NoSQL for Mere Mortals (2015)
Part IV: Column Family Databases
Chapter 9. Introduction to Column Family Databases
“The family is one of nature’s masterpieces.”
—GEORGE SANTAYANA
PHILOSOPHER
Topics Covered In This Chapter
In the Beginning, There Was Google BigTable
Differences and Similarities to Key-Value and Document Databases
Architectures Used in Column Family Databases
When to Use Column Family Databases
Deciding what is Big Data or a large database is somewhat subjective. Are a million rows in a MySQL table a large database? To some it is, to others it is just an average, perhaps even small, table. There is little room for debate, however, when you start to get into the realm of billions of rows and tens of thousands of columns in a table. That is a very large database (VLDB) by any standard.
Relational databases might scale to VLDBs with a small set of large servers, but the cost would be prohibitive for most. Key-value databases have useful features for this scale of database, but lack support for organizing many columns and keeping frequently used data together. Document databases might scale1 to this level but may not have some of the features you might expect at this scale, such as a SQL-like query language.
1. Chris Biow, and Miles Ward. “PetaMongo: A Petabyte Database for as Little as $200.” AWS re:Invent Conference, 2013. http://www.slideshare.net/mongodb/petamongo-a-petabyte-database-for-as-little-as-200.
Companies such as Google, Facebook, Amazon, and Yahoo! must contend with demands for very large database management solutions. In 2006, Google published a paper entitled “BigTable: A Distributed Storage System for Structured Data.”2 The paper described a new type of database, the column family database. Google designed this database for several of its large services, including web indexing, Google Earth, and Google Finance. BigTable became the model for implementing very large-scale NoSQL databases. Other column family databases include Cassandra, HBase, and Accumulo.
2. Fay Chang, et al. “BigTable: A Distributed Storage System for Structured Data.” OSDI’06: Seventh Symposium on Operating System Design and Implementation, Seattle, WA, November, 2006. http://research.google.com/archive/bigtable.html.
![]() Note
Note
Although the database community has standardized on the terms key value, document, and graph database, there is some variety in the terminology used with column family databases. The latter NoSQL databases are sometimes called wide column databases to emphasize their ability to manage tens of thousands (or more) of columns. They are also sometimes called data stores rather than databases because they lack some of the features of relational databases. This book uses the term column family database to (1) emphasize the importance of the column grouping function performed by column families and to (2) reinforce the idea that NoSQL databases are truly database management systems even when they lack some features of relational databases. Relational databases are popular and highly functional, but they do not define what constitutes a database or a database management system.
In the Beginning, There Was Google BigTable
The following are core features of Google BigTable:
• Developers have dynamic control over columns.
• Data values are indexed by row identifier, column name, and a time stamp.
• Data modelers and developers have control over location of data.
• Reads and writes of a row are atomic.
• Rows are maintained in a sorted order.
As Figure 9.1 shows, rows are composed of several column families. Each family consists of a set of related columns. For example, an address column family might contain
• Street address
• City
• State or province
• Postal code
• Country
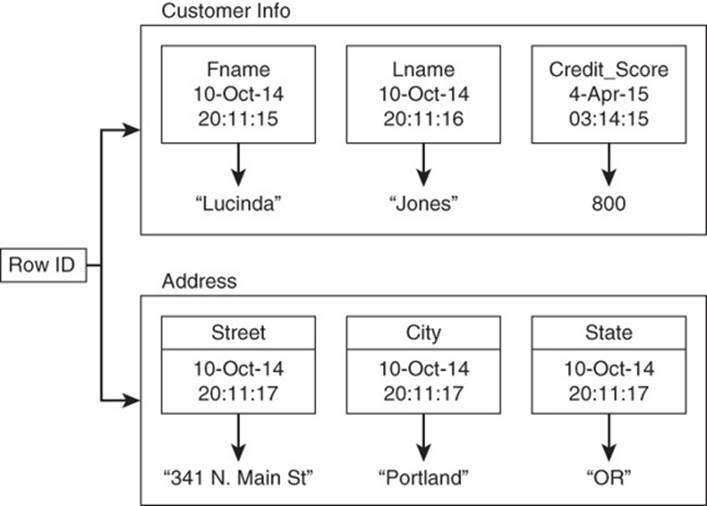
Figure 9.1 A row in a column family database is organized as a set of column families. Column families consist of related columns; a data value is indexed by a row, a column name, and a time stamp.
Column families are organized into groups of data items that are frequently used together. Column families for a single row may or may not be near each other when stored on disk, but columns within a column family are kept together.
BigTable takes the middle ground with respect to defining data structures. A data modeler defines column families prior to implementing the database, but developers can dynamically add columns to a column family. There is no need to update a schema definition. From a developer’s point of view, column families are analogous to relational tables and columns function like key-value pairs.
Utilizing Dynamic Control over Columns
The use of column families and dynamic columns enables database modelers to define broad, course-grained structures (that is, column families) without anticipating all possible fine-grained variations in attributes. Consider the address column family described earlier.
Let’s assume a company builds a column family database to store information about customers in the United States. The data modeler defines the address column family but no column names. The developer, who elicits detailed requirements from colleagues, determines that all customers are located in the United States. The developer adds a “State” column to the address column family. Several months later, the company expands its customer base into Canada, where regional governmental entities are known as provinces. The developer simply adds another column called “Province” to the database without having to wait for a data modeler to refine a database schema and update the database.
