Neo4j High Performance (2015)
Chapter 3. Efficient Data Modeling with Graphs
Databases are not dumps for data; rather, they are planned and strategically organized stores that befit a particular objective. This is where modeling comes into the picture. Modeling is motivated by a specific need or goal so that specific facets of the available information are aggregated together into a form that facilitates structuring and manipulation. The world cannot be represented in the way it actually is; rather, simplified abstractions can be formed in accordance with some particular goal. The same is true for graph data representations that are close logical representations of the physical-world objects. Systems managing relational data have storage structures far different from those that represent data close to natural language. Transforming the data in such cases can lead to semantic dissonance between how we conceptualize the real world and data storage structure. This issue is, however, overcome by graph databases. In this chapter, we will look at how we can efficiently model data for graphs. The topics to be covered in this chapter are:
· Data models and property graphs
· Neo4j design constraints
· Techniques for modeling graphs
· Designing schemas
· Modeling across multiple domains
· Data models
Data models
A data model tells us how the logical structure of a database is modeled. Data models are fundamental entities to introduce abstraction in DBMS. They define how data is connected to each other and how it will be processed and stored inside the system. There are two basic types of data models in which related data can be modeled: aggregated and connected.
The aggregated data model
Aggregated data is about how you might use aggregation in your model to simulate relationships when you can't explicitly define them. So, you might store different objects internally in separate sections of the data store and derive the relationships on the fly with the help of foreign keys, or any related fields between the object. Hence, you are aggregating data from different sources, for example, as depicted in the following diagram, a company might contain a collection of the people who work there, and a person might in turn be associated with several products within the company, from which you might extract the related data. The aggregation or grouping is used to form a link between entities rather than a well-defined relationship.
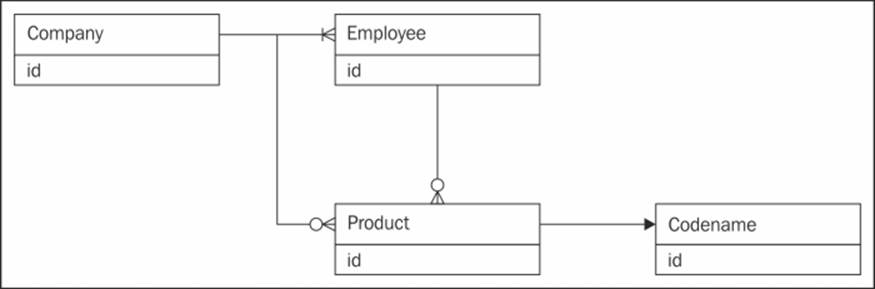
Connected data models
Connected data is about relationships that exist between different entities. We explicitly specify how the two entities are connected with a well-defined relationship and also the features of this relation, so we do not need to derive relationships. This makes data access faster and makes this the prominent data model for most graph databases, including Neo4j. An example would be a PLAYS_FOR relationship between a player and a team, as shown in the following diagram:
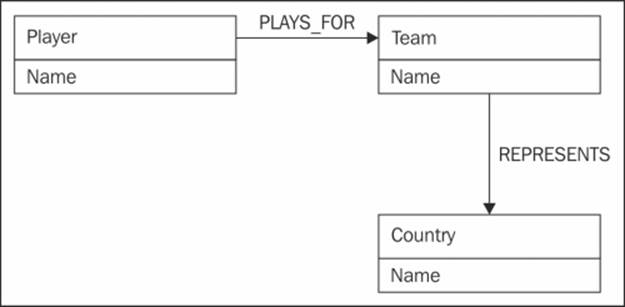
Property graphs
The graph structure that most graph databases including Neo4j use inherently classifies them into property graphs. A property graph stores the data in the form of nodes. These nodes are linked with relationships that provide structure to the graph. Relationships must have a direction and a label and must exist between a start node and an end node (dangling relationships are not permitted). Both nodes and relationships can have properties, which are key-value pairs that store characteristic information about that entity. The keys have to be strings that describe the property, while the value can be of any type. In property graphs, the number and type of properties can vary across the entities. You can basically store all the metadata about that entity into it in the form of properties. They are also useful in applying constraints to the queries for faster access with the help of indexes.
