Neo4j High Performance (2015)
Chapter 6. Neo4j Internals
Databases are constantly growing around real-world storage techniques and believed to be one of the complex accomplishments of engineering. Graph databases such as Neo4j are taking connected data storage to an entirely different level. However, most of us who work with Neo4j are left wondering about how it all works internally, because there is practically no documentation about the internal architecture of components. The kernel code base is not enormous and can be analyzed, but it is always good to have a guide to provide us with an understanding of the classes while abstracting the implementation details. Now that we have seen how we can use Neo4j as an efficient and secure data store for connected data, let's take a look at what lies under the hood and what goes on when you store, query, or traverse a graph data store. The way Neo4j stores data in the form of nodes and relationships inherently is intriguing and efficient, and you will get a great working knowledge of it if you try reading through the source. In this chapter, touching upon the core functionality, we will cover the following topics about the internal structure and working of the Neo4j database:
· The property store structure
· How caching works
· Memory and the API functionality
· Transaction and its components
· High availability and election of HA master
Introduction to Neo4j internals
It might look an efficient and beautiful solution for end users and developers, but, internally, it is a completely different story. The way the modules and submodules are interconnected is an interesting study. If you have a knack for tinkering with code and an understanding of Java, then you can yourself analyze the classes in the source code of Neo4j, which can be found at https://github.com/neo4j/neo4j.
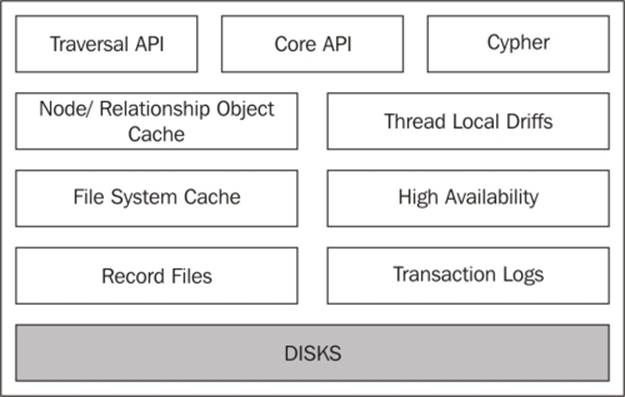
Working of your code
Let's take a look at a simple Hello World application code for Neo4j and understand what goes on under the hood when you try to perform some simple operations on Neo4j through the Java API. Here is the code for a sample app:
import org.neo4j.graphdb.*;
import org.neo4j.kernel.EmbeddedGraphDatabase;
/**
* Example class that constructs a simple graph with
* message attributes and then prints them.
*/
public class NeoOneMinute {
public enum MyRelationshipTypes implements RelationshipType {
KNOWS
}
public static void main(String[] args) {
GraphDatabaseService graphDb = new EmbeddedGraphDatabase("var/base");
Transaction tx = graphDb.beginTx();
try {
Node node1 = graphDb.createNode();
Node node2 = graphDb.createNode();
Relationship someRel = node1.createRelationshipTo(node2, MyRelationshipTypes.KNOWS);
node1.setProperty("message", "Hello, ");
node2.setProperty("message", "world!");
someRel.setProperty("message", "brave Neo4j ");
tx.success();
System.out.print(node1.getProperty("message"));
System.out.print(someRel.getProperty("message"));
System.out.print(node2.getProperty("message"));
}
finally {
tx.finish();
graphDb.shutdown();
}
}
}
The initiating point in the Neo4j program is the database service object defined from org.neo4j.graphdb.GraphDatabaseService and referred to as GraphDatabaseService. All the core functionalities for nodes, IDs, transactions and so on are exposed through this interface. This object is a wrapper over a few other classes and interfaces, GraphDbInstance being one of them, which starts with the config map that the user provides (empty in the preceding case). The org.neo4j.kernel.AutoConfigurator object then receives this, and the memory to be used for memory-mapped buffers is computed from JVM statistics. You can change this behavior by setting a false value for the use_memory_mapped_buffers flag, causing the config map to be passed to an object of the org.neo4j.kernel.Config class.
GraphDbModule, the TxModule for transactions, the manager objects for cache, persistence, and locking (CacheManager, PersistenceModule, LockManager, respectively) are then created and sustained until the application's execution ends. If no errors are thrown, then the embedded database has been initiated.