Indexing by Row, Column Name, and Time Stamp
In BigTable, a data value is indexed by its row identifier, column name, and time stamp (see Figure 9.2). The row identifier is analogous to a primary key in a relational database. It uniquely identifies a row. Remember, a single row can have multiple column families. Unlike row-oriented relational databases that store all of a row’s data values together, column family databases store only portions of rows together.
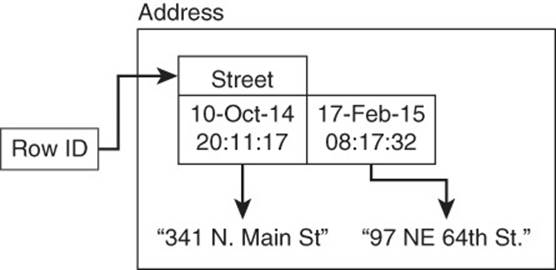
Figure 9.2 Data values are indexed by row identifier, column name, and time stamp. Multiple versions of a column value can exist. The latest version is returned by default when the column value is queried.
The column name uniquely identifies a column. The time stamp orders versions of the column value. When a new value is written to a BigTable database, the old value is not overwritten. Instead, a new value is added along with a time stamp. The time stamp allows applications to determine the latest version of a column value.
Controlling Location of Data
You might recall discussions from earlier chapters about the speed with which data is retrieved based on where is it located on a disk. Database queries can cause the database management system to retrieve blocks of data from different parts of a disk. This can cause the database management system to wait while the disk spins to the proper position and the read/write head of the drive moves to the proper position as well.
One way to avoid the need to read multiple blocks of data located on different parts of the disk is to keep data close together when it is frequently used together. Turning back to the address example again, there are few cases in which you would want the street address of a customer but not want the city or state. It is logical to keep this data together. Column families serve this purpose. Columns families store columns together in persistent storage, making it more likely that reading a single data block can satisfy a query.
![]() Caution
Caution
It might seem logical to keep streets, cities, and states close together on disks at all times, but that is not the case. Business intelligence systems, for example, often query for data by one of these attributes but not others. For example, a sales manager might issue a query to determine the number of tablets sold in the last month in the state of Colorado. There is no need to reference the city or street address of stores selling tablets. For applications such as these, data is more efficiently stored by columns. Columnar databases do just that. Instead of storing all data in a row together as row-oriented databases do or storing related groups of columns together, as column family databases do, columnar databases store columns of data together. Choosing a database management system with the appropriate storage model for your application is an important and early decision in application design (see Figure 9.3).
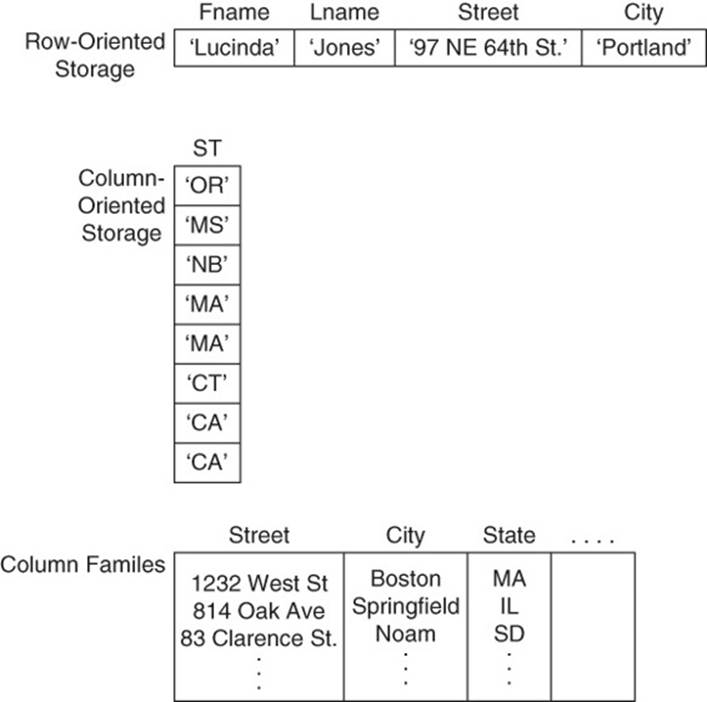
Figure 9.3 Different storage models offer different benefits. Choose a storage model that meets your query needs.
Reading and Writing Atomic Rows
The designers of BigTable decided to make all read and write operations atomic regardless of the number of columns read or written. This means that as you read a set of columns, you will be able to read all the columns needed or none of them. There are no partial results allowed with atomic operations (see Figure 9.4).
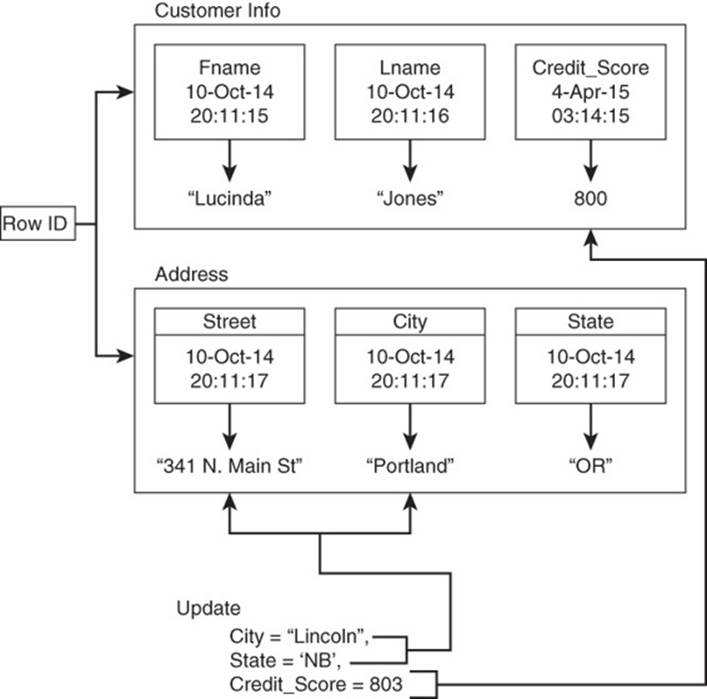
Figure 9.4 Read and write operations are atomic. All columns are read or written or none are.
