Data Push Apps with HTML5 SSE (2014)
Chapter 1. All About SSE...And Then Some
SSE stands for Server-Sent Events and it is an HTML5 technology to allow the server to push fresh data to clients. It is a superior solution to having the client poll for new data every few seconds. At the time of writing it is supported natively by 65% of desktop and mobile browsers, but in this book I will show how to develop fallback solutions that allow us to support more than 99% of desktop and mobile users. By the way, 10 years ago I used Flash exclusively for this kind of data push; things have evolved such that nothing in this book uses Flash.
NOTE
The browser percentages in this book come from the wonderful “Can I Use…” website. It, in turn, gets its numbers from StatCounter GlobalStats. And, to preempt the pedants, when I say “more than 99%” I really mean “it works on every desktop or mobile browser I’ve been able to lay my hands on.” Please forgive me if that doesn’t turn out to be exactly 99% of your users.
For users with JavaScript disabled, there is no hope: neither SSE nor our clever fallback solutions will work. However, because being told “impossible” annoys me as much as it annoys you, I will show you a way to give even these users a dynamic update (see What If JavaScript Is Disabled?).
The rest of this chapter will describe what HTML5 and data push are, discuss some potential applications, and spend some time comparing SSE to WebSockets, and comparing both of those to not using data push at all. If you already have a rough idea what data push is, I’ll understand if you want to jump ahead to the code examples in Chapter 2, and come back here later.
HTML5
I introduced SSE as an HTML5 technology earlier. In the modern Web, HTML is used to specify the structure and content of your web page or application, CSS is used to describe how it should look, and JavaScript is used to make it dynamic and interactive.
NOTE
JavaScript is for actions, CSS is for appearance; notice that HTML is for both structure and content. Two things. First, the logical organization (the “DOM”); second, the data itself. Typically when the data needs to be updated, the structure does not. It is this desire to change the content, without changing the structure, that drove the creation of data pull and data push technologies.
HTML was invented by Tim Berners-Lee, in about 1990. There was never a formally released HTML 1.0 standard, but HTML 2.0 was published at the end of 1995. At that time, people talked of Internet Years as being in terms of months, because the technology was evolving very quickly. HTML 2.0 was augmented with tables, image uploads, and image maps. They became the basis of HTML 3.2, which was released in January 1997. Then by December 1997 we had HTML 4.0. Sure, there were some tweaks, and there was XHTML, but basically that is the HTML you are using today—unless you are using HTML5.
Most of what HTML5 adds is optional: you can mostly use the HTML4 you know and then pick and choose the HTML5 features you want. There are a few new elements (including direct support for video, audio, and both vector and bitmap drawing) and some new form controls, and a few things that were deprecated in HTML4 have now been removed. But of more significance for us is that there are a whole bunch of new JavaScript APIs, one of which is Server-Sent Events. For more on HTML5 generally, the Wikipedia entry is as good a place to start as any.
The orthogonality of the HTML5 additions means that although all the code in this book is HTML5 (as shown by the <!doctype html> first line), just about everything not directly to do with SSE will be the HTML4 you are used to; none of the new HTML5 tags are used.
Data Push
Server-Sent Events (SSE) is an HTML5 technology that allows the server to push fresh data to clients (commonly called data push). So, just what is data push, and how does it differ from anything else you may have used? Let me answer that by first saying what it is not. There are two alternatives to data push: no-updates and data pull.
The first is the simplest of all: no-updates (shown in Figure 1-1). This is the way almost every bit of content on the Web works.
