Professional Embedded ARM Development (2014)
Part II. Reference
Appendix C. ARM Core Versions
Everything started with the ARM1, and ARM2 quickly fixed or improved any weak points of the ARM1. ARM3 was once again an internal chip, and no major projects used these chips. ARM’s commercial success started with the ARM6 chip.
ARM6
ARM6 was based on the ARMv3 architecture and was the first core to have full 32-bit memory address space (previous cores were 26-bit). It ran at 5V and had 33,500 transistors. The ARM60 was capable of 10 MIPS running at 12 MHz, but the later ARM600 was capable of 28 MIPS running at 33 MHz. The ARM600 also included 4 KB of unified cache, something that was previously developed for the ARM3. A cheaper version was soon delivered: the ARM610. Like its predecessor, it had 4 KB of cache but had no coprocessor bus and was slightly less powerful (17 MIPS at 20 MHz).
Panasonic introduced the 3DO Interactive Multiplayer, a games console based on the ARM60 in 1993. The Apple Newton 100 series were powered with an ARM610 core, one of the first mobile devices using ARM cores.
ARM7
In 1993, ARM introduced the ARM700 processor, using the ARMv3 core. It doubled the ARM6’s cache, to a full 8 KB of unified cache. It was also the first processor that could be powered by a 3.3V supply. Its performance improvement was between 50 and 100 percent, and the 3.3V version also used one-half the power of a 5V ARM6. ARM worked hard on the power consumption of the ARM7, using 0.8μm CMOS technology instead of 1μm CMOS technology. ARM7 was ARM’s push into the mobile sector and was extremely well received.
ARM7TDMI
The ARM7TDMI was the first ARM core to use the new ARMv4T architecture and introduced the Thumb extension. It ran at a clock speed of 70 MHz but did not include any cache. ARM710T and ARM720T versions included cache and MMUs but ran at lower clock speeds. The ARM740T included a cache and an MPU.
ARM7TDMI is one of ARM’s great success stories, being used in hundreds of devices where low power and good performance need to go hand in hand. It was used in the Apple iPod, the Lego Mindstorms NXT, the Game Boy Advance, and a huge range of mobile phones from Nokia. Samsung also used them directly inside its line of microSD cards.
ARM8
The ARM810 core used the previous ARMv4 architecture but included branch prediction and double-bandwidth memory, vastly improving performance. For most applications, ARM8 doubled performance compared to an ARM710 processor. It introduced a five-stage pipeline, whereas ARM7 had only three. At the cost of a little silicon, processor speeds could be roughly doubled by still using the same silicon fabrication process.
A few companies licensed the ARM8 core, but the arrival of StrongARM changed everything, being theoretically more than four times as powerful.
STRONGARM
The StrongARM project was a collaborative project between ARM and Digital Equipment Corporation to create a faster ARM core. The StrongARM was designed to address the needs of the high-end, low-power embedded market, where users needed more performance than ARM processors could deliver. Target devices were PDAs and set-top boxes.
To develop StrongARM, DEC became ARM’s first architecture licensee. This entitled it to design an ARM-compatible processor without using one of ARM’s own implementations as a starting point. DEC used its own in-house tools and processes to develop an efficient implementation.
In early 1996, the SA-110 was born. The first versions operated at 100, 160, and 200 MHz, with faster 166 and 233 MHz versions appearing at the end of 1996. The SA-110 was designed to be used with slow memory, and therefore it featured separate instruction cache and data cache, and each had a generous capacity of 16 Kb. It powered the Apple MessagePad 2000, contributing to its success.
In 1997, DEC announced the SA-1100. The SA-1100 was more specialized for mobile applications and added an integrated memory controller, a PCMCIA controller, and an LCD controller. These controllers came at a price; the data cache was reduced from 16 Kb to 8 Kb. The SA-1100 powered the Psion Series 7 subnotebook family.
In 1997, DEC agreed to sell its StrongARM group to Intel, as a lawsuit settlement. Intel took over the StrongARM project, using it to replace its line of RISC processors — the i860 and i960.
The SA-1110 was Intel’s derivative of the SA-110 targeted at the mobile sector. It added support for 66 MHz and 103 MHz SDRAM modules. A companion chip was available, the SA-1111, providing additional support for peripherals. It was used in part of the Compaq iPaq series, a hugely successful PocketPC range.
