Neo4j High Performance (2015)
Chapter 7. Administering Neo4j
In the course of time that Neo4j has been around, it has become a widely accepted tool for storage and processing of large scale, highly interconnected data. From major corporations such as eBay and Walmart, to research students, the utilities of Neo4j have spread across the world. What makes Neo4j a great tool, is the fact that it is open source, and community contributions are useful and valuable. Today, Neo4j can be interfaced with several frameworks and a plethora of tools have been developed to make operations like data loading, traversals, and testing, simpler and more effective. It is not always about having an effective place for your application; it is also about maintaining and administering it to obtain optimum performance from the application. In this chapter, we will first look at how to use the Neo4j adapters for some of the most popular languages and frameworks that are used today. In the latter part of the chapter, we will see how admins can tweak and change the configurations of a standard Neo4j system, so that an optimum performance system can be obtained. The topics to be covered in this chapter can be summarized as follows:
· Interfacing Neo4j with PHP, JavaScript, and Python
· Configuring Neo4j Server, JVM, and caches
· Memory mapped I/O settings
· Logging configurations
· Security of Neo4j Server
Interfacing with the tools and frameworks
Neo4j as a core data storage solution is quite powerful but, with the increasing sophistication of use and rapid development practices, several tools were developed as an effort to increase the efficiency and compatibility of a Neo4j system. Adapters for various wellknown languages for server-side and client-side development have sprung up, making the development process for Neo4j based web applications simpler. Let us take a look at the use of some of the Neo4j adapters for the most common web platform technologies.
Using Neo4j for PHP developers
PHP is one of the most widely popular web development languages for creating dynamic content based application. Some common frameworks such as Wordpress and CakePHP are developed with PHP. Now, if you are trying to develop a PHP application, and want Neo4j at the backend for data storage and processing, you can use the Neo4jPHP adapter very well. It is written by Josh Adell, and it exposes an API that encourages intuitiveness and flexibility of use. Neo4jPH also incorporates some advantageous performance enhancements of its own, in the form of lazy-loading and caching. Let us take a look at some basic usage of this tool.
Use an editor to create a script and name it connection_test.php. Add the following lines to it:
<?php
require('vendor/autoload.php');
$client = new Everyman\Neo4j\Client('localhost', 7474);
print_r($client->getServerInfo());
If you have a database instance running on a different machine or port, you need to accordingly change localhost to the complete address of the database machine, and 7474 to the appropriate port number.
You can now execute the script from a server instance or in a standalone manner to view the result:
> php connection_test.php
If your server information displays successfully, then you have set up a basic Neo4jPHP code. You can view the source of the project at https://github.com/jadell/neo4jphp along with the detailed documentation at https://github.com/jadell/neo4jphp/wiki/Introduction.
The JavaScript Neo4j adapter
JavaScript is one of the most widely used client-side scripting languages. You can now communicate with your client-side application along with the Neo4j server with the use of the request module of the Node.js framework. Any other JavaScript module which can interact with the Neo4j server by sending and receiving queries can also be used. You can get a detailed description of the formats and protocols of the Neo4j REST API endpoints from the official documentation at http://neo4j.com/docs/stable/rest-api-transactional.html. You can also perform operations like sending multiple statements in a request, as well as sharing a transaction between several requests. The following basic function can be used to access the remote REST endpoint with the help of JavaScript:
var req=require("request");
var traxUrl = "http://localhost:7474/db/data/transaction/commit";
function cypher(query,params,cb) {
req.post({uri:traxUrl,
json:{statements:[{statement:query,parameters:params}]}},
function(err,res) { cb(err,res.body)})
}
The cypher() function can send a cypher request from the JavaScript code to the Neo4j server and receive a response in JSON format. To use this function in your application, you can use the following format:
var query="MATCH (n:User) RETURN n, labels(n) as l LIMIT {limit}"
var params={limit: 10}
var cb=function(err,data) { console.log(JSON.stringify(data)) }
cypher(query,params,cb)
{"results":[
{"columns":["n","l"],
"data":[
{"row":[{"name":"Aran"},["User"]]}
]
}],
"errors":[]}
The JSON form of the results is displayed upon execution. For applications built on top of the Node.js framework, you can use the Node.js-specific driver for Neo4j as well. You can learn more about it at https://github.com/thingdom/node-neo4j.
