations provided by Hadoop.
TotalOrderPartitioner
TotalOrderPartitioner extends org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner<K,V>. The set of input records to a Reducer are in a sorted order ensuring proper ordering within an input partition. However, the Hadoop default partitioning strategy (HashPartitioner) does not enforce an ordering when partitioning the intermediate data and scatters the keys among the partitions. In use cases where we want to ensure a global order, we can use the TotalOrderPartitioner to enforce a total order to reduce the input records across the Reducer task. TotalOrderPartitioner requires a partition file as the input defining the ranges of the partitions. The org.apache.hadoop.mapreduce.lib.partition.InputSampler utility allows us to generate a partition file for the TotalOrderPartitioner by sampling the input data. TotalOrderPartitioner is used in the Hadoop TeraSort benchmark.
Job job = ……
……
job.setPartitionerClass(TotalOrderPartitioner.class);
TotalOrderPartitioner.setPartitionFile(jobConf,partitionFile);
KeyFieldBasedPartitioner
The org.apache.hadoop.mapreduce.lib.partition.KeyFieldBasedPartitioner<K,V> abstract class can be used to partition the intermediate data based on parts of the key. A key can be split into a set of fields by using a separator string. We can specify the indexes of the set of fields to be considered when partitioning. We can also specify the index of the characters within fields.
Secondary sorting – sorting Reduce input values
MapReduce frameworks sort the Reduce input data based on the key of the key-value pairs and also group the data based on the key. Hadoop invokes the reduce function for each unique key in the sorted order of keys with the list of values belonging to that key as the second parameter. However, the list of values for each key is not sorted in any particular order. There are many scenarios where it would be useful to have the list of Reduce input values for each key sorted based on some criteria as well. The examples include finding the maximum or minimum value for a given key without iterating the whole list, to optimize Reduce-side joins, to identify duplicate data products, and so on.
We can use the Hadoop framework to sort the Reduce input values using a mechanism called secondary sorting. We achieve this by forcing Hadoop framework to sort the reduce input key-value pairs using the key as well as using several designated fields from the value. However, the partitioning of Map output data and the grouping of the Reduce input data is still performed only using the key. This assures that the Reduce input data is grouped and sorted by the key, while the list of values belonging to a key would be in a sorted order as well.
How to do it...
The following steps show you how to perform secondary sorting of the Reduce input values in a Hadoop MapReduce computation:
1. First, implement a WritableComparable data type that can contain the actual key (visitorAddress) and the fields (responseSize) from the value that needs to be included in the sorted order. The comparator for this new compound type should enforce the sorting order, where the actual key comes first, followed by the sorting criteria derived from the value fields contained in this new type. We use this compound type as the Map output key type. Alternatively, you can also use an existing WritableComparable type as the Map output key type, which contains the actual key and the other fields from the value, by providing a comparable implementation for that data type to enforce the sorting order.
2. public class SecondarySortWritable … {
3. private String visitorAddress;
4. private int responseSize;
5. ………
6. @Override
7. public boolean equals(Object right) {
8. if (right instanceof SecondarySortWritable) {
9. SecondarySortWritable r = (SecondarySortWritable) right;
10. return (r.visitorAddress.equals(visitorAddress) && (r.responseSize == responseSize));
11. } else {
12. return false;
13. }
14. }
15.
16. @Override
17. public int compareTo(SecondarySortWritable o) {
18. if (visitorAddress.equals(o.visitorAddress)) {
19. return responseSize < o.responseSize ? -1 : 1;
20. } else {
21. return visitorAddress.compareTo(o.visitorAddress);
22. }
23. }
}
24. Modify the map and reduce functions to use the compound key that we created:
25.public class LogProcessorMap extends Mapper<Object, LogWritable, SecondarySortWritable, LogWritable > {
26. private SecondarySortWritable outKey ..
27.
28. public void map(Object key, …..{
29. outKey.set(value.getUserIP().toString(), value.getResponseSize().get());
30. context.write(outKey,value);
31. }
32.}
33.