The SA-1500 was a derivative of the SA-110 project, created by DEC, but was never put into production by Intel. Intel replaced the StrongARM series by another family, the XScale.
ARM9TDMI
Even before the StrongARM was released, ARM was already busy developing the ARM9T.
With the ARM9, ARM moved from the classic von Neumann architecture to a modified Harvard architecture, separating instruction and data cache. At the cost of added silicon, this modification alone greatly improved speed. By separating instructions from data, instruction fetches and data accesses could occur simultaneously. ARM9 also used the five5-stage pipeline introduced by the ARM8 core version.
ARM9TDMI was a replacement for the hugely popular ARM7TDMI. Applications designed for ARM7TDMI were roughly 30 percent faster on an ARM9TDMI.
ARM9E
ARM9E implemented the ARM9TDMI pipeline but added support for the ARMv5TE architecture, adding some DSP instructions. The multiplier unit width was also doubled, halving the time required for most multiplication operations.
ARM10
The ARM10 was a highly anticipated successor to the ARM9 family and was announced in October 1998. ARM10’s aim was to double ARM9’s performance by using optimization and advanced fabrication. To increase performance, ARM worked on two main aspects of the processor: pipeline optimization and instruction execution speed.
The pipeline in ARM9 processors was already advanced, but a pipeline is only as fast as its slowest element. Several optimizations were proposed, but most were rejected because they added too much complexity to the pipeline, which increased power consumption or overall price. A weak point was identified in the Decode stage. To increase pipeline speed, the original Decode section was split into two parts, Issue and Decode, where Issue partially decodes the instruction, and Decode reads registers with the rest of the decode sequence.
Further optimizations came from instruction optimization. The ARM10 came with a new multiplication core, a fast 16 × 32 hardware multiplier. This enabled the ARM10 processor to perform one 32-bit multiply and accumulate operation every clock cycle, a vast improvement from the previous 3–5 cycles on ARM9.
The ARM10 also supported Hit-Under-Miss in the data cache and included a static branch prediction scheme to offset the effect of a longer pipeline.
XSCALE
The XScale processor from Intel was the continuation of the StrongARM series. Following Intel’s acquisition of the StrongARM, XScale replaced Intel’s RISC systems and also powered an entire generation of hand-held devices.
In the mid-1990s, the PC sector was going mobile. Hewlett-Packard’s HP200LX computer was a palm top, a complete system held in a hand, and although far less powerful than a portable computer, it could be put into a pocket. Users could finally keep their agenda, notes, and contacts in a small-factor computer, available at any time. The HP200LX was based on an Intel CISC-compatible 80186 and contained an entire version of Windows. Boot-up times were relatively fast, but although the general idea was there, the technology wasn’t quite available. In 1996, Microsoft created Windows CE 1.0, which was the start of the Pocket PC era. It was a change of technology; it was no longer based on x86 processors that were fast but power hungry. The logical choice was to look at RISC processors, and the name Pocket PC was a marketing choice by Microsoft. Pocket PC referred to a specific set of hardware based on an ARMv4T-compatible CPU.
ARM11
ARM1136 introduced the ARMv6 architecture, adding SIMD instructions, multiprocessor support, TrustZone, and Thumb-2. It had a significantly improved pipeline, now comprised of 8 stages (though the ARM1156 pipeline architecture was slightly different, having limited dual-issue capability). It included dynamic branch prediction, reducing the risk of stalling the pipeline.
ARM11 also supported limited out-of-order completion, allowing the pipeline to continue execution if the result of a previous instruction is not needed by the following instructions. By giving the pipeline some time for memory reads and writes, it is possible to increase performance by avoiding pipeline stalls.
With the advanced pipeline, the ARM11 ran at speeds up to 1 GHz.
The ARM11 also had SIMD instructions, meaning single-instruction-multiple-data. Much like Intel’s MMX instruction set, these instructions are designed to perform repetitive instructions on multiple data sets, heavily used in audio and video codecs.
