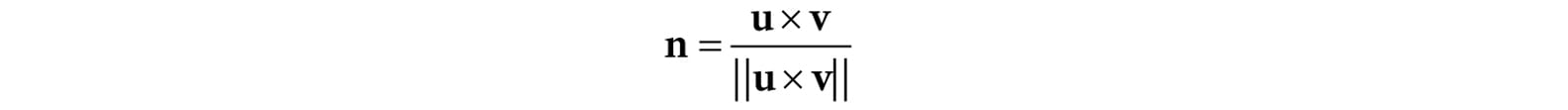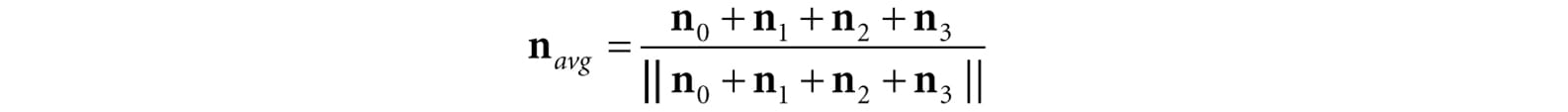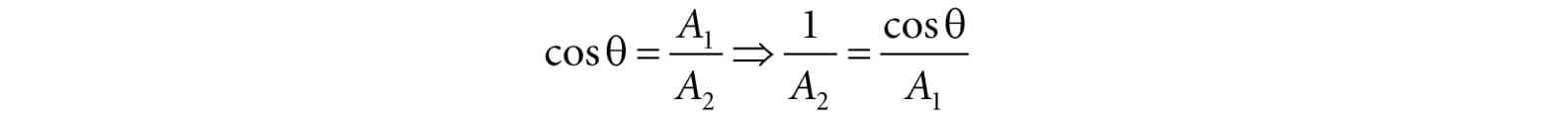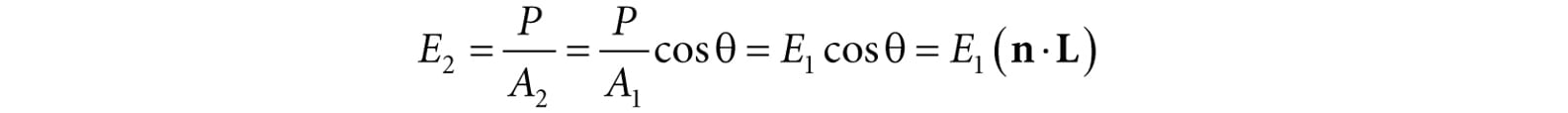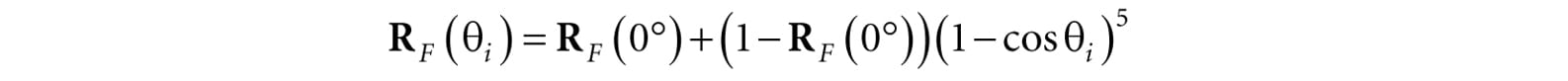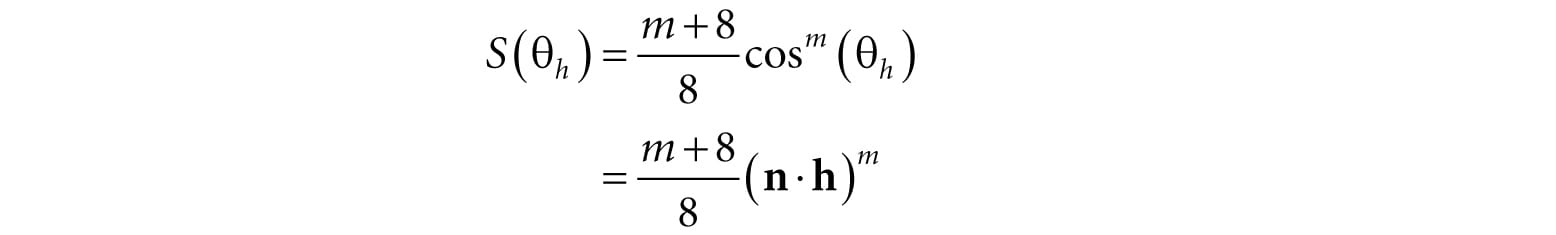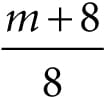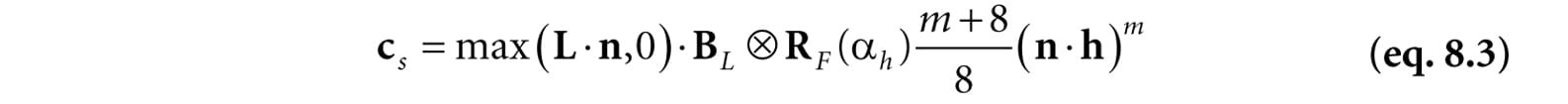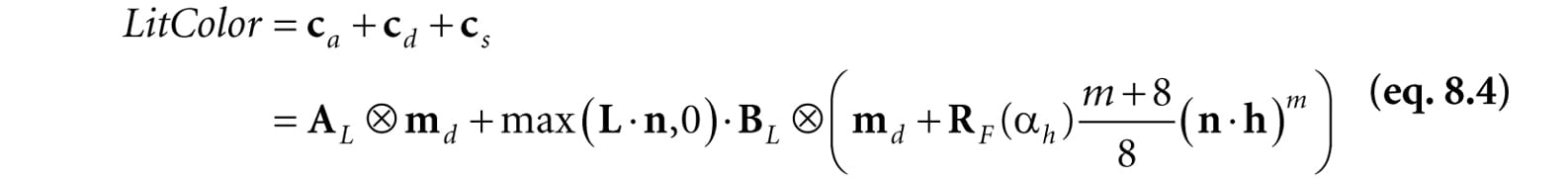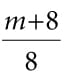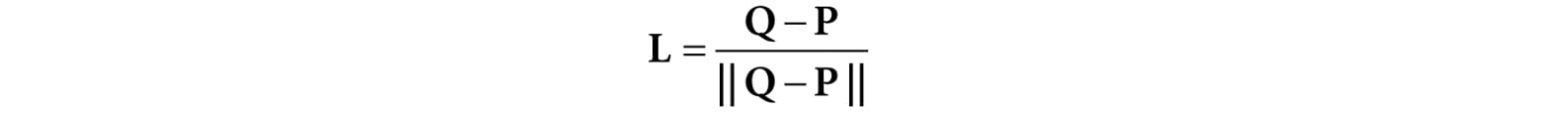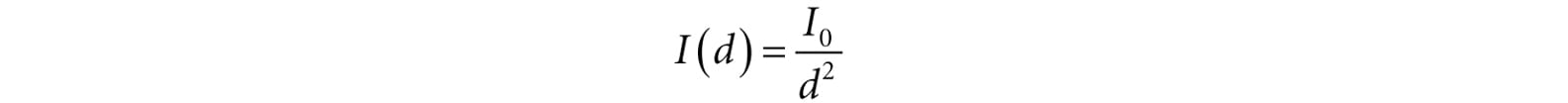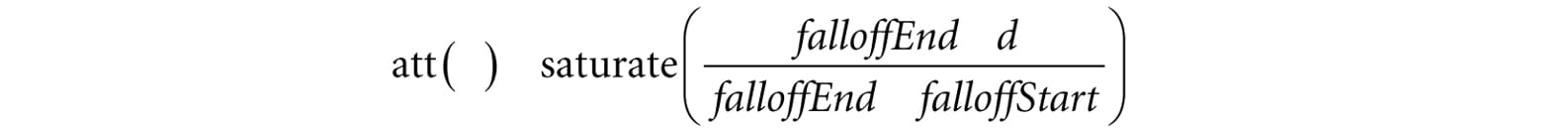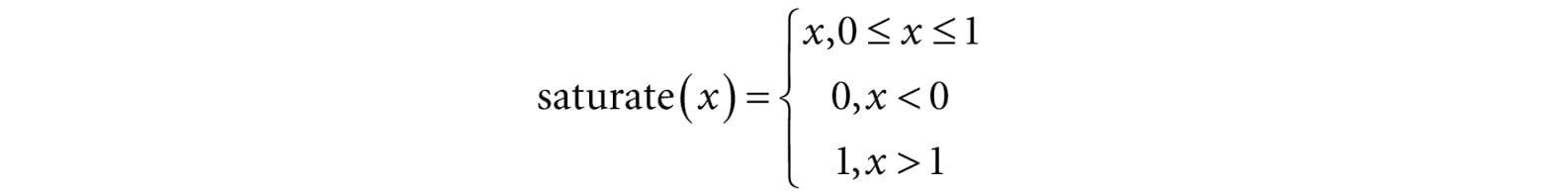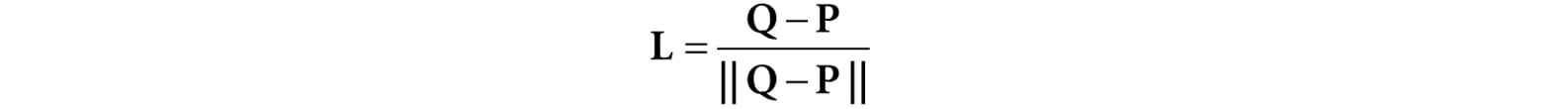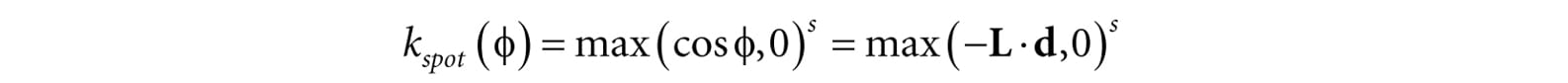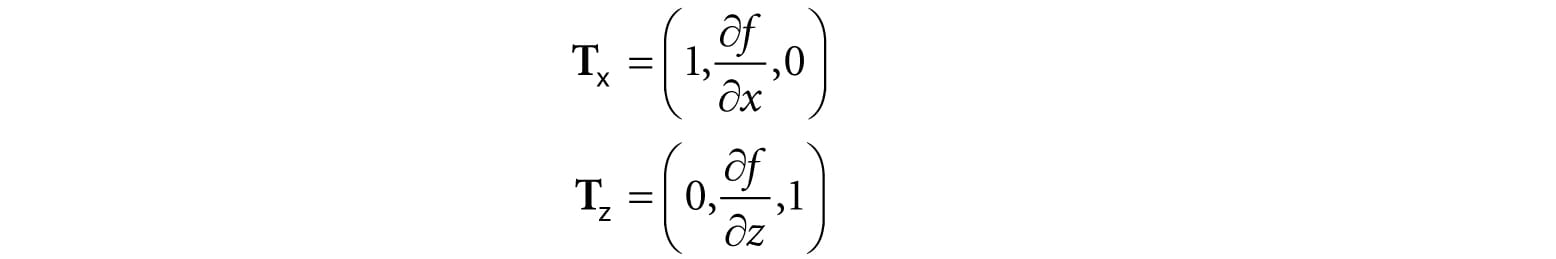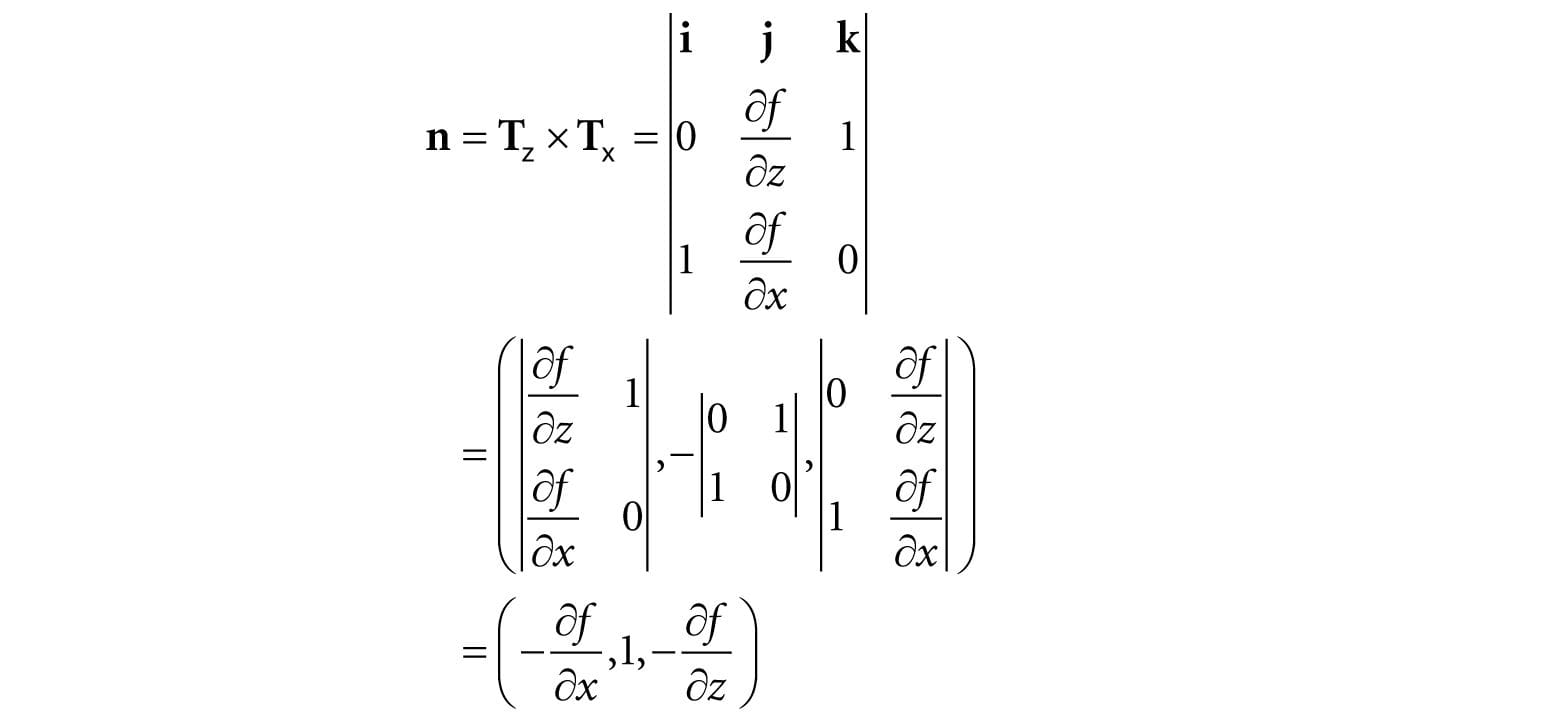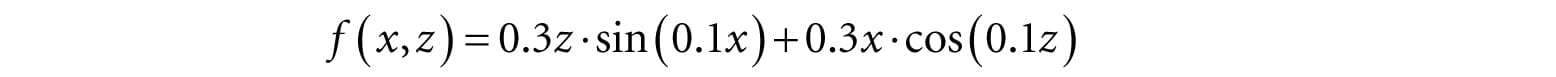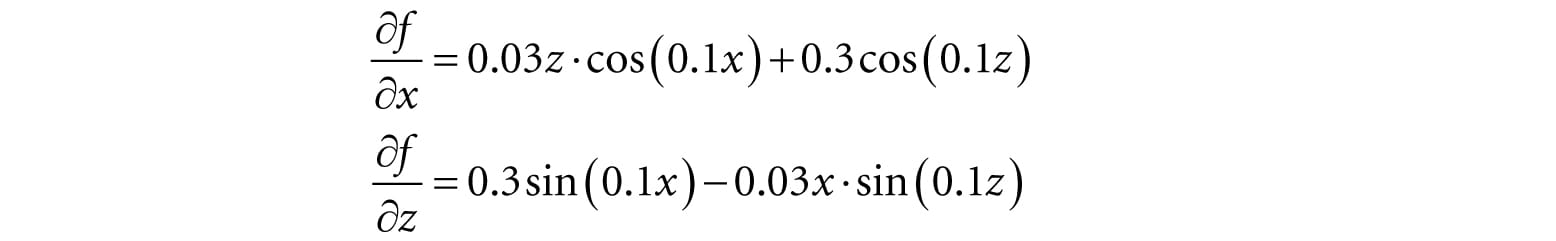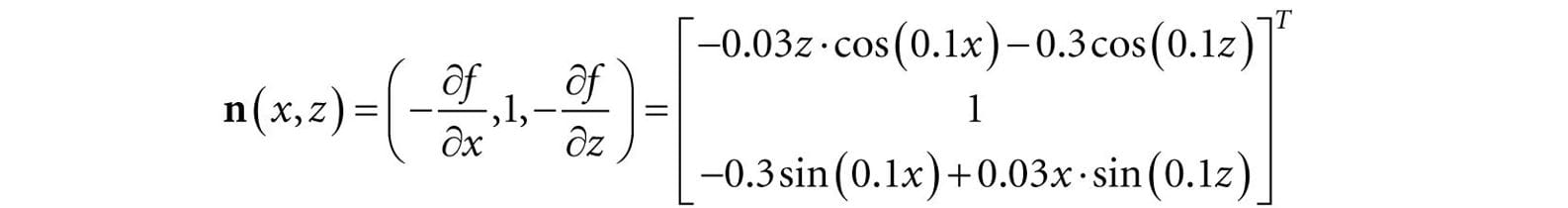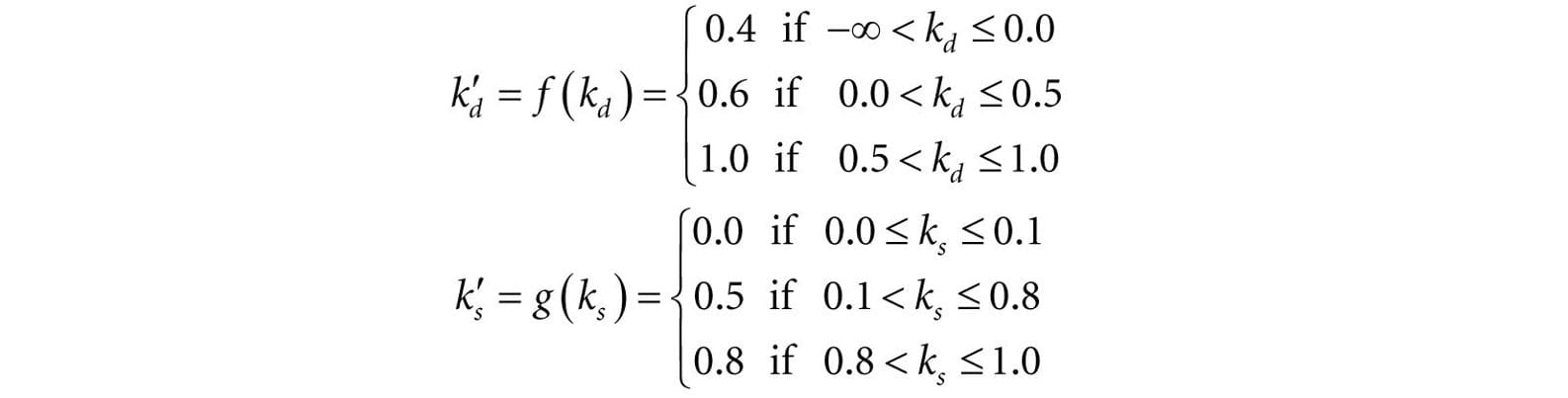Introduction to 3D Game Programming with DirectX 12 (Computer Science) (2016)
|
Part 2 |
DIRECT3D
Consider Figure 8.1. On the left we have an unlit sphere, and on the right, we have a lit sphere. As you can see, the sphere on the left looks rather flat—maybe it is not even a sphere at all, but just a 2D circle! On the other hand, the sphere on the right does look 3D—the lighting and shading aid in our perception of the solid form and volume of the object. In fact, our visual perception of the world depends on light and its interaction with materials, and consequently, much of the problem of generating photorealistic scenes has to do with physically accurate lighting models.