34.public class LogProcessorReduce extends
35. Reducer<SecondarySortWritable, LogWritable..{
36. ……
37. public void reduce(SecondarySortWritable key, Iterable<LogWritable> values {
38. ……
39. }
}
40. Implement a custom partitioner to partition the Map output data based only on the actual key (visitorAddress) contained in the compound key:
41.public class SingleFieldPartitioner extends… {
42. public int getPartition(SecondarySortWritable key, Writable value, int numPartitions) {
43. return (int)(key.getVisitorAddress().hashCode() % numPartitions);
44. }
}
45. Implement a custom grouping comparator to group the Reduce inputs only based on the actual key (visitorAddress):
46.public class GroupingComparator extends WritableComparator {
47. public GroupingComparator() {
48. super(SecondarySortWritable.class, true);
49. }
50.
51. @Override
52. public int compare(WritableComparable o1, WritableComparable o2) {
53. SecondarySortWritable firstKey = (SecondarySortWritable) o1;
54. SecondarySortWritable secondKey = (SecondarySortWritable) o2;
55. return (firstKey.getVisitorAddress()).compareTo(secondKey.getVisitorAddress());
}
56. Configure the partitioner, GroupingComparator, and the Map output key type in the driver program:
57.Job job = Job.getInstance(getConf(), "log-analysis");
58.……
59.job.setMapOutputKeyClass(SecondarySortWritable.class);
60.……
61.
62.// group and partition by the visitor address
63.job.setPartitionerClass(SingleFieldPartitioner.class);
job.setGroupingComparatorClass(GroupingComparator.class);
How it works...
We first implemented a custom WritableComparable key type that would hold the actual key and the sort fields of the value. We ensure the sorting order of this new compound key type to be the actual key followed by the sort fields from the value. This will ensure that the Reduce input data would be first sorted based on the actual key followed by the given fields of the value.
Then we implemented a custom partitioner that would partition the Map output data only based on the actual key field from the new compound key. This step ensures that each key-value pair with the same actual key would be processed by the same Reducer. Finally, we implemented a grouping comparator that would consider only the actual key field of the new key when grouping the reduced input key-value pairs. This ensures that each reduce function input will be the new compound key together with the list of values belonging to the actual key. The list of values would be in sorted order as that is defined in the comparator of the compound key.
See also
The Adding support for new input data formats – implementing a custom InputFormat recipe.
Broadcasting and distributing shared resources to tasks in a MapReduce job – Hadoop DistributedCache
We can use the Hadoop DistributedCache to distribute read-only file-based resources to the Map and Reduce tasks. These resources can be simple data files, archives, or JAR files that are needed for the computations performed by the Mappers or the Reducers.
How to do it...
The following steps show you how to add a file to the Hadoop DistributedCache and how to retrieve it from the Map and Reduce tasks:
1. Copy the resource to the HDFS. You can also use files that are already there in the HDFS.
2. $ hadoop fs –copyFromLocal ip2loc.dat ip2loc.dat
3. Add the resource to the DistributedCache from your driver program:
4. Job job = Job.getInstance……
5. ……
job.addCacheFile(new URI("ip2loc.dat#ip2location"));
6. Retrieve the resource in the setup() method of your Mapper or Reducer and use the data in the map() or reduce() function:
7. public class LogProcessorMap extends Mapper<Object, LogWritable, Text, IntWritable> {
8. private IPLookup lookupTable;
9.
10. public void setup(Context context) throws IOException{
11.
12. File lookupDb = new File("ip2location");
13. // Load the IP lookup table (a simple hashmap of ip
14. // prefixes as keys and country names as values) to
15. // memory
16. lookupTable = IPLookup.LoadData(lookupDb);
17. }
18.
19. public void map(…) {
20. String country = lookupTable.getCountry(value.ipAddress);
21. ……
22. }
}
How it works...
Hadoop copies the files added to the DistributedCache to all the worker nodes before the execution of any task of the job. DistributedCache copies these files only once per job. Hadoop also supports creating symlinks to the DistributedCache files in the working directory of the computation by adding a fragment with the desired symlink name to the URI. In the following example, we are using ip2location as the symlink to the ip2loc.dat file in the DistributedCache:
job.addCacheArchive(new URI("/data/ip2loc.dat#ip2location"));
We parse and load the data from the DistributedCache in the setup() method of the Mapper or the Reducer. Files with symlinks are accessible from the working directory using the provided symlink's name.
private IPLookup lookup;
public void setup(Context context) throws IOException{
File lookupDb = new File("ip2location");
// Load the IP lookup table to memory
lookup = IPLookup.LoadData(lookupDb);
}
public void map(…) {
String location =lookup.getGeoLocation(value.ipAddress);
……
}
We can also access the data in the DistributedCache directly using the getLocalCacheFiles() method, without using the symlink:
URI[] cacheFiles = context.getCacheArchives();
Note
DistributedCache does not work in Hadoop local mode.
