OCA/OCP Java SE 7 Programmer I & II Study Guide (Exams 1Z0-803 & 1Z0-804) (2015)
Part 2. OCP
Chapter 14. Concurrency
CERTIFICATION OBJECTIVES
• Use Collections from the java.util .concurrent Package with a Focus on the Advantages over and Differences from the Traditional java.util Collections
• Use Lock, ReadWriteLock, and ReentrantLock Classes in the java.util .cuncurrent.locks Package to Support Lock-Free Thread-Safe Programming on Single Variables
• Use Executor, ExecutorService, Executors, Callable, and Future to Execute Tasks Using Thread Pools
• Use the Parallel Fork/Join Framework
![]() Two-Minute Drill
Two-Minute Drill
Q&A Self Test
Concurrency with the java.util.concurrent Package
As you learned in the previous chapter on threads, the Java platform supports multithreaded programming. Supporting multithreaded programming is essential for any modern programming language because servers, desktop computers, laptops, and most mobile devices contain multiple CPUs. If you want your applications to take advantage of all of the processing power present in a modern system, you must create multithreaded applications.
Unfortunately, creating efficient and error-free multithreaded applications can be a challenge. The low-level threading constructs such as Thread, Runnable, wait(), notify(), and synchronized blocks are too primitive for many requirements and force developers to create their own high-level threading libraries. Custom threading libraries can be both error prone and time consuming to create.
The java.util.concurrent package provides high-level APIs that support many common concurrent programming use cases. When possible, you should use these high-level APIs in place of the traditional low-level threading constructs (synchronized, wait, notify). Some features (such as the new locking API) provide functionality similar to what existed already, but with more flexibility at the cost of slightly awkward syntax. Using the java.util.concurrent classes requires a solid understanding of the traditional Java threading types (Thread and Runnable) and their use (start, run, synchronized, wait, notify, join, sleep, etc.). If you are not comfortable with Java threads, you should return to the previous chapter before continuing with these high-level concurrency APIs.
CERTIFICATION OBJECTIVES
Apply Atomic Variables and Locks (OCP Objective 11.2)
11.2 Use Lock, ReadWriteLock, and ReentrantLock classes in the java.util.concurrent.locks package to support lock-free thread-safe programming on single variables.
The java.util.concurrent.atomic and java.util.concurrent.locks packages solve two different problems. They are grouped into a single exam objective simply because they are the only two packages below java.util.concurrent and both have a small number of classes and interfaces to learn. The java.util .concurrent.atomic package enables multithreaded applications to safely access individual variables without locking, while the java.util.concurrent.locks package provides a locking framework that can be used to create locking behaviors that are the same or superior to those of Java’s synchronized keyword.
Atomic Variables
Imagine a multiplayer video game that contains monsters that must be destroyed. The players of the game (threads) are vanquishing monsters, while at the same time a monster-spawning thread is repopulating the world to ensure players always have a new challenge to face. To keep the level of difficulty consistent, you would need to keep track of the monster count and ensure that the monster population stays the same (a hero’s work is never done). Both the player threads and the monster-spawning thread must access and modify the shared monster count variable. If the monster count somehow became incorrect, your players may find themselves with more adversaries than they could handle.
The following example shows how even the seemingly simplest of code can lead to undefined results. Here you have a class that increments and reports the current value of an integer variable:

A Thread that will increment the counter 10,000 times:

The code from within this application’s main method:

The trap in this example is that count++ looks like a single action when, in fact, it is not. When incrementing a field like this, what probably happens is the following sequence:
1. The value stored in count is copied to a temporary variable.
2. The temporary variable is incremented.
3. The value of the temporary variable is copied back to the count field.
We say “probably” in this example because while the Java compiler will translate the count++ statement into multiple Java bytecode instructions, you really have no control over what native instructions are executed. The JIT (Just In Time compiler)–based nature of most Java runtime environments means you don’t know when or if the count++ statement will be translated to native CPU instructions and whether it ends up as a single instruction or several. You should always act as if a single line of Java code takes multiple steps to complete. Getting an incorrect result also depends on many other factors, such as the type of CPU you have. Do both threads in the example run concurrently or in sequence? A large loop count was used in order to make the threads run longer and be more likely to execute concurrently.
While you could make this code thread-safe with synchronized blocks, the act of obtaining and releasing a lock flag would probably be more time consuming than the work being performed. This is where the java.util.concurrent.atomic package classes can benefit you. They provide variables whose values can be modified atomically. An atomic operation is one that, for all intents and purposes, appears to happen all at once. The java.util.concurrent.atomic package provides several classes for different data types, such as AtomicInteger, AtomicLong,AtomicBoolean, and AtomicReference, to name a few.
Here is a thread-safe replacement for the Counter class from the previous example:

In reality, even a method such as getAndIncrement() still takes several steps to execute. The reason this implementation is now thread-safe is something called CAS. CAS stands for Compare And Swap. Most modern CPUs have a set of CAS instructions. A basic outline of what is happening now is as follows:
1. The value stored in count is copied to a temporary variable.
2. The temporary variable is incremented.
3. Compare the value currently in count with the original value. If it is unchanged, then swap the old value for the new value.
Step 3 happens atomically. If step 3 finds that some other thread has already modified the value of count, then repeat steps 1–3 until we increment the field without interference.
The central method in a class like AtomicInteger is the boolean compareAndSet(int expect, int update) method, which provides the CAS behavior. Other atomic methods delegate to the compareAndSet method. The getAndIncrement method implementation is simply:

Locks
The java.util.concurrent.locks package is about creating (not surprisingly) locks. Why would you want to use locks when so much of java.util.concurrent seems geared toward avoiding overt locking? You use java.util.concurrent.locks classes and traditional monitor locking (the synchronized keyword) for roughly the same purpose: creating segments of code that require exclusive execution (one thread at a time).
Why would you create code that limited the number of threads that can execute it? While atomic variables work well for making single variables thread-safe, imagine if you have two or more variables that are related. A video game character might have a number of gold pieces that can be carried in his backpack and a number of gold pieces he keeps in an in-game bank vault. Transferring gold into the bank is as simple as subtracting gold from the backpack and adding it to the vault. If we have 10 gold pieces in our backpack and 90 in the vault, we have a total of 100 pieces that belong to our character. If we want to transfer all 10 pieces to the vault, we can first add 10 to the vault count and then subtract 10 from the backpack, or first subtract 10 from the backpack and then add 10 to the vault. If another thread were to try to assess our character’s wealth during the middle of our transfer, it might see 90 pieces or 110 pieces depending on the order of our operations, neither being the correct count of 100 pieces.
This other thread that is attempting to read the character’s total wealth might do all sorts of things, such as increase the likelihood of your character being robbed, or a variety of other actions to control the in-game economics. It becomes important for all game threads to be able to correctly gauge a character’s wealth even if there is a transfer in progress.
The solution to our balance inquiry transfer problem is to use locking. Create a single method to get a character’s wealth and another to perform gold transfers. You should never be able to check a character’s total wealth while a gold transfer is in progress. Having a single method to get a character’s total wealth is also important because you don’t want a thread to read the backpack’s gold count before a transfer and then the vault’s gold count after a transfer. That would lead to the same incorrect total as trying to calculate the total during a transfer.
Much of the functionality provided by the classes and interfaces of the java .util.concurrent.locks package duplicates that of traditional synchronized locking. In fact, the hypothetical gold transfer outlined earlier could be solved with either the synchronized keyword or classes in the java.util.concurrent.locks package. In Java 5, when java.util.concurrent was first introduced, the new locking classes performed better than the synchronized keyword, but there is no longer a vast difference in performance. So why would you use these newer locking classes? The java.util.concurrent.locks package provides
![]() The ability to duplicate traditional synchronized blocks.
The ability to duplicate traditional synchronized blocks.
![]() Nonblock scoped locking—obtain a lock in one method and release it in another (this can be dangerous, though).
Nonblock scoped locking—obtain a lock in one method and release it in another (this can be dangerous, though).
![]() Multiple wait/notify/notifyAll pools per lock—threads can select which pool (Condition) they wait on.
Multiple wait/notify/notifyAll pools per lock—threads can select which pool (Condition) they wait on.
![]() The ability to attempt to acquire a lock and take an alternative action if locking fails.
The ability to attempt to acquire a lock and take an alternative action if locking fails.
![]() An implementation of a multiple-reader, single-writer lock.
An implementation of a multiple-reader, single-writer lock.
ReentrantLock
The java.util.concurrent.locks.Lock interface provides the outline of the new form of locking provided by the java.util.concurrent.locks package. Like any interface, the Lock interface requires an implementation to be of any real use. Thejava.util.concurrent.locks.ReentrantLock class provides that implementation. To demonstrate the use of Lock, we will first duplicate the functionality of a basic traditional synchronized block.

Here is an equivalent piece of code using the java.util.concurrent.locks package. Notice how ReentrantLock can be stored in a Lock reference because it implements the Lock interface. This example blocks on attempting to acquire a lock, just like traditional synchronization.

It is recommended that you always follow the lock() method with a try-finally block, which releases the lock. The previous example doesn’t really provide a compelling reason for you to choose to use a Lock instance instead of traditional synchronization. One of the very powerful features is the ability to attempt (and fail) to acquire a lock. With traditional synchronization, once you hit a synchronized block, your thread either immediately acquires the lock or blocks until it can.

The ability to quickly fail to acquire the lock turns out to be powerful. You can process a different resource (lock) and come back to the failed lock later instead of just waiting for a lock to be released and thereby making more efficient use of system resources. There is also a variation of the tryLock method that allows you to specify an amount of time you are willing to wait to acquire the lock:

Another benefit of the tryLock method is deadlock avoidance. With traditional synchronization, you must acquire locks in the same order across all threads. For example, if you have two objects to lock against:
![]()
And you synchronize using the internal lock flags of both objects:

You should never acquire the locks in the opposite order because it could lead to deadlock. While thread A has only the o1 lock, thread B acquires the o2 lock. You are now at an impasse because neither thread can obtain the second lock it needs to continue.

Looking at a similar example using a ReentrantLock, start by creating two locks:
![]()
Next, you acquire both locks in thread A:

Notice the example is careful to always unlock any acquired lock, but ONLY the lock(s) that were acquired. A ReentrantLock has an internal counter that keeps track of the number of times it has been locked/unlocked, and it is an error to unlock without a corresponding successful lock operation. If a thread attempts to release a lock that it does not own, an IllegalMonitorStateException will be thrown.
Now in thread B, the locks are obtained in the reverse order in which thread A obtained them. With traditional locking, using synchronized code blocks and attempting to obtain locks in the reverse order could lead to deadlock.

