Game Programming Algorithms and Techniques: A Platform-Agnostic Approach (2014)
Chapter 11. Scripting Languages and Data Formats
When writing code that drives gameplay, it is increasingly common to utilize a scripting language. This chapter explores the advantages and disadvantages of using a scripting language, as well as several of the potential language options.
A further consideration is how data that describes the level and other properties of the game should be stored. As with scripting languages, there are several options for representing data, both binary and text based.
Scripting Languages
For many years, games were written entirely in assembly. That’s because extracting a high performance out of those earlier machines required a level of optimization that was only possible with assembly. But as computers became more powerful, and games became more complex, it made less and less sense. At a certain point, the opportunity cost of developing a game entirely in assembly was not worth it, which is why all game engines today are written in a high-level programming language such as C++.
In a similar vein, as computers have continued to improve, more and more games have shifted away from using C++ or similar languages for gameplay logic. Many games now write much of their gameplay code in a scripting language, which is an even higher-level language such as Lua, Python, or UnrealScript.
Because script code is easier to write, it is often possible for designers to work directly on the scripts. This gives them a much greater ability to prototype ideas without needing to dive into the engine code. Although certain core aspects of AAA games such as the physics or rendering system still are written in the core engine’s language, other systems such as the camera and AI behavior might be in script.
Tradeoffs
Scripting languages aren’t a panacea; there are tradeoffs that must be considered before using one. The first consideration is that the performance of script is simply not going to match the performance of a compiled language such as C++. Even when compared to a JIT- or VM-based language such as Java or C#, an interpreted scripting language such as Lua or Python will not have competitive performance. That’s because an interpreted language reads in the text-based code on demand, rather than compiling it in advance. Certain scripting languages do provide the option to compile into an intermediary; although this still won’t be as fast as a natively compiled language, it usually will be faster than an interpreted language.
Because there is still a performance gap, code that must be high performance typically should not be implemented in script. In the case of an AI system, the pathfinding algorithm (for example, A*) should be high performance and therefore should not be written in script. But the state machines that drive the AI behavior can absolutely be written in script, because they typically will not require complex computations. Some other examples of what might be in script versus in C++ for a sample game are listed in Table 11.1.
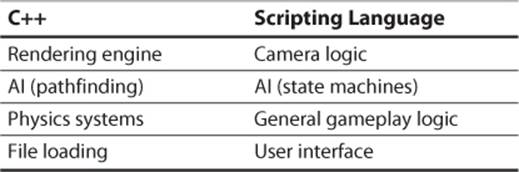
Table 11.1 Scripting Language Usage in Sample Game
One big advantage of a scripting language is that it can allow for more rapid iteration during development. Suppose that for a particular game, the AI state machines are written in C++. While playing the game, an AI programmer notices that one enemy is acting incorrectly. If the state machines are written in C++, the programmer may have many tools to diagnose the problem, but typically cannot fix it while the game is running. Although Visual Studio does have an “edit and continue” feature in C++, in practice this will only work in certain situations. This means that usually the programmer must stop the game, modify the code, build the executable, restart the game, and finally see if the problem went away.
But if this same scenario is encountered in a game where the AI state machines are written in script, it may be possible to reload the AI’s script dynamically and have the fix occur while the game is still running. This ability to dynamically reload scripts can be a huge productivity increase.
Returning to the C++ version of the AI behavior, suppose that there is a bug in a guard’s AI where sometimes a bad pointer is accessed. If you’ve programmed in C++ before, you know that accessing a bad pointer will usually result in a crash. If this bug keeps popping up all the time, the game will crash often. But if the state machine was instead written in script, it would be possible to have only the AI for that particular character stop functioning while the rest of the game continues to run. This second scenario is far more preferable than the first.
Furthermore, because scripts are files that are separate from the executable, it makes distributing changes much easier. On a large project, building the executable can take several minutes, and the resultant file might approach 100MB. This means that whenever there’s a new version, whoever wants it might have to download that entire file. On the other hand, if a scripting language is used, the user may only have to download a couple kilobytes of data, which is going to be a much faster process. This is especially helpful when deploying patches in a retail scenario, but it can also be useful during development.
Because of these productivity advantages, a good rule of thumb is that if the performance of the system is not mission-critical, it may be beneficial to write the system in script. There is, of course, the overhead of adding a scripting system to the game itself, but the time spent on that can be easily reclaimed if it leads to increased productivity for several members of the development team.
