Programming Android (2011)
Part I. Tools and Basics
Chapter 6. Effective Java for Android
In Chapter 2, we discussed the idiomatic use of Java. In this chapter, we’ll expand that idea to lay out Java idioms pertinent to the Android platform.
The Android Framework
Twenty years ago, an application probably ran from the command line and the bulk of its code was unique program logic. These days, though, applications need very complex support for interactive UIs, network management, call handling, and so on. The support logic is the same for all applications. The Android Framework addresses this in a way that has become fairly common as application environments have become increasingly complex: the skeleton application, or application template.
When you built the simple demo application that verified your Android SDK installation, back in Chapter 1, you created a complete running application. It was able to make network requests and display on and handle input from the screen. It could handle incoming calls and, although there was no way to use it, check your location. You hadn’t yet supplied anything for the application to do. That is the skeleton application.
Within the Android Framework, a developer’s task is not so much to build a complete program as it is to implement specific behaviors and then inject them into the skeleton at the correct extension points. The motto of MacApp, one of the original skeleton application frameworks, was: “Don’t call us, we’ll call you.” If creating Android applications is largely about understanding how to extend the framework, it makes sense to consider some generic best practices for making those extensions.
The Android Libraries
Android introduces several new packages that, together with a handful of package trees from the forest of traditional Java (J2SE) packages, make up the API for the Android Runtime Environment. Let’s take a minute to see what’s in this combined API:
android and dalvik
These package trees contain the entire Android-specific portion of the Android Runtime Environment. These libraries are the subject of much of this book, as they contain the Android GUI and text handling libraries (named android.graphics, android.view, android.widget, and android.text), as well as the application framework libraries called android.app, android.content, and android.database. They also contain several other key, mobile-oriented frameworks such as android.telephony and android.webkit. A fluent Android programmer will have to be very familiar with at least the first few of these packages. To navigate the Android documentation from a package tree perspective, you can start at the top of the Android developer documentation, at http://developer.android.com/reference/packages.html.
java
This package contains the implementations of the core Java runtime libraries. The java.lang package contains the definition of the class Object, the base class for all Java objects. java also contains the util package, which contains the Java Collections framework: Array, Lists, Map, Set, andIterator and their implementations. The Java Collections Library provides a well-designed set of data structures for the Java language—they relieve you of the need to write your own linked lists.
As mentioned in Chapter 2, the util package contains collections from two different lineages. Some originate from Java 1.1 and some from a more recent, re-engineered idea of collections. The 1.1 collections (e.g., Vector and Hashtable) are fully synchronized and are less consistent in their interfaces. The newer versions, (e.g., HashMap and ArrayList) are not synchronized, are more consistent, and are preferred.
In order to maintain compatibility with the Java language, the Android library also contains implementations of some legacy classes that you should avoid altogether. The Collections framework, for instance, contains the Dictionary class, which has been explicitly deprecated. TheEnumeration interface has been superseded by Iterator, and TimerTask has been replaced by ScheduledThreadPoolExecutor from the Concurrency framework. The Android reference documentation does a good job of identifying these legacy types.
java also contains base types for several other frequently used objects such as Currency, Date, TimeZone, and UUID, as well as basic frameworks for I/O and networking, concurrency, and security.
The awt and rmi packages are absent in the Android version of the java package hierarchy. The awt package has been replaced by Android GUI libraries. Remote messaging has no single replacement, but internal ServiceProviders using Parcelables, described in Serialization, provide similarfunctionality.
javax
This package is very similar to the java package. It contains parts of the Java language that are officially optional. These are libraries whose behavior is fully defined but that are not required as part of a complete implementation of the Java language. Since the Android Runtime Environment doesn’t include some of the parts that are required, the distinction exists in Android only to keep the Android packages looking as much like the Java packages as possible. Both package trees contain implementations of libraries described as part of the Java language.
The most important thing to be found in javax is the XML framework. There are both SAX and DOM parsers, an implementation of XPath, and an implementation of XSLT.
In addition, the javax package contains some important security extensions and the OpenGL API. A seasoned Java developer will notice that the Android Runtime Environment implementation of the javax packages is missing several important sections, notably those that have to do with UI and media. javax.swing, javax.sound, and other similar sections are all missing. There are Android-specific packages that replace them.
org.apache.http
This package tree contains the standard Apache implementation of an HTTP client and server, HttpCore. This package provides everything you need to communicate using HTTP, including classes that represent messages, headers, connections, requests, and responses.
The Apache HttpCore project can be found on the Web at http://hc.apache.org/httpcomponents-core/index.html.
org.w3c.dom, org.xml.sax, org.xmlpull, and org.json
These packages are the public API definitions for some common data formats: XML, XML Pull, and JSON.
Extending Android
Now that you have a basic road map to the Android Framework, the obvious question is: “How do I use it to build my application?” How do you extend the framework—which we’ve characterized as very complex, but a zombie—to turn it into a useful application?
As you would expect, this question has several answers. The Android libraries are organized to allow applications to obtain access into the framework at various levels.
Overrides and callbacks
The simplest and easiest to implement—and a coder’s first choice for adding new behaviors to the framework—should be the callback. The basic idea of a callback, a pattern quite common in the Android libraries, was already illustrated in Chapter 2. To create a callback extension point, a class defines two things. First it defines a Java interface (typically with a name ending in “Handler”, “Callback”, or “Listener”) that describes, but does not implement, the callback action. It also defines a setter method that takes, as an argument, an object implementing the interface.
Consider an application that needs a way to use text input from a user. Text entry, editing, and display, of course, require a large and complex set of user interface classes. An application need not concern itself with most of that, however. Instead, it adds a library widget—say, an EditText—to its layout (layouts and widgets are described in Assembling a Graphical Interface). The framework handles instantiating the widget, displaying it on the screen, updating its contents when the user types, and so on. In fact, it does everything except the part your application actually cares about: handing the content text to the application code. That is done with a callback.
The Android documentation shows that the EditText object defines the method addTextChangedListener that takes, as an argument, a TextWatcher object. The TextWatcher defines methods that are invoked when the EditText widget’s content text changes. The sample application code might look like this:
public class MyModel {
public MyModel(TextView textBox) {
textBox.addTextChangedListener(
new TextWatcher() {
public void afterTextChanged(Editable s) {
handleTextChange(s);
}
public void beforeTextChanged(
CharSequence s,
int start,
int count,
int after)
{ }
public void onTextChanged(
CharSequence s,
int start,
int count,
int after)
{ }
});
}
void handleTextChange(Editable s) {
// do something with s, the changed text.
}
}
MyModel might be the heart of your application. It is going to take the text that the user types in and do something useful with it. When it is created, it is passed a TextBox, from which it will get the text that the user types. By now, you are an old hand at parsing code like this: in its constructor,MyModel creates a new anonymous implementation of the interface TextWatcher. It implements the three methods that the interface requires. Two of them, onTextChanged and beforeTextChanged, do nothing. The third, though, afterTextChanged, calls the MyModel method handleTextChange.