Now, even if thread A was only in possession of the l1 lock, there is no possibility that thread B could block because we use the nonblocking tryLock method. Using this technique, you can avoid deadlocking scenarios, but you must deal with the possibility that both locks could not be acquired. Using a simple loop, you can repeatedly attempt to obtain both locks until successful (Note: This approach is CPU intensive; we’ll look at a better solution next):



It is remotely possible that this example could lead to livelock. Imagine if thread A always acquires lock1 at the same time that thread B acquires lock2. Each thread’s attempt to acquire the second lock would always fail, and you’d end up repeating forever, or at least until you were lucky enough to have one thread fall behind the other. You can avoid livelock in this scenario by introducing a short random delay with Thread.sleep(int) any time you fail to acquire both locks.
Condition
A Condition provides the equivalent of the traditional wait, notify, and notifyAll methods. The traditional wait and notify methods allow developers to implement an await/signal pattern. You use an await/signal pattern when you would use locking, but with the added stipulation of trying to avoid spinning (endless checking if it is okay to do something). Imagine a video game character that wants to buy something from a store, but the store is out of stock at the moment. The character’s thread could repeatedly lock the store object and check for the desired item, but that would lead to unneeded system utilization. Instead, the character’s thread can say, “I’m taking a nap, wake me up when new stock arrives.”
The java.util.concurrent.locks.Condition interface is the modern replacement for the wait and notify methods. A three-part code example shows you how to use a condition. Part one shows that a Condition is created from a Lock object:
![]()
When your thread reaches a point where it must delay until another thread performs an activity, you “await” the completion of that other activity. Before calling await, you must have locked the Lock used to produce the Condition. It is possible that the awaiting thread may be interrupted and you must handle the possible InterruptedException. When you call the await method, the Lock associated with the Condition is released. Before the await method returns, the lock will be reacquired. In order to use a Condition, a thread must first acquire a Lock. Part two of the three-part Condition example shows how a Condition is used to pause or wait for some event:

In another thread, you perform the activity that the first thread was waiting on and then signal that first thread to resume (return from the await method). Part three of the Condition example is run in a different thread than part two. This part causes the thread waiting in the second piece to wake up:

The signalAll() method causes all threads awaiting on the same Condition to wake up. You can also use the signal() method to wake up a single awaiting thread. Remember that “waking up” is not the same thing as proceeding. Each awoken thread will have to reacquire the Lockbefore continuing.
One advantage of a Condition over the traditional wait/notify operations is that multiple Conditions can exist for each Lock. A Condition is effectively a waiting/blocking pool for threads.

By having multiple conditions, you are effectively categorizing the threads waiting on a lock and can, therefore, wake up a subset of the waiting threads.
Conditions can also be used when you can’t use a BlockingQueue to coordinate the activities of two or more threads.
ReentrantReadWriteLock
Imagine a video game that was storing a collection of high scores using a non-thread-safe collection. With a non-thread-safe collection, it is important that if a thread is attempting to modify the collection, it must have exclusive access to the collection. To allow multiple threads to concurrently read the high score list or allow a single thread to add a new score, you could use a ReadWriteLock.
A ReentrantReadWriteLock is not actually a Lock; it implements the ReadWriteLock interface. What a ReentrantReadWriteLock does is produce two specialized Lock instances, one to a read lock and the other to a write lock.

These two locks are a matched set—one cannot be held at the same time as the other (by different threads). What makes these locks unique is that multiple threads can hold the read lock at the same time, but only one thread can hold the write lock at a time.
This example shows how a non-thread-safe collection (an ArrayList) can be made thread-safe, allowing concurrent reads but exclusive access by a writing thread:

Instead of wrapping a collection with Lock objects to ensure thread safety, you can use one of the thread-safe collections you’ll learn about in the next section.
CERTIFICATION OBJECTIVES
Use java.util.concurrent Collections (OCP Objective 11.1) and Use a Deque (OCP Objective 4.5)
11.1 Use collections from the java.util.concurrent package with a focus on the advantages over and differences from the traditional java.util collections.
4.5 Create and use List, Set, and Deque implementations.
Imagine an online video game with a list of the top 20 scores in the last 30 days. You could model the high score list using a java.util.ArrayList. As scores expire, they are removed from the list, and as new scores displace existing scores, remove and insert operations are performed. At the end of every game, the list of high scores is displayed. If the game is popular, then a lot of people (threads) will be reading the list at the same time. Occasionally, the list will be modified—sometimes by multiple threads—probably at the same time that it is being read by a large number of threads.
A traditional java.util.List implementation such as java.util.ArrayList is not thread-safe. Concurrent threads can safely read from an ArrayList and possibly even modify the elements stored in the list, but if any thread modifies the structure of the list (add or remove operation), then unpredictable behavior can occur.
Look at the ArrayListRunnable class in the following example. What would happen if there were a single instance of this class being executed by several threads? You might encounter several problems, including ArrayIndexOutOfBoundsException, duplicate values, skipped values, and null values. Not all threading problems manifest immediately. To observe the bad behavior, you might have to execute the faulty code multiple times or under different system loads. It is important that you are able to recognize the difference between thread-safe and non-thread-safe code yourself, because the compiler will not detect thread-unsafe code.

To make a collection thread-safe, you could surround all the code that accessed the collection in synchronized blocks or use a method such as Collections.synchronizedList(new ArrayList()). Using synchronization to safeguard a collection creates a performance bottleneck and reduces the liveness of your application. The java.util.concurrent package provides several types of collections that are thread-safe but do not use coarse-grained synchronization. When a collection will be concurrently accessed in an application you are developing, you should always consider using the collections outlined in the following sections.

Problems in multithreaded applications may not always manifest—a lot depends on the underlying operating system and how other applications affect the thread scheduling of a problematic application. On the exam, you might be asked about the “probable” or “most likely” outcome. Unless you are asked to identify every possible outcome of a code sample, don’t get hung up on unlikely results. For example, if a code sample uses Thread.sleep(1000) and nothing indicates that the thread would be interrupted while it was sleeping, it would be safe to assume that the thread would resume execution around one second after the call to sleep.
Copy-on-Write Collections
The copy-on-write collections from the java.util.concurrent package implement one of several mechanisms to make a collection thread-safe. By using the copy-on-write collections, you eliminate the need to implement synchronization or locking when manipulating a collection using multiple threads.
The CopyOnWriteArrayList is a List implementation that can be used concurrently without using traditional synchronization semantics. As its name implies, a CopyOnWriteArrayList will never modify its internal array of data. Any mutating operations on the List (add, set, remove, etc.) will cause a new modified copy of the array to be created, which will replace the original read-only array. The read-only nature of the underlying array in a CopyOnWriteArrayList allows it to be safely shared with multiple threads. Remember that read-only (immutable) objects are always thread-safe.
The essential thing to remember with a copy-on-write collection is that a thread that is looping through the elements in a collection must keep a reference to the same unchanging elements throughout the duration of the loop; this is achieved with the use of an Iterator. Basically, you want to keep using the old, unchanging collection that you began a loop with. When you use list.iterator(), the returned Iterator will always reference the collection of elements as it was when list.iterator() was called, even if another thread modifies the collection. Any mutating methods called on a copy-on-write–based Iterator or ListIterator (such as add, set, or remove) will throw an UnsupportedOperationException.
A for-each loop uses an Iterator when executing, so it is safe to use with a copy-on-write collection, unlike a traditional for loop.
![]()
The java.util.concurrent package provides two copy-on-write–based collections: CopyOnWriteArrayList and CopyOnWriteArraySet. Use the copy-on-write collections when your data sets remain relatively small and the number of read operations and traversals greatly outnumber modifications to the collections. Modifications to the collections (not the elements within) are expensive because the entire internal array must be duplicated for each modification.
A thread-safe collection does not make the elements stored within the collection thread-safe. Just because a collection that contains elements is thread-safe does not mean the elements themselves can be safely modified by multiple threads. You might have to use atomic variables, locks, synchronized code blocks, or immutable (read-only) objects to make the objects referenced by a collection thread-safe.
Concurrent Collections
The java.util.concurrent package also contains several concurrent collections that can be concurrently read and modified by multiple threads, but without the copy-on-write behavior seen in the copy-on-write collections. The concurrent collections include
![]() ConcurrentHashMap
ConcurrentHashMap
![]() ConcurrentLinkedDeque
ConcurrentLinkedDeque
![]() ConcurrentLinkedQueue
ConcurrentLinkedQueue
![]() ConcurrentSkipListMap
ConcurrentSkipListMap
![]() ConcurrentSkipListSet
ConcurrentSkipListSet
Be aware that an Iterator for a concurrent collection is weakly consistent; it can return elements from the point in time the Iterator was created or later. This means that while you are looping through a concurrent collection, you might observe elements that are being inserted by other threads. In addition, you may observe only some of the elements that another thread is inserting with methods such as addAll when concurrently reading from the collection. Similarly, the size method may produce inaccurate results. Imagine attempting to count the number of people in a checkout line at a grocery store. While you are counting the people in line, some people may join the line and others may leave. Your count might end up close but not exact by the time you reach the end. This is the type of behavior you might see with a weakly consistent collection. The benefit to this type of behavior is that it is permissible for multiple threads to concurrently read and write a collection without having to create multiple internal copies of the collection, as is the case in a copy-on-write collection. If your application cannot deal with these inconsistencies, you might have to use a copy-on-write collection.
The ConcurrentHashMap and ConcurrentSkipListMap classes implement the ConcurrentMap interface. A ConcurrentMap enhances a Map by adding the atomic putIfAbsent, remove, and replace methods. For example, the putIfAbsent method is equivalent to performing the following code as an atomic operation:

ConcurrentSkipListMap and ConcurrentSkipListSet are sorted. ConcurrentSkipListMap keys and ConcurrentSkipListSet elements require the use of the Comparable or Comparator interfaces to enable ordering.
Blocking Queues
The copy-on-write and the concurrent collections are centered on the idea of multiple threads sharing data. Sometimes, instead of shared data (objects), you need to transfer data between two threads. A BlockingQueue is a type of shared collection that is used to exchange data between two or more threads while causing one or more of the threads to wait until the point in time when the data can be exchanged. One use case of a BlockingQueue is called the producer-consumer problem. In a producer-consumer scenario, one thread produces data, then adds it to a queue, and another thread must consume the data from the queue. A queue provides the means for the producer and the consumer to exchange objects. The java.util.concurrent package provides several BlockingQueue implementations. They include
![]() ArrayBlockingQueue
ArrayBlockingQueue
![]() LinkedBlockingDeque
LinkedBlockingDeque
![]() LinkedBlockingQueue
LinkedBlockingQueue
![]() PriorityBlockingQueue
PriorityBlockingQueue
![]() DelayQueue
DelayQueue
![]() LinkedTransferQueue
LinkedTransferQueue
![]() SynchronousQueue
SynchronousQueue
General Behavior
A blocking collection, depending on the method being called, may cause a thread to block until another thread calls a corresponding method on the collection. For example, if you attempt to remove an element by calling take() on any BlockingQueue that is empty, the operation will block until another thread inserts an element. Don’t call a blocking operation in a thread unless it is safe for that thread to block. The commonly used methods in a BlockingQueue are described in the following table.
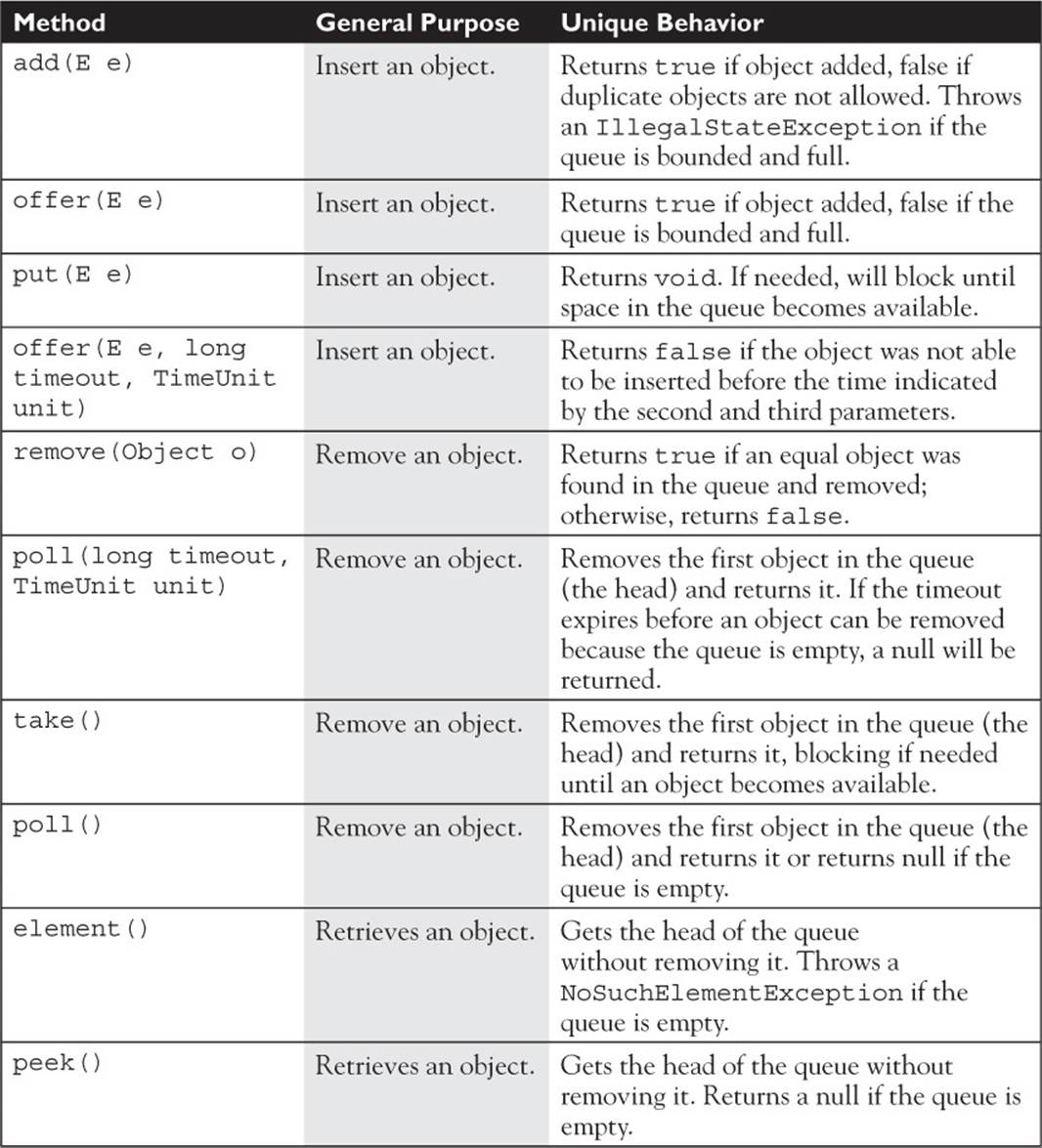
Bounded Queues
ArrayBlockingQueue, LinkedBlockingDeque, and LinkedBlockingQueue support a bounded capacity and will block on put(e) and similar operations if the collection is full. LinkedBlockingQueue is optionally bounded, depending on the constructor you use.

Special-Purpose Queues
A SynchronousQueue is a special type of bounded blocking queue; it has a capacity of zero. Having a zero capacity, the first thread to attempt either an insert or remove operation on a SynchronousQueue will block until another thread performs the opposite operation. You use aSynchronousQueue when you need threads to meet up and exchange an object.
A DelayQueue is useful when you have objects that should not be consumed until a specific time. The elements added to a DelayQueue will implement the java.util.concurrent.Delayed interface which defines a single method: public long getDelay(TimeUnit unit). The elements of a DelayQueue can only be taken once their delay has expired.
The LinkedTransferQueue
A LinkedTransferQueue (new to Java 7) is a superset of ConcurrentLinkedQueue, SynchronousQueue, and LinkedBlockingQueue. It can function as a concurrent Queue implementation similar to ConcurrentLinkedQueue. It also supports unbounded blocking (consumption blocking) similar to LinkedBlockingQueue via the take() method. Like a SynchronousQueue, a LinkedTransferQueue can be used to make two threads rendezvous to exchange an object. Unlike a SynchronousQueue, a LinkedTransferQueue has internal capacity, so the transfer(E) method is used to block until the inserted object (and any previously inserted objects) is consumed by another thread.
In other words, a LinkedTransferQueue might do almost everything you need from a Queue.
Because a LinkedTransferQueue implements the BlockingQueue, TransferQueue, and Queue interfaces, it can be used to showcase all the different methods that can be used to add and remove elements using the various types of queues. Creating a LinkedTransferQueue is easy. Because LinkedTransferQueue is not bound by size, a limit to the number of elements CANNOT be supplied to its constructor.
![]()
There are many methods to add a single element to a LinkedTransferQueue. Note that any method that blocks or waits for any period may throw an InterruptedException.

Shown next are the various methods to access a single value in a LinkedTransferQueue. Again, any method that blocks or waits for any period may throw an InterruptedException.


Use a LinkedTransferQueue (new to Java 7) instead of another comparable queue type. The other java.util.concurrent queues (introduced in Java 5) are less efficient than LinkedTransferQueue.
CERTIFICATION OBJECTIVES
Use Executors and ThreadPools (OCP Objective 11.3)
11.3 Use Executor, ExecutorService, Executors, Callable, and Future to execute tasks using thread pools.
Executors (and the ThreadPools used by them) help meet two of the same needs that Threads do:
1. Creating and scheduling some Java code for execution and
2. Optimizing the execution of that code for the hardware resources you have available (using all CPUs, for example)
With traditional threading, you handle needs 1 and 2 yourself. With Executors, you handle need 1, but you get to use an off-the-shelf solution for need 2. The java.util.concurrent package provides several different off-the-shelf solutions (Executors and ThreadPools), which you’ll read about in this chapter.
When you have multiple needs or concerns, it is common to separate the code for each need into different classes. This makes your application more modular and flexible. This is a fundamental programming principle called “separation of concerns.”
In a way, an Executor is an alternative to starting new threads. Using Threads directly can be considered low-level multithreading, while using Executors can be considered high-level multithreading. To understand how an Executor can replace manual thread creation, let us first analyze what happens when starting a new thread.
1. First, you must identify a task of some sort that forms a self-contained unit of work. You will typically code this task as a class that implements the Runnable interface.
2. After creating a Runnable, the next step is to execute it. You have two options for executing a Runnable:
![]() Option one Call the run method synchronously (i.e., without starting a thread). This is probably not what you would normally do.
Option one Call the run method synchronously (i.e., without starting a thread). This is probably not what you would normally do.
![]()
![]() Option two Call the method indirectly, most likely with a new thread.
Option two Call the method indirectly, most likely with a new thread.

The second approach has the benefit of executing your task asynchronously, meaning the primary flow of execution in your program can continue executing, without waiting for the task to complete. On a multiprocessor system, you must divide a program into a collection of asynchronous tasks that can execute concurrently in order to take advantage of all of the computing power a system possesses.
Identifying Parallel Tasks
Some applications are easier to divide into separate tasks than others. A single-user desktop application may only have a handful of tasks that are suitable for concurrent execution. Networked, multiuser servers, on the other hand, have a natural division of work. Each user’s actions can be a task. Continuing our computer game scenario, imagine a computer program that can play chess against thousands of people simultaneously. Each player submits their move, the computer calculates its move, and finally it informs the player of that move.
Why do we need an alternative to new Thread(r).start()? What are the drawbacks? If we use our online chess game scenario, then having 10,000 concurrent players might mean 10,001 concurrent threads. (One thread awaits network connections from clients and performs aThread(r).start() for each player.) The player thread would be responsible for reading the player’s move, computing the computer’s move, and making the response.
How Many Threads Can You Run?
Do you own a computer that can concurrently run 10,000 threads or 1,000 or even 100? Probably not—this is a trick question. A quad-core CPU (with four processors per unit) might be able to execute two threads per core for a total of eight concurrently executing threads. You can start 10,000 threads, but not all of them will be running at the same time. The underlying operating system’s task scheduler rotates the threads so that they each get a slice of time on a processor. Ten thousand threads all competing for a turn on a processor wouldn’t make for a very responsive system. Threads would either have to wait so long for a turn or get such small turns (or both) that performance would suffer.
In addition, each thread consumes system resources. It takes processor cycles to perform a context switch (saving the state of a thread and resuming another thread), and each thread consumes system memory for its stack space. Stack space is used for temporary storage and to keep track of where a thread returns to after completing a method call. Depending on a thread’s behavior, it might be possible to lower the cost (in RAM) of creating a thread by reducing a thread’s stack size.
To reduce a thread’s stack size, the Oracle JVM supports using the nonstandard-Xss1024k option to the java command. Note that decreasing the value too far can result in some threads throwing exceptions when performing certain tasks, such as making a large number of recursive method calls.
Another limiting factor in being able to run 10,000 threads in an application has to do with the underlying limits of the OS. Operating systems typically have limits on the number of threads an application can create. These limits can prevent a buggy application from spawning countless threads and making your system unresponsive. If you have a legitimate need to run 10,000 threads, you will probably have to consult your operating system’s documentation to discover possible limits and configuration options.
CPU-Intensive vs. I/O-Intensive Tasks
If you correctly configure your OS and you have enough memory for each thread’s stack space plus your application’s primary memory (heap), will you be able to run an application with 10,000 threads? It depends…. Remember that your processor can only run a small number of concurrent threads (in the neighborhood of 8 to 16 threads). Yet, many network server applications, such as our online chess game, would have traditionally started a new thread for each connected client. A system might be able to run an application with such a high number of threads because most of the threads are not doing anything. More precisely, in an application like our online chess server, most threads would be blocked waiting on I/O operations such as InputStream.read or OutputStream.write method calls.
When a thread makes an I/O request using InputStream.read and the data to be read isn’t already in memory, the calling thread will be put to sleep (“blocked”) by the system until the requested data can be loaded. This is much more efficient than keeping the thread on the processor while it has nothing to do. I/O operations are extremely slow when compared to compute operations—reading a sector from a hard drive takes much longer than adding hundreds of numbers. A processor might execute hundreds of thousands, or even millions, of instructions while awaiting the completion of an I/O request. The type of work (either CPU intensive or I/O intensive) a thread will be performing is important when considering how many threads an application can safely run. Imagine your world-class computer chess playing program takes one minute of processor time (no I/O at all) to calculate each move. In this scenario, it would only take about 16 concurrent players to cause your system to have periods of maximum CPU utilization.
If your tasks will be performing I/O operations, you should be concerned about how increased load (users) might affect scalability. If your tasks perform blocking I/O, then you might need to utilize a thread-per-task model. If you don’t, then all your threads may be tied up in I/O operations with no threads remaining to support additional users. Another option would be to investigate whether you can use nonblocking I/O instead of blocking I/O.
Fighting for a Turn
If it takes the computer player one minute to calculate a turn and it takes a human player about the same time, then each player only uses one minute of CPU time out of every two minutes of real time. With a system capable of executing 16 concurrent game threads, that means we could handle 32 connected players. But if all 32 players make their turn at once, the computer will be stuck trying to calculate 32 moves at once. If the system uses preemptive multitasking (the most common type), then each thread will get preempted while it is running (paused and kicked off the CPU) so a different thread can take a turn (time slice). In most JVM implementations, this is handled by the underlying operating system’s task scheduler. The task scheduler is itself a software program. The more CPU cycles spent scheduling and preempting threads, the less processor time you have to execute your application threads. Note that it would appear to the untrained observer that all 32 threads were running concurrently because a preemptive multitasking system will switch out the running threads frequently (millisecond time slices).
Decoupling Tasks from Threads
The best design would be one that utilized as many system resources as possible without attempting to over-utilize the system. If 16 threads are all you need to fully utilize your CPU, why would you start more than that? In a traditional system, you start more threads than your system can concurrently run and hope that only a small number are in a running state. If we want to adjust the number of threads that are started, we need to decouple the tasks that are to be performed (our Runnable instances) from our thread creation and starting. This is where ajava.util.concurrent.Executor can help. The basic usage looks something like this:

A java.util.concurrent.Executor is used to execute the run method in a Runnable instance much like a thread. Unlike a more traditional new Thread(r) .start(), an Executor can be designed to use any number of threading approaches, including
![]() Not starting any threads at all (task is run in the calling thread)
Not starting any threads at all (task is run in the calling thread)
![]() Starting a new thread for each task
Starting a new thread for each task
![]() Queuing tasks and processing them with only enough threads to keep the CPU utilized
Queuing tasks and processing them with only enough threads to keep the CPU utilized
You can easily create your own implementations of an Executor with custom behaviors. As you’ll see soon, several implementations are provided in the standard Java SE libraries. Looking at sample Executor implementations can help you to understand their behavior. This next example doesn’t start any new threads; instead, it executes the Runnable using the thread that invoked the Executor.

The following Executor implementation would use a new thread for each task:

This example shows how an Executor implementation can be put to use:

By coding to the Executor interface, the submission of tasks is decoupled from the execution of tasks. The result is that you can easily modify how threads are used to execute tasks in your applications.
There is no “right number” of threads for task execution. The type of task (CPU intensive versus I/O intensive), number of tasks, I/O latency, and system resources all factor into determining the ideal number of threads to use. You should perform testing of your applications to determine the ideal threading model. This is one reason why the ability to separate task submission from task execution is important.
Several Executor implementations are supplied as part of the standard Java libraries. The Executors class (notice the “s” at the end) is a factory for Executor implementations.

The Executor instances returned by Executors are actually of type ExecutorService (which extends Executor). An ExecutorService provides management capability and can return Future references that are used to obtain the result of executing a task asynchronously. We’ll talk more about Future in a few pages!

Three types of ExecutorService instances can be created by the factory methods in the Executors class: cached thread pool executors, fixed thread pool executors, and single thread pool executors.
Cached Thread Pools
![]()
A cached thread pool will create new threads as they are needed and reuse threads that have become free. Threads that have been idle for 60 seconds are removed from the pool.
Watch out! Without some type of external limitation, a cached thread pool may be used to create more threads than your system can handle.
Fixed Thread Pools—Most Common
![]()
A fixed thread pool is constructed using a numeric argument (4 in the preceding example) that specifies the number of threads used to execute tasks. This type of pool will probably be the one you use the most because it prevents an application from overloading a system with too many threads. Tasks that cannot be executed immediately are placed on an unbounded queue for later execution.
You might base the number of threads in a fixed thread pool on some attribute of the system your application is executing on. By tying the number of threads to system resources, you can create an application that scales with changes in system hardware. To query the number of available processors, you can use the java.lang.Runtime class.
![]()
ThreadPoolExecutor
Both Executors.newCachedThreadPool() and Executors. newFixedThreadPool(4) return objects of type java.util.concurrent .ThreadPoolExecutor (which implements ExecutorService and Executor). You will typically use the Executors factory methods instead of creatingThreadPoolExecutor instances directly, but you can cast the fixed or cached thread pool ExecutorService references if you need access to the additional methods. The following example shows how you could dynamically adjust the thread count of a pool at runtime:

Single Thread Pools
![]()
A single thread pool uses a single thread to execute tasks. Tasks that cannot be executed immediately are placed on an unbounded queue for later execution. Unlike a fixed thread pool executor with a size of 1, a single thread executor prevents any adjustments to the number of threads in the pool.
Scheduled Thread Pool
In addition to the three basic ExecutorService behaviors outlined already, the Executors class has factory methods to produce a ScheduledThreadPoolExecutor. A ScheduledThreadPoolExecutor enables tasks to be executed after a delay or at repeating intervals. Here, we see some thread scheduling code in action:

The Callable Interface
So far, the Executors examples have used a Runnable instance to represent the task to be executed. The java.util.concurrent.Callable interface serves the same purpose as the Runnable interface, but provides more flexibility. Unlike the Runnable interface, a Callable may return a result upon completing execution and may throw a checked exception. An ExecutorService can be passed a Callable instead of a Runnable.
Avoid using methods such as Object.wait, Object.notify, and Object.notifyAll in tasks (Runnable and Callable instances) that are submitted to an Executor or ExecutorService. Because you might not know what the threading behavior of an Executor is, it is a good idea to avoid operations that may interfere with thread execution. Avoiding these types of methods is advisable anyway since they are easy to misuse.
The primary benefit of using aCallableis the ability to return a result. Because an ExecutorService may execute the Callable asynchronously (just like a Runnable), you need a way to check the completion status of a Callable and obtain the result later. Ajava.util.concurrent.Future is used to obtain the status and result of a Callable. Without a Future, you’d have no way to obtain the result of a completed Callable and you might as well use a Runnable (which returns void) instead of a Callable. Here’s a simple Callable example that loops a random number of times and returns the random loop count:

Submitting a Callable to an ExecutorService returns a Future reference. When you use the Future to obtain the Callable’s result, you will have to handle two possible exceptions:
![]() InterruptedException Raised when the thread calling the Future’s get() method is interrupted before a result can be returned
InterruptedException Raised when the thread calling the Future’s get() method is interrupted before a result can be returned
![]() ExecutionException Raised when an exception was thrown during the execution of the Callable’s call() method
ExecutionException Raised when an exception was thrown during the execution of the Callable’s call() method

I/O activities in your Runnable and Callable instances can be a serious bottleneck. In preceding examples, the use of System.out.println() will cause I/O activity. If this wasn’t a trivial example being used to demonstrate Callable and ExecutorService, you would probably want to avoid repeated calls to println() in the Callable. One possibility would be to use StringBuilder to concatenate all output strings and have a single println() call before the call() method returns. Another possibility would be to use a logging framework (seejava.util.logging) in place of any println() calls.
ThreadLocalRandom
The first Callable example used a java.util.concurrent.ThreadLocalRandom. ThreadLocalRandom is a new way in Java 7 to create random numbers. Math.random() and shared Random instances are thread-safe, but suffer from contention when used by multiple threads. AThreadLocalRandom is unique to a thread and will perform better because it avoids any contention. ThreadLocalRandom also provides several convenient methods such as nextInt(int, int) that allow you to specify the range of possible values returned.
ExecutorService Shutdown
You’ve seen how to create Executors and how to submit Runnable and Callable tasks to those Executors. The final component to using an Executor is shutting it done once it is done processing tasks. An ExecutorService should be shut down once it is no longer needed to free up system resources and to allow graceful application shutdown. Because the threads in an ExecutorService may be nondaemon threads, they may prevent normal application termination. In other words, your application stays running after completing its main method. You could perform a System.exit(0) call, but it would preferable to allow your threads to complete their current activities (especially if they are writing data).

For long-running tasks (especially those with looping constructs), consider using Thread.currentThread().isInterrupted() to determine if a Runnable or Callable should return early. The ExecutorService.shutdownNow() method will typically call Thread.interrupt() in an attempt to terminate any unfinished tasks.
CERTIFICATION OBJECTIVES
Use the Parallel Fork/Join Framework (OCP Objective 11.4)
11.4 Use the parallel Fork/Join Framework.
The Fork-Join Framework provides a highly specialized ExecutorService. The other ExecutorService instances you’ve seen so far are centered on the concept of submitting multiple tasks to an ExecutorService. By doing this, you provide an easy avenue for an ExecutorService to take advantage of all the CPUs in a system by using a threads to complete tasks. Sometimes, you don’t have multiple tasks; instead, you have one really big task.
There are many large tasks or problems you might need to solve in your application. For example, you might need to initialize the elements of a large array with values. You might think that initializing an array doesn’t sound like a large complex task in need of a framework. The key is that it needs to be a large task. What if you need to fill up a 100,000,000-element array with randomly generated values? The Fork-Join Framework makes it easier to tackle big tasks like this, while leveraging all of the CPUs in a system.
Divide and Conquer
Certain types of large tasks can be split up into smaller subtasks; those subtasks might, in turn, be split up into even smaller tasks. There is no limit to how many times you might subdivide a task. For example, imagine the task of having to repaint a single long fence that borders several houses. The “paint the fence” task could be subdivided so that each household would be responsible for painting a section of the fence. Each household could then subdivide their section into subsections to be painted by individual family members. In this example, there are three levels of recursive calls. The calls are considered recursive because at each step we are trying to accomplish the same thing: paint the fence. In other words, Joe, one of the home owners, was told by his wife, “paint that (huge) fence, it looks old.” Joe decides that painting the whole fence is too much work and talks all the households along the fence into taking a subsection. Now Joe is telling himself “paint that (subsection of) fence, it looks old.” Again, Joe decides that it is still too much work and subdivides his section into smaller sections for each member of his household. Again, Joe tells himself “paint that (subsection of) fence, it looks old,” but this time, he decides that the amount of work is manageable and proceeds to paint his section of fence. Assuming everyone else paints their subsections (hopefully in a timely fashion), the result is the entire fence being painted.
When using the Fork-Join Framework, your tasks will be coded to decide how many levels of recursion (how many times to subdivide) are appropriate. You’ll want to split things up into enough subtasks that you have enough tasks to keep all of your CPUs utilized. Sometimes, the best number of tasks can be a little hard to determine because of factors we will discuss later. You might have to benchmark different numbers of task divisions to find the optimal number of subtasks that should be created.
Just because you can use Fork-Join to solve a problem doesn’t always mean you should. If our initial task is to paint eight fence planks, then Joe might just decide to paint them himself. The effort involved in subdividing the problem and assigning those tasks to workers (threads) can sometimes be more than the actual work you want to perform. The number of elements (or fence planks) is not the only thing to consider—the amount of work performed on each element is also important. Imagine if Joe was asked to paint a mural on each fence plank. Because processing each element (fence plank) is so time consuming, in this case, it might be beneficial to adopt a divide-and-conquer solution even though there is a small number of elements.
ForkJoinPool
The Fork-Join ExecutorService implementation is java.util.concurrent. ForkJoinPool. You will typically submit a single task to a ForkJoinPool and await its completion. The ForkJoinPool and the task itself work together to divide and conquer the problem. Any problem that can be recursively divided can be solved using Fork-Join. Anytime you want to perform the same operation on a collection of elements (painting thousands of fence planks or initializing 100,000,000 array elements), consider using Fork-Join.
To create a ForkJoinPool, simply call its no-arg constructor:
![]()
The no-arg ForkJoinPool constructor creates an instance that will use the Runtime.availableProcessors() method to determine the level of parallelism. The level of parallelism determines the number of threads that will be used by the ForkJoinPool.
There is also a ForkJoinPool(int parallelism) constructor that allows you to override the number of threads that will be used.
ForkJoinTask
Just as with Executors, you must capture the task to be performed as Java code. With the Fork-Join Framework, a java.util.concurrent.ForkJoinTask instance (actually a subclass—more on that later) is created to represent the task that should be accomplished. This is different from other executor services that primarily used either Runnable or Callable. A ForkJoinTask has many methods (most of which you will never use), but the following methods are important: compute(), fork(), and join().
A ForkJoinTask subclass is where you will perform most of the work involved in completing a Fork-Join task. ForkJoinTask is an abstract base class; we will discuss the two subclasses, RecursiveTask and RecursiveAction, later. The basic structure of any ForkJoinTask is shown in this pseudocode example:

Fork
With the Fork-Join Framework, each thread in the ForkJoinPool has a queue of the tasks it is working on; this is unlike mostExecutorServiceimplementations that have a single shared task queue. The fork() method places a ForkJoinTask in the current thread’s task queue. A normal thread does not have a queue of tasks—only the specialized threads in a ForkJoinPool do. This means that you can’t call fork() unless you are within a ForkJoinTask that is being executed by a ForkJoinPool.
Initially, only a single thread in a ForkJoinPool will be busy when you submit a task. That thread will begin to subdivide the tasks into smaller tasks. Each time a task is subdivided into two subtasks, you fork (or queue) the first task and compute the second task. In the event you need to subdivide a task into more than two subtasks, each time you split a task, you would fork every new subtask except one (which would be computed).
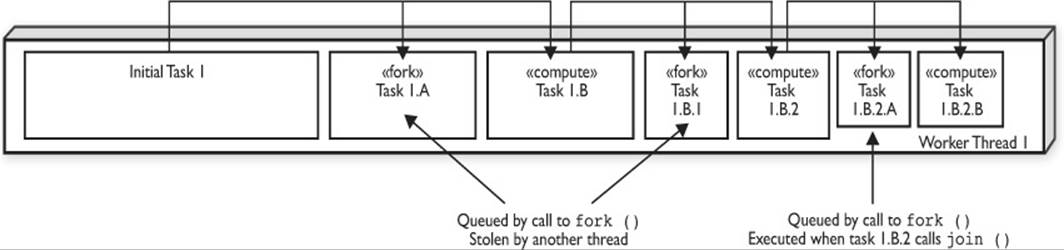
Work Stealing
Notice how the call to fork() is placed before the call to compute() or join(). A key feature of the Fork-Join Framework is work stealing. Work stealing is how the other threads in a ForkJoinPool will obtain tasks. When initially submitting a Fork-Join task for execution, a single thread from a ForkJoinPool begins executing (and subdividing) that task. Each call to fork() placed a new task in the calling thread’s task queue. The order in which the tasks are queued is important. The tasks that have been queued the longest represent larger amounts of work. In theForkJoinPaintTask example, the task that represents 100 percent of the work would begin executing, and its first queued (forked) task would represent 50 percent of the fence, the next 25 percent, then 12.5 percent, and so on. Of course, this can vary, depending on how many times the task will be subdivided and whether we are splitting the task into halves or quarters or some other division, but in this example, we are splitting each task into two parts: queuing one part and executing the second part.
The nonbusy threads in a ForkJoinPool will attempt to steal the oldest (and therefore largest) task from any Fork-Join thread with queued tasks. Given a ForkJoinPool with four threads, one possible sequence of events could be that the initial thread queues tasks that represent 50 percent and 25 percent of the work, which are then stolen by two different threads. The thread that stole the 50 percent task then subdivides that task and places a 25 percent task on its queue, which is then stolen by a fourth thread, resulting in four threads that each process 25 percent of the work.
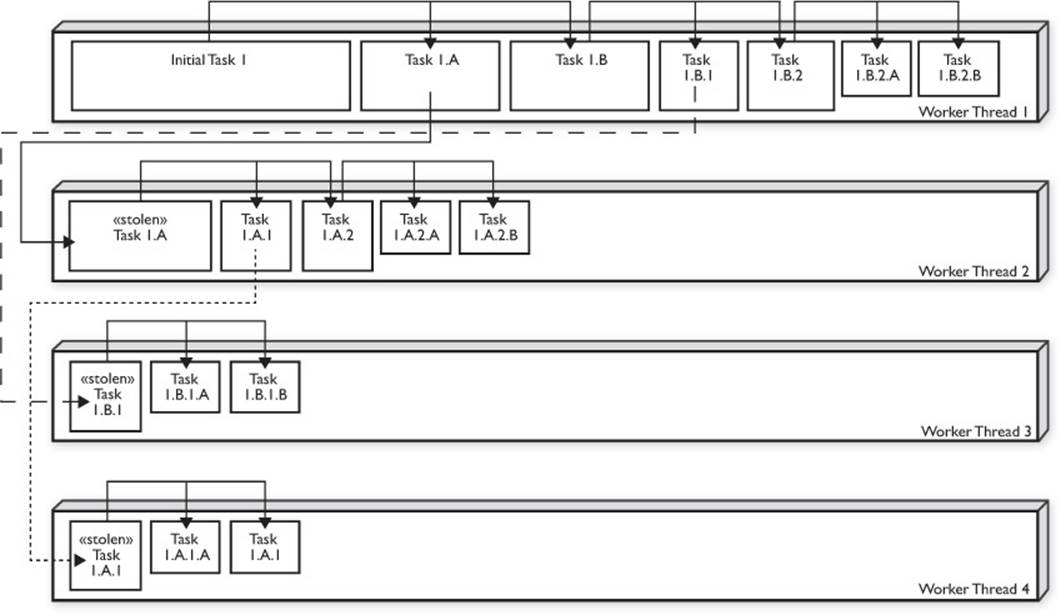
Of course, if everything was always this evenly distributed, you might not have as much of a need for Fork-Join. You could just presplit the work into a number of tasks equal to the number of threads in your system and use a regular ExecutorService. In practice, each of the four threads will not finish their 25 percent of the work at the same time—one thread will be the slow thread that doesn’t get as much work done. There are many reasons for this: The data being processed may affect the amount of computation (25 percent of an array might not mean 25 percent of the workload), or a thread might not get as much time to execute as the other threads. Operating systems and other running applications are also going to consume CPU time. In order to finish executing the Fork-Join task as soon as possible, the threads that finish their portions of the work first will start to steal work from the slower threads—this way, you will be able to keep all of the CPU involved. If you only split the tasks into 25 percent of the data (with four threads), then there would be nothing for the faster threads to steal from when they finish early. In the beginning, if the slower thread stole 25 percent of the work and started processing it without further subdividing and queuing, then there would be no work on the slow thread’s queue to steal. You should subdivide the tasks into a few more sections than are needed to evenly distribute the work among the number of threads in your ForkJoinPools because threads will most likely not perform exactly the same. Subdividing the tasks is extra work—if you do it too much, you might hurt performance. Subdivide your tasks enough to keep all CPUs busy, but not more than is needed. Unfortunately, there is no magic number to split your tasks into—it varies based on the complexity of the task, the size of the data, and even the performance characteristics of your CPUs.
Back to fence painting, make the isFenceSectionSmall() logic as simple as possible (low overhead) and easy to change. You should benchmark your Fork-Join code (using the hardware that you expect the code to typically run on) and find an amount of task subdivision that works well. It doesn’t have to be perfect; once you are close to the ideal range, you probably won’t see much variation in performance unless other factors come into play (different CPUs, etc.).
Join
When you call join() on the (left) task, it should be one of the last steps in the compute method, after calling fork() and compute(). Calling join() says “I can’t proceed unless this (left) task is done.” Several possible things can happen when you call join():
![]() The task you call join() on might already be done. Remember you are calling join() on a task that already had fork() called. The task might have been stolen and completed by another thread. In this case, calling join() just verifies the task is complete and you can continue on.
The task you call join() on might already be done. Remember you are calling join() on a task that already had fork() called. The task might have been stolen and completed by another thread. In this case, calling join() just verifies the task is complete and you can continue on.
![]() The task you call join() on might be in the middle of being processed. Another thread could have stolen the task, and you’ll have to wait until the joined task is done before continuing.
The task you call join() on might be in the middle of being processed. Another thread could have stolen the task, and you’ll have to wait until the joined task is done before continuing.
![]() The task you call join() on might still be in the queue (not stolen). In this case, the thread calling join() will execute the joined task.
The task you call join() on might still be in the queue (not stolen). In this case, the thread calling join() will execute the joined task.
RecursiveAction
ForkJoinTask is an abstract base class that outlines most of the methods, such as fork() and join(), in a Fork-Join task. If you need to create a ForkJoinTask that does not return a result, then you should subclass RecursiveAction. RecursiveAction extends ForkJoinTask and has a single abstract compute method that you must implement:
![]()
An example of a task that does not need to return a result would be any task that initializes an existing data structure. The following example will initialize an array to contain random values. Notice that there is only a single array throughout the entire process. When subdividing an array, you should avoid creating new objects when possible.
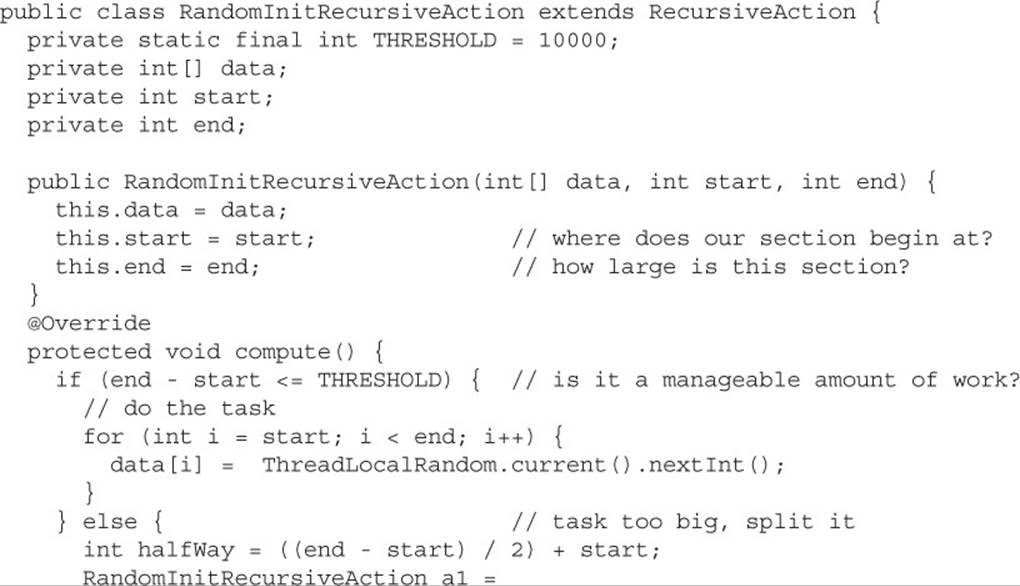

Sometimes, you will see one of the invokeAll methods from the ForkJoinTask class used in place of the fork/compute/join method combination. The invokeAll methods are convenience methods that can save some typing. Using them will also help you avoid bugs! The first task passed to invokeAll will be executed (compute is called), and all additional tasks will be forked and joined. In the preceding example, you could eliminate the three fork/compute/join lines and replace them with a single line:
![]()
To begin the application, we create a large array and initialize it using Fork-Join:

Notice that we do not expect any return values when calling invoke. A RecursiveAction returns nothing.
RecursiveTask
If you need to create a ForkJoinTask that does return a result, then you should subclass RecursiveTask. RecursiveTask extends ForkJoinTask and has a single abstract compute method that you must implement:
![]()
The following example will find the position in an array with the greatest value; if duplicate values are found, the first occurrence is returned. Notice that there is only a single array throughout the entire process. (Just like before, when subdividing an array, you should avoid creating new objects when possible.)

