Oracle Database 12c DBA Handbook (2015)
PART
I
Database Architecture
CHAPTER
4
Physical Database Layouts and Storage Management
Chapter 3 discussed the logical components of the database, tablespaces, and how to not only create the right number and types of tablespaces but also place table and index segments in the appropriate tablespace, based on their usage patterns and function. In this chapter, I’ll focus more on the physical aspects of a database, the datafiles, and where to store them to maximize I/O throughput and overall database performance.
The assumption throughout this chapter is that you are using locally managed tablespaces with automatic segment space management. In addition to reducing the load on the SYSTEM tablespace by using bitmaps stored in the tablespace itself instead of freelists stored in the table or index header blocks, automatic segment space management (by specifying AUTOALLOCATE or UNIFORM) makes more efficient use of the space in the tablespace. As of Oracle 10g, the SYSTEM tablespace is created as locally managed. As a result, this requires all read-write tablespaces to also be locally managed.
In the first part of this chapter, I’ll review some of the common problems and solutions when using traditional disk space management using a file system on a database server. In the second half of the chapter, I’ll present an overview of Automatic Storage Management (ASM), a built-in logical volume manager that eases administration, enhances performance, and improves availability.
Traditional Disk Space Storage
In lieu of using a third-party logical volume or Oracle’s Automatic Storage Management (discussed later in this chapter), you must be able to manage the physical datafiles in your database to ensure a high level of performance, availability, and recoverability. In general, this means spreading out your datafiles to different physical disks. In addition to ensuring availability by keeping mirrored copies of redo log files and control files on different disks, I/O performance is improved when users access tables that reside in tablespaces on multiple physical disks instead of one physical disk. Identifying an I/O bottleneck or a storage deficiency on a particular disk volume is only half the battle; once the bottleneck is identified, you need to have the tools and knowledge to move datafiles to different disks. If a datafile has too much space or not enough space, resizing an existing datafile is a common task.
In this section, I’ll discuss a number of different ways to resize tablespaces, whether they are smallfile or bigfile tablespaces. In addition, I’ll cover the most common ways to move datafiles, online redo log files, and control files to different disks.
Resizing Tablespaces and Datafiles
In an ideal database, all tablespaces and the objects within them are created at their optimal sizes. Resizing a tablespace proactively or setting up a tablespace to automatically extend can potentially avoid a performance hit when the tablespace expands or an application failure occurs if the datafile(s) within the tablespace cannot extend. More details on how to monitor space usage can be found in Chapter 6.
The procedures and methods available for resizing a tablespace are slightly different, depending on whether the tablespace is a smallfile or a bigfile tablespace. A smallfile tablespace, the only type of tablespace available before Oracle 10g, can consist of multiple datafiles. A bigfile tablespace, in contrast, consists of only one datafile, but the datafile can be much larger than a datafile in a smallfile tablespace: A bigfile tablespace with 32K blocks can have a datafile as large as 128TB. In addition, bigfile tablespaces must be locally managed.
Resizing a Smallfile Tablespace Using ALTER DATABASE
In the following examples, we attempt to resize the USERS tablespace, which contains one datafile, starting out at 5GB. First, we make it 15GB, then realize it’s too big, and shrink it down to 10GB. Then, we attempt to shrink it too much. Finally, we try to increase its size too much.
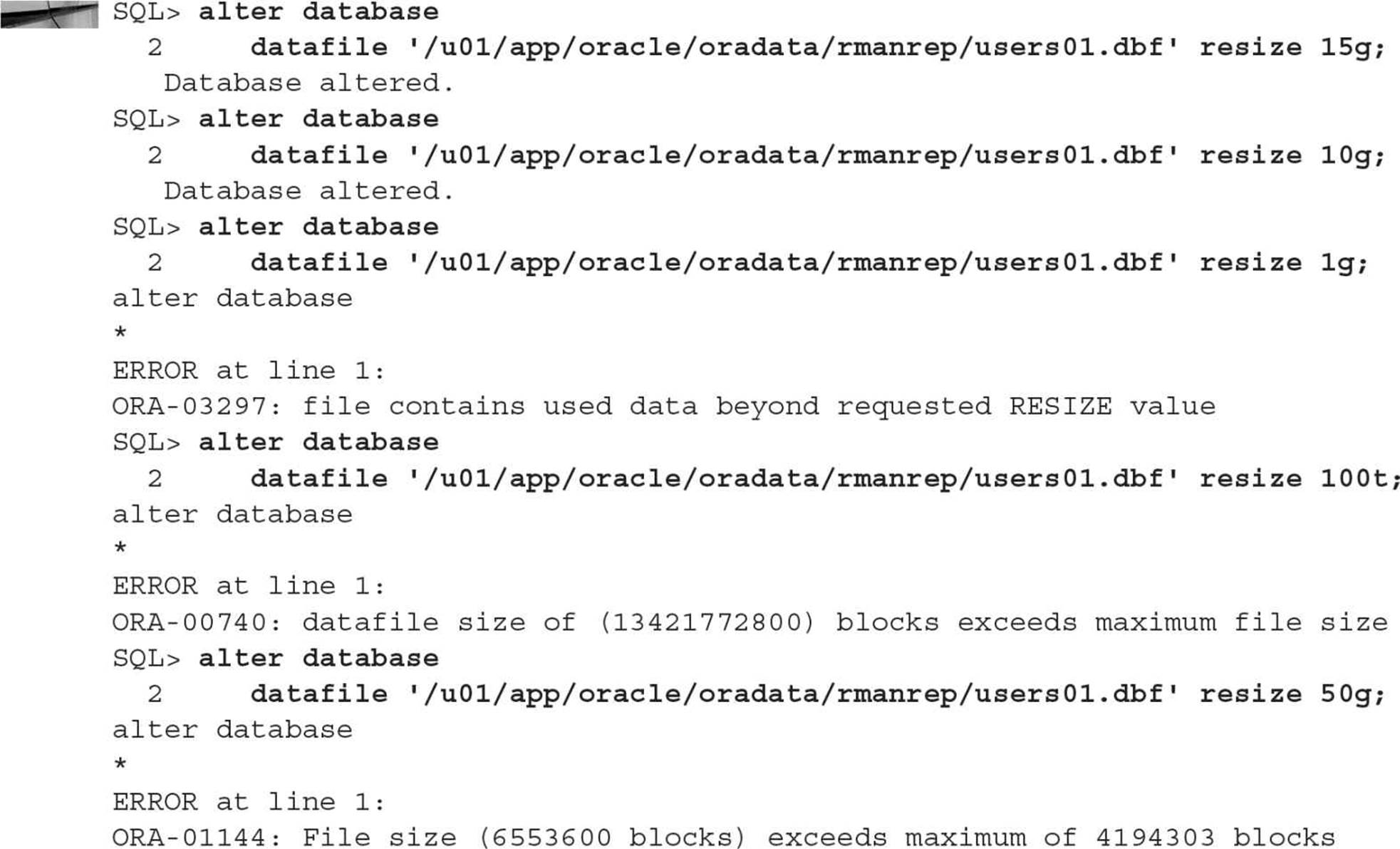
If the resize request cannot be supported by the free space available, or there is data beyond the requested decreased size, or an Oracle file size limit is exceeded, Oracle returns an error.
To avoid manual resizing of tablespaces reactively, we can instead be proactive and use the AUTOEXTEND, NEXT, and MAXSIZE clauses when modifying or creating a datafile. Table 4-1 lists the space-related clauses for modifying or creating datafiles in the ALTER DATAFILE and ALTER TABLESPACE commands.

TABLE 4-1. Datafile Extension Clauses
In the following example, we set AUTOEXTEND to ON for the datafile /u01/app/oracle/oradata/rmanrep/users01.dbf, specify that each extension of the datafile is 500MB, and specify that the total size of the datafile cannot exceed 10GB:

If the disk volume containing the datafile does not have the disk space available for the expansion of the datafile, we must either move the datafile to another disk volume or create a second datafile for the tablespace on another disk volume. In this example, we’re going to add a second datafile to the USERS tablespace on a different disk volume with an initial size of 500MB, allowing for the automatic extension of the datafile, with each extension 100MB and a maximum datafile size of 2000MB (2GB):

Notice that when we modify an existing datafile in a tablespace, we use the ALTER DATABASE command, whereas when we add a datafile to a tablespace, we use the ALTER TABLESPACE command. As you will see shortly, using a bigfile tablespace simplifies these types of operations.
Resizing a Smallfile Tablespace Using EM Database Express
Using EM Database Express, we can use either of the methods described in the preceding section: increase the size and turn on AUTOEXTEND for the tablespace’s single datafile, or add a second datafile.
Resizing a Datafile in a Smallfile Tablespace To resize a datafile in EM Database Express, from the database instance home page, choose Storage | Tablespaces. In Figure 4-1, the XPORT tablespace has been selected; it is over 80 percent full, so we will expand its size by extending the size of the existing datafile. This tablespace was originally created using this command:

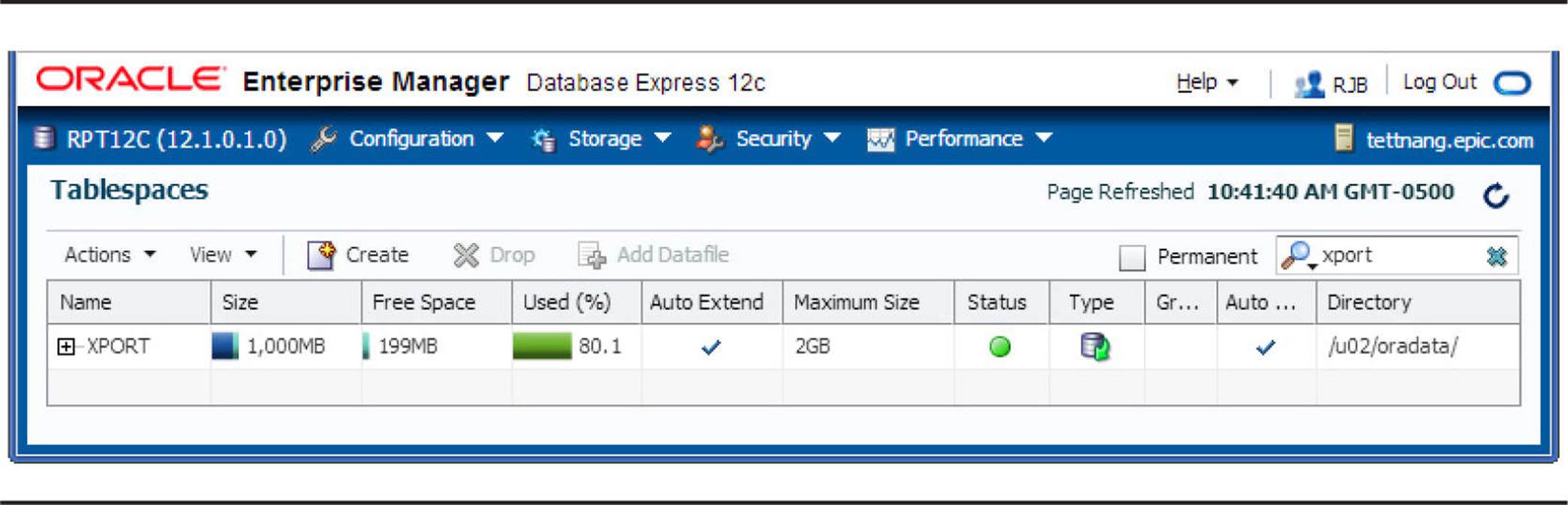
FIGURE 4-1. Using EM Database Express to edit tablespace characteristics
Rather than let the tablespace’s datafile autoextend, we will change the current size of the datafile to 2000MB from 1000MB.
By clicking the “+” icon to the left of XPORT, you can see the additional characteristics of the XPORT tablespace, as shown in Figure 4-2. The single datafile is /u02/oradata/xport.dbf.
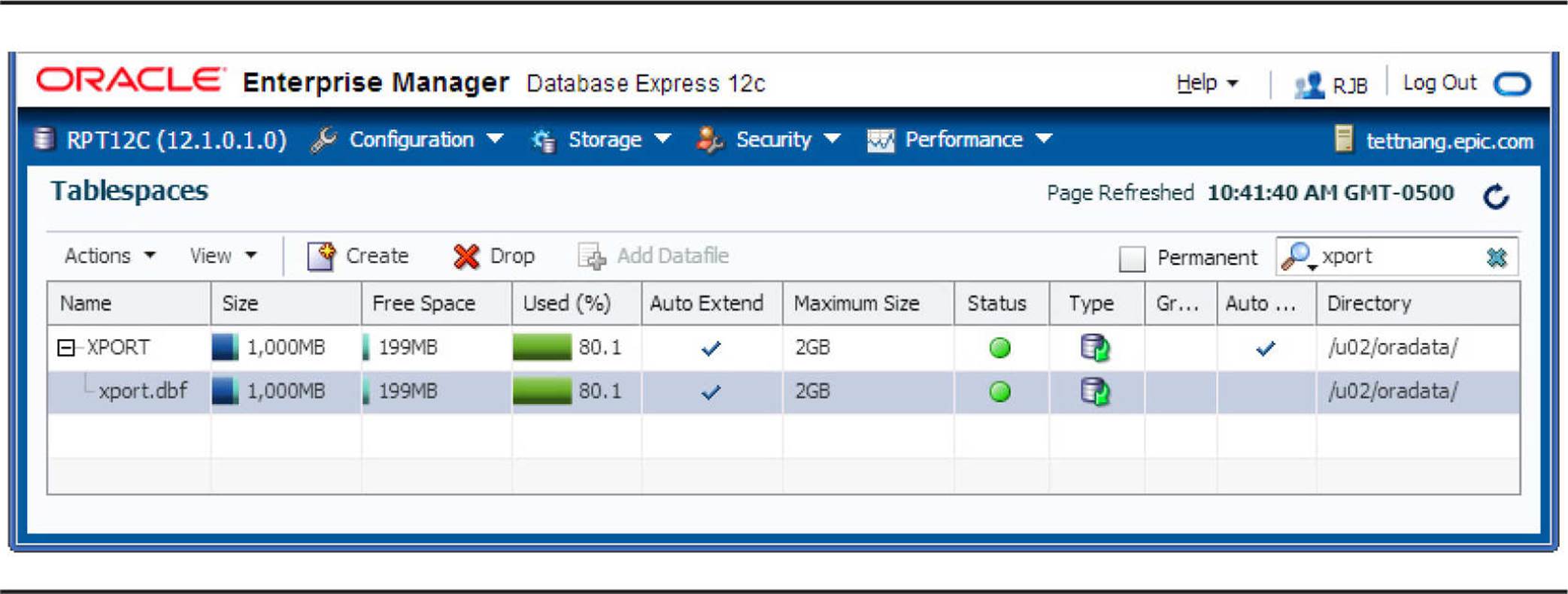
FIGURE 4-2. Tablespace characteristics
With the single XPORT datafile selected, choose Actions | Resize, and you will see the Resize Datafile dialog box, shown in Figure 4-3, where you can change the size of the datafile. Change the file size to 2G (2000MB) and click OK.
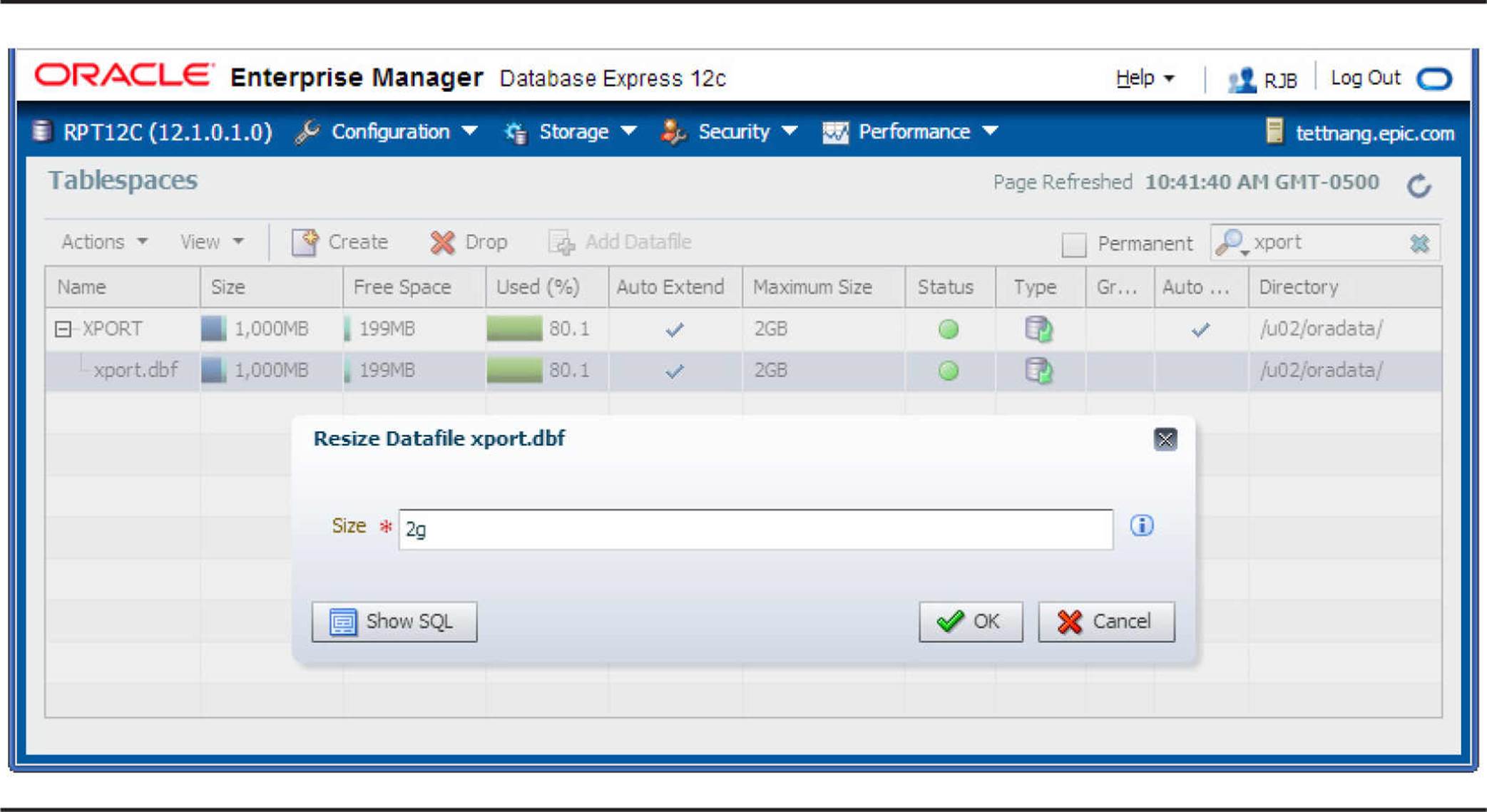
FIGURE 4-3. Editing a tablespace’s datafile
Before committing the changes, it is often beneficial to review the SQL commands about to be executed by clicking the Show SQL button on almost any page where a DDL operation is going to be executed. It is a good way to brush up on your SQL command syntax! Here is the command that was executed when you clicked OK:
![]()
When you click OK, Oracle changes the size of the datafile. The Tablespaces reflects the successful operation and the new size of the datafile, as you can see in Figure 4-4.
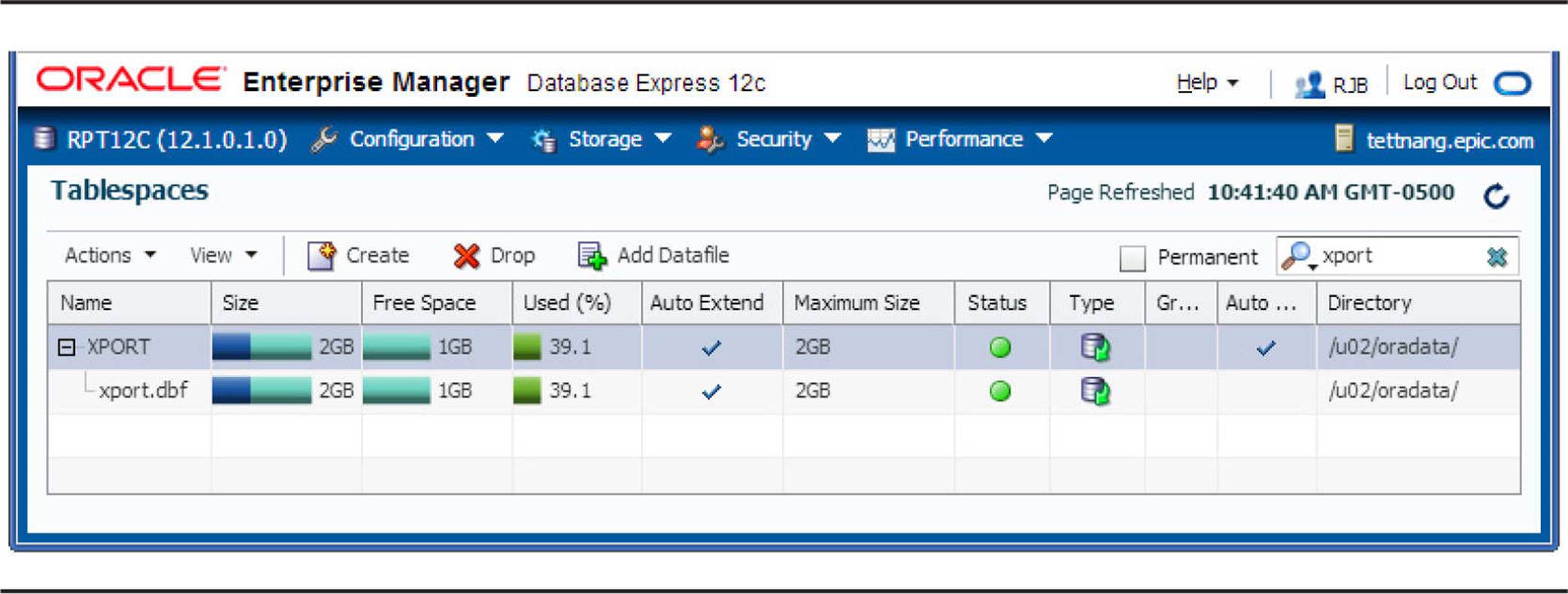
FIGURE 4-4. Datafile resizing results
Adding a Datafile to a Smallfile Tablespace Adding a datafile to a smallfile tablespace is just as easy as resizing a datafile using EM Database Express. In our preceding example, we expanded the datafile for the XPORT tablespace to 2000MB. Because the file system (/u02) containing the datafile for the XPORT tablespace is now at capacity, you will have to turn off AUTOEXTEND on the existing datafile and then create a new datafile on a different file system. To turn off AUTOEXTEND for the existing datafile from the Tablespaces page, choose Actions | Edit Auto Extend. In the dialog box that opens, uncheck the Auto Extend check box, as shown in Figure 4-5, and click OK. Here is the SQL command that is executed for this operation when you click OK:

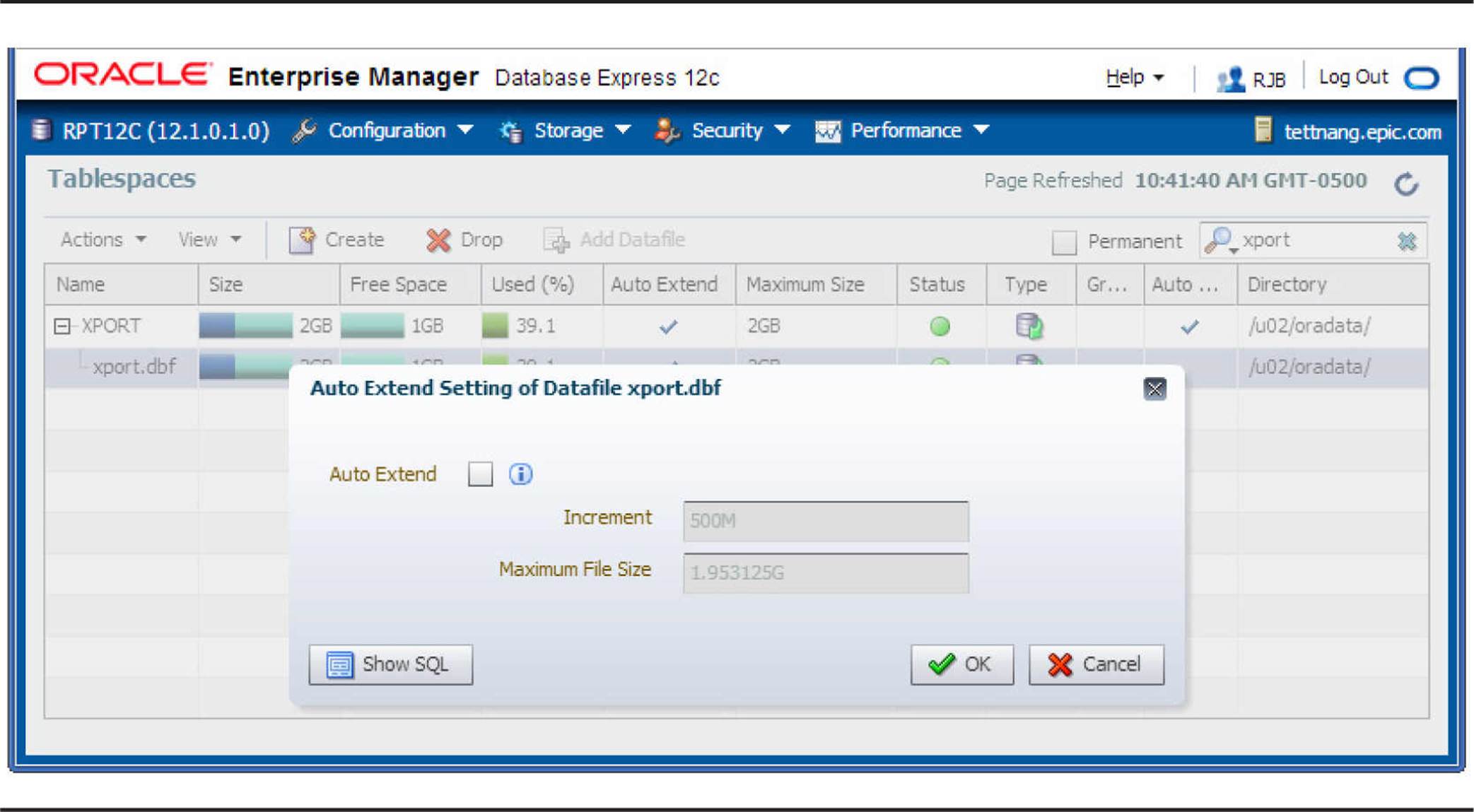
FIGURE 4-5. Editing a tablespace’s datafile characteristics
To add the second datafile on /u04, select the XPORT tablespace and click Add Datafile. You will see the dialog box shown in Figure 4-6. Specify the filename and directory location for the new datafile. Because you know that the /u04 file system has at least 500MB free, specify /u04/oradata as the directory and xport2.dbf as the filename, although the filename itself need not contain the tablespace name. In addition, set the file size to 500MB. Do not check the Auto Extend check box.
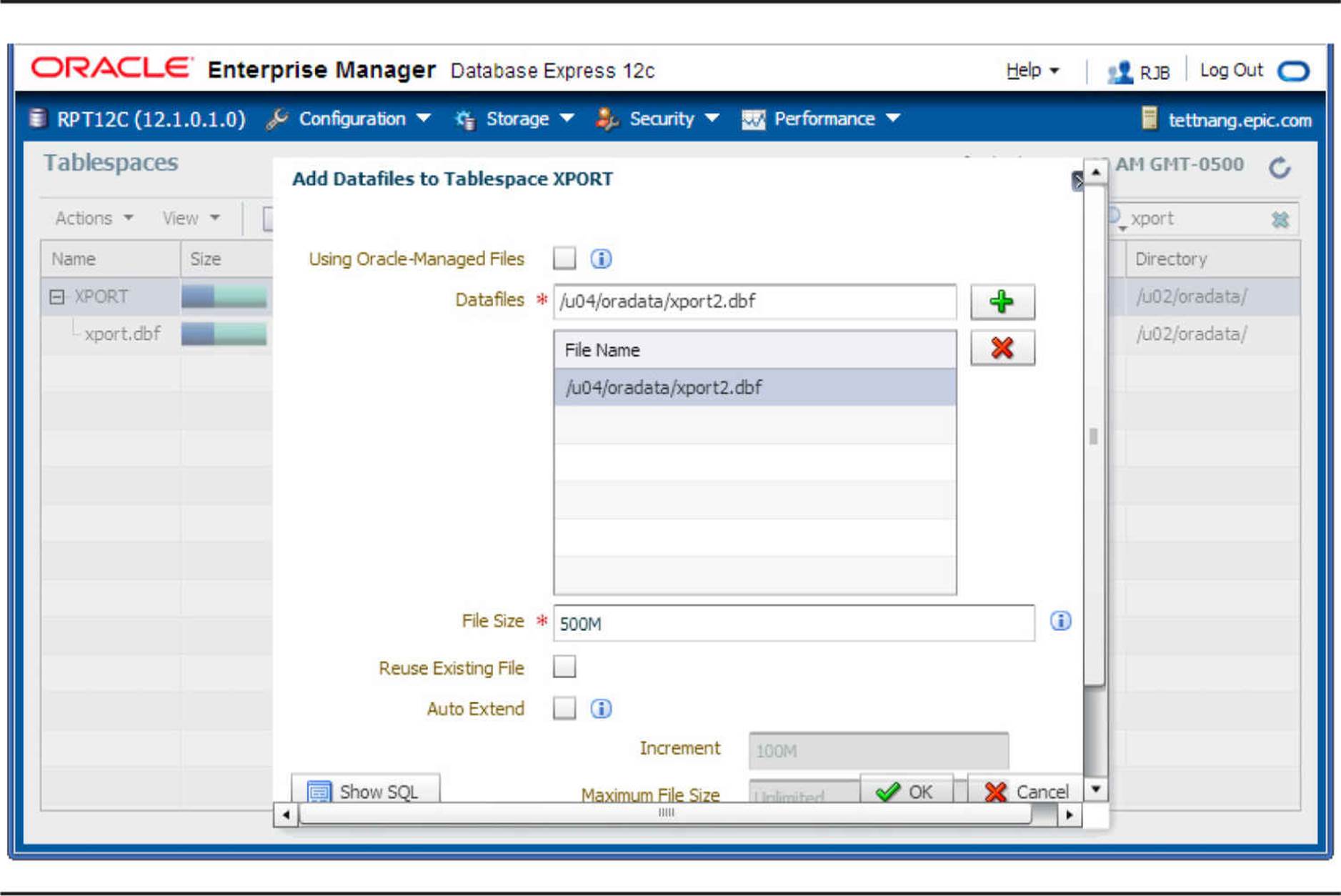
FIGURE 4-6. Adding a datafile to the XPORT tablespace
After clicking OK, you see the new size of the XPORT tablespace’s datafiles on the Tablespaces page, as shown in Figure 4-7.
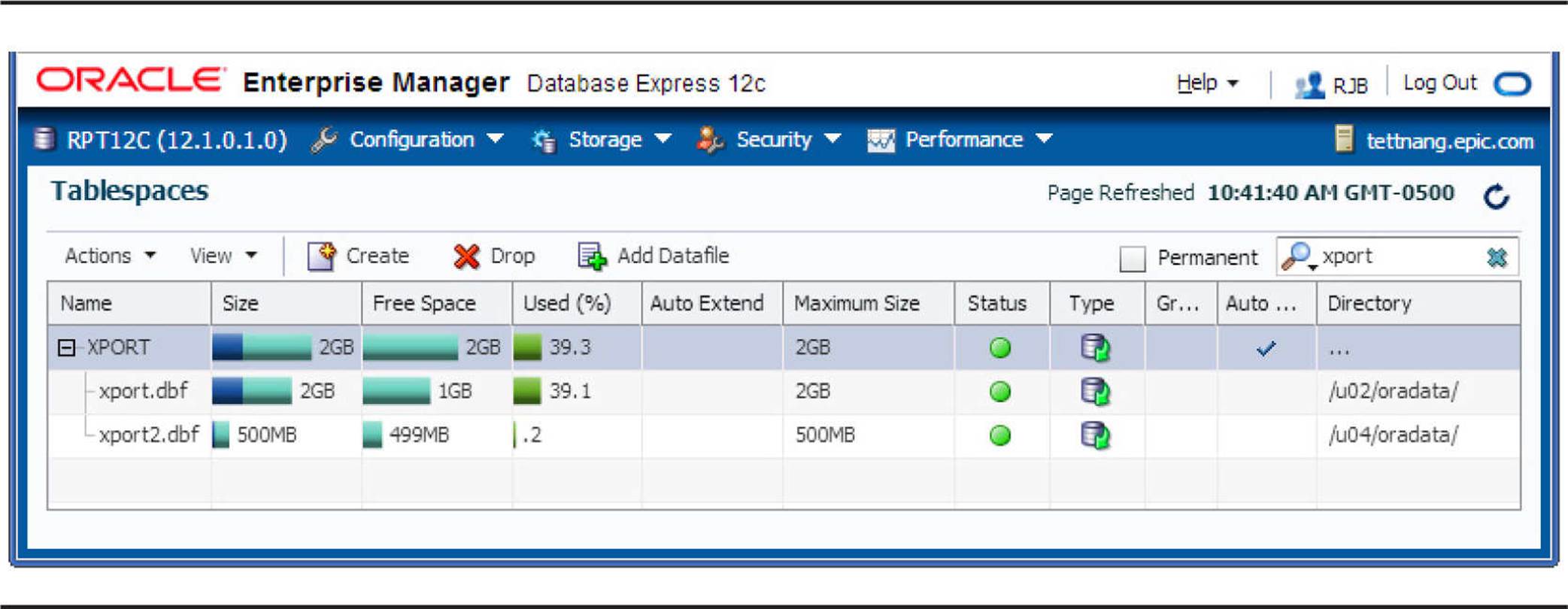
FIGURE 4-7. Results of adding a datafile
Dropping a Datafile from a Tablespace
In versions of Oracle Database prior to 11g, dropping a datafile from a tablespace was problematic; there was not a single command you could issue to drop a datafile unless you dropped the entire tablespace. You only had three alternatives:
![]() Live with it.
Live with it.
![]() Shrink it and turn off AUTOEXTEND.
Shrink it and turn off AUTOEXTEND.
![]() Create a new tablespace, move all the objects to the new tablespace, and drop the original tablespace.
Create a new tablespace, move all the objects to the new tablespace, and drop the original tablespace.
Although creating a new tablespace was the most ideal approach from a maintenance and metadata point of view, performing the steps involved was error-prone and involved some amount of downtime for the tablespace, impacting availability.
Using Cloud Control 12c or EM Database Express, you can drop a datafile and minimize downtime, and let Cloud Control 12c or EM Database Express generate the scripts for you if you want to run it manually. Following our previous example in which we expanded the XPORT tablespace by adding a datafile, I’ll step through an example of how you can remove the datafile by reorganizing the tablespace. On the Tablespaces page shown in Figure 4-7, select the datafile to be dropped (xport2.dbf in this case), and choose Actions | Drop, as shown in Figure 4-8.
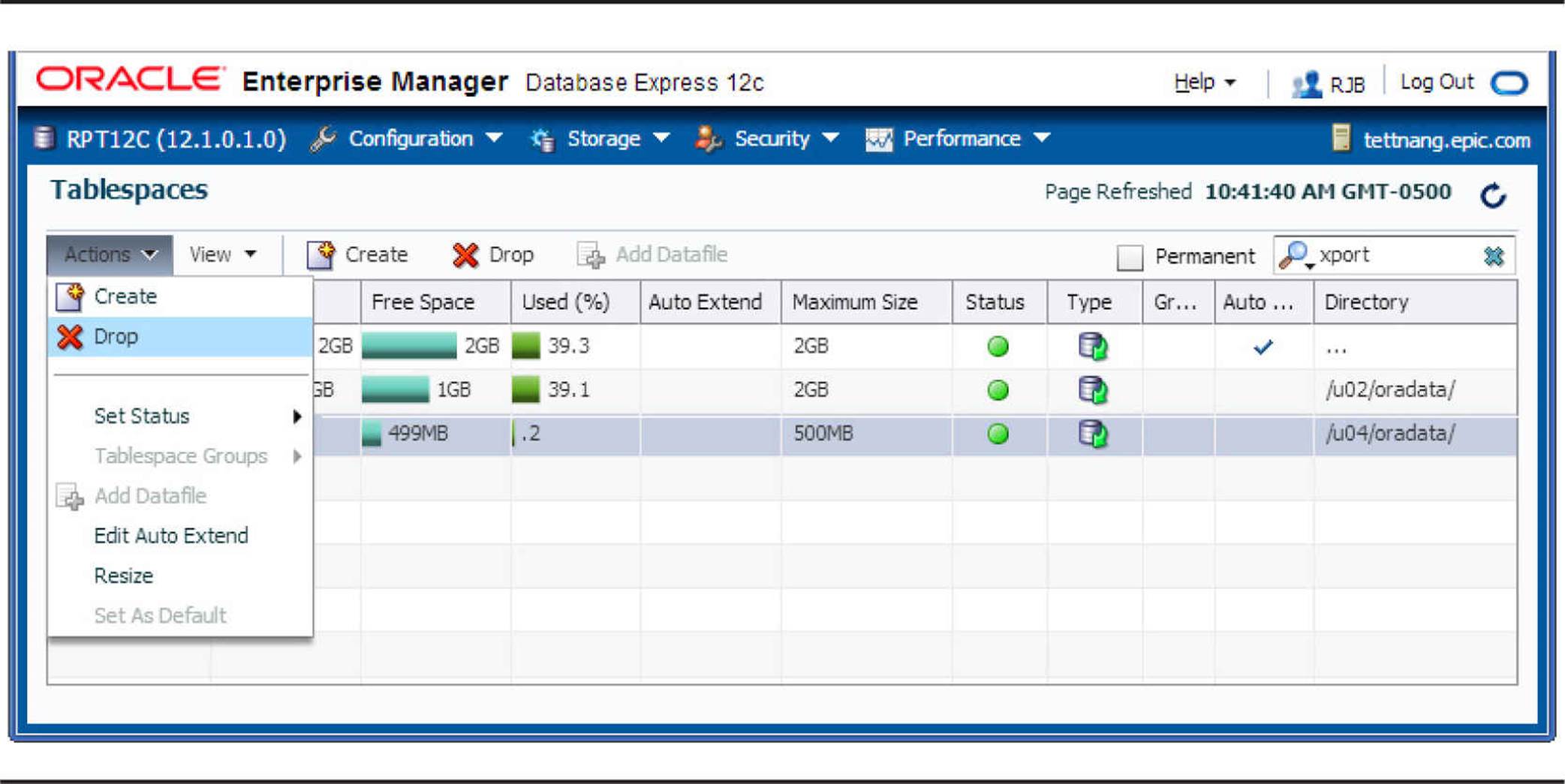
FIGURE 4-8. Dropping a datafile
If there are objects occupying the specified datafile to be dropped, you will have to reorganize the tablespace to move all of the objects to the first datafile or create a new tablespace and migrate the objects to the new tablespace.
Resizing a Bigfile Tablespace Using ALTER TABLESPACE
A bigfile tablespace consists of one and only one datafile. Although you will learn more about bigfile tablespaces in Chapter 6, this section presents a few details about how a bigfile tablespace can be resized. Most of the parameters available for changing the characteristics of a tablespace’s datafile, such as the maximum size, whether it can extend at all, and the size of the extents, are now modifiable at the tablespace level. Let’s start with a bigfile tablespace created as follows:

Operations that are valid only at the datafile level with smallfile tablespaces can be used with bigfile tablespaces at the tablespace level:

Although using ALTER DATABASE with the datafile specification for the DMARTS tablespace will work, the advantage of the ALTER TABLESPACE syntax is obvious: You don’t have to or need to know where the datafile is stored. As you might suspect, trying to change datafile parameters at the tablespace level with smallfile tablespaces is not allowed:

If a bigfile tablespace runs out of space because its single datafile cannot extend on the disk, you need to relocate the datafile to another volume, as discussed in the next section. Using Automatic Storage Management, presented later in this chapter, can potentially eliminate the need to manually move datafiles at all: Instead of moving the datafile, you can add another disk volume to the ASM storage group.
Moving Datafiles
To better manage the size of a datafile or improve the overall I/O performance of the database, it may be necessary to move one or more datafiles in a tablespace to a different location. There are three methods for relocating the datafiles: using ALTER DATABASE, using ALTER TABLESPACE, and via EM Database Control or EM Database Express, although neither EM Database Control nor EM Database Express provides all the commands necessary to relocate the datafile.
For Oracle Database 11g and earlier, the ALTER TABLESPACE method works for datafiles in all tablespaces except for SYSTEM, SYSAUX, the online undo tablespace, and the temporary tablespace. The ALTER DATABASE method works for datafiles in all tablespaces because the instance is shut down when the move operation occurs.
If you are using Oracle Database 12c, you can move any datafile while the entire database is online, even from a traditional file system to ASM or vice versa. However, there is some slight overhead using this method, so you should be cognizant of your service-level agreement (SLA) and ensure that the move operation will not adversely affect response time.
Moving Datafiles with ALTER DATABASE
The steps for moving one or more datafiles (non-ASM) with ALTER DATABASE are as follows:
1. Connect to the database as SYSDBA and shut down the instance.
2. Use operating system commands to move the datafile(s).
3. Open the database in MOUNT mode.
4. Use ALTER DATABASE to change the references to the datafile in the database.
5. Open the database in OPEN mode.
6. Perform an incremental or full backup of the database that includes the control file.
In the following example, I will show you how to move the datafile of the XPORT tablespace from the file system /u02 to the file system /u06. First, you connect to the database with SYSDBA privileges using the following command:
![]()
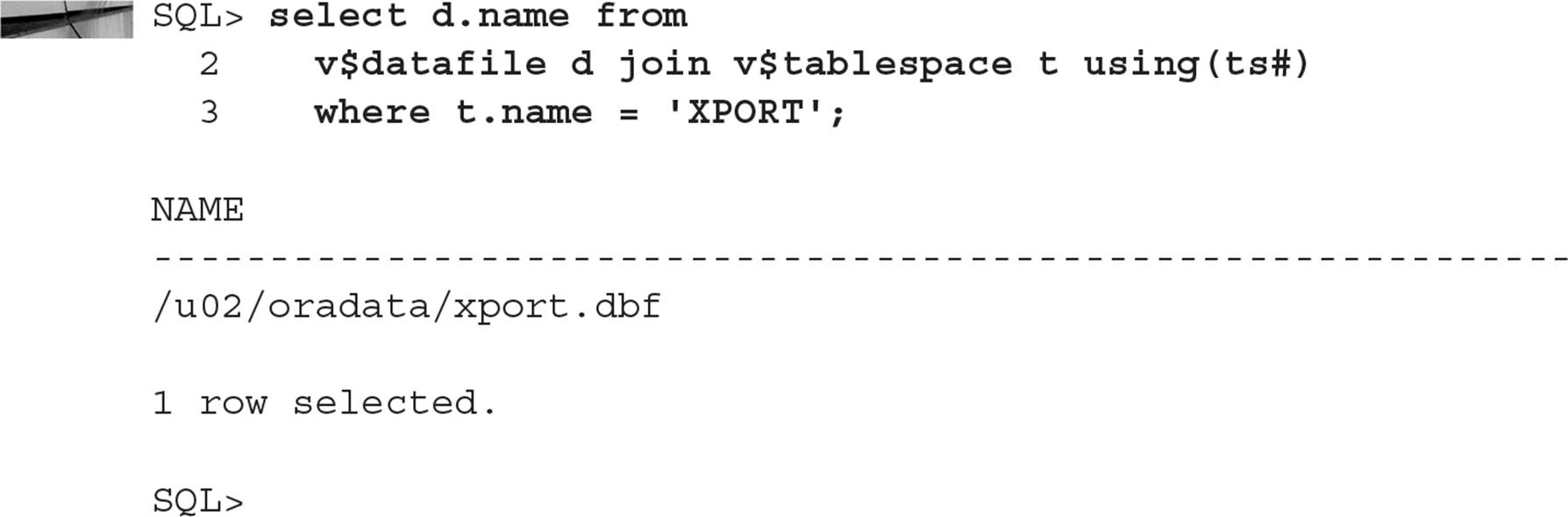
Next, you use a query against the dynamic performance views V$DATAFILE and V$TABLESPACE to confirm the names of the datafiles in the XPORT tablespace:
To complete step 1, shut down the database:

For step 2, you stay in SQL*Plus and use the “!” escape character to execute the operating system command to move the datafile:
![]()
In step 3, you start up the database in MOUNT mode so that the control file is available without opening the datafiles:

For step 4, you change the pathname reference in the control file to point to the new location of the datafile:

In step 5, you open the database to make it available to users:

Finally, in step 6, you can make a backup copy of the updated control file:

Alternatively, you can use RMAN to perform an incremental backup that includes a backup of the control file.
Moving Datafiles with ALTER TABLESPACE in Offline Mode (11g or earlier)
If the datafile you want to move is part of a tablespace other than SYSTEM, SYSAUX, the active undo tablespace, or the temporary tablespace, then it is preferable to use the ALTER TABLESPACE method to move a tablespace for one primary reason: The rest of the database, except for the tablespace whose datafile will be moved, remains available to all users during the entire operation.
The steps for moving one or more datafiles with ALTER TABLESPACE are as follows:
1. Using an account with the ALTER TABLESPACE privilege, take the tablespace offline.
2. Use operating system commands to move the datafile(s).
3. Use ALTER TABLESPACE to change the references to the datafile in the database.
4. Bring the tablespace back online.
In the ALTER DATABASE example, assume that you moved the datafile for the XPORT tablespace to the wrong file system. In this example, you’ll move it from /u06/oradata to /u05/oradata:
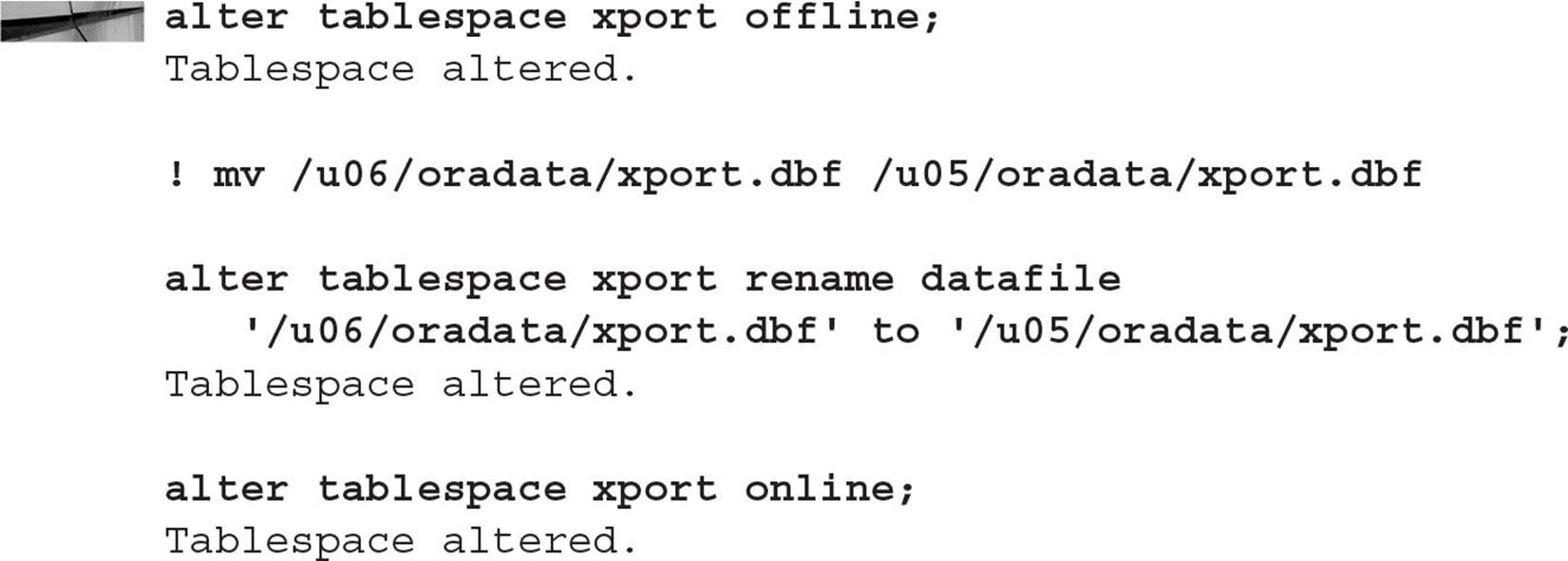
Note how this method is much more straightforward and much less disruptive than the ALTER DATABASE method. The only downtime for the XPORT tablespace is the amount of time it takes to move the datafile from one disk volume to another.
Moving Datafiles Online (Oracle Database 12c)
In Oracle Database 12c, you can move any datafile to or from an ASM disk group while the tablespace containing the datafile remains online. This enhances Oracle’s ease of manageability for the DBA and the availability for the user.
In this example, the DMARTS tablespace resides on the /u02 file system, and it needs to be moved to the +DATA disk group:
Moving the single datafile within the DMARTS tablespace to the +DATA disk group is accomplished with one command while the tablespace remains online:

Moving Online Redo Log Files
Although it is possible to indirectly move online redo log files by dropping entire redo log groups and re-adding the groups in a different location, this solution will not work if there are only two redo log file groups, because a database will not open with only one redo log file group. Temporarily adding a third group and dropping the first or second group is an option if the database must be kept open; alternatively, the method shown here will move the redo log file(s) while the database is shut down.
In the following example, we have three redo log file groups with two members each. One member of each group is on the same volume as the Oracle software and should be moved to a different volume to eliminate any contention between log file filling and accessing Oracle software components. The method you will use here is very similar to the method used to move datafiles with the ALTER DATABASE method.
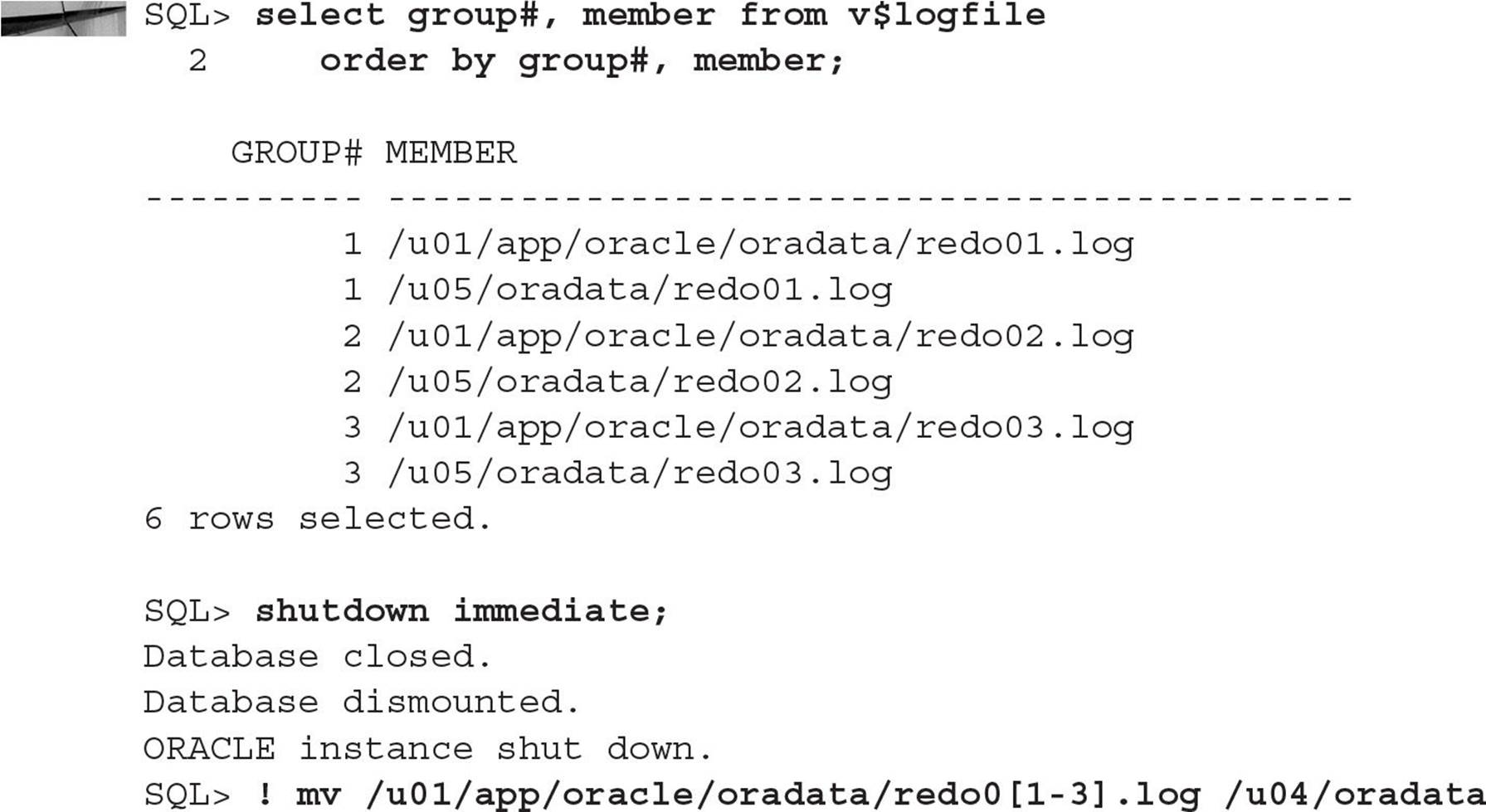
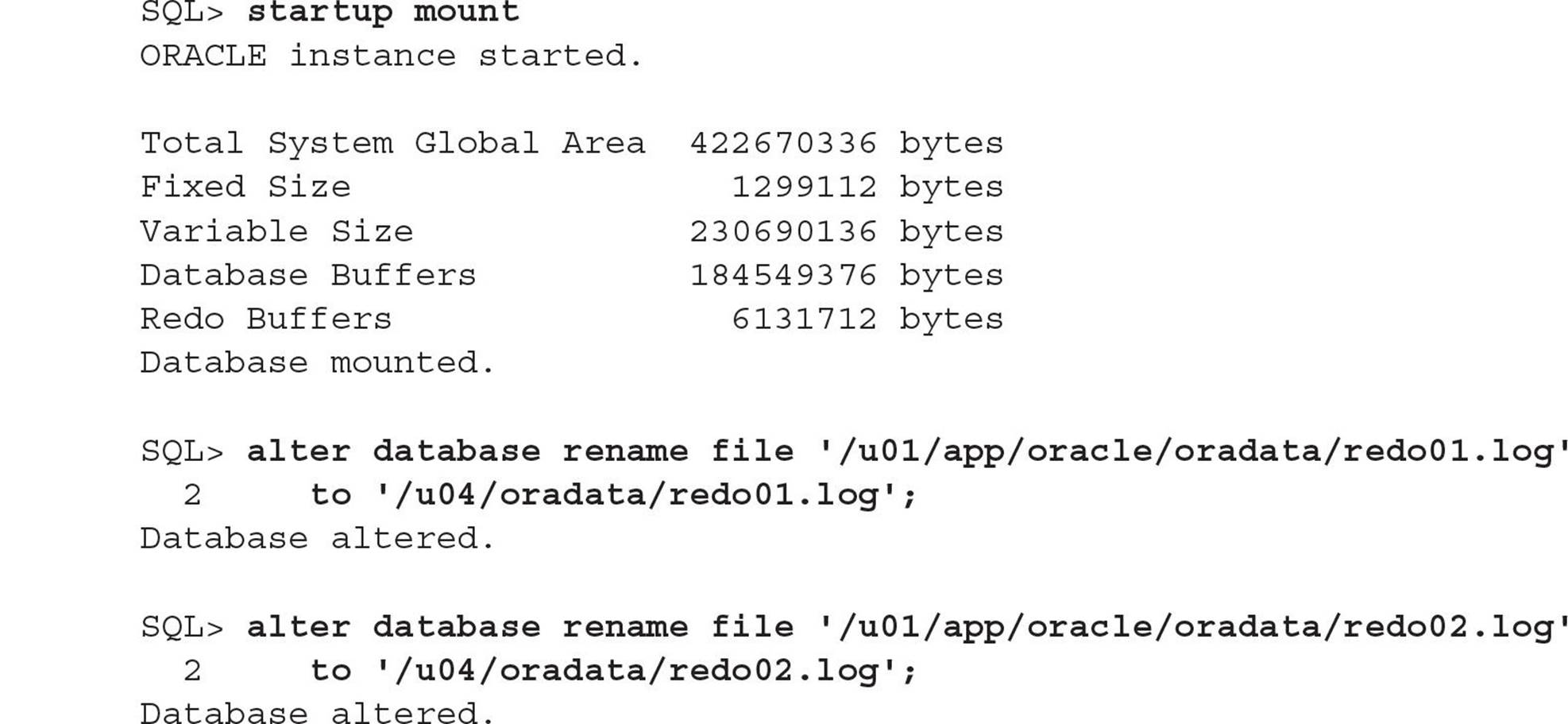
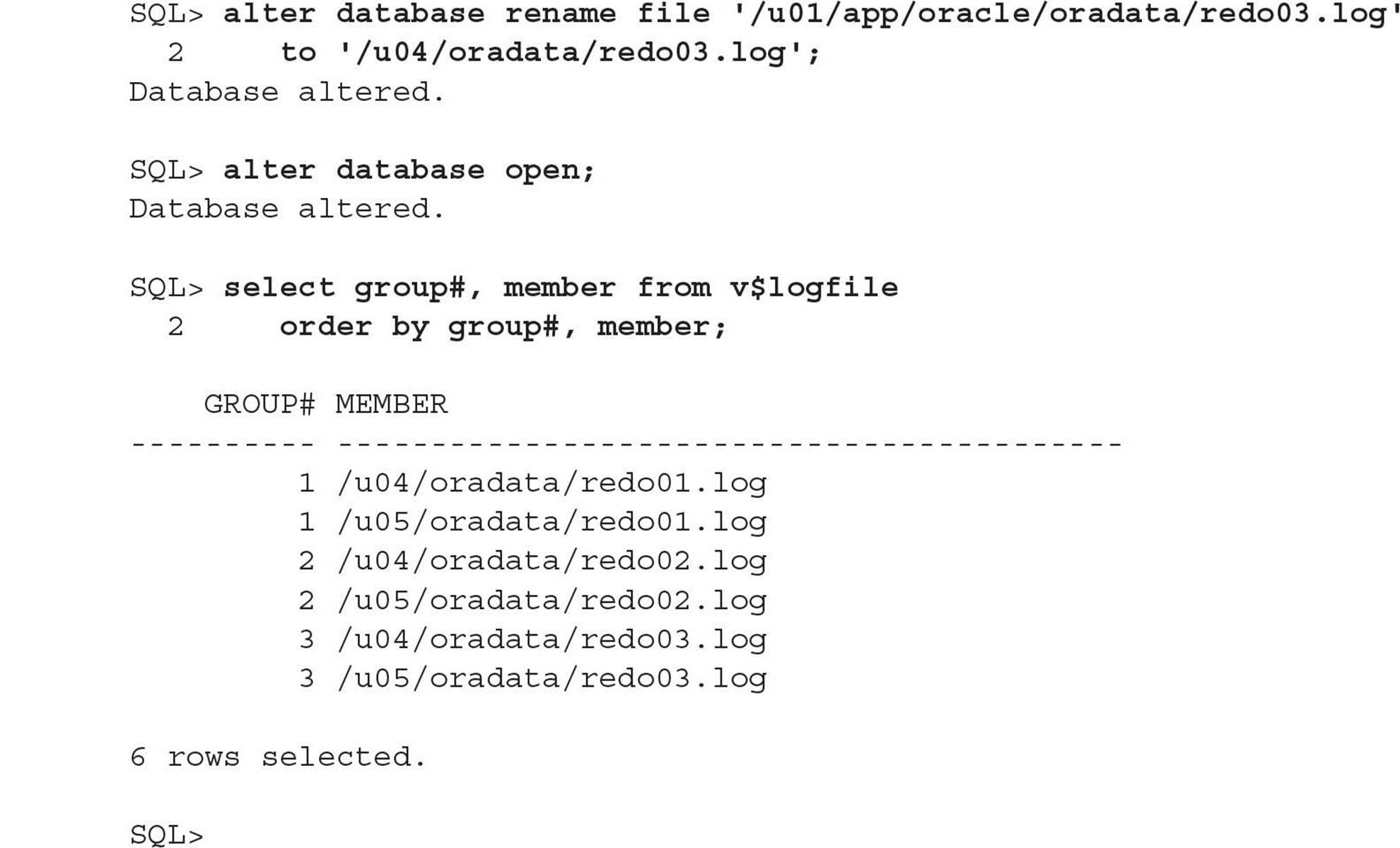
The I/O for the redo log files no longer contends with the Oracle software; in addition, the redo log files are multiplexed between two different mount points, /u04 and /u05.
Moving Control Files
Moving a control file when you use an initialization parameter file follows a procedure similar to the one you used for datafiles and redo log files: Shut down the instance, move the file with operating system commands, and restart the instance.
When you use a server parameter file (SPFILE), however, the procedure is a bit different. The initialization file parameter CONTROL_FILES is changed using ALTER SYSTEM … SCOPE=SPFILE when either the instance is running or it’s shut down and opened in NOMOUNT mode. Because the CONTROL_FILES parameter is not dynamic, the instance must be shut down and restarted in either case.
In this example, you discover that you have three copies of the control file in your database, but they are not multiplexed on different disks. You will edit the SPFILE with the new locations, shut down the instance so that you can move the control files to different disks, and then restart the instance.

