Statistics Done Wrong: The Woefully Complete Guide (2015)
Chapter 5. Bad Judges of Significance
Using too many statistical significance tests is a good way to get misleading results, but it’s also possible to claim significance for a difference you haven’t explicitly tested. Misleading error bars could convince you that a test is unnecessary, or a difference in the statistical significance of two treatments might convince you there’s a statistically significant difference between them. Let’s start with the latter.
Insignificant Differences in Significance
“We compared treatments A and B with a placebo. Treatment A showed a significant benefit over placebo, while treatment B had no statistically significant benefit. Therefore, treatment A is better than treatment B.”
We hear this all the time. It’s an easy way of comparing medications, surgical interventions, therapies, and experimental results. It’s straightforward. It seems to make sense.
However, a difference in significance does not always make a significant difference.1
One reason is the arbitrary nature of the p < 0.05 cutoff. We could get two very similar results, with p = 0.04 and p = 0.06, and mistakenly say they’re clearly different from each other simply because they fall on opposite sides of the cutoff. The second reason is that p values are not measures of effect size, so similar p values do not always mean similar effects. Two results with identical statistical significance can nonetheless contradict each other.
Instead, think about statistical power. If we compare our new experimental drugs Fixitol and Solvix to a placebo but we don’t have enough test subjects to give us good statistical power, then we may fail to notice their benefits. If they have identical effects but we have only 50% power, then there’s a good chance we’ll say Fixitol has significant benefits and Solvix does not. Run the trial again, and it’s just as likely that Solvix will appear beneficial and Fixitol will not.
It’s fairly easy to work out the math. Assume both drugs have identical nonzero effects compared to the placebo, and our experiments have statistical power B. This means the probability that we will detect each group’s difference from control is B, so the probability that we will detect Fixitol’s effect but not Solvix’s is B(1 – B). The same goes for detecting Solvix’s effect but not Fixitol’s. Add the probabilities up, and we find that the probability of concluding that one drug has a significant effect and the other does not is 2B(1 – B). The result is plotted in Figure 5-1.
Instead of independently comparing each drug to the placebo, we should compare them against each other. We can test the hypothesis that they are equally effective, or we can construct a confidence interval for the extra benefit of Fixitol over Solvix. If the interval includes zero, then they could be equally effective; if it doesn’t, then one medication is a clear winner. This doesn’t improve our statistical power, but it does prevent the false conclusion that the drugs are different. Our tendency to look for a difference in significance should be replaced by a check for the significance of the difference.
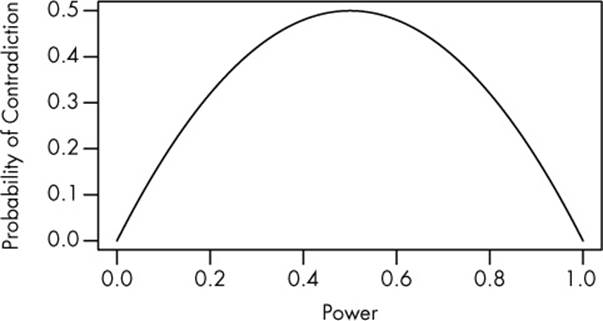
Figure 5-1. A plot of 2B(1–B), the probability that one drug will show a significant result and the other an insignificant result despite both drugs having identical effects. When the power is very low, both drugs give insignificant results; when the power is very high, both drugs give significant results.
This subtle distinction is important to keep in mind, for example, when interpreting the results of replication studies, in which researchers attempt to reproduce the results of previous studies. Some replication studies frame their negative results in terms of significance: “The original paper obtained a significant result, but this more careful study did not.” But even if the replication experiment was designed to have sufficient statistical power to detect the effect reported in the initial study, there was probably truth inflation—the initial study probably overstated the effect. Since a larger sample is required to detect a smaller effect, the true power of the replication experiment may be lower than intended, and it’s perfectly possible to obtain a statistically insignificant result that is nevertheless consistent with the earlier research.
