Achieving Extreme Performance with Oracle Exadata (Oracle Press) (2011)
PART I
Features and Foundations
CHAPTER 3
Exadata Software Features
As mentioned in the previous chapter, the Oracle Exadata Database Machine solution did not just spring into being from nothingness—this machine is built on a foundation laid by decades of software development at Oracle. But there are some software features that are new and unique to the Database Machine. This chapter will cover these features, as well as discussing the software used to manage the Exadata Storage Server.
Before diving into a discussion of these features, we should start by dispelling a fairly widespread misconception about the Oracle Exadata Database Machine, as stated in the following quote:
“The Oracle Exadata Database Machine delivers extreme performance through the use of the latest and fastest hardware components.”
There are parts of this statement that are correct. The Oracle Exadata Database Machine does use fast hardware components throughout. And the Database Machine does deliver extreme performance. But to credit the hardware exclusively for this performance is entirely off base.
In fact, the Oracle Exadata Database Machine is a complete solution, where the software and the hardware are tightly integrated and configured in a complementary fashion. But the real secret sauce for the Database Machine lies in its software. This software, at the highest level, aims and achieves a single goal—to use the resources of the Database Machine with as close to maximum efficiency as possible. It is this efficiency, designed and delivered by the Exadata software features, that leverages the performance capabilities of the hardware for maximum effect.
As you will see in the rest of this chapter, the Exadata software looks to implement efficiency across the three main resources used by databases—CPU, memory and storage—as well as reducing storage I/O operations. The Database Machine uses two basic strategies to optimize this efficiency. First of all, the software looks to allocate demand for resources in such a way that all resources are being fully utilized, reducing bottlenecks that can cause performance degradation. This allocation also helps to ensure that you can set performance expectations properly and continually satisfy those expectations.
Second, the software looks to diminish the demand for resources by cleverly eliminating usage that can be discarded without affecting the overall integrity of the database processes. After all, once you have squeezed all the efficiency you can out of the hardware, the next step is to reduce the need to utilize as many resources for any particular operation.
You will revisit these two foundation concepts again and again as you learn about the Exadata software in this chapter.
Smart Scan
Smart Scans are usually the place where discussions of Exadata software begin, mainly because of the dramatic effect these operations can have on performance. This section will contrast the operation of Smart Scans with the normal operations of the Oracle database, describe how Smart Scans are implemented, look at join filtering, and examine how to monitor the savings this feature delivers.
How Standard Queries Work
An Oracle database instance is the process that handles SQL statements, requests and receives data from the storage system, and delivers results back to the requesting process. For Oracle instances running on non-Exadata servers, the process of executing a simple query that selects from a single table proceeds like this:
![]() A query is submitted to the instance.
A query is submitted to the instance.
![]() The query is parsed, and an execution path is determined by the Oracle optimizer.
The query is parsed, and an execution path is determined by the Oracle optimizer.
![]() The execution path is used to identify the extents and request data blocks from the storage system. A block is the smallest amount of data that can be transferred from the storage system to the instance.
The execution path is used to identify the extents and request data blocks from the storage system. A block is the smallest amount of data that can be transferred from the storage system to the instance.
![]() The blocks are used to retrieve the rows and columns for that table from the storage system to the database instance.
The blocks are used to retrieve the rows and columns for that table from the storage system to the database instance.
![]() The database instance processes the blocks, eliminating the rows that do not meet any selection criteria and assembling the requested columns to return to the user in a result set.
The database instance processes the blocks, eliminating the rows that do not meet any selection criteria and assembling the requested columns to return to the user in a result set.
One particular point of potential inefficiency should leap out at you from this description—the requirement that all the potential blocks be read by the database instance. The database instance must implement selection criteria, which means many blocks are returned that are not needed to satisfy the query.
In addition, complete blocks are sent back to the instance. A block, of course, could contain rows of data that are not relevant for satisfying a particular query. And most queries only request a subset of columns from an entire row, making for even more inefficiency.
Blocks are served up from storage systems over internal pathways, which typically operate rapidly, but as database workloads scale, both in numbers of users and in the amount of data requested, even these pathways can become saturated, creating performance bottlenecks.
The Oracle database has a number of features that can reduce the number of blocks returned from the storage system, from the use of indexes for random reads, to partition pruning to eliminate large groups of blocks from consideration, to materialized views to eliminate the need to return large numbers of rows to perform aggregations. One of the main points of query optimization is to find the optimal execution path, which means, among other considerations, reducing the amount of I/O necessary to produce the desired query results. But the Oracle instance, outside the world of Exadata technology, is still bound to retrieve all potential data blocks, ensuring inefficiency in its use of I/O resources, because this method was the only one available for interacting with the storage system.
How Smart Scan Queries Work
Smart Scan, like most Oracle technology enhancements, works transparently. A query that can benefit from Smart Scan in the Exadata environment will use the feature without any changes or tuning. But the way that the data is requested and returned to the database server is significantly different from the way these tasks are accomplished with a standard query, resulting in potentially large performance gains for eligible queries. Smart Scan techniques can work on individual tables as well as tables that will be used in a join.
Individual Tables
The initial step in executing a query that will use Smart Scan is the same as with a standard query—the query is parsed and the Oracle optimizer determines an optimal execution plan. This similarity means that queries that use Smart Scan can still benefit from retrieving execution plans from the shared pool of the SGA.
Like a “standard” query, the Oracle database instance requests data from storage. Since the Exadata Database Machine always uses Automatic Storage Management (ASM, explained in Chapter 2), the request is for allocation units gathered from the ASM extent map. If the access method for the table uses a full scan for the table or the index, the database node also includes meta-data, which describes predicate information used for the query.
The Exadata Storage Server Software retrieves all the data from the disks (and may also use the Exadata Smart Flash Cache, as described later in this chapter) and uses the predicate information to reject all of the data that does meet the conditions imposed by the predicate.
A query will not use Smart Scan if the columns being requested by the query include a database large object (LOB), or if a table is a clustered table or an index-organized table. If a query would normally qualify for Smart Scan but doesn’t because the query contains a LOB, it’s easy to work around this restriction by breaking the query up into two queries—one without a LOB that can take advantage of Smart Scan, and another to retrieve the LOB based on the results of the first query.
If a query does not require a full scan, the Exadata software works as a normal data block server, sending blocks back to the requesting database instance, just as a standard Oracle database would return data.
But if the query can use Smart Scan, the Exadata software goes to work. The Smart Scan process reads data blocks and keeps the relevant rows to return to the database instance. The relevant rows are identified by filtering based on selection criteria specified in the query. Smart Scan filters on predicates that use most comparison operators, including >, <, =, !=, <=, =>, IS [NOT] NULL, LIKE, [NOT} BETWEEN, [NOT]IN, EXISTS, IS OF type, NOT, and AND, as well as most SQL functions. The 11.2.0.2 release of the Exadata Storage software allows for the use of OR predicates and IN lists.
You can get a list of comparison operators that support Smart Scan with the following SQL query:
SELECT * FROM v$sqlfn_metadata WHERE offloadable = 'YES';
In addition, Smart Scan performs column projection, meaning that only the columns required for the query are sent back to the database instance.