CORTEX
ARM11 was a huge success, and ARM processors were becoming more and more powerful, but also larger, and more expensive. Companies who had specific projects were having a hard time choosing which processor to use; either a powerful, latest generation ARM, or for smaller devices, an older ARM, without the recent advantages. ARM processors were being used for more and more devices, and not all of them required a fast CPU; some systems required slower processors, or even very small factor systems. Some ARM systems are so small that they are located inside an SD card, or even directly inside a cable. ARM rearranged their line of processors to target specific fields, and in 2004, the Cortex family was announced, beginning with the Cortex-M3.
The Cortex family has 3 classes of processors; the Cortex-A, the Cortex-R and the Cortex-M. ARM’s mastery of those three letters became almost obsessional. Cortex-A processors were designed for Application designs, where an entire multitasking operating system would be run. Cortex-R was designed for real-time applications, where very fast reaction times were required. Cortex-M was designed for ultra-low power microprocessor applications.
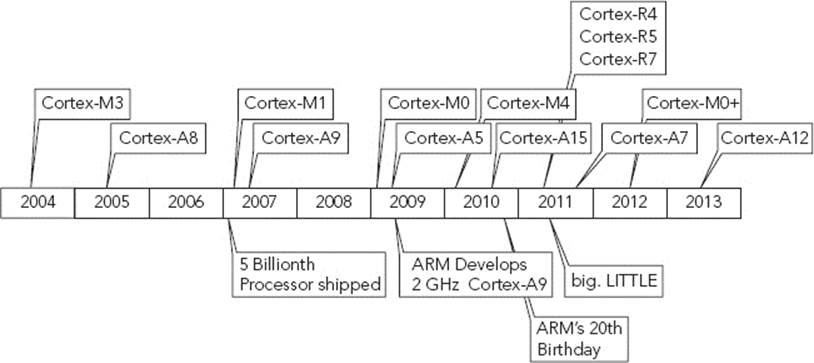
The very first Cortex processor was announced in 2004, with the Cortex-M3. The next year, the first Cortex-A design was announced, the Cortex-A8. The Cortex-R family was announced in 2011. Figure C-1 shows a timeline of the Cortex family, as well as some milestones from ARM.
FIGURE C-1: Cortex family timeline
Cortex-A
The Cortex-A processor is designed for Application systems. Application processors are the powerhouse chips, running complete operating systems, high-performance multimedia codecs, and demanding applications.
The Cortex-A series includes everything needed for devices hosting a rich operating system. They are sufficiently powerful and come with an MMU. By adding a few external components, it is possible to create advanced platforms. They are targeted at mobile devices that require advanced calculations or graphics. Smartphones, tablets, digital TVs, and infotainment systems are powered by a Cortex-A, and even laptops have been developed running on multi-core Cortex-A cores.
The first Cortex-A core was announced in 2005, and development has continued since. Cortex-A processors can include an optional NEON engine and FPU logic.
Cortex-A5
The Cortex-A5 was announced in 2007. It is designed to be used on entry-level smartphones, some feature phones, and digital multimedia devices. The Cortex-A5 was proposed as a replacement for 2 hugely popular CPUs; the ARM-926EJ-S and the ARM1176JZ-S. The Cortex-A5 is more powerful than an ARM1176JZ-S, while using about as much power as the ARM926EJ-S.
The Cortex-A5 is an in-order processor, meaning it has a simplified instruction prefetcher and decoder, meaning more power efficient, but more prone to processor stalls, and therefore not as advanced or as fast as other designs. The Cortex-A5 remains a budget processor.
Cortex-A7
The Cortex-A7 was announced a year after the Cortex-A15. It is architecturally identical to the Cortex-A15, as it contains the same technologies. Binary applications that run on a Cortex-A15 will run on the Cortex-A7. Heralded at the time as ARM’s most power-efficient application processor, it provided 50 percent greater performance than the Cortex-A8.
While the performance of the Cortex-A7 is overshadowed by the more powerful Cortex-A15, ARM also announced their big.LITTLE technology, linking both processors together. The Cortex-A15 is available as stand-alone, as is the Cortex-A7, but the Cortex-A7 can become a companion CPU to the Cortex-A15. Inside an operating system, the kernel can decide which processor to run an application on. Low-powered applications (like background applications, alarm clocks, and e-mail reading) can run on the energy efficient Cortex-A7, and demanding applications can run on the more powerful Cortex-15. By migrating applications from one processor to another, the kernel can also turn off one processor or the other when no processes are assigned to it, further reducing energy consumption.