Node and relationship management
NodeManager (defined in the org.neo4j.kernel.impl.core.NodeManager class) is one of the most crucial and large classes in the Neo4j source that provides an abstraction for the caching and the underlying persistent storage-exposing methods to operate on nodes and relationships. The configuration that is passed is then parsed and the caching for the nodes and relationships is initialized by figuring out their sizes. AdaptiveCacheManager abstracts the sizing issue of the caches. NodeManager handles the locking operations with the help of lock stripping. In order to maintain a balance between the level of concurrency and the performance of memory, an array stores ReentrantLocks and, depending upon the integral ID values of the node or the relationship, locking is performed by hashing over it. When you invoke the getNodeById() or getRelationshipById() method, it roughly follows these steps:
1. The cache is checked. If the entity already exists in the cache, it is returned from there.
2. Based on the ID passed as a parameter, a lock is acquired.
3. The cache is checked again. If it has currently come into existence, then it is returned (since multithreaded operations occur!).
4. The manager class is requested for persistent storage for the required entity. If unavailable, NotFoundException is thrown.
5. The retrieved value is returned in the form of an appropriate implementation plan.
6. The retrieved value is cached.
7. The lock is then released and the value is returned to the calling method.
This is the gist of the main work of NodeManager. However it is intended to be used to perform many other operations that are beyond the scope of this book, but you can check them out in the source.
Implementation specifics
The Node and Relationship interfaces defined in org.neo4j.graphdb provide implementations for NodeProxy and RelationshipProxy and contain the unique IDs for the nodes or relationships that are represented by them. They are used in the propagation of the method calls of the interface to the NodeManager object that is being used. This integral ID is what is returned from the method calls that are executed every time a node, relationship, or property is added to EmbeddedGraphDatabase.
Nodes and relationships also use the NodeImpl and RelationshipImpl classes defined in the org.neo4j.kernel.impl.core package; this package extends the core Primitive class to provide abstract implementations of Properties and help to delegate the loading and storing of property values to the object of NodeManager. It holds the value of the ID and is extended by the implementation classes (NodeImpl and RelationshipImpl), each of which implements the abstract methods accordingly along with operation-specific functions (for example, the NodeImpl class has a getRelationships() method while the RelationshipImpl class has getStartNode()).
These are some of the types of implementations that NodeManager handles internally.
Storage for properties
The property storage of Neo4j has seen several upgrades and improvements with recent releases, which has made it more usable and stable, while optimizing the layer to use lesser disk space without compromising on features, and improving the speed of operations.
The storage structure
Originally, the Neo4j property store was in the form of a doubly linked list, in which the nodes contained additional information about the structure, along with the property-related data. The node structure then is represented in the following format:
|
Byte(s) |
Information |
|
0 |
The 4 high bits of the previous pointer and inUse flag |
|
1 |
unused |
|
2 |
The 4 high bits of next pointer |
|
3-4 |
The type of property |
|
5-8 |
The index of property |
|
9-12 |
32 low bits of the previous pointer |
|
13-16 |
32 low bits of the next pointer |
|
17-24 |
Data for the property |
So, the 8 bytes at the end were used to store the value and were sufficient to hold all primitive types, small strings, or pointer references to the dynamic store where long strings or arrays are stored. This, however, has a redundancy, since the complete 8 bytes are only utilized when the data stored is long, double, or string and references are repeated for each property. This causes significant overhead. So, in the newer versions of Neo4j, this was optimized by designing PropertyRecord, which, instead of housing a single property, now emulates a container to incorporate a number of properties of variable lengths. You can get a clearer outline of the present structure here:
|
Byte(s) |
Information |
|
0 |
4 high bits of the previous pointer and 4 high bits of the next pointer |
|
1-4 |
The previous property record |
|
5–8 |
The next property record |
|
9–40 |
Payload |
As you can see, the inUse flag has been done away with and the space is optimized to include the payload more efficiently. There are 4 blocks of 8 bytes in the payload, each of which are used in a different manner depending upon the type of data stored in the property. The type and index of the property are necessary and always required and hence occupy the first 3 bytes of the blocks and 4 high bits of the 4th byte, respectively. The value of the property is dependent on the data type being stored. If you are using a primitive that can be accommodated in 4 bytes, then the 4th byte's lower 4 bits are skipped and the remainder of the 4 bytes are used to store the value. However, when you are storing arrays and nonshort strings using DynamicStore, you need 36 bits for the storage of the reference that uses the total lower 4 bits of the 4th byte and the remaining 4 bytes. These provisions for 4 properties are stored in the same PropertyRecord, thereby increasing the space efficiency of the storage. However, if doubles and longs are what you intend to store, then the remaining 36 bits are skipped over and the subsequent block is used to store the value. This causes unnecessary space wastage, but its occurrence is rare and overall more efficient than the original storage structure.