As another example, in 2007 the No. 7 Protect & Perfect Beauty Serum became a best seller for Boots, the UK pharmacy chain, after the BBC reported on a clinical trial that supposedly proved its effectiveness in reducing skin wrinkles. According to the trial, published by the British Journal of Dermatology, the serum reduced the number of wrinkles in 43% of test subjects, a statistically significant benefit, whereas the control treatment (the same serum without the active ingredient) benefited only 22% of subjects, a statistically insignificant improvement. The implication, touted in advertising, was that the serum was scientifically proven to be your best choice for wrinkle control—even though the authors had to admit in their paper that the difference between the groups was not statistically significant.2
This misuse of statistics is not limited to corporate marketing departments, unfortunately. Neuroscientists, for instance, use the incorrect method for comparing groups about half the time.3 You might also remember news about a 2006 study suggesting that men with multiple older brothers are more likely to be homosexual.4 How did they reach this conclusion? The authors explained their results by noting that when they ran an analysis of the effect of various factors on homosexuality, only the number of older brothers had a statistically significant effect. The number of older sisters or of nonbiological older brothers (that is, adopted brothers or stepbrothers) had no statistically significant effect. But as we’ve seen, this doesn’t guarantee there’s a significant difference between these different effect groups. In fact, a closer look at the data suggests there was no statistically significant difference between the effect of having older brothers versus older sisters. Unfortunately, not enough data was published in the paper to allow calculation of a p value for the comparison.1
This misinterpretation of inconclusive results contributes to the public impression that doctors can’t make up their minds about what medicines and foods are good or bad for you. For example, statin drugs have become wildly popular to reduce blood cholesterol levels because high cholesterol is associated with heart disease. But this association doesn’t prove that reducing cholesterol levels will benefit patients. A series of five large meta-analyses reviewing tens of thousands of patient records set out to answer this question: “Do statins reduce mortality in patients who have no history of cardiovascular disease?”
Three of the studies answered yes, statins do reduce mortality rates. The other two concluded there was not enough evidence to suggest statins are helpful.5 Doctors, patients, and journalists reading these articles were no doubt confused, perhaps assuming the research on statins was contradictory and inconclusive. But as the confidence intervals plotted in Figure 5-2 show, all five meta-analyses gave similar estimates of the effect of statins: the relative risk estimates were all near 0.9, indicating that during the trial periods, 10% fewer patients on statin drugs died. Although two studies did have confidence intervals overlapping a relative risk of one—indicating no difference between treatment and control—their effect size estimates matched the other studies well. It would be silly to claim there was serious disagreement between studies.
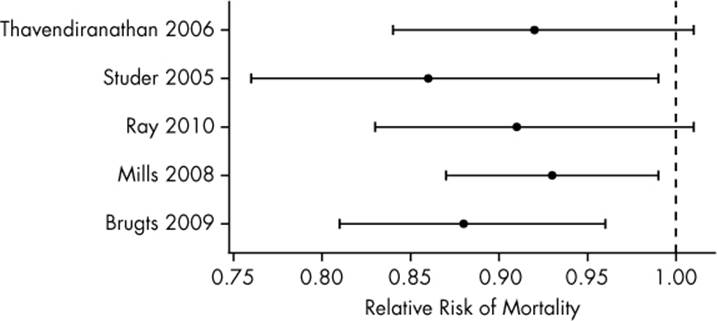
Figure 5-2. Confidence intervals for the relative risk of mortality among patients taking statin drugs, estimated by five different large meta-analyses. A relative risk of less than one indicates smaller mortality rates than among the control group. The meta-analyses are labeled by the lead author’s name and year of publication.
Ogling for Significance
In the previous section, I said that if we want to compare Fixitol and Solvix, we should use a significance test to compare them directly, instead of comparing them both against placebo. Why must I do that? Why can’t I just look at the two confidence intervals and judge whether they overlap? If the confidence intervals overlap, it’s plausible both drugs have the same effect, so they must not be significantly different, right? Indeed, when judging whether a significant difference exists, scientists routinely eyeball it, making use of plots like Figure 5-3.
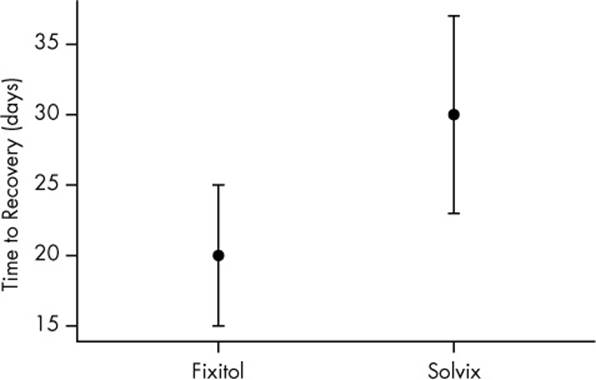
Figure 5-3. Time until recovery of patients using Fixitol or Solvix. Fixitol appears to be more effective, but the error bars overlap.
