Neo4j High Performance (2015)
Chapter 4. Neo4j for High-volume Applications
There is an exponential surge in the amount of data being created annually; a pattern that is going to exist for quite some time. As data gets more complex, it is increasingly challenging to get valuable insights and information from it. However, the volume and complexity of data are not the only issues. There appears to be a rise in semi-structured and highly interconnected data. Several major tech firms such as Facebook, Google, and Twitter have resorted to the graph approach to tackle complexity in the big data arena. The analysis of trends and patterns out of the collected raw data has begun to gain popularity. From professional outlook websites such as LinkedIn to tiny specialized social media applications cropping up each day, all have a graph-processing layer in their core applications. The graph-oriented approach has led many industries to come up with scalable systems to manage information.
A multitude of next-generation databases that provide better performance and support for semi-structured data form the backbone of the big data revolution today. These technologies not only make the analysis, storage, and management of high volumes of data simpler, they also scale up and scale out at an extraordinary rate. Graph databases are crucial players that have made it convenient to house an information web in your application that can be traversed through labeled relationships. Graph problems are existent all round us—from managing access rights and permission in security systems to looking for where you put the keys and from simple graphs to complex social ones—a graph database can provide more natural storage and rapid querying.
In this chapter, we will look at the use of graphs and the Neo4j database in scenarios that handle large volumes of data including:
· Graph processing
· Use of graphs in big data
· Transaction management
· The graphalgo package of Neo4j
· Introducing spring data Neo4j
Graph processing
Graph processing is an exciting development for those in the graph database space, since the utility of graph databases has been reinforced as a storage system as well as a computational model. However, the processing of graph-like data can be confused with graph databases due to the common data models they share, although each technique operates on fundamentally different scenarios. Some graph-processing platforms such as Pregel, developed by Google, are capable of achieving high-computational throughput, since it adopts the Bulk Synchronous Processing (BSP) model from the domain of parallel computing. This model supports the partition of the graph into multiple machines and uses the localized data from the vertices for computation. Exchange of local information takes place during the synchronization process. This model is used to process large interconnected datasets for business insights compared to traditional map-reduce operations, although high latency is a concern in this case.
For enterprise scenarios, a popular batch-processing platform for large volumes of data is Hadoop. Similar to Pregel, Hadoop is also a high-throughput and latency system that is used to optimize throughputs of computation for extremely large datasets and that too in parallel and exterior to the database. However, Hadoop is made for general computational use and although you can use it for processing graphs, the system and the components are "un-optimized" for graph-oriented operations.
What the two platforms have in common is the efficient handling of Online Analytical Processing (OLAP) for analytics, rather than simply dealing with transactions. This is contrary to the principles of Neo4j and other graph databases. These principles prioritize the optimization of storage and queries for Online Transaction Processing (OLTP), similar to relational databases, but implement a more powerful, simple, and expressive underlying data model. This can visualized from the following diagram:
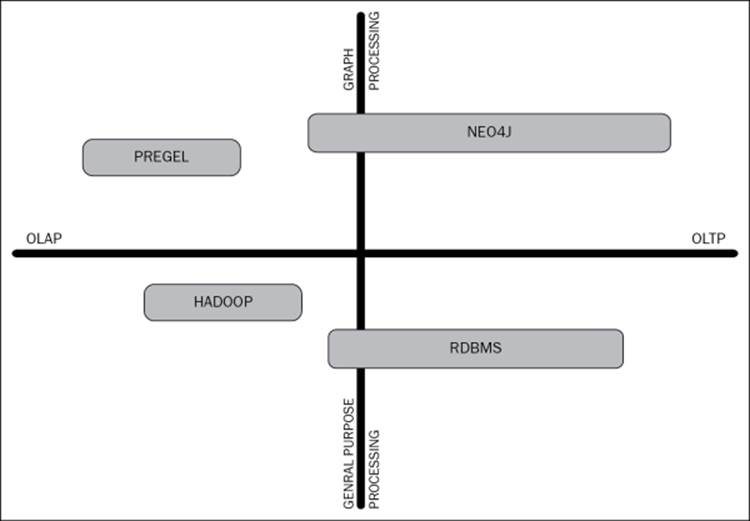
As depicted in the preceding diagram, Pregel is strictly an OLAP graph-processing tool; Hadoop is a completely general-purpose OLAP system but it is closer to the OLTP axis since several current extensions are available to achieve near real-time processing with Hadoop. Relational databases are mostly OLTP systems that can be logically adapted in systems that require OLAP processing. Neo4j is designed solely for graph data and primarily involves scenarios for OLTP operations, although it can also be used for OLAP since it has a native graph model and high-read capability.
