Pig Design Patterns (2014)
Chapter 2. Data Ingest and Egress Patterns
In the previous chapter, you were introduced to the high-level concepts of design patterns and saw how they were implemented using Pig. We explored the evolution of Hadoop and Pig, the limitations with traditional systems, and how Hadoop and Pig relate to the enterprise to solve specific issues related to Big Data. The Pig programming language was explained using a ready-made example that elaborated the language features.
We are about to see the power of using Pig design patterns to ingest and egress various data to and from Hadoop. This chapter's overarching goal is to act as a launch pad for a Hadoop practitioner to rapidly load data, start processing and analyzing it as quickly as possible, and then egress it to other systems, without being bogged down in the maze of writing complex MapReduce code.
This chapter begins with an overview of various types of data typically encountered in the Big Data environment and the source of this data. We then discuss several data ingest design patterns to import multistructured data stored in various source systems into Hadoop. We will also discuss the data egress design patterns that export the data stored in Hadoop to target systems in their native format. To illustrate the ingest and egress patterns, we consider various data formats, such as log files, images, CSV, JSON, and XML. The data sources considered to illustrate these patterns are filesystems, mainframes, and NoSQL databases.
The context of data ingest and egress
Data ingest is the process of getting the data into a system for later processing or storage. This process involves connecting to the data source, accessing the data, and then importing the data into Hadoop. Importing implies the copying of data from external sources into Hadoop and storing it in HDFS.
Data egress is the process of sending data out of the Hadoop environment after the data is processed. The output data will be in a format that matches that of the target systems. Data egress is performed in cases where downstream systems consume the data to create visualizations, serve web applications or web services, or perform custom processing.
With the advent of Hadoop, we are witnessing the capability to ingest and egress data at an unprecedented scale, quickly and efficiently. Enterprises are adopting newer paradigms to ingest and egress data according to the needs of their analytical value. There is a potential value in every data feed that enters an enterprise. These feeds primarily consist of the legacy enterprise data, unstructured data, and external data. The data ingest process deals with a variety of these feeds that are synchronized at regular intervals with the existing enterprise assets. Data egress deals with restricting the outbound data so that it meets the data requirements of the integrated downstream systems.
Once the data is within the enterprise perimeter, there is an increase in its ability to perform meaningful analysis on the raw data itself, even before it is converted into something more structured in the traditional sense (that is, information). We no longer require the data to be extremely organized and structured so that insights are gathered from it. However, with the proliferation of new aged algorithms, any type or form of data can be analyzed. This recently led to exciting business models in which enterprises suddenly found themselves unspooling data from tapes, stored for compliance purposes all these years, to uncover the hidden treasure and value from them. Enterprises are beginning to realize that no data is dispensable or useless, regardless of how unstructured or unrelated it may seem. They have started to scramble for every scrap of data that might hold the potential to give them a competitive edge in the industry.
The unstructured data is examined with renewed interest: if it can be integrated with the existing structured data sources in the enterprise and if this integration can result in better business outcomes through predictive analytics. Today's data scientists revel in heterogeneity. To explore unstructured data is their new challenge, and to find patterns from random distributions is the new normal. Spinning up a few Hadoop nodes on a cloud provider of choice, importing data, and running sophisticated algorithms have become regular chores for many of data scientists; this makes it relatively simple to process tons of various types of data from many disparate sources. All this underscores the importance of data ingest and egress to and from various sources, which forms the bedrock for the eventual value. In this chapter, we will discuss the how of ingest and egress through design patterns in Pig as well as give special impetus to the why.
Types of data in the enterprise
The following section details the enterprise-centric view of data and its relevance to the Big Data processing stack as depicted in the following diagram:
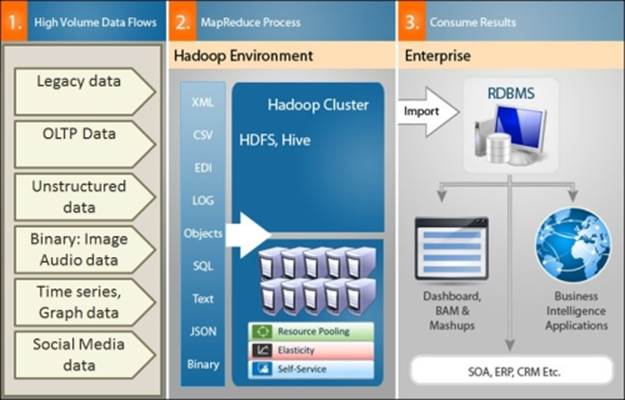
Data Variety in the enterprise
The following is an explanation of various categories of high-volume data:
· Legacy data: This data type includes data from all legacy systems and applications, encompassing the structured and semi-structured formats of data stored online or offline. There are lots of use cases for data types—seismic data, hurricane data, census data, urban planning data, and socioeconomic data. These types can be ingested into Hadoop and combined with the master data to create interesting, predictive mash-ups.
· Transactional (OLTP) data: Data from the transactional systems is traditionally loaded to the data warehouse. The advent of Hadoop has addressed the lack of extreme scalability in traditional systems; thus, transactional data is often modeled so that not all the data from the source systems is used in the analysis. Hadoop can be used to load and analyze the OLTP data in its entirety as a pre-processing or second-pass processing step. It can also be used to ingest, egress, and integrate transactional data from ERP, mainframe, SCM, and CRM systems to create powerful data products.
· Unstructured data: This data type includes documents, notes, memos, and contracts residing in enterprise content management platforms. These enterprise systems are geared toward producing and storing content without much analysis being performed on the data. Hadoop provides interfaces to ingest the content and process it by discovering context-based, user-defined rules. The output of content processing is used to define and design analytics to explore the mining of unstructured data using semantic technologies.
· Video: Many enterprises have started to harness into video-based data to gain key insights into use cases related to security surveillance, weather, media, and so on. Hadoop enables the ingest of the components in a video, such as the content, audio, and associated metadata. Hadoop integrates the contextualized video data and associated metadata with structured data in the Enterprise Data Warehouses (EDW) to further process the data using advanced algorithms.
· Audio: Data from call centers contains a lot of intelligence about customers, competition, and other categories. While the current data warehouse has limitations on the processing and integration of this type of data, Hadoop ingests this data seamlessly by integrating it with the existing data in the warehouse. Audio data extracts can be processed and stored as contextual data with the associated metadata in Hadoop.
· Images: Static images carry a lot of information that can be very useful for government agencies (geospatial integration), healthcare (X-ray and CAT scans), and other areas. Ingesting this data in Hadoop and integrating it with the data warehouse will provide large enterprises with benefits through analytical insights, which generate business opportunities where initially none existed, due to lack of data availability or processing capability.
· Numerical/patterns/graphs: This data type belongs to the semi-structured category. It includes seismic data, sensor data, weather data, stock market data, scientific data, RFID, cellular tower data, automotive on-board computer chips, GPS data, and streaming video. Other such data are patterns that occur, or numeric data or graphs that repeat their manifests in periodic time intervals. Hadoop helps to ingest this type of data and process it by integrating the results with the data warehouse. This processing will provide analytical opportunities to perform correlation analysis, cluster analysis, or Bayesian types of analysis, which will help identify opportunities in revenue leakage, customer segment behavior, and business risk modeling.
· Social media data: Typically classified as Facebook, LinkedIn, or Twitter data, the social media data transcends those channels. This data can be purchased from third-party aggregators, such as DataSift, Gnip, and Nielsen. Ingesting these types of data and combining them in Hadoop with structured data enables a wide variety of social network analysis applications, such as sentiment detection.
In the upcoming sections, we will examine the numerous ingest and egress patterns dealing with the aforementioned data types.
Ingest and egress patterns for multistructured data
The next sections describe the specific design patterns for ingesting unstructured data (images) and semi-structured text data (Apache log and custom log).The following is a brief overview of the formats:
· Apache Log formats: Extracting intelligence from this format is a widely used enterprise use case and is relevant across the board.
· Custom log format: This format represents an arbitrary log that can be parsed through a regex. Understanding this pattern will help you to extend it for many other similar use cases where a custom loader has to be written.
· Image format: This is the only pattern dealing with nontext data, and the pattern described to ingest images can be tweaked and applied to any type of binary data. We will also discuss the image egress pattern to illustrate the ease of egressing the binary data using Pig's extensibility features.
Considerations for log ingestion
The storage of logs depends on the characteristics of the use case. Typically, in the enterprise, logs are stored, indexed, processed, and used for analytics. The role of MapReduce starts from the point of ingestion to index and process the log data. Once the processing is done, it has to be stored on a system that provides read performance for real-time querying on the log indexes. In this section, we will examine the various options to store the log data for real-time read performance:
· One of the options is a wide variety of SQL-based relational databases. They are not a good fit to store large volumes of log data for the use cases that need querying in real time to gain insights.
· NoSQL databases seem to be a good option to store unstructured data due to the following characteristics:
· Document databases, such as CouchDB and MongoDB, store the data in documents, where each document can contain a variable number of fields or schemas. In the case of log processing, generally, the schemas are predetermined and will not change so frequently. Hence, document databases can be used in the use cases where schema flexibility (logs with different schemas) is the primary criterion.
· Column-oriented databases, such as HBase and Cassandra, store closely related data in columns, which are extendable. These databases are good for distributed storage and are performance centric. These are very efficient in reading operations and calculating on a set of columns. However, at the same time, these databases are not schema flexible like the other NoSQL counterparts. The database structure has to be predetermined before storing the data. Most of the common use cases of log file processing can be implemented in column-oriented databases.
· Graph databases, such as GraphLab and Neo4j, are not suitable for log file processing because the logs cannot be represented as the nodes or vertices of a graph.
· Key-value databases such as SimpleDB store values that are accessible by a certain key. A key-value database works well when the database scheme is flexible and for data that needs to be accessed frequently. Ideally, these databases are not suitable for log file processing where there is no explicit change in the schema over a period.
Considering the previously mentioned characteristics, the best practice is to choose the performance and distribution capabilities of columnar databases over the schema flexibility of a key value and document databases for logfile storage and processing. Another important criterion to help make a better decision is to choose a columnar database that has a good read performance instead of a good write performance, as millions of logs have to be read and aggregated for analysis.
In light of all the criteria, enterprises have successfully implemented log analytics platforms using HBase as their database of choice.
The Apache log ingestion pattern
The logfile ingestion pattern describes how you can use Pig Latin to ingest Apache logs into the Hadoop File System to further process them on your data pipeline.
We will discuss the relevance of Apache logs to the enterprise, and get an understanding of the various logs formats, how each format differs, and the use cases where logs are used in conjunction with Pig. You will also understand how Pig makes the ingestion of these logs a lot easier than programming them in MapReduce.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
The Apache Server logs are used for general purpose tracking and monitoring of server health. The Apache web servers create the Apache logs and store them in the local storage. These logs are moved periodically to the Hadoop cluster for storage on the Hadoop File System through the Apache Flume framework, which is distributed in major Hadoop distributions such as Cloudera.
The following is a quick high-level introduction to Flume:
· Flume is a distributed and reliable producer-consumer system to move large volumes of logs (automatically after they are configured) into Hadoop for processing
· The Flume agents run on the web servers (producer)
· The producer agent collects the log data periodically using collectors (consumer)
· The producer agent pushes the log data to the destination filesystem, HDFS
A snapshot of this architecture is depicted in following diagram:
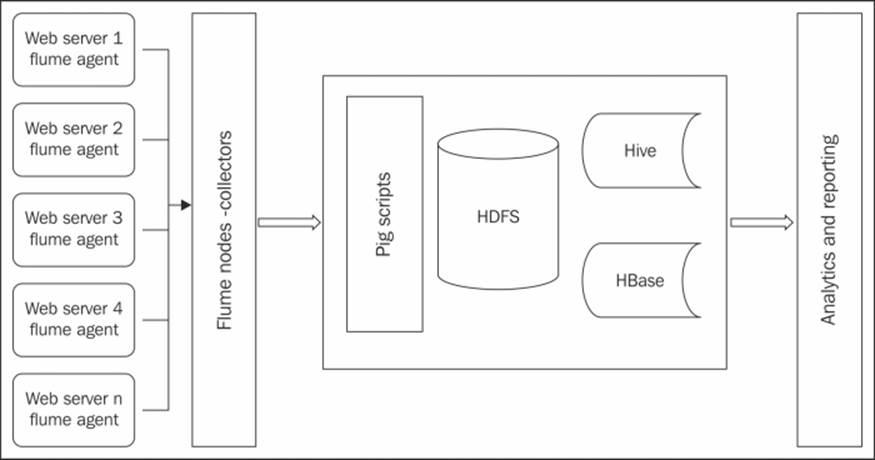
Typical log acquisition
Motivation
The log data is analyzed to understand and track the behavior of any application or web service. It contains a wealth of information about the application and its users, which is aggregated to find patterns, errors, or suboptimal user experience, thereby convertinginvisible log data into useful performance insights. These insights are leveraged across the enterprise in the form of specific use cases that range from product support to engineering and marketing, providing both operational and business intelligence.
