Oracle Database 12c DBA Handbook (2015)
PART
II
Database Management

CHAPTER
5
Developing and Implementing Applications
Managing application development can be a difficult process. From a DBA’s perspective, the best way to manage the development process is to become an integral part of teams involved in the process. In this chapter, you will learn the guidelines for migrating applications into databases and the technical details needed for implementation, including the sizing of database objects.
This chapter focuses on the design and creation of applications that use the database. These activities should be integrated with the database-planning activities described in Chapter 3 and Chapter 4. The following chapters in this part of the book address the monitoring and tuning activities that follow the database creation.
Implementing an application in a database by merely running a series of CREATE TABLE commands fails to integrate the creation process with the other major areas (planning, monitoring, and tuning). The DBA must be involved in the application development process in order to correctly design the database that will support the end product. The methods described in this chapter will also provide important information for structuring the database monitoring and tuning efforts.
The first section of this chapter addresses overall design and implementation considerations that directly impact performance. The following sections focus on implementation details such as resource management, sizing tables and indexes, quiescing the database for maintenance activities, and managing packaged applications.
Tuning by Design: Best Practices
At least 50 percent of the time—conservatively—performance problems are designed into an application. During the design of the application and the related database structures, the application architects may not know all the ways in which the business will use the application data over time. As a result, there may be some components whose performance is poor during the initial release, whereas other problems will appear later as the business usage of the application changes and increases.
In some cases, the fix will be relatively straightforward: changing an initialization parameter, adding an index, or rescheduling large operations to off-hours. In other cases, the problem cannot be fixed without altering the application’s architecture. For example, an application may be designed to heavily reuse functions for all data access so that functions call other functions, which call additional functions, even to perform the simplest database actions. As a result, a single database call may result in tens of thousands of function calls and database accesses. Such an application will usually not scale well; as more users are added to the system, the CPU burden of the number of executions per user will slow the performance for the individual users. Tuning the individual SQL statements executed as part of that application may yield little performance benefit; the statements themselves may be well-tuned already. Rather, it is the sheer number of executions that leads to the performance problem.
The following best practices may seem overly simplistic, but they are violated over and over in database applications, and those violations directly result in performance problems. There are always exceptions to the rules. The next change to your software or environment may allow you to violate the rules without affecting your performance. In general, though, following these rules will allow you to meet performance requirements as the application usage increases.
Do As Little As Possible
End users do not care, in general, if the underlying database structures are fully normalized to Fifth Normal Form or if they are laid out in compliance with object-oriented standards. Users want to perform a business process, and the database application should be a tool that helps that business process complete as quickly as possible. The focus of your design should not be the achievement of theoretical design perfection; it should always be on the end user’s ability to do his or her job. Therefore, you should simplify the processes involved at every step in the application.
This can be a difficult point to negotiate with application development teams. If application development teams or enterprise architects insist on perfectly normalized data models, DBAs should point out the number of database steps involved in even the simplest transaction. For example, INSERTs for a complex transaction (such as a line item for an invoice) may involve many code table lookups as well as multiple INSERTs. For a single user this may not present a problem, but with many concurrent users this design may lead to performance issues or locking issues. From a performance-planning perspective, INSERTs should involve as few tables as possible, and queries should retrieve data that is already stored in a format that is as close as possible to the final format requested by the users. Fully normalized databases and object-oriented designs tend to require a high number of joins during complex queries. Although you should strive to maintain a manageable data model, the first emphasis should be on the functionality of the application and its ability to meet the business’s performance needs.
In Your Application Design, Strive to Eliminate Logical Reads
In the past, there was a heavy focus on eliminating physical reads. Although this is still a good idea, no physical reads occur unless logical reads require them.
Let’s take a simple example. Select the current time from DUAL using the SYSDATE function. If you need the time to an accuracy of one second, the value will change 86,400 times per day. Yet there are application designers who repeatedly perform this query, executing it millions of times per day. Such a query likely performs few physical reads throughout the day. Therefore, if you are focused solely on tuning the physical I/O, you would likely disregard it. However, it can significantly impact the performance of the application. How? By using the CPU resources available. Each execution of the query will force Oracle to perform work, using processing power to find and return the correct data. As more and more users execute the command repeatedly, you may find that the number of logical reads used by the query exceeds all other queries. In some cases, multiple processors on the server are dedicated to servicing repeated small queries of this sort. If multiple users need to read the same data, you should store it in a table or in a package variable.

NOTE
Even though the DUAL table has been an internal (memory-based) table since Oracle Database 10g, accessing it will not generate consistent gets as long as you don’t use * as the column list in a query referencing DUAL.
Consider the following real-world example. A programmer wanted to implement a pause in a program, forcing it to wait 30 seconds between two steps. Because the performance of the environment would not be consistent over time, the programmer coded the routine in the following format (shown in pseudo-code):

