Neo4j High Performance (2015)
Chapter 8. Use Case – Similarity-based Recommendation System
In the previous chapters, we have studied about how to work with different aspects of the incredible graph database, Neo4j, from its installation, querying, and traversals, to performance optimizations at the production level. We have also had a peek under the hood of Neo4j in order to understand its functionality. Neo4j has a wide range of practical applications. Typically, any scenario that includes connected data represented graphically, Neo4j proves to be the perfect resource for storage and processing needs. With rapidly increasing connected devices and sensor driven technology, graph-based analytics solutions are becoming more popular in the business world, especially because they are simpler to interpret and visualize. Graph databases like Neo4j find extensive use in the route generation, fraud analysis, and impact analysis in networks. However, the latest and most popular use case of graph technologies is in the realm of recommendations. The booming sectors like social networks, job portfolio websites, and e-commerce solutions all operate with a sound recommendation engine at the backend. In this chapter let us understand how we can use Neo4j to address the issues in recommendation engines. The following topics will be discussed:
· Recommendation engine basics
· Building a recommendation engine
· Addressing map recommendation issues and visualization
The why and how of recommendations
In the consumer specific markets today, businesses need to stay a step ahead of the customer in order to flourish. Recommendations use the data that the customers generate, so that you can analyze patterns and behavior that can be used to suggest products, people, or point of sales. Over the years, several techniques have been developed to generate recommendations. Let us take a look at the major approaches:
Collaborative filtering
It is one of the most common techniques that recommendation engines today are based on. Collaborative Filtering refers to the method of pattern or information filtering with collaboration between various data sources, viewpoints, agents, etc. It uses previous or historical data of a user, or other users, to profile a pattern, and then uses it to predict what other content the user might like.
Let us take an example to understand this. On e-commerce websites, you are presented with suggestions for products that you might buy, based on the search history of your and other's profiles. Basically, based on the common data between you and other users, the websites can suggest products which the other people have browsed, but you haven't, yet. A similar scenario is applicable for social networks or dating websites. As an end user, when you have followed, befriended or expressed an interest in some people you would like to date, a system using collaborative filtering can give you suggestions for people who match your taste. The priority of the suggested results will depend upon what the results have in common with you, and what their tastes are.
In this way, the activities of other users is analyzed by the recommender system, thereby saving you precious time of browsing through profiles of irrelevant people. This is an extremely powerful system as it lets you benefit from the activities of people that you do not know or have never met. Thus collaborative filtering gives you a way to obtain concrete insights for applications that generate large sets of data.
Content-based filtering
Content-based filtering uses items or target descriptions along with the profile of the user's preferences. In such a system, each item is described and associated with certain keywords, and for each user, profiling is done for what the user likes. So the recommender system suggests items depending upon the user's own historical activities in order to recommend the items that best match.
Content-based filtering also uses weight values to signify how important the feature is for a particular user, and are calculated from the content rated by the user. User feedback, usually with likes, votes, or ratings, decide how important an attribute is for that user. An issue that content based recommendation faces, is being able to recommend content of multiple types based on patterns obtained from other types. For example, it is an easy task to recommend news based on the news browsing patterns of the user. However, it is a challenge to recommend products, forums, videos or music, based on the news browsing patterns. Pandora Radio is an excellent example of content based recommender, which uses the initial song of the user to find songs with similar characteristics.
The hybrid approach
We have seen the collaborative and content-based filtering methods, but research suggests that a hybrid of the two methods proves to be more effective. One way of generating hybrid results is to first separately get the results from the two methods and then combine them. You can also create a single model incorporating both techniques. Studies suggest that performance of the hybrid recommender systems is empirically better than that of the pure systems, and is known to give more accurate recommendations.
Netflix, the media content delivery website, is an excellent example of a hybrid system user. It compares the searching and viewing patterns of similar users and also provides results for movies that have some common characteristics of the users' high rated contents.
Let us take a look at some of the different techniques in which a hybrid system can be generated and used:
· Switching: This technique selects one or some of the recommendation components and applies it
· Weighted: In this technique, the numerical scores of the recommendation components are combined
· Mixed: Here, multiple recommendation systems operate together and the results from them are combined together
· Augmentation of features: A method is initially used to generate the feature set to be used and this set is then passed on the next method for providing recommendations
· Combination of features: A single recommendation system uses features from multiple different sources to generate results.
