Programming Android (2011)
Part I. Tools and Basics
Chapter 2. Java for Android
We don’t teach you Java in this book, but in this chapter we’ll help you understand the special use of Java within Android. Many people can benefit from this chapter: students who have learned some Java but haven’t yet stumbled over the real-life programming dilemmas it presents, programmers from other mobile environments who have used other versions of Java but need to relearn some aspects of the language in the context of Android programming, and Java programmers in general who are new to Android’s particular conventions and requirements.
If you find this chapter too fast-paced, pick up an introductory book on Java. If you follow along all right but a particular concept described in this chapter remains unclear to you, you might refer to the Java tutorial at http://download.oracle.com/docs/cd/E17409_01/javase/tutorial/index.html.
Android Is Reshaping Client-Side Java
Android is already the most widely used way of creating interactive clients using the Java language. Although there have been several other user interface class libraries for Java (AWT, SWT, Swing, J2ME Canvas, etc.), none of them have been as widely accepted as Android. For any Java programmer, the Android UI is worth learning just to understand what the future of Java UIs might look like.
The Android toolkit doesn’t gratuitously bend Java in unfamiliar directions. The mobile environment is simply different. There is a much wider variety of display sizes and shapes; there is no mouse (though there might be a touch screen); text input might be triple-tap; and so on. There are also likely to be many more peripheral devices: motion sensors, GPS units, cameras, multiple radios, and more. Finally, there is the ever-present concern about power. While Moore’s law affects processors and memory (doubling their power approximately every two years), no such law affects battery life. When processors were slow, developers used to be concerned about CPU speed and efficiency. Mobile developers, on the other hand, need to be concerned about energy efficiency. This chapter provides a refresher for generic Java; Android-specific libraries are discussed in detail in Chapter 3.
The Java Type System
There are two distinct, fundamental types in the Java language: objects and primitives. Java provides type safety by enforcing static typing, which requires that every variable must be declared with its type before it is used. For example, a variable named i declared as type int (a primitive 32-bit integer) looks like this:
int i;
This mechanism stands in contrast to nonstatically typed languages where variables are only optionally declared. Though explicit type declarations are more verbose, they enable the compiler to prevent a wide range of programming errors—accidental variable creation resulting from misspelled variable names, calls to nonexistent methods, and so on—from ever making it into running code. Details of the Java Type System can be found in the Java Language Specification.
Primitive Types
Java primitive types are not objects and do not support the operations associated with objects described later in this chapter. You can modify a primitive type only with a limited number of predefined operators: “+”, “-”, “&”, “|”, “=”, and so on. The Java primitive types are:
boolean
The values true or false
byte
An 8-bit 2’s-complement integer
short
A 16-bit 2’s-complement integer
int
A 32-bit 2’s-complement integer
long
A 64-bit 2’s-complement integer
char
A 16-bit unsigned integer representing a UTF-16 code unit
float
A 32-bit IEEE 754 floating-point number
double
A 64-bit IEEE 754 floating-point number
Objects and Classes
Java is an object-oriented language and focuses not on its primitives but on objects—combinations of data, and procedures for operating on that data. A class defines the fields (data) and methods (procedures) that comprise an object. In Java, this definition—the template from which objects are constructed—is, itself, a particular kind of object, a Class. In Java, classes form the basis of a type system that allows developers to describe arbitrarily complex objects with complex, specialized state and behavior.
In Java, as in most object-oriented languages, types may inherit from other types. A class that inherits from another is said to subtype or to be a subclass of its parent. The parent class, in turn, may be called the supertype or superclass. A class that has several different subclasses may be called the base type for those subclasses.
Both methods and fields have global scope within the class and may be visible from outside the object through a reference to an instance of the class.
Here is the definition of a very, very simple class with one field, ctr, and one method, incr:
public class Trivial {
/** a field: its scope is the entire class */
private long ctr;
/** Modify the field. */
public void incr() { ctr++; }
}
Object Creation
A new object, an instance of some class, is created by using the new keyword:
Trivial trivial = new Trivial();
On the left side of the assignment operator “=”, this statement defines a variable, named trivial. The variable has a type, Trivial, so only objects of type Trivial can be assigned to it. The right side of the assignment allocates memory for a new instance of the Trivial class and initializes the instance. The assignment operator assigns a reference to the newly created object to the variable.
It may surprise you to know that the definition of ctr, in Trivial, is perfectly safe despite the fact that it is not explicitly initialized. Java guarantees that it will be initialized to have the value 0. Java guarantees that all fields are automatically initialized at object creation: boolean is initialized tofalse, numeric primitive types to 0, and all object types (including Strings) to null.
WARNING
This applies only to object fields. Local variables must be initialized before they are referenced!
You can take greater control over the initialization of an object by adding a constructor to its class definition. A constructor definition looks like a method except that it doesn’t specify a return type. Its name must be exactly the name of the class that it constructs:
public class LessTrivial {
/** a field: its scope is the entire class */
private long ctr;
/** Constructor: initialize the fields */
public LessTrivial(long initCtr) { ctr = initCtr; }
/** Modify the field. */
public void incr() { ctr++; }
}
In fact, every class in Java has a constructor. The Java compiler automatically creates a constructor with no arguments, if no other constructor is specified. Further, if a constructor does not explicitly call some superclass constructor, the Java compiler will automatically add an implicit call to the superclass no-arg constructor as the very first statement. The definition of Trivial given earlier (which specifies no explicit constructor), actually has a constructor that looks like this:
public Trivial() { super(); }
Since the LessTrivial class explicitly defines a constructor, Java does not implicitly add a default. That means that trying to create a LessTrivial object, with no arguments, will cause an error:
LessTrivial fail = new LessTrivial(); // ERROR!!
LessTrivial ok = new LessTrivial(18); // ... works
There are two concepts that it is important to keep separate: no-arg constructor and default constructor. A default constructor is the constructor that Java adds to your class, implicitly, if you don’t define any other constructors. It happens to be a no-arg constructor. A no-arg constructor, on the other hand, is simply a constructor with no parameters. There is no requirement that a class have a no-arg constructor. There is no obligation to define one, unless you have a specific need for it.
CAUTION
One particular case in which no-arg constructors are necessary deserves special attention. Some libraries need the ability to create new objects, generically, on your behalf. The JUnit framework, for instance, needs to be able to create new test cases, regardless of what they test. Libraries that marshal and unmarshal code to a persistent store or a network connection also need this capability. Since it would be pretty hard for these libraries to figure out, at runtime, the exact calling protocol for your particular object, they typically require a no-arg constructor.
If a class has more than one constructor, it is wise to cascade them, to make sure only a single copy of the code actually initializes the instance and that all other constructors call it. For instance, as a convenience, we might add a no-arg constructor to the LessTrivial class, to accommodate a common case:
public class LessTrivial {
/** a field: its scope is the entire class */
private long ctr;
/** Constructor: init counter to 0 */
public LessTrivial() { this(0); }
/** Constructor: initialize the fields */
public LessTrivial(long initCtr) { ctr = initCtr; }
/** Modify the field. */
public void incr() { ctr++; }
}
Cascading methods is the standard Java idiom for defaulting the values of some arguments. All the code that actually initializes an object is in a single, complete method or constructor and all other methods or constructors simply call it. It is a particularly good idea to use this idiom with constructors that must make explicit calls to a superconstructor.
Constructors should be simple and should do no more work than is necessary to put an object into a consistent initial state. One can imagine, for instance, a design for an object that represents a database or network connection. It might create the connection, initialize it, and verify connectivity, all in the constructor. While this might seem entirely reasonable, in practice it creates code that is insufficiently modular and difficult to debug and modify. In a better design, the constructor simply initializes the connection state as closed and leaves it to an explicit open method to set up the network.
The Object Class and Its Methods
The Java class Object—java.lang.Object—is the root ancestor of every class. Every Java object is an Object. If the definition of a class does not explicitly specify a superclass, it is a direct subclass of Object. The Object class defines the default implementations for several key behaviors that are common to every object. Unless they are overridden by the subclass, the behaviors are inherited directly from Object.
The methods wait, notify, and notifyAll in the Object class are part of Java’s concurrency support. They are discussed in Thread Control with wait() and notify() Methods.
The toString method is the way an object creates a string representation of itself. One interesting use of toString is string concatenation: any object can be concatenated to a string. This example demonstrates two ways to print the same message: they both execute identically. In both, a new instance of the Foo class is created, its toString method is invoked, and the result is concatenated with a literal string. The result is then printed:
System.out.println(
"This is a new foo: " + new Foo());
System.out.println(
"This is a new foo: ".concat((new Foo()).toString()));
The Object implementation of toString returns a not-very-useful string that is based on the location of the object in the heap. Overriding toString in your code is a good first step toward making it easier to debug.