LongerShortString is a newly introduced type, which is an extension of the ShortString operating principle, in which a string is initially scanned to figure out whether it falls within an encoding. If it does, then the encoding is performed and a header is stored for it that contains the length of the string, the ID in the encoding table, and finally the original string. However, the UTF8 encoding scheme is used when the three and a half blocks of the property block are insufficient for storage and DynamicStringStore is used. In the case of an array, we first determine the smallest number of bits that can be used to store the values in it and, in the process, we drop the leading zeroes and maintain the same length for each element. For example, when given the array [5,4,3,2,1], each element does not take a separate set of 32 bits; rather, they are stored in 3 bits each. Similarly, only a single bit is used to store Boolean-valued array elements. In the case of dynamic arrays, a similar concept is used. So, such a data value is stored in the following format:
|
Number of Bits |
Stored Information |
|
4 |
Enumeration storing type of entity |
|
6 |
The array length |
|
6 |
Bits used for each item |
|
The remaining 16 |
Data elements |
There is one secret we are yet to explore: the inUse flag. It is, in fact, a marker to indicate whether a property exists and is in use or not. Each block is marked to distinguish whether it is in use and, since we are allowed to delete properties, a zero signifies that the current property is not in use or deleted. Moreover, the blocks are stored onto the disk in a defragmented manner. So, if some property from a set of properties is deleted, only the remaining two are written to disk, and the deleted property's 4th byte of the first block that is not used is marked as a zero, which indicates that it is actually not used. If you take some time to explore the source code of the Neo4j project, you will find these implementation details and strategies in WriteTransaction.
Migrating to the new storage
In a rare case, if you are dealing with an older version of Neo4j and considering an upgrade to the newer architecture, it cannot happen without the need to change, remove, or replace the existing data. You will need to recreate the existing database. This ensures that existing files are not overwritten, guarantees crash-resistance, and also backs up data. This process is relatively simple: read all nodes, relationships, and properties for them and then convert them to the new format before storing them. In the migration process, the size is significantly reduced as the deleted entities are omitted, which is noticeable if a lot of deletions have been performed on the database and it is not restarted often. The code and logic for migration is included in the source code of the Neo4j kernel in the org.neo4j.kernel.impl.storemigration package, which you can run both as part of a generic startup or in a standalone manner. You will be required to set "allow_store_upgrade"="true" in your config and then you can successfully execute the migration scripts.
Caching internals
Neo4j implements a caching mechanism that stores nodes and relationships as useful, internal objects for rapid in-memory access. It also makes extensive use of the java.nio package, where native I/O is utilized to use memory outside the Java heap for mapped memory. Least Recently Used (LRU) is one of the simplest and most popular algorithms for implementation and rapid operations for caching needs. The Java-specific implementation makes use of the SoftReference and WeakReference objects, which are treated in a special manner by the garbage collector for memory reclamation. This principle is utilized in caches that grow rapidly to fill the heap but, when the demand for memory arises for more important tasks, reclamation takes place. So, there are no hard upper limits to caching of objects, while simultaneously making memory available for other operations. Neo4j caches work on this principle by default.
Cache types
Neo4j maintains two separate caches for nodes and relationships that can be configured to have a variable upper bound in terms of size, which can be configured by the max_node_cache_size and max_relationship_cache_size options of the database. The implementations of caching techniques in Neo4j can be explored in the org.neo4j.kernel.impl.cache package. Neo4j provides four different types of caches built into the default package:
|
Cache type |
Property |
|
NoCache |
This is degenerate and stores nothing |
|
LruCache |
This utilizes LinkedHashMap of the java.util package along with a custom method to remove the oldest entry when deallocating space—removeEldestEntry(); this makes it an adaptable LRU cache |
|
SoftLruCache |
An LruCache using soft values to store references and queues for garbage-collected reference instances |
|
WeakLruCache |
An LruCache using hard values to store references and queues for garbage-collected reference instances |
Note
Weak and soft references are the basis of the behavior of Java Garbage Collector (GC) depending on the references of an object. If the GC finds that an object is softly reachable, it might clear these references in an atomic manner to free up memory. However, if the GC finds an object to be weakly reachable, then it will clear all the weak references automatically and atomically.
