Programming Android (2011)
Part III. A Skeleton Application for Android
Chapter 13. Exploring Content Providers
In Chapter 7, we saw that user interfaces that need to interact with remote services face interesting challenges, such as not tying up the UI thread with long-running tasks. We also noted in Chapter 3 that the Android content provider API shares symmetry with REST-style web services. Content provider data operations map straight onto REST data operations, and now we’ll show you how to translate content provider URIs to request network data. We suggest taking advantage of this symmetry by writing content providers to operate as an asynchronous buffer between the domain or unique aspects of your application, and the network requests that acquire the data on which your application operates. Writing your application in this way will simplify your application, and will solve common UI and network programming errors encountered in Android and other types of Java programming.
Historically, Java UI programmers, both enterprise and mobile, have written mobile and desktop-based applications in a rather brittle way, and sometimes did run network requests directly on the UI thread, often without caching data obtained from those requests. In most applications, showing anything in a UI would require accessing the network every time a user requested the display of data. Believe it or not, Unix workstations from the 1980s and 1990s would frequently lock up when access to remotely mounted filesystems became unavailable. If applications had used a local dynamic caching scheme, they would have been able to continue running for the duration in which the file server was absent, and then synchronize when it returned. Developers needed to pay conscious attention, but often did not, to make certain that their applications accessed and stored network data correctly.
The trend continued in J2ME, where developers could cache network state in the anemic record management system known as RMS. This library did not support a query language, or an MVC notification system. J2ME developers would need to spawn their own plain Java threads to make network requests, but in many cases did not, which led to brittle applications. If web browsers were to load network data on the UI thread, you would often see them completely freeze to the point where the operating system would have to kill the browser to get rid of it—whenever the network would hang, the UI thread would lock up. Pages and all the images they referenced would always have to be downloaded at every viewing, making for a very slow experience—assuming one of the requests did not hang the whole application. The takeaway from these anecdotes is that traditionally, operating systems have left the loading and caching of network data up to the application, providing little direct library support to help developers implement these tasks correctly.
To resolve these problems, you could use a completely asynchronous interface to handle network interaction and data storage. With such an approach, developers would not have to think about when it was OK to request data from the network—it would always be safe to use such an API, on or off the UI thread. Such considerations become significantly more important in a mobile environment, where intermittent network connectivity increases the likelihood of a hang in incorrectly written code.
We suggest using the content provider API as an asynchronous model of the network, and as a cache of network state so that your application View and Controller do not need their own mechanisms for opening connections or accessing a database. It’s easy to map the provider API onto the API of existing REST-based web services—the provider simply sits in between the application, forwarding requests to the network and caching results as needed. In this chapter, we will show you how this approach can simplify your application, and we will explain more general benefits of the technique, including how it introduces some of the more positive characteristics of web and AJAX programming to Android applications. For more information on AJAX programming, go to http://en.wikipedia.org/wiki/Ajax_(programming).
Developing RESTful Android Applications
We are not the only ones who see the benefits of this approach. At the Google I/O conference in May 2010, Virgil Dobjanschi of Google presented a talk that outlined the following three patterns for using content providers to integrate RESTful web services into Android applications:
Activity→Service→ContentProvider
This pattern involves an activity contacting a service to access application data, which in turn delegates to a content provider to access that data. In this scenario, the activity invokes an asynchronous method on a service that performs asynchronous RESTful invocations.
Activity→ContentProvider→Service
An activity contacts a content provider, which in turn delegates to a service to asynchronously load data. This approach allows the activity to use the convenience of the content provider API to interact with data. The content provider invokes methods on the asynchronous service implementation to invoke a RESTful request. This approach capitalizes on the convenient symmetry between the content provider API and RESTful use of HTTP.
Activity→ContentProvider→SyncAdapter
Android sync adapters provide a framework for synchronizing user data between a device and the cloud. Google Contacts uses a sync adapter. In this scenario, an activity uses the content provider API to access data synchronized by a sync adapter.
In this chapter, we’ll explore the second pattern in detail with our second Finch video example; this strategy will yield a number of important benefits for your applications. Due to the elegance with which this approach integrates network operations into Android MVC, we’ve given it the moniker “Network MVC.”
A future edition of Programming Android may address the other two approaches, as well as document more details of this Google presentation. After you finish reading this chapter, we suggest that you view Google’s talk.
A “Network MVC”
We like to think of the second pattern as a networked form of MVC, where the content provider itself pulls data from the network and then pumps it into the regular Android MVC. We’ll view the content provider as a model of network state—the provider can fulfill data requests with local state, or can retrieve data from the network. With this approach, the Controller and View code should not directly create network requests to access and manage application data. Instead, your application View and Controller should use the ContentResolver API to make data queries through a content provider, which alone should asynchronously load network resources and store the results in a local data cache. Additionally, the provider should always respond quickly to a request by initially avoiding a network invocation that might be needed to fulfill the request by using whatever data is already available in the local database. Executing the request in this manner ensures that the UI thread is blocked for no longer than absolutely necessary, and that the UI has some data to display as soon as possible, thus improving overall snappiness and user satisfaction when using the UI. Here is the provider sequence for querying data, in more detail:
1. The provider matches the incoming URI and queries local database contents for items that previously matched the query.
2. Our provider always attempts to obtain the latest state for the query and subsequently spawns an asynchronous REST request to load content from the network. You could make this behavior configurable based on the request.
3. The provider returns the cursor from the initial local query to the client.
4. The asynchronous loading thread should decide if data in the provider cache needs to be refreshed; if it does, the provider loads and parses data from the network.
5. When content arrives from the network, the provider directly inserts each new data item into the database and then notifies clients of the URIs for the new data. Since the insertion is already happening inside the content provider, there is no need to call ContentResolver.insert. Clients holding existing cursors that contain an older version of data can call Cursor.requery to refresh their data.
