Neo4j High Performance (2015)
Chapter 5. Testing and Scaling Neo4j Applications
When graph databases came into the picture, testing was an unchartered territory and developers had a hard time ensuring that applications were configured in a failsafe manner. With the introduction of several highly efficient graph data stores, including Titan and Neo4j, several projects and frameworks sprung up in addition to the built-in ones. Neo4j in particular is ACID in nature, transaction-friendly and easy to set up, but a viable testing framework is always useful to ensure that your application runs as intended and helps to identify hidden bugs. In this chapter, we will cover the following topics related to the testing of Neo4j applications:
· Testing Neo4j applications with the GraphAware Framework
· Unit testing with the Java API and GraphUnit
· Performance testing
· Benchmarking performance with Gatling
· Scaling options for Neo4j applications
Testing Neo4j applications
Neo4j as a graph database has several powerful and reliable features. Although it does include a basic unit testing module for embedded applications, the support for testing has still not made it into the core packages yet. You might not feel the need to test your applications if they seem to work on your local machines. However, it is always wise to have a rigorous testing scheme when your application is deployed on a larger or production scale or is handling critical data and huge traffic loads. So, when the need for testing arose for Neo4j, GraphAware came up with an advanced framework built on top of the core Neo4j libraries, but also included several advanced optimizations and features. Among them was the GraphAware server that allowed developers to buildRepresentational State Transfer (REST) API applications on top of the Spring MVC framework, in place of the earlier used JAX-RS. They also included a GraphAware runtime that provided customized modules for improved transactions and continuous graph computations on both embedded and server environments. In addition, it also provides a GraphAware testing framework that was available only for Java-based development before. So, embedded instances of Neo4j in applications, Spring-MVC-controlled applications, and extension development can be easily tested using this framework. The GraphAware framework speeds up application development with Neo4j by extending a platform to developers to create generic or domain-specific functionalities, analytical applications, advanced graph computation algorithms, and much more. The GraphAware test framework provides the flexibility to easily test code that interacts with the Neo4j database in any way. If you are a developer who is writing or planning to write Java code for Neo4j applications, or are developing modules for the GraphAware Framework and its APIs, then this testing framework is going to make your life easier. To include this testing module in your project, you can use Maven to specify it as a dependency in yourpom.xml file:
<dependency>
<groupId>com.graphaware.neo4j</groupId>
<artifactId>tests</artifactId>
<version>2.1.4.17</version>
<scope>test</scope>
</dependency>
Note
Check for the latest version number of the GraphAware Framework from http://graphaware.com/downloads/ when including the Maven dependency in the pom.xml file.
You can now work with unit, performance, and integration testing for your Neo4j applications.
Unit testing
Unit testing works on the smallest testable parts of the code that deal with few inputs and a single output. When you modify Neo4j data stores using Java code, especially in embedded applications, you make use of the ImpermanentGraphDatabase file together with Neo4j APIs to test the code. The APIs you can use include the Java API, is the Neo4j traversal framework, and Cypher. The REST API does not much use with Java code. As an alternative, you can use GraphUnit to perform the integration testing. We will take a look at both scenarios in the following sections. For the purpose of testing, let's take an example graph that initially creates two nodes and a relationship to connect them and sets properties on the nodes and the relationship. The assertions that a unit test would apply on this graph and its functionality would be:
· The creation of nodes and relationships was as expected, and the properties and labels were set correctly
· No additional entities were created or set, including nodes, relationships, properties, and labels
· The already existing sections of the graph, if any, remain unaltered
Not all the preceding objectives can be fulfilled by the use of Cypher. This is because Cypher is created for declarative operations on the graph database and not for imperative ones. So, only the first criterion can be fulfilled. It is also important to note that asserting the existence of an entity in the database is simple, but the process of ensuring that no extra entities were created, or no extra labels and properties were set is a rather difficult task.
So, unit tests can be performed by asserting the graph state using the low-level native Java APIs. Let's see how we can test using the Java API and the GraphUnit framework.