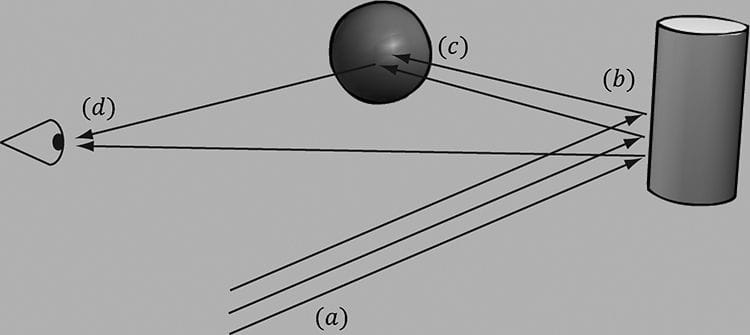
Figure 8.1. (a) An unlit sphere looks 2D. (b) A lit sphere looks 3D. Of course, in general, the more accurate the model, the more computationally expensive it is; thus a balance must be reached between realism and speed. For example, 3D special FX scenes for films can be much more complex and utilize very realistic lighting models than a game because the frames for a film are pre-rendered, so they can afford to take hours or days to process a frame. Games, on the other hand, are real-time applications, and therefore, the frames need to be drawn at a rate of at least 30 frames per second. Note that the lighting model explained and implemented in this book is largely based off the one described in [Möller08]. Objectives: 1. To gain a basic understanding of the interaction between lights and materials 2. To understand the differences between local illumination and global illumination 3. To find out how we can mathematically describe the direction a point on a surface is “facing” so that we can determine the angle at which incoming light strikes the surface 4. To learn how to correctly transform normal vectors 5. To be able to distinguish between ambient, diffuse, and specular light 6. To learn how to implement directional lights, point lights, and spotlights 7. To understand how to vary light intensity as a function of depth by controlling attenuation parameters 8.1 LIGHT AND MATERIAL INTERACTION When using lighting, we no longer specify vertex colors directly; rather, we specify materials and lights, and then apply a lighting equation, which computes the vertex colors for us based on light/material interaction. This leads to a much more realistic coloring of the object (compare Figure 8.1a and 8.1b again). Materials can be thought of as the properties that determine how light interacts with a surface of an object. Examples of such properties are the color of light the surface reflects and absorbs, the index of refraction of the material under the surface, how smooth the surface is, and how transparent the surface is. By specifying material properties we can model different kinds of real-world surfaces like wood, stone, glass, metals, and water. In our model, a light source can emit various intensities of red, green, and blue light; in this way, we can simulate many light colors. When light travels outwards from a source and collides with an object, some of that light may be absorbed and some may be reflected (for transparent objects, such as glass, some of the light passes through the medium, but we do not consider transparency here). The reflected light now travels along its new path and may strike other objects where some light is again absorbed and reflected. A light ray may strike many objects before it is fully absorbed. Presumably, some light rays eventually travel into the eye (see Figure 8.2) and strike the light receptor cells (named cones and rods) on the retina.
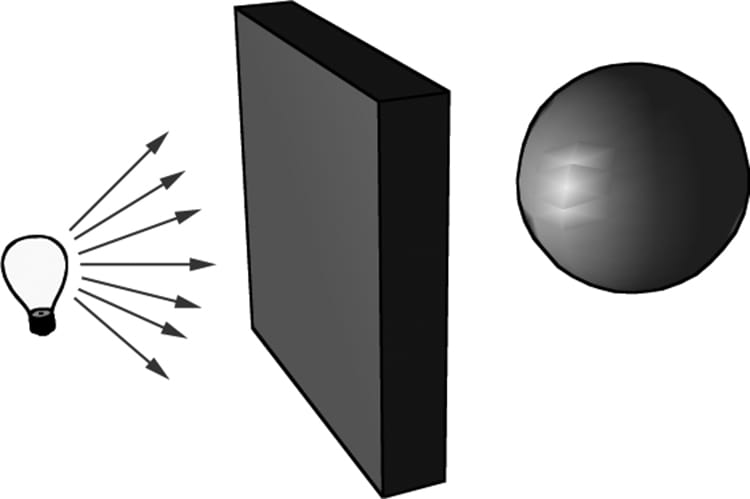
Figure 8.2. (a) Flux of incoming white light. (b) The light strikes the cylinder and some rays are absorbed and other rays are scatted toward the eye and sphere. (c) The light reflecting off the cylinder toward the sphere is absorbed or reflected again and travels into the eye. (d) The eye receives incoming light that determines what the eye sees. According to the trichromatic theory (see [Santrock03]), the retina contains three kinds of light receptors, each one sensitive to red, green, and blue light (with some overlap). The incoming RGB light stimulates its corresponding light receptors to varying intensities based on the strength of the light. As the light receptors are stimulated (or not), neural impulses are sent down the optic nerve toward the brain, where the brain generates an image in your head based on the stimulus of the light receptors. (Of course, if you close/cover your eyes, the receptor cells receive no stimulus and the brain registers this as black.) For example, consider Figure 8.2 again. Suppose that the material of the cylinder reflects 75% red light, 75% green light, and absorbs the rest, and the sphere reflects 25% red light and absorbs the rest. Also suppose that pure white light is being emitted from the light source. As the light rays strike the cylinder, all the blue light is absorbed and only 75% red and green light is reflected (i.e., a medium-high intensity yellow). This light is then scattered—some of it travels into the eye and some of it travels toward the sphere. The part that travels into the eye primarily stimulates the red and green cone cells to a semi-high degree; hence, the viewer sees the cylinder as a semi-bright shade of yellow. Now, the other light rays travel toward the sphere and strike it. The sphere reflects 25% red light and absorbs the rest; thus, the diluted incoming red light (medium-high intensity red) is diluted further and reflected, and all of the incoming green light is absorbed. This remaining red light then travels into the eye and primarily stimulates the red cone cells to a low degree. Thus the viewer sees the sphere as a dark shade of red. The lighting models we (and most real-time applications) adopt in this book are called local illumination models. With a local model, each object is lit independently of another object, and only the light directly emitted from light sources is taken into account in the lighting process (i.e., light that has bounced off other scene objects to strikes the object currently being lit is ignored). Figure 8.3 shows a consequence of this model.
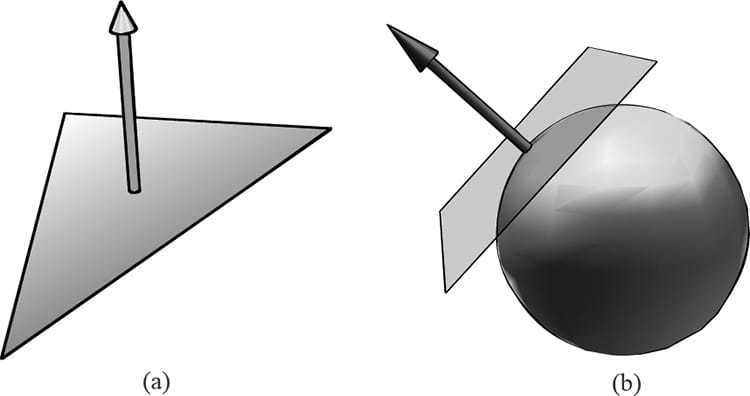
Figure 8.3. Physically, the wall blocks the light rays emitted by the light bulb and the sphere is in the shadow of the wall. However, in a local illumination model, the sphere is lit as if the wall were not there. On the other hand, global illumination models light objects by taking into consideration not only the light directly emitted from light sources, but also the indirect light that has bounced off other objects in the scene. These are called global illumination models because they take everything in the global scene into consideration when lighting an object. Global illumination models are generally prohibitively expensive for real-time games (but come very close to generating photorealistic scenes). Finding real-time methods for approximating global illumination is an area of ongoing research; see, for example, voxel global illumination [http://on-demand.gputechconf.com/gtc/2014/presentations/S4552-rt-voxel-based-global-illumination-gpus.pdf]. Other popular methods are to precompute indirect lighting for static objects (e.g., walls, statues), and then use that result to approximate indirect lighting for dynamic objects (e.g., moving game characters). 8.2 NORMAL VECTORS A face normal is a unit vector that describes the direction a polygon is facing (i.e., it is orthogonal to all points on the polygon); see Figure 8.4a. A surface normal is a unit vector that is orthogonal to the tangent plane of a point on a surface; see Figure 8.4b. Observe that surface normals determine the direction a point on a surface is “facing.”
Figure 8.4. (a) The face normal is orthogonal to all points on the face. (b) The surface normal is the vector that is orthogonal to the tangent plane of a point on a surface.
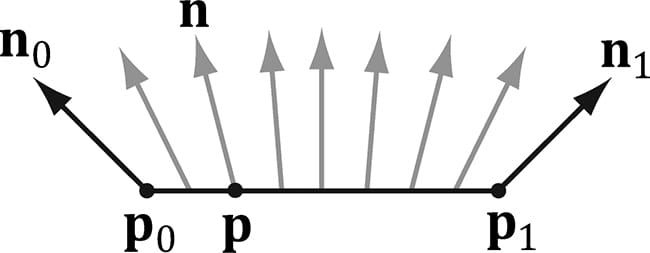
Figure 8.5. The vertex normals n0 and n1 are defined at the segment vertex points p0 and p1. A normal vector n for a point p in the interior of the line segment is found by linearly interpolating (weighted average) between the vertex normals; that is, n = n0 + t(n1 – n0) where t is such that p = p0 + t(p1 – p0) Although we illustrated normal interpolation over a line segment for simplicity, the idea straightforwardly generalizes to interpolating over a 3D triangle. For lighting calculations, we need the surface normal at each point on the surface of a triangle mesh so that we can determine the angle at which light strikes the point on the mesh surface. To obtain surface normals, we specify the surface normals only at the vertex points (so-called vertex normals). Then, in order to obtain a surface normal approximation at each point on the surface of a triangle mesh, these vertex normals will be interpolated across the triangle during rasterization (recall §5.10.3 and see Figure 8.5).