The clone and finalize methods are historical leftovers. The Java runtime will call the finalize method only if it is overridden in a subclass. If a class explicitly defines finalize, though, it is called for an object of the class just before that object is garbage-collected. Not only does Java not guarantee when this might happen, it actually can’t guarantee that it will happen at all. In addition, a call to finalize can resurrect an object! This is tricky: objects are garbage-collected when there are no live references to them. An implementation of finalize, however, could easily create a new live reference, for instance, by adding the object being finalized to some kind of list! Because of this, the existence of a finalize method precludes the defining class from many kinds of optimization. There is little to gain and lots to lose in attempting to use finalize.
The clone method creates objects, bypassing their constructors. Although clone is defined on Object, calling it on an object will cause an exception unless the object implements the Cloneable interface. The clone method is an optimization that can be useful when object creation has a significant cost. While clever uses of clone may be necessary in specific cases, a copy constructor—one which takes an existing instance as its only argument—is much more straightforward and, in most cases, has negligible cost.
The last two Object methods, hashCode and equals, are the methods by which a caller can tell whether one object is “the same as” another.
The definition of the equals method in the API documentation for the Object class stipulates the contract to which every implementation of equals must adhere. A correct implementation of the equals method has the following attributes, and the associated statements must always be true:
reflexive
x.equals(x)
symmetric
x.equals(y) == y.equals(x)
transitive
(x.equals(y) && y.equals(z)) == x.equals(z)
consistent
If x.equals(y) is true at any point in the life of a program, it is always true, provided x and y do not change.
Getting this right is subtle and can be surprisingly difficult. A common error—one that violates reflexivity—is defining a new class that is sometimes equal to an existing class. Suppose your program uses an existing library that defines the class EnglishWeekdays. Suppose, now, that you define a class FrenchWeekdays. There is an obvious temptation to define an equals method for FrenchWeekdays that returns true when it compares one of the EnglishWeekdays to its French equivalent. Don’t do it! The existing English class has no awareness of your new class and so will never recognize instances of your class as being equal. You’ve broken reflexivity!
hashCode and equals should be considered a pair: if you override either, you should override both. Many library routines treat hashCode as an optimized rough guess as to whether two objects are equal or not. These libraries first compare the hash codes of the two objects. If the two codes are different, they assume there is no need to do any more expensive comparisons because the objects are definitely different. The point of hash code computation, then, is to compute something very quickly that is a good proxy for the equals method. Visiting every cell in a large array, in order to compute a hash code, is probably no faster than doing the actual comparison. At the other extreme, it would be very fast to return 0, always, from a hash code computation. It just wouldn’t be very helpful.
Objects, Inheritance, and Polymorphism
Java supports polymorphism, one of the key concepts in object-oriented programming. A language is said to be polymorphic if objects of a single type can have different behavior. This happens when subtypes of a given class can be assigned to a variable of the base class type. An example will make this much clearer.
Subtypes in Java are declared through use of the extends keyword. Here is an example of inheritance in Java:
public class Car {
public void drive() {
System.out.println("Going down the road!");
}
}
public class Ragtop extends Car {
// override the parent's definition.
public void drive() {
System.out.println("Top down!");
// optionally use a superclass method
super.drive();
System.out.println("Got the radio on!");
}
}
Ragtop is a subtype of Car. We noted previously that Car is, in turn, a subclass of Object. Ragtop changes the definition of Car’s drive method. It is said to override drive. Car and Ragtop are both of type Car (they are not both of type Ragtop!) and have different behaviors for the method drive.
We can now demonstrate polymorphic 'margin-top:7.5pt;margin-right:0cm;margin-bottom:7.5pt; margin-left:20.0pt;line-height:normal;vertical-align:baseline'>Car auto = new Car();
auto.drive();
auto = new Ragtop();
auto.drive();
This code fragment will compile without error (despite the assignment of a Ragtop to a variable whose type is Car). It will also run without error and would produce the following output:
Going down the road!
Top down!
Going down the road!
Got the radio on!
The variable auto holds, at different times in its life, references to two different objects of type Car. One of those objects, in addition to being of type Car, is also of subtype Ragtop. The exact behavior of the statement auto.drive() depends on whether the variable currently contains a reference to the former or the latter. This is polymorphic behavior.
Like many other object-oriented languages, Java supports type casting to allow coercion of the declared type of a variable to be any of the types with which the variable is polymorphic:
Ragtop funCar;
Car auto = new Car();
funCar = (Ragtop) auto; //ERROR! auto is a Car, not a Ragtop!
auto.drive();
auto = new Ragtop();
Ragtop funCar = (Ragtop) auto; //Works! auto is a Ragtop
auto.drive();
While occasionally necessary, excessive use of casting is an indication that the code is missing the point. Obviously, by the rules of polymorphism, all variables could be declared to be of type Object, and then cast as necessary. To do that, however, is to abandon the value of static typing.
Java limits a method’s arguments (its actual parameters) to objects of types that are polymorphic with its formal parameters. Similarly, methods return values that are polymorphic with the declared return type. For instance, continuing our automotive example, the following code fragment will compile and run without error:
public class JoyRide {
private Car myCar;
public void park(Car auto) {
myCar = auto;
}
public Car whatsInTheGarage() {
return myCar;
}
public void letsGo() {
park(new Ragtop());
whatsInTheGarage().drive();
}
}
The method park is declared to take an object of type Car as its only parameter. In the method letsGo, however, it is called with an object of type Ragtop, a subtype of type Car. Similarly, the variable myCar is assigned a value of type Ragtop, and the method whatsInTheGarage returns it. The object is a Ragtop: if you call its drive method, it will tell you about its top and its radio. On the other hand, since it is also a Car, it can be used anywhere that one would use a Car. This subtype replacement capability is a key example of the power of polymorphism and how it works with type safety. Even at compile time, it is clear whether an object is compatible with its use, or not. Type safety enables the compiler to find errors, early, that might be much more difficult to find were they permitted to occur at runtime.
Final and Static Declarations
There are 11 modifier keywords that can be applied to a declaration in Java. These modifiers change the behavior of the declared object, sometimes in important ways. The earlier examples used a couple of them, public and private, without explanation: they are among the several modifiers that control scope and visibility. We’ll revisit them in a minute. In this section, we consider two other modifiers that are essential to a complete understanding of the Java type system: final and static.
A final declaration is one that cannot be changed. Classes, methods, fields, parameters, and local variables can all be final.
When applied to a class, final means that any attempt to define a subclass will cause an error. The class String, for instance, is final because strings must be immutable (i.e., you can’t change the content of one after you create it). If you think about it for a while, you will see that this can beguaranteed only if String cannot be subtyped. If it were possible to subtype the String class, a devious library could create a subclass of String, DeadlyString, pass an instance to your code, and change its value from “fred” to “‘; DROP TABLE contacts;” (an attempt to inject rogue SQL into your system that might wipe out parts of your database) immediately after your code had validated its contents!
When applied to a method, final means that the method cannot be overridden in a subclass. Developers use final methods to design for inheritance, when the supertype needs to make a highly implementation-dependent behavior available to a subclass and cannot allow that behavior to be changed. A framework that implemented a generic cache might define a base class CacheableObject, for instance, which the programmer using the framework subtypes for each new cacheable object type. In order to maintain the integrity of the framework, however, CacheableObject might need to compute a cache key that was consistent across all object types. In this case, it might declare its computeCacheKey method final.
When applied to a variable—a field, a parameter, or a local variable—final means that the value of the variable, once assigned, may not change. This restriction is enforced by the compiler: it is not enough that the value does not change, the compiler must be able to prove that it cannotchange. For a field, this means that the value must be assigned either as part of the declaration or in every constructor. Failure to initialize a final field at its declaration or in the constructor—or an attempt to assign to it anywhere else—will cause an error.
For parameters, final means that, within the method, the parameter value always has the value passed in the call. An attempt to assign to a final parameter will cause an error. Of course, since the parameter value is most likely to be a reference to some kind of object, it is possible that the object might change. The application of the keyword final to a parameter simply means that the parameter cannot be assigned.
NOTE
In Java, parameters are passed by value: the method arguments are new copies of the values that were passed at the call. On the other hand, most things in Java are references to objects and Java only copies the reference, not the whole object! References are passed by value!
