Pig Design Patterns (2014)
Chapter 4. Data Validation and Cleansing Patterns
In the previous chapter, you have studied the various patterns related to data profiling, through which you understood the different ways to get vital information about the attributes, content, context, structure, and condition of data residing in the Hadoop cluster. These data profiling patterns are applied in the data lifecycle before initiating the process of cleaning the data into a more useful form.
The following are the design patterns covered in this chapter:
· Constraint validation and cleansing pattern: This explains the validation of the data against a set of constraints to check if there are any missing values, if the values are within a range specified by a business rule or if the values conform to referential integrity and unique constraints. Depending on the business rule, either the invalid records are removed or appropriate cleansing steps are applied to the invalid data.
· Regex validation and cleansing pattern: This demonstrates validation of data by matching it with a specific pattern or length using regular expressions and pattern-based filtering of records to cleanse invalid data.
· Corrupt data validation and cleansing pattern: This sets the context to understand corruption of data ingested from various sources. This pattern details the impact of noise and outliers on data and the methods to detect and cleanse them.
· Unstructured text data validation and cleansing pattern: This demonstrates ways to validate and cleanse an unstructured data corpus by performing pre-processing steps, such as lowercase conversion, stopword removal, stemming, punctuation removal, extra spaces removal, identifying numbers, and identifying misspellings.
Data validation and cleansing for Big Data
Data validation and cleansing deal with the detection and removal of incorrect records from the data. The process of data validation and cleansing ensures that the inconsistencies in the data are identified well before the data is used in the analytics process. The inconsistent data is then replaced, modified, or deleted to make it more consistent.
Most of the data validation and cleansing is performed by analyzing the static constraints based on the schema. Examining the schema in conjunction with the constraints tells us about the existence of missing values, null values, ambiguity in representation, foreign key constraints, and so on.
Data validation and cleansing assume an increasingly important role in deriving value from the perspective of Big Data. While cleaning Big Data, one of the biggest trade-offs to be considered is the time-quality trade-off. Given that there is unlimited time, we can improve the quality of the bad data, but the challenge in devising a good data cleansing script is to cover as much data as possible within the time constraints and perform the cleansing successfully.
In a typical Big Data use case, the different types of data that are integrated can add to the complexity of the cleansing process. High-dimensional data from federated systems have their own cleansing approaches, whereas the huge volumes of longitudinal data differ in their cleansing approach. Streaming data could be time-series data that can be efficiently handled using a real-time cleansing approach rather than a batch-cleansing mechanism. Unstructured data, descriptive data, and web data have to be handled using a text pre-processing cleansing approach.
Bad data can result from various touch points in the Hadoop environment, and the following points outline the common cleansing issues mapped to these touch points:
· Cleansing issues in Big Data arising from data gathering: Inconsistency in data can arise due to errors in the methods of data gathering. These methods can range from manual entry to social media data (where nonstandard words are used), entering duplicate data, and measurement errors.
· Cleansing issues in Big Data arising from improper data delivery: This could be due to improper conversion of data after it has entered into an upstream system integrated with Hadoop. The reasons for bad data arising out of improper data delivery include inappropriate aggregation, nulls converted to default values, buffer overflows, and transmission problems.
· Cleansing issues in Big Data arising from problems in data storage: Inconsistent data could be the result of problems in physical and logical storage of data. Data inconsistency as a result of physical storage is a rare cause; it happens when data is stored for an extended period of time and tends to get corrupted, which is known as bit rot. The following issues result from storing data in logical storage structures: inadequate metadata, missing links in entity relationships, missing timestamps, and so on.
· Cleansing issues in Big Data arising from data integration: Integrating data from heterogeneous systems has a significant contribution to bad data, typically resulting in issues related to inconsistent fields. Varying definitions, differing field formats, incorrect time synchronization and the idiosyncrasies of legacy data, and wrong processing algorithms contribute to this.
Generally, the first step in Big Data validation and cleansing is to explore the data using various mathematical techniques to detect the existence of any inaccuracies in the data. This initial exploration is done by understanding the data type and domain of each attribute, its context, the acceptable values, and so on; after this, the actual data is validated to verify conformance to the acceptable limits. This gives an initial estimate on the characteristics of the inaccuracies and its whereabouts. In the validation phase, we can conduct this exploration activity by specifying the expected constraints to find and filter data not meeting the expected constraints, and then take required action on the data, in the cleansing step.
A sequence of data cleansing routines is run iteratively after we have explored the data and located the anomalies in it. These data cleansing routines refer to the master data and relevant business rules to perform cleansing and achieve the end result of a higher quality data. Data cleansing routines work to clean the data by filling in missing values, smoothing noisy data, identifying or removing outliers, and resolving inconsistencies. After the cleansing is performed, an optional control step is performed where the results are evaluated and exceptions are handled for the tuples not corrected within the cleansing process.
Choosing Pig for validation and cleansing
Implementing the validation and cleansing code in Pig within the Hadoop environment, reduces the time-quality trade-off and the requirement to move data to external systems to perform cleansing. The high-level overview of implementation is depicted in the following diagram:
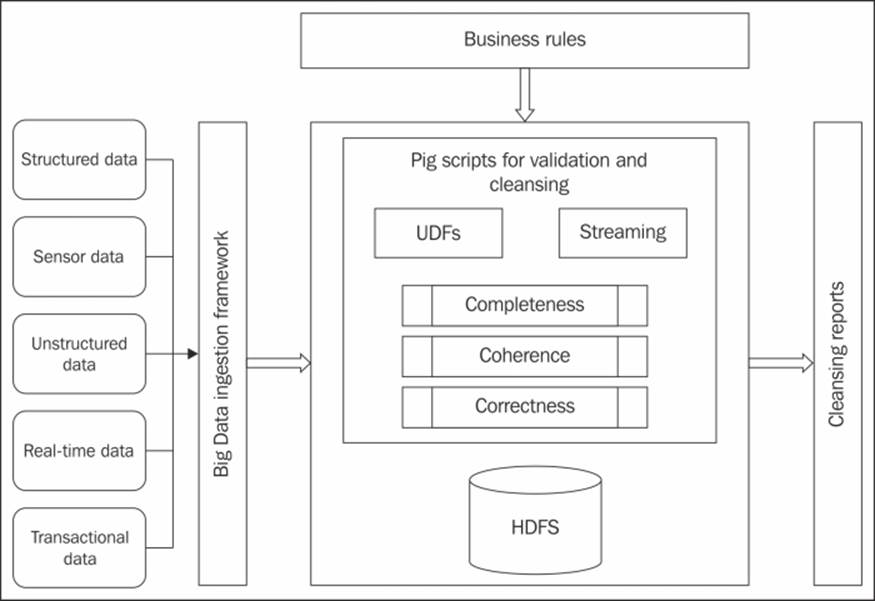
Implementing validation and cleansing in Pig
The following are the advantages of performing data cleansing within the Hadoop environment using Pig:
· Improved overall performance since validation and cleansing are done in the same environment. There is no need to transfer data to external systems for cleansing.