Big data and graphs
Graph data analysis is a prime technique to extract information from very large datasets by assessing the similarity or associativity of data points. The need for such techniques arose when social networks started gaining popularity and expanded their user base rapidly, but today, graph analysis has a much broader scope of application.
Since graph processing has caught up in the race for crunching data, big data platforms and communities have been innovatively adapting themselves to the needs for solving graph problems with frameworks, such as Apache Giraph (http://giraph.apache.org/) and MapReduce extensions such as Pregel (goo.gl/hW3L40), Surfer, and GBASE (http://goo.gl/3QkB46); it is becoming simpler to address graph-processing issues.
Hadoop is a large-scale distributed batch-processing framework that operates at high latencies unlike graph databases. So, if you implement graph processing on a Hadoop-based system, data locality will lead to a more efficient batch execution, and therefore, we will see a higher throughput. However, latency still remains the drawback. Hence, the approach of graph processing through Hadoop batch jobs will not be feasible for OLTP applications, since they require quite low latency in the order of milliseconds (as compared to the seconds in Hadoop). Hence, it will find more applications operating on static data in the OLAP domain. You can use this for report generation purposes from static data stored in warehouses, especially if the data is carefully laid out. In order to increase the efficiency of such a system, denormalization of the data needs to take place within the HBase data store, which increases the cognitive difference between the obtained data and the manner in which it is represented for the purpose of graph processing.
However, Neo4j rules out these drawbacks. If you use Neo4j for the purposes of graph processing, you do not need to denormalize the data or set up any specialized infrastructure. Neo4j works seamlessly in OLTP and uses the same database (most often, a read-only replica in sync with the master) for OLAP, should you require to use it. The main advantage here is the low latency even when dealing with larger read queries as well as when exposed to heavy online loads.
Hadoop-based, batch-oriented graph processing is beneficial in scenarios where you can read or process data external to the database as compared to manipulating it in place. So, to obtain efficient processing, data needs to be carefully placed in HBase with no scope of mutation in the course of the processing. Neo4j, on the other hand, supports mutations of the graph in place, which is an essential feature to run analytics on real-time web data.
Processing with Hadoop or Neo4j
The Hadoop-based solution processes batches to provide high throughputs but at the cost of high latency and denormalization of data. The Neo4j approach is the perfect candidate for OLTP processing on native graph data, with an added advantage of real-time OLAP operations that provide a modest throughput but speed things up with a quite low latency. So, depending upon the type of data and the requirement of your application, you can select one of the methods for an advanced graph-processing approach. If OLTP is what you need with deep analytical insights into your data in near real-time, then Neo4j is the answer to your prayers. For more relaxed scenarios that can bear the high latencies in order to achieve higher throughput, then you should consider graph-processing platforms such as Hadoop or Pregel (developed at Google).
In fact, there have also been attempts to combine Hadoop's processing capabilities with the native graph storage of Neo4j. You can check this out at http://goo.gl/OTgfML.