The A7 itself is an in-order processor, with an 8-stage pipeline. To be binary compatible with the A15, it also supports LPAE, allowing it to address one terabyte of address space. It also includes Virtualization extensions.
Cortex-A8
The Cortex-A8 was the first Cortex-A processor. Using a superscalar design, it achieves roughly twice as many instructions executed per clock cycle as previous designs, and is binary compatible to the ARM926, ARM1136 and ARM1176 processors. It also integrates advanced branch prediction, with ARM claiming up to 95 percent accuracy. The Cortex A8 is designed to be run up to frequencies of 1 GHz.
Cortex-A9
The Cortex-A9 is a more advanced version of the Cortex-A8, capable of higher clock speeds (up to 2 GHz), and with a multi-core architecture, allowing up to four processors in a single coherent cluster.
The Cortex-A9 is a speculative issue superscalar processor. By using advanced techniques, the processor executes code that might not actually be needed. For example, in branch code, both results might be calculated. If it turns out that some work was not needed, the results are discarded. The philosophy is to do work before knowing if it is needed, then discarding where appropriate, rather than creating a stall when new work is requested. If the execution was not required, then the changes are reverted. If the execution is required, then the changes are “committed,” effectively eliminating any processor stalls due to branch prediction, memory prefeteches or pipeline execution. This technology is especially useful in processors that handle databases, where lots of speculative execution is required.
Cortex-A12
The Cortex-A12 is a newcomer in the Cortex-A family. Released in 2013, it is designed as the successor to the Cortex-A9. It is an out-of-order speculative issue superscalar processor, providing more performance per watt than the Cortex-A9. Like the Cortex-A9, it can be configured with up to 4 cores. It has the NEON SIMD instruction set extension, includes TrustZone security extensions, and 40-bit Large Physical Address extensions, allowing the Cortex-A12 to address up to one terabyte of memory space.
This core targets mid-range devices, offering advanced functionality while retaining backwards compatibility with Cortex-A15, Cortex-A7, and Cortex-A9 processors, but offers 40 percent more performance than the Cortex-A9.
Cortex-A15
The Cortex-A15 processor is the most advanced processor of the 32-bit Cortex-A series. ARM has confirmed that the Cortex-A15 is 40 percent faster than the Cortex-A9, at an equivalent number of cores and clock speed. The Cortex-A15 is an out-of-order superscalar multi-core design, running at up to 2.5 GHz.
The Cortex-A15 can have four cores per coherent cluster, and can use the Cortex-A7 processor as a companion CPU, using ARM’s big.LITTLE technology.
With ultra-high powered applications in mind, it became clear that the 4 gigabyte memory limit imposed by the 32-bit design, a limit that seemed unobtainable a few years ago, was about to be broken, and would be a limitation. To counter this, the Cortex-A15 has 40-bit Large Physical Address Extensions (LPAE), allowing for a total addressable space of one terabyte.
The Cortex-A15 itself is an out-of-order speculative issue superscalar processor, using some of ARM’s most advanced technology to make this ARM’s fastest 32-bit processor.
Cortex-A50 Series
The Cortex-A50 series is the latest range of processors based on the 64-bit ARMv8 architecture. It supports the new AArch64, an execution state that runs alongside an enhanced version of ARM’s existing 32-bit instruction set. The Cortex-A53 and Cortex-A57 are only the beginning of the 64-bit revolution; more processors will follow soon.
Cortex-R
The Cortex-R profile is for real-time applications — for critical systems where reliability is crucial and speed is decisive. Real-time systems are designed to handle fast-changing data, and to be sufficiently responsive to handle the data throughput without slowing down. For this reason, Cortex-R processors are found in hard drives, network equipment, and embedded into critical systems, such as car brake assistance.
In the multi-core design, up to 4 cores can be used on the same chip, and a single-core version is also available.
In order to maximize reactivity, Cortex-R chips can contain tightly-coupled memory, but do not have a full MMU, instead they rely on memory protection units.
Cortex-R4
The first in the Cortex-R line, the Cortex-R4 is based on the ARMv7-R architecture, and was launched in May 2006. It is available in a synthesizable form. It slightly outperforms an ARM1156 at the same clock speed, and with a 40nm production, can obtain clock frequencies of almost 1 GHz. It includes branch prediction and instruction pre-fetch, allowing for fast reaction times.