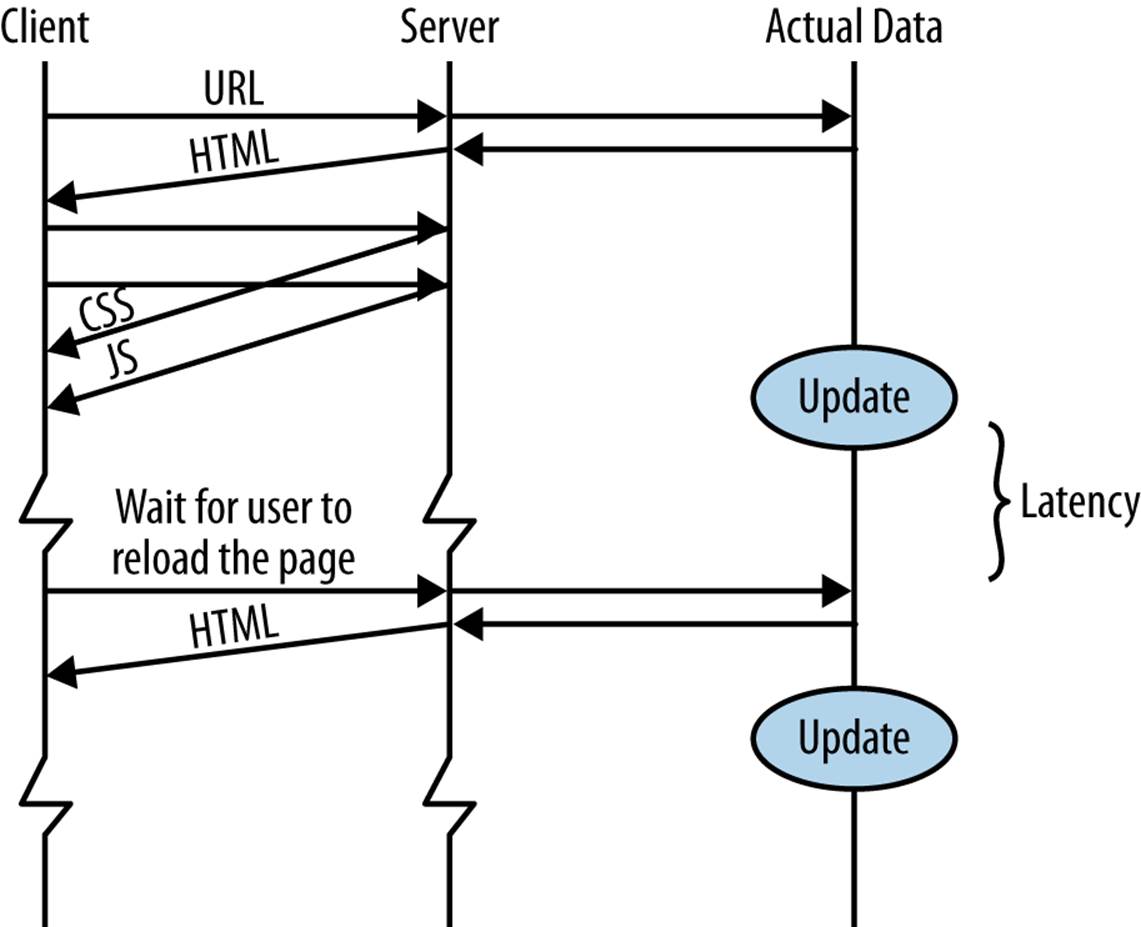
Figure 1-1. Alternative: no-updates
You type in a URL, and you get back an HTML page. The browser then requests the images, CSS files, JavaScript files, etc. Each is a static file that the browser is able to cache. Even if you are using a backend language, such as PHP, Ruby, Python, or any of the other dozens of choices todynamically generate the HTML for the user, as far as the browser is concerned the HTML file it receives is no different from a handmade static HTML file. (Yes, I know you can tell the browser not to cache the content, but that is missing the point. It is still static.)
The other alternative is data pull (shown in Figure 1-2).