Types of Scripting Languages
If you decide to use a scripting language for some gameplay logic, the next logical question is, which scripting language? Two different approaches need to be considered: using an existing scripting language, such as Lua or Python, and using a custom scripting language designed specifically for the game engine in question. Some examples of custom languages include UnrealScript and QuakeC.
The advantage of using an existing language is that it typically will be much less work, because writing a script parser can be a time-consuming and error-prone endeavor, even when you’re using tools that aid the process. Furthermore, because a custom language has a much smaller number of users than existing languages, there is a high likelihood of errors persisting in the language over long periods of time. See the following sidebar, “An Error in Operator Precedence,” for one such instance.
An Error in Operator Precedence
What is the result of the following arithmetic operation?
30 / 5 * 3
According to one proprietary scripting language I worked with, the answer is 2. That’s because the language in question incorrectly assigned multiplication a higher precedent than division. So the preceding code was being interpreted as follows:
30 / (5 * 3) = 2
However, because division and multiplication have equal precedent, the expression should instead be computed as this:
(30 / 5) * 3 = 18
This particular bug persisted in the scripting language for over a decade. No one had ever mentioned the problem to the programmer in charge of the scripting language, probably because programmers have a tendency to add lots of parentheses to mathematical expressions.
Once the bug was found, it was easy enough to fix. But it’s a cautionary tale of what can happen with a custom scripting language.
The other consideration is that established languages typically have been designed and developed by people who are extremely knowledgeable about compiler and virtual machine design—far more knowledgeable on the topic than most game programmers.
But the downside is that existing scripting languages may not always be well-suited for game applications. There may be performance or memory allocation concerns with the way the language is designed, or it may be difficult to bridge the code between the scripting language and the engine. A custom language, on the other hand, can be designed such that it is optimized specifically for game usage—even to the point where the language has features that are very game specific, as in UnrealScript.
One last consideration with existing scripting languages is that it’s easier to find developers familiar with them. There are many programmers who might already know a language such as Lua or Python, but it’s less likely that someone will know a language proprietary to a specific company or engine.
Lua
Lua is a general-purpose scripting language that’s perhaps the most popular scripting language used in games today. Some examples of games that have used Lua include World of Warcraft, Company of Heroes, and Grim Fandango. One reason why it’s so popular for games is because its interpreter is very lightweight—the reference C implementation is approximately 150KB in memory. It also has the relatively simple capability to set up native bindings, where functions called by Lua can execute code in C/C++. It also supports multitasking, so it’s possible to have many Lua functions running at the same time.
Syntactically, the language does have some similarities with C-family languages, though there are also several differences. Semicolons at the end of lines are optional, and braces are not used for control statements. An intriguing aspect of Lua is that the only complex data type it supports is the table, which can be used in a variety of different ways, including as an array, a list, a set, and so on. This is demonstrated in the following bit of code:
-- Comments use --
-- As an array
-- Arrays are 1-index based
t = { 1, 2, 3, 4, 5 }
-- Outputs 4
print( t[4] )
-- As a dictionary
t= { M="Monday", T="Tuesday", W="Wednesday" }
-- Outputs Tuesday
print( t[T] )
Even though Lua is not an object-oriented language, with the clever use of tables it is absolutely possible to implement OOP. This technique is used frequently because OOP makes sense for many usage cases in games.
UnrealScript
UnrealScript is a strictly object-oriented language designed by Epic for the Unreal Engine. Unlike many scripting languages, UnrealScript is compiled. Because it’s compiled, it has better performance than an interpreted language, but it does mean that reloading a script at runtime is not supported. Games powered by Unreal typically use UnrealScript for almost all of their gameplay. For games using the full engine (and not just the free UDK), native bindings allow for UnrealScript functions to be implemented in C++. An example of this is shown in Figure 11.1.