Neo4j with Python
Neo4j provides extensive support for Python and its web framework, Django. Py2neo is a simple library written by Nigel Small, providing access to the Neo4j REST API, and even supports Cypher queries. It has no external dependencies and is actively maintained on Github. You can follow the project at https://github.com/nigelsmall/py2neo.
For the Django framework, neo4django is an Object Graph Mapper (OGM) with which you can create the model definitions in Django, along with queries for Neo4j. It is also community supported and is useful for graph web applications running Django at the backend. The project can be found at https://github.com/scholrly/neo4django.
There are several other tools and frameworks to make the task of interfacing Python applications with Neo4j painless. The most popular ones are the BulbFlow framework (http://bulbflow.com/) which is an ORM for graph traversals using Gremlin at the backend. NeoModel (https://github.com/robinedwards/neomodel) is another tool with support for Django. However, a detailed discussion of these frameworks is beyond the scope of this book.
Admin tricks
A database is the life force behind an application, and that calls for a high degree of initial optimization depending upon the type and size of data to be stored and resources available on the server. Being written in Java, Neo4j also requires you to configure the Java related parameters properly as well. In the upcoming sections, we will look at how you can tweak your system and database configurations to maintain your Neo4j data store in good health.
Server configuration
For advanced usage of the Neo4j database, you can configure several parameters to keep the resources in check. The primary configuration file, Neo4j, is located in the conf/neo4j-server.properties directory. For normal development purposes, the default settings are sufficient. However, as an administrator, you can make suitable changes to the settings.
You can set the base directory on the disk where your database resides using the following property:
org.neo4j.server.database.location=/path/to/database/graph.db
The default port on which Neo4j operates is 7474. However, you can change the port for accessing the data, UI and administrative use, using the following setting:
org.neo4j.server.webserver.port=9098
You can even configure the client access pattern depending upon the address of the Neo4j database relative to the application that uses it. This helps in restricting the use of the database to the specific application. The default value is the loopback 127.0.0.1, which can be changed with:
#allowonly client's IP to connect
org.neo4j.server.webserver.address=192.168.0.2
#any client allowed to connect
org.neo4j.server.webserver.address=0.0.0.0
You can set the rrdb (round robin database directory) for collecting the metrics on the instance of database running. You can even specify to the database the URI path to be used for accessing the database with the REST API (it is a relative path and the default value is /db/data). The following settings are used:
org.neo4j.server.webadmin.rrdb.location=data/graph.db/../rrd
org.neo4j.server.webadmin.data.uri=/db/data/
The Neo4j WebAdmin interface uses a different relative path to provide access to the management tool. You can specify the URI setting as follows:
org.neo4j.server.webadmin.management.uri=/db/manage
If the Neo4j database resides on a separate machine in the network, you can restrict the class of network addresses that can access it (IPv4 or IPv6 or both). You need to modify the settings in the conf/neo4j-wrapper.conf file. Look for the section titled Java Additional Parameters, and append the following parameter to it:
wrapper.java.additional.3=-Djava.net.preferIPv4Stack=true
In order to configure the number of threads controlling the concurrency level in the servicing of the HTTP requests by the Neo4j server, you can use the following parameter:
org.neo4j.server.webserver.maxthreads=200
A timeout is used by the Neo4j server to manage orphaned or broken transactions. So, if no requests are received for an open transaction for a period configured in the timeout (the default is 60s), the transaction is rolled back by the server. You can configure it as:
org.neo4j.server.transaction.timeout=60
The main file for server configurations is conf/neo4j-server.properties. For parameters to tune the performance of the database at a low level, a second file called the neo4j.proprties file is used. You can explicitly set this file using theorg.neo4j.server.db.tuning.properties=neo4j.properties parameter which, if not set, the server looks for in the current directory as the neo4j-server.properties file. If no file is present, then a warning is logged by the server. When the neo4j.properties file is set and the server is restarted, this file is loaded and the database engine is configured accordingly.