Using the Java API
In order to use the testing facilities on an impermanent graph, the tests.jar file of the neo4j-kernel must be present on the classpath for use. It uses the standard JUnit fixtures to achieve the testing. This can be included in your project using the Maven dependency along with JUnit, as follows:
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-kernel</artifactId>
<version>2.1.4</version>
<scope>test</scope>
<type>test-jar</type>
</dependency>
Note
Note that the <type>test-jar</type> inclusion is important, without this you would include neo4j-kernel but not the testing libraries.
A new database can be created for testing purposes, which will be stopped after the tests are complete. Although, it is possible to use the database being tested upon for intermediate operations, it is not advised to do this since it can cause conflicts and unnecessary writes.
@Before
public void prepareTestDatabase(){
graphDb = new TestGraphDatabaseFactory().newImpermanentDatabase();
}
@After
public void destroyTestDatabase(){
graphDb.shutdown();
}
In the process of testing, you create nodes and assert their existence, while enclosing the write operations in a transaction:
Node n = null;
try ( Transaction tx = graphDb.beginTx() )
{
n = graphDb.createNode();
n.setProperty( "title", "Developer" );
tx.success();
}
// Check for a valid node Id
assertThat( n.getId(), is( greaterThan( -1L ) ) );
// A node is retrieved with the Id of the node created. The id's and
// property must be matching.
try ( Transaction tx = graphDb.beginTx() )
{
Node foundNode = graphDb.getNodeById( n.getId() );
assertThat( foundNode.getId(), is( n.getId() ) );
assertThat( (String) foundNode.getProperty( "title" ), is( "Developer" ) );
}
GraphUnit-based unit testing
GraphUnit contains a set of assertion methods that are useful in creating Neo4j tests. What they basically do is compare whether the graph created is the same as the graph that should be created. GraphUnit addresses the unit testing problems, thus ensuring that no extra properties, nodes, or relationships were altered in the graph. It gives developers the opportunity to express the desired state of the graph using Cypher and assert that this is indeed the case. The following method is used for this purpose:
public static void assertSameGraph(GraphDatabaseService database, String sameGraphCypher)
The first parameter is the database whose state is being asserted. The second parameter is a Cypher (typically CREATE) statement that expresses the desired state of the database. The graph in the database and the graph that should be created by the Cypher statement must be identical in order for the unit test to pass. Of course, the internal Neo4j node and relationship IDs are excluded from any comparisons.
If tests on graphs are large and if it is not the developer's intention to verify the state of the entire graph, GraphUnit provides another method:
public static void assertSubgraph(GraphDatabaseService database, String subgraphCypher)
The idea is the same, except that there are additional relationships and nodes in the database that are not expressed in the Cypher statement. However, the Cypher-defined subgraph must be present in the database with exactly the same node labels, relationship types, and properties on both nodes and relationships in order for the test to pass.
Note
For more insights into the set of assertion methods, you can visit http://graphaware.com/site/framework/latest/apidocs/com/graphaware/test/unit/GraphUnit.html.
Unit testing an embedded database
We can perform a simple unit test to assert that a pairing has been successfully saved. A pairing is formed with two entities that represent nodes. Each entity has a name and a directed relation between the entities. This structure is illustrated in the following figure:
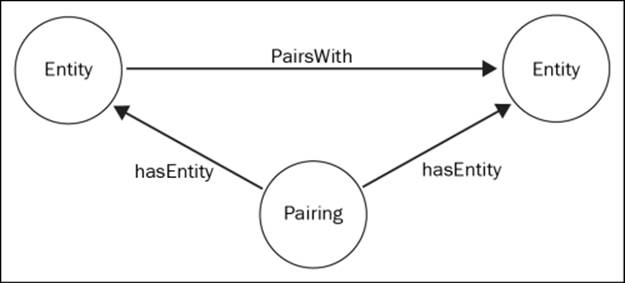
The code to test this simple structure using the Java API is large and is difficult to maintain for extended time periods. GraphUnit, on the other hand, enables you to compare the current graph state to the subgraph that you intended to create, which can be represented with the help of a Cypher statement. So, all you need to do is write a Cypher statement to create a subgraph that contains the two entities along with a pairing and use it as an argument to the assertSameGraph() method:
String entitySubgraph = "create (e1:Entity {name: 'Ferrari'}), (e2:Entity {name: 'Aston Martin'}), " + "(e1)<-[:hasEntity]-(p:Pairing {affinity: 0.50, allAffinities: [0.50]}), " + "(p)-[:hasEntity]->(e2) merge (e1)-[:pairsWith]-(e2)";
GraphUnit.assertSameGraph(getGraphDb(), entitySubgraph);
This will ensure that the structure represented by the Cypher query string is all that constitutes the graph that was created, with every property matching exactly.