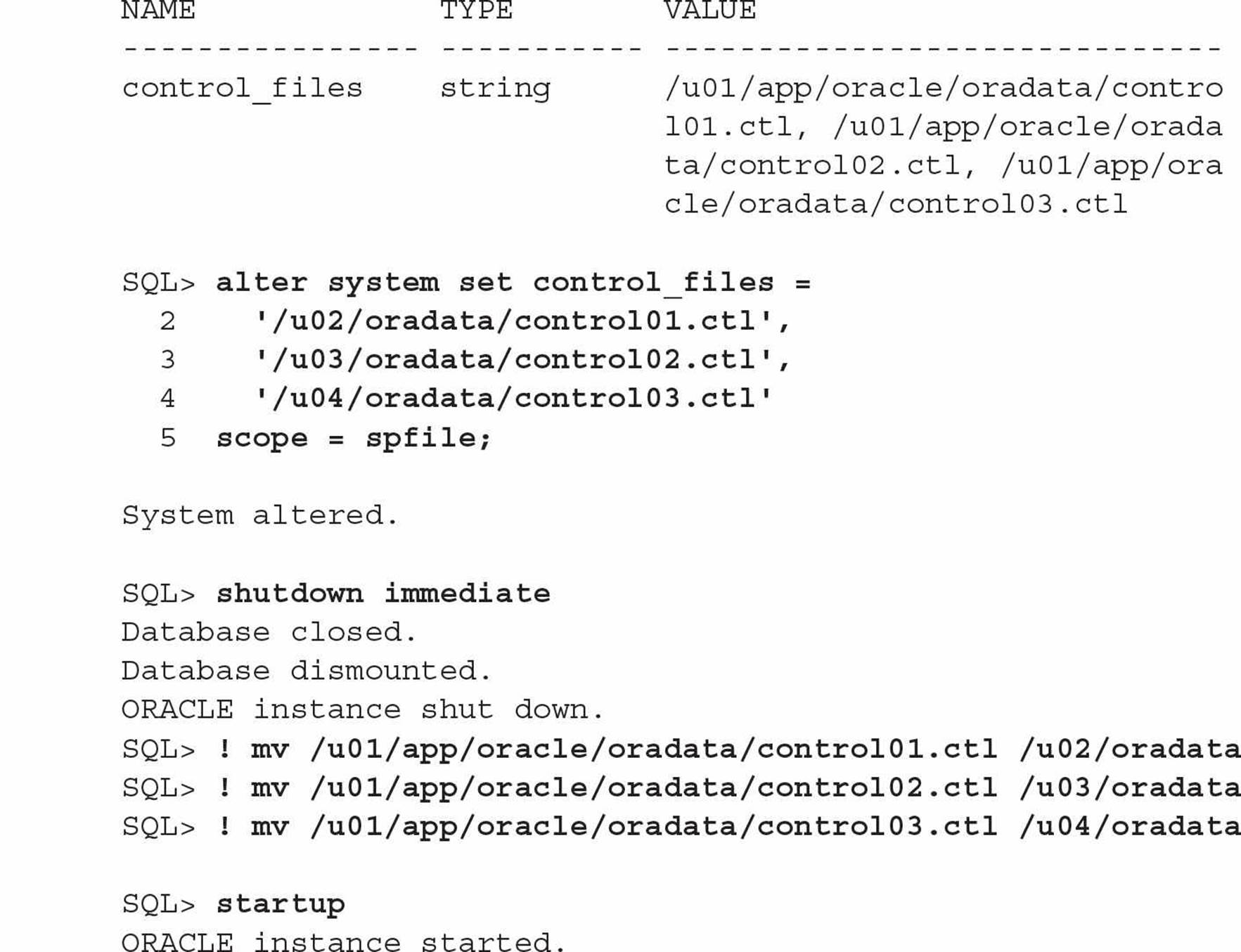
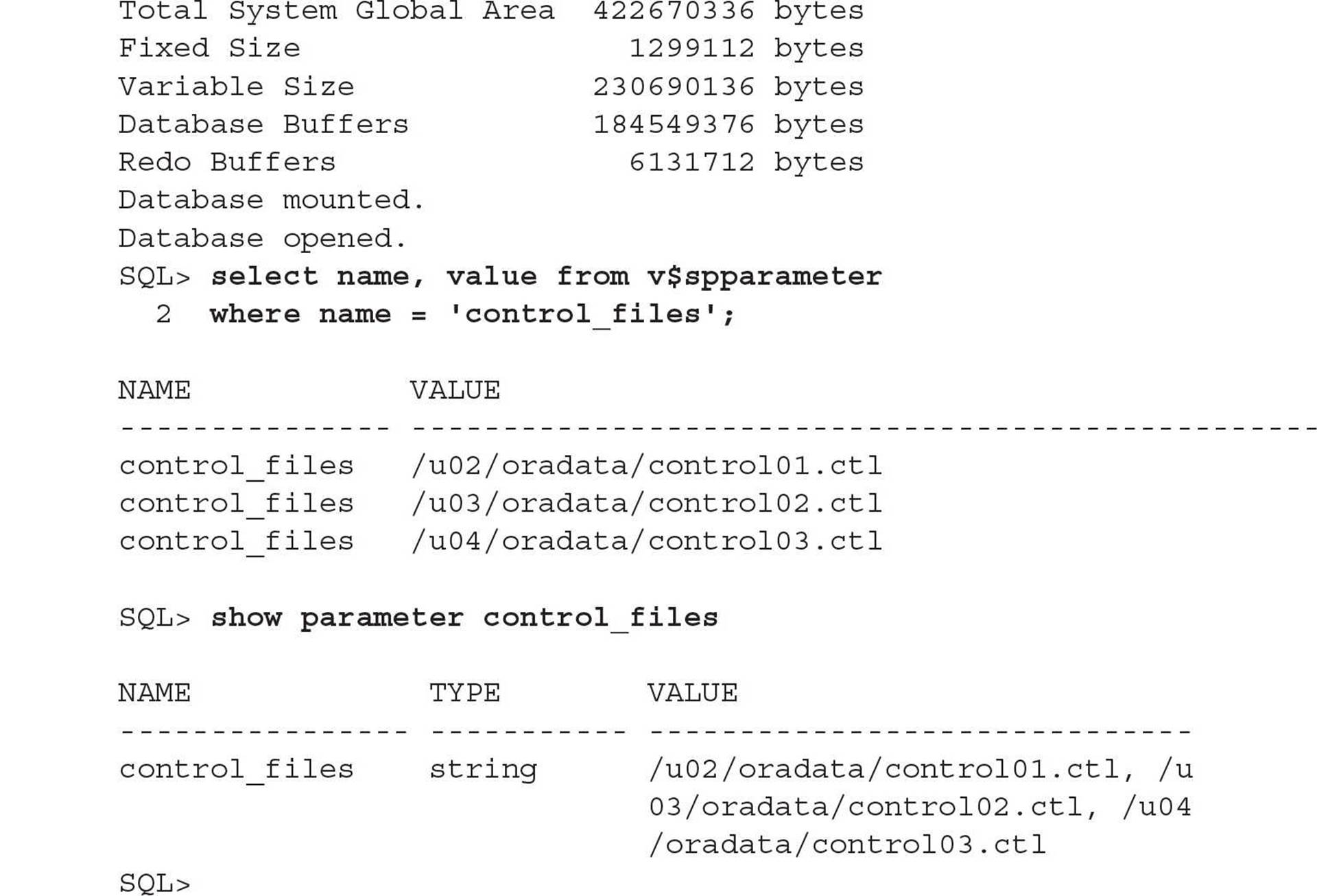
The three control files have been moved to separate file systems, no longer on the volume with the Oracle software and in a higher-availability configuration (if the volume containing one of the control files fails, two other volumes contain up-to-date control files).

NOTE
In a default installation of Oracle Database 11g or 12c using ASM disks for tablespace storage and the flash recovery area, one copy of the control file is created in the default tablespace ASM disk and another in the flash recovery area.
Making one or more copies of the control file to an ASM volume is just as easy: using the RMAN utility (described in detail in Chapter 12), restore a control file backup to an ASM disk location, as in this example:

The next step is identical to adding file system-based control files as I presented earlier in this section: change the CONTROL_FILES parameter to add the location +DATA/dw/controlfile/control_bak.ctl in addition to the existing control file locations, and then shut down and restart the database.
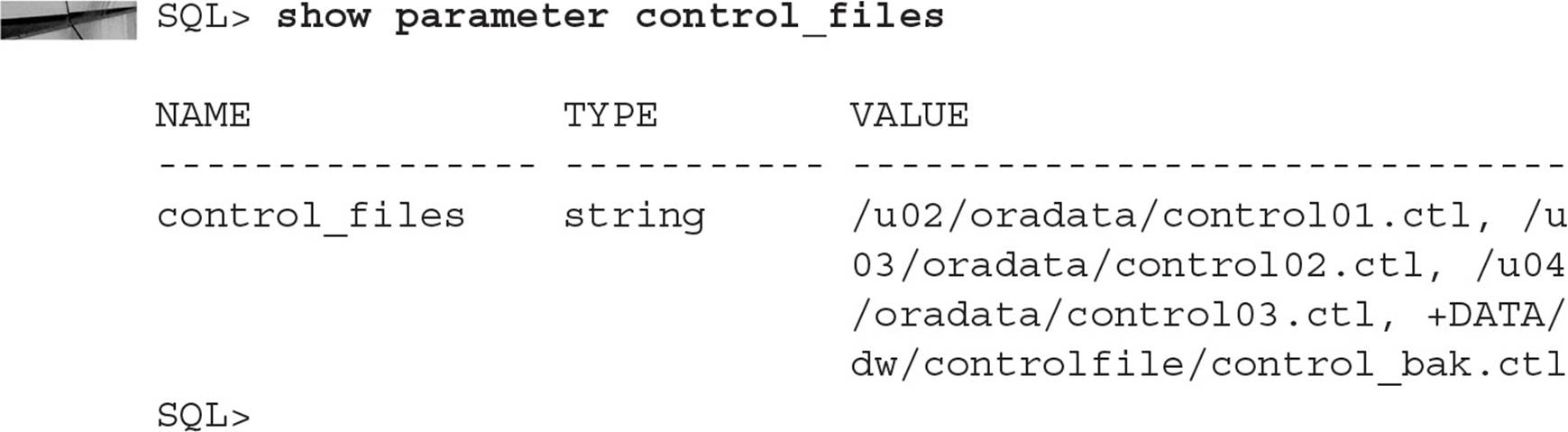
Similarly, you can use the Linux utility asmcmd to make copies of the control file from one disk group to another, and change the CONTROL_FILES parameter to reflect the new control file location. I present an overview of the asmcmd command later in this chapter.
Automatic Storage Management
In Chapter 3, I presented some of the file naming conventions used for ASM objects. In this section, I’ll delve more deeply into how we can create tablespaces—and ultimately datafiles behind the scenes—in an ASM environment with one or more disk groups.
When creating a new tablespace or other database structure, such as a control file or redo log file, you can specify a disk group as the storage area for the database structure instead of an operating system file. ASM takes the ease of use of Oracle Managed Files (OMF) and combines it with mirroring and striping features to provide a robust file system and logical volume manager that can even support multiple nodes in an Oracle Real Application Cluster (RAC). ASM eliminates the need to purchase a third-party logical volume manager.
ASM not only enhances performance by automatically spreading out database objects over multiple devices, but also increases availability by allowing new disk devices to be added to the database without shutting down the database; ASM automatically rebalances the distribution of files with minimal intervention.
We’ll also review the ASM architecture. In addition, I’ll show how you create a special type of Oracle instance to support ASM as well as how to start up and shut down an ASM instance. We’ll review the new initialization parameters related to ASM and the existing initialization parameters that have new values to support an ASM instance. Also, I’ll introduce the asmcmd command-line utility, new as of Oracle 10g Release 2, that gives you an alternate way to browse and maintain objects in your ASM disk groups. Finally, I’ll use some raw disk devices on a Linux server to demonstrate how disk groups are created and maintained.
ASM Architecture
ASM divides the datafiles and other database structures into extents, and it divides the extents among all the disks in the disk group to enhance both performance and reliability. Instead of mirroring entire disk volumes, ASM mirrors the database objects to provide the flexibility to mirror or stripe the database objects differently depending on their type. Optionally, the objects do not have to be striped at all if the underlying disk hardware is already RAID enabled, part of a storage area network (SAN), or part of a network-attached storage (NAS) device.
Automatic rebalancing is another key feature of ASM. When an increase in disk space is needed, additional disk devices can be added to a disk group, and ASM moves a proportional number of files from one or more existing disks to the new disks to maintain the overall I/O balance across all disks. This happens in the background while the database objects contained in the disk files are still online and available to users. If the impact to the I/O subsystem is high during a rebalance operation, the speed at which the rebalance occurs can be reduced using an initialization parameter.
ASM requires a special type of Oracle instance to provide the interface between a traditional Oracle instance and the file system; the ASM software components are shipped with the Oracle database software and are always available as a selection when you’re selecting the storage type for the SYSTEM, SYSAUX, and other tablespaces when the database is created.
Using ASM does not, however, prevent you from mixing ASM disk groups with manual Oracle datafile management techniques such as those I presented in Chapter 3 and earlier in this chapter. However, the ease of use and performance of ASM makes a strong case for eventually using ASM disk groups for all your storage needs.
Two Oracle background processes introduced in Oracle Database 10g support ASM instances: RBAL and ARBn. RBAL coordinates the disk activity for disk groups, whereas ORBn, where n can be a number from 0 to 9 or the letter A (Oracle Database 12c), performs the actual extent movement between disks in the disk groups.
For databases that use ASM disks, there are also two new background processes as of Oracle Database 10g: ASMB and RBAL. ASMB performs the communication between the database and the ASM instance, whereas RBAL performs the opening and closing of the disks in the disk group on behalf of the database.
Creating an ASM Instance
ASM requires a dedicated Oracle instance to manage the disk groups. An ASM instance generally has a smaller memory footprint, in the range of 100MB to 150MB, and is automatically configured when ASM (as part of the Grid Infrastructure) is specified as the database’s file storage option when the Oracle software is installed and an existing ASM instance does not already exist, as you can see in the Oracle Universal Installer screen in Figure 4-9.
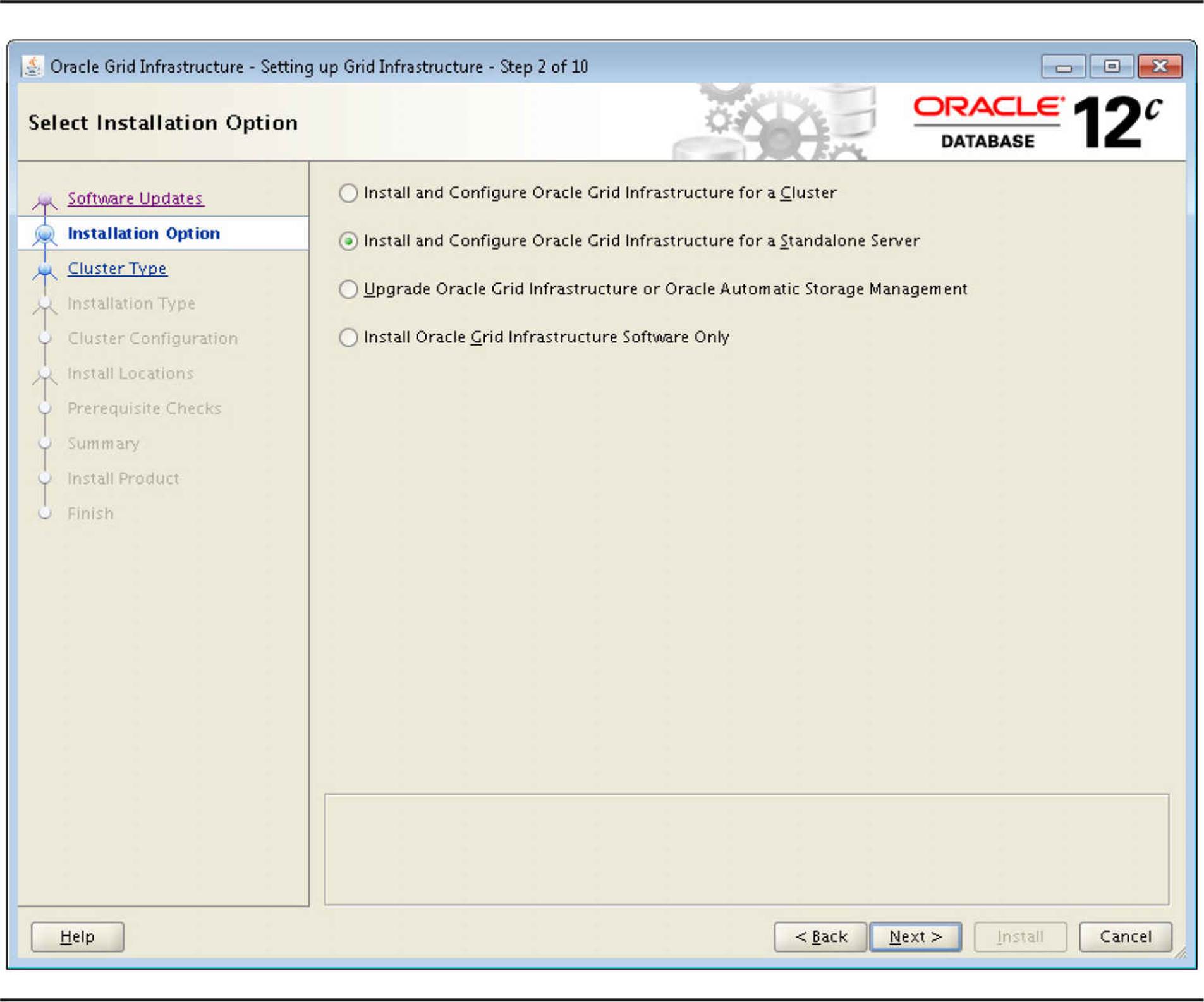
FIGURE 4-9. Specifying Grid Infrastructure (ASM) as the database file storage method
Oracle best practices for servers with over 128GB of memory recommend having the ASM instance’s initialization parameters set to something close to this:
![]() SGA_TARGET=1250M (ASMM)
SGA_TARGET=1250M (ASMM)
![]() PGA_AGGREGATE_TARGET=400M
PGA_AGGREGATE_TARGET=400M
![]() MEMORY_TARGET=0 or not set (No AMM)
MEMORY_TARGET=0 or not set (No AMM)
As an example of disk devices used to create ASM disk groups, suppose our Linux server has two unused disks with the capacities listed in Table 4-2.