· Pig is highly suitable to write code for validating and cleansing scripts since the built-in functions are geared towards processing messy data and for exploratory analysis.
· Pig enables automating of the cleansing process by chaining complex workflows, which is very handy for datasets that are periodically updated.
The constraint validation and cleansing design pattern
The constraint validation and cleansing pattern deals with validating the data against a set of rules and techniques and then cleansing the invalid data.
Background
Constraints tell us about the properties that the data should comply with. They can be applied to the entire database, a table, a column, or an entire schema. These constraints are rules created at design time to prevent the data from getting corrupt and reduce the overhead of processing wrong data; they dictate what values are valid for a data.
Constraints, such as null checks and range checks, can be used to know if the data ingested in Hadoop is valid or not. Often, constraint validation and cleansing on the data in Hadoop can be performed based on the business rules that actually determine the type of constraint that has to be applied on a particular subset of data.
In cases where a given column has to belong to a particular type, a data type constraint is applied. When we want to enforce a constraint, such as numbers or dates should fall within a specified range, a range constraint is applied. These range constraints typically specify a minimum and maximum value for comparison. Mandatory constraint enforces a hard validation rule to ensure that certain important fields do not remain empty, which in essence checks for null or missing values and eliminates them using a range of methods. Set membership constraint enforces the rule that the data values should always be from a pre-determined set of values.
Invalid data could be a result of ingesting data into Hadoop from legacy systems where there are no constraints implemented in the software and ingesting data from sources such as spreadsheets where it is relatively difficult to set a constraint on what a user chooses to enter in a cell.
Motivation
The constraint validation and cleansing design pattern implements a Pig script to validate the data by examining if it is within certain, specified, and mandatory range constraints and then cleans it.
There are many ways to check if the data residing in Hadoop abides by the mandatory constraints, and one of the most useful ways is to check for null or missing values. If there are missing values in a given set of data, it is important to understand if these missingvalues account for the lack of data quality, since in many situations it is okay to have missing values in the data.
Finding null or missing values is relatively simple, but cleansing them by filling the missing values with the appropriate values is a complex task and typically depends on the business case.
Based on the business case, the null values can be ignored or they can be manually entered as a part of the cleansing process, but this method is the least recommended. For categorical variables, a constant global label such as "XXXXX" can be used to depict missing values, in cases where this label cannot clash with other existing values of the table or the missing values can be replaced by the most frequently occurring value (mode). Depending on the data distribution, it is recommended to use the mean value for data that is in normal distribution and the median value for data that is in skewed distribution. The usage of mean and median is applicable only to numerical data types. Using a probabilistic measure, such as Bayesian inference or a decision tree, the missing values can be calculated in a more precise manner than the other cases, but this is a time consuming method.
The range constraints limit the values that can be used in the data by specifying the upper and lower limits of valid values. The design pattern first performs the validity check of the data and finds out if the data is not within the range specified. This invalid data is cleansed as per the business rules by filtering the invalid data, or by replacing the invalid values with the maximum range value if the invalid data is higher than the range; conversely, the invalid value is replaced with the minimum range value if the invalid data is lower than the range.
Unique constraints limit the existence of a value to be unique across a table. This is applicable to primary keys where the existence of duplicate values amounts to invalid data. A table can have any number of unique constraints with the primary key defined as one of them. After the data is ingested by Hadoop, we can use this design pattern to perform validation to find if the data adheres to the unique constraints and cleanse it by removing the duplicates.
Use cases
You can use this design pattern when an enormous volume of structured data is ingested and you want to perform integrity checks on the data by validating it against the mandatory, range, and unique constraints and then cleanse it.
Pattern implementation
This design pattern is implemented in Pig as a standalone script. The script loads the data and validates it based on the constraints specified. The following is a brief description of how the pattern is being implemented:
· Mandatory constraints: The script checks the data for invalid and missing data, which does not abide by the mandatory constraints, and cleanses it by replacing the missing values by the median.
· Range constraints: The script has a range constraint defined, which states that the valid values of the column claim_amount should be between a lower and upper bound. The script validates the data, and finds all the values that are outside the range. In the cleansing step, these values are filtered; they can also be updated to the minimum and maximum values of the range as per a predefined business rule.
· Unique constraints: The script performs a check to verify if the data is distinct and then cleanses it by removing duplicate values.
Code snippets
To illustrate the working of this pattern, we have considered an automobile insurance claims dataset stored on the HDFS that contains two files. automobile_policy_master.csv is the master file; it contains a unique ID, vehicle details, price, and the premium paid for it. The master file is used to validate the data present in the claims file. The automobile_insurance_claims.csv file contains automobile insurance claims data, specifically the vehicle repair charges claims; it contains attributes, such as CLAIM_ID, POLICY_MASTER_ID,VEHICLE_DETAILS, and CLAIM_DETAILS. For this pattern, we will be performing constraint validation and cleansing on CLAIM_AMOUNT, POLICY_MASTER_ID, AGE, and CITY, as given in the following code:
/*
Register Datafu and custom jar files
*/
REGISTER '/home/cloudera/pdp/jars/datatypevalidationudf.jar';
REGISTER '/home/cloudera/pdp/jars/datafu.jar';
/*
Define aliases for Quantile UDF from Datafu and custom UDF DataTypeValidationUDF.