This all works very nicely. Perhaps the two required methods that this particular application doesn’t happen to use, beforeTextChanged and onTextChanged, clutter things a bit. Aside from that, though, the code separates concerns beautifully. MyModel has no idea how a TextView displays text, where it appears on the screen, or how it gets the text that it contains. The tiny relay class, an anonymous instance of TextWatcher, simply passes the changed text between the view and MyModel. MyModel, the model implementation, is concerned only with what happens when the text changes.
This process, attaching the UI to its behaviors, is often called wiring up. Although it is quite powerful, it is also quite restrictive. The client code—the code that registers to receive the callback—cannot change the behavior of the caller. Neither does the client receive any state information beyond the parameters passed in the call. The interface type—TextWatcher in this case—represents an explicit contract between the callback provider and the client.
Actually, there is one thing that a callback client can do that will affect the calling service: it can refuse to return. Client code should treat the callback as a notification only and not attempt to do any lengthy inline processing. If there is any significant work to be done—more than a few hundred instructions or any calls to slow services such as the filesystem or the network—they should be queued up for later execution, probably on another thread. We’ll discuss how to do this, in depth, in AsyncTask and the UI Thread.
By the same token, a service that attempts to support multiple callback clients may find itself starved for CPU resources, even if all the clients are relatively well behaved. While addTextChangedListener supports the subscription of multiple clients, many of the callbacks in the Android library support only one. With these callbacks (setOnKeyListener, for instance) setting a new client for a particular callback on a particular object replaces any previous client. The previously registered client will no longer receive any callback notifications. In fact, it won’t even be notified that it is no longer the client. The newly registered client will, thenceforward, receive all notifications. This restriction in the code reflects the very real constraint that a callback cannot actually support an unlimited number of clients. If your code must fan notifications out to multiple recipients, you will have to implement a way of doing it so that it is safe in the context of your application.
The callback pattern appears throughout the Android libraries. Because the idiom is familiar to all Android developers, it makes a lot of sense to design your own application code this way too. Whenever one class might need notifications of changes in another—especially if the association changes dynamically, at runtime—consider implementing the relationship as a callback. If the relationship is not dynamic, consider using dependency injection—a constructor parameter and a final field—to make the required relationship permanent.
Using polymorphism and composition
In Android development, as in other object-oriented environments, polymorphism and composition are compelling tools for extending the environment. By design, the previous example demonstrates both. Let’s pause for a second to reinforce the concepts and restate their value as design goals.
The anonymous instance of TextWatcher that is passed to addTextChangedListener as a callback object uses composition to implement its behavior. The instance does not, itself, implement any behavior. Instead, it delegates to the handleTextChange method in MyModel, preferring has-a implementation to is-a. This keeps concerns clear and separate. If MyModel is ever extended, for example, to use text that comes from another source, the new source will also use handleTextChange. It won’t be necessary to track down code in several anonymous classes.
The example also demonstrates the use of polymorphism. The instance passed in to the addTextChangedListener method is strongly and statically typed. It is an anonymous subtype of TextWatcher. Its particular implementation—in this case, delegation to the handleTextChange in MyModel—is nearly certain to be unlike any other implementation of that interface. Since it is an implementation of the TextWatcher interface, though, it is statically typed, no matter how it does its job. The compiler can guarantee that the addTextChangedListener in EditText is passed only objects that are, at least, intended to do the right job. The implementation might have bugs, but at least addTextChangedListener will never be passed, say, an object intended to respond to network events. That is what polymorphism is all about.
It is worth mentioning one particular antipattern in this context, because it is so common. Many developers find anonymous classes to be a verbose and clumsy way of essentially passing a pointer to a function. In order to avoid using them, they skip the messenger object altogether, like this:
// !!! Anti-pattern warning
public class MyModel implements TextWatcher {
public MyModel(TextView textBox) {
textBox.addTextChangedListener(this);
}
public void afterTextChanged(Editable s) {
handleTextChange(s);
}
public void beforeTextChanged(
CharSequence s,
int start,
int count,
int after)
{ }
public void onTextChanged(
CharSequence s,
int start,
int count,
int after)
{ }
void handleTextChange(Editable s) {
// do something with s, the changed text.
}
}
Sometimes this approach makes sense. If the callback client, MyModel in this case, is small, simple, and used in only one or two contexts, this code is clear and to the point.
On the other hand, if (as the name MyModel suggests) the class will be used broadly and in a wide variety of circumstances, eliminating the messenger classes breaks encapsulation and limits extension. Obviously, it’s going to be messy to extend this implementation to handle input from a second TextBox that requires different behavior.
Nearly as bad, though, is something called interface pollution, which happens when this idea is taken to an extreme. It looks like this:
// !!! Anti-pattern ALERT!
public class MyModel
implements TextWatcher, OnKeyListener, View.OnTouchListener,
OnFocusChangeListener, Button.OnClickListener
{
// ....
}
Code like this is seductively elegant, in a certain way, and fairly common. Unfortunately, though, MyModel is now very tightly coupled to every one of the events it handles.
As usual, there are no hard and fast rules about interface pollution. There is, as already noted, lots of working code that looks just like this. Still, smaller interfaces are less fragile and easier to change. When an object’s interface expands beyond good taste, consider using composition to split it up into manageable pieces.
Extending Android classes
While callbacks provide a clear, well-defined means of extending class behavior, there are circumstances in which they do not provide sufficient flexibility. An obvious problem with the callback pattern is that sometimes your code needs to seize control at some point not foreseen by the library designers. If the service doesn’t define a callback, you’ll need some other way to inject your code into the flow of control. One solution is to create a subclass.
Some classes in the Android library were specifically designed to be subclassed (e.g., the BaseAdapter class from android.widgets, and AsyncTask, described shortly). In general, however, subclassing is not something that a designer should do lightly.
A subclass can completely replace the behavior of any nonfinal method in its superclass and, thus, completely violate the class architectural contract. Nothing in the Java typing system will prevent a subclass of TextBox, for example, from overriding the addTextChangedListener method so that it ignores its argument and does not notify callback clients of changes in text box content. (You might imagine, for example, an implementation of a “safe” text box that does not reveal its content.)
Such a violation of contract—and it isn’t always easy to recognize the details of the contract—can give rise to two classes of bugs, both quite difficult to find. The first and more obvious problem occurs when a developer uses a rogue subclass like the safe text box, described earlier.
Suppose a developer constructs a view containing several widgets and uses the addTextChangedListener method on each to register for its callbacks. During testing, though, he discovers that some widgets aren’t working as expected. He examines his code for hours before it occurs to him that “it’s as though that method isn’t doing anything!” Suddenly, dawn breaks and he looks at the source for the widget to confirm that it has broken the class semantic contract. Grrr!
More insidious than this, though, is that the Android Framework itself might change between releases of the SDK. Perhaps the implementation of the addTextChangedListener method changes. Maybe code in some other part of the Android Framework starts to call addTextChangedListener, expecting normal behavior. Suddenly, because the subclass overrides the method, the entire application fails in spectacular ways!