A computer cluster contains many individual servers, each with its own logging facility. This makes it difficult for server administrators to analyze the overall performance of an entire cluster. Combining log files of the individual servers into one log file can be very useful to get information about the performance of the cluster. The combined log files make it possible to visualize the cluster's performance and detect problems in the cluster in a short period of time. However, storing server logs of a cluster for a few days results in datasets of several gigabytes. Analyzing such a large quantity of data requires a lot of processing power and memory. A distributed system such as Hadoop is best suited for this kind of processing power and memory.
The size of web logs can grow to hundreds of GB, and Hadoop ingests these files for further analysis and considers various dimensions, such as time, geography of origin, and type of browser, to extract patterns and vital information.
Use cases
This design pattern can be used in the following use cases:
· To find the users who are linked to the website.
· To find the number of website visitors and unique users. This can be done across spatial and temporal dimensions.
· To find peak load hours in temporal and spatial directions.
· To analyze the visits of bots and worms.
· To find stats relevant to site performance.
· To analyze the server's responses and requests and gain insights into the root causes of web server issues.
· To analyze which page or part of the website is more interesting to the user.
Pattern implementation
The Apache access log ingestion pattern is implemented in Pig through the usage of the ApacheCommonLogLoader and ApacheCombinedLogLoader classes of piggybank. These functions extend the LoadFunc class of Pig.
Code snippets
The two different types of logs that are used in the following example are the Common Log Format named access_log_Jul95 and the Combined Log Format named access.log. In the enterprise setting, these logs are extracted using the Flume agent residing on the web server where the log is generated.
The following table illustrates the constituent attributes of each type:
|
Attribute |
Common log format |
Combined log format |
|
IP address |
Yes |
Yes |
|
User ID |
Yes |
Yes |
|
Time of request |
Yes |
Yes |
|
Text of request |
Yes |
Yes |
|
Status code |
Yes |
Yes |
|
Size in bytes |
Yes |
Yes |
|
Referer |
Yes |
|
|
HTTP agent |
Yes |
Code for the CommonLogLoader class
The following Pig script illustrates the usage of the CommonLogLoader class to ingest the access_log_Jul95 log file into the Pig relation logs:
/*
Register the piggybank jar file to be able to use the UDFs in it
*/
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
/*
Assign the aliases ApacheCommonLogLoader and DayExtractor to piggybank's CommonLogLoader and DateExtractor UDFs
*/
DEFINE ApacheCommonLogLoader org.apache.pig.piggybank.storage.apachelog.CommonLogLoader();
DEFINE DayExtractor org.apache.pig.piggybank.evaluation.util.apachelogparser.DateExtractor('yyyy-MM-dd');
/*
Load the logs dataset using the alias ApacheCommonLogLoader into the relation logs
*/
logs = LOAD '/user/cloudera/pdp/datasets/logs/access_log_Jul95' USING ApacheCommonLogLoader
AS (addr: chararray, logname: chararray, user: chararray, time: chararray,
method: chararray, uri: chararray, proto: chararray,
status: int, bytes: int);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation logs on the console
*/
DUMP logs;
Code for the CombinedLogLoader class
The following Pig script illustrates the usage of the CombinedLogLoader class to ingest the access.log file into the Pig relation logs:
/*
Register the piggybank jar file to be able to use the UDFs in it
*/
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
/*
Load the logs dataset using piggybank's CombinedLogLoader into the relation logs
*/
logs = LOAD '/user/cloudera/pdp/datasets/logs/access.log'
USING org.apache.pig.piggybank.storage.apachelog.CombinedLogLoader()
AS (addr: chararray, logname: chararray, user: chararray, time: chararray,
method: chararray, uri: chararray, proto: chararray,
status: int, bytes: int,
referer: chararray, useragent: chararray);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the relation logs on the console
DUMP logs;
Results
As a consequence of using this pattern, data from the Apache log file is stored in a bag. The following are a few ways in which a Pig relation can be stored with invalid values:
· If the log file has invalid data, then nulls are stored in the bag.
· If the data types are not defined in the schema after the AS clause, then all the columns are defaulted to bytearray in the bag. Pig performs conversions later, based on the context in which that data is used. It is sometimes required to typecast the columns explicitly to reduce parse time errors.
Additional information
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/apachelog/CombinedLogLoader.html
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/apachelog/CommonLogLoader.html
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/evaluation/util/apachelogparser/package-summary.html
The complete code and datasets for this section are in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The Custom log ingestion pattern
The custom log ingestion pattern describes how you can use Pig Latin to ingest any kind of logs into the Hadoop File System to further process logs on your data pipeline.
We will discuss the relevance of custom logs in the enterprise, and get an understanding of how these logs are generated and transferred to the Hadoop cluster and of the use cases where logs are used in conjunction with Pig. You will also understand how Pig makes ingestion of these logs a lot easier than programming them in MapReduce.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
Most of the logs use certain conventions to delimit the constituent fields, similar to a CSV file, but there are situations where we encounter text files, which are not properly separated (by a tab or a comma).These logs are required to be cleaned before they can be analyzed. Data can be cleaned before it arrives in HDFS via Flume, Chukwa, or Scribe and stored in a format where Pig or Hive can easily process it for analytics. If data is already stored in an uncleaned format in HDFS, you can write a Pig script to clean up the data and analyze it by loading it in Hive or HBase for it to be used later.
Motivation
Pig's reputation for handling unstructured data stems from its native support for data with partial or unknown schemas. While loading data, it is optional to specify the schema, and it is possible that the schema can be specified after the loading has been completed. This is in stark contrast with other systems such as Hive, where you have to enforce a schema before loading.
Use this pattern when the text data is not standardized and formatted yet.
Use cases
The following are the generic use cases where this pattern can be applied:
· To ingest any text or log file that doesn't have a well-defined schema
· To ingest text or log files and experimentally figure out what schema can be imposed on it, based on the suitability for analytics
Pattern implementation
The unstructured text ingestion pattern is implemented in Pig through the usage of the TextLoader function of piggybank. These functions inherit the LoadFunc class.
Pig has a nice feature that deciphers the type of data if the schema is not explicitly specified. In such cases, fields are set to the default bytearray type and then the correct type is inferred based on the usage and context of the data in the next statements.
The TextLoader function of piggybank enables you to load the text file, splitting on new lines and loading each line into a Pig tuple. If a schema is specified using the AS clause, each of the tuple is considered chararray. If no schema is specified by omitting the clause, then the resultant tuples will not have the schema.
Similarly, you can use the MyRegexLoader class to load the contents of the file after filtering the rows using the regex pattern specified. A regular expression format can be specified using MyRegExLoader. This function returns a matched regex as chararray if a pattern is passed to it as a parameter.
Code snippets
In this use case, we illustrate the ingestion of application log files to help identify potential performance issues in a web server by analyzing the request/response patterns. We will use the sample_log.1 dataset to calculate the average response time taken by each service. This log file contains event logs embedded along with the web service request and response information generated by a web application in the format shown in the following code. Here, we are interested in extracting only the request response pairs, ignoring the event information related to INFO, DEBUG, and ERRORS:
/* other unstructured event logs related to INFO, DEBUG, and ERROR logs are depicted here */
Request <serviceName> <requestID> <Timestamp>
Response <serviceName> <requestID> <Timestamp>
/* other unstructured event logs related to INFO, DEBUG, and ERROR logs are depicted here */
The following code snippet shows the usage of MyRegexLoader to load the lines that match the specified regular expression:
/*
Register the piggybank jar file to be able to use the UDFs in it
*/
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
/*
Load the logs dataset using piggybank's MyRegExLoader into the relation logs.
MyRegexLoader loads only the lines that match the specified regex format
*/
logs = LOAD '/user/cloudera/pdp/datasets/logs/sample_log.1'
USING org.apache.pig.piggybank.storage.MyRegExLoader(
'(Request|Response)(\\s+\\w+)(\\s+\\d+)(\\s+\\d\\d/\\d\\d/\\d\\d\\s+\\d\\d:\\d\\d:\\d\\d:\\d\\d\\d\\s+CST)')
AS (type:chararray, service_name:chararray, req_id:chararray, datetime:chararray);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the relation logs on the console
DUMP logs;
Further processing would be done on the extracted logs to calculate the average response time taken by each service and identifying potential performance issues.
The following code snippet shows the usage of TextLoader to load the custom log:
/*
Load the logs dataset using TextLoader into the relation logs
*/
logs = LOAD '/user/cloudera/pdp/datasets/logs/sample_log.1' USING TextLoader AS (line:chararray);
/*
The lines matching the regular expression are stored in parsed_logs.
FILTER function filters the records that do not match the pattern
*/
parsed_logs = FILTER logs BY $0 MATCHES '(Request|Response)(\\s+\\w+)(\\s+\\d+)(\\s+\\d\\d/\\d\\d/\\d\\d\\s+\\d\\d:\\d\\d:\\d\\d:\\d\\d\\d\\s+CST)';
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the relation parsed_logs on the console
DUMP parsed_logs;
Results
As a consequence of using this pattern, data from the log file is stored in a bag. This bag is used in the subsequent steps for analysis.
The following are a few ways in which a Pig relation could be stored with invalid values:
· If the log file has invalid data, then nulls are stored in the Bag.
· If the data types are not defined in the schema after the AS clause, then all the columns are defaulted to bytearray in the bag. Pig performs conversions later based on the context in which that data is used. It is sometimes required to typecast the columns explicitly to reduce parse time errors.
· You can define data types after the AS clause, but care has to be taken when defining appropriate data types for each of the columns. A null will be stored in the Bag when the data type casting cannot happen such as in cases where a chararray type is forcibly typecasted to an int result in a null. However, int can be casted to chararray. (For example, int 27 can be typecast into chararray "27".)
· You have to pay special attention to data in a relation that could result in a null. Relational operators such as COUNT disregard nulls, but the COUNT_STAR function does not ignore it and counts a null as if there is a value to it.
Additional information
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/MyRegExLoader.html
· http://pig.apache.org/docs/r0.11.1/func.html#textloader
The complete code and datasets for this section can be found in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The image ingress and egress pattern
The design patterns in this section describe how you can use Pig Latin to ingest and egress a set of images into and from the Hadoop File System to further process images in your data pipeline.
We will discuss the relevance of images in the enterprise and get an understanding of the various ways images can be created and stored, the optimal way of gathering images to be processed on Hadoop, and the use cases where images are used in conjunction with Pig. You will also understand how Pig makes it easy to ingest these images with a custom UDF written in Java.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
There are many documented use cases of Hadoop that deal with structured data and unstructured text data. However, we have evidence of many cases that exploit the real power of Hadoop to process the other forms of unstructured data, such as images, videos, and sound files.
In terms of processing images, Hadoop plays a key role in analyzing images taken by weather/military/civil satellites, that is, when the image size is large and the resolution is high and they need to be processed by a farm of servers.
Hadoop offers an effective storage mechanism for large images or a set of small images. Unlike the process of storing images in a RDBMS as a BLOB without the ability to perform a massive-scaled, meaningful analysis on them using SQL, specific image processing algorithms can be written on Hadoop, which can work on individual images and on a bundle of images for performing high-end image analysis in a parallel way.
Motivation
This pattern is applicable in cases where you want to load and process a large number of image files in Hadoop. The loading of the images into the data pipeline is accomplished by a UDF written in Java.