As data is identified through the Smart Scan process, it is returned back to the Oracle database instance. But remember, Smart Scan queries are no longer returning standard data blocks to the instance, but a more concentrated set of rows and columns. Because of this, the results are sent back to the Program Global Area (PGA) of the requesting process rather than the normal SGA destination of the data buffers. Once the data arrives at the PGA, the normal processing of the query continues to create the result set to send back to the requesting client.
Sending data directly to the PGA without placing blocks into the buffer cache in the SGA is the same way that parallel servers operate, so Smart Scan queries work appropriately with all other types of Oracle features.
NOTE
You may have noticed something here. If the results of a Smart Scan are not returned to the data buffers, then those results cannot help to populate those buffers for performance improvements in other queries. However, later in this chapter you will learn about the Exadata Smart Flash Cache, which can be used to cache data blocks from tables used for Smart Scan queries.
Join Filtering
Smart Scan uses predicate filtering and column projection on individual tables to reduce the amount of data sent back to the database instance. In addition to these single-table techniques, Smart Scan does join filtering.
Oracle has already been using a technique utilizing a Bloom filter to determine which rows may be needed to implement a join. A Bloom filter allows determination of membership in a set of values without requiring the space to store all the values. In the case of join filtering, a Bloom filter is created with the values of the join column for the smaller table in the join, and this filter is used by the Exadata Storage software to eliminate row candidates from the larger table, which will not be required to satisfy the join condition.
Bloom filters are uniquely suited to this task since they never return false-negative results, although they may have some false positives. In other words, using a Bloom filter to eliminate rows will never eliminate a row that is needed for a join, although it may allow rows that are not needed for the join. The Bloom filter will never jeopardize data integrity by preventing appropriate rows for joins, although it may not be as completely efficient as it might be (ideally) by letting some unnecessary rows be returned.
Prior to Exadata, Bloom filters were used for joins where the optimizer determined that they could contribute to the optimal execution path.
With Exadata, the use of Bloom filters has been pushed to the Exadata Storage Server, which means that this performance-enhancing technique no longer requires CPU utilization on the database server, and that the Bloom filter can cut down on the amount of data being returned from the Exadata Storage Server. The join itself is actually completed by the database instance.
NOTE
In the current release of the Exadata Storage Server Software, Bloom filters are also used for comparison with the maximum and minimum values in a storage index, which is described later in this chapter.
Join filtering further eliminates the amount of data returned to the database instance by removing rows that will not be needed for a join.
You can recognize a step in an execution plan that may use offloading by the use of a new keyword in the name of the operation, as shown in Figure 3-1. The word “storage” used in this section indicates that a predicate is eligible to be offloaded to the Exadata Storage Server—in other words, if the predicate was used with a Smart Scan operation.
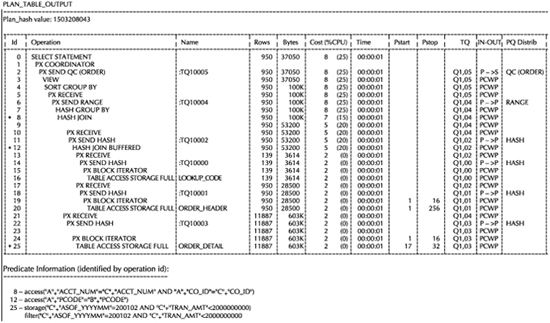
FIGURE 3-1. Execution plan which uses Bloom filters
NOTE
The presence of this keyword does not guarantee that the predicate was evaluated on the Exadata Storage Server, since there are other conditions that may prevent this from happening, as discussed in the following section.
The use of Smart Scan can have a truly dramatic effect on the amount of data returned to the database instance. The storage system is no longer returning data blocks, which usually contain extraneous rows and columns, to the database instance for further evaluation as to whether they will actually be needed to satisfy a query. Instead, only the rows and columns needed to address the needs of the query are returned and, in the case of a join, the rows that may be used in the join (for the most part, as explained in the description of the operation of a Bloom filter). Less data returned means less bandwidth required, as well as potentially faster response times. Less data returned also saves on memory used by the database node. Smart Scan contributes mightily to the efficient use of I/O resources by dramatically reducing the amount of data returned from the storage system, as well as reducing the amount of data processed by the database instance itself.
Monitoring Savings from Smart Scan
Oracle provides some new measures in the standard V$ performance views that allow you to see how much I/O is being saved by the use of Smart Scan technology. The statistics are shown in Table 3-1.
The EXPLAIN PLAN, shown in Figure 3-2, gives an indication of the steps in an execution plan that will benefit from Smart Scan.
You can see that steps 12 and 14 have the word STORAGE in the name of their operation. There are two important things to understand about the use of these operation names. The first relevant fact is that you can control whether the EXPLAIN PLAN displays these types of operation names. The setting of the CELL_OFFLOAD_PLAN_DISPLAY parameter, set with an ALTER SYSTEM or ALTER SESSION command, controls the display with the following settings:

TABLE 3-1. Monitoring Smart Scan Savings
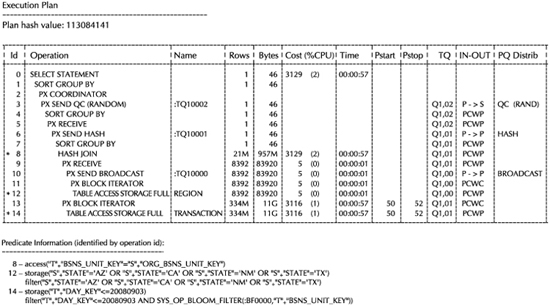
FIGURE 3-2. An EXPLAIN PLAN for a query that may use Smart Scan
![]() AUTO, the default, will use these display names if an operation can be offloaded to the Exadata Storage Server, if there is a storage cell attached, and if the table in question is on an attached cell.
AUTO, the default, will use these display names if an operation can be offloaded to the Exadata Storage Server, if there is a storage cell attached, and if the table in question is on an attached cell.
![]() ALWAYS shows these operation names if an operation could be offloaded, whether there is a cell attached or not.
ALWAYS shows these operation names if an operation could be offloaded, whether there is a cell attached or not.
![]() NEVER does not show these extended operation names.
NEVER does not show these extended operation names.
You can understand the reason to use each of these—AUTO for a situation where an Exadata Storage Server is part of the environment, ALWAYS to see which portions of a query could benefit from the presence of an Exadata Storage Server, and NEVER to simply ignore this possibility.
The second important fact to understand is that the presence of the STORAGE keyword, either in the operation name or the predicate information at the bottom of the plan, does not guarantee that a step will be offloaded. Instead, think of this keyword as indicating eligibility for offloading. The actual decision to use offload processing or not is done by the Exadata Storage Server, and there are scenarios where the Exadata Storage Server will decide that using Smart Scan will not result in any performance gain, as described in the Exadata documentation.
The only foolproof way to see if a query used Smart Scan is to query the V$SQL or related tables for one of the categories listed previously.