You can minimize the danger of this kind of problem by calling superimplementation for an overridden method, like this:
public void addTextChangedListener(TextWatcher watcher) {
// your code here...
super.addTextChangedListener(watcher)
// more of your code here...
}
This guarantees that your implementation augments but does not replace existing behavior, even as, over time, the superclass implementation changes. There is a coding rule, enforced in some developer communities, called “Design for Extension.” The rule mandates that all methods be either abstract or final. While this may seem draconian, consider that an overriding method, by definition, breaks the object’s semantic contract unless it at least calls the superimplementation.
Organizing Java Source
Chapter 1 introduced the basics of the Android SDK. Chapter 5 narrowed the focus with a closer look at one of the most common tools for Android development, the Eclipse IDE. Let’s move one step closer and look at the organization of code within a project.
To reiterate, a project, as introduced in Projects, is a workspace devoted to producing a single deployable artifact. In the wider world of Java, that artifact might be no more than a library (a .jar file that cannot be run by itself but that implements some specific functionality). It might, on the other hand, be a deployable web application or a double-clickable desktop application.
In the Android space, the artifact is most likely to be a single runnable service: a ContentProvider, a Service, or an Activity. A content provider that is used by a single activity certainly might start its life as a part of the activity project. As soon as a second activity needs to use it, though, it is time to consider refactoring it into its own project.
Traditionally, the Java compiler expects directory trees to hold the source (.java) files that it parses and the binary (.class) files that it produces as output. While it’s not necessary, it’s much easier to manage a project if those trees have different roots, commonly directories named src and bin, respectively.
In an Android project, there are two other important directory trees, res and gen. The first of these, res, contains definitions for static resources: colors, constant strings, layouts, and so on. Android tools preprocess these definitions, and turn them into highly optimized representations and the Java source through which application code refers to them. The autogenerated code, along with code created for AIDL objects (see AIDL and Remote Procedure Calls ), is put into the gen directory. The compiler compiles the code from both directories to produce the contents of bin. The full structure of a project was described in detail in Chapter 3.
NOTE
When you add your project to a revision control system like Git, Subversion, or Perforce, be sure to exclude the bin and gen directories!
Your application source code goes in the src directory. As noted in Chapter 2, you should put all your code into a package whose name is derived from the domain name of the owner of the code. Suppose, for instance, that you are a developer at large, doing business as awesome-android.net. You are under contract to develop a weather-prediction application for voracious-carrier.com. You will probably choose to put all your code into the package com.voraciouscarrier.weatherprediction, or possibly com.voracious_carrier.weather_prediction. Although the character “-” is perfectly legal in a DNS domain name, it is not legal in a Java package name. The UI for this ambitious application might go in com.voraciouscarrier.weatherprediction.ui and the model in com.voraciouscarrier.weatherprediction.futureweather.
If you look inside the src directory in your project, you will see that it contains a single directory, com. com in turn contains the directory voraciouscarrier, and so on. The source directory tree mirrors the package tree. The Java compiler expects this organization and may be unable to compile your code if it is violated.
Eventually, when the FutureWeather content provider becomes valuable on its own, you’ll want to factor it out into a new project with a package namespace that is not restricted by the name of the application in which it was originally created. Doing this by hand is a nightmare. You have to create a new directory structure, correctly place the files within that structure, correct the package names that are at the head of each source file, and, finally, correct any references to things that have moved.
Eclipse refactoring tools are your best friend. With just a few clicks you can create a new project for the now standalone subtree, cut and paste the content provider code into it, and then rename the packages as appropriate. Eclipse will fix most things, including the changed references.
It’s worth a reminder that shortcutting package names—using a package named just weatherprediction, for instance—is a bad idea. Even if you are pretty sure the code you are creating will never be used outside its current context, you may want to use externally produced code in that context. Don’t set yourself up for a name collision.
Concurrency in Android
As mentioned in Chapter 2, writing correct concurrent programs can be very difficult. The Android libraries provide some convenient tools to make concurrency both easier and safer.
When discussing concurrent programs, developers get into the habit of talking as though writing code with multiple threads actually causes those threads to execute at the same time—as though threading actually makes the program run faster. Of course, it isn’t quite that simple. Unless there are multiple processors to execute the threads, a program that needs to perform multiple, unrelated, compute-bound tasks will complete those tasks no more quickly if they are implemented as separate threads than it will if they are on the same thread. In fact, on a single processor, the concurrent version may actually run somewhat more slowly because of the overhead due to context switching.
Multithreaded Java applications were around for a long time before most people could afford machines with more than one processor on which to run them. In the Android world, multithreading is an essential tool, even though the majority of devices will probably have only a single CPU for another year or so. So what is the point of concurrency if not to make a program run faster?
If you’ve been programming for any length of time at all, you probably don’t even think about how absolutely essential it is that the statements in your code are executed in a rigid sequential order. The execution of any given statement must, unconditionally, happen before the execution of the next statement. Threads are no more than an explicit way of relaxing this constraint. They are the abstraction that developers use to make it possible to write code that is still ordered, logical, and easy to read, even when tasks embodied by the code are not related by ordering.
Executing independent threads concurrently doesn’t introduce any intrinsic complexity when the threads are completely independent (e.g., if one is running on your computer and the other is running on mine). When two concurrent processes need to collaborate, however, they have to rendezvous. For instance, data from the network might have to be displayed on the screen or user input pushed to a data store. Arranging the rendezvous, especially in the context of code optimizers, pipelined processors, and multilayered memory cache, can be quite complex. This can become painfully apparent when a program that has run, apparently without problem, on a single processor, suddenly fails in strange and difficult-to-debug ways when run in a multiprocessor environment.
The rendezvous process, making data or state from one thread visible to another, is usually called publishing a reference. Whenever one thread stores state in a way that makes it visible from another thread, it is said to be publishing a reference to that state. As mentioned in Chapter 2, the only way that a reference can be published safely is if all threads that refer to the data synchronize on the same object during use. Anything else is incorrect and unsafe.
AsyncTask and the UI Thread
If you’ve worked with any modern GUI framework, the Android UI will look entirely familiar. It is event-driven, built on a library of nestable components, and, most relevant here, single-threaded. Designers discovered years ago that, because a GUI must respond to asynchronous events from multiple sources, it is nearly impossible to avoid deadlock if the UI is multithreaded. Instead, a single thread owns both the input (touch screen, keypad, etc.) and output devices (display, etc.) and executes requests from each, sequentially, usually in the order they were received.
While the UI runs on a single thread, nearly any nontrivial Android application will be multithreaded. The UI must, for instance, respond to the user and animate the display regardless of whether the code that retrieves data from the network is currently processing incoming data. The UI must be quick and responsive and cannot, fundamentally, be ordered with respect to other, long-running processes. The long-running processes must be run asynchronously.
One convenient tool for implementing an asynchronous task in the Android system is, in fact, called AsyncTask. It completely hides many of the details of the threads used to run the task.
