Data Push Apps with HTML5 SSE (2014)
Chapter 4. Living in More Than the Present Moment
We are doing well. We now have a fairly sophisticated server, which is relatively easy to test, and a basic frontend so at least we can see it is working. It is almost time to restore the balance and improve that frontend, too. But before we return our attention back to the frontend, there is one more change I want to make on the backend. It is a change to the structure of our data, and therefore will break compatibility with the fx_client.basic.*.html files we’ve seen previously.
More Structure in Our Data
Currently each JSON record is one tick, one item of data. The main change we will make is in allowing multiple rows of data to be passed. We also had a couple of “header” fields: one the name of the symbol, the other a server timestamp. So our data structure will become like this:
|
symbol:string |
|
timestamp:string (“YYYY-MM-DD HH:MM:SS.sss”) |
|
rows:array |
And each row in the rows container has this structure:
|
timestamp:string (“YYYY-MM-DD HH:MM:SS.sss”) |
|
bid:double |
|
ask:double |
Why are we doing this? One reason is to be ready for if/when we have arrays of data to send (for instance, supporting historical data requests). Of course, we could just send each row as its own row of JSON; doing it that way adds a few bytes, perhaps a dozen bytes per row. A better reason is we are telling the client this is a logical block of data. Our message callback is called for each SSE message we send; chances are your application will update the display after each. If we send a few hundred rows as a block, the client can process them as a block, and then just update the display once at the end.
Another reason for doing this is that it gives us a bit more flexibility. We could add a type field to change the meaning of rows, perhaps to say it is gzipped CSV, not a JSON array. It allows us to add a version number. Who knows what we will want to do in the future?[18]
After all that chat, the code for the change is quite small; it only affects the generate() function in our FXPair class. Relative to fxpair.milliseconds.php, the second half of the generate() function in fxpair.structured.php looks like this:
$ts = gmdate("Y-m-d H:i:s",$t).sprintf(".%03d", ($t*1000)%1000);
return array(
"symbol" => $this->symbol,
"timestamp" => $ts,
"rows" => array(
array(
"timestamp" => $ts,
"bid" => number_format($bid, $this->decimal_places),
"ask" => number_format($ask, $this->decimal_places),
)
)
);
NOTE
In PHP, an array with named keys is called an associative array; it will become an object in the JSON. An array with no keys (as here), or numeric keys, will become an array in the JSON.
Notice that I set the timestamp of the message, and the timestamp of the data, to be the same. They need not be the same, though: the timestamp in the rows might have come from a stock exchange and have the official exchange timestamp on it, so it might be a few milliseconds earlier than the message timestamp. Or if it is historical data, it might be months or years earlier.
Refactoring the PHP
The PHP script is under 40 lines, so there is not really that much to refactor. But I’m betting that seeing this block of code over and over is starting to set your teeth on edge:
$d = $symbols[$ix]->generate($t);
echo "data:".json_encode($d)."\n\n";
@ob_flush();@flush();
So I will replace it with this:
sendData($symbols[$ix]->generate($t));
And the implementation of sendData() is simple:
function sendData($data){
echo "data:";
echo json_encode($data)."\n";
echo "\n";
@flush();@ob_flush();
}
(Splitting it into three echo commands is not actually to make it fit this book’s formatting; it is ready for the change we will make in Chapter 6. Here is a hint: the middle line is the actual data, whereas the “data:” prefix and the extra LF are the SSE protocol.)
You can see this change in the book’s source code: fx_server.structured.php; the only other change is to include fxpair.structured.php instead of fxpair.milliseconds.php.
Refactoring the JavaScript
Our current JavaScript is all of six lines. But to take this further, it will help to have some structure; some of the design decisions we make here are also preparing the way for the fallbacks for older browsers.
First up, we need a couple of globals:
var url = "fx_server.structured.php?";
var es = null;
NOTE
Why do we put the question mark at the end of the URL? Later we will want to append values to the URL, and doing it this way allows us to append without having to know if we are the first parameter (which has to be prefixed with ?) or one of the later ones (which need to be prefixed with &).