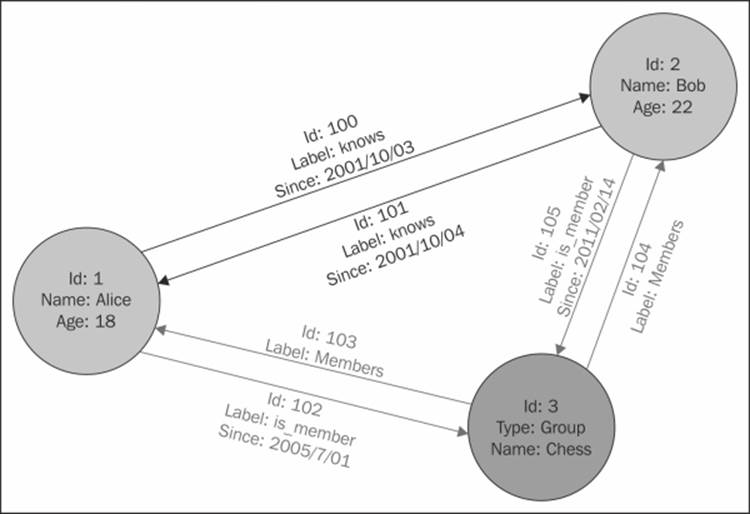
A simple property graph
These are all that are required to create the most sophisticated and rich semantic models for the graphs. Diagrams are an excellent way to view and design graph structure models since they clarify the data model. However, in order to implement these models in the Neo4j graph systems, you will need tools such as Cypher that provide elegant constructs to design the most complex of systems, some of which we will see later in the chapter.
Design constraints in Neo4j
Neo4j is very versatile in terms of data structuring, but everything has its limitations. So, a designer ought to know where Neo4j gives up so that he can weigh his data size and type and boil down to an efficient data model.
Size of files: Neo4j is based on Java at its core, so its file handling is dependent upon the nonblocking input/output system. Although there are several optimizations for interconnected data in the layout of storage files, there are no requirements of raw devices in Neo4j. Hence, the limitation on the file sizes is determined by the core operating system's ability to handle large files. There is no such built-in limit that makes it adaptable to big data scenarios. There is, however, a process of internal memory-mapping of the underlying file storage to the maximum extent. The beauty also lies in the fact that in systems where memory gradually becomes a constraint and the system is unable to keep all data in memory, Neo4j will make use of buffers that will dynamically reallocate the memory-mapped input/output windows to memory areas where most activity takes place. This helps to maintain the speed of ACID interactions.
Data read speed: Most organizations scale and optimize their hardware to deliver higher business value from already-existing resources. Neo4j's techniques of data reads provide efficient use of all available system hardware. In Neo4j, there is no blockage or locking of any read operation; hence, deadlocks need not be worried about and transactions are not required for reads. Neo4j implements a threaded access to the database for reads, so you can run simultaneous queries to the extent supported by your underlying system and on all available processors. For larger servers, this provides great scale-up options.
Data write speeds: Optimizing the write speed is something most organizations worry about. Writes occur in two different scenarios:
· Write in a continuous track in a sustained way
· Bulk write operations for initial data loads, batch processes, or backups
In order to facilitate writes in both these scenarios, Neo4j inherently has two modes of writing to the underlying layer of storage. In the normal ACID transactional operations, it maintains isolation, that is, reads can occur in the duration of the write process. When the commit is executed, Neo4j persists the data to the disk, and if the system fails, a recovery to the consistent state can be obtained. This requires access for writes to the disk and the data to be flushed to the disk. Hence, the limitation for writes on each machine is the I/O speed of the bus. In the case of deployment to production scenarios, high-speed flash SSDs are the recommended storage devices, and yes, Neo4j is flash ready.
Neo4j also comes with a batch inserter that can be used to directly work on the stored data files. This mode does not guarantee security for transactions, so they cannot be used in a multithreaded write scenario. The write process is sequential in nature on a single write thread without flushing to logs; hence, the system has great boosts to performance. The batch inserter is handy for the import of large datasets in nontransactional scenarios.