A final variable may be assigned no more than once. Since using a variable without initializing it is also an error, in Java, a final variable must be assigned exactly once. The assignment may take place anywhere in the enclosing block, prior to use.
A static declaration belongs to the class in which it is described, not to an instance of that class. The opposite of static is dynamic. Any entity that is not declared static is implicitly dynamic. This example illustrates:
public class QuietStatic {
public static int classMember;
public int instanceMember;
}
public class StaticClient {
public void test() {
QuietStatic.classMember++;
QuietStatic.instanceMember++; // ERROR!!
QuietStatic ex = new QuietStatic();
ex.classMember++; // WARNING!
ex.instanceMember++;
}
}
In this example, QuietStatic is the name of a class, and ex is a reference to an instance of that class. The static member classMember is an attribute of the class; you can refer to it simply by qualifying it with the class name. On the other hand, instanceMember is a member of an instance of the class. An attempt to refer to it through the class reference causes an error. That makes sense. There are many different variables called instanceMember, one belonging to each instance of QuietStatic. If you don’t explicitly specify which one you are talking about, there’s no way for Java to figure it out.
As the second pair of statements demonstrates, Java does actually allow references to class (static) variables through instance references. It is misleading, though, and considered a bad practice. Most compilers and IDEs will generate warnings if you do it.
The implications of static versus dynamic declarations can be subtle. It is easiest to understand the distinction for fields. Again, while there is exactly one copy of a static definition, there is one copy per instance of a dynamic definition. Static class members allow you to maintain information that is held in common by all members of a class. Here’s some example code:
public class LoudStatic {
private static int classMember;
private int instanceMember;
public void incr() {
classMember++;
instanceMember++;
}
@Override public String toString() {
return "classMember: " + classMember
+ ", instanceMember: " + instanceMember;
}
public static void main(String[] args) {
LoudStatic ex1 = new LoudStatic();
LoudStatic ex2 = new LoudStatic();
ex1.incr();
ex2.incr();
System.out.println(ex1);
System.out.println(ex2);
}
}
and its output:
classMember: 2, instanceMember: 1
classMember: 2, instanceMember: 1
The initial value of the variable classMember in the preceding example is 0. It is incremented by each of the two different instances. Both instances now see a new value, 2. The value of the variable instanceMember also starts at 0, in each instance. On the other hand, though, each instance increments its own copy and sees the value of its own variable, 1.
Static class and method definitions are similar in that, in both cases, a static object is visible using its qualified name, while a dynamic object is visible only through an instance reference. Beyond that, however, the differences are trickier.
One significant difference in behavior between statically and dynamically declared methods is that statically declared methods cannot be overridden in a subclass. The following, for instance, fails to compile:
public class Star {
public static void twinkle() { }
}
public class Arcturus extends Star {
public void twinkle() { } // ERROR!!
}
public class Rigel {
// this one works
public void twinkle() { Star.twinkle(); }
}
There is very little reason to use static methods in Java. In early implementations of Java, dynamic method dispatch was significantly slower than static dispatch. Developers used to prefer static methods in order to “optimize” their code. In Android’s just-in-time-compiled Dalvik environment, there is no need for this kind of optimization anymore. Excessive use of static methods is usually an indicator of bad architecture.
The difference between statically and dynamically declared classes is the subtlest. Most of the classes that comprise an application are static. A typical class is declared and defined at the top level—outside any enclosing block. Implicitly, all such declarations are static. Most other declarations, on the other hand, take place within the enclosing block of some class and are, by default, dynamic. Whereas most fields are dynamic by default and require a modifier to be static, most classes are static.
NOTE
A block is the code between two curly braces: { and }. Anything—variables, types, methods, and so on—defined within the block is visible within the block and within lexically nested blocks. Except within the special block defining a class, things defined within a block are not visible outside the block.
This is, actually, entirely consistent. According to our description of static—something that belongs to the class, not to an instance of that class—top-level declarations should be static (they belong to no class). When declared within an enclosing block, however—for example, inside the definition of a top-level class—a class definition is also dynamic by default. In order to create a dynamically declared class, just define it inside another class.
This brings us to the difference between a static and a dynamic class. A dynamic class has access to instance members of the enclosing class (since it belongs to the instance). A static class does not. Here’s some code to demonstrate:
public class Outer {
public int x;
public class InnerOne {
public int fn() { return x; }
}
public static class InnerTube {
public int fn() {
return x; // ERROR!!!
}
}
}
public class OuterTest {
public void test() {
new Outer.InnerOne(); // ERROR!!!
new Outer.InnerTube();
}
}
A moment’s reflection will clarify what is happening here. The field x is a member of an instance of the class Outer. In other words, there are lots of variables named x, one for each runtime instance of Outer. The class InnerTube is a part of the class Outer, but not of any instances of Outer. It has no way of identifying an x. The class InnerOne, on the other hand, because it is dynamic, belongs to an instance of Outer. You might think of a separate class InnerOne for each instance of Outer (though this is not, actually, how it is implemented). Consequently, InnerOne has access to the members of the instance of Outer to which it belongs.
OuterTest demonstrates that, as with fields, we can use the static inner definition (in this case, create an instance of the class) simply by using its qualified name. The dynamic definition is useful, however, only in the context of an instance.
Abstract Classes
Java permits a class declaration to entirely omit the implementation of one or more methods by declaring the class and unimplemented methods to be abstract:
public abstract class TemplatedService {
public final void service() {
// subclasses prepare in their own ways
prepareService();
// ... but they all run the same service
runService()
}
public abstract void prepareService();
private final void runService() {
// implementation of the service ...
}
}
public class ConcreteService extends TemplatedService {
void prepareService() {
// set up for the service
}
}
An abstract class cannot be instantiated. Subtypes of an abstract class must either provide definitions for all the abstract methods in the superclass or must, themselves, be declared abstract.
As hinted in the example, abstract classes are useful in implementing the common template pattern, which provides a reusable piece of code that allows customization at specific points during its execution. The reusable pieces are implemented as an abstract class. Subtypes customize the template by implementing the abstract methods.
For more information on abstract classes, see the Java tutorial at http://download.oracle.com/javase/tutorial/java/IandI/abstract.html.
Interfaces
Other languages (e.g., C++, Python, and Perl) permit a capability known as multiple implementation inheritance, whereby an object can inherit implementations of methods from more than one parent class. Such inheritance hierarchies can get pretty complicated and behave in unexpected ways (such as inheriting two field variables with the same name from two different superclasses). Java’s developers chose to trade the power of multiple inheritance for simplicity. Unlike the mentioned languages, in Java a class may extend only a single superclass.
Instead of multiple implementation inheritance, however, Java provides the ability for a class to inherit from several types, using the concept of an interface. Interfaces provide a way to define a type without defining its implementation. You can think of interfaces as abstract classes with all abstract methods. There is no limit on the number of interfaces that a class may implement.
Here’s an example of a Java interface and a class that implements it:
public interface Growable {
// declare the signature but not the implementation
void grow(Fertilizer food, Water water);
}
public interface Eatable {
// another signature with no implementation
void munch();
}
/**
* An implementing class must implement all interface methods
*/
public class Beans implements Growable, Eatable {
@Override
public void grow(Fertilizer food, Water water) {
// ...
}
@Override
public void munch() {
// ...
}
}
Again, interfaces provide a way to define a type distinct from the implementation of that type. This kind of separation is common even in everyday life. If you and a colleague are trying to mix mojitos, you might well divide tasks so that she goes to get the mint. When you start muddling things in the bottom of the glass, it is irrelevant whether she drove to the store to buy the mint or went out to the backyard and picked it from a shrub. What’s important is that you have mint.
As another example of the power of interfaces, consider a program that needs to display a list of contacts, sorted by email address. As you would certainly expect, the Android runtime libraries contain generic routines to sort objects. Because they are generic, however, these routines have no intrinsic idea of what ordering means for the instances of any particular class. In order to use the library sorting routines, a class needs a way to define its own ordering. Classes do this in Java using the interface Comparable.
Objects of type Comparable implement the method compareTo. One object accepts another, similar object as an argument and returns an integer that indicates whether the argument object is greater than, equal to, or less than the target. The library routines can sort anything that is Comparable. A program’s Contact type need only be Comparable and implement compareTo to allow contacts to be sorted:
public class Contact implements Comparable<Contact> {
// ... other fields
private String email;
public Contact(
// other params...
String emailAddress)
{
// ... init other fields from corresponding params
email = emailAddress;
}
public int compareTo(Contact c) {
return email.compareTo(c.email);
}
}
public class ContactView {
// ...
private List<Contact> getContactsSortedByEmail(
List<Contact> contacts)
{
// getting the sorted list of contacts
// is completely trivial
return Collections.sort(contacts);
}
// ...