GraphUnit contains another method to check whether the Neo4j graph contains a desired subgraph in it. This will assert the existence of the subgraph specified by the cypher query and filter out the other nodes and relationships:
GraphUnit.assertSubgraph(getGraphDb(), entitySubgraph);
GraphUnit needs an org.neo4j.graphdb.GraphDataService handle to the database that needs to tested. It can be used effectively with the impermanent or embedded graph databases. To test server instances of Neo4j using the REST API, we can use GraphAware RestTest, which we will discuss later in the chapter.
Apart from basic code testing, GraphUnit can also be used to verify that the import of data into a graph completes successfully or not. Since data import from CSV or other formats is not performed as transactions, this is important to check the integrity of the data load process. So, you can use GraphUnit to write a single unit test that verifies the subgraphs in the database created after the import, rather than inspecting the graph visually or running queries to check.
public class graphUnitTestDemo
{
@Test
public void testActor()
{
String actorSubgraph = "Match (country:Country {name: 'BRITAIN'})<-[:From]-(actor {name: 'PIERCE BROSNAN'}), (m:Movie {id: 5}), (min:Minutes {id: 35}) create (actor)-[:ActedIn]->(genre:Genre{type: 'Action'})-[:In]->(m) create (m)-[:BelongsTo]->(country)";
GraphUnit.assertSubgraph(getGraphDb(), actorSubgraph);
}
@Test
public void testReferee()
{
String refSubgraph = "Match (m:Movie {id:5}) match (c:Country {name:'BRITAIN'}) create (m)-[:Director]->(d:Director {name:'The Doctor'})-[:HomeCountry]->(c)";
GraphUnit.assertSameGraph(getGraphDb(), refSubgraph);
}
}
This is a much simpler, convenient, and effective way to test the graph at hand.
There are several benefits of this testing technique, especially concerning readability. Moreover, the GraphUnit version for testing is actually more fail-safe since it results in failure, when the graph contents are more than or different to that explicitly mentioned in the Cypher statement.
Unit testing a Neo4J server
The GraphAware RestTest library was created to test code that is designed to connect to a standalone server instance of Neo4j. You can set up the testing functionality on your Neo4j server by including the following JAR files in the plugins directory:
· graphaware-resttest-2.1.3.15.6.jar
· graphaware-server-community-all-2.1.3.15.jar ( or graphaware-server-enterprise-all-2.1.3.15.jar, depending upon your server installation.)
Note
You can download the JAR files from http://graphaware.com/downloads/. Check the latest versions of the JAR files while downloading. You will also need to restart your server after dropping the preceding JAR files in the plugins directory to be able to use the APIs.
The testing process is pretty simple. You can direct POST requests to the predefined URLs defined in the RestTest framework to check a specific functionality. In the server mode deployment, there are three URLs defined that you can use:
· http://server-ip-address:7474/graphaware/resttest/clear in order to clear the database.
· http://server-ip-address:7474/graphaware/resttest/assertSameGraph in order to assert the database state. The body of the request must contain a URL-encoded Cypher CREATE statement defining the expected state of the graph.
· http://server-ip-address:7474/graphaware/resttest/assertSubgraph in order to assert the database state for a given subgraph. The body of the request must contain a URL-encoded Cypher CREATE statement to define the state of the subgraph.
A call to the first API endpoint will clear the database. The second API endpoint provides a functionality that is similar to the assertSameGraph() method of GraphUnit. This helps verify that the graph existing in the database matches the one that will be created through the Cypher CREATE statement included in the request body. Every aspect of the graph, including nodes, relationships, their labels and properties, needs to be exactly the same. However, the internal IDs that Neo4j uses to reference nodes/relationships are ignored while matching the graphs. If the matching is successful, the response returned is an OK(200) HTTP response. Otherwise, if the assertion fails, an EXPECTATION_FAILED HTTP response is returned with a status code of 417.