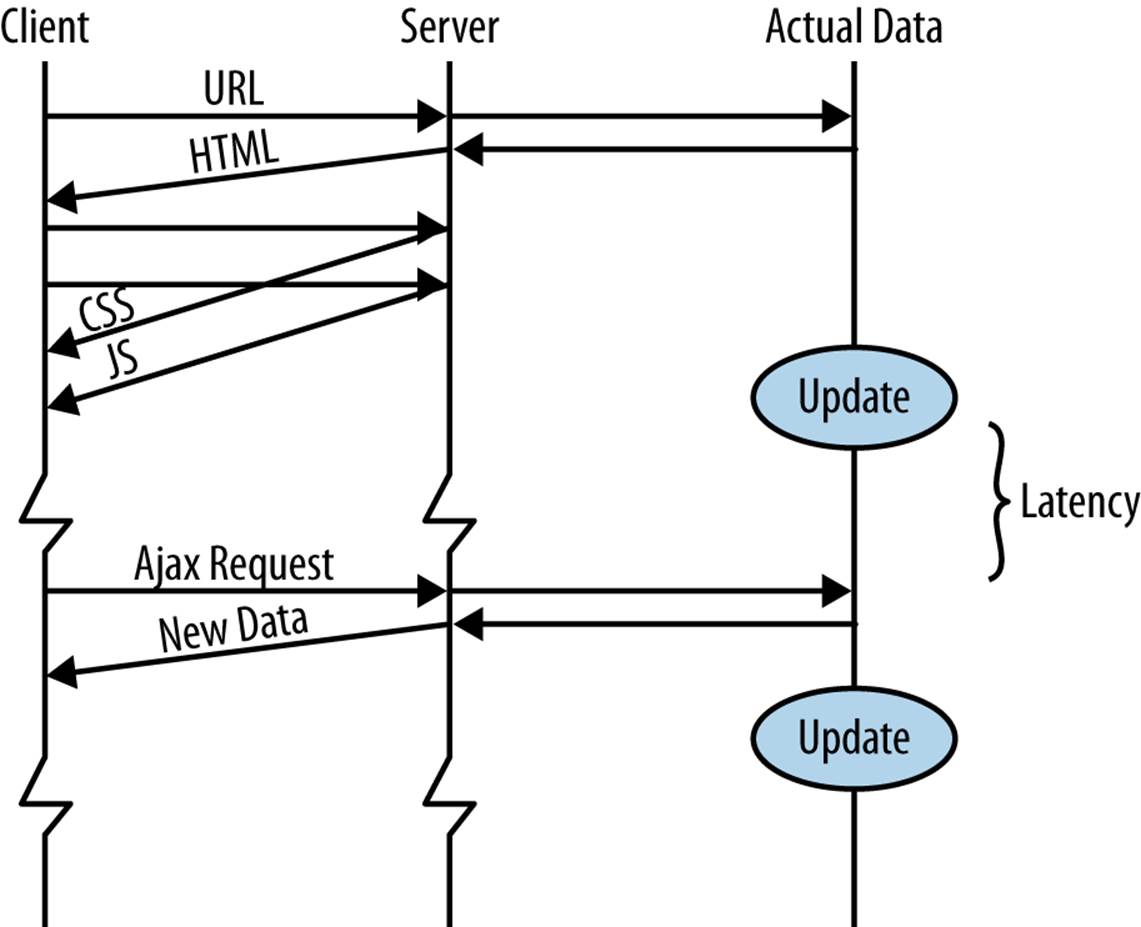
Figure 1-2. Alternative: data pull (regular polling)
Based on some user action, or after a certain amount of time, or some other trigger, the browser makes a request to the server to get an up-to-date version of some, or all, of its data. In the crudest approach, either JavaScript or a meta tag (see What If JavaScript Is Disabled?) tells the whole HTML page to reload. For that to make sense, either the page is one of those made dynamically by a server-side language, or it is static HTML that is being regularly updated.
In more sophisticated cases, Ajax techniques are used to just request fresh data, and when the data is received a JavaScript function will use it to update part of the DOM. There is a very important concept here: only fresh data is requested, not all the structure on the HTML page. This is really what we mean by data pull: pulling in just the new data, and updating just the affected parts of our web page.
NOTE
Jargon alert. Ajax? DOM?
Ajax is introduced in Chapter 6, when we use it for browsers that don’t have native SSE support. I won’t tell you what it stands for, because it would only confuse you. After all, it doesn’t have to be asynchronous, and it doesn’t have to use XML. It is hard to argue with the J in Ajax, though. You definitely need JavaScript.
DOM? Document Object Model. This is the data structure that represents the current web page. If you’ve written document.getElementById('x').... in JavaScript, or $('#x').... in JQuery, you’ve been using the DOM.
That is what data push isn’t. It is not static files. And it is not a request made by the browser for the latest data. Data push is where the server chooses to send new data to the clients (see Figure 1-3).