· Cascading: It is a priority based technique in which different recommendation systems have different priorities, which are used to settle ties in results
Building a recommendation system
Let us see how we can use Neo4j as the backbone to develop recommendation systems for different data scenarios. For this purpose, we will be using the collaborative filtering approach to process the data in hand and churn out relevant results.
In order to understand how the process works, let us use a simple data set of a dating site where you can sign in and view the profile of people who you could potentially date, and you can follow or like them, or vice versa. The graphical representation of such a dataset will represent the people as nodes, and the like operations from one person to another is represented as edges between them.
As shown in the following diagram, consider a user, John, who has just registered on the website and created a profile for himself. He begins browsing through profiles of women, searching for a person that might interest him. After going through the profiles of several people, he likes the profiles of three of them – Donna, Rose, and Martha. Now, as John is trying his luck, there are other users on the site who are also actively searching. It turns out that Jack, Rory, Sean, and Harry have also liked profiles of some of the people that John has liked. So, it can be inferred that their tastes are aligned and similar. So, it is quite probable that John might like some of the other people that the guys have already liked, but whose profiles John has yet to come across. This is where the collaborative filtering comes into play, and we can suggest more options for John to view, so that he has to deal with a lesser number of irrelevant profiles.
The following diagram is an illustration of what type of relationships from our dataset are being used by the recommender:
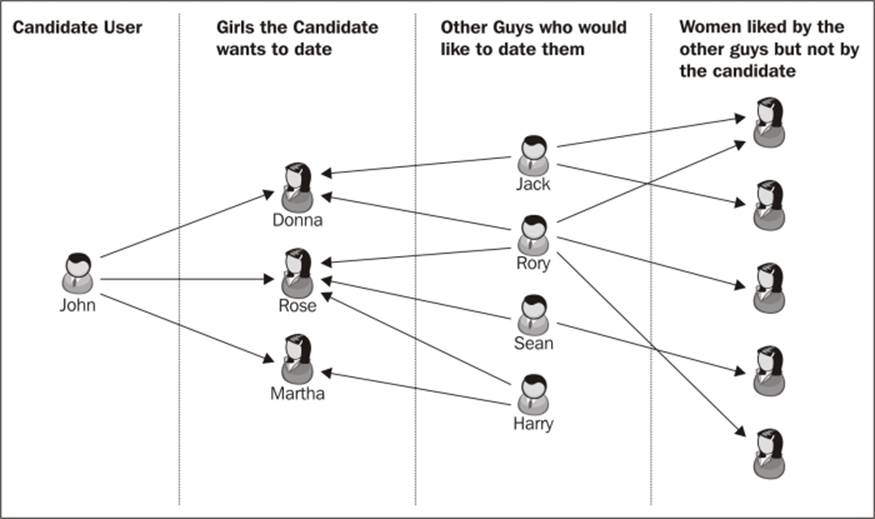
Creating this type of a system would require complex search and set operations for a production-level implementation. This is where Neo4j comes to the rescue. What we are essentially doing in the technique above, is searching for some desired patterns in the graphical representation of our data, and analyzing the results of each sub-search to obtain a final result set. This reminds us of a Neo4j specific tool we have studied before – Cypher. It is beneficial to use Cypher in recommender systems, because of the following reasons:
· It works on the principal of pattern matching, and therefore is perfect for implementing collaborative recommendation algorithms.
· Cypher, being a declarative query language, does not need you to write code for how to match the query patterns. You will simple need to mention what to match and get results. This leads to simpler and smaller codes for creating complex recommendation systems.
· Cypher, designed specifically for Neo4j will give optimum performance for relatively large datasets, compared to writing native code for generating recommendations.
The following code segment illustrates how the scenario described above can be represented using Cypher.