In the third endpoint case, the RestTest API validates whether the graph structure created by the Cypher query provided is a subgraph of the graph in the database server. This is equivalent to the assertSubGraph() method of the GraphUnit API. The response code of the outcomes are the same as mentioned previously.
Performance testing
Apart from the validity and correctness of your code units, it is also essential at times to run database jobs to analyze how queries, operations, and the database itself is performing. These include mission critical operations such as banking, financial analytics, and real-time datasets, where errors can be catastrophic. This is, however, not a simple task. A database is a complex ecosystem that incorporates many moving entities, namely transaction sizes, frequency of commits, database content, type, and size of cache. The GraphAware Testing framework also provides the PerformanceTestSuite and PerformanceTest classes to make the performance testing process simple.
To deal with moving entities, the tests can define a parameter list that contains the desired entity. The test framework will then proceed to generate every possible permutation and use each of them to run the performance test a number of times. Among other things, in the performance tests you implement, you can specify the following entities as parameters:
· The number of times to run the tests and get performance metrics
· The number of dry runs to perform so that a warm cache is established to test speed of cache retrievals
· The parameters that are to be used
· When to discard the test database and build a new one
Here's a simple example of performance test code that you can write:
public class PerformanceTestDemo implements PerformanceTest {
enum Scenario {
FIRST_SCENARIO,
OTHER_SCENARIO
}
/**{@inheritDoc}*/
@Override
public String longName() {return "Test Long Name";}
/**{@inheritDoc}*/
@Override
public String shortName() {return "test-short-name";}
/**{@inheritDoc}*/
@Override
public List<Parameter> parameters() {
List<Parameter> result = new LinkedList<>();
result.add(new CacheParameter("cache")); //no cache, low-level cache, high-level cache
result.add(new EnumParameter("scenario", Scenario.class));
return result;
}
/**{@inheritDoc}*/
@Override
public int dryRuns(Map<String, Object> params) {
return ((CacheConfiguration) params.get("cache")).needsWarmup() ? 10000 : 100;
}
/**{@inheritDoc}*/
@Override
public int measuredRuns() {
return 100;
}
/**{@inheritDoc}*/
@Override
public Map<String, String> databaseParameters(Map<String, Object> params) {
return ((CacheConfiguration) params.get("cache")).addToConfig(Collections.<String, String>emptyMap());
}
/**{@inheritDoc}*/
@Override
public void prepareDatabase(GraphDatabaseService database, final Map<String, Object> params) {
//create 100 nodes in batches of 100
new NoInputBatchTransactionExecutor(database, 100, 100, new UnitOfWork<NullItem>() {
@Override
public void execute(GraphDatabaseService database, NullItem input, int batchNumber, int stepNumber) {
database.createNode();
}
}).execute();
}
/**{@inheritDoc}*/
@Override
public RebuildDatabase rebuildDatabase() {
return RebuildDatabase.AFTER_PARAM_CHANGE;
}
/**{@inheritDoc}*/
@Override
public long run(GraphDatabaseService database, Map<String, Object> params) {
Scenario scenario = (Scenario) params.get("scenario");
switch (scenario) {
case FIRST_SCENARIO:
//run test for scenario 1
return 20; //the time it takes in microseconds
case OTHER_SCENARIO:
//run test for scenario 2
return 20; //the time it takes in microseconds
default:
throw new IllegalStateException("Unknown scenario");
}
}
/**{@inheritDoc}*/
@Override
public boolean rebuildDatabase(Map<String, Object> params) {
throw new UnsupportedOperationException("never needed, database rebuilt after every param change");
}
}
You change the run method implementation to do some real work. Then add this test to a test suite and run it:
public class RunningDemoTest extends PerformanceTestSuite {
/**{@inheritDoc}*/
@Override
protected PerformanceTest[] getPerfTests() {
return new PerformanceTest[]{new PerformanceTestDemo()};
}
}
This example code skeleton shows a custom class that implements the PerformanceTest class of the GraphAware library, which overrides the methods that need to be tweaked according to your requirement. The result is a total of 6 parameter permutations (the product of 2 scenarios and 3 cache types), each executed 100 times, as we have defined. When the test run process is complete, a file with the name test-short-name-***.txt (*** being the timestamp) appears in the project root directory. The file contains the runtimes of each test round for the parameter permutations. For example, the Test Long Name result file would contain something like this:
cache;scenario;times in microseconds...