Imagine the two plotted points indicate the estimated time until recovery from some disease in two different groups of 10 patients. The width of these error bars could represent three different things.
1. Twice the standard deviation of the measurements. Calculate how far each observation is from the average, square each difference, and then average the results and take the square root. This is the standard deviation, and it measures how spread out the measurements are from their mean. Standard deviation bars stretch from one standard deviation below the mean to one standard deviation above.
2. The 95% confidence interval for the estimate.
3. Twice the standard error for the estimate, another way of measuring the margin of error. If you run numerous identical experiments and obtain an estimate of Fixitol’s effectiveness from each, the standard error is the standard deviation of these estimates. The bars stretch one standard error below and one standard error above the mean. In the most common cases, a standard error bar is about half as wide as the 95% confidence interval.
It is important to notice the distinction between these. The standard deviation measures the spread of the individual data points. If I were measuring how long it takes for patients to get better when taking Fixitol, a high standard deviation would tell me it benefits some patients much more than others. Confidence intervals and standard errors, on the other hand, estimate how far the average for this sample might be from the true average—the average I would get if I could give Fixitol to every single person who ever gets the disease. Hence, it is important to know whether an error bar represents a standard deviation, confidence interval, or standard error, though papers often do not say.[14]
For now, let’s assume Figure 5-3 shows two 95% confidence intervals. Since they overlap, many scientists would conclude there is no statistically significant difference between the groups. After all, groups one and two might not be different—the average time to recover could be 25 days in both groups, for example, and the differences appeared only because group one got lucky this time.
But does this really mean the difference isn’t statistically significant? What would its p value be?
I can calculate p using a t test, the standard statistical test for telling whether the means of two groups are significantly different from each other. Plugging in the numbers for Fixitol and Solvix, I find that p < 0.05! There is a statistically significant difference between them, even though the confidence intervals overlap.
Unfortunately, many scientists skip the math and simply glance at plots to see whether confidence intervals overlap. Since intervals can overlap but still represent a statistically significant difference, this is actually a much more conservative test—it’s always stricter than requiring p < 0.05.6And so significant differences will be missed.
Earlier, we assumed the error bars in Figure 5-3 represent confidence intervals. But what if they are standard errors or standard deviations? Could we spot a significant difference by just looking for whether the error bars overlap? As you might guess, no. For standard errors, we have the opposite problem we had with confidence interval bars: two observations might have standard errors that don’t overlap, but the difference between the two is not statistically significant. And standard deviations do not give enough information to judge significance, whether they overlap or not.
A survey of psychologists, neuroscientists, and medical researchers found that the majority judged significance by confidence interval overlap, with many scientists confusing standard errors, standard deviations, and confidence intervals.7 Another survey, of climate science papers, found that a majority of papers that compared two groups with error bars made this error.8 Even introductory textbooks for experimental scientists, such as John Taylor’s An Introduction to Error Analysis, teach students to judge by eye, hardly mentioning formal hypothesis tests at all.
There is exactly one situation when visually checking confidence intervals works, and it is when comparing the confidence interval against a fixed value, rather than another confidence interval. If you want to know whether a number is plausibly zero, you may check to see whether its confidence interval overlaps with zero. There are, of course, formal statistical procedures that generate confidence intervals that can be compared by eye and that even correct for multiple comparisons automatically. Unfortunately, these procedures work only in certain circumstances; Gabriel comparison intervals, for example, are easily interpreted by eye but require each group being compared to have the same standard deviation.9 Other procedures handle more general cases, but only approximately and not in ways that can easily be plotted.10 (The alternative, doing a separate test for each possible pair of variables and then using the Bonferroni correction for multiple comparisons, is tedious and conservative, lowering the statistical power more than alternative procedures.)
Overlapping confidence intervals do not mean two values are not significantly different. Checking confidence intervals or standard errors will mislead. It’s always best to use the appropriate hypothesis test instead. Your eyeball is not a well-defined statistical procedure.
TIPS
§ Compare groups directly using appropriate statistical tests, instead of simply saying, “This one was significant, and this one wasn’t.”
§ Do not judge the significance of a difference by eye. Use a statistical test.
§ Remember that if you compare many groups, you need to adjust for making multiple comparisons!
[14] And because standard error bars are about half as wide as the 95% confidence interval, many papers will report “standard error bars” that actually span two standard errors above and below the mean, making a confidence interval instead.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.