Other Offloaded Processing
The term “Smart Scan” is sometimes used by Oracle to describe all the operations that are shifted from the database instances to the Exadata Storage Server. Although these other processes are executed on the Exadata Storage Server, the same place where the Smart Scan processing takes place, these other operations do not operate in the same way, so they will be described in this section on offloaded processing.
Fast File Creation
Whenever the Oracle database has to add to its internal storage, the disk blocks need to be initialized, which is a process that requires writing to each individual block in the extent.
The Exadata Storage Server Software can handle this initialization process with the CPUs that are part of the Storage Server. When data blocks need to be added and initialized, the database server sends the meta-data to the Exadata Storage Server and the Storage Server handles the actual write operations for the process. This feature means that file creation, as well as the addition of more storage space, is much cheaper than the standard method of using database CPU cycles.
Although fast file creation does not necessarily occur very often, the ability to essentially make delays previously caused by this process disappear provides a noticeable increase in response time in the scenarios that require this operation, including tasks such as migrating data to the Exadata platform.
You can see the I/O savings realized by this feature with the following statistic in the V$SYSSTATS, V$SQL, and related views:
cell physical IO bytes saved during optimized file creation
Incremental Backup
Backup is one of those tasks with a stealth profile, an absolute requirement for any professional IT operation, but one whose impact is unnoticed until it rears its ugly head and interferes with other operations seen as more crucial for day-to-day operations. These scenarios typically occur when backup operations start to intrude on the production use of an Oracle database.
Oracle has added a lot of features over the years to reduce the impact of essential backup operations, which is a good thing, as the volume of data has steadily grown. Most shops use an incremental backup, which only backs up data that has changed since the last incremental or full backup. Oracle Recovery Manager (RMAN), the primary backup and recovery for the Oracle database, uses block tracking to reduce the amount of data required in an incremental backup. Block tracking marks blocks that have changed since the last backup, and then backs up only groups of blocks that have been marked.
The Exadata Storage Server Software extends the savings produced by block tracking by allowing a smaller amount of data to be sent to the database node running the RMAN operation. The software will only send back the blocks that have been changed, reducing the amount of data sent to the database server and processed for backup, which improves the overall performance of the database backup.
Data Mining Scoring
In Chapter 2, you read about data mining, where the Oracle database could use sophisticated algorithms to look for trends and anomalies in historical data. Oracle Data Mining can produce results that can be extremely valuable in making strategic decisions, such as how to increase sales to your best existing customers or which trends indicate a profitable change in allocating production resources.
Data mining uses the value embedded in your historical data to direct and support your best business analysts, but the process of rating the data to produce results, known as scoring, can be CPU intensive.
Exadata Storage Server Software can push this scoring to the CPUs on the Storage Server, eliminating the need to use resources on the database server to perform this task. Internal comparisons have shown that offloading scoring can deliver responses that are up to ten times faster than using database server resources for this operation.
Although not all shops use Oracle Data Mining, where this valuable feature is used, the ability to eliminate the CPU processing required for data mining from the database servers reduces the load on these servers. This reduction not only results in faster performance for the queries that include data mining, but also in improved performance across the board, as the previously required CPU resources can be used for other operations.
Encryption
Encryption is a tool used by an increasing number of Oracle shops, as compliance requirements become more restrictive and universal. Oracle Advanced Security Option provides a capability known as Transparent Data Encryption. As its name implies, Transparent Data Encryption allows data to be encrypted without any change in the application code that accesses the encrypted data. This feature means that organizations can achieve compliance through encryption without the time-consuming and error-prone process of modifying their home-grown applications, as well as allowing packaged applications to benefit from encryption.
Most database operations can be performed on encrypted data without having to go through a decryption operation. The data is only decrypted before it is sent back to the user, which means that the database server does not have to waste CPU cycles decrypting data that is not actually required to satisfy the SQL request.
Exadata Storage Server Software takes these advantages even further. First of all, Exadata Smart Scan operations can be performed on encrypted data, allowing the benefits from these features to be used with encrypted data. Second, the actual decryption of data can be performed on the CPUs in the Storage Server, eliminating virtually all the overhead required for this process from the workload of the database server. Third, encryption works well with compression, which reduces the size of the data and correspondingly reduces the overhead of encrypting data. Finally, as mentioned in the previous chapter, the Exadata Storage Server and X2-2 database nodes can offload decryption operations to hardware-based instructions in the Westmere chip.
The interaction between Exadata Storage Server Software and Transparent Data Encryption is a great illustration of the power of the complete Oracle solution. A useful feature is not only supported by the advances of the Oracle Exadata Database Machine, but extended to allow the use of the feature with even better performance.
Exadata Hybrid Columnar Compression
Storage is one of the key resources used by any database. Storage volume continues to grow, not only because of requirements for new applications and data collection, but also due to the inevitable growth of data as it accumulates over time.
Compression is one of the key approaches used by Oracle and other databases to reduce the amount of storage required for data. Compression not only reduces the storage requirements for historical data, but also reduces the size of data used by the Oracle database, with corresponding reductions in memory usage and an increase in I/O bandwidth.
Oracle has had compression for many years, as discussed in Chapter 2. Oracle introduced compression with what is now referred to as basic table compression. This compression capability is included as a part of the standard Oracle database, but the compression only works on direct load operations. This restriction meant that any data added to the database or modified through update operations would not be compressed, which limited the benefit that could be gained through this type of compression.
Oracle Database 11g introduced Advanced Compression, which includes a compression option known as OLTP compression. This compression not only uses a better algorithm for compression and decompression, which increases the amount of data compression while reducing the overhead needed to decompress the data, but also compresses data added through database writes without the overhead of compression spawned by every database change.
NOTE
The OLTP designation in the name of this feature is somewhat misleading, as Advanced Compression is also used by many data warehouses, since compression is implemented for data added to the warehouse by many types of refresh operations that operate with smaller amounts of data.
Exadata Hybrid Columnar Compression is an Exadata feature that offers the benefits of compression in a slightly different way.
What Is Exadata Hybrid Columnar Compression?
Exadata Hybrid Columnar Compression (EHCC) is a type of compression that is only available on the Exadata Storage Server. As its name implies, one of the distinguishing features of Exadata Hybrid Columnar Compression is that data using this type of compression is organized for storage by columns. But there is much more to Exadata Hybrid Columnar Compression than simply a different type of storage.
The “hybrid” portion of the feature name refers to a difference in how Oracle stores columnar data, which allows better utilization across the complete spectrum of database operations, allowing for broader usage of Exadata Hybrid Columnar Compression. In addition, Exadata Hybrid Columnar Compression uses different types of compression algorithm.
How It Works
Columnar storage is not a brand-new concept in the database world. Other databases have offered columnar storage for a while, but universal columnar storage, even for a single table, can present problems.
Virtually no feature provides equal benefits for all types of operations, whether in a database or any other type of software. The sweet spot for columnar storage is those tables where only a few columns will be accessed in a typical query. In order for a database to satisfy a data request, the columns requested have to be accessed and assembled. A larger number of columns results in more work for a pure columnar storage database when many of these columns are requested by a query. And, unfortunately, queries that require a large number of columns coupled with a small number of rows are not that uncommon in the overall mix of a production database. These queries end up requiring pure columnar databases to perform a lot of work for a small result set, reducing the benefit produced by columnar storage in general.