Is this a reasonable approach? Absolutely not! It will do what the developer wanted, but at a significant cost to the application. What’s more, there is nothing a DBA can do to improve its performance. In this case, the cost will not be due to I/O activity, as the DUAL table will stay in the instance’s memory area, but rather due to CPU activity. Every time this program is run, by every user, the database will spend 30 seconds consuming as many CPU resources as the system can support. In this particular case the SELECT SYSDATE FROM DUAL query accounts for over 40 percent of all the CPU time used by the application. All of that CPU time is wasted. Tuning the database initialization parameters will not solve the problem. Tuning the individual SQL statement will not help; the application design must be revised to eliminate the needless execution of commands. For instance, in this case the developer could have used a SLEEP command at the operating system level or within a PL/SQL program using the DBMS_LOCK.SLEEP procedure to enforce the same behavior without the database accesses.
For those who still favor tuning based on the buffer cache hit ratio (wait-based tuning is preferable in 11g and 12c), this database has a hit ratio of almost 100 percent due to the high number of completely unnecessary logical reads without related physical reads. The buffer cache hit ratio compares the number of logical reads to the number of physical reads; if 10 percent of the logical reads require physical reads, the buffer cache hit ratio is 90 percent. Low hit ratios identify databases that perform a high number of physical reads; extremely high hit ratios such as found in this example may identify databases that perform an excessive number of logical reads. You must look beyond the buffer cache hit ratio to the commands that are generating the logical reads and the physical reads.
In Your Application Design, Strive to Avoid Trips to the Database
Remember that you are tuning an application, not a query. When tuning database operations, you may need to combine multiple queries into a single procedure so that the database can be visited once rather than multiple times for each screen. This bundled-query approach is particularly relevant for “thin-client” applications that rely on multiple application tiers. Look for queries that are interrelated based on the values they return, and see if there are opportunities to transform them into single blocks of code. The goal is not to make a monolithic query that will never complete; the goal is to avoid doing work that does not need to be done. In this case, the constant back-and-forth communication between the database server, the application server, and the end user’s computer is targeted for tuning.
This problem is commonly seen on complex data-entry forms in which each field displayed on the screen is populated via a separate query. Each of those queries is a separate trip to the database. As with the example in the previous section, the database is forced to execute large numbers of related queries. Even if each of those queries is tuned, the burden from the number of commands multiplied by the number of users will consume a large percentage of the CPU resources available on the server. Such a design may also impact the network usage, but the network is seldom the problem: the issue is the number of times the instance is accessed.
Within your packages and procedures, you should strive to eliminate unnecessary database accesses. Store commonly needed values in local variables instead of repeatedly querying the database. If you don’t need to make a trip to the database for information, don’t make it. That sounds simple, but you would be amazed at how often application developers fail to consider this advice.
There is no initialization parameter that can make this change take effect. It is a design issue and requires the active involvement of developers, designers, DBAs, and application users in the application performance planning and tuning process.
For Reporting Systems, Store the Data the Way the Users Will Query It
If you know which queries will be executed, such as via parameterized reports, you should strive to store the data so that Oracle will do as little work as possible to transform the format of the data in your tables into the format presented to the user. This may require the creation and maintenance of materialized views or reporting tables. That maintenance is, of course, extra work for the database and DBA to perform—but it is performed in batch mode and does not directly affect the end user. The end user, on the other hand, benefits from the ability to perform the query faster. The database as a whole will perform fewer logical and physical reads because the accesses to the base tables to populate and refresh the materialized views are performed infrequently when compared to the end-user queries against the views.
Avoid Repeated Connections to the Database
Opening a database connection may take more time than the commands you execute within that connection. If you need to connect to the database, keep the connection open and reuse the connection. See Chapter 17 for more information on Oracle Net and optimizing database connections.
One application designer took normalization to the extreme, moving all code tables into their own database. As a result, most operations in the order-processing system repeatedly opened database links to access the code tables, thus severely hampering the performance of the application. Again, tuning the database initialization parameters is not going to lead to the greatest performance benefit; the application is slow by design.
Use the Right Indexes
In an effort to eliminate physical reads, some application developers create numerous indexes on every table. Aside from their impact on data load times, many of the indexes may never be needed to support queries. In OLTP applications, you should not use bitmap indexes; if a column has few distinct values, you should consider leaving it unindexed. The optimizer supports “skip-scan” index accesses, so it may choose an index on a set of columns even if the leading column of the index is not a limiting condition for the query. For platforms such as Oracle Exadata, you may need very few if any indexes at all to run a query as fast as possible with the added bonus of not needing to maintain those indexes during DML operations.
Do It As Simply As Possible
Once you have eliminated the performance costs of unnecessary logical reads, unneeded database trips, unmanaged connections, and inappropriate indexes, take a look at the commands that remain.
Go Atomic
You can use SQL to combine many steps into one large query. In some cases, this may benefit your application: you can create stored procedures and reuse the code and thus reduce the number of database trips performed. However, you can take this too far, creating large queries that fail to complete quickly enough. These queries commonly include multiple sets of grouping operations, inline views, and complex multi-row calculations against millions of rows.
If you are performing batch operations, you may be able to break such a query into its atomic components, creating temporary tables to store the data from each step. If you have an operation that takes hours to complete, you almost always can find a way to break it into smaller component parts. Divide and conquer the performance problem.
For example, a batch operation may combine data from multiple tables, perform joins and sorts, and then insert the result into a table. On a small scale, this may perform satisfactorily. On a large scale, you may have to divide this operation into multiple steps:
1. Create a work table (possibly as an Oracle global temporary table). Insert rows into it from one of the source tables for the query, selecting only those rows and columns that you care about later in the process.
2. Create a second work table for the columns and rows from the second table.
3. Create any needed indexes on the work tables. Note that all the steps to this point can be parallelized: the inserts, the queries of the source tables, and the creation of the indexes.
4. Perform the join, again parallelized. The join output may go into another work table.
5. Perform any sorts needed. Sort as little data as possible.
6. Insert the data into the target table.
Why go through all these steps? Because you can tune them individually, you may be able to tune them to complete much faster individually than Oracle can complete them as a single command. For batch operations, you should consider making the steps as simple as possible. You will need to manage the space allocated for the work tables, but this approach can generate significant benefits to your batch-processing performance.
Eliminate Unnecessary Sorts
As part of the example in the preceding section, the sort operation was performed last. In general, sort operations are inappropriate for OLTP applications. Sort operations do not return any rows to the user until the entire set of rows is sorted. Row operations, on the other hand, return rows to the user as soon as those rows are available.
Consider the following simple test: Perform a full table scan of a large table. As soon as the query starts to execute, the first rows are displayed. Now, perform the same full table scan but add an ORDER BY clause on an unindexed column. No rows will be displayed until all the rows have been sorted. Why does this happen? Because for the second query Oracle performs a SORT ORDER BY operation on the results of the full table scan. Because it is a set operation, the set must be completed before the next operation is performed.
Now, imagine an application in which there are many queries executed within a procedure. Each of the queries has an ORDER BY clause. This turns into a series of nested sorts: no operation can start until the one before it completes.
Note that UNION operations perform sorts. If it is appropriate for the business logic, use a UNION ALL operation in place of a UNION, because a UNION ALL does not perform a sort.
NOTE
A UNION ALL operation does not eliminate duplicate rows from the result set, so it may generate more rows and therefore different results than a UNION.
Eliminate the Need to Use Undo
When performing a query, Oracle will need to maintain a read-consistent image of the rows queried. If a row is modified by another user, the database will need to query the undo segment to see the row as it existed at the time your query began. Application designs that call for queries to frequently access data that others may be changing at the same time force the database to do more work: it has to look in multiple locations for one piece of data. Again, this is a design issue. DBAs may be able to configure the undo segment areas to reduce the possibility of queries encountering “Snapshot too old” errors, but correcting the fundamental problem requires a change to the application design.
Tell the Database What It Needs to Know
Oracle’s optimizer relies on statistics when it evaluates the thousands of possible paths to take during the execution of a query. How you manage those statistics can significantly impact the performance of your queries.
Keep Your Statistics Updated
How often should you gather statistics? With each major change to the data in your tables, you should collect statistics on those tables. If you have partitioned the tables, you can analyze them on a partition-by-partition basis. As of Oracle Database 10g, you can use the Automatic Statistics Gathering feature to automate the collection of statistics. By default, that process gathers statistics during a maintenance window from 10 P.M. to 6 A.M. each night and all day on weekends. Of course, manual statistics gathering is still available when you have volatile tables that are being dropped or deleted during the day, or when bulk-loaded tables increase in size by more than 10 percent. For partitioned tables on Oracle Database 11g or 12c, incremental statistics keep global statistics up to date when partition-level statistics are created or updated. Oracle Database 12c takes statistics gathering to a new level by allowing concurrent statistics collection on tables in a schema or partitions within a table. In addition, a new hybrid histogram type in Oracle Database 12c combines a height-based histogram with a frequency histogram.
Because the analysis job is usually a batch operation performed after hours, you can tune it by improving sort and full table scan performance at the session level. If you are performing the analysis manually, increase the settings for the DB_FILE_MULTIBLOCK_READ_COUNT parameter at the session level or the PGA_AGGREGATE_TARGET parameter at the system level to gathering the statistics. If you are not using PGA_AGGREGATE_TARGET or do not want to modify a system-wide setting, increase SORT_AREA_SIZE (which is modifiable at the session level) instead. The result will be enhanced performance for the sorts and full table scans the analysis performs.
CAUTION
Increasing the DB_FILE_MULTIBLOCK_READ_COUNT parameter in a RAC database environment can cause performance problems when too many blocks are shipped across the interconnect. This value is platform-dependent but is 1MB on most platforms.
Hint Where Needed
In most cases, the cost-based optimizer (CBO) selects the most efficient execution path for queries. However, you may have information about a better path. You may give Oracle a hint to influence the join operations, the overall query goal, the specific indexes used, or the parallelism of the query.
Maximize the Throughput in the Environment
In an ideal environment, there is never a need to query information outside the buffer cache; all of the data stays in memory all of the time. Unless you are working with a very small database, however, this is not a realistic approach. In this section, you will see guidelines for maximizing the throughput of the environment.
Use the Appropriate Database Block Size
You should use an 8KB block size for all tablespaces unless otherwise recommended by Oracle support or if you have rows with a very large average row length greater than 8KB. All Oracle development and testing, especially for database appliances such as Exadata, uses 8KB block sizes.
Design to Throughput, Not Disk Space
If you take an application that is running on eight 256GB disks and move it to a single 2TB disk, will the application run faster or slower? In general, it will run slower because the throughput of the single disk is unlikely to be equal to the combined throughput of the eight separate disks. Rather than designing your disk layout based on the space available (a common method), design it based on the throughput of the disks available. You may decide to use only part of each disk. The remaining space on the disk will not be used by the production application unless the throughput available for that disk improves.
Avoid the Use of the Temporary Segments
Whenever possible, perform all sorts in memory. Any operation that writes to the temporary segments is potentially wasting resources. Oracle uses temporary segments when the SORT_AREA_SIZE parameter (or PGA_AGGREGATE_TARGET, if it is used) does not allocate enough memory to support the sorting requirements of operations. Sorting operations include index creations, ORDER BY clauses, statistics gathering, GROUP BY operations, and some joins. As noted earlier in this chapter, you should strive to sort as few rows as possible. When performing the sorts that remain, perform them in memory.
Divide and Conquer Your Data
If you cannot avoid performing expensive operations on your database, you can attempt to split the work into more manageable chunks. Often you can severely limit the number of rows acted on by your operations, substantially improving performance.
Use Partitions
Partitions can benefit end users, DBAs, and application support personnel. For end users, there are two potential benefits: improved query performance and improved availability for the database. Query performance may improve because of partition elimination. The optimizer knows which partitions may contain the data requested by a query. As a result, the partitions that will not participate are eliminated from the query process. Because fewer logical and physical reads are needed, the query should complete faster.
NOTE
The Partitioning Option is an extra-cost option for the Enterprise Edition of the database software.
The availability improves because of the benefits partitions generate for DBAs and application support personnel. Many administrative functions can be performed on single partitions, allowing the rest of the table to be unaffected. For example, you can truncate a single partition of a table. You can split a partition, move it to a different tablespace, or switch it with an existing table (so that the previously independent table is then considered a partition). You can gather statistics on one partition at a time. All these capabilities narrow the scope of administrative functions, reducing their impact on the availability of the database as a whole.
Use Materialized Views
You can use materialized views to divide the types of operations users perform against your tables. When you create a materialized view, you can direct users to query the materialized view directly or you can rely on Oracle’s query rewrite capability to redirect queries to the materialized view. As a result, you will have two copies of the data—one that services the input of new transactional data, and a second (the materialized view) that services queries. As a result, you can take one of them offline for maintenance without affecting the availability of the other. Also, the materialized view can pre-join tables and pre-generate aggregations so that user queries perform as little work as possible.
Use Parallelism
Almost every major operation can be parallelized, including queries, inserts, object creations, and data loads. The parallelism options allow you to involve multiple processors and I/O channels in the execution of a single command, effectively dividing the command into multiple smaller coordinated commands. As a result, the command may perform better. You can specify a degree of parallelism at the object level and can override it via hints in your queries.
Test Correctly
In most development methodologies, application testing has multiple phases, including module testing, full system testing, and performance stress testing. Many times, the full system test and performance stress test are not performed adequately due to time constraints as the application nears its delivery deadline. The result is that applications are released into production without any way to guarantee that the functionality and performance of the application as a whole will meet the needs of the users. This is a serious and significant flaw and should not be tolerated by any user of the application. Users do not need just one component of the application to function properly; they need the entire application to work properly in support of a business process. If they cannot do a day’s worth of business in a day, the application fails.
This is a key tenet regarding identifying the need for tuning: If the application slows the speed of the business process, it should be tuned. The tests you perform must be able to determine if the application will hinder the speed of the business process under the expected production load.
Test with Large Volumes of Data
As described earlier in this chapter, objects within the database function differently after they have been used for some time. For example, a table’s PCTUSED setting may make it likely that blocks will be only half-used or rows will be chained. Each of these scenarios causes performance problems that will only be seen after the application has been used for some time.
A further problem with data volume concerns indexes. As a B-tree index grows in size, it may split internally—in other words, an additional level is added to the index. As a result, you can picture the new level as being an index within the index. The additional level in the index increases the negative effect of the index on data load rates. You will not see this impact until after the index is split. Applications that work acceptably for the first week or two in production only to suddenly falter after the data volume reaches critical levels do not support the business needs. In testing, there is no substitute for production data loaded at production rates while the tables already contain a substantial amount of data. When leaf blocks are split and index maintenance occurs, Oracle has to lock all branch blocks above the leaf, including the root block. During this maintenance operation, contention will occur from other sessions that need to access the index.
Test with Many Concurrent Users
Testing with a single user does not reflect the expected production usage of most database applications. You must be able to determine if concurrent users will encounter deadlocks, data consistency issues, or performance problems. For example, suppose an application module uses a work table during its processing. Rows are inserted into the table, manipulated, and then queried. A separate application module does similar processing and uses the same table. When executed at the same time, the two processes attempt to use each other’s data. Unless you are testing with multiple users executing multiple application functions simultaneously, you may not discover this problem and the business data errors it will generate.
Testing with many concurrent users will also help to identify areas in the application where users frequently use undo segments to complete their queries, thus impacting performance.
Test the Impact of Indexes on Your Load Times
Every INSERT, UPDATE, or DELETE of an indexed column may be slower than the same transaction against an unindexed table. There are some exceptions—sorted data has much less of an impact, for example—but the rule is generally true. The impact is dependent on your operating environment, the data structures involved, and the degree to which the data is sorted.
How many rows per second can you insert in your environment? Perform a series of simple tests. Create a table with no indexes and insert a large number of rows into it. Repeat the tests to reduce the impact of physical reads on the timing results. Calculate the number of rows inserted per second. In most environments you can insert tens of thousands of rows per second into the database. Perform the same test in your other database environments so you can identify any that are significantly different from the others.
Now consider your application. Are you able to insert rows into your tables via your application at anywhere near the rate you just calculated? Many applications run at less than 5 percent of the rate the environment will support. They are bogged down by unneeded indexes or the type of code design issues described earlier in this chapter. If your application’s load rate decreases, say, from 40 rows per second to 20 rows per second, your tuning focus should not be solely on how that decrease occurred but also on how the application managed to get only 40 rows per second inserted in an environment that supports thousands of rows inserted per second. Adding another index is easy to do but will add three times the amount of overhead during DML operations (INSERT, DELETE, UPDATE, MERGE).
Make All Tests Repeatable
Most regulated industries have standards for tests. Their standards are so reasonable that all testing efforts should follow them. Among the standards is that all tests must be repeatable. To be compliant with the standards, you must be able to re-create the data set used, the exact action performed, the exact result expected, and the exact result seen and recorded. Pre-production tests for validation of the application must be performed on the production hardware. Moving the application to different hardware requires retesting the application. The tester and the business users must sign off on all tests.
Most people, on hearing those restrictions, would agree that they are good steps to take in any testing process. Indeed, your business users may be expecting that the people developing the application are following such standards, even if they are not required by the industry. But are they followed? And if not, then why not? The two commonly cited reasons for not following such standards are time and cost. Such tests require planning, personnel resources, business user involvement, and time for execution and documentation. Testing on production-caliber hardware may require the purchase of additional servers. Those are the most evident costs, but what is the business cost of failing to perform such tests? The testing requirements for validated systems in some healthcare industries were implemented because those systems directly impact the integrity of critical products such as the safety of the blood supply. If your business has critical components served by your application (and if it does not, then why are you building the application?), you must consider the costs of insufficient, rushed testing and communicate those potential costs to the business users. The evaluation of the risks of incorrect data or unacceptably slow performance must involve the business users. In turn, that may lead to an extended deadline to support proper testing.
In many cases, the rushed testing cycle occurs because a testing standard was not in place at the start of the project. If there is a consistent, thorough, and well-documented testing standard in place at the enterprise level when the project starts, the testing cycle will be shorter when it is finally executed. Testers will have known long in advance that repeatable data sets will be needed. Templates for tests will be available. If there is an issue with any test result, or if the application needs to be retested following a change, the test can be repeated. Also, the application users will know that the testing is robust enough to simulate the production usage of the application. In addition, the testing environment must support automation of tasks that will be automated in production, especially if the developers used many manual processes in the development environment. If the system fails the tests for performance reasons, the problem may be a design issue (as described in the previous sections) or a problem with an individual query.
Standard Deliverables
How do you know if an application is ready to be migrated to a production environment? The application development methodology must clearly define, both in format and in level of detail, the required deliverables for each stage of the life cycle. These should include specifications for each of the following items:
![]() Entity relationship diagram
Entity relationship diagram
![]() Physical database diagram
Physical database diagram
![]() Space requirements
Space requirements
![]() Tuning goals for queries and transaction processing
Tuning goals for queries and transaction processing
![]() Security requirements
Security requirements
![]() Data requirements
Data requirements
![]() Query execution plans
Query execution plans
![]() Acceptance test procedures
Acceptance test procedures
In the following sections, you will see descriptions of each of these items.
Entity Relationship Diagram
The entity relationship (E-R) diagram illustrates the relationships that have been identified among the entities that make up the application. E-R diagrams are critical for providing an understanding of the goals of the system. They also help to identify interface points with other applications and to ensure consistency in definitions across the enterprise.
Physical Database Diagram
A physical database diagram shows the physical tables generated from the entities and the columns generated from the defined attributes in the logical model; most, if not all, data modeling tools support the automatic translation of a logical database diagram to the physical database design. A physical database diagramming tool is usually capable of generating the DDL necessary to create the application’s objects.
You can use the physical database diagram to identify tables that are most likely to be involved in transactions. You should also be able to identify which tables are commonly used together during a data entry or query operation. You can use this information to effectively plan the distribution of these tables (and their indexes) across the available physical devices (or among ASM disk groups) to reduce the amount of I/O contention encountered.
In data warehousing applications, the physical database diagram should show the aggregations and materialized views accessed by user queries. Although they contain derived data, they are critical components of the data access path and must be documented.
Space Requirements
The space requirements deliverable should show the initial space requirements for each database table and index. The recommendations for the proper size of tables, clusters, and indexes are shown in the “Sizing Database Objects” section later in this chapter.
Tuning Goals for Queries and Transaction Processing
Changes to the application design may have significant impact on the application’s performance. Application design choices may also directly affect your ability to tune the application. Because application design has such a great effect on the DBA’s ability to tune its performance, the DBA must be involved in the design process.
You must identify the performance goals of a system before it goes into production. The role of expectation in perception cannot be overemphasized. If the users have an expectation that the system will be at least as fast as an existing system, anything less will be unacceptable. The estimated response time for each of the most-used components of the application must be defined and approved.
It is important during this process to establish two sets of goals: reasonable goals and “stretch” goals. Stretch goals represent the results of concentrated efforts to go beyond the hardware and software constraints that limit the system’s performance. Maintaining two sets of performance goals helps to focus efforts on those goals that are truly mission-critical versus those that are beyond the scope of the core system deliverables. In terms of the goals, you should establish control boundaries for query and transaction performance; the application performance will be judged to be “out of control” if the control boundaries are crossed.
Security Requirements
The development team must specify the account structure the application will use, including the ownership of all objects in the application and the manner in which privileges will be granted. All roles and privileges must be clearly defined. The deliverables from this section will be used to generate the account and privilege structure of the production application (see Chapter 10 for a full review of Oracle’s security capabilities).
Depending on the application, you may need to specify the account usage for batch accounts separately from that of online accounts. For example, the batch accounts may use the database’s automatic login features, whereas the online users have to manually sign in. Your security plans for the application must support both types of users.
Like the space requirements deliverable, security planning is an area in which the DBA’s involvement is critical. The DBA should be able to design an implementation that meets the application’s needs while fitting in with the enterprise database security plan.
Data Requirements
The methods for data entry and retrieval must be clearly defined. Data-entry methods must be tested and verified while the application is in the test environment. Any special data-archiving requirements of the application must also be documented because they will be application specific.
You must also describe the backup and recovery requirements for the application. These requirements can then be compared to the enterprise database backup plans (see Chapter 13 for guidelines). Any database recovery requirements that go beyond the site’s standard will require modifying the site’s backup standard or adding a module to accommodate the application’s needs.
Query Execution Plans
Execution plans are the steps that the database will go through while executing queries. They are generated via the EXPLAIN PLAN or SET AUTOTRACE commands or the SQL Monitoring tool, as described in Chapter 8. Recording the execution plans for the most important queries against the database will aid in planning the index usage and tuning goals for the application. Generating them prior to production implementation will simplify tuning efforts and identify potential performance problems before the application is released. Generating the explain plans for your most important queries will also facilitate the process of performing code reviews of the application.
If you are implementing a third-party application, you may not have visibility to all the SQL commands the application is generating. As described in Chapter 8, you can use Oracle’s automated tuning and monitoring utilities to identify the most resource-intensive queries performed between two points in time; many of the new automated tuning features introduced in Oracle Database 12c, such as improved accuracy of automatic degree of parallelism (DOP) and adaptive SQL plan management, can help you fix issues with queries that are not easily visible or accessible.
Acceptance Test Procedures
Developers and users should very clearly define what functionality and performance goals must be achieved before the application can be migrated to production. These goals will form the foundation of the test procedures that will be executed against the application while it is in the test environment.
The procedures should also describe how to deal with unmet goals. The procedures should very clearly list the functional goals that must be met before the system can move forward. A second list of noncritical functional goals should also be provided. This separation of functional capabilities will aid in both resolving scheduling conflicts and structuring appropriate tests.
NOTE
As part of acceptance testing, all interfaces to the application should be tested and their input and output verified.
Resource Management
You can use the Database Resource Manager to control the allocation of system resources among database users. The Database Resource Manager gives DBAs more control over the allocation of system resources than is possible with operating system controls alone.
Implementing the Database Resource Manager
You can use the Database Resource Manager to allocate percentages of system resources to classes of users and jobs. For example, you could allocate 75 percent of the available CPU resources to your online users, leaving 25 percent to your batch users. To use the Database Resource Manager, you will need to create resource plans, resource consumer groups, and resource plan directives.
Prior to using the Database Resource Manager commands, you must create a “pending area” for your work. To create a pending area, use the CREATE_PENDING_AREA procedure of the DBMS_RESOURCE_MANAGER package. When you have completed your changes, use the VALIDATE_PENDING_AREA procedure to check the validity of the new set of plans, subplans, and directives. You can then either submit the changes (via SUBMIT_PENDING_AREA) or clear the changes (via CLEAR_PENDING_AREA). The procedures that manage the pending area do not have any input variables, so a sample creation of a pending area uses the following syntax:
![]()
If the pending area is not created, you will receive an error message when you try to create a resource plan.
To create a resource plan, use the CREATE_PLAN procedure of the DBMS_RESOURCE_MANAGER package. The syntax for the CREATE_PLAN procedure is shown in the following listing:

When you create a plan, give the plan a name (in the plan variable) and a comment. By default, the CPU allocation method will use the “emphasis” method, allocating CPU resources based on percentage. The following example shows the creation of a plan called DEVELOPERS:

NOTE
The hyphen (-) character is a continuation character in SQL*Plus, allowing a single command to span multiple lines.
In order to create and manage resource plans and resource consumer groups, you must have the ADMINISTER_RESOURCE_MANAGER system privilege enabled for your session. DBAs have this privilege with the WITH ADMIN OPTION. To grant this privilege to non-DBAs, you must execute the GRANT_SYSTEM_PRIVILEGE procedure of the DBMS_RESOURCE_MANAGER_PRIVS package. The following example grants the user LYNDAG the ability to manage the Database Resource Manager:

You can revoke LYNDAG’s privileges via the REVOKE_SYSTEM_PRIVILEGE procedure of the DBMS_RESOURCE_MANAGER package.
With the ADMINISTER_RESOURCE_MANAGER privilege enabled, you can create a resource consumer group using the CREATE_CONSUMER_GROUP procedure within DBMS_RESOURCE_MANAGER. The syntax for the CREATE_CONSUMER_GROUP procedure is shown in the following listing:

You will be assigning users to resource consumer groups, so give the groups names that are based on the logical divisions of your users. The following example creates two groups—one for online developers and a second for batch developers:

Once the plan and resource consumer groups are established, you need to create resource plan directives and assign users to the resource consumer groups. To assign directives to a plan, use the CREATE_PLAN_DIRECTIVE procedure of the DBMS_RESOURCE_MANAGER package. The syntax for the CREATE_PLAN_DIRECTIVE procedure is shown in the following listing:
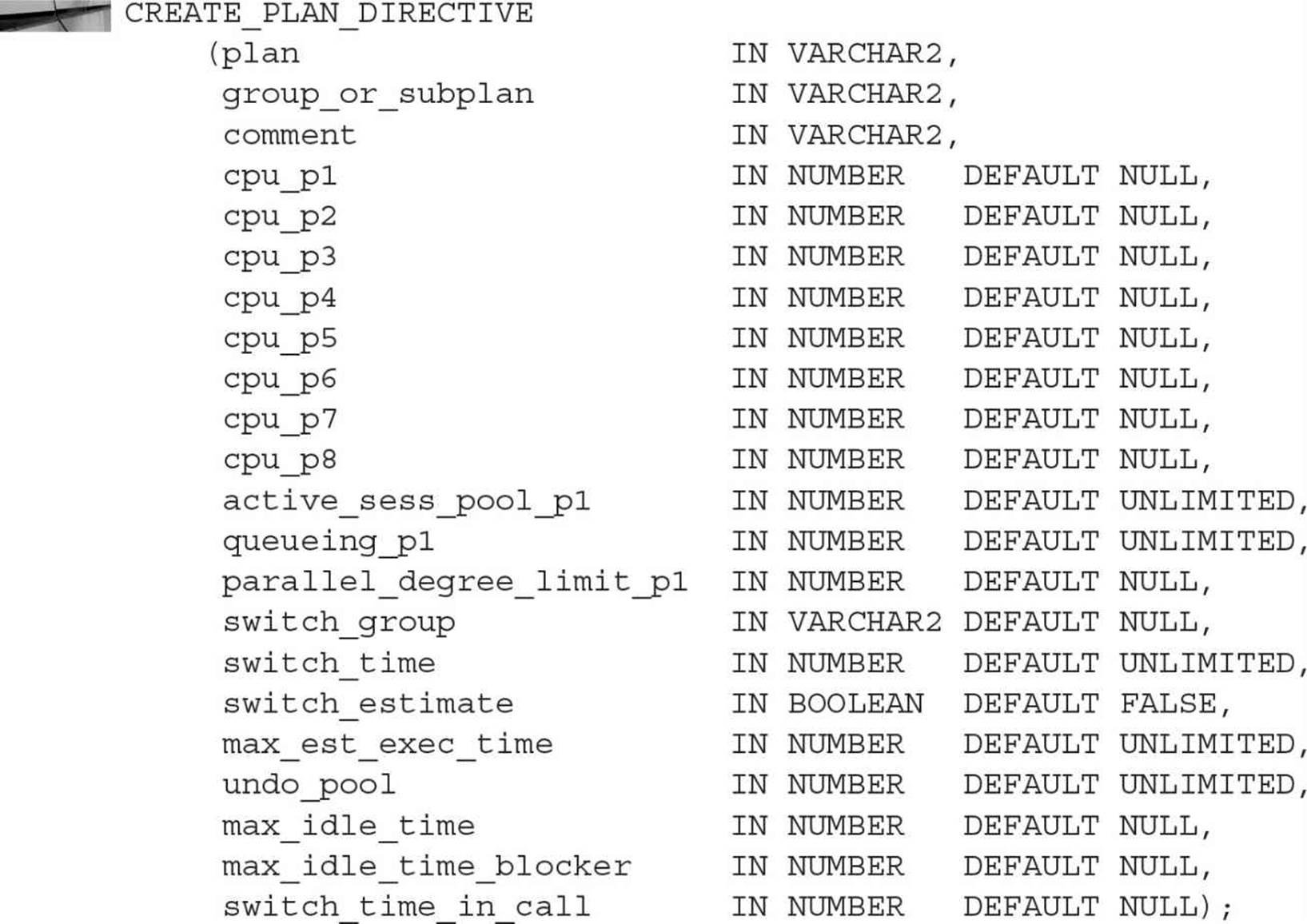
The multiple CPU variables in the CREATE_PLAN_DIRECTIVE procedure support the creation of multiple levels of CPU allocation. For example, you could allocate 75 percent of all your CPU resources (level 1) to your online users. Of the remaining CPU resources (level 2), you could allocate 50 percent to a second set of users. You could split the remaining 50 percent of resources available at level 2 to multiple groups at a third level. The CREATE_PLAN_DIRECTIVE procedure supports up to eight levels of CPU allocations.
The following example shows the creation of the plan directives for the ONLINE_DEVELOPERS and BATCH_DEVELOPERS resource consumer groups within the DEVELOPERS resource plan:

In addition to allocating CPU resources, the plan directives restrict the parallelism of operations performed by members of the resource consumer group. In the preceding example, batch developers are limited to a degree of parallelism of 6, reducing their ability to consume system resources. Online developers are limited to a degree of parallelism of 12.
NOTE
Oracle Database 12c includes runaway query management to proactively prevent queries that have hit their limit in one consumer group to affect other consumer groups where that same query may appear.
To assign a user to a resource consumer group, use the SET_INITIAL_CONSUMER_GROUP procedure of the DBMS_RESOURCE_MANAGER package. The syntax for the SET_INITIAL_CONSUMER_GROUP procedure is shown in the following listing:

If a user has never had an initial consumer group set via the SET_INITIAL_CONSUMER_GROUP procedure, the user is automatically enrolled in the resource consumer group named DEFAULT_CONSUMER_GROUP.
To enable the Resource Manager within your database, set the RESOURCE_MANAGER_PLAN database initialization parameter to the name of the resource plan for the instance. Resource plans can have subplans, so you can create tiers of resource allocations within the instance. If you do not set a value for the RESOURCE_MANAGER_PLAN parameter, resource management is not performed in the instance.
You can dynamically alter the instance to use a different resource allocation plan using the RESOURCE_MANAGER_PLAN initialization parameter; for example, you could create a resource plan for your daytime users (DAYTIME_USERS) and a second for your batch users (BATCH_USERS). You could create a job that each day executes this command at 6:00 A.M.:
![]()
Then at a set time in the evening, you could change consumer groups to benefit the batch users:
![]()
The resource allocation plan for the instance will thus be altered without needing to shut down and restart the instance.
When using multiple resource allocation plans in this fashion, you need to make sure you don’t accidentally use the wrong plan at the wrong time. For example, if the database is down during a scheduled plan change, your job that changes the plan allocation may not execute. How will that affect your users? If you use multiple resource allocation plans, you need to consider the impact of using the wrong plan at the wrong time. To avoid such problems, you should try to minimize the number of resource allocation plans in use.
In addition to the examples and commands shown in this section, you can update existing resource plans (via the UPDATE_PLAN procedure), delete resource plans (via DELETE_PLAN), and cascade the deletion of a resource plan plus all its subplans and related resource consumer groups (DELETE_PLAN_CASCADE). You can update and delete resource consumer groups via the UPDATE_CONSUMER_GROUP and DELETE_CONSUMER_GROUP procedures, respectively. Resource plan directives may be updated via UPDATE_PLAN_DIRECTIVE and deleted via DELETE_PLAN_DIRECTIVE.
When you are modifying resource plans, resource consumer groups, and resource plan directives, you should test the changes prior to implementing them. To test your changes, create a pending area for your work. To create a pending area, use the CREATE_PENDING_AREA procedure of the DBMS_RESOURCE_MANAGER package. When you have completed your changes, use the VALIDATE_PENDING_AREA procedure to check the validity of the new set of plans, subplans, and directives. You can then either submit the changes (via SUBMIT_PENDING_AREA) or clear the changes (via CLEAR_PENDING_AREA). The procedures that manage the pending area do not have any input variables, so a sample validation and submission of a pending area uses the following syntax:

Switching Consumer Groups
Three of the parameters in the CREATE_PLAN_DIRECTIVE procedure allow sessions to switch consumer groups when resource limits are met. As shown in the previous section, the parameters for CREATE_PLAN_DIRECTIVE include SWITCH_GROUP, SWITCH_TIME, and SWITCH_ESTIMATE.
The SWITCH_TIME value is the length of time, in seconds, a job can run before it is switched to another consumer group. The default SWITCH_TIME value is NULL (unlimited). You should set the SWITCH_GROUP parameter value to the group the session will be switched to once the SWITCH_TIME limit is reached. By default, SWITCH_GROUP is NULL. If you set SWITCH_GROUP to the value CANCEL_SQL, the current call will be canceled when the switch criteria is met. If the SWITCH_GROUP value is KILL_SESSION, the session will be killed when the switch criteria is met.
You can use the third parameter, SWITCH_ESTIMATE, to tell the database to switch the consumer group for a database call before the operation even begins to execute. If you set SWITCH_ESTIMATE to TRUE, Oracle will use its execution time estimate to automatically switch the consumer group for the operation instead of waiting for it to reach the SWITCH_TIME value.
You can use the group-switching features to minimize the impact of long-running jobs within the database. You can configure consumer groups with different levels of access to the system resources and customize them to support fast jobs as well as long-running jobs. The ones that reach the SWITCH_TIME limit will be redirected to the appropriate groups before they even execute.
Using SQL Profiles
As of Oracle 10g, you can use SQL profiles to further refine the SQL execution plans chosen by the optimizer. SQL profiles are particularly useful when you are attempting to tune code that you do not have direct access to (for example, within a packaged application). The SQL profile consists of statistics that are specific to the statement, allowing the optimizer to know more about the exact selectivity and cost of the steps in the execution plan.
SQL profiling is part of the automatic tuning capability presented in Chapter 8. Once you accept a SQL profile recommendation, it is stored in the data dictionary. To control a SQL profile’s usage you can use a category attribute. See Chapter 8 for further details on the use of the automatic tools for detection and diagnosis of SQL performance issues.
Sizing Database Objects
Choosing the proper space allocation for database objects is critical. Developers should begin estimating space requirements before the first database objects are created. Afterward, the space requirements can be refined based on the actual usage statistics. In the following sections, you will see the space estimation methods for tables, indexes, and clusters. You’ll also see methods for determining the proper settings for PCTFREE and PCTUSED.
NOTE
You can enable Automatic Segment Space Management (ASSM) when you create a tablespace; you cannot enable this feature for existing tablespaces. If you are using ASSM, Oracle ignores the PCTUSED, FREELISTS, and FREELIST GROUPS parameters. All new tablespaces should use ASSM and be locally managed.
Why Size Objects?
You should size your database objects for three reasons:
![]() To preallocate space in the database, thereby minimizing the amount of future work required to manage objects’ space requirements
To preallocate space in the database, thereby minimizing the amount of future work required to manage objects’ space requirements
![]() To reduce the amount of space wasted due to overallocation of space
To reduce the amount of space wasted due to overallocation of space
![]() To improve the likelihood of a dropped free extent being reused by another segment
To improve the likelihood of a dropped free extent being reused by another segment
You can accomplish all these goals by following the sizing methodology shown in the following sections. This methodology is based on Oracle’s internal methods for allocating space to database objects. Rather than rely on detailed calculations, the methodology relies on approximations that will dramatically simplify the sizing process while simplifying the long-term maintainability of the database.
The Golden Rule for Space Calculations
Keep your space calculations simple, generic, and consistent across databases. There are far more productive ways to spend your work time than performing extremely detailed space calculations that Oracle may ignore anyway. Even if you follow the most rigorous sizing calculations, you cannot be sure how Oracle will load the data into the table or index.
In the following section, you’ll see how to simplify the space-estimation process, freeing you to perform much more useful DBA functions. These processes should be followed whether you are generating the DEFAULT STORAGE values for a dictionary managed tablespace or the extent sizes for locally managed tablespaces.
The Ground Rules for Space Calculations
Oracle follows a set of internal rules when allocating space:
![]() Oracle only allocates whole blocks, not parts of blocks.
Oracle only allocates whole blocks, not parts of blocks.
![]() Oracle allocates sets of blocks rather than individual blocks.
Oracle allocates sets of blocks rather than individual blocks.
![]() Oracle may allocate larger or smaller sets of blocks, depending on the available free space in the tablespace.
Oracle may allocate larger or smaller sets of blocks, depending on the available free space in the tablespace.
Your goal should be to work with Oracle’s space-allocation methods instead of against them. If you use consistent extent sizes, you can largely delegate the space allocation to Oracle.
The Impact of Extent Size on Performance
There is no direct performance benefit gained by reducing the number of extents in a table. In some situations (such as for parallel queries), having multiple extents in a table can significantly reduce I/O contention and enhance your performance. Regardless of the number of extents in your tables, they need to be properly sized; as of Oracle Database 10g, you should rely on automatic (system-managed) extent allocation if the objects in the tablespace are of varying sizes. Unless you know the precise amount of space you need for each object and the number and size of extents, use AUTOALLOCATE when you create a tablespace, as in this example:

The EXTENT MANAGEMENT LOCAL clause is the default for CREATE TABLESPACE; AUTOALLOCATE is the default for tablespaces with local extent management.
Oracle reads data from tables in two ways: by ROWID (usually immediately following an index access) and via full table scans. If the data is read via ROWID, the number of extents in the table is not a factor in the read performance. Oracle will read each row from its physical location (as specified in the ROWID) and retrieve the data.
If the data is read via a full table scan, the size of your extents can impact performance to a very small degree. When reading data via a full table scan, Oracle will read multiple blocks at a time. The number of blocks read at a time is set via the DB_FILE_MULTIBLOCK_READ_COUNT database initialization parameter and is limited by the operating system’s I/O buffer size. For example, if your database block size is 8KB and your operating system’s I/O buffer size is 128KB, you can read up to 16 blocks per read during a full table scan. In that case, setting DB_FILE_MULTIBLOCK_READ_COUNT to a value higher than 16 will not affect the performance of the full table scans. Ideally, the product of DB_FILE_MULTIBLOCK_READ_COUNT * BLOCK_SIZE should therefore be 1MB.
Estimating Space Requirements for Tables
You use the CREATE_TABLE_COST procedure of the DBMS_SPACE package to estimate the space required by a table. The procedure determines the space required for a table based on attributes such as the tablespace storage parameters, the tablespace block size, the number of rows, and the average row length. The procedure is valid for both dictionary-managed and locally managed tablespaces.
TIP
When you create a new table using Oracle Cloud Control 12c (or Oracle Enterprise Manager DB Control in previous versions), you can click the Estimate Table Size button to estimate table size for a given estimated row count.
There are two versions of the CREATE_TABLE_COST procedure (it is overloaded so you can use the same procedure both ways). The first version has four input variables: TABLESPACE_NAME, AVG_ROW_SIZE, ROW_COUNT, and PCT_FREE. Its output variables are USED_BYTES and ALLOC_BYTES. The second version’s input variables are TABLESPACE_NAME, COLINFOS, ROW_COUNT, and PCT_FREE; its output variables are USED_BYTES and ALLOC_BYTES. Descriptions of the variables are provided in the following table:
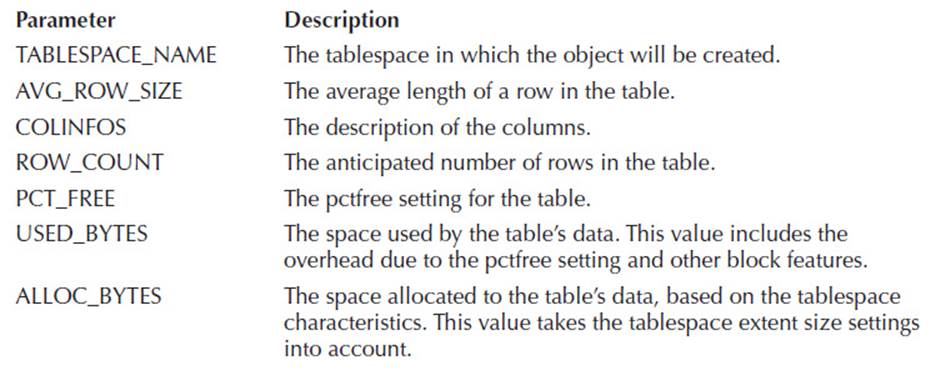
For example, if you have an existing tablespace named USERS, you can estimate the space required for a new table in that tablespace. In the following example, the CREATE_TABLE_COST procedure is executed with values passed for the average row size, the row count, and the PCTFREE setting. The USED_BYTES and ALLOC_BYTES variables are defined and are displayed via the DBMS_OUTPUT.PUT_LINE procedure:

The output of this PL/SQL block will display the used and allocated bytes calculated for these variable settings. You can easily calculate the expected space usage for multiple combinations of space settings prior to creating the table. Here is the output from the preceding example:


NOTE
You must use the SET SERVEROUTPUT ON command to enable the script’s output to be displayed within a SQL*Plus session.
Estimating Space Requirements for Indexes
Similarly, you can use the CREATE_INDEX_COST procedure of the DBMS_SPACE package to estimate the space required by an index. The procedure determines the space required for a table based on attributes such as the tablespace storage parameters, the tablespace block size, the number of rows, and the average row length. The procedure is valid for both dictionary-managed and locally managed tablespaces.
For index space estimations, the input variables include the DDL commands executed to create the index and the name of the local plan table (if one exists). The index space estimates rely on the statistics for the related table. You should be sure those statistics are correct before starting the space-estimation process; otherwise, the results will be skewed.
The variables for the CREATE_INDEX_COST procedure are described in the following table:

Because the CREATE_INDEX_COST procedure bases its results on the table’s statistics, you cannot use this procedure until the table has been created, loaded, and analyzed. The following example estimates the space required for a new index on the BOOKSHELF table. The tablespace designation is part of the CREATE INDEX command passed to the CREATE_INDEX_COST procedure as part of the DDL variable value.