JVM configurations
Neo4j is written in Java and hence, the settings for JVM also decide the resource constraints that are imposed upon the database. You can however, configure these properties in the conf/neo4j-wrapper.conf file in NEO4J_HOME in your installation. Here are a few common properties that you can tweak according to your requirements:
|
Name of property |
What it stands for |
|
wrapper.java.initmemory |
Initial size of heap (in MB) |
|
wrapper.java.maxmemory |
Maximum size of heap (in MB) |
|
wrapper.java.additional.N |
Additional literal parameter of the JVM (N is the number of each literal) |
The underlying JVM has two parameters that are used to control the main memory – one each for the stack and the heap. In Neo4j, the heap size is a critical parameter, since it controls the allocation of objects (number of objects) by the database engine. The stack, on the other hand, is the deciding factor for the depth of the call stack for the application.
Generally, the notion is that having a large heap size is better. With a large heap, Neo4j can handle transactions that are much larger, and also experience high concurrency in transactions. Neo4j speed will also increase as a bigger section of the graph and will fit in the caches, leading to more frequently used nodes and relationships being quickly accessible. Also, with a larger heap, the nodes and relationship caches will be much larger as well.
However, as an admin, you need to make sure that the heap fits in the system's main memory, because if paging to disk occurs, then the performance is adversely affected. Also, if your heap size is much larger than the requirement of the application, then the JVM garbage collection leaves dead objects lying around for a longer time. This, in turn, will cause longer pauses for garbage collection, and latency issues which is not desired by the application. In a 32 bit JVM, the default heap size is 64 megabytes, which is too small for practical applications (a 64-bit JVM heap is not useful either). Memory is a critical factor when transactions are prominent in the system. The following figure shows the memory footprints of different transaction types:
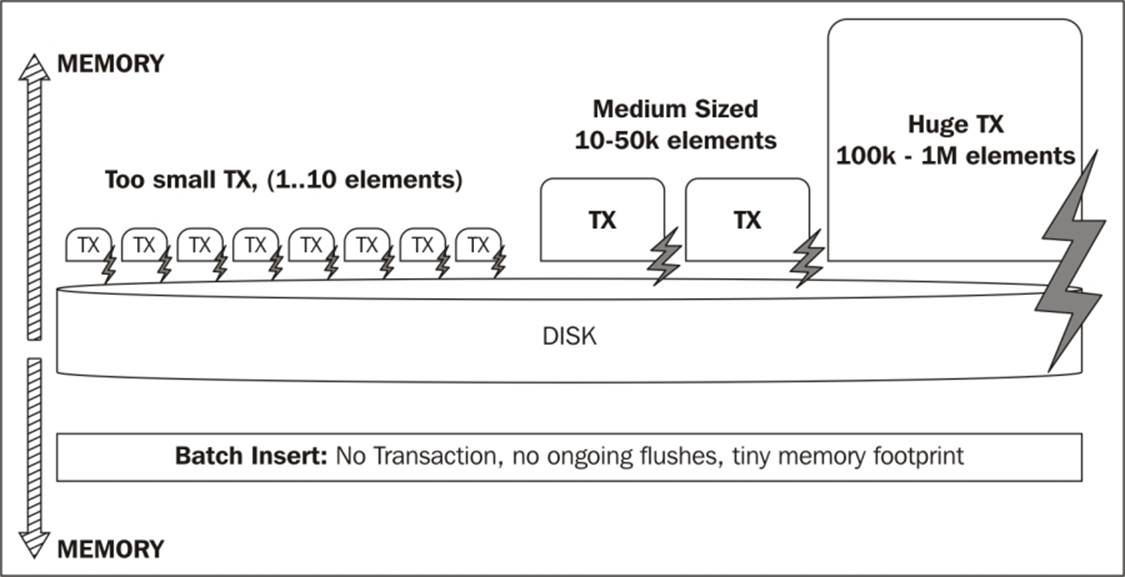
Depending on the cache implementation being used, a suitable heap size coupled with garbage collection can be used to handle most traffic by the database. The default soft reference cache (LRU based) needs a heap larger than the data to be kept in it, thereby being able to cache most nodes and relationships. It will let the heap get too full, then it will trigger a garbage collection which will result in loss of cached data. The cache storage can be prolonged by using a much larger cache. If a strong reference cache is being used, then the entire graph must fit in the heap (cache). Thus large heaps can avoid out-of-memory exceptions and maintain high overall throughput.