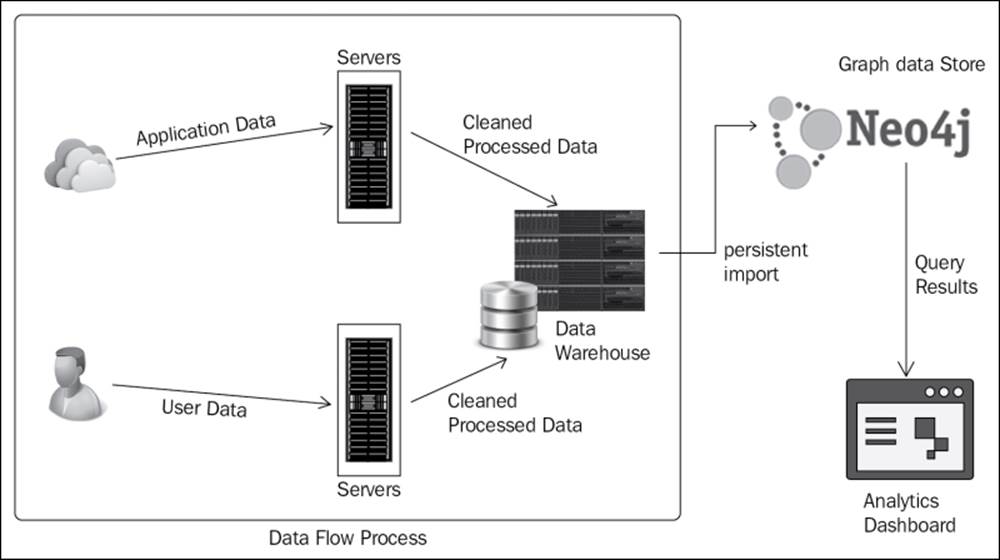
Neo4j performs best in an in-memory dataset that leads to blazing-fast traversals and implementations of complex logic. However, as the number of datasets increase, it becomes difficult to incorporate all of it in memory for processing. Also, distributing the dataset across multiple Neo4j instances is possible but decreases the traversal speed. So, an alternate approach needs to be found. Analytics of the data is not generally an online process. You can make use of this fact to intermittently load only that part of the data you would require for the current analytical transaction, process it, and then load new data for another. So, only when the need to populate the analytics dashboard field arises do you load and process the data in Neo4j. This process is illustrated in the preceding diagram. This technique is beneficial since the importing of data in Neo4j costs relatively less compared to the analytical processing of graphs in a relational or distributed data store.
Managing transactions
Consider corporate scenarios, or businesses generating tons of critical data; operating on them in real time is a responsibility. On one hand, there are corporations such as Twitter or IMDb where the volume of data is high but the criticality of data is not a top priority. However, on the other hand, there are firms that handle high volumes of connected financial or medical data, where maintaining the integrity of data is of the utmost importance. Such scenarios require ACID transactions, which most databases today have built-in support for. Neo4j is a fully ACID database, as we discussed in Chapter 1, Getting Started with Neo4j; it ensures the following properties with respect to transactions:
· Atomicity: When a part of the transaction is unsuccessful, the state of the database is not changed
· Consistency: The transaction maintains the database in a consistent state
· Isolation: When transactions take place, the data being operated upon is not accessible to any other process
· Durability: It is possible to roll back or recover the committed transaction results
Neo4j has provision to ensure that whenever graph access, indexing, or schema-altering operations take place, they must be processed in transactions. This is implemented with the help of locks. Neo4j allows nonrepeatable reads, in other words, the transactions acquire write-level locks that are only released when the transaction terminates. You can also acquire write locks manually on entities (nodes or relationships) for higher isolation levels such as SERIALIZABLE. The default level is READ_COMMITTED. The core API for a transaction also has provisions to handle deadlocks, which we will discuss later in the chapter.
A transaction is confined at the thread level. You also nest your transactions, where the nested transactions are part of the scope of the highest-level transaction. These transactions are referred to as flat nested transactions. In such transactions, when there is an exception in a nested transaction, the complete highest-level transaction needs to roll back, since alterations of a nested transaction alone cannot be rolled back.