Exadata Hybrid Columnar Compression takes a slightly different approach, as shown in Figure 3-3. Exadata Hybrid Columnar Compression uses the concept of a compression unit, which stores data by columns, but only for a set of rows.
A compression unit can be retrieved with a single I/O operation, which is more efficient than a purely columnar storage option, which requires one or more I/O operations per column. This advantage, in turn, means less unnecessary overhead for those queries that require a greater number of columns, which means you can use the advantages of Exadata Hybrid Columnar Compression for a broader set of tables, increasing the overall benefits you can gain from this feature.
Exadata Hybrid Columnar Compression creates compression units for data as the data is initially loaded into the database with direct load operations. You can use an ALTER TABLE statement to modify how new direct loaded data is compressed, but the only way to get uncompressed data to use EHCC is to use the DBMS_REDEFINITION package to change the compression on a partition or table. Data added to a table with Exadata Hybrid Columnar Compression with INSERT operations after this initial load is still compressed, but at a lower level of compression.
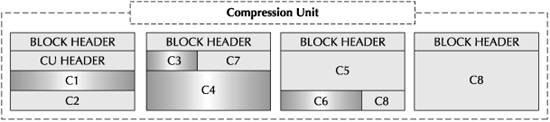
FIGURE 3-3. Exadata Hybrid Columnar Compression compression unit
The same conditions apply when data in a compression unit is updated—the new data is removed from the compression unit and compressed with an alternate compression method, and the entire compression unit is locked for the duration of the update, which means that you typically only want to use Exadata Hybrid Columnar Compression for data that is no longer being updated.
As you look at the diagram of a compression unit, you can see that the overall unit holds data from all the columns in the table. As data is loaded into a table or partition with Exadata Hybrid Columnar Compression enabled, the Exadata Storage Server Software estimates the number of rows that can fit into a compression unit, based on the size of the rows and the estimated compression of the data, using the Exadata Hybrid Columnar Compression compression algorithms.
Compression Options
Exadata Hybrid Columnar Compression allows you to choose between two different levels of compression, and each of these levels allows a further specification of high or low compression. Query compression can reduce storage requirements to a tenth of standard storage. Queries can sometimes run faster with this type of compression, as the decompression (described later in this chapter) does not impose a very large CPU impact and the number of I/O operations is reduced due to the compression.
Archive compression can provide even greater storage compression, with improvements from 15 times to 70 times, depending on the composition of the data. Query performance for tables or partitions with archive compression is frequently a bit slower, but archive compression can still accommodate schema changes, so you can add and drop columns to a table with the archive compression option for Exadata Hybrid Columnar Compression in use. The potentially dramatic difference in storage requirements for archive compression leads to the possibility of keeping historical data available online, which makes any query overhead insignificant when compared with the option of having to bring historical data back online.
Decompression
Compression saves storage and reduces I/O operations, but the data still needs to be decompressed before it can be used in result sets.
Although all compression is performed by the CPUs in the database nodes, EHCC data can be decompressed by the CPUs in the Exadata Storage Server or those in the database nodes. The choice is made based on the type of query processing performed. A Smart Scan query returns result sets directly to the PGA, so the CPUs on the Exadata Storage Server perform the decompression. Queries that cannot use Smart Scan return standard data blocks to the database node—if these blocks are compressed with EHCC, the database server CPUs must decompress them, which requires cycles and memory space to store the decompressed data.
NOTE
This decompression only has to happen on the columns required by the query. Remember that the block headers in an EHCC block detail where the different columns are stored, so if a block does not contain requested columns, there is no need for decompression.
These different locations for decompression have some impact on resource utilization on the database nodes, which you should be aware of as you plan your compression approach.
Advantages
Of course, Exadata Hybrid Columnar Compression gives you the benefit of reduced storage, saving disk costs and allowing for the use of larger amounts of data in your Exadata-based databases. But the size reduction provided by Exadata Hybrid Columnar Compression also has implications for the use of other resources.
For instance, a reduced storage footprint leads to a corresponding reduction in memory requirements for active use of the compressed data. Reduced memory requirements not only provide for greater efficiency in the use of memory, but can also alter the way that queries are satisfied. A tenfold reduction in the size of data could mean that an entire table can now be cached in the Exadata Smart Flash Cache, which will be discussed later. Think of the benefits produced here—the complete elimination of traditional disk I/O for the table.
Keep in mind that Exadata Hybrid Columnar Compression will have the greatest impact on queries that are disk-bound, as opposed to queries where the limitation is the CPU. The source of benefits comes from reduced storage, which has an effect if the performance of a query is bounded by I/O speed.
ILM and Oracle Compression
As you have already read, Exadata Hybrid Columnar Compression is not the only compression option available for the Oracle database. Although Exadata Hybrid Columnar Compression will usually produce the greatest benefits with the highest levels of compression, you may not want to use it in all scenarios. For instance, if your database usage patterns call for a lot of INSERT and UPDATE activity, you may find that the ability of Advanced Compression to compress these types of data produces more benefits overall for those portions of data that experience this type of activity.
The practice of Information Lifecycle Management, or ILM, is designed to achieve maximum benefits for your data in terms of both performance and storage savings throughout its useful life. This lifecycle involves periods of a lot of write activity, when the data is relatively current, and a gradual reduction in changes as the data ages. Oracle’s multiple compression options, coupled with the ability to apply the options to partitions as well as complete tables, are ideally suited to implementing an ILM strategy.
You can choose to use Advanced Compression for partitions that receive the bulk of write activity, getting a good level of compression savings while still having data actively compressed as it is added or modified, while possibly leaving the most active partitions uncompressed. As the data in a partition ages, you can convert the compression to query compression with Exadata Hybrid Columnar Compression, increasing the compression benefits while still allowing rapid access of the data in the partition. As the partition’s data moves towards almost complete quiescence, you can modify the Exadata Hybrid Columnar Compression level to archive compression, providing even more benefits while still having the data available online.
Storage Indexes
Storage indexes, like Exadata Hybrid Columnar Compression, are a feature of the Exadata Storage Server Software that extends benefits already provided by the Oracle database. As reviewed in Chapter 2, partitioning provides a way to eliminate portions of a table that will not be relevant for a query through the means of partition pruning. Storage indexes provide a similar benefit, but work in a different and more flexible way.
A storage index tracks high and low values for columns in rows stored in 1MB storage regions on the Exadata Storage Server. The Exadata Storage Server Software can use the values in the storage index to eliminate storage regions from consideration for use in satisfying a query, the same way that partitions are used to eliminate data that will not contribute to query results. Although the benefit produced by storage indexes is basically the same as that produced by partitions, storage indexes are in-memory structures that are automatically collected for multiple columns in a region. The Exadata Storage Server Software can use values for any of the columns tracked in the storage index to perform storage region elimination based on the values in the index.
How Storage Indexes Work
Storage indexes are fairly simple in concept, as shown in Figure 3-4.