We would like to move the call to create the EventSource object into a function called startEventSource(), which looks like this:
function startEventSource(){
if(es)es.close();
es = new EventSource(url);
es.addEventListener("message", function(e){processOneLine(e.data);}, false);
es.addEventListener("error", handleError, false);
}
We will write that handleError function in the next chapter; for the moment, just write:
function handleError(e){}
Next we are going to wrap the call to startEventSource() in a function called connect, so it looks like this:
function connect(){
if(window.EventSource)startEventSource();
//else handle fallbacks here
}
You may have heard that all problems in programming can be solved by adding another layer of indirection. Well, obviously we are adding a layer of abstraction here…so what is the problem we are solving? Again it is for the fallback support: code that will be used by all techniques (e.g., keep-alive) goes in connect(), as well as the detection of which technique to use. Code specific to using SSE goes in startEventSource().
Then, to get everything rolling, we will call connect() once the page has loaded. The simplest way is to put this code in a <script> block at the very bottom of the page:
setTimeout(connect, 100);
If you are using JQuery, the following way may be more familiar (and you can put this code anywhere if done this way; it does not need to go at the bottom):
$(function(){ setTimeout(connect, 100); });
NOTE
We use a 0.1s timeout because some versions of some browsers need it. For instance, on some versions of Safari, without using a timeout you might see a permanent “loading” animation. I hate the “magic number” of 100ms, but it appears to be sufficient.
The other refactor we did was to move our processing to its own function, processOneLine(s), which takes a single line of JSON as the parameter:
function processOneLine(s){
var d = JSON.parse(s);
if(d.seed){
var x = document.getElementById("seed");
x.innerHTML += "seed=" + d.seed;
}
else if(d.symbol){
var x = document.getElementById(d.symbol);
for(var ix in d.rows){
var r = d.rows[ix];
x.innerHTML = r.bid;
}
}
}
This function also shows how we handle the change in the JSON format, described in the previous section. I am using a loop here to show how to process each row in the received data. In this case, each row updates the same div so, effectively, only the last row of data is being used. But most of the time you will care about all the data, and want to use a loop.
See fx_client.basic.structured.html for the file after all this refactoring. It behaves exactly like the previous version (fx_client.basic.adjusting.html), the goal of any good refactoring session. Never mix adding features with refactoring.
By the way, when you are actually only interested in the final row of data, that whole block can be written as:
var x = document.getElementById(d.symbol);
x.innerHTML = d.rows[ d.rows.length - 1 ].bid;
You can do this because d.rows is an array, not an object. If d.rows was an object (e.g., with timestamps as the keys) you would always have to use the loop. Speaking of which, because d.rows is an array, you could also write the main loop this way:
for(var ix = 0;ix < d.rows.length;++ix){
var r = d.rows[ix];
x.innerHTML = r.bid;
}
Adding a History Store
In our application, we currently use each value as we get it, but then we forget about it. If we instead keep a record of everything we receive, it creates new possibilities. For instance, we could make a tabular view of all data received in the last 5 minutes or 24 hours. Or we could make a chart.
Let’s start by adding this global variable to store the history for all our symbols:
var fullHistory = {};
It is an object in JavaScript, but we will use it as an associative array (aka map, dictionary, hash, key-value pair store); the key will be the symbol name, and the value will be another associative array. Then when we get a line of data (one JSON record, which contains one or more rows of data), we do:
if(!fullHistory.hasOwnProperty(d.symbol))
fullHistory[d.symbol] = {};
That just creates an entry (an empty JavaScript object) for a particular feed, the first time we see it. Then, to fill it, we use something like:
for(var ix in d.rows){
var r = d.rows[ix];
fullHistory[d.symbol][r.key] = r.value;
}
That code snippet assumes a key field and a value field in each row. In our code r.timestamp will be the key, and the value will be set to an array of two values: [r.bid,r.ask]. So, in full, our new processOneLine(s) function becomes:
function processOneLine(s){
var d = JSON.parse(s);
if(d.seed){
var x = document.getElementById("seed");
x.innerHTML += "seed=" + d.seed;
}
else if(d.symbol){
if(!fullHistory.hasOwnProperty(d.symbol))fullHistory[d.symbol] = {};
var x = document.getElementById(d.symbol);
for(var ix in d.rows){
var r = d.rows[ix];
x.innerHTML = d.rows[ix].bid;
fullHistory[d.symbol][r.timestamp] = [r.bid,r.ask];
}
update_history_table(d.symbol);
}
}
If we want to take that history store, and show the most recent 10 items as an HTML table for one of the symbols, how do we do it? The following function makes a table for one symbol:
function makeHistoryTbody(history){
var tbody = document.createElement("tbody");
var keys = Object.keys(history).sort().slice(-10).reverse();
var timestamp, v, row, cell;
for(var n = 0;n < keys.length;n++){
timestamp = keys[n];
v = history[timestamp];
row = document.createElement("tr");
cell = document.createElement("th");
cell.appendChild(document.createTextNode(timestamp));
row.appendChild(cell);
cell = document.createElement("td");
cell.appendChild(document.createTextNode(v[0]));
row.appendChild(cell);
cell = document.createElement("td");
cell.appendChild(document.createTextNode(v[1]));
row.appendChild(cell);
tbody.appendChild(row);
}
return tbody;
}
So we create an HTML DOM tbody object, then grab the keys of the most recent 10 entries in our data history. (The reverse() at the end puts the most recent quote at the top of our table.) Then we loop through them, create a table row for them, append three table cells to the row, and then append the row to the tbody, which we return.