Let’s consider a very simplistic application that initializes a game engine, displaying some interstitial graphic while the content loads. Figure 6-1 shows a very basic example of such an application. When you push the button, it initializes the game level and then displays a welcome message in a text box.
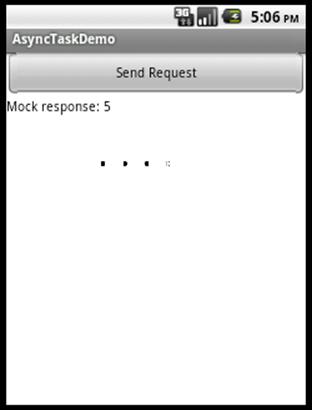
Figure 6-1. Simple application to initialize a game
Here is the boilerplate code for the application. All that is missing is the code that actually initializes the game and updates the text box:
/** AsyncTaskDemo */
public class AsyncTaskDemo extends Activity {
int mInFlight;
/** @see android.app.Activity#onCreate(android.os.Bundle) */
@Override
public void onCreate(Bundle state) {
super.onCreate(state);
setContentView(R.layout.asyncdemo);
final View root = findViewById(R.id.root);
final Drawable bg = root.getBackground();
final TextView msg = ((TextView) findViewById(R.id.msg));
final Game game = Game.newGame();
((Button) findViewById(R.id.start)).setOnClickListener(
new View.OnClickListener() {
@Override public void onClick(View v) {
// !!! initialize the game here!
} });
}
Now, let’s suppose, for this example, that we simply want to display an animated background (the crawling dots in Figure 6-1) while the user waits for the game to initialize. Here’s a sketch of the necessary code:
/**
* Synchronous request to remote service
* DO NOT USE!!
*/
void initGame(
View root,
Drawable bg,
Game game,
TextView resp,
String level)
{
// if the animation hasn't been started yet,
// do so now
if (0 >= mInFlight++ ) {
root.setBackgroundResource(R.anim.dots);
((AnimationDrawable) root.getBackground()).start();
}
// initialize the game and get the welcome message
String msg = game.initialize(level);
// if this is the last running initialization
// remove and clean up the animation
if (0 >= --mInFlight) {
((AnimationDrawable) root.getBackground()).stop();
root.setBackgroundDrawable(bg);
}
resp.setText(msg);
}
This is pretty straightforward. The user might mash the start button, so there might be multiple initializations in flight. If the interstitial background is not already showing, show it and remember that there is one more game starting up. Next, make the slow call to the game engine initializer. Once the game completes its initialization, clean up. If this is the last game to complete initialization, clear the interstitial animation. Finally, display the greeting message in the text box.
While this code is very nearly what is needed to make the example application work as specified, it breaks down in one very important way: it blocks the UI thread for the entire duration of the call to game.initialize. That has all sorts of unpleasant effects.
The most apparent of these is that the background animation won’t work. Even though the logic for setting up and running the animation is very nearly correct, the code specifies quite clearly that nothing else can happen in the UI until the call to the remote service is complete.
It gets worse. The Android Framework actually monitors application UI threads to prevent broken or malicious programs from hanging a device. If an application takes too long to respond to input, the framework will suspend it, alert the user that there is a problem, and offer her a chance to force it to close. If you build and run this example application, with initGame implemented as shown in the example (try it; it’s actually somewhat instructive), the first time you click the Send Request button the UI will freeze. If you click a couple more times, you will see an alert similar to the one shown in Figure 6-2.
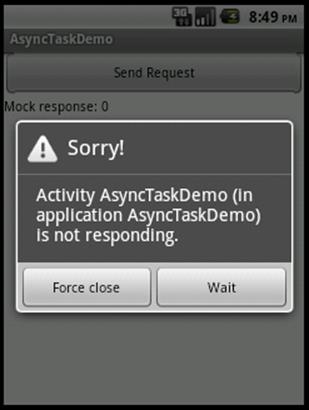
Figure 6-2. Unresponsive application
AsyncTask to the rescue! Android provides this class as a relatively safe, powerful, and easy-to-use way to run background tasks correctly. Here is a reimplementation of initGame as an AsyncTask:
private final class AsyncInitGame
extends AsyncTask<String, Void, String>
{
private final View root;
private final Game game;
private final TextView message;
private final Drawable bg;
public AsyncInitGame(
View root,
Drawable bg,
Game game,
TextView msg)
{
this.root = root;
this.bg = bg;
this.game = game;
this.message = msg;
}
// runs on the UI thread
@Override protected void onPreExecute() {
if (0 >= mInFlight++) {
root.setBackgroundResource(R.anim.dots);
((AnimationDrawable) root.getBackground()).start();
}
}
// runs on the UI thread
@Override protected void onPostExecute(String msg) {
if (0 >= --mInFlight) {
((AnimationDrawable) root.getBackground()).stop();
root.setBackgroundDrawable(bg);
}
message.setText(msg);
}
// runs on a background thread
@Override protected String doInBackground(String... args) {
return ((1 != args.length) || (null == args[0]))
? null
: game.initialize(args[0]);
}
}
This code is nearly identical to the first example. It has been divided into three methods that execute nearly the same code, in the same order, as in initGame.
This AsyncTask is created on the UI thread. When the UI thread invokes the task’s execute method, first the onPreExecute method is called on the UI thread. This allows the task to initialize itself and its environment—in this case, installing the background animation. Next the AsyncTask creates a new background thread to run the doInBackground method concurrently. When, eventually, doInBackground completes, the background thread is deleted and the onPostExecute method is invoked, once again in the UI thread.
Assuming that this implementation of an AsyncTask is correct, the click listener need only create an instance and invoke it, like this:
((Button) findViewById(R.id.start)).setOnClickListener(
new View.OnClickListener() {
@Override public void onClick(View v) {
new AsyncInitGame(
root,
bg,
game,
msg)
.execute("basic");
} });
In fact, AsyncInitGame is complete, correct, and reliable. Let’s examine it in more detail.
First, notice that the base class AsyncTask is abstract. The only way to use it is to create a subclass specialized to perform some specific job (an is-a relationship, not a has-a relationship). Typically, the subclass will be simple, anonymous, and define only a few methods. A regard for good style and separation of concerns, analogous to the issues mentioned in Chapter 2, suggests keeping the subclass small and delegating implementation to the classes that own the UI and the asynchronous task, respectively. In the example, for instance, doInBackground is simply a proxy to the Gameclass.
In general, an AsyncTask takes a set of parameters and returns a result. Because the parameters have to be passed between threads and the result returned between threads, some handshaking is necessary to ensure thread safety. An AsyncTask is invoked by calling its execute method with some parameters. Those parameters are eventually passed on, by the AsyncTask mechanism, to the doInBackground method, when it runs on a background thread. In turn, doInBackground produces a result. The AsyncTask mechanism returns that result by passing it as the argument to doPostExecute, run in the same thread as the original execute. Figure 6-3 shows the data flow.