There's more...
The following sections show you how to distribute the compressed archives using DistributedCache, how to add resources to the DistributedCache using the command line, and how to use the DistributedCache to add resources to the classpath of the Mapper and the Reducer.
Distributing archives using the DistributedCache
We can use the DistributedCache to distribute archives as well. Hadoop extracts the archives in the worker nodes. You can also provide symlinks to the archives using the URI fragments. In the next example, we use the ip2locationdb symlink for theip2locationdb.tar.gz archive.
Consider the following MapReduce driver program:
Job job = ……
job.addCacheArchive(new URI("/data/ip2locationdb.tar.gz#ip2locationdb"));
The extracted directory of the archive can be accessible from the working directory of the Mapper or the Reducer using the symlink provided earlier:
Consider the following Mapper program:
public void setup(Context context) throws IOException{
Configuration conf = context.getConfiguration();
File lookupDbDir = new File("ip2locationdb");
String[] children = lookupDbDir.list();
…
}
You can also access the non-extracted DistributedCache archived files directly using the following method in the Mapper or Reducer implementation:
URI[] cachePath;
public void setup(Context context) throws IOException{
Configuration conf = context.getConfiguration();
cachePath = context.getCacheArchives();
…
}
Adding resources to the DistributedCache from the command line
Hadoop supports adding files or archives to the DistributedCache using the command line, provided that your MapReduce driver programs implement the org.apache.hadoop.util.Tool interface or utilize org.apache.hadoop.util.GenericOptionsParser. Files can be added to the DistributedCache using the –files command-line option, while archives can be added using the –archives command-line option. Files or archives can be in any filesystem accessible for Hadoop, including your local filesystem.
These options support a comma-separated list of paths and the creation of symlinks using the URI fragments.
$ hadoop jar C4LogProcessor.jar LogProcessor-files ip2location.dat#ip2location indir outdir
$ hadoop jar C4LogProcessor.jar LogProcessor-archives ip2locationdb.tar.gz#ip2locationdb indir outdir
Adding resources to the classpath using the DistributedCache
You can use DistributedCache to distribute JAR files and other dependent libraries to the Mapper or Reducer. You can use the following methods in your driver program to add the JAR files to the classpath of the JVM running the Mapper or the Reducer:
public static void addFileToClassPath(Path file,Configuration conf,FileSystem fs)
public static void addArchiveToClassPath(Path archive,Configuration conf, FileSystem fs)
Similar to the –files and –archives command-line options we described in the Adding resources to the DistributedCache from the command line subsection, we can also add the JAR files to the classpath of our MapReduce computations by using the –libjarscommand-line option. In order for the –libjars command-line option to work, MapReduce driver programs should implement the Tool interface or should utilize GenericOptionsParser.
$ hadoop jar C4LogProcessor.jar LogProcessor-libjars ip2LocationResolver.jar indir outdir
Using Hadoop with legacy applications – Hadoop streaming
Hadoop streaming allows us to use any executable or a script as the Mapper or the Reducer of a Hadoop MapReduce job. Hadoop streaming enables us to perform rapid prototyping of the MapReduce computations using Linux shell utility programs or using scripting languages. Hadoop streaming also allows the users with some or no Java knowledge to utilize Hadoop to process data stored in HDFS.
In this recipe, we implement a Mapper for our HTTP log processing application using Python and use a Hadoop aggregate-package-based Reducer.
How to do it...
The following are the steps to use a Python program as the Mapper to process the HTTP server log files:
1. Write the logProcessor.py python script:
2. #!/usr/bin/python
3. import sys
4. import re
5. def main(argv):
6. regex =re.compile('……')
7. line = sys.stdin.readline()
8. try:
9. while line:
10. fields = regex.match(line)
11. if(fields!=None):
12. print"LongValueSum:"+fields.group(1)+
13. "\t"+fields.group(7)
14. line =sys.stdin.readline()
15. except"end of file":
16. return None
17.if __name__ == "__main__":
main(sys.argv)
18. Use the following command from the Hadoop installation directory to execute the Streaming MapReduce computation:
19.$ hadoop jar \
20. $HADOOP_MAPREDUCE_HOME/hadoop-streaming-*.jar \
21. -input indir \
22. -output outdir \
23. -mapper logProcessor.py \
24. -reducer aggregate \
25. -file logProcessor.py
How it works...