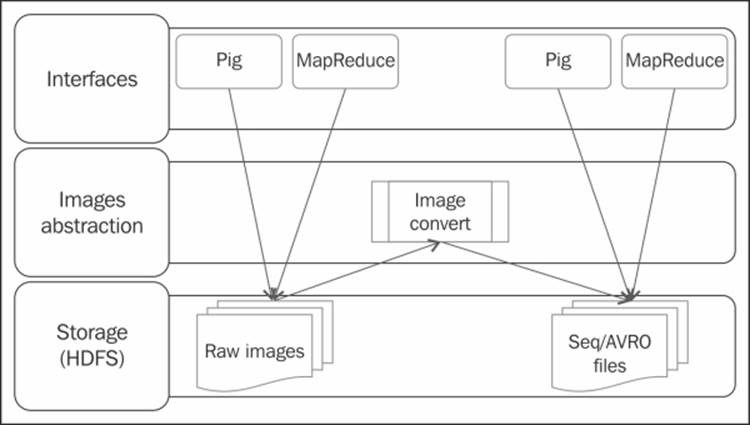
Image ingress and egress
Ingesting the unstructured image data and combining it with the structured image metadata, such as tags, EXIF information, and object tags, which provide the contextual information, has led to newer developments in social media analytics and other areas—such as security, intelligence gathering, weather predictions, and facial recognition. This idea could be extended to a wider range of image features that allow us to examine and analyze images in a revolutionary way.
After ingesting the images into Hadoop, the actual processing of raw images is a complex task involving multiple calculations on the raw pixels level. These calculations are accomplished by the low-level C and C++ algorithms. Hadoop is integrated with these algorithms using Hadoop streaming to wrap these and work as a standard Hadoop job.
The image egress pattern attempts to show a simple mechanism in which the binary images existing as a sequence file in the HDFS are output as image files. The motivation for this pattern lies in the ability of Hadoop-based image processing algorithms to perform complex computations on images to join its constituent tiles to create a bigger image.
Hadoop works effectively by grouping image files into a small number of large files as opposed to an enormous number of tiny image files. Using a large number of small image files, whose size is less than the HDFS block size of 64 MB, could cause many reads from the disk and heavy lookup in the NameNode, resulting in a huge amount of network traffic to transfer these files from one node to another. This causes unproductive data access. This design pattern explores a way to overcome this limitation in Hadoop by grouping these image files into sequence files. You can extend this pattern to ingest and process other types of binary files such as sound and video.
The ingestion design pattern is applicable to images that are part of a large corpus of image files, where each image is distinct and combining them is not natural. The pattern is not applicable to a very large image that is split among the nodes of the Hadoop cluster. An illustration of the architecture is shown in the previous diagram.
Use cases
You may consider applying the image ingestion pattern as a pre-processing step in the following use cases:
· Ingest multiple images to apply the various types of image filters on each of the images
· Perform batch enhancements to the image quality
· Understand the content of the images, for example, apply AI-based unsupervised computer vision algorithms to extract features such as roads, canals, or buildings from within the image
· Use images for pattern matching as in the case of medical and GIS imagery
You may consider applying the image egress pattern in use cases where noise has to be removed from the images. The original images are loaded in Hadoop and processed to remove noise; the noise-filtered images are egressed back by combining multiple tiles of the images to create a new image.
Pattern implementation
The following sections describe the pattern implementation of the image ingest pattern followed by image egress.
The image Ingress Implementation
The image ingestion pattern is implemented in Pig through the usage of a custom loader function that is implemented as a UDF in Java. This ImageToSequenceFileUDF converts the image(s) into a sequence file. The input is the HDFS path of the images directory and the output is the sequence file path.
The sequence file stores the contents of the image file as a value, mapped to the filename key. As the sequence file can be split, it can be processed by streaming or using MapReduce. MapReduce internally uses a marker to split the files into block-sized chunks and operates on them independently. The sequence file supports compression with many codecs, and block compression is used for the maximum efficiency of storage and retrieval. There will not be any reducer in this case to prevent the shuffling of data and consumption of bandwidth. This will enable using Hadoop for its scalable advantages in case you have a large amount of image data stored in the sequence files.
The image egress implementation
The image egress pattern is implemented in Pig through the usage of a custom storage function that is implemented as a UDF in Java. This SequenceToImageStorage class converts the sequence file into images and stores it in the specified location on the disk. The input to this function is the path of the sequence files.
Code snippets
The following sections describes the code of the image ingest pattern followed by the image egress.
The image ingress
To illustrate the working of this pattern, we considered a set of image files stored in a folder accessible to the Hadoop File System, HDFS. There is no pre-processing done on the images; they are stored in the raw format (JPEG). The following code primarily has two major parts. Firstly, the Pig Latin script, which loads the file containing the path to images folder, and secondly, the custom UDF written in Java that does the actual work behind the scenes to decompose an image or a set of images to a sequence file.
Pig script
The following is the Pig script to read image files and convert them into a sequence file:
/*
Register the custom loader imagelibrary.jar, it has UDFs to convert images to sequence file and sequence file to images
*/
REGISTER '/home/cloudera/pdp/jars/imagelibrary.jar';
/*
Load images_input file, it contains the path to images directory
*/
images_file_path = LOAD '/user/cloudera/pdp/datasets/images/images_input' AS (link:chararray);
/*
ImageToSequenceFileUDF converts multiple image files to a sequence file.
This ensures that there are no large number of small files on HDFS, instead multiple small images are converted into a single sequence file.
Another advantage of sequence file is that it is splittable.
The sequence file contains key value pairs, key is the image file name and value is the image binary data.
It returns the path of the sequence file.
*/
convert_to_seq = FOREACH images_file_path GENERATE com.mycustomudf.ImageToSequenceFileUDF();
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the convert_to_seq on the console
DUMP convert_to_seq;
Image to a sequence UDF snippet
The following is the Java code snippet of ImagetoSequenceFileUDF that shows the conversion of image file(s) to a sequence file:
public static String createSequenceFile(Path inPutPath)
{
.
.
for(int i=0;i<status.length;i++)
{
//FSDataInputStream is opened at the given path
dataInputStream = fileSystem.open(status[i].getPath());
// extracting image name from the absolute path
fileName = status[i].getPath().toString().
substring(status[i].getPath().toString().
lastIndexOf("/")+1);
byte buffer[] = new byte[dataInputStream.available()];
//buffer.remaining() bytes will be read into buffer.
dataInputStream.read(buffer);
/*Add a key/value pair. Key is the image filename and
value is the BytesWritable object*/
seqFileWriter.append(new Text(fileName),
new BytesWritable(buffer));
.
.
}
}
The image egress
The following section describes the code for the image egress.
Pig script
The following is the Pig script to egress contents of the sequence file into images:
/*
Register the custom jar, it has UDFs to convert images to sequence file and sequence file to images
*/
REGISTER '/home/cloudera/pdp/jars/imagelibrary.jar';
/*
Load images_input file, it contains the path to images directory
*/
images_file_path = LOAD '/user/cloudera/pdp/datasets/images/images_input' AS (link:chararray);
/*
ImageToSequenceFileUDF function converts multiple image files to a sequence file.
This ensures that there are no large number of small files on HDFS, instead multiple small images are converted into a single sequence file.
Another advantage of sequence file is that it is splittable.
The sequence file contains key value pairs, key is the image file name and value is the image binary data.
It returns the path of the sequence file.
*/
convert_to_seq = FOREACH images_file_path GENERATE com.mycustomudf.ImageToSequenceFileUDF();
/*
* Some processing logic goes here which is deliberately left out to improve readability.
* It is assumed that in-between the load and store steps, a user performs some image processing step such as stitching multiple image tiles together.
*/
/*
The custom UDF SequenceToImageStorage reads the sequence file and writes out images.
It reads each key/value pair and writes out the contents as images with keyname as the filename in the folder seq_to_img_output
*/
STORE convert_to_seq INTO '/user/cloudera/pdp/output/images/seq_to_img_output' USING com.mycustomudf.SequenceToImageStorage();
Sequence to an image UDF
The following is a snippet of the custom store function, SequenceToImageStorage, to read a sequence file and write out the contents to image file(s):
@Override
public void putNext(Tuple tuples) throws IOException {
.
.
// Do this for each key/value pair
while (seqFilereader.next(key, value))
{
bufferString = value.toString().split(" ");
buffer =new byte[bufferString.length];
for(int i=0;i<bufferString.length;i++)
{
/*
String parameter parsed as signed integer in the radix given by the second parameter
*/
buffer[i] = (byte)
Integer.parseInt(bufferString[i], 16);
}
/*
output path of the image which is the path specified, key is the image name
*/
outPutPath=new Path(location+"/"+key);
// FSDataOutputStream will be created at the given Path.
seqFileWriter = fileSystem.create(outPutPath);
// All bytes in array are written to the output stream
seqFileWriter.write(buffer);
}
.
.
}
The SequenceFile.Reader class of Hadoop API is used to read the sequence file to get the key-value pairs. The key-value pairs are iterated and then for each pair, a new file is created with a key name, and the value is written as bytes into the file, thus generating multiple image files.
Results
As a consequence of applying the image ingestion pattern, the corpus of images is parsed by the Java UDF into sequence files. Each of the sequence files is decomposed later into the RGB values and stored in a Pig Latin map relation. The next stages of data pipeline use the map relation to further process the sequence files.
As a result of the image egress pattern, the sequence file stored in HDFS is converted into image files so that the upstream image display systems can use these images.
Additional information
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/SequenceFileLoader.html
· http://pig.apache.org/docs/r0.11.1/udf.html#load-store-functions
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The ingress and egress patterns for the NoSQL data
This section describes the patterns that deal with ingesting data from two classes of NoSQL data. To illustrate the power of Pig to readily support NoSQL databases and the use cases associated with it, we have chosen document databases such as MongoDB and columnar databases such as HBase.
MongoDB ingress and egress patterns
The MongoDB ingress and egress patterns describe how you can use Pig Latin to store the contents of MongoDB document collections in the Hadoop File System (Pig relations) to process data and then write the processed data back into the MongoDB.
We will discuss the relevance of the data stored in MongoDB to the enterprise and understand the various ways in which the MongoDB data can be accessed, the motivation to perform ingest and egress, and the use cases where MongoDB data is used in conjunction with Pig. You will also understand how Pig makes the ingestion and egression of this data a lot more intuitive than doing it using MapReduce code written in Java.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. The example code snippets enable better understanding of the patterns from the Pig language perspective, followed by the results of using the pattern.
Background
MongoDB is a NoSQL database designed from the ground up to store data in the form of document collections, unlike the rows and columns of RDBMS. It is highly scalable and makes the retrieval of documents easy, owing to the extensive indexing capability and the use of JSON for integration with external applications. MongoDB is extremely flexible and handles variable schemas. (It is not mandatory to have the same schema for each of the documents in the collection.) As MongoDB stores data as documents and almost all attributes of these document collections are indexed, it is a highly effective solution as an operational store to process real-time queries, unlike Hadoop which excels in offline batch processing and aggregating of data from various sources.
Motivation
In a typical enterprise, MongoDB and Hadoop are integrated in scenarios where Hadoop is required to handle more extreme data loads compared to what MongoDB is capable of to aggregate data and facilitate complex analytics.
The data from MongoDB is ingested into Hadoop and processed with MapReduce jobs. Hadoop combines the data with additional data from other enterprise sources using the Pig data pipelines to develop a multidata aggregation solution. After processing the data in the Pig data pipelines, it is written back into MongoDB for ad-hoc analysis and querying. This ensures that existing applications can use the egressed data from Hadoop to create visualizations or drive other systems.
In many enterprise use cases, Hadoop functions as a central data repository that integrates the data with different data stores. In this case, MongoDB can function as one of the data sources that feeds Hadoop periodically using MapReduce jobs. Once the MongoDB data is ingested into Hadoop, the combined bigger datasets are processed and made available to further query them.
MongoDB also acts as one of the Operational Data Store (ODS), which connects to other data stores and data warehouses. Obtaining analytical insights involves the movement of data from these connected data sources and the performing of ETL, for which Pig can be effectively used. Hadoop acts as an ETL hub to pull data from one store, perform various transformations using the MapReduce jobs, and load the data onto another store.
Note
It is important to note that ingesting data directly from an external source (MongoDB) has very different operational performance characteristics than data already loaded/transferred into HDFS.
Use cases
You might want to consider using the patterns of data ingress and egress in the following scenarios where integrating MongoDB with Hadoop reaps rich dividends:
· MongoDB and Hadoop handle different workloads, near real time and batch, respectively. Consider using the ingress design pattern in use cases where you want to offload loads to Hadoop to be batch processed and thus, free up resources in MongoDB. Consider using the egress design pattern to make the MongoDB a sink to export data from Hadoop and enable real-time query operations.