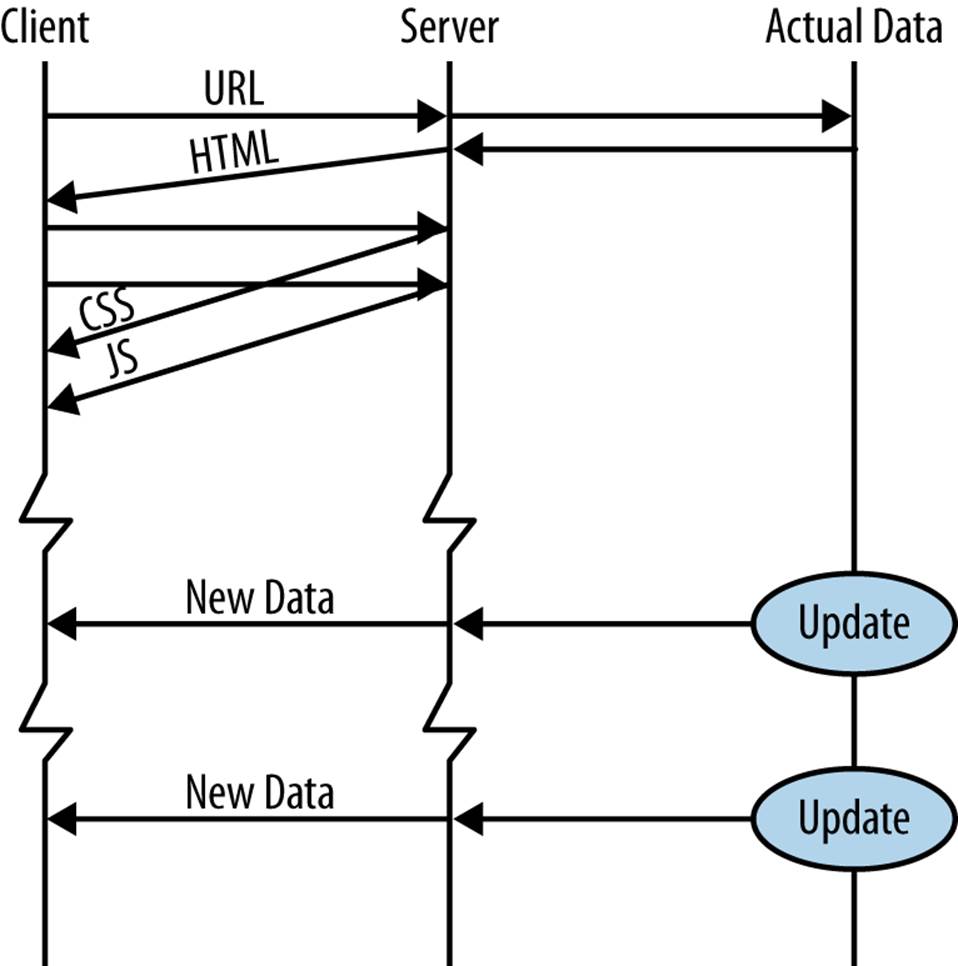
Figure 1-3. Data push
When the data source has new data, it can send it to the client(s) immediately, without having to wait for them to ask for it. This new data could be breaking news, the latest stock market prices, a chat message from another online friend, a new weather forecast, the next move in a strategy game, etc.
The functionality of data pull and data push is the same: the user gets to see new data. But data push has some advantages. Perhaps the biggest advantage is lower latency. Assuming a packet takes 100ms to travel between server and client, and the data pull client is polling every 10 seconds, with data push the client gets to see the data 100ms after the server has it. With data pull, the client gets to see the data between 100ms and 10100ms (average 5100ms) after the server has it; everything depends on the timing of the poll request. On average, the data pull latency is 51 times worse. If the data pull method polls every 2 seconds, the average comes down to 1100ms, which is merely 11 times worse. However, if no new data were available, that would result in more wasted requests and more wasted resources (bandwidth, CPU cycles, etc.).
That is the balancing act that will always be frustrating you with data pull: to improve latency you have to poll more often; to save bandwidth and connection overhead you have to poll less often. Which is more important to you—latency or bandwidth? When you answer “both,” that is when you need a data push technology.