Each Map task launches the Hadoop streaming executable as a separate process in the worker nodes. The input records (the entries or lines of the log file, not broken into key-value pairs) to the Mapper are provided as lines to the standard input of that process. The executable should read and process the records from the standard input until the end of the file is reached.
line = sys.stdin.readline()
try:
while line:
………
line =sys.stdin.readline()
except "end of file":
return None
Hadoop streaming collects the outputs of the executable from the standard output of the process. Hadoop streaming converts each line of the standard output to a key-value pair, where the text up to the first tab character is considered the key and the rest of the line as the value. The logProcessor.py python script outputs the key-value pairs, according to this convention, as follows:
If (fields!=None):
print "LongValueSum:"+fields.group(1)+ "\t"+fields.group(7);
In our example, we use the Hadoop aggregate package for the reduction part of our computation. The Hadoop aggregate package provides Reducer and combiner implementations for simple aggregate operations such as sum, max, unique value count, and histogram. When used with Hadoop streaming, the Mapper outputs must specify the type of aggregation operation of the current computation as a prefix to the output key, which is the LongValueSum in our example.
Hadoop streaming also supports the distribution of files to the worker nodes using the –file option. We can use this option to distribute executable files, scripts, or any other auxiliary file needed for the streaming computation. We can specify multiple –file options for a computation.
$ hadoop jar …… \
-mapper logProcessor.py \
-reducer aggregate \
-file logProcessor.py
There's more...
We can specify Java classes as the Mapper and/or Reducer and/or combiner programs of Hadoop streaming computations. We can also specify InputFormat and other options to a Hadoop streaming computation.
Hadoop streaming also allows us to use Linux shell utility programs as Mapper and Reducer. The following example shows the usage of grep as the Mapper of a Hadoop streaming computation.
$ hadoop jar
$HADOOP_MAPREDUCE_HOME/hadoop-streaming-*.jar \
–input indir \
-output outdir \
-mapper 'grep "wiki"'
Hadoop streaming provides the Reducer input records of each key group line by line to the standard input of the process that is executing the executable. However, Hadoop streaming does not have a mechanism to distinguish when it starts to feed records of a new key to the process. Hence, the scripts or the executables for Reducer programs should keep track of the last seen key of the input records to demarcate between key groups.
Extensive documentation on Hadoop streaming is available at http://hadoop.apache.org/mapreduce/docs/stable1/streaming.html.
See also
The Data preprocessing using Hadoop streaming and Python and De-duplicating data using Hadoop streaming recipes in Chapter 10, Mass Text Data Processing.
Adding dependencies between MapReduce jobs
Often we require multiple MapReduce applications to be executed in a workflow-like manner to achieve our objective. Hadoop ControlledJob and JobControl classes provide a mechanism to execute a simple workflow graph of MapReduce jobs by specifying the dependencies between them.
In this recipe, we execute the log-grep MapReduce computation followed by the log-analysis MapReduce computation on an HTTP server log dataset. The log-grep computation filters the input data based on a regular expression. The log-analysis computation analyses the filtered data. Hence, the log-analysis computation is dependent on the log-grep computation. We use the ControlledJob class to express this dependency and use the JobControl class to execute both the related MapReduce computations.
How to do it...