With this sequence, the View and Controller eventually get updated with network data, but only the content provider creates the network request. We view a request for a resource that does not currently exist in the provider’s data set as a request to load the resource—the network request that loads data into the cache is a side effect of the activity provider query.
Figure 13-1 illustrates the operations taking place inside the content provider during execution of operations in the sequence.
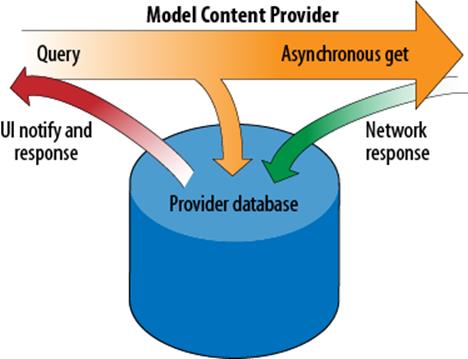
Figure 13-1. Network provider caching content on behalf of the client
For each query, this sequence uses a single Cursor object created by a provider and then returned to the view. Only the provider has the requirement to notify the UI when data changes. The View and Controller do not have to collect data, and do not have to update the model. When data is available, the content provider notifies the cursor for the query. The role of data management is encapsulated inside the content provider, which simplifies the code in the View and Controller. The provider client requests data and receives a cursor quickly; the cursor is notified when network data arrives. It’s critical to recall that notification depends on database and Cursor objects remaining open as long as content provider clients are using them. Closed cursors and databases will result in client views showing no results, which can make it difficult to know if a component such as a list is empty because its cursor was closed erroneously, or if a given query actually had no results.
Summary of Benefits
It’s worth summarizing the benefits of the Network MVC approach:
§ Increased perceived performance overall, and increased actual performance from caching, are among the main benefits of this pattern. Mobile programming often performs like the Web would with no caching system.
§ Storing data in memory is not a good idea, since you do not know when Android will remove your activity from memory. This pattern emphasizes storing data in the content provider as quickly as possible.
§ Most potential UI thread-safety violations cannot happen. Android View components have already been written to dynamically update to reflect current cursor contents. If the size of the data in the model shrinks, ListView will make sure to reduce the number of times it iterates over the cursor. Other component systems, for readers familiar with J2SE Swing, would leave this type of task up to the developer, which would leave open the possibility that the list component might iterate beyond the bounds of its model on deletion of data elements.
§ This approach leverages the cursor management system and the user interface’s built-in capabilities for dynamic updates in response to content observation events. User interface developers don’t need to write their own polling and update systems; they just rely on content observation and the content provider interface.
§ Like with any correct request for network resources, it’s not possible for the UI thread to hang on the network.
§ Delivery of network events happens without requiring the presence of a user interface. Even if a particular activity is not present when a network event arrives, the content provider will still be around to handle it. When the user loads the activity, a query will reveal the event that arrived in the background. The absence of an active UI activity will not result in events simply getting dropped.
§ Elements of the application are encapsulated and have a special purpose, since, as we’ve mentioned, the content provider handles all network and SQLite interactions. The View and Controller just use a provider as a generic system for data management.
§ It’s easier to write applications since it’s difficult to use the API incorrectly—just make content provider calls and the system handles the REST (pun intended).
§ Finally, in a book on mobile programming, it’s easy to focus on device issues, but if clients end up relying on their cache, and referring to the network only when absolutely necessary, they will end up significantly reducing the network load on systems that serve data to devices. This pattern provides a significant benefit for servers as well as clients.
OUR APPROACH IN CONTEXT
To be clear, we are suggesting that applications should write content providers to access and store network data wherever possible. While this might seem like an onerous burden at first, consider that web browsers also use an asynchronous mechanism for loading URI referenced content. For readers familiar with basic web programming, the default Android API may be more flexible and extensive than that found in AJAX, but AJAX has long had a foolproof architecture. Modern browsers load URI data using asynchronous I/O mechanisms (see http://en.wikipedia.org/wiki/Asynchronous_io), which prevents most opportunities for a browser user interface to hang. While it may not seem like the browser is doing much when a given URI fails to load, the UI thread itself is never in danger of blocking due to a network connection becoming unresponsive. If the UI thread were to hang, the whole browser would stop working. It would not even be able to tell you that it was hung—especially since many browsers are entirely single-threaded. Instead, browsers are able to provide you with the opportunity to halt any given page load request, and then load another page that will hopefully be more responsive. Going further, all modern browsers make use of a persistent web cache, and we are simply suggesting that Android applications should also have a similar construct.
Beyond the pattern we are describing, Google provides specific documentation for improving application responsiveness, and reducing the likelihood of “Application Not Responding” notifications, at http://developer.android.com/guide/practices/design/responsiveness.html.
Code Example: Dynamically Listing and Caching YouTube Video Content
To demonstrate the prescribed architecture, we present the Finch video listing application that allows a user to perform a mobile video search using the RESTful API, at http://gdata.youtube.com. Our example code is written with an eye toward intermittent connectivity in a mobile environment. The application preserves user data so that it will remain usable even when the network cannot be reached—even if that means our application can only display older, locally cached results when that happens.
When a user runs a query, the application attempts to retrieve the latest YouTube results for that query. If the application successfully loads new results, it will flush results that are older than one week. If the application were to blindly drop old results before running an update query, it might end up with no results to view, which would render the app useless until network access returned. The screen in Figure 13-2 shows a query for the keyword “dogs”. Pressing Enter in the search box or hitting the refresh button spawns a new query.