}
Internally, the Collections.sort routine knows only that contacts is a list of things of type Comparable. It invokes the class’s compareTo method to decide how to order them.
As this example demonstrates, interfaces enable the developer to reuse generic routines that can sort any list of objects that implement Comparable. Beyond this simple example, Java interfaces enable a diverse set of programming patterns that are well described in other sources. We frequently and highly recommend the excellent Effective Java by Joshua Bloch (Prentice Hall).
Exceptions
The Java language uses exceptions as a convenient way to handle unusual conditions. Frequently these conditions are errors.
Code trying to parse a web page, for instance, cannot continue if it cannot read the page from the network. Certainly, it is possible to check the results of the attempt to read and proceed only if that attempt succeeds, as shown in this example:
public void getPage(URL url) {
String smallPage = readPageFromNet(url);
if (null != smallPage) {
Document dom = parsePage(smallPage);
if (null != dom) {
NodeList actions = getActions(dom);
if (null != action) {
// process the action here...
}
}
}
}
Exceptions make this more elegant and robust:
public void getPage(URL url)
throws NetworkException, ParseException, ActionNotFoundException
{
String smallPage = readPageFromNet(url);
Document dom = parsePage(smallPage);
NodeList actions = getActions(dom);
// process the action here...
}
public String readPageFromNet(URL url) throws NetworkException {
// ...
public Document parsePage(String xml) throws ParseException {
// ...
public NodeList getActions(Document doc) throws ActionNotFoundException {
// ...
In this version of the code, each method called from getPage uses an exception to immediately short-circuit all further processing if something goes wrong. The methods are said to throw exceptions. For instance, the getActions method might look something like this:
public NodeList getActions(Document dom)
throws ActionNotFoundException
{
Object actions = xPathFactory.newXPath().compile("//node/@action")
.evaluate(dom, XPathConstants.NODESET);
if (null == actions) {
throw new ActionNotFoundException("Action not found");
}
return (NodeList) actions;
}
When the throw statement is executed, processing is immediately interrupted and resumes at the nearest catch block. Here’s an example of a try-catch block:
for (int i = 0; i < MAX_RETRIES; i++) {
try {
getPage(theUrl);
break;
}
catch (NetworkException e) {
Log.d("ActionDecoder", "network error: " + e);
}
}
This code retries network failures. Note that it is not even in the same method, readPageFromNet, that threw the NetworkException. When we say that processing resumes at the “nearest” try-catch block, we’re talking about an interesting way that Java delegates responsibility for exceptions.
If there is no try-catch block surrounding the throw statement within the method, a thrown exception makes it seem as though the method returns immediately. No further statements are executed and no value is returned. In the previous example, for instance, none of the code following the attempt to get the page from the network needs to concern itself with the possibility that the precondition—a page was read—was not met. The method is said to have been terminated abruptly and, in the example, control returns to getActions. Since getActions does not contain a try-catch block either, it is terminated abruptly too. Control is passed back (up the stack) to the caller.
In the example, when a NetworkException is thrown, control returns to the first statement inside the example catch block, the call to log the network error. The exception is said to have been caught at the first catch statement whose argument type is the same type, or a supertype, of the thrown exception. Processing resumes at the first statement in the catch block and continues normally afterward.
In the example, a network error while attempting to read a page from the network will cause both ReadPageFromNet and getPage to terminate abruptly. After the catch block logs the failure, the for loop will retry getting the page, up to MAX_RETRIES times.
It is useful to have a clear understanding of the root of the Java exception class tree, shown in Figure 2-1.
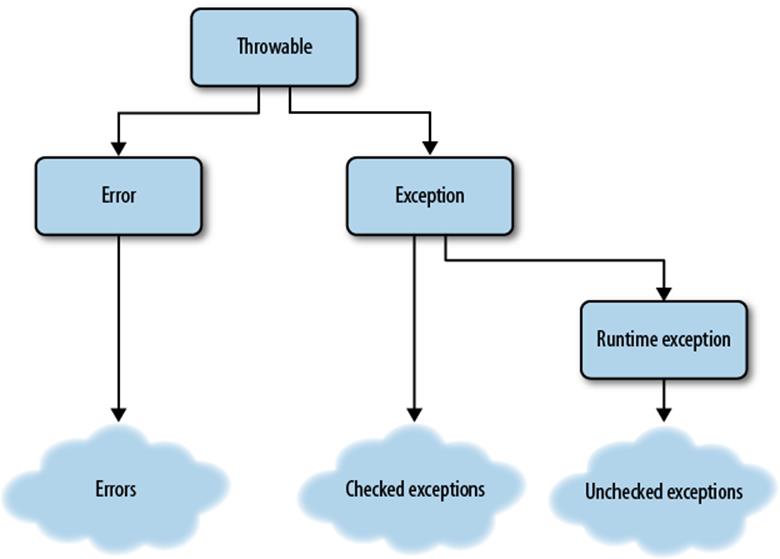
Figure 2-1. Exception base classes
All exceptions are subclasses of Throwable. There is almost never any reason to make reference to Throwable in your code. Think of it as just an abstract base class with two subclasses: Error and Exception. Error and its subclasses are reserved for problems with the Dalvik runtime environment itself. While you can write code that appears to catch an Error (or a Throwable), you cannot, in fact, catch them. An obvious example of this, for instance, is the dreaded OOME, the OutOfMemoryException error. When the Dalvik system is out of memory, it may not be able to complete execution of even a single opcode! Writing tricky code that attempts to catch an OOME and then to release some block of preallocated memory might work—or it might not. Code that tries to catch Throwable or Error is absolutely whistling in the wind.
Java requires the signature of a method to include the exceptions that it throws. In the previous example, getPage declares that it throws three exceptions, because it uses three methods, each of which throws one. Methods that call getPage must, in turn, declare all three of the exceptions thatgetPage throws, along with any others thrown by any other methods that it calls.
As you can imagine, this can become onerous for methods far up the call tree. A top-level method might have to declare tens of different kinds of exceptions, just because it calls methods that throw them. This problem can be mitigated by creating an exception tree that is congruent to the application tree. Remember that a method needs only to declare supertypes for all the exceptions it throws. If you create a base class named MyApplicationException and then subclass it to create MyNetworkException and MyUIException for the networking and UI subsystems, respectively, your top-layer code need only handle MyApplicationException.
Really, though, this is only a partial solution. Suppose networking code somewhere way down in the bowels of your application fails, for instance, to open a network connection. As the exception bubbles up through retries and alternatives, at some point it loses any significance except to indicate that “something went wrong.” A specific database exception, for instance, means nothing to code that is trying to prepopulate a phone number. Adding the exception to a method signature, at that point, is really just a nuisance: you might as well simply declare that all your methods throw Exception.
RuntimeException is a special subclass of Exception. Subclasses of RuntimeException are called unchecked exceptions and do not have to be declared. This code, for instance, will compile without error:
public void ThrowsRuntimeException() {
throw new RuntimeException();
}
There is considerable debate in the Java community about when to use and when not to use unchecked exceptions. Obviously, you could use only unchecked exceptions in your application and never declare any exception in any of your method signatures. Some schools of Java programming even recommend this. Using checked exceptions, however, gives you the chance to use the compiler to verify your code and is very much in the spirit of static typing. Experience and taste will be your guide.
The Java Collections Framework
The Java Collections Framework is one of Java’s most powerful and convenient tools. It provides objects that represent collections of objects: lists, sets, and maps. The interfaces and implementations that comprise the library are all to be found in the java.util package.
There are a few legacy classes in java.util that are historic relics and are not truly part of the framework. It’s best to remember and avoid them. They are Vector, Hashtable, Enumeration, and Dictionary.
Collection interface types
Each of the five main types of object in the Collections Library is represented by an interface:
Collection
This is the root type for all of the objects in the Collection Library. A Collection is a group of objects, not necessarily ordered, not necessarily addressable, possibly containing duplicates. You can add and remove things from it, get its size, and iterate over it (more on iteration in a moment).
List
A List is an ordered collection. There is a mapping between the integers 0 and length–1 and the objects in the list. A List may contain duplicates. You can do anything to a List that you can do to a Collection. In addition, though, you can map an element to its index and an index to an element with the get and indexOf methods. You can also change the element at a specific index with the add(index, e) method. The iterator for a List returns the elements in order.