8.2.1 Computing Normal Vectors To find the face normal of a triangle Δp0, p1, p2 we first compute two vectors that lie on the triangle’s edges: u = p1 – p0 v = p2 – p0 Then the face normal is:
Below is a function that computes the face normal of the front side (§5.10.2) of a triangle from the three vertex points of the triangle. XMVECTOR ComputeNormal(FXMVECTOR p0, FXMVECTOR p1, FXMVECTOR p2) { XMVECTOR u = p1 - p0; XMVECTOR v = p2 - p0; return XMVector3Normalize( XMVector3Cross(u,v)); }
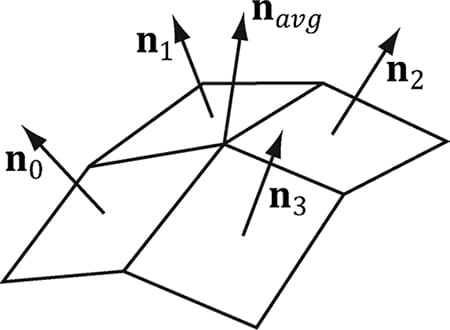
Figure 8.6. The middle vertex is shared by the neighboring four polygons, so we approximate the middle vertex normal by averaging the four polygon face normals. For a differentiable surface, we can use calculus to find the normals of points on the surface. Unfortunately, a triangle mesh is not differentiable. The technique that is generally applied to triangle meshes is called vertex normal averaging. The vertex normal n or an arbitrary vertex v in a mesh is found by averaging the face normals of every polygon in the mesh that shares the vertex v. For example, in Figure 8.6, four polygons in the mesh share the vertex v thus, the vertex normal for v is given by:
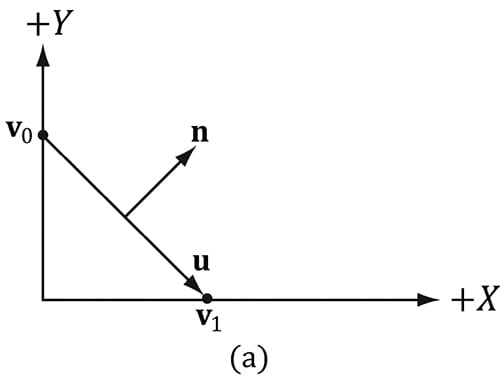
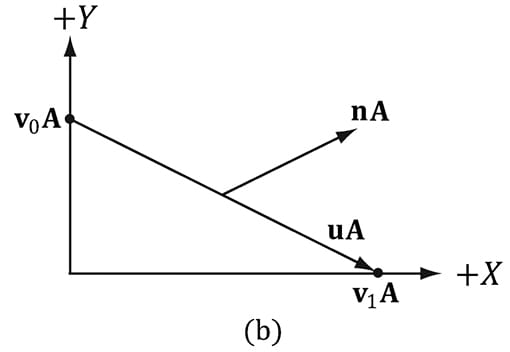
In the above example, we do not need to divide by 4, as we would in a typical average, since we normalize the result. Note also that more sophisticated averaging schemes can be constructed; for example, a weighted average might be used where the weights are determined by the areas of the polygons (e.g., polygons with larger areas have more weight than polygons with smaller areas). The following pseudocode shows how this averaging can be implemented given the vertex and index list of a triangle mesh: // Input: // 1. An array of vertices (mVertices). Each vertex has a // position component (pos) and a normal component (normal). // 2. An array of indices (mIndices). // For each triangle in the mesh: for(UINT i = 0; i < mNumTriangles; ++i) { // indices of the ith triangle UINT i0 = mIndices[i*3+0]; UINT i1 = mIndices[i*3+1]; UINT i2 = mIndices[i*3+2]; // vertices of ith triangle Vertex v0 = mVertices[i0]; Vertex v1 = mVertices[i1]; Vertex v2 = mVertices[i2]; // compute face normal Vector3 e0 = v1.pos - v0.pos; Vector3 e1 = v2.pos - v0.pos; Vector3 faceNormal = Cross(e0, e1); // This triangle shares the following three vertices, // so add this face normal into the average of these // vertex normals. mVertices[i0].normal += faceNormal; mVertices[i1].normal += faceNormal; mVertices[i2].normal += faceNormal; } // For each vertex v, we have summed the face normals of all // the triangles that share v, so now we just need to normalize. for(UINT i = 0; i < mNumVertices; ++i) mVertices[i].normal = Normalize(&mVertices[i].normal)); 8.2.2 Transforming Normal Vectors Consider Figure 8.7a where we have a tangent vector u = v1 − v0 orthogonal to a normal vector n. If we apply a non-uniform scaling transformation A we see from Figure 8.7b that the transformed tangent vector uA = v1A − v0A does not remain orthogonal to the transformed normal vector nA.
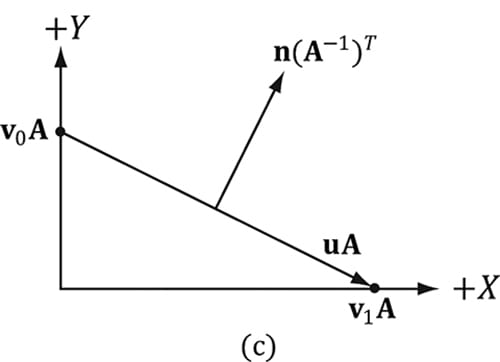
Figure 8.7. (a) The surface normal before transformation. (b) After scaling by 2 units on the x-axis the normal is no longer orthogonal to the surface. (c) The surface normal correctly transformed by the inverse-transpose of the scaling transformation. So our problem is this: Given a transformation matrix A that transforms points and vectors (non-normal), we want to find a transformation matrix B that transforms normal vectors such that the transformed tangent vector is orthogonal to the transformed normal vector (i.e., uA·nB = 0). To do this, let us first start with something we know: we know that the normal vector n is orthogonal to the tangent vector u:
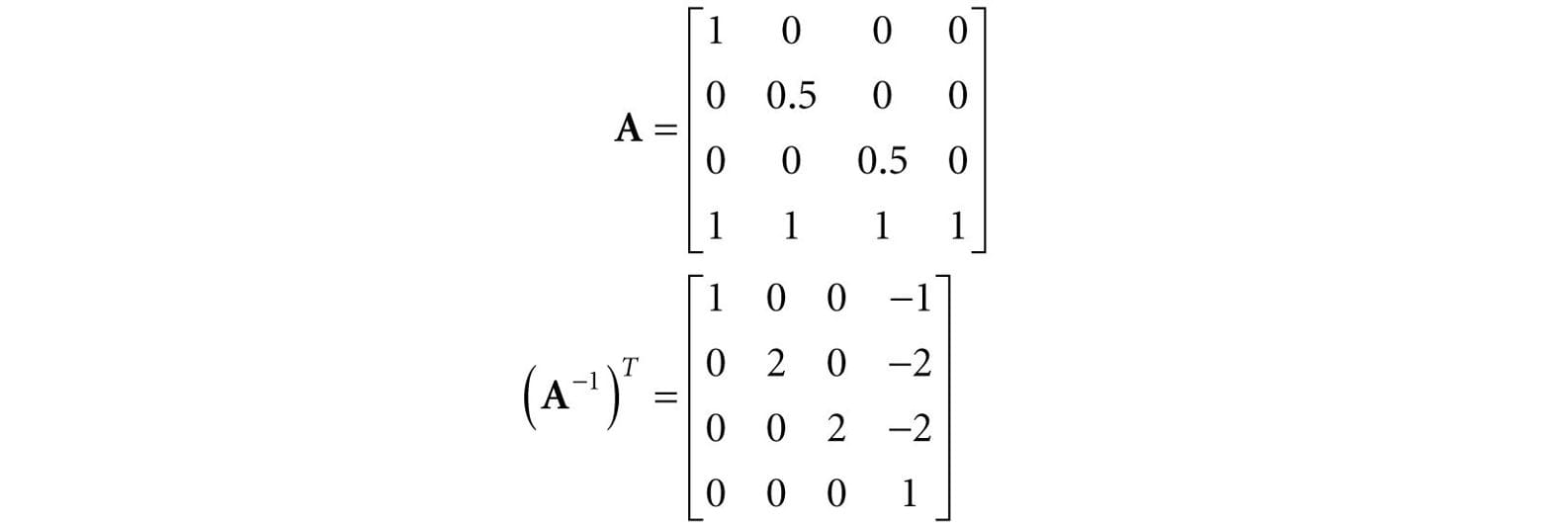
Thus B = (A−1)T (the inverse transpose of A) does the job in transforming normal vectors so that they are perpendicular to its associated transformed tangent vector uA. Note that if the matrix is orthogonal (AT = A−1), then B = (A−1)T = (AT)T = A; that is, we do not need to compute the inverse transpose, since A does the job in this case. In summary, when transforming a normal vector by a nonuniform or shear transformation, use the inverse-transpose. We implement a helper function in MathHelper.h for computing the inverse-transpose: static XMMATRIX InverseTranspose(CXMMATRIX M) { XMMATRIX A = M; A.r[3] = XMVectorSet(0.0f, 0.0f, 0.0f, 1.0f); XMVECTOR det = XMMatrixDeterminant(A); return XMMatrixTranspose(XMMatrixInverse(&det, A)); } We clear out any translation from the matrix because we use the inverse-transpose to transform vectors, and translations only apply to points. However, from §3.2.1 we know that setting w = 0 for vectors (using homogeneous coordinates) prevents vectors from being modified by translations. Therefore, we should not need to zero out the translation in the matrix. The problem is if we want to concatenate the inverse-transpose and another matrix that does not contain non-uniform scaling, say the view matrix (A−1)T V, the transposed translation in the fourth column of (A−1)T “leaks” into the product matrix causing errors. Hence, we zero out the translation as a precaution to avoid this error. The proper way would be to transform the normal by: ((AV)−1)T. Below is an example of a scaling and translation matrix, and what the inverse-transpose looks like with a fourth column not [0, 0, 0, 1]T:
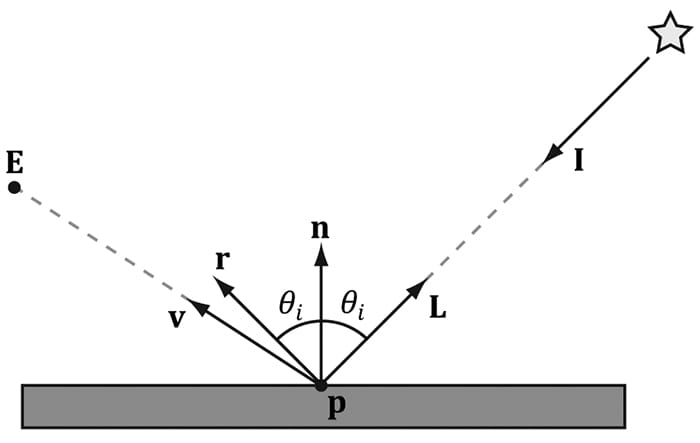
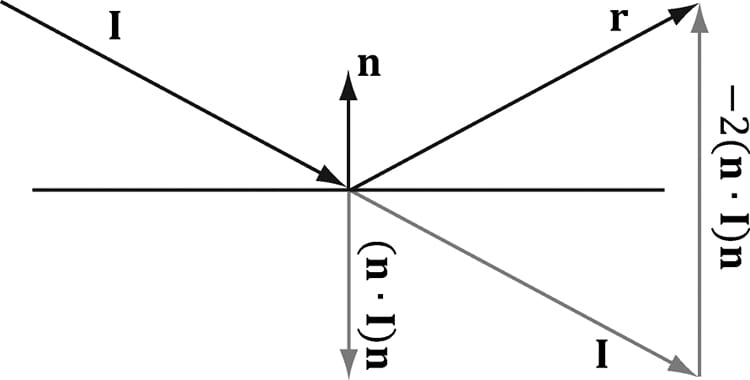
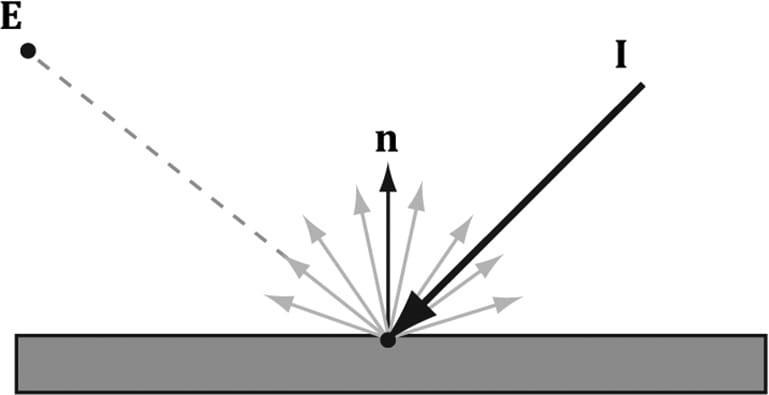
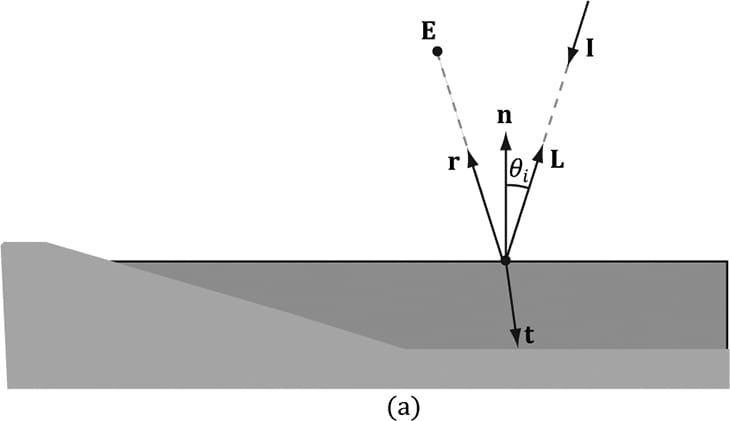
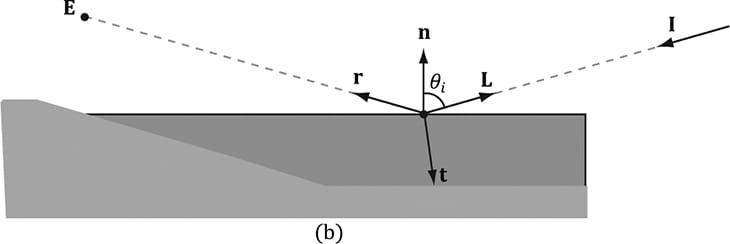
8.3 IMPORTANT VECTORS IN LIGHTING In this section, we summarize some important vectors involved with lighting. Referring to Figure 8.8, E is the eye position, and we are considering the point p the eye sees along the line of site defined by the unit vector v. At the point p the surface has normal n, and the point is hit by a ray of light traveling with incident direction I. The light vector L is the unit vector that aims in the opposite direction of the light ray striking the surface point. Although it may be more intuitive to work with the direction the light travels I, for lighting calculations we work with the light vector L; in particular, for calculating Lambert’s Cosine Law, the vector L is used to evaluate L·n = cos θi, where θiis the angle between L and n. The reflection vector r is the reflection of the incident light vector about the surface normal n. The view vector (or to-eye vector) v = normalize(E − p) is the unit vector from the surface point p to the eye point E that defines the line of site from the eye to the point on the surface being seen. Sometimes we need to use the vector −v, which is the unit vector from the eye to the point on the surface we are evaluating the lighting of.
Figure 8.8. Important vectors involved in lighting calculations. The reflection vector is given by: r = I – 2(n·I)n; see Figure 8.9. (It is assumed that n is a unit vector.) However, we can actually use the HLSL intrinsic reflect function to compute r for us in a shader program.