When a table is accessed as part of a Smart Scan query, the Exadata Storage Server Software tracks the data in 1MB storage regions. For each storage region, Exadata tracks the high and low values for many of the columns stored in the region. The storage index is an in-memory collection of these statistics for all storage regions.
When a Smart Scan query hits the Exadata Storage Server, the values in the storage index may be used to eliminate storage regions from consideration in the query, based on predicate evaluation or the use of a Bloom filter for joins, as with standard Smart Scan processing.
Storage indexes are not enabled for National Language Support (NLS) columns or columns containing large objects. If an operation writes to a storage region and changes values for a column being tracked in the storage index, the write could invalidate the column values if that new value falls outside the high and low boundaries for the column.
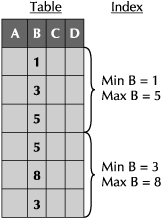
FIGURE 3-4. Storage indexes
Storage indexes are memory structures that are built the first time a Smart Scan query hits the storage region. If a cell has to be rebooted, the storage index for that cell has to be rebuilt. Whether a column’s storage index values have been invalidated or the entire storage index is gone, the new values are calculated whenever a Smart Scan query accesses data in the storage region. Successive Smart Scan queries also refine the values kept for a storage region by only tracking for those columns whose high and low values allow for effective selectivity for the storage region.
Because of the potential for invalidation or destruction, you should think of a storage index as an evolving entity. You don’t have to do anything to aid in the periodic recovery of the storage index or its values—the natural operation of Smart Scans will take care of this for you.
You can see how much value a storage index is providing by looking for the
cell physical IO bytes saved by storage index
value in the V$SYSSTAT, V$SQL, and related views.
Storage Indexes at Work
The most important thing to know about storage indexes is the simple fact that storage indexes never have an adverse effect on performance. There are times when storage indexes can help to eliminate a significant amount of physical I/O, reducing demands on the Exadata Storage Server disks, as well as bandwidth required to move the data to the database server nodes, cases where storage indexes will provide faster response time and performance. Other cases will not benefit from storage indexes, but they will not suffer any performance degradation from this lack of usage.
The queries that can get the most benefits from storage indexes are those where the values for a column used as a selection criteria are closely bunched in storage. In other words, if a query does a selection based on a column like ORDER_NUMBER, if those numbers can be grouped so that a compact range occupies a 1MB storage region tracked by a storage index, the index will have maximum effect in eliminating regions where the values will not be selected.
Since data is placed in blocks as it is inserted into the database, you can maximize the effect of storage indexes if you sort data on columns that will benefit from storage indexes—columns whose similar values will make the storage index on 1MB of data more selective. This sorting will often result in effective storage indexes for columns where similar ranges of values are collocated in a record. Take the example of an order header, which includes a unique ORDER_NUMBER that increases with each new order; an ORDER_DATE, which should follow the same incremental pattern; and a SHIPPING_DATE, which will also typically increment along the same lines, although this value may have more variation. A query that used any number of these columns would probably benefit from storage indexes if the data was inserted into the table with sorting along the lines of any of these columns.
Storage indexes can also work in conjunction with partitioning in a similar manner. Using the same columns as the previous example, assume that you have a table partitioned on the ORDER_DATE column. If a query were to select based on this column, partition pruning would kick in to eliminate rows that did not match the selection criteria. But any query that selected on the ORDER_NUMBER or the SHIPPING_DATE would not benefit from this partitioning scheme. However, storage indexes would provide similar I/O elimination benefits based on the collocation of those values. The storage index would allow for elimination of storage regions based on these columns whose values closely track those of the partition key without any administrative work or overhead.
Storage indexes work to eliminate I/O from being performed, which saves cycles in the Exadata Storage Server as well as increasing effective use of bandwidth between the Exadata Storage Server and the database nodes of the Sun Oracle Database Machine by avoiding having to send that data to the database nodes.
Exadata Smart Flash Cache
The Exadata Storage Servers include some flash storage as a hardware component, as will be described in the next chapter on Exadata hardware. However, there is a significant amount of intelligence in the software that utilizes this hardware component, which is covered in this section on Exadata Smart Flash Cache.
What Is the Exadata Smart Flash Cache?
The hardware component of the Exadata Smart Flash Cache is a set of PCIe flash cards that come with each Exadata Storage Server cell. The PCIe designation refers to the Peripheral Component Interconnect Express, an interconnect that provides much greater bandwidth than older interfaces. Each PCIe card has 96GB of storage, and each cell has four cards, bringing the total flash storage to 384GB per cell. Although a detailed discussion of this hardware component is beyond the scope of this chapter, be aware that these flash cards have the capability of avoiding issues related to degradation through use, as well as providing stable storage capabilities.
The main benefit that the hardware component of Exadata Smart Flash Cache provides is much faster access than standard, disk-based access. The throughput and size of the flash cache provided by the Exadata Smart Flash Cache provides the foundation for enhanced performance, but the way that the Exadata Storage Server Software uses the Exadata Smart Flash Cache leverages these enhancements for maximum effect.
NOTE
Please do not confuse the Exadata Smart Flash Cache with the Database Flash Cache. Although both use flash technology, the Database Flash Cache is located in the database server node and essentially provides an extension to the standard operations of the SGA. The Exadata Smart Flash Cache, as you will see in the following pages, works in a different manner and is a part of the Exadata Storage Server. In addition, the Database Flash Cache is not supported in the Exadata environment.
How Can You Use the Exadata Smart Flash Cache?
The Exadata Smart Flash Cache can be used in two basic ways. The first, and most popular, way to use the cache is as a standard cache. The Exadata Storage Server Software caches data blocks into the Exadata Smart Flash Cache and ages blocks out of the Exadata Smart Flash Cache as required.
You can also use the Exadata Smart Flash Cache to create a flash disk. This disk is used just as you would use a standard cell disk—you can build grid disks from the flash disks. This approach would give you what appears to ASM as a standard Exadata grid disk, but with the performance of flash.
There are two basic reasons why this approach is not widely used. The first involves how disks are normally used by ASM—with redundancy for availability. Even if you use normal redundancy for your flash disks, you would lose half the capacity of the flash storage as the data is mirrored.
The second reason is because of the optimizations built into the Oracle database long ago. As you know, the Oracle database uses “lazy writes” to write to actual database blocks, allowing these potentially time-consuming writes to be taken out of the critical path for write performance. Instead, Oracle only requires a write to a sequential log file to complete a transaction while guaranteeing integrity. A write to a sequential log file is a fast operation—in fact, a write to a sequential file on disk is essentially as fast as the same write to a flash-based disk. This reality reduces the performance gains that can come from flash-based grid disks.
The Exadata Smart Flash Cache simply passes write operations through to disk, and so you would lose at least half the capacity of the cache by using it as a flash-based disk (depending on the level of redundancy) without a great increase in benefits, most customers decide to simply use the Exadata Smart Flash Cache as a cache.
How Does Exadata Smart Flash Cache Determine What Is Cached?