The parameters to Quantile constructor specify list of quantiles to compute
The parameter to the DataTypeValidationUDF constructor specifies the Data type that would be used for validation
*/
DEFINE Quantile datafu.pig.stats.Quantile('0.25','0.5','0.75');
DEFINEDataTypeValidationUDF com.validation.DataTypeValidationUDF('double');
/*
Load automobile insurance claims data set into the relation claims and policy master data set into the relation policy_master
*/
claims = LOAD'/user/cloudera/pdp/datasets/data_validation/automobile_insurance_claims.csv' USING PigStorage(',') AS(claim_id:chararray, policy_master_id:chararray,registration_no:chararray, engine_no:chararray,chassis_no:chararray,customer_id:int,age:int,first_name:chararray,last_name:chararray,street:chararray,address:chararray, city:chararray, zip:long,gender:chararray, claim_date:chararray,garage_city:chararray,bill_no:long,claim_amount:chararray,garage_name:chararray,claim_status:chararray);
policy_master = LOAD'/user/cloudera/pdp/datasets/data_validation/automobile_policy_master.csv' USING PigStorage(',') AS(policy_master_id:chararray, model:int, make:chararray,price:double, premium:float);
/*
Remove duplicate tuples from the relation claims to ensure that the data meets unique constraint
*/
claims_distinct = DISTINCT claims;
/*
Invoke the custom DataTypeValidationUDF with the parameter claim_amount.
The UDF returns the tuples where claim_amount does not match the specified data type (double), these values are considered as invalid.
Invalid values are stored in the relation invalid_claims_amt
*/
claim_distinct_claim_amount = FOREACH claims_distinct GENERATEclaim_amount AS claim_amount;
invalid_c_amount = FOREACH claim_distinct_claim_amount GENERATEDataTypeValidationUDF(claim_amount) AS claim_amount;
invalid_claims_amt = FILTER invalid_c_amount BY claim_amount ISNOT NULL;
/*
Filter invalid values from the relation claims_distinct and segregate the valid and invalid claim amount
*/
valid_invalid_claims_amount_join = JOIN invalid_claims_amt BY claim_amount RIGHT, claims_distinct BY claim_amount;
valid_claims_amount = FILTER valid_invalid_claims_amount_join BY$0 IS NULL;
invalid_claims_amount = FILTER valid_invalid_claims_amount_join BY$0 IS NOT NULL;
/*
For each invalid_claims_amount, generate all the values and specify the reason for considering these values as invalid
*/
invalid_datatype_claims = FOREACH invalid_claims_amount GENERATE$1 AS claim_id,$2 AS policy_master_id, $3 AS registration_no,$4 AS engine_no, $5 AS chassis_no,$6 AS customer_id,$7 AS age,$8 AS first_name,$9 AS last_name, $10 AS street, $11 AS address,$12 AS city, $13 AS zip, $14 AS gender, $15 AS claim_date,$16 AS garage_city,$17 AS bill_no, $18 AS claim_amount,$19 ASgarage_name, $20 AS claim_status,'Invalid Datatype forclaim_amount' AS reason;
valid_datatype_claims = FOREACH valid_claims_amount GENERATE $1 ASclaim_id,$2 AS policy_master_id, $3 AS registration_no,$4 AS engine_no, $5 AS chassis_no,$6 AS customer_id,$7 AS age,$8 AS first_name,$9 AS last_name, $10 AS street, $11 AS address,$12 AS city, $13 AS zip, $14 AS gender, $15 AS claim_date,$16 AS garage_city,$17 AS bill_no, $18 AS claim_amount,$19 AS garage_name, $20 AS claim_status;
/*
Compute quantiles using Datafu's Quantile UDF
*/
groupd = GROUP valid_datatype_claims ALL;
quantiles = FOREACH groupd {
sorted = ORDER valid_datatype_claims BY age;
GENERATE Quantile(sorted.age) AS quant;
}
/*
Check for occurrence of null values for the column Age which is a numerical field and for city which is a categorical field.
The nulls in age column are replaced with median and the nulls in city column are replaced with a constant string XXXXX.
*/
claims_replaced_nulls = FOREACH valid_datatype_claims GENERATE $0,$1 ,$2 , $3 ,$4 , $5 ,(int) ($6 is null ? FLOOR(quantiles.quant.quantile_0_5) : $6) AS age, $7, $8 ,$9 , $10 ,($11 is null ? 'XXXXX' : $11) AS city, $12, $13 , $14 , $15 ,$16 ,(double)$17 , $18 ,$19;
/*
Ensure Referential integrity by checking if the policy_master_id in the claims dataset is present in the master dataset.
The values in the claims dataset that do not find a match in the master dataset are considered as invalid values and are removed.
*/
referential_integrity_check = JOIN claims_replaced_nulls BYpolicy_master_id, policy_master BY policy_master_id;
referential_integrity_invalid_data = JOIN policy_master BYpolicy_master_id RIGHT, claims_replaced_nulls BYpolicy_master_id;
referential_check_invalid_claims = FILTERreferential_integrity_invalid_data BY $0 IS NULL;
/*
For each referential_check_invalid_claims, generate all the values and specify the reason for considering these values as invalid
*/
invalid_referential_claims = FOREACHreferential_check_invalid_claims GENERATE $5 ,$6, $7, $8 ,$9 ,$10 , $11, $12, $13 , $14 , $15 , $16 ,$17 , $18 ,$19,$20, $21 ,(chararray) $22 , $23 ,$24,'Referential check Failed for policy_master_id' AS reason;
/*
Perform Range validation by checking if the values in the claim_amount column are within a range of 7% to 65% of the price in the master dataset.
The values that fall outside the range are considered as invalid values and are removed.
*/
referential_integrity_valid_claims = FILTERreferential_integrity_check BY( claims_replaced_nulls::claim_amount>=(policy_master::price*7/100) ANDclaims_replaced_nulls::claim_amount<=(policy_master::price*65/100 ));
valid_claims = FOREACH referential_integrity_valid_claims GENERATE$0, $1 ,$2 , $3 ,$4 , $5 ,$6 , $7, $8 ,$9 , $10 , $11 , $12,$13 , $14 , $15 , $16 ,$17 , $18 ,$19;
invalid_range = FILTER referential_integrity_check BY( claims_replaced_nulls::claim_amount<=(policy_master::price*7/100) ORclaims_replaced_nulls::claim_amount>=(policy_master::price*65/100 ));
/*
For each invalid_range, generate all the values and specify the reason for considering these values as invalid
*/
invalid_claims_range = FOREACH invalid_range GENERATE $0, $1 ,$2 ,$3 ,$4 , $5 ,$6, $7, $8 ,$9 , $10 , $11, $12, $13 , $14 , $15 ,$16 ,(chararray)$17 , $18 ,$19,'claim_amount not within range' AS reason;
/*
Combine all the relations containing invalid values.
*/
invalid_claims = UNIONinvalid_datatype_claims,invalid_referential_claims,invalid_claims_range;
/*
The results are stored on the HDFS in the directories valid_data and invalid_data
The values that are not meeting the constraints are written to a file in the folder invalid_data. This file has an additional column specifying the reason for elimination of the record, this can be used for further analysis.