Size of data: For data in Neo4j, the limitation is the size of the address space for all the keys used as primary keys in lookup for nodes, relationships, and their properties and types. The address space at present is as follows:
|
Entity |
Address space size |
|
Nodes |
235 (about 34 billion) |
|
Relationships |
235 (about 34 billion) |
|
Relationship types |
215 (about 32,000) |
|
Properties |
236 to 238 according to the type of the property (up to about 274 billion, but will always be a minimum of about 68 billion) |
Security: There might arise scenarios where unauthorized access to the data in terms of modification and theft needs to be prevented. Neo4j has no explicitly supported data encryption methods but can use Java's core encryption constructs to secure the data before storing in the system. Security can also be ensured at the level of the file system using an encrypted data storage layer. Hence, security should be ensured at all levels of the hosted system to avoid malicious read-writes, data corruption, and Distributed denial of service (DDOS) attacks.
Graph modeling techniques
Graph databases including Neo4j are versatile pieces of software that can be used to model and store almost any form of data including ones that would be traditionally stored in RDBMS or document databases. Neo4j in particular is designed to have capabilities as a high-performance store for day-to-day transactional data as well as being usable for some level of analytics. Almost all domains including social, medical, and finance bring up problems that can easily be handled by modeling data in the form of graphs.
Aggregation in graphs
Aggregation is the process in which we can model trees or any other arbitrary graph structures with the help of denormalization into a single record or document entity.
· The maximum efficiency in this technique is achieved when the tree to be aggregated is to be accessed in a single read (for example, a complete hierarchy of comments of a post is to be read when the page with the post is loaded)
· Random accesses to the entries or searching on them can cause problems
· Aggregated nodes can lead to inefficient updates in contrast with independent nodes
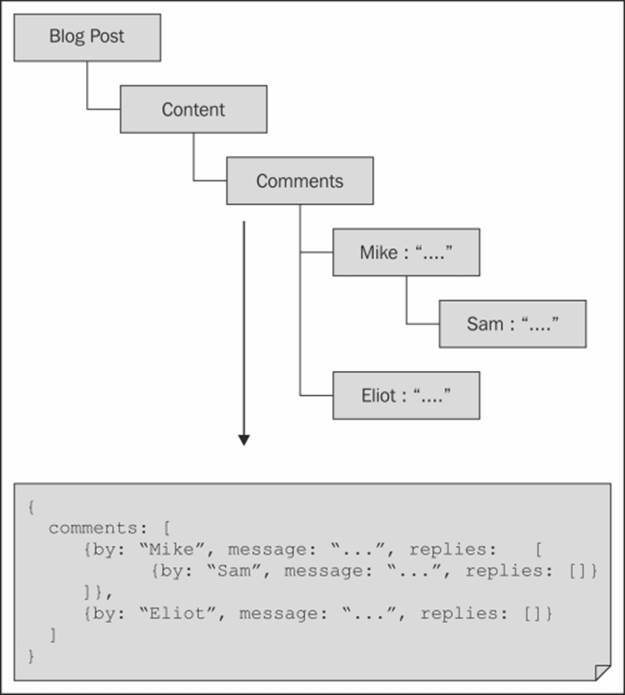
Aggregation of entities in a blog post tree
Graphs for adjacency lists
The simplest method of graph modeling is adjacency lists where every node can be modeled in the form of isolated records containing arrays with immediate descendants or ancestors. It facilitates the searching of nodes with the help of the identifiers and keys of their parents or ancestors and also graph traversal by pursuing hops for each query. This technique is, however, usually inefficient for retrieving complete trees for any given node and for depth- or breadth-based traversals.
Materialized paths
Traversal of tree-like hierarchical structures can sometimes lead to recursive traversals. These can be avoided with the help of materialized paths that are considered as a form of denormalization technique. We make the identifying keys of the node's parents and children as attributes or properties of the node. In this way, we minimize traversals by direct reference to the predecessors and descendants.