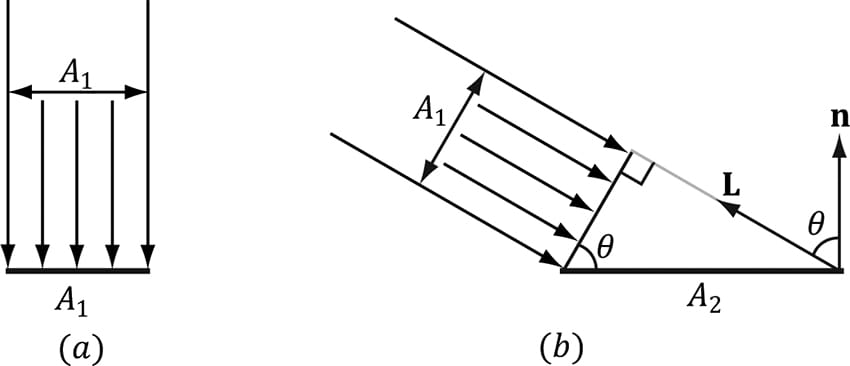
Figure 8.9. Geometry of reflection. 8.4 LAMBERT&RSQUO;S COSINE LAW We can think of light as a collection of photons traveling through space in a certain direction. Each photon carries some (light) energy. The amount of (light) energy emitted per second is called radiant flux. The density of radiant flux per area (called irradiance) is important because that will determine how much light an area on a surface receives (and thus how bright it will appear to the eye). Loosely, we can think of irradiance as the amount of light striking an area on a surface, or the amount of light passing through an imaginary area in space. Light that strikes a surface head-on (i.e., the light vector L equals the normal vector n) is more intense than light that glances a surface at an angle. Consider a small light beam with cross sectional area A1 with radiant flux P passing through it. If we aim this light beam at a surface head-on (Figure 8.10a), then the light beam strikes the area A1 on the surface and the irradiance at A1 is E1 = P/A1. Now suppose we rotate the light beam so that it strikes the surface at an angle (Figure 8.10b), then the light beam covers the larger area A2 and the irradiance striking this area is E2 = P/A2. By trigonometry, A1 and A2 are related by:
Therefore,
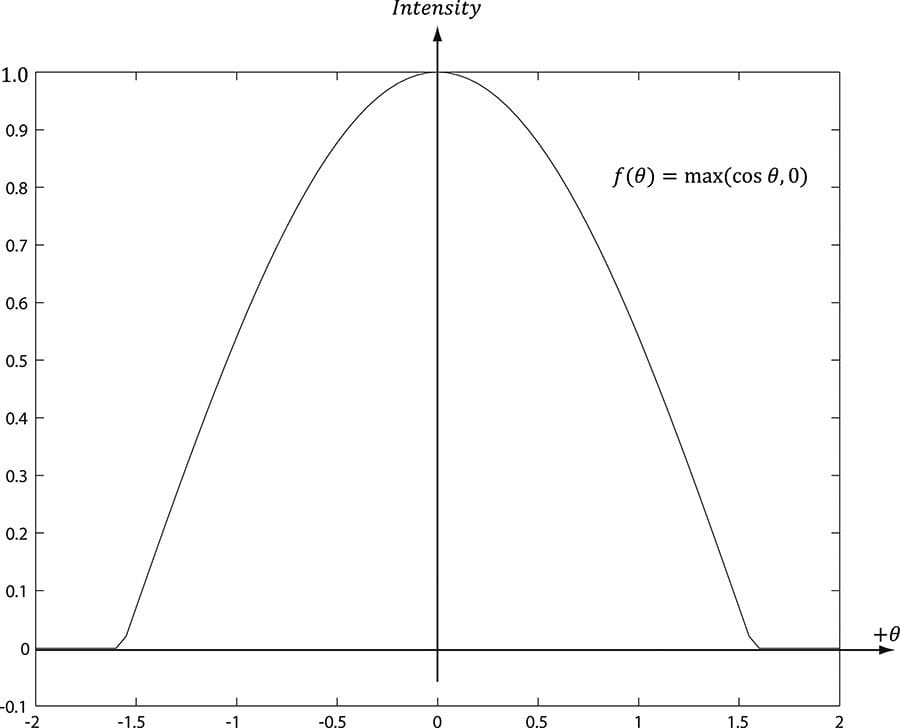
Figure 8.10. (a) A light beam with cross sectional area A1 strikes a surface head-on. (b) A light beam with cross sectional area A1 strikes a surface at an angle to cover a larger area A2 on the surface, thereby spreading the light energy over a larger area, thus making the light appear “dimmer.” In other words, the irradiance striking area A2 is equal to the irradiance at the area A1 perpendicular to the light direction scaled by n·L = cos θ. This is called Lambert’s Cosine Law. To handle the case where light strikes the back of the surface (which results in the dot product being negative), we clamp the result with the max function: f(θ) = max(cosθ, 0) = max(L·n, 0) Figure 8.11 shows a plot of f(θ) to see how the intensity, ranging from 0.0 to 1.0 (i.e., 0% to 100%), varies with θ.
Figure 8.11. Plot of the function f (θ) = max(cosθ, 0) = max(L·n, 0) for −2 ≤ θ ≤ 2. Note that π/2 ≈ 1.57. 8.5 DIFFUSE LIGHTING Consider the surface of an opaque object, as in Figure 8.12. When light strikes a point on the surface, some of the light enters the interior of the object and interacts with the matter near the surface. The light will bounce around in the interior, where some of it will be absorbed and the remaining part scattered out of the surface in every direction; this is called a diffuse reflection. For simplification, we assume the light is scattered out at the same point the light entered. The amount of absorption and scattering out depends on the material; for example, wood, dirt, brick, tile, and stucco would absorb/scatter light differently (which is why the materials look different). In our approximation for modeling this kind of light/material interaction, we stipulate that the light scatters out equally in all directions above the surface; consequently, the reflected light will reach the eye no matter the viewpoint (eye position). Therefore, we do not need to take the viewpoint into consideration (i.e., the diffuse lighting calculation is viewpoint independent), and the color of a point on the surface will always look the same no matter the viewpoint.
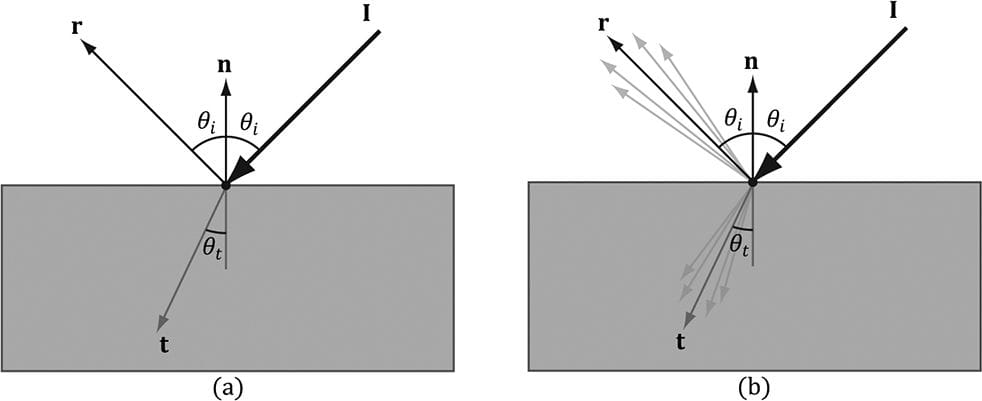
Figure 8.12. Incoming light scatters equally in every direction when striking a diffuse surface. The idea is that light enters the interior of the medium and scatters around under the surface. Some of the light will be absorbed and the remaining will scatter back out of the surface. Because it is difficult to model this subsurface scattering, we assume the re-emitted light scatters out equally in all directions above the surface about the point the light entered. We break the calculation of diffuse lighting into two parts. For the first part, we specify a light color and a diffuse albedo color. The diffuse albedo specifies the amount of incoming light that the surface reflects due to diffuse reflectance (by energy conservation, the amount not reflected is absorbed by the material). This is handled with a component-wise color multiplication (because light can be colored). For example, suppose some point on a surface reflects 50% incoming red light, 100% green light, and 75% blue light, and the incoming light color is 80% intensity white light. That is to say, the quantity of incoming light is given by BL = (0.8, 0.8, 0.8) and the diffuse albedo is given by md = (0.5, 1.0, 0.75); then the amount of light reflected off the point is given by: cd = BL ⊗ md = (0.8, 0.8, 0.8) ⊗ (0.5, 1.0, 0.75) = (0.4, 0.8, 0.6) Note that the diffuse albedo components must be in the range 0.0 to 1.0 so that they describe the fraction of light reflected. The above formula is not quite correct, however. We still need to include Lambert’s cosine law (which controls how much of the original light the surface receives based on the angle between the surface normal and light vector). Let BL represent the quantity of incoming light, md be the diffuse albedo color, L be the light vector, and n be the surface normal. Then the amount of diffuse light reflected off a point is given by: cd = max (L·n, 0) · BL ⊗ md (eq. 8.1) 8.6 AMBIENT LIGHTING As stated earlier, our lighting model does not take into consideration indirect light that has bounced off other objects in the scenes. However, much light we see in the real world is indirect. For example, a hallway connected to a room might not be in the direct line of site with a light source in the room, but the light bounces off the walls in the room and some of it may make it into the hallway, thereby lightening it up a bit. As a second example, suppose we are sitting in a room with a teapot on a desk and there is one light source in the room. Only one side of the teapot is in the direct line of site of light source; nevertheless, the backside of the teapot would not be completely black. This is because some light scatters off the walls or other objects in the room and eventually strikes the backside of the teapot. To sort of hack this indirect light, we introduce an ambient term to the lighting equation: ca = AL ⊗ md (eq. 8.2) The color AL specifies the total amount of indirect (ambient) light a surface receives, which may be different than the light emitted from the source due to the absorption that occurred when the light bounced off other surfaces. The diffuse albedo md specifies the amount of incoming light that the surface reflects due to diffuse reflectance. We use the same value for specifying the amount of incoming ambient light the surface reflects; that is, for ambient lighting, we are modeling the diffuse reflectance of the indirect (ambient) light. All ambient light does is uniformly brighten up the object a bit—there is no real physics calculation at all. The idea is that the indirect light has scattered and bounced around the scene so many times that it strikes the object equally in every direction. 8.7 SPECULAR LIGHTING We used diffuse lighting to model diffuse reflection, where light enters a medium, bounces around, some light is absorbed, and the remaining light is scattered out of the medium in every direction. A second kind of reflection happens due to the Fresnel effect, which is a physical phenomenon. When light reaches the interface between two media with different indices of refraction some of the light is reflected and the remaining light is refracted (see Figure 8.13). The index of refraction is a physical property of a medium that is the ratio of the speed of light in a vacuum to the speed of light in the given medium. We refer to this light reflection process as specular reflection and the reflected light as specular light. Specular light is illustrated in Figure 8.14a.
Figure 8.13. (a) The Fresnel effect for a perfectly flat mirror with normal n. The incident light I is split where some of it reflects in the reflection direction r and the remaining light refracts into the medium in the refraction direction t. All these vectors are in the same plane. The angle between the reflection vector and normal is always θi, which is the same as the angle between the light vector L = −I and normal n. The angle θt between the refraction vector and −n depends in the indices of refraction between the two mediums and is specified by Snell’s Law. (b) Most objects are not perfectly flat mirrors but have microscopic roughness. This causes the reflected and refracted light to spread about the reflection and refraction vectors. If the refracted vector exits the medium (from the other side) and enters the eye, the object appears transparent. That is, light passes through transparent objects. Real-time graphics typically use alpha blending or a post process effect to approximate refraction in transparent objects, which we will explain later in this book. For now, we consider only opaque objects. For opaque objects, the refracted light enters the medium and undergoes diffuse reflectance. So we can see from Figure 8.14b that for opaque objects, the amount of light that reflects off a surface and makes it into the eye is a combination of body reflected (diffuse) light and specular reflection. In contrast to diffuse light, specular light might not travel into the eye because it reflects in a specific direction; that is to say, the specular lighting calculation is viewpoint dependent. This means that as the eye moves about the scene, the amount of specular light it receives will change.
Figure 8.14. (a) Specular light of a rough surface spreads about the reflection vector r. (b) The reflected light that makes it into the eye is a combination of specular reflection and diffuse reflection. 8.7.1 Fresnel Effect Let us consider a flat surface with normal n that separates two mediums with different indices of refraction. Due to the index of refraction discontinuity at the surface, when incoming light strikes the surface some reflects away from the surface and some refracts into the surface (see Figure 8.13). The Fresnel equations mathematically describe the percentage of incoming light that is reflected, 0 ≤ RF ≤ 1. By conservation of energy, if RF is the amount of reflected light then (1 − RF) is the amount of refracted light. The value RF is an RGB vector because the amount of reflection depends on the light color. How much light is reflected depends on the medium (some materials will be more reflective than others) and also on the angle θi between the normal vector n and light vector L. Due to their complexity, the full Fresnel equations are not typically used in real-time rendering; instead, the Schlick approximation is used:
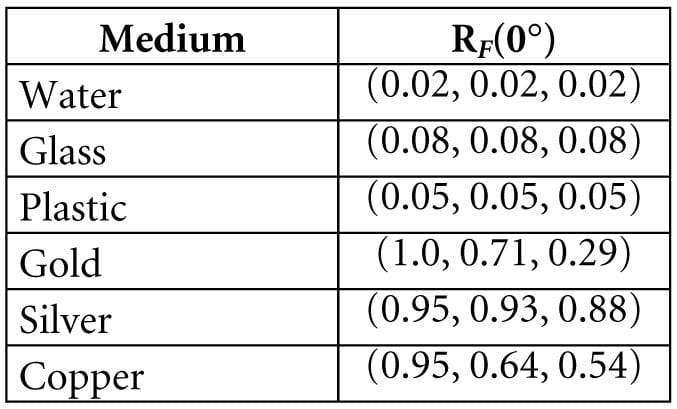
RF(0°) is a property of the medium; below are some values for common materials [Möller08]:
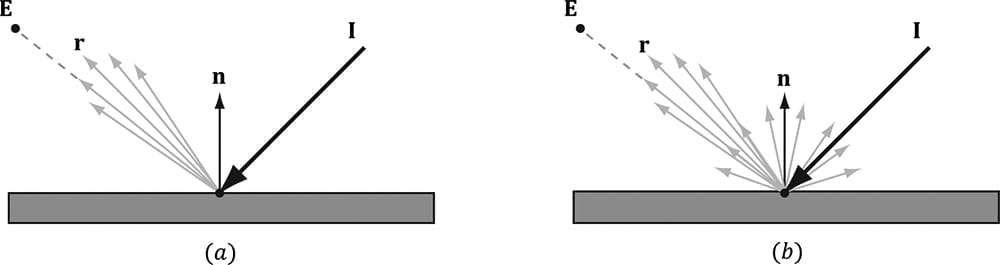
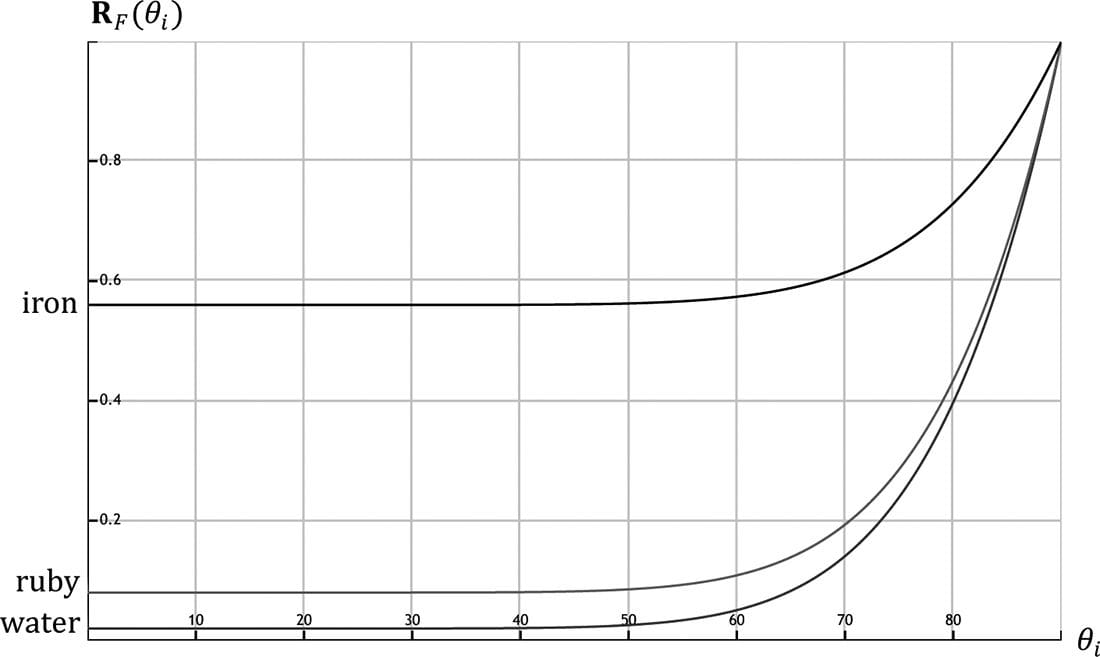
Figure 8.15 shows a plot of the Schlick approximation for a couple different RF(0°). The key observation is that the amount of reflection increases as θi → 90°. Let us look at a real-world example. Consider Figure 8.16. Suppose we are standing a couple feet deep in a calm pond of relatively clear water. If we look down, we mostly see the bottom sand and rocks of the pond. This is because the light coming down from the environment that reflects into our eye forms a small angle θi near 0.0°; thus, the amount of reflection is low, and, by energy conservation, the amount of refraction high. On the other hand, if we look towards the horizon, we will see a strong reflection in the pond water. This is because the light coming down from the environment that makes it into our eye forms an angle θi closer to 90.0°, thus increasing the amount of reflection. This behavior is often referred to as the Fresnel effect. To summarize the Fresnel effect briefly: the amount of reflected light depends on the material (RF(0°)) and the angle between the normal and light vector.