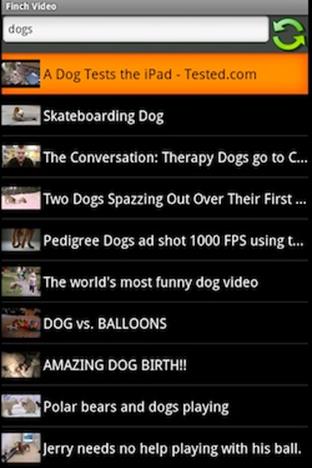
Figure 13-2. Finch video SampleApplication
Our application includes a caching content provider that queries the YouTube API to access YouTube video metadata. Query results are cached in a SQLite table called video, as part of the content provider query method. The provider makes use of the Finch framework for invoking asynchronous REST requests. The UI consists of an activity as shown in Figure 13-2, a list with a search query box, and a refresh button. The list dynamically refreshes on content provider data notification. Whenever the user enters a search query and then presses Enter, the activity invokes the query request on the FinchVideoContentProvider with the appropriate URI query. We’ll now explore the details of this example.
Structure of the Source Code for the Finch YouTube Video Example
This section briefly examines relevant Java source within the Finch YouTube video application that is unique to the simple version of our video listing application. To start, the files reside in two different directories: that of the Finch video application directory for Chapter 12, and that of the Finch Framework library on which Chapter 12 has a dependency. The source files that make up our YouTube application include:
Chapter 12 files in $(FinchVideo)/src/
$(FinchVideo)/src/com/oreilly/demo/pa/finchvideo/FinchVideo.java
The FinchVideo class contains the Videos class, which serves the same function as FinchVideo.SimpleVideos did in the simple video app. The FinchVideo.Videos class defines several more constants in addition to the names of the content provider columns that our simple version defined for the YouTube application. Neither the FinchVideo class nor the Videos class contain any executable code.
$(FinchVideo)/src/com/oreilly/demo/pa/finchvideo/provider/FinchVideoContentProvider.java
This is the main content provider that serves YouTube metadata and carries out asynchronous RESTful requests on the YouTube GData API.
$(FinchVideo)/lib-src/com/oreilly/demo/pa/finchvideo/provider/YouTubeHandler.java
This parses responses from the YouTube GData API and inserts data entries as they arrive.
Finch framework source code in $(FinchFramework)/lib-src
$(FinchFramework)/lib-src/com/finchframework/finch/rest/RESTfulContentProvider.java
This contains a simple framework for invoking RESTful HTTP requests from within an Android content provider. FinchVideoContentProvider extends this class to reuse behavior for asynchronously managing HTTP requests.
$(FinchFramework)/lib-src/com/finchframework/finch/rest/FileHandler.java
$(FinchFramework)/lib-src/com/finchframework/finch/rest/FileHandlerFactory.java
These are simple frameworks for downloading URI content to a file-based cache. They handle the response when the app requests thumbnail URIs.
$(FinchFramework)/lib-src/com/finchframework/finch/rest/ResponseHandler.java
This provides a simple abstraction layer for handling downloaded HTTP content from the YouTube API. YouTubeHandler extends this class.
$(FinchFramework)/lib-src/com/finchframework/finch/rest/UriRequestTask.java
This is a runnnable object specialized to download HTTP content. It uses the Apache HTTP client framework.
Stepping Through the Search Application
In Figure 13-3, we depict the steps involved as our content provider services search requests from the View and Controller using a REST-style network request. The content provider has the opportunity to cache network results in SQLite tables before notifying observers listening to URIs associated with the relevant data. Requests should move asynchronously between components. The View and Controller should not directly or synchronously invoke their own network requests.
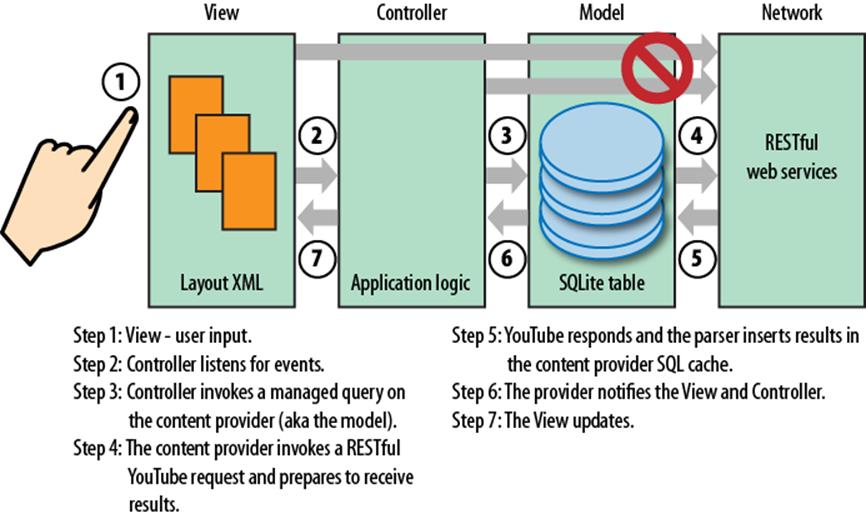
Figure 13-3. The sequence of events that implement a client request for content provider data
The rest of this chapter steps through our second Finch video example to implement this pattern in an Android application. We recommend keeping Figure 13-3 and its steps in mind as we move forward. Note that the steps do not always appear in order as we describe the code to you, but we’ll note the steps in bold without having to break from the flow of the code.
Step 1: Our UI Collects User Input
Our UI in Figure 13-2 uses a simple EditText to collect search keywords.
Step 2: Our Controller Listens for Events
Our FinchVideoActivity registers a text listener, our “Controller,” that receives an event when the user presses the Enter key:
class FinchVideoActivity {
...
mSearchText.setOnEditorActionListener(
new EditText.OnEditorActionListener() {
public boolean onEditorAction(TextView textView,
int actionId,
KeyEvent keyEvent)
{
...
query();
...
}
);
Step 3: The Controller Queries the Content Provider with a managedQuery on the Content Provider/Model
The controller then invokes the activity’s query method in response to user text input (for a search):
// inside FinchVideoActivity
...