The final link is to replace the currently displayed tbody with our new one. This function does that:
function updateHistoryTable(symbol){
var tbody = makeHistoryTbody(fullHistory[symbol]);
var x = document.getElementById("history_" + symbol);
x.parentNode.replaceChild(tbody, x);
tbody.id = x.id;
}
The final file, fx_client.history.html, uses some CSS and some responsive web design principles so it will look good and use the space effectively on both mobile and desktop. Figures 4-1, 4-2, and 4-3 show how it looks just after being loaded, after a few seconds, and after running for a while, respectively.

Figure 4-1. fx_client.history.html, just after starting
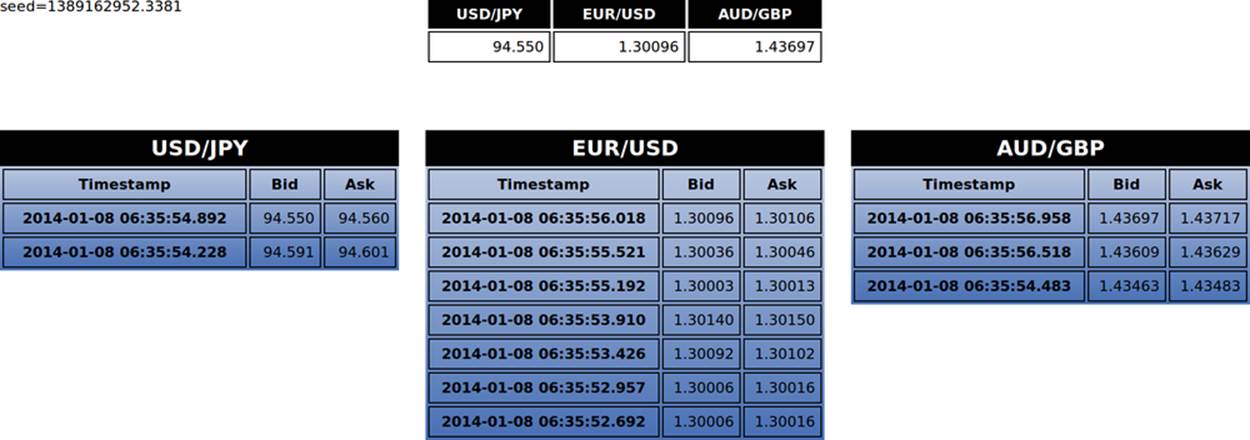
Figure 4-2. fx_client.history.html, after running for about 5 seconds
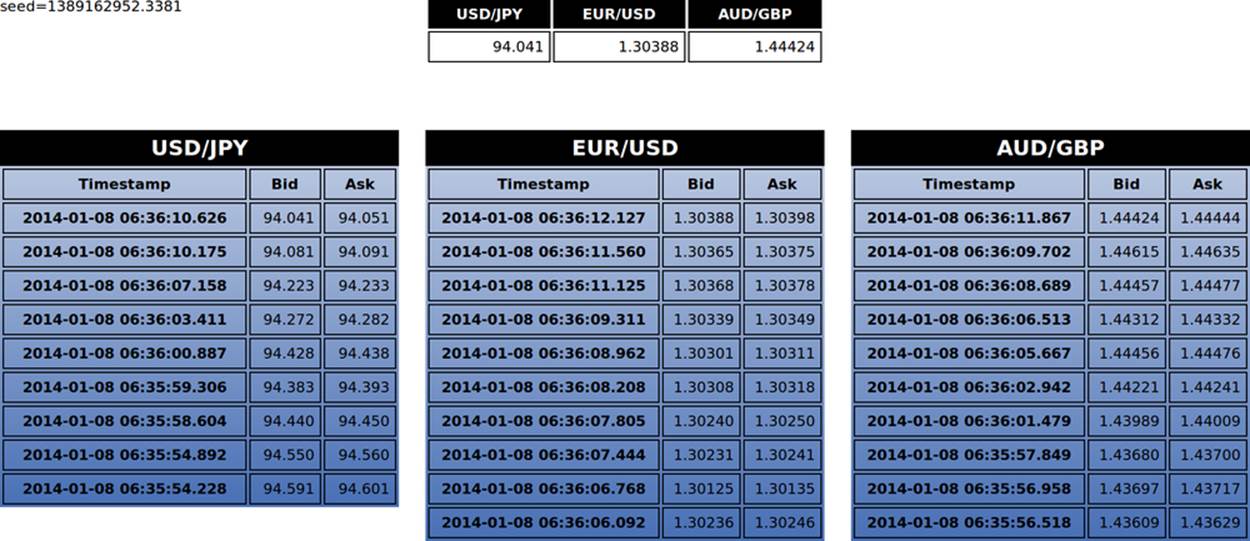
Figure 4-3. fx_client.history.html, after running for some time
I’m not going to go into the CSV and web design, because it is off-topic for this book, but let’s just look at one of the three tables:
<table class="price-table">
<caption>USD/JPY</caption>
<thead>
<tr>
<th>Timestamp</th>
<th>Bid</th>
<th>Ask</th>
</tr>
</thead>
<tbody id="history_USD/JPY"></tbody>
</table>
Each table has a static caption and header, and then we give the tbody an id so that we can find it and replace just that part of the table.
NOTE
Object.keys is available in all browsers where SSE is also available, so no problem there. However, when we start adding fallbacks we will need a polyfill for IE8 and earlier. We will introduce the polyfill when we first need it. Be aware that the polyfill is slower: it is an O(n) algorithm (where n is the number of keys), whereas a native Object.keys should be O(1).
One final word of caution: as you watch this page chug away, busily updating itself, remember we are deliberately only showing the last 10 quotes for each symbol. But we are storing all the quotes ever received in memory. You need to balance functionality against the client’s resources (available memory in this case). If you know you’ll never need them all, consider truncating the fullHistory object at regular intervals.
Persistent Storage