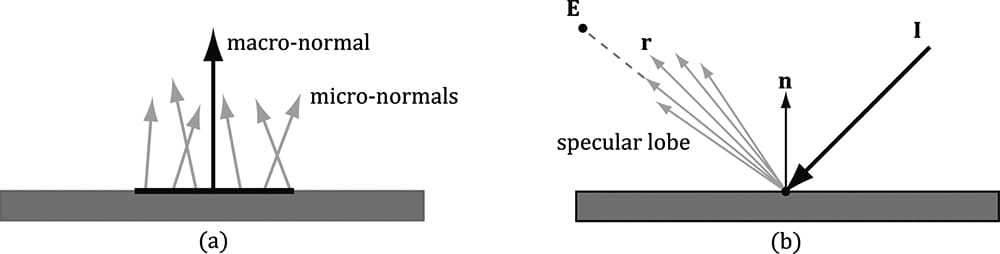
Figure 8.15. The Schlick approximation plotted for different materials: water, ruby, and iron. Metals absorb transmitted light [Möller08], which means they will not have body reflectance. Metals do not appear black, however, as they have high RF(0°) values which means they reflect a fair amount of specular light even at small incident angles near 0°. 8.7.2 Roughness Reflective objects in the real world tend not to be perfect mirrors. Even if an object’s surface appears flat, at the microscopic level we can think of it as having roughness. Referring to Figure 8.17, we can think of a perfect mirror as having no roughness and its micro-normals all aim in the same direction as the macro-normal. As the roughness increases, the direction of the micro-normals diverge from the macro-normal, causing the reflected light to spread out into a specular lobe.
Figure 8.16. (a): Looking down in the pond, reflection is low and refraction high because the angle between L and n is small. (b) Look towards the horizon and reflection is high and refraction low because the angle between L and n is closer to 90°.
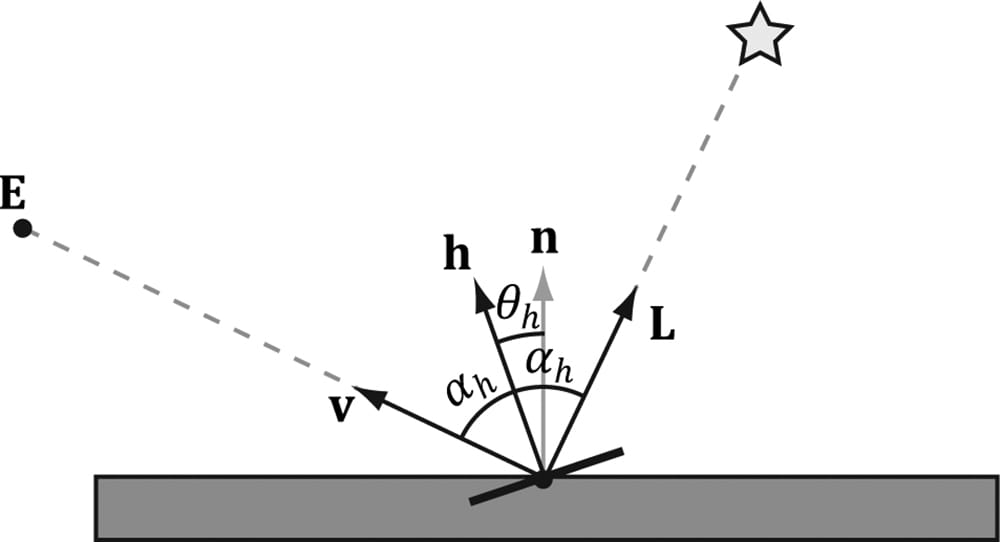
Figure 8.17. (a) The black horizontal bar represents the magnification of a small surface element. At the microscopic level, the area has many micro-normals that aim in different directions due to roughness at the microscopic level. The smoother the surface, the more ali gned the micro-normals will be with the macro-normal; the rougher the surface, the more the micro-normals will diverge from the macro-normal. (b) This roughness causes the specular reflected light to spread out. The shape of the of the specular reflection is referred to as the specular lobe. In general, the shape of the specular lobe can vary based on the type of surface material being modeled. To model roughness mathematically, we employ the microfacet model, where we model the microscopic surface as a collection of tiny flat elements called microfacets; the micro-normals are the normals to the microfacets. For a given view v and light vector L, we want to know the fraction of microfacets that reflect L into v; in other words, the fraction of microfacets with normal h = normalize(L + v); see Figure 8.18. This will tell us how much light is reflected into the eye from specular reflection—the more microfacets that reflect L into v the brighter the specular light the eye sees.
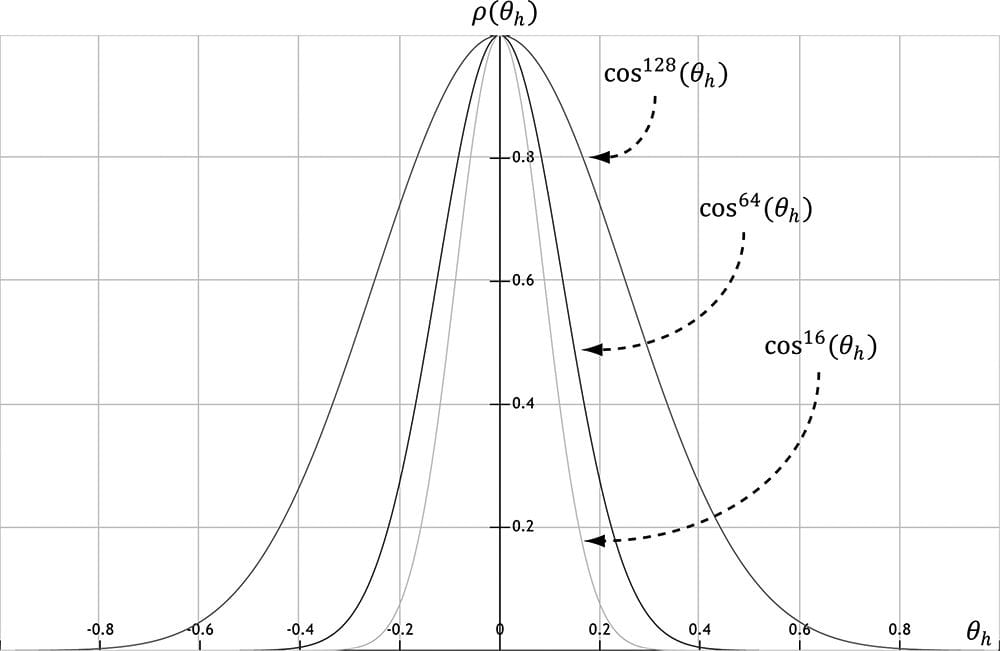
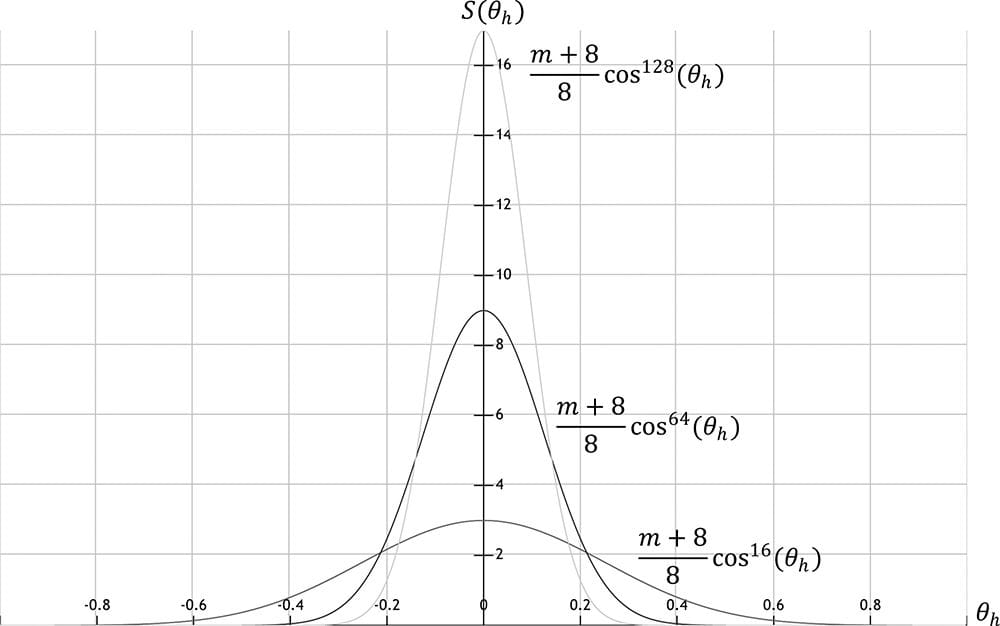
Figure 8.18. The microfacets with normal h reflect L into v. The vector h is called the halfway vector as it lies halfway between L and v. Moreover, let us also introduce the angle θh between the halfway vector h and the macro-normal n. We define the normalized distribution function ρ(θh) ∈ [0, 1] to denote the fraction of microfacets with normals h that make an angle θh with the macro-normal n. Intuitively, we expect that ρ(θh) achieves its maximum when θh= 0°. That is, we expect the microfacet normals to be biased towards the macro-normal, and as θh increases (as h diverges from the micro-normal n) we expect the fraction of microfacets with normal h to decrease. A popular controllable function to model ρ(θh) that has the expectations just discussed is: ρ(θh) = cosm(θh) Note that cos(θh) = (n·h) provided both vectors and unit length. Figure 8.19 shows ρ(θh) = cosh(θh) for various m. Here m controls the roughness, which specifies the fraction of microfacets with normals h that make an angle θhwith the macro-normal n. As m decreases, the surface becomes rougher, and the microfacet normals increasingly diverge from the macro-normal. As m increases, the surface becomes smoother, and the microfacet normals increasingly converge to the macro-normal.
Figure 8.19. A function to model roughness. We can combine ρ(θh) with a normalization factor to obtain a new function that models the amount of specular reflection of light based on roughness:
Figure 8.20 shows this function for various m. Like before, m controls the roughness, but we have added the normalization factor so that light energy is conserved; it is essentially controlling the height of the curve in Figure 8.20 so that the overall light energy is conserved as the specular lobe widens or narrows with m. For a smaller m, the surface is rougher and the specular lobe widens as light energy is more spread out; therefore, we expect the specular highlight to be dimmer since the energy has been spread out. On the other hand, for a larger m, the surface is smoother and the specular lobe is narrower; therefore, we expect the specular highlight to be brighter since the energy has been concentrated. Geometrically, m controls the spread of the specular lobe. To model smooth surfaces (like polished metal) you will use a large m, and for rougher surfaces you will use a small m.
Figure 8.20. A function to model specular reflection of light due to roughness. To conclude this section, let us combine Fresnel reflection and surface roughness. We are trying to compute how much light is reflected into the view direction v (see Figure 8.18). Recall that microfacets with normals h reflect light into v. Let αh be the angle between the light vector and half vector h, then RF(αh) tells us the amount of light reflected about h into v due to the Fresnel effect. Multiplying the amount of reflected light RF(αh) due to the Fresnel effect with the amount of light reflected due to roughness S(θh) gives us the amount of specular reflected light: Let (max(L·n, 0)·BL) represent the quantity of incoming light that strikes the surface point we are lighting, then the fraction of (max(L·n, 0)·BL) specularly reflected into the eye due to roughness and the Fresnel effect is given by:
Observe that if L·n ≤ 0 the light strikes the back of the surface we are computing; hence the front-side surface receives no light. 8.8 LIGHTING MODEL RECAP Bringing everything together, the total light reflected off a surface is a sum of ambient light reflectance, diffuse light reflectance and specular light reflectance: 1. Ambient Light ca: Models the amount of light reflected off the surface due to indirect light. 2. Diffuse Light cd: Models light that enters the interior of a medium, scatters around under the surface where some of the light is absorbed and the remaining light scatters back out of the surface. Because it is difficult to model this subsurface scattering, we assume the re-emitted light scatters out equally in all directions above the surface about the point the light entered. 3. Specular Light cs: Models the light that is reflected off the surface due to the Fresnel effect and surface roughness. This leads to the lighting equation our shaders implement in this book:
All of the vectors in this equation are assumed to be unit length. 1. L: The light vector aims toward the light source. 2. n: The surface normal. 3. h: The halfway vector lies halfway between the light vector and view vector (vector from surface point being lit to the eye point). 4. AL: Represent the quantity of incoming ambient light. 5. BL: Represent the quantity of incoming direct light. 6. md: Specifies the amount of incoming light light that the surface reflects due to diffuse reflectance. 7. L·n : Lambert’s Cosine Law. 8. αh: Angle between the half vector h and light vector L. 9. RF(αh): Specifies the amount of light reflected about h into the eye due to the Fresnel effect. 10.m: Controls the surface roughness. 11.(n·h)h: Specifies the fraction of microfacets with normals h that make an angle θhwith the macro-normal n. 12. : Normalization factor to model energy conservation in the specular reflection. Figure 8.21 shows how these three components work together.
Figure 8.21. (a) Sphere colored with ambient light only, which uniformly brightens it. (b) Ambient and diffuse lighting combined. There is now a smooth transition from bright to dark due to Lambert’s cosine law. (c) Ambient, diffuse, and specular lighting. The specular lighting yields a specular highlight.