// sends the query to the finch video content provider
private void query() {
if (!mSearchText.searchEmpty()) {
String queryString =
FinchVideo.Videos.QUERY_PARAM_NAME + "=" +
Uri.encode(mSearchText.getText().toString());
Uri queryUri =
Uri.parse(FinchVideo.Videos.CONTENT_URI + "?" +
queryString);
Cursor c = managedQuery(queryUri, null, null, null, null);
mAdapter.changeCursor(c);
}
}
Step 4: Implementing the RESTful Request
Step 4 is quite a bit more involved than the other components of the sequence so far. We’ll need to walk through our RESTful FinchVideoContentProvider as we did for SimpleFinchVideoContentProvider. To start, FinchVideoContentProvider extends our utility called RESTfulContentProvider which in turn extends ContentProvider:
FinchVideoContentProvider extend RESTfulContentProvider {
RESTfulContentProvider provides asynchronous REST operations in a way that allows the Finch provider to plug in custom request-response handler components. We’ll explain this in more detail shortly, when we discuss our enhanced query method.
Constants and Initialization
FinchVideoContentProvider initialization is pretty close to the simple video content provider. As with the simple version, we set up a URI matcher. Our only extra task is to add support for matching specific thumbnails. We don’t add support for matching multiple thumbnails, since our viewer activity does not need that support—it only needs to load individual thumbnails:
sUriMatcher.addURI(FinchVideo.AUTHORITY,
FinchVideo.Videos.THUMB + "/#", THUMB_ID);
Creating the Database
We create the Finch video database with Java code that executes the following SQL:
CREATE TABLE video (_ID INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT, description TEXT, thumb_url TEXT,
thumb_width TEXT, thumb_height TEXT, timestamp TEXT,
query_text TEXT, media_id TEXT UNIQUE);
Note that we’ve added the ability to store the following attributes beyond the simple version of our database:
thumb_url, thumb_width, thumb_height
This is the URL, width, and height associated with a given video thumbnail.
timestamp
When we insert a new video record, we stamp it with the current time.
query_text
We store the query text, or query keywords, in the database with each result for that query.
media_id
This is a unique value for each video response that we receive from the GData API. We don’t allow two video entries to have the same media_id.
A Networked Query Method
Here’s what we’ve been leading up to: the implementation of the FinchYouTubeProvider query method calls out to the network to satisfy a query request for YouTube data. It does this by calling a method of its superclass, RESTfulContentProvider.asyncQueryRequest(String queryTag, String queryUri). Here queryTag is a unique string that allows us to reject duplicate requests when appropriate, and queryUri is the complete URI that we need to asynchronously download. Specifically, we invoke requests on the following URI after we have appended URLEncoder.encoded query parameters obtained from our application’s search text input field:
/** URI for querying video, expects appended keywords. */
private static final String QUERY_URI =
"http://gdata.youtube.com/feeds/api/videos?" +
"max-results=15&format=1&q=";
TIP
You can learn how to create a GData YouTube URI that meets the needs of your application quite easily. Google has created a beta (what else?) utility located at http://gdata.youtube.com. If you visit this page in your browser, it will show you a web UI consisting of a plethora of options that you can customize to create a URI like the one shown in the previous code listing. We have used the UI to select up to 15 results, and have selected the use of a mobile video format.
Our networked query method does the usual URI match, and then adds the following tasks, which represent “Step 4: Implementing the RESTful Request” from our sequence:
/**
* Content provider query method that converts its parameters into a YouTube
* RESTful search query.
*
* @param uri a reference to the query for videos, the query string can
* contain, "q='key_words'". The keywords are sent to the google YouTube
* API where they are used to search the YouTube video database.
* @param projection
* @param where not used in this provider.
* @param whereArgs not used in this provider.
* @param sortOrder not used in this provider.
* @return a cursor containing the results of a YouTube search query.
*/
@Override
public Cursor query(Uri uri, String[] projection, String where,
String[] whereArgs, String sortOrder)
{
Cursor queryCursor;
int match = sUriMatcher.match(uri);
switch (match) {
case VIDEOS:
// the query is passed out of band of other information passed
// to this method -- it's not an argument.
String queryText = uri.
getQueryParameter(FinchVideo.Videos.QUERY_PARAM_NAME);![]()
if (queryText == null) {
// A null cursor is an acceptable argument to the method,
// CursorAdapter.changeCursor(Cursor c), which interprets
// the value by canceling all adapter state so that the
// component for which the cursor is adapting data will
// display no content.
return null;
}
String select = FinchVideo.Videos.QUERY_TEXT_NAME +
" = '" + queryText + "'";
// quickly return already matching data
queryCursor =
mDb.query(VIDEOS_TABLE_NAME, projection,
select,
whereArgs,
null,
null, sortOrder);![]()
// make the cursor observe the requested query
queryCursor.setNotificationUri(
getContext().getContentResolver(), uri);![]()
/*
* Always try to update results with the latest data from the
* network.
*
* Spawning an asynchronous load task thread guarantees that
* the load has no chance to block any content provider method,
* and therefore no chance to block the UI thread.
*
* While the request loads, we return the cursor with existing
* data to the client.
*
* If the existing cursor is empty, the UI will render no
* content until it receives URI notification.
*
* Content updates that arrive when the asynchronous network
* request completes will appear in the already returned cursor,
* since that cursor query will match that of
* newly arrived items.
*/
if (!"".equals(queryText)) {
asyncQueryRequest(queryText, QUERY_URI + encode(queryText));![]()
}
break;
case VIDEO_ID:
case THUMB_VIDEO_ID:
long videoID = ContentUris.parseId(uri);
queryCursor =
mDb.query(VIDEOS_TABLE_NAME, projection,
FinchVideo.Videos._ID + " = " + videoID,
whereArgs, null, null, null);
queryCursor.setNotificationUri(
getContext().getContentResolver(), uri);
break;
case THUMB_ID:
String uriString = uri.toString();
int lastSlash = uriString.lastIndexOf("/");
String mediaID = uriString.substring(lastSlash + 1);
queryCursor =
mDb.query(VIDEOS_TABLE_NAME, projection,
FinchVideo.Videos.MEDIA_ID_NAME + " = " +
mediaID,
whereArgs, null, null, null);
queryCursor.setNotificationUri(
getContext().getContentResolver(), uri);
break;
default:
throw new IllegalArgumentException("unsupported uri: " +
QUERY_URI);
}
return queryCursor;
}
![]()
Extract a query parameter out of the incoming URI. We need to send this parameter in the URI itself and not with the other arguments to the query method, since they have different functions in the query method and could not be used to hold query keywords.
