Neo4j in Action (2015)
Part 2. Application Development with Neo4j
In part 2 we’ll cover aspects of building applications with Neo4j.
Chapter 6 introduces Cypher, the human graph query language. Cypher provides a language-independent way to both query and manipulate the graph, and this chapter explores how you can use it to interact with your graph domain model. With Neo4j being a fully ACID-compliant database,chapter 7 focuses on transactions, and how you can control and take advantage of this feature to ensure your application can query and store data in a consistent manner. Chapter 8 returns to the traversal API, with an even deeper dive to explore some more advanced options for navigating the graph via this dedicated API.
Chapter 9 introduces Spring Data Neo4j (SDN), a graph object mapping library which, for certain application use cases such as those manipulating a very rich domain model, can prove very useful for speeding up and simplifying development.
Chapter 6. Cypher: Neo4j query language
This chapter covers
· Explaining Cypher
· Executing Cypher queries
· Writing read-only Cypher queries
· Manipulating graph data using Cypher
In previous chapters we used the Neo4j Core Java API to manipulate and query graph data. This obviously required some Java skills to write and understand the implemented code. In addition, as the complexity of the queries increased, the code grew in both size and complexity, making it difficult to understand in some cases. This is where a query language comes in handy, allowing you to query and manipulate graphs using the power of expressive language structures that are also simple to read.
Neo4j’s query language is called Cypher. In this chapter we’re going to explain the nature of Cypher, demonstrate its basic syntax for graph operations, and cover some of the advanced features that can be useful in day-to-day development and maintenance of Neo4j databases.
6.1. Introduction to Cypher
Cypher is a declarative query language for graphs that uses graph pattern-matching as a main mechanism for graph data selection (for both read-only and mutating operations). The declarative pattern-matching nature of Cypher means that you can query the graph by describing what you need to get from it.
To explain how Cypher works, let’s take a look at Cypher in action.
6.1.1. Cypher primer
Figure 6.1 shows a simple graph representing a social network.
Figure 6.1. A social network graph to be queried
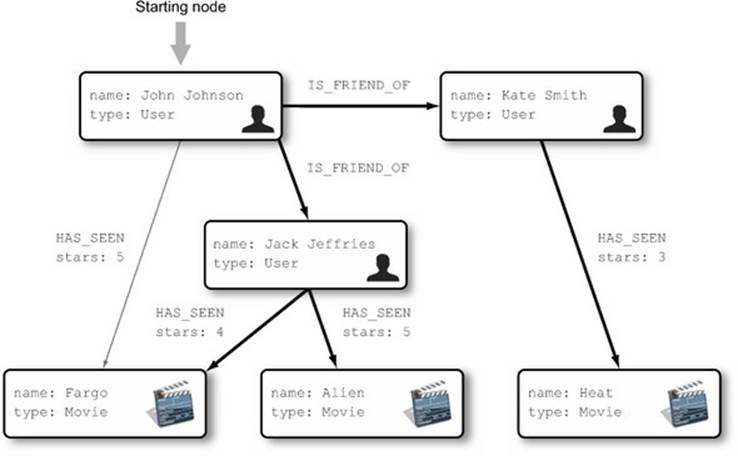
In chapter 4, when we discussed the Neo4j Traversal API, we demonstrated how to find all the movies a user has seen using Java code. As a reminder, the following listing shows the Java code used.
Listing 6.1. Traversing the graph using Java API to find all movies the user has seen
try (Transaction tx = graphDb.beginTx()) {
Node userJohn = graphDb.getNodeById(JOHN_JOHNSON_NODE_ID);
Iterable<Relationship> allRelationships = userJohn.getRelationships();
Set<Node> moviesForJohn = new HashSet<Node>();
for(Relationship r : allRelationships){
if(r.getType().name().equalsIgnoreCase("HAS_SEEN")){
Node movieNode = r.getEndNode();
moviesForJohn.add(movieNode);
}
}
for(Node movie : moviesForJohn){
logger.info("User has seen movie: " + movie.getProperty("name"));
}
tx.success();
The traversal has three phases:
1. Find a starting node by ID.
2. Traverse the graph from the starting node by following the HAS_SEEN relationships.
3. Return the nodes that are at the end of the HAS_SEEN relationships.
Now let’s see how you could write the same query using Cypher, following the same three phases of traversal:

Just as in the Java code, you first need to find the starting node by using the node ID, which can be achieved in Cypher using the start and node keywords ![]() . Note the name of the starting node—user—so that you can refer to it later in the same Cypher query.
. Note the name of the starting node—user—so that you can refer to it later in the same Cypher query.
Next, you set the pattern you need your result to match. The pattern is a description of all subgraphs you want to inspect within your data, and it consists of a number of nodes connected with relationships. Typical graph patterns consist of two nodes connected by a relationship, which is represented in the format ()-[]-(). Nodes are specified using parentheses, (), and relationships are specified using square brackets, []. Nodes and relationships are linked using hyphens. The node in the start clause (user in the preceding example) is used to fix the left side of the pattern. The whole pattern has two known elements (left-side node and the relationship), which you use to find all nodes that match the right side (nodes named movie in our example).
Finally, you’re interested in all movies that match, so you use the return keyword to return them (again, referencing the node by the name introduced before). A semicolon is used to mark the end of the Cypher query.
When you run this Cypher query, you’ll see exactly the same results as you did with the corresponding Java API solution, but with much simpler query syntax. Cypher is much simpler to read and understand for developers, operational staff, and anyone with enough domain understanding.
Note
From Neo4j 2.0, the start clause is optional. If the start clause is omitted, Neo4j will try to infer it from the node labels and properties in the match clause of the query. For clarity and compatibility with earlier Neo4j versions, all queries in this chapter will have explicitly defined startclauses. For more details on inferred start clauses, go to http://docs.neo4j.org/chunked/stable/query-start.html.
That said, how do you actually execute the Cypher query? Don’t worry—we’ll explain that in the next section.
6.1.2. Executing Cypher queries
There are a number of ways you can execute Cypher queries. Neo4j ships with a couple of tools that support Cypher executions, and Cypher can also be executed from Java code, much like SQL. Table 6.1 shows the Cypher execution options.
Table 6.1. Tools and techniques for executing Cypher queries
|
Tool |
Description |
|
Neo4j Shell |
Command-line tool |
|
Neo4j Web Admin Console |
Web-based interface |
|
Java |
Programmatically |
|
REST |
Over HTTP using REST interface |
Let’s take a look at each of the first three options in more detail. The fourth option, using REST to execute Cypher queries, will be discussed in chapter 10.
Executing Cypher using the Neo4j Shell
The Neo4j Shell is a command-line tool that’s part of the Neo4j distribution. It can be used to connect to either of the following:
· A local Neo4j database —Connect by pointing the shell to the directory where the Neo4j data is stored.
· A remote Neo4j server over RMI —Connect by providing the shell with the host name and port to connect to.
The Neo4j Shell start script is located in the $NEO4j_HOME/bin/directory, where $NEO4J_HOME is the directory where Neo4j binaries are installed.
Table 6.2 illustrates how to connect to a local or remote Neo4j instance on both Linux-based and Windows systems.
Table 6.2. Neo4j Shell startup script syntax for Linux and Windows environments
|
Database type |
Linux command |
Windows command |
|
Local Neo4j database |
$NEO4J_HOME/bin/neo4j-shell–path=/var/neo4j/db |
$NEO4J_HOME/bin/neo4j-shell.bat–path=/var/neo4j/db |
|
Remote Neo4j database |
$NEO4J_HOME/bin/neo4j-shell–host=localhost–port=1337 |
$NEO4J_HOME/bin/neo4j-shell.bat–host=localhost port=1337 |
Before you start running queries, you need to populate the graph database. For this example, we’re going to use the same data set from chapters 3 and 4 (social network of movie lovers). The location of database files on disk we used is /var/neo4j/db because we used a Linux-based system, but you can replace it with the directory of your choice based on your OS (for example, c:\neo4j\db on Windows).
Connect to the Neo4j database using the Neo4j Shell by running the following command from the $NEO4J_HOME/bin directory:
· neo4j-shell -path=/var/neo4j/db (Linux)
· neo4j-shell.bat -path=/var/neo4j/db (Windows)
After you press Enter, you should be inside the Neo4j Shell, as illustrated in figure 6.2, ready to run commands.
Figure 6.2. The Neo4j Shell ready to accept commands
Note
Make sure you have read permissions to the Neo4j data directory when starting the shell.
Cypher is natively supported by Neo4j Shell, so you don’t need any special commands; just type the Cypher query in the console and press Enter. The results are returned in tabular format, very similar to the output of SQL queries run against a relational database. Figure 6.3 illustrates the output of a Cypher query that finds all movies that a particular user has seen.
Figure 6.3. Cypher is executed in the Neo4j Shell natively, resulting in tabular output.
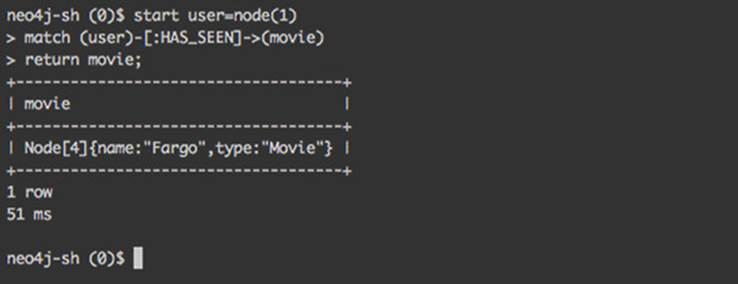
As you can see, the result is just as you’d expect, based on the graph in figure 6.1. User 1 (John Johnson) has indeed seen only one movie: Fargo. You’re returning movie nodes in the query, so the result is represented as such. Fargo is a node in the database, with an internal ID of 4 and two properties, name and type, with expected values, and the Cypher output illustrates that.
And that’s it; you’ve executed your first Cypher query. You got the expected result by simply describing the subgraph you’re interested in, without having to write any Java code and without worrying about transactions.
Executing Cypher using the Web Admin Console
The Neo4j server comes with another useful operational tool, the Web Admin Console, a browser-based rich web interface to a Neo4j instance. It has plenty of features, allowing you to query, manipulate, and visualize Neo4j graph data, manage Lucene indexes, and maintain and monitor a Neo4j configuration. You can find more details about the Web Admin Console in chapter 11.
To access the Neo4j Web Admin Console, you need a running Neo4j server configured to point to your database location, such as /var/neo4j/db from the previous example. Follow these steps:
1. Install the Neo4j server by downloading the correct version and following the instructions detailed in appendix A of this book.
2. Edit the main Neo4j server configuration file, located at $NEO4J_HOME/conf/neo4j-server.properties. Locate the following line,
org.neo4j.server.database.location=data/graph.db
and replace the data directory so it points to the graph database you created in the previous section:
org.neo4j.server.database.location=/var/neo4j/db
3. Save the configuration file.
4. Start the Neo4j server using the following command:
$NEO4J_HOME/bin/neo4j start
With the server up and running (which can take a few seconds), you’ll be able to access the Neo4j Web Admin Console by pointing your browser to http://localhost:7474. You should see the Web Admin Console homepage illustrated in figure 6.4.
Figure 6.4. Homepage of the Neo4j Web Admin Console in the browser
The Web Admin Console embeds a fully functional Cypher execution engine running inside the browser (using some JavaScript wizardry). You can type your Cypher query in the text field at the top of the page, and as you press Enter, you’ll see the result in the browser window. Figure 6.5illustrates a Cypher query executing in the Web Admin Console.
Figure 6.5. Executing a Cypher query inside the Web Admin Console
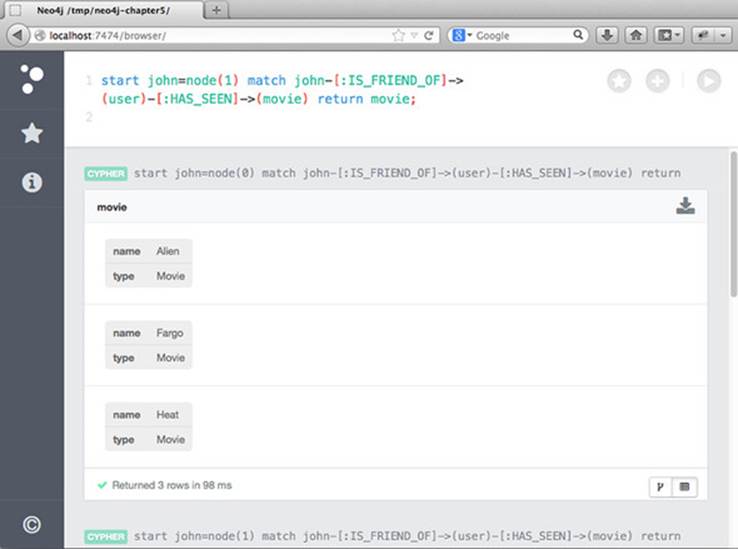
Running Cypher inside the Web Admin Console is great when you don’t have command-line access to the server running the Neo4j instance.
Note
The Neo4j Web Admin Console has another nice feature—you can visualize the results of your Cypher query in the browser. To toggle between tabular and visual results, you can use the two buttons at the bottom-right corner of the browser.
So far you’ve run Cypher queries manually, using tools provided as part of the Neo4j distribution. We mentioned how easy it is to query the graph without writing a single line of Java code. But what about integrating Cypher with your custom application implemented in Java? Not to worry—the Neo4j Core Java API includes a Cypher API, making it easy to run Cypher queries from your Java code.
Executing Cypher from Java code
It’s easy to query relational databases from Java using JDBC drivers and the JDBC API. Obtain the connection, create and execute the statement, iterate through the result set, and you have JDBC database queries in no time. You’ll be pleased to know that executing Cypher queries in Java is even simpler!
The following code demonstrates the execution of the same sample Cypher query we executed in the Web Admin Console in figure 6.5, which finds all movies that a particular user has seen:

As you can see, all you need to do is instantiate Neo4j’s ExecutionEngine for Cypher ![]() and pass the valid Cypher query to it
and pass the valid Cypher query to it ![]() ,
, ![]() . The ExecutionResult.toString() method creates the output in the same format as the Neo4j Shell, which makes it useful for debugging and troubleshooting.
. The ExecutionResult.toString() method creates the output in the same format as the Neo4j Shell, which makes it useful for debugging and troubleshooting.
To iterate over Cypher query results in Java, all you have to do is iterate over the ExecutionResult object returned by the execute(...) method:
ExecutionResult result = engine.execute(cql);
for(Map<String,Object> row : result){
System.out.println("Row:" + row);
}
Each iterator element contains a single result row, represented as a Java Map, where the keys are column names and the values are actual result values.
The previous snippet iterates through Cypher query results row by row. Another option is to iterate through the results by a single column, which is useful if you’re not interested in all columns returned, as the following code illustrates:

Cypher and Scala
Although the core Neo4j graph engine is implemented in Java, the Neo4j Cypher engine is implemented in Scala, the popular, hybrid, functional programming language that runs on the Java virtual machine (JVM). For more information on Scala, see www.scala-lang.org/.
Alternatives to Cypher
Cypher isn’t the only query language available for graphs. Another popular graph query language is Gremlin, which Neo4j also supports. Gremlin is actually a set of interfaces that define how the graph can be traversed and manipulated, and these interfaces must be implemented by every graph engine that wishes to be compatible. That means you can theoretically use the same Gremlin queries to work with data in any compatible graph database, making your code portable. Gremlin is an open source library and part of the popular Tinkerpop stack of graph libraries (https://github.com/tinkerpop/gremlin).
The main difference between Cypher and Gremlin is in their nature—Gremlin is an imperative language where users describe how to traverse the graph, Cypher is a declarative language that uses pattern matching to describe what parts of the graph data are required. This makes Cypher easier to read and understand. Gremlin is portable between different graph databases, but Cypher is developed by the Neo4j team and works only on Neo4j graph databases.
The Gremlin syntax and use are beyond the scope of this book, but you can find out more at https://github.com/tinkerpop/gremlin.
You now know how to execute a Cypher query, using both web-based and command-line utilities, and using the Java API. It’s time to start writing some Cypher queries.
6.2. Cypher syntax basics
Cypher syntax consists of four different parts, each with a specific role:
· Start —Finds the starting node(s)in the graph
· Match —Matches graph patterns, allowing you to locate the subgraphs of interesting data
· Where —Filters out data based on some criteria
· Return —Returns the results you’re interested in
Cypher’s pattern-matching nature makes the graph patterns the key aspect of any query. That’s why we’re going to first take a look at Cypher’s graph pattern-matching techniques.
6.2.1. Pattern matching
Pattern matching is the key aspect of Cypher that gives you great power to describe subgraph structures in a human-readable syntax. The following snippet illustrates matching the pattern of two nodes connected via a single named relationship:
start user=node(1)
match (user)-[:HAS_SEEN]->(movie)
return movie;
When describing a relationship, the relationship type is specified after a colon (:) within the square brackets. The type should appear exactly as it was defined when the relationship was created (syntax is case-sensitive). This simple query describes a single HAS_SEEN relationship using the[:HAS_SEEN] syntax.
The direction of the relationships is described using ASCII art in Cypher. The relationship is connected to its ending node using the ASCII arrow (a single hyphen character, followed by the greater-than or preceded by the less-than character, []-> or <-[]). The starting node of the relationship is connected using the single hyphen character ([]-). In the preceding example, the match (user)-[:HAS_SEEN]->(movie) pattern specifies the HAS_SEEN relationship from the user node toward the movie node.
If you don’t care about the relationship direction, or you’re not sure which is the starting or ending node of the relationship, you can use the single hyphen character on both sides, in which case it reads as “any.” If you want to know if two users are friends, regardless of the direction, the following pattern can be used:
start user1=node(1)
match (user1)-[:IS_FRIEND_OF]-(user2)
return user2;
Let’s now take a look at how the node and relationship identifiers are used in Cypher.
Using node and relationship identifiers
Both nodes and relationships in Cypher queries can be associated with identifiers, which are used to reference the same graph entity later in the same query. In the following example, the node named movie has been referenced in the return clause.
Relationships can be named as well, using slightly different syntax:
![]()
To give a name to a relationship, simply specify the name you want to give it within the square brackets, before the relationship type.
Naming nodes and relationships can be very useful when creating complex patterns, because you can reference them later in other parts of a Cypher query. But if you don’t need to reference the graph entity later, avoiding identifiers will make your query easier to read and understand.
In the preceding example, the nodes in the pattern were named (user is the starting node and movie is the node you want to return from the query), but not the relationship, because there was no plan to reference it anywhere else. To make the relationship anonymous, simply leave the relationship type within the square brackets, after the colon character, just as you did in the original query:
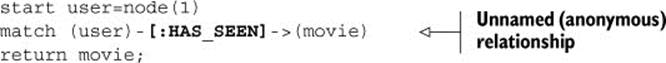
Nodes can similarly be anonymous. To make a node anonymous, use empty parentheses to specify the node, (). To illustrate this, let’s write another Cypher query, where you want to return all HAS_SEEN relationships from the user node, without worrying about movie nodes:

Using empty parentheses, you describe the fact that you expect a node, but you’re not interested in any of its properties, nor do you want to reference it later, so you leave it unnamed.
Note
Named nodes can be specified without parentheses in a Cypher match clause, such as start user=node(1) match user-[:HAS_SEEN]->movie return movie. In complex queries, you can remove the parentheses where possible, to declutter the query and make it more readable. Anonymous nodes must have parentheses.
All the patterns you’ve matched so far were quite simple, consisting of two nodes connected via a single relationship. Let’s see how you can use more complex pattern matching with Cypher.
Complex Pattern Matching
Cypher supports quite complex pattern matching. Let’s look at another example: finding all movies that User 1’s friends have seen. You already solved this problem using the Neo4j Traversal API in chapter 4, so let’s see how you can solve it using Cypher:
![]()
Starting from the known node named john (with ID 1), you match the outgoing IS_FRIEND_OF relationship to another node (which is left anonymous), which in turn has a HAS_SEEN relationship to another named node, movie.
You don’t need to name any relationships or intermediate nodes because you’re not interested in them; all you want to return are nodes representing movies that John’s friends have seen.
Running this query will return all movie nodes that any of John’s friends have seen, whether or not John has seen them:
| Node[5]{name->"Alien",type->"Movie"} |
| Node[4]{name->"Fargo",type->"Movie"} |
| Node[6]{name->"Heat",type->"Movie"} |
If you want this social network to recommend movies based on the taste of John’s friends, then you should skip the movies that John has already seen. To get the result you want, filter the result you got in the previous example using a pattern that matches movies already seen by John. Using Cypher, you can match multiple patterns in the same query, referencing the same nodes in both patterns if required.
Look at the query in the following snippet:

Multiple patterns in Cypher are differentiated using a comma (,) as a separator. The first pattern here is the one used in the previous example—matching movies that John’s friends have seen ![]() . The second pattern matches all movies that John has seen already
. The second pattern matches all movies that John has seen already ![]() .
.
Note
The resulting nodes will have to match all comma-separated patterns, acting effectively as a big AND clause.
The interesting bit here is that you use the same nodes as anchors in both patterns (both patterns start with the same john node, and both patterns match the same node named movie).
If you run this query, you’ll get a single result, Fargo:
| Node[4]{name->"Fargo",type->"Movie"} |
Obviously, this isn’t the result you wanted. You matched all movies John’s friends have seen (resulting in all three movies), and then matched those to the movies John has seen, resulting in all movies that both John and some of John’s friends have seen.
While this can be a useful query (if you want an answer to “What movies do John and his friends have in common?”), this isn’t the answer you want here.
You need to replace the second pattern with a pattern that matches the nonexistence of the relationship: movies that John has not seen. The following snippet illustrates how you can use the NOT clause syntax to find all movies that John’s friends have seen, but John hasn’t:

The first pattern is exactly the same as before—matching movies John’s friends have seen ![]() . The second pattern, part of the where clause, filters out the movies returned by the first pattern, optionally connected via a HAS_SEEN relationship
. The second pattern, part of the where clause, filters out the movies returned by the first pattern, optionally connected via a HAS_SEEN relationship ![]() .
.
Note
The where clause used in this example ![]() filters out the results of the query that you’re not interested in, much like the SQL where clause in a relational database. We’ll discuss the where clause in more detail later in this chapter.
filters out the results of the query that you’re not interested in, much like the SQL where clause in a relational database. We’ll discuss the where clause in more detail later in this chapter.
The final result contains two movies (Heat and Alien), as you’d expect, given the data set illustrated in figure 6.1. Figure 6.6 shows the result after running the query in the Neo4j Shell.
Figure 6.6. Result of the query execution in Neo4j Shell, finding movie recommendations for the user based on the movies their friends have seen
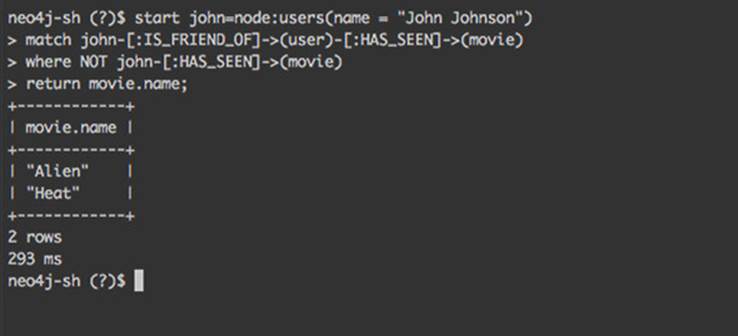
You’ve now used Cypher to find movie recommendations for a user based on friends’ ratings, but excluding the movies the user already watched. The solution to the same problem using Java APIs in chapter 4 resulted in over 40 lines of code. This time you did it in a 5-line Cypher query. The Cypher query is also much more readable and potentially understandable for anyone who understands the application domain, even if they don’t have any programming skills.
Note
In this chapter we’re covering the basic Cypher concepts and syntax, and some advanced use of Cypher queries. For a full list of Cypher features and syntax, refer to the extensive online documentation in the Neo4j Manual: http://docs.neo4j.org/chunked/stable/cypher-query-lang.html.
Let’s now take a more in-depth look at the anatomy of a Cypher query.
6.2.2. Finding the starting node
The querying of a Neo4j graph database follows a standard pattern: find the starting node(s) and run a traversal. You’ve followed this pattern in all your traversals so far, using the Neo4j Core API, the Traversal API, and Cypher. Starting nodes can be located by direct lookup by unique node ID, or, more typically, by using a Lucene index lookup, as you learned in chapter 5. Let’s review the direct lookup by ID first.
Node lookup by ID
As far as Cypher is concerned, starting nodes are specified at the beginning of the Cypher query, after the start keyword. In the examples so far, you’ve been loading the starting node with a direct ID lookup, as in the following snippet:
![]()
You can load the node by ID by simply specifying the ID in the parentheses right after the node keyword ![]() .
.
That works if you have one starting node, but sometimes you may need to apply the same pattern for multiple starting nodes and get all matching results—if, for example, you want to find all movies that either John or Jack have seen.
Loading multiple nodes by IDs
To use multiple IDs in the start clause, you need to list ID arguments as comma-separated values, as the following snippet demonstrates:

The start clause specifies two node IDs, using a single identifier: user ![]() . Next comes the pattern matching to find all movies that the user has seen. The user identifier references either nodes 1 or 3, so the pattern will match all movies that either User 1 (John, in this case) or User 3 (Jack) has seen. The resulting output looks like this:
. Next comes the pattern matching to find all movies that the user has seen. The user identifier references either nodes 1 or 3, so the pattern will match all movies that either User 1 (John, in this case) or User 3 (Jack) has seen. The resulting output looks like this:
|Node[5]{name->"Alien",type->"Movie"}|
|Node[4]{name->"Fargo",type->"Movie"}|
Note
The distinct keyword in the return clause of the last query was used to eliminate duplicate results. Distinct works the same as in SQL queries—by excluding duplicated columns in the result set. Both Jack and John have seen Fargo, so if you didn’t use the distinct keyword, Fargowould be returned twice in the result.
So far, so good. But most of the time you don’t know the IDs of the nodes you’re interested in—you know some other property, like a user’s name, a movie title, or something similar. In the next section you’ll learn how to use that information to load starting nodes.
Using an index to look up the starting node(s)
In chapter 5 we introduced indexing as a recommended way to look up starting nodes in a traversal. Cypher also supports direct access to Lucene indexes, so the typical traversal idiom in Neo4j becomes
1. Look up one or more nodes using the Lucene index.
2. Do a traversal starting from the node found in step 1.
How do you apply this pattern with Cypher? Cypher queries work by using pattern matching, so the typical usage would look like this:
1. Look up one or more nodes using the Lucene index.
2. Perform pattern matching by attaching the nodes you looked up in step 1 to the pattern.
3. Return the entities you’re interested in.
The only question now is how to perform the Lucene index lookup in the start clause of the Cypher query instead of loading nodes by ID. It’s very simple, as illustrated in this snippet:
![]()
The start clause syntax is slightly different now. The node:users part specifies that you’re interested in a node from the users index. The index name must match the index name you used when you added the node to the index. The arguments in parentheses specify the key-value pair you’re looking for in the index; in this case, you’re matching the property name with the value "John Johnson". If such an index entry is found in the users index, that node will be loaded from the Neo4j database and used in the Cypher query.
This index lookup syntax requires an exact match of the key-value pair, and it is case-sensitive, so nodes with a name property of "john johnson" or "John Johnso" wouldn’t be returned. At the same time, if multiple nodes are indexed with the same key-value pair (if you had more than one John Johnson in the database), all matching nodes would be loaded; it behaves similarly to the earlier example with multiple IDs.
If you want to use the full power of Lucene queries to look up start nodes, you can use a slightly different syntax with a native Lucene query:
![]()
This example will behave exactly the same as the previous one, with the only difference being in the argument to the index lookup. This time the entire index argument is passed within double quotes, and it contains a native Lucene query. This allows you to take advantage of the powerful Lucene query constructs, like wildcards or multiple property matching.
Note
The documentation about native Lucene querying capabilities is available on the Lucene website: http://lucene.apache.org/core/3_6_0/queryparsersyntax.html.
Here’s an example of using a native Lucene query in Cypher:

Note
Automatic indexing, which we described in chapter 5, can also be used as part of a Cypher query in the same manner. All you have to do is use node_auto_index for the index name instead of users in the preceding query.
Next, let’s take a look at how you can use schema-based indexes on labels to look up start nodes in a Cypher query.
Using a schema-based index to look up the starting node(s)
In earlier chapters we discussed how you can type Neo4j nodes by assigning labels to nodes. We also mentioned how labels can be used as schema-based, built-in indexes for graph lookups. You can use the same indexes to look up nodes in Cypher.
Let’s take a look at how you can use labels to find user nodes by name:

The label that specifies the schema index to use is defined as part of the node identifier, separated by a colon ![]() . You must put the node identifier with the associated label inside parentheses. The index query is specified as part of the where clause, very similar to how it’s done in SQL
. You must put the node identifier with the associated label inside parentheses. The index query is specified as part of the where clause, very similar to how it’s done in SQL ![]() .
.
Note
Label-based indexes can only be used for lookups on the full property values. For a full text search, you’ll have to use manually created indexes as discussed in the previous section.
You now know how to use an index to look up nodes in the start clause of a Cypher query. But what if you want to fix multiple nodes on your graph pattern when executing a Cypher query and match them separately? What if you want to find all movies that both John and Jack have seen? Don’t worry—this is also easy to achieve with Cypher, by specifying distinct multiple starting nodes as graph entry points.
Multiple start nodes in Cypher
To specify multiple entry points to the graph, you can use a comma-separated list in the start clause of the Cypher query, as the following snippet illustrates:

Starting nodes are presented as a comma-separated list, with each node having its own identifier that can be used throughout the query ![]() . When you’re matching patterns, all starting nodes can be part of a single pattern, or they can be used in separate patterns as in this example
. When you’re matching patterns, all starting nodes can be part of a single pattern, or they can be used in separate patterns as in this example ![]() . Both patterns in this example refer to the movie node (called by the same name in both patterns, so it represents the same node), which is the result of your Cypher query
. Both patterns in this example refer to the movie node (called by the same name in both patterns, so it represents the same node), which is the result of your Cypher query ![]() .
.
6.2.3. Filtering data
Starting nodes and graph patterns are sometimes not enough to get the results you need using a Cypher query. In some cases, you’ll need to perform additional filtering on nodes and relationships to determine what to return. Just as in SQL for relational databases, the query filtering in Cypher is performed using the where clause.
Typically, the where clause filters the results based on some property of a node or relationship. Let’s look at an example that finds all friends of user John who were born after 1980. Let’s assume that every user node has a yearOfBirth integer property holding the user’s year of birth. The following snippet illustrates the solution:

You find the starting node by performing the index lookup ![]() , and you pattern match the friend nodes with an IS_FRIEND_OF relationship regardless of the direction
, and you pattern match the friend nodes with an IS_FRIEND_OF relationship regardless of the direction ![]() . Next, you filter only the matching friend nodes that have a yearOfBirth property greater than 1980
. Next, you filter only the matching friend nodes that have a yearOfBirth property greater than 1980 ![]() . BecauseyearOfBirth is an integer property, you can perform a standard number comparison in the where clause.
. BecauseyearOfBirth is an integer property, you can perform a standard number comparison in the where clause.
For string properties, in addition to the standard equals (=) comparison, you can use regular expressions to filter out specific values. To find all friends who have an email address containing “gmail.com”, for example, you could run the following query:

As you can see, the regular expression comparison operator in Cypher is =~ (equals tilde). The regular expression is placed between two forward slashes (/). The expression itself follows the standard Java regular expression syntax (see http://docs.oracle.com/javase/tutorial/essential/regex/for more information).
But what would happen if you don’t have an email address stored for all users or nodes? As we discussed earlier, Neo4j allows for a semi-structured, schemaless data structure, so no two nodes have to have the same set of properties. The sample data set distributed with this book has anemail property for some of the user nodes but not all. Let’s see how to use Cypher to query for properties that aren’t shared by all nodes.
To filter nodes that have a given property, regardless of the property value (for example, all friends who have a Twitter account), you need to use the Cypher function has:

As you can see, filtering results in Cypher isn’t difficult, and it looks very similar to the SQL where clause.
In the next section we’ll take a look at the different types of results you can return from a Cypher query.
6.2.4. Getting the results
The results of a Cypher query are returned in the return clause. So far you’ve used it to return nodes you’re interested in, but the return clause isn’t limited to nodes only—you can also return relationships, properties of both nodes and relationships, and even entire paths of the subgraph.
Note
A path in Neo4j represents the collection of nodes connected via relationships; for example, node1–[:relationship1]-node2–[:relationship2]-node3.
Returning properties
In one of the earlier examples, you used Cypher to find all movies that John’s friends have seen but John hasn’t, and you returned matching movie nodes from the query. If you were using this data to display recommended movie titles on a web page, you’d be returning entire movie nodes with all properties—much more data than you need. The better approach would be to just return the node property you’re interested in from the query.
The following snippet illustrates this:

If you run this query from Neo4j Shell, for example, you can see that the output is much less verbose than what you’ve seen previously:
| "Alien" |
| "Heat" |
Note
If the property you’re referencing isn’t present on all entities in the result set, it will be returned as null for those entities that don’t have the property.
Returning relationships
Sometimes it makes more sense to query the graph for certain relationships. Suppose you want to display the ratings a user has given to the movies they’ve has seen. The rating is a property of a HAS_SEEN relationship (the actual property name is stars, referring to the number of stars awarded to the movie), so you need to return those relationships. The following snippet illustrates this:

The query starts by looking up user John Johnson from the index and matching all movie nodes he has seen ![]() . Then it returns the instances of the HAS_SEEN relationship. Note that to return a relationship, it needs to have an identifier (here r).
. Then it returns the instances of the HAS_SEEN relationship. Note that to return a relationship, it needs to have an identifier (here r).
The output of this query would look like this:
| :HAS_SEEN[2] {stars->5} |
If you’re only interested in the stars property of the relationship, you can return just that property from the query. Just like node properties, relationship properties can be referenced in the return clause. Here’s a snippet that illustrates this:
![]()
This time, instead of the entire relationship entity, you’re only returning the stars property you’re interested in.
Returning paths
In addition to nodes and properties, you can return entire paths from the Cypher query. For example, when you’re looking for movie recommendations based on the movies John’s friends have seen, you may be interested in finding out how each movie is recommended by returning the full path from the starting user node, via all friends, to the recommended movie. The following snippet illustrates this:

To return the path as a query result, you need to be able to reference it by giving it an identifier ![]() . Then, you simply return the referenced path by specifying the identifier in the return clause.
. Then, you simply return the referenced path by specifying the identifier in the return clause.
The returned path output will contain all nodes and relationships that belong to it:
| "Alien"
| [
Node[1]{
name->"John Johnson",
year_of_birth->1982,
type->"User"
},
:IS_FRIEND_OF[1] {},
Node[3]{
name->"Jack Jeffries",
cars_owned->[Ljava.lang.String;@3927ff0d,type->"User"
},
:HAS_SEEN[5] {stars->5},
Node[5]{
name->"Alien",type->"Movie"
}
] |
| "Heat"
| [
Node[1]{
name->"John Johnson",
year_of_birth->1982,
type->"User"
},
:IS_FRIEND_OF[0] {},
Node[2]{
name->"Kate Smith",
locked->true,type->"User"
},
:HAS_SEEN[3] {stars->3},
Node[6]{name->"Heat",type->"Movie"}
] |
Note
In the previous example you returned both a node property and a path from the Cypher query. All returnable graph entities discussed here can be specified in any desired combination.
When displaying data on a screen or printing on paper, you usually won’t want to display all results at once, but rather split them into pages for better readability and usability. In the next section you’ll learn how to page the results of a Cypher query.
Paging results
If your result set contains a lot of entries, you may need to page the results for rendering on a web page. To page Cypher query results, Neo4j has three self-explanatory clauses:
· order —Orders the full result set before paging, so that paging returns consistent results regardless of whether you’re going forward or backward through the pages
· skip —Offsets the result set so you can go to a specified page
· limit —Limits the number of returned results to the page size
Suppose one of the users in your database is a real movie buff, who has seen and rated hundreds of movies. If you were to display all of that user’s movie ratings (stars awarded) on a single page, the type would be unreadably small (or it wouldn’t fit).
You could decide to display only 20 movies per web page, ordered by movie name. To query the graph to get such paged results, you’d use the order, limit, and skip clauses. The following query returns the third page (entries 21–30):
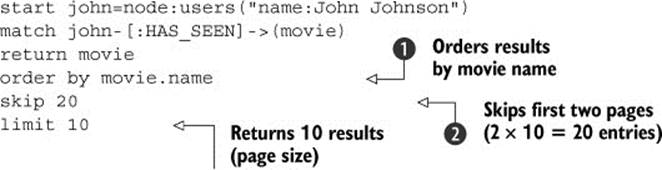
After matching the movies the user has seen, as we’ve discussed, you order the results by the name property ![]() . Because you’re interested in the third page of the results, you skip two pages’ worth (20) of entries
. Because you’re interested in the third page of the results, you skip two pages’ worth (20) of entries ![]() . Finally, you limit the returned result set to the page size (10 in this example).
. Finally, you limit the returned result set to the page size (10 in this example).
Note
The Neo4j online documentation includes an easily printable Cypher reference card with common syntax and query details: http://neo4j.org/resources/cypher.
Cypher performance
In simple queries, you can see that the performance of Cypher queries roughly matches that of the Neo4j Traversal API or Core Java API. But when running more complex queries, with complex pattern matching or intensive filtering, Cypher will not perform as well as the Traversal API or Core Java API. In some cases the difference can be an order of magnitude or more greater.
As Cypher is relatively young, its developers have concentrated on adding all required functionality to it first; performance has not been the priority. As of Neo4j 2.0, however, Cypher binds to the Neo4j engine lower on the stack than the Traversal API. This will make it possible to fine-tune Cypher performance to be better than the Traversal API. Once the feature set becomes stable, you can expect performance tuning of the Cypher parser and execution engine to produce much better results.
Given its simplicity and expressiveness, Cypher is the best option for most graph queries, but for very complex traversals or inserts of big data sets, you may want to use the Core Java API and Traversal API. We covered the basics of the Core Java API in chapters 3, 4, and 5. For in-depth coverage of the Traversal API, see chapter 8. In future versions of Neo4j, you can expect Cypher to become the most efficient and fastest way to interact with Neo4j.
We’ve come to the end of the Cypher syntax section. You’ve learned how to perform pattern matching in Cypher, how to filter out results, how to return not only nodes but other graph entities directly, and how to order and limit returned result sets.
Our discussion so far has been related to reading data from Neo4j. In the next section we’ll show you how to create, update, and delete graph data using Cypher.
6.3. Updating your graph with Cypher
From Neo4j version 1.7 on, you can use Cypher to run mutating operations against your graph database to create, update, and delete nodes and relationships and their properties.
The syntax for mutating operations is very intuitive, so let’s take a look at a few examples.
Note
Cypher graph mutating operations are a relatively new feature of the Neo4j database, so the syntax for mutation may be subject to significant changes in future releases. This book is based on the Neo4j version 2.0 Cypher syntax. You’re advised to consult the Neo4j Manual for the latest syntax (http://docs.neo4j.org/chunked/stable/query-write.html).
Let’s start with creating nodes and relationships.
6.3.1. Creating new graph entities
To create a node with properties, you can use the following syntax:
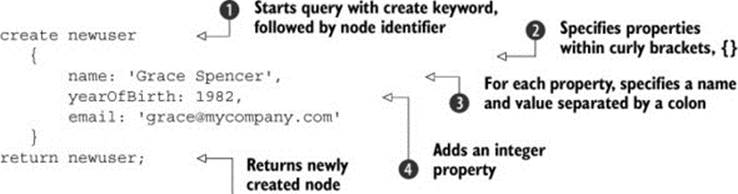
The command that creates graph entities is, unsurprisingly, create, followed by the node identifier ![]() . Following that, you specify a comma-separated list of properties to be added to the node, enclosed with curly brackets
. Following that, you specify a comma-separated list of properties to be added to the node, enclosed with curly brackets ![]() . Each property is specified by its name, followed by a colon, followed by a property value
. Each property is specified by its name, followed by a colon, followed by a property value ![]() . String property values are enclosed in single quotes, but numeric and Boolean properties don’t need any quotes
. String property values are enclosed in single quotes, but numeric and Boolean properties don’t need any quotes ![]() . Finally, you return the newly created node using its identifier, just like in the previous Cypher examples.
. Finally, you return the newly created node using its identifier, just like in the previous Cypher examples.
Okay, you’ve created a node, so how about creating a relationship? Let’s make the newly added user Grace a friend of John:

You want to create a relationship between the existing two nodes, so you need to somehow reference them first. This is done exactly the same way as specifying start nodes in a read-only query, using the start clause and node lookup ![]() . Next, in the create clause, you simply specify the graph path as a pattern referencing starting nodes by their identifiers and setting the relationship you want to create between them
. Next, in the create clause, you simply specify the graph path as a pattern referencing starting nodes by their identifiers and setting the relationship you want to create between them ![]() .
.
Cypher and transactions
When running Cypher from a command line or web interface, each query execution is wrapped in a single transaction. You don’t have to worry about starting or finishing transactions or dealing with their failure—everything will be taken care of by the Neo4j engine. If the query succeeds, the transaction will automatically commit. If the query fails, the transaction will be rolled back.
In an application context, Cypher queries will execute with the existing transaction context. If you create a transaction programmatically, you can use multiple queries within the same transaction and commit or roll back everything at the end.
Because we’re using Neo4j Shell or the Web Admin Console to run the Cypher examples throughout this chapter, each query is automatically wrapped in a single transaction, so no additional setup is necessary.
For in-depth information about Neo4j transactions, read chapter 7 on Neo4j transactions.
So far you’ve created a node with some properties and a relationship. But you could have done all that in a single command, as the following snippet illustrates:

In this example, you fixed an existing john node ![]() . In the create clause, you specified the pattern from john, via a non-existent IS_FRIEND_OF relationship, to a non-existent node grace, with the same properties as before
. In the create clause, you specified the pattern from john, via a non-existent IS_FRIEND_OF relationship, to a non-existent node grace, with the same properties as before ![]() . Cypher is smart enough to recognize which nodes and relationships are fixed (john from the start clause), and which are new and should be created in the database (the IS_FRIEND_OF relationship and grace node). This is a very powerful approach for creating full paths of new nodes and relationships with properties.
. Cypher is smart enough to recognize which nodes and relationships are fixed (john from the start clause), and which are new and should be created in the database (the IS_FRIEND_OF relationship and grace node). This is a very powerful approach for creating full paths of new nodes and relationships with properties.
The Cypher create clause will create all elements in the matching pattern regardless of whether or not they exist. If you ran the previous node snippet, which creates John’s friend Grace Spencer, twice, you’d end up with two Grace Spencer nodes and two IS_FRIEND_OF relationships from John’s node. This is probably not what you’d want. To create only graph entities that don’t already exist, you should use the create unique Cypher command, illustrated in the following snippet:
start john = node:users(name = "John Johnson")
create unique john
-[r:IS_FRIEND_OF]->
(grace {
name: 'Grace Spencer',
yearOfBirth: 1982, email: 'grace@mycompany.com'
})
return r, grace;
The only change from the previous example is the use of the create unique command. Running this snippet multiple times will not multiply the number of entities—you will always have one Grace Spencer node and one IS_FRIEND_OF relationship between the John and Grace nodes.
Now you know how to create new nodes, relationships, and properties, but how about deleting them? The next section will discuss deleting data from Neo4j using Cypher.
6.3.2. Deleting data
To delete a node, Cypher provides a delete command. Let’s delete the user Grace you just created:

But if you run this command, you’ll get an error, warning you that the node has relationships. In Neo4j, you can only delete a node if it doesn’t have any relationships (either incoming or outgoing). To make sure you can delete a node, you need to delete its relationships at the same time, as shown in the following snippet:

Here you use the standard pattern to match all relationships coming into or going out of the grace node ![]() , and delete all relationships that start or end at the specified node
, and delete all relationships that start or end at the specified node ![]() .
.
The output of the delete query doesn’t contain any data, but it will show the number of deleted nodes and relationships:
Nodes deleted: 1
Relationships deleted: 1
Finally, let’s take a look at how you can update properties on existing nodes using Cypher.
6.3.3. Updating node and relationship properties
Let’s say you made a mistake with John’s year of birth, and you need to update it. The command to do that would look like this:
![]()
You can see that the syntax is very simple: first you select the node to update ![]() , then you use the set command to set the selected property of the node to the new value. If the property you’re setting doesn’t already exist, it will be created by this command.
, then you use the set command to set the selected property of the node to the new value. If the property you’re setting doesn’t already exist, it will be created by this command.
You can specify multiple nodes to add the same property to all of them:
start user=node(1,2)
set user.group = 'ADMINISTRATOR'
Neo4j doesn’t allow null property values on graph entities. In effect, a null property value is treated as a non-existent property. So if you want to remove a property, you would use the delete command. This is demonstrated in the following snippet:
start n=node(1)
delete n.group;
Graph-mutating operations in Cypher are a relatively new feature of Neo4j at the time of writing. We’ve demonstrated some useful examples that should get you going. For more detailed and up-to-date information on the evolving Cypher syntax, see the Neo4j Manual athttp://docs.neo4j.org/chunked/stable/cypher-query-lang.html.
Schema indexing in Cypher
In chapter 5 we introduced the concept of schema indexing, and the improved automatic indexing feature of Neo4j, where indexes are fully maintained by the Neo4j engine as part of a node’s lifecycle. You also learned how to use schema indexing from Java code. It’s possible to perform all schema-indexing operations from Cypher as well.
The detailed description of the Cypher syntax required to achieve this is out of scope for this book, but you can consult the Neo4j Manual for all the details (http://docs.neo4j.org/chunked/stable/query-schema-index.html).
Note that graph-mutating operations in Neo4j don’t support updates to manually created indexes. If you need to index your newly created nodes using custom indexes (not schema indexes), you’ll have to use the Neo4j Core Java API, language bindings, or REST API.
We’ve covered a lot about Cypher so far, but there’s much more to it under the surface. In the next section we’ll look at some of the other Cypher goodies.
6.4. Advanced Cypher
You’ve learned how to write and execute fairly complex Cypher queries so far, but there’s much more to Cypher than that. In this section we’re going to take a look at some of the advanced features in Cypher, like data aggregation, Cypher functions, and chaining multiple queries together. Let’s start with data aggregation.
6.4.1. Aggregation
Just like GROUP BY in SQL, Cypher supports aggregating functions in queries. Instead of using a dedicated GROUP BY clause, the grouping key in Cypher is defined as all non-aggregating results of the query. Here’s how you could count the number of friends for each user in the graph:

You’re looking at the entire graph in this example, so all nodes are used as starting nodes ![]() . For each user node, you match their direct friends by following one level of the IS_FRIEND_OF relationship
. For each user node, you match their direct friends by following one level of the IS_FRIEND_OF relationship ![]() . The return clause contains one non-aggregating entry (user node) and one aggregated function (count)
. The return clause contains one non-aggregating entry (user node) and one aggregated function (count) ![]() . This means that you’re using the user node to group the counts by, getting one result row per user. You can use the aggregated values to order the entire result set in the order by clause as well
. This means that you’re using the user node to group the counts by, getting one result row per user. You can use the aggregated values to order the entire result set in the order by clause as well ![]() .
.
In addition to the count function, Cypher supports all the usual aggregation functions from SQL: SUM for summing numeric values, AVG for calculating averages, and MAX and MIN for finding the maximum or minimum values of numeric properties.
To find the average age of all John’s friends, you can use the following query:

Here you’re checking that the node has a year of birth property set, before using it in mathematical calculations ![]() . Then you return the calculated average value
. Then you return the calculated average value ![]() .
.
Note
To get the age of the user, you subtract the year of birth from the current year. We’re using this book’s publication year of 2014 in this example.
Let’s now have a look at Cypher’s built-in functions.
6.4.2. Functions
Cypher supports a number of functions that you can use to evaluate expressions in your query. Let’s look at some of them.
Cypher functions are used to access internal attributes of graph entities, such as node and relationship IDs and relationship labels (types). In the count example, you’ve seen the ID(node) function used to retrieve the internal ID of a given node. In addition, you can use theTYPE(relationship) function to find the type for a relationship.
To demonstrate the use of the TYPE function, let’s find an answer to the following question: “How many relationships of each type start or finish at user John?” The following snippet shows the required Cypher query:

The first two steps in the example are very familiar: find the starting node using the index lookup ![]() , and find all its neighboring nodes using the match clause
, and find all its neighboring nodes using the match clause ![]() . The identifier rel is used to reference every relationship later in the query. Finally, you return the type of each relationship using the TYPE function, along with the count
. The identifier rel is used to reference every relationship later in the query. Finally, you return the type of each relationship using the TYPE function, along with the count ![]() . As TYPE is a non-aggregating function, the results will be grouped by relationship type.
. As TYPE is a non-aggregating function, the results will be grouped by relationship type.
Cypher also supports functions that allow you to easily work with iterable collections within the query. As an example, let’s solve the following problem: John would like to be introduced to Kate on Facebook. He doesn’t know Kate and would like to find out which of his friends, and friends of his friends, know her, up to the third level. Because he needs to use Facebook, he’s only interested in people who are on Facebook already (who have the facebookId property set). The following snippet shows the required query:
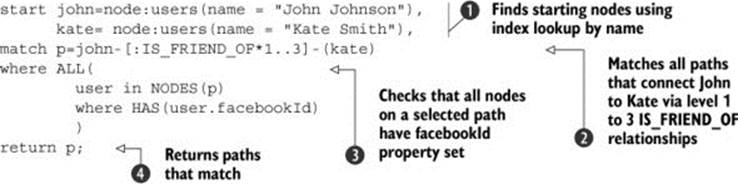
You start the query by locating known starting nodes representing John and Kate in the Neo4j database ![]() . In the match clause you find all paths that connect John and Kate by following the IS_FRIEND_OF relationships up to the third level
. In the match clause you find all paths that connect John and Kate by following the IS_FRIEND_OF relationships up to the third level ![]() . You’re using the identifier p to reference the matching path later in the query.
. You’re using the identifier p to reference the matching path later in the query.
The smart bit comes in the where clause ![]() . You use the NODES(p) Cypher function to extract the collection of all nodes in the given path. You check that each node has the facebookId property by using the HAS function. Then you use the ALL function to apply the HAS predicate to every element of the collection of nodes. The function ALL will return true if every element in the given iterable matches the predicate, so if one of the nodes on the path p doesn’t have a facebookId property, the path will be discarded.
. You use the NODES(p) Cypher function to extract the collection of all nodes in the given path. You check that each node has the facebookId property by using the HAS function. Then you use the ALL function to apply the HAS predicate to every element of the collection of nodes. The function ALL will return true if every element in the given iterable matches the predicate, so if one of the nodes on the path p doesn’t have a facebookId property, the path will be discarded.
Finally, you return the paths that fulfill all criteria ![]() . The path will contain all people John will need to contact so he can be introduced to Kate on Facebook.
. The path will contain all people John will need to contact so he can be introduced to Kate on Facebook.
You’ve seen quite a few functions in action in this example:
· HAS(graphEntity.propertyName) —Returns true if the property with a given name exists on a node or relationship.
· NODES(path) —Transforms a path into an iterable collection of nodes.
· ALL(x in collection where predicate(x)) —Returns true if every single element of collection matches the given predicate.
Neo4j supports a lot more functions with similar purposes to the ones we described here. For example, like the NODES(path) function, the RELATIONSHIPS(path) function returns a collection of all relationships on the given path.
In addition to ALL, Neo4j supports other predicate-based Boolean functions:
· NONE(x in collection where predicate(x)) —Returns true if no elements of the supplied collection match the predicate; otherwise it returns false.
· ANY(x in collection where predicate(x)) —Returns true if at least one element matches the predicate; if none matches, it returns false.
· SINGLE(x in collection where predicate(x)) —Returns true if exactly one element of the collection matches the predicate; if no elements or more than one element matches, this function returns false.
Note
There is simply not enough space in this book to cover all the Neo4j functions in detail. For more information, please read the comprehensive Neo4j Manual (http://docs.neo4j.org/chunked/stable/query-function.html).
6.4.3. Piping using the with clause
In Cypher you can chain the output of one query to another, creating powerful graph constructs. The chaining (or piping) clause in Cypher is with.
To illustrate its use, let’s build on a previous example where you used Cypher to count the number of relationships of each type from the john node. Let’s add a requirement to include only relationships that occur more than once: if John has seen two movies, that HAS_SEEN relationship would be included, but if he has seen just one movie (or no movies at all), the relationship wouldn’t be included.
The problem involves filtering on an aggregated function. In SQL, filtering on aggregate functions is done using the HAVING clause, but Cypher doesn’t support that. Instead, in Cypher you can use with, as the following snippet illustrates:

The query starts with the index lookup of the starting node, then matches all relationships connected to it. But, instead of returning the aggregated result as before, you chain it using the with clause ![]() . In the with clause, you rename the output that will be used as input in the chained command (type and count). After chaining, the output defined using the with clause acts as input to the new where clause
. In the with clause, you rename the output that will be used as input in the chained command (type and count). After chaining, the output defined using the with clause acts as input to the new where clause ![]() . Finally, you return the matching result
. Finally, you return the matching result ![]() .
.
Note
It’s mandatory to name the output fields of the with clause before they’re used in a chained query.
If Cypher is evolving that quickly, will you have to rewrite your Cypher queries every time you upgrade to the next Neo4j version? We’ll look at how you can deal with different versions of Cypher syntax next.
6.4.4. Cypher compatibility
We’ve already mentioned that Cypher is a quickly evolving language, and its syntax is subject to frequent change. To add valuable new functionality to Cypher, its developers sometimes need to introduce breaking changes, which will make queries written for earlier Neo4j versions fail when they’re run against a Neo4j database with a newer version.
Fortunately, there’s a simple configuration that will allow you to run queries against any of the supported Neo4j Cypher engines. You can specify the exact version of Neo4j your query syntax conforms to just before you query:

You can specify the required Neo4j version using the CYPHER keyword followed by the Neo4j version at the beginning of your query, just before the start clause ![]() .
.
Note
The Cypher examples in this chapter have been tested with Neo4j version 2.0.
In addition to applying the Cypher parser version to all queries, you can set the global configuration option to cypher_parser_version. This option is set in the neo4j.properties file. For the location of this file in both the server and embedded modes, look at chapter 10, where we discuss different configuration options.
6.5. Summary
You’ve now been introduced to Cypher, Neo4j’s query language. You’ve learned how to execute Cypher queries against your graph database, how to write efficient Cypher queries to extract data from your graph, and how Cypher makes your queries simpler and more readable, without sacrificing the performance of the traversals too much. The graph data-manipulation feature also makes Cypher useful for all maintenance tasks in Neo4j.
In the next chapter, we’re going to take a deep dive into Neo4j transactions.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2025 All site design rights belong to S.Y.A.