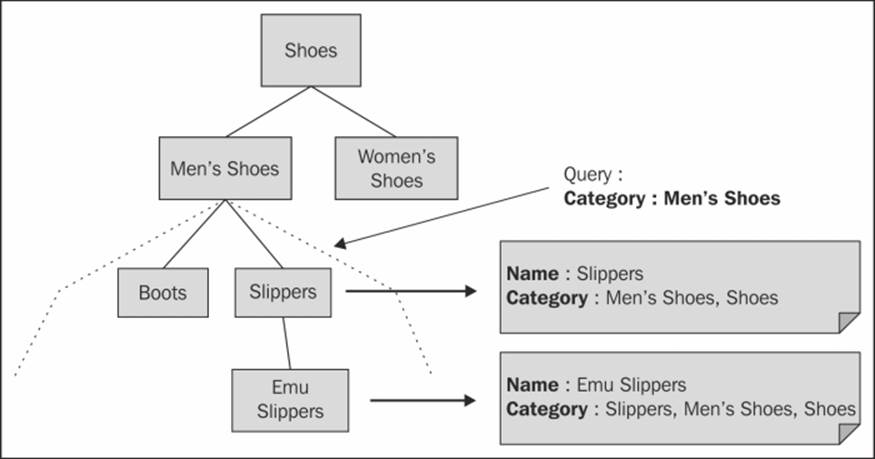
Since the technique allows the conversion of graph-like structures into flat documents, we can use it for full text-based searches. In the previous data scenario, the product list or even the subcategories can be retrieved using the category name in the query.
You can store materialized paths in the form of an ID set, or you can concatenate the IDs into a single string. Storing as a string allows us to make use of regular expressions to search the nodes for complete or partial criteria. This is shown in the following diagram (the node is included in the path):
Modeling with nested sets
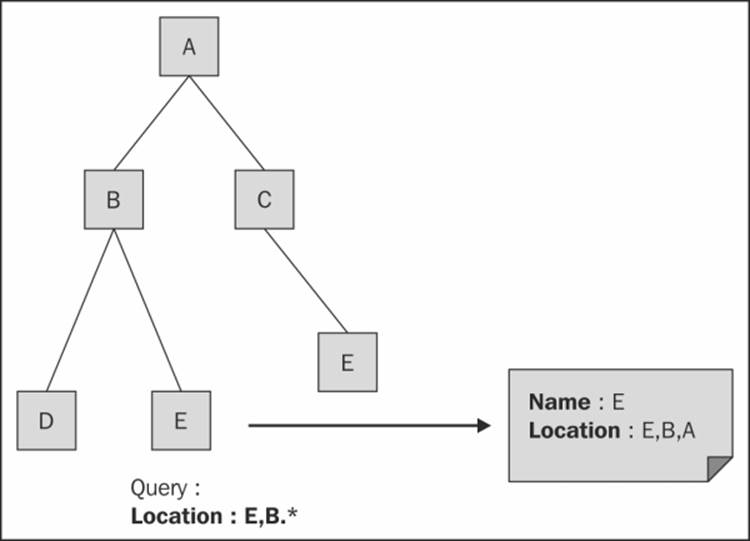
We can also use model-graph-based structures with the help of nested sets. Although it is used consistently with relational database systems, it is also applicable to NoSQL data stores. In this technique, we store the leaf nodes in the tree in the form of an array and then map the intermediate nodes to a range of child nodes using the initial and final indexes. This is illustrated in the following diagram:
In due course, for data that is not modified, this structure will prove to be quite efficient since it takes up comparatively small memory and it fetches all the leaf nodes without traversals. On frequently changing data, it is not as effective since insertions and updation lead to extensive index updates and therefore is a costly affair.