Similarly, if you update several columns in different column values, atomic writes guarantee that the write to all columns will succeed or they will all fail. You will never be left with partially written data. For example, if a customer moves from Portland, Oregon, to Lincoln, Nebraska, and you update the customer’s address, you would never find a case in which the city changes from Portland to Lincoln but the state does not change from Oregon to Nebraska.
Maintaining Rows in Sorted Order
BigTable maintains rows in sorted order. This makes it straightforward to perform range queries. Sales transactions, for example, may be ordered by date. When a user needs to retrieve a list of sales transactions for the past week, the data can be retrieved without sorting a large transaction table or using a secondary index that maintains date order.
Of course, you can only order a table in one way, so you must choose carefully when defining a sort order. The original BigTable implementation did not include support for multiple indexes on tables. You could define tables with the same information as a secondary index and manage that table yourself.
Google BigTable introduced a data management system designed to scale to petabytes of data using commodity hardware. The design balanced data modeling features with the need to scale. The designers of Google BigTable anticipated the need for hundreds of column families, tens of thousands (or more) columns, and billions of rows. As a result, the column family database has some features of key-value databases, document databases, and relational databases.
![]() Note
Note
Google BigTable is a good reference point for understanding column family databases. It is, however, only used by Google and is not publicly available. The two most widely used and publicly available column family databases are Cassandra (http://cassandra.apache.org/) and HBase (http://hbase.apache.org/).
HBase runs within the Hadoop ecosystem, whereas Cassandra is designed to function without Hadoop or other Big Data systems. Because Cassandra is the more independent of the two most popular column family databases, it will be used as the reference model for the remainder of the column family discussion.
Differences and Similarities to Key-Value and Document Databases
Column family databases have characteristics similar to other NoSQL databases—key-value and document databases in particular. This is not surprising because all NoSQL databases were designed to address problems that challenged traditional relational databases. In addition, many NoSQL databases employ distributed database techniques to address scalability and availability concerns.
Column Family Database Features
Key-value databases are the simplest of all NoSQL architectures. They consist of a keyspace, which is essentially a logical structure for isolating keys and values maintained for a particular purpose. You may implement a keyspace for each application, or you may have a single keyspace that is used by multiple applications. Whichever approach you choose, a keyspace is used to store related keys and their values.
Column families are analogous to keyspaces in key-value databases. Developers are free to add keys and values in key-value databases just as they are free to add columns and values to column families. In Cassandra terminology, a keyspace is analogous to a database in relational databases. In both key-value databases and Cassandra, a keyspace is the outermost logical structure used by data modelers and developers.
Unlike key-value databases, the values in columns are indexed by a row identifier as well as by a column name (and time stamp). (See Figure 9.5.)
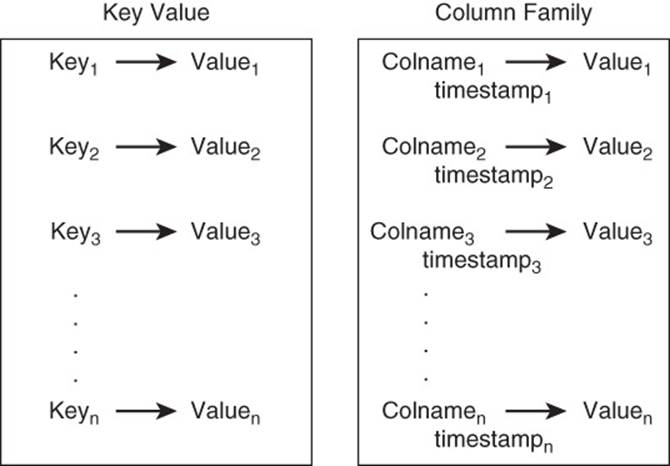
Figure 9.5 Keyspaces in key-value databases are analogous to column families in the way they maintain collections of attributes. Indexing, however, is different between the two database types.
Column Family Database Similarities to and Differences from Document Databases
Document databases extend the functionality found in key-value databases by allowing for highly structured and accessible data structures. Documents are analogous to rows in a relational database and store multiple fields of data, typically in a JSON or XML structure. You could also store JSON or XML strings in key-value databases, but those databases do not support querying based on contents of the JSON or XML string.
![]() Note
Note
Some key-value databases provide search engines to index the contents of JSON or XML documents stored as values, but this is not a standard component of key-value databases.
If you stored the following document in a key-value database, you could set or retrieve the entire document, but you could not query and extract a subset of the data, such as the address.
{
"customer_id":187693,
"name": "Kiera Brown",
"address" : {
"street" : "1232 Sandy Blvd.",
"city" : "Vancouver",
"state" : "Washington",
"zip" : "99121"
}
"first_order" : "01/15/2013",
"last_order" : "06/27/2014"
}
Document databases enable you to query and filter based on elements in the document. For example, you could retrieve the address of customer Kiera Brown with the following command (using MongoDB syntax):
db.customers.find( { "customer_id":187693 }, { "address":
1 } )
Column family databases support similar types of querying that allow you to select subsets of data available in a row. Cassandra uses a SQL-like language called Cassandra Query Language (CQL) that uses the familiar SELECT statement to retrieve data.