![]()
Check first for data already in the local database that matches the query keywords.
![]()
Set the notification URI so that cursors returned from the query method will receive update events whenever the provider changes data they are observing. This action sets up Step 6 of our sequence, which will enable the view to update when the provider fires notification events when it changes data, as it will when data returns from a given request. Once notification arrives, Step 7 occurs when the UI repaints. Note that Steps 6 and 7 are out of order in our description, but it’s appropriate to talk about those stages here since they relate to the notification URI and the query.
![]()
Spawn an asynchronous query to download the given query URI. The method asyncQueryRequest encapsulates the creation of a new thread to service each request. Note that this is Step 5 in our diagram; the asynchronous request will spawn a thread to actually initiate network communication and the YouTube service will return a response.
RESTfulContentProvider: A REST helper
Now we’ll look into the behaviors that FinchVideoProvider inherits from RESTfulContentProvider in order to execute RESTful requests. To start we’ll consider the behavior of a given YouTube request: as we’ve seen, query requests run asynchronously from the main thread. A RESTful provider needs to handle a few special cases: if a user searches for “Funny Cats” while another request for the same keywords is in progress, our provider will drop the second request. On the other hand, if a user searches for “dogs” and then “cats” before “dogs” finishes, our provider allows “dogs” to run in parallel to “cats”, since the user might search again for “dogs” and then obtain the benefit of cached results in which she had shown some interest.
RESTfulContentProvider enables a subclass to asynchronously spawn requests and, when request data arrives, supports custom handling of the response using a simple plug-in interface called ResponseHandler. Subclasses should override the abstract method,RESTfulContentProvider.newResponseHandler, to return handlers specialized to parse response data requested by their host provider. Each handler will override the method ResponseHandler.handleResponse(HttpResponse) to provide custom handling for HttpEntitys contained in passed HttpResponseobjects. For example, our provider uses YouTubeHandler to parse a YouTube RSS feed, inserting database video rows for each entry it reads. More detail on this in a bit...
Additionally, the class RESTfulContentProvider enables a subclass to easily make asynchronous requests and reject duplicate requests. RESTfulContentProvider tracks each request with a unique tag that enables a subclass to drop duplicate queries. Our FinchVideoContentProvider uses the user’s query keywords as the request tag since they uniquely identify a given search request.
Our FinchVideoContentProvider overrides newResponseHandler as follows:
/**
* Provides a handler that can parse YouTube GData RSS content.
*
* @param requestTag unique tag identifying this request.
* @return a YouTubeHandler object.
*/
@Override
protected ResponseHandler newResponseHandler(String requestTag) {
return new YouTubeHandler(this, requestTag);
}
Now we’ll discuss the implementation of RESTfulContentProvider to explain the operations it provides to subclasses. The class UriRequestTask provides a runnable for asynchronously executing REST requests. RESTfulContentProvider uses a map, mRequestsInProgress, keyed by a string to guarantee uniqueness of requests:
/**
* Encapsulates functions for asynchronous RESTful requests so that subclass
* content providers can use them for initiating requests while still using
* custom methods for interpreting REST-based content such as RSS, ATOM,
* JSON, etc.
*/
public abstract class RESTfulContentProvider extends ContentProvider {
protected FileHandlerFactory mFileHandlerFactory;
private Map<String, UriRequestTask> mRequestsInProgress =
new HashMap<String, UriRequestTask>();
public RESTfulContentProvider(FileHandlerFactory fileHandlerFactory) {
mFileHandlerFactory = fileHandlerFactory;
}
public abstract Uri insert(Uri uri, ContentValues cv, SQLiteDatabase db);
private UriRequestTask getRequestTask(String queryText) {
return mRequestsInProgress.get(queryText);![]()
}
/**
* Allows the subclass to define the database used by a response handler.
*
* @return database passed to response handler.
*/
public abstract SQLiteDatabase getDatabase();
public void requestComplete(String mQueryText) {
synchronized (mRequestsInProgress) {
mRequestsInProgress.remove(mQueryText);![]()
}
}
/**
* Abstract method that allows a subclass to define the type of handler
* that should be used to parse the response of a given request.
*
* @param requestTag unique tag identifying this request.
* @return The response handler created by a subclass used to parse the
* request response.
*/
protected abstract ResponseHandler newResponseHandler(String requestTag);
UriRequestTask newQueryTask(String requestTag, String url) {
UriRequestTask requestTask;
final HttpGet get = new HttpGet(url);
ResponseHandler handler = newResponseHandler(requestTag);
requestTask = new UriRequestTask(requestTag, this, get,![]()
handler, getContext());
mRequestsInProgress.put(requestTag, requestTask);
return requestTask;
}
/**
* Creates a new worker thread to carry out a RESTful network invocation.
*
* @param queryTag unique tag that identifies this request.
*
* @param queryUri the complete URI that should be accessed by this request.
*/
public void asyncQueryRequest(String queryTag, String queryUri) {
synchronized (mRequestsInProgress) {
UriRequestTask requestTask = getRequestTask(queryTag);
if (requestTask == null) {
requestTask = newQueryTask(queryTag, queryUri);![]()
Thread t = new Thread(requestTask);
// allows other requests to run in parallel.
t.start();
}
}
}
...