TABLE 4-2. Raw Disks for ASM Disk Groups
You configure the first disk group within the Oracle Universal Installer, as shown in Figure 4-10.
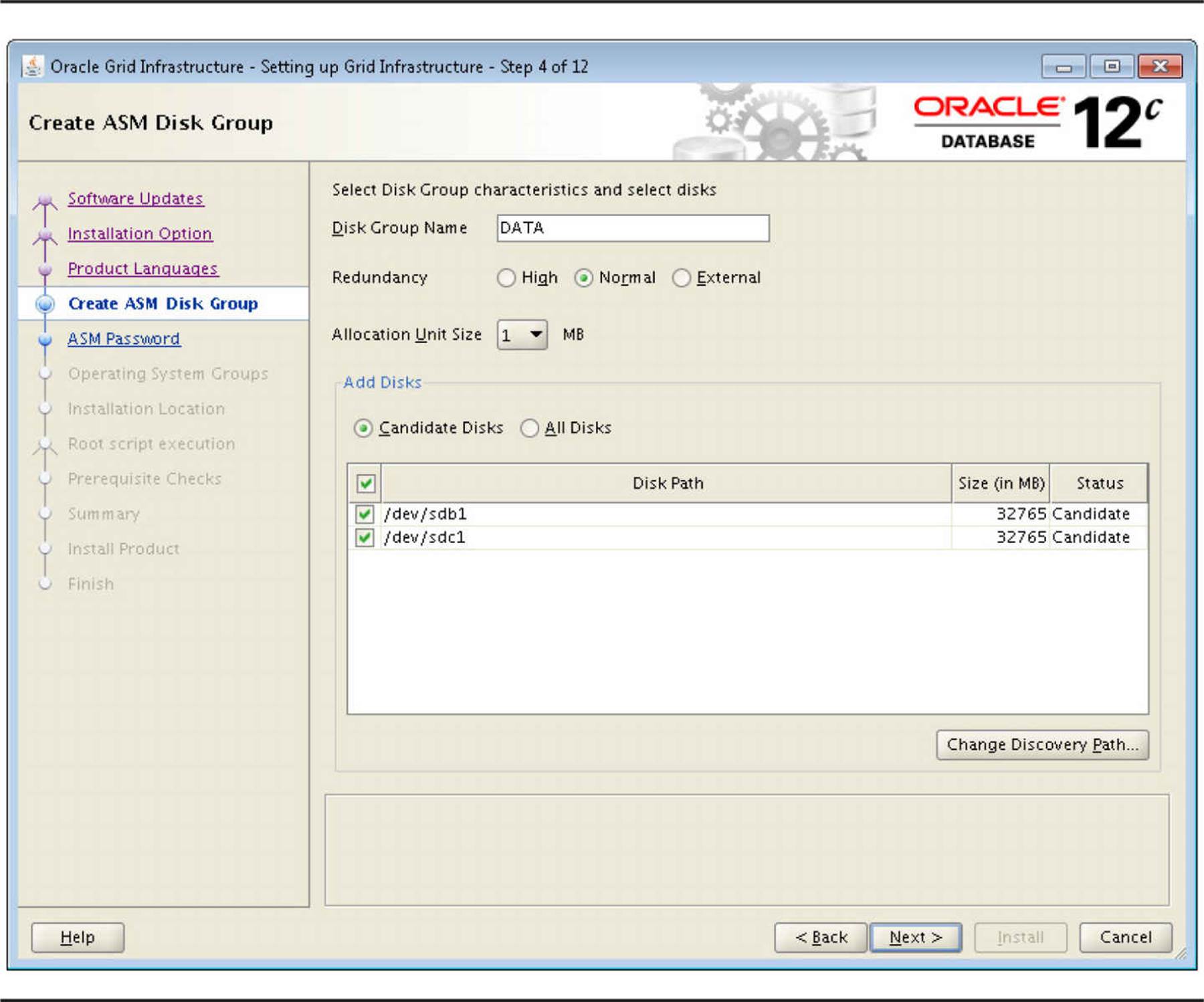
FIGURE 4-10. Configuring the initial ASM disk group with OUI
The name of the first disk group is DATA, and you will be using /dev/sdb1 and /dev/sdc1 to create the normal redundancy disk group. If an insufficient number of raw disks are selected for the desired redundancy level, OUI generates an error message. After the database is created, both the regular instance and the ASM instance are started.
An ASM instance has a few other unique characteristics. Although it does have an initialization parameter file and a password file, it has no data dictionary, and therefore all connections to an ASM instance are via SYS and SYSTEM using operating system authentication only. If you are using Oracle Database 12c, however, you can create a password file and even put it in an ASM disk group, much like you can do with an RDBMS password file, as in this example:
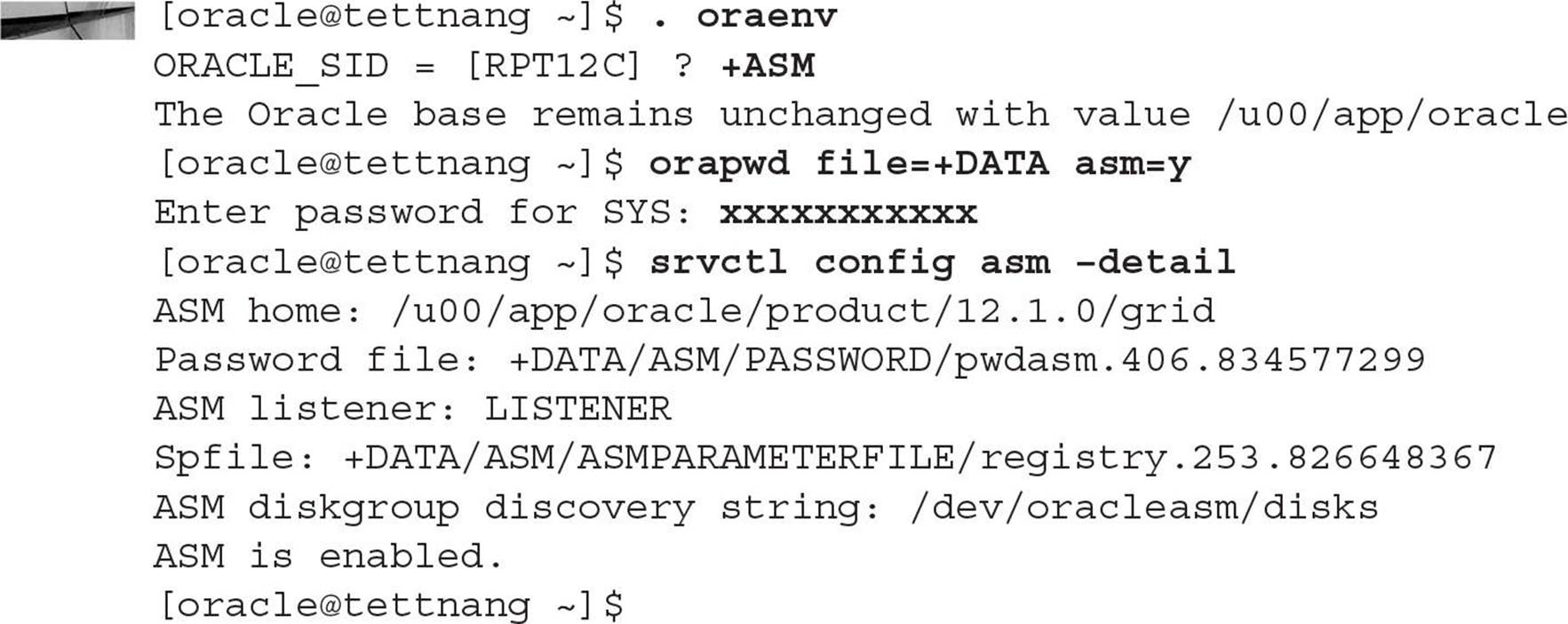
Disk group commands such as CREATE DISKGROUP, ALTER DISKGROUP, and DROP DISKGROUP are only valid in an ASM instance. Finally, an ASM instance is either in a NOMOUNT or MOUNT state; it is never in an OPEN state.
ASM Instance Components
ASM instances cannot be accessed using the variety of methods available with a traditional database. In this section, I’ll talk about the privileges available to you that connect with SYSASM privilege. I’ll also distinguish an ASM instance by the new and expanded initialization parameters (introduced in Oracle Database 10g and enhanced in Oracle Database 11g and 12c) available only for an ASM instance. At the end of this section, I’ll present the procedures for starting and stopping an ASM instance along with the dependencies between ASM instances and the database instances they serve.
Accessing an ASM Instance
As mentioned earlier in the chapter, an ASM instance does not have a data dictionary, so access to the instance is restricted to users who can authenticate with the operating system—in other words, connecting as SYSASM by an operating system user in the dba group.
Users who connect to an ASM instance as SYSASM can perform all ASM operations, such as creating and deleting disk groups as well as adding and removing disks from disk groups. In Oracle Database 11g and 12c, a user with the SYSDBA privilege can still perform the same tasks as a user with SYSASM privileges, but that role is deprecated and will not have the same privileges as SYSASM in future releases.
The SYSOPER users have a much more limited set of commands available in an ASM instance. In general, the commands available to SYSOPER users give only enough privileges to perform routine operations for an already configured and stable ASM instance. The following list contains the operations available as SYSOPER:
![]() Starting up and shutting down an ASM instance
Starting up and shutting down an ASM instance
![]() Mounting or dismounting a disk group
Mounting or dismounting a disk group
![]() Altering a disk group’s disk status from ONLINE to OFFLINE, or vice versa
Altering a disk group’s disk status from ONLINE to OFFLINE, or vice versa
![]() Rebalancing a disk group
Rebalancing a disk group
![]() Performing an integrity check of a disk group
Performing an integrity check of a disk group
![]() Accessing the V$ASM_* dynamic performance views
Accessing the V$ASM_* dynamic performance views
In Oracle Database 12c, the following three new privileges for ASM instances have been added. These roles are task-oriented and help to enforce enterprise separation of duties requirements.
![]() SYSBACKUP Perform backup and recovery from RMAN or the SQL*Plus command line
SYSBACKUP Perform backup and recovery from RMAN or the SQL*Plus command line
![]() SYSDG Perform Data Guard operations with Data Guard Broker or at the dgmgrl command line
SYSDG Perform Data Guard operations with Data Guard Broker or at the dgmgrl command line
![]() SYSKM Manage encryption keys for Transparent Data Encryption (TDE)
SYSKM Manage encryption keys for Transparent Data Encryption (TDE)
ASM Initialization Parameters
A number of initialization parameters are either specific to ASM instances or have new values within an ASM instance. An SPFILE is highly recommended instead of an initialization parameter file for an ASM instance. For example, parameters such as ASM_DISKGROUPS will automatically be maintained when a disk group is added or dropped, potentially freeing you from ever having to manually change this value.
The ASM-related initialization parameters are presented next.
INSTANCE_TYPE For an ASM instance, the INSTANCE_TYPE parameter has a value of ASM. The default, for a traditional Oracle instance, is RDBMS.
DB_UNIQUE_NAME The default value for the DB_UNIQUE_NAME parameter is +ASM and is the unique name for a group of ASM instances within a cluster or on a single node.
ASM_POWER_LIMIT To ensure that rebalancing operations do not interfere with ongoing user I/O, the ASM_POWER_LIMIT parameter controls how fast rebalance operations occur. For Oracle Database 12c, the values range from 0 to 1024 (1 to 11 in Oracle Database 11g unless you are using version 11.2.0.2 and the COMPATIBLE.ASM disk group attribute is set to 11.2.0.2 or higher), with 1024 being the highest possible value; the default value is 1 (low I/O overhead). Because this is a dynamic parameter, you may set this to a low value during the day and set it higher overnight whenever a disk-rebalancing operation must occur.
ASM_DISKSTRING The ASM_DISKSTRING parameter specifies one or more strings, operating system dependent, to limit the disk devices that can be used to create disk groups. If this value is NULL, all disks visible to the ASM instance are potential candidates for creating disk groups. For the examples in this chapter for our test server, the value of the ASM_DISKSTRING parameter is /dev/raw/*:

ASM_DISKGROUPS The ASM_DISKGROUPS parameter specifies a list containing the names of the disk groups to be automatically mounted by the ASM instance at startup or by the ALTER DISKGROUP ALL MOUNT command. Even if this list is empty at instance startup, any existing disk group can be manually mounted.
LARGE_POOL_SIZE The LARGE_POOL_SIZE parameter is useful for both regular and ASM instances; however, this pool is used differently for an ASM instance. All internal ASM packages are executed from this pool. The default value for this parameter is usually sufficient, which is 12MB for a single instance and 16GB in a RAC environment.
ASM_PREFERRED_READ_FAILURE_GROUPS The ASM_PREFERRED_READ_FAILURE_GROUPS parameter, new to Oracle Database 11g, contains a list of the preferred failure groups for a given database instance when using clustered ASM instances. This parameter is instance specific: each instance can specify a failure group that is closest to the instance’s node (for example, a failure group on the server’s local disk) to improve performance.
ASM Instance Startup and Shutdown
An ASM instance is started much like a database instance, except that the STARTUP command defaults to STARTUP MOUNT. Because there is no control file, database, or data dictionary to mount, the ASM disk groups are mounted instead of a database. The command STARTUP NOMOUNT starts up the instance but does not mount any ASM disks. In addition, you can specify STARTUP RESTRICT to temporarily prevent database instances from connecting to the ASM instance to mount disk groups.
NOTE
Even though the ASM instance is in a MOUNT state, the STATUS column is set to STARTED instead of MOUNTED, as in an RDBMS instance.
Performing a SHUTDOWN command on an ASM instance performs the same SHUTDOWN command on any database instances using the ASM instance; before the ASM instance finishes a shutdown, it waits for all dependent databases to shut down. The only exception to this is if you use the SHUTDOWN ABORT command on the ASM instance, which eventually forces all dependent databases to perform a SHUTDOWN ABORT.
For multiple ASM instances sharing disk groups, such as in a Real Application Clusters (RAC) environment, the failure of an ASM instance does not cause the database instances to fail. Instead, another ASM instance performs a recovery operation for the failed instance.
ASM Dynamic Performance Views
A few new dynamic performance views are associated with ASM instances. Table 4-3 contains the common ASM-related dynamic performance views. I’ll provide further explanation, where appropriate, later in this chapter for some of these views.
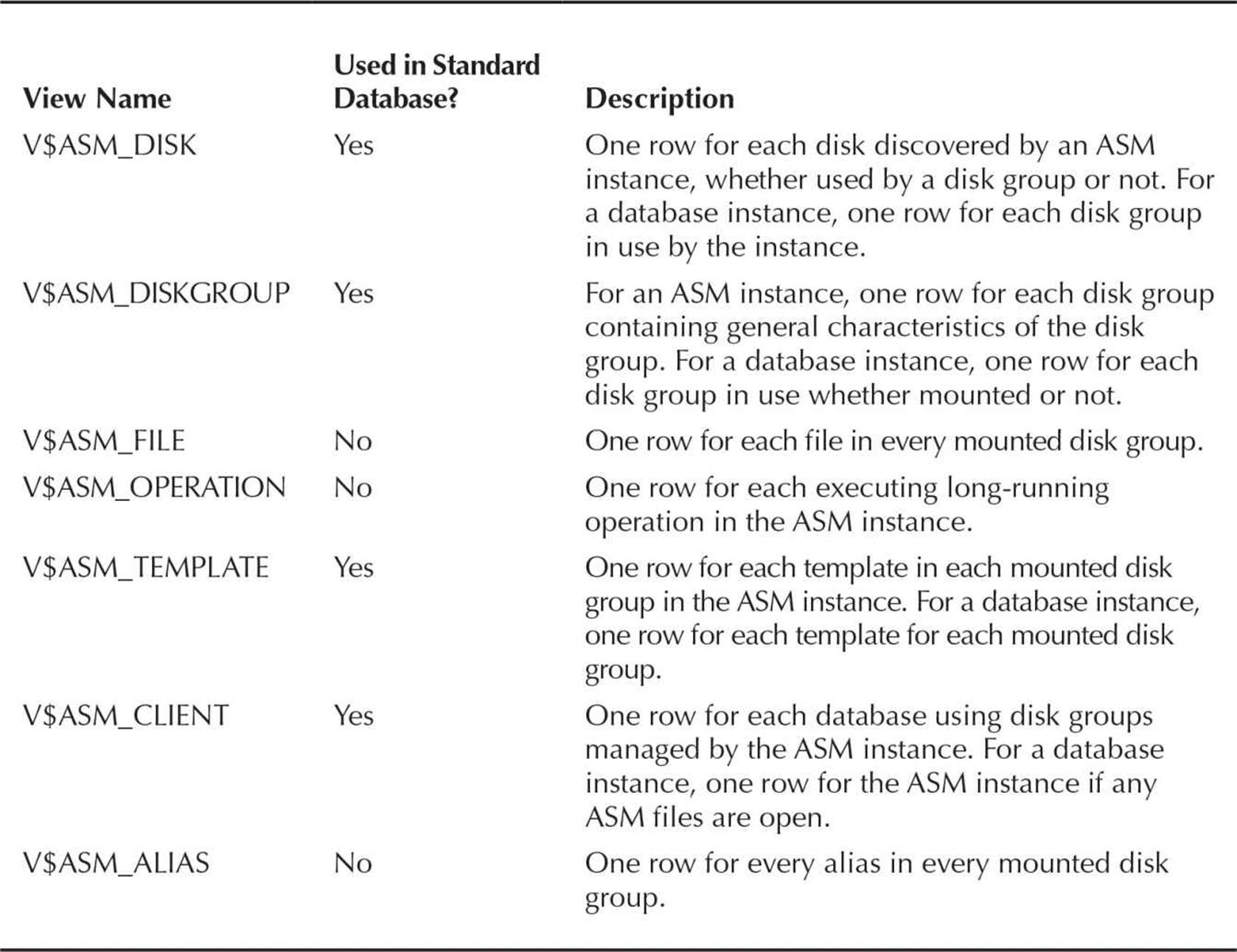
TABLE 4-3. ASM-Related Dynamic Performance Views
ASM Filename Formats
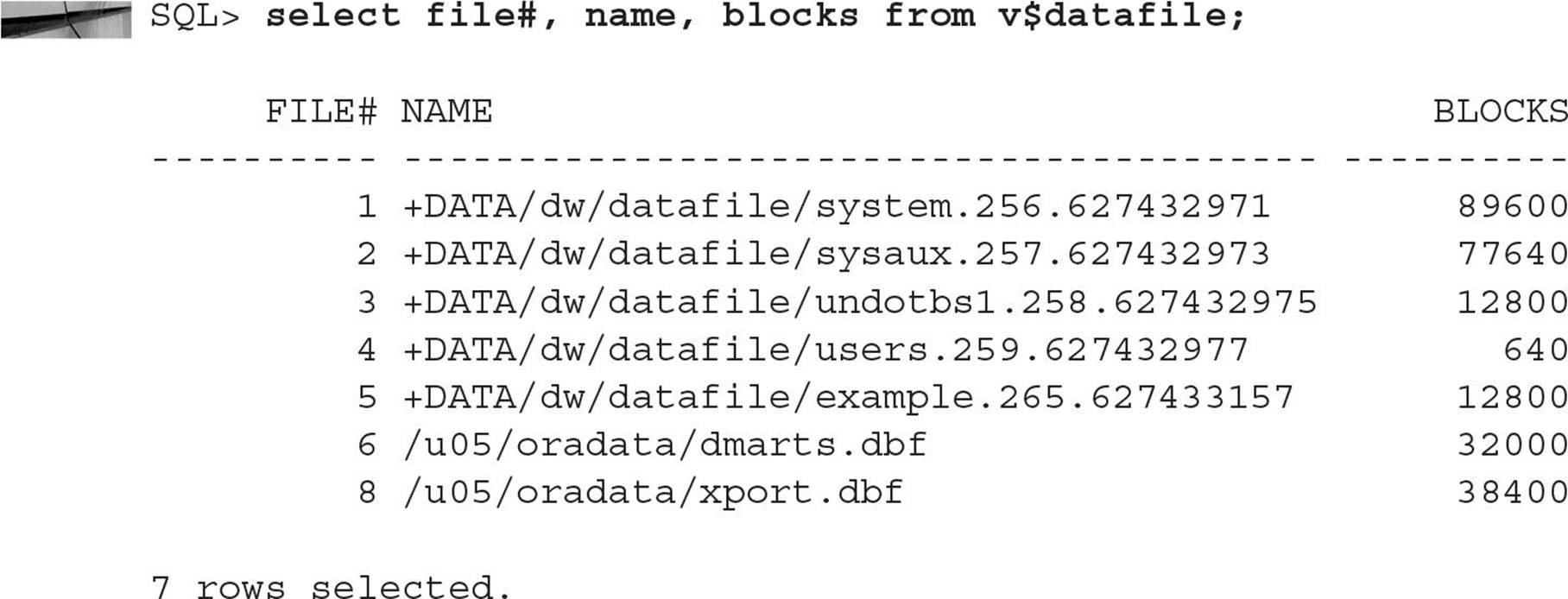
All ASM files are Oracle Managed Files (OMF), so the details of the actual filename within the disk group is not needed for most administrative functions. When an object in an ASM disk group is dropped, the file is automatically deleted. Certain commands will expose the actual filenames, such as ALTER DATABASE BACKUP CONTROLFILE TO TRACE, as well as some data dictionary and dynamic performance views. For example, the dynamic performance view V$DATAFILE shows the actual filenames within each disk group. Here is an example:
ASM filenames can be one of six different formats. In the sections that follow, I’ll give an overview of the different formats and the context where they can be used—either as a reference to an existing file, during a single-file creation operation, or during a multiple-file creation operation.
Fully Qualified Names
Fully qualified ASM filenames are used only when referencing an existing file. A fully qualified ASM filename has the format
![]()
where group is the disk group name, dbname is the database to which the file belongs, file type is the Oracle file type, tag is information specific to the file type, and the file.incarnation pair ensures uniqueness. Here is an example of an ASM file for the USERS tablespace:
![]()
The disk group name is +DATA, the database name is dw, it’s a datafile for the USERS tablespace, and the file number/incarnation pair 259.627432977 ensures uniqueness if you decide to create another ASM datafile for the USERS tablespace.
Numeric Names
Numeric names are used only when referencing an existing ASM file. This allows you to refer to an existing ASM file by only the disk group name and the file number/incarnation pair. The numeric name for the ASM file in the preceding section is
![]()
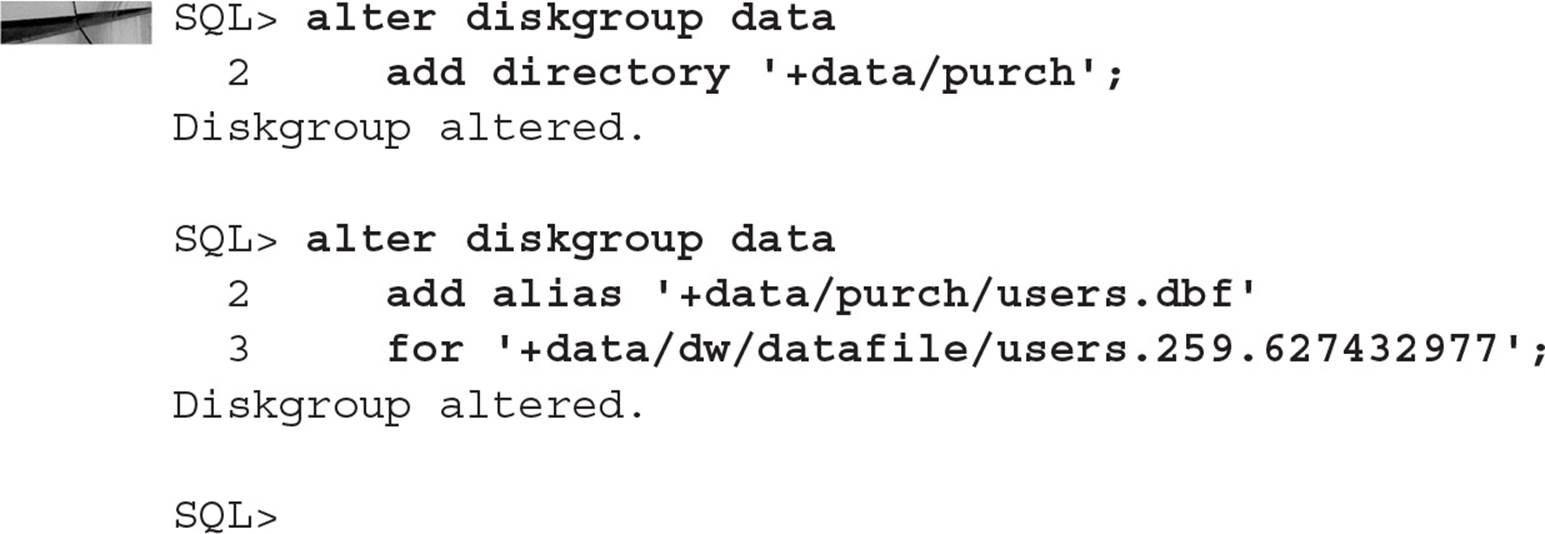
Alias Names
An alias can be used when either referencing an existing object or creating a single ASM file. Using the ALTER DISKGROUP ADD ALIAS command, a more readable name can be created for an existing or a new ASM file, and it’s distinguishable from a regular ASM filename because it does not end in a dotted pair of numbers (the file number/incarnation pair), as shown here:
Alias with Template Names
An alias with a template can only be used when creating a new ASM file. Templates provide a shorthand for specifying a file type and a tag when creating a new ASM file. Here’s an example of an alias using a template for a new tablespace in the +DATA disk group:

The template DATAFILE specifies COARSE striping, MIRROR for a normal-redundancy group, and HIGH for a high-redundancy group; it is the default for a datafile. Because we did not fully qualify the name, the ASM name for this diskgroup is as follows:
![]()
I’ll talk more about ASM templates in the upcoming section “ASM File Types and Templates.”
Incomplete Names
An incomplete filename format can be used either for single-file or multiple-file creation operations. Only the disk group name is specified, and a default template is used depending on the type of file, as shown here:

Incomplete Names with Template
As with incomplete ASM filenames, an incomplete filename with a template can be used either for single-file or multiple-file creation operations. Regardless of the actual file type, the template name determines the characteristics of the file.
Even though we are creating a tablespace in the following example, the striping and mirroring characteristics of an online log file (fine striping) are used for the new tablespace instead as the attributes for the datafile (coarse striping):

ASM File Types and Templates
ASM supports all types of files used by the database except for operating system executables. Table 4-4 contains the complete list of ASM file types; the ASM File Type and Tag columns are those presented previously for ASM file naming conventions.
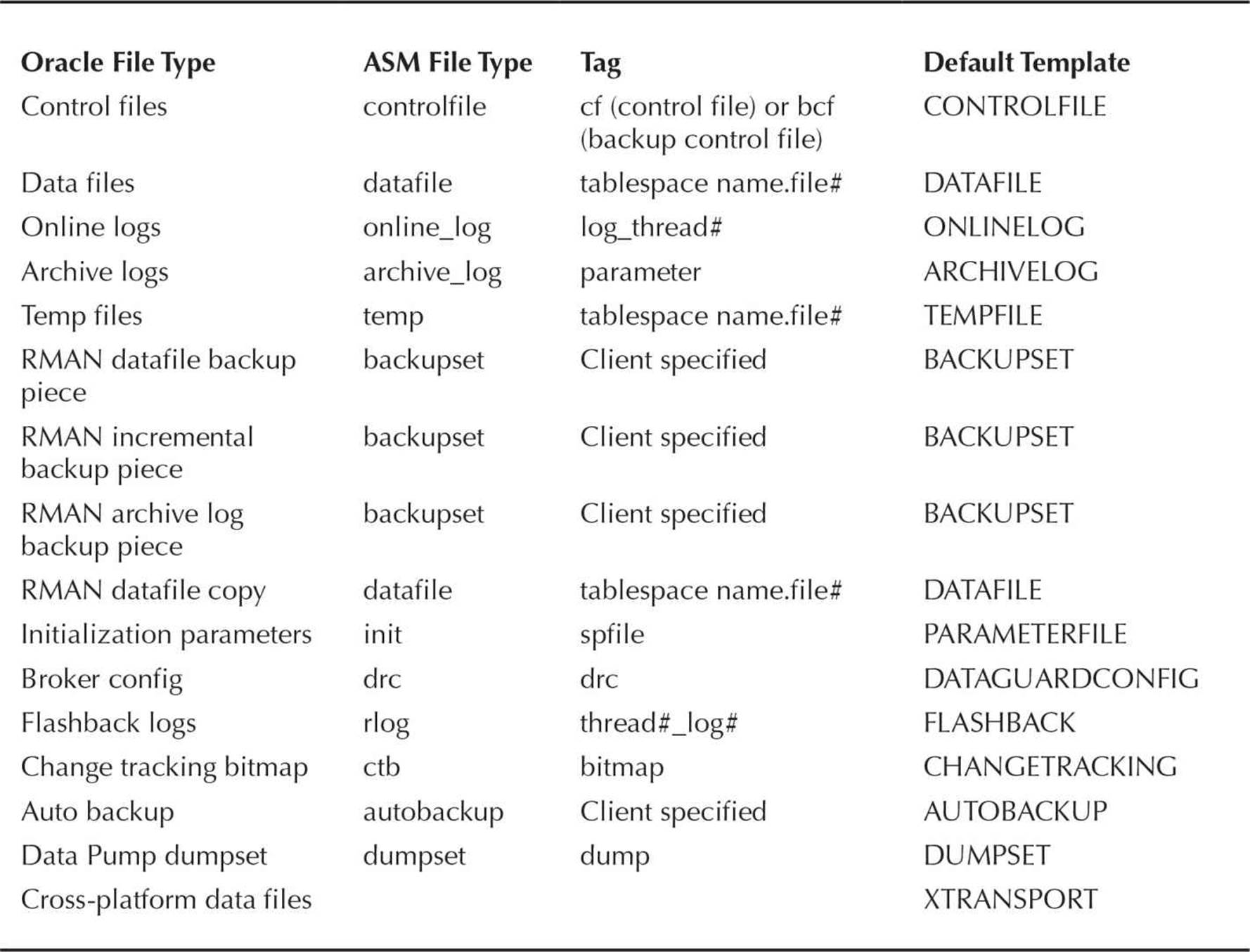
TABLE 4-4. ASM File Types
The default ASM file templates referenced in the last column of Table 4-4 are presented in Table 4-5.
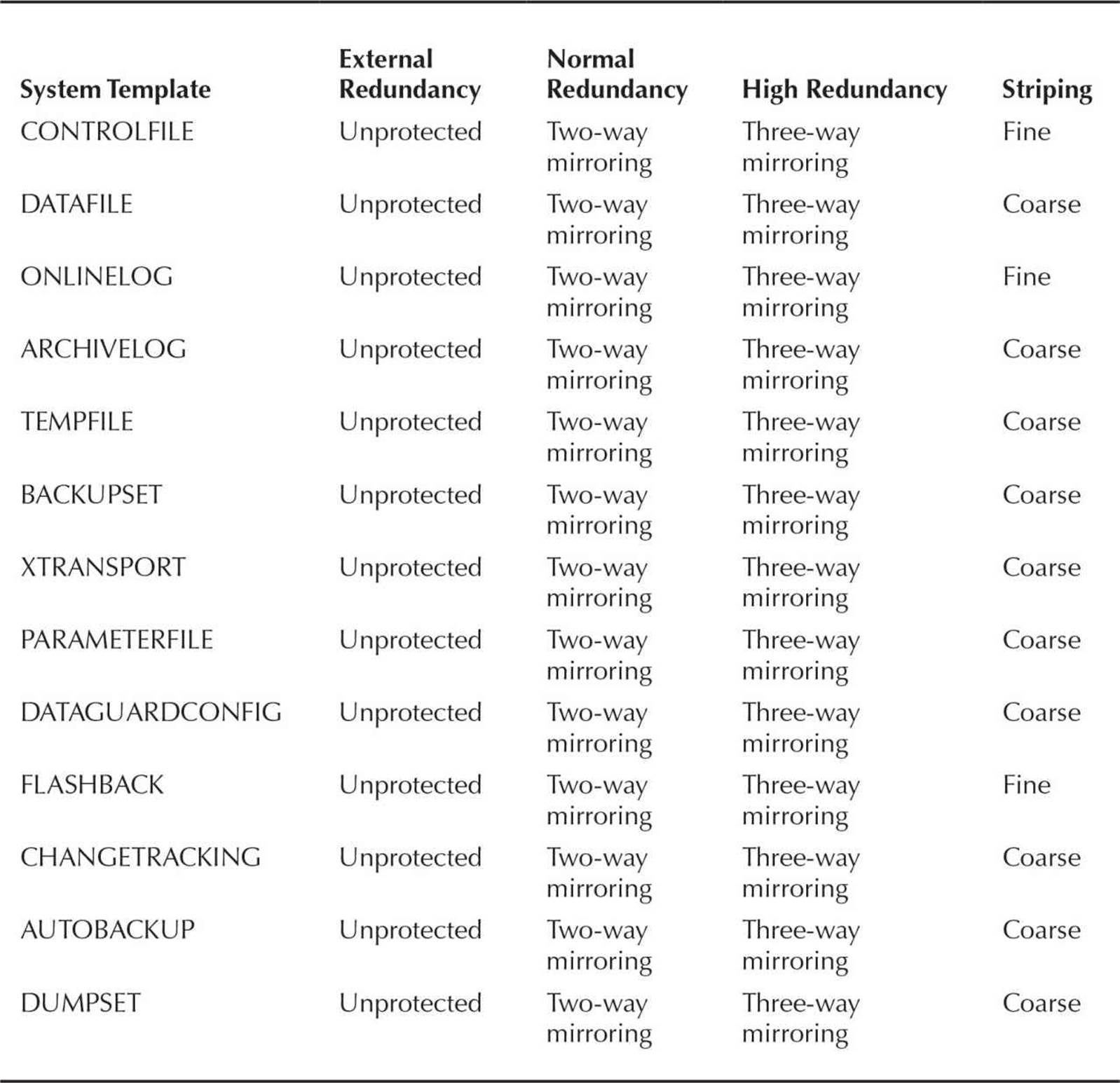
TABLE 4-5. ASM File Template Defaults
When a new disk group is created, a set of ASM file templates copied from the default templates in Table 4-5 is saved with the disk group; as a result, individual template characteristics can be changed and apply only to the disk group where they reside. In other words, the DATAFILE system template in disk group +DATA1 may have the default coarse striping, but the DATAFILE template in disk group +DATA2 may have fine striping. You can create your own templates in each disk group as needed.
When an ASM datafile is created with the DATAFILE template, by default the datafile is 100MB and autoextensible, and the maximum size is 32,767MB (32GB).
Administering ASM Disk Groups
Using ASM disk groups benefits you in a number of ways: I/O performance is improved, availability is increased, and the ease with which you can add a disk to a disk group or add an entirely new disk group enables you to manage many more databases in the same amount of time. Understanding the components of a disk group as well as correctly configuring a disk group are important goals for a successful DBA.
In this section, I’ll delve more deeply into the details of the structure of a disk group. Also, I’ll review the different types of administrative tasks related to disk groups and show how disks are assigned to failure groups; how disk groups are mirrored; and how disk groups are created, dropped, and altered. At the command line, I’ll give you an introduction to the asmcmd command-line utility that you can use to browse, copy, and manage ASM objects.
Disk Group Architecture
As defined earlier in this chapter, a disk group is a collection of physical disks managed as a unit. Every ASM disk, as part of a disk group, has an ASM disk name that is either assigned by the DBA or automatically assigned when it is assigned to the disk group.
Files in a disk group are striped on the disks using either coarse striping or fine striping. Coarse striping spreads files in units of 1MB each across all disks. Coarse striping is appropriate for a system with a high degree of concurrent small I/O requests, such as an OLTP environment. Alternatively, fine striping spreads files in units of 128KB, is appropriate for traditional data warehouse environments or OLTP systems with low concurrency, and maximizes response time for individual I/O requests.
Disk Group Mirroring and Failure Groups
Before defining the type of mirroring within a disk group, you must group disks into failure groups. A failure group is one or more disks within a disk group that share a common resource, such as a disk controller, whose failure would cause the entire set of disks to be unavailable to the group. In most cases, an ASM instance does not know the hardware and software dependencies for a given disk. Therefore, unless you specifically assign a disk to a failure group, each disk in a disk group is assigned to its own failure group.
Once the failure groups have been defined, you can define the mirroring for the disk group; the number of failure groups available within a disk group can restrict the type of mirroring available for the disk group. There are three types of mirroring available: external redundancy, normal redundancy, and high redundancy.
External Redundancy External redundancy requires only one disk location and assumes that the disk is not critical to the ongoing operation of the database or that the disk is managed externally with high-availability hardware such as a RAID controller.
Normal Redundancy Normal redundancy provides two-way mirroring and requires at least two failure groups within a disk group. Failure of one of the disks in a failure group does not cause any downtime for the disk group or any data loss other than a slight performance hit for queries against objects in the disk group; when all disks in the failure group are online, read performance is typically improved because the requested data is available on more than one disk.
High Redundancy High redundancy provides three-way mirroring and requires at least three failure groups within a disk group. The failure of disks in two out of the three failure groups is for the most part transparent to the database users, as in normal redundancy mirroring.
Mirroring is managed at a very low level. Extents, not disks, are mirrored. In addition, each disk will have a mixture of both primary and mirrored (secondary and tertiary) extents on each disk. Although a slight amount of overhead is incurred for managing mirroring at the extent level, it provides the advantage of spreading out the load from the failed disk to all other disks instead of a single disk.
Disk Group Dynamic Rebalancing
Whenever you change the configuration of a disk group—whether you are adding or removing a failure group or a disk within a failure group—dynamic rebalancing occurs automatically to proportionally reallocate data from other members of the disk group to the new member of the disk group. This rebalance occurs while the database is online and available to users; any impact to ongoing database I/O can be controlled by adjusting the value of the initialization parameter ASM_POWER_LIMIT to a lower value.
Not only does dynamic rebalancing free you from the tedious and often error-prone task of identifying hot spots in a disk group, it also provides an automatic way to migrate an entire database from a set of slower disks to a set of faster disks while the entire database remains online. Faster disks are added as a new failure group in the existing disk group with the slower disks and the automatic rebalance occurs. After the rebalance operations complete, the failure groups containing the slower disks are dropped, leaving a disk group with only fast disks. To make this operation even faster, both the ADD and DROP operations can be initiated within the same ALTER DISKGROUP command.
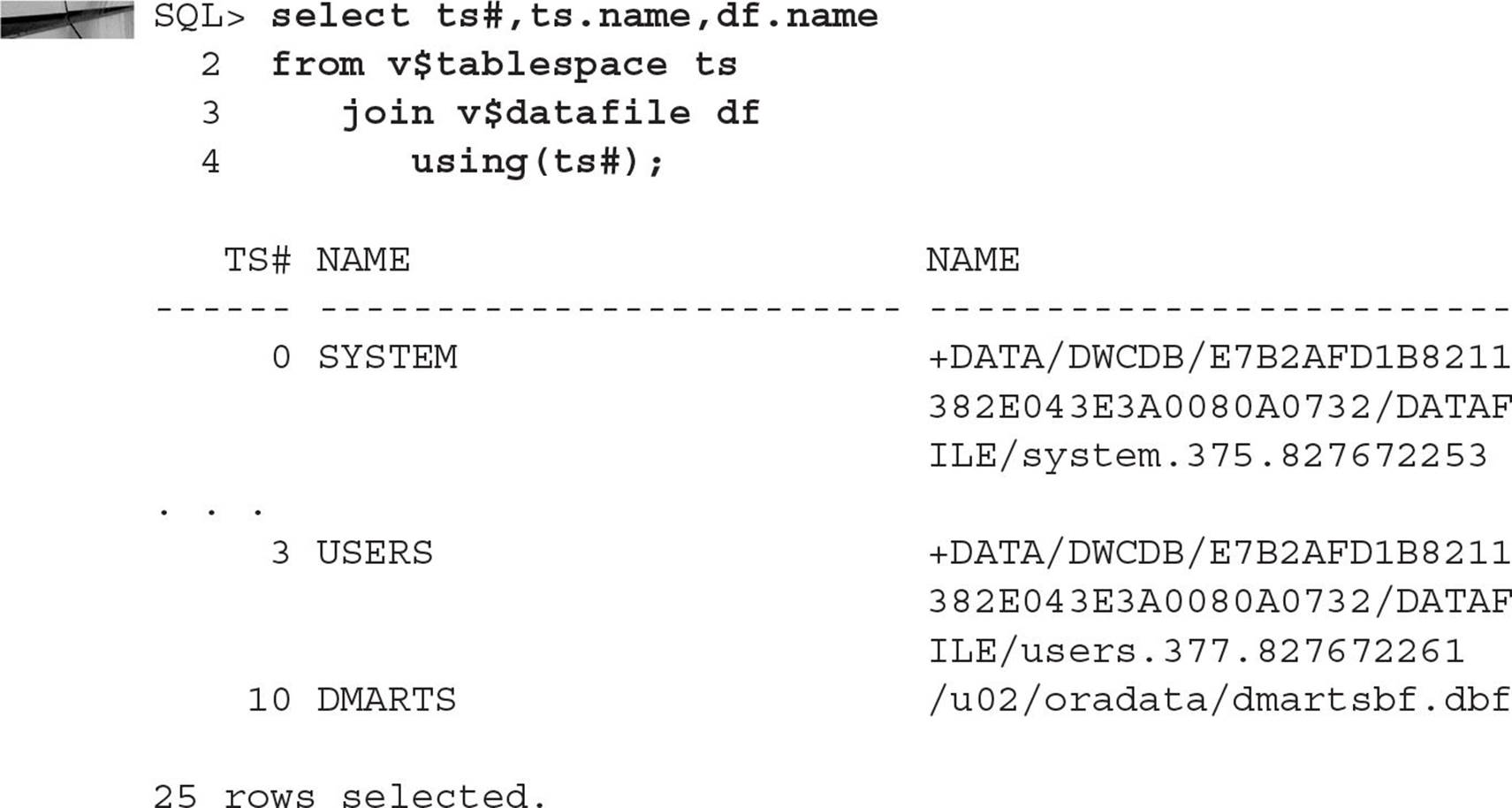
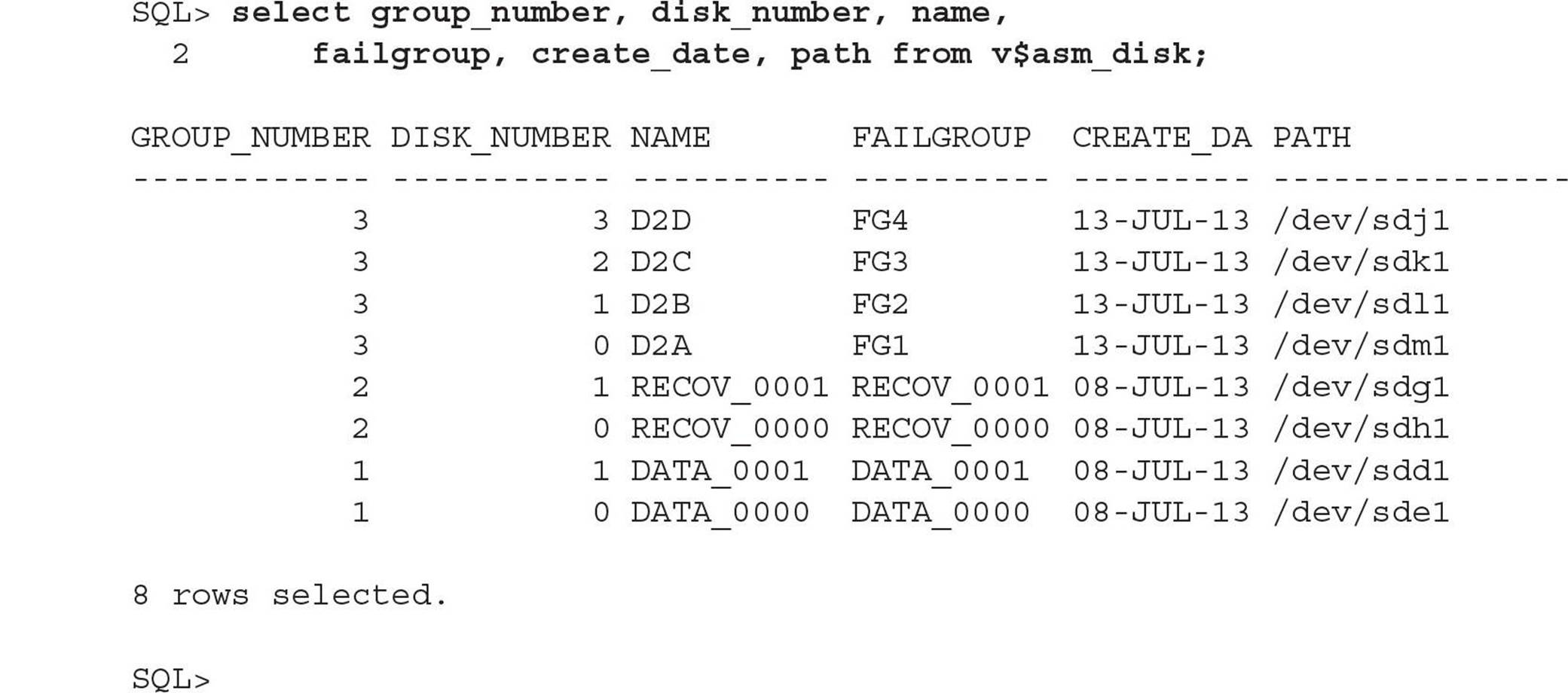
As an example, suppose you want to create a new disk group with high redundancy to hold tablespaces for a new credit card authorization. Using the view V$ASM_DISK, you can view all disks discovered using the initialization parameter ASM_DISKSTRING, along with the status of the disk (in other words, whether it is assigned to an existing disk group or is unassigned). Here is the command:
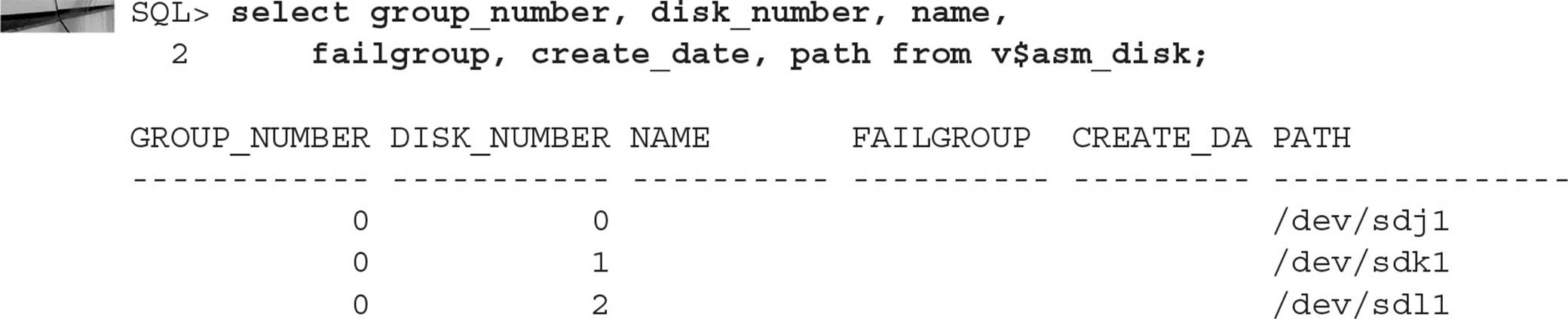