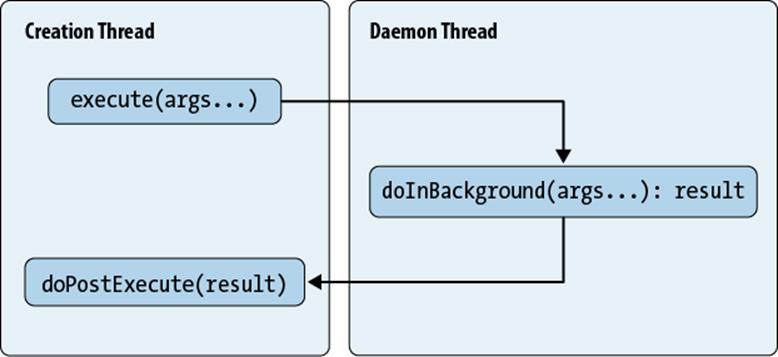
Figure 6-3. Data flow in AsyncTask
In addition to making this data flow thread-safe, AsyncTask also makes it type-safe. AsyncTask is a classic example of a type-safe template pattern. The abstract base class (AsyncTask) uses Java generics to allow implementations to specify the types of the task parameters and result.
When defining a concrete subclass of AsyncTask, you provide actual types for Params, Progress, and Result, the type variables in the definition of AsyncTask. The first and last of these type variables (Params and Result) are the types of the task parameters and the result, respectively. We’ll get to that middle type variable in a minute.
The concrete type bound to Params is the type of the parameters to execute, and thus the type of the parameters to doInBackground. Similarly, the concrete type bound to Result is the type of the return value from doInBackground, and thus the type of the parameter to onPostExecute.
This is all a bit hard to parse, and the first example, AsyncInitGame, didn’t help much because the input parameter and the result are both of the same type, String. Here are a couple of examples in which the parameter and result types are different. They provide a better illustration of the use of the generic type variables:
public class AsyncDBReq
extends AsyncTask<PreparedStatement, Void, ResultSet>
{
@Override
protected ResultSet doInBackground(PreparedStatement... q) {
// implementation...
}
@Override
protected void onPostExecute(ResultSet result) {
// implementation...
}
}
public class AsyncHttpReq
extends AsyncTask<HttpRequest, Void, HttpResponse>
{
@Override
protected HttpResponse doInBackground(HttpRequest... req) {
// implementation...
}
@Override
protected void onPostExecute(HttpResponse result) {
// implementation...
}
}
In the first example, the argument to the execute method of an AsyncDBReq instance will be one or more PreparedStatement variables. The implementation of doInBackground for an instance of AsyncDBReq will take those PreparedStatement parameters as its arguments and will return a ResultSet. The instance onPostExecute method will take that ResultSet as a parameter and use it appropriately.
Similarly, in the second example, the call to the execute method of an AsyncHttpReq instance will take one or more HttpRequest variables. doInBackground takes those requests as its parameters and returns an HttpResponse. onPostExecute handles the HttpResponse.
WARNING
Note that an instance of an AsyncTask can be run only once. Calling execute on a task a second time will cause it to throw an IllegalStateException. Each task invocation requires a new instance.
As much as AsyncTask simplifies concurrent processing, its contract imposes strong constraints that cannot be verified automatically. It is absolutely essential to take great care not to violate these constraints! Violations will cause exactly the sort of bug described at the beginning of this section: failures that are intermittent and very difficult to find.
The most obvious of these constraints is that the doInBackground method, since it is run on a different thread, must make only thread-safe references to variables inherited into its scope. Here, for example, is a mistake that is easy to make:
// ... some class
int mCount;
public void initButton1( Button button) {
mCount = 0;
button.setOnClickListener(
new View.OnClickListener() {
@SuppressWarnings("unchecked")
@Override public void onClick(View v) {
new AsyncTask<Void, Void, Void>() {
@Override
protected Void doInBackground(Void... args) {
mCount++; // !!! NOT THREAD SAFE!
return null;
}
}.execute();
} });
}
Although there is nothing to alert you to the problem—no compiler error, no runtime warning, probably not even an immediate failure when the bug is driven—this code is absolutely incorrect. The variable mCount is being accessed from two different threads, without synchronization.
In light of this, it may be a surprise to see that access to mInFlight is not synchronized in AsyncTaskDemo. This is actually OK. The AsyncTask contract guarantees that onPreExecute and onPostExecute will be run on the same thread, the thread from which execute was called. Unlike mCount, mInFlightis accessed from only a single thread and has no need for synchronization.
Probably the most pernicious way to cause the kind of concurrency problem we’ve just warned you about is by holding a reference to a parameter. This code, for instance, is incorrect. Can you see why?
public void initButton(
Button button,
final Map<String, String> vals)
{
button.setOnClickListener(
new View.OnClickListener() {
@Override public void onClick(View v) {
new AsyncTask<Map<String, String>, Void, Void>() {
@Override
protected Void doInBackground(
Map<String, String>... params)
{
// implementation, uses the params Map
}
}.execute(vals);
vals.clear(); // !!! THIS IS NOT THREAD SAFE !!!
} });
}
The problem is pretty subtle. If you noticed that the argument to initButton, vals, is being referenced concurrently, without synchronization, you are correct! It is passed into the AsyncTask, as the argument to execute, when the task is invoked. The AsyncTask framework can guarantee that this reference is published correctly onto the background thread when doInBackground is called. It cannot, however, do anything about the reference to vals that is retained and used later, in the initButton method. The call to vals.clear modifies state that is being used on another thread, without synchronization. It is, therefore, not thread-safe.
The best solution to this problem is to make sure the arguments to AsyncTask are immutable. If they can’t be changed—like a String, an Integer, or a POJO with only final fields—they are thread-safe and need no further care. The only way to be certain that a mutable object passed to anAsyncTask is thread-safe is to make sure that only the AsyncTask holds a reference. Because the parameter vals is passed into the initButton method in the previous example (Figure 6-1), it is completely impossible to guarantee that there are no dangling references to it. Even removing the call tovals.clear would not guarantee that this code was correct, because the caller of initButton might hold a reference to the map that is eventually passed as the parameter vals. The only way to make this code correct is to make a complete (deep) copy of the map and all the objects it contains!
Developers familiar with the Java Collections package might argue that an alternative to making a complete, deep copy of the map parameter would be to wrap it in an unmodifiableMap, like this:
public void initButton(
Button button,
final Map<String, String> vals)
{
button.setOnClickListener(
new View.OnClickListener() {
@Override public void onClick(View v) {
new AsyncTask<Map<String, String>, Void, Void>() {
@Override
protected Void doInBackground(
Map<String, String>... params)
{
// implementation, uses the params Map
}
}.execute(Collections.unmodifiableMap(vals));
vals.clear(); // !!! STILL NOT THREAD SAFE !!!
} });
}
Unfortunately, this is still not correct. Collections.unmodifiableMap provides an immutable view of the map it wraps. It does not, however, prevent processes with access to a reference to the original, mutable object from changing that object at any time. In the preceding example, although theAsyncTask cannot change the map value passed to it in the execute method, the onClickListener method still changes the map referenced by vals at the same time the background thread uses it, without synchronization. Boom!