Other Names for Data Push
The need for data push is as old as the Web,[1] and over the years people have found many novel solutions, most of them with undesirable compromises. You may have heard of some other technologies—Comet, Ajax Push, Reverse Ajax, HTTP Streaming—and be wondering what the difference is between them. These are all talking about the same thing: the fallback techniques we will study in Chapters 6 and 7. SSE was added as an HTML5 technology to have something that is both easy to use and efficient. If your browser supports it, SSE is always[2] superior to the Comet technologies. (Later in this chapter is a discussion of how SSE and WebSockets differ.)
By the way, you will sometimes see SSE referred to as EventSource, because that is the name of the related object in JavaScript. I will call it SSE everywhere in this book, and I will only use EventSource to refer to the JavaScript object.
Potential Applications
What is SSE good for? SSE excels when you need to update part of a web application with fresh data, without requiring any action on the part of the user. The central example application we will use to explore how to implement data push and SSE is pushing foreign exchange (FX) prices. Our goal is that each time the EUR/USD (Euro versus US Dollar) exchange rate changes at our broker, the new price will appear in the browser, as close to immediately as physically possible.
This fits the SSE protocol perfectly: the updates are frequent and low latency is important, and they are all flowing from the server to the client (the client never needs to send prices back). Our example backend will fabricate the price data, but it should be obvious how to use it to distribute real data, FX or otherwise.
With only a drop of imagination you should be able to see how this example can apply to other domains. Pushing the latest bids in an auction web application. Pushing new reviews to a book-seller website. Pushing new high scores in an online game. Pushing new tweets or news articles for keywords you are interested in. Pushing the latest temperatures in the core of that Kickstarter-financed nuclear fusion reactor you have been building in your back garden.
Another application would be sending alerts. This might be part of a social network like Facebook, where a new message causes a pop up to appear and then fade away. Or it might be part of the interface for an email service like Gmail, where it inserts a new entry in your inbox each time new mail arrives. Or it could be connected to a calendar, and give you notice of an upcoming meeting. Or it could warn you of your disk usage getting high on one of your servers. You get the idea.
What about chat applications? Chat has two parts: receiving the messages of others in the chat room (as well as other activities, such as members entering or leaving the chat room, profile changes, etc.), and then posting your messages. This two-way communication is usually a perfect match for WebSockets (which we will take a proper look at in a moment), but it does not mean it is not also a good fit for SSE. The way you handle the second part, posting your messages, is with a good old-fashioned Ajax request.
As an example of the kind of “chat” application to which SSE is well-suited, it can be used to stream in the tweets you are interested in, while a separate connection is used for you to write your own tweets. Or imagine an online game: new scores are distributed to all players by SSE, and you just need a way to send each player’s new score to the server at the end of their game. Or consider a multiplayer real-time strategy game: the current board position is constantly being updated and is distributed to all players using SSE, and you use the Ajax channel when you need to send a player’s move to the central server.
Comparison with WebSockets
You may have heard of another HTML5 technology called WebSockets, which can also be used to push data from server to client. How do you decide if you should be using SSE or WebSockets? The executive summary goes like this: anything you can do with WebSockets can be done with SSE, and vice versa, but each is better suited to certain tasks.
WebSockets is a more complicated technology to implement server side, but it is a real two-way socket, which means the server can push data to the client and the client can push data back to the server.
Browser support for WebSockets is roughly the same as SSE: most major desktop browsers support both.[3] The native browser for Android 4.3 and earlier supports neither, but Firefox for Android and Chrome for Android have full support. Android 4.4 supports both. Safari has had SSE support since 5.0 (since 4.0 on iOS), but has only supported WebSockets properly since Safari 6.0 (older versions supported an older version of the protocol that had security problems, so it ended up being disabled by the browsers).
SSE has a few notable advantages over WebSockets. For me the biggest of those is convenience: you don’t need any new components—just carry on using whatever backend language and frameworks you are already used to. You don’t need to dedicate a new virtual machine, a new IP, or a new port to it. It can be added just as easily as adding another page to an existing website. I like to think of this as the existing infrastructure advantage.