The database constantly monitors the transaction state, which basically involves the following operations:
1. A transaction begins.
2. Operations are performed on the database.
3. Indicate whether the transaction was a success or a failure.
4. The transaction finishes.
The transaction must finish in order to release the acquired locks and the memory used. In Neo4j, we use a try-finally code segment where the transaction is started and the write operations are performed. The try block should end by marking the transaction successful and the transaction should be finished by the finally block, where the commit or rollback operation is performed depending upon the success status of the transaction. It is important to keep in mind that any alterations performed in a transaction are in memory, which is why for high-volume scenarios with frequent transactions, we need to divide the updates into multiple higher- or top-level transactions to prevent the shortage of memory:
Transaction tx = graphDb.beginTx();
try
{
// operations on the graph
// ...
tx.success();
}
finally
{
tx.close();
}
Since transactions operate with thread pools, other errors might be occurring when a transaction experiences a failure. When a transaction thread has not finished properly, it is not terminated and marked for rollback and will result in errors when a write operation is attempted for that transaction. When performing a read operation, the previous value committed will be read, unless the transaction that is currently being processed makes changes just before the read. By default, the level of isolation implemented isREAD_COMMITTED, which means that no locks are imposed on read operations, and hence, the read operations can occur in a nonrepeatable fashion. If you manually specify the read and write locks to be used, then you can implement a higher level of isolation, namely, SERIALIZABLE or REPEATABLE_READ. Generally, write locks are implemented when you create, modify, or delete a particular entity as outlined in the following points:
· Writelock a node or relationship when you add, change, or remove properties.
· The creation and deletion of nodes and relationships require you to implement a write lock. For relationships, the two connecting nodes need to be write-locked as well.
Neo4j comes equipped with deadlock detection, where a deadlock occurring due to the locking arrangement can be detected before it happens and Neo4j churns out an exception to indicate the deadlock. Also, the transaction is flagged to be rolled back before the exception is thrown. When the locks held are released in the finally block, other transaction operations that were busy waiting on the resource can now take up the lock and proceed. However, the user can choose to retry the failed/deadlocked transaction at a later time.
Deadlock handling
When deadlocks occur frequently, it is generally an indication that the concurrent write requests are not possible to execute to maintain consistency and isolation. To avoid such scenarios, concurrent write updates must be executed in a reasonable fashion. For example, deadlocks can happen when we randomly create or delete relationships between the two given nodes. The solution is to always execute the updates in a specific order (first on node 1 and then on node 2 always) or by manually ensuring that there are no conflicting operations in the concurrent threads by confining similar types of operations to a single thread.
All tasks performed by the Neo4j API are thread-safe in nature, unless you explicitly specify otherwise. So, any other synchronized blocks in your code should not include operations relating to Neo4j. There is a special case that Neo4j includes while deleting nodes or relationships. If you try to delete a node or relationship completely, the properties will undergo deletion, while the relationships will be spared. What? Why? That's because Neo4j imposes a constraint on relationships that have valid start and end nodes. So, if you try to delete nodes that are still connected by relationships, an exception is raised on committing transactions. So, the transaction must be planned in such a way that no relationships to a node being deleted must exist when the current transaction is about to be committed. The semantic conventions that must be followed when a delete operation is required to be performed are summarized as follows:
· When you delete a node or relationship, all properties are deleted.
· Before committing, a node must not have relationships attached to it.
· A node or relationship is not actually deleted unless a commit takes place; hence, you can reference a deleted entity before commits. However, you cannot write to such a reference.
Uniqueness of entities
Duplication is another issue to deal with when multithreaded operations are in play. It is possible that there is only one player with a given name in the world, but transactions on concurrent threads trying to create such a node can end up creating duplicated entities. Such operations need to be prevented. One naïve approach would be to use a single thread to create the particular entities. Another popular approach that is used most often is to use the get_or_create operation. We can guarantee uniqueness with the help of indexing where legacy indices are used as locks for the smallest unique identity of the entity to enable creation only if the lookup for that particular entity fails. The other existing one is simply returned. This concept of get_or_create exists for Cypher as well as the Java API. This ensures uniqueness across all transactions and threads.