Exadata Storage Server Software makes intelligent decisions on what data to cache in the Exadata Smart Flash Cache. When data is read as part of a SQL operation, the Exadata Storage Server Software checks to see if the data is likely to be accessed again and if the data is not part of a large scan. The Exadata Smart Flash Cache does not cache the results of large I/O operations, since this would end up pushing a lot of data out of the cache as it added the scan results to it. If the data does not fit this profile and the data is not a large object, the data block is placed into the Exadata Smart Flash Cache.
The Exadata Storage Server Software will also cache data from some modify operations. Once the write to the log file is confirmed, allowing the write operation to complete, the block can be considered for addition to the Exadata Smart Flash Cache. The Exadata Storage Server Software is smart enough to know to eliminate some types of writes from consideration, such as writes for backups, mirroring operations, Data Pump operations, ASM rebalances, and the like.
The decision process described previously is the default process, used by data objects that have the CELL_FLASH_CACHE attribute set to DEFAULT. There are two other options for this attribute. If the attribute is set to NONE, the data object is not considered for storage in the Exadata Smart Flash Cache. If the attribute is set to KEEP, the data object is kept in the Exadata Smart Flash Cache, regardless of the type of operation that presented the data to the Exadata Storage Server Software. By using the KEEP attribute, you can ensure that data that would not normally be kept in the Exadata Smart Flash Cache, such as an LOB or data that is part of a full table scan, will be placed into the cache.
Data kept in the KEEP portion of the Exadata Smart Flash Cache cannot be forced out of the cache by the algorithm used for default objects. However, the KEEP cache does have an aging algorithm, but one that is much less aggressive than the algorithm used for default objects. In general, the KEEP cache algorithm will change the attribute of its data to DEFAULT after a certain period, at which point the data is subject to the default aging algorithm.
In addition, no more than 80 percent of the storage in the Exadata Smart Flash Cache on a cell can be used for the KEEP portion of the cache. As a best practice, you should typically not assign the KEEP attribute to data objects that cannot fit simultaneously into the Exadata Smart Flash Cache, which will mean the objects are never aged out of the cache. Since the whole purpose of the KEEP attribute is to ensure that a data object will be present in the Exadata Smart Flash Cache, assigning more data to this cache would undercut the essential aim of the attribute.
You can change the CELL_FLASH_CACHE attribute on an object at runtime, as you would other attributes on data objects. This would change the attribute on data from an object that is already in the cache, but will not actually affect the residency of those blocks. For instance, if you were to change the CELL_FLASH_CACHE attribute of a data object from KEEP to NONE, the data blocks for that object already in the cache would have their attribute set to DEFAULT, which would cause them to be affected by the default algorithm. The data blocks would not, however, be flushed out of the cache.
NOTE
You can flush the Exadata Smart Flash Cache by using the DROP FLASHCACHE command of CellCLI.
Exadata Smart Flash Cache Statistics
There are two places you can get statistics regarding the use of the Exadata Smart Flash Cache. The first is by using the LIST METTRICCURRENT command of CellCLI, which is discussed later in this chapter, as partially shown in the following code:
CellCLI> LIST METRICCURRENT WHERE -
objectType='FLASHCACHE'
FC_BY_USED 72119 MB
FC_IO_RQ_R 55395828 IO requests
FC_IO_RQ_R_MISS 123184 IO requests
More than 30 statistics relating to the use of the Exadata Smart Flash Cache are available.
You can also use the FLASHCACHECONTENT object with CellCLI commands, described later in this chapter, to determine whether an object is currently being kept in the Exadata Smart Flash Cache. The following code shows an example of the type of information you can get about an object. Please note that you have to get the objectNumber for an object by querying the DBA_OBJECTS view for the object_id of the object.
CellCLI> LIST FLASHCACHECONTENT
WHERE objectNumber=57435 DETAIL
cachedKeepSize: 0
cachedSize: 495438874
dbID: 70052
hitCount: 415483
missCount: 2059
objectNumber: 57435
tableSpaceNumber: 1
Using the same object_id, you can find out how many reads for a particular object were satisfied from the Exadata Smart Flash Cache:
SQL> SELECT statistic_name, value
2 FROM V$SEGMENT_STATISTICS
3 WHERE dataobj#= 57435 AND ts#=5 AND
4 statistic_name='optimized physical reads';
STATISTIC_NAME VALUE
------------------------ ------
optimized physical reads 743502
Keep in mind that another, similarly named statistic—physical read requests optimized—includes both those reads that were satisfied from the Exadata Smart Flash Cache and the number of disk I/Os eliminated by the use of a storage index.
You can also get cumulative statistics regarding the effectiveness of the Exadata Smart Flash Cache from the V$SYSSTAT view, as shown here:
SQL> SELECT name, value FROM V$SYSSTAT WHERE
2 NAME IN ('physical read total IO requests',
3 'cell flash cache read hits');
NAME VALUE
________________________________ ______
physical read total IO requests 15673
cell flash cache read hits 14664
By comparing the cell flash cache read hits with the physical read total I/O requests, you can determine the comparative effectiveness of the Exadata Smart Flash Cache.
Benefits from Exadata Smart Flash Cache
It may seem a bit reductionist to have to call out the advantages of a cache. The faster performance of the flash storage means that data is retrieved faster, improving response time, right? But keep in mind that Exadata Smart Flash Cache actually can do more than just improve performance by reducing retrieval time.
The Exadata Storage Server Software is aware of the amount of data that will need to be retrieved to satisfy a query. And although data is retrieved from the Exadata Smart Flash Cache much faster than from the disk in a storage cell, the retrieval does take some amount of time. When appropriate, the Exadata Storage Server Software will retrieve data from both the Exadata Smart Flash Cache and disk, delivering maximum data flow. In this way, the throughput produced by the Exadata Smart Flash Cache and standard disk retrieval are combined to give maximum throughput to satisfy a particular query and provide maximum efficiency.
I/O Resource Manager
I/O Resource Manager is different from the software features discussed previously in this chapter in two ways. First of all, I/O Resource Manager does not directly improve efficiency of operation by reducing the amount of resources required. Instead, I/O Resource Manager contributes to improved efficiency by ensuring that in a scenario where there is more demand for a resource than can be simultaneously supplied by the Exadata Storage Server, the most critical operations will deliver a consistent quality of service.
The second way that I/O Resource Manager is different from the previously discussed features is that I/O Resource Manager is essentially an extension of an existing feature of the Oracle Database—the Database Resource Manager.
But you should not let these differences deter you from an appreciation of the benefits that I/O Resource Manager can deliver, as these benefits can be substantial.
Benefits from I/O Resource Manager
I/O Resource Manager gives you the ability to provision the I/O bandwidth from the Exadata Storage Server to the database grid by consumer group, database, and category. In doing so, I/O Resource Manager, or IORM, delivers the most precious quality of performance—consistency.
Remember that there are really two definitions of performance. The definition used by IT personnel has to do with actual timings of discrete or aggregate operations. The more important definition comes from users, who have an expectation of performance that trumps the more mundane measurement. A SQL query that takes 5 seconds to return results could be seen either as slow if the query was expected to return in 2 seconds or blazingly fast if the expectation was for results in 20 seconds.