The second advantage is server-side simplicity. As we will see in Chapter 2, the backend code is literally just a few lines. In contrast, the WebSockets protocol is complicated and you would never think to tackle it without a helper library. (I did; it hurt.)
Because SSE works over the existing HTTP/HTTPS protocols, it works with existing proxy servers and existing authentication techniques; proxy servers need to be made WebSocket aware, and at the time of writing many are not (though this situation will improve). This also ties into another advantage: SSE is a text protocol and you can debug your scripts very easily. In fact, in this book we will use curl and will even run our backend scripts directly at the command line when testing and developing.
But that leads us directly into a potential advantage of WebSocket over SSE: it is a binary protocol, whereas SSE uses UTF-8. Sure, you could send binary data over the SSE connection: the only characters with special meaning in SSE are CR and LF, and those are easy to escape. But binary data is going to be bigger when sent over SSE. If you are sending large amounts of binary data from server to client, WebSockets is the better choice.
BINARY DATA VERSUS BINARY FILES
If you want to send large binary files over either WebSockets or SSE, stop and think if that is what you should be doing. Wouldn’t using good old HTTP for that be better? It will save you from having to reinvent all kinds of wheels (authorization, encryption, proxies, caching, keep-alive). And, if your concern is efficient use of socket connections, take a good look at HTTP/2.0.[4]
When I talk about “large amounts of binary data” I mean when you need to implement binary Internet protocols, such as SSH, inside a browser. If all you want to do is push a new banner ad to a user, the best way is to send just the URL over SSE (or WebSockets), and then have the browser use good old HTTP to fetch it.
But the biggest advantage of WebSockets over SSE is that it is two-way communication. That means it is just as easy to send data to the server as to receive data from the server. When using SSE, the way we normally pass data from client to server is using a separate Ajax request. Relative to WebSockets, using Ajax in this way adds overhead. However, it only adds a bit of overhead,[5] so the question becomes: when does it start to matter? If you need to pass data to the server once/second or even more frequently, you should be using WebSockets. Once every one to five seconds and you are in a gray area; it is unlikely to matter whether you go with WebSockets or SSE, but if you are expecting heavy load it is worth benchmarking. Less frequently than once every five or so seconds and you won’t notice the difference.
What of performance for passing data from the server to the client? Well, assuming it is textual data, not binary (as mentioned previously), there is no difference between SSE and WebSockets. They are both are using a TCP/IP socket, and both are lightweight protocols. No difference in latency, bandwidth, or server load…except when there is. Eh? What does that mean?
The difference applies when you are enjoying the existing infrastructure advantage of SSE, and have a web server sitting between your client and your server script. Each SSE connection is not just using a socket, but it is also using up a thread or process in Apache. If you are using PHP, it is starting a new PHP instance especially for the connection. Apache and PHP will be using a chunk of memory, and that limits the number of simultaneous connections you can support. So, to get the exact same data push performance for SSE as you get for WebSockets, you have to write your own backend server. Of course, those of you using Node.js will be using your own web server anyway, and wonder what the fuss is about. We take a look at using Node.js to do just that, in Chapter 2.
A word on WebSocket fallbacks for older browsers. At the moment just over two-thirds of browsers can use these new technologies; on mobile it is a lower percentage. Traditionally, when a two-way socket was needed, Flash was used, and polyfill of WebSockets is often done with Flash. That is complicated enough, but when Flash is not available it is even worse. In simple terms: WebSocket fallbacks are hard, SSE fallbacks are easier.
When Data Push Is the Wrong Choice
Most of what I will talk about in this section applies equally well to both the HTML5 data push technologies (SSE and WebSockets) and the fallback solutions we will look at in Chapters 6 and 7; the thing they have in common is that they keep a dedicated socket open for each connected client.
First let us consider the static situation, with no data push involved. Each time users open a web page, a socket connection is opened between their browser and your server. Your server gathers the information to send back to them, which may be as simple as loading a static HTML file or an image from disk, or as complex as running a server-side language that makes multiple database connections, compiles CoffeeScript to JavaScript, and combines it all together (using a server-side template) to send back. The point being that once it has sent back the requested information, the socket is then closed.[6] Each HTTP request opens one of these relatively short-lived socket connections. These sockets are a limited resource on your machine, but as each one completes its task, it gets thrown back in the pile to be recycled. It is really very eco-friendly; I’m surprised there isn’t government funding for it.