nocache;FIRST_SCENARIO;15;15;15;15;15;15;15;...
nocache;OTHER_SCENARIO;15;15;15;15;15;15;15;...
lowcache;FIRST_SCENARIO;15;15;15;15;15;15;15;...
lowcache;OTHER_SCENARIO;15;15;15;15;15;15;15;...
highcache;FIRST_SCENARIO;15;15;15;15;15;15;15;...
highcache;OTHER_SCENARIO;15;15;15;15;15;15;15;...
It is also worth noting that Facebook has open sourced a benchmarking tool for social graph databases called LinkBench, which makes it possible for the Neo4j community to compare their performance metrics with a real and large dataset. You can check out the details of this system at https://github.com/graphaware/linkbench-neo4j.
Benchmarking performance with Gatling
With Benchmarking, we can compare our Neo4j process and performance metrics with stats from other players in the industry. It is a method to measure the quality, time, and cost of implementing a solution in a production scenario. It is also a useful measure to constantly evaluate your needs and the current system metrics to analyze when a change might be required to hardware or software tools.
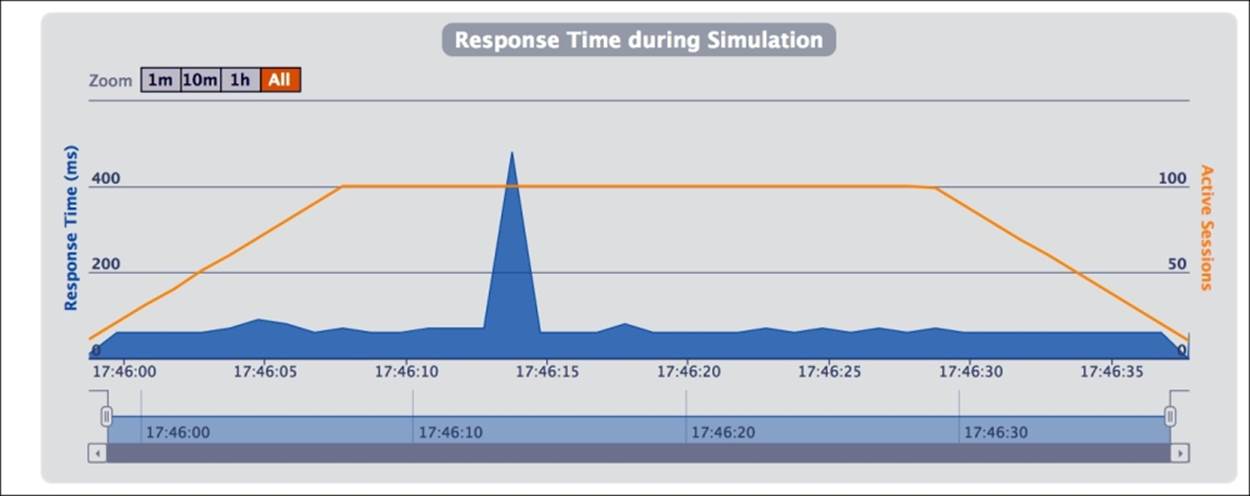
Response time metrics from Gatling
Although the Neo4j dashboard gives a good idea of the database state and metrics, you can use Gatling, a load testing framework based on Scala, Netty, and Akka that can test your whole application to measure end-to-end performance. The only challenge of this tool is that you need to write your code in Scala. You can use the built-in HTTP library to send requests to the REST server and evaluate the response and create simulations in real time to measure performance. You can learn about Gatling in detail athttp://gatling.io/. Gatling also provides a splendid interface to view your metrics graphically; the following are some examples:
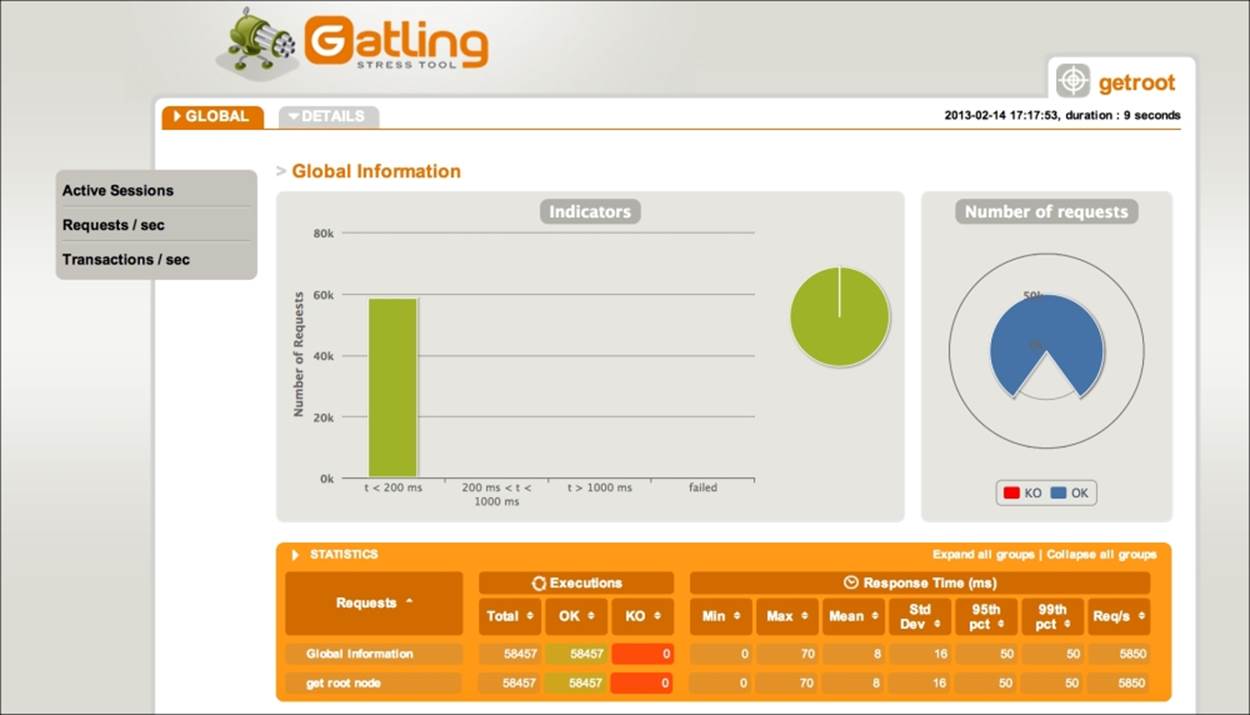
The Gatling interface