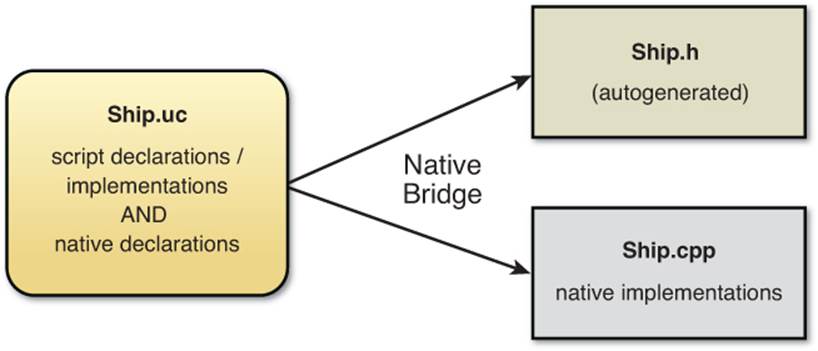
Figure 11.1 UnrealScript native bindings of a Ship class.
Syntactically, UnrealScript looks very much like C++ or Java. Because it’s strictly object oriented, every class derives from Object in one way or another, and nearly every class representing a character on the screen is derived from Actor. One very unique feature of UnrealScript is built-in support for states. It is possible to have different function overloads depending on the state, which makes it very easy to set up state machines for AI behavior, for example. In the code snippet that follows, a different Tick function (Unreal’s object update function) is called depending on the current state of the class:
// Auto means this state is entered by default
auto state Idle
{
function Tick(float DeltaTime)
{
// Update in Idle state
...
// If I see an enemy, go to Alert state
GotoState('Alert');
}
Begin:
`log("Entering Idle State")
}
state Alert
{
function Tick(float DeltaTime)
{
// Update in Alert state
...
}
Begin:
`log("Entering Alert State")
}
Visual Scripting Systems
An increasing number of game engines now implement visual scripting systems that look a lot like flow charts. These systems are typically used for setting up level logic. The idea is that rather than requiring level designers to write any text-based code, it instead is easier to set up the actions that occur with a flow chart. For example, if a level designer wants to have enemies spawn when the player opens a door, this might be done with a visual scripting system. In the Unreal Engine, the visual scripting system used is called Kismet; a screenshot of it in action is shown in Figure 11.2.
Figure 11.2 Kismet visual scripting system.
Implementing a Scripting Language
Although the full implementation of a scripting language is well beyond the scope of this book, it’s worthwhile to at least discuss the main components necessary to implement one. This is both to give a sense of how complex the problem is and to at least provide some guidance on how to start off on the right track.
The basics of implementing a custom scripting language is very similar to that of creating a general compiler; therefore, many of the topics covered in this section can be studied in much further detail in a book focused on compilers (such as the one detailed in the references). Learning at least the basics of how a compiler works is important, even if you aren’t going to implement one, because it’s what makes high-level programming possible. Without compiler theory, everyone would still be writing code in assembly, which at the very least would mean there would be far fewer qualified programmers.
Tokenization
The first step necessary to read in a language is to take the stream of text and break it down into a series of tokens such as identifiers, keywords, operators, and symbols. This process is known as tokenization, or more formally as lexical analysis. Table 11.2 shows a simple C file broken down into its tokens.
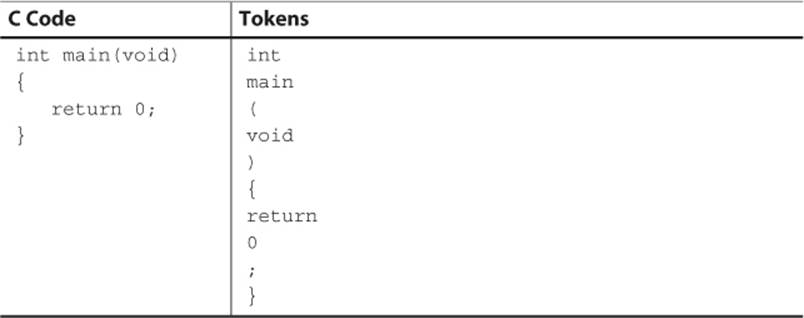
Table 11.2 Simple C File Tokenized
Although it certainly is possible to write a tokenizer (also known as a scanner or lexer) by hand, it definitely is not recommended. Manually writing such code is extremely error prone simply because there are so many cases that must be handled. For example, a tokenizer for C++ must be able to recognize that only one of these is the actual new keyword:
newnew
_new
new_new
_new_
new
Instead of manually writing a tokenizer, it is preferable to use a tool such a flex, which generates a tokenizer for you. The way flex works is you give it a series of matching rules, known as regular expressions, and state which regular expressions match which tokens. It will then automatically generate code (in the case of flex, in C) for a tokenizer that emits the correct tokens based on the given rules.