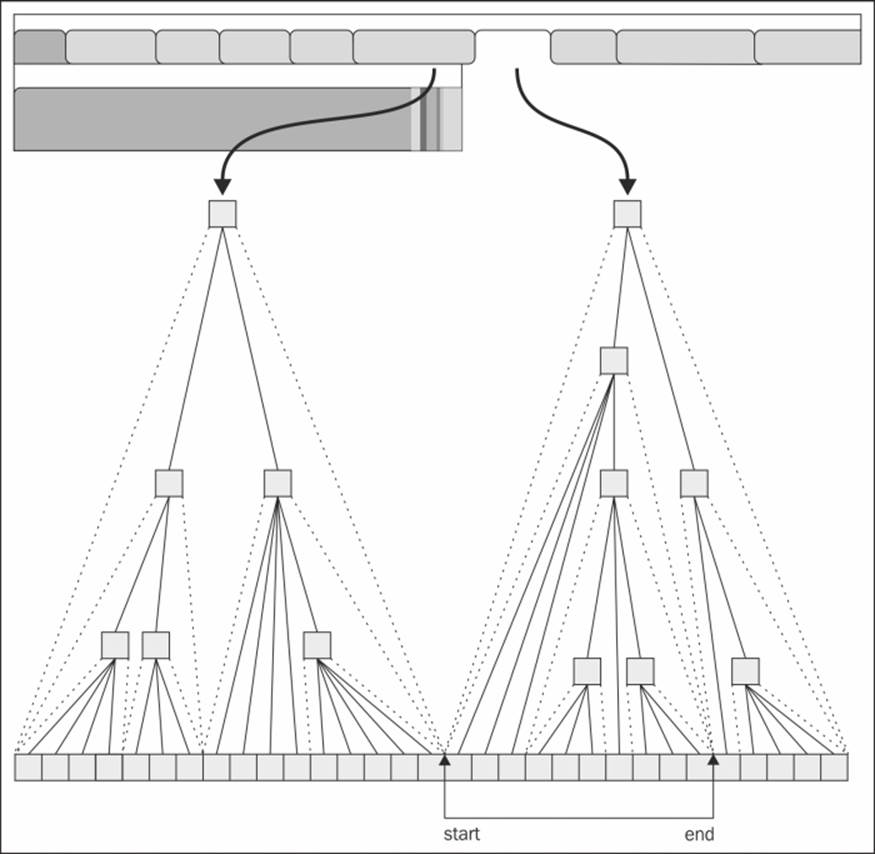
Flattening with ordered field names
The operation of search engines is based on flattened documents of fields and values. In datasets for such applications, the goal of modeling is to map existing entities to plain documents or unified nodes that can be challenging when the structure of the graph is complex. We can combine multiple related nodes or relationships into single entities based on their use. For example, you can combine nodes. This technique is not really scalable since the complexity of the query is seen to grow quite rapidly as a function of a count of the structures that are combined.
Schema design patterns
Designing a schema will vary according to the scenario of data and operations that are being used. So, once you have designed and implemented your graph model, you need to use the appropriate schema to retrieve interesting information and patterns from the graph. The tool of preference would be Cypher, as it is essentially built around graphs. Let's look at some design scenarios.
Hyper edges
The data entities can have different levels of classifications, for example, different groups contain a given user, with different roles for each group and a user being part of several groups. The user can take up various roles in multiple groups apart from the one they are a member of. The association that exists between the user, their groups, and the roles can be depicted with the help of a hyper edge. This can be implemented in a property graph model with the help of a node that captures an n-ary relationship.
Note
In mathematics, a hypergraph is a generalization of a graph in which an edge can connect any number of vertices. One edge that contains an arbitrary number of nodes is a hyper edge. Property graphs cannot natively support hyper edges. If you need a hyper edge in your model, then this can be simulated by introducing an extra node.