Column family databases, like document databases, do not require all columns in all rows. Some rows in a column family database may have values for all columns, whereas others will have values for only some columns in some column families (see Figure 9.6).
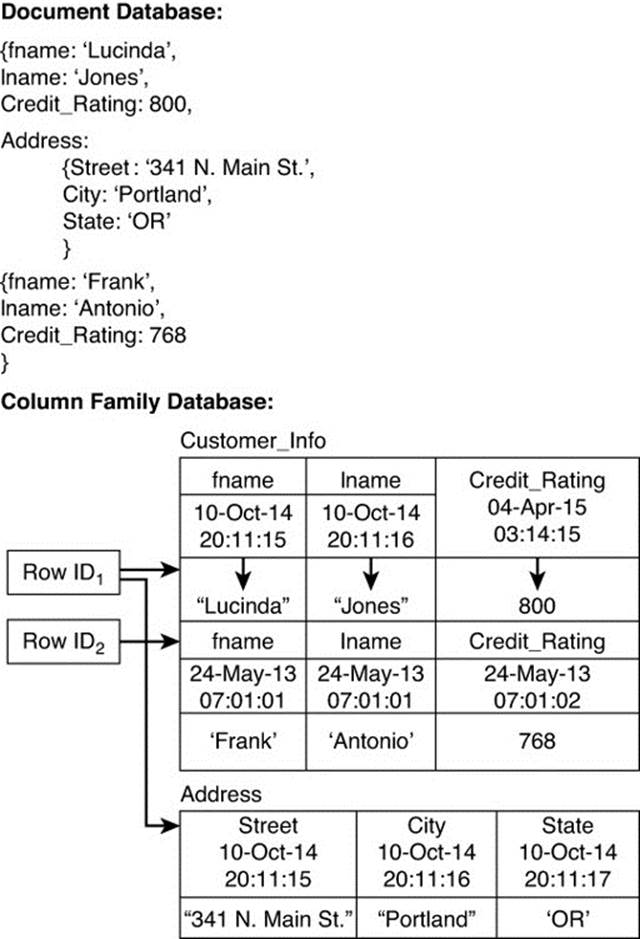
Figure 9.6 Column family databases, like document databases, may have values for some or all columns. Columns can be added programmatically as needed in both document and column family databases.
In both column family and document databases, columns or fields can be added as needed by developers.
Column Family Database Versus Relational Databases
Column family databases have some features that are similar to features in relational databases and others that are superficially similar but different in implementation.
Both column family databases and relational databases use unique identifiers for rows of data. These are known as row keys in column family databases and as primary keys in relational databases. Both row keys and primary keys are indexed for rapid retrieval.
Both types of databases can be thought of as storing tabular data, at least at some level of abstraction. The actual storage model varies, even between relational databases. Column family databases use the concept of maps (also known as dictionaries or associative arrays). A column key maps from a column name to a column value. A column family is a map/dictionary/associative array that points to a map/dictionary/associative array of columns (see Figure 9.7). In a sense, you have a map of map.
![]()
Figure 9.7 Column family databases store data using maps of maps to column values.
Other important differences between column family databases and relational databases pertain to typed columns, transactions, joins, and subqueries.
Column family databases do not support the concept of a typed column. Column values can be seen as a series of bytes that are interpreted by an application, not the database. This provides developers with a great deal of flexibility because they can choose to interpret a string of bytes in different ways, depending on other values in a row. It also leaves developers with the responsibility to validate data before it is stored in the database.
Avoiding Multirow Transactions
Although you can expect to find atomic reads and writes with respect to a single row, column family databases such as Cassandra do not support multirow transactions. If you need to have two or more operations performed as a transaction, it is best to find a way to implement that operation using a single row of data. This may require some changes to your data model and is one of the considerations you should take into account when designing and implementing column families.
![]() Note
Note
Cassandra 2.0 introduced “lightweight transactions.” These enable developers to specify conditions on INSERT and UPDATE operations. If the condition is satisfied, the operation is performed; otherwise, it is not performed. This feature is useful, but does not implement the full-blown ACID type of transaction found in relational databases and some NoSQL databases.
Avoiding Subqueries
There should be minimal need for joins and subqueries in a column family database. Column families promote denormalization and that eliminates, or at least reduces, the need for joins.
In relational databses, a subquery is an inner query that runs, typically, as part of the WHERE clause of an outer query. For example, you might need to select all sales transactions performed by a salesperson with a last name of Smith. A SQL query such as the following could be used:
SELECT
*
FROM
sales_transactions
WHERE
SELECT
sales_person_id
FROM
sales_persons
WHERE
last_name = ‘Smith’
The part of the statement that begins with SELECT sales _ person _ id FROM ... is a subquery and executes in the context of the outer query. These types of subqueries are supported by relational databases but not by column family databases. Instead, a column family with salesperson information could be included with sales transaction data that would likely be maintained in another column family (see Figure 9.8).