There is also a third technique called pessimistic locking that is implemented across common nodes or a single node, where a lock is manually created and used to check for synchronization. However, this approach does not apply to a high-availability scenario.
Events for transactions
Event handlers for transactions keep track of what happens in the course of a transaction before it goes for a commit. You need to register an event handler to an instance of the GraphDatabaseService, events can be received. Handlers are not notified if the transaction does not perform any writes or the transaction fails to commit. There are two methods, beforeCommit and afterCommit, that calculate the changes in the data (the difference) due to that commit and that constitutes an event.
Let's now see a simple example where a transaction is executed through the Java API to see how the components fit together:
public void transactionDemo() {
GraphDatabaseService graphDatabase;
Node node1;
Node node2;
Relationship rel;
graphDatabase = new GraphDatabaseFactory().newEmbeddedDatabase( DB_PATH );
registerShutdownHook( graphDatabase );
Transaction txn = graph.beginTx();
try {
node1 = graphDatabase.createNode();
node1.setProperty( "name", "David Tennant" );
node2 = graphDatabase.createNode();
node2.setProperty( "name", "Matt Smith" );
rel = node1.createRelationshipTo( node2, RelTypes.KNOWS );
rel.setProperty( "name", "precedes " );
node1.getSingleRelationship( RelTypes.KNOWS, Direction.OUTGOING ).delete();
node1.delete();
node2.delete();
txn.success();
} catch (Exception e) {
txn.failure();
} finally {
txn.finish();
}
}
When you are using the Neo4j REST server or operating in the high-availability mode, then the following syntax can be used:
POST http://localhost:7474/db/data/transaction/commit
Accept: application/json; charset=UTF-8
Content-Type: application/json
{
"statements" : [ {
"statement" : "CREATE (n {props}) RETURN n",
"parameters" : {
"props" : {
"name" : "My Node"
}
}
} ]
}
The preceding REST request begins a transaction and commits it after completion. If you want to keep the transaction open for more requests, then you need to drop the commit option from the POST request as follows:
POST http://localhost:7474/db/data/transaction
Post this at the end of the transaction to commit:
POST http://localhost:7474/db/data/transaction/9/commit
Transactions are the core components that make Neo4j ACID-compliant and suitable for use in scenarios where high volumes of complex critical data are being used. Transactions, if managed efficiently, can make your application robust and consistent, even in scenarios that require real-time updates.
The graphalgo package
A graph provides a very attractive solution when you want to model real-world data. As they are more flexible than RDBMS, they offer an intuitive approach and are practically relevant to the way we think of stuff. The graph world revolves around several featured algorithms that are used to process graphs and for route calculation, detection of loops, calculation of the shortest path, subgraph and pattern matching being a few of them. Although you can implement your own collection of algorithms and tweaks, Neo4j also includes a set of predefined algorithms that you use most for rapid application development, even for scenarios that involve large volumes of data. They are packaged in a library called the graphalgo that you can use directly in your Java code fragments. The REST API also exposes a few of these algorithms such as dijkstra's and A* to be used with requests sent to the REST server. The graphalgo interfaces can be accessed and used in your programs using methods of the GraphAlgoFactory class. Some of the methods that can prove quite useful at times are:
· allPaths(PathExpander, int): This method returns an algorithm that can be used to calculate all possible paths between two specified nodes. Paths with loops can also be calculated using this method.
· allSimplePaths(PathExpander, int): This method returns an algorithm that does a similar job as the allPaths algorithm, except that it returns paths that do not contain a loop.
· aStar(PathExpander, CostEvaluator<Double>, EstimateEvaluator<Double>): This method returns a variable of type PathFinder that can use the A* algorithm to calculate the path with the minimum weight/cost between two specified nodes.
· dijkstra(PathExpander, CostEvaluator<Double>): This method returns a variable of type PathFinder that operates similar to the one in the previous method, except it uses the Dijkstra's algorithm instead of A*.