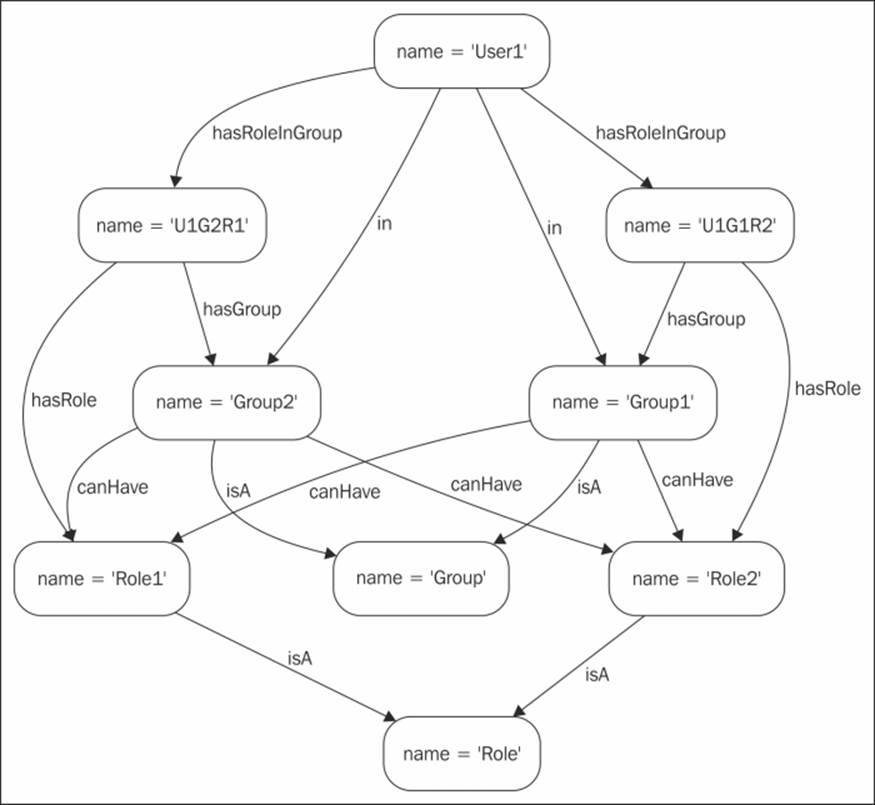
In order to compute a user's role in a certain group (Group2 in this case), we make use of the following Cypher query for the traversal of the node with HyperEdge and calculate the results:
MATCH ({ name: 'User1' })-[:hasRoleInGroup]->(hyperEdge)-[:hasGroup]->({ name: 'Group2' }),(hyperEdge)-[:hasRole]->(role)
RETURN role.name
The result returns the role of User1 as Role1.
To calculate all the roles of a given user in the groups and display them in the form of an alphabetically sorted table, we need the traversal of the node with the HyperEdge:
MATCH ({ name: 'User1' })-[:hasRoleInGroup]->(hyperEdge)-[:hasGroup]->(group),(hyperEdge)-[:hasRole]->(role)
RETURN role.name, group.name
ORDER BY role.name ASC
The preceding query generates the following results:
|
role.name |
group.name |
|
"Role1" |
"Group2" |
|
"Role2" |
"Group1" |
Implementing linked lists
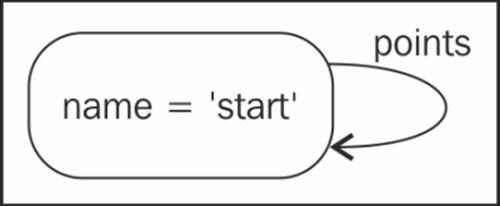
Since a graph database inherently stores data as a graph, it becomes an increasingly powerful tool to implement graph-based data structures such as linked lists and trees. For a linked list, we require the head or start node as the reference of the list. This node will have an outbound relation with the first element in the list and an inbound relation from the last element in the list. For an empty list, the reference points to itself. Such a linked list is called a circular list.