Now compare that to data push. You never finish serving the request: you always have more information to send, so the socket is kept open forever. Therefore, because they are a limited resource,[7] we have a limit on the number of SSE users you can have connected at any one time.
You could think of it this way. You are offering telephone support for your latest application, and you have 10 dedicated call center staff, servicing 1,000 customers. When a customer hits a problem he calls the support number, one of the staff answers, helps him with the problem, then hangs up. At quiet times some of your 10 staff are not answering calls. At other times, all 10 are busy and new callers get put into a queue until a staff member is freed up. This matches the typical web server model.
But now imagine you have a customer call and say: “I don’t have a problem at the moment, but I’m going to be using your software for the next few hours, and if I have a problem I want to get an immediate answer, and not risk being put on hold. So could you just stay on the line, please?” If you offer this service, and the customer has no questions, you’ve wasted 10% of your call center capacity for the duration of those few hours. If 10 customers did this, the other 990 customers are effectively shut out. This is the data push model.
But it is not always a bad thing. Consider if that user had one question every few seconds for the whole afternoon. By keeping the line open you have not wasted 10% of your call capacity, but actually increased it! If he had to make a fresh call (data pull) for each of those questions, think of the time spent answering, identifying the customer, bringing up his account, and even the time spent with a polite good-bye at the end. There is also the inefficiency involved if he gets a different staff member each time he calls, and they have to get up to speed each time. By keeping the line open you have not only made that customer happier, but also made your call center more efficient. This is data push working at its best.
The FX trading prices example, introduced earlier, suits SSE very well: there are going to be lots of price changes, and low latency is very important: a customer can only trade at the current price, not the price 60 seconds ago. On the other hand, consider the long-range weather forecast. The weather bureau might release a new forecast every 30 minutes, but most of the time it won’t change from “warm and sunny.” And latency is not too critical either. If we don’t hear that the forecast has changed from “warm and sunny” to “warm and partly cloudy” the very moment the weather forecasters announce it, does it really matter? Is it worth holding a socket open, or would straightforward polling (data pull) of the weather service every 30 or 60 minutes be good enough?
What about infrequent events where latency does matter? What if we know there will be a government announcement of economic growth at 8:30 a.m. and we want it shown to customers of our web application as soon as the figures are released? In this case we would do better to set a timer that does a long-poll Ajax call (see Chapter 6) that would start just a few seconds before the announcement is due. Holding a socket open for hours or days beforehand would be a waste.
A similar situation applies to predictable downtime. Going back to our example of receiving live FX prices, there is no point holding the connection open on the weekends. The connection could be closed at 5 p.m. (New York local time) on a Friday, and a timer set to open it again at 5 p.m. on Sunday. If your computer infrastructure is built on top of a pay-as-you-go cloud, that means you can shut down some of your instances Friday evening, and therefore cut your costs by up to 28%! See Adding Scheduled Shutdowns/Reconnects, in Chapter 5, where we will do exactly that.
Decisions, Decisions…
The previous two sections discussed the pros and cons of data pull, SSE, and WebSockets, but how do you know which is best for you? The question is complex, based on the behavior of the application, business decisions about customer expectations for latency, business decisions about hosting costs, and the technology that customers and your developers are using. Here is a set of questions you should be asking yourself:
§ How often are server-side events going to happen?
The higher this is the better data push (whether SSE or WebSockets) will be.
§ How often are client-side events going to happen?
If such events occur less than once every five seconds, and especially if there is less than one event every second, WebSockets is going to be a better choice than SSE. If such events occur less than once every 5 to 10 seconds, this becomes a minor factor in the decision-making process.
§ Are the server-side events not just fairly infrequent but also happening at predictable times?
When such events are less frequent than once a minute, data pull has the advantage that it won’t be holding open a socket. Be aware of the issues with lots of clients trying to all connect at the same time.
§ How critical is latency? Put a number on it.
Is an extra half a second going to annoy people? Is an extra 60 seconds not really going to matter?
The more that latency matters, the more that data push is a superior choice over data pull.
§ Do you need to push binary data from server to client?