The soft and weak LruCaches extend org.neo4j.kernel.impl.cache.ReferenceCache, including a pollClearedValues() method to get rid of dead references from the hashmap. If you need to explore the code, the cache contents are managed by the NodeManager class, while AdaptiveCacheManager handles memory consumptions and is configurable.
AdaptiveCacheManager
AdaptiveCacheManager manages the cache sets and their configurations along with adapting them to the size changes. A worker thread is spawned which, on every adaptive_cache_worker_sleep_time milliseconds (which is 3000 by default), wakes to re-adjust the size of the caches. In the case of ReferenceCaches, a call to the pollClearedValues() method is initiated. In the case of LruCache, the adaptSize() method is invoked on every cache and the size is re-adjusted depending upon the JVM memory statistics passed to the resize()method that removes elements until the new size is achieved.
The caching mechanism in Neo4j is mainly used to cache nodes and relationships implementations so that they can be retrieved from persistent storage and are completely abstracted by NodeManager.
Transactions
Transactions are an integral part of the Neo4j ecosystem and primarily dominated by the use of two major components—the Write-Ahead Log (WAL) and the Wait-For Graph (WFG) for detection of deadlocks prior to their occurrence.
The Write Ahead log
The WAL in the Neo4j transaction system ensures atomicity and durability in transactions. Every change during a transaction persists on disk as and when the request for the change is received, without modifying the database content. When the transaction is committed, the changes are made to the data store and subsequently removed from the disk. So, when the system fails during a commit, the transactions can be read back and database changes can be ensured. This guarantees atomic changes and durability of commit operations.
All the changes during transactions occur in states. On initiating a transaction (with the beginTx() method), a state called TX_STARTED is assigned to it. There are similar states assigned while preparing a transaction, committing it, and rolling it back. The changes stored during transactions are called commands. Every operation performed on the database including creation and deletion corresponds to a command and, collectively, they define what transactions are. In Neo4j, the WAL is implemented with the help ofXaLogicalLog defined in org.neo4j.kernel.impl.transaction.xaframework in the source, which aids in the management of intermediate files for storage of commands during a transaction. The LogEntry class provides an abstraction over the way in which XaLogicalLogstores its information, which contains information for phases and stored commands of a transaction. So, whenever the transaction manager (txManager) indicates the change of a phase in a given transaction, or the addition of a command, it flags XaLogicalLog, which writes an appropriate entry to the file.
Basically, files are used to store transaction logs in the root directory of the database. The first file, nioneo_logical.log.active, is simply a marker that indicates which of the log files is currently active. The remaining are the active log files that follow the naming convention nioneo_logical.log.1 or nioneo_logical.log.2; only one of them is active at a given time and read and written to with the help of a memory buffer or heap as defined in the use_memory_mapped_buffers configuration parameter. Neo4j also has an option to maintain backup files in a versioned manner through the configuration parameter keep_logical_logs. They use the nioneo_logical.log.v<version_no> format to store the file. What logically happens is if you are set to store backups, your log files are not deleted after the transaction; instead, they are renamed to a backup file.
The logical log entries have an integral identifier for the transaction, assigned to them by XaLogicalLog. It also maintains xidIdentMap, which maps the identifier to the LogEntry.Start state in order to reference active transactions. Now it is evident that write operations are appended to the log after the file offset of the start entry. You can obtain all information about the transaction after the offset. So we can optimize the lookup time and store the offset of the Start entry along with xidIdentMap corresponding to the identifier for that transaction; we no longer need to scan the log file for the offset of the transaction and directly go to the indicated start of transaction. The LogEntry.Prepare state is achieved when the current transaction is being prepped for a commit. When the process of a transactional commit has been initiated, the state written can be LogEntry.OnePhaseCommit or LogEntry.TwoPhaseCommit, depending on whether we are writing to EmbeddedGraphDatabase or a distributed scenario (generally using a JTA/JTS service), respectively. When a transaction is completed and is no longer needed to exist in an active state, the LogEntry.Done state is written. At this state, the identifier to the start state is also removed from the map (xidIdentMap) where it was stored. LogEntry.Command is not a state as such, but a method for encapsulation of the transaction commands. The writeCommand() of XaLogicalLog takes in a command as an argument and writes it to disk.