START Person = node(2)
MATCH Person-[IS_INTERESTED_BY]->someone<-[:IS_INTERESTED_BY]-otherguy-[:IS_INTERESTED_BY]->recommendations
WHERE not(Person = otherguy)
RETURN count(*) AS PriorityWeight, recommendations.name AS name
ORDER BY PriorityWeight DESC, name DESC;
Let us see what different parts of the preceding Cypher segment are doing in the overall scenario:
1. We initially select the user who is the candidate for the recommendations using the following query:
START Person = node(2)
2. The main pattern that we are searching for is about finding the women that are liked by the people who co-incidentally share common likes with our recommendation candidate. The following query illustrates it:
MATCH Person-[IS_INTERESTED_BY]->someone<-[:IS_INTERESTED_BY]-otherguy-[:IS_INTERESTED_BY]->recommendations
3. We rule out the consideration of our candidate as a tertiary user, since by default, the candidate, John, shares the same likes as himself which would result in a redundant case. Hence the following statement:
WHERE not(Paul = otherguy)
4. Using the count method, we monitor the number of ways a result is obtained during the query execution, using the following statement:
RETURN count(*) AS PriorityWeight, recommendations.name AS name
5. Finally, we return the results in the order of relevance (using the sort method for ordering):
ORDER BY PriorityWeight DESC, name DESC;
Let us take an example of another social dataset to understand a more complex pattern for recommending people to date. This dataset (social2.db in the code for this chapter) contains names of people along with their genders, dating orientations, attributes/qualities the person has, where they live, and the qualities they a looking for in potential partner.
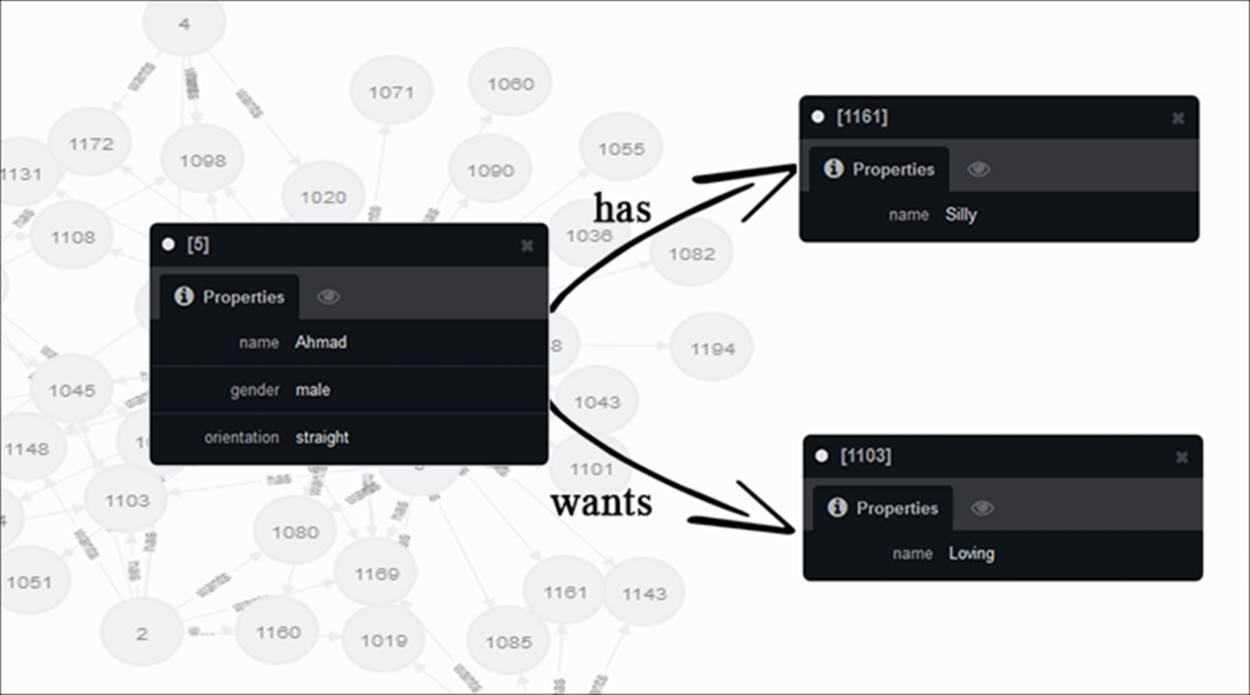
So, let us build upon the recommendation algorithm, one step at a time:
1. First, we need the name of the person who is looking for a person to date. The following statement can be used if you know the name:
START me=node:users_index(name = 'Albert')
2. In order to provide recommendations, we need to consider people living in a nearby location or same town, since a person from Alaska will not prefer to date someone from California (you know how long distance dates turn out!!). So the following statement can be used to filter:
MATCH me-[:lives_in]->city<-[:lives_in]-person
3. From the results obtained in the preceding step, we need to match the genders of the prospective person with the candidate depending upon his/her orientation.