To close this section, note that AsyncTask has one more method, not used in the example: onProgressUpdate. It is there to allow the long-running tasks to push periodic status safely back to the UI thread. Here is how you might use it to implement a progress bar showing the user how much longer the game initialization process will take:
public class AsyncTaskDemoWithProgress extends Activity {
private final class AsyncInit
extends AsyncTask<String, Integer, String>
implements Game.InitProgressListener
{
private final View root;
private final Game game;
private final TextView message;
private final Drawable bg;
public AsyncInit(
View root,
Drawable bg,
Game game,
TextView msg)
{
this.root = root;
this.bg = bg;
this.game = game;
this.message = msg;
}
// runs on the UI thread
@Override protected void onPreExecute() {
if (0 >= mInFlight++) {
root.setBackgroundResource(R.anim.dots);
((AnimationDrawable) root.getBackground()).start();
}
}
// runs on the UI thread
@Override protected void onPostExecute(String msg) {
if (0 >= --mInFlight) {
((AnimationDrawable) root.getBackground()).stop();
root.setBackgroundDrawable(bg);
}
message.setText(msg);
}
// runs on its own thread
@Override protected String doInBackground(String... args) {
return ((1 != args.length) || (null == args[0]))
? null
: game.initialize(args[0], this);
}
// runs on the UI thread
@Override protected void onProgressUpdate(Integer... vals) {
updateProgressBar(vals[0].intValue());
}
// runs on the UI thread
@Override public void onInitProgress(int pctComplete) {
publishProgress(Integer.valueOf(pctComplete));
}
}
int mInFlight;
int mComplete;
/** @see android.app.Activity#onCreate(android.os.Bundle) */
@Override
public void onCreate(Bundle state) {
super.onCreate(state);
setContentView(R.layout.asyncdemoprogress);
final View root = findViewById(R.id.root);
final Drawable bg = root.getBackground();
final TextView msg = ((TextView) findViewById(R.id.msg));
final Game game = Game.newGame();
((Button) findViewById(R.id.start)).setOnClickListener(
new View.OnClickListener() {
@Override public void onClick(View v) {
mComplete = 0;
new AsyncInit(
root,
bg,
game,
msg)
.execute("basic");
} });
}
void updateProgressBar(int progress) {
int p = progress;
if (mComplete < p) {
mComplete = p;
((ProgressBar) findViewById(R.id.progress))
.setProgress(p);
}
}
}
This example presumes that game initialization takes, as an argument, a Game.InitProgressListener. The initialization process periodically calls the listener’s onInitProgress method to notify it of how much work has been completed. In this example, then, onInitProgress will be called from beneath doInBackground in the call tree, and therefore on the background thread. If onInitProgress were to call AsyncTaskDemoWithProgress.updateProgressBar directly, the subsequent call to bar.setStatus would also take place on the background thread, violating the rule that only the UI thread can modify View objects. It would cause an exception like this:
11-30 02:42:37.471: ERROR/AndroidRuntime(162):
android.view.ViewRoot$CalledFromWrongThreadException:
Only the original thread that created a view hierarchy can touch its views.
In order to correctly publish the progress back to the UI thread, onInitProgress instead calls the AsyncTask method publishProgress. The AsyncTask handles the details of scheduling publishProgress on the UI thread so that onProgressUpdate can safely use View methods.
Let’s leave this detailed look into the AsyncTask by summarizing some of the key points it illustrated:
§ The Android UI is single-threaded. To use it well a developer must be comfortable with the task queue idiom.
§ In order to retain UI liveness, tasks that take more than a couple of milliseconds, or a few hundred instructions, should not be run on the UI thread.
§ Concurrent programming is really tricky. It’s amazingly easy to get it wrong and very hard to check for mistakes.
§ AsyncTask is a convenient tool for running small, asynchronous tasks. Just remember that the doInBackground method runs on a different thread! It must not write any state visible from another thread or read any state writable from another thread. This includes its parameters.
§ Immutable objects are an essential tool for passing information between concurrent threads.
Threads in an Android Process
Together, AsyncTask and ContentProvider form a very powerful idiom and can be adapted to a wide variety of common application architectures. Nearly any MVC pattern in which the View polls the Model can (and probably should) be implemented this way. In an application whose architecture requires the Model to push changes to the View or in which the Model is long-lived and continuously running, AsyncTask may not be sufficient.
Recall that cardinal rule for sharing data between threads that we introduced back in Synchronization and Thread Safety. In its full generality, that rule is pretty onerous. The investigation of AsyncTask in the preceding section, however, illustrated one idiom that simplifies correct coordination of concurrent tasks in Android: the heavy lifting of publishing state from one thread into another was completely hidden in the implementation of a template class. At the same time, the discussion also reinforced some of the pitfalls of concurrency that lie in wait to entrap the incautious coder. There are other idioms that are safe and that can simplify specific classes of concurrent problems. One of them—a common idiom in Java programming in general—is baked into the Android Framework. It is sometimes called thread confinement.
Suppose that a thread, the DBMinder, creates an object and modifies it over a period of time. After it has completed its work, it must pass the object to another thread, DBViewer, for further processing. In order to do this, using thread confinement, DBMinder and DBViewer must share a drop point and an associated lock. The process looks like this:
1. DBMinder seizes the lock and stores a reference to the object in the drop.
2. DBMinder destroys all its references to the object!
3. DBMinder releases the lock.
4. DBViewer seizes the lock and notices that there is an object reference in the drop.
5. DBViewer recovers the reference from the drop and then clears the drop.
6. DBViewer releases the lock.
This process works for any object regardless of whether that object is thread-safe itself. This is because the only state that is ever shared among multiple threads is the drop box. Both threads correctly seize a single lock before accessing it. When DBMinder is done with an object, it passes it to DBViewer and retains no references: the state of the passed object is never shared by multiple threads.
Thread confinement is a surprisingly powerful trick. Implementations usually make the shared drop an ordered task queue. Multiple threads may contend for the lock, but each holds it only long enough to enqueue a task. One or more worker threads seize the queue to remove tasks for execution. This is a pattern that is sometimes called the producer/consumer model. As long as a unit of work can proceed entirely in the context of the worker thread that claims it, there is no need for further synchronization. If you look into the implementation of AsyncTask you will discover that this is exactly how it works.
Thread confinement is so useful that Android has baked it into its framework in the class called Looper. When initialized as a Looper, a Java thread turns into a task queue. It spends its entire life removing things from a local queue and executing them. Other threads enqueue work, as described earlier, for the initialized thread to process. As long as the enqueuing thread deletes all references to the object it enqueues, both threads can be coded without further concern for concurrency. In addition to making it dramatically easier to make programs that are correct, this also removes any inefficiency that might be caused by extensive synchronization.
Perhaps this description of a task queue brings to mind a construct to which we alluded earlier in this chapter? Android’s single-threaded, event-driven UI is, simply, a Looper. When it launches a Context the system does some bookkeeping and then initializes the launch thread as a Looper. That thread becomes the main thread for a service and the UI thread for an activity. In an activity, the UI framework preserves a reference to this thread, and its task queue becomes the UI event queue: all the external drivers, the screen, the keyboard, the call handler, and so on, enqueue actions on this queue.