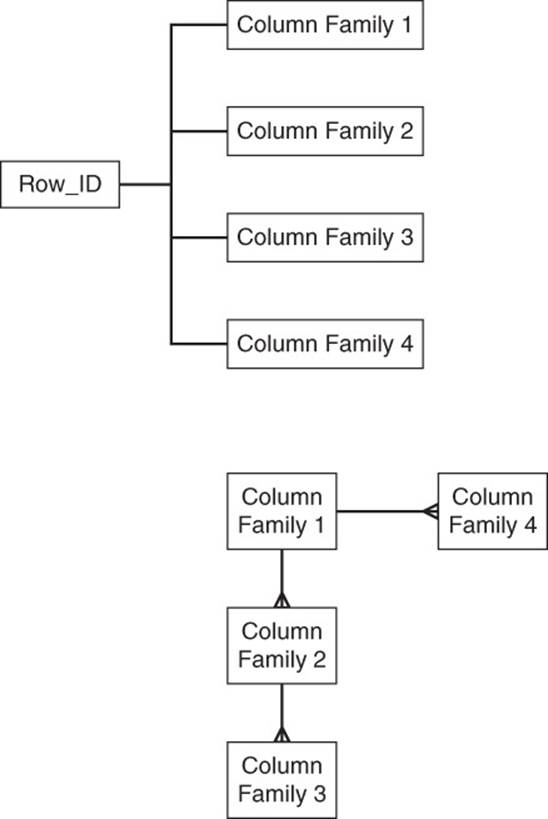
Figure 9.8 Instead of using joins and subqueries, as in a relational databases, column family databases use denormalization to maintain related information using a common row identifier.
This concludes the introduction to the logical model of column family databases. It is now time to consider architectural approaches to implementing column family databases.
Architectures Used in Column Family Databases
Broadly speaking, there are two commonly used types of architectures used with distributed databases: multiple node type and peer-to-peer type. Multiple node type architectures have at least two types of nodes, although there may be more.
HBase is built on Hadoop and makes use of various Hadoop nodes, including name nodes, data nodes, and a centralized server for maintaining configuration data about the cluster. Peer-to-peer type architectures have only one type of node. Cassandra, for example, has a single type of node. Any node can assume responsibility for any service or task that must be run in the cluster.
HBase Architecture: Variety of Nodes
Apache HBase uses the Hadoop infrastructure. A full description of Hadoop architecture is beyond the scope of this chapter, but the most important parts for HBase are outlined here.
The Hadoop File System, HDFS, uses a master-slave architecture that consists of name nodes and data nodes. The name nodes manage the file system and provide for centralized metadata management. Data nodes actually store data and replicate data as required by configuration parameters.
Zookeeper is a type of node that enables coordination between nodes within a Hadoop cluster. Zookeeper maintains a shared hierarchical namespace. Because clients need to communicate with Zookeeper, it is a potential single point of failure for HBase. Zookeeper designers mitigate risks of failure by replicating Zookeeper data to multiple nodes.
In addition to the Hadoop services used by HBase, the database also has server processes for managing metadata about the distribution of table data. RegionServers are instances that manage Regions, which are storage units for HBase table data. When a table is first created in HBase, all data is stored in a single Region. As the volume of data grows, additional Regions are created and data is partitioned between the multiple Regions. RegionServers, which host Regions, are designed to run with 20–200 Regions per server; each Region should store between 5GB and 20GB of table data.3 A Master Server oversees the operation of RegionServers (see Figure 9.9).
3. The Apache HBase Reference Guide: http://hbase.apache.org/book/regions.arch.html.
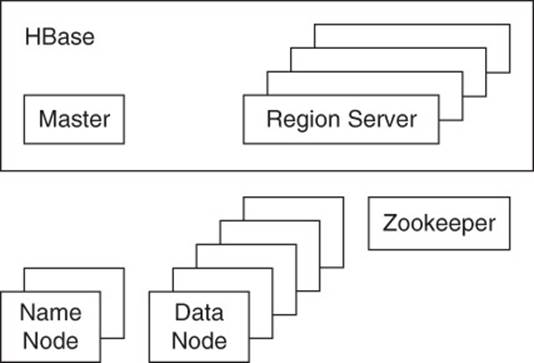
Figure 9.9 Apache HBase depends on multiple types of nodes that make up the Hadoop environment.
When a client device needs to read or write data from HBase, it can contact the Zookeeper server to find the name of the server that stores information about the corresponding Region’s storage location within the cluster. The client device can then cache that information so it does not need to query Zookeeper again for those device details. The client then queries the server with the Region information to find out which server has data for a given row key (in the case of a read) or which server should receive data associated with a row key (in the case of the write).
An advantage of this type of architecture is that servers can be deployed and tuned for specific tasks, for example, managing the Zookeeper. It does, however, require system administrators to manage multiple configurations and to tune each configuration separately. An alternative approach is to use a single type of node that can assume any role required in the cluster. Cassandra uses this approach.
Cassandra Architecture: Peer-to-Peer
Apache Cassandra, like Apache HBase, is designed for high availability, scalability, and consistency. Cassandra takes a different architectural approach than HBase. Rather than use a hierarchical structure with fixed functions per server, Cassandra uses a peer-to-peer model (see Figure 9.10). All Cassandra nodes run the same software. They may, however, serve different functions for the cluster.