By dividing up the overall bandwidth for a database or cell, IORM lets you ensure that there will be sufficient resources to meet customer expectations. IORM, like other resource plan aspects, does not start to limit I/O resources until those resources are oversubscribed, which means that this feature will not “waste” bandwidth by limiting access when there is enough to spare. Instead, IORM guarantees that a particular group of sessions will always get at least a particular percentage of I/O bandwidth.
The actual implementation of IORM plans gives you a great deal of flexibility, as the next section details.
Architecture of an IORM Plan
You can use IORM to provision bandwidth in a number of ways. As mentioned previously, IORM is an extension of Database Resource Manager, so before describing these options, a brief review of key Database Resource Manager concepts is appropriate.
Database Resource Manager was described in detail in Chapter 2. The basic unit that Database Resource Manager uses to define resource limits is the consumer group, which can be identified in a wide variety of ways, from user names to applications to time of day, or any combination of these and other factors. Database Resource Manager creates a resource plan, which is used to allocate resources between different consumer groups. Individual sessions can switch consumer groups based on conditions, and the entire resource plan can be changed at runtime without any interruption in service.
A resource plan has multiple levels of priorities, with resources divided between different consumer groups at each level. A superior priority will take all the resources that are assigned to different consumer groups at that level—any remaining resources will be given to the next priority level, which assigns these resources based on its own directives. You will see the operation of levels and resource assignments in the next section, which details IORM at work.
You can assign allocation directives, which associate a consumer group with a percentage of resources, to three different entities, as shown in Figure 3-5.
You can divide I/O bandwidth between different workloads accessing a single database, which is referred to as intradatabase resource management. This type of division gives you the ability to allocate the overall percentage of I/O operations for a database between different consumer groups. For instance, if you had the same database being used by executives, people taking orders, and batch jobs running production reports, you could divide the resources between them to ensure an appropriate minimum level of service for each group. Intradatabase directives are part of an overall Database Resource Manager resource plan, defined in the Database Resource Manager framework.
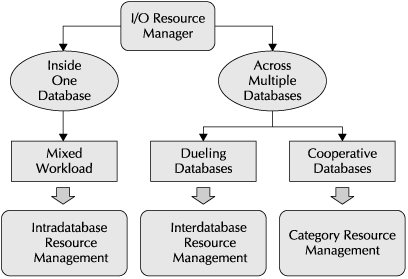
FIGURE 3-5. IORM plans
You can also divide I/O bandwidth between different databases, which is referred to as interdatabase resource management. With interdatabase directives, you divide up the I/O for an entire cell between different databases that reside within that cell. Interdatabase directives are defined using the ALTER IORMPLAN CellCLI command. As this command implies, you can only have a single IORMPLAN defined for an Exadata Storage Server cell at a time. The interdatabase plan can have multiple levels in the same way that a plan defined by the Database Resource Manager can. Although an interdatabase resource plan is associated with a specific Exadata cell, the current plan persists through a cell reboot.
The last method of allocation of I/O resources is a category. Just as consumer groups allow you to collect groups of database resource consumers, a category is a collection of consumer groups. A consumer group is associated with a category when it is defined through the Database Resource Manager interface. A category plan divides resources between different categories, and can have multiple levels like the other types of plans.
The different levels of I/O plans are implemented in the following way. If a category plan exists, resources are first divided between the different categories, based on the directives in the plan. If a particular Exadata cell contains more than one database and an interdatabase plan exists, the allocated resources are again divided between the participants in the plan. Finally, the I/O resources allocated to the database are divided according to the intradatabase plan.
IORM at Work
With the previous brief description, you understand the basic architecture of how plans are defined for use by the I/O Resource Manager. The illustration shown in Figure 3-6 gives you some idea of how the various levels of the plan work together.
The plan is shown for a single Exadata cell, which is labeled Cell 1. For the sake of clarity, each section of the plan only has a single level. However, please remember the way priority levels work—only the I/O resources not consumed by a superior level are made available to a lower level, where directives can further divide the allocation.
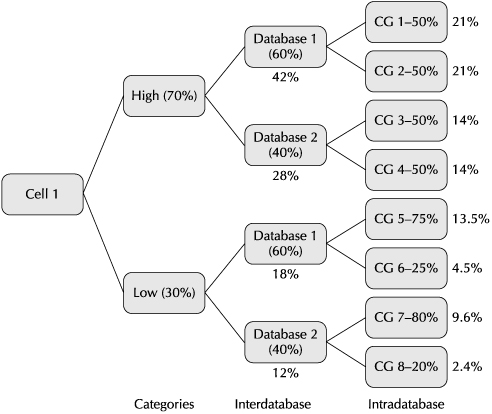
FIGURE 3-6. An IORM plan
You can see that there are directives dividing I/O requests between two categories, simply named High and Low, with 70 percent and 30 percent allocation, respectively. Consumer groups 1, 2, 3, and 4 are part of the High category, with consumer groups 5, 6, 7, and 8 comprising the Low category.
There are interdatabase directives that divide the I/O bandwidth between Database 1, which gets 60 percent of the resources, and Database 2, which gets the remaining 40 percent. In practice, this means that I/O from Database 1 for the High category will get 42 percent of I/O bandwidth in times of oversubscription, since this is 60 percent of the 70 percent given to that category. Similarly, Database 1 for the Low category will get 18 percent of the I/O bandwidth, since this is 60 percent of the 30 percent allotted for that category.
There are also directives for intradatabase allocations, which further divide the I/O bandwidth. Consumer group 1 gets 50 percent of the I/O for Database 1, which works out to 21 percent of the overall I/O available—50 percent (the intradatabase percentage) of the 42 percent available for Database 1 in the High category. Consumer group 5, which gets 75 percent of the allocation for Database 1 in the Low category, ends up with 13.5 percent, 75 percent of the 18 percent for that category and database.
You can start to see how flexible I/O Resource Management can be, especially when you couple it with the fact that resource plans can be dynamically changed. But you may be wondering how the Exadata Storage Server Software is able to implement these potentially complex scenarios.
It really is not that hard, as you can see in Figure 3-7.
You can see that the end of the line is a simple queue used to grab I/O requests. The disk simply takes requests off the disk queue. Upstream from this queue are a number of separate queues, one for each consumer group. The percentage allocations assigned by the different directives in the plan are used to control which queue is used by IORM next. So if a queue for consumer group 1 calls for the group to get 80 percent of the requests for Database 1, IORM would go to that queue first 80 percent of the time. At the end of the line, the plan directs the I/O Resource Manager how to prioritize requests for each database.
IORM, like other aspects of the Exadata Storage Server Software stack, also makes sure that essential operations proceed without interruption. Write operations for the redo log, essential in completing write operations with integrity, and control file I/Os always take top priority, regardless of the resource plan. You can either assign DBWR (database writer) operations to a specific consumer group or leave them in a default group. You can also assign a priority for fast file creation operations, described earlier, as part of the overall plan.