Set
A Set is an unordered collection that does not contain duplicates. You can do anything to a Set that you can do to a Collection. Attempting to add an element to a Set that already contains it, though, does not change the size of the Set.
Map
A Map is like a list except that instead of mapping integers to objects it maps a set of key objects to a collection of value objects. You can add and remove key-value pairs from the Map, get its size, and iterate over it, just like any other collection. Examples of maps might include mapping words to their definitions, dates to events, or URLs to cached content.
Iterator
An Iterator returns the elements of the collection from which it is derived, each exactly once, in response to calls to its next method. It is the preferred means for processing all the elements of a collection. Instead of:
for (int i = 0; i < list.size(); i++) {
String s = list.get(i)
// ...
}
the following is preferred:
for (Iterator<String> i = list.iterator(); i.hasNext();) {
String s = i.next();
// ...
}
In fact, the latter may be abbreviated, simply, as:
for (String s: list) {
// ...
}
Collection implementation types
These interface types have multiple implementations, each appropriate to its own use case. Among the most common of these are the following:
ArrayList
An ArrayList is a list that is backed by an array. It is quick to index but slow to change size.
LinkedList
A LinkedList is a list that can change size quickly but is slower to index.
HashSet
A HashSet is a set that is implemented as a hash. add, remove, contains, and size all execute in constant time, assuming a well-behaved hash. A HashSet may contain (no more than one) null.
HashMap
A HashMap is an implementation of the Map interface that uses a hash table as its index. add, remove, contains, and size all execute in constant time, assuming a well-behaved hash. It may contain a (single) null key, but any number of values may be null.
TreeMap
A TreeMap is an ordered Map: objects in the map are sorted according to their natural order if they implement the Comparable interface, or according to a Comparator passed to the TreeMap constructor if they do not.
Idiomatic users of Java prefer to use declarations of interface types instead of declarations of implementation types, whenever possible. This is a general rule, but it is easiest to understand here in the context of the collection framework.
Consider a method that returns a new list of strings that is just like the list of strings passed as its second parameter, but in which each element is prefixed with the string passed as the first parameter. It might look like this:
public ArrayList<String> prefixList(
String prefix,
ArrayList<String> strs)
{
ArrayList<String> ret
= new ArrayList<String>(strs.size());
for (String s: strs) { ret.add(prefix + s); }
return ret;
}
There’s a problem with this implementation, though: it won’t work on just any list! It will only work on an ArrayList. If, at some point, the code that calls this method needs to be changed from using an ArrayList to a LinkedList, it can no longer use the method. There’s no good reason for that, at all.
A better implementation might look like this:
public List<String> prefix(
String prefix,
List<String> strs)
{
List<String> ret = new ArrayList<String>(strs.size());
for (String s: strs) { ret.add(prefix + s); }
return ret;
}
This version is more adaptable because it doesn’t bind the method to a particular implementation of the list. The method depends only on the fact that the parameter implements a certain interface. It doesn’t care how. By using the interface type as a parameter it requires exactly what it needs to do its job—no more, no less.
In fact, this could probably be further improved if its parameter and return type were Collection.
Java generics
Generics in Java are a large and fairly complex topic. Entire books have been written on the subject. This section introduces them in their most common setting, the Collections Library, but will not attempt to discuss them in detail.
Before the introduction of generics in Java, it wasn’t possible to statically type the contents of a container. One frequently saw code that looked like this:
public List makeList() {
// ...
}
public void useList(List l) {
Thing t = (Thing) l.get(0);
// ...
}
// ...
useList(makeList());
The problem is obvious: useList has no guarantee that makeList created a list of Thing. The compiler cannot verify that the cast in useList will work, and the code might explode at runtime.
Generics solve this problem—at the cost of some significant complexity. The syntax for a generic declaration was introduced, without comment, previously. Here’s a version of the example, with the generics added:
public List<Thing> makeList() {
// ...
}
public void useList(List<Thing> l) {
Thing t = l.get(0);
// ...
}
// ...
useList(makeList());
The type of the objects in a container is specified in the angle brackets (<>) that are part of the container type. Notice that the cast is no longer necessary in useList because the compiler can now tell that the parameter l is a list of Thing.
Generic type descriptions can get pretty verbose. Declarations like this are not uncommon:
Map<UUID, Map<String, Thing>> cache
= new HashMap<UUID, Map<String, Thing>>();
Garbage Collection
Java is a garbage-collected language. That means your code does not manage memory. Instead, your code creates new objects, allocating memory, and then simply stops using those objects when it no longer needs them. The Dalvik runtime will delete them and compress memory, as appropriate.
In the not-so-distant past, developers had to worry about long and unpredictable periods of unresponsiveness in their applications when the garbage collector suspended all application processing to recover memory. Many developers, both those that used Java in its early days and those that used J2ME more recently, will remember the tricks, hacks, and unwritten rules necessary to avoid the long pauses and memory fragmentation caused by early garbage collectors. Garbage collection technology has come a long way since those days. Dalvik emphatically does not have these problems. Creating new objects has essentially no overhead. Only the most demandingly responsive of UIs—perhaps some games—will ever need to worry about garbage collection pauses.
Scope
Scope determines where variables, methods, and other symbols are visible in a program. Outside of a symbol’s scope, the symbol is not visible at all and cannot be used. We’ll go over the major aspects of scope in this section, starting with the highest level.
Java Packages
Java packages provide a mechanism for grouping related types together in a universally unique namespace. Such grouping prevents identifiers within the package namespace from colliding with those created and used by other developers in other namespaces.
A typical Java program is made up of code from a forest of packages. The standard Java Runtime Environment supplies packages like java.lang and java.util. In addition, the program may depend on other common libraries like those in the org.apache tree. By convention, application code—code you create—goes into a package whose name is created by reversing your domain name and appending the name of the program. Thus, if your domain name is androidhero.com, the root of your package tree will be com.androidhero and you will put your code into packages likecom.androidhero.awesomeprogram and com.androidhero.geohottness.service. A typical package layout for an Android application might have a package for persistence, a package for the UI, and a package for application logic or controller code.
In addition to providing a unique namespace, packages have implications on member (field and method) visibility for objects in the same package. Classes in the same package may be able to see each other’s internals in ways that are not available to classes outside the package. We’ll return to this topic in a moment.
To declare a class as part of a package, use the package keyword at the top of the file containing your class definition:
package your.qualifieddomainname.functionalgrouping
Don’t be tempted to shortcut your package name! As surely as a quick, temporary implementation lasts for years, so the choice of a package name that is not guaranteed unique will come back to haunt you.
Some larger projects use completely different top-level domains to separate public API packages from the packages that implement those APIs. For example, the Android API uses the top-level package, android, and implementation classes generally reside in the package, com.android. Sun’s Java source code follows a similar scheme. Public APIs reside in the java package, but the implementation code resides in the package sun. In either case, an application that imports an implementation package is clearly doing something fast and loose, depending on something that is not part of the public API.
While it is possible to add code to existing packages, it is usually considered bad form to do so. In general, in addition to being a namespace, a package is usually a single source tree, at least up as far as the reversed domain name. It is only convention, but Java developers usually expect that when they look at the source for the package com.brashandroid.coolapp.ui, they will see all the source for the UI for CoolApp. Most will be surprised if they have to find another source tree somewhere with, for instance, page two of the UI.
NOTE
The Android application framework also has the concept of a Package. It is different, and we’ll consider it in Chapter 3. Don’t confuse it with Java package names.
For more information on Java packages, see the Java tutorial at http://download.oracle.com/javase/tutorial/java/package/packages.html.
Access Modifiers and Encapsulation
We hinted earlier that members of a class have special visibility rules. Definitions in most Java blocks are lexically scoped: they are visible only within the block and its nested blocks. The definitions in a class, however, may be visible outside the block. Java supports publishing top-level members of a class—its methods and fields—to code in other classes, through the use of access modifiers. Access modifiers are keywords that modify the visibility of the declarations to which they are applied.
There are three access-modifying keywords in the Java language: public, protected, and private. Together they support four levels of access. While access modifiers affect the visibility of a declaration from outside the class containing it, within the class, normal block scoping rules apply, regardless of access modification.
The private access modifier is the most restrictive. A declaration with private access is not visible outside the block that contains it. This is the safest kind of declaration because it guarantees that there are no references to the declaration, except within the containing class. The more privatedeclarations there are in a class, the safer the class is.
The next most restrictive level of access is default or package access. Declarations that are not modified by any of the three access modifiers have default access and are visible only from other classes in the same package. Default access can be a very handy way to create state shared between objects, similar to the use of the friend declaration in C++.