· pathsWithLength(PathExpander, int): It returns an algorithm that can be used to a specific weighted path between two nodes.
· shortestPath(PathExpander, int): From this method, you get an algorithm to calculate all possible shortest paths that exist between a given pair of nodes.
All the preceding algorithms use an instance of PathExpander as a parameter, which contains the logic to decide which relationship to expand on, or select the next relationship in the process of traversal. Alternatively, the preceding methods also allow the use ofRelationshipExpander, which is a similarly flexible way of getting the relationships from a particular node. All the preceding methods return a value of the type PathFinder, which you can use to retrieve the paths from the algorithms. Let's see the use of some of these through an example:
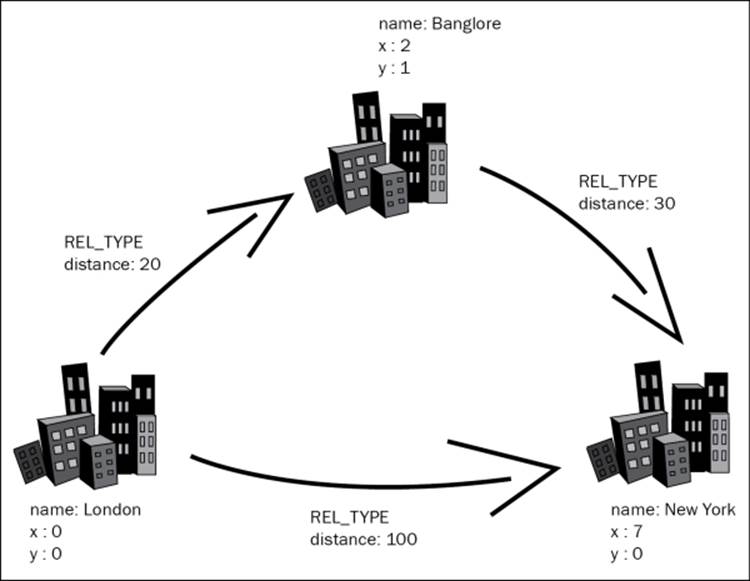
The preceding diagram illustrates a graphical scenario of interconnected cities that we will be using for our example. The following code shows how the graph can be created and operated upon:
//Create a sample graph
Node cityA = createNode( "city", "London", "x", 0d, "y", 0d );
Node cityB = createNode( "city", "New York", "x", 7d, "y", 0d );
Node cityC = createNode( "city", "Bangalore", "x", 2d, "y", 1d );
Relationship distAB = createRelationship( cityA, cityC, "distance",20d );
Relationship distBC = createRelationship( cityC, cityB, "distance",30d );
Relationship distAC = createRelationship( cityA, cityB, "distance",100d );
EstimateEvaluator<Double> estimateEvaluator = new EstimateEvaluator<Double>()
{
@Override
public Double getCost( final Node node, final Node goal )
{
double costx = (Double) node.getProperty( "x" ) - (Double) goal.getProperty( "x" );
double costy = (Double) node.getProperty( "y" ) - (Double) goal.getProperty( "y" );
double answer = Math.sqrt( Math.pow( costx, 2 ) + Math.pow( costy, 2 ) );
return answer;
}
};
//Use the A* algorithm
PathFinder<WeightedPath> astarFinder = GraphAlgoFactory.aStar(PathExpanders.allTypesAndDirections(),
CommonEvaluators.doubleCostEvaluator( "distance" ), estimateEvaluator );
WeightedPath astarPath = astarFinder.findSinglePath( cityA, cityB );
//Using the Dijkstra's algorithm
PathFinder<WeightedPath> dijkstraFinder = GraphAlgoFactory.dijkstra(
PathExpanders.forTypeAndDirection( ExampleTypes.REL_TYPE, Direction.BOTH ), "distance" );
WeightedPath shortestPath = dijkstraFinder.findSinglePath( cityA, cityC );
//print the weight of this path
System.out.println(shortestPath.weight());
//Using the find all paths method
PathFinder<Path> allPathFinder = GraphAlgoFactory.shortestPath(
PathExpanders.forTypeAndDirection( ExampleTypes.REL_TYPE, Direction.OUTGOING ), 15 );
Iterable<Path> all_paths = allPathFinder.findAllPaths( cityA, cityC );
The REST interface of the Neo4j server is also capable of executing these graph algorithms, where you can define the start node and the type of algorithm in the body of the POST request, as illustrated here:
POST http://localhost:7474/db/data/node/264/path
Accept: application/json; charset=UTF-8
Content-Type: application/json
{
"to" : "http://localhost:7474/db/data/node/261",
"cost_property" : "cost",
"relationships" : {
"type" : "to",
"direction" : "out"
},
"algorithm" : "dijkstra"
}
These algorithms operate efficiently in moderate to large graphs. However, when you are processing graphs that require visiting billions of vertices that are highly connected in the graph, you can tweak these algorithms to improve performance. For example, if your graph cannot fit on a single instance and you resort to a cluster, then you need to modify your algorithm to traverse across machines, or to calculate in parts. However, for most big data scenarios today, they provide optimal performance.