A weak reference cache, on the other hand, can be allocated heap, just enough for handling the peak load (average memory x peak load) and is beneficial in low latency scenarios.
|
Number of primitives |
RAM size |
Heap configuration |
Reserved RAM for the OS |
|
10M |
2GB |
512MB |
The rest |
|
100M |
8GB+ |
1-4GB |
1-2GB |
|
1B+ |
16GB-32GB+ |
4GB+ |
1-2GB |
Caches
Caches in Neo4j are of two basic types:
· File buffer cache: It is used to cache the storage file data as it is stored on the storage media
· Object cache: It is used for caching of nodes, relationships and properties to be used for speeding traversals, and transactions
The Neo4j data is stored in the file buffer cache in a format identical to that used for the representation of a persistent storage medium. This cache is helpful in improving the read/write performance by writing to cache, and delaying writing to the persistent storage till the rotation of the logical log. It is a safe operation since all stored files for the transaction can be recovered in case a crash occurs.
Let us take a look at how data is stored in Neo4j and the files used for storage onto the underlying file system. Each file in the Neo4j storage file stores uniform records of a fixed size and a specific type:
|
Store file |
Record size |
Contents |
|
neostore.nodestore.db |
15 B |
Nodes |
|
neostore.relationshipstore.db |
34 B |
Relationships |
|
neostore.propertystore.db |
41 B |
Properties for nodes and relationships |
|
neostore.propertystore.db.strings |
128 B |
Values of string properties |
|
neostore.propertystore.db.arrays |
128 B |
Values of array properties |
You can configure the size of the records during the creation of the data store with the help of the array_block_size and the string_block_size parameters. These settings come in handy when you expect to store large data records in the entities. Another advantage of these records is that you can estimate the storage requirements of the data in the graph, and calculate a rough cache size for the file buffer caches.
A file buffer cache exists for every distinct storage file. The file is divided by the cache into multiple equal-sized windows containing even numbers of records. In the process of caching, the windows that are most active are held in memory and the hit/miss ratio for each window is constantly tracked. When the ratio for a window that is uncached is found to be greater than those in the cache, one window from the cache is removed and is replaced by this window.
The object cache is used to cache nodes, relationships, and properties to optimize them for speedy graph traversals. Reading from the object cache experiences five to ten times the speed of accessing a file buffer cache. As soon as a node or relationship is accessed, it is added to the object cache. However, populations of the cached objects occur lazily. Loading of the properties only occur when the property is accessed. If a node is loaded into the cache, its relationships are not loaded until they are accessed.