The previous section showed how we can store all the data that is streamed to us, opening up a world of possibilities: tables, real-time charts, client-side analysis using the latest machine learning technologies, and so on. You could be beating the markets without ever having to leave the browser…until you close the browser, that is. Then all that downloaded data, and all your calculations, disappear down the drain.
HTML5 technologies to the rescue! In fact, we have a choice. However, FileSystem is not widely implemented yet, and neither is IndexedDB (though a polyfill is available that extends its reach a bit). So we will go with Web Storage. Some common restrictions for all of these new HTML5 storage APIs is that the user’s permission is needed to approve the storage, and that the storage is by origin. We will look at the exact definition of an origin in Chapter 9, but the idea is that an application running at http://example.com/ cannot see data created by an application running athttp://other.site/.
Web Storage is more commonly known as localStorage. This allows us to store name/value pairs, and typically browsers will give an application 5MB of storage. The best thing about Web Storage is it is available just about everywhere—IE8 onward (polyfill available for IE6 and IE7), Firefox since 3.5, Chrome since forever, Safari4 onward, Android 2.1 onward, and Opera 10.5 onward (see the Can I Use Web Storage? page).
The downside is that it doesn’t take structured data, only strings. This means our history object has to be converted to a string using JSON.stringify(). That is a bit inefficient, and if we start to deal with lots of data, there is also the memory and CPU time required to convert between them.
The code to use Web Storage is quite straightforward, requiring just two changes to our existing code. First, to save the data, insert this line in processOneLine(s):
function processOneLine(s){
var d = JSON.parse(s);
...
else if(d.symbol){
if(!fullHistory.hasOwnProperty(d.symbol))fullHistory[d.symbol] = {};
...
updateHistoryTable(d.symbol);
localStorage.fullHistory = JSON.stringify(fullHistory);
}
}
Yes, it is that simple. JSON.stringify() turns our fullHistory object into a string. The assignment to localStorage.XXX either creates the XXX key or replaces it. You could also write this as localStorage.setItem("fullHistory", JSON.stringify(fullHistory));.