}
![]()
The method getRequestTask uses mRequestsInProgress to access any identical requests in progress, which allows the asyncQueryRequest to block duplicate requests with a simple if statement.
![]()
When a request completes after the ResponseHandler.handleResponse method returns, RESTfulContentProvider removes the task from mRequestsInProgress.
![]()
newQueryTask creates instances of UriRequestTask that are instances of Runnable that will, in turn, open an HTTP connection, and then call handleResponse on the appropriate handler.
![]()
Finally, our code has a unique request, creates a task to run it, and then wraps the task in a thread for asynchronous execution.
While RESTfulContentProvider contains the guts of the reusable task system, for completeness we’ll show you the other components in our framework.
UriRequestTask
UriRequestTask encapsulates the asynchronous aspects of handling a REST request. It’s a simple class that has fields that enable it to execute a RESTful GET inside its run method. Such an action would be part of Step 4, “Implementing the RESTful Request,” of our sequence. As discussed, once it has the response from the request, it passes it to an invocation of ResponseHandler.handleResponse. We expect the handleResponse method to insert database entries as needed, which we’ll see in YouTubeHandler:
/**
* Provides a runnable that uses an HttpClient to asynchronously load a given
* URI. After the network content is loaded, the task delegates handling of the
* request to a ResponseHandler specialized to handle the given content.
*/
public class UriRequestTask implements Runnable {
private HttpUriRequest mRequest;
private ResponseHandler mHandler;
protected Context mAppContext;
private RESTfulContentProvider mSiteProvider;
private String mRequestTag;
private int mRawResponse = -1;
// private int mRawResponse = R.raw.map_src;
public UriRequestTask(HttpUriRequest request,
ResponseHandler handler, Context appContext)
{
this(null, null, request, handler, appContext);
}
public UriRequestTask(String requestTag,
RESTfulContentProvider siteProvider,
HttpUriRequest request,
ResponseHandler handler, Context appContext)
{
mRequestTag = requestTag;
mSiteProvider = siteProvider;
mRequest = request;
mHandler = handler;
mAppContext = appContext;
}
public void setRawResponse(int rawResponse) {
mRawResponse = rawResponse;
}
/**
* Carries out the request on the complete URI as indicated by the protocol,
* host, and port contained in the configuration, and the URI supplied to
* the constructor.
*/
public void run() {
HttpResponse response;
try {
response = execute(mRequest);
mHandler.handleResponse(response, getUri());
} catch (IOException e) {
Log.w(Finch.LOG_TAG, "exception processing asynch request", e);
} finally {
if (mSiteProvider != null) {
mSiteProvider.requestComplete(mRequestTag);
}
}
}
private HttpResponse execute(HttpUriRequest mRequest) throws IOException {
if (mRawResponse >= 0) {
return new RawResponse(mAppContext, mRawResponse);
} else {
HttpClient client = new DefaultHttpClient();
return client.execute(mRequest);
}
}
public Uri getUri() {
return Uri.parse(mRequest.getURI().toString());
}
}
YouTubeHandler
As required by the abstract method, RESTfulContentProvider.newResponseHandler, we’ve seen that our FinchVideoContentProvider returns YouTubeHandler to handle YouTube RSS feeds. YouTubeHandler uses a memory saving XML Pull parser to parse incoming data, iterating through requested XML RSS data. YouTubeHandler contains some complexity, but generally, it’s just matching XML tags as needed to create a ContentValues object that it can insert into the FinchVideoContentProvider’s database. Part of Step 5 occurs when the handler inserts the parsed result into the provider database:
/**
* Parses YouTube Entity data and inserts it into the finch video content
* provider.
*/
public class YouTubeHandler implements ResponseHandler {
public static final String MEDIA = "media";
public static final String GROUP = "group";
public static final String DESCRIPTION = "description";
public static final String THUMBNAIL = "thumbnail";
public static final String TITLE = "title";
public static final String CONTENT = "content";
public static final String WIDTH = "width";
public static final String HEIGHT = "height";
public static final String YT = "yt";
public static final String DURATION = "duration";
public static final String FORMAT = "format";
public static final String URI = "uri";
public static final String THUMB_URI = "thumb_uri";
public static final String MOBILE_FORMAT = "1";
public static final String ENTRY = "entry";
public static final String ID = "id";
private static final String FLUSH_TIME = "5 minutes";
private RESTfulContentProvider mFinchVideoProvider;
private String mQueryText;
private boolean isEntry;
public YouTubeHandler(RESTfulContentProvider restfulProvider,
String queryText)
{
mFinchVideoProvider = restfulProvider;
mQueryText = queryText;
}
/*
* Handles the response from the YouTube GData server, which is in the form
* of an RSS feed containing references to YouTube videos.
*/
public void handleResponse(HttpResponse response, Uri uri)
throws IOException
{
try {
int newCount = parseYoutubeEntity(response.getEntity());![]()
// only flush old state now that new state has arrived
if (newCount > 0) {
deleteOld();
}
} catch (IOException e) {
// use the exception to avoid clearing old state, if we cannot
// get new state. This way we leave the application with some
// data to work with in absence of network connectivity.
// we could retry the request for data in the hope that the network
// might return.
}
}
private void deleteOld() {
// delete any old elements, not just ones that match the current query.