Regular Expressions
Regular expressions (also known as regex) have many uses beyond tokenization. For example, most IDEs can perform a search across code files using regular expressions, which can be a very handy way to find specific types of sequences. Although general regular expressions can become rather complex, matching patterns for a scripting language only require using a very small subset of regular expressions.
The most basic regular expression would be to match specific keywords, which must be the same series of characters every time. In order to match this, the regex is simply the series of characters with or without quotes:
// Matches new keyword
new
// Also matches new keyword
"new"
In a regular expression, there are also operators that have special meaning. The [] operator means any character contained within the brackets will be matched. This can also be combined with a hyphen to specify any character within a range. Here’s an example:
// Matches aac, abc, or acc
a[abc]c
// Matches aac, abc, acc, ..., azc
a[a-z]c
// You can combine multiple ranges...
// Matches above as well as aAc, ..., aZc
a[a-zA-Z]c
The + operator means “one or more of a particular character,” and the * operator means “zero or more of a particular character.” These can be combined with the [] operator to create expressions that can define most of the types of tokens in a particular language:
// Matches one or more number (integer token)
[0-9]+
// Matches a single letter or underscore, followed by zero or more
// letters, numbers, and underscores (identifier in C++)
[a-zA-Z_][a-zA-Z0-9_]*
In any event, once a list of tokens and the regular expressions corresponding to them is created, this data can then be fed to a program such a flex in order to automatically generate a tokenizer. Once a script is fed into this tokenizer and broken down into tokens, it’s time to move on to the next step.
Syntax Analysis
The job of syntax analysis is to go through the stream of tokens and ensure that they conform to the rules of the language’s grammar. For example, an if statement must have the appropriate number and placement of parentheses, braces, a test expression, and a statement to execute. As the syntax of the script is verified, an abstract syntax tree (AST) is generated, which is a tree-based data structure that defines the layout of the entire program. An AST for a simple math expression is illustrated in Figure 11.3.
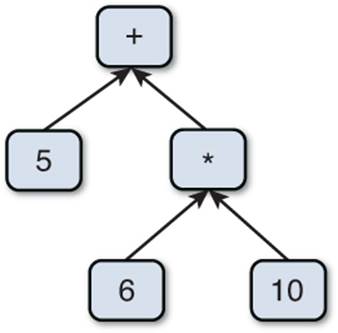
Figure 11.3 AST for 5 + 6 * 10.
Notice how if the tree in Figure 11.3 were traversed with a post-order traversal (left child, right child, parent), the result would be 5 6 10 * +, which happens to correspond how the infix expression 5 + 6 * 10 would be written in postfix notation. This is not by chance—it turns out that postfix expressions are much easier to compute since they work so well with a stack. Ultimately, all ASTs (whether mathematical expressions or otherwise) will be traversed in a post-order manner after syntax analysis.
But in order to traverse the AST, we first must generate one. The first step toward generating an AST is to define the grammar of the language. A classic way to define grammars for computer languages is to use Backus-Naur Form, which is often abbreviated as BNF. BNF is designed to be relatively succinct; the grammar for a calculator that can do integral addition and subtraction might be defined as follows:
<integer> ::== [0-9]+
<expression> ::== <expression> "+" <expression>
| <expression> "-" <expression>
| <integer>
The ::== operator means “is defined as,” the | operator means “or,” and <> are used to denote grammar rule names. So the preceding BNF grammar says that an expression can be either an expression plus another expression, or an expression minus another expression, or an integer. Thus, 5 + 6 would be valid because 5 and 6 are both integers, which means they can both be expressions, which in turn means they can be added together.
As with tokenization, there are tools you can use to help with syntax analysis. One such tool is bison, which allows for C/C++ actions to be executed whenever a grammar rule is matched. The general usage of the action is to have it create the appropriate node that goes into the AST. For instance, if an addition expression were matched, an addition node could be generated that has two children: one each for the left and right operands.
This means it’s best to have a class corresponding to each possible node type. So the addition/subtraction grammar would need to have four different classes: an abstract base expression class, an integer node, an addition node, and a subtraction node. This hierarchy is shown in Figure 11.4.