The other half of Looper is Handler. A Handler, created on a Looper thread, provides a portal to the Looper queue. When a Looper thread wishes to allow some other enqueued thread access to its task queue, it creates a new Handler and passes it to the other thread. There are several shortcuts that make it easier to use a Handler: View.post(Runnable), View.postDelayed(Runnable, long), and Activity.runOnUiThread(Runnable).
There is yet another convenient and powerful paradigm in the Android toolkit for interprocess communication and work sharing: the ContentProvider, which we’ll discuss in Chapter 12. Consider whether a content provider can fit your needs before you build your own architecture on the low-level components discussed in this section. Content providers are flexible and extensible, and handle concurrent processing in a way that is fast enough for all but the most time-sensitive applications.
Serialization
Serialization is converting data from a fast, efficient, internal representation to something that can be kept in a persistent store or transmitted over a network. Converting data to its serialized form is often called marshaling it. Converting it back to its live, in-memory representation is calleddeserializing or unmarshaling.
Exactly how data is serialized depends on the reason for serializing it. Data serialized for transmission over a network, for instance, may not need to be legible in flight. Data serialized for storage in a database, however, will be far more useful if the representation permits SQL queries that are easy to construct and make sense. In the former case the serialization format might be binary. In the latter it is likely to be labeled text.
The Android environment addresses four common uses for serialization:
Life cycle management
Unlike larger devices—laptop and desktop machines, for instance—Android devices cannot count on being able to swap an application to a fast backing store when that application becomes inactive. Instead, the framework provides an object called a Bundle. When an application is suspended it writes its state into the Bundle. When the application is re-created the Android Framework promises to supply a copy of the same Bundle during its initialization. An application must be able to serialize anything it wants to keep across its suspension and to store the serialized version in the Bundle.
Persistence
In addition to the immediate application state kept in a Bundle, most applications manage some kind of persistent data store. This data store is most likely an SQLite database wrapped in a ContentProvider. Applications must convert back and forth between the internal representation of object data and the representations of those same objects in the database. In larger systems, this process—called object-relational mapping or just ORM—is supported by frameworks such as Hibernate and iBATIS. Android’s local data store is simpler and lighter weight. It is described inChapter 10.
Local interprocess communication
The Android Framework promotes an architecture that breaks larger, monolithic applications into smaller components: UIs, content providers, and services. These components do not have access to each other’s memory space and must pass information across process boundaries as serialized messages. Android provides a highly optimized tool for this, AIDL.
Network communication
This is the part that makes mobile devices exciting. The ability to connect to the Internet and to use the incredible variety of services available there is what Android is all about. Applications need to be able to handle the protocols imposed by any external service, which includes translating internal information into queries to those services, and retranslating the response.
The following sections describe the various classes at your disposal for achieving these goals.
Java Serialization
Java defines a serialization framework through the Serializable marker interface and the pair of serialization types called ObjectOutputStream and ObjectInputStream. Because Java serialization mostly just works, even experienced Java programmers may not recognize its complexity. It is certainly outside the scope of this book. Josh Bloch devotes nearly 10% of his seminal book Effective Java (Prentice Hall) to a discussion of Java’s serialization framework and how to use it correctly. The chapter is worthwhile reading as a way to understand the issues, even if you don’t expect to use Java’s framework.
Android does support Java serialization. The Bundle type, for instance, has the pair of methods putSerializable and getSerializable, which, respectively, add a Java Serializable to and recover it from a Bundle. For example:
public class JSerialize extends Activity {
public static final String APP_STATE
= "com.oreilly.android.app.state";
private static class AppState implements Serializable {
// definitions, getters and setters
// for application state parameters here.
// ...
}
private AppState applicationState;
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedAppState) {
super.onCreate(savedAppState);
applicationState = (null == savedAppState)
? new AppState(/* ... */)
: (AppState) savedAppState.getSerializable(APP_STATE);
setContentView(R.layout.main);
// ...
}
/**
* @see android.app.Activity#onSaveInstanceState(android.os.Bundle)
*/
@Override
protected void onSaveInstanceState(Bundle outState) {
super.onSaveInstanceState(outState);
outState.putSerializable(APP_STATE, applicationState);
}
}
In this example, the application keeps some global state information—perhaps a list of recently used items—as a Serializable object. When a JSerialize activity is paused so that another activity can replace it in memory, the Android Framework invokes the JSerialize callback methodonSaveInstanceState, passing a Bundle object. The callback method uses Bundle.putSerializable to save the state of the object into the Bundle. When JSerialize is resumed, the onCreate method retrieves the state from the Bundle using getSerializable.
AIDL AND REMOTE PROCEDURE CALLS
In order to declare an AIDL interface, you’ll need several things:
§ An AIDL file that describes the API.
§ For every nonsimple type used in the API, a subclass of Parcelable defining the type, and an AIDL file naming the type as parcelable. One caution when doing this: you must be willing to distribute the source for those classes to all clients that serialize them.
§ A service that returns an implementation of the API stub, in response to onBind. onBind must be prepared to return the correct implementation for each intent with which it might be called. The returned instance provides the actual implementations of the API methods.
§ On the client, an implementation of ServiceConnection. onServiceConnected should cast the passed binder, using API.Stub.asInterface(binder), and save the result as a reference to the service API. onServiceDisconnected must null the reference. It calls bindService with an Intent that the API service provides, the ServiceConnection, and flags that control service creation.
§ Binding that is asynchronous. Just because bindService returns true does not mean that you have a reference to the service yet. You must release the thread and wait for the invocation of onServiceConnected to use the service.
Parcelable
Although the Android Framework supports Java serialization, it is usually not the best choice as a way to marshal program state. Android’s own internal serialization protocol, Parcelable, is lightweight, highly optimized, and only slightly more difficult to use. It is the best choice for local interprocess communication. For reasons that will become apparent when we revisit Parcelable objects in Classes That Support Serialization, they cannot be used to store objects beyond the lifetime of an application. They are not an appropriate choice for marshaling state to, say, a database or a file.
Here’s a very simple object that holds some state. Let’s see what it takes to make it “parcelable”:
public class SimpleParcelable {
public enum State { BEGIN, MIDDLE, END; }
private State state;
private Date date;
State getState() { return state; }
void setState(State state) { this.state = state; }
Date getDate() { return date; }
void setDate(Date date) { this.date = date; }
}
An object must meet three requirements in order to be parcelable:
§ It must implement the Parcelable interface.
§ It must have a marshaler, an implementation of the interface method writeToParcel.
§ It must have an unmarshaler, a public static final variable named CREATOR, containing a reference to an implementation of Parcelable.Creator.