Let's initialize a linked list with no elements for which we first create a node that references itself. This is the start node used for reference; hence, it does not set a value as its property:
CREATE (start {name: 'START'})-[:POINTS]->(start)
RETURN start
In order to add a value to it, we need to first find the relationship in which the new value should be placed. In this spot, in the place of the existing relationship, we add a new connecting node with two relationships to nodes on either ends. You also need to keep in mind that the nodes on either end can be the start node, which is the case when the list has no elements. To avoid the creation of two new value nodes, we are required to use the UNIQUE clause with the CREATE command. This can be illustrated with a Cypher query as follows:
MATCH (start)-[:POINTS*0..]->(prev),(next)-[:POINTS*0..]->(start),(prev)-[old:POINTS]->(next)
WHERE start.name = 'START' AND (prev.value < 25 OR next = start) AND (25 < next.value OR next =
start)
CREATE UNIQUE (prev)-[:POINTS]->({ value:25 })-[:POINTS]->(next)
DELETE old
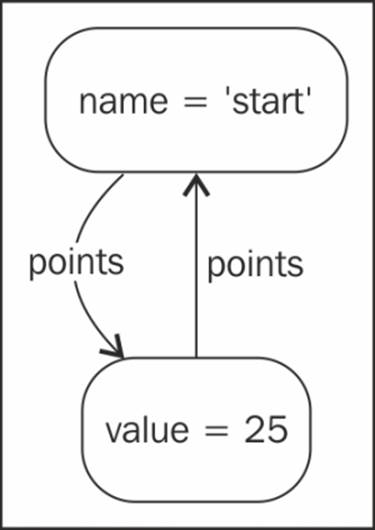
What this clause does is that it looks for the appropriate position of the value 25 in the list and replaces that relationship with a node containing 25 connected with two new relationships.
Complex similarity computations
When you have a heavily populated graph, you can perform numerous complex computations on it and derive interesting relations in large datasets of financial organizations, stock market data, social network data, or even sports data. For example, consider finding the similarity between two players based on the frequency with which they have been eating certain food (weird, huh!):
MATCH (roger { name: 'roger' })-[rel1:EATS]->(food)<-[rel2:EATS]-(raphael)
WITH roger,count(DISTINCT rel1) AS H1,count(DISTINCT rel2) AS H2,raphael
MATCH (roger)-[rel1:EATS]->(food)<-[rel2:EATS]-(raphael)
RETURN sum((1-ABS(rel1.times/H1-rel2.times/H2))*(rel1.times+rel2.times)/(H1+H2)) AS similarity
Hence, complex computations can be carried out with minimal code involvement.
Route generation algorithms
The greatest advantage of having your data in the form of a graph is that you generate custom paths based on your requirements. For example, you need to find the common friend of two people; what you essentially have to do is find the shortest paths of length 2using the two users and the connecting relationship between the entities. This will give us the users who are connected to the given people by a friend hop count of 1. Neo4j has a few graph de facto algorithms including those for the shortest path, which can be used in the following format:
PathFinder<Path> PathToFind = GraphAlgoFactory.shortestPath(
Traversal.expanderForTypes( FRNDS_WITH ), 2 );
Iterable<Path> CommonPaths = PathToFind.findAllPaths( person1, person2 );
If Cypher is what appeals to you, then to return mutual friends of person1 and person2 by using traversals of the graph, you need the following snippet:
start person1 = node(3),person2 = node(24) match (person1)--(Relation)--(person2) return Relation;
If you are interested in getting all the friends of a given person person1, then all you need to do is this:
start person1 = node(3) match person1--relation--person2 where person1--person2 return relation;
Let's look at a code snippet that uses Neo4j's existing traversal algorithms on a graph modeled with weighted edges to calculate the least total weight (call this distance for now):
import org.neo4j.graphdb.Node;
import org.neo4j.kernel.Traversal;
import org.neo4j.graphalgo.PathFinder;
import org.neo4j.graphalgo.CostEvaluator;
import org.neo4j.graphdb.Direction;
import org.neo4j.graphalgo.WeightedPath;
import org.neo4j.graphalgo.GraphAlgoFactory;
import org.neo4j.graphalgo.CommonEvaluators;
import org.neo4j.graphdb.RelationshipExpander;
/**
* Finding shortest path (least weighted) in a graph
*/
public class DijkstraPath
{
private final GraphServiceHelper graph;
//Included in the code folder
private static final String WEIGHT = "weight";
private static final CostEvaluator<Double> evalCost;
private static final PathFinder<WeightedPath> djktraFindPath;
private static final RelationshipExpander relExpndr;
static
{
// configure the path finder
evalCost = CommonEvaluators.doubleCostEvaluator( WEIGHT );
relExpndr = Traversal.expanderForTypes(GraphServiceHelper.MyDijkstraTypes.REL, Direction.BOTH );
djktraFindPath = GraphAlgoFactory.dijkstra( relExpndr, evalCost );
}
public DijkstraPath()
{
graph = new GraphServiceHelper( "path_to_database" );
}
private void constructGraph()
{
graph.createRelationship( "n1", "n2", WEIGHT, 10d );
graph.createRelationship( "n2", "n5", WEIGHT, 10d );
graph.createRelationship( "n1", "n3", WEIGHT, 5d );
graph.createRelationship( "n3", "n4", WEIGHT, 10d );
graph.createRelationship( "n4", "n5", WEIGHT, 5d );
}
/**
* Find the path.