The following steps show you how to add a MapReduce computation as a dependency of another MapReduce computation:
1. Create the Configuration and the Job objects for the first MapReduce job and populate them with the other needed configurations:
2. Job job1 = ……
3. job1.setJarByClass(RegexMapper.class);
4. job1.setMapperClass(RegexMapper.class);
5. FileInputFormat.setInputPaths(job1, new Path(inputPath));
6. FileOutputFormat.setOutputPath(job1, new Path(intermedPath));
……
7. Create the Configuration and Job objects for the second MapReduce job and populate them with the necessary configurations:
8. Job job2 = ……
9. job2.setJarByClass(LogProcessorMap.class);
10.job2.setMapperClass(LogProcessorMap.class);
11.job2.setReducerClass(LogProcessorReduce.class);
12.FileOutputFormat.setOutputPath(job2, new Path(outputPath));
………
13. Set the output directory of the first job as the input directory of the second job:
FileInputFormat.setInputPaths(job2, new Path(intermedPath +"/part*"));
14. Create ControlledJob objects using the Job objects created earlier:
15.ControlledJob controlledJob1 = new ControlledJob(job1.getConfiguration());
ControlledJob controlledJob2 = new ControlledJob(job2.getConfiguration());
16. Add the first job as a dependency to the second job:
controlledJob2.addDependingJob(controlledJob1);
17. Create the JobControl object for this group of jobs and add the ControlledJob objects created in step 4 to the newly created JobControl object:
18.JobControl jobControl = new JobControl("JobControlDemoGroup");
19.jobControl.addJob(controlledJob1);
jobControl.addJob(controlledJob2);
20. Create a new thread to run the group of jobs added to the JobControl object. Start the thread and wait for its completion:
21. Thread jobControlThread = new Thread(jobControl);
22. jobControlThread.start();
23. while (!jobControl.allFinished()){
24. Thread.sleep(500);
25. }
jobControl.stop();
How it works...
The ControlledJob class encapsulates the MapReduce job and keeps track of the job's dependencies. A ControlledJob class with depending jobs becomes ready for submission only when all of its depending jobs are completed successfully. A ControlledJob class fails if any of the depending jobs fail.
The JobControl class encapsulates a set of ControlledJobs and their dependencies. JobControl tracks the status of the encapsulated ControlledJobs and contains a thread that submits the jobs that are in the READY state.
If you want to use the output of a MapReduce job as the input of a dependent job, the input paths to the dependent job have to be set manually. By default, Hadoop generates an output folder per Reduce task name with the part prefix. We can specify all the partprefixed subdirectories as input to the dependent job using wildcards.
FileInputFormat.setInputPaths(job2, new Path(job1OutPath +"/part*"));
There's more...
We can use the JobControl class to execute and track a group of non-dependent tasks as well.
Apache Oozie is a workflow system for Hadoop MapReduce computations. You can use Oozie to execute Directed Acyclic Graphs (DAG) of MapReduce computations. You can find more information on Oozie from the project's home page athttp://oozie.apache.org/.
The ChainMapper class, available in the older version of Hadoop MapReduce API, allowed us to execute a pipeline of Mapper classes inside a single Map task computation in a pipeline. ChainReducer provided similar support for Reduce tasks. This API still exists in Hadoop 2 for backward compatibility reasons.
Hadoop counters to report custom metrics
Hadoop uses a set of counters to aggregate the metrics for MapReduce computations. Hadoop counters are helpful to understand the behavior of our MapReduce programs and to track the progress of the MapReduce computations. We can define custom counters to track the application-specific metrics in MapReduce computations.
How to do it...
The following steps show you how to define a custom counter to count the number of bad or corrupted records in our log processing application:
1. Define the list of custom counters using enum:
2. public static enum LOG_PROCESSOR_COUNTER {
3. BAD_RECORDS
};
4. Increment the counter in your Mapper or Reducer:
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS).increment(1);
5. Add the following to your driver program to access the counters:
6. Job job = new Job(getConf(), "log-analysis");
7. ……
8. Counters counters = job.getCounters();
9. Counter badRecordsCounter = counters.findCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS);
System.out.println("# of Bad Records:"+ badRecordsCounter.getValue());
10. Execute your Hadoop MapReduce computation. You can also view the counter values in the admin console or in the command line.
11.$ hadoop jar C4LogProcessor.jar \
12. demo.LogProcessor in out 1
13.………
14.12/07/29 23:59:01 INFO mapred.JobClient: Job complete: job_201207271742_0020
15.12/07/29 23:59:01 INFO mapred.JobClient: Counters: 30
16.12/07/29 23:59:01 INFO mapred.JobClient: demo.LogProcessorMap$LOG_PROCESSOR_COUNTER
17.12/07/29 23:59:01 INFO mapred.JobClient: BAD_RECORDS=1406
18.12/07/29 23:59:01 INFO mapred.JobClient: Job Counters
19.………
20.12/07/29 23:59:01 INFO mapred.JobClient: Map output records=112349
21.# of Bad Records :1406
How it works...
You have to define your custom counters using enum. The set of counters in an enum will form a group of counters. The ApplicationMaster aggregates the counter values reported by the Mappers and the Reducers.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.