The output of the script will show the used and allocated bytes values for the proposed index for the employee’s first name:
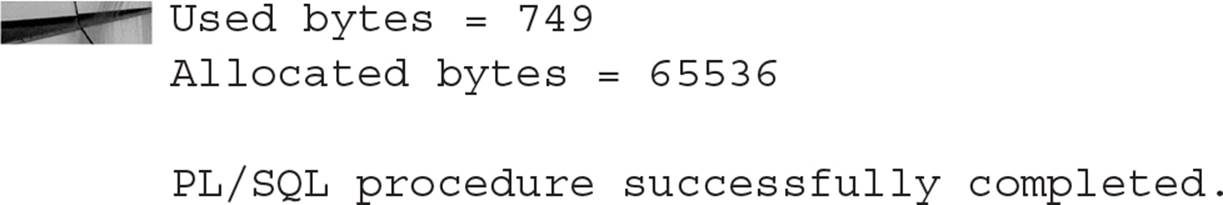
Estimating the Proper Value for PCTFREE
The PCTFREE value represents the percentage of each data block that is reserved as free space. This space is used when a row that has already been stored in that data block grows in length, either by updates of previously NULL fields or by updates of existing values to longer values. The size of a row can increase (and therefore move the row within a block) during an update when a NUMBER column increases its precision or a VARCHAR2 column increases in length.
There is no single value for PCTFREE that will be adequate for all tables in all databases. To simplify space management, choose a consistent set of PCTFREE values:
![]() For indexes whose key values are rarely changed: 2
For indexes whose key values are rarely changed: 2
![]() For tables whose rows seldom change: 2
For tables whose rows seldom change: 2
![]() For tables whose rows frequently change: 10 to 30
For tables whose rows frequently change: 10 to 30
Why maintain free space in a table or index even if the rows seldom change? Oracle needs space within blocks to perform block maintenance functions. If there is not enough free space available (for example, to support a large number of transaction headers during concurrent inserts), Oracle will allocate part of the block’s PCTFREE area. You should choose a PCTFREE value that supports this allocation of space. To reserve space for transaction headers in INSERT-intensive tables, set the INITRANS parameter to a non-default value (the minimum is 2). In general, your PCTFREE area should be large enough to hold several rows of data.
NOTE
Oracle automatically allows up to 255 concurrent update transactions for any data block, depending on the available space in the block; the space occupied by the transaction entries will take up no more than half of the block.
Because PCTFREE is tied to the way in which updates occur in an application, determining the adequacy of its setting is a straightforward process. The PCTFREE setting controls the number of rows that are stored in a block in a table. To see if PCTFREE has been set correctly, first determine the number of rows in a block. You can use the DBMS_STATS package to gather statistics. If the PCTFREE setting is too low, the number of migrated rows will steadily increase due to total row length increase. You can monitor the database’s V$SYSSTAT view (or the Automatic Workload Repository) for increasing values of the “table fetch continued row” action; these indicate the need for the database to access multiple blocks for a single row.
Chained rows occur when the entire row will not fit in an empty block or the number of columns in a row is greater than 255. As a result, part of the row is stored in the first block and the rest of the row in one or more successive blocks.
NOTE
When rows are moved due to inadequate space in the PCTFREE area, the move is called a row migration. Row migration will impact the performance of your transactions.
The DBMS_STATS procedure, while powerful, does not collect statistics on chained rows. You can still use the ANALYZE command, which is otherwise deprecated in favor of DBMS_STATS, to reveal chained rows, as in this example:
![]()
NOTE
For indexes that will support a large number of INSERTs, PCTFREE may need to be as high as 50 percent if the INSERTs are always in the middle of the index, but otherwise 10 percent is usually adequate for indexes on increasing values of a numeric column.
Reverse Key Indexes
In a reverse key index, the values are stored backwards (in reverse order). For example, a value of 2201 is stored as 1022. If you use a standard index, consecutive values are stored near each other. In a reverse key index, consecutive values are not stored near each other. If your queries do not commonly perform range scans and you are concerned about I/O contention (in a RAC database environment) or concurrency contention (buffer busy waits statistic in Automatic Database Diagnostic Monitor) in your indexes, reverse key indexes may be a tuning solution to consider. When sizing a reverse key index, follow the same method used to size a standard index, as shown in the prior sections of this chapter.
There is a downside to reverse key indexes, however: they need a high value for PCTFREE to allow for frequent INSERTs, and must be rebuilt often, more often than a standard B-tree index.
Sizing Bitmap Indexes
If you create a bitmap index, Oracle will dynamically compress the bitmaps generated. The compression of the bitmap may result in substantial storage savings. To estimate the size of a bitmap index, estimate the size of a standard (B-tree) index on the same columns using the methods provided in the preceding sections of this chapter. After calculating the space requirements for the B-tree index, divide that size by 10 to determine the most likely maximum size of a bitmap index for those columns. In general, bitmap indexes will be between 2 and 10 percent of the size of a comparable B-tree index for a bitmap index with low cardinality. The size of the bitmap index will depend on the variability and number of distinct values in the indexed columns; if a bitmap index is created on a high-cardinality column, the space occupied by a bitmap index may exceed the size of a B-tree index on the same column!
NOTE
Bitmap indexes are only available in Oracle Enterprise Edition and Standard Edition One.
Sizing Index-Organized Tables
An index-organized table is stored sorted by its primary key. The space requirements of an index-organized table closely mirror those of an index on all of the table’s columns. The difference in space estimation comes in calculating the space used per row, because an index-organized table does not have RowIDs.
The following listing gives the calculation for the space requirement per row for an index-organized table (note that this storage estimate is for the entire row, including its out-of-line storage):
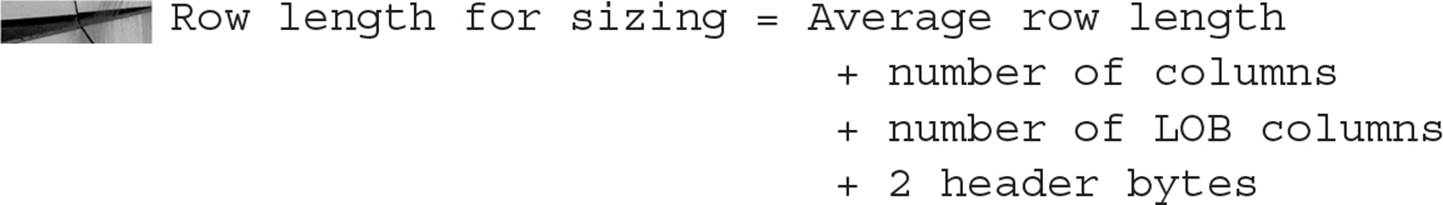
Enter this value as the row length when using the CREATE_TABLE_COST procedure for the index-organized table.
Sizing Tables That Contain Large Objects (LOBs)
LOB data (in BLOB or CLOB datatypes) is usually stored apart from the main table. You can use the LOB clause of the CREATE TABLE command to specify the storage attributes for the LOB data, such as a different tablespace. In the main table, Oracle stores a LOB locator value that points to the LOB data. When the LOB data is stored out of line, between 36 and 86 bytes of control data (the LOB locator) remain inline in the row piece.
Oracle does not always store the LOB data apart from the main table. In general, the LOB data is not stored apart from the main table until the LOB data and the LOB locator value total more than 4000 bytes. Therefore, if you will be storing short LOB values, you need to consider their impact on the storage of your main table. If your LOB values are less than 32,768 characters, you may be able to use VARCHAR2 datatypes instead of LOB datatypes in Oracle Database 12c for the data storage, but those VARCHAR2 columns will still be stored out of line as a SecureFile LOB.
NOTE
You can define VARCHAR2 columns up to 32,767 characters in length in Oracle Database 12c if you set the initialization parameter MAX_STRING_SIZE=EXTENDED.
To explicitly specify where the LOB will reside if its size is 4000 bytes or less, use the DISABLE STORAGE IN ROW or ENABLE STORAGE IN ROW clause in the LOB storage clause of the CREATE TABLE statement. If a LOB is stored inline, and its value starts out with a size less than 4000 bytes, it will migrate to out of line. If an out-of-line LOB’s size becomes less than 4000 bytes, it stays out of line.
Sizing Partitions
You can create multiple partitions of a table. In a partitioned table, multiple separate physical partitions constitute the table. For example, a SALES table may have four partitions: SALES_NORTH, SALES_SOUTH, SALES_EAST, and SALES_WEST. You should size each of those partitions using the table-sizing methods described earlier in this chapter. You should size the partition indexes using the index-sizing methods shown earlier in this chapter.
Using Global Temporary Tables
You can create global temporary tables (GTTs) to hold temporary data during your application processing. The table’s data can be specific to a transaction or maintained throughout a user’s session. When the transaction or session completes, the data is truncated from the table.
To create a GTT, use the CREATE GLOBAL TEMPORARY TABLE command. To automatically delete the rows at the end of the transaction, specify ON COMMIT DELETE ROWS, as shown here:

You can then insert rows into MY_TEMP_TABLE during your application processing. When you commit, Oracle will truncate MY_TEMP_TABLE. To keep the rows for the duration of your session, specify ON COMMIT PRESERVE ROWS instead.
From the DBA perspective, you need to know if your application developers are using this feature. If they are, you need to account for the space required by their temporary tables during their processing. Temporary tables are commonly used to improve processing speeds of complex transactions, so you may need to balance the performance benefit against the space costs. You can create indexes on temporary tables to further improve processing performance, again at the cost of increased space usage.
NOTE
GTTs and their indexes do not allocate any space until the first INSERT into them occurs. When they are no longer in use, their space is deallocated. In addition, if you are using PGA_AGGREGATE TARGET, Oracle will try to create the tables in memory and will only write them to a temporary tablespace if necessary.
Supporting Tables Based on Abstract Datatypes
User-defined datatypes, also known as abstract datatypes, are a critical part of object-relational database applications. Every abstract datatype has related constructor methods used by developers to manipulate data in tables. Abstract datatypes define the structure of data: for example, an ADDRESS_TY datatype may contain attributes for address data, along with methods for manipulating that data. When you create the ADDRESS_TY datatype, Oracle will automatically create a constructor method called ADDRESS_TY. The ADDRESS_TY constructor method contains parameters that match the datatype’s attributes, facilitating inserts of new values into the datatype’s format. In the following sections, you will see how to create tables that use abstract datatypes, along with information on the sizing and security issues associated with that implementation.
You can create tables that use abstract datatypes for their column definitions. For example, you could create an abstract datatype for addresses, as shown here:

Once the ADDRESS_TY datatype has been created, you can use it as a datatype when creating your tables, as shown in the following listing:

When you create an abstract datatype, Oracle creates a constructor method for use during inserts. The constructor method has the same name as the datatype, and its parameters are the attributes of the datatype. When you insert records into the CUSTOMER table, you need to use the ADDRESS_TY datatype’s constructor method to insert address values, as shown here:

In this example, the INSERT command calls the ADDRESS_TY constructor method in order to insert values into the attributes of the ADDRESS_TY datatype.
The use of abstract datatypes increases the space requirements of your tables by 8 bytes for each datatype used. If a datatype contains another datatype, you should add 8 bytes for each of the datatypes.
Using Object Views
The use of abstract datatypes may increase the complexity of your development environment. When you query the attributes of an abstract datatype, you must use a syntax different from the syntax you use against tables that do not contain abstract datatypes. If you do not implement abstract datatypes in all your tables, you will need to use one syntax for some of your tables and a separate syntax for other tables and you will need to know ahead of time which queries use abstract datatypes.
For example, the CUSTOMER table uses the ADDRESS_TY datatype described in the previous section:

The ADDRESS_TY datatype, in turn, has four attributes: STREET, CITY, STATE, and ZIP. If you want to select the STREET attribute value from the ADDRESS column of the CUSTOMER table, you may write the following query:
![]()
However, this query will not work. When you query the attributes of abstract datatypes, you must use correlation variables for the table names. Otherwise, there may be an ambiguity regarding the object being selected. To query the STREET attribute, use a correlation variable (in this case, “C”) for the CUSTOMER table, as shown in the following example:
![]()
As shown in this example, you need to use correlation variables for queries of abstract datatype attributes even if the query only accesses one table. There are therefore two features of queries against abstract datatype attributes: the notation used to access the attributes and the correlation variables requirement. In order to implement abstract datatypes consistently, you may need to alter your SQL standards to support 100-percent usage of correlation variables. Even if you use correlation variables consistently, the notation required to access attribute values may cause problems as well, because you cannot use a similar notation on tables that do not use abstract datatypes.
Object views provide an effective compromise solution to this inconsistency. The CUSTOMER table created in the previous examples assumes that an ADDRESS_TY datatype already exists. But what if your tables already exist? What if you had previously created a relational database application and are trying to implement object-relational concepts in your application without rebuilding and re-creating the entire application? What you would need is the ability to overlay object-oriented (OO) structures such as abstract datatypes on existing relational tables. Oracle provides object views as a means for defining objects used by existing relational tables.
If the CUSTOMER table already exists, you could create the ADDRESS_TY datatype and use object views to relate it to the CUSTOMER table. In the following listing, the CUSTOMER table is created as a relational table, using only the normally provided datatypes:

If you want to create another table or application that stores information about people and addresses, you may choose to create the ADDRESS_TY datatype. However, for consistency, that datatype should be applied to the CUSTOMER table as well. The following examples will use the ADDRESS_TY datatype created in the preceding section.
To create an object view, use the CREATE VIEW command. Within the CREATE VIEW command, specify the query that will form the basis of the view. The code for creating the CUSTOMER_OV object view on the CUSTOMER table is shown in the following listing:

The CUSTOMER_OV view will have two columns: NAME and ADDRESS (the latter is defined by the ADDRESS_TY datatype). Note that you cannot specify OBJECT as an option within the CREATE VIEW command.
Several important syntax issues are presented in this example. When a table is built on existing abstract datatypes, you select column values from the table by referring to the names of the columns (such as NAME) instead of their constructor methods. When creating the object view, however, you refer to the names of the constructor methods (such as ADDRESS_TY) instead. Also, you can use WHERE clauses in the query that forms the basis of the object view. You can therefore limit the rows that are accessible via the object view.
If you use object views, you as the DBA will administer relational tables the same way as you did before. You will still need to manage the privileges for the datatypes (see the following section of this chapter for information on security management of abstract datatypes), but the table and index structures will be the same as they were before the creation of the abstract datatypes. Using the relational structures will simplify your administration tasks while allowing developers to access objects via the object views of the tables.
You can also use object views to simulate the references used by row objects. Row objects are rows within an object table. To create an object view that supports row objects, you need to first create a datatype that has the same structure as the table, as shown here:

Next, create an object view based on the CUSTOMER_TY type while assigning object identifier, or OID, values to the rows in CUSTOMER:

The first part of this CREATE VIEW command gives the view its name (CUSTOMER_OV) and tells Oracle that the view’s structure is based on the CUSTOMER_TY datatype. An OID identifies the row object. In this object view, the NAME column will be used as the OID.
If you have a second table that references CUSTOMER via a foreign key or primary key relationship, you can set up an object view that contains references to CUSTOMER_OV. For example, the CUSTOMER_CALL table contains a foreign key to the CUSTOMER table, as shown here:

The NAME column of CUSTOMER_CALL references the same column in the CUSTOMER table. Because you have simulated OIDs (called pkOIDs) based on the primary key of CUSTOMER, you need to create references to those OIDs. Oracle provides an operator called MAKE_REF that creates the references (called pkREFs). In the following listing, the MAKE_REF operator is used to create references from the object view of CUSTOMER_CALL to the object view of CUSTOMER:

Within the CUSTOMER_CALL_OV view, you tell Oracle the name of the view to reference and the columns that constitute the pkREF. You could now query CUSTOMER_OV data from within CUSTOMER_CALL_OV by using the DEREF operator on the CUSTOMER_ID column:

You can thus return CUSTOMER data from your query without directly querying the CUSTOMER table. In this example, the CALL_DATE column is used as a limiting condition for the rows returned by the query.
Whether you use row objects or column objects, you can use object views to shield your tables from the object relationships. The tables are not modified; you administer them the way you always did. The difference is that the users can now access the rows of CUSTOMER as if they are row objects.
From a DBA perspective, object views allow you to continue creating and supporting standard tables and indexes while the application developers implement the advanced object-relational features as a layer above those tables.
Security for Abstract Datatypes
The examples in the previous sections assumed that the same user owned the ADDRESS_TY datatype and the CUSTOMER table. What if the owner of the datatype is not the table owner? What if another user wants to create a datatype based on a datatype you have created? In the development environment, you should establish guidelines for the ownership and use of abstract datatypes just as you would for tables and indexes.
For example, what if the account named ORANGE_GROVE owns the ADDRESS_TY datatype, and the user of the account named CON_K tries to create a PERSON_TY datatype? I’ll show you the problem with type ownership, and then show you an easy solution later in this section. For example, CON_K executes the following command:

If CON_K does not own the ADDRESS_TY abstract datatype, Oracle will respond to this CREATE TYPE command with the following message:
![]()
The compilation errors are caused by problems creating the constructor method when the datatype is created. Oracle cannot resolve the reference to the ADDRESS_TY datatype because CON_K does not own a datatype with that name.
CON_K will not be able to create the PERSON_TY datatype (which includes the ADDRESS_TY datatype) unless ORANGE_GROVE first grants her EXECUTE privilege on the type. The following listing shows this GRANT command in action:
![]()

NOTE
You must also grant EXECUTE privilege on the type to any user who will perform DML operations on the table.
Now that the proper GRANTs are in place, CON_K can create a datatype that is based on ORANGE_GROVE’s ADDRESS_TY datatype:

CON_K’s PERSON_TY datatype will now be successfully created. However, using datatypes based on another user’s datatypes is not trivial. For example, during INSERT operations, you must fully specify the name of the owner of each type. CON_K can create a table based on her PERSON_TY datatype (which includes ORANGE_GROVE’s ADDRESS_TY datatype), as shown in the following listing:

If CON_K owned the PERSON_TY and ADDRESS_TY datatypes, an INSERT into the CUSTOMER table would use the following format:

This command will not work. During the INSERT, the ADDRESS_TY constructor method is used, and ORANGE_GROVE owns it. Therefore, the INSERT command must be modified to specify ORANGE_GROVE as the owner of ADDRESS_TY. The following example shows the corrected INSERT statement, with the reference to ORANGE_GROVE shown in bold:

Solving this problem is easy: you can create and use a public synonym for a datatype. Continuing with the previous examples, ORANGE_GROVE can create a public synonym like so and grant EXECUTE privileges on the type:

As a result, any user, including CON_K, can now reference the type using the synonym for creating new tables or types:

In a relational-only implementation of Oracle, you grant the EXECUTE privilege on procedural objects, such as procedures and packages. Within the object-relational implementation of Oracle, the EXECUTE privilege is extended to cover abstract datatypes as well, as you can see in the example earlier in this section. The EXECUTE privilege is used because abstract datatypes can include methods—in other words, PL/SQL functions and procedures that operate on the datatypes. If you grant someone the privilege to use your datatype, you are granting the user the privilege to execute the methods you have defined on the datatype. Although ORANGE_GROVE did not yet define any methods on the ADDRESS_TY datatype, Oracle automatically creates constructor methods that are used to access the data. Any object (such as PERSON_TY) that uses the ADDRESS_TY datatype uses the constructor method associated with ADDRESS_TY.
You cannot create public types, but as you saw earlier in this section, you can create public synonyms for your types to ease datatype management; one solution would be to create all types using a single schema name and create the appropriate synonyms. The users who reference the type do not have to know the owner of the types to use them effectively.
Indexing Abstract Datatype Attributes
In the preceding example, the CON_K_CUSTOMERS table was created based on a PERSON_TY datatype and an ADDRESS_TY datatype. As shown in the following listing, the CON_K_CUSTOMERS table contains a scalar (non-object-oriented) column CUSTOMER_ID and a PERSON column that is defined by the PERSON_TY abstract datatype:

From the datatype definitions shown in the previous section of this chapter, you can see that PERSON_TY has one column, NAME, followed by an ADDRESS column defined by the ADDRESS_TY datatype.
When referencing columns within the abstract datatypes during queries, updates, and deletes, specify the full path to the datatype attributes. For example, the following query returns the CUSTOMER_ID column along with the NAME column. The NAME column is an attribute of the datatype that defines the PERSON column, so you refer to the attribute as PERSON.NAME, as shown here:

You can refer to attributes within the ADDRESS_TY datatype by specifying the full path through the related columns. For example, the STREET column is referred to as PERSON.ADDRESS.STREET, which fully describes its location within the structure of the table. In the following example, the CITY column is referenced twice, once in the list of columns to select and once within the WHERE clause:

Because the CITY column is used with a range search in the WHERE clause, the optimizer may be able to use an index when resolving the query. If an index is available on the CITY column, Oracle can quickly find all the rows that have CITY values starting with the letter C, specified in the predicate.
To create an index on a column that is part of an abstract datatype, you need to specify the full path to the column as part of the CREATE INDEX command. To create an index on the CITY column (which is part of the ADDRESS column), you can execute the following command:

This command will create an index named I_CON_K_CUSTOMER_CITY on the PERSON.ADDRESS.CITY column. Whenever the CITY column is accessed, the optimizer will evaluate the SQL used to access the data and determine if the new index can be useful to improve the performance of the access.
When creating tables based on abstract datatypes, you should consider how the columns within the abstract datatypes will be accessed. If, like the CITY column in the previous example, certain columns will commonly be used as part of limiting conditions in queries, they should be indexed. In this regard, the representation of multiple columns in a single abstract datatype may hinder your application performance, because it may obscure the need to index specific columns within the datatype.
When you use abstract datatypes, you become accustomed to treating a group of columns as a single entity, such as the ADDRESS columns or the PERSON columns. It is important to remember that the optimizer, when evaluating query access paths, will consider the columns individually. You therefore need to address the indexing requirements for the columns even when you are using abstract datatypes. In addition, remember that indexing the CITY column in one table that uses the ADDRESS_TY datatype does not affect the CITY column in a second table that uses the ADDRESS_TY datatype. If there is a second table named BRANCH that uses the ADDRESS_TY datatype, then its CITY column will not be indexed unless you explicitly create an index for it. Also keep in mind that extra indexes on abstract datatypes adds three times the overhead for each additional index, much like an index on non-abstract datatypes.
Quiescing and Suspending the Database
You can temporarily quiesce or suspend the database during your maintenance operations. Using these options allows you to keep the database open during application maintenance, avoiding the time or availability impact associated with database shutdowns.
While the database is quiesced, no new transactions will be permitted by any accounts other than SYS and SYSTEM. New queries or attempted logins will appear to hang until you unquiesce the database. The quiesce feature is useful when performing table maintenance or complicated data maintenance. To use the quiesce feature, you must first enable the Database Resource Manager, as described earlier in this chapter. In addition, the RESOURCE_MANAGER_PLAN initialization parameter must have been set to a valid plan when the database was started, and it must not have been disabled following database startup.
While logged in as SYS or SYSTEM (other SYSDBA privileged accounts cannot execute these commands), quiesce the database as follows:
![]()
Any non-DBA sessions logged into the database will continue until their current command completes, at which point they will become inactive. Currently inactive sessions will stay quiesced. In Real Application Clusters configurations, all running instances will be quiesced.
To see if the database is in quiesced state, log in as SYS or SYSTEM and execute the following query:
![]()
The ACTIVE_STATE column value will be either NORMAL (unquiesced), QUIESCING (active non-DBA sessions are still running), or QUIESCED.
To unquiesce the database, use the following command:
![]()
Instead of quiescing the database, you can suspend it. A suspended database performs no I/O to its datafiles and control files, allowing the database to be backed up without I/O interference. To suspend the database, use the following command:
![]()
NOTE
Do not use the ALTER SYSTEM SUSPEND command unless you have put the database in hot backup mode.
Although the ALTER SYSTEM SUSPEND command can be executed from any SYSDBA privileged account, you can only resume normal database operations from the SYS and SYSTEM accounts. Use SYS and SYSTEM to avoid potential errors while resuming the database operations. In Real Application Clusters configurations, all instances will be suspended. To see the current status of the instance, use the following command:
![]()
The database will be either SUSPENDED or ACTIVE. To resume the database, log in as SYS or SYSTEM and execute the following command:
![]()
Supporting Iterative Development
Iterative development methodologies typically consist of a series of rapidly developed prototypes. These prototypes are used to define the system requirements as the system is being developed. These methodologies are attractive because of their ability to show the customers something tangible as development is taking place. However, there are a few common pitfalls that occur during iterative development that undermine its effectiveness.
First, effective versioning is not always used. Creating multiple versions of an application allows certain features to be “frozen” while others are changed. It also allows different sections of the application to be in development while others are in test. Too often, one version of the application is used for every iteration of every feature, resulting in an end product that is not adequately flexible to handle changing needs (which was the alleged purpose of the iterative development).
Second, the prototypes are not always thrown away. Prototypes are developed to give the customer an idea of what the final product will look like; they should not be intended as the foundation of a finished product. Using them as a foundation will not yield the most stable and flexible system possible. When performing iterative development, treat the prototypes as temporary legacy systems.
Third, the divisions between development, test, and production environments are clouded. The methodology for iterative development must very clearly define the conditions that have to be met before an application version can be moved to the next stage. It may be best to keep the prototype development completely separate from the development of the full application.
Finally, unrealistic timelines are often set. The same deliverables that applied to the structured methodology apply to the iterative methodology. The fact that the application is being developed at an accelerated pace does not imply that the deliverables will be any quicker to generate.
Iterative Column Definitions
During the development process, your column definitions may change frequently. You can drop columns from existing tables. You can drop a column immediately, or you can mark it as UNUSED to be dropped at a later time. If the column is dropped immediately, the action may impact performance. If the column is marked as UNUSED, there will be no impact on performance. The column can actually be dropped at a later time when the database is less heavily used.
To drop a column, use either the SET UNUSED clause or the DROP clause of the ALTER TABLE command. You cannot drop a pseudo-column, a column of a nested table, or a partition key column.
In the following example, column COL2 is dropped from a table named TABLE1:
![]()
You can mark a column as UNUSED, as shown here:
![]()
NOTE
As of Oracle Database 12c, you can use SET UNUSED COLUMN … ONLINE to prevent blocking locks on the table and therefore enhance availability.
Marking a column as UNUSED does not release the space previously used by the column. You can also drop any unused columns:
![]()
You can query USER_UNUSED_COL_TABS, DBA_UNUSED_COL, and ALL_UNUSED_COL_TABS to see all tables with columns marked as UNUSED.
NOTE
Once you have marked a column as UNUSED, you cannot access that column. If you export the table after designating a column as UNUSED, the column will not be exported.
You can drop multiple columns in a single command, as shown in the following example:
![]()
NOTE
When dropping multiple columns, you should not use the COLUMN keyword of the ALTER TABLE command. The multiple column names must be enclosed in parentheses, as shown in the preceding example.
If the dropped columns are part of primary keys or unique constraints, you will also need to use the CASCADE CONSTRAINTS clause as part of your ALTER TABLE command. If you drop a column that belongs to a primary key, Oracle will drop both the column and the primary key index.
If you cannot immediately arrange for a maintenance period during which you can drop the columns, mark them as UNUSED. During a later maintenance period, you can complete the maintenance from the SYS or SYSTEM account.
Forcing Cursor Sharing
Ideally, application developers should use bind variables in their programs to maximize the reuse of their previously parsed commands in the shared SQL area. If bind variables are not in use, you may see many very similar statements in the library cache: queries that differ only in the literal value in the WHERE clause.
Statements that are identical except for their literal value components are called similar statements. Similar statements can reuse previously parsed commands in the shared SQL area if the CURSOR_SHARING initialization parameter is set to FORCE. Use EXACT (the default) if the SQL statements must match exactly including all literals.
NOTE
As of Oracle Database 12c, a value of SIMILAR for CURSOR_SHARING has been deprecated and FORCE should be used instead.
Managing Package Development
Imagine a development environment with the following characteristics:
![]() None of your standards are enforced.
None of your standards are enforced.
![]() Objects are created under the SYS or SYSTEM account.
Objects are created under the SYS or SYSTEM account.
![]() Proper distribution and sizing of tables and indexes is only lightly considered.
Proper distribution and sizing of tables and indexes is only lightly considered.
![]() Every application is designed as if it were the only application you intend to run in your database.
Every application is designed as if it were the only application you intend to run in your database.
As undesirable as these conditions are, they are occasionally encountered during the implementation of purchased packaged applications. Properly managing the implementation of packages involves many of the same issues that were described for the application development processes in the previous sections. This section will provide an overview of how packages should be treated so they will best fit with your development environment.
Generating Diagrams
Most CASE tools have the ability to reverse-engineer packages into a physical database diagram. Reverse engineering consists of analyzing the table structures and generating a physical database diagram that is consistent with those structures, usually by analyzing column names, constraints, and indexes to identify key columns. However, normally there is no one-to-one correlation between the physical database diagram and the entity relationship diagram. Entity relationship diagrams for packages can usually be obtained from the package vendor; they are helpful in planning interfaces to the package database.
Space Requirements
Most Oracle-based packages provide fairly accurate estimates of their database resource usage during production usage. However, they usually fail to take into account their usage requirements during data loads and software upgrades. You should carefully monitor the package’s undo requirements during large data loads. A spare DATA tablespace may be needed as well if the package creates copies of all its tables during upgrade operations.
Tuning Goals
Just as custom applications have tuning goals, packages must be held to tuning goals as well. Establishing and tracking these control values will help to identify areas of the package in need of tuning (see Chapter 8).
Security Requirements
Unfortunately, many packages that use Oracle databases fall into one of two categories: either they were migrated to Oracle from another database system, or they assume they will have full DBA privileges for their object owner accounts.
If the packages were first created on a different database system, their Oracle port very likely does not take full advantage of Oracle’s functional capabilities, such as sequences, triggers, and methods. Tuning such a package to meet your needs may require modifying the source code.
If the package assumes that it has full DBA authority, it must not be stored in the same database as any other critical database application. Most packages that require DBA authority do so in order to add new users to the database. You should determine exactly which system-level privileges the package administrator account actually requires (such as CREATE SESSION and CREATE USER, for example). You can create a specialized system-level role to provide this limited set of system privileges to the package administrator.
Packages that were first developed on non-Oracle databases may require the use of the same account as another Oracle-ported package. For example, ownership of a database account called SYSADM may be required by multiple applications. The only way to resolve this conflict with full confidence is to create the two packages in separate databases.
Data Requirements
Any processing requirements that the packages have, particularly on the data-entry side, must be clearly defined. These requirements are usually well documented in package documentation.
Version Requirements
Applications you support may have dependencies on specific versions and features of Oracle. If you use packaged applications, you will need to base your kernel version upgrade plans on the vendor’s support for the different Oracle versions. Furthermore, the vendor may switch the optimizer features it supports. For example, it may require that your COMPATIBLE parameter be set to a specific value. Your database environment will need to be as flexible as possible in order to support these changes.
Because of these restrictions outside of your control, you should attempt to isolate the packaged application to its own instance. If you frequently query data across applications, the isolation of the application to its own instance will increase your reliance on database links. You need to evaluate the maintenance costs of supporting multiple instances against the maintenance costs of supporting multiple applications in a single instance.
Execution Plans
Generating execution plans requires accessing the SQL statements that are run against the database. The shared SQL area in the SGA maintains the SQL statements that are executed against the database (accessible via the V$SQL_PLAN view). Matching the SQL statements against specific parts of the application is a time-consuming process. You should attempt to identify specific areas whose functionality and performance are critical to the application’s success and work with the package’s support team to resolve performance issues. You can use the Automated Workload Repository (see Chapter 8) to gather all the commands generated during testing periods and then determine the explain plans for the most resource-intensive queries in that set. If the commands are still in the shared SQL area, you can see the statistics via V$SQL and the explain plan via V$SQL_PLAN and see both of them using Cloud Control 12c.
Acceptance Test Procedures
Purchased packages should be held to the same functional requirements that custom applications must meet. The acceptance test procedures should be developed before the package has been selected; they can be generated from the package-selection criteria. By testing in this manner, you will be testing for the functionality you need rather than what the package developers thought you wanted.
Be sure to specify what your options are in the event the package fails its acceptance test for functional or performance reasons. Critical success factors for the application should not be overlooked just because it is a purchased application.
The Testing Environment
When establishing a testing environment, follow these guidelines:
![]() It should be larger than your production environment. You need to be able to forecast future performance and test scalability.
It should be larger than your production environment. You need to be able to forecast future performance and test scalability.
![]() It must contain known data sets, explain plans, performance results, and data result sets.
It must contain known data sets, explain plans, performance results, and data result sets.
![]() It must be used for each release of the database and tools, as well as for new features.
It must be used for each release of the database and tools, as well as for new features.
![]() It must support the generation of multiple test conditions to enable the evaluation of the features’ business costs. You do not want to have to rely on point analysis of results; ideally, you can determine the cost/benefit curves of a feature as the database grows in size.
It must support the generation of multiple test conditions to enable the evaluation of the features’ business costs. You do not want to have to rely on point analysis of results; ideally, you can determine the cost/benefit curves of a feature as the database grows in size.
![]() It must be flexible enough to allow you to evaluate different licensing cost options.
It must be flexible enough to allow you to evaluate different licensing cost options.
![]() It must be actively used as a part of your technology implementation methodology.
It must be actively used as a part of your technology implementation methodology.
When testing transaction performance, be sure to track the incremental load rate over time. In general, the indexes on a table will slow the performance of loads when they reach a second internal level. See Chapter 8 for details on indexes and load performance.
When testing, your sample queries should represent each of the following groups:
![]() Queries that perform joins, including merge joins, nested loops, outer joins, and hash joins
Queries that perform joins, including merge joins, nested loops, outer joins, and hash joins
![]() Queries that use database links
Queries that use database links
![]() DML statements that use database links
DML statements that use database links
![]() Each type of DML statement (INSERT, UPDATE, and DELETE statements)
Each type of DML statement (INSERT, UPDATE, and DELETE statements)
![]() Each major type of DDL statement, including table creations, index rebuilds, and grants
Each major type of DDL statement, including table creations, index rebuilds, and grants
![]() Queries that use parallelism (if that option is in use in your environment)
Queries that use parallelism (if that option is in use in your environment)
The sample set should not be fabricated; it should represent your operations, and it must be repeatable. Generating the sample set should involve reviewing your major groups of operations as well as the OLTP operations executed by your users. The result will not reflect every action within the database, but will allow you to be aware of the implications of upgrades and thus allow you to mitigate your risk and make better decisions about implementing new options.
Summary
Creating an effective Oracle database is much more than the CREATE DATABASE command. There are many prerequisites to consider such as the overall architecture of the application: what are the service level agreements with the eventual users of the system? Has the data model been completed and verified to contain the data elements that end users require?
From a development point of view you must decide which Oracle features are best suited for the application and its growth pattern. Using Oracle features such as partitioning, materialized views, and parallelism will ensure adequate response times and efficient use of the database server itself.
Once the database is up and running, your job as a DBA is not over—you must monitor the database to ensure that the SLAs are being met and predict when a hardware upgrade is necessary along with the required disk space needed to ensure that the system will be available when users need it.

All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.