*/
STORE valid_claims INTO'/user/cloudera/pdp/output/data_validation_cleansing/constraints_validation_cleansing/valid_data';
STORE invalid_claims INTO'/user/cloudera/pdp/output/data_validation_cleansing/constraints_validation_cleansing/invalid_data';
Results
The following is a snippet of the original dataset; we have eliminated a few columns to improve readability.
claim_id,policy_master_id,cust_id,age,city,claim_date,claim_amount
A123B39,A213,39,34,Maryland,5/13/2012,147157
A123B39,A213,39,34,Maryland,5/13/2012,147157
A123B13,A224,13,,Minnesota,2/18/2012,8751.24
A123B70,A224,70,59,,4/2/2012,8751.24
A123B672,A285AC,672,52,Las Vegas,10/19/2012,7865.73
A123B726,A251ext,726,26,Las Vegas,4/6/2013,4400
A123B21,A214,21,41,Maryland,2/28/2009,1230000000
A123B40,A214,40,35,Austin,6/30/2009,29500
A123B46,A220,46,32,Austin,12/29/2011,13986 Amount
A123B20,A213,20,42,Redmond,5/18/2013,147157 Price
A123B937,A213,937,35,Minnesota,9/27/2009,147157
The following is the result of applying this pattern to the dataset:
· Valid data
· A123B39,A213,39,34,Maryland,5/13/2012,147157
· A123B13,A224,13,35,Minnesota,2/18/2012,8751.24
· A123B70,A224,70,59,XXXXX,4/2/2012,8751.24
A123B937,A213,937,35,Minnesota,9/27/2009,147157
· Invalid data
· A123B672,A285AC,672,52,Las Vegas,10/19/2012,7865.73,Referential check Failed for policy_master_id
· A123B726,A251ext,726,26,Las Vegas,4/6/2013,4400,Referential check Failed for policy_master_id
· A123B21,A214,21,41,Maryland,2/28/2009,1230000000,claim_amount not within range
· A123B40,A214,40,35,Austin,6/30/2009,29500,claim_amount not within range
· A123B46,A220,46,32,Austin,12/29/2011,13986 Amount,InvalidDatatype for claim_amount
A123B20,A213,20,42,Redmond,5/18/2013,147157 Price,InvalidDatatype for claim_amount
The resultant data is divided into valid and invalid data. In the previous results, the duplicate record with claim_id A123B39 is removed, the null value for age is replaced by 35 (median) for the record with claim_id A123B13, and the null value for city is replaced by XXXXXfor the record with claim_id A123B70. Along with these, the valid data has the list of records that match the data type, range, and referential integrity constraints on the columns claim_amount and policy_master_id. The invalid data is written to a file in the folderinvalid_data. The last column of the file mentions the reason for considering the record as invalid.
Additional information
The complete code and datasets for this section are in the following GitHub directories:
· Chapter4/code/
· Chapter4/datasets/
The regex validation and cleansing design pattern
This design pattern deals with using the regex functions to validate the data. The regex functions can be used to validate the data to match a specific length or pattern and to cleanse the invalid data.
Background
This design pattern discusses ways to use a regex function to identify and clean data that has invalid field lengths. The pattern also identifies all the occurrences of values with the specified date format from within the data and removes the invalid values that do not comply with the format specified.
Motivation
Identifying string data with incorrect length is one of the quickest ways to understand if the data is accurate. Often we will need this string length parameter to judge the data without actually looking deeper into the data. This will be useful in use cases where it is mandatory to have an upper limit to the string length, such as the US state codes that generally have an upper limit of length as two.
Finding all the patterns of strings that match the date pattern is one of the most common transformations done on data. Dates are prone to be represented in multiple ways (DD/MM/YY, MM/DD/YY, YYYY/MM/DD, and so on). Transformation includes finding the occurrence of these patterns and standardizing all of these formats into a uniform date format that is mandated by the business rule.
Use cases
Regular expressions are used in cases that require full or partial pattern matches on strings. The following are a few common use cases that come up while doing extract, transform, and load (ETL):
· String length and pattern validation: Regular expressions are used to validate the data if the structure of the data is in a standard format and if the data matches a specified length. For example, it can help validate data if the field starts with an alphabet and is followed by a three-digit number.
· Filtering fields that do not match a specific pattern: This can be used in the cleansing phase if your business case mandates you to eliminate the data that does not match a specific pattern; for example, filtering the records where dates do not match a predefined format.
· Splitting string into tokens: Unstructured text can be parsed and split into tokens using regular expressions. A common example is splitting the text into words by tokenizing it with \s, which denotes splitting by space. Another use could be to split a string using a pattern to get the prefix or suffix. For example, extracting the numeric value of 100 from a string "100 dollars".
· Extracting data that matches a pattern: This has uses where you want to extract some text that matches a pattern out of a huge file. Logfile pre-processing is an example for this; you can form a regular expression to extract the request or response patterns from a huge log and further analysis can be performed on the extracted data.
Pattern implementation
This design pattern is implemented in Pig as a standalone script. The script loads the data and validates it against the regular expression patterns.
· String pattern and length: The script validates the values in the policy_master_id column to match a predefined length and pattern. The values that do not match the pattern or length are removed.
· Date format: The script validates values in the column claim_date to match the MM/DD/YYYY date format; the records with invalid date format are filtered.
Code snippets
To illustrate the working of this pattern, we have considered an automobile insurance claims dataset stored on the HDFS that contains two files. automobile_policy_master.csv is the master file; it contains a unique ID, vehicle details, price, and the premium paid for it. The master file is used to validate the data present in the claims file. The automobile_insurance_claims.csv file contains automobile insurance claims data, specifically the vehicle repair charges claims; it contains attributes, such as CLAIM_ID, POLICY_MASTER_ID,VEHICLE_DETAILS, and CLAIM_DETAILS. For this pattern, we will be performing regex validation and cleansing on POLICY_MASTER_ID and CLAIM_DATE, as given in the following code:
/*
Load automobile insurance claims dataset into the relation claims
*/
claims = LOAD'/user/cloudera/pdp/datasets/data_validation/automobile_insurance_claims.csv' USING PigStorage(',') AS(claim_id:chararray, policy_master_id:chararray,registration_no:chararray, engine_no:chararray,chassis_no:chararray,customer_id:int,age:int,first_name:chararray,last_name:chararray,street:chararray,address:chararray,city:chararray,zip:long,gender:chararray, claim_date:chararray,garage_city:chararray,bill_no:long,claim_amount:chararray,garage_name:chararray,claim_status:chararray);
/*
Validate the values in the column policy_master_id with a regular expression to match the pattern where the value should start with an alphabet followed by three digits.