You can configure the object cache using the cache_type parameter to specify the type of cache implementation to be used, mentioned separately for nodes and relationships. The available options for cache types are:
|
Cache type |
Description |
|
none |
No high level cache is used. Object caching does not take place. |
|
soft |
Uses available memory optimally, and useful in high performing traversals. If cache size is inadequate for frequently used parts, garbage collector issues may occur. The community edition of Neo4j has this as the default cache type. |
|
weak |
It provides relatively short life spans for cached objects. For applications requiring high throughput, and where the frequently accessed section of the graph cannot fully fit into memory, this is a suitable solution. |
|
strong |
Best option for small completely in-memory graphs. This technique loads all data into memory without any removals or releases. |
|
hpc |
This refers to the high-performance cache. It dedicates memory chunks for caching nodes and relationships and is the best option in most scenarios. It facilitates fast lookups/writes and has a very small footprint. This cache type is available and is the default option for the Enterprise edition of Neo4j. |
Apart from the cache_type parameter, there are a few other parameters that can be used to configure the way caches operate in Neo4j, and their resource constraints. Some of the important parameters are listed as follows:
|
Configuration option |
Description (what it controls) |
Example value |
|
cache.memory_ratio |
The percent of the available memory that will be used for caching. The default is 50 percent. |
60.0 |
|
node_cache_array_fraction |
The dedicated fraction of the heap size for the cache array for nodes (max ten). |
8 |
|
relationship_cache_array_fraction |
The dedicated fraction of the heap size for the cache array for relationships (max ten). |
7 |
|
node_cache_size |
The maximum amount of heap memory dedicated for caching nodes. |
3G |
|
relationship_cache_size |
The maximum amount of the heap memory dedicated to caching relationships. |
800M |
Memory mapped I/O configuration
Memory mapped I/O can be used for read/writes to every file in the Neo4j storage. The best performance will be obtained if complete memory mapping of the file can occur, but if there is a shortage of memory for that, then Neo4j tries to optimize the memory use.
Note
Neo4j makes extensive use of the java.nio native Java package. Use of the native I/O package allows the allocation of memory external to the Java heap, which has to be handled separately. It will also depend on other system processes using memory. Neo4j allocates memory, which is a total of the JVM heap memory and the memory mapping needs, leaving the remaining memory for system processes.
It is not a great idea to use the complete available system memory for heap memory. The Neo4j data store (in the Neo4j database directory) stores the data in separate files which are outlined as follows:
· nodestore: It is used to store node information
· relationshipstore: It is used to store relationship information
· propertystore: All simple properties of nodes and relationships, occurring as primitive types are saved in this file
· propertystore strings: It is the storage for string type properties
· propertystore arrays: It is the storage of all array type properties
You can configure the memory mapping configurations for the mentioned files separately using the mapped_memory option along with the following parameters:
neostore.nodestore.db.mapped_memory=75M
neostore.relationshipstore.db.mapped_memory=100M
neostore.propertystore.db.mapped_memory=180M
neostore.propertystore.db.strings.mapped_memory=210M
neostore.propertystore.db.arrays.mapped_memory=210M
Tip
If traversal speed is the highest priority, it is good to memory map the node and relationship stores as much as possible.
Traversal speed optimization example
Let us see an example that Neo4j uses to illustrate mapped memory allocation. In order to tune the settings for memory mapping, we need to first look up the size of the files in the data store in the Neo4j database directory. Let us take a case where the size of the files is found to be as follows:
neostore.nodestore.db: 14MB
neostore.propertystore.db: 510MB
neostore.propertystore.db.strings: 1.2GB
neostore.relationshipstore.db: 304MB
Let us say the system being used has a total memory of 4 GB, with 50 percent reserved for the system programs. The memory allocated to the Java Heap is 1.5 gigabytes leaving about 0.5 gigabytes for memory-mapping purposes. For obtaining optimum traversal speed, you can use a configuration for the memory mapping as follows:
neostore.nodestore.db.mapped_memory=15M
neostore.relationshipstore.db.mapped_memory=285M
neostore.propertystore.db.mapped_memory=100M
neostore.propertystore.db.strings.mapped_memory=100M
neostore.propertystore.db.arrays.mapped_memory=0M
Since our data had no file for array based properties, we can safely allocate no memory for memory mapping array based properties.
Batch insert example
Memory mapping can also be used to optimize batch insertion speed. Let us take a look at an example that Neo4j uses to demonstrate this. Suppose we have a graph with 10M nodes that are connected with 100M relationships. Every object has distinct primitive and string type properties. For simplicity, let's say there are no array based properties. We need to give more memory to the node and relationship stores. The allocations can be made as follows:
neostore.nodestore.db.mapped_memory=90M
neostore.relationshipstore.db.mapped_memory=3G
neostore.propertystore.db.mapped_memory=50M
neostore.propertystore.db.strings.mapped_memory=100M
neostore.propertystore.db.arrays.mapped_memory=0M
The configuration is intended to store the entire graph in memory. A naive way to calculate memory needed for mapping the nodes is by using the number_of_nodes * 9 bytes formula and, as for relationships, it can be number_of_relationships * 33 bytes. You will know why, if you have read about storage basics in the previous chapter. It is important to note that the above configuration requires a Java heap of more than 3.3G since, for batch inserter mode normal, Java buffers which are allocated on the JVM heap memory are used in place of memory mapped ones.