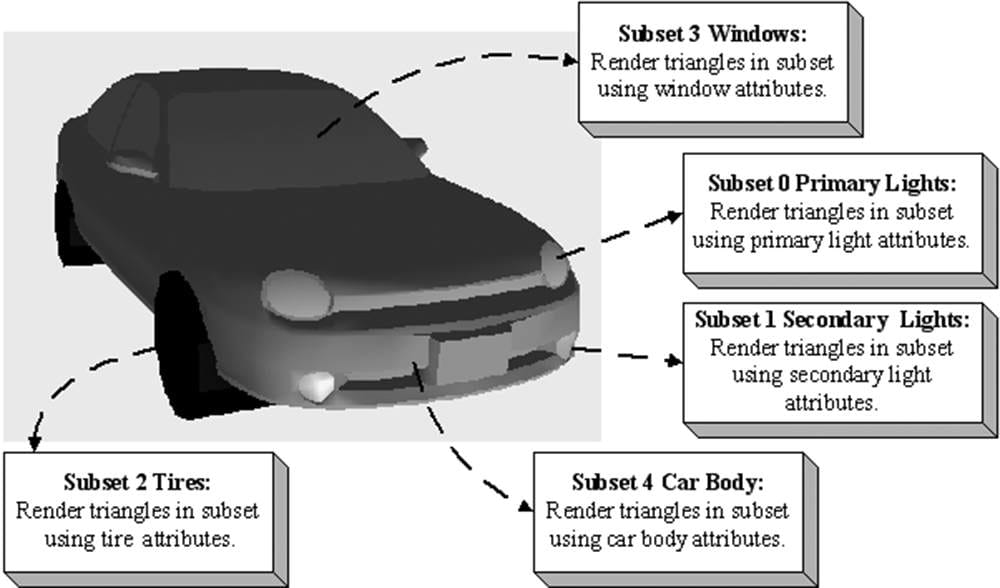
8.9 IMPLEMENTING MATERIALS Our material structure looks like this, and is defined in d3dUtil.h: // Simple struct to represent a material for our demos. struct Material { // Unique material name for lookup. std::string Name; // Index into constant buffer corresponding to this material. int MatCBIndex = -1; // Index into SRV heap for diffuse texture. Used in the texturing // chapter. int DiffuseSrvHeapIndex = -1; // Dirty flag indicating the material has changed and we need to // update the constant buffer. Because we have a material constant // buffer for each FrameResource, we have to apply the update to each // FrameResource. Thus, when we modify a material we should set // NumFramesDirty = gNumFrameResources so that each frame resource // gets the update. int NumFramesDirty = gNumFrameResources; // Material constant buffer data used for shading. DirectX::XMFLOAT4 DiffuseAlbedo = { 1.0f, 1.0f, 1.0f, 1.0f }; DirectX::XMFLOAT3 FresnelR0 = { 0.01f, 0.01f, 0.01f }; float Roughness = 0.25f; DirectX::XMFLOAT4X4 MatTransform = MathHelper::Identity4x4(); }; Modeling real-world materials will require a combination of setting realistic values for the DiffuseAlbedo and FresnelR0, and some artistic tweaking. For example, metal conductors absorb refracted light [Möller08] that enters the interior of the metal, which means metals will not have diffuse reflection (i.e., the DiffuseAlbedo would be zero). However, to compensate that we are not doing 100% physical simulation of lighting, it may give better artistic results to give a low DiffuseAlbedo value rather than zero. The point is: we will try to use physically realistic material values, but are free to tweak the values as we want if the end result looks better from an artistic point of view. In our material structure, roughness is specified in a normalized floating-point value in the [0, 1] range. A roughness of 0 would indicate a perfectly smooth surface, and a roughness of 1 would indicate the roughest surface physically possible. The normalized range makes it easier to author roughness and compare the roughness between different materials. For example, a material with a roughness of 0.6 is twice as rough as a material with roughness 0.3. In the shader code, we will use the roughness to derive the exponent m used in Equation 8.4. Note that with our definition of roughness, the shininess of a surface is just the inverse of the roughness: shininess = 1 – roughness ∈ [0, 1]. A question now is at what granularity we should specify the material values? The material values may vary over the surface; that is, different points on the surface may have different material values. For example, consider a car model as shown in Figure 8.22, where the frame, windows, lights, and tires reflect and absorb light differently, and so the material values would need to vary over the car surface.
Figure 8.22. A car mesh divided into five material attribute groups. To implement this variation, one solution might be to specify material values on a per vertex basis. These per vertex materials would then interpolated across the triangle during rasterization, giving us material values for each point on the surface of the triangle mesh. However, as we saw from the “Hills” demo in Chapter 7, per vertex colors are still too coarse to realistically model fine details. Moreover, per vertex colors add additional data to our vertex structures, and we need to have tools to paint per vertex colors. Instead, the prevalent solution is to use texture mapping, which will have to wait until the next chapter. For this chapter, we allow material changes at the draw call frequency. To do this, we define the properties of each unique material and put them in a table: std::unordered_map<std::string, std::unique_ptr<Material>> mMaterials; void LitWavesApp::BuildMaterials() { auto grass = std::make_unique<Material>(); grass->Name = "grass"; grass->MatCBIndex = 0; grass->DiffuseAlbedo = XMFLOAT4(0.2f, 0.6f, 0.6f, 1.0f); grass->FresnelR0 = XMFLOAT3(0.01f, 0.01f, 0.01f); grass->Roughness = 0.125f; // This is not a good water material definition, but we do not have // all the rendering tools we need (transparency, environment // reflection), so we fake it for now. auto water = std::make_unique<Material>(); water->Name = "water"; water->MatCBIndex = 1; water->DiffuseAlbedo = XMFLOAT4(0.0f, 0.2f, 0.6f, 1.0f); water->FresnelR0 = XMFLOAT3(0.1f, 0.1f, 0.1f); water->Roughness = 0.0f; mMaterials["grass"] = std::move(grass); mMaterials["water"] = std::move(water); } The above table stores the material data in system memory. In order for the GPU to access the material data in a shader, we need to mirror the relevant data in a constant buffer. Just like we did with per-object constant buffers, we add a constant buffer to each FrameResource that will store the constants for each material: struct MaterialConstants { DirectX::XMFLOAT4 DiffuseAlbedo = { 1.0f, 1.0f, 1.0f, 1.0f }; DirectX::XMFLOAT3 FresnelR0 = { 0.01f, 0.01f, 0.01f }; float Roughness = 0.25f; // Used in the chapter on texture mapping. DirectX::XMFLOAT4X4 MatTransform = MathHelper::Identity4x4(); }; struct FrameResource { public: … std::unique_ptr<UploadBuffer<MaterialConstants>> MaterialCB = nullptr; … }; Note that the MaterialConstants structure contains a subset of the Material data; specifically, it contains just the data the shaders need for rendering. In the update function, the material data is then copied to a subregion of the constant buffer whenever it is changed (“dirty”) so that the GPU material constant buffer data is kept up to date with the system memory material data: void LitWavesApp::UpdateMaterialCBs(const GameTimer& gt) { auto currMaterialCB = mCurrFrameResource->MaterialCB.get(); for(auto& e : mMaterials) { // Only update the cbuffer data if the constants have changed. If // the cbuffer data changes, it needs to be updated for each // FrameResource. Material* mat = e.second.get(); if(mat->NumFramesDirty > 0) { XMMATRIX matTransform = XMLoadFloat4x4(&mat->MatTransform); MaterialConstants matConstants; matConstants.DiffuseAlbedo = mat->DiffuseAlbedo; matConstants.FresnelR0 = mat->FresnelR0; matConstants.Roughness = mat->Roughness; currMaterialCB->CopyData(mat->MatCBIndex, matConstants); // Next FrameResource need to be updated too. mat->NumFramesDirty--; } } } Now each render item contains a pointer to a Material. Note that multiple render items can refer to the same Material object; for example, multiple render items might use the same “brick” material. In turn, each Material object has an index that specifies were its constant data is in the material constant buffer. From this, we can offset to the virtual address of the constant data needed for the render item we are drawing, and set it to the root descriptor that expects the material constant data. (Alternatively, we could offset to a CBV descriptor in a heap and set a descriptor table, but we defined our root signature in this demo to take a root descriptor for the material constant buffer instead of a table.) The following code shows how we draw render items with different materials: void LitWavesApp::DrawRenderItems( ID3D12GraphicsCommandList* cmdList, const std::vector<RenderItem*>& ritems) { UINT objCBByteSize = d3dUtil::CalcConstantBufferByteSize (sizeof(ObjectConstants)); UINT matCBByteSize = d3dUtil::CalcConstantBufferByteSize (sizeof(MaterialConstants)); auto objectCB = mCurrFrameResource->ObjectCB->Resource(); auto matCB = mCurrFrameResource->MaterialCB->Resource(); // For each render item… for(size_t i = 0; i < ritems.size(); ++i) { auto ri = ritems[i]; cmdList->IASetVertexBuffers(0, 1, &ri->Geo->VertexBufferView()); cmdList->IASetIndexBuffer(&ri->Geo->IndexBufferView()); cmdList->IASetPrimitiveTopology(ri->PrimitiveType); D3D12_GPU_VIRTUAL_ADDRESS objCBAddress = objectCB->GetGPUVirtualAddress() + ri->ObjCBIndex*objCBByteSize; D3D12_GPU_VIRTUAL_ADDRESS matCBAddress = matCB->GetGPUVirtualAddress() + ri->Mat->MatCBIndex*matCBByteSize; cmdList->SetGraphicsRootConstantBufferView(0, objCBAddress); cmdList->SetGraphicsRootConstantBufferView(1, matCBAddress); cmdList->DrawIndexedInstanced(ri->IndexCount, 1, ri->StartIndexLocation, ri->BaseVertexLocation, 0); } } We remind the reader that we need normal vectors at each point on the surface of a triangle mesh so that we can determine the angle at which light strikes a point on the mesh surface (for Lambert’s cosine law). In order to obtain a normal vector approximation at each point on the surface of the triangle mesh, we specify normals at the vertex level. These vertex normals will be interpolated across the triangle during rasterization. So far we have discussed the components of light, but we have not discussed specific kinds of light sources. The next three sections describe how to implement, parallel, point, and spot lights. 8.10 PARALLEL LIGHTS A parallel light (or directional light) approximates a light source that is very far away. Consequently, we can approximate all incoming light rays as parallel to each other (Figure 8.23). Moreover, because the light source is very far away, we can ignore the effects of distance and just specify the light intensity where the light strikes the scene.
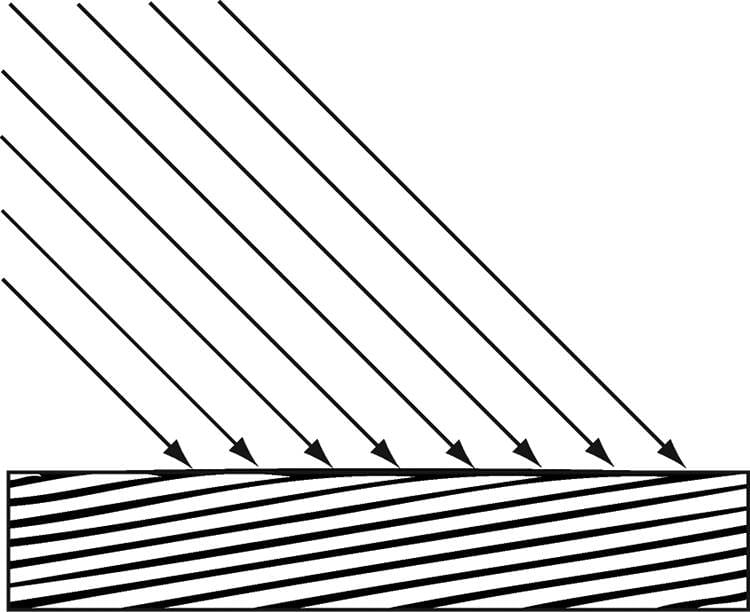
Figure 8.23. Parallel light rays striking a surface. A parallel light source is defined by a vector, which specifies the direction the light rays travel. Because the light rays are parallel, they all use the same direction vector. The light vector, aims in the opposite direction the light rays travel. A common example of a light source that can accurately be modeled as a directional light is the sun (Figure 8.24).
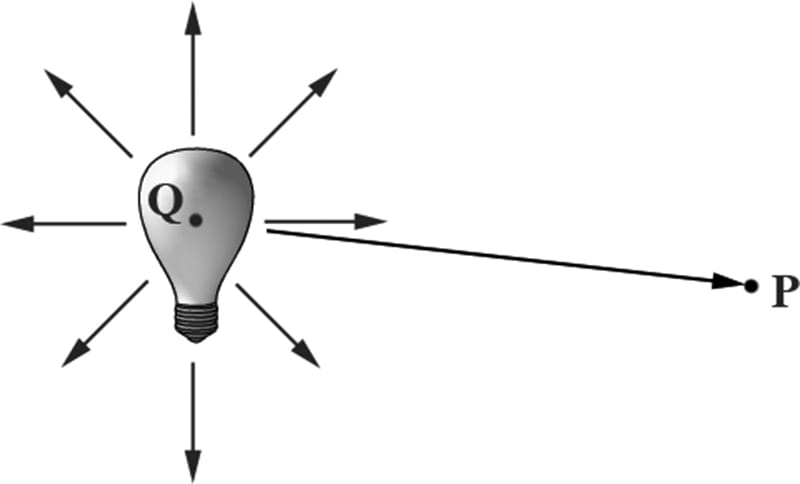
Figure 8.24. The figure is not drawn to scale, but if you select a small surface area on the Earth, the light rays striking that area are approximately parallel. 8.11 POINT LIGHTS A good physical example of a point light is a lightbulb; it radiates spherically in all directions (Figure 8.25). In particular, for an arbitrary point P, there exists a light ray originating from the point light position Q traveling toward the point. As usual, we define the light vector to go in the opposite direction; that is, the direction from the point P to the point light source Q:
Essentially, the only difference between point lights and parallel lights is how the light vector is computed—it varies from point to point for point lights, but remains constant for parallel lights.
Figure 8.25. Point lights radiate in every direction; in particular, for an arbitrary point P there exists a light ray originating from the point source Q towards P. 8.11.1 Attenuation Physically, light intensity weakens as a function of distance based on the inverse squared law. That is to say, the light intensity at a point a distance d away from the light source is given by:
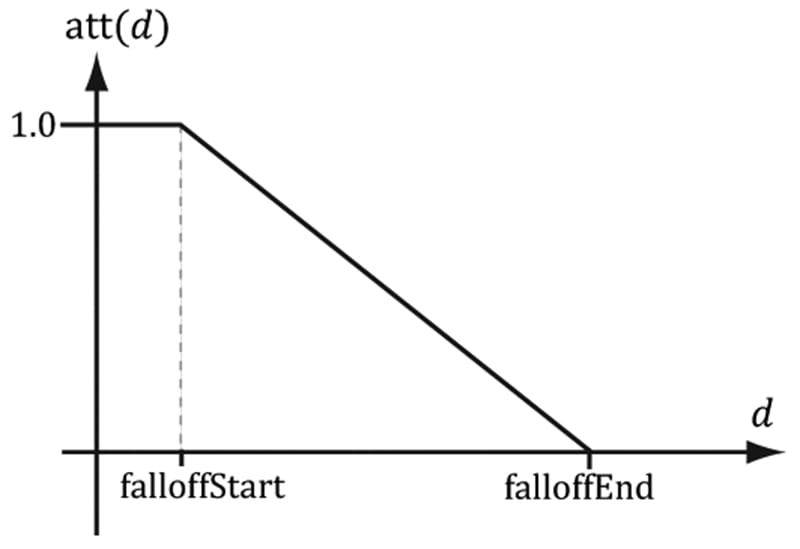
where I0 is the light intensity at a distance d = 1 from the light source. This works well if you set up physically based light values and use HDR (high dynamic range) lighting and tonemapping. However, an easier formula to get started with, and the one we shall use in our demos, is a linear falloff function:
A graph of this function is depicted in Figure 8.26. The saturate function clamps the argument to the range [0, 1]:
Figure 8.26. The attenuation factor that scales the light value stays at full strength (1.0) until the distance d reaches falloffStart, it then linearly decays to 0.0 as the distance reaches falloffEnd. The formula for evaluating a point light is the same as Equation 8.4, but we must scale the light source value BL by the attenuation factor att(d). Note that attenuation does not affect ambient term, as the ambient term is used to model indirect light that has bounced around. Using our falloff function, a point whose distance from the light source is greater than or equal to falloffEnd receives no light. This provides a useful lighting optimization: in our shader programs, if a point is out of range, then we can return early and skip the lighting calculations with dynamic branching. 8.12 SPOTLIGHTS A good physical example of a spotlight is a flashlight. Essentially, a spotlight has a position Q, is aimed in a direction d, and radiates light through a cone (see Figure 8.27).