· MongoDB itself has a MapReduce implementation, which runs on the MongoDB database. However, it is slower than the Hadoop MapReduce as it is implemented in JavaScript, and it has fewer data types and libraries to perform complex analytics. Consider using the ingress design pattern in use cases that has data to be offloaded to Hadoop to take advantage of Hadoop's library support, machine learning, ETL capabilities, and the scale of processing. Consider using the egress design pattern to move data from Hadoop into MongoDB and to take advantage of Mongo DB's MapReduce implementation.
· MongoDB has support for few basic data aggregation capabilities to generate aggregates in the SQL style that requires a higher learning curve to understand the aggregation framework. Consider using the ingress design pattern in cases where you want to take advantage of Hadoop to perform complex aggregation tasks.
· This design pattern can be used in cases where there is a huge amount of unstructured data and you need to use MongoDB for real-time analysis. In this case, you can use the ingress design pattern to create a structure out of the ingested raw data in Hadoop and export the data into MongoDB using the egress design pattern to facilitate optimized storage in MongoDB for real-time querying and analytics.
Pattern implementation
The following diagram shows the MongoDB connector integration:
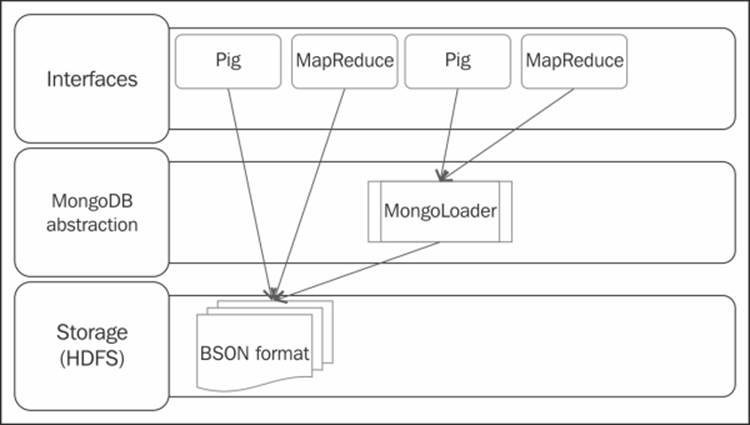
MongoDB connector integration
Hadoop and MongoDB can be integrated using the MongoDB connector for Hadoop. This connector helps to move data to and from MongoDB into the Hadoop ecosystem and allows access through other programming languages (Hadoop streaming). The connector's integration with Pig is depicted in the previous diagram.
The ingress implementation
Pig uses the MongoLoader function to load MongoDB data into a Pig Latin relation. Using this function, the data is loaded directly from the database. Pig can also read from the MongoDB native format (BSON) using the BSONLoader function.
The MongoLoader function can work in the schema-less mode in which the field names are not specified. In this mode, the records are interpreted as tuples containing a single map (document). This case is useful when you do not know the schema of the MongoDB collection. The MongoLoader function can also work in the schema mode where you specify field names that maps the fields in the Pig script with those in the document.
The egress implementation
The data in a Pig relation can be written into MongoDB in two ways. The first way is to use the BSONStorage function to perform the storage of a relation into a .BSON file that can be imported later into MongoDB. This method has the advantage of writing at high throughput in the native storage format of MongoDB. The second way uses MongoDB's wrapper to connect to the database and write directly into it through the usage of the MongoStorage function. This function will operate on a tuple level by storing each tuple it receives into the corresponding document in MongoDB. The schema of the Pig relation and the MongoDB document is mapped before the writing commences. Using the second method will give you a lot of flexibility to write data at record or tuple level, but it compromises on the speed of I/O.
The MongoStorage function can also be used to update the existing document collection in MongoDB by specifying the update key in the constructor. If the update key is specified, the first document (value) corresponding to the key will be updated by the contents of the Pig tuple.
Code snippets
In the following example code, we have considered the contents of the nasdaqDB.store_stock data already residing in MongoDB. This dataset consists of NASDAQ data spanning from the 1970s to 2010; this includes the stock tracking data of various companies and how they performed on a specific day with its trading volume figures. This dataset is alphabetically organized by the ticker symbol and stored as JSON objects in MongoDB.
The ingress code
The following code performs the task of connecting to MongoDB, setting up the connection, loading the MongoDB native file, parsing it, and retrieving only the specified schema in the MongoLoader constructor by mapping the fields of the MongoDB document with the fields specified in the schema. This abstraction is performed by just one call to the MongoLoader function.
/*
Register the mongo jar files to be able to use MongoLoader UDF
*/
REGISTER '/home/cloudera/pdp/jars/mongo.jar';
REGISTER '/home/cloudera/pdp/jars/mongo-hadoop-pig.jar';
/*
Load the data using MongoLoader UDF, it connects to MongoDB, loads the native file and parses it to retrieve only the specified schema.
*/
stock_data = LOAD 'mongodb://slave1/nasdaqDB.store_stock' USING com.mongodb.hadoop.pig.MongoLoader('exchange:chararray, stock_symbol:chararray, date:chararray, stock_price_open:float, stock_price_high:float, stock_price_low:float, stock_price_close:float, stock_volume:long, stock_price_adj_close:chararray') AS (exchange,stock_symbol,date,stock_price_open,stock_price_high,stock_price_low,stock_price_close,stock_volume,stock_price_adj_close);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation stock_data on the console
*/
DUMP stock_data;
The egress code
The following code depicts the writing of data existing in a stock_data Pig relation to a MongoDB document collection:
/*
Register the mongo jar files and piggybank jar to be able to use the UDFs
*/
REGISTER '/home/cloudera/pdp/jars/mongo.jar';
REGISTER '/home/cloudera/pdp/jars/mongo_hadoop_pig.jar';
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
/*
Assign the alias MongoStorage to MongoStorage class
*/
DEFINE MongoStorage com.mongodb.hadoop.pig.MongoStorage();
/*
Load the contents of files starting with NASDAQ_daily_prices_ into a Pig relation stock_data
*/
stock_data= LOAD '/user/cloudera/pdp/datasets/mongo/NASDAQ_daily_prices/NASDAQ_daily_prices_*' USING org.apache.pig.piggybank.storage.CSVLoader() as (exchange:chararray, stock_symbol:chararray, date:chararray, stock_price_open:chararray, stock_price_high:chararray, stock_price_low:chararray, stock_price_close:chararray, stock_volume:chararray, stock_price_adj_close:chararray);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Store data to MongoDB by specifying the MongoStorage serializer. The MongoDB URI nasdaqDB.store_stock is the document collection created to hold this data.
*/
STORE stock_data INTO 'mongodb://slave1/nasdaqDB.store_stock' using MongoStorage();
Results
As a consequence of applying the ingest design pattern on a MongoDB document collection, the contents of the collection specified by the MongoDB URI are loaded into a stock_data Pig relation. Similarly, the egress design pattern stores the contents of a stock_dataPig relation into the nasdaqDB.store.stock MongoDB document collection.
The following are a few ways specific to MongoLoader implementation in which a Pig relation can be stored with invalid values:
· If the input MongoDB document contains a field that is not mapped in the schema of the constructor, the MongoLoader function will store nulls for that field in a Pig relation.
· If the MongoDB document does not contain a field that is specified in the schema of the constructor, the entire row or tuple of a relation is set to null.
· If there is a type mismatch between MongoDB documents fields and the schema specified, MongoLoader will set the field as a null in a Pig relation.
Additional information
· https://github.com/mongodb/mongo-hadoop/blob/master/pig/README.md
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The HBase ingress and egress pattern
The HBase ingress and egress pattern describes how you can use Pig Latin to ingest the contents of the HBase tables into the Pig relations to further process data and then egress the processed data into HBase.
We will discuss the relevance of HBase to the enterprise and understand the various ways in which the HBase data is stored internally and accessed externally as well as of the use cases where HBase data is used in conjunction with Pig. You will also understand how Pig makes the ingestion and egression of the HBase data a lot easier with the ready-made functions provided.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. The example code snippets enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
HBase is a column-oriented NoSQL database created by taking inspiration from Google's Big Table implementation and is specifically designed to store schema-flexible data and access it in real time. It is linearly scalable for data containing billions of columns and features compression of data and in memory operations for lightning fast access.
The HBase data is internally stored in a custom optimized format called the Indexed Storefiles in the HDFS. HBase uses HDFS to take advantage of its storage and high availability features. As HDFS cannot store data to perform random reads and writes, HBase uses a binary format optimized for random read-write access to overcome the limitation of HDFS. The storage of HBase-indexed store files on HDFS makes it perfectly suitable for MapReduce to work on it without the need to import the data from elsewhere.
Logically, HBase stores data in a nested multidimensional map abstraction that has sorted key value pairs and a time stamp associated with the key value. The time stamp enables the latest version of the data to be stored in a sorted order so that the lookup can be easier. HBase implements the concept of fast and slow changing data to store them accordingly using the versions. The data in the multidimensional nested map is retrieved using a primary key, called a rowkey in HBase, through which all the nested data can be dereferenced.
The multidimensional map has two important nested structures (implemented as a map), called the column family and the columns belonging to the column family. The schema of the column family cannot change over the storage lifetime, whereas the schema of the columns inside a column family can have flexible schema, which may change per row. This data organization is inherently suitable to store unrelated and unstructured data suitable for real-time access (as everything is in a map).
Motivation
The need to ingest HBase tables into Pig facilitates its batch processing using the MapReduce framework to achieve the use case goals. After the HBase data has been processed in the Pig data pipeline, it is sometimes required to store it back into HBase to provide real-time access to queries that run natively on HBase. It is in this context that the ingress and egress patterns of HBase data have a special appeal.
The data in HBase is natively accessed through the HBase Java client API calls to put and get data. This API is good enough for an integration with external applications that need real-time query capability. The API, however, does not have the power to perform batch data processing to create data aggregations and complex pipelines to generate analytical insights. This batch processing capability comes with low-level abstractions such as MapReduce or the high-level flexibility of Pig.
Java MapReduce jobs can be written to access data stored in HBase and process it, but Pig scores heavily for simplicity and terse-optimized code when compared to the Java code that one has to write to access the data in HBase.
Accessing the data stored in HBase with the operators in Pig enables the data to be manipulated in the Pig data pipeline and consumed for transformation using the batch processing. Storing the data into HBase from a Pig relation, enables HBase to provide the application's access to query it in real time.
As the data resides in HDFS in the form of Indexed Storefiles, Pig needs to be told how to serialize and deserialize data to and from the HBase format in a way that Pig can understand and process. Pig needs to understand explicitly how to translate between column families, columns in the HBase abstractions, and Pig's native data types. This pattern explains how to accomplish the tasks of ingesting and egressing data to and from HBase using the HBaseStorage Pig function.
Note
Unlike the MongoDB example, here we read the HBase files that are already stored in HDFS. We do not connect to the HBase servers and read the data from them over the network.
Use cases
The following are the use cases for Pig to ingest and egress data from HBase:
· Use the ingestion design pattern to create a data pipeline to integrate real-time data residing in HBase to perform analytics.
· Use the ingestion design pattern to access data in HBase to perform high-level data aggregates in Pig for consumption in downstream systems. Pig can act as an ETL hub to transform data in HBase to integrate it with other applications' data.
· Use the egress design pattern to store the contents of a flat file existing in HDFS into an HBase table. This pattern is also useful to store the results of a complex data integration or transformation pipeline in HBase for the purpose of real-time querying.
Pattern implementation
The following sections describe the pattern implementation of HBase ingest pattern followed by HBase egress.
The ingress implementation
Data in HBase can be ingested in the following two ways:
· The first option is to export entire tables using MapReduce EXPORT job that reads parallelly to get the contents of the table into a HDFS sequence file. A deserializer can be written in Java or Pig to access the contents of this sequence file for later manipulation. This option is slightly difficult to implement owing to the fact that we have to access the contents of HBase from the backend and then deserialize the files. Moreover, this works on one table at a time and to access multiple tables; the list of tables have to be iterated.
· The second option is to implement the HBase ingest design pattern to use the Pig's built-in load function called HBaseStorage. This is a straightforward option to connect to the HBase table and get the contents of the table directly into a Pig relation. The tasks of deserialization to map the HBase types to Pig types and execution of MapReduce jobs that performs parallel import are taken care of by Pig. HBaseStorage also comes with the additional advantage of loading data into Pig relations, using all the column families or only a subset of columns of the column families. As the columns contain key value types, they can be typecast to the Pig's map type.
The egress implementation
Pig implements the egress design pattern using the HBaseStorage function. This pattern is very similar to the ingest pattern implementation, except for the usage of the STORE clause. The STORE clause conveys to the Pig compiler what data to extract from the Pig relation specified and serializes it into the HBase table in the parameters.