The interface method writeToParcel is the marshaler. It is called for an object when it is necessary to serialize that object to a Parcel. The marshaler’s job is to write everything necessary to reconstruct the object state to the passed Parcel. Typically, this will mean expressing the object state in terms of the six primitive data types: byte, double, int, float, long, and String. Here’s the same simple object, but this time with the marshaler added:
public class SimpleParcelable implements Parcelable {
public enum State { BEGIN, MIDDLE, END; }
private static final Map<State, String> marshalState;
static {
Map<State, String> m = new HashMap<State, String>();
m.put(State.BEGIN, "begin");
m.put(State.MIDDLE, "middle");
m.put(State.END, "end");
marshalState = Collections.unmodifiableMap(m);
}
private State state;
private Date date;
@Override
public void writeToParcel(Parcel dest, int flags) {
// translate the Date to a long
dest.writeLong(
(null == date)
? -1
: date.getTime());
dest.writeString(
(null == state)
? ""
: marshalState.get(state));
}
State getState() { return state; }
void setState(State state) { this.state = state; }
Date getDate() { return date; }
void setDate(Date date) { this.date = date; }
}
Of course, the exact implementation of writeToParcel will depend on the contents of the object being serialized. In this case, the SimpleParcelable object has two pieces of state and writes both of them into the passed Parcel.
Choosing a representation for most simple data types usually won’t require anything more than a little ingenuity. The Date in this example, for instance, is easily represented by its time since the millennium.
Be sure, though, to think about future changes to data when picking the serialized representation. Certainly, it would have been much easier in this example to represent state as an int whose value was obtained by calling state.ordinal. Doing so, however, would make it much harder to maintain forward compatibility for the object. Suppose it becomes necessary at some point to add a new state, State.INIT, before State.BEGIN. This trivial change makes new versions of the object completely incompatible with earlier versions. A similar, if slightly weaker, argument applies to using state.toString to create the marshaled representation of the state.
The mapping between an object and its representation in a Parcel is part of the particular serialization process. It is not an inherent attribute of the object. It is entirely possible that a given object has completely different representations when serialized by different serializers. To illustrate this principle—though it is probably overkill, given that the type State is locally defined—the map used to marshal state is an independent and explicitly defined member of the parcelable class.
SimpleParcelable, as shown earlier, compiles without errors. It could even be marshaled to a parcel. As yet, though, there is no way to get it back out. For that, we need the unmarshaler:
public class SimpleParcelable implements Parcelable {
// Code elided...
private static final Map<String, State> unmarshalState;
static {
Map<String, State> m = new HashMap<String, State>();
m.put("begin", State.BEGIN);
m.put("middle", State.MIDDLE);
m.put("end", State.END);
unmarshalState = Collections.unmodifiableMap(m);
}
// Unmarshaler
public static final Parcelable.Creator<SimpleParcelable> CREATOR
= new Parcelable.Creator<SimpleParcelable>() {
public SimpleParcelable createFromParcel(Parcel src) {
return new SimpleParcelable(
src.readLong(),
src.readString());
}
public SimpleParcelable[] newArray(int size) {
return new SimpleParcelable[size];
}
};
private State state;
private Date date;
public SimpleParcelable(long date, String state) {
if (0 <= date) { this.date = new Date(date); }
if ((null != state) && (0 < state.length())) {
this.state = unmarshalState.get(state);
}
}
// Code elided...
}
This snippet shows only the newly added unmarshaler code: the public, static final field called CREATOR and its collaborators. The field is a reference to an implementation of Parcelable.Creator<T>, where T is the type of the parcelable object to be unmarshaled (in this case SimpleParcelable). It’s important to get all these things exactly right! If CREATOR is protected instead of public, not static, or spelled “Creator”, the framework will be unable to unmarshal the object.
The implementation of Parcelable.Creator<T> is an object with a single method, createFromParcel, which unmarshals a single instance from the Parcel. The idiomatic way to do this is to read each piece of state from the Parcel, in exactly the same order as it was written in writeToParcel (again, this is important), and then to call a constructor with the unmarshaled state. Since the unmarshaling constructor is called from class scope, it can be package-protected, or even private.
Classes That Support Serialization
The Parcel API is not limited to the six primitive types mentioned in the previous section. The Android documentation gives the complete list of parcelable types, but it is helpful to think of them as divided into four groups.
The first group, simple types, consists of null, the six primitives (int, float, etc.), and the boxed versions of the six primitives (Integer, Float, etc.).
The next group consists of object types implementing Serializable or Parcelable. These objects are not simple, but they know how to serialize themselves.
Another group, collection types, covers arrays, lists, maps, bundles, and sparse arrays of the preceding two types (int[], float[], ArrayList<?>, HashMap<String, ?>, Bundle<?>, SparseArray<?>, etc.).
Finally, there are some special cases: CharSequence and active objects (IBinder).
While all these types can be marshaled into a Parcel, there are two to avoid if possible: Serializable and Map. As mentioned earlier, Android supports native Java serialization. Its implementation is not nearly as efficient as the rest of Parcelable. Implementing Serializable in an object is not an effective way to make it parcelable. Instead, objects should implement Parcelable and add a CREATOR object and a writeToParcel method as described in Parcelable. This can be a tedious task if the object hierarchy is complex, but the performance gains are usually well worth it.
The other parcelable type to avoid is the Map. Parcel doesn’t actually support maps in general; only those with keys that are strings. The Android-specific Bundle type provides the same functionality—a map with string keys—but is, in addition, type-safe. Objects are added to a Bundle with methods such as putDouble and putSparseParcelableArray, one for each parcelable type. Corresponding methods such as getDouble and getSparseParcelableArray get the objects back out. A Bundle is just like a map except that it can hold different types of objects for different keys in a way that is perfectly type-safe. Using a Bundle eliminates the entire class of hard-to-find errors that arise when, say, a serialized float is mistakenly interpreted as an int.
Type safety is also a reason to prefer the methods writeTypedArray and writeTypedList to their untyped analogs writeArray and writeList.
Serialization and the Application Life Cycle
As mentioned earlier, an Android application may not have the luxury of virtual memory. On a small device, there is no secondary store to which a running but hidden application can be pushed to make room for a new, visible application. Still, a good user experience demands that when the user returns to an application, it looks the way it did when he left it. The responsibility for preserving state across suspension falls to the application itself. Fortunately, the Android Framework makes preserving state straightforward.
The example in Java Serialization showed the general framework mechanism that allows an application to preserve state across suspensions. Whenever the application is evicted from memory, its onSaveInstanceState method is called with a Bundle to which the application can write any necessary state. When the application is restarted, the framework passes the same Bundle to the onCreate method so that the application can restore its state. By sensibly caching content data in a ContentProvider and saving lightweight state (e.g., the currently visible page) to the onSaveInstanceBundle, an application can resume, without interruption.
The framework provides one more tool for preserving application state. The View class—the base type for everything visible on the screen—has a hook method, onSaveInstanceState, that is called as part of the process of evicting an application from memory. In fact, it is called fromActivity.onSaveInstanceState, which is why your application’s implementation of that method should always call super.onSaveInstanceState.
This method allows state preservation at the very finest level. An email application, for instance, might use it to preserve the exact location of the cursor in the text of an unsent mail message.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.