For safety-critical applications, the Cortex-R4 has optional parity and ECC checks on all RAM interfaces, and the optional TCM can be completely configured as a separate instruction/data, or unified memory. It is equipped with a Memory Protection Unit, capable of handling 12 regions. Cortex-R4 supports dual-core lockstep configuration for safety-critical applications.
Cortex-R5
The Cortex-R5 was released in 2010, 4 years after the Cortex-R4, and complements the Cortex-R4 with an enriched feature set. It remains binary compatible with the Cortex-R4. Cortex-R5 provides improved support for multi-processing in a dual-core configuration.
Cortex-R7
The Cortex-R7 increased the pipeline length from 8 to 11, and allows for out-of-order execution. The Memory Protection Unit was also changed from previous models, now allowing for up to 16 regions. Cortex-R7 provides full support for SMP/AMP multi-processing in a fully-coherent dual-core configuration.
Cortex-M
The Cortex-M processor is designed for microcontroller applications. These applications typically require little processing power, but need lots of input and output lines, very small form factor, deterministic interrupt response and exceptionally low power consumption. Cortex-M chips are used heavily in Bluetooth devices, touchscreen controllers, remote control devices and even embedded directly into some cables. Some devices using Cortex-M boast a battery life of years, not just hours.
The Cortex-M package footprint is often extremely small, in some cases, just a few millimeters squared (NXP’s LPC1102 chips are 2.17 × 2.32mm, containing 32 kbytes of flash and 8 kbytes or RAM).
Cortex-M chips are designed for rapid development, since the entire application, including the vector tables, can be written in C.
Cortex-M0
The Cortex-M0 design uses the ARMv6-M architecture. It uses only Thumb instructions with the Thumb-2 technology, allowing both 16-bit and 32-bit instructions. However, not all instructions are available. The entire 16-bit Thumb subset can be used, with the exception of CBZ, CBNZ, and IT. Of the 32-bit instructions, only BL, DMB, DSB, ISB, MRS and MSR can be used.
The Cortex-M0 has a 3-stage pipeline without branch prediction. It handles one non-maskable interrupt and up to 32 physical interrupts, with an interrupt latency of 16 cycles. It also implements some advanced sleep functions, including deep sleep.
Cortex-M0+
The Cortex-M0+ design is an augmented version of the Cortex-M0. It is more power efficient, and uses the same instruction set as the M0. It has some features from the Cortex-M3 and Cortex-M4, such as the Memory Protection Unit and the relocatable vector table, but also adds its own features, such as the Micro Trace Buffer and single-cycle I/O interface. The pipeline was decreased from 3 to 2, improving power usage.
Cortex-M1
The Cortex-M1 design is an optimized core that was created specifically to be loaded into FPGA chips. It supports all the instructions supported by the Cortex-M0, and the only difference is a very slightly degraded 32-bit hardware multiply unit. Where the Cortex-M0 could do multiplications in either 1 or 32 cycles, the Cortex-M1 executes the same instruction in either 3 or 33 cycles.
Cortex-M3
The Cortex-M3 is the first Cortex to use the new ARMv7-M architecture. It uses a 3-stage pipeline, and also includes branch speculation, attempting to increase speed by guessing the output of a branch, and pre-loading instructions into the pipeline.
The Cortex-M3 has 240 prioritizable interrupts, and non-maskable interrupt. Interrupt latency was reduced to 12 cycles.
Compared to the Cortex-M0, the Cortex-M3 uses slightly more power, but has a huge advantage; it uses the entire Thumb instruction set. While the Cortex-M0, Cortex-M0+, and Cortex-M1 could only use very few 32-bit instructions, a much larger set of 32-bit instructions can be used, including division instructions. Finally, an ARM processor was able to use hardware division.
The Cortex-M3 also has a memory protection unit, allowing read-write access or prevention for up to 8 memory regions.
Cortex-M4
The Cortex-M4 is almost identical to a Cortex-M3, but with the addition of DSP instructions for more mathematical intense applications in binary data. It is also slightly faster than the Cortex-M3, since its pipeline includes advanced branch speculation. The Cortex-M4 supports an optional Floating Point Unit.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.