The ingress and egress implementation options are illustrated in the following diagram:
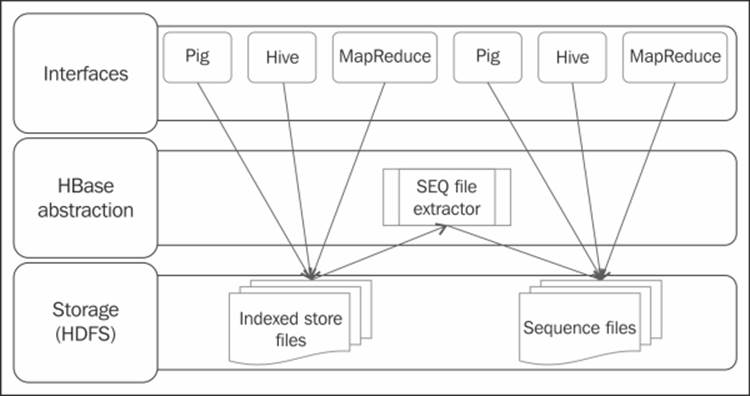
HBase Integration with Pig
Code snippets
The following code example uses a dataset that has sample synthetic retail transactions. It contains attributes such as the transaction date, customer ID, product subclass, product ID, amount, asset, and sales price. This data is already stored in HBase to illustrate this example. The HBase table hbase://retail_transactions is accessed through the Pig Latin's HBaseStorage function.
The ingress code
The following code snippet illustrates the ingestion of the HBase data into a Pig relation:
/*
Load data from HBase table retail_transactions, it contains the column families transaction_details, customer_details and product_details.
The : operator is used to access columns in a column family.
First parameter to HBaseStorage is the list of columns and the second parameter is the list of options
The option -loadkey true specifies the rowkey should be loaded as the first item in the tuple, -limit 500 specifies the number of rows to be read from the HBase table
*/
transactions = LOAD 'hbase://retail_transactions'
USING org.apache.pig.backend.hadoop.hbase.HBaseStorage(
'transaction_details:transaction_date customer_details:customer_id customer_details:age customer_details:residence_area product_details:product_subclass product_details:product_id product_details:amount product_details:asset product_details:sales_price', '-loadKey true -limit 500')
AS (id: bytearray, transaction_date: chararray, customer_id: int, age: chararray, residence_area: chararray, product_subclass: int, product_id: long, amount: int, asset: int, sales_price: int);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the relation transactions on the console
DUMP transactions;
The egress code
The following code illustrates content storage of a Pig relation into HBase table:
/*
Load the transactions dataset using PigStorage into the relation transactions
*/
transactions = LOAD '/user/cloudera/pdp/datasets/hbase/transactions.csv' USING PigStorage( ',' ) AS (
listing_id: chararray,
transaction_date: chararray,
customer_id: int,
age: chararray,
residence_area: chararray,
product_subclass: int,
product_id: long,
amount: int,
asset: int,
sales_price: int);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Use HBaseStorage to store data from the Pig relation transactions into a HBase table hbase://retail_transactions.
The individual contents of transactions are mapped to three column families transaction_details, product_details and customer_details.
*/
STORE transactions INTO 'hbase://retail_transactions' USING org.apache.pig.backend.hadoop.hbase.HBaseStorage('transaction_details:transaction_date customer_details:customer_id customer_details:age customer_details:residence_area product_details:product_subclass product_details:product_id product_details:amount product_details:asset product_details:sales_price');
Results
As a result of applying the HBase data ingestion pattern, the data in the HBase table represented by the column families and the corresponding columns will be loaded in a Pig relation. In this design pattern, the type of result loaded into the Pig relation varies based on the parameters passed. If you specify columns using the column family and a column identifier (CFName:CName), then the resultant type will be a tuple that consists of scalar values. If you specify the columns using a column family name along with a part of the column name followed by an asterisk (CFName:CN*), the resultant column type would be a MAP of the column descriptors as keys.
It is important to note that while retrieving a time series or event-based data stored in HBase, Pig cannot be used to get time stamp information for an HBase value.
As a result of applying the HBase data egress pattern, the data in the pig relation is stored into the HBase table, mapped to the respective column families and the corresponding columns.
Additional information
· http://pig.apache.org/docs/r0.11.1/func.html#HBaseStorage
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The ingress and egress patterns for structured data
The following section takes the example of Hive as one of the sources from where we can ingest structured data and discuss different ways to do that. Hive is selected to illustrate the structured data ingest pattern since it is the most widely used data sink to consume structured data in the enterprise. Also, by understanding this pattern, you can extend it to other structured data.
The Hive ingress and egress patterns
The Hive ingestion pattern describes how you can use Pig Latin to ingest and egress data to and from the Hive tables into the Hadoop File System to further process on your data pipeline.
We will discuss the relevance of Hive to the enterprise and understand the various ways in which the Hive data is stored internally (RCFile, the sequence file, and so on) and accessed externally (HQL and Pig/MapReduce). You will explore the use cases where the Hive data is used in conjunction with Pig. You will also understand how Pig makes the ingestion of the Hive data a lot easier with the ready-made functions provided and then comprehend the role of the Hadoop ecosystem component, HCatalog, to simplify the connection and access the mechanism of Hive tables with Pig.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
Hive makes Hadoop development easy for programmers who are familiar with SQL and have worked on RDBMS. Hive uses HDFS for the physical storage of the data and it gives a table-level abstraction from a logical perspective. Hive implements its own SQL-like dialect, HiveQL, to access data and manipulate it. HiveQL provides operators, such as SELECT, GROUP, and JOIN, that are converted into MapReduce before being executed on the Hadoop cluster.
In the enterprises, Hive has gained widespread acceptance for use cases of data warehouses, BI-analytics, dashboards, and so on. All these use cases have the common thread of data in Hive being already cleansed, properly labeled, type casted, and neatly organized in tables so that any ad-hoc query or report can be generated effortlessly. Contrasting with this situation is the one with Pig, whose use cases have to deal with freshly minted data from varied sources, which is messy and without a name, category, or metadata associated to make sense out of it. Hence, the relevance of Pig in researching the data itself: to create a quick prototype and find sense in the seeming randomness of the schema-less data.
The storage of Hive data in HDFS is done through the serialization of Hive table's content into a physical file that can be stored in the HDFS. In the context of Hive, the HDFS is used to provide the features of high availability, fault tolerance, and the ability to run MapReduce on the Hive-specific files. Currently, Hive supports four different files for storage: plain text file, binary sequence file, ORC file, and the RCFile. Each of these file formats have their own serialization and deserialization functions associated, which converts the table-level abstraction of the data stored in Hive into a file that is stored in the HDFS.
Hive stores the information about what goes into the physical files in an external metadata store implemented on an RDBMS (Derby by default and MySQL by choice). This metadata store contains all the information of tables, schema, types, physical file mapping, and so on. Whenever a user performs a data manipulation operation, this metastore is first queried for the whereabouts of the data and then the actual data is accessed.
Motivation
Hive stores the data in a ready-to-use format for ad-hoc analytics and reporting. The data ingestion pattern is relevant to the Hive data that is ingested and integrated with the newly arrived data in the Pig data pipeline; then the combined data from Hive and Pig is aggregated, summarized, and transformed for further use in advanced analytical models.
The data egress pattern is applicable to the data already existing in a Pig data pipeline and there are ways to store it directly into a Hive table.
The external Hadoop ecosystem components, such as Pig, HBase, or MapReduce, access Hive data by understanding which storage format (text, RCFile, or sequence file) is used to store Hive data in HDFS, along with the metadata information of the tables and schemas from the metastore.
This ingress and egress design patterns describe ways to read and write data to and from Hive using Pig.
Note
Similar to HBase, we load Hive files that are already in HDFS. This is in contrast to MongoDB where we read the data directly from an external source and not from HDFS.
Use cases
The primary use case of the Hive ingest design pattern is to provide Pig access to the data stored in Hive. Pig uses this data for the following reasons:
· To integrate it with other unstructured sources
· To cleanse and transform the combined data
· To aggregate and summarize using a combination of other data sources in the Pig pipeline
The primary use case of the Hive egress design pattern is to provide a mechanism for the transformed data in the Pig pipeline to be stored in the Hive table. You may consider using this design pattern for the following purposes:
· To export data to Hive after integrating it with external data in the Pig data pipeline
· To export cleansed and transformed data to Hive from the Pig data pipeline
· To export aggregates to Hive or to some other downstream systems for the purpose of further processing or analytics
Pattern implementation
The following sections describes the pattern implementation of Hive ingest pattern followed by Hive egress:
The ingress implementation
The following are the two ways to load the Hive data into a Pig Latin relation:
· One way is to explicitly specify the deserializer to retrieve data from Hive. As an illustration, HiveColumnarLoader is a deserializer for Pig and is specific to data loaded or serialized into Hive using the RCFile format. Similarly, we can use Piggybank'sSequenceFileLoader to load data already stored in the SequenceFile format from Hive. Both these examples are closely coupled with the location of the files, the format of the schemas used to store them, if compression is used or not, and so on.
· The second way is to use the HCatalog's capability to accomplish the loading of Hive data into Pig. This process has many advantages compared to the previous point. HCatalog provides an abstract way of looking at the storage of the files. It wraps the metastore and the storage information from the HDFS to provide a uniform perspective of accessing the tables. Using HCatalog, you no longer need to worry about the storage location of the file, the format of the schema, or if the compression is used or not. All you have to specify is the table name to the HCatalog loader and it does the necessary plumbing behind the scenes to diagram out the underlying storage format, location, and schema. The user is now made agnostic of the table's location, partitions, schema, compression type, and storage format. HCatalog simplifies this through a table-level abstraction and does the hard work under the covers.
The egress implementation
The egress design pattern is implemented using the HCatalog capability to store the data from a Pig relation into a Hive table. HCatalog provides an HCatStorer interface, which stores the contents of a Pig relation into a Hive table managed by HCatalog. For more information on why HCatalog interfaces are the best choice to perform load and store operations, please refer to the second point in the previous The ingress implementation section.
The approach followed by these design patterns is illustrated in the following diagram:
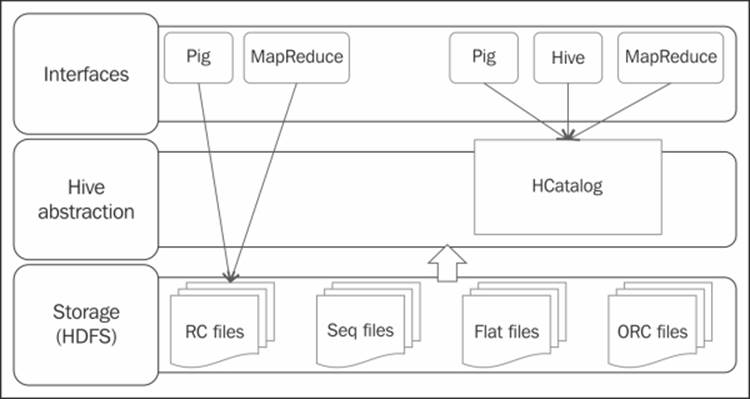
Hive integration with Pig
Code snippets
The following code example uses a sample retail transactions dataset. It contains attributes such as Transaction ID, Date, Customer ID, Amount, Category, Product, City, State, and Spend by. This data is already stored in Hive to illustrate this example. The Hive's native storage RCFile, which has the contents for this table, is used to illustrate direct access; HCatalogLoader is also illustrated in the next example.
The ingress Code
The following code illustrates ingesting data from Hive.
Importing data using RCFile
The following code illustrates the usage of HiveColumnarLoader that loads data from a Hive table stored in a RCFile:
/*
Register the Piggybank jar file to be able to use the UDFs in it
*/
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
-- Register Hive common and exec jars
REGISTER '/usr/lib/hive/lib/hive-common-0.11.0.1.3.0.0-107.jar';
REGISTER '/usr/lib/hive/lib/hive-exec-0.11.0.1.3.0.0-107.jar';
/*
Load retail_transactions_rc RCfile and specify the names of the columns of the table and their types in the constructor of HiveColumnarLoader.
*/
transactions = LOAD '/apps/hive/warehouse/transactions_db.db/retail_transactions_rc' USING org.apache.pig.piggybank.storage.HiveColumnarLoader('transaction_no int,transaction_date string,cust_no int,amount double,category string,product string,city string,state string,spendby string');
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation transactions on the console
*/
DUMP transactions;
Importing data using HCatalog
The following code illustrates the loading of data from Hive using HCatalog:
/*
Specify the table name as the input to the HCatLoader function provided by HCatalog.