|
The LogEntry state |
Operation for trigger |
|
Start |
This indicates that the transaction is now active |
|
Prepare |
This indicates that the transaction is being prepped for a commit |
|
OnePhaseCommit |
This initiates a commit in EmbeddedGraphDatabase |
|
TwoPhaseCommit |
This initiates commits in a distributed scenario |
|
Done |
This indicates that a transaction is complete |
|
Command (not an actual state) |
Encapsulation for the commands in the transaction |
So, all the state changes of a transaction are stored in the form of LogEntry that contains the state indicator flags and transaction identifier. No deletions occur whatsoever. Writing a Done state indicates that the transaction has passed. Also, the commands causing the state change are also persisted to disk.
We mentioned that all commands are appended with no deletions and the storage to disk can create massive files for large transactions. Well, that's where the concept of log rotation comes in, which is triggered once the size of the log file exceeds a threshold (the default value is 10 MB). The rotate() method of XaLogicalLog is invoked when the log file size exceeds the threshold during the appending of a command and there is no live transaction taking up any space greater than 5 MB. The rotate() function performs the following:
1. Checks the currently used log file from the .active file, which stores the reference.
2. Writes the content of the buffer for the log file to disk and creates the new log file with the version and identifier of the last committed transaction in the header.
3. Initiates reading of entries from the offset of Start. All LogEntries that belong to the current transaction are copied to the new log file and offset is updated accordingly.
4. Disposes of the previous log file and updates the reference to the new log file in the .active file.
All the operations are synchronized, which pauses all updating transactions till the rotate operations are over.
How does all this facilitate recovery? When termination of XaLogicalLog occurs, if the map is empty and no transactions are live, the .active file stores a marker that indicates the closure of the transaction, and the log files are removed. So, when a restart occurs, and the .active file is in the "nonclean" (or not closed) mode, it means that there are transactions pending. In this case, the last active log file is found from the .active file and the doInternalRecovery() method of XaLogicalLog is started. The dangling transactions are recreated and the transaction is reattempted.
The setRecovered() method is used to indicate that a transaction has been successfully recovered, which avoids its re-entry into the WAL during subsequent recovery processes.
Detecting deadlocks
Neo4j, being an ACID database solution, needs to ensure that a transaction is completed (whether successfully or unsuccessfully), thereby stopping all active threads and avoiding deadlocks in the process. The core components that provide this functionality include RWLock (Read Write Lock), LockManager, and RagManager (Resource Allocation Graph Manager).
RWLock
RWLock provides an implementation of the Java ReentrantReadWriteLock for Neo4j, which allows concurrency in reading but single-threaded, exclusive write access to the locked resource. Being re-entrant in nature, it facilitates the holder of the lock to re-acquire the lock again. The lock also uses RagManager to detect whether waiting on a resource can lead to possible future deadlocks. Essentially, RWLock maintains a reference to the locking resources, that is, the threads and counts for read and write locks. If a request for the read lock is processed by some thread, it checks whether writes locks exist; if they do, then they should be held by the calling resource itself which, when true, make sure the lock is granted. Otherwise, RagManager is used to detect whether the thread can be allowed to wait without a deadlock scenario. Write locks are handled in a similar fashion. To release locks, the counts are reduced and waiting threads are invoked in a FIFO manner.
RAGManager
RAGManager operates with primarily the checkWaitOn() and checkWaitOnRecursive() utility methods. It is informed of all acquired and released locks on resources. Before invoking wait() on a thread, RWLock gets possible deadlock information from RAGManager. It is essentially a WFG that stores a graph of the resources and threads waiting on them. The checkWaitOn() method traverses the WFG to find whether a back edge exists to the candidate that needs a lock, in which case, a DeadlockDetectedException exception is raised, which terminates the thread. This leads to an assertion that the transaction will not complete, thereby enforcing atomicity. So, loops are avoided in a transaction.