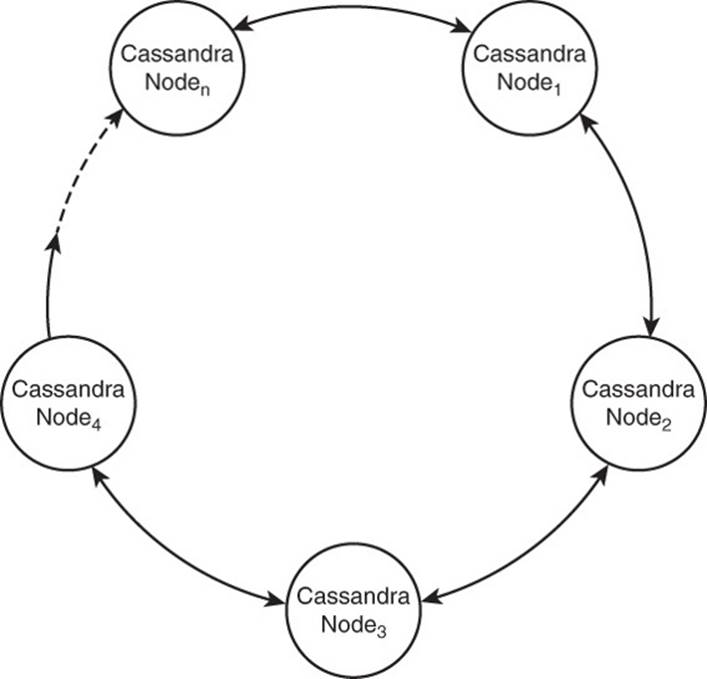
Figure 9.10 Cassandra uses a peer-to-peer architecture in which all nodes are the same.
There are several advantages to the peer-to-peer approach. The first is simplicity. No node can be a single point of failure. Scaling up and down is fairly straightforward: Servers are added or removed from the cluster. Servers in a peer-to-peer network communicate with each other and, eventually, new nodes are assigned a set of data to manage. When a node is removed, servers hosting replicas of data from the removed node respond to read and write requests.
Because peer-to-peer networks do not have a single master coordinating server, the servers in the cluster are responsible for managing a number of operations that a master server would handle, including the following:
• Sharing information about the state of servers in the cluster
• Ensuring nodes have the latest version of data
• Ensuring write data is stored when the server that should receive the write is unavailable
Cassandra has protocols to implement all of these functions.
Getting the Word Around: Gossip Protocol
Sharing information about the state of servers in a cluster can sound like a trivial problem. Each server can simply ping or request update information from each of the other servers. The problem is that this type of all-servers-to-all-other-servers protocol can quickly increase the volume of traffic on the network and the amount of time each server has to dedicate to communicating with other servers.
Consider a variety of scenarios. When there are only two servers in a cluster, they each request information from and receive information from each other; 2 messages are exchanged. If you add a third server to the cluster, the servers generate 6 messages between the three of them. Increase the number to four servers, and they generate 12 messages. By the time you reach a 100-node cluster, 9,900 messages are sent through the cluster to communicate status information. The number of messages sent is a function of the number of servers in the cluster. If N is the number of servers, then N×(N–1) is the number of messages needed to update all servers with information about all other servers (see Figure 9.11).
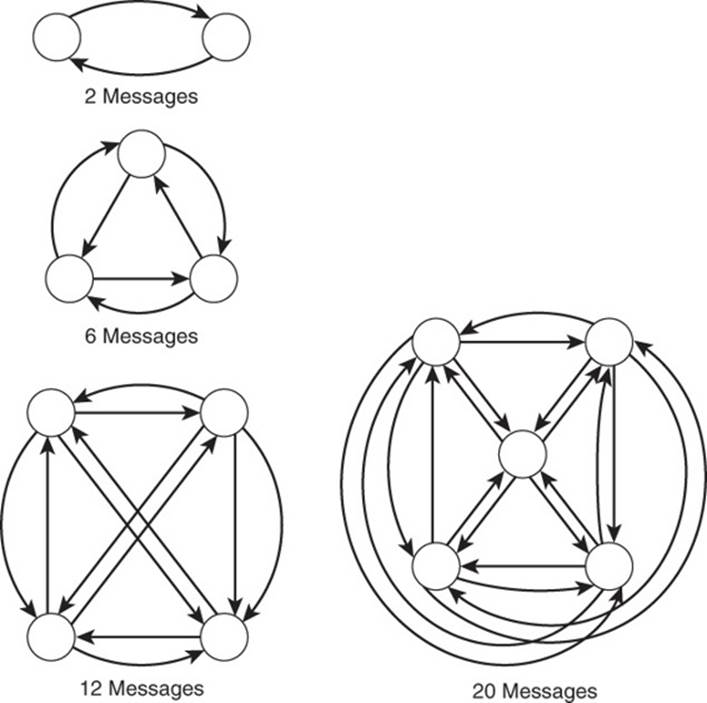
Figure 9.11 The number of messages sent in a complete server-to-server communication protocol grows more rapidly each time a server is added to the cluster.
A more-efficient method of sharing information is to have each server update another server about itself as well as all the servers it knows about. Those servers can then share what they know with a second set of other servers. The second set, which might receive information from a few different servers, can pass on all the status information it has been sent instead of just passing on its own information.
To get an idea of how efficient an information-sharing scheme can be, consider a seven-node cluster. Servers 1 and 2 send status information to Server 3. Servers 4 and 5 send status information to Server 6. Servers 3 and 6 send their own status information plus status information about two other servers to Server 7. Server 7 now has information about every server in the cluster. Server 7 sends the complete set of information to Servers 3 and 6. Server 3 then passes the information on to Servers 1 and 2 while Server 6 passes the information on to Servers 4 and 5. All nodes in the cluster now have complete status information about the cluster.