What we take away from the entire performance testing and benchmarking processes is the prospect of finding loopholes and bottlenecks in the system. We can then apply tweaks and tools to get the Neo4j system run more efficiently. Like any complex system, Neo4j can be properly tuned to achieve optimal performance. When you view the time-varying performance of your graph data store based on the workload characteristics, you can figure out whether it is possible to amortize your setup steps across many queries.
There are several tweaks possible that can help in increasing the performance of the Neo4j system depending on the type of data stored, the size of data, or the type of query operations performed on the data. However, here are a couple of common generic techniques that can help improve the performance of the Neo4j subsystem:
· Warm cache: This refers to creating a cache of the relevant and most updated data in the database, thereby reducing the lookup time for most parts of the requests. Benchmarking should measure the empty and warm caching behavior of your Neo4j system to provide an good performance metric.
· Simpler algorithms: Sometimes, blips in performance metrics are not always the fault of the database or data, but that of the application-specific algorithms you use. It is obvious that the algorithms that fit your database must be chosen, but complexity and sophistication define performance too. Think of graph traversals!
Scaling Neo4j applications
Large datasets in the Neo4j world refer to those that are substantially larger compared to the main memory of the system. In scenarios with such datasets, it is not possible for the Neo4j system to cache the entire database in memory, thereby providing blazingly fast traversals on the graph, because it will eventually lead to disk operations. Earlier, it was recommended to scale the system vertically using more RAM or solid state drives that have much lower seek times for the data on the disk compared to spinning drives. While SSDs considerably increase performance, even the fastest SSDs cannot replace the RAM, which in the end is the limiting factor.