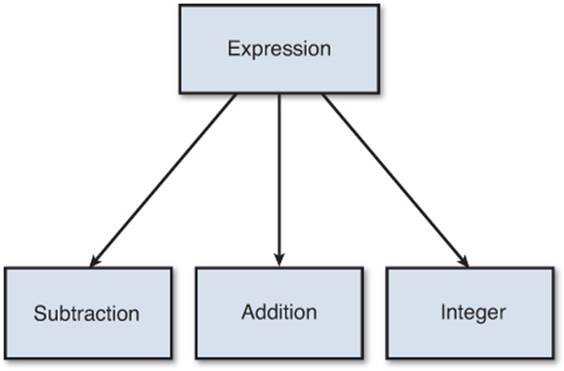
Figure 11.4 Class hierarchy for basic addition/subtraction expressions.
Code Execution or Generation
Once an AST is generated from the script file, there are two potential courses of action, both of which require using a post-order traversal. For a more traditional compiler, the goal of the AST traversal would be to generate the actual code that will be run on the target machine. So when C++ code is compiled, the AST is traversed and code is generated in assembly that is designed specifically to work on the target platform.
If the game’s scripting language is compiled, such as UnrealScript, then it would definitely make sense to perform the code-generation step. But if the language is interpreted, code generation is unnecessary. Instead, it would be preferable to just traverse the AST and execute any actions that the nodes represent.
For the addition/subtraction example, the nodes could be defined in the following manner:
abstract class Expression
function Execute()
end
class Integer inherits Expression
// Stores the integral value
int value
// Constructor
...
function Execute()
// Push value onto calculator's stack
...
end
end
class Addition inherits Expression
// LHS/RHS operands
Expression lhs, rhs
// Constructor
...
function Execute()
// Post-order means execute left child, then right child,
// then myself.
lhs.Execute()
rhs.Execute()
// Add top two values on calculator's stack, push result back on
...
end
end
// Subtraction node identical to Addition, except it subtracts
...
With the preceding classes, it would then be possible to calculate the result of the AST by calling Execute on the root node. Once that call returns, the lone value on the stack will correspond to the result of the operation.
For example, the expression 5 + 6 would have an AST where the root node is an Addition class, the left child is an Integer class with a value of 5, and the right child is an Integer class with a value of 6. So if Execute is called on that root Addition node, it would first callExecute on 5, which will push 5 onto the calculator stack. Then Execute on 6 pushes 6 onto the calculator stack. Finally, Execute on the root mode will add the top two values on the stack, which gives 11, and push that back on, giving the final result of the operation.
Of course, if the scripting language in question supports far more than just basic arithmetic, the contents of the Execute functions will become more complex. But this basic principle of a post-order traversal carries over regardless of the complexity of the language or node type.
Data Formats
Another decision that must be made during game development is how the data describing elements such as levels and other game properties should be stored. For a very simple game, you might be able to get away with having most of the data hard-coded, but it’s not an ideal solution. By having data stored in external files, you allow for nonprogrammers to edit it. This also opens up the possibility of creating tool programs (such as a level editor) that allow the data to be more easily manipulated.
When you’re deciding on a data format, the first decision is whether or not the data should be binary or text-based. A binary file is one that contains data that’s mostly unreadable by a human. If you open up a binary file in a text editor, it will be a stream of random characters. An example of a binary format is PNG or any other image file format. A text-based file, on the other hand, is a format that is composed of standard ASCII characters and therefore can be read by a human. As with the decision on whether or not a scripting language should be used, there are tradeoffs between both approaches. Ultimately, it will make sense to store some data in a binary format while storing other data in a text-based one.
Tradeoffs
The primary advantage of using a binary file is that it’s going to be a smaller file, and also one that can be loaded more quickly. Rather than having to spend time parsing in text and converting it into the appropriate in-memory format, it’s often possible to directly load in chunks of the binary file without any conversion. Because efficiency is so important for games, it’s on that merit alone that binary typically wins out for files that are going to contain large amounts of information, such as the layout of a level.
However, the extra speed does come with a cost. One big disadvantage of binary files is that they don’t work as well with a source control system (if you aren’t familiar with source control, you should check Appendix B, “Useful Tools for Programmers”). The reason is that it can be very hard to figure out what has changed between two versions of a binary file.