![]() Note
Note
Cassandra’s protocol and gossip protocols in general do not operate exactly like this example. Gossip protocols implement random selection, and there may be some redundancy in information delivery. Rather than try to depict the complexities of a random process, a deterministic protocol example is used instead. In both random and deterministic protocols, aggregating information into fewer messages can convey the same amount of information more efficiently than nonaggregating protocols.
Cassandra’s gossip protocol works as follows:4
4. Eben Hewitt. Cassandra: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2010.
• A node in the cluster initiates a gossip session with a randomly selected node.
• The initiating node sends a starter message (known as a Gossip-DigestSyn message) to a target node.
• The target node replies with an acknowledgment (known as a GossipDigestAck message).
• After receiving the acknowledgment from the target node, the initiating node sends a final acknowledgment (a GossipDigestAck2 message) to the target node.
In the course of this message exchange, each server is updated about the state of servers as known by the other server. In addition, version information about each server’s state is exchanged. With this additional piece of data, each party in the exchange can determine which of the two has the most up-to-date data about each of the servers discussed.
Thermodynamics and Distributed Database: Why We Need Anti-Entropy
If you have studied physics, you might have come across the laws of thermodynamics. The second law of thermodynamics describes a feature of entropy, which is the state of randomness and lack of order in a system or object. A broken glass, for example, has higher entropy than an unbroken glass. The second law of thermodynamics states that the amount of entropy (or disorder) in a closed system does not decrease. A broken glass does not repair itself and restore itself to the state of less entropy found in an unbroken glass.
Databases, especially distributed databases, are subject to a kind of entropy, too. The mechanical parts of a database server are certainly subject to entropy—just ask anyone who has suffered a disk failure—but that is not the kind of entropy discussed here. Distributed database designers have to address information entropy. Information entropy increases when data is inconsistent in the database. If one replica of data indicates that Lucinda Jones last made a purchase on January 15, 2014, and another replica has data that indicates she last made a purchase on November 23, 2014, the system is in an inconsistent state.
Cassandra uses an anti-entropy algorithm, that is, one that increases order, to correct inconsistencies between replicas. When a server initiates an anti-entropy session with another server, it sends a hash data structure, known as a Merkle or hash tree, derived from the data in a column family. The receiving server calculates a hash data structure from its copy of the column family. If they do not match, the servers determine which of the two has the latest information and updates the server with the outdated data (see Figure 9.12).
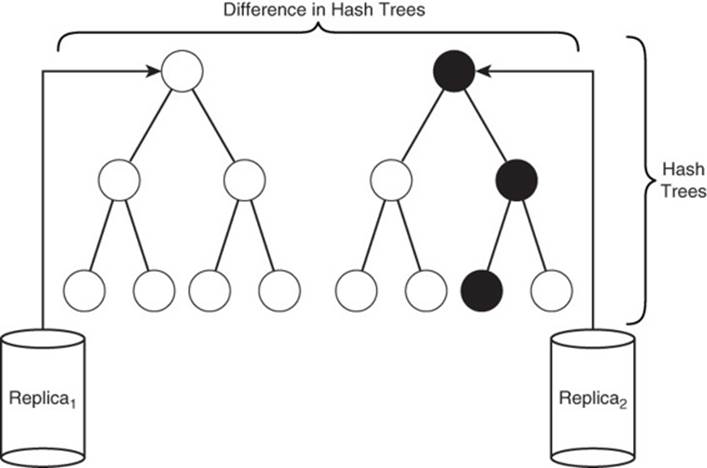
Figure 9.12 Cassandra regularly compares replicas of data to ensure they are up to date. Hashes are used to make this a relatively fast operation.
Hold This for Me: Hinted Handoff
Cassandra is known for being well suited for write-intensive applications. This is probably due in part to its ability to keep accepting write requests even when the server that is responsible for handling the write request is unavailable. To understand how this high-availability write service works, let’s take a step back and consider how read operations work.
Figure 9.13 shows the basic flow of information when a client device makes a request to the Cassandra database.
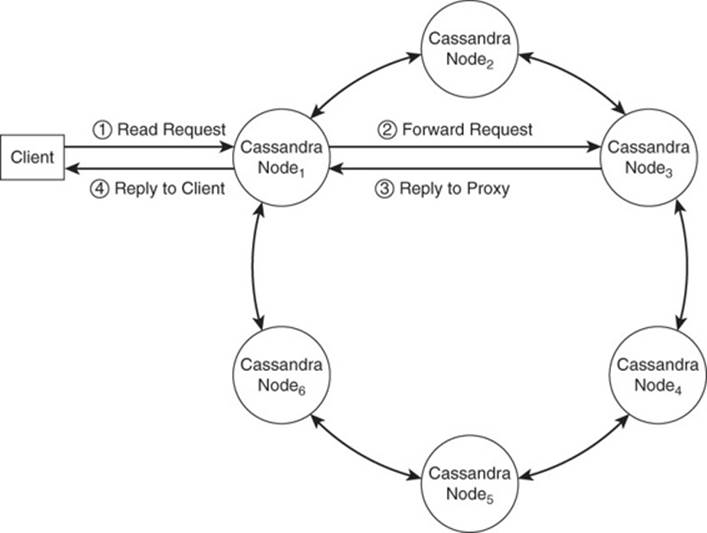
Figure 9.13 Any node in a Cassandra cluster can handle a client request. All nodes have information about the state of the cluster and can act as a proxy for a client, forwarding the request to the appropriate node in the cluster.