Neo4j server logging
The Neo4j server logs the information about the activities that takes place during the operating lifetime of the server. It is not an overhead; it is in fact an essential constituent for debugging, monitoring, and recovery. Neo4j provides support for logging of key server activity, HTTP request activity as well as garbage collection activity. Let us take a look at how to make use of these.
Server logging configurations
For event logging within the Neo4j server, the java.util.logging library of Java is used. You can configure the logging parameters in the conf/logging.properties file. The default level of logging is INFO, and the messages are printed on the terminal, as well as written to a rolling file located at data/log. Depending on the development stage and requirements, you can change the default behavior or even turn off the logging, using:
java.util.logging.ConsoleHandler.level=OFF
This will turn off all console output. The log files have a size limit of 10M after which rotation takes place. The files are named as neo4j.<id>.<rotation sequence #>.log. You can configure the naming scheme, frequency of rotation, and the size of the backlog using the following parameters respectively:
java.util.logging.FileHandler.pattern
java.util.logging.FileHandler.limit
java.util.logging.FileHandler.count
You can check out more about the FileHandler class of logging at https://docs.oracle.com/javase/7/docs/api/java/util/logging/FileHandler.html.
HTTP logging configurations
Along with events that occur within the Neo4j server, we can also log the HTTP requests and responses that are serviced by the Neo4j server. To achieve this, we need to configure the logger, location of logging, and the optimal format of the logs. You can enable HTTP logging by appending the following parameters defined in the conf/neo4j-server.properties file:
org.neo4j.server.http.log.enabled=true
org.neo4j.server.http.log.config=conf/neo4j-http-logging.xml
The first parameter indicates to the server that HTTP logging has been enabled for the server. You can toggle the behavior by setting the value to false. The second parameter specifies the format of logging, the file rollover settings that govern how the log output is formatted and stored. By default, an hourly log rotation is used and the generic common log format (http://en.wikipedia.org/wiki/Common_Log_Format).
If the log writes to a file, then the server initially checks whether the directory is existent with appropriate write permissions, failing which a failure is reported and the server does not start.
Garbage collection logging
We can also collect the logs from the garbage collector. In order to enable GC logging, we have to uncomment the following parameter so that the appropriate value is passed on to the server:
wrapper.java.additional.3=-Xloggc:data/log/neo4j-gc.log
GC logging cannot be directed to the terminal; we can find the log statements in data/log/ne4j-gc.log, or the appropriate directory that we had set in the preceding option value.
Logical logs
Logical logs are used as journals for the operations, and prove to be useful in scenarios when a recovery is needed for the database after a crash has occurred. The logs are generally rotated when the size exceeds a threshold (the default is 25M) and you can specify how many logs need to be kept. The reason for storing the logical log history is to serve incremental backups and keep the Neo4j HA clusters operational. When not enabled, the latest populated logical log is stored. We can configure the format using the following parameters:
keep_logical_logs=<true/false>
keep_logical_logs=<amount><type>
Some sample configurations can be specified as follows:
# To indefinitely keep logical logs
keep_logical_logs=true
# To store most recent populated log
keep_logical_logs=false
# To keep logical logs containing committed transactions for past 30 days.
keep_logical_logs=30 days
# To store logical logs that contain the most recent 500,000 transactions
keep_logical_logs=500k txs
The type option supports a few other cases which are listed as follows:
|
Type |
Description |
Example |
|
files |
Number of recent logical logs to persist |
25 files |
|
size |
Maximum disk size that log files can occupy |
250M size |
|
txs |
Number of most recent transactions to log |
10M txs |
|
hours |
Store logs of committed transactions from past N hours from now. |
12 hours |
|
days |
Store logs of committed transactions in past N days from now. |
30 days |
Open file size limit on Linux
When working with Neo4j, you need several files to be read in a concurrent manner, since the different entities are stored in different files. However, Linux platforms generally define an upper bound on the number of files that can be concurrently opened. You can check the limit for the current system user with:
user@localhost:~$ ulimit -n
1024
The default value (1024) is inadequate for most practical scenarios involving indexed entities or multiple server connections. You can increase this limit to a higher value. Generally, a value over 40000 is recommended, depending on the patterns of use. For the current session, you can change this value using the ulimit command, logging in as the root user for the system. To make a system-wide persistent effect, you need to follow these steps:
1. Open a terminal and log in as the root user using the following command:
2. user@localhost:~$ sudo su –
3. When your prompt changes to root@localhost:~# you can use a text editor like vim or nano to open the /etc/security/limits.conf file.
4. Add the following lines to the file:
5. neo4j soft nofile 40000
neo4j hard nofile 40000
6. Open the sudoers file at /etc/pam.d/su and add/uncomment the following line
session required pam_limits.so
7. Restart your system to let the changes take effect.
In the preceding steps replace neo4j with the name of your current user. If you still see exceptions such as Too many open files or Could not stat() directory then the limit needs to be increased even further.
Neo4j server security
So, till now we looked at how to configure a Neo4j server in order to obtain optimum performance. However, in a practical scenario, we also need to ensure that our database server is secure enough to handle confidential and critical data. In this section, we will look at some aspects of securing the Neo4j database server.
Port and remote connection security
When a Neo4j server is started, the default behavior is to bind the host to the localhost with the connection port as 7474. Hence only local requests from the same machine are serviced. You can configure this behavior in the conf/neo4j-server.properties file by uncommenting, adding, or modifying the following lines:
# http port (for all data, administrative, and UI access)
org.neo4j.server.webserver.port=7474
#let the webserver only listen on the specified IP. Default
#is localhost (only accept local connections). Uncomment to allow
#any connection.
#org.neo4j.server.webserver.address=0.0.0.0
You can also restrict access to the database from only the machines(s) on which the application resides. So, only requests from this machine will be serviced. You can also provide open access (a security nightmare) by changing the incoming address to 0.0.0.0. The following setting is used for this:
org.neo4j.server.webserver.address=0.0.0.0
Support for HTTPS
There is built-in support for encrypted communication with SSL over HTTPS in a Neo4j server installation. A private key and a self-signed SSL certificate is generated when the server is initiated. In production scenarios, self-signed certificates are not reliable. Hence, you can configure your own certificates and keys. You can either replace the generated key and certificate with your own, or modify the conf/neo4j-server.properties file to change the location of the key and certificates:
# Certificate location (auto generated if the file does not exist)
org.neo4j.server.webserver.https.cert.location=ssl/myapp.cert
# Private key location (auto generated if the file does not exist)
org.neo4j.server.webserver.https.key.location=ssl/myapp.key
You need to ensure that the key is encrypted and has the appropriate file permissions to enable read/write access for the server. There is also support for chained SSL certificates, where the certificates need to be merged in a single PEM file with the private key assuming the DER format. The option to enable/disable HTTPS support and define the port can be configured with these options:
# Support toggle for https: on/off
org.neo4j.server.webserver.https.enabled=true
# Port for https (for all data, administrative, and UI access)
org.neo4j.server.webserver.https.port=443
Server authorization rules
Apart from restrictions at the IP level, more detailed security policies may be required for administrators. The authorization policies for the Neo4j server controls access to database aspects on the basis of user or application credentials. The security rules must first be registered with the server, making scenarios for external lookup and authentication on the basis of role possible. The detailed configuration for this is managed in the org.neo4j.server.rest.security.SecurityRule package.