The protected access modifier permits all the access rights that were permitted by default access but, in addition, allows access from within any subtype. Any class that extends a class with protected declarations has access to those declarations.
Finally, public access, the weakest of the modifiers, allows access from anywhere.
Here’s an example that will make this more concrete. There are four classes in two different packages here, all of which refer to fields declared in one of the classes, Accessible:
package over.here;
public class Accessible {
private String localAccess;
String packageAccess;
protected String subtypeAccess;
public String allAccess;
public void test() {
// all of the assignments below work:
// the fields are declared in an enclosing
// block and are therefore visible.
localAccess = "success!!";
packageAccess = "success!!";
subtypeAccess = "success!!";
allAccess = "success!!";
}
}
package over.here;
import over.here.Accessible;
// this class is in the same package as Accessible
public class AccessibleFriend {
public void test() {
Accessible target = new Accessible();
// private members are not visible
// outside the declaring class
target.localAccess = "fail!!"; // ERROR!!
// default access visible within package
target.packageAccess = "success!!";
// protected access is superset of default
target.subtypeAccess = "success!!";
// visible everywhere
target.allAccess = "success!!";
}
}
package over.there;
import over.here.Accessible;
// a subtype of Accessible
// in a different package
public class AccessibleChild extends Accessible {
// the visible fields from Accessible appear
// as if declared in a surrounding block
public void test() {
localAccess = "fail!!"; // ERROR!!
packageAccess = "fail!!"; // ERROR!!
// protected declarations are
// visible from subtypes
subtypeAccess = "success!!";
// visible everywhere
allAccess = "success!!";
}
}
package over.there;
import over.here.Accessible;
// a class completely unrelated to Accessible
public class AccessibleStranger {
public void test() {
Accessible target = new Accessible();
target.localAccess = "fail!!"; // ERROR!!
target.packageAccess = "fail!!"; // ERROR!!
target.subtypeAccess = "success!!"; // ERROR!!
// visible everywhere
target.allAccess = "success!!";
}
}
Idioms of Java Programming
Somewhere between getting the specifics of a programming language syntax right and good pattern-oriented design (which is language-agnostic), is idiomatic use of a language. An idiomatic programmer uses consistent code to express similar ideas and, by doing so, produces programs that are easy to understand, make optimal use of the runtime environment, and avoid the “gotchas” that exist in any language syntax.
Type Safety in Java
A primary design goal for the Java language was programming safety. Much of the frequently maligned verbosity and inflexibility of Java, which is not present in languages such as Ruby, Python, and Objective-C, is there to make sure a compiler can guarantee that entire classes of errors will never occur at runtime.
Java’s static typing has proven to be valuable well beyond its own compiler. The ability for a machine to parse and recognize the semantics of Java code was a major force in the development of powerful tools like FindBugs and IDE refactoring tools.
Many developers argue that, especially with modern coding tools, these constraints are a small price to pay for being able to find problems immediately that might otherwise manifest themselves only when the code is actually deployed. Of course, there is also a huge community of developers who argue that they save so much time coding in a dynamic language that they can write extensive unit and integration tests and still come out ahead.
Whatever your position in this discussion, it makes a lot of sense to make the best possible use of your tools. Java’s static binding absolutely is a constraint. On the other hand, Java is a pretty good statically bound language. It is a lousy dynamic language. It is actually possible to do fairly dynamic things with Java by using its reflection and introspection APIs and doing a lot of type casting. Doing so, except in very limited circumstances, is using the language and its runtime environment to cross-purposes. Your program is likely to run very slowly, and the Android tool chain won’t be able to make heads or tails of it. Perhaps most important, if there are bugs in this seldom-used part of the platform, you’ll be the first to find them. We suggest embracing Java’s static nature—at least until there is a good, dynamic alternative—and taking every possible advantage of it.
Encapsulation
Developers limit the visibility of object members in order to create encapsulation. Encapsulation is the idea that an object should never reveal details about itself that it does not intend to support. To return to the mojito-making example, recall that, when it comes time to make the cocktail, you don’t care at all how your colleague got the necessary mint. Suppose, though, that you had said to her, “Can you get the mint? And, oh, by the way, while you are out there, could you water the rosebush?” It is no longer true that you don’t care how your colleague produces mint. You now depend on the exact way that she does it.
In the same way, the interface (sometimes abbreviated as API) of an object consists of the methods and types that are accessible from calling code. By careful encapsulation, a developer keeps implementation details of an object hidden from code that uses it. Such control and protection produce programs that are more flexible and allow the developer of an object to change object implementation over time without causing ripple-effect changes in calling code.
Getters and setters
A simple, but common, form of encapsulation in Java involves the use of getter and setter methods. Consider a naive definition of a Contact class:
public class Contact {
public String name;
public int age;
public String email;
}
This definition makes it necessary for external objects to access the fields of the class directly. For example:
Contact c = new Contact();
c.name = "Alice";
c.age = 13;
c.email = "alice@mymail.com";
It will take only a tiny amount of use in the real world to discover that contacts actually have several email addresses. Unfortunately, adding a multiple-address feature to the naive implementation requires updating every single reference to Contact.email, in the entire program.
In contrast, consider the following class:
class Contact {
private int age;
private String name;
private String email;
Contact(int age, String name, String email) {
this.age = age;
this.name = name;
this.email = email;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getEmail() {
return address;
}
}
Use of the private access modifier prevents direct access to the fields of this version of the Contact class. Use of public getter methods provides the developer with the opportunity to change how the Contact object returns the name, age, or email address of the Contact. For example, the email address could be stored by itself, as in the preceding code or concatenated from a username and a hostname if that happened to be more convenient for a given application. Internally, the age could be held as an int or as an Integer. The class can be extended to support multiple email addresses without any change to any client.
Java does allow direct reference to fields and does not, like some languages, automatically wrap references to the fields in getters and setters. In order to preserve encapsulation, you must define each and every access method yourself. Most IDEs provide code generation features that will do this quickly and accurately.
Wrapper getter and setter methods provide future flexibility, whereas direct field access means that all code that uses a field will have to change if the type of that field changes, or if it goes away. Getter and setter methods represent a simple form of object encapsulation. An excellent rule of thumb recommends that all fields be either private or final. Well-written Java programs use this and other, more sophisticated forms of encapsulation in order to preserve adaptability in more complex programs.
Using Anonymous Classes
Developers who have experience working with UI development will be familiar with the concept of a callback: your code needs to be notified when something in the UI changes. Perhaps a button is pushed and your model needs to make a corresponding change in state. Perhaps new data has arrived from the network and it needs to be displayed. You need a way to add a block of code to a framework, for later execution on your behalf.
Although the Java language does provide an idiom for passing blocks of code, it is slightly awkward because neither code blocks nor methods are first-class objects in the language. There is no way, in the language, to obtain a reference to either.
You can have a reference to an instance of a class. In Java, instead of passing blocks or functions, you pass an entire class that defines the code you need as one of its methods. A service that provides a callback API will define its protocol using an interface. The service client defines an implementation of this interface and passes it to the framework.
Consider, for instance, the Android mechanism for implementing the response to a user keypress. The Android View class defines an interface, OnKeyListener, which, in turn, defines an onKey method. If your code passes an implementation of OnKeyListener to a View, its onKey method will be called each time the View processes a new key event.
The code might look something like this:
public class MyDataModel {
// Callback class
private class KeyHandler implements View.OnKeyListener {
public boolean onKey(View v, int keyCode, KeyEvent event) {
handleKey(v, keyCode, event)
}
}
/** @param view the view we model */
public MyDataModel(View view) { view.setOnKeyListener(new KeyHandler()) }
/** Handle a key event */
void handleKey(View v, int keyCode, KeyEvent event) {
// key handling code goes here...
}
}
When a new MyDataModel is created, it is informed about the view to which it is attached by an argument to the constructor. The constructor creates a new instance of the trivial callback class, KeyHandler, and installs it in the view. Any subsequent key events will be relayed to the model instance’s handleKey method.
While this certainly gets the job done, it can get pretty ugly, especially if your model class needs to handle multiple kinds of events from multiple views! After a while, all those type definitions clutter up the top of your program. The definitions can be a long way from their use and, if you think about it, they really serve no purpose at all.
Java provides a way to simplify this somewhat, using an anonymous class. Here is a code fragment similar to the one shown earlier, except that it is implemented using an anonymous class:
public class MyDataModel {
/** @param view the view we model */
public MyDataModel(View view) {
view.setOnKeyListener(
// this is an anonymous class!!
new View.OnKeyListener() {
public boolean onKey(View v, int keyCode, KeyEvent event) {
handleKey(v, keyCode, event)
} } );
}
/** Handle a key event */
void handleKey(View v, int keyCode, KeyEvent event) {
// key handling code goes here...