Introduction to Spring Data Neo4j
The Spring MVC web framework is a project that exposes a model-view-controller architecture along with components that can be used for the development of loosely coupled and highly flexible web-based applications. The MVC-based approach is useful for differentiating the various aspects of an application—the input and the business and UI logic—and provides a loosely coupled relation between the elements.
The Spring Data project was designed to ease the process of using relatively newer technologies, such as map-reduce jobs, nonrelational and schema-less databases, and cloud data services, to build Spring-powered applications. As far as graph databases are considered, this project currently has support for Neo4j integration.
Spring Data Neo4j is a project that exposes a simple Plain Old Java Object (POJO) model for developers to program with, which is useful in reducing the boilerplate code (code that sees inclusion in several places without much alteration) that goes into the creation of applications with Neo4j. This helps to extend the Java Persistence API (JPA) data model in order to provide a cross-store solution for persistence that uses new parts such as entities, properties, and relationships exclusively to handle graphs. However, it is integrated in a transparent manner with pre-existing JPA entities, which provides an edge over simple JPA-based applications. The Spring Data Neo4j framework also includes features to map the annotated entity classes with the underlying Neo4j graph database. It uses a template programming model that presents a similar approach to the Spring templates, and this accounts for the interactivity with graphs and also has repository support. The following are some of the salient features of this framework:
· It integrates well with property graphs and has support for Gremlin and Cypher
· Transparent access to the Neo4j server with the REST API can also be run as an extension to the Neo4j server
· It has dynamic field traversal support and also extensive indexing practices
· Object-graph mapping for Java object entities
· Support for Spring Data repositories and dynamic type projections
Let's take a look at how you can set up a Spring Data Neo4j project to build an application that runs Neo4j as a data store. Using a dependency management system such as Maven or Gradle is the recommended approach to setting up the project. To include the latest stable build of SDN in your project, specify the following dependency in your pom.xml file:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-Neo4j</artifactId>
<version>3.2.0.RELEASE</version>
</dependency>
Alternatively, if you intend to use REST API calls to access the remote Neo4j server, then the SDN dependency for REST should be included:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-Neo4j-rest</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
Similar to other Spring Data projects, you need to define the special XML namespaces in order to configure your project. We simply need to provide the interface methods to define the custom finders we need to implement, and at runtime, Spring injects the appropriate implementation at runtime. The following context can be used for configuration:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:Neo4j="http://www.springframework.org/schema/data/Neo4j"
xsi:schemaLocation="http://www.springframework.org/schema/beans <a href="http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">http://www.springframework.org/schema/beans/spring-beans-3.0.xsd</a>
<a href="http://www.springframework.org/schema/context">http://www.springframework.org/schema/context</a> <a href="http://www.springframework.org/schema/context/spring-context-3.0.xsd">http://www.springframework.org/schema/context/spring-context-3.0.xsd</a>
<a href="http://www.springframework.org/schema/data/Neo4j">http://www.springframework.org/schema/data/Neo4j</a> <a href="http://www.springframework.org/schema/data/Neo4j/spring-Neo4j.xsd">http://www.springframework.org/schema/data/Neo4j/spring-Neo4j.xsd"</a>>