This function abstracts the storage location, files type, schema from the user and takes only the table name as input
*/
transactions = LOAD 'transactions_db.retail_transactions' USING org.apache.hcatalog.pig.HCatLoader();
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation transactions on the console
*/
DUMP transactions;
The egress code
The following code illustrates the egression of data to Hive using HCatStorer:
-- Register piggybank and hcatalog-pig-adapter jars
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
REGISTER '/usr/lib/hcatalog/share/hcatalog/hcatalog-pig-adapter.jar';
/*
Load the transactions dataset into the relation transactions
*/
transactions = LOAD '/user/cloudera/pdp/datasets/hive/retail_transactions.csv' USING org.apache.pig.piggybank.storage.CSVLoader() AS (transaction_no:int, transaction_date:chararray, cust_no:int, amount:double, category:chararray, product:chararray, city:chararray, state:chararray, spendby:chararray);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Specify the Hive table name transactions_db.retail_transactions as the input to the HCatStorer function.
The contents of the relation transactions are stored into the Hive table.
*/
STORE transactions INTO 'transactions_db.retail_transactions' using org.apache.hcatalog.pig.HCatStorer();
Results
After applying the ingest design pattern, the data in Hive tables is loaded in a Pig relation and is ready to be further processed. While using HCatLoader, it is important to interpret correctly how the data types of HCatalog are mapped to Pig types. All the primitive types of Pig are mapped to their HCatalog' s corresponding types, except for the bytearray type that is mapped to binary in HCatalog. In the complex data types, the map of HCatalog is mapped to a map in Pig, a list of HCatalog is mapped to a bag in Pig, and struct of HCatalog is mapped to a tuple in Pig.
Applying the egress design pattern, the data in the Pig relation is stored in the Hive tables to report and perform ad-hoc analyses in Hive. All the schema conversion rules mentioned for HCatLoader in the previous paragraph are applicable to HCatStorer too. TheHCatStorer class takes a string parameter that represents the key-value pair of a partitioned table. If you want to store the contents of a Pig relation in a partitioned table, this argument should be mandatorily specified.
Additional information
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/HiveColumnarLoader.html
· https://cwiki.apache.org/confluence/display/Hive/HCatalog+LoadStore
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
The ingress and egress patterns for semi-structured data
This section describes design patterns for semi-structured data such as XML, JSON, and the mainframe data. We have chosen XML and JSON as they are the most popular encoding formats for Internet data exchange. There is a wealth of data locked in documents, journals, and content management systems that could potentially be benefitted through analytics. The choice of the mainframe data for this use case is primarily due to the fact that this is a relatively unexplored territory in many enterprises that could gain eventual popularity as new patterns emerge.
The mainframe ingestion pattern
The mainframe ingestion pattern describes how you can use Pig Latin to ingest the data exported from mainframes into the Hadoop File System to be further processed on your data pipeline.
We will discuss the relevance of processing data stored in the mainframe to the enterprise, and get a deeper understanding of the various ways in which the mainframe stores the data internally and accesses it. We will also discuss the motivation to perform the ingest and the use cases where the mainframe data is used in conjunction with Pig. You will also understand how Pig makes the ingestion of this data a lot more intuitive (using UDFs) than doing it using MapReduce code written in Java.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
Mainframes seem to have a long life ahead, and it is hard to imagine a world without these workhorses crunching those transactions continuously for decades. Such is the stability of these machines that even at extreme throughput of data, they perform faithfully without ever blinking for a second. No wonder these wonders of engineering have been the backbone of businesses ranging from aircrafts and automobiles to financial services and governments by selling, tracking, inserting, and updating every transaction for these entities continuously for years at a stretch.
With the experience of powering the industrial revolution in the 1960s, the mainframes have evolved with time, to become even more powerful and handle the specific high throughput transactional workloads they are designed for. Today, they use custom-built processors and other high-end hardware to implement virtualization, scale vertically, and exhibit transactional integrity, despite extreme throughput. Mainframes can clearly deliver superlative results than any other architecture at extreme throughput combined with unbelievably high-availability levels with reliability and top-notch security baked in.
Motivation
Hadoop is increasingly playing a vital role to offload much of the transactional data from mainframes and perform batch processing on it. This is in tune with improving the transaction throughput and batch processing times for the mainframes, by moving the processing from an expensive and custom-built system to the commodity hardware housing the Hadoop framework. Similarly, when the batch processing capability of a mainframe is not efficiently scalable (within a price point versus performance band), it is advantageous to offload processing to Hadoop, which does it at a better price/performance ratio. This is represented in the following diagram:
Mainframe batch processing and offloading to Hadoop
Use cases
This design pattern can be applied to address the following use cases:
· To migrate data from mainframes to Pig for integration with data from other systems and create advanced analytics
· To offload noncritical batch workloads to Pig and free up the mainframe throughput considerably
· To rewrite COBOL code in Pig to bring in the advantages of reuse, maintainability, simplicity, and compactness
Pattern implementation
By offloading, the relevant processing to Hadoop implies rewriting the code written in COBOL to MapReduce and transferring data from the mainframes.
COBOL is the lingua franca for the mainframes to access databases such as DB2, perform batch processing, and process online transactions. It is not suitable to implement sophisticated algorithms on, which could benefit newer business requirements such as risk modeling, predictive analytics, and so on.
To migrate the COBOL code to MapReduce, we can choose parts of functionalities implemented in the mainframe that are amenable to the constructs of a mapper and reducer. As an illustration, the legacy COBOL code to sort billions of records, merge them with other data sources and group them, and performe complex transformations can be implemented in Pig more efficiently than COBOL. Add to the Pig code the power of a Java UDF, which performs advanced analytics on the data pipeline; this combination could work wonders. Thus, migrating code to Pig Latin to perform specific processing effectively could pay rich dividends.
Migrating the mainframe data has its own set of challenges. Typically, mainframes internally store various types of data in VSAM files, flat files, and a DBMS. For Hadoop to access this data, it has to be converted into a format it can comprehend and then physically transfer it through a file transfer mechanism to the Hadoop cluster. VSAM files can be converted into flat files for Hadoop consumption using specific utilities such as IDCAMS.
Every mainframe DBMS have their specialized utilities that understand the DBMS internal file storage format and convert them to flat files. We may have to deal with the conversion of these flat files from one code page in the mainframes to another in the target machines of the Hadoop cluster. Generally, the flat files exported from the mainframes are in the denormalized CSV format. This is represented in following diagram:
Mainframe data extraction and ingestion into Hadoop
To understand the physical layout and definition of each column in the CSV format, a mainframe-specific copybook is used. In Hadoop, this information provided by the copybook is used as a schema to parse the CSV and decode the meaning of the contents of the CSV file. Thus, the ingestion of the mainframe data requires two inputs: one is the flat file itself and the other is the copybook.
Pig has a built-in loader that can read CSV files, but the parsing has to be done on the CSV in conjunction with the contents of the copybook. Hence, a Java UDF or a custom loader has to be written to accomplish this.
Code snippets
The following code example uses a dataset that has sample vehicle insurance claims data related to vehicle repair charges claims, from a mainframe to a CSV file. The metadata and physical layout of the data elements in the VSAM file is defined in the copybook. The copybook contains fields such as claim, policy, vehicle, customer, and garage details. The Java code snippet in the following section parses the copybook, retrieves the metadata, and uses it to load the data in the CSV file.
The following Pig script uses a custom loader implementation to load data extracted from mainframes into a CSV file. Here, the VSAMLoader uses the copybook file to determine the metadata of the CSV file and loads it:
/*
Register custom UDF vsamloader.jar and cb2java jar which is a dynamic COBOL copybook parser for Java
*/
REGISTER '/home/cloudera/pdp/jars/vsamloader.jar';
REGISTER '/home/cloudera/pdp/jars/cb2java0.3.1.jar';
/*
Load the contents of the automobile insurance claims dataset using custom UDF.
VSAMLoader uses the copybook file to parse the data and returns the schema to be used to load the data
*/
data = LOAD '/user/cloudera/pdp/datasets/vsam/automobile_insurance_claims_vsam.csv' USING com.mycustomloader.vsamloader.VSAMLoader();
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Display the contents of the relation data on the console
DUMP data;
-- Display the schema of the relation data
DESCRIBE data;
The following is a Java code snippet of VSAMLoader, which is a custom loader implementation:
@Override
public ResourceSchema getSchema(String arg0, Job arg1) throws IOException {
.
.
while (it.hasNext()) {
Map.Entry pairs = (Map.Entry) it.next();
//Get the next key/value pairs
String key = (String) pairs.getKey();
String value = (String) pairs.getValue();
/*For Group and Alphanumeric types in copybook, return
pig compliant type chararray*/
if (value.toString()
.equals("class net.sf.cb2java.copybook.Group")
|| value.toString().equals("class net.sf.cb2java.copybook.AlphaNumeric")){
fieldSchemaList.add(new FieldSchema(key,
org.apache.pig.data.DataType.CHARARRAY));
}
/*For Decimal type in copybook, return
pig compliant type integer*/
else if (value.toString()
.equals("class net.sf.cb2java.copybook.Decimal")){
fieldSchemaList.add(new FieldSchema(key,
org.apache.pig.data.DataType.INTEGER));
}
// Else return default bytearray
else
{
fieldSchemaList.add(new FieldSchema(key,
org.apache.pig.data.DataType.BYTEARRAY));
}
}
return new ResourceSchema(new Schema(fieldSchemaList));
}
In the custom loader code of the vsamloader jar implementation, we use an external API to parse the copybook file and get all the values. We then implement an interface called LoadMetaData from Pig API and its getSchema() method, which will return the schema that we obtained by parsing the copybook. An ArrayList class of type FieldSchema is used, which will eventually be populated with the column names and their data types in the copybook file. This ArrayList is returned as the new schema, which will be used by Pig while it is loading the VSAM file.
Results
The result of applying the pattern on the data extract of the mainframe is the loading of the data in the flat file into the Pig Latin relation, ready to be further processed. As there are no ready-made functionalities available in Pig to understand the copybook format, we have extended Pig through a custom loader. Care has to be taken to properly map the schema in the custom loader as not all data types of COBOL can be readily mapped to the Java counterparts. For example, COBOL has limited support for Boolean and datetype and we have to implement specialized conversion to process it in Java to get accurate results. Please see the links in the next section for more information.
Additional information
· http://pig.apache.org/docs/r0.11.1/udf.html#load-store-functions
· http://pic.dhe.ibm.com/infocenter/dmanager/v7r5/index.jsp?topic=%2Fcom.ibm.dserver.rulestudio%2FContent%2FBusiness_Rules%2F_pubskel%2FInfocenter_Primary%2Fps_DS_Rule_Designer772.html
· http://www.3480-3590-data-conversion.com/article-reading-cobol-layouts-1.html
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
XML ingest and egress patterns
This section describes how you can use Pig Latin to ingest and egress the contents of documents or logs encoded with XML to and from the Hadoop File System to be further processed on your data pipeline.
We will discuss the relevance of processing the data stored in XML to the enterprise and understand the various ways in which Pig can be used to access XML data (raw XML and binary). You will understand the pros and cons of using raw and binary XML parsing and then comprehend the motivation and the use cases where the XML data is used in conjunction with Pig. You will also understand how Pig makes the ingestion of this data a lot more intuitive and efficient (by using Avro) than doing it using the MapReduce code written in Java.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives as applicable. An example code snippet is used to enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
XML is one of the most widely used protocol for storage and transfer of data in an intuitive way, that makes comprehending the meaning of data relatively easy for humans and machines alike. XML, being a textual format rather than a binary format, has the special ability to encode data with its relevant metadata to clarify the meaning on its own. Owing to this feature, XML has become the defacto standard of data transmission for most Internet applications. The versatility of XML is evidenced in the fact that it can represent not only documents but haphazard data structures in web services. Today, we see that there are thousands of XML-based taxonomies, information exchange formats, and document formats —such as MS Office, SOAP, RSS, XHTML, and ATOM—that are being widely used. All these XML-based data storage and transmission formats contain a wealth of information from an analytics perspective.