}
}
While it might take a minute to parse, this code is almost identical to the previous example. It passes a newly created instance of a subtype of View.OnKeyListener as an argument in the call to view.setOnKeyListener. In this example, though, the argument to the call to view.setOnKeyListener is special syntax that defines a new subclass of the interface View.OnKeyListener and instantiates it in a single statement. The new instance is an instance of a class that has no name: it is anonymous. Its definition exists only in the statement that instantiates it.
Anonymous classes are a very handy tool and are the Java idiom for expressing many kinds of code blocks. Objects created using an anonymous class are first-class objects of the language and can be used anywhere any other object of the same type would be legal. For instance, they can be assigned:
public class MyDataModel {
/** @param view the view we model */
public MyDataModel(View view1, View view2) {
// get a reference to the anonymous class
View.OnKeyListener keyHdlr = new View.OnKeyListener() {
public boolean onKey(View v, int keyCode, KeyEvent event) {
handleKey(v, keyCode, event)
} };
// use the class to relay for two views
view1.setOnKeyListener(keyHdlr);
view2.setOnKeyListener(keyHdlr);
}
/** Handle a key event */
void handleKey(View v, int keyCode, KeyEvent event) {
// key handling code goes here...
}
}
You might wonder why the anonymous class in this example delegates its actual implementation (the handleKey method) to the containing class. There’s certainly no rule that constrains the content of the anonymous class: it absolutely could contain the complete implementation. On the other hand, good, idiomatic taste suggests putting the code that changes an object’s state into the object class. If the implementation is in the containing class, it can be used from other methods and callbacks. The anonymous class is simply a relay and that is all it should do.
Java does have some fairly strong constraints concerning the use of the variables that are in scope—anything defined in any surrounding block—within an anonymous class. In particular, an anonymous class can only refer to a variable inherited from the surrounding scope if that variable is declared final. For example, the following code fragment will not compile:
/** Create a key handler that matches the passed key */
public View.OnKeyListener curry(int keyToMatch) {
return new View.OnKeyListener() {
public boolean onKey(View v, int keyCode, KeyEvent event) {
if (keyToMatch == keyCode) { foundMatch(); } // ERROR!!
} };
}
The remedy is to make the argument to curry final. Making it final, of course, means that it cannot be changed in the anonymous class. But there is an easy, idiomatic way around that:
/** Create a key handler that increments and matches the passed key */
public View.OnKeyListener curry(final int keyToMatch) {
return new View.OnKeyListener() {
private int matchTarget = keyToMatch;
public boolean onKey(View v, int keyCode, KeyEvent event) {
matchTarget++;
if (matchTarget == keyCode) { foundMatch(); }
} };
}
Modular Programming in Java
While class extension in Java offers developers significant flexibility in being able to redefine aspects of objects as they are used in different contexts, it actually takes a reasonable amount of experience to make judicious use of classes and interfaces. Ideally, developers aim to create sections of code that are tolerant of change over time and that can be reused in as many different contexts as possible, in multiple applications or perhaps even as libraries. Programming in this way can reduce bugs and the application’s time to market. Modular programming, encapsulation, and separation of concerns are all key strategies for maximizing code reuse and stability.
A fundamental design consideration in object-oriented development concerns the decision to delegate or inherit as a means of reusing preexisting code. The following series of examples contains different object hierarchies for representing automotive vehicles that might be used in a car gaming application. Each example presents a different approach to modularity.
A developer starts by creating a vehicle class that contains all vehicle logic and all logic for each different type of engine, as follows:
// Naive code!
public class MonolithicVehicle {
private int vehicleType;
// fields for an electric engine
// fields for a gas engine
// fields for a hybrid engine
// fields for a steam engine
public MonolithicVehicle(int vehicleType) {
vehicleType = vehicleType;
}
// other methods for implementing vehicles and engine types.
void start() {
// code for an electric engine
// code for a gas engine
// code for a hybrid engine
// code for a steam engine
}
}
This is naive code. While it may be functional, it mixes together unrelated bits of implementation (e.g., all types of vehicle engines) and will be hard to extend. For instance, consider modifying the implementation to accommodate a new engine type (nuclear). The code for each kind of car engine has unrestricted access to the code for every other engine. A bug in one engine implementation might end up causing a bug in another, unrelated engine. A change in one might result in an unexpected change to another. And, of course, a car that has an electric engine must drag along representations of all existing engine types. Future developers working on the monolithic vehicle must understand all the complex interactions in order to modify the code. This just doesn’t scale.
How might we improve on this implementation? An obvious idea is to use subclassing. We might use the class hierarchy shown in the following code to implement different types of automotive vehicles, each tightly bound to its engine type:
public abstract class TightlyBoundVehicle {
// has no engine field
// each subclass must override this method to
// implement its own way of starting the vehicle
protected abstract void startEngine();
public final void start() { startEngine(); }
}
public class ElectricVehicle extends TightlyBoundVehicle {
protected void startEngine() {
// implementation for engine start electric
}
public class GasVehicle extends TightlyBoundVehicle {
protected void startEngine() {
// implementation for engine start gas
}
}
public void anInstantiatingMethod() {
TightlyBoundVehicle vehicle = new ElectricVehicle();
TightlyBoundVehicle vehicle = new GasVehicle();
TightlyBoundVehicle vehicle = new HybridVehicle();
TightlyBoundVehicle vehicle = new SteamVehicle();
}
This is clearly an improvement. The code for each engine type is now encapsulated within its own class and cannot interfere with any others. You can extend individual types of vehicles without affecting any other type. In many circumstances, this is an ideal implementation.
On the other hand, what happens when you want to convert your tightly bound gas vehicle to biodiesel? In this implementation, cars and engines are the same object. They cannot be separated. If the real-world situation that you are modeling requires you to consider the objects separately, your architecture will have to be more loosely coupled:
interface Engine {
void start();
}
class GasEngine implements Engine {
void start() {
// spark plugs ignite gas
}
}
class ElectricEngine implements Engine {
void start() {
// run power to battery
}
}
class DelegatingVehicle {
// has an engine field
private Engine mEngine;
public DelegatingVehicle(Engine engine) {
mEngine = engine;
}
public void start() {
// delegating vehicle can use a gas or electric engine
mEngine.start();
}
}
void anInstantiatingMethod() {
// new vehicle types are easily created by just
// plugging in different kinds of engines.
DelegatingVehicle electricVehicle =
new DelegatingVehicle(new ElectricEngine());
DelegatingVehicle gasVehicle = new DelegatingVehicle(new GasEngine());
//DelegatingVehicle hybridVehicle = new DelegatingVehicle(new HybridEngine());
//DelegatingVehicle steamVehicle = new DelegatingVehicle(new SteamEngine());
}
In this architecture, the vehicle class delegates all engine-related behaviors to an engine object that it owns. This is sometimes called has-a, as opposed to the previous, subclassed example, called is-a. It can be even more flexible because it separates the knowledge of how an engine actually works from the car that contains it. Each vehicle delegates to a loosely coupled engine type and has no idea how that engine implements its behavior. The earlier example makes use of a reusable DelegatingVehicle class that does not change at all when it is given a new kind of engine. A vehicle can use any implementation of the Engine interface. In addition, it’s possible to create different types of vehicle—SUV, compact, or luxury, for instance—that each make use of any of the different types of Engine.
Using delegation minimizes the interdependence between the two objects and maximizes the flexibility to change them later. By preferring delegation over inheritance, a developer makes it easier to extend and improve the code. By using interfaces to define the contract between an object and its delegates, a developer guarantees that the delegates will have the expected behavior.
Basic Multithreaded Concurrent Programming in Java
The Java language supports concurrent threads of execution. Statements in different threads are executed in program order, but there is no ordering relationship between the statements in different threads. The basic unit of concurrent execution in Java is encapsulated in the classjava.lang.Thread. The recommended method of spawning a thread uses an implementation of the interface java.lang.Runnable, as demonstrated in the following example:
// program that interleaves messages from two threads
public class ConcurrentTask implements Runnable {
public void run() {
while (true) {
System.out.println("Message from spawned thread");
}
}
}
public void spawnThread() {
(new Thread(new ConcurrentTask())).start();
while (true) {
System.out.println("Message from main thread");
}
}
In the preceding example, the method spawnThread creates a new thread, passing a new instance of ConcurrentTask to the thread’s constructor. The method then calls start on the new thread. When the start method of the thread is called, the underlying virtual machine (VM) will create a new concurrent thread of execution, which will, in turn, call the run method of the passed Runnable, executing it in parallel with the spawning thread. At this point, the VM is running two independent processes: order of execution and timing in one thread are unrelated to order and timing in the other.