For example, suppose a game stores its level data in a binary format (such as the .pkg files that Unreal uses). Now further suppose that a designer goes into the level editor and makes ten different changes to the level. Without testing the level, the designer then decides to submit the updated level. For whatever reason, this level actually does not load after the changes. At this point, to fix the game so that the level can load, the only course of action is to revert to the previous version of the file, thus losing all ten changes. But what if only one of the ten changes was bad? In a binary file, there’s typically no way to go through and actually change the one part of it that’s bad, so all the changes have to be undone.
Granted, this scenario does expose some other problems—why is the designer checking in something without testing it, and why can the level editor save bad data? But the fact of the matter is that between two revisions of this hypothetical binary level file format, it’s going to be very hard to tell what has changed without loading the level.
For a text-based file format, however, it would be very easy to look at two different versions of the file and see the differences between them. This means that if there were ten changes to a level, with one not working, it would be possible to go through and actually remove the specific change that’s breaking the level.
There’s also the fact that a text-based file format can be more easily edited by end users. For something such as configuring the keyboard input, it may be preferable to have a text file so it’s very easy to change in a standard text editor. But on the other hand, this may be a disadvantage for the level data, because it would be easy for a player to change the behavior of the game and break it.
One final option is to use both text-based and binary representations for the same data. During development, being able to easily track changes is extremely helpful, so all level and game object data could be stored in text. Then, for the release version, we could introduce a bake step that converts the text into a more efficient binary format. These binary files would never be saved into source control, and the developers would only ever modify the text versions. This way, we can get the advantages of a text-based file format for development as well as the advantages of a binary format for release. Because it has the benefits of both, this approach is very popular. The only concern here is one of testing—the development team needs to be extra vigilant to ensure that any changes to the text format do not cause bugs to appear in the binary format.
Binary Formats
For storing game data, more often than not a binary file format is going to be a custom format. There really are a lot of different ways to store the data, which also will depend on the language/framework. If it’s a C++ game, sometimes the easiest way to save data is to directly write the contents of a class to the output file, which is a process called serialization. But there are some hurdles to consider—for example, any dynamically allocated data in the class is going to have pointers, so you need to actually perform a deep copy and reconstruct that data dynamically. However, the overall design of a binary file format is a bit too advanced for this book.
INI
The simplest text-based file format is likely INI, which is often used for setting files that an end user might want to change. An INI file is broken down into sections, and each section has a list of keys and values. For example, graphics settings in an INI file might look like this:
[Graphics]
Width=1680
Height=1050
FullScreen=true
Vsync=false
Although INI files work well for very simple data, they become very cumbersome with more complex data. This wouldn’t be a great file format to use for the layout of a level, for instance, because INI does not support any idea of nesting parameters and sections.
Because INI is so simple and widely used, a large number of easy-to-use libraries is available. In C/C++, one particular library I’m a fan of is minIni, because it works on a wide variety of platforms and is very easy to use.
XML
XML, or Extensible Markup Language, is a file format that is an expansion of the concept of HTML. Rather than using set HTML tags such as <html>, <head>, <body>, and so on, in XML you can have any custom tags and attributes you want. So to the uninitiated, it might look a lot like HTML, even though it’s not. The Witcher 2 used XML extensively to store all the parameters of the different items that could be found in the game. For example, here’s an entry that stores the stats of a particular sword:
<ability name="Forgotten Sword of Vrans _Stats">
<damage_min mult="false" always_random="false" min="50" max="50"/>
<damage_max mult="false" always_random="false" min="55" max="55"/>
<endurance mult="false" always_random="false" min="1" max="1"/>
<crt_freeze display_perc="true" mult="false" always_random="false"
min="0.2" max="0.2" type="critical"/>
<instant_kill_chance display_perc="true" mult="false"
always_random="false" min="0.02" max="0.02" type="bonus"/>
<vitality_regen mult="false" always_random="false" min="2" max="2"/>
</ability>
One big criticism of XML is that it requires a lot of additional characters to express the data. There are many < and > symbols, and you always need to qualify each parameter with the name, quotes, and so on. You also always have to make sure there are matching closing tags. All this combined leads to larger text files.
But one big advantage of XML is that it allows for the enforcement of sticking to a schema, or a set of requirements on which tags and properties must be used. This means that it can be easy to validate an XML file and make sure it conforms and declares all the necessary parameters.