Be aware of what is happening here: every time a single piece of data comes through, our entire history is being turned into a string, replacing what is already there. In one of my tests, after an hour or so Firefox was using 25% of one CPU (compared to 4% at the start), and the string being made was 500KB in length. Those aren’t fatal numbers, but after a few more hours they would be.
OPTIMIZATIONS
There are two independent optimizations possible. You could split the data by symbol. So the line would change to:
localStorage.setItem("fullHistory." + d.symbol,
JSON.stringify( fullHistory[d.symbol]) );
We have three symbols, so this means each string is 1/3 of the original size, which effectively means if the failure point was previously 4 hours, it is now 12 hours. You could take this idea further by putting part of the datestamp in the key name. For example, each hour’s data could end up in its own bucket. This adds quite a bit of complexity though, because you now will need anotherlocalStorage entry to keep track of which time periods you have data stored for. (Alternatively, the localStorage API provides a way to iterate through all stored data: for(var ix = 0; ix < localStorage.length; ix++){var key = localStorage.key(i); ... } .)
The other optimization is to save the data on a 30-second timer using setInterval, instead of each time we get data. This definitely reduces overall CPU usage, but remember that instead of, say, a constant 100% CPU usage, after a certain amount of time, you will get a 100% CPU burst every 30 seconds. The other thing to remember is that when the browser closes, then up to 30 seconds worth of data gets lost.
The other change needed in our code is to use the persistent storage. At the top of connect() these lines are added:
function connect(){
if(localStorage.fullHistory){
fullHistory = JSON.parse(localStorage.fullHistory);
updateHistoryTable("USD/JPY");
updateHistoryTable("EUR/USD");
updateHistoryTable("AUD/GBP");
}
if(window.EventSource)startEventSource();
//else handle fallbacks here
}
This is simply the reverse of how the data was saved, using JSON.parse instead of JSON.stringify. It could also have been written fullHistory = JSON.parse(localStorage.getItem("fullHistory"));.
The other three lines update the display with the previously stored data.
If it does not work, check your browser settings. In some browsers the policy of what is allowed is shared with cookies, so you may need to allow cookies to be stored too. If it is working when you click the browser’s reload button, but not working after closing all browser windows, check for privacy settings that say all cookies should be deleted at the end of a browser session.
NOTE
To delete the data, it is as simple as localStorage.removeItem('fullHistory');. If you implemented the idea of splitting the data into hourly buckets, mentioned in the sidebar Optimizations, then you could use this to just delete the oldest data.
How much data can you store? It is browser-specific, but generally you can expect at least 5MB (about 11 to 12 hours for our FX demo application). What happens when you reach the limit? Typically the setItem() call will fail, throwing a QUOTA_EXCEEDED_ERR exception that you could catch and deal with. The previously stored data for that key is kept. The Opera browser will first pop up a dialog giving the user the chance to allow more storage. Firefox has the dom.storage.default_quota key (found in about:config), which a user could first edit.
HOW TO REDUCE THE SIZE OF THE DATA?
One idea is to compress the JSON string before storing it. A web search will find zip, gzip, and LZW implementations in JavaScript. JSON compresses well.
You could also try summarizing the data instead of storing the raw data. This is lossy compression, rather than the lossless compression suggestions of the previous paragraph. For instance, in a finance application, it is very common to turn raw ticks into bars. So a one-minute bar will just store the opening price, closing price, high and low price, and the volume or number of ticks for each 60-second period. With some careful planning you can have almost constant space usage. For instance, you could store 10 minutes of raw data, two hours’ worth of one-minute bars, one week’s worth of hourly bars, and years worth of daily bars.
The downside to both ideas is the extra CPU load and the extra complexity.
Now We Are Historians…
This chapter started by improving the structure of the code that Chapter 3 left us with. Then we built on our new base to learn how to store a history, and display both the latest prices and a subset of that history. Then we looked at how to integrate this with another HTML5 technology, Web Storage, so clients can have a persistent data cache. We are now done with features, and the next chapter is all about making our application production-quality.
[18] We already did this earlier, in an ad hoc way, when we sent an SSE message that specifies the chosen seed and nothing else.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.