Setup server authorization rules enforcement
Let us look at a scenario in which a security rule for failure is being registered for restriction of access to all the external URIs. This can be configured in the conf/neo4j-server.properties file:
org.neo4j.server.rest.security_rules=rule.CompleteRestrictionSecurityRule
The code for the CompleteRestrictionSecurityRule class can be defined in the following manner:
publicclassCompleteRestrictionSecurityRuleimplementsSecurityRule
{
publicstaticfinalStringMYREALM="MyApplication";
@Override
publicbooleanisAuthorized( HttpServletRequestrequest )
{
returnfalse; // Forces failure always
// Logic for authorization coded here
}
@Override
publicStringforUriPath()
{
return"/*"; //For any incoming URI path
}
@Override
publicStringwwwAuthenticateHeader()
{
returnSecurityFilter.basicAuthenticationResponse(MYREALM);
}
}
This rule restricts all types of access to the server from external locations. For a production scenario, you can configure the rule class to check for login credentials in order to authorize users to the application.
Sample request
POST http://localhost:7474/db/data/relationship/1
Accept:application/json; charset=UTF-8
Sample response
401:Unauthorized
WWW-Authenticate:Basic realm="MyApplication"
Security rules targeting with wildcards
Unlike the previous case, where all incoming requests are blocked, we can also target the restriction to some specific type of URIs with the use of wildcards. We need to register for this with a predefined wildcard URI path, with * specifying any section of the path. For example, /users* will block those requests that access the user root. In a similar fashion, the /users*type* expression refers to URIs accessing the type option for users like /users/mark/type/new.
You can use the defined CompleteRestrictionSecurityRule security rule class with a modification to the forUriPath method as follows:
publicStringforUriPath()
{
return"/secure/*";
}
This rule restricts only those requests that attempt to access the data under the /secure/ directory. So, with wildcards, you can flexibly control access to different parts of the server API.
Sample request
GET http://localhost:7474/secure/any/path/after/this/stuff
Accept:application/json; charset=UTF-8
Sample response
401:Unauthorized
WWW-Authenticate:Basic realm="MyApplication"
You can use multiple or a chain of wildcards in order to restrict a specific URI type or a pattern of URIs. Consider the case when the forUriPath() method is changed to take this form:
publicStringforUriPath()
{
return"/protected/*/something/else/*/final/bit";
}
The type of requests that this blocks are very specific and targeted in nature. An example of the type of request restricted is as follows:
Sample request
GET http://localhost:7474/protected/any/x/y/z/path/something/else/any/subpath/final/bit/anything
Accept:application/json; charset=UTF-8
Example response
401:Unauthorized
WWW-Authenticate:Basic realm="MyApplication"
Note
As a default behavior, the Neo4j server allows functionality for remote scripting, thereby allowing complete access to the underlying database instance from anywhere. This is better for development purposes. However, in production stages, allowing remote scripting is a potential high security risk, and you need to impose a sound security layer.
Other security options
Apart from the numerous security configurations discussed, for critical deployments it is wise to use an additional proxy similar to Apache's mod_proxy (http://httpd.apache.org/docs/2.2/mod/mod_proxy.html). This can provide access control to specific IPs, a range of IPs and even URI patterns. So you can essentially allow /db/data available to external clients while /db/admin/ can be made accessible from a specific IP. The configuration would look something like this:
<Proxy *>
Order Deny,Allow
Deny from all
Allow from 192.168.0
</Proxy>
The proxy server gives the same functionality as Neo4j's default SecurityRule feature and you can also use both together with proper non-conflicting configurations. However, admins often prefer Apache to the default Neo4j feature.
Summary
In this chapter, we first looked at the utilities and adapters that have been developed for use with most popular languages and frameworks with Neo4j. We also looked into the configurations and tricks that administrators can make use of in order to obtain optimum performance out of their deployments. In the process, we also discussed caches, memory mapped I/O and logging configurations, and how we can secure access to a Neo4j server instance.
In the next chapter, we will be looking at a use case of Neo4j, where we will work on a recommendation engine, and discuss the best practices for development and deployment of a practical application.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.