As with the other common file formats, a lot of different parsers support loading in XML. The most popular one for C/C++ is arguably TinyXML (and its companion for C++, ticpp). Some languages also have built-in XML parsing; for instance, C# has a System.Xml namespace devoted to XML files.
JSON
JSON, or JavaScript Object Notation, is a newer file format than INI or XML, but it’s also one that’s gained a great deal of popularity in recent years. Although JSON is more commonly used for transmitting data over the Internet, it certainly is possible to use it as a lightweight data format in a game. Recall that we used JSON to store the sound metadata in Chapter 6, “Sound.” There are several third-party libraries that can parse JSON, including libjson (http://libjson.sourceforge.net) for C++ and JSON.NET for C# and other .NET languages.
Depending on the type of data being stored, a JSON file may be both smaller and more efficient to parse than a comparable XML file. But this isn’t always the case. For example, if we were to take the sword data from The Witcher 2 and instead store it in a JSON file, it actually ends up being larger than the XML version:
"ability": {
"name": "Forgotten Sword of Vrans _Stats",
"damage_min": {
"mult": false, "always_random": false, "min": 50, "max": 50
},
"damage_max": {
"mult": false, "always_random": false, "min": 55, "max": 55
},
"endurance": {
"mult": false, "always_random": false, "min": 1, "max": 1
},
"crt_freeze": {
"display_perc": true, "mult": false, "always_random": false,
"min": 0.2, "max": 0.2, "type": "critical"
},
"instant_kill_change": {
"display_perc": true, "mult": false, "always_random": false,
"min": 0.2, "max": 0.2, "type": "bonus"
},
"vitality_regen": {
"mult": false, "always_random": false, "min": 2, "max": 2
}
}
Even if you try to reduce the sizes of both the JSON and XML files by removing all extraneous whitespaces and carriage returns, in this particular instance the JSON file still ends up being slightly larger than the XML one. So although JSON can be a great text-based file format in some situations, in the case of The Witcher 2, the developers likely made the correct decision to use XML instead.
Case Study: UI Mods in World of Warcraft
Now that we’ve explored scripting languages and text-based data representations, let’s take a look at a system that uses both: user interface modifications in World of Warcraft. In most games, the UI is whatever the designers and programmers implemented, and you’re stuck with it. Although there are often some options and settings, most games do not allow configuration of the UI beyond that. However, in an MMORPG, players have a lot of different preferences—for instance, some players might want the enemy health to be shown in the center of the screen, whereas others might want it in the top right.
What Blizzard wanted to do is create a UI system that was heavily customizable. They wanted a system that not only allowed the placement of elements to be changed, but for entirely new elements to be added. In order to facilitate this, they required creating a system that heavily relied on scripting languages and text-based data.
The two main components of a UI mod in World of Warcraft are the layout and the behavior. The layout of interfaces, such as placement of images, controls, buttons, and so on, is stored in XML. The behavior of the UI is then implemented using the Lua scripting language. Let’s look at both aspects in more detail.
Layout and Events
The layout of the interface is entirely XML driven. It’s set up with base widgets such as frames, buttons, sliders, and check boxes that the UI developer can use. So if you want a menu that looks like a built-in window, it’s very much possible to declare an interface that uses the appropriate elements. The system goes a step further in that one can inherit from a particular widget and overwrite certain properties. Therefore, it would be possible to have a custom button XML layout that derives from the base one and maybe modifies only certain parameters.
It’s also in the XML file where the add-on specifies whether there are any particular events to register. In a WoW add-on, many different events can be registered, some specific to widgets and some specific to the game as a whole. Widget-based events include clicking a button, opening a frame, and sliding a slider. But the real power of the event system is the plethora of game events. Whenever your character deals or takes damage or you chat with another player, check an item on an auction house, or perform one of many different actions, a game event is generated. It is possible for a UI add-on to register to any of these events. For example, a UI add-on that determines your DPS (damage per second) can be implemented by tracking the combat damage events.
Behavior
The behavior of each interface add-on is implemented in Lua. This allows for quick prototyping of behavior, and it’s further possible to reload the UI while the game is running. Because they utilize a table-based inheritance system, mods can implement member functions that override parent systems. The bulk of the code for most add-ons is focused on processing the events and doing something tangible with that information. Every event that is registered must have corresponding Lua code to handle it.