The values that do not match the pattern or length are considered as invalid values and are removed.
*/
valid_policy_master_id = FILTER claims BY policy_master_id MATCHES'[aA-zZ][0-9]{3}';
/*
Invalid values are stored in the relation invalid_length
*/
invalid_policy_master_id = FILTER claims BY NOT(policy_master_id MATCHES '[aA-zZ][0-9]{3}');
invalid_length = FOREACH invalid_policy_master_id GENERATE $0,$1 ,$2 , $3 ,$4 , $5 ,$6 , $7, $8 ,$9 , $10 , $11, $12, $13 ,$14 , $15 , $16 ,$17 , $18 ,$19,'Invalid length or pattern for policy_master_id' AS reason;
/*
Validate the values in the column claim_date to match MM/DD/YYYY format, also validate the values given for MM and DD to fall within 01 to 12 for month and 01 to 31 for day
The values that do not match the pattern are considered as invalid values and are removed.
*/
valid_claims = FILTER valid_policy_master_id BY( claim_date MATCHES '^(0?[1-9]|1[0-2])[\\/](0?[1-9]|[12][0-9]|3[01])[\\/]\\d{4}$');
/*
Invalid values are stored in the relation invalid_date
*/
invalid_dates = FILTER valid_policy_master_id BY NOT( claim_date MATCHES '^(0?[1-9]|1[0-2])[\\/](0?[1-9]|[12][0-9]|3[01])[\\/]\\d{4}$');
invalid_date = FOREACH invalid_dates GENERATE $0, $1 ,$2 , $3 ,$4 , $5 ,$6 , $7, $8 ,$9 , $10 , $11, $12, $13 , $14 , $15 ,$16 ,$17 , $18 ,$19,'Invalid date format for claim_date' AS reason;
/*
Combine the relations that contain invalid values.
*/
invalid_claims = UNION invalid_length,invalid_date;
/*
The results are stored on the HDFS in the directories valid_data and invalid_data
The invalid values are written to a file in the folder invalid_data. This file has an additional column specifying the reason for elimination of the record, this can be used for further analysis.
*/
STORE valid_claims INTO'/user/cloudera/pdp/output/data_validation_cleansing/regex_validation_cleansing/valid_data';
STORE invalid_claims INTO'/user/cloudera/pdp/output/data_validation_cleansing/regex_validation_cleansing/invalid_data';
Results
The following is a snippet of the original dataset; we have eliminated a few columns to improve readability.
claim_id,policy_master_id,cust_id,age,city,claim_date,claim_amount
A123B1,A290,1,42,Minnesota,1/5/2011,8211
A123B672,A285AC,672,52,Las Vegas,10/19/2012,7865.73
A123B726,A251ext,726,26,Las Vegas,4/6/2013,4400
A123B2,A213,2,35,Redmond,1/22/2009,147157
A123B28,A221,28,19,Austin,6/37/2012,31930.2
A123B888,A247,888,49,Las Vegas,21/20/2012,873
A123B3,A214,3,23,Maryland,7/8/2011,8400
The following is the result of applying this pattern to the dataset:
· Valid data
· A123B1,A290,1,42,Minnesota,1/5/2011,8211
· A123B2,A213,2,35,Redmond,1/22/2009,147157
A123B3,A214,3,23,Maryland,7/8/2011,8400
· Invalid data
· A123B672,A285AC,672,52,Las Vegas,10/19/2012,7865.73,Invalid length or pattern for policy_master_id
· A123B726,A251ext,726,26,Las Vegas,4/6/2013,4400,Invalid length or pattern for policy_master_id
· A123B28,A221,28,19,Austin,6/37/2012,31930.2,Invalid date format for claim_date
A123B888,A247,888,49,Las Vegas,21/20/2012,873,Invalid date format for claim_date
As shown previously, the resultant data is divided into valid and invalid data. Valid data has the list of records that match the regex pattern for validating policy_master_id and claim_date. The invalid data is written to a file in the folder invalid_data; the last column of the file mentions the reason for considering this record as invalid. We chose to filter invalid data; however, the cleansing technique depends on the business case where the invalid data might have to be transformed to valid data.
Additional information
The complete code and datasets for this section are in the following GitHub directories:
· Chapter4/code/
· Chapter4/datasets/
The corrupt data validation and cleansing design pattern
This design pattern discusses data corruption from the perspective of the corrupt data being treated as a noise or as an outlier. The techniques to identify and cleanse the corrupt data are discussed in detail.
Background
This design pattern explores the usage of Pig to validate and cleanse corrupt data from a dataset. It tries to set the context of data corruption from various sources of Big Data ranging from sensor to structured data. This design pattern probes the data corruption angle from two perspectives, one is noise and the other is outliers, as given in the following list:
· Noise can be defined as a random error in measurement that has caused corrupt data to be ingested along with the correct data. The amount of error is not too far away from the expected value.
· Outliers are also a kind of noise but the value of error is too far away from the expected value. Outliers can have a very high influence on the accuracy of an analysis. They are often measurements or recording errors. Some of them can represent phenomena of interest, something significant from the viewpoint of the application domain, which implies that not all outliers should be eliminated.
Data corruption can manifest as noise or outliers, the major difference between them being the degree of variation to the expected value. Noisy data varies to a lesser degree and has values closer to the original data, whereas outliers vary to a large degree and the values are way off the original data. Illustrating the example in the following set of numbers, 4 can be considered as noise and 21 as an outlier.
A = [1,2,1,4,1,2,1,1,1,2,21,1,2,2]
Corrupt data increases the amount of effort required to perform analytics and also adversely affects the accuracy of the data mining analysis. The following points illustrate a few sources of data corruption as applicable to Big Data:
· Data corruption in sensor data: Sensor data has become one of the biggest sources of volume amongst the wide array of Big Data sources that pervades our data universe. These sensors generally generate a huge amount of data over a very long period of time and this leads to various computational challenges arising due to the inaccuracy of data. Hadoop is extensively used in mining longitudinal sensor data for patterns and one of the biggest challenges faced in this process is the natural errors and incompleteness of the sensor data. The sensors have inadequate battery life because of which many of them probably may not be able to send accurate data over an extended period of time, thus corrupting the data.