If there is a lot of binary data, WebSockets is superior to SSE. (It might be that XHR polling is better than SSE too.)
If the binary data is small, you can encode it for use with SSE, and the difference is a matter of a few bytes.
§ Do you need to push binary data from client to server?
This makes no difference: both XMLHttpRequest[8] (i.e., Ajax, which is how SSE sends messages from client to server), and WebSockets deal with binary data.
§ Are most of your users on landline or on mobile connections?
Notebook users who are using an LTE WiFi router, or who are tethering, count as mobile users. A phone that has a strong WiFi connection to a fiber-optic upstream connection counts as a landline user. It is the connection that matters, not the power of the computer or the size of the screen.
Be aware that mobile connections have much greater latency, especially if the connection needs to wake up. This makes data pull (polling) a worse choice on mobile connections than on landline connections.
Also, a WiFi connection that is overloaded (e.g., in a busy coffee shop) drops more and more packets, and behaves more like a mobile connection than a landline connection.
§ Is battery life a key concern for your mobile users?
You have a compromise to make between latency and battery life. However, data pull (except the special case where the polling can be done predictably because you know when the data will appear) is generally going to be a worse choice than data push (SSE or WebSockets).
§ Is the data to be pushed relatively small?
Some 3G mobile connections have a special low-power mode that can be used to pass small messages (200 to 1000 bps). But that is a minor thing. More important is that a large message will be split up into TCP/IP segments. If one of those segments gets lost, it has to be resent. TCP guarantees that data arrives in the order it was sent, so this lost packet will hold up the whole message from being processed. It will also block later messages from arriving. So, on noisy connections (e.g., mobile, but also an overloaded WiFi connection), the bigger your data messages are the more extra packets that will get sent.
Consider using data push as a control channel, and telling the browser to request the large file directly. This is very likely to be processed in its own socket, and therefore will not block your data push socket (which exists because you said latency was important).
§ Is the data push aspect a side feature of the web application, or the main thing? Are you short on developer resources?
SSE is easier to work with, and works with existing infrastructure, such as Apache, very neatly. This cuts down testing time. The bigger the project, and the more developer resources you have, the less this matters.
NOTE
For more technical details on some of the subjects raised in the previous few sections, and especially if efficiency and dealing with high loads are your primary concern, I highly recommend High Performance Browser Networking, by Ilya Grigorik (O’Reilly).
Take Me to Your Code!
In brief, if you have data on your website that you’d like to be fresher, and are currently using Ajax polling, or page reloads, or thinking about using them, or thinking about using WebSockets but it seems rather low level, then SSE is the technology you have been looking for. So without further delay, let’s jump into the Hello World example of the data push world.
[1] If you think data push and data pull only became possible with Ajax (popularized in 2005), think again. Flash 6 was released in March 2002 and its Flash Remoting technology gave us the same thing, but with no annoying browser differences (because just about everyone had Flash installed at that time).
[2] Well, okay, not always always. See When Data Push Is the Wrong Choice and Is Long-Polling Always Better Than Regular Polling?.
[3] Internet Explorer is the exception, with no native SSE support even as of IE11; WebSocket support was added in IE10.
[4] See http://en.wikipedia.org/wiki/HTTP_2.0, or check out High Performance Browser Networking by Ilya Grigorik (O’Reilly).
[5] Well, a few hundred bytes in HTTP/1.1, even more if you have lots of cookies or other headers being passed. In HTTP/2.0, it is much less.
[6] Most requests actually use HTTP persistent connection, which shares the socket between the first HTML request and the images; the connection is then killed after a few seconds of no activity (five seconds in Apache 2.2). I just mention this for the curious; it makes no difference to our comparison of the normal web versus data push solutions.
[7] How limited? It depends on your server OS, but maybe 60,000 per IP address. But then the firewall and/or load balancer might have a say. And memory on your server is a factor, too. It makes my head hurt trying to think about it in this way, which is why I prefer to benchmark the actual system you build to find its limits.
[8] Strictly, the second version of XMLHttpRequest. See http://caniuse.com/xhr2. IE9 and earlier and Android 2.x have no support. But none of those browsers support WebSockets or SSE either, so it still has no effect on the decision process.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.