LockManager
The sole purpose and existence of the LockManager class is the synchronization of RWLock accesses, or creation of the locks and, whenever required, passing an instance of the RAGManager and appropriate removal at times. At a high level of abstraction, Neo4j uses this class for the purpose of locking.
The scheme of locks and detection of deadlock simply ensures that the graph primitives are not granted locks in an order that can lead to a deadlock. It, however, does not protect you from the application-code-level deadlocks arising when you write multithreaded applications.
The XaTransaction class in Neo4j that is the central authority in the transactional behavior is XaTransaction. For any transaction that deals with a Neo4j resource, the fundamental structure is defined by this class, which deals with the holding of XaLogicalLog to persist the state of the transaction, its operations, and storage of the transaction identifier. It also includes the addCommand() method, which is used for normal transactional operations, and the injectCommand() method, which is used at the time of recovery. The core class in Neo4j, which implements WriteTransaction transactions extends the XaTransaction class, thereby exposing the extended interface. Two types of fields are dealt with here:
· Records: This stores an integer to record a map for a particular primitive, where the integer is the ID of the primitive
· Commands: These are stored in the form of command object lists
In the course of normal operations, the actions performed on a Neo4j primitive are stored in the form of record objects in the store. As per the operation, the record is modified and placed in its appropriate map. In the prepare stage, the records are transformed into commands and are put in the corresponding Command Object list. At this point, an apt LogEntry.Command state is written to XaLogicalLog. When doCommit() is invoked, the commands are executed individually, which releases the locks held and finally the commands are cleared. If a request for doRollback() is received, the records in the map are checked. If it has been flagged as created, the record's ID is freed by the underlying store and, subsequently, the command and record collections are cleared. So, if a transaction results in failure, an implicit rollback is initiated and injectCommand() is used to directly add the commands in the commands list prior to the next commit operation. The IDs that are not yet freed are recovered from IdGenerator of the underlying storage as and when the database is restarted.
Commands
The command class extends XaCommand to be used in NeoStore. The command class defines a way for storage in LogBuffer, reading back from it followed by execution. NodeCommand is treated differently from RelationshipCommand and likewise for every primitive. From the operations perspective, NodeCommand in command has two essential components to work with: NodeRecord, which stores the changes that need to be performed on the store and NodeStore, which persists the changes. When execution is initiated, the store is asked to perform updates on NodeRecord. To persist the command to disk, the writeToFile() method is used, which sets a marker to the entry and writes the record fields. In order to read it back, the readCommand() method is invoked, which restructures NodeCommand. Other primitive command types follow the same procedure of operation:
· TransactionImpl
· TxManager
· TxLog
We have seen that transactions can be implemented over NeoStore. Likewise, there can also be transactions over a Lucene Index. All these transactions can be committed. However, since the transactions between indexes and primitives are connected, ifWriteTransaction results in failure, then LuceneTransaction must also fail and vice versa. The TransactionalImpl class takes care of this. Resources are added to TransactionImpl with the help of enlistResource(), which are bound together with the help of theTwoPhaseCommit (2PC) protocol and, when a commit operation is requested, all the enlisted resources are asked to get prepared and they return a status of whether the changes succeeded or not. When all return an OK, they proceed with the commit; otherwise, a rollback is initiated. Also, each time a transaction status change occurs, a notification is sent to TxManager and the corresponding record is added to txLog. This WAL is used for failure recovery. The identifier for TransactionImpl is called globalId and every resource that enlists with it is assigned a corresponding branchId, which are bound together as an abstraction called Xid. So, when a resource is enlisted for the first time, it calls TxManager and writes a record to txLog that marks the initiation of a new transaction. In the case of a failure, when a transaction needs to be reconstructed from the log, we can associate the transaction with the resources that were being managed by it.
TxManager abstracts the TransactionalImpl object from the program. On starting a new transaction, a TransactionalImpl object is created and mapped to the thread currently in execution. All methods in TxManager (except the resume method) automatically receive theTransactionImpl object. TxLog works in a similar fashion as XaLogicalLog with regard to the writing of entries and the rotation of files.