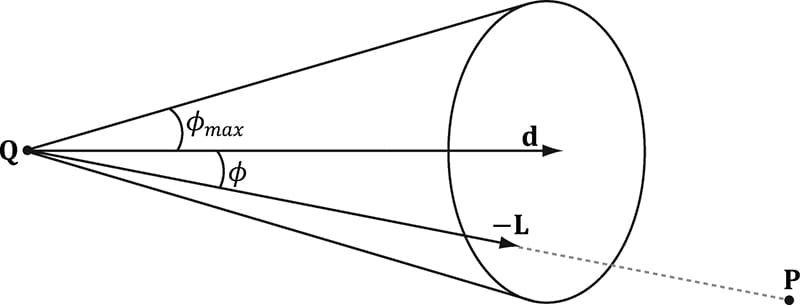
Figure 8.27. A spotlight has a position Q, is aimed in a direction d, and radiates light through a cone with angle φmax. To implement a spotlight, we begin as we do with a point light: the light vector is given by:
where P is the position of the point being lit and Q is the position of the spotlight. Observe from Figure 8.27 that P is inside the spotlight’s cone (and therefore receives light) if and only if the angle ϕ between −L and d is smaller than the cone angle ϕmax. Moreover, all the light in the spotlight’s cone should not be of equal intensity; the light at the center of the cone should be the most intense and the light intensity should fade to zero as ϕ increases from 0 to ϕmax. So how do we control the intensity falloff as a function of ϕ, and also how do we control the size of the spotlight’s cone? We can use a function with the same graph as in Figure 8.19, but replace θh with ϕ and m with s:
This gives us what we want: the intensity smoothly fades as ϕ increases; additionally, by altering the exponent s, we can indirectly control ϕmax (the angle the intensity drops to 0); that is to say, we can shrink or expand the spotlight cone by varying s. For example, if we set s = 8, the cone has approximately a 45° half angle. The spotlight equation is just like Equation 8.4, except that we multiply the light source value BL by both the attenuation factor att(d) and the spotlight factor kspot to scale the light intensity based on where the point is with respect to the spotlight cone. We see that a spotlight is more expensive than a point light because we need to compute the additional kspot factor and multiply by it. Similarly, we see that a point light is more expensive than a directional light because the distance d needs to be computed (this is actually pretty expensive because distance involves a square root operation), and we need to compute and multiply by the attenuation factor. To summarize, directional lights are the least expensive light source, followed by point lights, followed by spotlights being the most expensive light source. 8.13 LIGHTING IMPLEMENTATION This section discusses the details for implementing directional, point, and spot lights. 8.13.1 Light Structure In d3dUtil.h, we define the following structure to support lights. This structure can represent directional, point, or spot lights. However, depending on the light type, some values will not be used; for example, a point light does not use the Direction data member. struct Light { DirectX::XMFLOAT3 Strength; // Light color float FalloffStart; // point/spot light only DirectX::XMFLOAT3 Direction;// directional/spot light only float FalloffEnd; // point/spot light only DirectX::XMFLOAT3 Position; // point/spot light only float SpotPower; // spot light only }; The LightingUtils.hlsl file defines structures that mirror these: struct Light { float3 Strength; float FalloffStart; // point/spot light only float3 Direction; // directional/spot light only float FalloffEnd; // point/spot light only float3 Position; // point light only float SpotPower; // spot light only }; The order of data members listed in the Light structure (and also the MaterialConstants structure) is not arbitrary. They are cognizant of the HLSL structure packing rules. See Appendix B (“Structure Packing”) for details, but the main idea is that in HLSL, structure padding occurs so that elements are packed into 4D vectors, with the restriction that a single element cannot be split across two 4D vectors. This means the above structure gets nicely packed into three 4D vectors like this: vector 1: (Strength.x, Strength.y, Strength.z, FalloffStart) vector 2: (Direction.x, Direction.y, Direction.z, FalloffEnd) vector 3: (Position.x, Position.y, Position.z, SpotPower) On the other hand, if we wrote our Light structure like this struct Light { DirectX::XMFLOAT3 Strength; // Light color DirectX::XMFLOAT3 Direction;// directional/spot light only DirectX::XMFLOAT3 Position; // point/spot light only float FalloffStart; // point/spot light only float FalloffEnd; // point/spot light only float SpotPower; // spot light only }; struct Light { float3 Strength; float3 Direction; // directional/spot light only float3 Position; // point light only float FalloffStart; // point/spot light only float FalloffEnd; // point/spot light only float SpotPower; // spot light only }; then it would get packed into four 4D vectors like this: vector 1: (Strength.x, Strength.y, Strength.z, empty) vector 2: (Direction.x, Direction.y, Direction.z, empty) vector 3: (Position.x, Position.y, Position.z, empty) vector 4: (FalloffStart, FalloffEnd, SpotPower, empty) The second approach takes up more data, but that is not the main problem. The more serious problem is that we have a C++ application side structure that mirrors the HLSL structure, but the C++ structure does not follow the same HLSL packing rules; thus, the C++ and HLSL structure layouts are likely not going to match unless you are careful with the HLSL packing rules and write them so that they do. If the C++ and HLSL structure layouts do not match, then we will get rendering bugs when we upload data from the CPU to GPU constant buffers using memcpy. 8.13.2 Common Helper Functions The below three functions, defined in LightingUtils.hlsl, contain code that is common to more than one type of light, and therefore we define in helper functions. 1. CalcAttenuation: Implements a linear attenuation factor, which applies to point lights and spot lights. 2. SchlickFresnel: The Schlick approximation to the Fresnel equations; it approximates the percentage of light reflected off a surface with normal n based on the angle between the light vector L and surface normal n due to the Fresnel effect. 3. BlinnPhong: Computes the amount of light reflected into the eye; it is the sum of diffuse reflectance and specular reflectance. float CalcAttenuation(float d, float falloffStart, float falloffEnd) { // Linear falloff. return saturate((falloffEnd-d) / (falloffEnd - falloffStart)); } // Schlick gives an approximation to Fresnel reflectance // (see pg. 233 "Real-Time Rendering 3rd Ed."). // R0 = ( (n-1)/(n+1) )^2, where n is the index of refraction. float3 SchlickFresnel(float3 R0, float3 normal, float3 lightVec) { float cosIncidentAngle = saturate(dot(normal, lightVec)); float f0 = 1.0f - cosIncidentAngle; float3 reflectPercent = R0 + (1.0f - R0)*(f0*f0*f0*f0*f0); return reflectPercent; } struct Material { float4 DiffuseAlbedo; float3 FresnelR0; // Shininess is inverse of roughness: Shininess = 1-roughness. float Shininess; }; float3 BlinnPhong(float3 lightStrength, float3 lightVec, float3 normal, float3 toEye, Material mat) { // Derive m from the shininess, which is derived from the roughness. const float m = mat.Shininess * 256.0f; float3 halfVec = normalize(toEye + lightVec); float roughnessFactor = (m + 8.0f)*pow(max(dot(halfVec, normal), 0.0f), m) / 8.0f; float3 fresnelFactor = SchlickFresnel(mat.FresnelR0, halfVec, lightVec); // Our spec formula goes outside [0,1] range, but we are doing // LDR rendering. So scale it down a bit. specAlbedo = specAlbedo / (specAlbedo + 1.0f); return (mat.DiffuseAlbedo.rgb + specAlbedo) * lightStrength; } The following intrinsic HLSL functions were used: dot, pow, and max, which are, respectively, the vector dot product function, power function, and maximum function. Descriptions of most of the HLSL intrinsic functions can be found in Appendix B, along with a quick primer on other HLSL syntax. One thing to note, however, is that when two vectors are multiplied with operator*, the multiplication is done component-wise.
8.13.3 Implementing Directional Lights Given the eye position E and given a point p on a surface visible to the eye with surface normal n, and material properties, the following HLSL function outputs the amount of light, from a directional light source, that reflects into the to-eye direction v = normalize (E − p). In our samples, this function will be called in a pixel shader to determine the color of the pixel based on lighting. float3 ComputeDirectionalLight(Light L, Material mat, float3 normal, float3 toEye) { // The light vector aims opposite the direction the light rays travel. float3 lightVec = -L.Direction; // Scale light down by Lambert’s cosine law. float ndotl = max(dot(lightVec, normal), 0.0f); float3 lightStrength = L.Strength * ndotl; return BlinnPhong(lightStrength, lightVec, normal, toEye, mat); } 8.13.4 Implementing Point Lights Given the eye position E and given a point p on a surface visible to the eye with surface normal n, and material properties, the following HLSL function outputs the amount of light, from a point light source, that reflects into the to-eye direction v = normalize (E − p) . In our samples, this function will be called in a pixel shader to determine the color of the pixel based on lighting. float3 ComputePointLight(Light L, Material mat, float3 pos, float3 normal, float3 toEye) { // The vector from the surface to the light. float3 lightVec = L.Position - pos; // The distance from surface to light. float d = length(lightVec); // Range test. if(d > L.FalloffEnd) return 0.0f; // Normalize the light vector. lightVec /= d; // Scale light down by Lambert’s cosine law. float ndotl = max(dot(lightVec, normal), 0.0f); float3 lightStrength = L.Strength * ndotl; // Attenuate light by distance. float att = CalcAttenuation(d, L.FalloffStart, L.FalloffEnd); lightStrength *= att; return BlinnPhong(lightStrength, lightVec, normal, toEye, mat); } 8.13.5 Implementing Spotlights Given the eye position E and given a point p on a surface visible to the eye with surface normal n, and material properties, the following HLSL function outputs the amount of light, from a spot light source, that reflects into the to-eye direction v = normalize (E − p). In our samples, this function will be called in a pixel shader to determine the color of the pixel based on lighting. float3 ComputeSpotLight(Light L, Material mat, float3 pos, float3 normal, float3 toEye) { // The vector from the surface to the light. float3 lightVec = L.Position - pos; // The distance from surface to light. float d = length(lightVec); // Range test. if(d > L.FalloffEnd) return 0.0f; // Normalize the light vector. lightVec /= d; // Scale light down by Lambert’s cosine law. float ndotl = max(dot(lightVec, normal), 0.0f); float3 lightStrength = L.Strength * ndotl; // Attenuate light by distance. float att = CalcAttenuation(d, L.FalloffStart, L.FalloffEnd); lightStrength *= att; // Scale by spotlight float spotFactor = pow(max(dot(-lightVec, L.Direction), 0.0f), L.SpotPower); lightStrength *= spotFactor; return BlinnPhong(lightStrength, lightVec, normal, toEye, mat); } 8.13.6 Accumulating Multiple Lights Lighting is additive, so supporting multiple lights in a scene simply means we need to iterate over each light source and sum its contribution to the point/pixel we are evaluating the lighting of. Our sample framework supports up to sixteen total lights. We can use any combination of directional, point, or spot lights, but the total must not exceed sixteen. Moreover, our code uses the convention that directional lights must come first in the light array, point lights come second, and spot lights come last. The following code evaluates the lighting equation for a point #define MaxLights 16 // Constant data that varies per material. cbuffer cbPass : register(b2) { … // Indices [0, NUM_DIR_LIGHTS) are directional lights; // indices [NUM_DIR_LIGHTS, NUM_DIR_LIGHTS+NUM_POINT_LIGHTS) are // point lights; // indices [NUM_DIR_LIGHTS+NUM_POINT_LIGHTS, // NUM_DIR_LIGHTS+NUM_POINT_LIGHT+NUM_SPOT_LIGHTS) // are spot lights for a maximum of MaxLights per object. Light gLights[MaxLights]; }; float4 ComputeLighting(Light gLights[MaxLights], Material mat, float3 pos, float3 normal, float3 toEye, float3 shadowFactor) { float3 result = 0.0f; int i = 0; #if (NUM_DIR_LIGHTS > 0) for(i = 0; i < NUM_DIR_LIGHTS; ++i) { result += shadowFactor[i] * ComputeDirectionalLight(gLights[i], mat, normal, toEye); } #endif #if (NUM_POINT_LIGHTS > 0) for(i = NUM_DIR_LIGHTS; i < NUM_DIR_LIGHTS+NUM_POINT_LIGHTS; ++i) { result += ComputePointLight(gLights[i], mat, pos, normal, toEye); } #endif #if (NUM_SPOT_LIGHTS > 0) for(i = NUM_DIR_LIGHTS + NUM_POINT_LIGHTS; i < NUM_DIR_LIGHTS + NUM_POINT_LIGHTS + NUM_SPOT_LIGHTS; ++i) { result += ComputeSpotLight(gLights[i], mat, pos, normal, toEye); } #endif return float4(result, 0.0f); } Observe that the number of lights for each type is controlled with #defines. The idea is for the shader to only do the lighting equation for the number of lights that are actually needed. So if an application only requires three lights, we only do the calculations for three lights. If your application needs to support a different number of lights at different times, then you just generate different shaders using different #defines.
