Oracle Database 12c DBA Handbook (2015)
PART
II
Database Management
CHAPTER
11
Multitenant Database Architecture
Using a database appliance such as Oracle Exadata helps database administrators consolidate dozens, if not hundreds, of databases in one server room rack. Managing each of these databases separately, however, is still a challenge from a resource management perspective. Instances for each of the databases may use their memory and CPU resources inefficiently, preventing even more databases from being deployed to the server. With pluggable databases (PDBs), introduced in Oracle Database 12c, you can leverage your database resources more efficiently because many different databases (each consisting of a collection of schemas) can coexist within a single container database (CDB). A CDB is also known as a multitenant container database.
Pluggable databases make database administration simpler for a DBA. Performance metrics are gathered for all PDBs as a whole. In addition, the DBA needs to manage only one SGA, and not one for each PDB. Fewer database patches need to be applied as well: Only one CDB needs to be patched instead of having to patch each PDB within the CDB. With PDBs, hardware is used more efficiently, and the DBA can manage many more databases in the same amount of time.
Developers, network administrators, storage administrators, and database application users will rarely interact with a PDB or know they are using a PDB. One day the PDB may be plugged into container database CDB01 and the next day into container database CDB02, which is the point: A CDB acts just like any other database except that it decreases the maintenance effort for the DBA and provides generally higher availability for database users.
Even though the complexity of a CDB is higher than that of a traditional (pre-12c) database, the tools to manage CDBs and PDBs keep up with the complexity. Enterprise Manager Cloud Control 12c Release 3 fully supports the monitoring of CDBs and PDBs; Oracle SQL Developer version 4.0 and newer have a DBA module to perform most if not all of the operations you’ll typically perform in a CDB environment.
This chapter covers several high-level topics; specifically, it gives an overview of the multitenant architecture and explains how PDBs are provisioned, how you manage security, and how you perform backup and recovery using RMAN. Your first decision will be whether you want to create a multitenant container at all—in most cases, you will. It’s easy to fix any mistakes you make by over-provisioning a CDB: Just unplug one or more PDBs from the over-provisioned CDB and plug it or them back into another CDB on the same or different server. In addition to moving a PDB to another container, I’ll show you how to create a new one from a seed template and clone an existing PDB.
The first part of the chapter sounds a lot like an introductory Oracle database administration course. You will find out how to set up the connections to a database, start up and shut down a database, and set the parameters for a database. The difference is that you’re doing those things for the container (CDB) as a whole and differently for each PDB within the CDB. You’ll find out that some database parameters apply only at the CDB level, whereas other parameters can be set at the PDB level. Once you start up a CDB, you can have each PDB in a different state. Some PDBs will remain in the MOUNT state while the rest can be OPEN as READ ONLY or READ WRITE.
Managing permanent and temporary tablespaces in a multitenant environment is similar to managing those tablespace types in a non-CDB environment. The SYSTEM and SYSAUX tablespaces exist in the CDB (CDB$ROOT) and in each PDB with some SYSTEM and SYSAUX objects shared from the CDB to the individual PDBs. Otherwise, the CDB and each PDB can have its own segregated permanent tablespaces. For temporary tablespaces, every PDB can use the temporary tablespace in the CDB. However, if a particular PDB has specific temporary tablespace requirements that might not operate efficiently with the CDB’s shared temporary tablespace, then that PDB can have its own temporary tablespace.
Security is important in any database environment, and a multitenant database environment is no exception. A DBA in a multitenant environment must understand the distinction between common and local users along with the roles and privileges assigned to each. Much like an application user has no knowledge of whether a database is a PDB or a non-CDB, a DBA can have a local user account in a PDB and manage that PDB with no privileges or visibility outside of the PDB.
In a multitenant environment, you still need to perform backups and recoveries, but you’ll use the same tools as in a non-CDB environment and be able to back up more databases in less time than in a non-CDB environment. As in any database environment, you need to back up and recover a CDB or PDB. The methods you use to back up the entire CDB or just a PDB are slightly different and, as you’d expect, have different impacts.
Understanding the Multitenant Architecture
In this section, I’ll expand on some of the concepts outlined in the chapter introduction and demonstrate the mechanics of creating a new CDB using several different tools. Once the CDB is in place, you can create a new PDB by cloning the seed database (PDB$SEED).
Databases created in Oracle 11g are not left out, though. You can either upgrade the pre-12c database to 12.1 and then plug it into an existing CDB or use Data Pump export (expdp) on the 11g database and then use Data Pump import (impdp) on a new PDB.
In a multitenant environment, a database can be one of three types: a standalone database (non-CDB), a container database, or a pluggable database. In the following sections, I’ll describe the multitenant architecture in greater detail along with the many advantages of using a multitenant environment.
Leveraging Multitenant Databases
Previous to Oracle Database 12c, the only type of database you could create was a non-CDB (as it’s called now; the concept of a CDB or PDB had not yet been conceived then) either as a standalone database or as part of a cluster (Real Applications Cluster). Even if you ran multiple non-CDB instances on the same server, each instance would have its own memory structures (SGA, PGA, and so forth) and database files (storage structures).
Even with the efficient management of memory and disk space within each database, there is a duplication of memory structures and database objects. In addition, when upgrading a database version, at least one software upgrade must be performed on each server containing an application. With more efficient use of memory and disk via multitenant databases, more applications can be consolidated onto a much smaller number of servers or even one server.
In addition to consolidating multiple data dictionaries into a single CDB, new databases can be provisioned quickly within the container by copying a subset of objects specific to the PDB. If you want to upgrade only one PDB to a new version of the database, you can unplug the database from the current CDB and plug it into a new CDB that is at the correct version in the time it takes to export and import the PDB’s metadata.
Using PDBs makes efficient use of resources while still maintaining a separation of duties and application isolation.

NOTE
The multitenant architecture includes both the container database and the pluggable databases that run inside the container database. A non-CDB does not mean a pluggable database but instead a single traditional Oracle database regardless of version, sometimes referred to as a standalone database. Oracle’s documentation may refer to a user container, which is the same as a PDB. A PDB can be either plugged in or unplugged and will always be a PDB.
Understanding Multitenant Configurations
Given the multitenant architecture of Oracle Database 12c, you can leverage CDBs and PDBs in a number of ways:
![]() Multitenant configuration A single CDB that contains zero, one, or more PDBs at any given time
Multitenant configuration A single CDB that contains zero, one, or more PDBs at any given time
![]() Single-tenant configuration A single CDB with a single PDB (licensing for the multitenant option is not required)
Single-tenant configuration A single CDB with a single PDB (licensing for the multitenant option is not required)
![]() Non-CDB Oracle 11g architecture (standalone database and instance)
Non-CDB Oracle 11g architecture (standalone database and instance)
Figure 11-1 shows a sample of a multitenant configuration with one CDB and one non-CDB instance. The CDB instance has three PDBs.
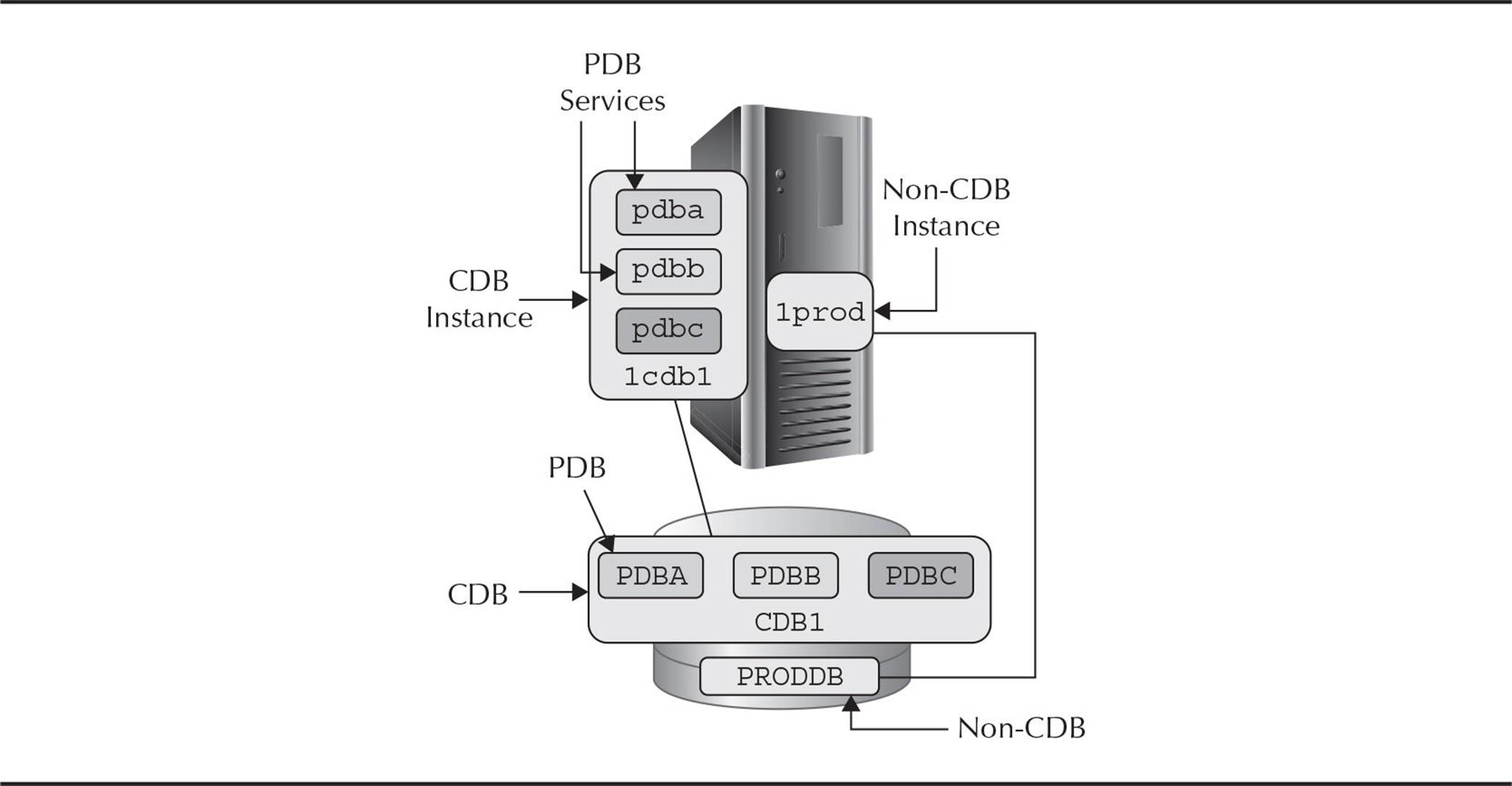
FIGURE 11-1. Multitenant architecture with a CDB and a non-CDB
The following sections describe the three types of containers and databases: system containers (CDBs), user containers (PDBs), and standalone databases (non-CDBs).
System Container Database Architecture
Creating a system container (in other words, a CDB) is as easy as checking a radio button in the Database Configuration Assistant (DBCA). The resulting database is only the container for new databases that can be provisioned either by copying the seed database or by plugging in a database that was previously a tenant of this CDB or unplugged from a different CDB. Figure 11-2 shows a typical CDB configuration.
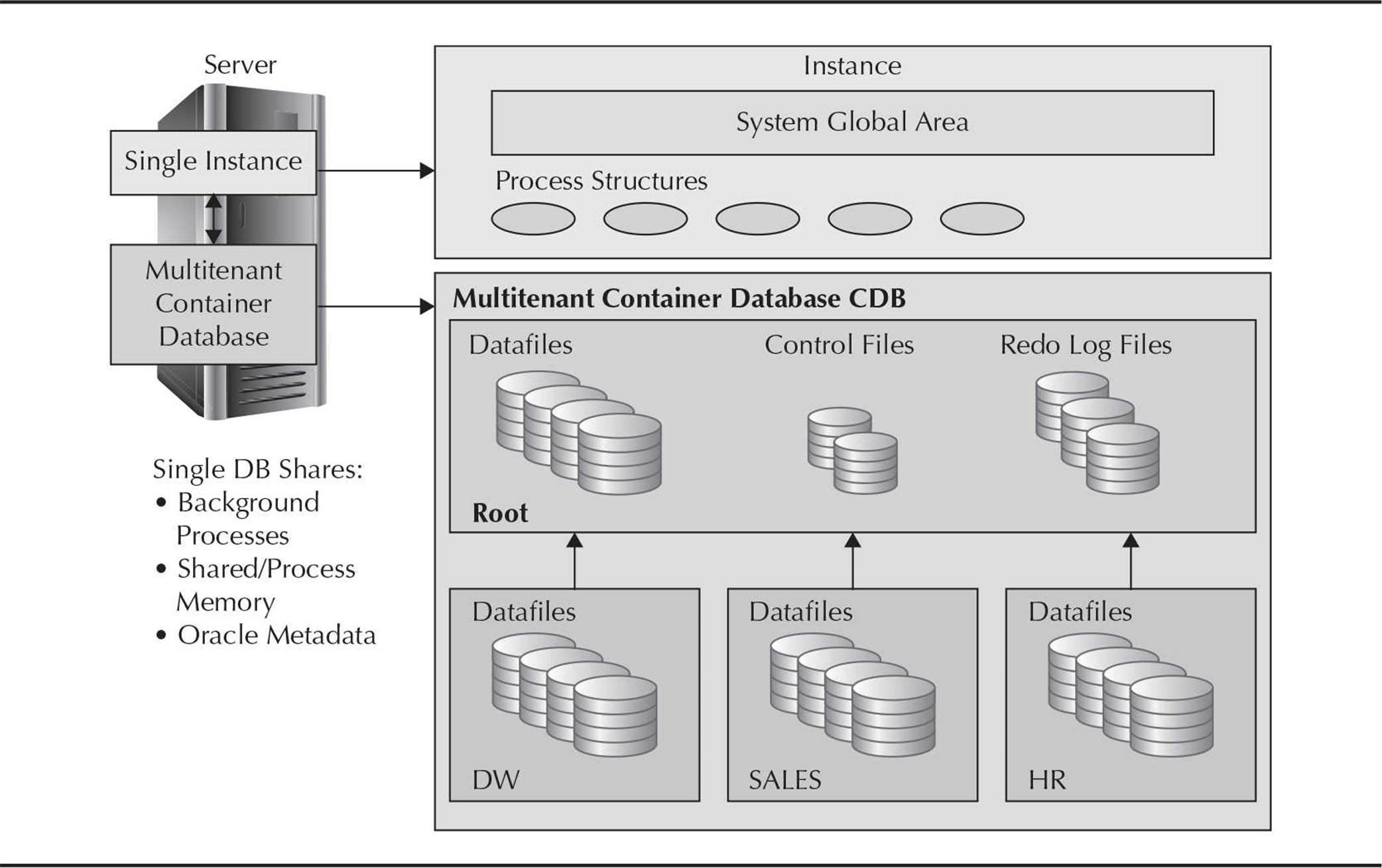
FIGURE 11-2. Typical container database
The single CDB in Figure 11-2 has three PDBs: DW, SALES, and HR. All three PDBs share a single instance and its process structures. The root container has the control files and redo log files shared by all PDBs along with datafiles that contain system metadata common to all databases. The individual applications have their own datafiles isolated from all other PDBs within the container. A SYS user is owned by the root container and can manage the root container and all PDBs.
As noted earlier, a CDB has a single database instance and set of related datafiles regardless of the number of PDBs in the CDB. The definition and usage of tablespaces and objects in a non-CDB or pre-12c database are mostly the same, with the following exceptions and qualifications:
![]() Redo log files The redo log files are shared with the root container and all PDBs. Entries in the redo log files identify the source of the redo (which PDB or the root container). All user containers share the same ARCHIVELOG mode as well.
Redo log files The redo log files are shared with the root container and all PDBs. Entries in the redo log files identify the source of the redo (which PDB or the root container). All user containers share the same ARCHIVELOG mode as well.
![]() Undo tablespace All containers share the same undo tablespace.
Undo tablespace All containers share the same undo tablespace.
![]() Control files The control files are shared. Datafiles added from any PDB are recorded in the common control file.
Control files The control files are shared. Datafiles added from any PDB are recorded in the common control file.
![]() Temporary tablespaces One temporary tablespace is required in the CDB and is the initial default temporary tablespace for each PDB. However, based on application requirements, each PDB may have its own temporary tablespace.
Temporary tablespaces One temporary tablespace is required in the CDB and is the initial default temporary tablespace for each PDB. However, based on application requirements, each PDB may have its own temporary tablespace.
![]() Data dictionary Each user container has its own data dictionary in its copy of the SYSTEM tablespace (common objects have pointers to the SYSTEM tablespace in the system container database) with its private metadata.
Data dictionary Each user container has its own data dictionary in its copy of the SYSTEM tablespace (common objects have pointers to the SYSTEM tablespace in the system container database) with its private metadata.
![]() SYSAUX tablespace Each PDB has its own copy of the SYSAUX tablespace.
SYSAUX tablespace Each PDB has its own copy of the SYSAUX tablespace.
Tablespaces can be created within each PDB specific to the application. Each tablespace’s datafile is identified in the CDB’s data dictionary with a container ID in the column CON_ID. Further information about container metadata is presented later in the chapter.
User Container Databases
User containers (in other words, PDBs) have SYSTEM tablespaces just like non-CDBs do but have links to the common metadata across the entire container. Only the user metadata specific to the PDB is stored in the PDB’s SYSTEM tablespace. The object names are the same in a PDB as in a non-CDB or the CDB, such as OBJ$, TAB$, and SOURCE$. Thus, the PDB appears to an application as a standalone database. A DBA can be assigned to manage only that application with new roles and privileges created in Oracle Database 12c (discussed later in “Leveraging CDB Security Features”). The DBA for an application in a PDB is also not aware that there may be one or many other PDBs sharing resources in the CDB.
Non-CDB Databases
Standalone (in other words, non-CDB) databases can still be created in Oracle Database 12c (with the Oracle Database 11g architecture). The system metadata and user metadata are stored in the same SYSTEM tablespace along with PL/SQL code and other user objects. A non-CDB can be converted to a PDB using the DBMS_PDB package. If a non-CDB database is at Oracle Database 11g, it must be upgraded to 12c first and then converted using DBMS_PDB. Other options for upgrading include Data Pump Export/Import or an ETL tool such as Oracle Data Integrator (ODI).
Provisioning in a Multitenant Environment
Once you create one or more container databases, you must decide which pluggable databases will be created in each container. Initial resource consumption estimates may be wrong, but given the flexibility of moving PDBs between containers. you will not incur as much downtime moving a PDB to a new container as you would creating a new non-CDB database or using RMAN to clone or move a database to another server.
CDBs and PDBs need to be dropped sometimes, as in a non-CDB environment. I’ll cover the two-step process to remove a PDB from a CDB and free up the disk space allocated to the PDB. Dropping CDBs may not happen as often, but when you do drop a CDB, you’ll be dropping all PDBs within the CDB as well unless you unplug them first.
Understanding Pluggable Database Provisioning
In the previous section, I made the distinction between system containers (CDBs) and user containers (PDBs). The system container is also known as the root container. When a new CDB is created, a seed container is the template for a new PDB and makes it easy to create a new PDB within a CDB.
Understanding Root Containers
The root container within a CDB contains global Oracle metadata only. This metadata includes CDB users such as SYS, which is global to all current and future PDBs within the CDB. Once a new PDB is provisioned, all user data resides in datafiles owned by the PDB. No user data resides in the root container. The root container is named CDB$ROOT, and you’ll see where this metadata is stored later in this chapter.
Leveraging Seed PDBs
When you create a new CDB, one PDB is created: the seed PDB. It has the structure or template for a PDB that will contain the user data for a new application database. The seed database is named PDB$SEED. This provisioning operation is fast because it primarily consists of creating a couple of small tablespaces and empty tables for user metadata.
Using Intra-CDB Links
When databases are deployed as non-CDB databases in Oracle Database 11g or as a non-CDB in Oracle Database 12c, you often have reasons to share data between databases, whether the databases are on separate servers or even on the same server. In both Oracle Database 12c and many previous versions of Oracle, you use database links to access tables in other databases. You use database links to access tables from other PDBs within the same CDB as well. But since the objects in two PDBs reside within the same container, you are using a fast version of a database link under the covers. Remember that a PDB does not know where another PDB or non-CDB database resides, so the definition and use of a database link are the same regardless of where both databases reside.
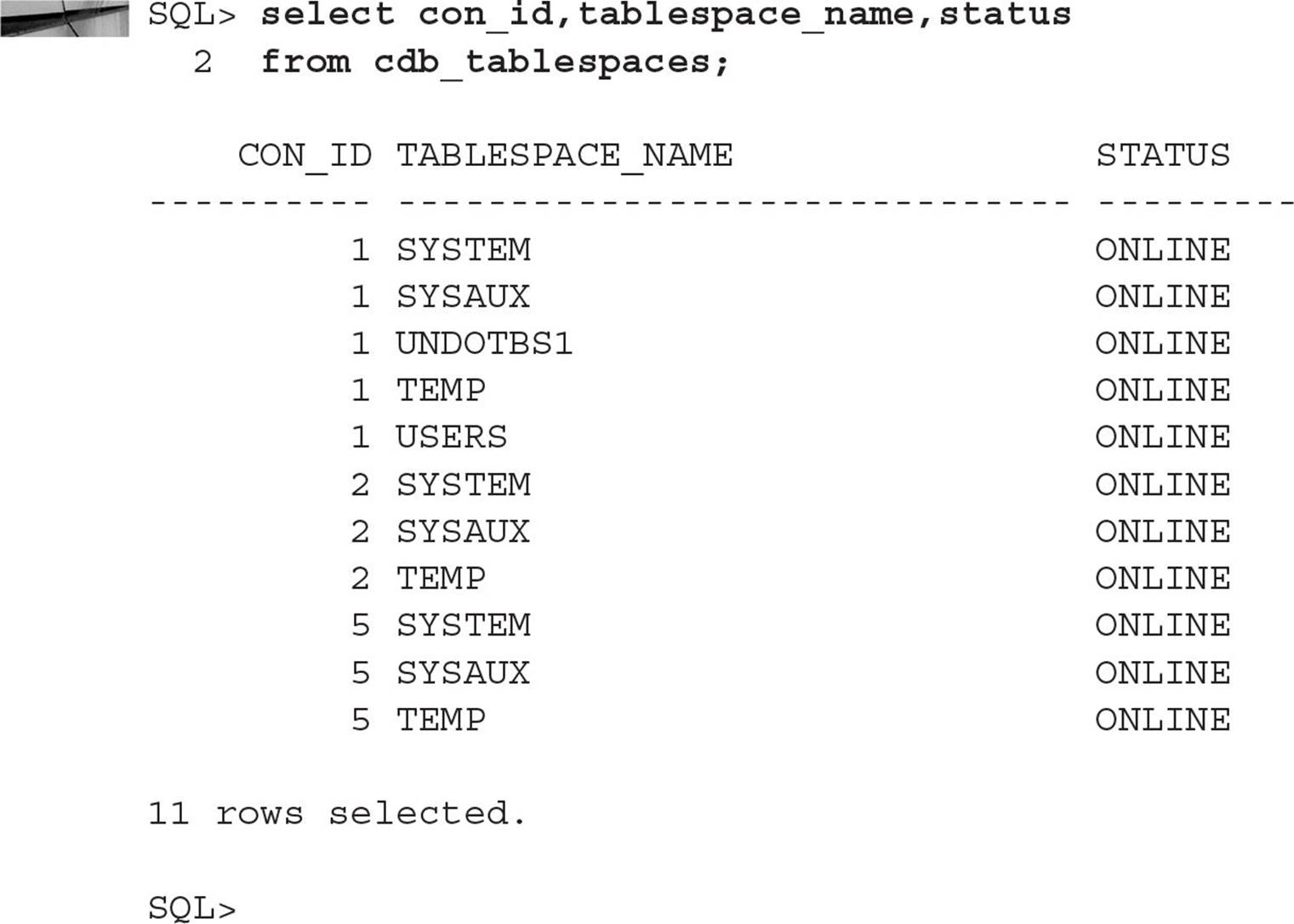
Querying V$CONTAINERS
The system container’s dynamic performance view V$CONTAINERS has just about everything you want to know about the user containers and the system container in your CDB. In the following example, you view the available PDBs and then open the PDB DW_01 to make it available to users:
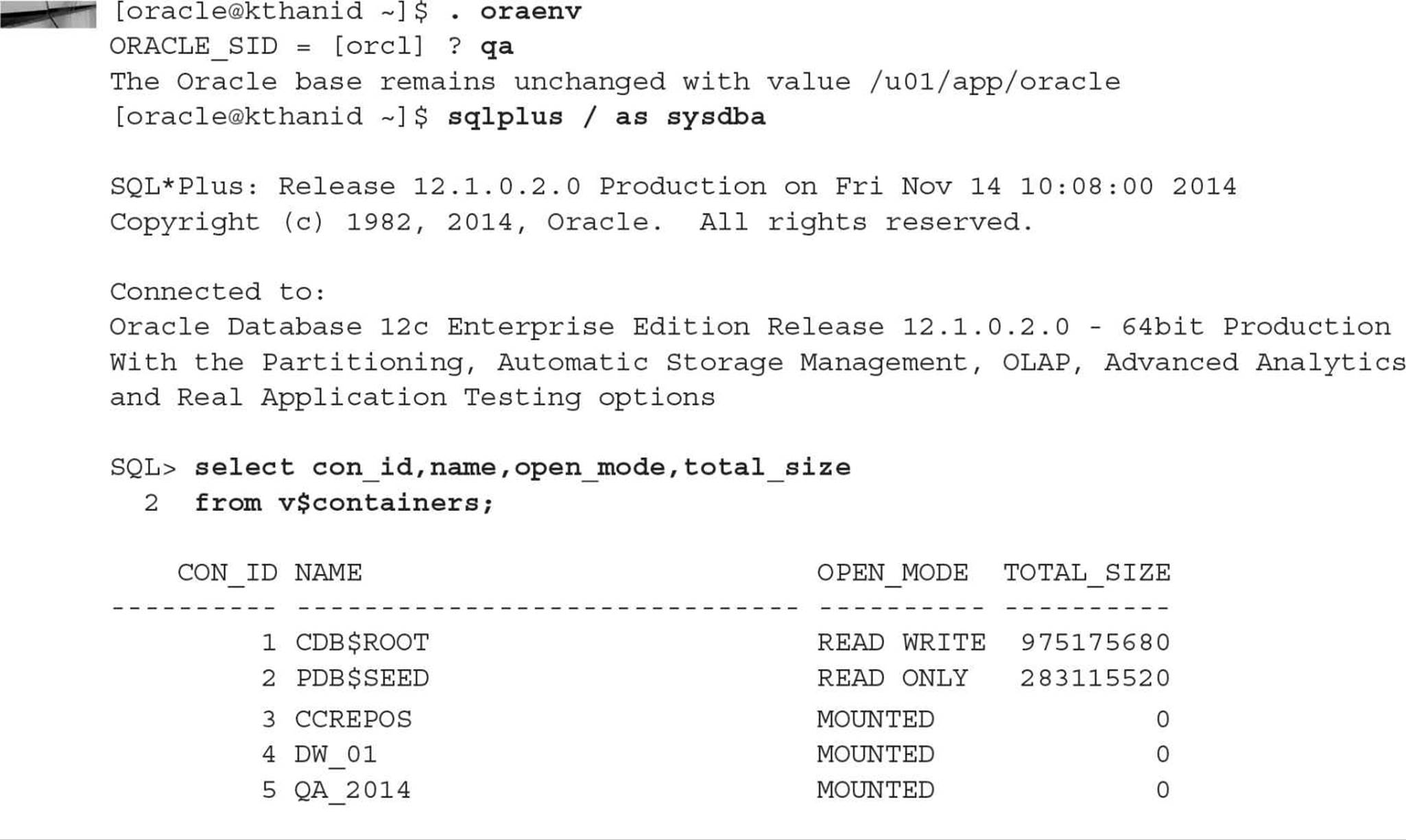
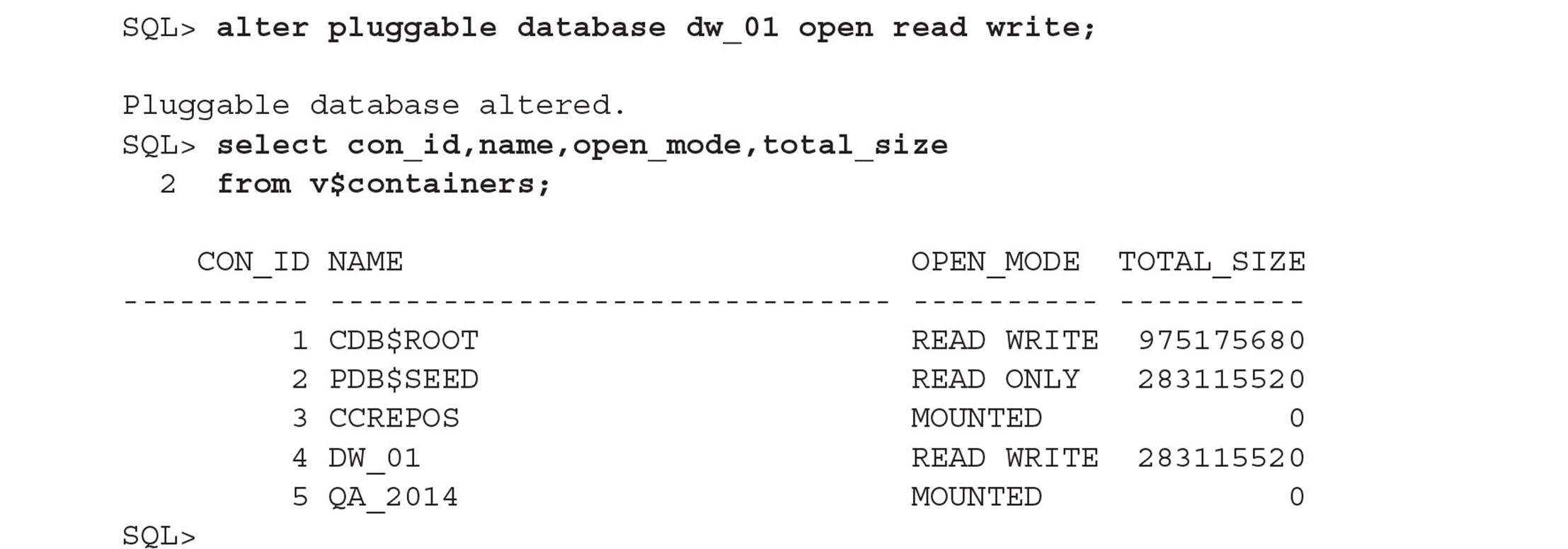
A system container (in other words, a CDB) has one and only one seed database and one root container; user containers are optional (but you will eventually have one or more). A CDB can contain up to 253 user containers (in other words, PDBs), which includes the seed database. Both the root container (CDB$ROOT) and the seed database (PDB$SEED) are displayed in V$CONTAINERS along with the PDBs.
Leveraging CDB Security Features
The multitenant architecture necessarily requires new security objects and a new security hierarchy because you must be able to maintain the same separation of duties and application partitioning that existed when each application was stored in its own database.
To administer the entire CDB and all of the PDBs within the system container, you need one “superuser” also known as the container database administrator (CDBA). Each PDB within a CDB has DBA privileges within the CDB and is known as the pluggable database administrator (PDBA). In a non-CDB, the DBA role works the same as in Oracle Database 11g.
Users (privileged or otherwise) are of two types in a multitenant environment: common or local. As the name implies, a common user has access to all PDBs within a CDB, and a local user has access only within a specific PDB. Privileges are granted the same way. Privileges can be granted across all containers or local to only one PDB.
The new data dictionary table, CDB_USERS, contains users who exist in the data dictionary table DBA_USERS across all PDBs. When you add a new common user to the CDB, the user also shows up in the DBA_USERS table in each PDB. As with all other features of multitenant features, the DBA_USERS table in each PDB contains only those users specific to that PDB, and those users have the same characteristics as users created in non-CDB databases or pre-12c databases.
As you might expect, a common user can perform global operations such as starting up or shutting down the CDB as well as unplugging or plugging in a PDB. To unplug a database, you must first shut down the PDB and then issue the ALTER PLUGGABLE DATABASE command to create the XML metadata file so that the PDB can be plugged in later to the current or another CDB:


In addition to new data dictionary views like CDB_USERS, a CDB contains corollaries to other DBA_ views you would see in a non-CDB database, such as CDB_TABLESPACES and CDB_PDBS:
From a PDB local user’s perspective, all of the DBA_ views behave just as they would in a non-CDB database.
Configuring and Creating a CDB
Creating a multitenant container database has many uses and many configurations. Compared to previous versions of Oracle Database, the flexibility of grouping or consolidating databases using the multitenant architecture (compared to using RAC or multiple non-CDB databases on the same server) has increased dramatically while at the same time not increasing the complexity of managing multiple databases within a CDB. In fact, managing multiple PDBs within a CDB not only makes more efficient use of memory and CPU resources but makes it easier to manage multiple databases. As mentioned in previous chapters, you’ll be able to do things like perform upgrades on the CDB, which in turn automatically upgrades the PDBs that reside in the CDB.
Container databases can be used by developers, by testers, and of course in a production environment. For a new application, you can clone an existing database or create a new database using the seed database in a fraction of the time it takes to create a new standalone database. For testing applications in new hardware and software environments, you can easily unplug a database from one CDB and plug it into another CDB on the same or different server.
In the following sections, I’ll show you how to create a new CDB using either SQL*Plus or the Database Configuration Assistant (DBCA). To view and manage the diagnostic information in a multitenant environment, I’ll review how the Automatic Diagnostic Repository (ADR) is structured. To close out this section, you’ll get a recap of the new data dictionary views available at the container level.
Creating a CDB Using Different Methods
As with many Oracle features, you have many tools at your disposal to create and maintain objects, which in this case means CDBs and PDBs. What tool you use depends on the level of control you need when creating these objects as well as whether you need to script the operation in a batch environment. Table 11-1 shows the tools you can use to perform various operations on CDBs and PDBs.
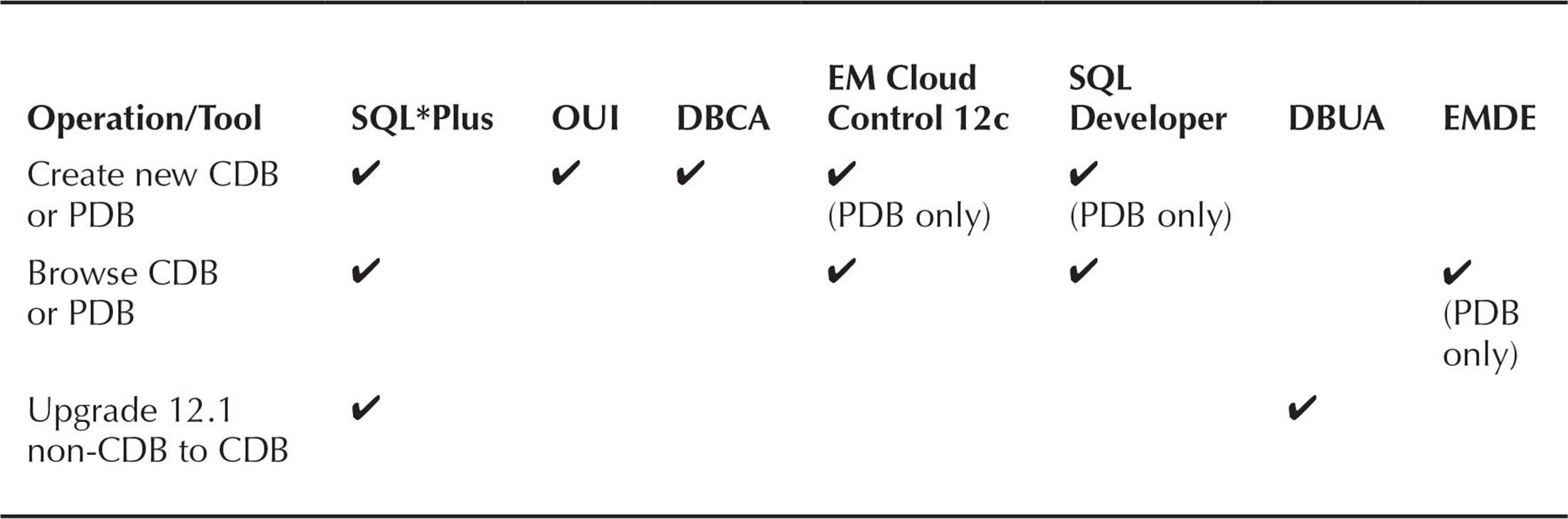
TABLE 11-1. CDB- and PDB-Compatible Oracle Tools
To create a new CDB, you have three options: SQL*Plus, the Database Configuration Assistant, and the Oracle Universal Installer (OUI). Enterprise Manager Database Express (EMDE) cannot create a CDB or browse the CDB or PDB architecture. However, EMDE can view any PDB as if it were a standalone database (non-CDB).
Using SQL*Plus to Create a CDB Using SQL*Plus to create a CDB is similar in many ways to creating a new standalone database instance. The differences are apparent when you use some of the new keywords available with the CREATE DATABASE command such as ENABLE PLUGGABLE DATABASE and SEED FILE_NAME_CONVERT. Once the initial CDB is created, you run the same post-creation scripts as you would in an Oracle 11g database or non-CDB 12c database.
The steps to create the CDB are as follows:
1. Create an init.ora file with the typical parameters for any instance, such as DB_NAME, CONTROL_FILES, and DB_BLOCK_SIZE, plus the new parameter ENABLE_PLUGGABLE_DATABASE.
2. Set the ORACLE_SID environment variable.
3. Create the CDB using the CREATE DATABASE command with the ENABLE PLUGGABLE DATABASE keywords.
4. Set a special session parameter to indicate that this is a new CDB:
![]()
5. Close and open the seed PDB.
6. Run the post-creation scripts, including the following:


Using SQL*Plus to create a new CDB is the ultimate in control, but as you can see, it can be quite convoluted. Unless you want to create many databases at once with slight changes in parameters or the same set of databases on several servers, then using DBCA (discussed in the next section) might be an easier and less error-prone method for creating a CDB.
Using DBCA to Create a CDB
The Database Configuration Assistant tool is likely the tool you’ll use to create a new CDB. In fact, it gives you the options to create a non-CDB database (much like a pre-12.1 database), just a CDB, or a CDB with a new PDB. In Figure 11-3, I am using the “express” method to create a new container database called CDB58, which will reside in the existing Automatic Storage Management (ASM) disk group +DATA. The recovery files will reside in +RECOV. An initial PDB called RPTQA10 will be created along with the container.
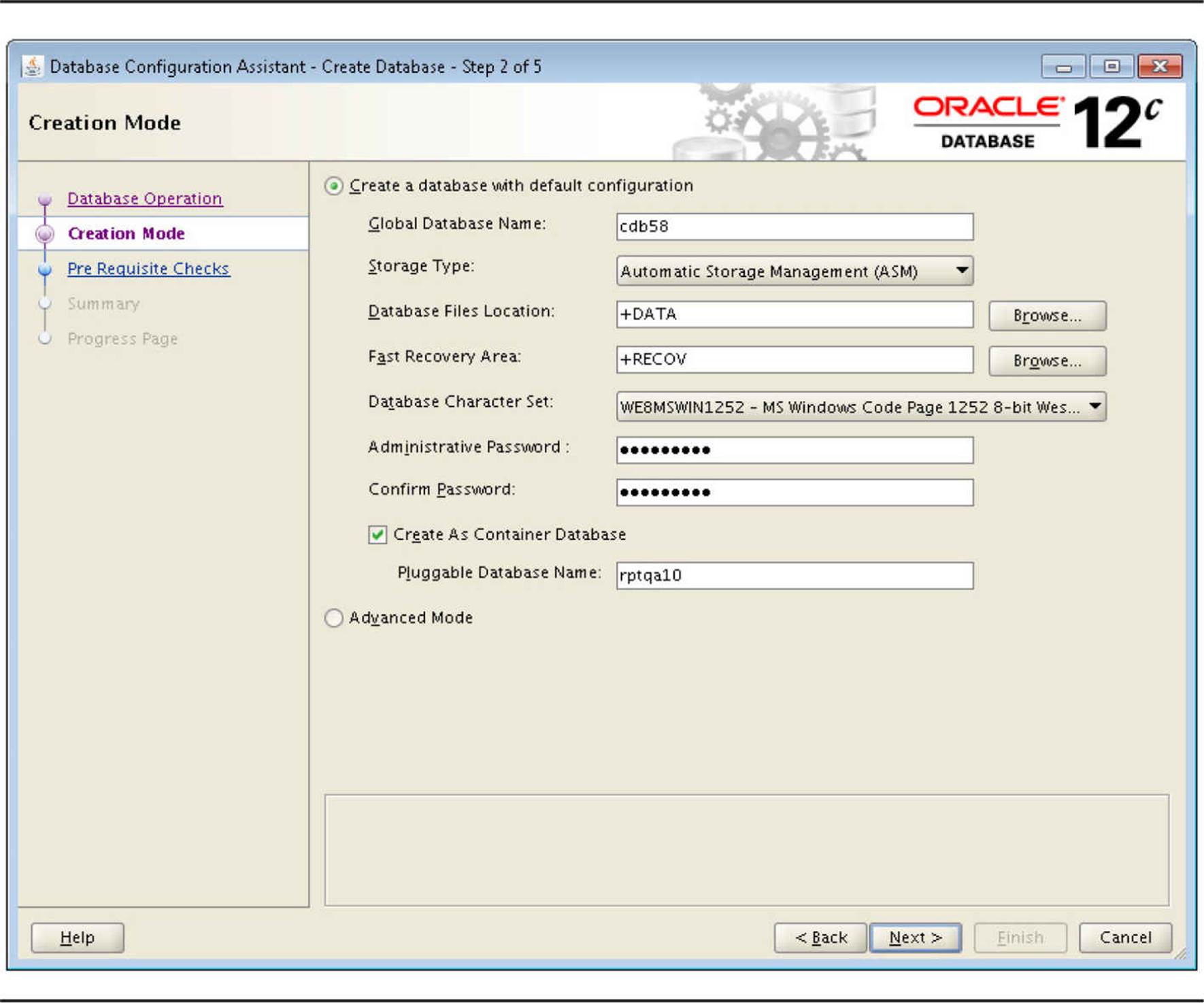
FIGURE 11-3. Creating a container database using DBCA
In the next window, you can review the summary of the CDB to be created. Note in Figure 11-4 that creating a CDB creates a PDB as well.
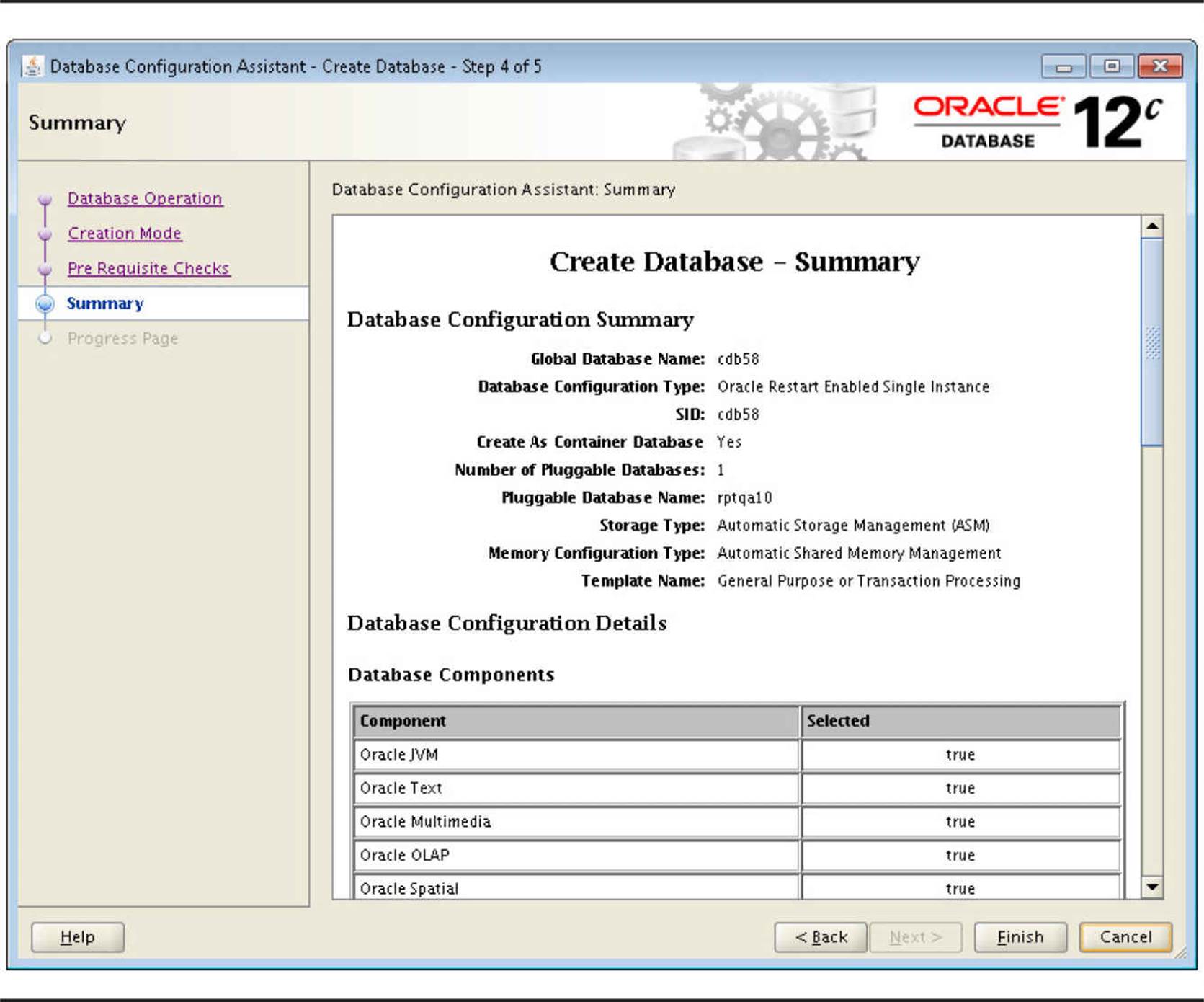
FIGURE 11-4. Create Database - Summary page
The Progress Page in Figure 11-5 shows the progress of creating the CDB and the initial PDB.
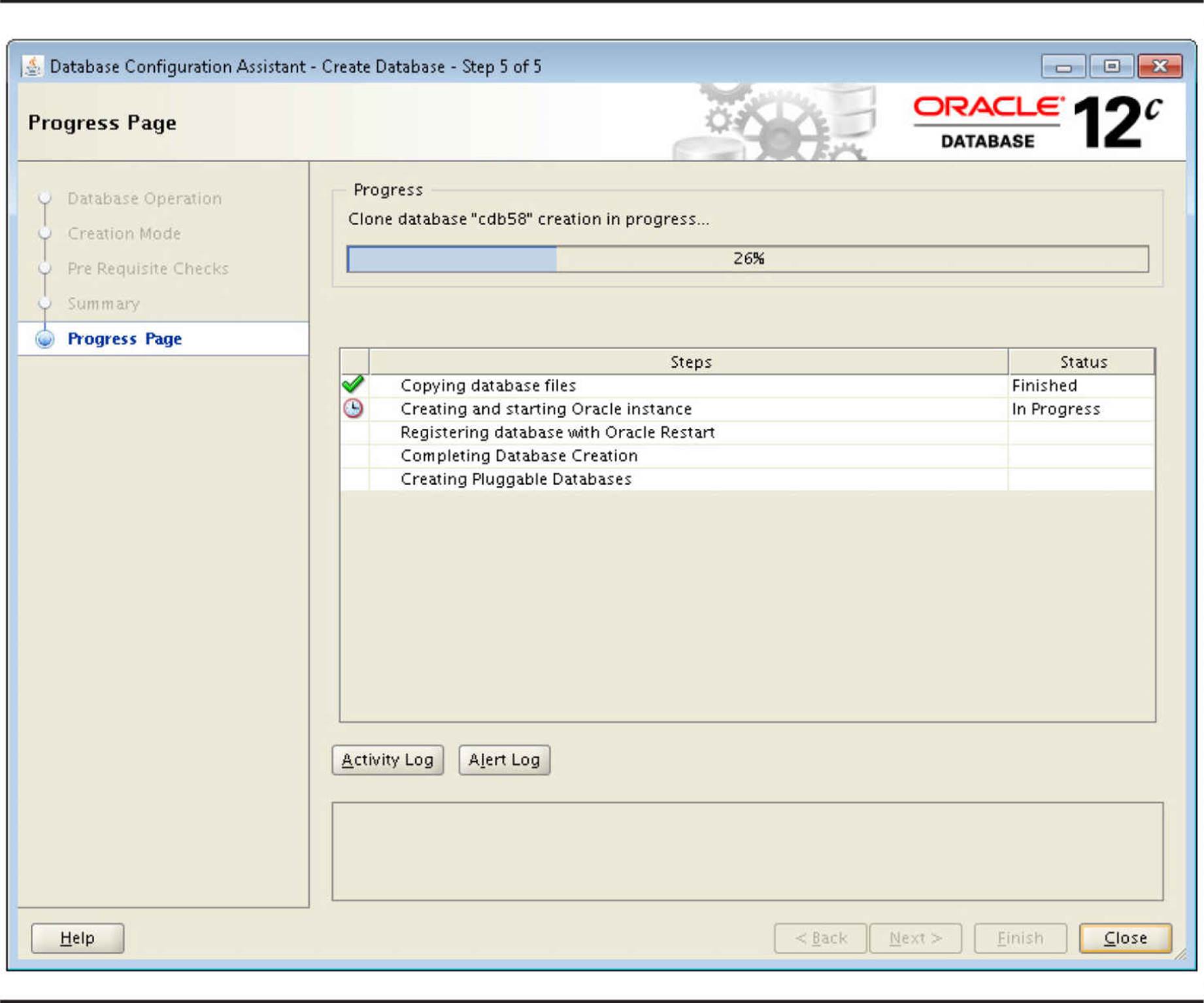
FIGURE 11-5. Container database Progress Page
Once the installation completes, you can see the new CDB listed in /etc/oratab:

But where is the initial PDB? For clues you can check the listener:

The listener hands off any requests for service rptqa10 to the PDB with the same name in the container database CDB58.
Using OUI to Create a CDB
Using the Oracle Universal Installer is much like one-stop shopping. You can install the Oracle database files, create a new CDB, and create a new PDB all in one session. Since you’ll likely install the database software only once on a server, using OUI to create a new container or PDB happens only once per server. In Figure 11-6 I am launching OUI to install the database software, create a CDB named CDB99, and create a single PDB called QAMOBILE. By default, OUI will use ASM for database files if an ASM disk group is available on the server.
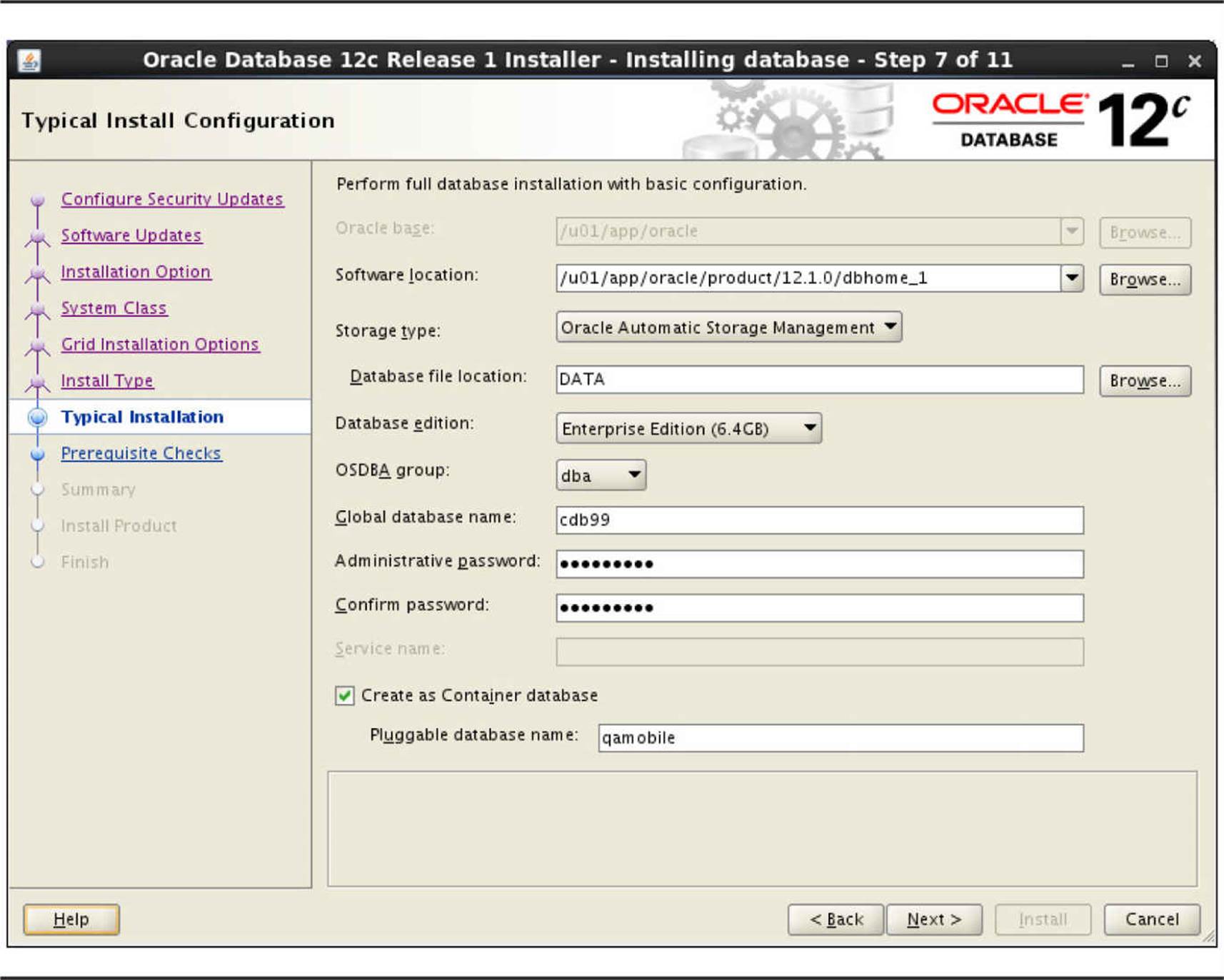
FIGURE 11-6. Installing Oracle Database software and container database using OUI
Understanding New Data Dictionary Views: The Sequel
Earlier in this chapter I presented a brief overview of the new data dictionary views available in a multitenant environment. Remember that from the perspective of a local user, there is no distinction between a non-CDB and a PDB. The local user still sees the container-related dynamic performance views and data dictionary views, but the rows returned are filtered based on the privileges and scope of the database user.
For example, a common user with DBA privileges (particularly the SELECT ANY DICTIONARY system privilege) can see all PDBs in the CDB:
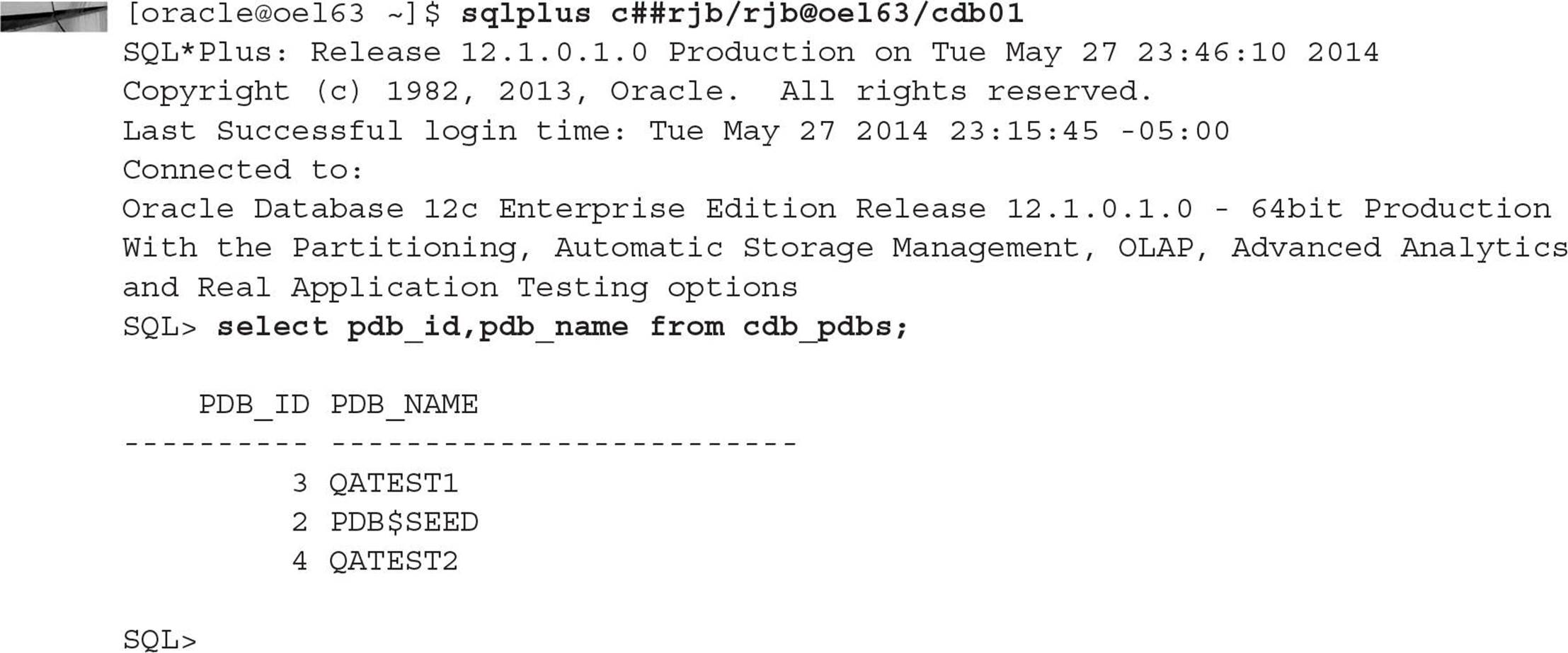
A nonprivileged common user won’t even see that data dictionary view:
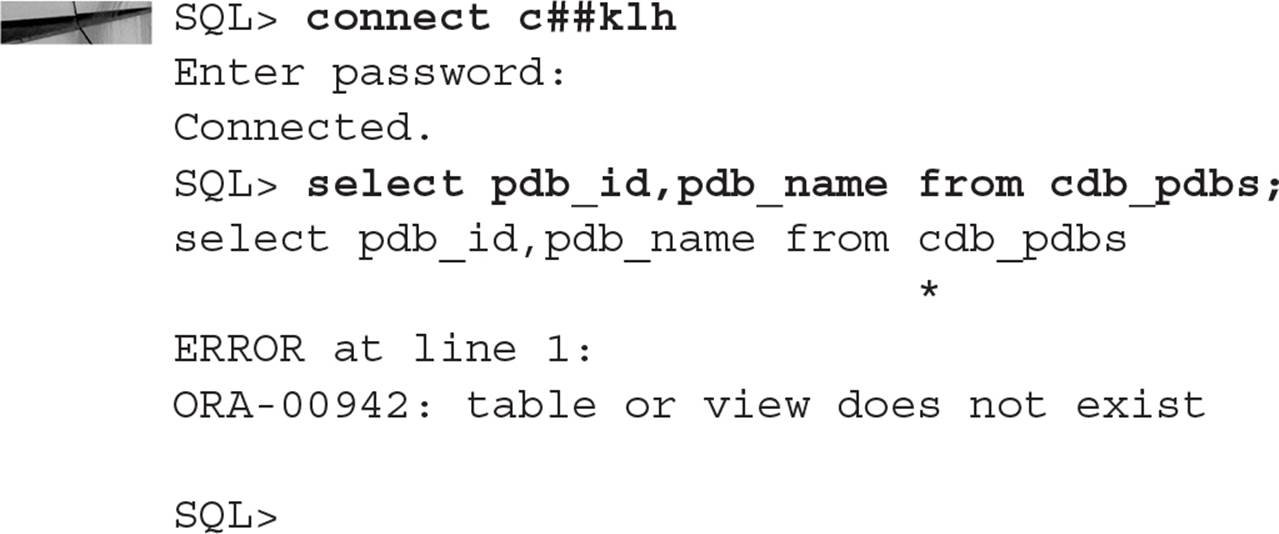
Local users, even with DBA privileges, will see data dictionary views like CDB_PDBS but won’t see any PDBs:


In previous versions of Oracle Database, the USER_ views show objects owned by the user accessing the view, the ALL_ views show objects accessible to the user accessing the view, and the DBA_ views show all objects in the database and are accessible to users with the SELECT ANY DICTIONARY system privilege, which is usually granted via the DBA role. Whether the database is a non-CDB, a CDB, or a PDB, the DBA_ views show the objects relative to where the view is accessed. For example, in a PDB, the DBA_TABLESPACES view shows tablespaces that exist only in that PDB.
If you are in the root container, DBA_USERS shows only common users, since in the root container only common users exist. In a PDB, DBA_USERS shows both common and local users.
For databases created in Oracle Database 12c, the CDB_ data dictionary views show object information across all PDBs and all of the CDB_ views even exist for non-CDBs. For local users and non-CDBs, the CDB_ views show the same information as the equivalent DBA_ view: the visibility does not go past the PDB or non-CDB even if the local user has the DBA role. Here are some CDB_ data dictionary views, including the new data dictionary view CDB_PDBS:
![]() CDB_PDBS All PDBs within the CDB
CDB_PDBS All PDBs within the CDB
![]() CDB_TABLESPACES All tablespaces within the CDB
CDB_TABLESPACES All tablespaces within the CDB
![]() CDB_DATA_FILES All datafiles within the CDB
CDB_DATA_FILES All datafiles within the CDB
![]() CDB_USERS All users within the CDB (common and local)
CDB_USERS All users within the CDB (common and local)
Figure 11-7 shows the hierarchy of data dictionary views in a multitenant environment. At the CDB_ view level, the main difference in the structure of the table is the new column CON_ID, which is the container ID that owns the objects. The root container and the seed container are containers as well, of course, and have their own CON_ID.

FIGURE 11-7. Multitenant data dictionary view hierarchy
Note that even common users (whose names are prefixed with C##) cannot access the CDB_ views unless they have the SELECT ANY DICTIONARY system privilege or have that privilege granted via a role such as the DBA role.
Creating PDBs
Once you have created the container database, you can add a new PDB regardless of whether or not you created a new PDB when you created the CDB. There are four methods: creating a PDB by cloning the seed PDB, cloning an existing PDB, plugging in a previously unplugged PDB, or plugging in a non-CDB.
Using PDB$SEED to Create a New PDB
Every container database has a read-only seed database container called PDB$SEED that is used for quickly creating a new pluggable database. When you create a new PDB from PDB$SEED, the following things happen, regardless of whether you use SQL*Plus, SQL Developer, or Enterprise Manager Cloud Control 12c. Each of these steps is performed with a CREATE PLUGGABLE DATABASE statement, either manually or via DBCA:
![]() Datafiles in PDB$SEED are copied to the new PDB.
Datafiles in PDB$SEED are copied to the new PDB.
![]() Local versions of the SYSTEM and SYSAUX tablespaces are created.
Local versions of the SYSTEM and SYSAUX tablespaces are created.
![]() Local metadata catalog is initialized (with pointers to common read-only objects in the root container).
Local metadata catalog is initialized (with pointers to common read-only objects in the root container).
![]() The common users SYS and SYSTEM are created.
The common users SYS and SYSTEM are created.
![]() A local user is created and is granted the local PDB_DBA role.
A local user is created and is granted the local PDB_DBA role.
![]() A new default service for the PDB is created and is registered with the listener.
A new default service for the PDB is created and is registered with the listener.
Given the relatively small amount of data creation and movement in those steps, the creation of the PDB is very fast.
Cloning a PDB to Create a New PDB
If you need a new database that’s similar to one that already exists, you can clone an existing database within the CDB. The new PDB will be identical to the source except for the PDB name and the DBID. In this example, you’ll use the DBA features of SQL Developer to clone the PDB. No worries about what’s going on under the covers; each step of the way you can see the DDL that SQL Developer runs to create the clone.
Before cloning an existing PDB, you must close it and reopen it in READ ONLY mode:

You can browse the DBA connections for the container database CDB01 and its PDBs. Right-click the QA_2014 PDB and select Clone Pluggable Database, as shown in Figure 11-8.
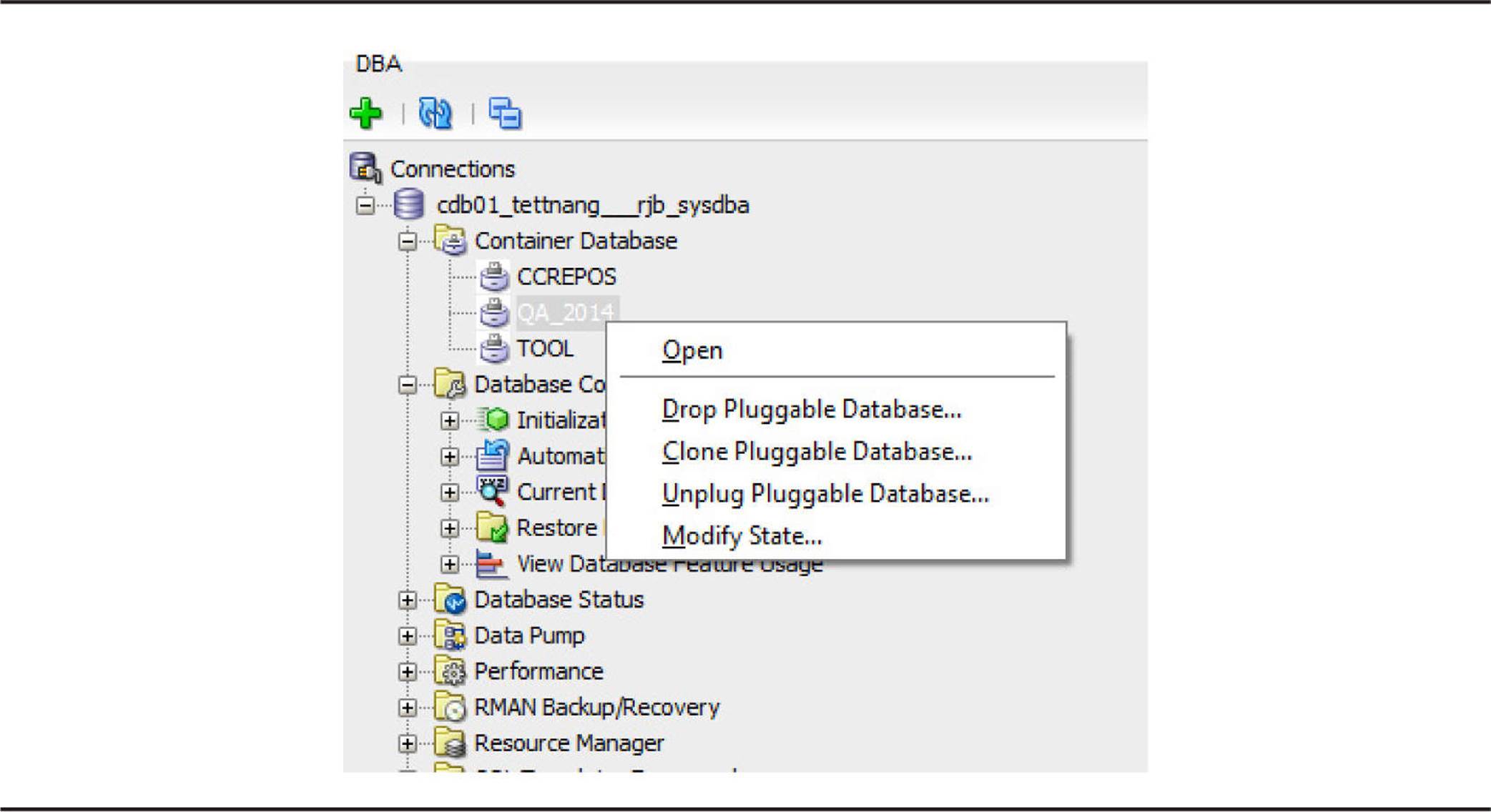
FIGURE 11-8. Selecting a database to clone in SQL Developer
In the dialog box that opens, as shown in Figure 11-9, change the database name to QA_2015. All other features and options of QA_2014 are retained for QA_2015.
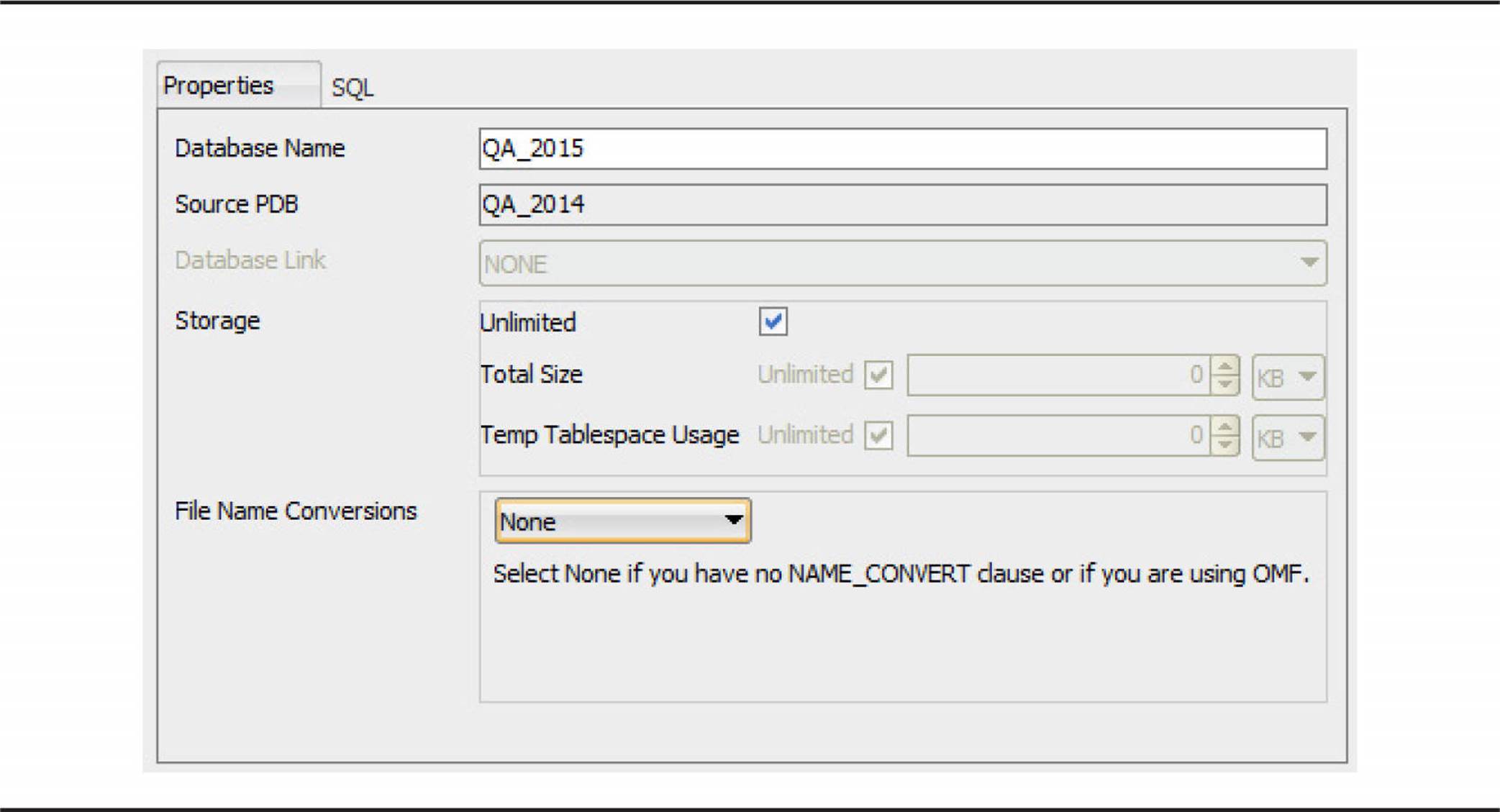
FIGURE 11-9. Specifying PDB clone characteristics
The SQL tab shows the command that SQL Developer will run to clone the database:

Once you click the Apply button, the cloning operation proceeds and creates the new PDB. As with the SQL*Plus method of creating a new PDB, you have to open the new PDB as READ WRITE:

Finally, you need to open the QA_2014 database as READ WRITE again since it was set to READ ONLY for the clone operation:

Plugging a Non-CDB into a CDB
You may have a standalone (non-CDB) Oracle 12c database that you’d like to consolidate into an existing CDB. If you have a pre-12c database, you must upgrade it to 12c first or use an alternate method to move that database (see the “Unplugging a PDB Using Different Methods” section of this chapter). For an existing non-CDB 12c database, it’s a straightforward process involving the PL/SQL procedure DBMS_PDB.DESCRIBE.
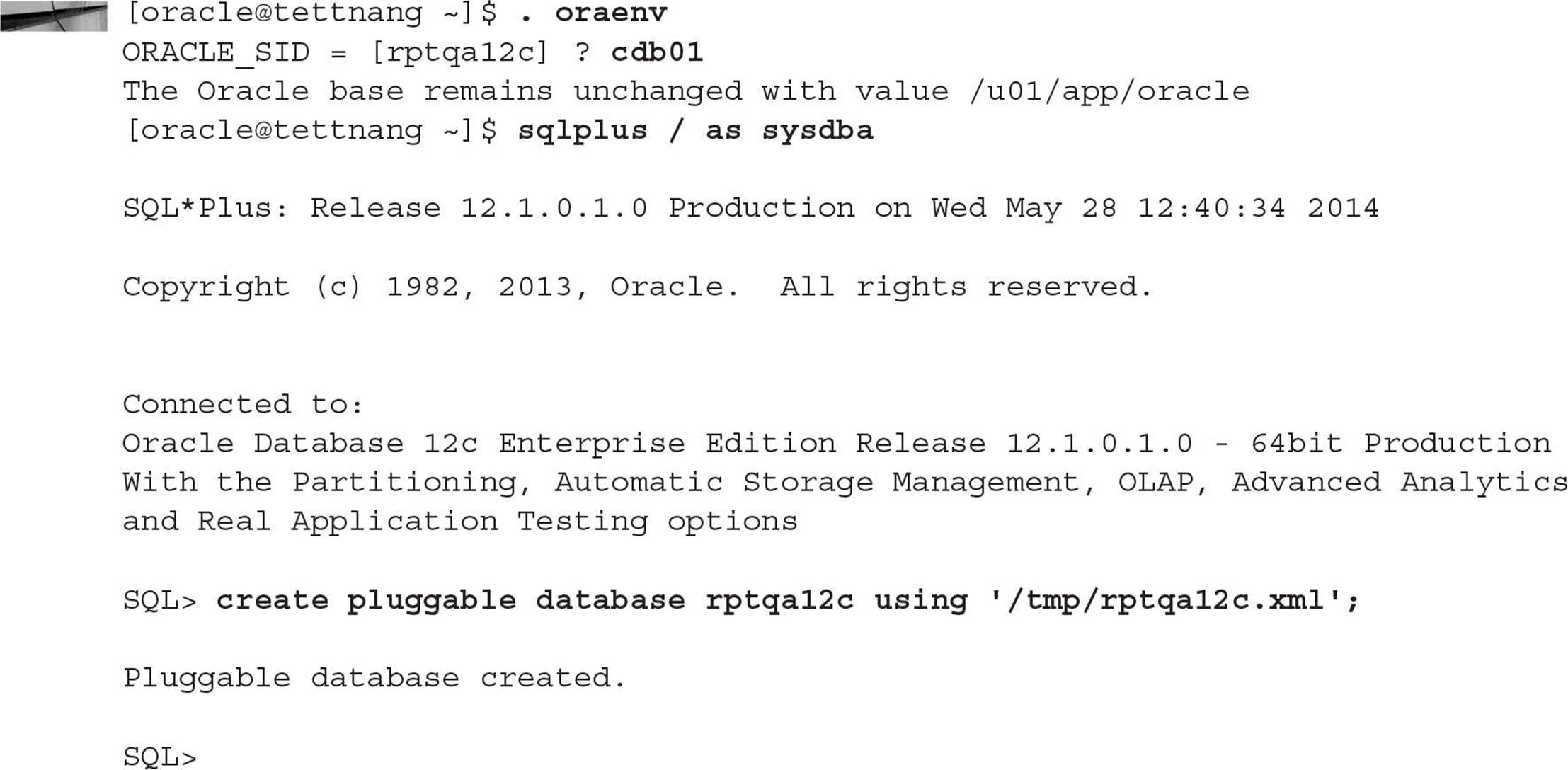
Using DBMS_PDB.DESCRIBE, you can quickly export the metadata for a non-CDB to an XML OS file. On the tettnang server, there are three instances, ASM, CDB01, and RPTQA12C:

Here is how you would export the metadata for the RPTQA12C database. Connect to the target database (the database that will be assimilated into CDB01), change its status to READ ONLY, and run the procedure:

The XML looks like this:
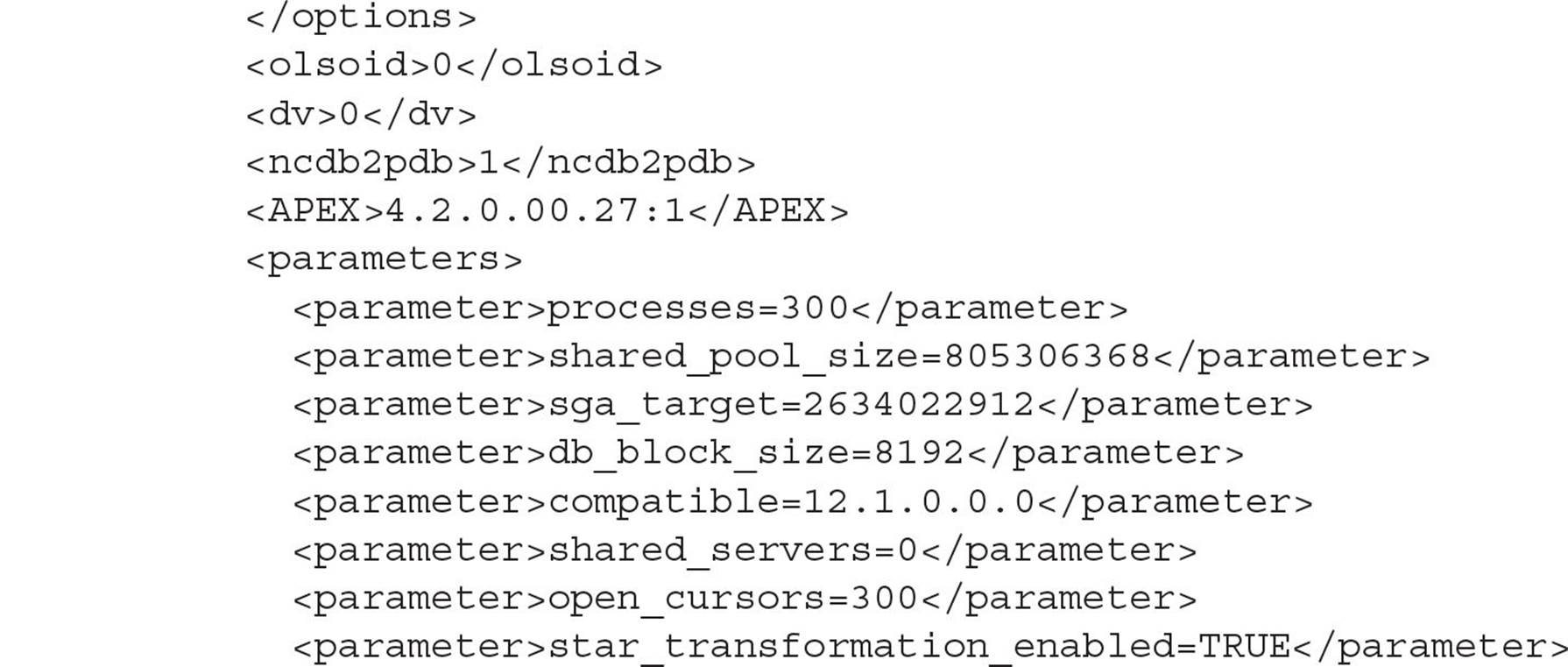

Next, connect to the container database CDB01 and import the XML for RPTQA12C:
The plugging operation may take as little as a minute or two if the datafiles for the non-CDB database are in the same ASM disk group as the destination CDB. Some final cleanup and configuration is needed before the plugged-in database can be used. The script noncdb_to_pdb.sql cleans up unnecessary metadata in a multitenant environment. In addition, you must open the newly plugged-in database just as you would with a clone operation:


Plugging an Unplugged PDB into a CDB
You may have several unplugged databases at any given time. Usually you’re in the process of migrating a PDB from one container to another on the same or a different server. In any case, an unplugged database can’t be opened outside of a CDB, so you’ll likely plug an unplugged database (PDB) back into a CDB. In this example, the PDB CCREPOS is currently unplugged and has its XML file located in /tmp/ccrepos.xml on the server. The steps to plug a currently unplugged PDB into a CDB are both straightforward and finish quickly—just as most multitenant operations do! All you have to do is run one command to plug it in and another command to open it. Connect as a common user with the ALTER PLUGGABLE DATABASE privilege as follows (connecting as SYSDBA to CDB01 with OS authentication works great):
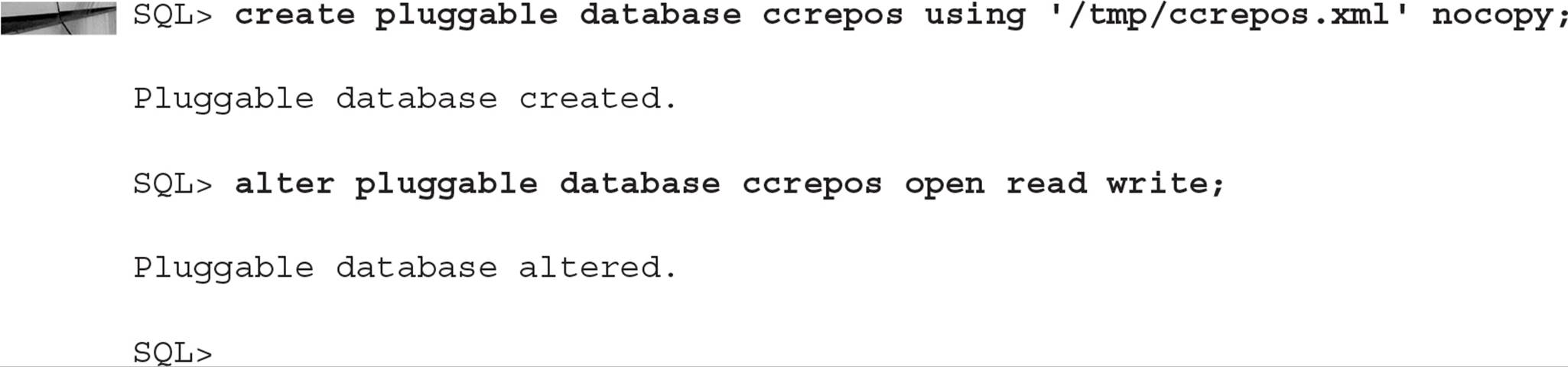
Note that a PDB must be dropped, and not just unplugged, from a CDB before it can be plugged back in. Using the NOCOPY option saves time if the PDB’s datafiles are already in the correct location.
Unplugging and Dropping a PDB
Since a PDB is by nature highly mobile, it’s likely that you’ll move it to another CDB on the same server or another server. You may just unplug it to make it unavailable to users (and prevent common users from opening it inadvertently). You may also unplug it to drop it completely. There are a few different ways to unplug and then drop a PDB.
Unplugging a PDB Using Different Methods
You can unplug a PDB using either SQL*Plus or SQL Developer. Both methods are easy and fast. Which one you should use depends on your comfort level and which tool you happen to have open at the time.
Unplugging a PDB Using SQL*Plus When you unplug a PDB from a CDB, you make the PDB unavailable to users, but its status remains UNPLUGGED. To drop the PDB from the CDB, see the next section, “Dropping a PDB.” Before you can unplug a PDB, you must first close it, as shown next. When you unplug it, you specify the location of an XML file for the PDB’s metadata. This metadata will ensure that the PDB will be pluggable later, either into the same or another CDB.

Unplugging a PDB Using SQL Developer Using SQL Developer to unplug a PDB is even easier than using SQL*Plus. From the CDB’s connection in the DBA window, expand the Container Database branch and right-click the PDB to be unplugged. Select Unplug Pluggable Database from the context menu, as shown in Figure 11-10.
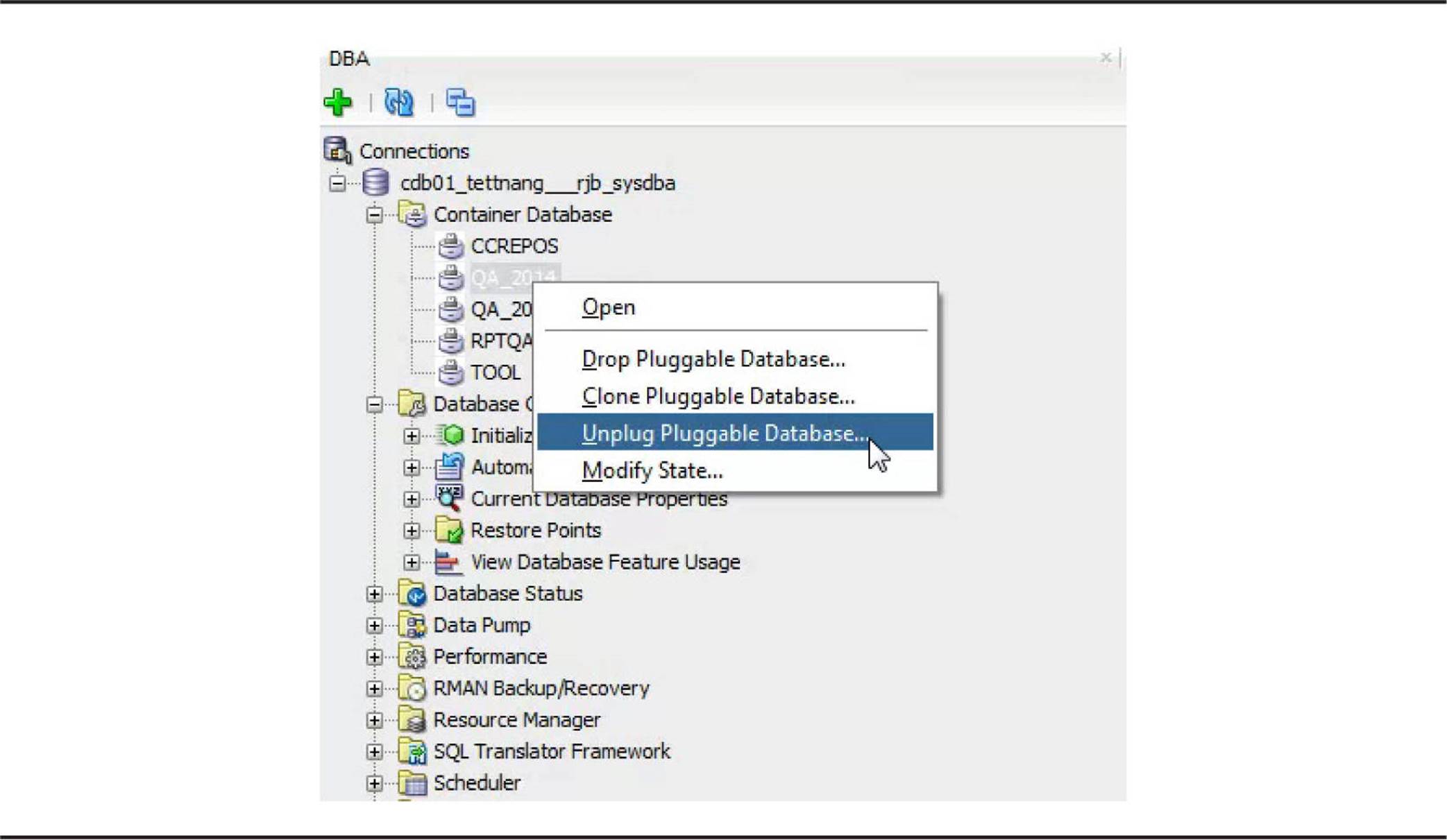
FIGURE 11-10. Unplugging a PDB from SQL Developer
The Unplug dialog box gives you the opportunity to specify the name and location of the XML file containing the PDB’s metadata, as you can see in Figure 11-11.
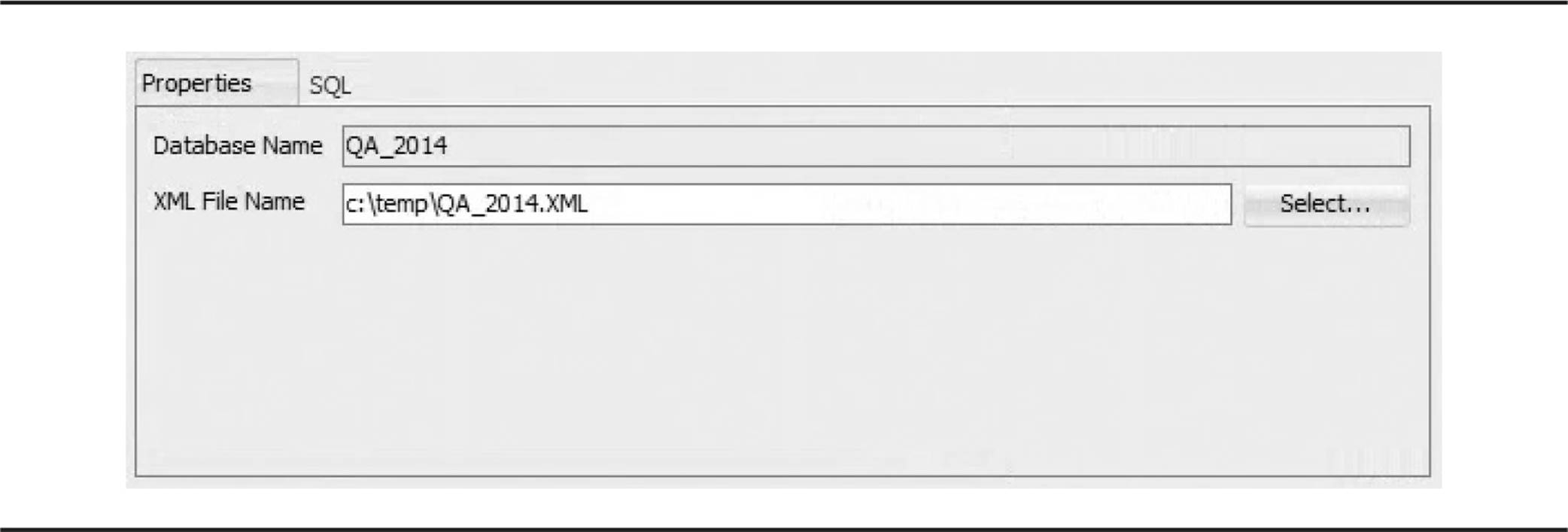
FIGURE 11-11. Specifying the location for the unplugged PDB’s XML file
Dropping a PDB
As with most CDB and PDB operations, you can use both SQL*Plus and SQL Developer to drop a PDB. In addition, you can use DBCA and Enterprise Manager Cloud Control 12c to drop a PDB. When you drop a PDB, all references to the PDB are removed from the CDB’s control file. By default, the datafiles are retained; therefore, if you had previously unplugged that PDB, you can use the XML file to plug that PDB back into the same or another CDB. In this example, you will drop the QA_2014 PDB along with its datafiles. It will no longer be available to plug into another database even if you still have the XML metadata.

If you have an RMAN backup of the QA_2014 PDB, you could restore it from there. Otherwise, if you want to remove all remaining traces of QA_2014, you’ll have to manually remove the backups of QA_2014 using RMAN.
NOTE
You can neither unplug, open, or drop the seed database PDB$SEED.
Migrating a Pre-12.1 Non-CDB Database to a CDB
Converting Oracle Database 12c non-CDBs to a PDB is fast and straightforward, but what if your database is a previous version such as 11g or even 10g? You have a few options available depending on whether you want to keep the original database intact for some length of time.
Using the Upgrade Method to Migrate a Non-CDB If your application is not sensitive or dependent on the version of the database (which you should have verified by now), then your cleanest option is to upgrade the non-CDB in place up to version 12c (12.1.0.1 or later) and then plug it into the CDB using the methods mentioned earlier in this chapter. The biggest advantage to this method is that you don’t need to allocate any extra space for the migration as you would for the other two methods.
Using the Data Pump Method to Migrate a Non-CDB To use the Data Pump method, you’ll use Data Pump Export/Import as you would in a non-CDB environment. Create a new PDB from the seed database in the CDB and adjust the initialization parameters to be comparable to those in the existing database.
One of the advantages with this method is that you can leave the current non-CDB in place to ensure compatibility with Oracle Database 12c before dropping the original database.
Using the Database Link Method to Migrate a Non-CDB Using database links, you create a new PDB from the seed database and copy over the application’s tables using database links. This is the most labor-intensive option but is probably the easiest if the number of tables in an application is small. A table migration would look like this:
![]()
Managing CDBs and PDBs
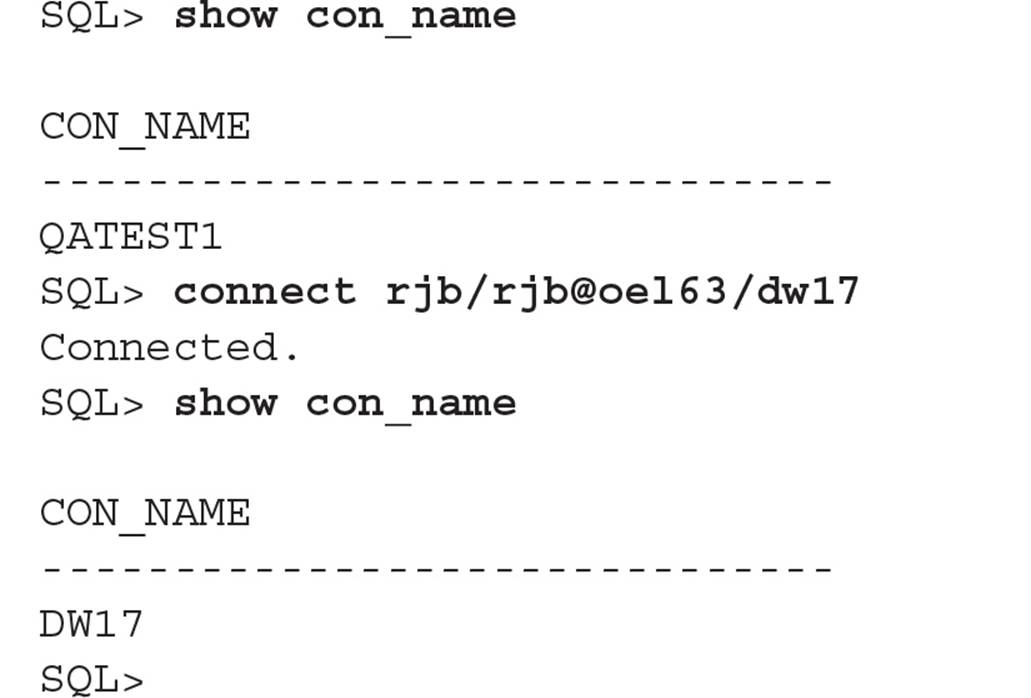
You connect to a PDB or CDB much like you connect to a non-CDB. You can connect to a CDB via OS authentication and the common user SYS. Otherwise, you will connect to either a CDB or one of the PDBs within the CDB using a service name. The service name is referenced either using an EasyConnect string or within a tnsnames.ora entry. This method is the same whether you are using SQL*Plus or SQL Developer.
By default a service name is created for each new, cloned, or plugged-in PDB. If that is not sufficient in your environment, you’ll use the DBMS_SERVICE package to create additional services for the PDB.
Understanding CDB and PDB Service Names
In a non-CDB environment, a database instance is associated with at least one service managed by at least one listener. One listener can manage a combination of non-CDB and PDB services. The database server oel63 has two databases: DBAHANDBOOK and CDB01. As you might suspect, the database CDB01 is a multitenant database, and DBAHANDBOOK is a non-CDB, but they are both Oracle Database version 12c and are managed by a single listener called LISTENER:
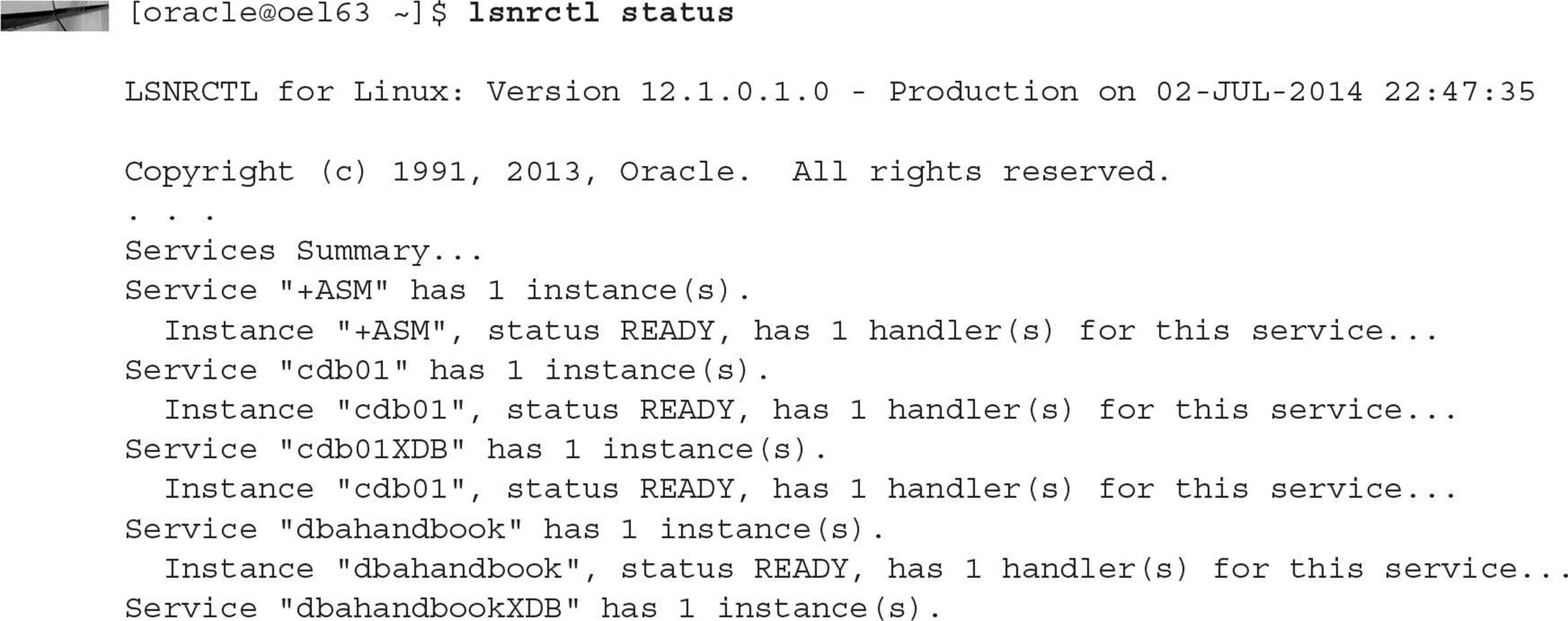

The container database CDB01 has two PDBs, DW17 and QATEST1, and the same listener manages connections for both PDBs.
Every container in a CDB has its own service name. The CDB itself has the default service name, which is the same as the container name plus the domain, if any. For each PDB created or cloned, a new service is created and managed by the default listener unless otherwise specified. As you might expect, the only exception to this rule is the seed container (PDB$SEED). Since it is read-only and used only to create new PDBs, there is no reason to create a service and connect to it.
In addition to using the service name to connect to the CDB or any PDBs contained within, you can use OS authentication and connect as SYSDBA just as you would with a non-CDB. You’ll be connected as the SYS user—a common user with privileges to maintain all PDBs within the CDB.
The transparency of a PDB and how it appears as a non-CDB to nonprivileged users extends to how you connect using entries in tnsnames.ora or using Oracle EasyConnect. As you may recall, the format for an EasyConnect connect string is as follows:
![]()
Therefore, for connecting to the user RJB in the PDB named DW17 in the CDB named CDB01 on the server oel63, you would use the following when starting SQL*Plus:

Notice that no reference to CDB01 is necessary. The PDB’s service name masks the existence of the CDB or any other PDBs in the CDB.
Connecting to a CDB or PDB Using SQL Developer
Connecting to the root container or any PDB within a container using SQL Developer is just as easy. You use the username (common or local), server name, port, and service name. In other words, this is EasyConnect format. Figure 11-12 shows several connections to CDB01 plus a connection to a non-CDB.
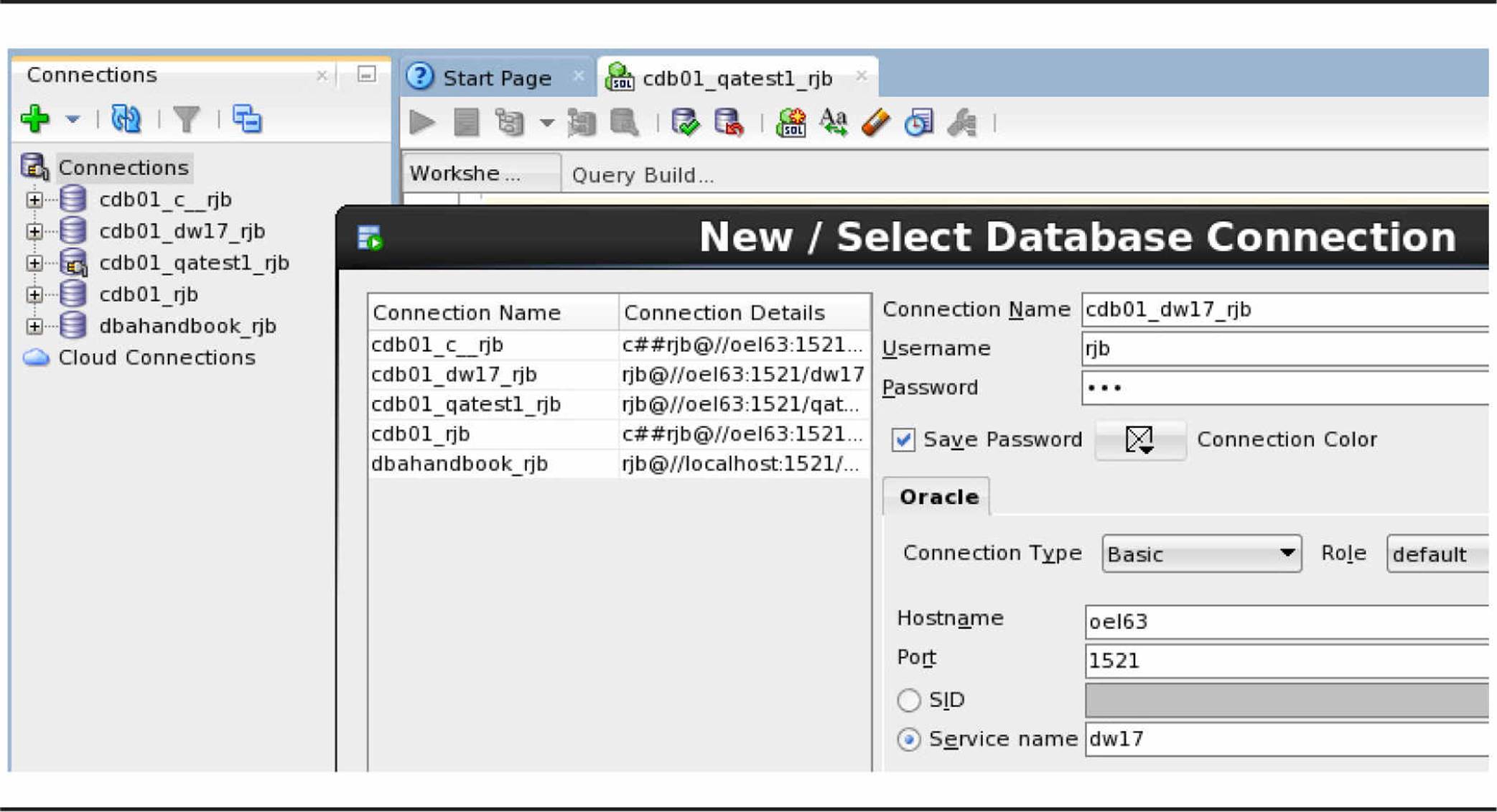
FIGURE 11-12. Connecting to CDBs and PDBs in SQL Developer
Creating Services for CDBs or PDBs
If you’re using a standalone server environment with Oracle Restart or a clustered environment using Oracle Clusterware, you’ll automatically get a new service created with every new or cloned PDB or non-CDB (database instance). If you want additional services for a PDB, use the srvctl command like this:

In a non-Oracle Restart or non-clustered environment, you can use the DBMS_SERVICE package to create and start the service. To create the same new service as in the previous example with srvctl but instead using DBMS_SERVICE, you would do the following:

Note the slight difference in the example with DBMS_SERVICE: The actual service name is still dwsvc2, but the service name exposed to end users is dwsvcnew and would be used in the connection string for clients accessing this service.
Switching Connections Within a CDB
As you may infer from examples in previous chapters, you can switch containers within a session if you either are a common user with the SET CONTAINER system privilege or have a local user in each container and you connect using the service name:
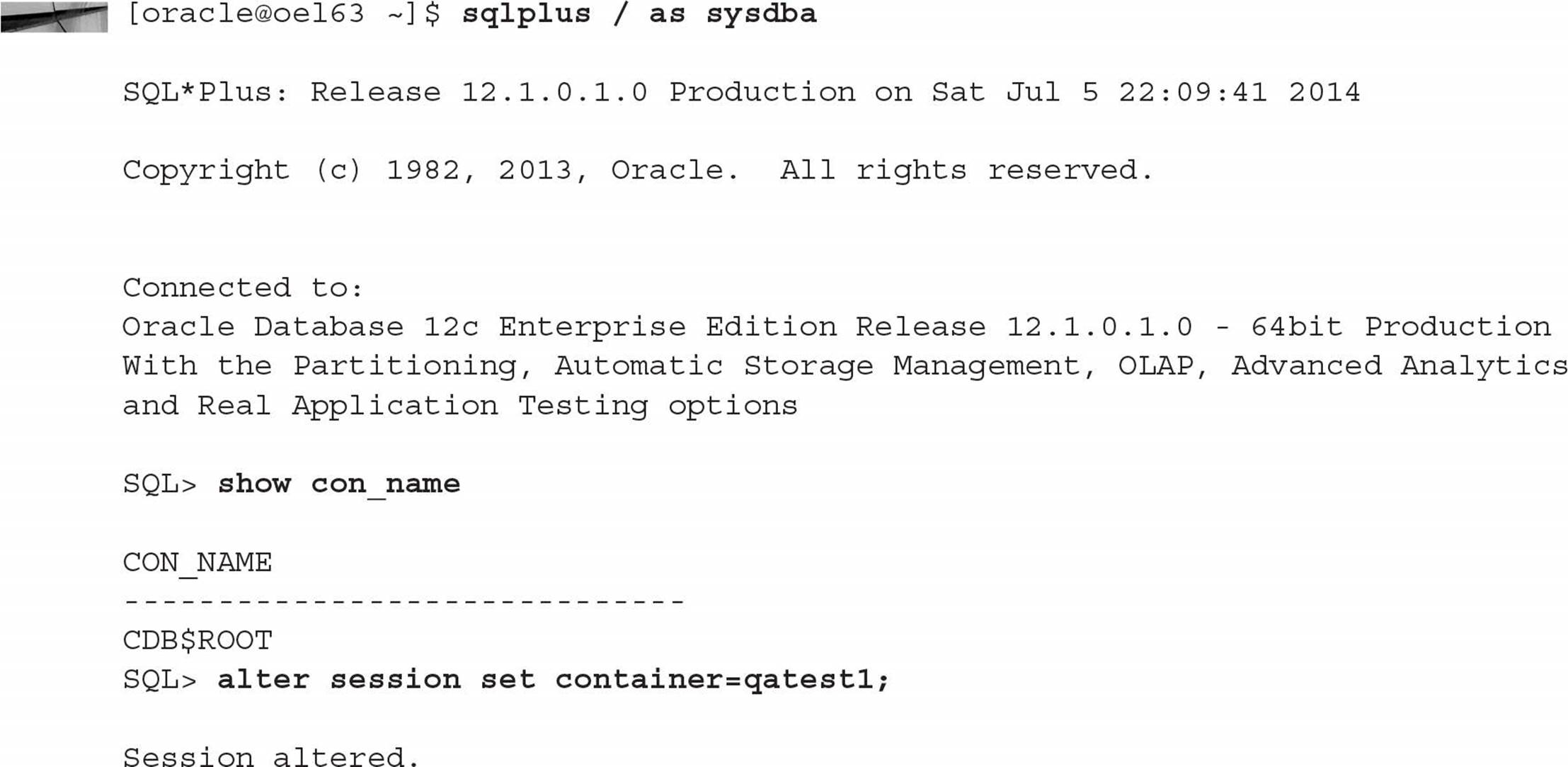
You can have a pending transaction in the first PDB, switch to a different PDB, and then switch back to the first PDB, and you still have the option to COMMIT or ROLLBACK the pending transaction.
NOTE
Common users who have the SET CONTAINER system privilege or local users who switch containers using CONNECT local_user@PDB_NAME do not automatically commit pending transactions when switching containers.
Starting Up and Shutting Down CDBs and PDBs
Starting up and shutting down a CDB or opening and closing a PDB will seem familiar to any Oracle DBA who starts up and shuts down a non-CDB. The point that is often missed is that a CDB is ultimately a single database instance, and each PDB shares the resources of the CDB’s instance. This is to be expected since each PDB is logically partitioned from each other PDB using the CON_ID column in every table that is shared among the root and each PDB. This logical partitioning extends to user accounts and security as well; thus, it appears to non-common users that the PDB has its own dedicated instance.
NOTE
As you might expect, in a clustered (RAC) environment a CDB has one instance on each node of the cluster.
Since the CDB is a database instance, anything running within the CDB is shut down or disconnected when the CDB is shut down. This means that a PDB is not open for users until the CDB has been started and explicitly opened (either manually by the DBA or via a trigger), and similarly the PDB is closed when the CDB instance is shut down.
In the following sections, I’ll show you how CDBs and PDBs are started up and shut down as well as how to automate the process. You’ll also want to know how to change parameters that are specific to a PDB as well as create PDB-specific versions of database objects such as temporary tablespaces if the default global temporary tablespace does not meet the needs of the PDB’s application.
CDB Instance Startup
The CDB instance is most like a traditional non-CDB instance. Figure 11-13 shows the five possible states for CDBs and PDBs in a multitenant environment.
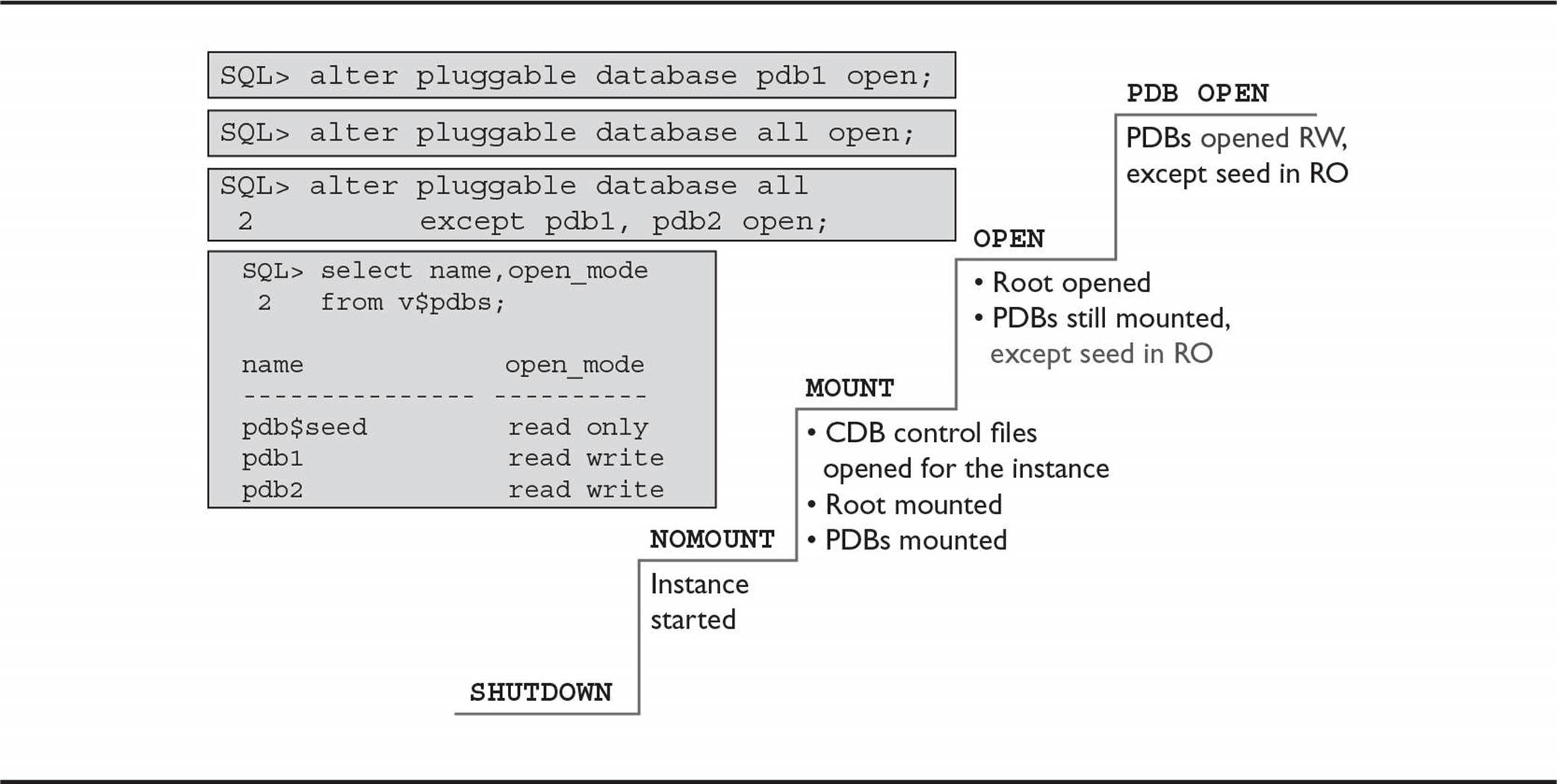
FIGURE 11-13. CDB and PDB states
From the shutdown state, you can perform a STARTUP NOMOUNT (connecting AS SYSDBA using OS authentication) to start a CDB instance by opening the SPFILE, creating the processes and memory structures, but not yet opening the control file:


At this point in the startup process, the instance has no information about the PDBs within the CDB yet. You would typically perform a STARTUP NOMOUNT when you need to re-create or restore a missing control file for the CDB instance.
A lot of things happen when you move a CDB to the MOUNT state, as you can see in Figure 11-13. Not only are the CDB’s control files opened for the instance, but both the CDB$ROOT and all PDBs are changed to the MOUNT state:
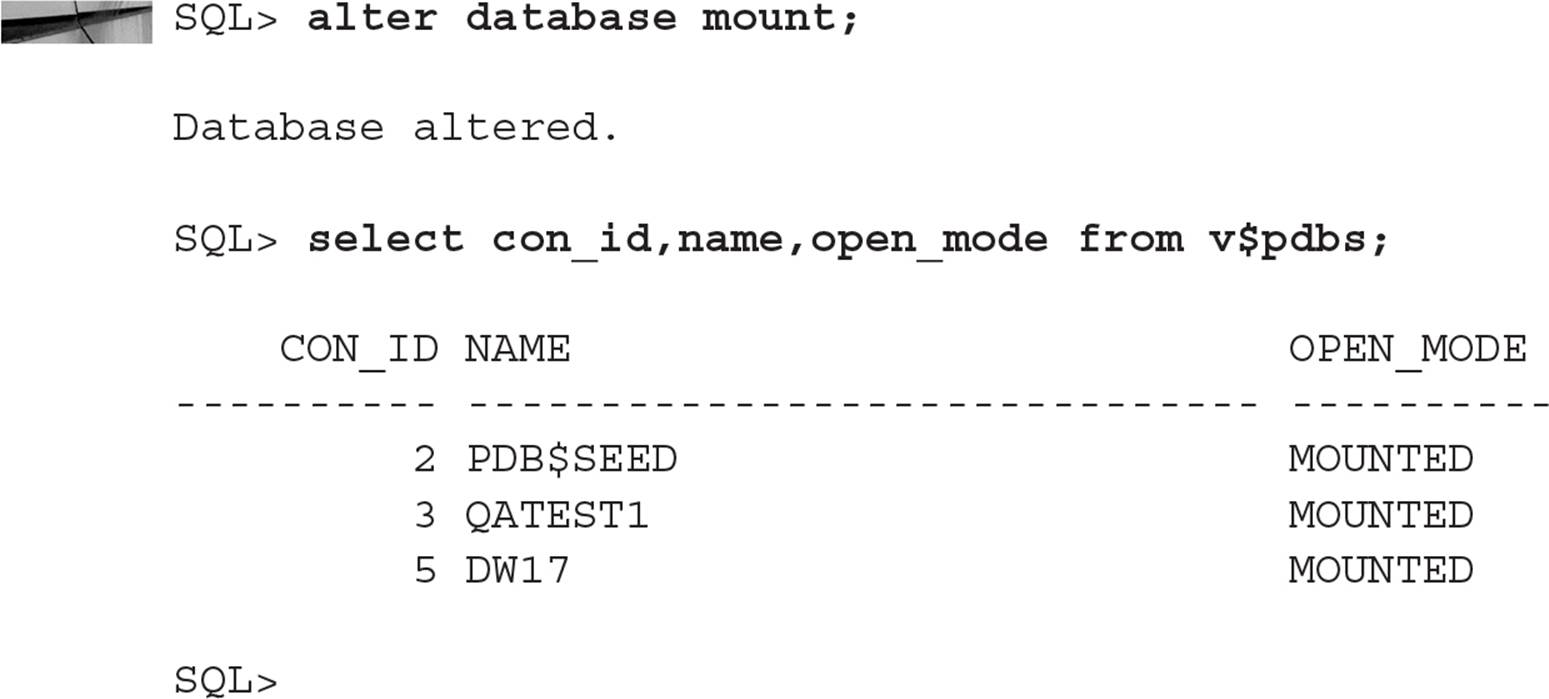
If any datafile operations are necessary (restore and recovery, for example), this is where you would perform those, especially if those operations are required on the PDB’s SYSTEM tablespace.
The final step to make the root container available for opening PDBs is to change the CDB’s state to OPEN. After CDB$ROOT is OPEN, it’s available for read and write operations. The PDBs are still mounted with the seed database PDB$SEED mounted as READ ONLY:
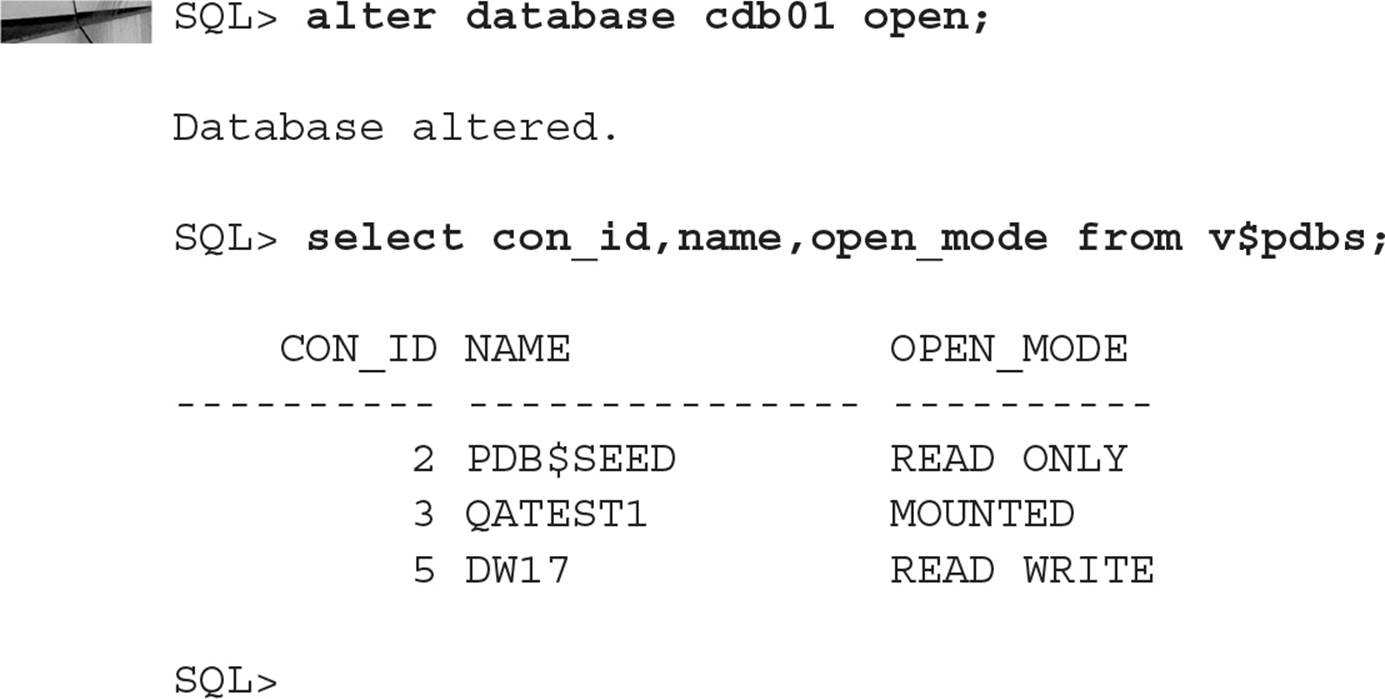
Because I created a second service for the PDB named DW17 earlier in the chapter and Oracle Restart is installed in this environment, DW17 is automatically opened in READ WRITE mode. The seed database PDB$SEED is always opened READ ONLY.
Once the CDB is opened (in other words, the root’s datafiles are available along with the global temporary tablespace and the online redo log files), the PDBs are mounted but not yet open and available to users. Unless a PDB is opened with a trigger or via Oracle Restart, it remains in the MOUNTED state.
At this point, the CDB instance behaves much like a non-CDB instance. In the next section, you’ll see how individual PDBs are opened and closed.
Opening and Closing a PDB
Once you have the root (CDB$ROOT) container of a CDB open, you can perform all desired operations on the PDBs within the CDB, including but not limited to cloning PDBs, creating a new PDB from the seed, unplugging a PDB, or plugging in a previously unplugged PDB. Remember that the seed container, PDB$SEED, is always open when CDB$ROOT is open but with an OPEN_MODE of READ ONLY.
There are quite a few options when you want to open or close a PDB. You can use ALTER PLUGGABLE DATABASE when connected as SYSDBA or SYSOPER, or if you’re connected as SYSDBA within a PDB, you can use the same commands without having to specify the PDB name. In addition, you can selectively open or close one or more PDBs with the ALL or EXCEPT ALL option.
Using the ALTER PLUGGABLE DATABASE Command You can open or close a PDB from any container by specifying the PDB name; alternatively, you can change the session context to a specific PDB and perform multiple operations on that PDB without qualifying it, as in these examples. Regardless of the current container, you can open and close any PDB by explicitly specifying the PDB name:
Alternatively, you can set the default PDB name at the session level:

To set the default container back to the root container, use CONTAINER=CDB$ROOT in the ALTER SESSION command.
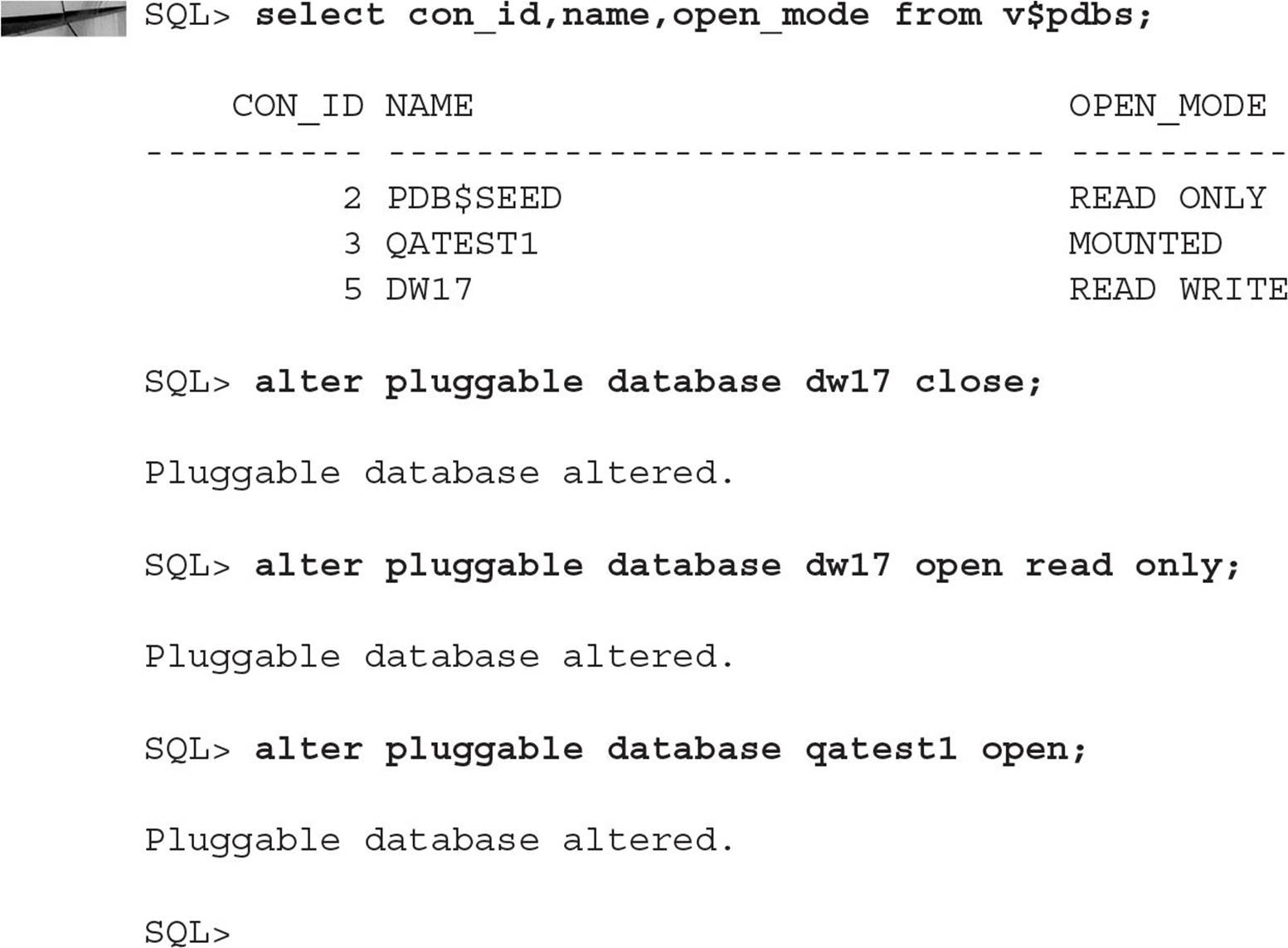
Selectively Opening or Closing PDBs Even if you configure the PDBs in your CDB to open automatically with triggers, what if you have dozens of PDBs in your CDB and you want to open all of them except for one? You can use ALL EXCEPT to accomplish this in one command:
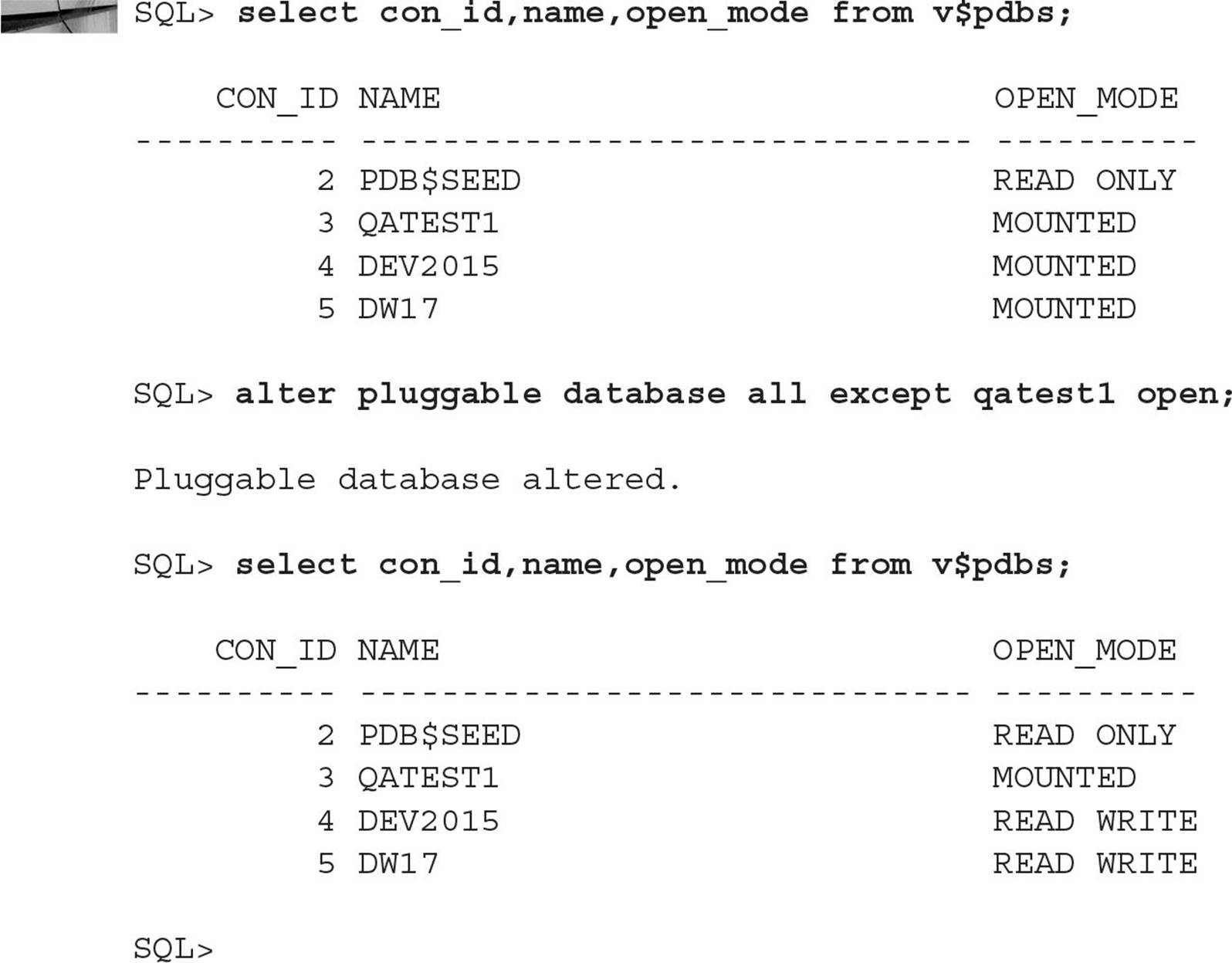
If you want to close all PDBs at once, just use ALL:
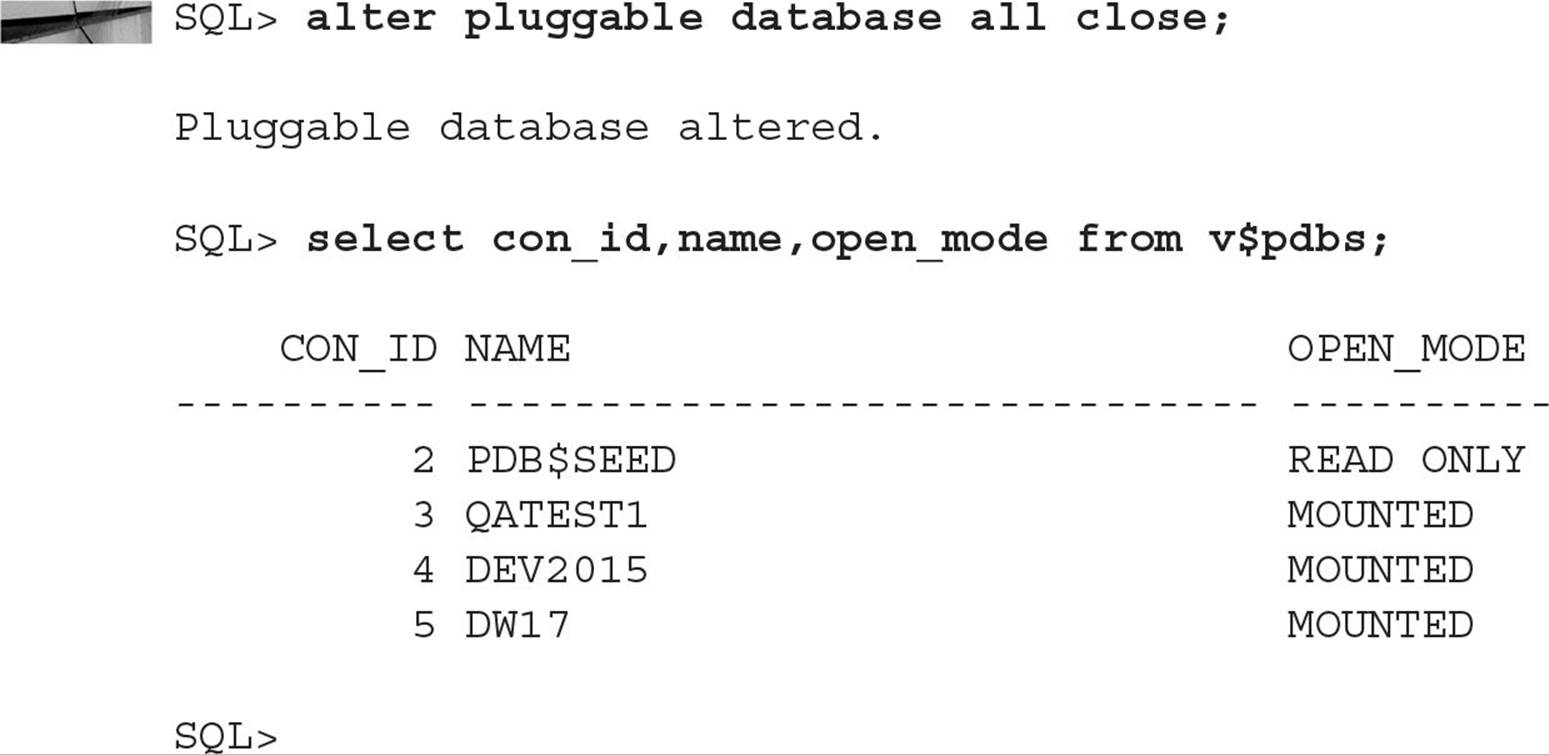
Opening or closing all PDBs leaves the root container in its current state, and, as noted earlier, the seed container PDB$SEED is always READ ONLY and is in the MOUNT state only when the CDB is in the MOUNT state.
NOTE
For a specific PDB, you can use either SHUTDOWN or SHUTDOWN IMMEDIATE. There is no PDB equivalent to the TRANSACTIONAL or ABORT options for a CDB instance or a non-CDB instance.
When you close one or more PDBs, you can add the IMMEDIATE keyword to roll back any pending transactions within the PDB. If you leave off the IMMEDIATE keyword, the PDB is not shut down until all pending transactions have been either committed or rolled back, just as in a non-CDB database instance, and all user sessions are disconnected by the user. If your session context is in a specific PDB, you can also use the SHUTDOWN IMMEDIATE statement to close the PDB, but note that this does not affect any other PDBs and that the root container’s instance is still running.
CDB Instance Shutdown When you are connected to the root container, you can shut down the CDB instance and close all PDBs with one command, much like you would shut down a non-CDB database instance:

When specifying IMMEDIATE, the CDB instance does not wait for a COMMIT or ROLLBACK of pending transactions, and all user sessions to any PDB are disconnected. Using TRANSACTIONAL waits for all pending transactions to complete and then disconnects all sessions before terminating the instance.
As described in the previous section, you can use the same command to shut down a specific PDB, but only that PDB’s datafiles are closed, and its services will no longer accept connection requests until it is opened again.
Automating PDB Startup There are new options available in database event triggers for a multitenant environment. One of these triggers is persistent, while two others are not; the reason for this will be clear shortly.
By default, after a CDB instance starts, all PDBs within the CDB are in MOUNT mode. If your PDB is not automatically opened by any other method (such as Oracle Restart), you can create a database trigger to start up all PDBs, just a few, or just one. In the container database CDB01, the pluggable database DW17 starts up automatically via Oracle Restart; for the DEV2015 pluggable database, you’ll create a trigger to change its status to OPEN READ WRITE when the container database is open, as shown here:
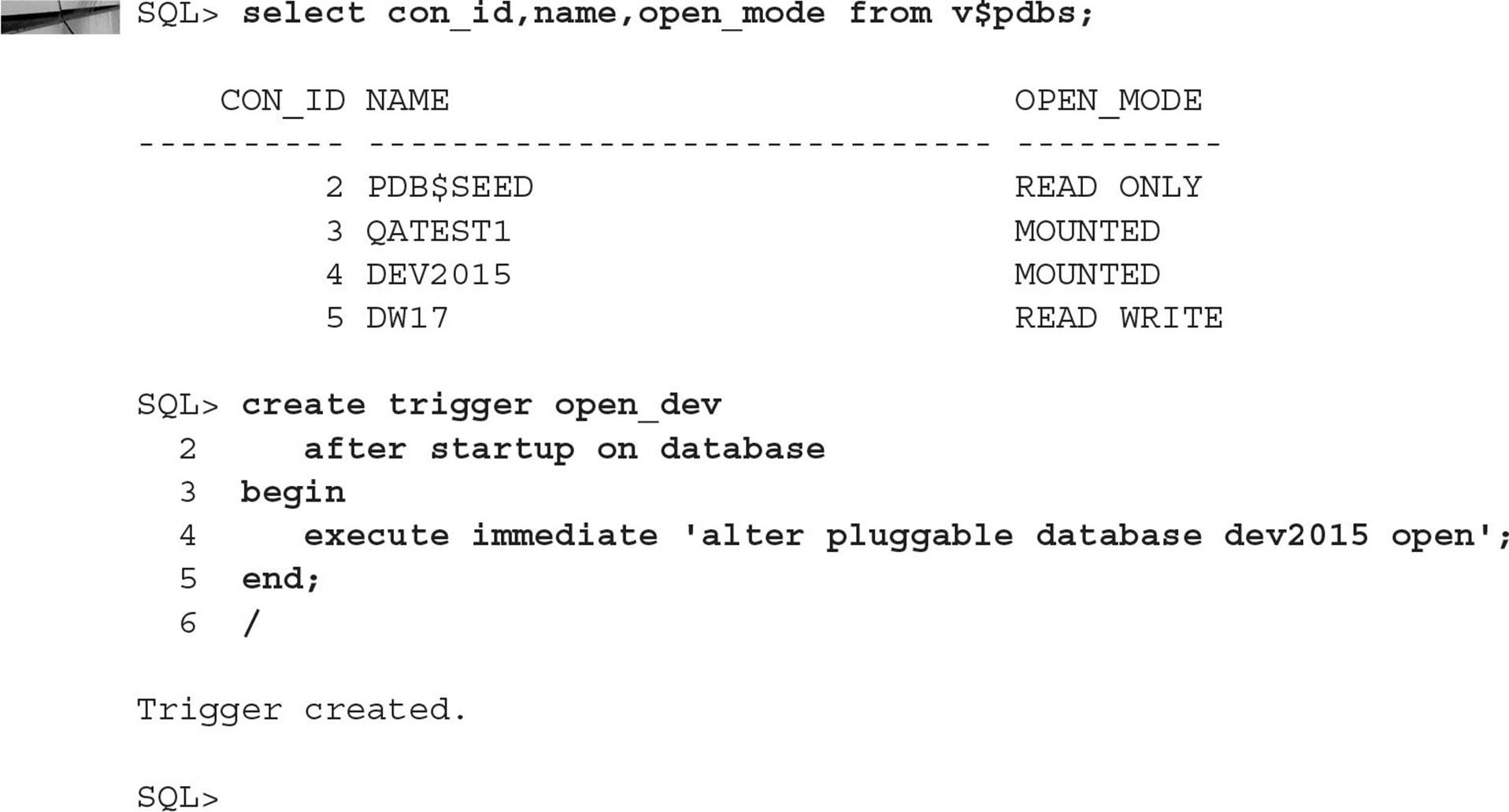
Next, shut down and restart the container CDB01 and see what happens:
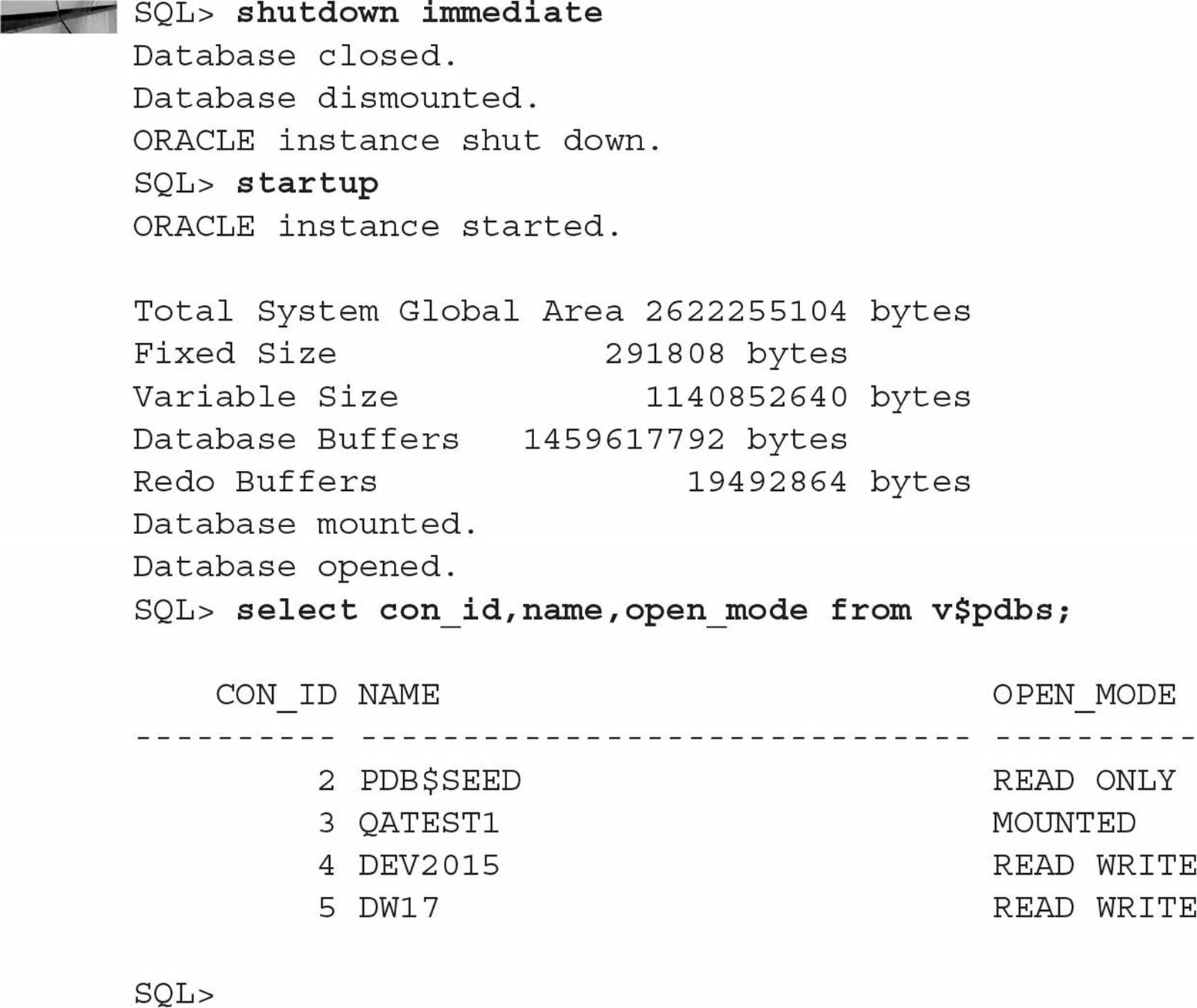
The AFTER STARTUP ON DATABASE trigger is persistent unless you drop or disable it. Two new database event triggers for Oracle Database 12c, AFTER CLONE and BEFORE UNPLUG, are more dynamic. Both of those triggers must be specified with ON PLUGGABLE DATABASE; otherwise, the trigger will be invalid and not fire.
You would use a trigger such as AFTER CLONE for a PDB that you’ll frequently clone in a testing or development environment. The trigger itself exists in the source PDB and will persist unless you explicitly drop it. However, when you create a new PDB by cloning the existing PDB that contains this trigger, you can perform one-time initialization tasks in the cloned PDB right after it is cloned. Once those tasks are completed, the trigger is deleted so that any clones of the already cloned database won’t perform those initialization tasks.
Changing PDB Status In a non-CDB environment you often have reason to restrict access to a database either for maintenance tasks or to prepare it for a transportable tablespace or database operation. This is also true in a CDB environment. Previously in this chapter you saw how to open a PDB as READ ONLY. For any PDB that you want restricted to users with SYSDBA privileges (granted to either a global user or a local user), use the RESTRICTED clause just as you would in a non-CDB environment:

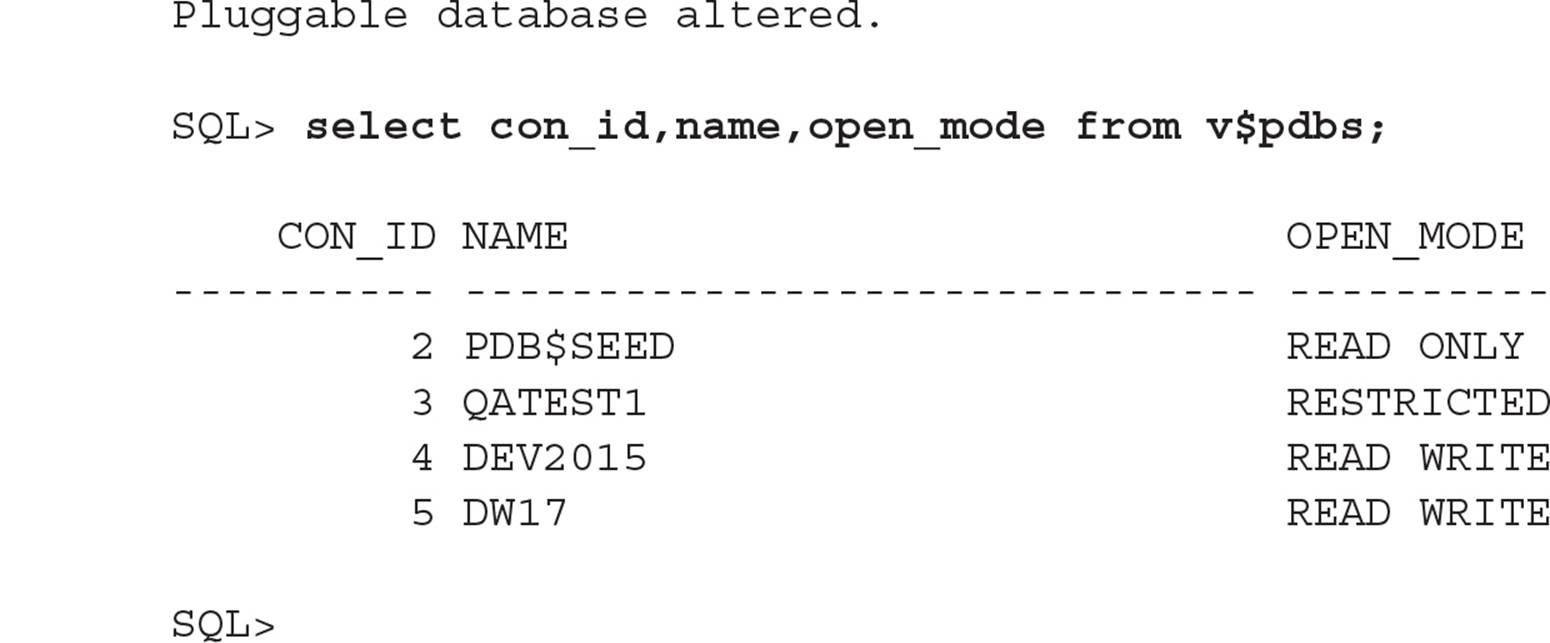
To turn off RESTRICTED mode, close and reopen the PDB without the RESTRICTED keyword.
There are several operations you can perform on a PDB that do not require restarting the PDB in RESTRICTED mode:
![]() Take PDB datafiles offline or bring them back online
Take PDB datafiles offline or bring them back online
![]() Change the PDB’s default tablespace
Change the PDB’s default tablespace
![]() Change the PDB’s default temporary tablespace (local tablespace)
Change the PDB’s default temporary tablespace (local tablespace)
![]() Change the maximum size of a PDB:
Change the maximum size of a PDB:
alter pluggable database storage (maxsize 50g);
![]() Change the name of a PDB
Change the name of a PDB
These dynamic settings help to maximize the availability of a PDB and allow you to make changes to a PDB much more quickly because you would not have to shut down and restart the database as in a non-CDB environment.
Changing Parameters in a CDB
Although the application developer or database user of a PDB will not see any difference in how a PDB operates compared to a non-CDB, some of the differences require careful consideration by the global and local DBAs. A subset of parameters can be changed at the PDB level, but for the most part, a PDB inherits the parameter settings of the CDB. In addition, some ALTER SYSTEM commands behave slightly differently depending on the context in which they are run by the DBA.
Understanding the Scope of Parameter Changes
Because a CDB is a database instance and PDBs share this instance, some of the CDB’s parameters (stored in an SPFILE, of course) apply to the CDB and all PDBs and cannot be changed for any given PDB. You can identify the parameters that can be changed at the PDB level by looking at the ISPDB_MODIFIABLE column of V$PARAMETER. The data dictionary view PDB_SPFILE$ shows the non-default values for specific parameters across all PDBs:

The settings local to a PDB stay with the PDB even when the PDB has been cloned or unplugged.
Using ALTER SYSTEM in a Multitenant Environment
Many of the ALTER SYSTEM commands you would use in a non-CDB environment work as you’d expect in a multitenant environment, with a few caveats and exceptions. Some of the ALTER SYSTEM commands affect only the PDB or the CDB in which they are run. In contrast, some ALTER SYSTEM commands can be run only in the root container.
Using PDB-Specific ALTER SYSTEM Commands Within a PDB (as a local DBA or a global DBA with a PDB as the current container), the following ALTER SYSTEM commands affect objects, parameters, or sessions specific to the PDB with no effect on any other PDBs or the root container:
![]() ALTER SYSTEM FLUSH SHARED_POOL
ALTER SYSTEM FLUSH SHARED_POOL
![]() ALTER SYSTEM FLUSH BUFFER_CACHE
ALTER SYSTEM FLUSH BUFFER_CACHE
![]() ALTER SYSTEM ENABLE RESTRICTED SESSION
ALTER SYSTEM ENABLE RESTRICTED SESSION
![]() ALTER SYSTEM KILL SESSION
ALTER SYSTEM KILL SESSION
![]() ALTER SYSTEM SET <parameter>
ALTER SYSTEM SET <parameter>
As you might expect, if flushing the shared pool in a PDB affected the shared pool of any other PDB, the side effects would be dramatic and unacceptable!
Understanding ALTER SYSTEM Commands with Side Effects in a PDB There are a few ALTER SYSTEM commands that you can run at the PDB level but affect the entire CDB. For example, running ALTER SYSTEM CHECKPOINT affects datafiles across the entire container unless the datafiles belong to a PDB that is opened as READ ONLY or are OFFLINE.
Using CDB-Specific ALTER SYSTEM Commands Some ALTER SYSTEM commands are valid only for the entire container and must be run by a common user with SYSDBA privileges in the root container. For example, running ALTER SYSTEM SWITCH LOGFILE switches to the next online redo log file group. Since the online redo log files are common to all containers, this is the expected behavior.
Manage Permanent and Temporary Tablespaces in CDB and PDBs
In a multitenant environment, tablespaces and the datafiles that comprise them belong to either the root container or one of the PDBs within the CDB. Of course, some objects are shared across all PDBs, and these objects are stored in the root container’s tablespaces and shared with the PDB via database links. There are some syntax changes to the CREATE DATABASE command as well as behavior changes to CREATE TABLESPACE and other tablespace-related commands within a PDB.
Using CREATE DATABASE
The CREATE DATABASE statement for a CDB is nearly identical to that for a non-CDB, with a couple of exceptions. Oracle recommends that you use the DBCA to create a new CDB, but if you must use a CREATE DATABASE command (for example, to create dozens of CDBs in a script), you will use the USER_DATA TABLESPACE clause to specify a default tablespace for user objects for all PDBs created in this CDB. This tablespace is not used in the root container.
Using CREATE TABLESPACE
Creating a new tablespace in a CDB (root) container with CREATE TABLESPACE looks the same as creating a tablespace in any PDB. If you are connected to CDB$ROOT, then the tablespace is visible and usable only in the root container; similarly, a tablespace created when connected to a PDB is visible only to that PDB and cannot be used by any other PDB unless connected with a database link.
For ease of management, Oracle recommends using separate directories to store datafiles for each PDB and the CDB. Even better, if you use ASM, you’ll automatically get your datafiles and other database objects segregated into separate directories by container ID. Here is how the datafiles for the container database CDB01 are stored in an ASM disk group:
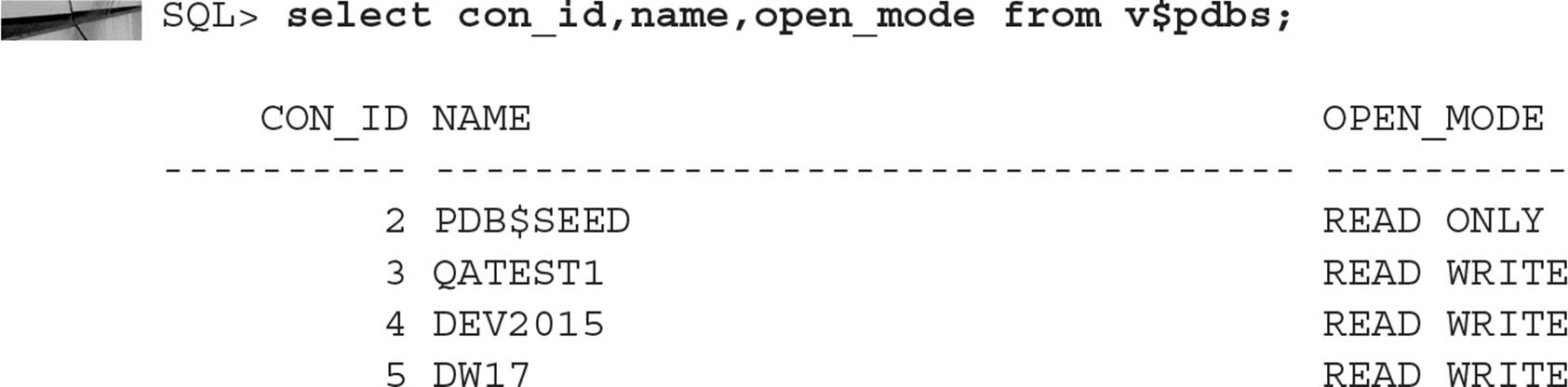
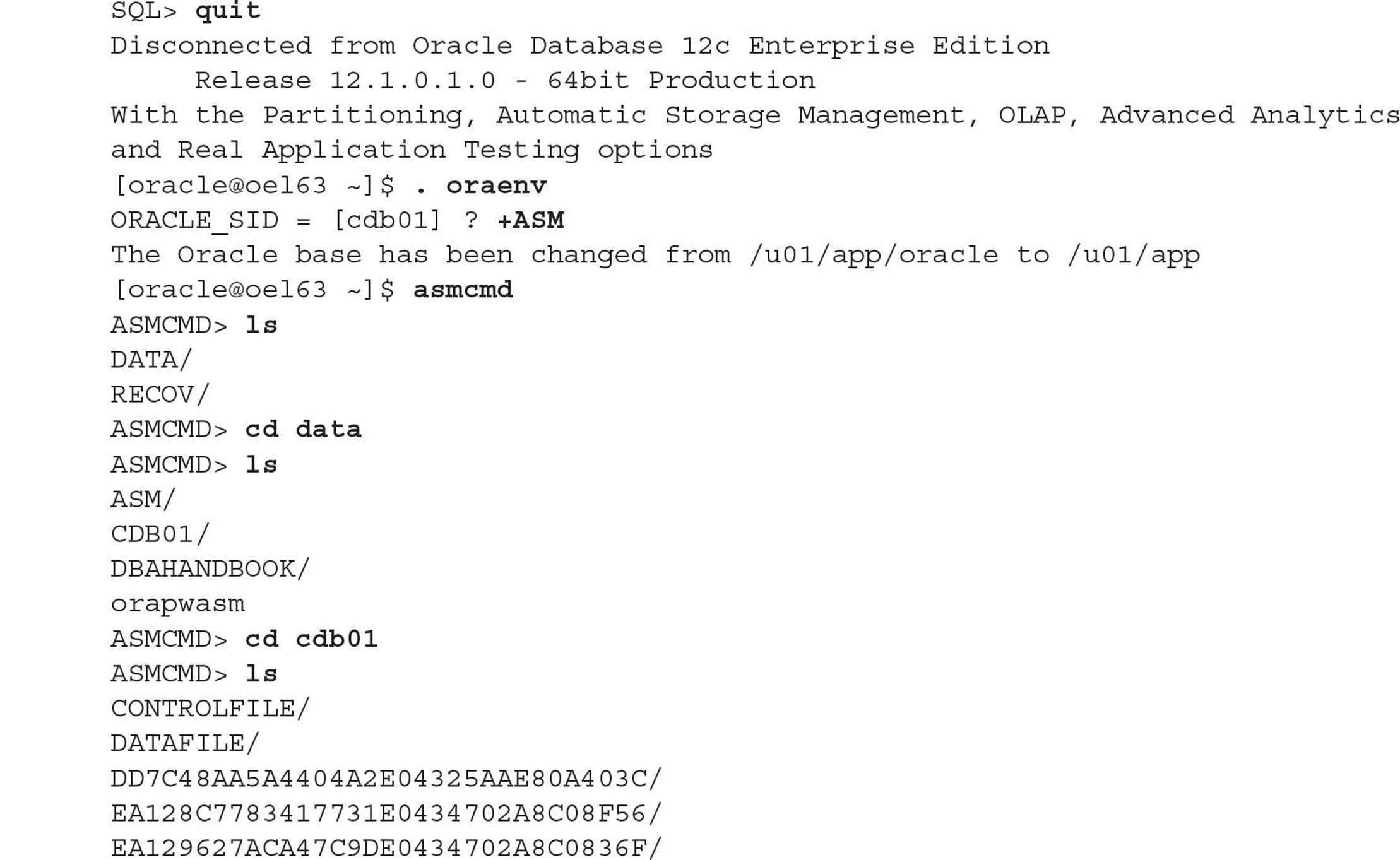
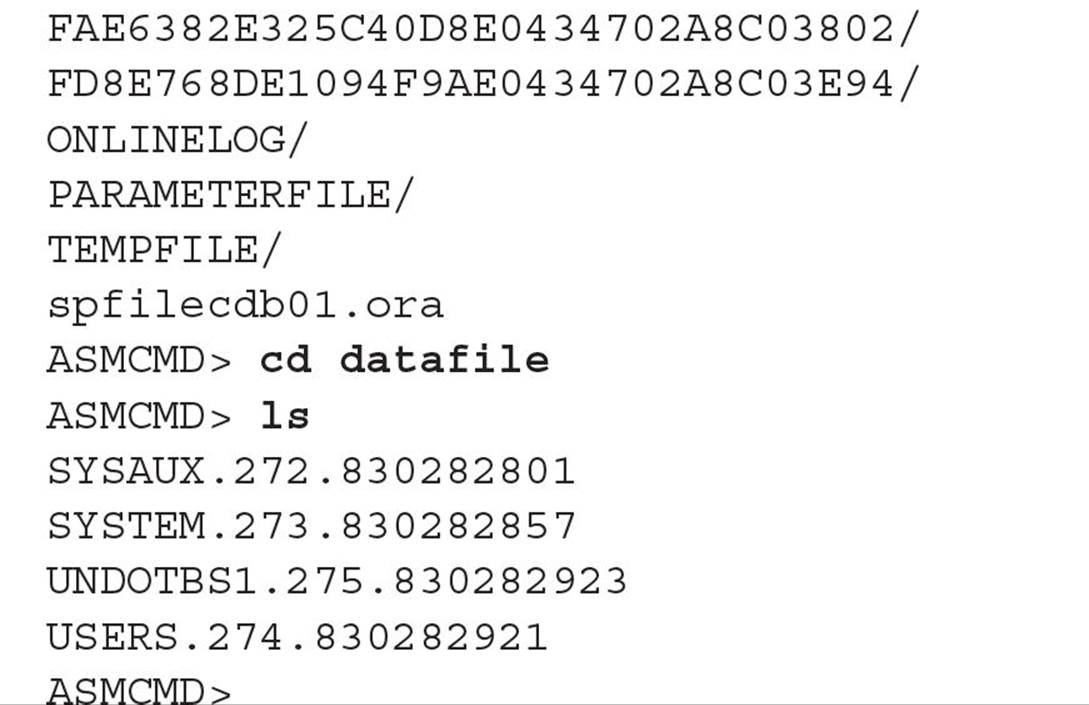
The container’s datafiles are stored in the DATAFILE subdirectory; each of the PDBs has its own set of datafiles in one of those subdirectories with the long string of hexadecimal digits. You use Oracle Managed Files (OMF) with ASM in this scenario; you don’t need to know or care what those hexadecimal characters are since the locations of the datafiles are managed automatically.
Changing the Default Tablespace in a PDB
Changing the default tablespace in a CDB or PDB is identical to changing the default tablespace in a non-CDB. For both CDBs and PDBs, you use the ALTER DATABASE DEFAULT TABLESPACE command. If you’re changing the default tablespace for a PDB, you should add the PLUGGABLE keyword because the ALTER DATABASE command within a PDB will be deprecated in a future release. In this example, you set the container to QATEST1, create a new tablespace within QATEST1, and change the default tablespace to be the tablespace you just created:
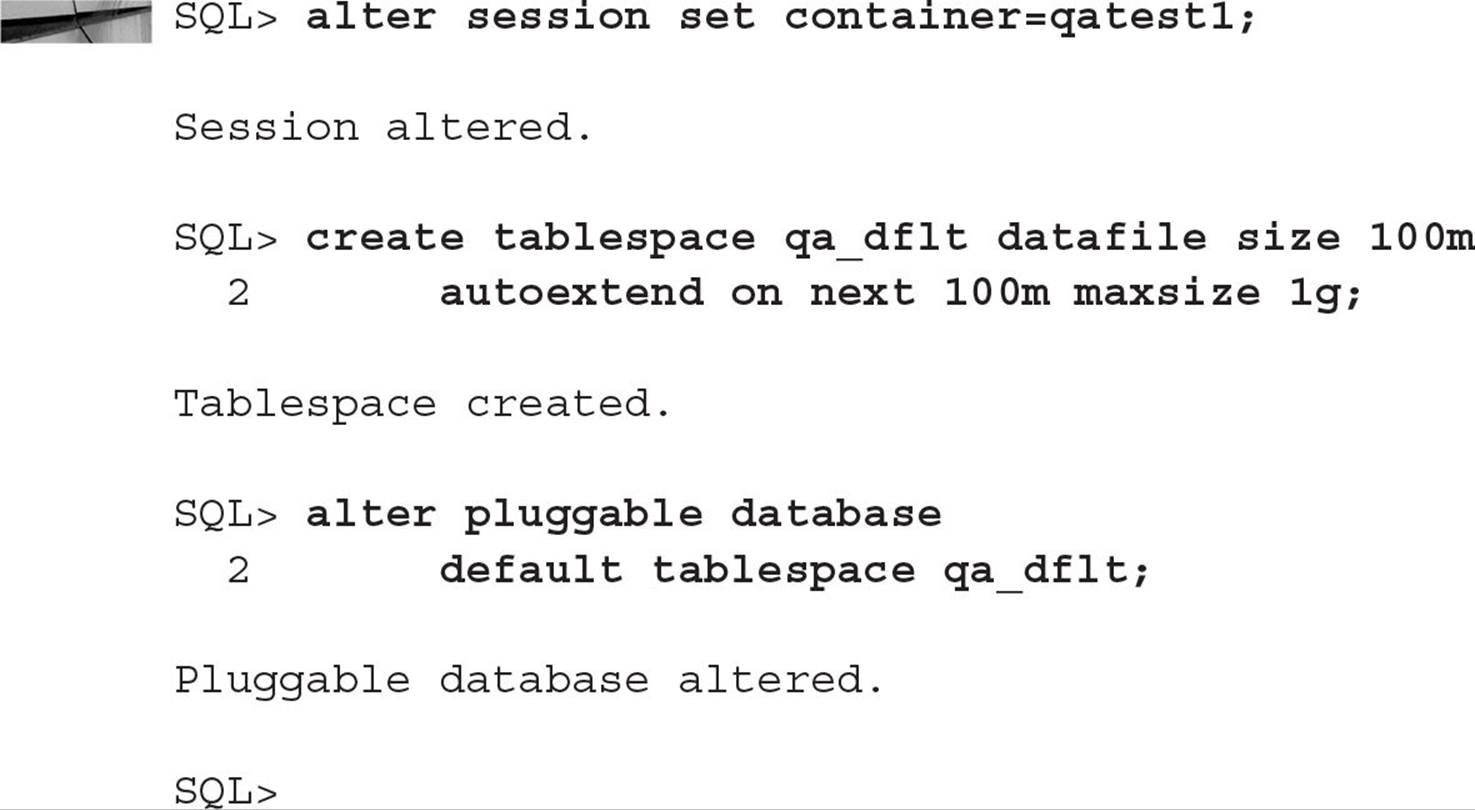
Going forward, any new local users within QATEST1 that don’t have a specific default permanent tablespace will use the tablespace QA_DFLT.
Using Local Temporary Tablespaces
For any CDB, you can have one default temporary tablespace or temporary tablespace group defined at the CDB level that can be used for all PDBs as their temporary tablespace. You can, however, create a temporary tablespace for a PDB that is used only by that PDB. In this example, you create a new temporary tablespace called QA_DFLT_TEMP in the PDB QATEST1 and make it the default temporary tablespace for QATEST1:

A temporary tablespace created within a PDB stays with that PDB when it’s unplugged and plugged back into the same or a different CDB. If a user is not assigned a specific temporary tablespace, then that user is assigned the default temporary tablespace for the PDB. If there is no default temporary tablespace for the PDB, then the default temporary tablespace for the CDB applies.
Multitenant Security
As described earlier in the chapter, in a multitenant environment, there are two types of users: common users and local users. A common user in a CDB (root container) has visibility and an account available in the root container and automatically in each PDB within the CDB. Common users do not automatically have the same privileges in every PDB; this flexibility simplifies your authentication processes but makes it easy to fine-tune the authorization in each PDB.
Managing Common and Local Users
The names of common users start with C##, which makes it easy to distinguish a common user from a local user in each PDB. Creating a local user is exactly like creating a user in a non-CDB. You can create a local user either with a common user or with another local user with the CREATE USER privileges:

The root container (CDB$ROOT) cannot have local users, only common users. Common users have the same identity and password in the root container and every PDB, both current and future. Having a common user account doesn’t automatically mean you have the same privileges across every PDB including the root container. The accounts SYS and SYSTEM are common users who can set any PDB as their default container. For new common users, the username must begin with C## or c##, although creating a username with lowercase letters by using double quotation marks around the username is highly discouraged.
When you create a common user with the CREATE USER command, you typically add CONTAINER=ALL to the command, as in this example:

If you are connected to the root container and have the CREATE USER privilege, the CONTAINER=ALL clause is optional. The same applies to a local user and the CONTAINER=CURRENT clause. The C##SECADMIN user now has DBA privileges in the root container. This user has an account set up in each PDB but no privileges in any PDB unless explicitly assigned:

To allow the user C##SECADMIN to at least connect to the QATEST1 database, grant the appropriate privileges as follows:
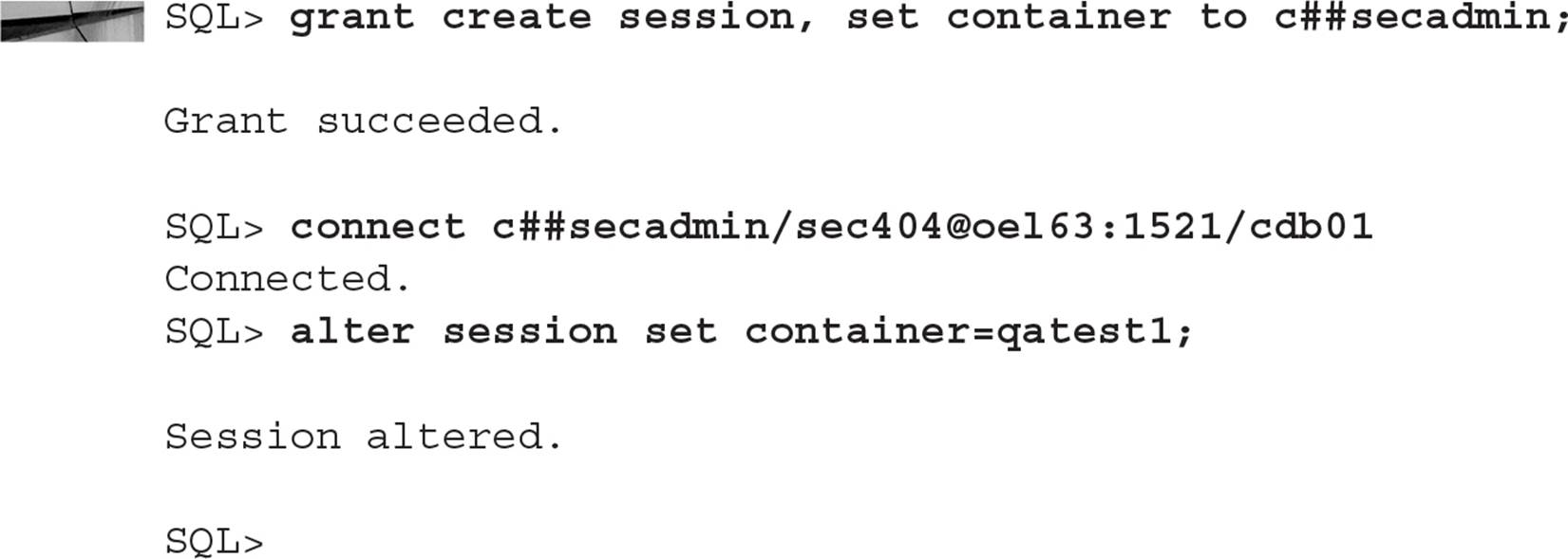
When using CREATE USER, you can optionally specify the default tablespace, the default temporary tablespace, and the profile. These three attributes must exist in each PDB; otherwise, those values will be set to the PDB defaults for those items.
What if a common user is created while one of the PDBs is currently not OPEN, in RESTRICTED mode, or in READ ONLY mode? The new common user’s attributes are synced the next time the other PDBs are opened.
Managing Common and Local Privileges
Common and local privileges apply to common and local users. If a privilege is granted across all containers to a common user, it’s a common privilege. Similarly, a privilege granted in the context of a single PDB is a local privilege regardless of whether the user is local or common.
In the previous section, the user C##SECADMIN, a common user, was granted the CREATE SESSION privilege but only on the QATEST1 container. If C##SECADMIN needs access to all PDBs by default, use the CONTAINER=ALL keyword to grant that privilege across all current and new PDBs in the CDB:
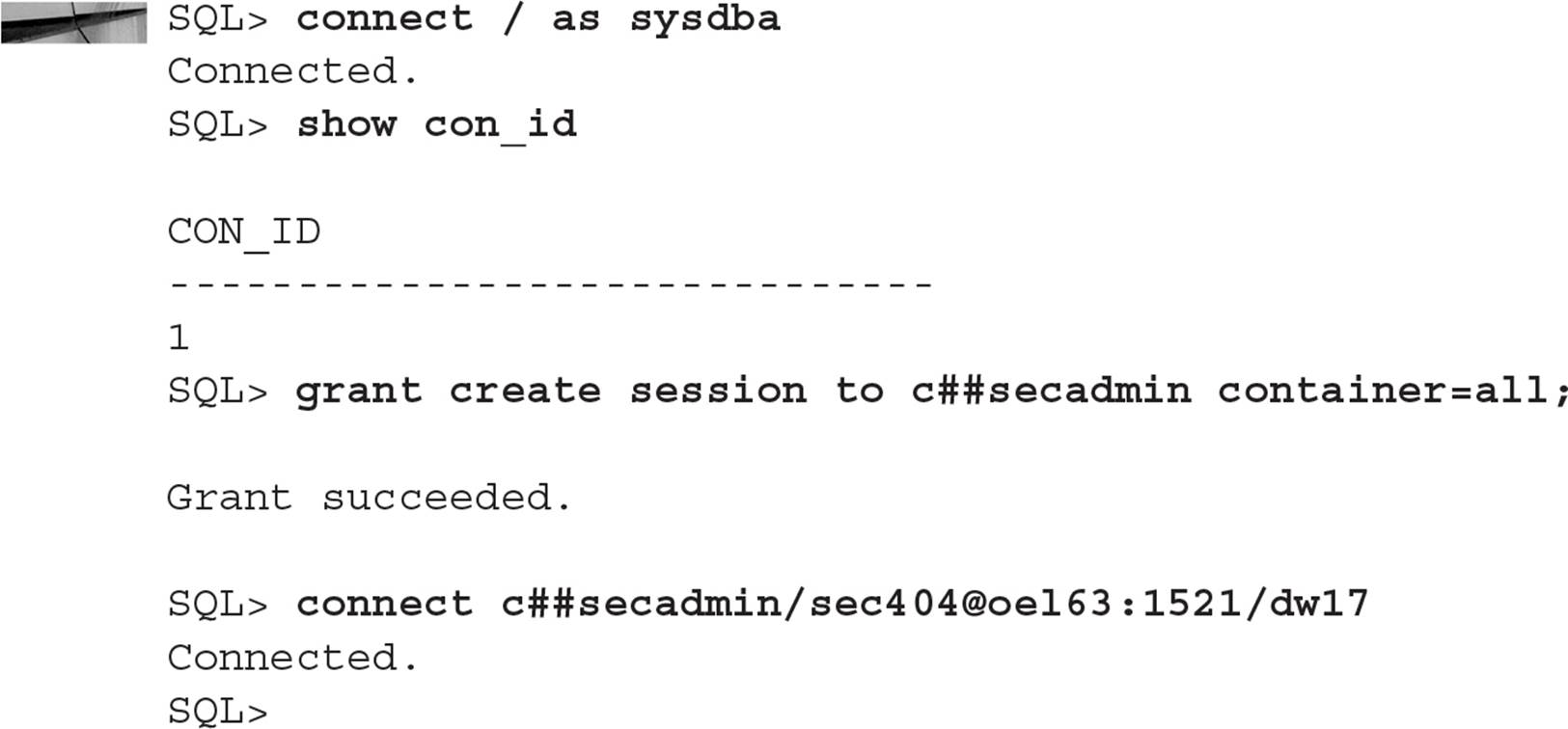
From a security perspective, you can grant common users privileges in the root container but no other containers. Remember that only common users can connect to the root container regardless of the privileges granted; for a common user to connect to the root container, the user will need the CREATE SESSION privilege in the context of the root container, as you can see in this example:


To fix this issue for C##ROOTADM, you need to grant the CREATE SESSION privilege in the context of the root container:
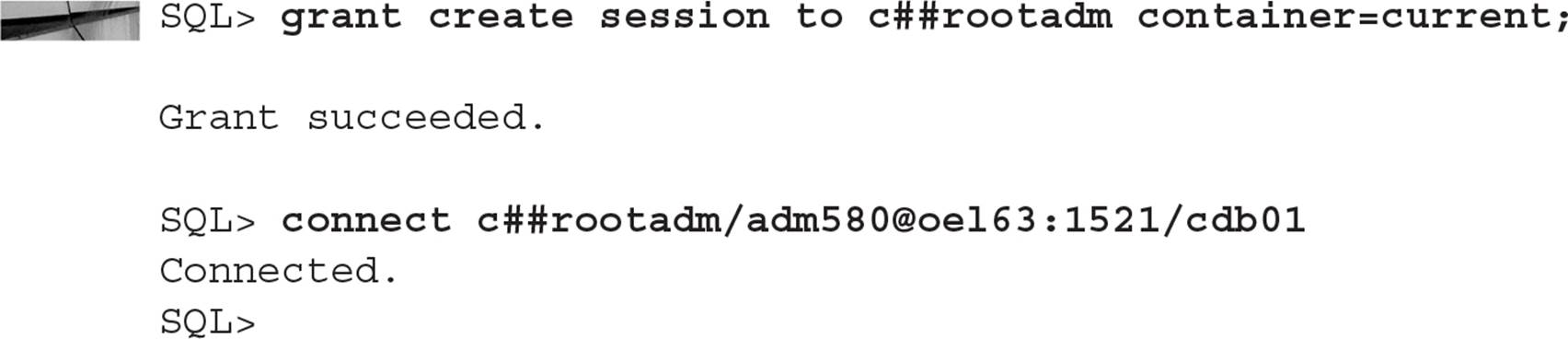
You revoke privileges from users and roles using the REVOKE command as in previous releases and non-CDBs. The key difference of using GRANT and REVOKE in a multitenant environment is the addition of the CONTAINER clause where you specify the context of the GRANT or REVOKE. Here are some examples of the CONTAINER clause:
![]() CONTAINER=QATEST1 (privileges valid only in the PDB QATEST1)
CONTAINER=QATEST1 (privileges valid only in the PDB QATEST1)
![]() CONTAINER=ALL (privileges valid across all PDBs, current and future)
CONTAINER=ALL (privileges valid across all PDBs, current and future)
![]() CONTAINER=CURRENT (privileges granted or revoked in the current container)
CONTAINER=CURRENT (privileges granted or revoked in the current container)
To grant a privilege with CONTAINER=ALL, the grantor must have the SET CONTAINER privilege along with the GRANT ANY PRIVILEGE system privilege.
Managing Common and Local Roles
Roles, just like system and object privileges, work much the same in a multitenant environment as they do in a non-CDB environment. Common roles use the same conventions as common users and start with C##; a common role can have the same privileges across all containers or specific privileges or no privileges in a subset of containers. You use the CONTAINER clause to specify the context of the role:


Note in the example that a common role (C##MV) was granted to a local user (DW_REPL) in DW17. The user DW_REPL inherits all the privileges in the role C##MV but only in the DW17 PDB. The reverse is also possible: A common user (such as C##RJB) can be granted a local role (such as LOCAL_ADM) in a specific PDB (such as QATEST1), and therefore the privileges granted via LOCAL_ADM are available only in QATEST1 for C##RJB.
Enabling Common Users to Access Data in Specific PDBs
Just as in a non-CDB environment, you may want to share objects with users in other PDBs. By default, any tables created by a common or local user are nonshared and are accessible only in the PDB where they were created.
Shared tables, on the other hand, have some restrictions. Only Oracle-supplied common users (such as SYS or SYSTEM) can create shared tables; common users that the DBA creates (even with DBA privileges such as CREATE USER, DROP ANY TABLE, and so forth) cannot create shared tables.
The two types of shared objects are “links”: Object Links and Metadata Links. Object Links connect every PDB to a table in the root container, and each PDB sees the same rows. A good example of this is Automatic Workload Repository (AWR) data in tables like DBA_HIST_ACTIVE_SESS_HISTORY, which has the column CON_ID so you can identify which container the row in DBA_HIST_ACTIVE_SESSION_HISTORY applies to.
In contrast, Metadata Links allow access to tables in the root container plus their own private copies of the data. Most of the DBA_ views use this method. For example, looking at the DBA_USERS view in the PDB QATEST1, there is no CON_ID column from the PDB perspective:
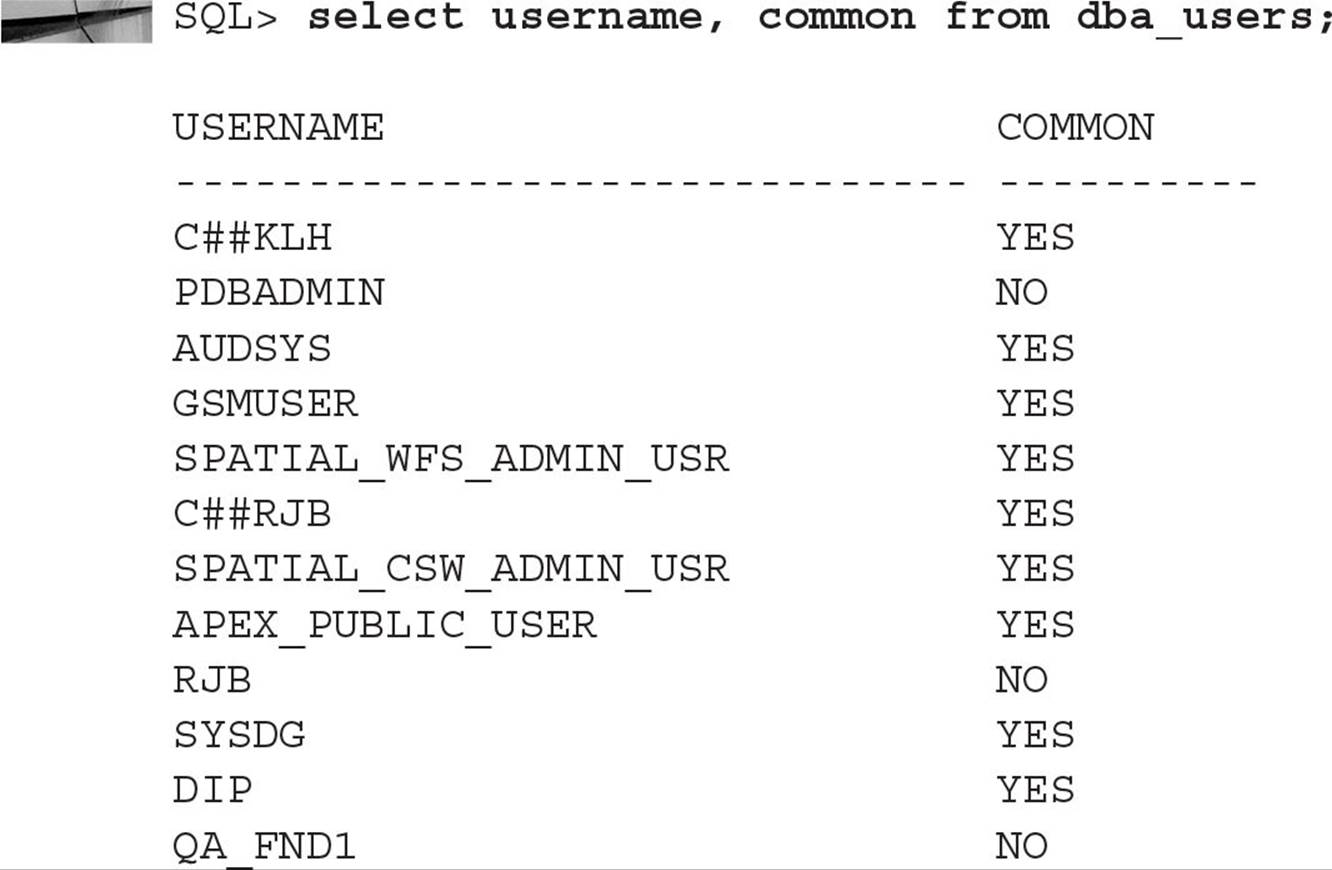
However, from the same table in the root container, you can look at CDB_USERS and see the local and common users across all containers:

The common users such as C##RJB exist for every PDB (other than the seed database). Users such as QAFRED exist only in the PDB with CON_ID=3 (QATEST1). Note also that the common users you create must start with C##; Oracle-supplied common users do not need this prefix.
By default, common users cannot see information about specific PDBs. This follows the principle of least privilege required to accomplish a task; a common user won’t automatically be able to connect to a specific PDB nor see metadata about any PDB unless explicitly granted.
To leverage the granularity of data dictionary views by common users, you’ll use the ALTER USER command to specify a common user, what container data they can access, and what container they can access it from. For example, you may want only the common user C##RJB to see rows in V$SESSION for the PDB DW17 when connected to the PDB QATEST1. You would use the following command to accomplish this:

To view the list of users and the container objects accessible to them, look in DBA_CONTAINER_DATA:
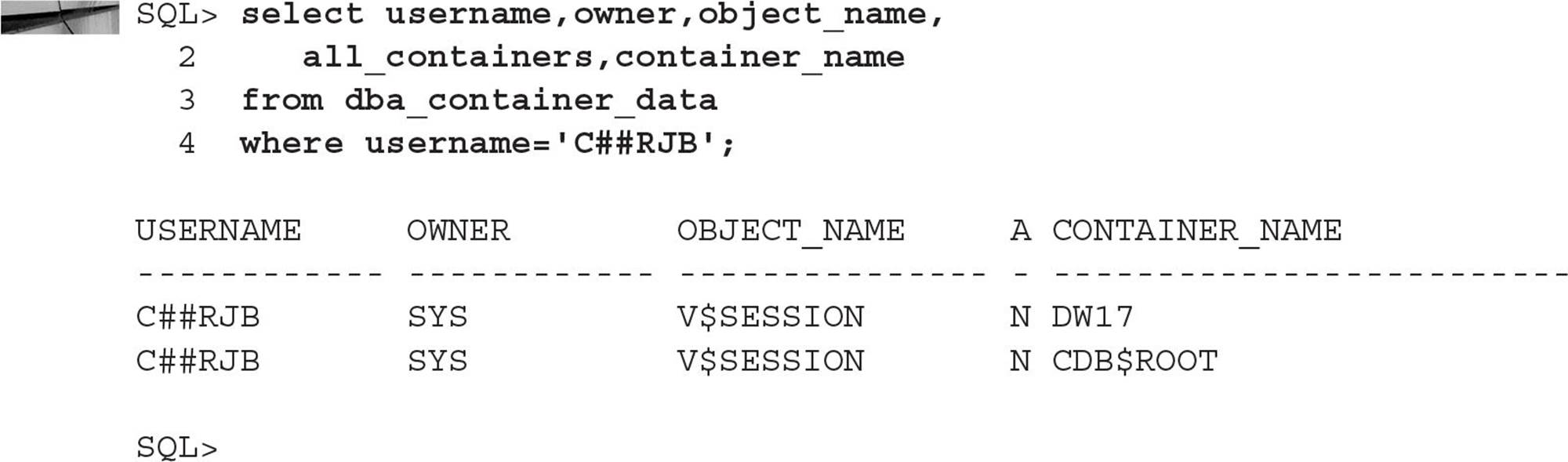
The common user C##RJB will be able to see only rows in V$SESSION for the container DW17.
Backup and Recovery in Multitenant Environments
There are several backup and recovery options for a CDB or a PDB. Using ARCHIVELOG mode enhances the recoverability of a database, but in a multitenant environment you can enable ARCHIVELOG mode only at the CDB level since the redo log files are only at the CDB level. Otherwise, you can still back up your database in much the same way as in a non-CDB environment. You can back up the entire CDB, a single PDB, a tablespace, a datafile, or even a single block anywhere in the container.
The Data Recovery Advisor works much the same way as it did in previous releases of Oracle Database: When a failure occurs, the Data Recovery Advisor gathers failure information into the Automatic Diagnostic Repository (ADR). The Data Recovery Advisor also has proactive features to check for failures before they are detected by a user session.
You can also easily duplicate a PDB using RMAN. Using RMAN gives you more flexibility when copying a PDB compared to using the CREATE PLUGGABLE DATABASE … FROM … option. For example, you can use the RMAN DUPLICATE command to copy all PDBs within its CDB to a new CDB with the same PDBs plus the root and seed databases.
Performing Backups of a CDB and All PDBs
For multitenant databases, the RMAN syntax has been modified and new clauses have been added. At the OS level, the environment variable ORACLE_SID was previously set at the instance level, but now that all databases within a CDB are running in the same database instance, you can connect to a single PDB with RMAN using the service name and not the instance name. Here’s an example:

As in previous releases, you can connect to the CDB with RMAN using the syntax you’re familiar with:

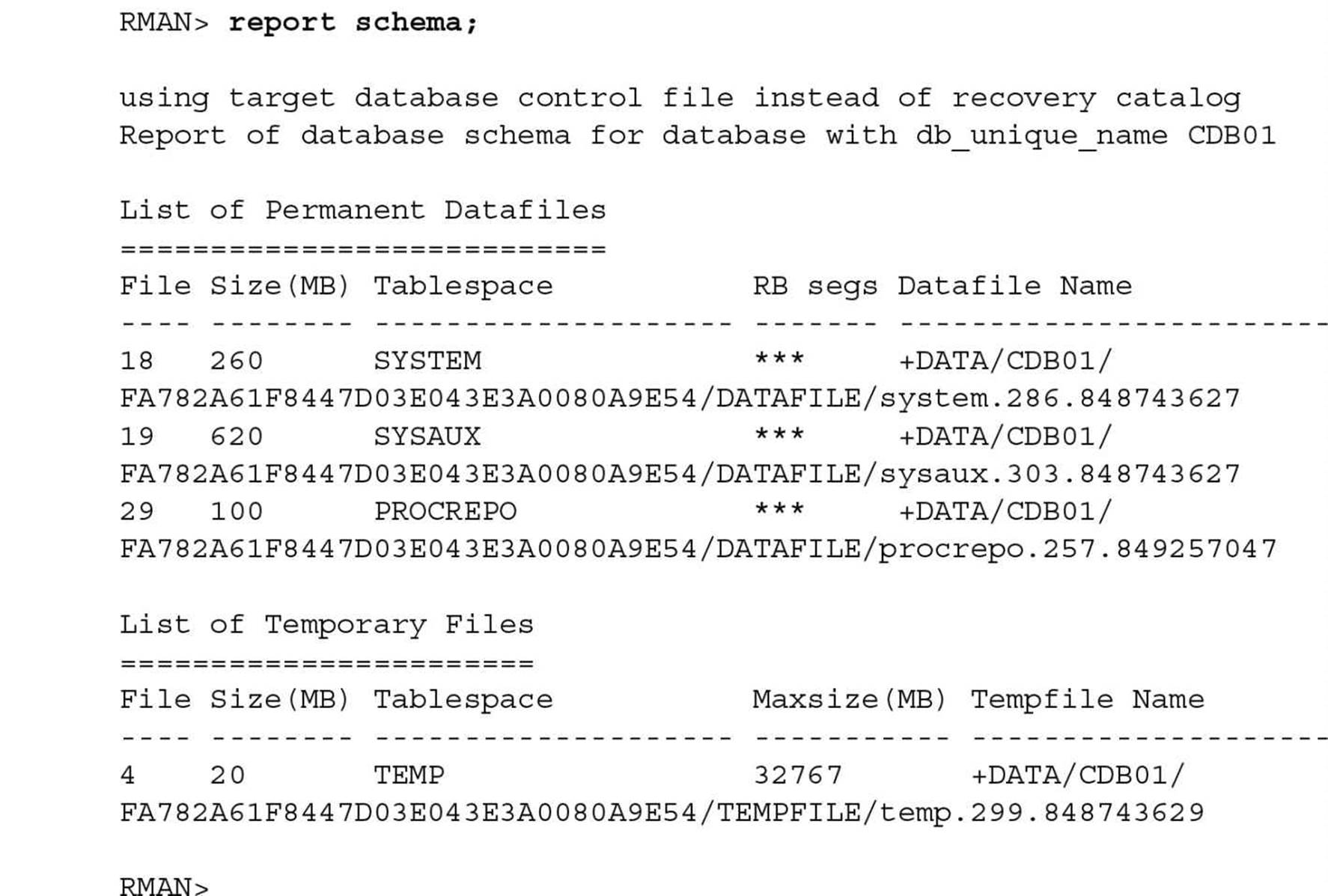
Note, however, that the target database is displayed as CDB01 in both cases. How else would you know that you’re connected to a specific PDB instead of the CDB? To find out, just use the REPORT SCHEMA command:
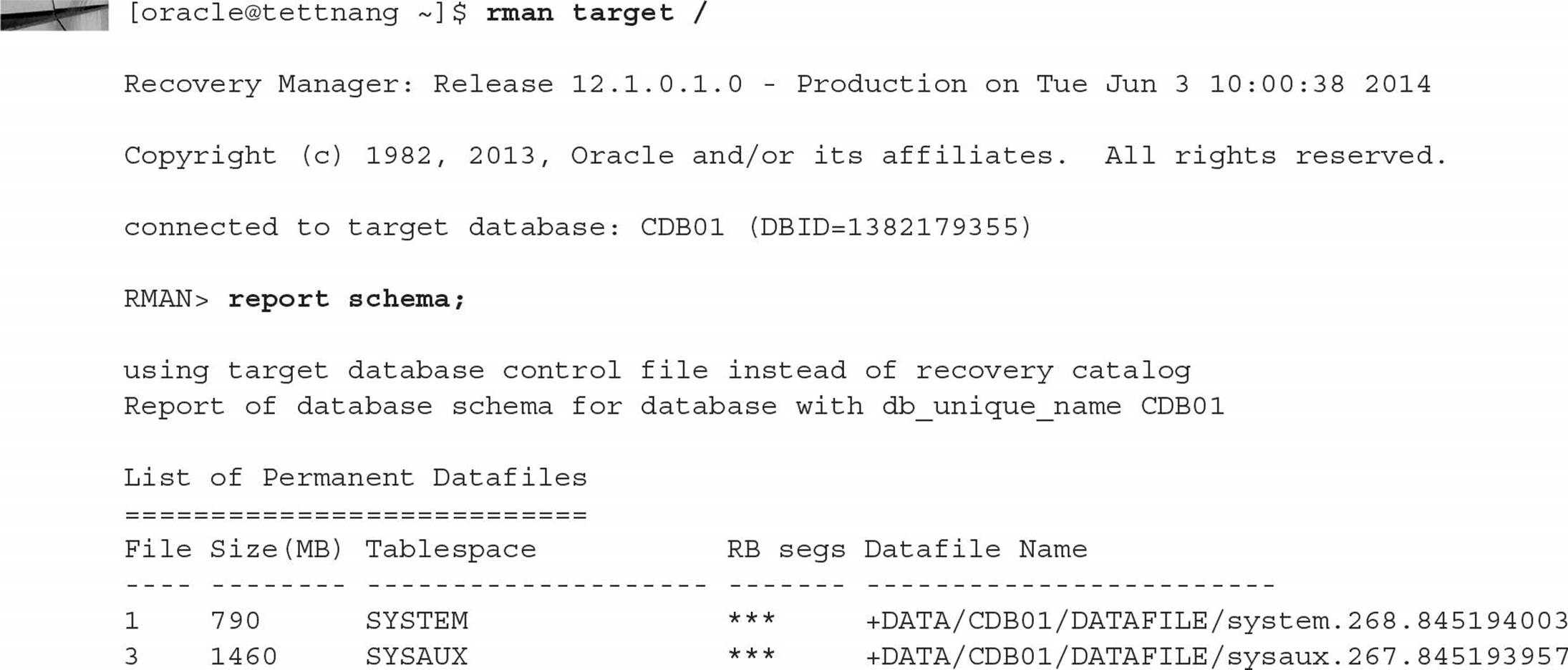
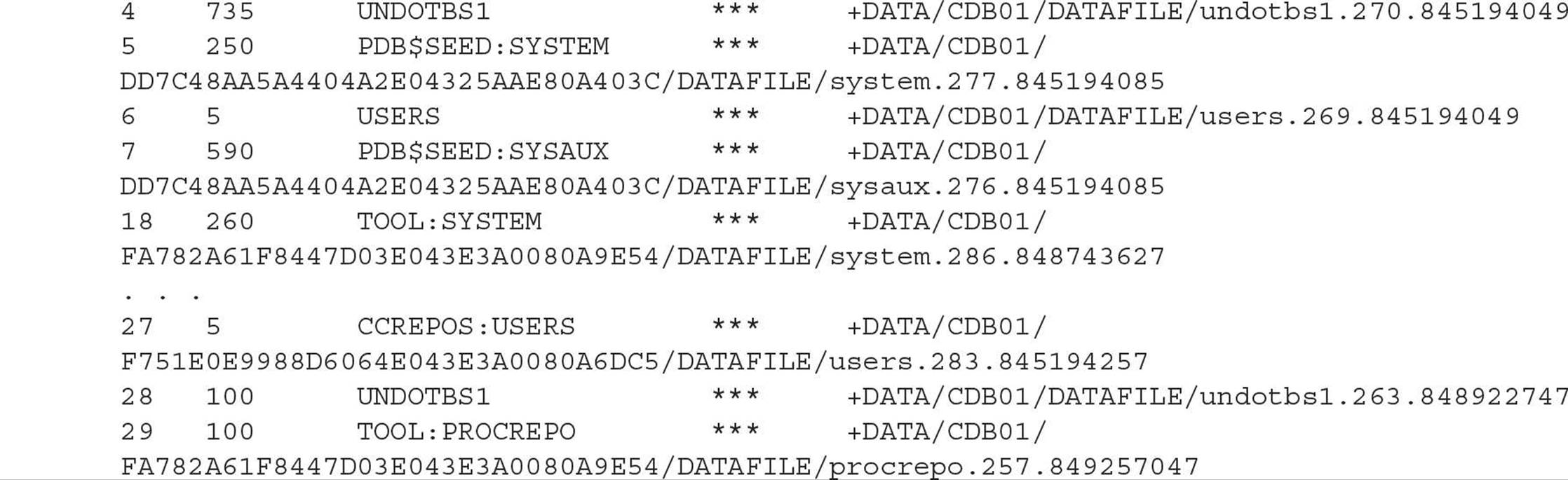
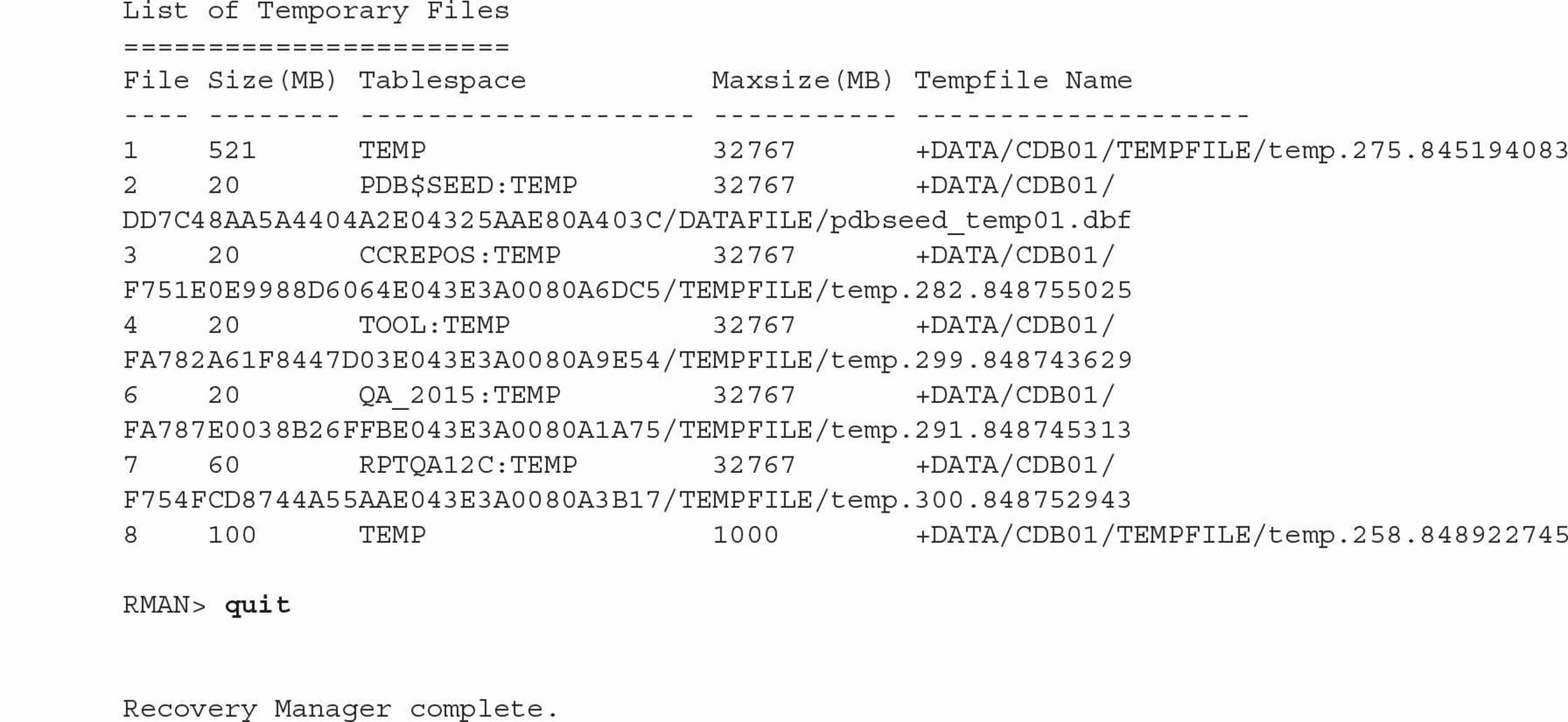
Note that connecting to the CDB shows all tablespaces, including those of the seed and root containers. Connecting to an individual PDB returns different (but expected) results for the REPORT SCHEMA command:

The RMAN BACKUP, RESTORE, and RECOVER commands have been enhanced to include the PLUGGABLE keyword when operating on one or more PDBs:
![]()
In addition, you can qualify a tablespace backup with a PDB name to back up one specific tablespace within the PDB:

Without any qualification, when connected to the CDB, any RMAN commands operate on the root container and all PDBs. To back up just the root container, use the name CDB$ROOT, which as you know from Chapter 11 is the name of the root container within the CDB.
Backing Up CDBs
As mentioned in the previous section, you can back up the entire CDB as a full backup, a single PDB within the CDB, or individual tablespaces in any of the PDBs or root container. To run RMAN and back up a container, the user must have a common account with either the SYSDBA or SYSBACKUP privilege in the root container. To accommodate separation of duties, Oracle recommends assigning only the SYSBACKUP privilege to a database user who is responsible only for database backups and recovery.
Since a CDB is most similar to a pre-12c database (non-CDB), your backups will look similar to RMAN backups you created in Oracle Database 11g. You can create backupsets or image copies along with the control file, SPFILE, and optionally the archived redo log files.
Backing up the CDB (and all PDBs) with the container open requires ARCHIVELOG mode as in previous releases; if the CDB is in NOARCHIVELOG mode, then the container must be open in MOUNT mode (and therefore no PDBs are open as well). Here is an example:

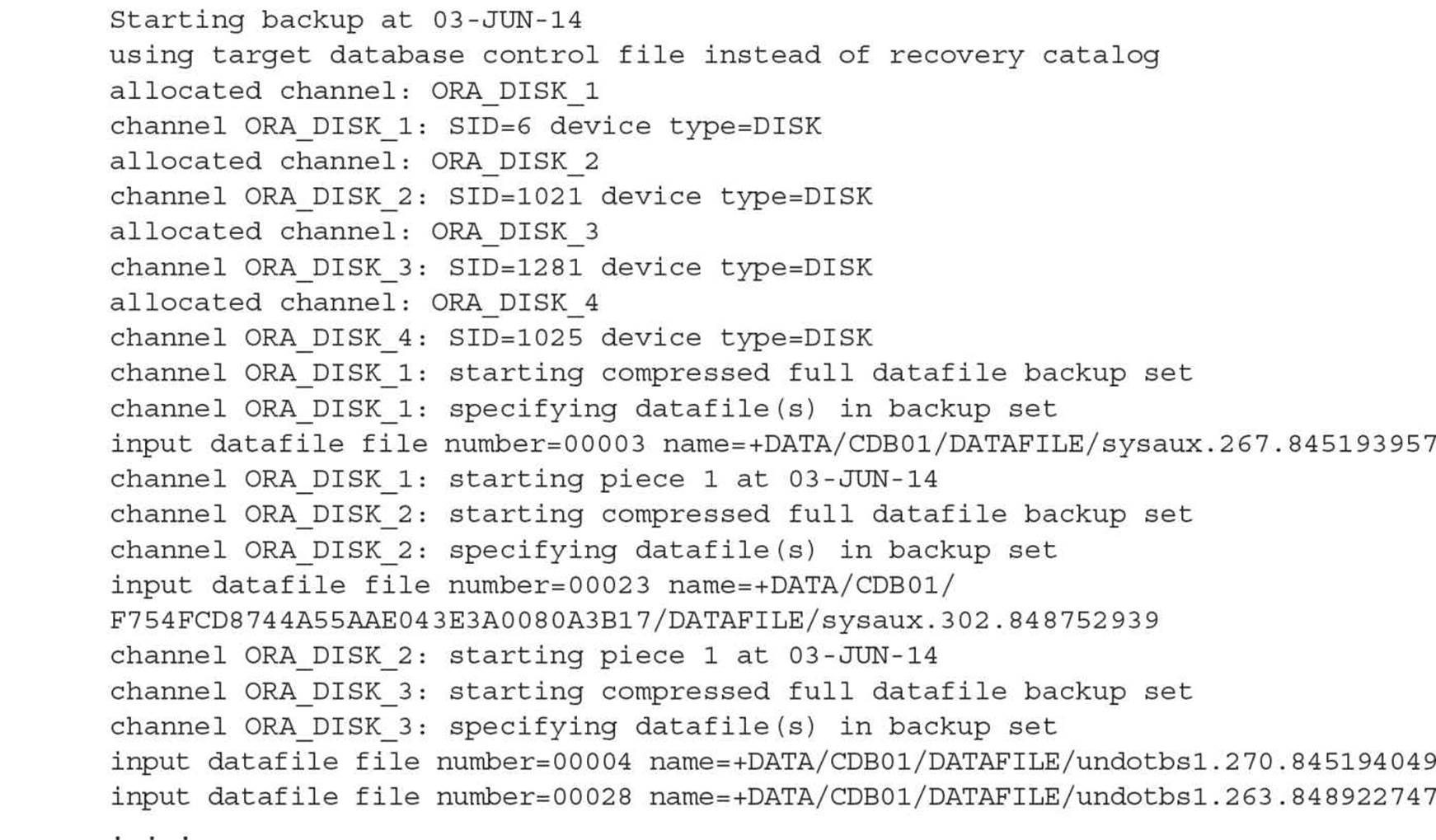
Note the references to tablespaces and datafiles like this:

It’s the datafile for the SYSAUX tablespace in one of the PDBs. To find out which one, you can look in the dynamic performance view V$PDBS at the column GUID. The globally unique identifier (GUID) value is a long hexadecimal string that uniquely identifies the container even when it’s unplugged from one CDB and plugged back into another.
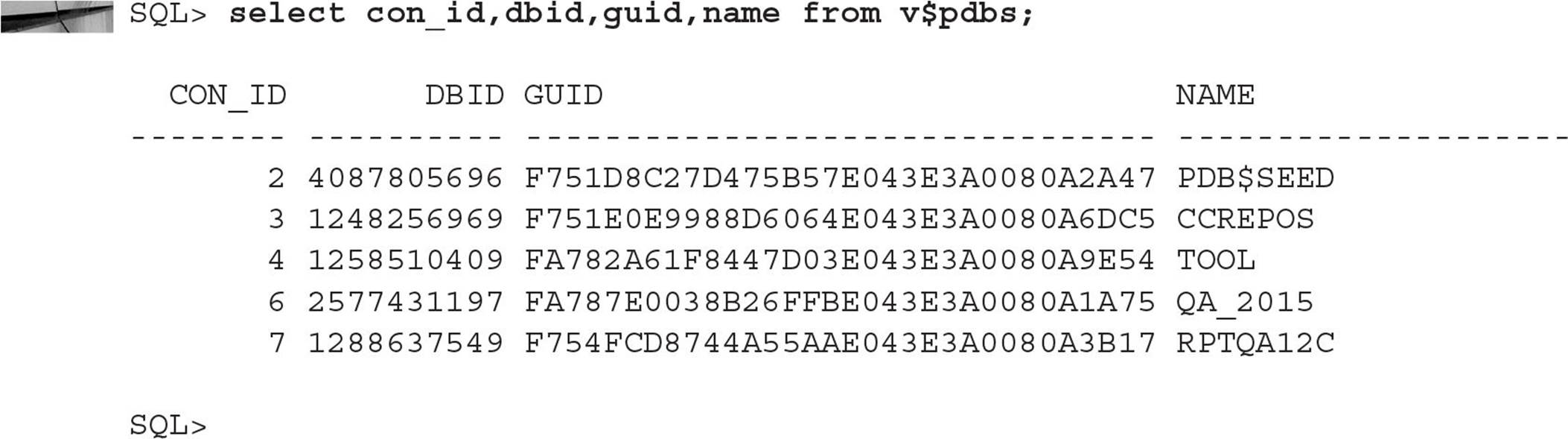
In this case, the SYSAUX datafile belongs to the RPTQA12C PDB.
If you want to perform a partial CDB backup, you connect to the container (CDB) with RMAN and back up one or more containers in a single command along with the root container using the PLUGGABLE DATABASE clause, as in this example:
![]()
In a recovery scenario, you can restore and recover the TOOL PDB separately from the RPTQA12C PDB or just the root container.
Backing Up PDBs
Backing up a PDB is also similar to backing up a non-CDB in Oracle Database 12c or previous releases. Note that backing up a PDB is identical to backing up part of a CDB but without the root container (CDB$ROOT). For separation of duties, you can have a user with SYSBACKUP privileges in only one PDB. They will connect only to the PDB and then back it up as if it were a non-CDB. This example shows a backup administrator connecting to only the CCREPOS PDB as a local user and performing a full RMAN backup:
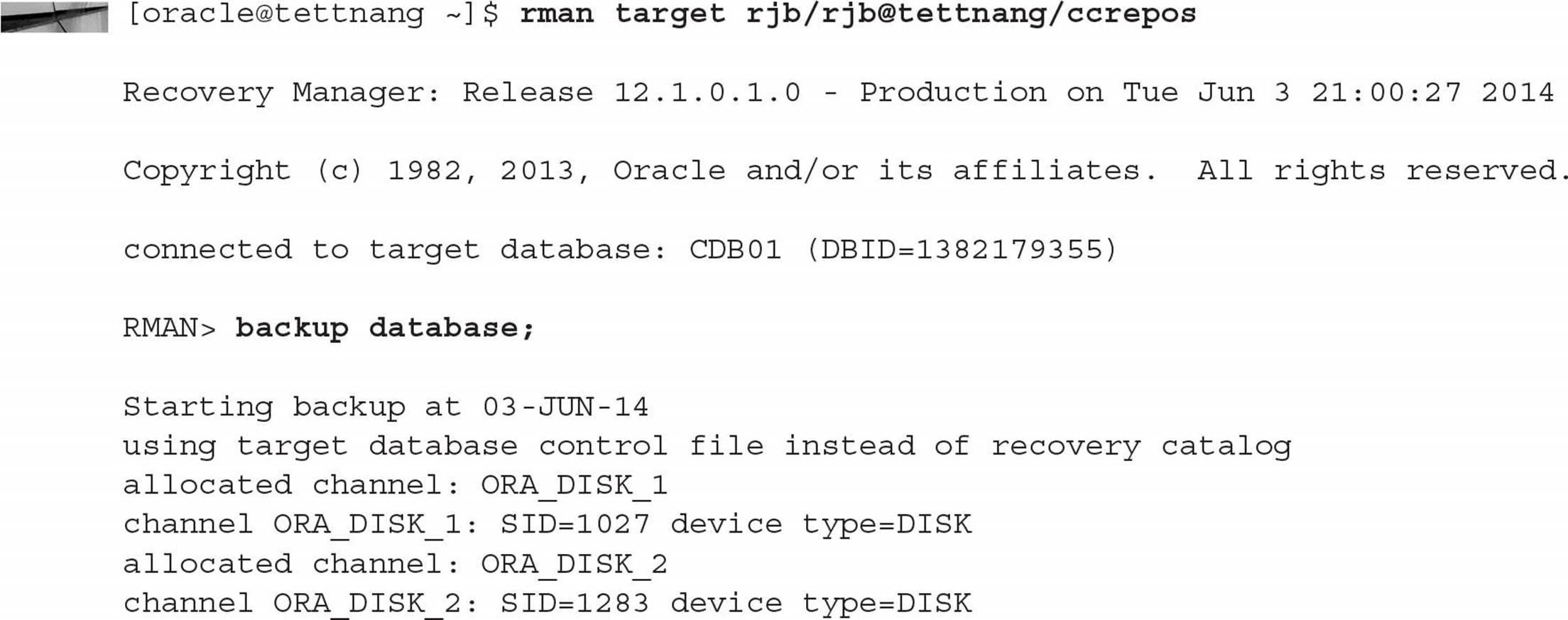
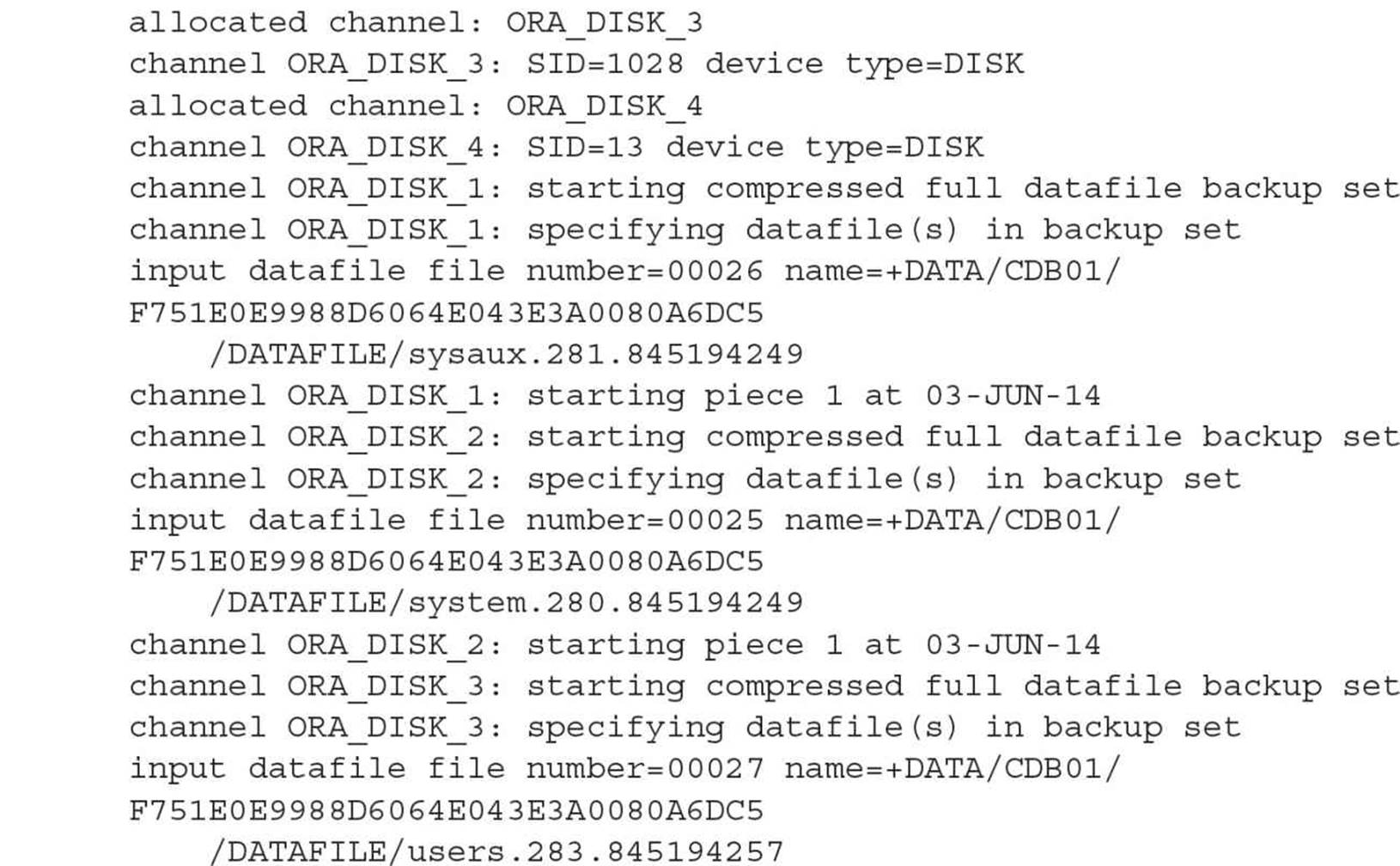

Note that you do not need to specify the PLUGGABLE keyword since you’re doing the backup from the perspective of a single PDB. Even though you’re backing up a single PDB, the control file is included in the full backup despite the fact that the control file is shared across the entire container along with the SPFILE.
Recovering from PDB Datafile Loss
As with non-CDB databases, both PDBs and a CDB can suffer from instance failure or media failure requiring some kind of recovery operation. The recovery can occur at the CDB level, the PDB level, a tablespace within a PDB, a datafile, or even an individual block. The one major difference is instance recovery: Since all PDBs and the CDB share a single instance, all PDBs go down if the CDB goes down, and thus crash recovery for the instance occurs only at the CDB level. Similarly, any objects that are global and exist at the CDB level, such as the control files, redo log files, or datafiles from the root’s SYSTEM or UNDO tablespaces, require media recovery at the CDB level only.
In the following sections, I’ll review the types of media failure and how to recover from them. Many of the scenarios have the same recovery solution as a non-CDB, and in the case of a single PDB, the recovery of that PDB can occur with little or no disruption to other PDBs that may be open at the time.
Tempfile Recovery
Recall from earlier in this chapter that a temporary tablespace (with one or more tempfiles) exists at the CDB level, but each PDB can have its own temporary tablespace if the application has different requirements. If a PDB’s DML or SELECT statements require the TEMP tablespace at the CDB level and it is suddenly lost because of media failure, the statement will fail. In this example, one of the ASM administrators accidentally deletes one of the tempfiles belonging to the CDB:
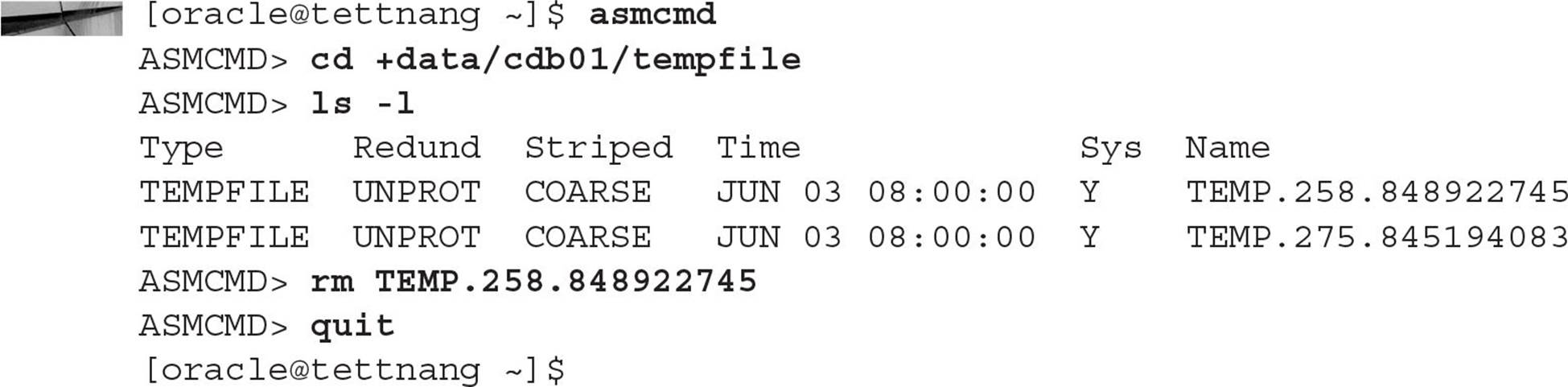
The easy but draconian solution to fix the problem would be to restart the entire CDB. Instead, you can just add another tempfile to the TEMP tablespace and drop the one that no longer exists:

As with non-CDBs, if a temporary tablespace (at either the CDB or PDB level) is missing at container startup, it is re-created automatically.
Recovering from Control File Loss
Losing one or all control files is just as serious as losing a control file in a non-CDB. Oracle best practices dictate that you have at least three copies of the control file available. If you lose all copies of the control file, you can get them from the latest RMAN autobackup. In this example, the copy of the control file in the +RECOV disk group is missing, and the CDB will not start (and as a result, none of the PDBs can start):
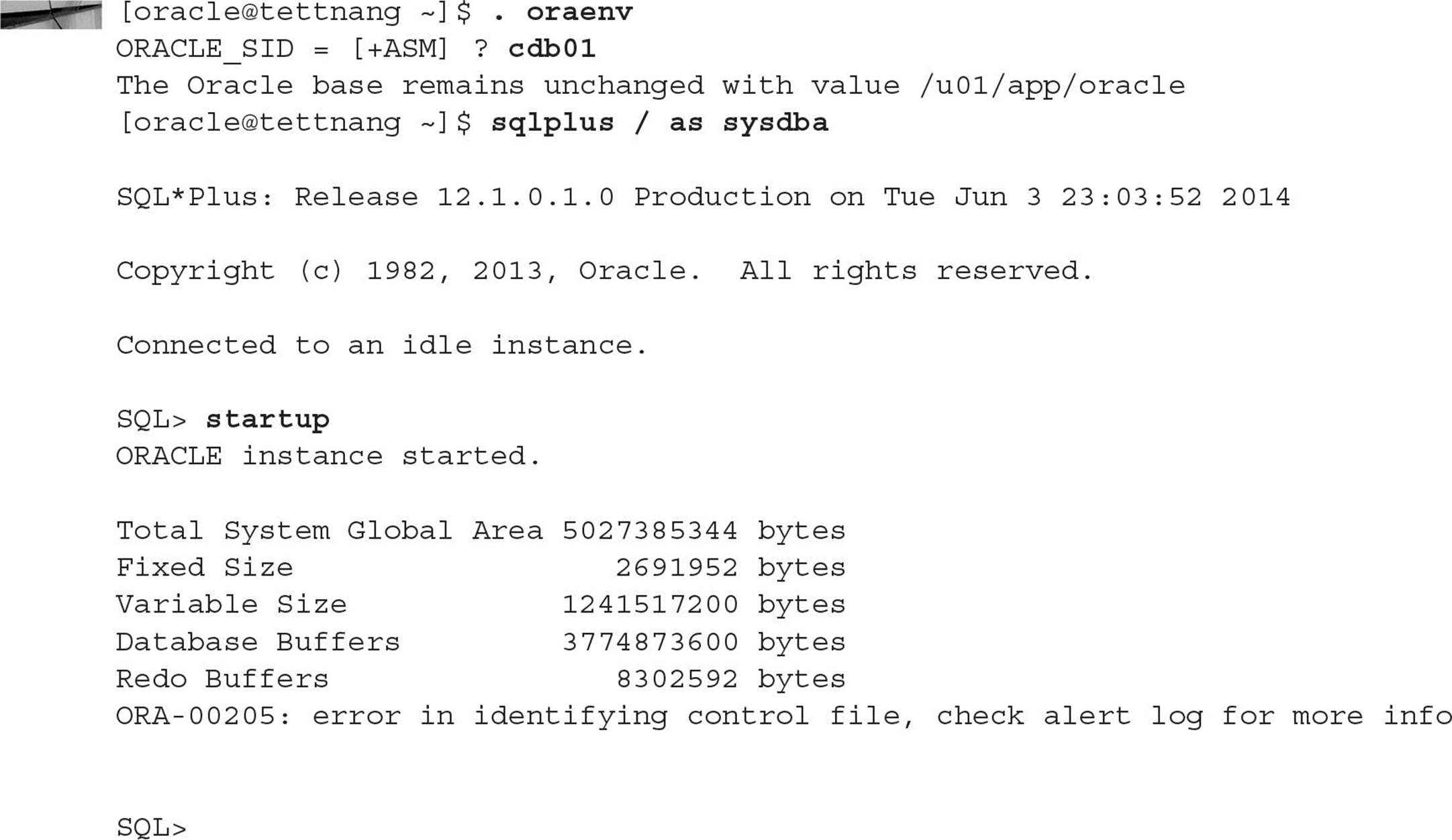
Shut down the instance and recover the control file from the last RMAN backup:

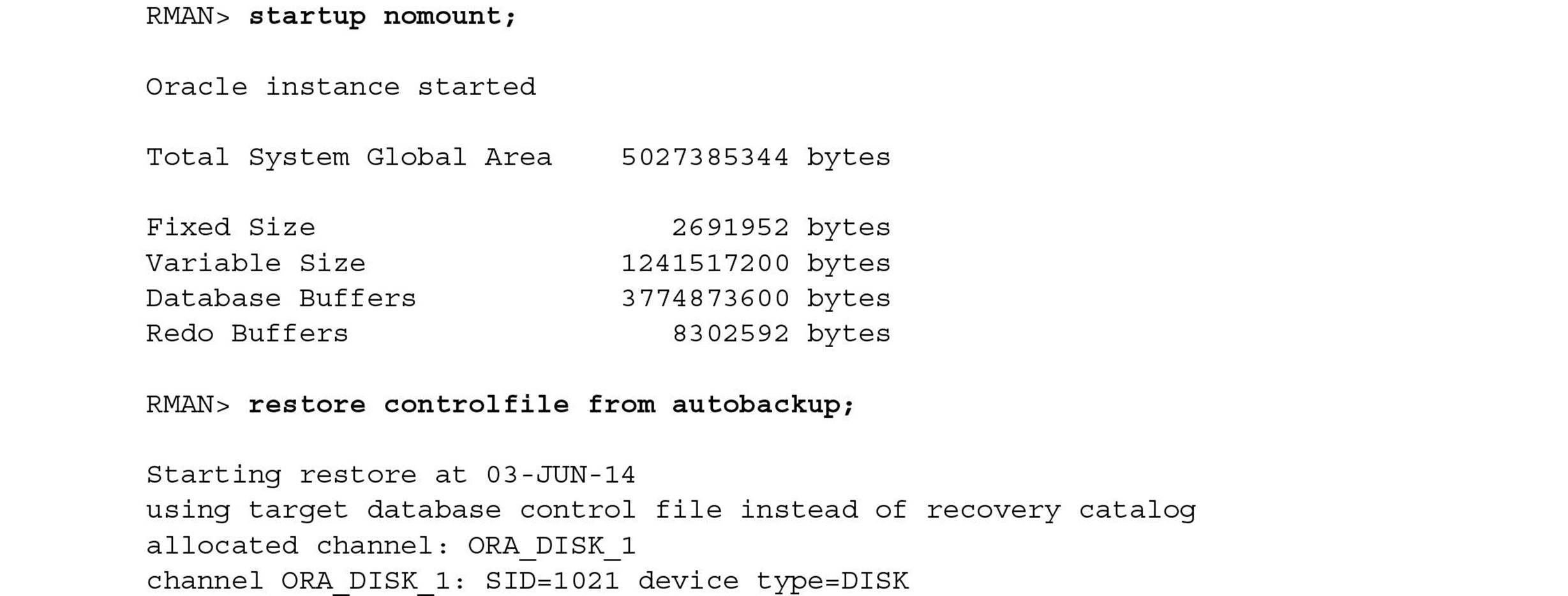
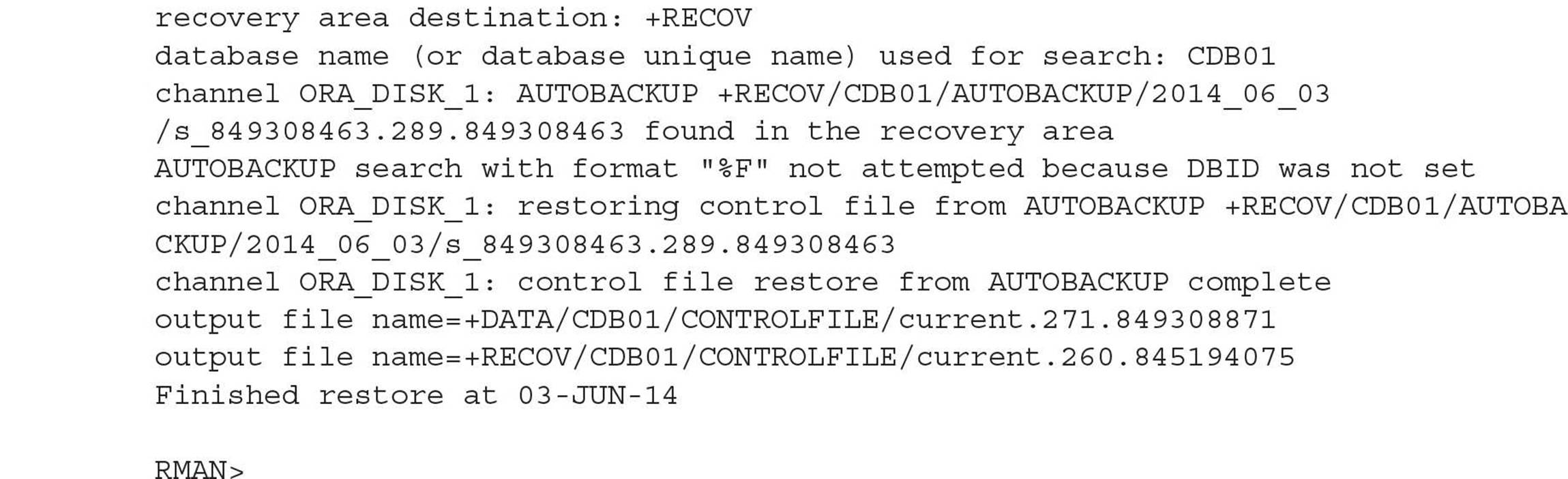
Even though only one copy of the control file was lost, the RMAN recovery operation restores both copies; the remaining control file is almost certainly out of sync with the autobackup version:
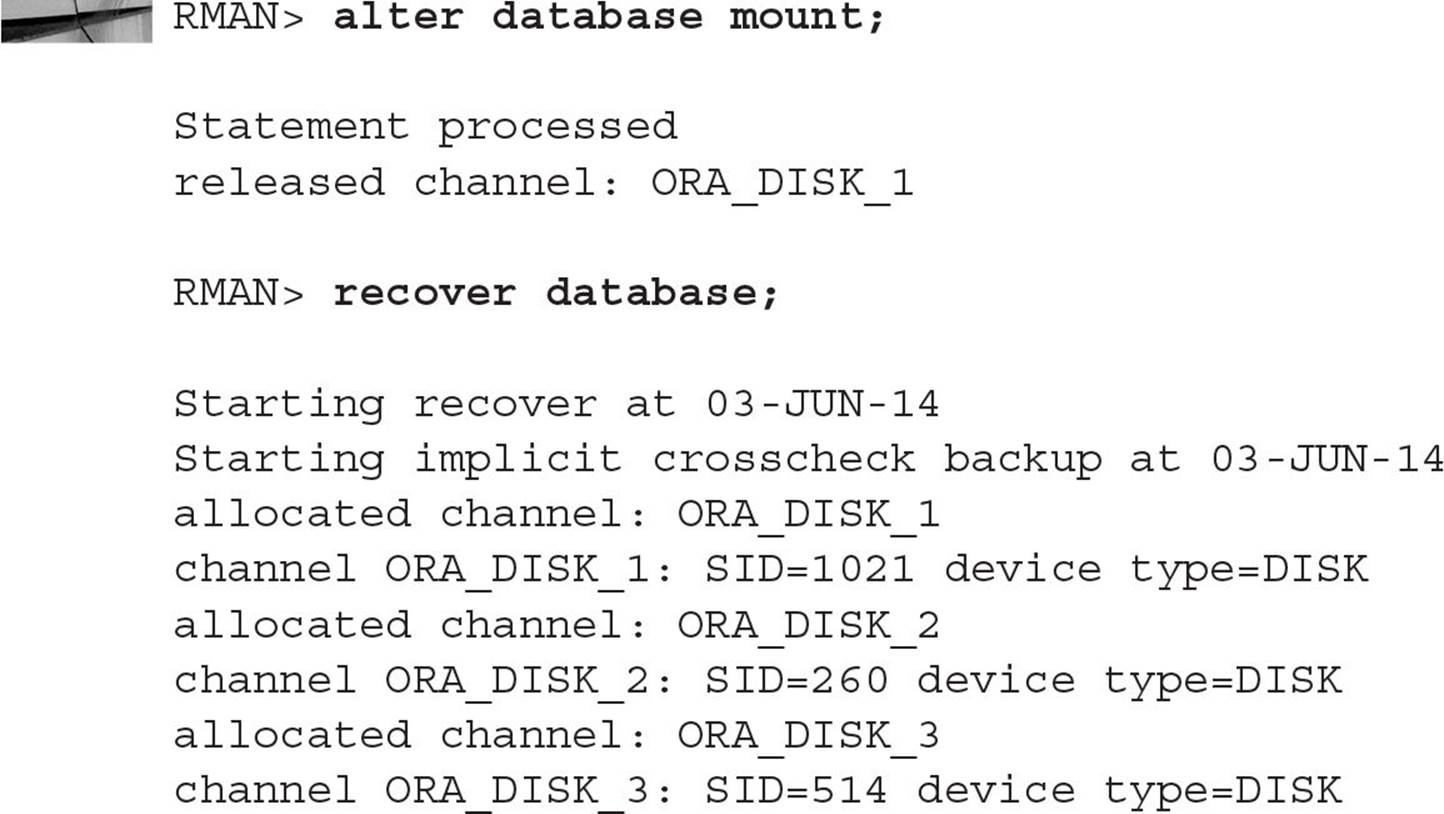
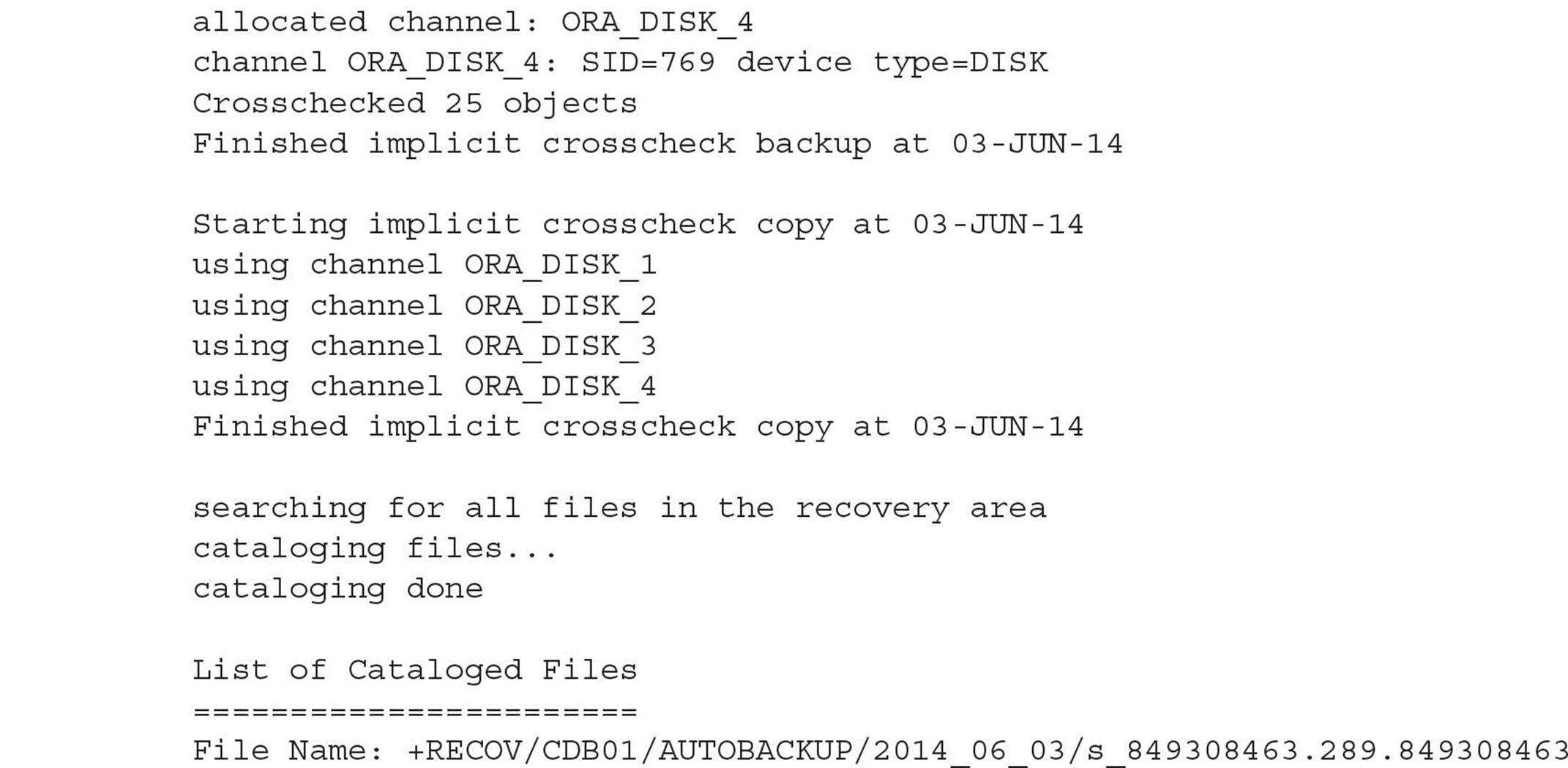
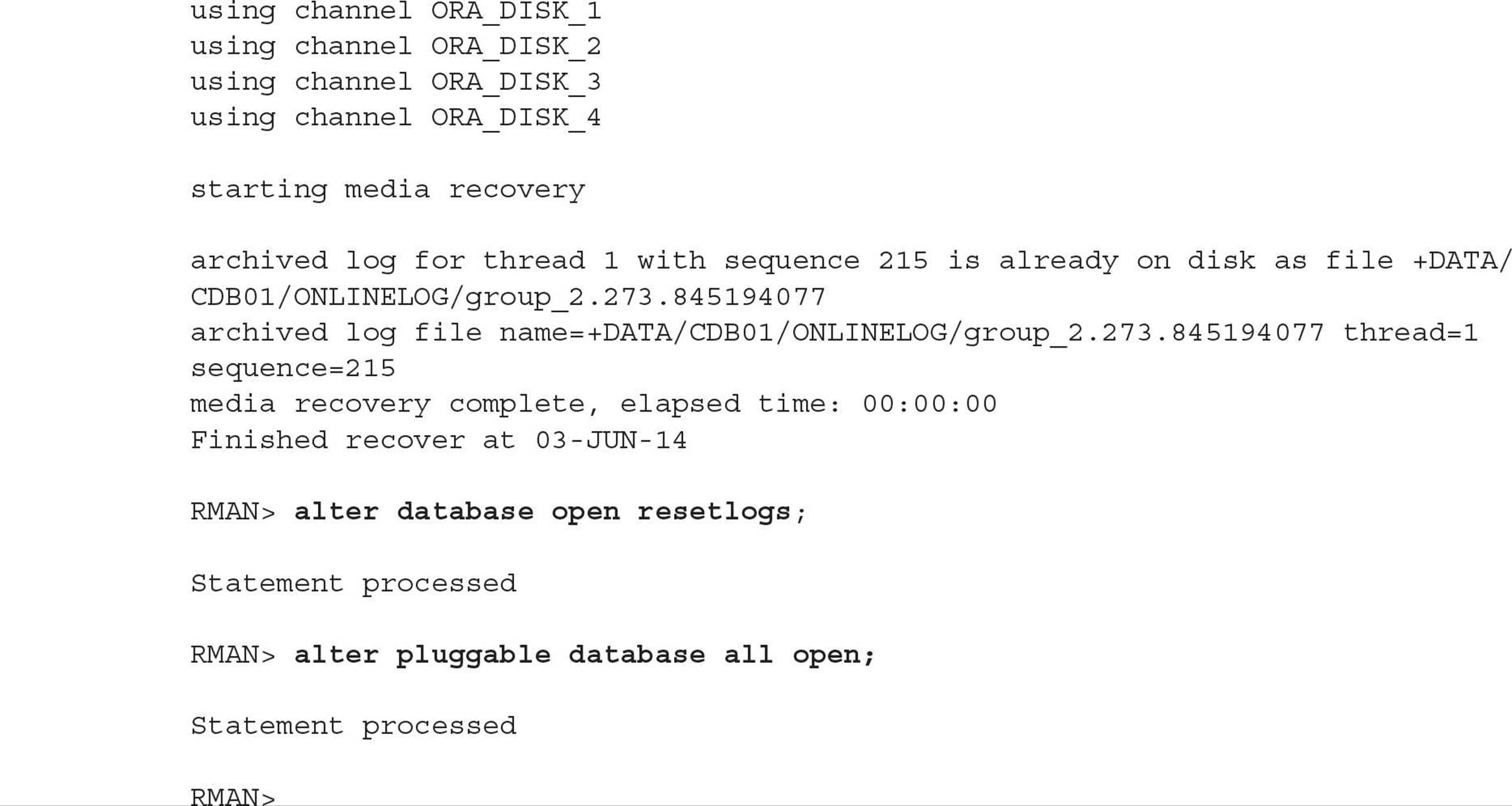
Data loss will not occur unless you have objects defined in the recovered control file that were created after the last RMAN autobackup of the control file.
Recovering from Redo Log File Loss
Redo log files are only at the CDB level and therefore are recovered in much the same way as in a non-CDB. Redo log files should be multiplexed with at least two copies. If one copy of a redo log group is lost or corrupted, the database writes to the remaining log group members, and an alert is issued. No database recovery is required, but the missing or corrupted redo log group member should be replaced as soon as possible to avoid possible data loss.
If all members of a redo log file group go missing or become corrupted, the database shuts down, and media recovery will likely be required since there are committed transactions in the lost redo log file group that have not yet been written to the datafiles. If the entire log file group was on a disk that was temporarily offline, just changing the status of the log file group to ONLINE will trigger an automatic instance recovery, and no data should be lost.
Recovering from Root Datafile Loss
Losing the critical SYSTEM or UNDO tablespace datafiles is just as serious as losing them in a non-CDB. If the instance does not shut down automatically, you’ll have to shut down the CDB and perform media recovery. The media recovery will also affect any PDBs that were open at the time of datafile loss or corruption.
The recovery process is the same as in a non-CDB for the loss of SYSTEM or UNDO. Losing a noncritical tablespace (such as an application-specific tablespace) does allow the CDB to remain open along with all PDBs while you perform media recovery.
Recovering the SYSTEM or UNDO Tablespace
As an example, suppose the datafiles for the CDB’s SYSTEM tablespace are accidentally deleted while the CDB is down. Starting it up gives the expectedly ominous message:
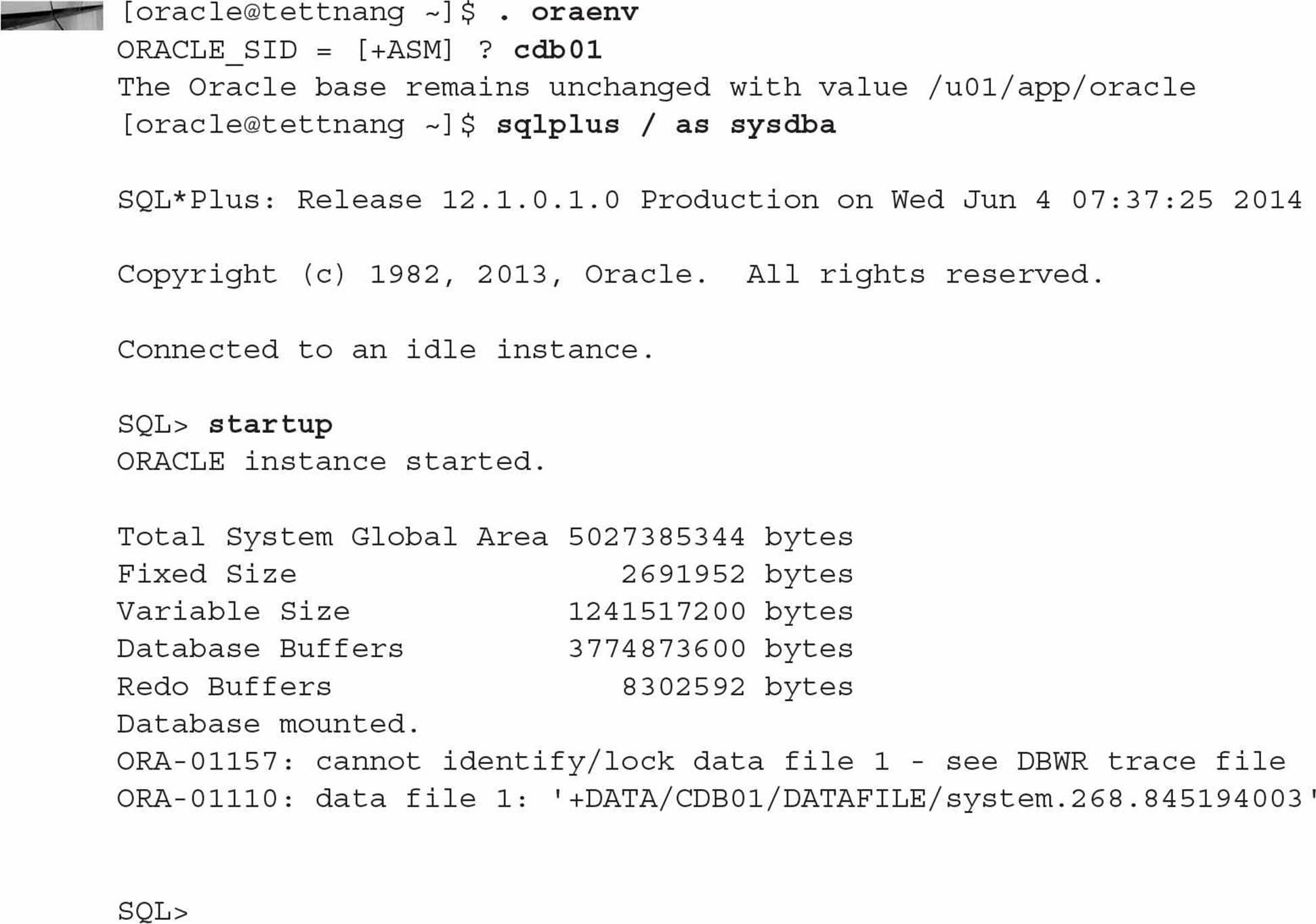
Since you’re in ARCHIVELOG mode and you did a recent full backup, you can restore and recover the CDB’s SYSTEM tablespace up to the point in time when the CDB was shut down last. Stop the instance and initiate recovery as you would with a non-CDB:

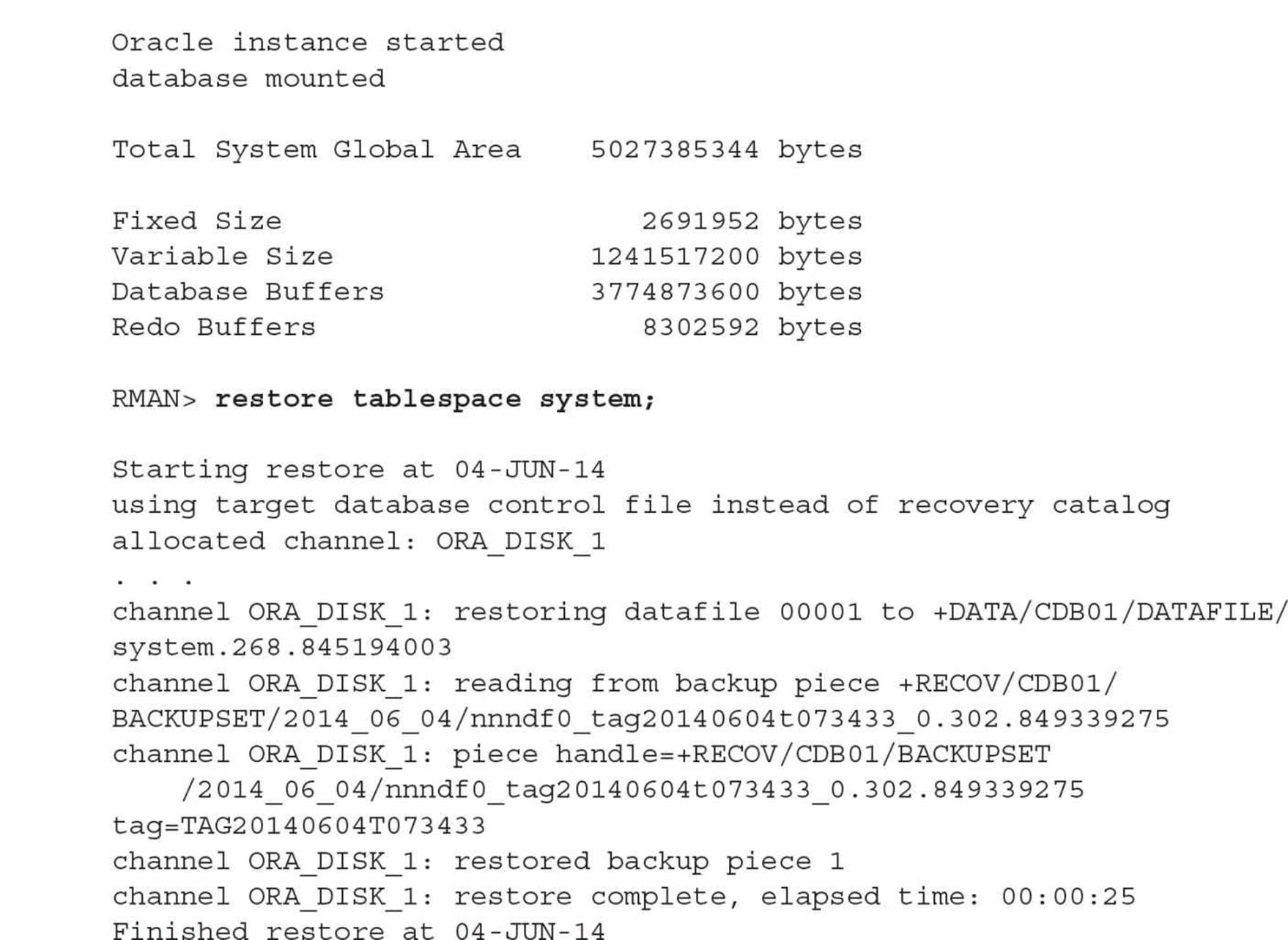
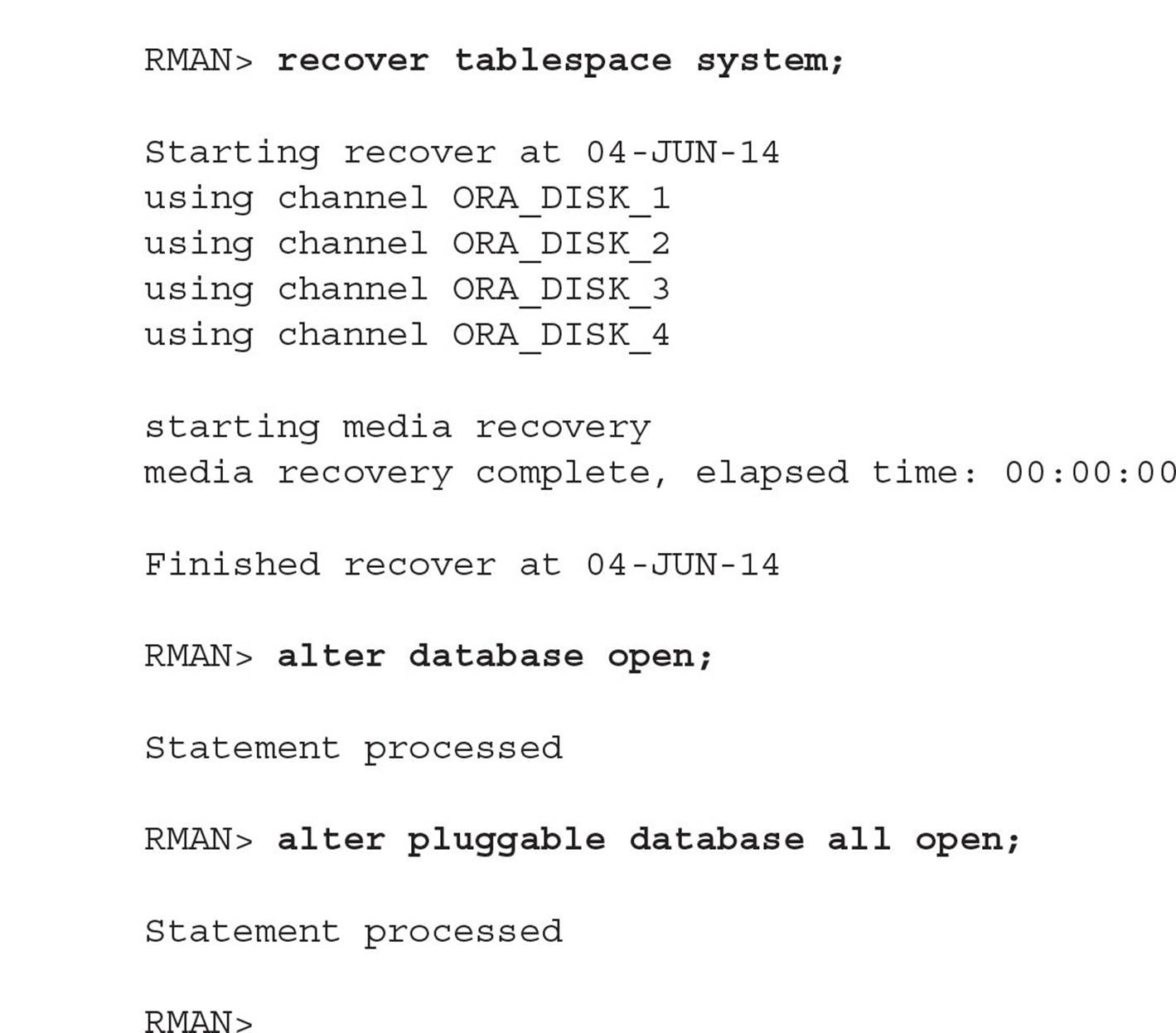
Note that in Oracle Database 12c, nearly all commands you would run in SQL*Plus are now available in RMAN without having to qualify them with the SQL keyword.
Recovering the SYSAUX or Other Root Tablespace
Restoring and recovering a missing noncritical root container tablespace other than SYSTEM or UNDO (such as SYSAUX) is even easier; there is no need to shut down the database (if it’s not down already). You merely have to take the tablespace with the missing datafiles offline, perform a tablespace restore and recovery, and then bring the tablespace online. All PDBs and the root container can remain online during this operation since root-specific tablespaces other than SYSTEM, TEMP, and UNDO are not shared with any PDB (other than TEMP if the PDB does not have its own TEMP tablespace). The series of commands looks something like this:

Recovering PDB Datafiles
Since all PDBs operate independently as if they were a non-CDB, any failure or datafile loss in a PDB has no effect on the root container or other PDBs unless the datafiles in the PDB’s SYSTEM tablespace are lost or damaged. Otherwise, restoring/recovering datafiles in a PDB is much the same as restoring and recovering datafiles in a CDB or non-CDB.
PDB SYSTEM Datafile Loss The loss of the SYSTEM tablespace in an open PDB is one of the few cases where the entire CDB must be shut down to recover the PDB’s SYSTEM tablespace. Otherwise, if the PDB is closed and won’t open because of a damaged or missing SYSTEM datafile, the CDB and other PDBs can remain open during the PDB’s restore and recovery operation.
In this example, the SYSTEM datafile for the PDB CCREPOS is accidentally dropped while CCREPOS is closed. Trying to open CCREPOS fails as expected:

Next, start RMAN and initiate a recovery on the SYSTEM tablespace. Be sure to qualify the tablespace name with the PDB name in the RESTORE command:
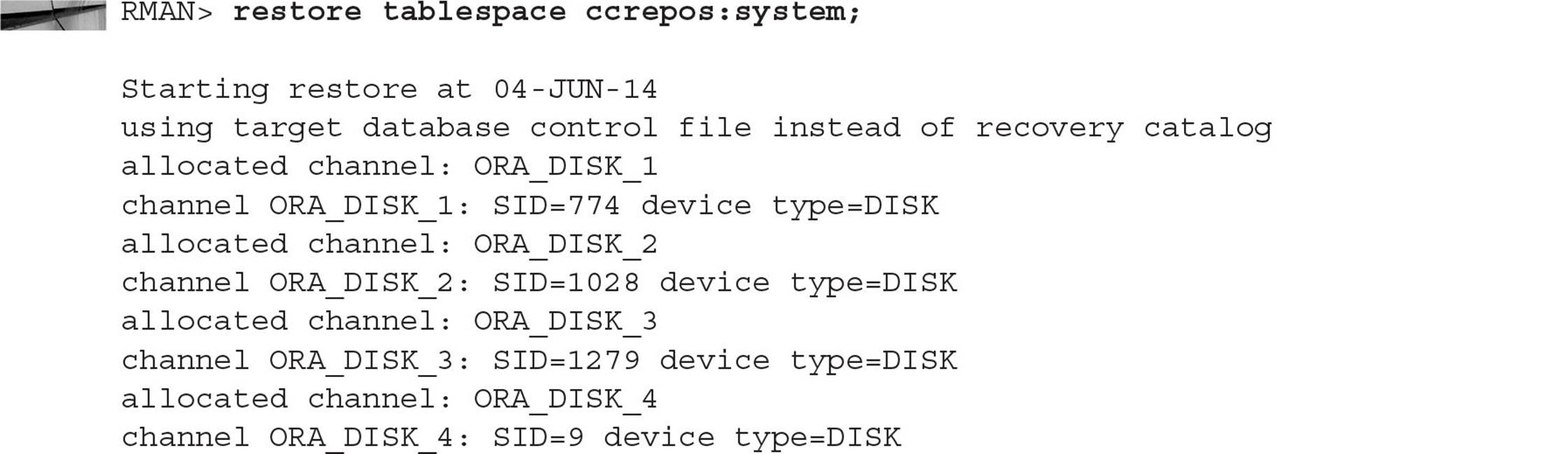
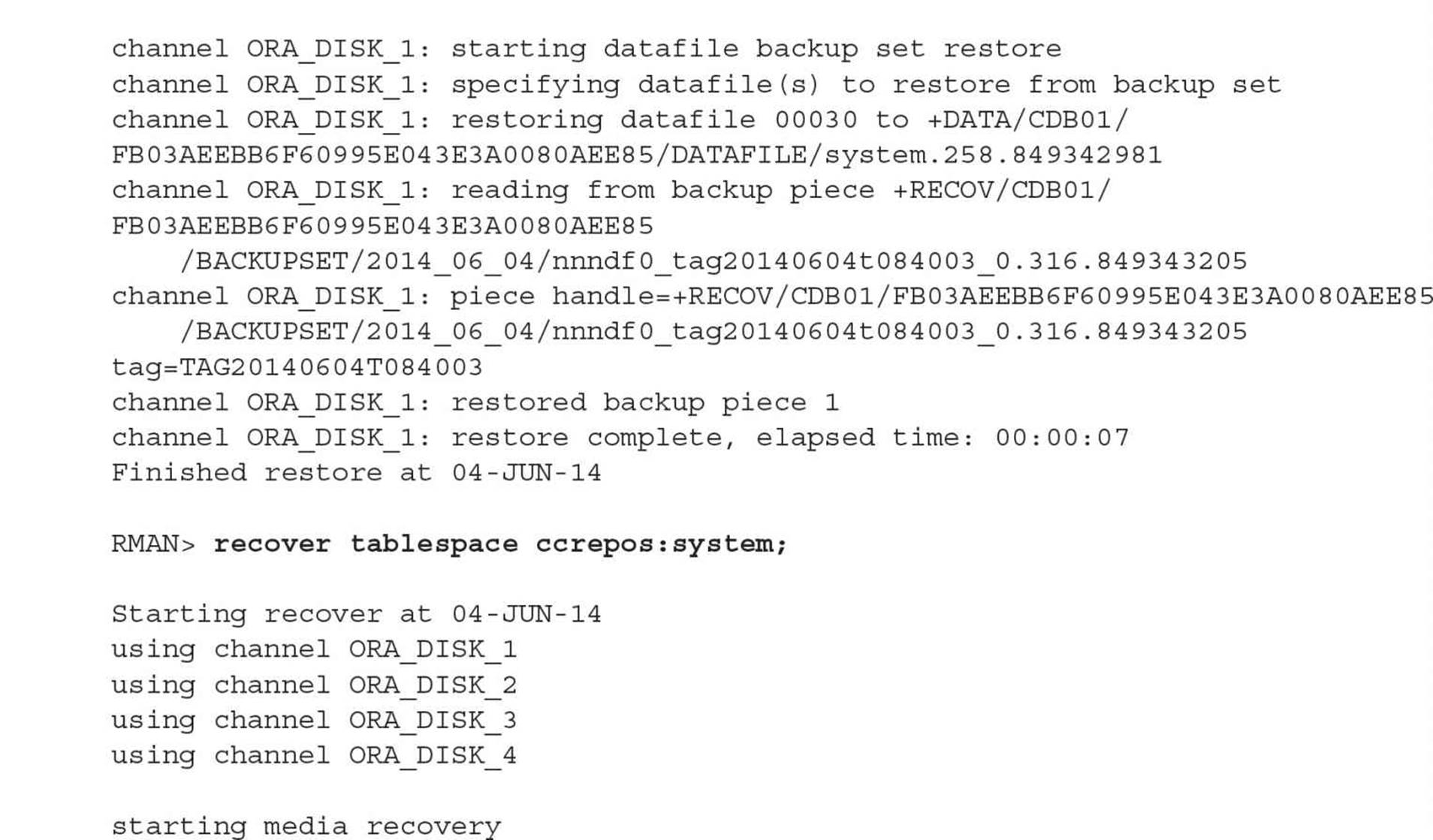
PDB Non-SYSTEM Datafile Loss Recovering a non-SYSTEM datafile in a PDB uses the same steps as recovering a non-SYSTEM datafile or tablespace in a CDB: offline the tablespace and then restore and recover. The only difference is that you qualify the tablespace name with the PDB name, like this:
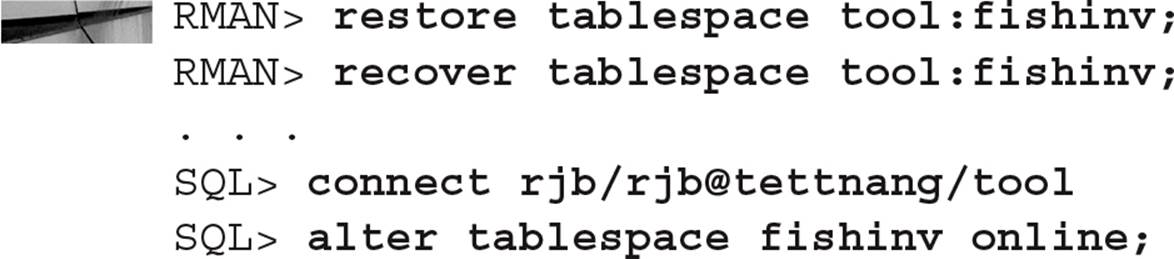
Using the Data Recovery Advisor
The Data Recovery Advisor (DRA) can both proactively and reactively analyze failures. In both scenarios, it does not automatically fix problems it finds but instead provides one or more possible fixes and gives you the option and the commands to perform the fix. As of Oracle Database 12c release 1 (12.1.0.1), only non-CDBs and single-instance CDBs are supported (non-RAC environments).
In previous releases of Oracle RMAN, you could perform proactive checks of the database’s datafiles with the VALIDATE command. In a CDB environment, the VALIDATE command has been enhanced to analyze individual PDBs or the entire CDB.
Data Failures
In one of the scenarios presented earlier, the SYSTEM tablespace’s datafiles of the CCREPOS PDB were lost. You might come to that conclusion after viewing the alert log or, more likely, after a user submits a help-desk ticket saying she can’t get into the CCREPOS database. You suspect that there might be more failures, so you start RMAN and use the DRA commands LIST FAILURE, ADVISE FAILURE, and REPAIR FAILURE to fix one or more issues.
To view and repair any issues with the CDB containing the CCREPOS PDB, start RMAN from the root container and run the LIST FAILURE DETAIL command:
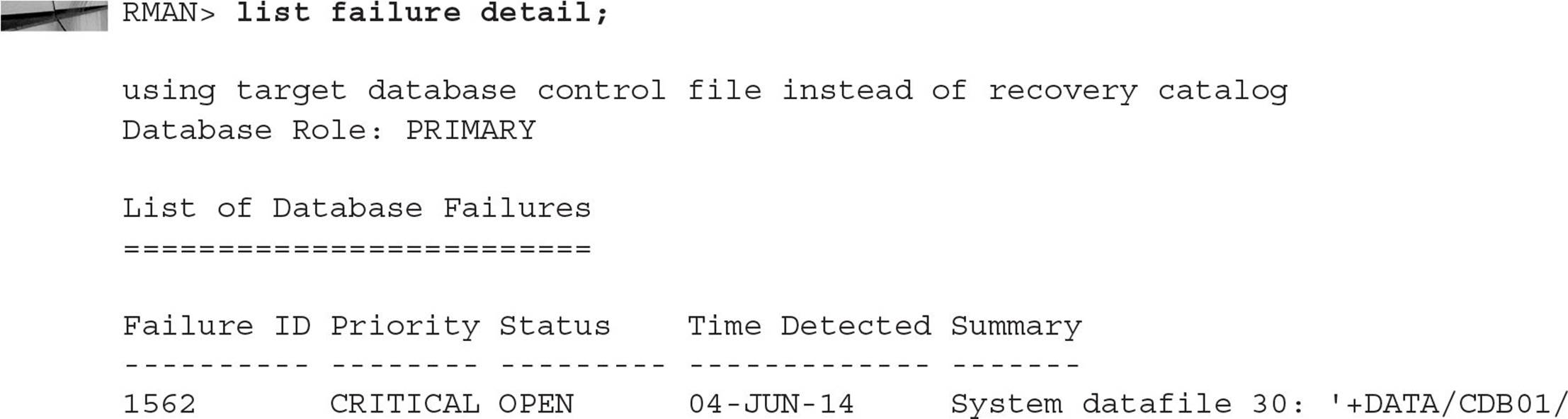
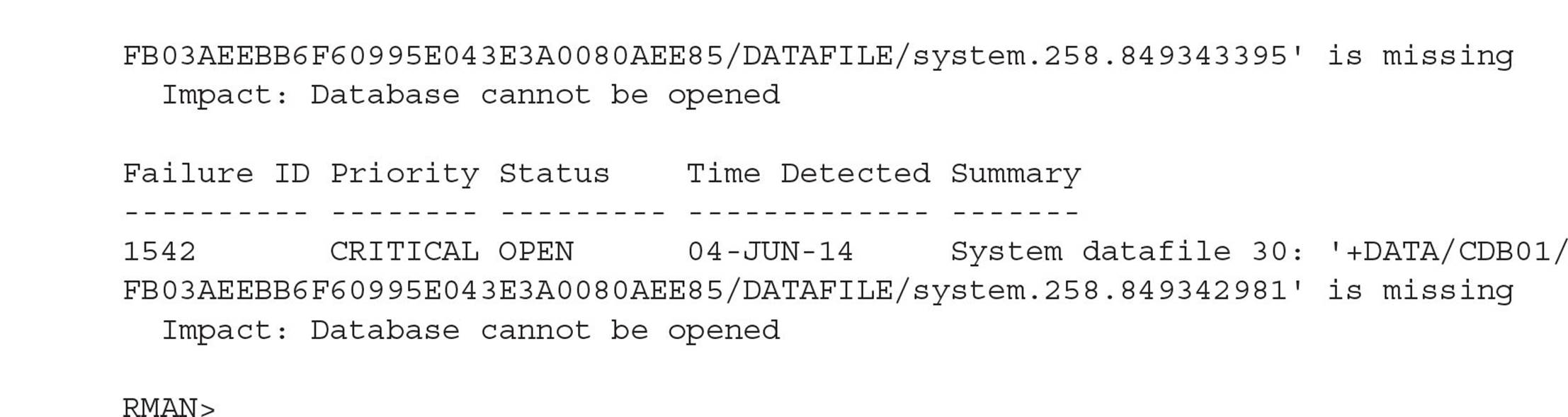
It looks like the SYSTEM datafile was lost once already (and recovered) earlier in the chapter! But the failure was not cleared from RMAN, so use CHANGE FAILURE to clear the earlier event:
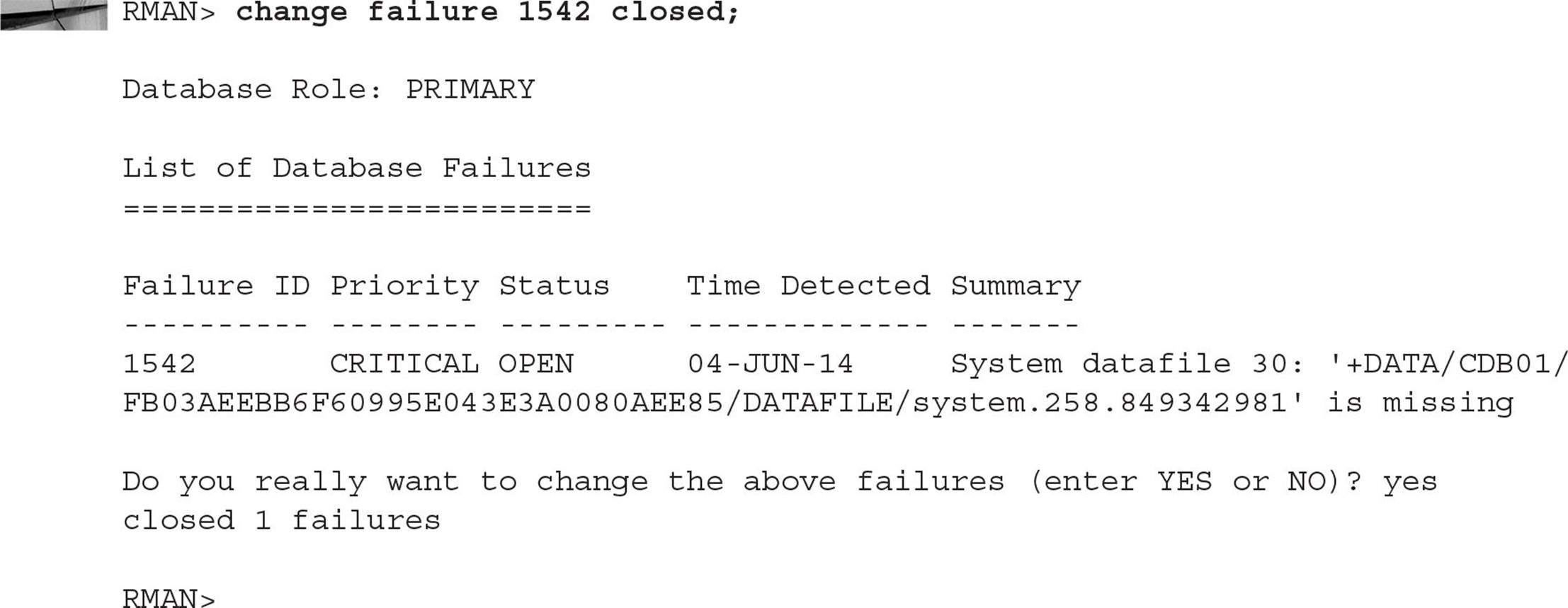
Next, let’s see what RMAN recommends to fix the problem:
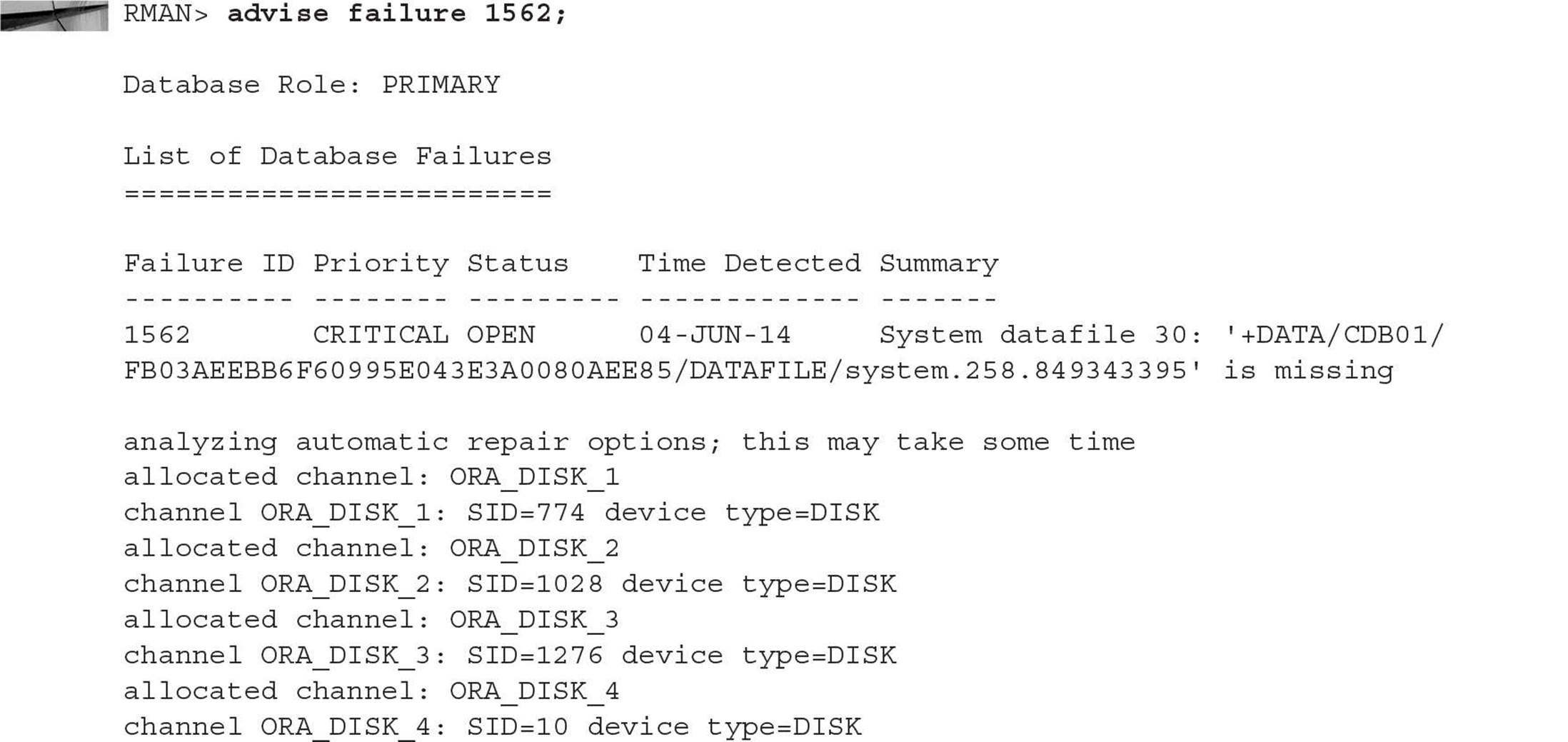
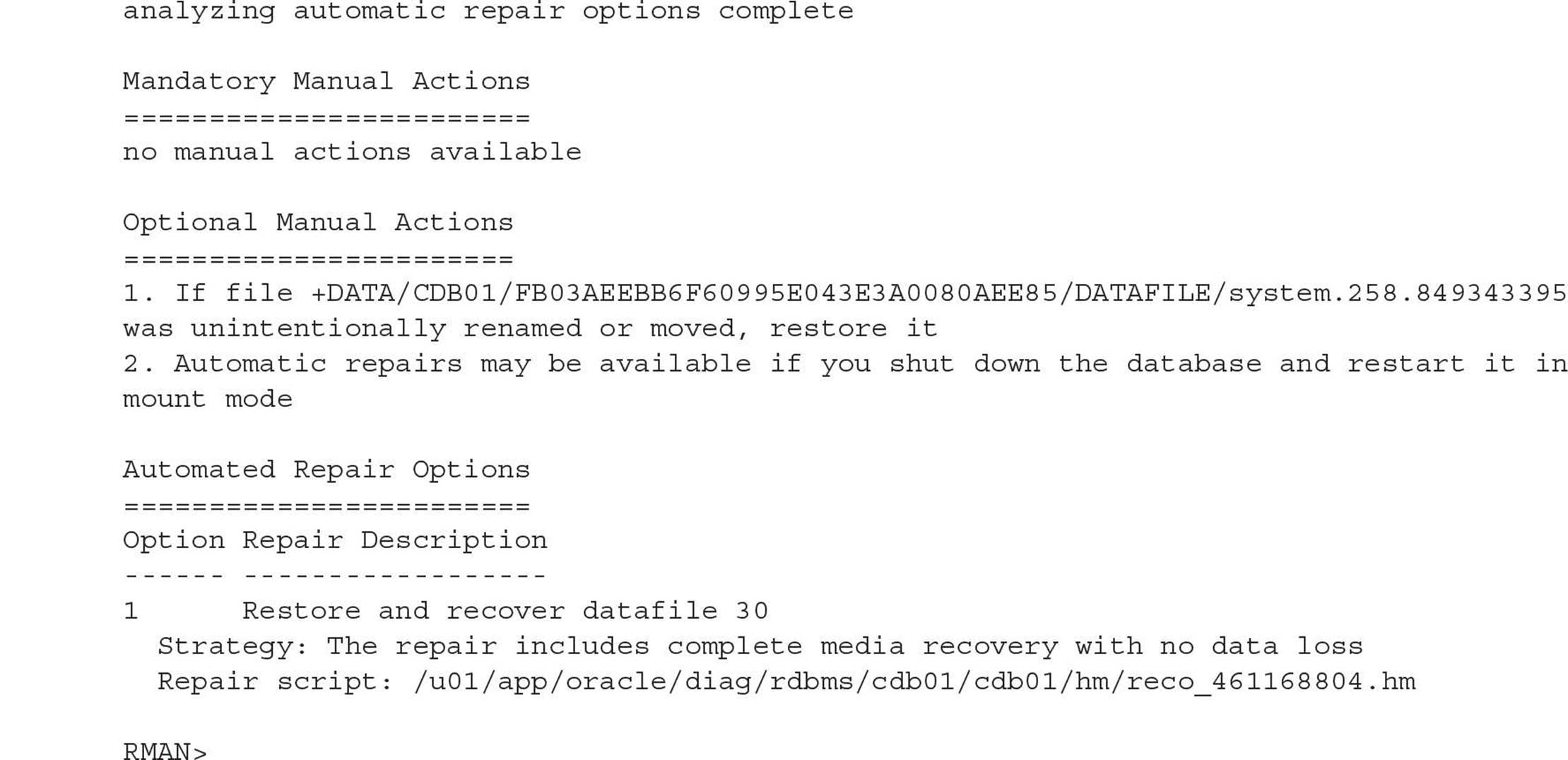
The repair script generated by RMAN is as follows:

The script is generated to run as is in RMAN. Knowing that the CCREPOS PDB is closed, however, means you can skip the first and last commands and just run the RESTORE and RECOVER commands:
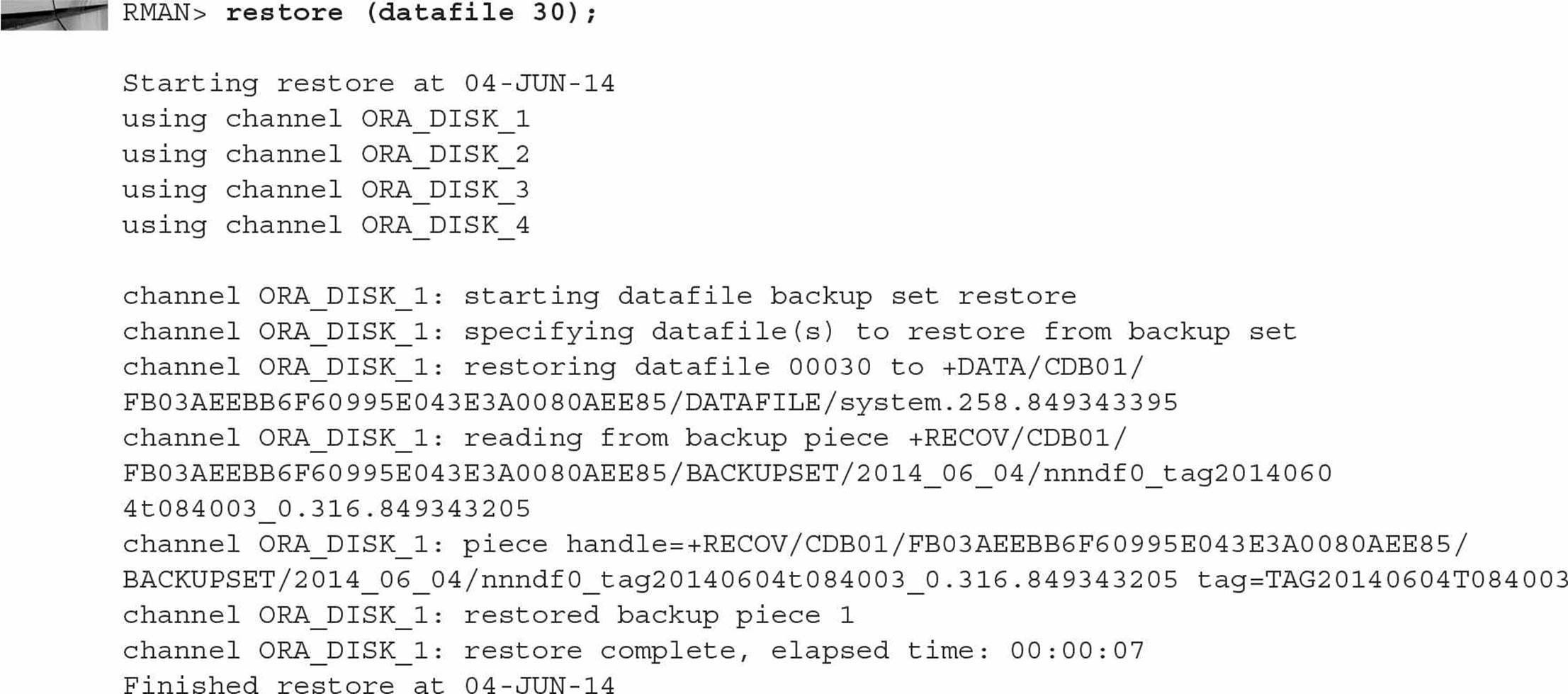
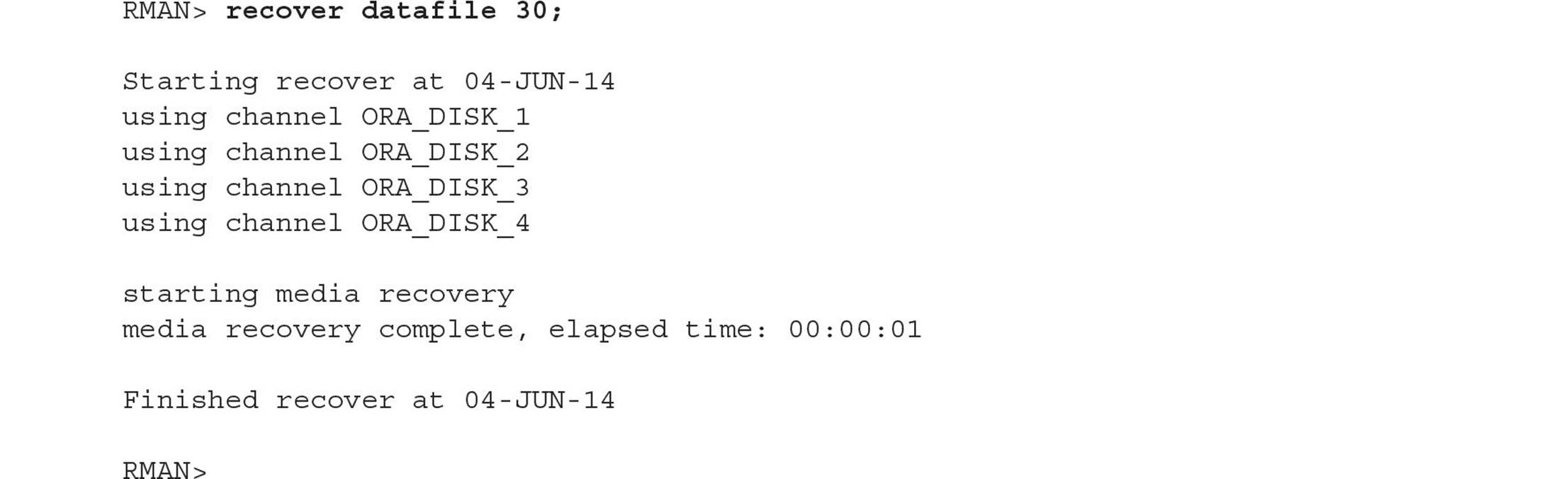
Finally, open the PDB and see whether all is well:

Since CCREPOS starts fine now, you can clear the failure in RMAN:
PITR Scenarios
There are occasions where you want to roll the entire database back to a point in time before a logical corruption occurred. If the flashback retention is not sufficient to rewind back as far as you would like, then you have to resort to restoring the entire database and applying incremental backups and archived redo logs to a point in time right before the logical corruption occurred (for example, dropping several large tables or updating hundreds of tables with the wrong date).
Therefore, point-in-time recovery (PITR) is a good solution for a PDB tablespace or the entire PDB. As you might expect, all other PDBs and the CDB are unaffected when performing PITR for a PDB. As with a non-CDB PITR, when you perform an incomplete recovery, you have to open the PDB with RESETLOGS. For a tablespace within the PDB, the PDB remains open for the duration of the tablespace PITR.
In the following example, in the PDB named TOOL, you have a series of routine transactions and a logically consistent database as of SCN 4759498:

Later in the day, at SCN=4767859, all of the rows in the table BIG_IMPORT are accidentally deleted, and neither the flashback data for that table nor UNDO data is available. The only viable option is to recover the tablespace USERS to SCN=4759498 using PITR:

If this PDB did not use a flash recovery area, the AUXILIARY DESTINATION clause would specify the location to hold temporary files for the auxiliary instance, including the datafiles, control files, and online log files.
Using Flashback CDB
If you do have enough space for flashback logs for a specific recovery window across all PDBs in a CDB, then using Flashback CDB is another good option for recovery when doing a full CDB restore and recovery operation would take significantly longer. Even if you have plenty of disk space for flashback logs, the flashback operation is across all PDBs and the CDB. If an individual PDB needs to be flashed back, you would instead use PDB PITR and leave the rest of the PDBs and CDB at their current SCN.
To configure the fast recovery area, enable ARCHIVELOG mode, set your flashback retention target, and turn on flashback:

One other caveat to using Flashback CDB is that you won’t be able to flash back the CDB to a point in time earlier than any PDB that has been rewound with database PITR.
Identifying Block Corruption
The RMAN VALIDATE command works in a CDB environment much like it did in previous releases of Oracle with the expected granularity in Oracle Database 12c to validate individual PDBs, the root container, or the entire CDB. Connecting to the root container in RMAN, you can use the VALIDATE command as in this example to check the existence of all datafiles in the TOOL and CCREPOS PDBs as well as check for any block corruptions:
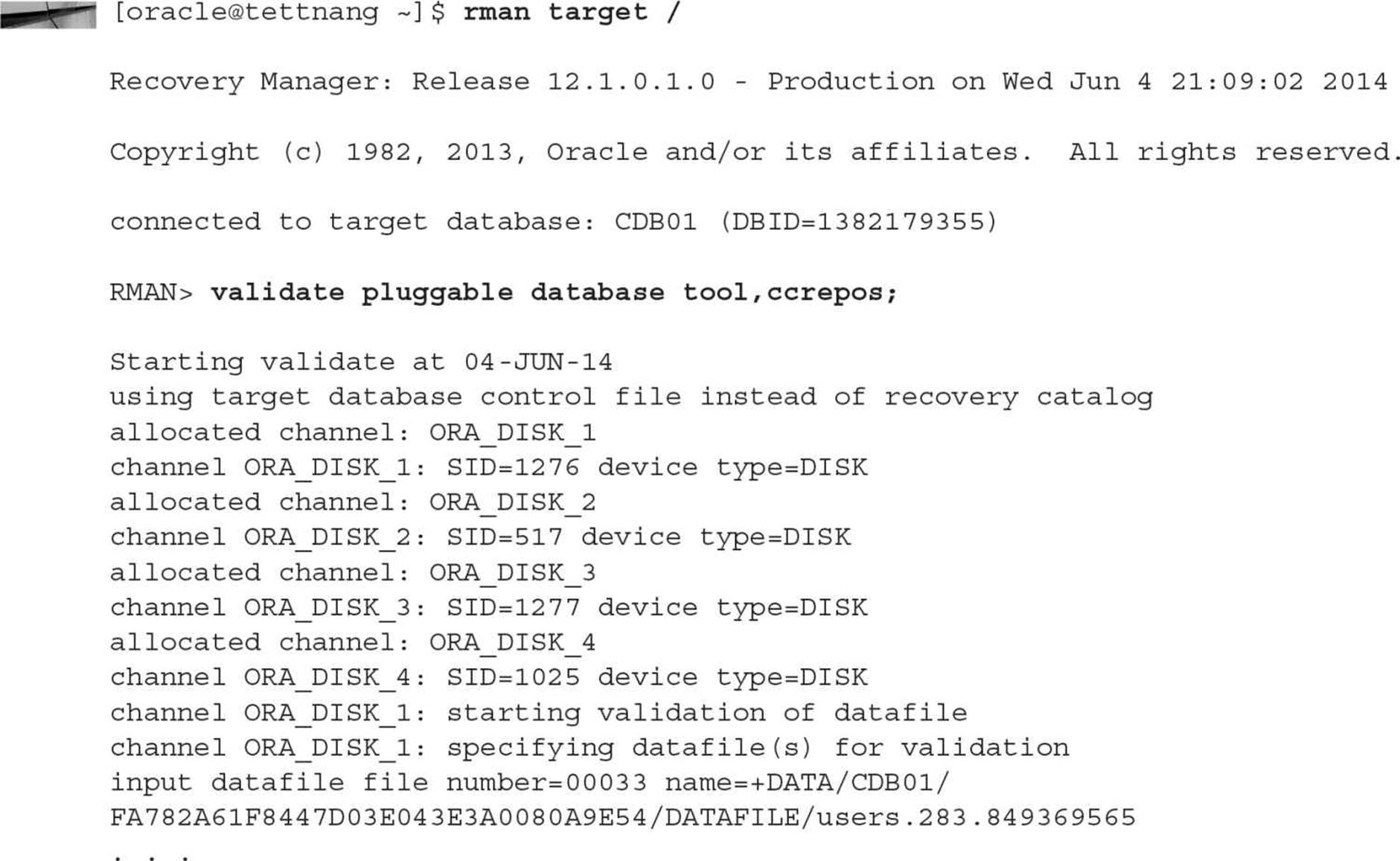
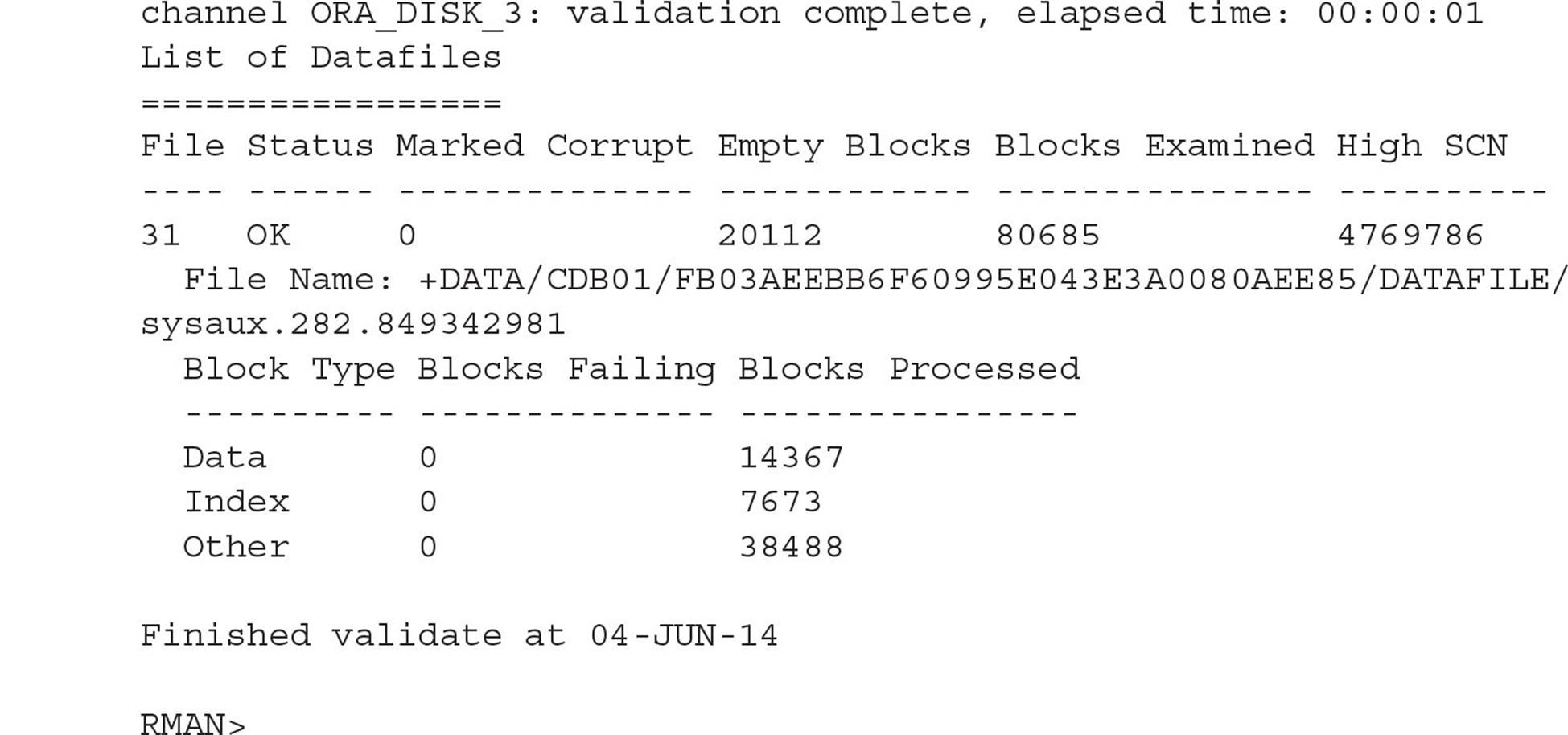
Duplicating PDBs Using RMAN
Earlier in this chapter I showed you how to clone a PDB using the CREATE PLUGGABLE DATABASE … FROM command. RMAN gives you more flexibility and scalability when duplicating one or more PDBs within a CDB or the entire CDB.
As in any RMAN DUPLICATE operation, you must create an auxiliary instance for the destination CDB and PDBs. Even when duplicating a PDB, the auxiliary instance must be started with the initialization parameter ENABLE_PLUGGABLE_DATABASE=TRUE, and therefore the target is a complete CDB with the root container (CDB$ROOT) and the seed database (PDB$SEED).
To duplicate a single PDB called TOOL to a new CDB called NINE, the RMAN DUPLICATE command would look like this:
![]()
If you want to copy two or more PDBs, you just add them to the end of the DUPLICATE command:
![]()
Exclusions are allowed in the DUPLICATE command. If you want to clone an entire CDB but without the CCREPOS PDB, do this:
![]()
Finally, you can duplicate not only PDBs but also individual tablespaces to a new CDB:

In this example you want a new CDB with a new PDB called QA_2015_CCREPOS with only the USERS tablespace from the existing PDB called TOOL.
Summary
Oracle’s multitenant architecture, new to Oracle Database 12c, gives the database administrator an entire range of new capabilities to simplify and reduce maintenance activities as well as respond to changing resource needs and maximize utilization of existing infrastructure.
Creating a new database or even cloning an existing database occurs in a fraction of the time as in previous releases of Oracle: One reason is that the shared resources in a container database, such as the base data dictionary, make up the bulk of the metadata in a new database and do not need to be copied for each individual pluggable database. The temporary and undo tablespaces are already in place along with the online redo log files—a PDB can, however, have its own temporary tablespace if desired to accommodate a specific application workload that might be different from that of other PDBs sharing the same CDB.
Moving a PDB to another container either on the same server or on a different server is as easy as shutting down the database, creating an XML file with the PDB’s metadata, and moving the database files themselves to a location where the new CDB can access them.
The best part of using this feature is that you can use the same tools you used before. You’ll still use RMAN to back up and recover a PDB, the initialization parameters will for the most part behave as they did in previous releases, and users will not have to make any changes to their applications to run efficiently in a multitenant environment.

All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.