Issue: Player Automation
Although the WoW UI system was extremely successful at launch, there were some issues that arose. One concern during development was the idea of player automation, or the player being able to automate the gameplay with a UI mod. In order to combat this, the system was designed such that a UI mod could only ever perform one action per key press. Therefore, if you pressed the spacebar, at most, the add-on would only be able to cast a single spell.
Although this prevented full automation, it still was possible to make an add-on that did most of the work. For example, a healer character could use an add-on that performed this logic every time the spacebar is pressed:
1. Iterate through all players in the group.
2. Find the player with the lowest hit points and target him or her.
3. Based on the player’s health, cast the appropriate healing spell.
Then a player could run through a level and continuously spam the spacebar. If the logic is sound enough, it will work to keep the whole group alive with minimal skill on the part of the healer. To solve this problem, Blizzard changed the system so that UI mods could not cast any spells at all. Although this didn’t entirely eliminate automation (as there are always external third-party programs that try to do so), it eliminated the use of UI mods to greatly streamline gameplay.
Issue: The UI Breaking
Another issue with the UI system is that because core behavior of the interface can be easily modified by players, it was very much possible to render the game unplayable. The most common way this happened was when new major patches were released. Often, these releases would also coincide with changes to the UI API, which meant if you were running older mods, they could potentially break the entire interface.
This became problematic for Blizzard’s technical support, because every time a new patch was released they were inundated with people who could no longer attack, chat, or cast spells, often due to broken UI mods. Although there was an option to disable out-of-date add-ons, most players did not use the feature because most older mods worked in new patches.
The solution ultimately became to add a new “secure” code path that represented any calls from the built-in UI. These secure calls handled all of the basic functionality, such as attacking and chatting, and add-ons were no longer allowed to override these functions. Instead of overriding them, they had to hook onto the functions, which means that after a secure function executes, the custom hook has an opportunity to execute.
Conclusion
Ultimately, the UI add-on system for World of Warcraft was extremely successful, so much so that most MMORPGs released since have employed similar systems. The number of add-ons created by the community is enormous, and some became so successful that Blizzard incorporated elements into the core game interface. Ultimately, the design of a system that was so flexible and powerful would not have been possible without the use of both scripting languages and a text-based file format.
Summary
Scripting languages have seen an increase in usage in games due to the improvements in productivity. Because of this, many gameplay programmers now spend much of their time programming in script. Some games might use an existing scripting language such as Lua, whereas others might use a language custom-built for their game engine. If a custom scripting language must be implemented, many of the techniques used to create a compiler must be employed, including lexical and syntax analysis.
As for the question of how to store game data, there are tradeoffs between text-based and binary formats. A text-based format makes it much easier to glean changes between revisions, whereas a binary format will almost always be more efficient. Some sample text-based formats this chapter covered included INI, XML, and JSON. Finally, in the World of Warcraft UI we saw a system that combines both a scripting language and text-based data files.
Review Questions
1. What are the advantages and disadvantages of using a scripting language in a game?
2. What are three examples of systems that make sense to implement with a scripting language?
3. Give an example of a custom scripting language. What advantages and disadvantages might this have over a general scripting language?
4. What is a visual scripting system? What might it be used for?
5. Break down the following C++ statement into its corresponding tokens:
int xyz = myFunction();
6. What does the following regular expression match?
[a-z][a-zA-Z]*
7. What is an abstract syntax tree and what is it used for?
8. Describe the tradeoffs between a binary and text-based file format for game data.
9. What file format might you use to store basic configuration settings, and why?
10. What are the two main components of creating an interface mod in World of Warcraft?
Additional References
Aho, Alfred, et. al. Compilers: Principles, Techniques, and Tools (2nd Edition). Boston: Addison-Wesley, 2006. This revised edition of the classic “Dragon Book” goes through many of the main concepts behind designing a compiler. Much of this knowledge can also be applied to the implementation of a custom scripting language.
“The SCUMM Diary: Stories behind one of the greatest game engines ever made.” Gamasutra. http://tinyurl.com/pypbhp8. This extremely interesting article covers the development of the SCUMM engine and scripting language, which powered nearly all of the classic LucasArts adventure games.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.