Motivation
Using Hadoop for the ingestion and egress of XML is an inherently complex job and has some tradeoffs with flexibility. The complexity arises from the arbitrary nesting, and the space required for the metadata itself could be phenomenal. While XML gives you the flexibility to mimic the real world by encoding data with lots of metadata information by the inclusion of tags and other optional fields in the XML, this evidently results in the deep nesting of the attributes, and makes the computation even more complex and time-consuming over vast amounts of data. This implies that loading an XML document into the memory of a computer is a nontrivial, complex CPU-intensive job.
Owing to the abovementioned complexities, Hadoop offers multiple benefits to process large and complex XML data faster, using less costly operations by ingesting, transforming, and egressing XML for further consumption by downstream systems. To handle XML in Hadoop, you may have to consider the nature of processing the XML data and its context.
Motivation for ingesting raw XML
One reason to ingest and process XML in Hadoop is when you do not know the schema of the XML ahead of time and want to understand the schema as you read the files. The highlights of this approach are given as follows:
· The XML data is loaded in its raw format, its schema is discovered at the time of querying, and its transformation is performed after the discovery
· This approach is more exploratory in nature; it offers fast initial loads since the data is not cleaned up or stored in the binary format using serialization
· It supports greater flexibility so that more than one schema can be used to parse the XML for different types of analytic queries
· It is suitable for well-defined formats that could result in the XML data being parsed for every query with a slight hit on the query's performance.
Motivation for ingesting binary XML
The other reason to ingest and process XML in Hadoop is when you already know the schema of the XML and you want to perform high-performance queries on the XML. The highlights of this approach are as follows:
· The XML has to be parsed initially, serialized to disc in the binary format, split across nodes, compressed, and optimized for querying
· This approach works if there is a huge amount of cleansing and reformatting required at the load time
· It is suitable if there is a need to perform repetitive queries on the production workloads
· This approach is not very suitable if the schema is not known at the time of the load as it takes a long time to load, preprocess, and store the XML in a format that can be queried.
Motivation for egression of XML
Hadoop can be used to create and output XML files from structured data such as CSV, Hive tables, and so on, residing in HDFS. The XML files can be also be ingested directly into Hadoop so that they can be validated or transformed using Pig and written back as XML to conform to the exchange format of the downstream systems.
Use cases
The XML ingestion pattern can be used in the following use cases to address the following:
· It can be used for the ingestion of XML-based document data from content management systems such as technical documents, reference manuals, and journals. The ingestion is done prior to creating search indexes using Lucene and performing analytics on it.
· It can be adopted for the ingestion of XML logs that contain SOAP and EDXL-CAP kind of messaging texts for the request and response analysis between systems. As an example, XML-encoded messages can be picked up from the network fault management systems and analytics performed to understand or predict future failure of subsystems.
The XML egress pattern can be used in cases where it is needed to convert the structured data in HDFS (delimited flat files or hive tables) to be processed and serialized into XML, so that the upstream systems can use the XML to further process the data.
Pattern implementation
Pig provides constructs to directly load raw XML files, and supports the loading of the preprocessed XML files.
The implementation of the XML raw ingestion
The Piggybank library provides the XMLLoader function to access the contents of the XML file. The parameter of the XMLLoader function is an XML tag name that is converted internally into a single record tuple. This record contains the text enclosed within the start XML tag and the end XML tag. Using the returned tuple from the XML file, you may have to perform further parsing to decompose the record-level XML value to its constituent values; typically, a regex function, REGEX_EXTRACT, is used on a flattened projection.
The implementation of the XML binary ingestion
Converting XML into a binary format amenable for the purpose of splitting, is a two-step process.
· In the first step, in order to parse the XML document, the file can be completely read into a memory-based data structure, and a parser such as DOM can be used to randomly access all elements of the data. Alternatively, you can access the contents of the file in a serial fashion and control the parsing one step at a time. This can be done with the XML SAX parser and it is slightly slower to perform. The DOM parsing has the advantage of chaining multiple processors, but it is difficult to program, while the SAX parsing has the advantage of easy programmability and the ease of splitting. However, on the flipside, SAX is slow to perform as it is a serial access mechanism to parse the XML document.
· In the second step, to convert the parsed XML into a splittable binary format that Hadoop can process, Avro is the best choice to perform serialization that meets these criteria, and it helps to convert the XML document to a byte stream for storage in the on-disk format. Avro is specifically designed for Hadoop, making it a highly compressible and splittable binary format, which is very similar to the sequence files. Unlike the sequence files, which are accessible only through Java API, Avro files can be accessed from other languages such as C, C++, C#, Ruby, and Python. Using its unique format for interoperability, the Avro files can be transferred from being code written in one language to a different code written in another language, even from a complied language such as C to a scripting one such as Pig.
· Each Avro file wraps the underlying contents of the XML file with metadata that contains information needed to deserialize or read the contents. Avro stores both the metadata and the actual contents of the file together in a single file, making it simpler for other programs to understand the metadata first and then process the embedded data. Typically, the metadata is stored in the JSON format and the data is stored in the binary format.
· The Avro file also includes a marker that is used to split the data on the multiple nodes of the cluster. Before accessing the serialized Avro file, the XML file has to be preparsed into the Avro format, which is read into Pig Latin's relations by the usage of piggybank's AvroStorage.
The above implementation aspects are depicted in the following diagram:
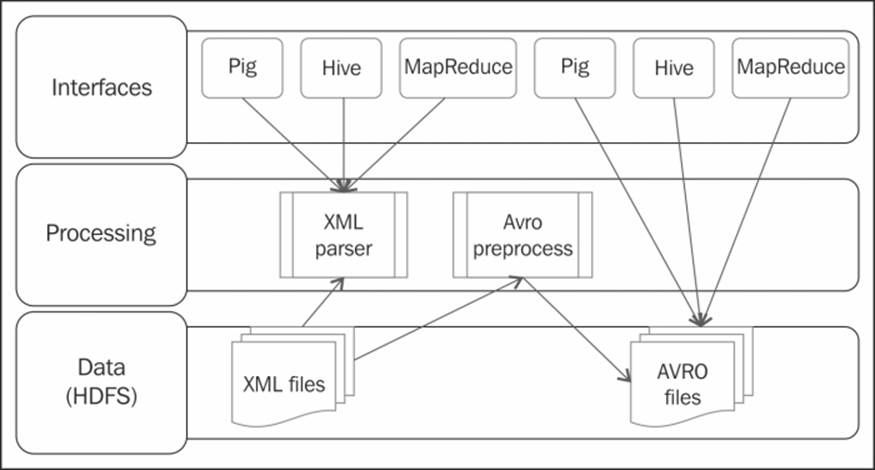
XML data ingress and egress
Code snippets
The following code example uses an XML dataset that has MedlinePlus health discussions.
The XML raw ingestion code
The XML data consists of tags for data elements such as topic title, the relevant URL, primary language, date, vocabulary, summary, membership, and other related health topics and content in other languages. The following code snippet parses the XML tags and loads the contents as a relation into the Pig Latin script:
-- Register piggybank jar
REGISTER '/home/cloudera/pig-0.11.0/contrib/piggybank/java/piggybank.jar';
/*
XMLLoader accesses the specified XML file and retrieves the record level value to be stored in the tuple data specified by the parameter to the XMLLoader.
*/
data = LOAD '/user/cloudera/pdp/datasets/xml/mplus_topics_2013-09-26.xml' USING org.apache.pig.piggybank.storage.XMLLoader('article');
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Print the contents of the relation data to the console
*/
DUMP data;
The XML binary ingestion code
The following code performs the binary ingestion of XML:
-- Register piggybank jar
REGISTER '/usr/share/pig/contrib/piggybank/java/piggybank.jar';
-- Register Avro and JSON jar files
REGISTER '/home/cloudera/pdp/jars/avro-1.7.4.jar';
REGISTER '/home/cloudera/pdp/jars/json-simple-1.1.1.jar';
/*
Assign the alias AvroStorage to piggybank's AvroStorage UDF
*/
DEFINE AvroStorage org.apache.pig.piggybank.storage.avro.AvroStorage();
/*
Load the dataset using the alias AvroStorage into the relation health_topics
*/
health_topics = LOAD '/user/cloudera/pdp/datasets/xml/mplus-topics_2013-09-26.avro' USING AvroStorage;
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
-- Print the contents of the relation health_topics to the console
DUMP health_topics;
The flow of steps involved in the conversion of the XML file to AVRO is depicted in following diagram:
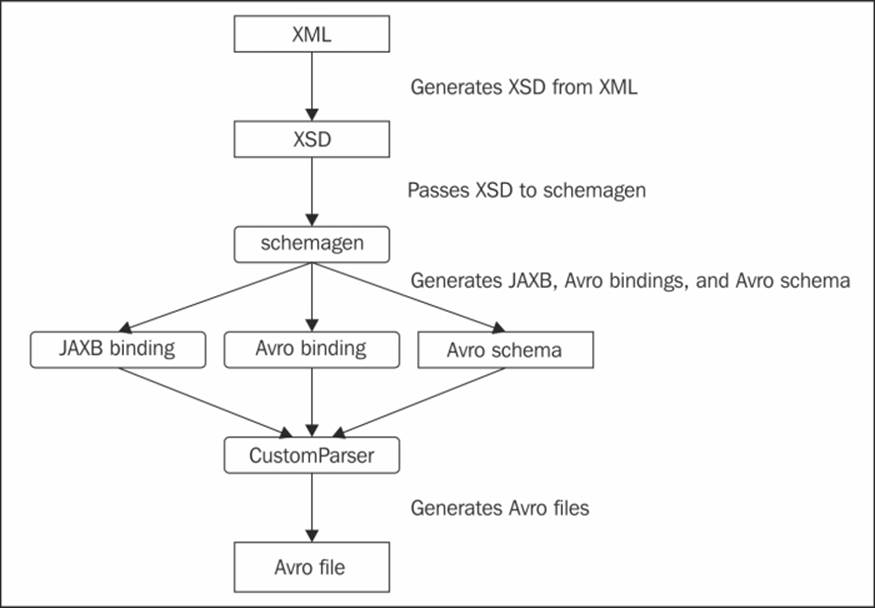
XML to Avro pre-processing
We have used a third-party tool to generate the XSD from the given XML file and schemagen to generate JAXB, Avro bindings, and Avro schema. Internally, schemagen uses the JAXB binding compiler XJC; then it generates a code model from the XSD schema file. The XJC plugin is then executed, which creates the JSON-formatted Avro schemas. The XJC plugin invokes Avro's Java schema compiler to generate new Java classes for serialization to and from Avro.
The XML egress code
The following is the Pig script to convert the contents of the CSV file into an XML format.
Pig script
A custom storage function XMLStorage is used to accomplish the conversion of the CSV file's contents into an XML format:
/*
Register custom UDF jar that has a custom storage function XMLStorage to store the data into XML file.
*/
REGISTER '/home/cloudera/pdp/jars/xmlgenerator.jar';
/*
Load the transactions dataset using PigStorage into the relation transactions
*/
transactions = LOAD '/user/cloudera/pdp/datasets/hbase/transactions.csv' USING PigStorage( ',' ) AS (
listing_id: chararray,
transaction_date: chararray,
customer_id: int,
age: chararray,
residence_area: chararray,
product_subclass: int,
product_id: long,
amount: int,
asset: int,
sales_price: int);
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Custom UDF XMLStorage generates the XML file and stores it in the xml folder
*/
STORE transactions INTO '/user/cloudera/pdp/output/xml' USING com.xmlgenerator.XMLStorage();
The XML storage
The following is the code for the XML storage:
protected void write(Tuple tuple)
{
// Retrieving all fieds from the schema
ResourceFieldSchema[] fields = schema.getFields();
//Retrieve values from tuple
List<Object> values = tuple.getAll();
/*creating xml element by using fields as element tag
and tuple value as element value*/
Element transactionElement =
xmlDoc.createElement(XMLStorage.elementName);
for(int counter=0;counter<fields.length;counter++)
{
//Retrieving element value from value
String columnValue =
String.valueOf(values.get(counter));
//Creating element tag from fields
Element columnName =
xmlDoc.createElement(fields[counter].getName().toString().trim());
//Appending value to element tag
columnName.appendChild
(xmlDoc.createTextNode(columnValue));
//Appending element to transaction element
transactionElement.appendChild(columnName);
}
//Appending transaction element to root element
rootElement.appendChild(transactionElement);
}
The write method takes a tuple, which represents a row in the CSV file, as an input. This method creates an XML element for each field in the tuple. The process is repeated for all the rows in the CSV and consequently, an XML file is generated.