Cursor old = null;
try {
SQLiteDatabase db = mFinchVideoProvider.getDatabase();
old = db.query(FinchVideo.Videos.VIDEO, null,
"video." + FinchVideo.Videos.TIMESTAMP +
" < strftime('%s', 'now', '-" + FLUSH_TIME + "')",
null, null, null, null);
int c = old.getCount();
if (old.getCount() > 0) {
StringBuffer sb = new StringBuffer();
boolean next;
if (old.moveToNext()) {
do {
String ID = old.getString(FinchVideo.ID_COLUMN);
sb.append(FinchVideo.Videos._ID);
sb.append(" = ");
sb.append(ID);
// get rid of associated cached thumb files
mFinchVideoProvider.deleteFile(ID);
next = old.moveToNext();
if (next) {
sb.append(" OR ");
}
} while (next);
}
String where = sb.toString();
db.delete(FinchVideo.Videos.VIDEO, where, null);
Log.d(Finch.LOG_TAG, "flushed old query results: " + c);
}
} finally {
if (old != null) {
old.close();
}
}
}
private int parseYoutubeEntity(HttpEntity entity) throws IOException {
InputStream youTubeContent = entity.getContent();
InputStreamReader inputReader = new InputStreamReader(youTubeContent);
int inserted = 0;
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(false);
XmlPullParser xpp = factory.newPullParser();
xpp.setInput(inputReader);
int eventType = xpp.getEventType();
String startName = null;
ContentValues mediaEntry = null;
// iterative pull parsing is a useful way to extract data from
// streams, since we don't have to hold the DOM model in memory
// during the parsing step.
while (eventType != XmlPullParser.END_DOCUMENT) {
if (eventType == XmlPullParser.START_DOCUMENT) {
} else if (eventType == XmlPullParser.END_DOCUMENT) {
} else if (eventType == XmlPullParser.START_TAG) {
startName = xpp.getName();
if ((startName != null)) {
if ((ENTRY).equals(startName)) {
mediaEntry = new ContentValues();
mediaEntry.put(FinchVideo.Videos.QUERY_TEXT_NAME,
mQueryText);
}
if ((MEDIA + ":" + CONTENT).equals(startName)) {
int c = xpp.getAttributeCount();
String mediaUri = null;
boolean isMobileFormat = false;
for (int i = 0; i < c; i++) {
String attrName = xpp.getAttributeName(i);
String attrValue = xpp.getAttributeValue(i);
if ((attrName != null) &&
URI.equals(attrName))
{
mediaUri = attrValue;
}
if ((attrName != null) && (YT + ":" + FORMAT).
equals(MOBILE_FORMAT))
{
isMobileFormat = true;
}
}
if (isMobileFormat && (mediaUri != null)) {
mediaEntry.put(URI, mediaUri);
}
}
if ((MEDIA + ":" + THUMBNAIL).equals(startName)) {
int c = xpp.getAttributeCount();
for (int i = 0; i < c; i++) {
String attrName = xpp.getAttributeName(i);
String attrValue = xpp.getAttributeValue(i);
if (attrName != null) {
if ("url".equals(attrName)) {
mediaEntry.put(
FinchVideo.Videos.
THUMB_URI_NAME,
attrValue);
} else if (WIDTH.equals(attrName))
{
mediaEntry.put(
FinchVideo.Videos.
THUMB_WIDTH_NAME,
attrValue);
} else if (HEIGHT.equals(attrName))
{
mediaEntry.put(
FinchVideo.Videos.
THUMB_HEIGHT_NAME,
attrValue);
}
}
}
}
if (ENTRY.equals(startName)) {
isEntry = true;
}
}
} else if(eventType == XmlPullParser.END_TAG) {
String endName = xpp.getName();
if (endName != null) {
if (ENTRY.equals(endName)) {
isEntry = false;
} else if (endName.equals(MEDIA + ":" + GROUP)) {
// insert the complete media group
inserted++;
// Directly invoke insert on the finch video
// provider, without using content resolver. We
// would not want the content provider to sync this
// data back to itself.
SQLiteDatabase db =
mFinchVideoProvider.getDatabase();
String mediaID = (String) mediaEntry.get(
FinchVideo.Videos.MEDIA_ID_NAME);
// insert thumb uri
String thumbContentUri =
FinchVideo.Videos.THUMB_URI + "/" + mediaID;
mediaEntry.put(FinchVideo.Videos.
THUMB_CONTENT_URI_NAME,
thumbContentUri);
String cacheFileName =
mFinchVideoProvider.getCacheName(mediaID);
mediaEntry.put(FinchVideo.Videos._DATA,
cacheFileName);
Uri providerUri = mFinchVideoProvider.
insert(FinchVideo.Videos.CONTENT_URI,
mediaEntry, db);![]()
if (providerUri != null) {
String thumbUri = (String) mediaEntry.
get(FinchVideo.Videos.THUMB_URI_NAME);
// We might consider lazily downloading the
// image so that it was only downloaded on
// viewing. Downloading more aggressively
// could also improve performance.
mFinchVideoProvider.
cacheUri2File(String.valueOf(ID),
thumbUrl);![]()
}
}
}
} else if (eventType == XmlPullParser.TEXT) {
// newline can turn into an extra text event
String text = xpp.getText();
if (text != null) {
text = text.trim();
if ((startName != null) && (!"".equals(text))){
if (ID.equals(startName) && isEntry) {
int lastSlash = text.lastIndexOf("/");
String entryId =
text.substring(lastSlash + 1);
mediaEntry.put(FinchVideo.Videos.MEDIA_ID_NAME,
entryId);
} else if ((MEDIA + ":" + TITLE).
equals(startName)) {
mediaEntry.put(TITLE, text);
} else if ((MEDIA + ":" +
DESCRIPTION).equals(startName))
{
mediaEntry.put(DESCRIPTION, text);
}
}
}
}
eventType = xpp.next();
}
// an alternate notification scheme might be to notify only after
// all entries have been inserted.
} catch (XmlPullParserException e) {
Log.d(Ch11.LOG_TAG,
"could not parse video feed", e);
} catch (IOException e) {
Log.d(Ch11.LOG_TAG,
"could not process video stream", e);
}
return inserted;
}
}
![]()
Our handler implements handleResponse by parsing a YouTube HTTP entity in its method, parseYoutubeEntity, which inserts new video data. The handler then deletes old video data by querying for elements that are older than a timeout period, and then deleting the rows of data in that query.
![]()
The handler has finished parsing a media element, and uses its containing content provider to insert its newly parsed ContentValues object. Note that this is Step 5, “Response handler inserts elements into local cache,” in our sequence.