· Data corruption in structured data: In the structured Big Data context, any data, be it numeric or categorical, that has been stored in Hadoop in such a manner that it cannot be read or used by any of the data processing routines written for the data can be considered corrupt.
Motivation
Corrupt data can be validated and cleansed by applying appropriate noise and outlier detection techniques. The common techniques employed for this purpose are binning, regression, and clustering, as given in the following list:
· Binning: This technique can be used to identify noise and outliers. This technique is also used for removal of noisy data by applying a smoothing function. Binning works by creating a set of sorted values partitioned into bins. These values are partitioned by equal frequency or equal width. In order to smoothen the data (or remove noise), the original data values that are in a given partition or a bin, are replaced by the mean or median of that partition. In the current design pattern, we will be illustrating the applicability of binning to remove noise.
· Regression: It is a technique that fits the data values to a function. Noise removal can be done using regression by identifying the regression function and removing all the data values that lie far away from the function's predicted value. Linear regression finds the "most appropriate" line function to fit two variables so that one variable can be used to predict the other. Multiple linear regressions, similar to linear regressions, is where more than two variables are involved and the data is fit to a poly-dimensional surface.
· Clustering: Outlier analysis can be performed using clustering by grouping similar values together to find the values that are outside of the cluster and may be considered as an outlier. A cluster consists of values that are similar to other values in the same cluster and at the same time, dissimilar to the values in the other clusters. A cluster of values can be treated as a group to compare with other cluster values at macro level.
One more method of finding the outliers is to compute the interquartile range (IQR). In this method, three quartiles (Q1, Q2, and Q3) are first calculated from the values. The quartiles divide the values into four equal groups with each group comprising a quarter of data. The upper fence and lower fence are calculated using the three quartiles and any value above or below these two fences is considered as an outlier. The fences are a guideline to define the range outside which an outlier exists. In the current design pattern, we are using this method to find the outliers.
Use cases
You can consider using this design pattern to cleanse corrupt data by removing noise and outliers. This design pattern will be helpful to understand how to classify data into noise or outliers and then remove them.
Pattern implementation
This design pattern is implemented as a standalone Pig script using a third-party library datafu.jar. The script has the implementation for identifying and removing noise and outliers.
Binning techniques identify and remove noise. In binning, the values are sorted and are distributed into a number of bins. The minimum and maximum values are identified for each bin and are set as bin boundaries. Each bin value is replaced by the nearest bin boundary value. This method is called smoothing by bin boundaries. To identify outliers, we are using the standard box plot rule method; it finds outliers based on the upper and lower quartiles of the data distribution. The Q1 and Q3 of the data distribution and their interquartile distance is calculated, using (Q1 - c * IQD, Q3 + c *IQD), which gives the range that that the data should fall in. Here, c is a constant with a value 1.5. The values that fall outside this range are considered outliers. The script uses the Datafu library to calculate quartiles.
Code snippets
To illustrate the working of this pattern, we have considered an automobile insurance claims dataset stored on the HDFS that contains two files. automobile_policy_master.csv is the master file; it contains a unique ID, vehicle details, price, and the premium paid for it. The master file is used to validate the data present in the claims file. The automobile_insurance_claims.csv file contains automobile insurance claims data, specifically vehicle repair charges claims; it contains attributes, such as CLAIM_ID, POLICY_MASTER_ID,VEHICLE_DETAILS, and CLAIM_DETAILS. For this pattern, we will be performing corrupt data validation and cleansing on CLAIM_AMOUNT and AGE, as given in the following code:
/*
Register Datafu jar file
*/
REGISTER '/home/cloudera/pdp/jars/datafu.jar';
/*
Define alias for the UDF quantile
The parameters specify list of quantiles to compute
*/
DEFINE Quantile datafu.pig.stats.Quantile('0.25','0.50','0.75');
/*
Load automobile insurance claims data set into the relation claims
*/
claims = LOAD'/user/cloudera/pdp/datasets/data_validation/automobile_insurance_claims.csv' USING PigStorage(',') AS(claim_id:chararray, policy_master_id:chararray,registration_no:chararray, engine_no:chararray,chassis_no:chararray,customer_id:int,age:int,first_name:chararray,last_name:chararray,street:chararray,address:chararray,city:chararray,zip:long,gender:chararray, claim_date:chararray,garage_city:chararray,bill_no:long,claim_amount:double,garage_name:chararray,claim_status:chararray);
/*
Sort the relation claims by age
*/
claims_age_sorted = ORDER claims BY age ASC;
/*
Divide the data into equal frequency bins.
Minimum and maximum values are identified for each bin and are set as bin boundaries.
Replace each bin value with the nearest bin boundary.
*/
bin_id_claims = FOREACH claims_age_sorted GENERATE(customer_id - 1) * 10 / (130- 1 + 1) AS bin_id, $0 ,$1 ,$2 ,$3 ,$4 ,$5 ,$6 ,$7 ,$8 ,$9 ,$10 ,$11 ,$12 ,$13 ,$14 ,$15 ,$16 ,$17 ,$18 ,$19 ;
group_by_id = GROUP bin_id_claims BY bin_id;
claims_bin_boundaries = FOREACH group_by_id
{
bin_lower_bound=(int) MIN(bin_id_claims.age);
bin_upper_bound = (int)MAX(bin_id_claims.age);
GENERATE bin_lower_bound AS bin_lower_bound, bin_upper_bound ASbin_upper_bound, FLATTEN(bin_id_claims);
};
smoothing_by_bin_boundaries = FOREACH claims_bin_boundariesGENERATE $3 AS claim_id,$4 AS policy_master_id,$5 ASregistration_no,$6 AS engine_no,$7 AS chassis_no,$8 AS customer_id,( ( $9 - bin_lower_bound ) <=( bin_upper_bound - $9 ) ? bin_lower_bound : bin_upper_bound )AS age,$10 AS first_name,$11 AS last_name,$12 AS street,$13 AS address,$14 AS city,$15 AS zip,$16 AS gender,$17 AS claim_date,$18 AS garage_city,$19 AS bill_no,$20 AS claim_amount,$21 AS garage_name,$22 AS claim_status;
/*
Identify outliers present in the column claim_amount by calculating the quartiles, interquartile distance and the upper and lower fences.
The values that do not fall within this range are considered as outliers and are filtered out.