<context:spring-configured/>
<context:annotation-config/>
<Neo4j:config storeDirectory="target/data/db"/>
<Neo4j:repositories base-package="com.comsysto.Neo4j.showcase"/>
</beans>
If you plan to use your Spring application to interface with the REST API, then you need to include the server URL to direct the calls, as shown in the following code:
<!-- REST Connection to Neo4j server -->
<bean id="restGraphDatabase" class="org.springframework.data.Neo4j.rest.SpringRestGraphDatabase">
<constructor-arg value="http://localhost:7474/db/data/" />
</bean>
<!-- Neo4j configuration (creates Neo4jTemplate) -->
<Neo4j:config graphDatabaseService="restGraphDatabase" />
Example
//Creating a node entity
@NodeEntity
class Player {
@Indexed(unique=true)
private String player_name;
@RelatedTo(direction = Direction.BOTH, elementClass = Player.class)
private Set<Player> coPlayers;
public Player() {}
public Player(String player_name) { this.player_name = player_name; }
private void playedWith(Player coPlayer) { coPlayers.add(coPlayer); }
}
Player ronaldo = new Player("Ronaldo").persist();
Player beckham = new Player("Beckham").persist();
Player rooney = new Player("Rooney").persist();
beckham.playedWith(ronaldo);
beckham.playedWith(rooney);
// Persist creates relationships to graph database
beckham.persist();
for (Player coPlayer : beckham.getFriends()) {
System.out.println("Friend: " + coPlayer);
}
// The Method findAllByTraversal() is part of @NodeEntity
for (Player coPlayer : ronaldo.findAllByTraversal(Player.class,
Traversal.description().evaluator(Evaluators.includingDepths(1, 2)))) {
System.out.println("Ronaldo's coPlayers to depth 2: " + coPlayer);
}
// Add <datagraph:repositories base-package="com.your.repo"/> to context config.
interface com.example.repo.PlayerRepository extends GraphRepository<Player> {}
@Autowired PlayerRepository repo;
beckham = repo.findByPropertyValue("player_name", "beckham");
long numberOfPeople = repo.count();
The preceding code denotes a scenario where we relate players who have played together. The SDN domain class defines the Node entity along with its data and indexes and relationships. The persist() method creates the entities into the database. Apart from the basic CRUD operations, you can also run Cypher queries with SDN if you have included the REST library in your dependency list for the project:
@Query("start movie=node({self}) match
movie-->genre<--similar return similar")
Iterable<Movie> similarMovies;
SDN is a highly efficient framework built on top of Spring; however, when you want to load larger datasets into such applications, you might find things getting a bit complex. In Neo4j, the batch inserter is the answer to bulk data loads, but SDN does not support batch inserter out of the box. SDN is simply a layer of mapping between the Neo4j entities and the Java types. You need to explicitly write code to insert data in batches using TypeRepresentationStrategy defined for the nodes and relationships, which creates a__type__ property for the defined entities and __type__ indexes for nodes and relationships. You can look further into these issues at http://projects.spring.io/spring-data-Neo4j/.
Summary
It's one thing to handle and store big data and a different one to understand it. This is where Neo4j comes in handy as a super tool. In this chapter, we saw that not only can you store your data in a more organized and logical manner, you can also easily interpret the relationships that exist in the data with minimal efforts. So, as the data grows in size, a graph database can make life easier for an analyst and a developer. We looked at techniques that need to be kept in mind while developing applications to handle large volumes of graph data.
In the next chapter, we will take a look at how you can go about testing the Neo4j applications that you have built or are about to build. You will also learn about the options available for scaling a Neo4j graph database.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.