A client device needs to request data from the database. It issues a read operation and Node 1 receives the request. Node 1 uses the row key in the read request and looks up information about which node should process the request. It determines that Node 2 is responsible for data associated with that row key and passes the information on to it. Node 2 performs the read operation and sends the data back to Node 1. Node 1, in turn, passes the read results back to the client.
Now consider a similar situation but with a write request. The client sends a request to Node 1 to write data associated with a row key. Node 1 queries its local copy of metadata about the cluster and determines that Node 3 should process this request. Node 1, however, knows that Node 3 is unavailable because the gossip protocol informed Node 1 about the status of Node 3 a few seconds ago. Rather than lose the write information or change the permanent location of data associated with that row key, Node 1 initiates a hinted handoff.
A hinted handoff entails storing information about the write operation on a proxy node and periodically checking the status of the unavailable node. When that node becomes available again, the node with the write information sends, or “hands off,” the write request to the recently recovered node (see Figure 9.14).
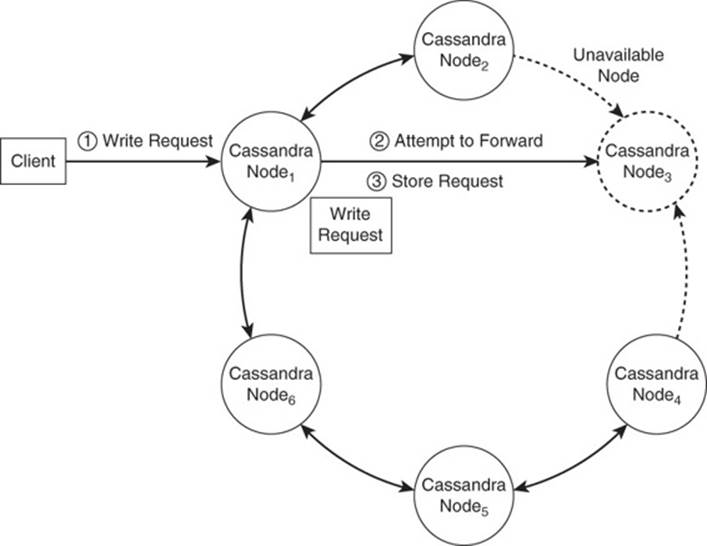
Figure 9.14 If a node is unavailable, then other nodes can receive write requests on its behalf and forward them to the intended node when it becomes available.
The architectures of column family databases allow for significant scalability. They can also be challenging to deploy and manage. It is important to choose a type of database that fits your needs but also minimizes the administrative overhead, development effort, and compute resources required.
When to Use Column Family Databases
Column family databases are appropriate choices for large-scale database deployments that require high levels of write performance, a large number of servers or multi–data center availability.
Cassandra’s peer-to-peer architecture with support for hinted handoff means the database will always be able to accept write operations as long as at least one node is functioning and reachable. Write-intensive operations, such as those found in social networking applications, are good candidates for using column family databases.
![]() Tip
Tip
If your write-intensive application also requires transactions, then a column family database may not be the best choice. You might want to consider a hybrid approach that uses a database that supports ACID transactions (for example, a relational database or a key-value database such as FoundationDB5).
5. FoundationDB. “ACID Claims.” https://foundationdb.com/acid-claims.
Column family databases are also appropriate when a large number of servers are required to meet expected workloads. Although column family databases can run on a single node, this configuration is more appropriate for development, testing, and getting to know a database management system. Column family databases typically run with more than several servers. If you find one or a few servers satisfy your performance requirements, you might find that key-value, document, or even relational databases are a better option.
Cassandra supports multi–data center deployment, including multi–data center replication. If you require continuous availability even in the event of a data center outage, then consider Cassandra for your deployment.
If you are considering column family databases for the flexibility of the data model, be sure to evaluate key-value and document databases. You may find they meet your requirements and run well in an environment with a single server or a small number of servers.
Summary
Column family databases are some of the most scalable databases available. They provide developers with the flexibility to change the columns of a column family. They also support high availability, in some cases even cross–data center availability.
The next two chapters delve deeper into column family databases. Chapter 10, “Column Family Database Terminology,” describes key terminology you will need to understand data modeling for column family databases as well as additional terms related to implementation. Chapter 11, “Designing for Column Family Databases,” focuses on data modeling techniques and implementation issues developers should understand when deploying applications built on column family databases.
Review Questions
1. Name at least three core features of Google BigTable.
2. Why are time stamps used in Google BigTable?
3. Identify one similarity between column family databases and key-value databases.
4. Identify one similarity between column family databases and document databases.
5. Identify one similarity between column family databases and relational databases.
6. What types of Hadoop nodes are used by HBase?
7. Describe the essential characteristics of a peer-to-peer architecture.
8. Why does Cassandra use a gossip protocol to exchange server status information?
9. What is the purpose of the anti-entropy protocol used by Cassandra?
10. When would you use a column family database instead of another type of NoSQL database?
References
Apache HBase Reference Guide: http://hbase.apache.org/book/regions.arch.html
Biow, Chris, and Miles Ward. “PetaMongo: A Petabyte Database for as Little as $200.” AWS re:Invent Conference, 2013: http://www.slideshare.net/mongodb/petamongo-a-petabyte-database-for-as-little-as-200
Chang, Fay, et al. “BigTable: A Distributed Storage System for Structured Data.” OSDI’06: Seventh Symposium on Operating System Design and Implementation, Seattle, WA, November, 2006: http://research.google.com/archive/bigtable.html
FoundationDB. “ACID Claims”: https://foundationdb.com/acid-claims
Hewitt, Eben. Cassandra: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2010.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.