In order to service huge workloads and manage large sets of data in Neo4j, partitioning graphs across multiple physical instances seem complex way to scale graph data. In versions up to 1.2, scaling seemed to be the con of this graph data store, but with the introduction of Neo4j High Availability (HA), there has been significant insight to handling large datasets and design solutions for scalability and availability.
One significant pattern that uses Neo4j HA is cache sharding, which is used to maintain increased performance with massive datasets that exceed the available main memory space of the system. Cache sharding is not the traditional sharding that most databases implement today. This is due to the fact that it expects a complete dataset to be present on each instance of the database. Instead, to implement cache sharding, the workload is partitioned among each database instance in order to increase the chances of hitting a warm cache for a particular request; believe it or not, warm caches in Neo4j give extremely high performance.
There are several issues that Neo4j HA addresses, the following being the prominent features:
· It implements a fault-tolerant architecture for the database, in which you can configure multiple Neo4j slave database instances to be exact replica sets of a single Neo4j master database. Hence, the end user application that runs Neo4j will be perfectly operational when there is a hardware failure.
· It provides a read-mostly, horizontally scaling architecture that facilitates the system to handle much higher read traffic as compared to a single instance of the Neo4j database, since every instance contains a complete graph dataset.
In other words, cache sharding refers to the injection of some logic into the load balancer of the high availability cluster of Neo4j, thereby directing queries to some specific node in the cluster based on a rule or property (such as sessions or start values). If implemented properly, each node in the cluster will be able to house a part of the total graph in the corresponding object cache so that the required traversal can be made.
The architecture for this solution is represented in the following figure. Thus, instead of typical graph sharding, we reduce the solution to that of consistent routing, which is a technique that has been in use with web farms for ages.
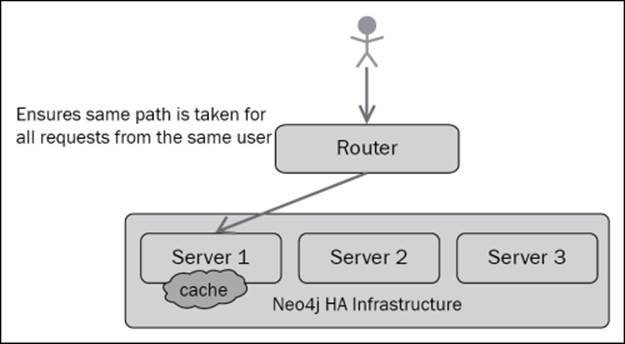
The logic that is used to perform the routing varies according to the domain of the data. At times, you can use specific characteristics of the data, such as label names or indexes for routing, whereas sometimes, sticky sessions are good enough. One simple technique is the database instance that serves a request for the first time for some user will also serve all subsequent requests for that user, with a high probability of processing the requests from a warm cache. You can use domain knowledge of the requests to route, for example, in the case of geographical or location-specific data, you route requests that pertain to particular locations to Neo4j instances that have data for that location in their warm cache. In a way, we are shooting up the likelihood of nodes and relationships being cached and hence, it becomes faster to access and process.
Apart from reading from the databases, to run multiple servers to harness the caching capabilities, we also need to sync data between these servers. This is where Neo4j HA comes into play. Effectively, with the deployment of Neo4J HA, a multimaster cluster is formed. A write to any instance propagates the write with the help of the HA protocol. When the elected master in the cluster is being written to, the data is first persisted there due to its ACID nature, and then, the modification is eventually transferred to the slaves through the HA protocol in order to maintain consistency.
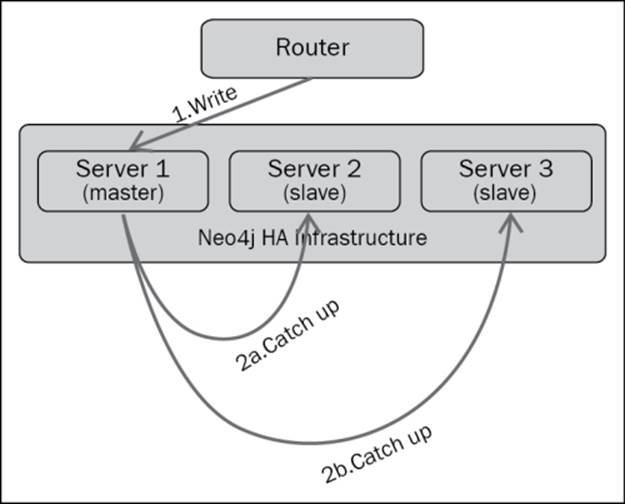
If a cluster slave mode processes a write operation, then it updates the elected master node with the help of a transaction, and initially, the results are persisted in both. Other slaves are updated from the master with the use of the HA protocol.