4. We also need to match the qualities that our candidate is looking for and the qualities that the prospective person possesses. We can't be selfish though!
5. We also check if the candidate possesses the qualities that the prospective person is looking for. Hence, the following statement follows:
6. WHERE me.orientation = person.orientation AND
7. ((me.gender <> person.gender AND me.orientation = "straight")) AND
8. me-[:wants]->()<-[:has]-person AND
9. me-[:has]->()<-[:wants]-person
10.WITH DISTINCT city.name AS city_name, person, me
MATCH me-[:wants]->attributes<-[:has]-person-[:wants]->requirements<-[:has]-me
11. To check the results obtained at this stage, you can collect the results from the preceding statement, process them to find the number of matching attributes between the candidate and the prospective person, by using the following statement:
12.RETURN city_name, person.name AS person_name,
13. COLLECT(attributes.name) AS my_interests,
14. COLLECT(requirements.name) AS their_interests,
15. COUNT(attributes) AS matching_wants,
COUNT(requirements) AS matching_has
16. Depending on the practical utility of the application for which the recommender operates, you can even sort the results on the basis of relevance, and display to the candidate the top results.
17.ORDER BY (COUNT(attributes)/(1.0 / COUNT(requirements))) DESC
LIMIT 10
Hence, the overall Cypher query for this recommendation algorithm will look like the following:
START me=node:users_index(name = 'Albert')
MATCH me-[:lives_in]->city<-[:lives_in]-person
WHERE me.orientation = person.orientation AND
((me.gender <> person.gender AND me.orientation = "straight")) AND
me-[:wants]->()<-[:has]-person AND
me-[:has]->()<-[:wants]-person
WITH DISTINCT city.name AS city_name, person, me
MATCH me-[:wants]->attributes<-[:has]-person-[:wants]->requirements<-[:has]-me
RETURN city_name, person.name AS person_name,
COLLECT(attributes.name) AS my_interests,
COLLECT(requirements.name) AS their_interests,
COUNT(attributes) AS matching_wants,
COUNT(requirements) AS matching_has
ORDER BY (COUNT(attributes)/(1.0 / COUNT(requirements))) DESC
LIMIT 10
If you start Neo4j with the social2.db dataset provided in the code for this chapter, you will find that the preceding query generates the following results view in the web interface:
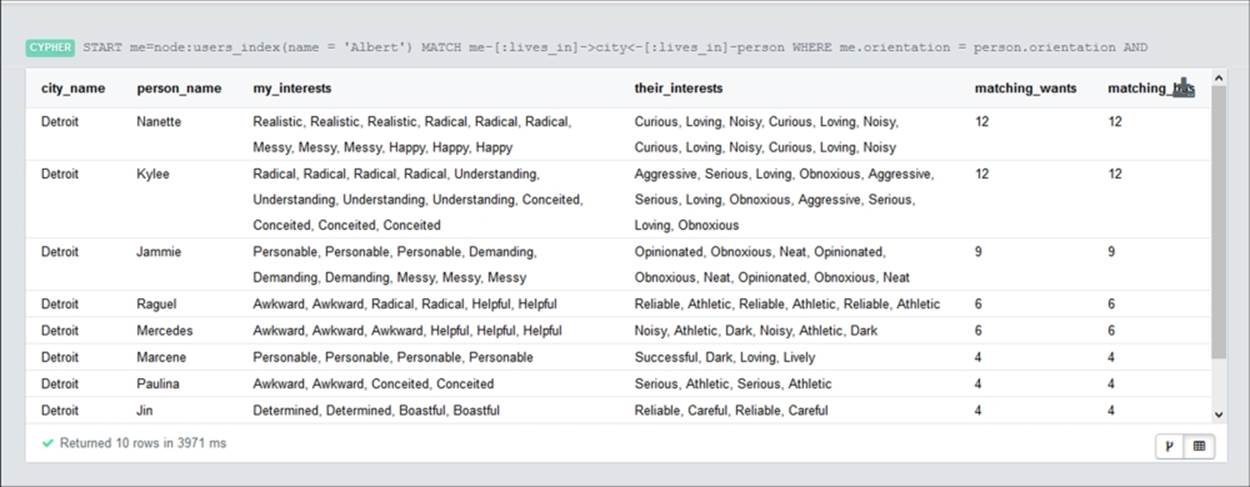
Thus, the results are displayed in tabular format containing the people with the most matching traits with our candidate. You can also export these results from the interface to be used in a tertiary part of your web application.