*/
groupd = GROUP smoothing_by_bin_boundaries ALL;
quantiles = FOREACH groupd {
sorted = ORDER smoothing_by_bin_boundaries BY claim_amount;
GENERATE Quantile(sorted.claim_amount) AS quant;
}
valid_range = FOREACH quantiles GENERATE(quant.quantile_0_25 - 1.5 * (quant.quantile_0_75 - quant.quantile_0_25)) ,(quant.quantile_0_75 + 1.5 *(quant.quantile_0_75 - quant.quantile_0_25));
claims_filtered_outliers = FILTER smoothing_by_bin_boundaries BYclaim_amount>= valid_range.$0 AND claim_amount<= valid_range.$1;
/*
Store the invalid values in the relation invalid_claims
*/
invalid_claims_filter = FILTER smoothing_by_bin_boundaries BY claim_amount<= valid_range.$0 OR claim_amount>= valid_range.$1;
invalid_claims = FOREACH invalid_claims_filter GENERATE $0 ,$1 ,$2 ,$3 ,$4 ,$5 ,$6 ,$7 ,$8 ,$9 ,$10 ,$11 ,$12 ,$13 ,$14 ,$15 ,$16 ,$17 ,$18 ,$19,'claim_amount identified as Outlier' as reason;
/*
The results are stored on the HDFS in the directories valid_data and invalid_data
The invalid values are written to a file in the folder invalid_data. This file has an additional column specifying the reason for elimination of the record, this can be used for further analysis.
*/
STORE invalid_claims INTO'/user/cloudera/pdp/output/data_validation_cleansing/corrupt_data_validation_cleansing/invalid_data';
STORE claims_filtered_outliers INTO'/user/cloudera/pdp/output/data_validation_cleansing/corrupt_data_validation_cleansing/valid_data';
Results
The following is a snippet of the original dataset; we have eliminated a few columns to improve readability.
claim_id,policy_master_id,cust_id,age,city,claim_date,claim_amount
A123B6,A217,6,42,Las Vegas,6/25/2010,-12495
A123B11,A222,11,21,,11/5/2012,293278.7,claim_amount identified asOutlier
A123B2,A213,2,42,Redmond,1/22/2009,147157,claim_amount identifiedas Outlier
A123B9,A220,9,21,Maryland,9/20/2011,13986
A123B4,A215,4,42,Austin,12/16/2011,35478
The following is the result of applying this pattern on the dataset:
· Valid data
· A123B6,A217,6,42,Las Vegas,6/25/2010,-12495
· A123B9,A220,9,21,Maryland,9/20/2011,13986
A123B4,A215,4,42,Austin,12/16/2011,35478
· Invalid data
· A123B11,A222,11,21,,11/5/2012,293278.7,claim_amount identified as Outlier
A123B2,A213,2,42,Redmond,1/22/2009,147157,claim_amount identified as Outlier
As shown previously, the resultant data is divided into valid and invalid data. Valid data has the list of records where the noise is smoothened for the age column. Outlier detection is done on the claim_amount column, the lower and upper fences are identified as-34929.0 and 70935.0; the values that do not fall in this range are identified as outliers and are written to a file in the folder invalid_data. The last column of this file shows the reason for considering this record as invalid. The outliers are filtered and the data is stored in the valid_data folder. The previous script removes the outliers; however, this decision can vary as per the business rule.
Additional information
The complete code and datasets for this section are in the following GitHub directories:
· Chapter4/code/
· Chapter4/datasets/
The unstructured text data validation and cleansing design pattern
The unstructured text validation and cleansing pattern demonstrates ways to cleanse unstructured data by applying various data pre-processing techniques.
Background
Processing huge amounts of unstructured data with Hadoop is a challenging task in terms of cleaning it and making it ready for processing. Textual data, which includes documents, mails, text files, and chat files, is inherently unorganized without a defined data model when it is ingested by Hadoop.
In order to open the unstructured data for analysis, we have to bring in a semblance of structure to it. The foundation of organizing unstructured data is to integrate it with structured data existing in the enterprise by performing a planned and controlled cleansing transformation and flow of data across the data store, for operational and/or analytical use. Integration of unstructured data is necessary to make the queries and analytics performed on the resultant data meaningful.
One of the first steps after unstructured data ingestion is to discover the metadata from the textual data and organize it in a way that facilitates further processing, thus removing a few of the irregularities and ambiguities from the data. This metadata creation itself is a multistep iterative process employing various data parsing, cleansing, and transformation techniques ranging from simple entity extraction and semantic tagging to natural language processing using artificial intelligence algorithms.
Motivation
This design pattern demonstrates one way to cleanse an unstructured data corpus by performing pre-processing steps, such as lowercase conversion, stopword removal, stemming, punctuation removal, extra spaces removal, identifying numbers, and identifying misspellings.
The motivation for this pattern is to understand the various kinds of inconsistencies in unstructured data and help identify these issues and cleanse them.
Unstructured data is prone to multiple quality issues ranging from integrity to inconsistency. The following are the common cleansing steps for unstructured text:
· Textual data can also be represented using alternative forms of spellings; for instance, a name can be written in different ways and searching for that particular name will not give a result if it is spelled differently but still refers to the same entity. This aspect can be considered as a form of misspelling. Integrating and cleansing these alternative spellings to refer to the same entity would mitigate the ambiguity. Effective conversion of unstructured text to structured format requires us to take into account all the alternative spellings.
· Misspellings also account for many irregularities that will affect the accuracy of the analytics. In order to make the data processable, we have to identify the misspelled words and replace them with the correct ones.
· Numerical value identification from within the text enables us to pick all the numbers. These extracted numbers can be included or eliminated from further processing depending on the business context. Data cleansing can also be performed by extracting numbers from text; for instance, if the text consists of a phrase "one thousand", it can be transformed into 1000 so that appropriate analytics can be performed.
· Extraction of data, which matches certain patterns using regex, can be a cleansing method. For instance, dates can be extracted from within the text by specifying a pattern. If the extracted dates are not in the standard format (DD/MM/YY), standardizing the dates could be one of the cleansing activities performed to read and index the unstructured data by date.
Use cases
You can consider using this design pattern to cleanup the unstructured data by removing misspellings, punctuations, and so on after the data has already been ingested by Hadoop.
Pattern implementation
This design pattern is implemented as a standalone Pig script, which internally uses right-outer join to remove the stop words. The list of stop words are first loaded into a relation from an external text file and then used in the outer join.
The LOWER function is used to convert all the words into lower case. Punctuations are removed by using the REPLACE function matching the specific literal. Similarly, numbers are removed by matching all the patterns of numbers in the text using REPLACE.
The code for implementing the misspelled words uses a Bloom filter, which has been recently included in Pig 0.10 version as a UDF.