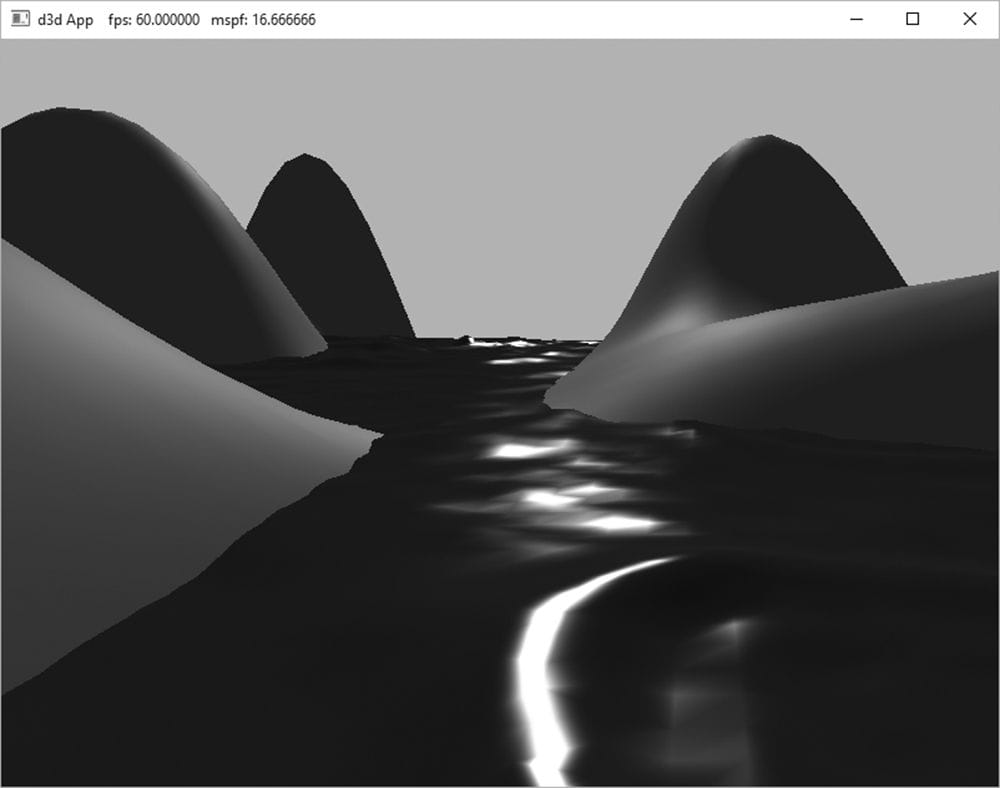
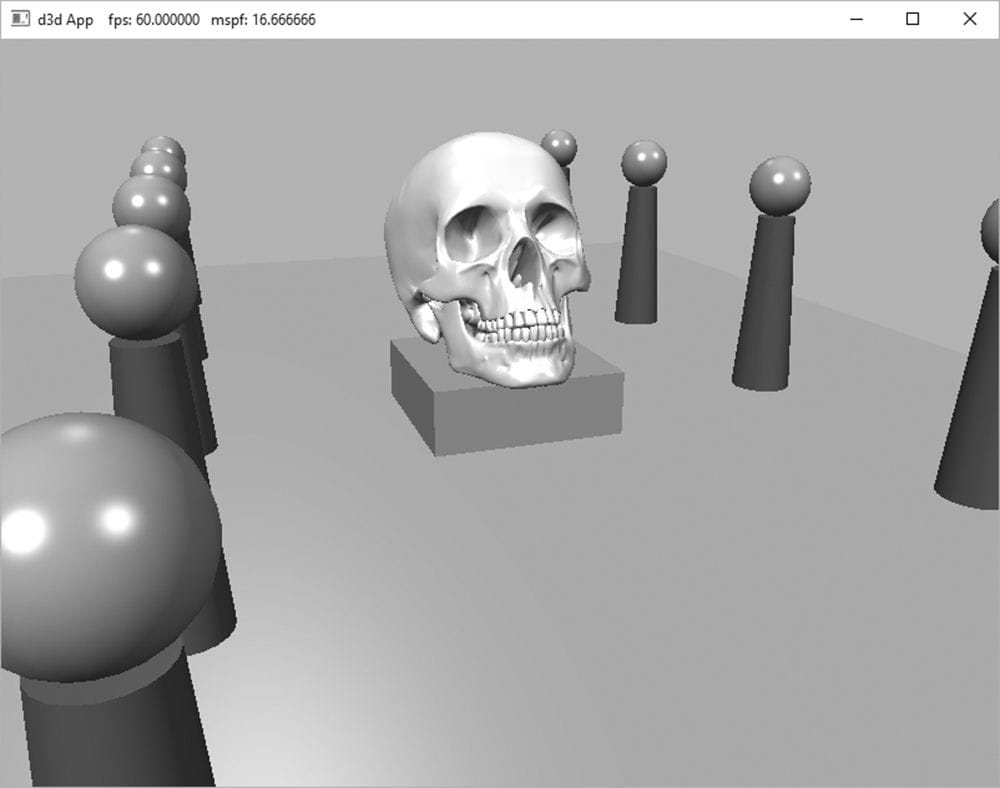
8.13.7 The Main HLSL File The below code contains the vertex and pixel shaders used for the demo of this chapter, and makes use of the HLSL code in LightingUtil.hlsl we have been discussing up to now. //********************************************************************* // Default.hlsl by Frank Luna (C) 2015 All Rights Reserved. // // Default shader, currently supports lighting. //********************************************************************* // Defaults for number of lights. #ifndef NUM_DIR_LIGHTS #define NUM_DIR_LIGHTS 1 #endif #ifndef NUM_POINT_LIGHTS #define NUM_POINT_LIGHTS 0 #endif #ifndef NUM_SPOT_LIGHTS #define NUM_SPOT_LIGHTS 0 #endif // Include structures and functions for lighting. #include "LightingUtil.hlsl" // Constant data that varies per frame. cbuffer cbPerObject : register(b0) { float4x4 gWorld; }; cbuffer cbMaterial : register(b1) { float4 gDiffuseAlbedo; float3 gFresnelR0; float gRoughness; float4x4 gMatTransform; }; // Constant data that varies per material. cbuffer cbPass : register(b2) { float4x4 gView; float4x4 gInvView; float4x4 gProj; float4x4 gInvProj; float4x4 gViewProj; float4x4 gInvViewProj; float3 gEyePosW; float cbPerObjectPad1; float2 gRenderTargetSize; float2 gInvRenderTargetSize; float gNearZ; float gFarZ; float gTotalTime; float gDeltaTime; float4 gAmbientLight; // Indices [0, NUM_DIR_LIGHTS) are directional lights; // indices [NUM_DIR_LIGHTS, NUM_DIR_LIGHTS+NUM_POINT_LIGHTS) are // point lights; // indices [NUM_DIR_LIGHTS+NUM_POINT_LIGHTS, // NUM_DIR_LIGHTS+NUM_POINT_LIGHT+NUM_SPOT_LIGHTS) // are spot lights for a maximum of MaxLights per object. Light gLights[MaxLights]; }; struct VertexIn { float3 PosL : POSITION; float3 NormalL : NORMAL; }; struct VertexOut { float4 PosH : SV_POSITION; float3 PosW : POSITION; float3 NormalW : NORMAL; }; VertexOut VS(VertexIn vin) { VertexOut vout = (VertexOut)0.0f; // Transform to world space. float4 posW = mul(float4(vin.PosL, 1.0f), gWorld); vout.PosW = posW.xyz; // Assumes nonuniform scaling; otherwise, need to use // inverse-transpose of world matrix. vout.NormalW = mul(vin.NormalL, (float3x3)gWorld); // Transform to homogeneous clip space. vout.PosH = mul(posW, gViewProj); return vout; } float4 PS(VertexOut pin) : SV_Target { // Interpolating normal can unnormalize it, so renormalize it. pin.NormalW = normalize(pin.NormalW); // Vector from point being lit to eye. float3 toEyeW = normalize(gEyePosW - pin.PosW); // Indirect lighting. float4 ambient = gAmbientLight*gDiffuseAlbedo; // Direct lighting. const float shininess = 1.0f - gRoughness; Material mat = { gDiffuseAlbedo, gFresnelR0, shininess }; float3 shadowFactor = 1.0f; float4 directLight = ComputeLighting(gLights, mat, pin.PosW, pin.NormalW, toEyeW, shadowFactor); float4 litColor = ambient + directLight; // Common convention to take alpha from diffuse material. litColor.a = gDiffuseAlbedo.a; return litColor; } 8.14 LIGHTING DEMO The lighting demo builds off the “Waves” demo from the previous chapter. It uses one directional light to represent the sun. The user can rotate the sun position using the left, right, up, and down arrow keys. While we have discussed how material and lights are implemented, the following subsections go over implementation details not yet discussed. Figure 8.28 shows a screen shot of the lighting demo.
Figure 8.28. Screenshot of the lighting demo. 8.14.1 Vertex Format Lighting calculations require a surface normal. We define normals at the vertex level; these normals are then interpolated across the pixels of a triangle so that we may do the lighting calculations per pixel. Moreover, we no longer specify a vertex color. Instead, pixel colors are generated by applying the lighting equation for each pixel. To support vertex normals we modify our vertex structures like so: // C++ Vertex structure struct Vertex { DirectX::XMFLOAT3 Pos; DirectX::XMFLOAT3 Normal; }; // Corresponding HLSL vertex structure struct VertexIn { float3 PosL : POSITION; float3 NormalL : NORMAL; }; When we add a new vertex format, we need to describe it with a new input layout description: mInputLayout = { { "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 }, { "NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 12, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 } }; 8.14.2 Normal Computation The shape functions in GeometryGenerator already create data with vertex normals, so we are all set there. However, because we modify the heights of the grid in this demo to make it look like terrain, we need to generate the normal vectors for the terrain ourselves. Because our terrain surface is given by a function y = f(x, z), we can compute the normal vectors directly using calculus, rather than the normal averaging technique described in §8.2.1. To do this, for each point on the surface, we form two tangent vectors in the +x- and +z- directions by taking the partial derivatives:
These two vectors lie in the tangent plane of the surface point. Taking the cross product then gives the normal vector:
The function we used to generate the land mesh is:
The partial derivatives are:
The surface normal at a surface point (x, f (x, z), z) is thus given by:
We note that this surface normal is not of unit length, so it needs to be normalized before lighting calculations. In particular, we do the above normal calculation at each vertex point to get the vertex normals: XMFLOAT3 LitWavesApp::GetHillsNormal(float x, float z)const { // n = (-df/dx, 1, -df/dz) XMFLOAT3 n( -0.03f*z*cosf(0.1f*x) - 0.3f*cosf(0.1f*z), 1.0f, -0.3f*sinf(0.1f*x) + 0.03f*x*sinf(0.1f*z)); XMVECTOR unitNormal = XMVector3Normalize(XMLoadFloat3(&n)); XMStoreFloat3(&n, unitNormal); return n; } The normal vectors for the water surface are done in a similar way, except that we do not have a formula for the water. However, tangent vectors at each vertex point can be approximated using a finite difference scheme (see [Lengyel02] or any numerical analysis book).
8.14.3 Updating the Light Direction As shown in §8.13.7, our array of Lights is put in the per-pass constant buffer. The demo uses one directional light to represent the sun, and allows the user to rotate the sun position using the left, right, up, and down arrow keys. So every frame, we need to calculate the new light direction from the sun, and set it to the per-pass constant buffer. We track the sun position in spherical coordinates (ρ, θ, ϕ), but the radius ρ does not matter, because we assume the sun is infinitely far away. In particular, we just use ρ = 1 so that it lies on the unit sphere and interpret (1, θ, ϕ) as the direction towards the sun. The direction of the light is just the negative of the direction towards the sun. Below is the relevant code for updating the sun. float mSunTheta = 1.25f*XM_PI; float mSunPhi = XM_PIDIV4; void LitWavesApp::OnKeyboardInput(const GameTimer& gt) { const float dt = gt.DeltaTime(); if(GetAsyncKeyState(VK_LEFT) & 0x8000) mSunTheta -= 1.0f*dt; if(GetAsyncKeyState(VK_RIGHT) & 0x8000) mSunTheta += 1.0f*dt; if(GetAsyncKeyState(VK_UP) & 0x8000) mSunPhi -= 1.0f*dt; if(GetAsyncKeyState(VK_DOWN) & 0x8000) mSunPhi += 1.0f*dt; mSunPhi = MathHelper::Clamp(mSunPhi, 0.1f, XM_PIDIV2); } void LitWavesApp::UpdateMainPassCB(const GameTimer& gt) { … XMVECTOR lightDir = -MathHelper::SphericalToCartesian(1.0f, mSunTheta, mSunPhi); XMStoreFloat3(&mMainPassCB.Lights[0].Direction, lightDir); mMainPassCB.Lights[0].Strength = { 0.8f, 0.8f, 0.7f }; auto currPassCB = mCurrFrameResource->PassCB.get(); currPassCB->CopyData(0, mMainPassCB); }
8.14.4 Update to Root Signature Lighting introduces a new material constant buffer to our shader programs. To support this, we need to update our root signature to support an additional constant buffer. As with per-object constant buffers, we use a root descriptor for the material constant buffer to support binding a constant buffer directly rather than going through a descriptor heap. 8.15 SUMMARY 1. With lighting, we no longer specify per-vertex colors but instead define scene lights and per-vertex materials. Materials can be thought of as the properties that determine how light interacts with a surface of an object. The per-vertex materials are interpolated across the face of the triangle to obtain material values at each surface point of the triangle mesh. The lighting equations then compute a surface color the eye sees based on the interaction between the light and surface materials; other parameters are also involved, such as the surface normal and eye position. 2. A surface normal is a unit vector that is orthogonal to the tangent plane of a point on a surface. Surface normals determine the direction a point on a surface is “facing.” For lighting calculations, we need the surface normal at each point on the surface of a triangle mesh so that we can determine the angle at which light strikes the point on the mesh surface. To obtain surface normals, we specify the surface normals only at the vertex points (so-called vertex normals). Then, in order to obtain a surface normal approximation at each point on the surface of a triangle mesh, these vertex normals will be interpolated across the triangle during rasterization. For arbitrary triangle meshes, vertex normals are typically approximated via a technique called normal averaging. If the matrix A is used to transform points and vectors (non-normal vectors), then (A−1)T should be used to transform surface normals. 3. A parallel (directional) light approximates a light source that is very far away. Consequently, we can approximate all incoming light rays as parallel to each other. A physical example of a directional light is the sun relative to the earth. A point light emits light in every direction. A physical example of a point light is a light bulb. A spotlight emits light through a cone. A physical example of a spotlight is a flashlight. 4. Due to the Fresnel effect, when light reaches the interface between two media with different indices of refraction some of the light is reflected and the remaining light is refracted into the medium. How much light is reflected depends on the medium (some materials will be more reflective than others) and also on the angle θi between the normal vector n and light vector L. Due to their complexity, the full Fresnel equations are not typically used in real-time rendering; instead, the Schlick approximation is used. 5. Reflective objects in the real-world tend not to be perfect mirrors. Even if an object’s surface appears flat, at the microscopic level we can think of it as having roughness. We can think of a perfect mirror as having no roughness and its micro-normals all aim in the same direction as the macro-normal. As the roughness increases, the direction of the micro-normals diverge from the macro-normal causing the reflected light to spread out into a specular lobe. 6. Ambient light models indirect light that has scattered and bounced around the scene so many times that it strikes the object equally in every direction, thereby uniformly brightening it up. Diffuse light models light that enters the interior of a medium and scatters around under the surface where some of the light is absorbed and the remaining light scatters back out of the surface. Because it is difficult to model this subsurface scattering, we assume the re-emitted light scatters out equally in all directions above the surface about the point the light entered. Specular light models the light that is reflected off the surface due to the Fresnel effect and surface roughness. 8.16 EXERCISES 1. Modify the lighting demo of this chapter so that the directional light only emits mostly red light. In addition, make the strength of the light oscillate as a function of time using the sine function so that the light appears to pulse. Using colored and pulsing lights can be useful for different game moods; for example, a pulsing red light might be used to signify emergency situations. 2. Modify the lighting demo of this chapter by changing the roughness in the materials. 3. Modify the “Shapes” demo from the previous chapter by adding materials and a three-point lighting system. The three-point lighting system is commonly used in film and photography to get better lighting than just one light source can provide; it consists of a primary light source called the key light, a secondary fill light usually aiming in the side direction from the key light, and a back light. We use three-point lighting as a way to fake indirect lighting that gives better object definition than just using the ambient component for indirect lighting. Use three directional lights for the three-point lighting system.
Figure 8.29. Screenshot of the solution to Exercise 3. 4. Modify the solution to Exercise 3 by removing the three-point lighting, and adding a point centered about each sphere above the columns. 5. Modify the solution to Exercise 3 by removing the three-point lighting, and adding a spotlight centered about each sphere above the columns and aiming down. 6. One characteristic of cartoon styled lighting is the abrupt transition from one color shade to the next (in contrast with a smooth transition) as shown in Figure 8.30. This can be implemented by computing kd and ks in the usual way, but then transforming them by discrete functions like the following before using them in the pixel shader:
Modify the lighting demo of this chapter to use this sort of toon shading. (Note: The functions f and g above are just sample functions to start with, and can be tweaked until you get the results you want.)
Figure 8.30. Screenshot of cartoon lighting. All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL) If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval. © 2016-2026 All site design rights belong to S.Y.A. |