![]()
The provider initiates its own asynchronous request after it inserts a new media entry to also download thumbnail content. We’ll explain more about this feature of our provider shortly.
insert and ResponseHandlers
Going into Step 5 in a bit more detail, our Finch video provider implements insert in much the same way as our simple video provider. Also, as we’ve seen in our application, video insertion happens as a side effect of the query method. It’s worth pointing out that our insert method is broken into two pieces. We intend that content provider clients call the first form and that response handlers call the second form, shown in the following code. The first form delegates to the second. We break up insert because the response handler is part of the content provider and does not need to route through the content resolver to itself:
@Override
public Uri insert(Uri uri, ContentValues initialValues) {
// Validate the requested uri
if (sUriMatcher.match(uri) != VIDEOS) {
throw new IllegalArgumentException("Unknown URI " + uri);
}
ContentValues values;
if (initialValues != null) {
values = new ContentValues(initialValues);
} else {
values = new ContentValues();
}
SQLiteDatabase db = getDatabase();
return insert(uri, initialValues, db);
}
YouTubeHandler uses the following method to directly insert rows into the simple video database. Note that we don’t insert the media if the database already contains a video entry with the same mediaID as the one we are inserting. In this way, we avoid duplicate video entries, which could occur when integrating new data with older, but not expired, data:
public Uri insert(Uri uri, ContentValues values, SQLiteDatabase db) {
verifyValues(values);
// Validate the requested uri
int m = sUriMatcher.match(uri);
if (m != VIDEOS) {
throw new IllegalArgumentException("Unknown URI " + uri);
}
// insert the values into a new database row
String mediaID = (String) values.get(FinchVideo.Videos.MEDIA_ID);
Long rowID = mediaExists(db, mediaID);
if (rowID == null) {
long time = System.currentTimeMillis();
values.put(FinchVideo.Videos.TIMESTAMP, time);
long rowId = db.insert(VIDEOS_TABLE_NAME,
FinchVideo.Videos.VIDEO, values);
if (rowId >= 0) {
Uri insertUri =
ContentUris.withAppendedId(
FinchVideo.Videos.CONTENT_URI, rowId);
mContentResolver.notifyChange(insertUri, null);
return insertUri;
} else {
throw new IllegalStateException("could not insert " +
"content values: " + values);
}
}
return ContentUris.withAppendedId(FinchVideo.Videos.CONTENT_URI, rowID);
}
File Management: Storing Thumbnails
Now that we’ve explained how our RESTful provider framework operates, we’ll end the chapter with an explanation of how the provider handles thumbnails.
Earlier we described the ContentResolver.openInputStream method as a way for content providers to serve files to clients. In our Finch video example, we use this feature to serve thumbnail images. Storing images as files allows us to avoid use of database blobs and their performance overhead, and allows us to only download images when a client requests them. For a content provider to serve files, it must override the method ContentProvider.openFile, which opens a file descriptor to the file being served. The content resolver takes care of creating an input stream from the file descriptor. The simplest implementation of this method will call openFileHelper to activate the convenience utility that allows the ContentResolver to read the _data variable to load the file it references. If your provider does not override this method at all, you will see an exception generated that has a message as follows: No files supported by provider at .... Our simple implementation only allows read-only access, as shown in the following code:
/**
* Provides read-only access to files that have been downloaded and stored
* in the provider cache. Specifically, in this provider, clients can
* access the files of downloaded thumbnail images.
*/
@Override
public ParcelFileDescriptor openFile(Uri uri, String mode)
throws FileNotFoundException
{
// only support read-only files
if (!"r".equals(mode.toLowerCase())) {
throw new FileNotFoundException("Unsupported mode, " +
mode + ", for uri: " + uri);
}
return openFileHelper(uri, mode);
}
Finally, we use a FileHandler implementation of ResponseHandler to download image data from YouTube thumbnail URLs corresponding to each media entry. Our FileHandlerFactory allows us to manage cache files stored in a specified cache directory. We allow the factory to decide where to store the files:
/**
* Creates instances of FileHandler objects that use a common cache directory.
* The cache directory is set in the constructor to the file handler factory.
*/
public class FileHandlerFactory {
private String mCacheDir;
public FileHandlerFactory(String cacheDir) {
mCacheDir = cacheDir;
init();
}
private void init() {
File cacheDir = new File(mCacheDir);
if (!cacheDir.exists()) {
cacheDir.mkdir();
}
}
public FileHandler newFileHandler(String id) {
return new FileHandler(mCacheDir, id);
}
// not really used since ContentResolver uses _data field.
public File getFile(String ID) {
String cachePath = getFileName(ID);
File cacheFile = new File(cachePath);
if (cacheFile.exists()) {
return cacheFile;
}
return null;
}
public void delete(String ID) {
String cachePath = mCacheDir + "/" + ID;
File cacheFile = new File(cachePath);
if (cacheFile.exists()) {
cacheFile.delete();
}
}
public String getFileName(String ID) {
return mCacheDir + "/" + ID;
}
}
/**
* Writes data from URLs into a local file cache that can be referenced by a
* database ID.
*/
public class FileHandler implements ResponseHandler {
private String mId;
private String mCacheDir;
public FileHandler(String cacheDir, String id) {
mCacheDir = cacheDir;
mId = id;
}
public
String getFileName(String ID) {
return mCacheDir + "/" + ID;
}
public void handleResponse(HttpResponse response, Uri uri)
throws IOException
{
InputStream urlStream = response.getEntity().getContent();
FileOutputStream fout =
new FileOutputStream(getFileName(mId));
byte[] bytes = new byte[256];
int r = 0;
do {
r = urlStream.read(bytes);
if (r >= 0) {
fout.write(bytes, 0, r);
}
} while (r >= 0);
urlStream.close();
fout.close();
}
}
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.