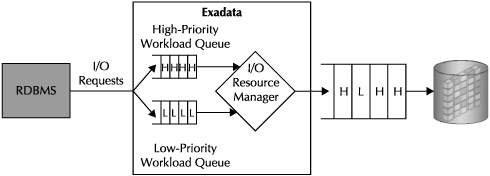
FIGURE 3-7. IORM queue management
The Exadata Storage Server provides a rich set of metrics, which can give you a great deal of information about the operation of IORM at the category, database, or consumer group level. For more details on these tracking options, please refer to the Exadata documentation.
Interacting with Exadata Storage Server Software
This chapter has described the special software features that come with the Exadata Storage Server. Most of these features just work and do not require extensive interaction from you. There is also software included with the Exadata Storage Server that is used to control and monitor the operation of the previously described features. You have seen a few mentions about this software earlier in this chapter, and will learn much more about the actual use of these programs and command interfaces in subsequent chapters, most notably Chapter 5 on management, as it relates to specific tasks. But before leaving this chapter, you should get a general introduction to the management software that comes with Exadata, as well as a general overview of the command interface to this software.
Management Software Components
Figure 3-8 illustrates the basic components of management software that control the Exadata Storage Server.
The key operational component is the CELLSRV process. This process handles incoming requests from the database grid and returns data to that grid. As the CELLSRV process handles all input and output operations to an Exadata Storage Server cell, this component is also responsible for implementing the directives imposed by the I/O Resource Manager.
The primary interface to the operations of the Exadata Storage Server for administrators is the Management Server, usually referred to as MS. Administrators talk to the MS through the CellCLI interface, which uses commands that will be described in more detail later. The Management Server runs on the Exadata Storage Server cell that it controls.
The Restart Server, or RS, monitors the status of the cell and the Management Server and, as the name implies, is used to restart either of these in the event of a failure.
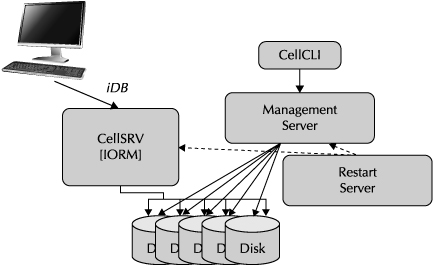
FIGURE 3-8. Management components of the Exadata Storage Server
Command Interfaces
Three command interfaces are used to interact with the Exadata Storage Server—the CellCLI, dcli, and ADRCI, which are described in the following sections.
CellCLI
The CellCLI is the command interface to the Management Server, which handles the configuration and monitoring of the Exadata Storage Server cells. The CellCLI operates on a set of objects, which are detailed in the CellCLI command overview section that follows. Each type of object has a set of attributes that affect the operation of a particular instance of the object. An administrator has five basic actions that can be performed on an object:
![]() LIST, which describes the object and its attributes, either at a summary level or with the modifier DETAIL for a more complete listing. You can use a WHERE clause with the LIST command to limit the object instances, which are displayed based on attribute values, as well as using this command for a single instance of an object.
LIST, which describes the object and its attributes, either at a summary level or with the modifier DETAIL for a more complete listing. You can use a WHERE clause with the LIST command to limit the object instances, which are displayed based on attribute values, as well as using this command for a single instance of an object.
![]() CREATE, which creates a new instance of the object.
CREATE, which creates a new instance of the object.
![]() DROP, which removes a specific instance of an object.
DROP, which removes a specific instance of an object.
![]() ALTER, which modifies the object and its attributes.
ALTER, which modifies the object and its attributes.
![]() DESCRIBE, which gives information about the object and its attributes.
DESCRIBE, which gives information about the object and its attributes.
The basic format of all CellCLI commands is
<verb> <object-type> [ALL |object-name] [<options>]
You can use the LIST command on all objects, but some objects cannot be created, dropped or altered, as detailed in the object table (shown later; Table 3-3).
dcli
dcli is a way to issue commands on multiple cells from a single interface. You can use dcli to run either CellCLI commands or standard operating system commands on Exadata Storage Server cells. You cannot run dcli commands interactively—the commands are simply sent to a collection of cells and executed. You can specify the cells that should execute the commands with command options.
A dcli command returns a result that indicates if the command was completed successfully on all target cells, whether the command did not complete on some cells, or whether a local error prevented any of the commands from being executed. Keep in mind that if a local dcli process is terminated, the commands sent to the remote cells may still run.
ADRCI
ADRCI is the interface to the Automatic Diagnostic Repository (ADR), which is located on each Exadata Storage Server cell. This repository tracks information relating to any problems on the cell. ADRCI includes the Incident Packaging System, which places all relevant information into a package for communicating details of an incident to Oracle support.
CellCLI Command Overview
There are actually two types of commands used with CellCLI—the commands used to control the CellCLI process and those commands used on CellCLI objects. Tables 3-2 and 3-3 list the administrative commands and then the object types used by CellCLI.


TABLE 3-2. CellCLI Administrative Commands
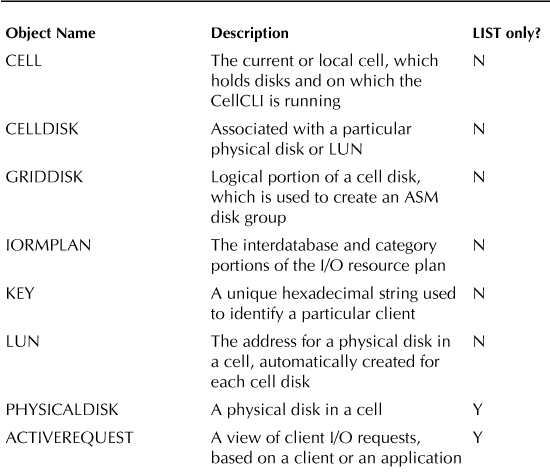

TABLE 3-3. CellCLI Objects
Summary
This chapter covered the main features of Exadata software. Smart Scan and other types of offload processing from database nodes to the Exadata Storage Server provide a way for the performance of overall workloads to be significantly improved. This occurs by both reducing the amount of data sent to the database servers from storage and correspondingly reducing the amount of work required by those database servers.
Exadata Hybrid Columnar Compression is a completely new form of compression that can deliver a significant reduction in database storage for the tables or partitions that use this feature. Reduced data not only saves storage space, but also can improve query performance by requiring less I/O. EHCC has several compression options, and is appropriate for data that is not subject to much write activity.
Storage indexes work transparently to reduce the amount of I/O to satisfy query requirements for Smart Scan queries. The reduction means less work by the Exadata Storage Servers and improved performance where applicable.
The Exadata Smart Flash Cache uses flash-based storage to improve the retrieval performance for commonly used data, and Exadata software makes intelligent choices to determine what type of data can provide the biggest benefit from being stored in the flash cache.
I/O Resource Manager provides a way to provision I/O bandwidth among different groups of users. I/O Resource Manager can provision I/O operations within a single database, between databases, or between categories of databases.
This chapter closed with an overview of Exadata software used to interact with the Exadata Storage Servers for management as well as monitoring.
The next chapter will cover the hardware components of the Oracle Exadata Database Machine.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.