The Bloom filter is a space-optimized data structure specifically used to filter a smaller dataset from a larger dataset by testing whether an element belonging to the smaller dataset is a member of the larger one or not. The Bloom filter achieves drastic space optimization by internally implementing a clever mechanism to store each element to use a constant amount of memory no matter the size of the element. Even though the Bloom filter has an enormous space advantage compared to other structures, the filtering is not completely accurate since there can be scope for false positives.
Pig has support for the Bloom filters through calls to BuildBloom, which builds a Bloom filter by loading and training it from the list of values loaded from the dictionary corpus stored in a Pig relation. The trained Bloom filter, stored in a distributed cache and passed on to the Mapper function internally, is used to perform the actual filtering operation on the input data by doing a FILTER operation using the BLOOM UDF. The resultant set filtered would be the correctly spelled words after the Bloom filter has eliminated all the misspelled words.
Code snippets
To demonstrate the working of this pattern, we have considered the text corpus of Wikipedia stored in a folder accessible to the HDFS. This sample corpus consists of the wiki pages related to Computer Science and Information Technology. A few misspelled words are deliberately introduced into the corpus to demonstrate the functionality of this pattern.
/*
Define alias for the UDF BuildBloom.
The first parameter to BuildBloom constructor is the hashing technique to use, the second parameter specifies the number of distinct elements that would be placed in the filter and the third parameter is the acceptable rate of false positives.
*/
DEFINE BuildBloom BuildBloom('jenkins', '75000', '0.1');
/*
Load dictionary words
*/
dict_words1 = LOAD'/user/cloudera/pdp/datasets/data_validation/unstructured_text/dictionary_words1.csv' as (words:chararray);
dict_words2 = LOAD'/user/cloudera/pdp/datasets/data_validation/unstructured_text/dictionary_words2.csv' as (words:chararray);
/*
Load stop words
*/
stop_words_list = LOAD'/user/cloudera/pdp/datasets/data_validation/unstructured_text/stopwords.txt' USING PigStorage();
stopwords = FOREACH stop_words_list GENERATEFLATTEN(TOKENIZE($0));
/*
Load the document corpus and tokenize to extract the words
*/
doc1 = LOAD'/user/cloudera/pdp/datasets/data_validation/unstructured_text/computer_science.txt' AS (words:chararray);
docWords1 = FOREACH doc1 GENERATE FLATTEN(TOKENIZE(words)) ASword;
doc2 = LOAD'/user/cloudera/pdp/datasets/data_validation/unstructured_text/information_technology.txt' AS (words:chararray);
docWords2 = FOREACH doc2 GENERATE FLATTEN(TOKENIZE(words)) ASword;
/*
Combine the contents of the relations docWords1 and docWords2
*/
combined_docs = UNION docWords1, docWords2;
/*
Convert to lowercase, remove stopwords, punctuations, spaces, numbers.
Replace nulls with the value "dummy string"
*/
lowercase_data = FOREACH combined_docs GENERATEFLATTEN(TOKENIZE(LOWER($0))) as word;
joind = JOIN stopwords BY $0 RIGHT OUTER, lowercase_data BY $0;
stop_words_removed = FILTER joind BY $0 IS NULL;
punctuation_removed = FOREACH stop_words_removed
{
replace_punct = REPLACE($1,'[\\p{Punct}]','');
replace_space = REPLACE(replace_punct,'[\\s]','');
replace_numbers = REPLACE(replace_space,'[\\d]','');
GENERATE replace_numbers AS replaced_words;
}
replaced_nulls = FOREACH punctuation_removed GENERATE(SIZE($0) > 0 ? $0 : 'dummy string') as word;
/*
Remove duplicate words
*/
unique_words_corpus = DISTINCT replaced_nulls;
/*
Combine the two relations containing dictionary words
*/
dict_words = UNION dict_words1, dict_words2;
/*
BuildBloom builds a bloom filter that will be used in Bloom.
Bloom filter is built on the relation dict_words which contains all the dictionary words.
The resulting file dict_words_bloom is used in bloom filter by passing it to Bloom.
The call to bloom returns the words that are present in the dictionary, we select the words that are not present in the dictionary and classify them as misspelt words. The misspelt words are filtered from the original dataset and are stored in the folder invalid_data.
*/
dict_words_grpd = GROUP dict_words all;
dict_words_bloom = FOREACH dict_words_grpd GENERATEBuildBloom(dict_words.words);
STORE dict_words_bloom into 'dict_words_bloom';
DEFINE bloom Bloom('dict_words_bloom');
filterd = FILTER unique_words_corpus BY NOT(bloom($0));
joind = join filterd by $0, unique_words_corpus by $0;
joind_right = join filterd by $0 RIGHT, unique_words_corpus BY $0;
valid_words_filter = FILTER joind_right BY $0 IS NULL;
valid_words = FOREACH valid_words_filter GENERATE $1;
misspellings = FOREACH joind GENERATE $0 AS misspelt_word;
/*
The results are stored on the HDFS in the directories valid_data and invalid_data.
The misspelt words are written to a file in the folder invalid_data.
*/
STORE misspellings INTO'/user/cloudera/pdp/output/data_validation_cleansing/unstructured_data_validation_cleansing/invalid_data';
STORE valid_words INTO'/user/cloudera/pdp/output/data_validation_cleansing/unstructured_data_validation_cleansing/valid_data';
Results
The following are the words that are identified as misspellings and are stored in the folder invalid_data. We chose to filter these words from the original dataset. However, this depends on the business rule; if the business rule mandates that misspelt words have to be replaced with their correct spellings, the appropriate steps have to be taken to correct the spellings.
sme
lemme
puttin
speling
wntedly
mistaces
servicesa
insertingg
missspellingss
telecommunications
Additional information
The complete code and datasets for this section are in the following GitHub directories:
· Chapter4/code/
· Chapter4/datasets/
Summary
In this chapter, you have studied various Big Data validation and cleansing techniques that deal with the detection and cleansing of incorrect or inaccurate records from the data. These techniques ensure that the inconsistencies in the data are identified by validating the data against a set of rules before the data is used in the analytics process, and then the inconsistent data is replaced, modified, or deleted as per the business rule to make it more consistent. In this chapter, we build upon our learnings from the previous chapter on data profiling.
In the next chapter, we will focus on the data transformation patterns that can be applied to a variety of data formats. After reading this chapter, readers will be able to choose the right pattern to transform the data by using techniques such as aggregation, generalizations, and joins.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.