The preceding algorithm is a simple representation of a recommendation system. Much more complex systems can be constructed by combining multiple such clauses together. Of course, similar operations can be performed with map data as well, for recommendations of places to visit, or with sales data for providing suggestions to customers for products they are likely to buy. However, all this is possible in a minimalistic approach with the help of graph based technologies like Neo4j and Cypher.
Recommendations on map data
Map data is more complex and critical than sales or social data. However, its one advantage over the others, is that it is mostly static in nature. So what kind of recommendations can we generate for map data? Suppose a user searches for a location on the map, you can generate suggestions for nearby places of interest depending upon the user's search history. For example, if a user searches for restaurants once in a while, you could generate suggestions for restaurants in any new locations that he visits. Let us look at how to approach this issue.
Consider a map data set which represents the locations in the form of nodes, and the roads connecting them in the form of bi-directional relationships. The Location entity and its properties can be illustrated as follows
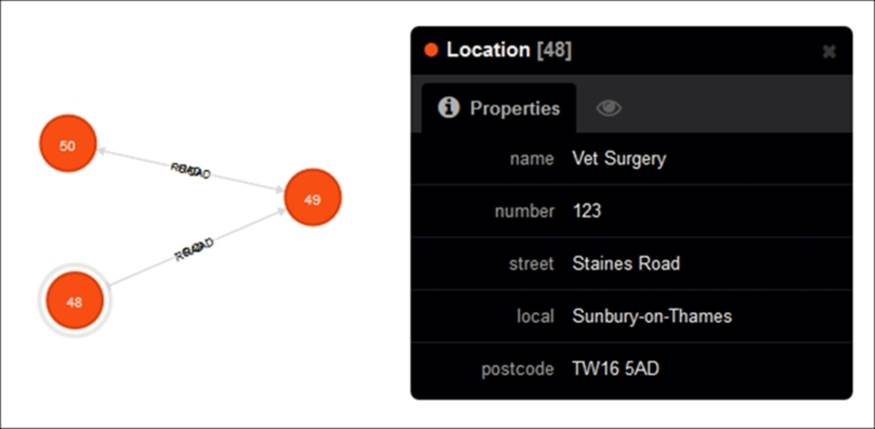
The Road entity and its property structure can be illustrated in the web interface as follows:
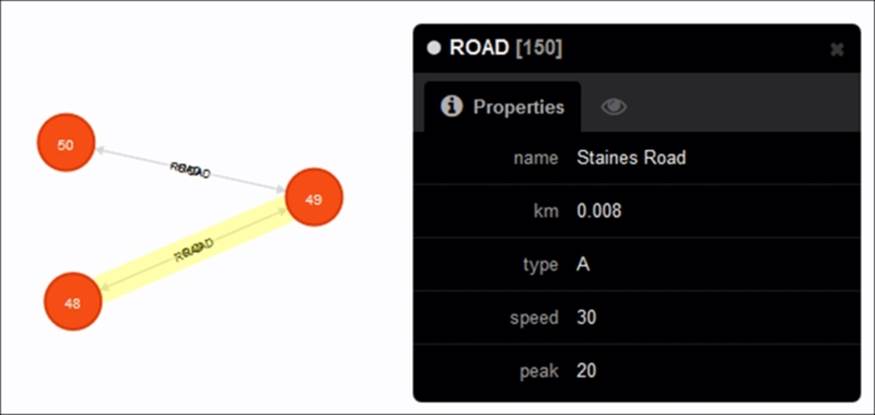
So, the map graph by itself is not sufficient to create a recommendation system. We will need to add it to scenarios involving user specific data, such as location based searches (advertisements or establishments to be recommended based on location and proximity of the user) or favorable logistic paths (delivery of goods through cab services is a very good example, where a cabbie can deliver goods to a location if he is already headed that way. Hence, a recommender system can be devised to suggest delivery locations to cabbies based on the areas they frequent or routes they take. The possibilities are endless when you can reference a map graph from a social or transport graph. So you combine the social graph and the map graph given above, by linking a person from the first to his corresponding locality in the second. This dual layered graph will now allow you to operate on the map, when you are simultaneously traversing the social graph.