So, if your system crashes during the execution phase of commands in a transaction, without a rollback, then what happens? In such a situation, the complete transaction is replayed and the commands that were already executed before the failure would be processed again.
High availability
Neo4j in recent years has adapted to handling larger data in a more reliable manner with the introduction of the high availability mode. Its architecture and operations revolve around a core concept: the algorithm for master election. In this section, we will take a look at why we need the master and the algorithm based on which the master is elected.
HA and the need for a master
High availability in Neo4j replicates the graph on all the machines in the cluster and manages write operations between them. High availability does not decentralize the stored graph (which is called sharding); it replicates the complete graph. One machine in the replica set has the authority to receive and propagate updates as well as keep track of locks and context in transactions. This machine is referred to as the master in the HA cluster and the supreme entity that handles, monitors, and takes care of the resources in replica machines.
When you set up a Neo4j cluster, you do not need to designate a master or allocate specialized resources to particular machines. This would create a single point of failures and defeat the purpose of HA when the master fails. Rather, the cluster elects its own master node when needed in a dynamic manner.
The nodes in the cluster need to communicate and they make use of a method called atomic broadcasting, which is used to send messages to all instances in a reliable manner. It is reliable since there is no loss of messages, the ordering of the messages is preserved, and no messages are corrupt or duplicated. In a narrower perspective, the operations are handled by a service called neo4j-coordinator, which basically has the following objectives to take care of:
· A method to indicate that each machine in the cluster participates in HA, something like a heartbeat. Failure to send this indication indicates that the instance is unable to handle operations for the clusters.
· In Neo4j, the preceding method also helps to identify how many and which machines currently exist in the cluster.
· A notification system for use in broadcasting of alerts to the remaining cluster.
The master election
The master keeps the knowledge of the real graph, or the graph's most updated database version. The latest version is determined by the latest transaction ID that was executed. The ID for transactions can be a monotonically increasing entity, as they are serialized in nature, which causes the last committed transaction ID to reflect the database version. This information, however, is internally generated in the database, but we require some external priority-enforcing information to be used for elections in cases where two machines have the same transaction IDs for the latest one. The external information can vary from machine to machine, ranging from the machine's IP to its CPU ID presented in the form of a configurable parameter in Neo4j called ha.server_id. The Lower the value of the server ID of an instance, the higher will be its priority for being elected as master.
So, depending upon the irregular "heartbeat" received from the current master in the cluster, an instance can initiate an election and collect the last transaction ID from each cluster machine. The one having the largest value is the elected master, with the server ID acting as the tiebreaker. On election, the result is notified to the cluster and all the machines along with the new master execute the same algorithm. When the conclusion from all machines coincide, the notification is stopped.
Finally, let's see how atomic broadcast is implemented. Apache Zookeeper is used to implement the Atomic Broadcast protocol (around Version 1.8) that guarantees delivery of messages in an order. Zookeeper is capable of setting a watch on a file in its distributed hierarchical filesystem with provisions for notifications in the event of addition or deletion of nodes. However, later versions might be equipped with Neo4j's own atomic broadcast. In Neo4j, the first machine creates a node defined as the root of the cluster. An ephemeral node (a node valid for the client's lifetime) is added as a child of the root with the server ID as the name and latest transaction ID of its database as its content. For administrative purposes, a node called master-notify is created along with its watch. When more machines are added, they find the root and perform the same basic operations (apart from the administrative ones). Any node can read and write the content of any other node (the node in the cluster and not the one in the graph!).
So, the ephemeral node exists during the lifetime of an instance and is removed from the children of the root when the instance fails and a deletion event is sent to all other instances. If the failed instance was a master, then it will trigger an election and the result will be broadcast by a write to the master-notify node. A master election can also be triggered when a new instance is added to the cluster. Hence, the transaction ID must be up to date to avoid the current master from losing the election. Hence, the coordinator service needs to be configured and maintained. After this head start, you can now explore more of the HA source.
Summary
In this chapter, we took a peek into the working of Neo4j under the hood, though not in detail, but enough to give you a start to explore the source yourself. You learned how the core classes for storage, the caching mechanism, and the transactions, worked. We also explored the high availability cluster operations and the master election mechanism.
In the next chapter we will take a look at a few useful tools that are built for and around Neo4j to ease the life of users and admins and look into relevant use cases for the same.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.