Results
The result of applying the pattern on the medline XML files is the loading of the data into the Pig Latin relation, which is ready to be further processed. Make sure that the XML file is formatted properly and all the elements have start and end tags, else XMLLoadercould return an invalid value.
Applying the egress design pattern, the data in the relation transactions is written as an XML file in the specified path.
Additional information
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/XMLLoader.html
· http://pig.apache.org/docs/r0.11.0/api/org/apache/pig/piggybank/storage/avro/AvroStorage.html
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
JSON ingress and egress patterns
The JSON ingestion pattern describes how you can use Pig Latin to ingest and egress data represented as JSON to and from the Hadoop File System to further process it in the data pipeline.
We will discuss the relevance of processing the data stored in JSON to the enterprise and understand the various ways in which Pig can be used to access and store the JSON data (simple JSON and nested JSON). You will understand the pros and cons of using simple JSON and nested JSON parsing, comprehend the motivation, and the use cases where JSON data is used in conjunction with Pig. You will also understand how Pig makes the ingestion of this data a lot more intuitively (by using external libraries such as elephant-bird) than doing it using the MapReduce code written in Java.
The subsequent discussion of the implementation-level detail of this pattern is meant to familiarize you with the important concepts and alternatives, as applicable. An example code snippet is used to enable the better understanding of the pattern from the Pig language perspective, followed by the results of using the pattern.
Background
JSON is one more way of structuring text. JSON is a data interchange format that describes the data in a hierarchical way, so that machines and humans alike can read and perform operations on it.
JSON represents data in a much simpler way, more like the key-value pairs where the values can be very primitive, such as integers, strings, and arrays. JSON is not designed to support extremely complex and nested data types like XML does. It is less verbose and requires just a look-up function to retrieve the values, since the data is stored in key-value pairs. This makes JSON very compact and suitable to represent data more efficiently, unlike XML. In XML, data is represented in a complex nested way with rich data types, making parsing XML trees very intricate. In the real world, JSON is used to store simple data types and XML is used to model the complexity of data types, which offers features that let you be more expressive about the structure of the data.
Motivation
The rise of JSON as one of the most popular standard for data representation is largely due to the strong rise of social web companies, such as LinkedIn, Twitter, and Facebook. These enterprises along with many other firms, which have the need to exchange their internal business data (such as social conversations or any data with a smaller footprint) with the external world, are predominantly moving toward using APIs that can carry simple and efficient payload without the complexities of XML. JSON is the preferred format for these APIs owing to its simplicity and implementation as a key-value data source, enabling the ease of parsing.
Along with the rise of social media, we can see the advent of NoSQL databases that have made JSON their mainstay. Many of these databases, such as MongoDB, CouchDB, and Riak, have JSON as their primary storage format. Owing to the usage of JSON, these databases exhibit extremely high-performance characteristics along with the ability to scale horizontally. These databases are designed specifically for the needs of Internet-scale applications where the need for real-time response is paramount.
There is also an accelerated proliferation of non-social media-centric enterprises, where JSON is used currently to storelog files that have multiple headers and other key-value pairs. The log data in the JSON format represents user sessions and user activities especially well, with information on each user activity nested under the session's information. This data nesting in the JSON format provides natural advantages while performing advanced analytics. JSON is also a good choice for enterprises dealing with the sensor data, containing varied attributes collected for different measurements.
While JSON excels as a storage format of choice to perform quick retrieval and carry Internet payloads more efficiently, there are many use cases (such as log processing and sensor analysis) where data represented in JSON is not only used for lookups, but also extensively integrated with other enterprise data assets to perform analytics. This integration implies the performing of batch processing on a combination of JSON and other structured data. The ingest design patterns discussed in the following sections describe ways to accomplish the JSON ingestion into the data pipeline.
The output of a batch processing data pipeline can sometimes be summarized into ready-to-use data represented in JSON. This is applicable in use cases where the batch-processed JSON output is fed into the NoSQL databases consuming JSON, and in cases where JSON can be used as a payload for web services. The egress design pattern shows how we can use Pig to perform the conversion of data stored in the data pipeline into the JSON format.
Use cases
The following are the use cases for Pig to ingest and egress JSON data:
· Use the ingestion design pattern to integrate JSON data into Pig relation so that the combined data in the data pipeline is used for analytics.
· Use the ingestion design pattern to consume JSON APIs from Twitter and other social media sources, to perform advanced analytics such as sentiment mining.
· Use the ingestion design pattern to ingest sensor data stored in JSON for machine failure analytics.
· Use the egress design pattern to store the contents of a flat file existing in HDFS into the JSON format. This pattern is also useful to store the results of complex data integration or transformation pipeline in JSON format for downstream system access.
Pattern implementation
The following sections show the ingress and egress implementations.
The ingress implementation
JSON can be loaded into a Pig relation using the JSONLoader function, which loads the contents of the JSON file into a map. The JSONLoader function can work with or without schema information.
· In case the schema information is provided in JSONLoader, the mapping between the Pig and JSON data types is straightforward and follows the schema specified.
· In case the schema information is not provided in JSONLoader, the Pig relation's data type is set to the default bytearray, and the actual schema is inferred later in the execution cycle. To process a large JSON file and perform parallel processing on it, you may have to format the JSON file with one JSON-object format per line. This prerequisite is applicable when you need to parse a very large JSON file that exceeds the size of the HDFS-storage block, and when you have control over the format of JSON to include one JSON object per line.
· In cases where JSON files cannot be formatted to include one JSON object per line, it is not possible for MapReduce to perform a split on the JSON file, since JSON is nested and the same element is used at various levels. The JSON format is in contrast with XML, which has a start and end tag to denote the boundaries of the nested data structure. The solution for this problem is addressed in the elephant-bird library's implementation of LZOJSONLoader, that allows the determining of the split boundaries of the nested JSON files. The elephant-bird library is an open source library of utilities for working with JSON and other formats, courtesy of Twitter. It is available at https://github.com/kevinweil/elephant-bird.
The egress implementation
Use the JsonStorage function to store the contents of a Pig relation in the JSON format. The content of the Pig relation is stored as a single JSON line in the output. While performing schema mapping, the JsonStorage function maps the Pig tuples to JSON objects. Similarly, it maps the Pig map to a JSON object, while the Pig bag corresponds to the JSON array.
The general idea of how JSON is ingested and egressed using Pig is depicted in the following diagram:
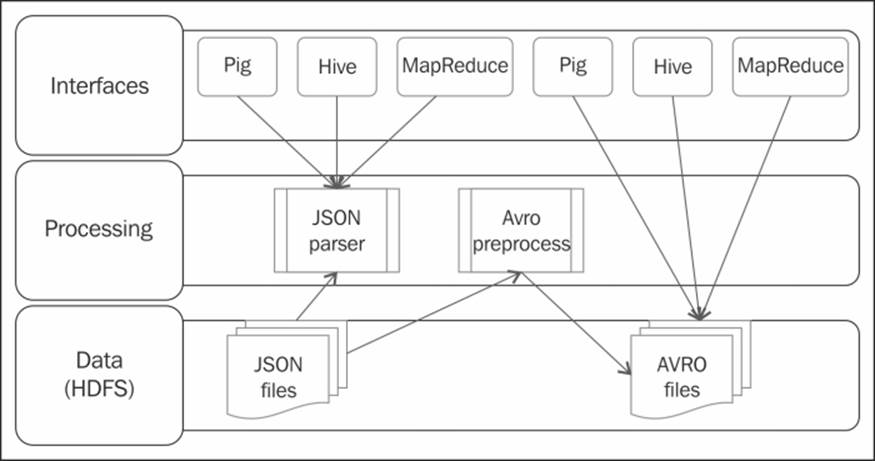
JSON Hadoop Integration
Code snippets
The following code example uses a sample dataset from the enron corpus, which has emails from 150 users with an average of 757 messages per user. The fields in the dataset are Message ID, Date, From address, Subject of the email, Body of the email, To addresses,Addresses marked in cc, and Addresses marked in bcc.
The ingress code
The following section shows the code and its explanation to ingest the data stored in the JSON format into a Pig relation.
The code for simple JSON
The code to load JSON files using JsonLoader is shown as follows:
/*
Use JSONLoader UDF, it takes in the parameter of the JSON schema and loads the contents of the JSON file emails.json into a map enron_emails
*/
enron_emails = LOAD '/user/cloudera/pdp/datasets/json/emails.json' USING JsonLoader('body:chararray, from:chararray, tos:chararray, ccs:chararray, bccs:chararray, date:chararray, message_id:chararray, subject:chararray');
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation enron_emails on the console
*/
DUMP enron_emails;
It is important to note that the JsonLoader does not use the AS clause to supply the schema.
The code for nested JSON
The Pig script to load nested JSON is shown as follows, and we use the elephant-bird libraries to accomplish this:
/*
Register elephant-bird and JSON jar files
*/
REGISTER '/home/cloudera/pdp/jars/elephant-bird-core-3.0.5.jar';
REGISTER '/home/cloudera/pdp/jars/elephant-bird-pig-3.0.5.jar';
REGISTER '/home/cloudera/pdp/jars/json-simple-1.1.1.jar';
/*
Use ElephantBird's JsonLoader for loading a nested JSON file
The parameter –nestedload denotes nested loading operation
*/
emails = LOAD '/user/cloudera/pdp/datasets/json/emails.json' USING com.twitter.elephantbird.pig.load.JsonLoader('-nestedLoad');
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Display the contents of the relation emails on the console
*/
DUMP emails;
The egress code
The following section shows the code and its explanation to egress data stored in a Pig relation to JSON format:
/*
Load the JSON file using JsonLoader to the relation enron_emails
*/
enron_emails = LOAD '/user/cloudera/pdp/datasets/json/emails.json' USING JsonLoader('body:chararray, from:chararray, tos:chararray, ccs:chararray, bccs:chararray, date:chararray, message_id:chararray, subject:chararray');
/*
* Some processing logic goes here which is deliberately left out to improve readability
*/
/*
Use JsonStorage to store the contents of the relation to a json file
*/
STORE enron_emails into '/user/cloudera/pdp/output/json/output.json' USING JsonStorage();
Results
Applying the ingest design pattern will result in the JSON data getting stored in a Pig relation. The JsonLoader stores a null in a Pig relation if the fields do not parse correctly, or if the they cannot be found. JsonLoader does not care about the order of the fields in the constructor; you can specify them in any order. JsonLoader parses them correctly as long as the field name matches. If there is a type mismatch, JsonLoader performs automatic typecasting based on the feasibility. It can cast an int to a string, but will not cast a stringto an int. As best practice, you may consider using the JsonLoader function without the schema definition to understand the top-level view of all the keys in the JSON object and get a better overview of the data.
Applying the egress design pattern will result in data from a Pig relation stored in the JSON format. The JsonStorage function uses a buffering technique for storage in the JSON format. This buffering capability is used in the bulk loading of data and increases the performance of the storage. A fixed-size buffer in kilobytes can be specified in the JsonStorage constructor.
Additional information
· http://pig.apache.org/docs/r0.11.1/func.html#jsonloadstore
· https://github.com/kevinweil/elephant-bird
· http://pig.apache.org/docs/r0.11.1/func.html#jsonloadstor
The complete code and datasets for this section is in the following GitHub directories:
· chapter2/code/
· chapter2/datasets/
Summary
In this chapter, we started by understanding the types of data in the enterprise setting and explored the relevance of each of these data types, how they are used once they were inside the enterprise, and how Hadoop comes into the picture to process it.
In the subsequent sections, we began by looking at specific types of data more closely and applied the ingress and egress design patterns on it. We covered the most relevant data types from unstructured, structured, and semi-structured categories. We have also attempted to highlight design patterns for advanced data types such as images and mainframes to deliberate on the power of the Pig's adaptability and extensibility. In each of the design pattern showcased in this book, we began to understand the contextual relevance of the pattern from the background details, followed by the motivation and applicability of the pattern to a particular data type. The code and pattern implementation is discussed threadbare to ease the implementation aspects of the design pattern. We discussed why choosing Pig is better and talked about various options available to address specific cases within a design pattern.
In the next chapter, we will understand in greater detail the data profiling patterns that can be applied to various data formats. The goal of the next chapter is to make you adept in using Pig to understand the content, context, structure, and condition of data by profiling it. Pig provides a rich set of primitives to profile data and you will learn the appropriate design patterns to use in profiling enterprise-grade data. You will also learn to extend Pig's capability to cater to more advanced usages of data profiling.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.