*/
private void executeDijkstraFindPath()
{
Node begin = graph.getNode( "n1" );
Node endd = graph.getNode( "n5" );
WeightedPath path = djktraFindPath.findSinglePath( begin, endd );
for ( Node node : path.nodes() )
{
System.out.println( node.getProperty( GraphServiceHelper.NAME ) );
}
}
/**
* Shutdown the graphdb.
*/
private void stop()
{
graph.shutdown();
}
/**
* Execute the example.
*/
public static void main( final String[] args )
{
DijkstraPath obj = new DijkstraPath();
obj.constructGraph();
obj.executeDijkstraFindPath();
obj.stop();
}
}
Modeling across multiple domains
Most organizations use Neo4j for the purpose of business applications. Developers might sometimes argue that in designing the underlying data model, there ought to be multiple graphs that are classified on the basis of subdivided domains. Others might insist on having all of the data of the domain in a single large graph. If you consider the facts, both these scenarios have their own trade-offs.
If the subdivided domain datasets are queried frequently in such a way that the traversals are spread across multiple domains, then the developer who suggested a single large graph is right. However, if you are confident that the subdivided domains will rarely need to interact among themselves, then it would be effective to use the multiple small graphs. This will make the system more robust and decrease the query response time.
With all this said, it is important to outline that the more messy your graph looks with interconnections of all kinds, the more complex queries you can practically run to derive highly interesting relationships that will make your application more complex and intelligent. For example, if your comprehension of music was to be completely independent of your ability to play soccer, then the movements of the goalkeeper will not appear like dancing (if you are thinking of music while watching a match, you could actually interpret the movements as a dance). Humans on the other hand are capable of seamlessly mixing so many different variations.
Domains or subdomains for that matter are rarely different in the truest sense; they overlap at times, which can be a benefit for your app if the traversals can make use of explicit continuities in such cases. Performance depends on how frequently you traverse and the methods you use for it. The data size and density of related data are rather insignificant for performance if you decide to subdivide your graph into chunks.
Although it would not be a preferred choice on single machines, if you need to subdivide your graph based on domains, you need to keep in mind that Neo4j graphs are essentially directories in the filesystem. So, in order to link them, you would be required to create a class to dynamically load the path of the database needed into memory for the querying process and remove it when the result of the query is obtained. In a real-time scenario where loads of queries need to processed on the fly, this is not a good idea. However, for scenarios where you need to warehouse your data for analysis purposes, it definitely works well.
Insights for businesses require us to understand the underlying network actions in a complex chain of values. This might require us to perform joins across several domains with little or no distortion in the details of each domain. This process is simplified with property graphs, where we can model a chain of values as a forest (that is, a graph of graphs) that can include interdomain relationships on rare occasions.
Summary
Even though modeling graphs seems to be a quite expressive method of handling the level of complexity associated with a problem domain, this expressivity is not a guarantee that the graph is fit for the purpose it is designed for. There are several issues of wrong modeling among graph data users, but eventually, you learn which model is suitable for the scenario at hand.
In this chapter, we looked at how vivid modeling is possible when you have data in graphs. We also looked at how Neo4j data can be modeled with Cypher as a tool to decipher interesting relationships directly, which would otherwise require several hours of computation.
In the next chapter, we will look at scenarios that handle high-volume data in Neo4j applications.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.