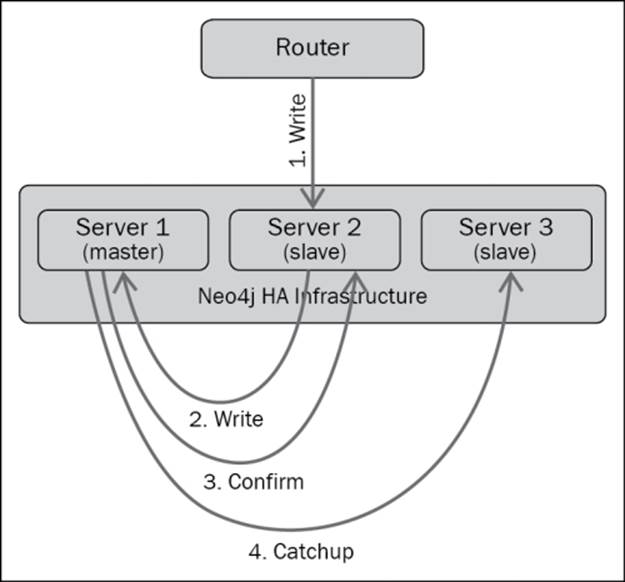
With the use of such a pattern, a Neo4J HA cluster acts as a high-performance database for efficient read-write operations. Additionally, a good strategy for routing, it helps to perform in-memory and blazingly fast traversals for applications.
The following is a summary of the scaling techniques implemented, depending on the data at hand and the cost strategy:
Type 1:
Dataset size: Order of tens of GBs
Strategy: Scale a single machine vertically with more RAM
Reason: Most server racks contain the RAM of the order of 128 GB for a typical machine. Since Neo4j loves RAM for data caching, where O (dataset) ≈ O (memory), all of the data can be cached into memory, and operations on it can take place at extremely high speeds.
Weaknesses: Clustering needed for availability; disk performance limits the write scalability
Type 2:
Dataset size: Order of hundreds of GBs
Strategy: Cache sharding techniques
Reasoning: The data is too big to fit in the RAM of a single machine, but is possible to replicate onto disks of many machines. Cache sharding increases the chances of hitting a warm cache in order to provide high performance. Cache misses, however, are not critical and can be optimized using SSDs in the place of spinning disks.
Weaknesses: You need a router/load balancer in the Neo4j infrastructure for consistent routing.
Type 3:
Dataset size: TBs and more
Strategy: Sharding based on domain-specific knowledge
Reasoning: With such large datasets, which are not replicable across instances, sharding provides a way out. However, since there is no algorithm (yet) to arbitrarily shard graph data, we depend on the knowledge of the domain in order to predict which node to allocate to which machine or instance.
Weaknesses: It is difficult to classify or relate all domains for sharding purposes.
In most scenarios that developers face, these heuristics are a good choice. It's simple to calculate the scale of your data and accordingly plan a suitable Neo4j deployment. It also provides a glimpse into the future of connected data—while most enterprises dealing with connected data are in the tens to hundreds of GB segments, with the current rate, there will soon be a requirement for greater data-crunching techniques.
Summary
In this chapter, you learned that testing, though it might seem unimportant, is essential and rather simple for graph data in Neo4j applications. You also learned about the Neo4j framework from GraphAware including the GraphUnit testing libraries for Unit tests. We saw how to test the performance of the Neo4j system and an introduction to benchmarking it using Gatling to obtain performance metrics. We also looked at ways to scale Neo4j applications, with Cache Sharding being an essential technique.
In the next chapter, we will be digging into the internals of Neo4j which affect the processing, storage, APIs, and performance of this amazing graph database.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.