A similar approach can be taken for airlines or logistic graphs, where the map component of the graph and the chief operation can be logically segregated, but physically linked. Now you can devise your own recommendation algorithms to consider location info for generating suggestions. Since you have now used pattern matching to generate recommendations for social data, we leave for you an exercise to devise a recommender for maps, according to any of the scenarios discussed earlier.
Visualization of graphs
Recommendations not only help the end user or consumer, but are a boon for analysts and business managers as well. Using graph databases like Neo4j to create such systems also brings the added advantage of great visualization support through its own web interface as well as several third party tools. Visualization serves two basic purposes which are outlined as follows:
· Better understanding of the data and the level of connectivity of the data makes it easier to plan the development process
· Analysts can use visualizations to suggest improvements to the result generation process since a visual outlook gives a better perspective
If we consider the example of the dating application earlier, a visual overview can assist in the identification of anomalies or outlier entities. For example, if a person is a trouble seeker and likes to spam other people's profiles, it would show up in the majority of connections being singular. Such cases can be identified and protected against, by using proper visualization method.
There are several tools available that help to visualize graph data. The web interface of Neo4j comes with its own visualization tool, where the results are displayed in the form of a fluid graph interface with dynamic functionality to view the information about specific displayed entities. This is how our complete map graph is visualized in the web interface of Neo4j:
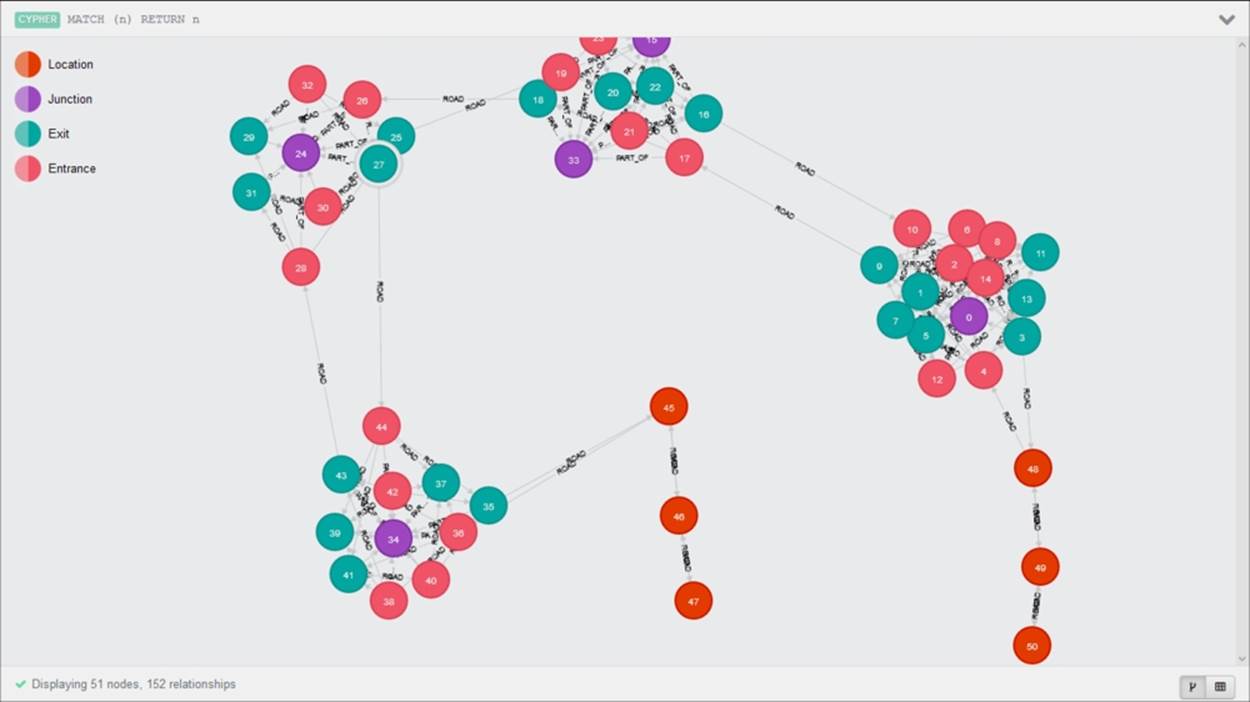
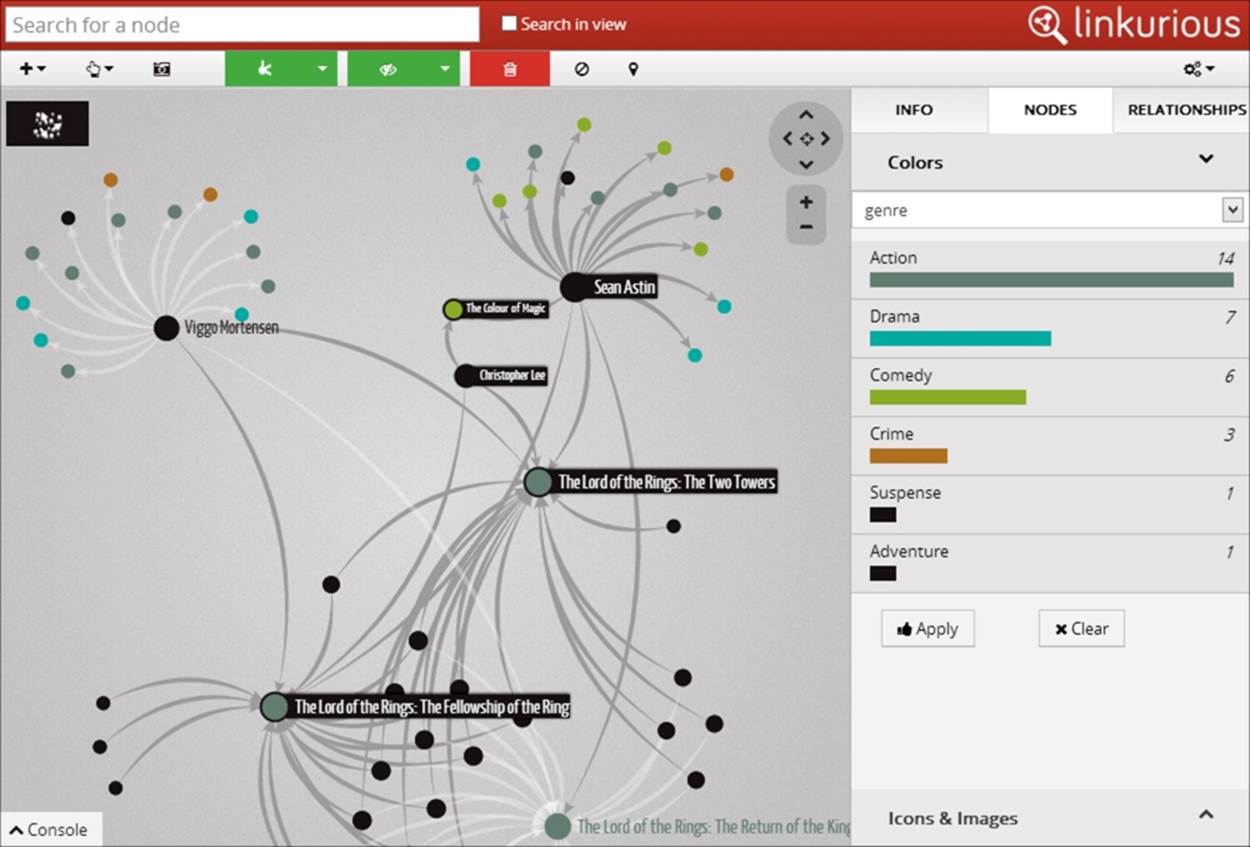
The gephi open source project is also an excellent tool to visualize complex and dynamic graphs. It is a great tool for data analysis and inference and can support a large number of graph sources. However, Linkurious is a project that deserves special mention as it is built with Neo4j in mind. It is a versatile tool, which provides a frontend to most of the graph database operations. Not only does it allow you to visualize and explore the database, it also provides a search functionality to search your graph data without any code (like a Google for graphs). You can even edit entities in the graph from the Linkurious frontend.
Note
You can learn more about the project at https://linkurio.us/. If you are an admin, you will love to work with this.
Here's what the interface looks like:
Summary
In this chapter, we have seen how Neo4j, as a graph database, is the best available option for creating recommendation systems based on similarity. This takes advantage of the pattern matching nature of the Cypher query language. We also looked at a social network recommender example, and also discussed how to incorporate map data into the generated suggestions. Finally, we saw the importance of data visualization and the major tools available for this objective. Thus, this book not only brings to you the in-depth study and administration of the Neo4j database, but also leaves you with one of the critical and widely popular use cases in the industry today.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.