Out of the eight disks available for ASM, only four of them are assigned to two disk groups, DATA and RECOV, each in its own failure group. The disk group name can be obtained from the view V$ASM_DISKGROUP:

Note that if you had a number of ASM disks and disk groups, you could have joined the two views on the GROUP_NUMBER column and filtered the query result by GROUP_NUMBER. Also, you see from V$ASM_DISKGROUP that both of the disk groups are NORMAL REDUNDANCY groups consisting of two disks each.
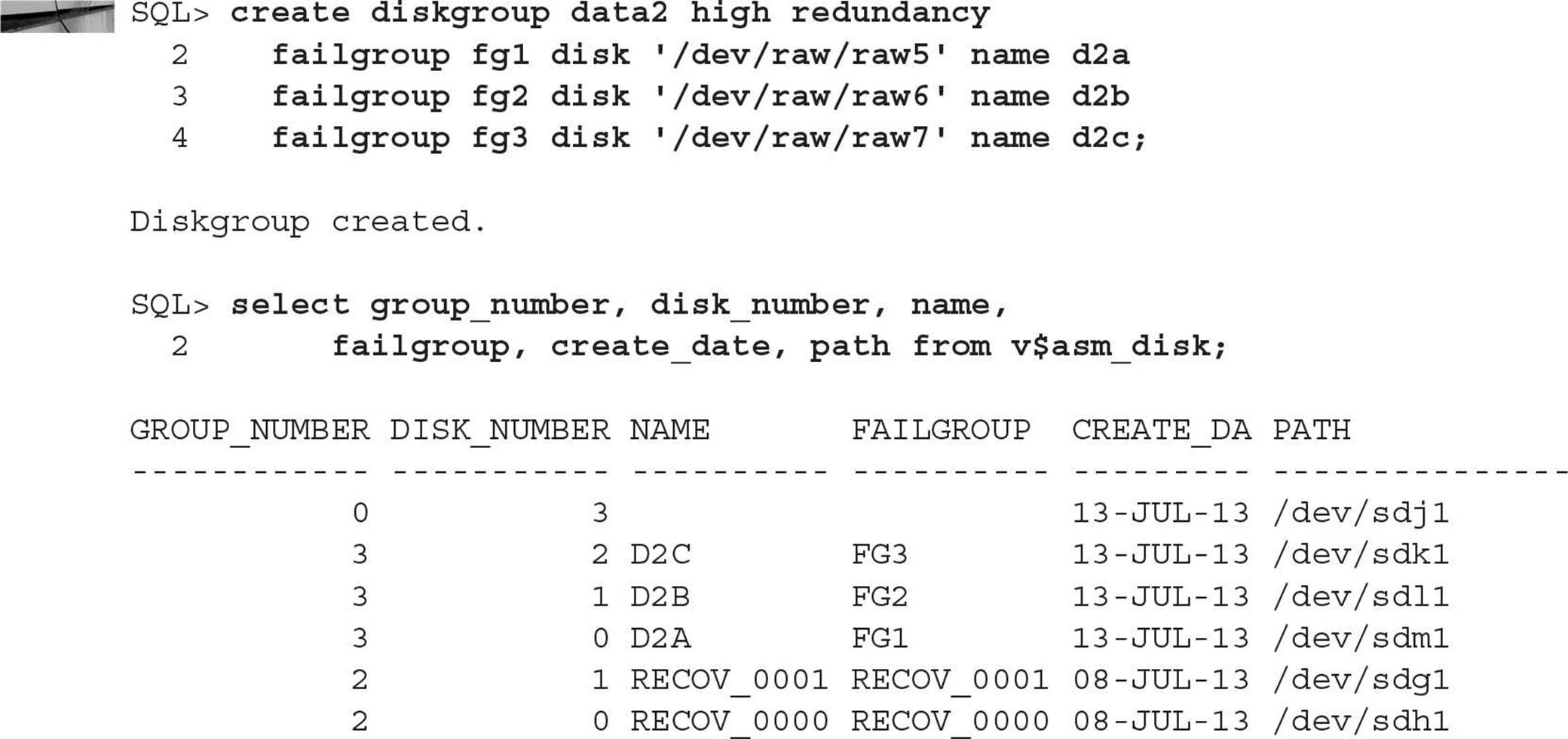
Your first step is to create the disk group:
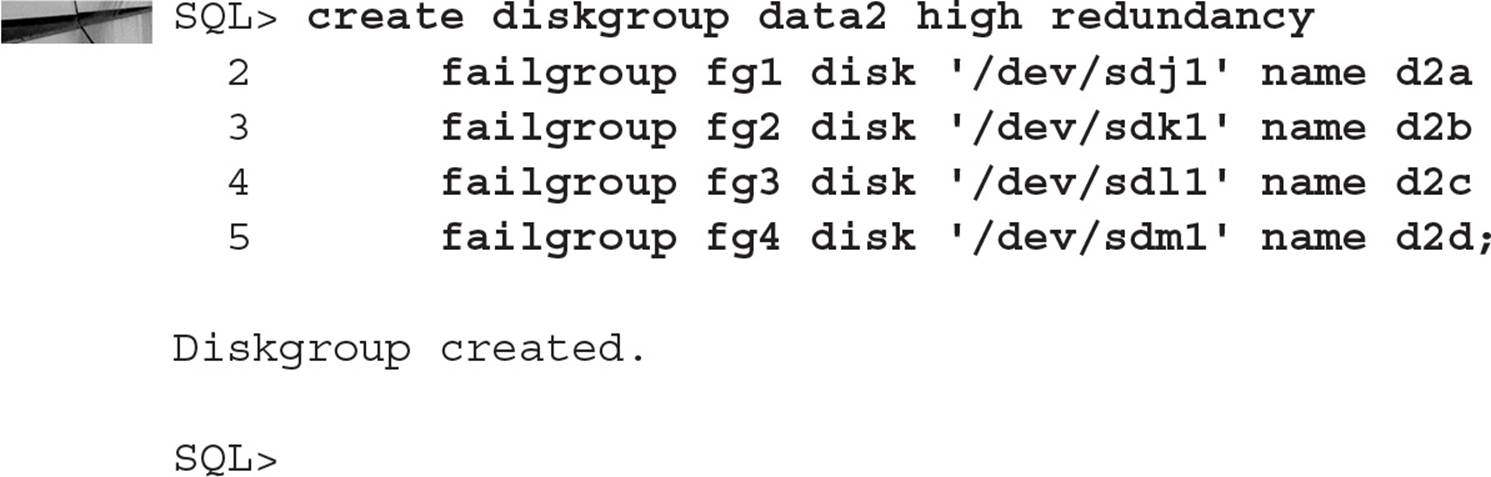
Looking at the dynamic performance views, you see the new disk group available in V$ASM_DISKGROUP and the failure groups in V$ASM_DISK:

However, if disk space is tight, you don’t need four members; for a high-redundancy disk group, only three failure groups are necessary, so you drop the disk group and re-create it with only three members:

If the disk group has any database objects other than disk group metadata, you have to specify the INCLUDING CONTENTS clause in the DROP DISKGROUP command. This is an extra safeguard to make sure that disk groups with database objects are not accidentally dropped. Here is the command:

Now that the configuration of the new disk group has been completed, you can create a tablespace in the new disk group from the database instance:

Because ASM files are OMF, you don’t need to specify any other characteristics when you create the tablespace.
Disk Group Fast Mirror Resync
Mirroring the files in your disk groups improves performance and availability; when a failed disk in a disk group is repaired and brought back online, however, the re-mirroring of the entire new disk can be time consuming. There are occasions when a disk in a disk group needs to be brought offline because of a disk controller failure; the entire disk does not need remirroring, and only the data changed during the failed disk’s downtime needs to be resynced. As a result, you can use the ASM fast mirror resync feature introduced in Oracle Database 11g.
To implement fast mirror resync, you set the time window within which ASM will not automatically drop the disk in the disk group when a transient planned or unplanned failure occurs. During the transient failure, ASM keeps track of all changed data blocks so that when the unavailable disk is brought back online, only the changed blocks need to be remirrored instead of the entire disk.
To set a time window for the DATA disk group, you must first set the compatibility level of the disk group to 11.1 or higher for both the RDBMS instance and the ASM instance (this only needs to be done once for the disk group):

The only side effect to using a higher compatibility level for the RDBMS and ASM instance is that only other instances with a version number 12.1.0.0.0 or higher can access this disk group. Next, set the disk group attribute DISK_REPAIR_TIME as in this example:

The default disk repair time is 3.6 hours, which should be more than adequate for most planned and unplanned (transient) outages. Once the disk is back online, run this command to notify the ASM instance that the disk DATA_0001 is back online:

This command starts the background procedure to copy all changed extents on the remaining disks in the disk group to the disk DATA_0001 that is now back online.
Altering Disk Groups
Disks can be added and dropped from a disk group; also, most characteristics of a disk group can be altered without re-creating the disk group or impacting user transactions on objects in the disk group.
When a disk is added to a disk group, a rebalance operation is performed in the background after the new disk is formatted for use in the disk group. As mentioned earlier in this chapter, the speed of the rebalance is controlled by the initialization parameter ASM_POWER_LIMIT.
Continuing with our example in the preceding section, suppose you decide to improve the I/O characteristics of the disk group DATA by adding the last available disk to the disk group, as follows:

The command returns immediately and the formatting and rebalancing continue in the background. You then check the status of the rebalance operation by checking the view V$ASM_OPERATION:

Because the estimate for completing the rebalance operation is 16 minutes, you decide to allocate more resources to the rebalance operation and change the power limit for this particular rebalance operation:
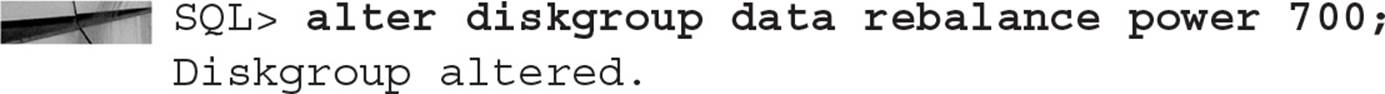
Checking the status of the rebalance operation confirms that the estimated time to completion has been reduced to 2 minutes instead of 16:

About four minutes later, you check the status once more:
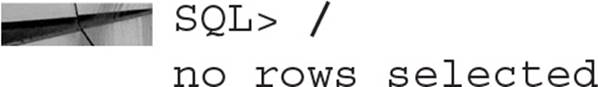
Finally, you can confirm the new disk configuration from the V$ASM_DISK and V$ASM_DISKGROUP views:
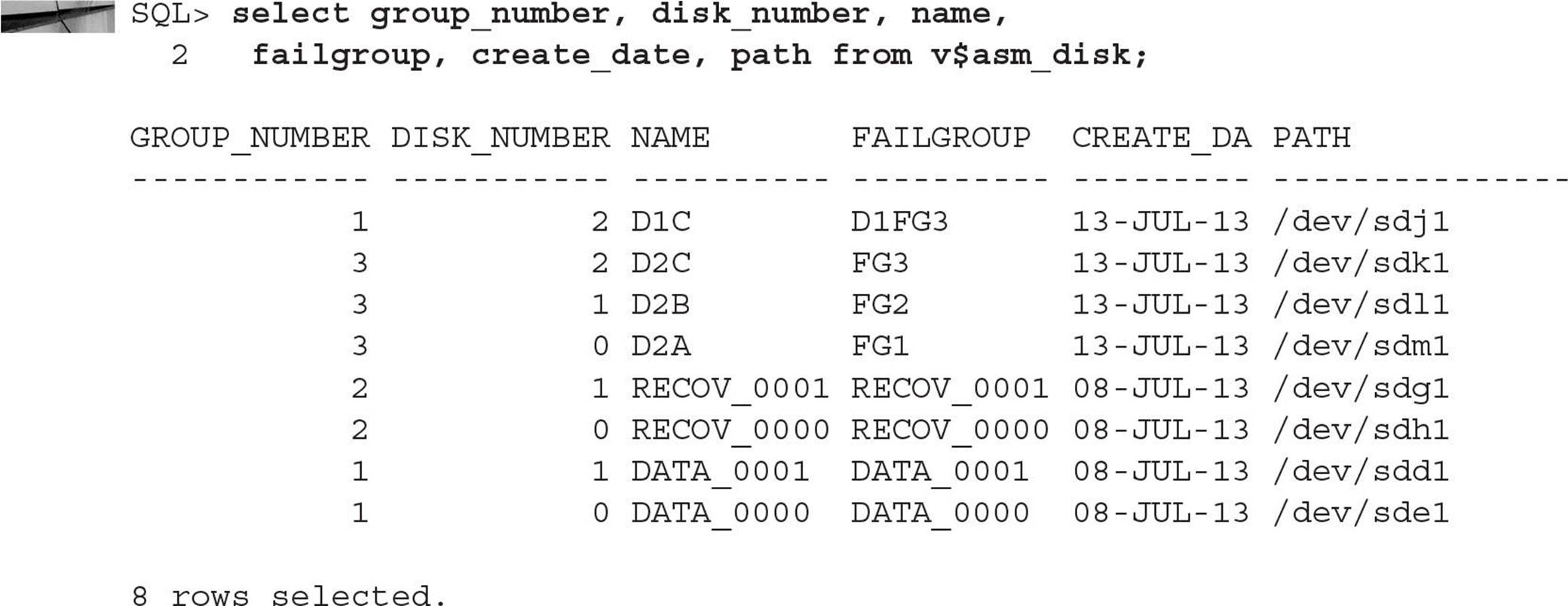

Note that the disk group DATA is still normal redundancy, even though it has three failure groups. The I/O performance of SELECT statements against objects in the DATA disk group will not necessarily be improved due to additional copies of extents available in the disk group, but the availability of the disk group will be higher since it can tolerate the loss of one disk and still maintain normal redundancy.
Other disk group ALTER commands are listed in Table 4-6.

TABLE 4-6. Disk Group ALTER Commands
Using the asmcmd Command
The asmcmd utility, added in Oracle 10g Release 2, is a command-line utility that provides you an easy way to browse and maintain objects within ASM disk groups by using a command set similar to Linux shell commands such as ls and mkdir. The hierarchical nature of objects maintained by the ASM instance lends itself to a command set similar to what you would use to browse and maintain files in a Linux file system.
Before you can use asmcmd, you must ensure that the environment variables ORACLE_BASE, ORACLE_HOME, and ORACLE_SID are set to point to the ASM instance; for the ASM instance used in this chapter, these variables are set as follows:

In addition, you must be logged into the operating system as a user in the dba group, since the asmcmd utility connects to the database with SYSDBA privileges. The operating system user is usually oracle but can be any other user in the dba group.
You can use asmcmd one command at a time by using the format asmcmd command, or you can start asmcmd interactively by typing just asmcmd at the Linux shell prompt. To get a list of available commands, use help from the ASMCMD> for more details. Table 4-7 lists the asmcmd commands and a brief description of their purpose; the asmcmd commands available only in Oracle Database 11g and 12c are noted in the middle column.
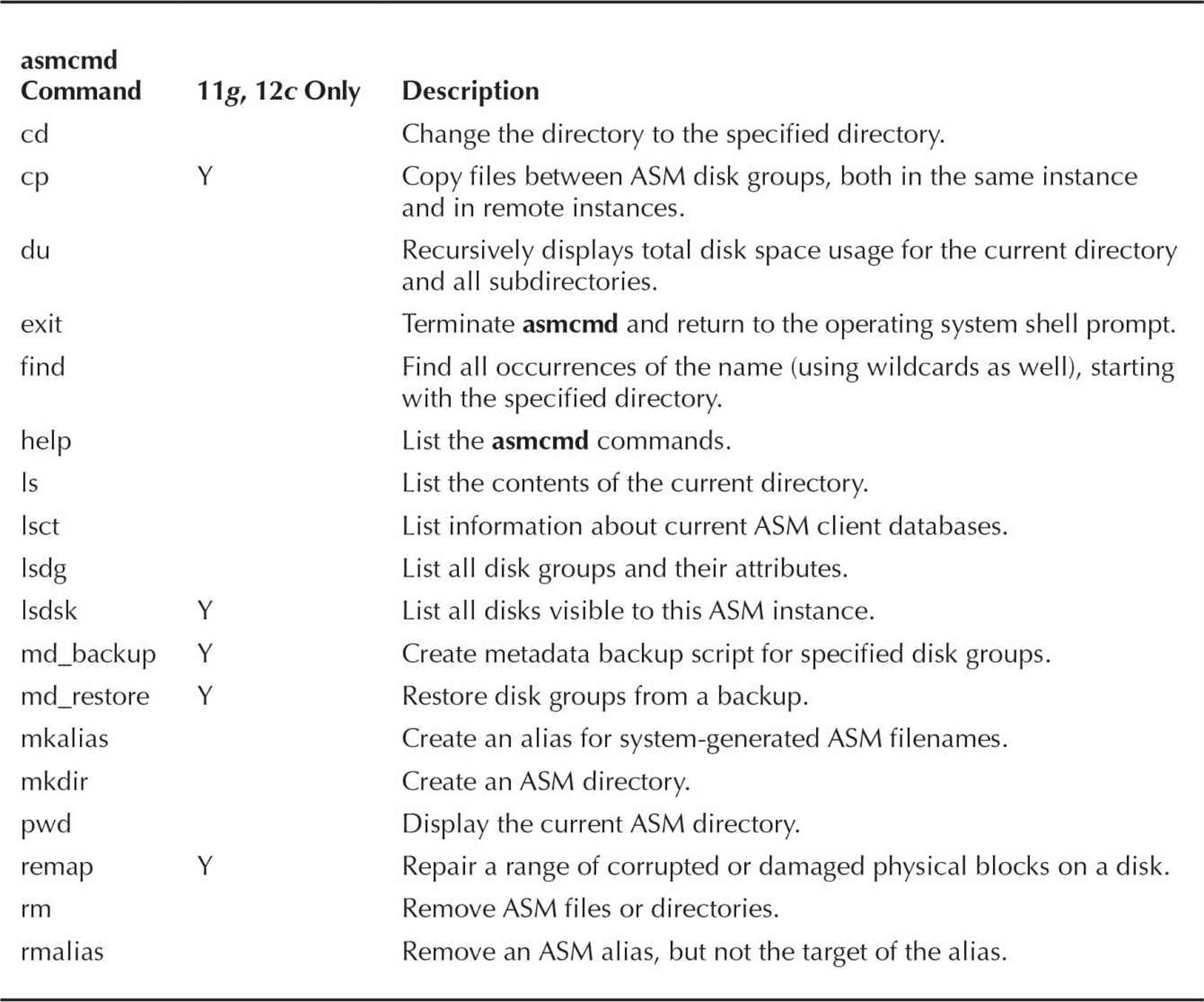
TABLE 4-7. asmcmd Command Summary
When you start asmcmd, you start out at the root node of the ASM instance’s file system; unlike in a Linux file system, the root node is designated by a plus sign (+) instead of a leading forward slash (/), although subsequent directory levels use a forward slash. In this example, you start asmcmd and query the existing disk groups, along with the total disk space used within all disk groups:
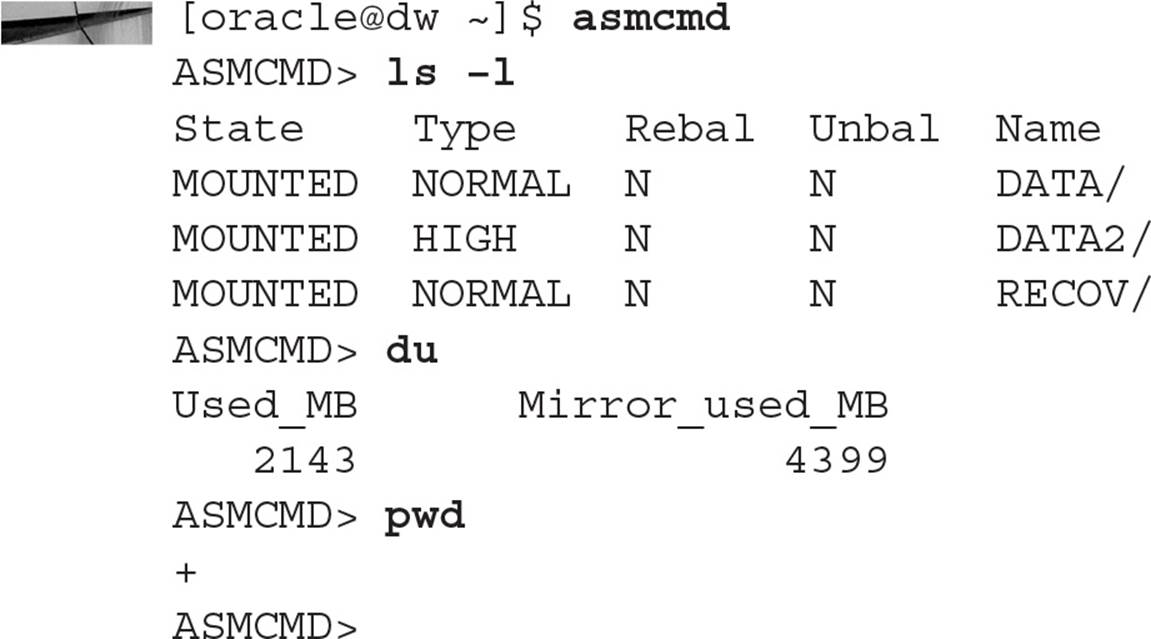
As with the Linux shell ls command, you can append -l to get a more detailed listing of the objects retrieved by the command. The ls command shows the three disk groups in the ASM instance used throughout this chapter, +DATA, +DATA2, and +RECOV.
Note also that the du command only shows the used disk space and total disk space used across mirrored disk groups; to get the amount of free space in each disk group, use the lsdg command instead.
In this example, you want to find all files that have the string user in the filename:
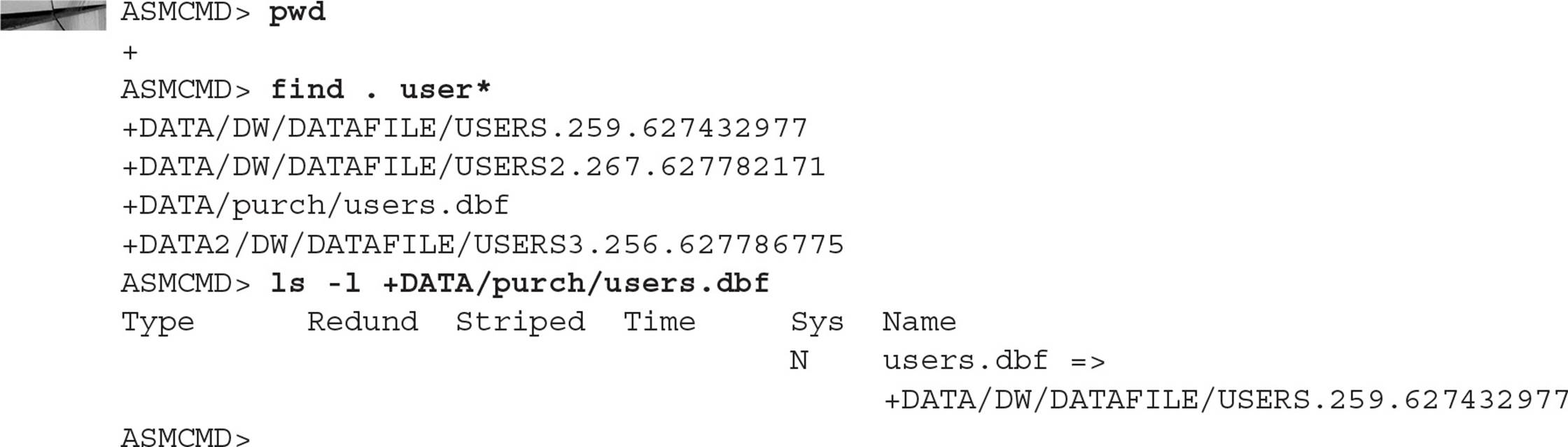
Note the line with +DATA/purch/users.dbf: the find command finds all ASM objects; in this case, it finds an alias as well as datafiles that match the pattern.
Finally, you can perform file backups to external file systems or even other ASM instances. This example uses the cp command to back up the database’s SPFILE to the /tmp directory on the host’s file system:
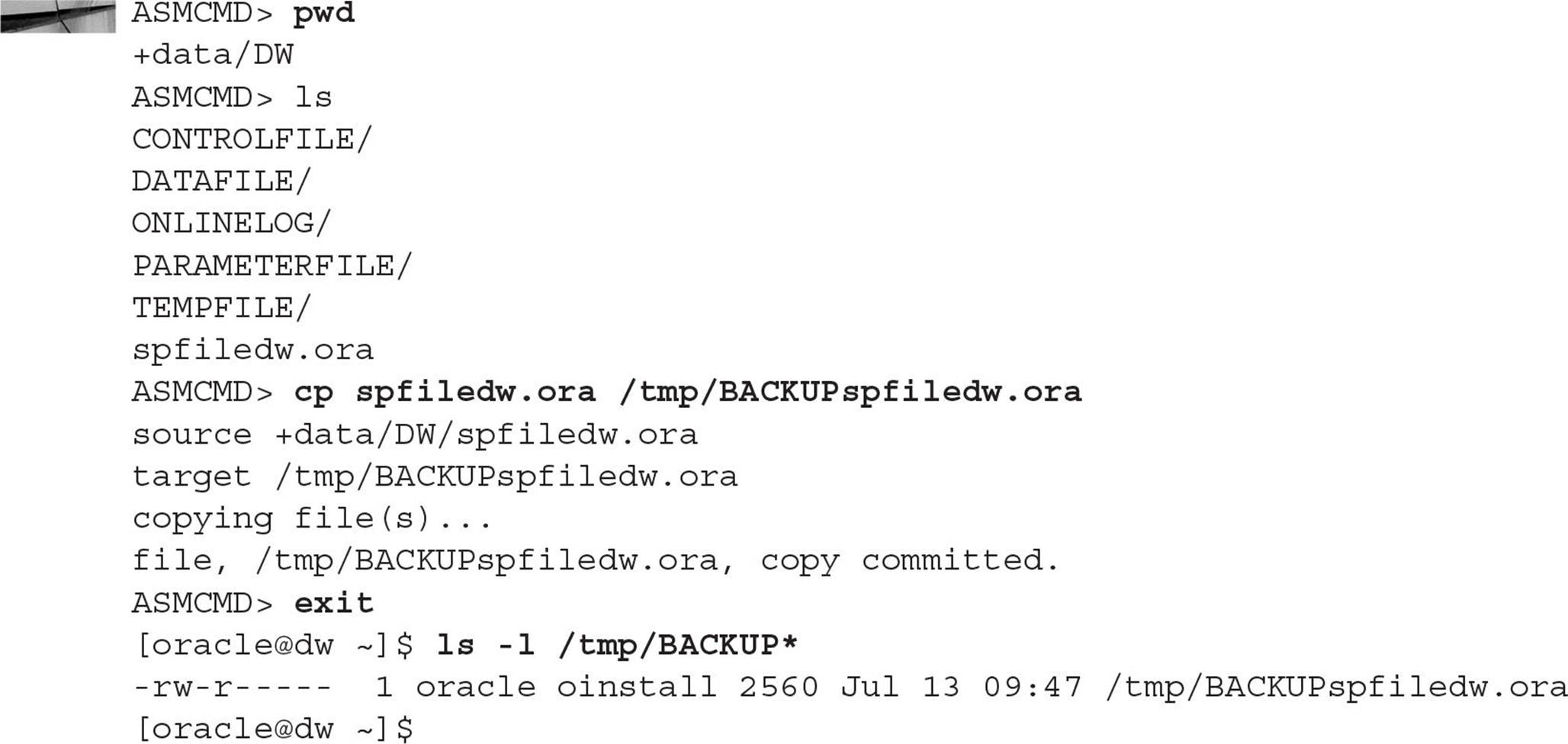
This example also shows how all database files for the database dw are stored within the ASM file system. It looks like they are stored on a traditional host file system, but instead are managed by ASM, providing built-in performance and redundancy features (optimized for use with Oracle Database 12c), making the DBA’s life a bit easier when it comes to datafile management.
Summary
Oracle Database provides you with a wealth of tools to easily manage your tablespaces and datafiles. If you are creating smallfile tablespaces, you can manage tablespace size at the datafile level; if you create your tablespaces as bigfile tablespaces you can manage disk space and other attributes at the tablespace level. There are very few reasons why you wouldn’t want to create all new tablespaces as bigfile tablespaces.
Using ASM for your disk storage provides both ease of use and performance benefits. The setup of an ASM instance only takes a few steps and once it’s set up you may never have to change any parameters of the ASM instance. When you have to add or drop disks from an ASM disk group, Oracle automatically relocates database objects across all disks to maintain performance; no manual rebalancing operation is required. It’s automatic! If you must really dig deep into the internal ASM disk structure, Oracle provides an OS command called asmcmd which gives you Linux-like access to the directory structure within the ASM disk groups.

All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.