The class Thread is not final. It is possible to define a new, concurrent task by sub-classing Thread and overriding its run method. There is no advantage to that approach, however. In fact, using a Runnable is more adaptable. Because Runnable is an interface, the Runnable that you pass in to theThread constructor may extend some other, useful class.
Synchronization and Thread Safety
When two or more running threads have access to the same set of variables, it’s possible for the threads to modify those variables in a way that can produce data corruption and break the logic in one or more of those threads. These kinds of unintended concurrent access bugs are called thread safety violations. They are difficult to reproduce, difficult to find, and difficult to test.
Java does not explicitly enforce restrictions on access to variables by multiple threads. Instead, the primary mechanism Java provides to support thread safety is the synchronized keyword. This keyword serializes access to the block it controls and, more important, synchronizes visible state between two threads. It is very easy to forget, when trying to reason about concurrency in Java, that synchronization controls both access and visibility. Consider the following program:
// This code is seriously broken!!!
public class BrokenVisibility {
public static boolean shouldStop;
public static void main(String[] args) {
new Thread(
new Runnable() {
@Override public void run() {
// this code runs in the spawned thread
final long stopTime
= System.currentTimeMillis() + 1000;
for (;;) {
shouldStop
= System.currentTimeMillis() > stopTime;
}
}
}
).start();
// this runs in the main thread
for (;;) {
if (shouldStop) { System.exit(0); }
}
}
}
One might think, “Well, there’s no need to synchronize the variable shouldStop. Sure, the main thread and the spawned thread might collide when accessing it. So what? The spawned thread will, after one second, always set it to true. Boolean writes are atomic. If the main thread doesn’t see it as true this time, surely it will see it as true the next time.” This reasoning is dangerously flawed. It does not take into account optimizing compilers and caching processors! In fact, this program may well never terminate. The two threads might very easily each use their own copy ofshouldStop, existing only in some local processor hardware cache. Since there is no synchronization between the two threads, the cache copy might never be published so that the spawned thread’s value is visible from the main thread.
There is a simple rule for avoiding thread safety violations in Java: when two different threads access the same mutable state (variable) all access to that state must be performed holding a single lock.
Some developers may violate this rule, after reasoning about the behavior of shared state in their program, in an attempt to optimize code. Since many of the devices on which the Android platform is currently implemented cannot actually provide concurrent execution (instead, a single processor is shared, serially, across the threads), it is possible that these programs will appear to run correctly. However, when, inevitably, mobile devices have processors with multiple cores and large, multilayered processor caches, incorrect programs are likely to fail with bugs that are serious, intermittent, and extremely hard to find.
When implementing concurrent processes in Java, the best approach is to turn to the powerful java.util.concurrent libraries. Here you will find nearly any concurrent structure you might require, optimally implemented and well tested. In Java, there is seldom more reason for a developer to use the low-level concurrency constructs than there is for him to implement his own version of a doubly linked list.
The synchronized keyword can be used in three contexts: to create a block, on a dynamic method, or on a static method. When used to define a block, the keyword takes as an argument a reference to an object to be used as a semaphore. Primitive types cannot be used as semaphores, but any object can.
When used as a modifier on a dynamic method, the keyword behaves as though the contents of the method were wrapped in a synchronized block that used the instance itself as the lock. The following example demonstrates this:
class SynchronizationExample {
public synchronized void aSynchronizedMethod() {
// a thread executing this method holds
// the lock on "this". Any other thread attempting
// to use this or any other method synchronized on
// "this" will be queued until this thread
// releases the lock
}
public void equivalentSynchronization() {
synchronized (this) {
// this is exactly equivalent to using the
// synchronized keyword in the method def.
}
}
private Object lock = new Object();
public void containsSynchronizedBlock() {
synchronized (lock) {
// A thread executing this method holds
// the lock on "lock", not "this".
// Threads attempting to seize "this"
// may succeed. Only those attempting to
// seize "lock" will be blocked
}
}
This is very convenient but must be used with caution. A complex class that has multiple high-use methods and synchronizes them in this way may be setting itself up for lock contention. If several external threads are attempting to access unrelated pieces of data simultaneously, it is best to protect those pieces of data with separate locks.
If the synchronized keyword is used on a static method, it is as though the contents of the method were wrapped in a block synchronized on the object’s class. All static synchronized methods for all instances of a given class will contend for the single lock on the class object itself.
Finally, it is worth noting that object locks in Java are reentrant. The following code is perfectly safe and does not cause a deadlock:
class SafeSeizure {
private Object lock = new Object();
public void method1() {
synchronized (lock) {
// do stuff
method2();
}
}
public void method2() {
synchronized (lock) {
// do stuff
}
}
}
Thread Control with wait() and notify() Methods
The class java.lang.Object defines the methods wait() and notify() as part of the lock protocol that is part of every object. Since all classes in Java extend Object, all object instances support these methods for controlling the lock associated with the instance.
A complete discussion of Java’s low-level concurrency tools is well beyond the scope of this book. Interested developers should turn to Brian Goetz’s excellent Java Concurrency in Practice (Addison-Wesley Professional). This example, however, illustrates the essential element necessary to allow two threads to cooperate. One thread pauses while the other completes a task that it requires:
/**
* Task that slowly fills a list and notifies the
* lock on "this" when finished. Filling the
* list is thread safe.
*/
public class FillListTask implements Runnable {
private final int size;
private List<String> strings;
public FillListTask(int size) {
this.size = size;
}
public synchronized boolean isFinished() {
return null != strings;
}
public synchronized List<String> getList() {
return strings;
}
@Override
public void run() {
List<String> strs = new ArrayList<String>(size);
try {
for (int i = 0; i < size; i++ ) {
Thread.sleep(2000);
strs.add("element " + String.valueOf(i));
}
synchronized (this) {
strings = strs;
this.notifyAll();
}
}
catch (InterruptedException e) {
// catch interrupted exception outside loop,
// since interrupted exception is a sign that
// the thread should quit.
}
}
/**
* Waits for the fill list task to complete
*/
public static void main(String[] args)
throws InterruptedException
{
FillListTask task = new FillListTask(7);
new Thread(task).start();
// The call to wait() releases the lock
// on task and suspends the thread until
// it receives a notification
synchronized (task) {
while (!task.isFinished()) {
task.wait();
}
}
System.out.println("Array full: " + task.getList());
}
}
In fact, most developers will never use low-level tools like wait and notify, turning instead to the java.util.concurrent package for higher-level tools.
Synchronization and Data Structures
Android supports the feature-rich Java Collections Library from Standard Edition Java. If you peruse the library, you’ll find that there are two versions of most kinds of collections: List and Vector, HashMap and Hashtable, and so on. Java introduced an entirely new collections framework in version 1.3. The new framework completely replaces the old collections. To maintain backward compatibility, however, the old versions were not deprecated.
The new collections should be preferred over their legacy counterparts. They have a more uniform API, there are better tools to support them, and so on. Perhaps most important, however, the legacy collections are all synchronized. That might sound like a great idea but, as the following example shows, it is not necessarily sufficient:
public class SharedListTask implements Runnable {
private final Vector<String> list;
public SharedListTask(Vector<String> l) {
this.list = l;
}
@Override
public void run() {
// the size of the list is obtained early
int s = list.size();
while (true) {
for (int i = 0; i < s; i++ ) {
// throws IndexOutOfBoundsException!!
// when the list is size 3, and s is 4.
System.out.println(list.get(i));
}
}
}
public static void main(String[] args) {
Vector<String> list = new Vector<String>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
new Thread(new SharedListTask(list)).start();
try { Thread.sleep(2000); }
catch (InterruptedException e) { /* ignore */ }
// the data structure is fully synchronized,
// but that only protects the individual methods!
list.remove("three");
}
}
Even though every use of the Vector is fully synchronized and each call to one of its methods is guaranteed to be atomic, this program breaks. The complete synchronization of the Vector is not sufficient, of course, because the code makes a copy of its size and uses it even while another thread changes that size.
Because simply synchronizing the methods of a collection object itself is so often insufficient, the collections in the new framework are not synchronized at all. If the code handling the collection is going to have to synchronize anyway, synchronizing the collection itself is redundant and wasteful.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.