To begin the application, we reuse the RecursiveAction example to create a large array and initialize it using Fork-Join. After initializing the array with random values, we reuse the ForkJoinPool with our RecursiveTask to find the position with the greatest value:


Notice that a value is returned by the call to invoke when using a RecursiveTask.
If your application will repeatedly submit tasks to a ForkJoinPool, then you should reuse a single ForkJoinPool instance and avoid the overhead involved in creating a new instance.
Embarrassingly Parallel
A problem or task is said to be embarrassingly parallel if little or no additional work is required to solve the problem in a parallel fashion. Sometimes, solving a problem in parallel adds so much more overhead that the problem can be solved faster serially. TheRandomInitRecursiveAction example, which initializes an array to random values, has no additional overhead because what happens when processing one subsection of an array has no bearing on the processing of another subsection. Technically, there is a small amount of overhead even in the RandomInitRecursiveAction; the Fork-Join Framework and the if statement that determines whether or not the problem should be subdivided both introduce some overhead. Be aware that it can be difficult to get performance gains that scale with the number of CPUs you have. Typically, four CPUs will result in less than a 4× speedup when moving from a serial to a parallel solution.
The FindMaxPositionRecursiveTask example, which finds the largest value in an array, does introduce a small additional amount of work because you must compare the result from each subsection and determine which is greater. This is only a small amount, however, and adds little overhead. Some tasks may introduce so much additional work that any advantage of using parallel processing is eliminated (the task runs slower than serial execution). If you find yourself performing a lot of processing after calling join(), then you should benchmark your application to determine if there is a performance benefit to using parallel processing. Be aware that performance benefits might only be seen with a certain number of CPUs. A task might run on one CPU in 5 seconds, on two CPUs in 6 seconds, and on four CPUs in 3.5 seconds.
The Fork-Join Framework is designed to have minimal overhead as long as you don’t over-subdivide your tasks and the amount of work required to join results can be kept small. A good example of a task that incurs additional overhead but still benefits from Fork-Join is array sorting. When you split an array into two halves and sort each half separately, you then have to combine the two sorted arrays, as shown in the following example:

In the previous example, everything after the call to invokeAll is related to merging two sorted subsections of an array into a single larger sorted subsection.
Because Java applications are portable, the system running your application may not have the hardware resources required to see a performance benefit. Always perform testing to determine which problem and hardware combinations see performance increases when using Fork-Join.
CERTIFICATION SUMMARY
This chapter covered the required concurrency knowledge you’ll need to apply on the certification exam. The java.util.concurrent package and its subpackages form a high-level, multithreading framework in Java. You should become familiar with threading basics before attempting to apply the Java concurrency libraries, but once you learn java.util.concurrent, you may never extend Thread again.
Callables and Executors (and their underlying thread pools) form the basis of a high-level alternative to creating new Thread s directly. As the trend of adding more CPU cores continues, knowing how to get Java to make use of them all concurrently could put you on easy street. The high-level APIs provided by java.util.concurrent help you create efficient multithreaded applications while eliminating the need to use low-level threading APIs such as wait(), notify(), and synchronized, which can be a source of hard-to-detect bugs.
When using an Executor, you will commonly create a Callable implementation to represent the work that needs to be executed concurrently. A Runnable can be used for the same purpose, but a Callable leverages generics to allow a generic return type from its call method.Executor or ExecutorService instances with predefined behavior can be obtained by calling one of the factory methods in the Executors class like so: ExecutorService es = Executors. newFixedThreadPool(100);.
Once you obtain an ExecutorService, you submit a task in the form of a Runnable or Callable or a collection of Callable instances to the ExecutorService using one of the execute, submit, invokeAny, or invokeAll methods. An ExecutorService can be held onto during the entire life of your application if needed, but once it is no longer needed, it should be terminated using the shutdown and shutdownNow methods.
We looked at the Fork-Join Framework, which supplies a highly specialized type of Executor. Use the Fork-Join Framework when the work you would typically put in a Callable can be split into multiple units of work. The purpose of the Fork-Join Framework is to decrease the amount of time it takes to solve a problem by leveraging the additional CPUs in a system. You should only run a single Fork-Join task at a time in an application, because the goal of the framework is to allow a single task to consume all available CPU resources in order to be solved as quickly as possible. In most cases, the effort of splitting a single task into multiple tasks that can be operated on by the underlying Fork-Join threads will introduce additional overhead. Don’t assume that applying Fork-Join will grant you a performance benefit for all problems. The overhead involved may be large enough that any benefit of applying the framework is offset.
When applying the Fork-Join Framework, first subclass either RecursiveTask (if a return result is desired) or RecursiveAction. Within one of these ForkJoinTask subclasses, you must implement the compute method. The compute() method is where you divide the work of a task into parts and then call the fork and join methods or the invokeAll method. To execute the task, create a ForkJoinPool instance with ForkJoinPool pool = new ForkJoinPool(); and submit the RecursiveTask or RecursiveAction to the pool with the pool.invoke(task) method. While the Fork-Join API itself is not that large, creating a correct and efficient implementation of a ForkJoinTask can be challenging.
We learned about the java.util.concurrent collections. There are three categories of collections: copy-on-write collections, concurrent collections, and blocking queues. The copy-on-write and concurrent collections are similar in use to the traditional java.util collections, but are designed to be used efficiently in a thread-safe fashion. The copy-on-write collections (CopyOnWriteArrayList and CopyOnWriteArraySet) should be used for read-heavy scenarios. When attempting to loop through all the elements in one of the copy-on-write collections, always use anIterator. The concurrent collections included
![]() ConcurrentHashMap
ConcurrentHashMap
![]() ConcurrentLinkedDeque
ConcurrentLinkedDeque
![]() ConcurrentLinkedQueue
ConcurrentLinkedQueue
![]() ConcurrentSkipListMap
ConcurrentSkipListMap
![]() ConcurrentSkipListSet
ConcurrentSkipListSet
These collections are meant to be used concurrently without requiring locking. Remember that iterators of these five concurrent collections are weakly consistent. ConcurrentHashMap and ConcurrentSkipListMap are ConcurrentMap implementations that add atomic putIfAbsent,remove, and replace methods to the Map interface. Seven blocking queue implementations are provided by the java.util.concurrent package:
![]() ArrayBlockingQueue
ArrayBlockingQueue
![]() LinkedBlockingDeque
LinkedBlockingDeque
![]() LinkedBlockingQueue
LinkedBlockingQueue
![]() PriorityBlockingQueue
PriorityBlockingQueue
![]() DelayQueue
DelayQueue
![]() LinkedTransferQueue
LinkedTransferQueue
![]() SynchronousQueue
SynchronousQueue
These blocking queues are used to exchange objects between threads—one thread will deposit an object and another thread will retrieve that object. Depending on which queue type is used, the parameters used to create the queue, and the method being called, an insert or a removal operation may block until it can be completed successfully. In Java 7, the LinkedTransferQueue class was added that acts as a superset of several blocking queue types; you should prefer it when possible.
The java.util.concurrent.atomic and java.util.concurrent.locks packages contain additional utility classes you might consider using in concurrent applications. The java.util.concurrent.atomic package supplies thread-safe classes that are similar to the traditional wrapper classes (such as java.lang .Integer) but with methods that support atomic modifications. The java.util .concurrent.locks.Lock interface and supporting classes enable you to create highly customized locking behaviors that are more flexible than traditional object monitor locking (the synchronized keyword).
![]() TWO-MINUTE DRILL
TWO-MINUTE DRILL
Here are some of the key points from the certification objectives in this chapter.
Apply Atomic Variables and Locks (OCP Objective 11.2)
![]() The java.util.concurrent.atomic package provides classes that are similar to volatile fields (changes to an atomic object’s value will be correctly read by other threads without the need for synchronized code blocks in your code).
The java.util.concurrent.atomic package provides classes that are similar to volatile fields (changes to an atomic object’s value will be correctly read by other threads without the need for synchronized code blocks in your code).
![]() The atomic classes provide a compareAndSet method that is used to validate that an atomic variable’s value will only be changed if it matches an expected value.
The atomic classes provide a compareAndSet method that is used to validate that an atomic variable’s value will only be changed if it matches an expected value.
![]() The atomic classes provide several convenience methods such as addAndGet that will loop repeatedly until a compareAndSet succeeds.
The atomic classes provide several convenience methods such as addAndGet that will loop repeatedly until a compareAndSet succeeds.
![]() The java.util.concurrent.locks package contains a locking mechanism that is an alternative to synchronized methods and blocks. You get greater flexibility at the cost of a more verbose syntax (such as having to manually call lock.unlock() and having an automatic release of a synchronization monitor at the end of a synchronized code block).
The java.util.concurrent.locks package contains a locking mechanism that is an alternative to synchronized methods and blocks. You get greater flexibility at the cost of a more verbose syntax (such as having to manually call lock.unlock() and having an automatic release of a synchronization monitor at the end of a synchronized code block).
![]() The ReentrantLock class provides the basic Lock implementation. Commonly used methods are lock(), unlock(), isLocked(), and tryLock(). Calling lock() increments a counter and unlock() decrements the counter. A thread can only obtain the lock when the counter is zero.
The ReentrantLock class provides the basic Lock implementation. Commonly used methods are lock(), unlock(), isLocked(), and tryLock(). Calling lock() increments a counter and unlock() decrements the counter. A thread can only obtain the lock when the counter is zero.
![]() The ReentrantReadWriteLock class provides a ReadWriteLock implementation that supports a read lock (obtained by calling) and a write lock (obtained by calling).
The ReentrantReadWriteLock class provides a ReadWriteLock implementation that supports a read lock (obtained by calling) and a write lock (obtained by calling).
Use java.util.concurrent Collections (OCP Objective 11.1)
![]() Copy-on-write collections work well when there are more reads than writes because they make a new copy of the collection for each write. When looping through a copy-on-write collection, use an iterator (remember, for-each loops use an iterator).
Copy-on-write collections work well when there are more reads than writes because they make a new copy of the collection for each write. When looping through a copy-on-write collection, use an iterator (remember, for-each loops use an iterator).
![]() None of the concurrent collections make the elements stored in the collection thread-safe—just the collection itself.
None of the concurrent collections make the elements stored in the collection thread-safe—just the collection itself.
![]() ConcurrentHashMap, ConcurrentSkipListMap, and ConcurrentSkipListSet should be preferred over synchronizing with the more traditional collections.
ConcurrentHashMap, ConcurrentSkipListMap, and ConcurrentSkipListSet should be preferred over synchronizing with the more traditional collections.
![]() ConcurrentHashMap and ConcurrentSkipListMap are ConcurrentMap implementations that enhance a standard Map by adding atomic operations that validate the presence and value of an element before performing an operation: putIfAbsent(K key, V value), remove(Object key, Object value), replace(K key, V value), and replace(K key, V oldValue, V newValue).
ConcurrentHashMap and ConcurrentSkipListMap are ConcurrentMap implementations that enhance a standard Map by adding atomic operations that validate the presence and value of an element before performing an operation: putIfAbsent(K key, V value), remove(Object key, Object value), replace(K key, V value), and replace(K key, V oldValue, V newValue).
![]() Blocking queues are used to exchange objects between threads. Blocking queues will block (hence the name) when you call certain operations, such as calling take() when there are no elements to take. There are seven different blocking queues that have slightly different behaviors; you should be able to identify the behavior of each type.
Blocking queues are used to exchange objects between threads. Blocking queues will block (hence the name) when you call certain operations, such as calling take() when there are no elements to take. There are seven different blocking queues that have slightly different behaviors; you should be able to identify the behavior of each type.
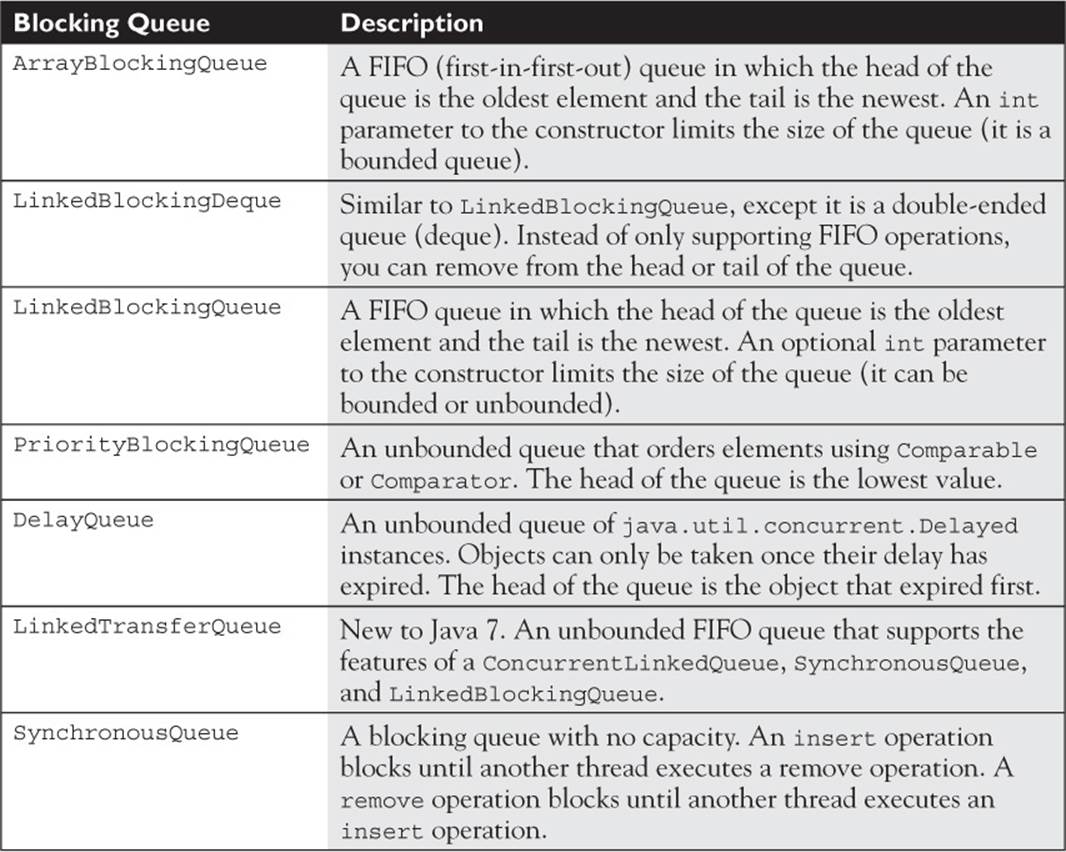
![]() Some blocking queues are bounded, meaning they have an upper bound on the number of elements that can be added, and a thread calling put(e) may block until space becomes available.
Some blocking queues are bounded, meaning they have an upper bound on the number of elements that can be added, and a thread calling put(e) may block until space becomes available.
Use Executors and ThreadPools (OCP Objective 11.3)
![]() An Executor is used to submit a task for execution without being coupled to how or when the task is executed. Basically, it creates an abstraction that can be used in place of explicit thread creation and execution.
An Executor is used to submit a task for execution without being coupled to how or when the task is executed. Basically, it creates an abstraction that can be used in place of explicit thread creation and execution.
![]() An ExecutorService is an enhanced Executor that provides additional functionality, such as the ability to execute a Callable instance and to shut down (nondaemon threads in an Executor may keep the JVM running after your main method returns).
An ExecutorService is an enhanced Executor that provides additional functionality, such as the ability to execute a Callable instance and to shut down (nondaemon threads in an Executor may keep the JVM running after your main method returns).
![]() The Callable interface is similar to the Runnable interface, but adds the ability to return a result from its call method and can optionally throw an exception.
The Callable interface is similar to the Runnable interface, but adds the ability to return a result from its call method and can optionally throw an exception.
![]() The Executors (plural) call provides factory methods that can be used to construct ExecutorService instances, for example: ExecutorService ex = Executors.newFixedThreadPool(4);.
The Executors (plural) call provides factory methods that can be used to construct ExecutorService instances, for example: ExecutorService ex = Executors.newFixedThreadPool(4);.
Use the Parallel Fork/Join Framework (OCP Objective 11.4)
![]() Fork-Join enables work stealing among worker threads in order to keep all CPUs utilized and to increase the performance of highly parallelizable tasks.
Fork-Join enables work stealing among worker threads in order to keep all CPUs utilized and to increase the performance of highly parallelizable tasks.
![]() A pool of worker threads of type ForkJoinWorkerThread are created when you create a new ForkJoinPool(). By default, one thread per CPU is created.
A pool of worker threads of type ForkJoinWorkerThread are created when you create a new ForkJoinPool(). By default, one thread per CPU is created.
![]() To minimize the overhead of creating new threads, you should create a single Fork-Join pool in an application and reuse it for all recursive tasks.
To minimize the overhead of creating new threads, you should create a single Fork-Join pool in an application and reuse it for all recursive tasks.
![]() A Fork-Join task represents a large problem to solve (often involving a collection or array).
A Fork-Join task represents a large problem to solve (often involving a collection or array).
![]() When executed by a ForkJoinPool, the Fork-Join task will subdivide itself into Fork-Join tasks that represent smaller segments of the problem to be solved.
When executed by a ForkJoinPool, the Fork-Join task will subdivide itself into Fork-Join tasks that represent smaller segments of the problem to be solved.
![]() A Fork-Join task is a subclass of the ForkJoinTask class, either RecursiveAction or RecursiveTask.
A Fork-Join task is a subclass of the ForkJoinTask class, either RecursiveAction or RecursiveTask.
![]() Extend RecursiveTask when the compute() method must return a value, and extend RecursiveAction when the return type is void.
Extend RecursiveTask when the compute() method must return a value, and extend RecursiveAction when the return type is void.
![]() When writing a ForkJoinTask implementation’s compute() method, always call fork() before join() or use one of the invokeAll() methods instead of calling fork() and join().
When writing a ForkJoinTask implementation’s compute() method, always call fork() before join() or use one of the invokeAll() methods instead of calling fork() and join().
![]() You do not need to shut down a Fork-Join pool before exiting your application because the threads in a Fork-Join pool typically operate in daemon mode.
You do not need to shut down a Fork-Join pool before exiting your application because the threads in a Fork-Join pool typically operate in daemon mode.
SELF TEST
The following questions might be some of the hardest in the book. It’s just a hard topic, so don’t panic. (We know some Java book authors who didn’t do well with these topics and still managed to pass the exam.)
1. The following block of code creates a CopyOnWriteArrayList, adds elements to it, and prints the contents:

What is the result?
A. 6
B. 12
C. 4 2
D. 4 2 6
E. Compilation fails
F. An exception is thrown at runtime
2. Given:

Which shows the output that will be produced?
A. 12
B. 10
C. 4 2 6
D. 4 6
E. Compilation fails
F. An exception is thrown at runtime
3. Which methods from a CopyOnWriteArrayList will cause a new copy of the internal array to be created? (Choose all that apply.)
A. add
B. get
C. iterator
D. remove
4. Given:
ArrayBlockingQueue <Integer> abq = new ArrayBlockingQueue <>(10);
Which operation(s) can block indefinitely? (Choose all that apply.)
A. abq.add(1);
B. abq.offer(1);
C. abq.put(1);
D. abq.offer(1, 5, TimeUnit.SECONDS);
5. Given:
ConcurrentMap<String, Integer> ages = new ConcurrentHashMap<>(); ages.put(“John”, 23);
Which method(s) would delete John from the map only if his value was still equal to 23?
A. ages.delete(“John”, 23);
B. ages.deleteIfEquals(“John”, 23);
C. ages.remove(“John”, 23);
D. ages.removeIfEquals(“John”, 23);
6. Which method represents the best approach to generating a random number between one and ten if the method will be called concurrently and repeatedly by multiple threads?
A. public static int randomA() {
Random r = new Random();
return r.nextInt(10) + 1;
}
B. private static Random sr = new Random();
public static int randomB() {
return sr.nextInt(10) + 1;
}
C. public static int randomC() {
int i = (int)(Math.random() * 10 + 1); return i;
}
D. public static int randomD() {
ThreadLocalRandom lr = ThreadLocalRandom.current();
return lr.nextInt(1, 11);
}
7. Given:
AtomicInteger i = new AtomicInteger();
Which atomically increment i by 9? (Choose all that apply.)
A. i.addAndGet(9);
B. i.getAndAdd(9);
C. i.set(i.get() + 9);
D. i.atomicIncrement(9);
E. i = i + 9;
8. Given:
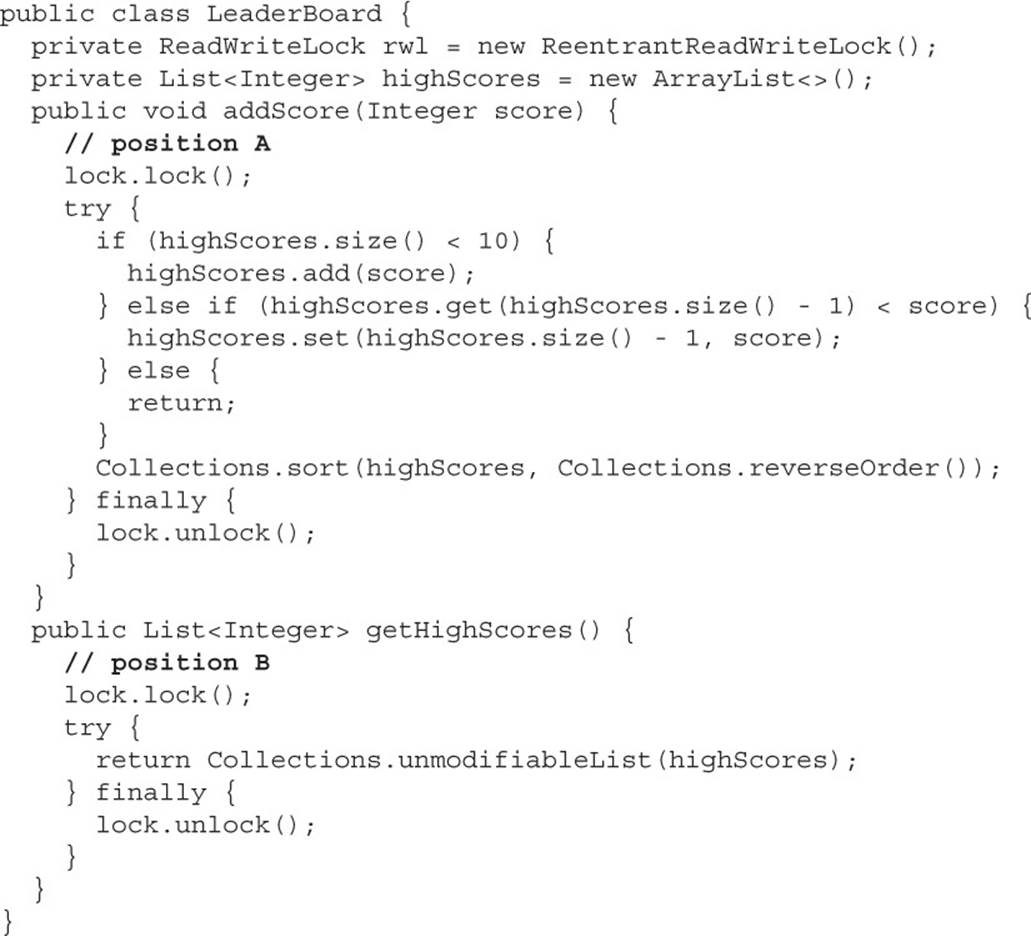
Which block(s) of code best match the behavior of the methods in the LeaderBoard class? (Choose all that apply.)
A. Lock lock = rwl.reentrantLock(); // should be inserted at position A
B. Lock lock = rwl.reentrantLcock(); // should be inserted at position B
C. Lock lock = rwl.readLock(); // should be inserted at position A
D. Lock lock = rwl.readLock(); // should be inserted at position B
E. Lock lock = rwl.writeLock(); // should be inserted at position A
F. Lock lock = rwl.writeLock(); // should be inserted at position B
9. Given:

What is the result?

10. Which class contains factory methods to produce preconfigured ExecutorService instances?
A. Executor
B. Executors
C. ExecutorService
D. Exec utorServiceFactory
11. Given:

Which set(s) of lines, when inserted, would correctly use the ExecutorService argument to execute the Callable and return the Callable’s result? (Choose all that apply.)

12. Which are true? (Choose all that apply.)
A. A Runnable may return a result, but must not throw an Exception
B. A Runnable must not return a result nor throw an Exception
C. A Runnable must not return a result, but may throw an Exception
D. A Runnable may return a result and throw an Exception
E. A Callable may return a result, but must not throw an Exception
F. A Callable must not return a result nor throw an Exception
G. A Callable must not return a result, but may throw an Exception
H. A Callable may return a result and throw an Exception
13. Given:
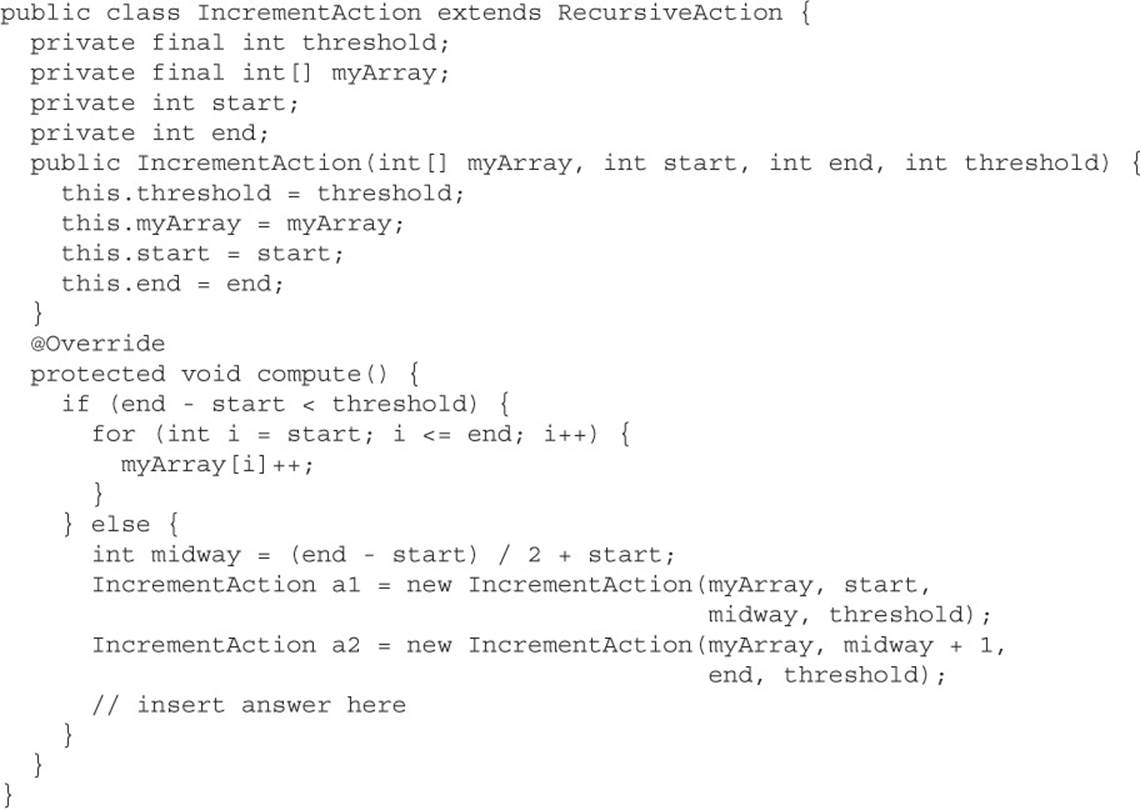
Which line(s), when inserted at the end of the compute method, would correctly take the place of separate calls to fork() and join()? (Choose all that apply.)
A. compute();
B. forkAndJoin(a1, a2);
C. computeAll(a1, a2);
D. invokeAll(a1, a2);
14. When writing a RecursiveTask subclass, which are true? (Choose all that apply.)
A. fork() and join() should be called on the same task
B. fork() and compute() should be called on the same task
C. compute() and join() should be called on the same task
D. compute() should be called before fork()
E. fork() should be called before compute()
F. join() should be called after fo rk() but before compute()
SELF TEST ANSWERS
1. ![]() C is correct. The Iterator is obtained before 6 is added. As long as the reference to the Iterator is maintained, it will only provide access to the values 4 and 2.
C is correct. The Iterator is obtained before 6 is added. As long as the reference to the Iterator is maintained, it will only provide access to the values 4 and 2.
![]() A, B, D, E, and F are incorrect based on the above. (OCP Objective 11.1)
A, B, D, E, and F are incorrect based on the above. (OCP Objective 11.1)
2. ![]() C is correct. Because the Iterator is obtained before the number 2 is removed, it will reflect all the elements that have been added to the collection.
C is correct. Because the Iterator is obtained before the number 2 is removed, it will reflect all the elements that have been added to the collection.
![]() A, B, D, E, and F are incorrect based on the above. (OCP Objective 11.1)
A, B, D, E, and F are incorrect based on the above. (OCP Objective 11.1)
3. ![]() A and D are correct. Of the methods listed, only add and remove will modify the list and cause a new internal array to be created.
A and D are correct. Of the methods listed, only add and remove will modify the list and cause a new internal array to be created.
![]() B and C are incorrect based on the above. (OCP Objective 11.1)
B and C are incorrect based on the above. (OCP Objective 11.1)
4. ![]() C is correct. The add method will throw an IllegalStateException if the queue is full. The two offer methods will return false if the queue is full. Only the put method will block until space becomes available.
C is correct. The add method will throw an IllegalStateException if the queue is full. The two offer methods will return false if the queue is full. Only the put method will block until space becomes available.
![]() A, B, and D are incorrect based on the above. (OCP Objective 11.1)
A, B, and D are incorrect based on the above. (OCP Objective 11.1)
5. ![]() C is correct; it uses the correct syntax.
C is correct; it uses the correct syntax.
![]() The methods for answers A, B, and D do not exist in a ConcurrentHashMap. A traditional Map contains a single-argument remove method that removes an element based on its key. The ConcurrentMap interface (which ConcurrentHashMap implements) added the two-argumentremove method, which takes a key and a value. An element will only be removed from the Map if its value matches the second argument. A boolean is returned to indicate if the element was removed. (OCP Objective 11.1)
The methods for answers A, B, and D do not exist in a ConcurrentHashMap. A traditional Map contains a single-argument remove method that removes an element based on its key. The ConcurrentMap interface (which ConcurrentHashMap implements) added the two-argumentremove method, which takes a key and a value. An element will only be removed from the Map if its value matches the second argument. A boolean is returned to indicate if the element was removed. (OCP Objective 11.1)
6. ![]() D is correct. The ThreadLocalRandom creates and retrieves Random instances that are specific to a thread. You could achieve the same effect prior to Java 7 by using the java.lang .ThreadLocal and java.util.Random classes, but it would require several lines of code. Math .randomis thread-safe, but uses a shared java.util.Random instance and can suffer from contention problems.
D is correct. The ThreadLocalRandom creates and retrieves Random instances that are specific to a thread. You could achieve the same effect prior to Java 7 by using the java.lang .ThreadLocal and java.util.Random classes, but it would require several lines of code. Math .randomis thread-safe, but uses a shared java.util.Random instance and can suffer from contention problems.
![]() A, B, and C are incorrect based on the above. (OCP Objective 11.3)
A, B, and C are incorrect based on the above. (OCP Objective 11.3)
7. ![]() A and B are correct. The addAndGet and getAndAdd both increment the value stored in an AtomicInteger.
A and B are correct. The addAndGet and getAndAdd both increment the value stored in an AtomicInteger.
![]() Answer C is not atomic because in between the call to get and set, the value stored by i may have changed. Answer D is invalid because the atomicIncrement method is fictional, and answer E is invalid because auto-boxing is not supported for the atomic classes. The difference between the addAndGet and getAndAdd methods is that the first is a prefix method (++x) and the second is a postfix method (x++). (Objective 11.2)
Answer C is not atomic because in between the call to get and set, the value stored by i may have changed. Answer D is invalid because the atomicIncrement method is fictional, and answer E is invalid because auto-boxing is not supported for the atomic classes. The difference between the addAndGet and getAndAdd methods is that the first is a prefix method (++x) and the second is a postfix method (x++). (Objective 11.2)
8. ![]() D and E are correct. The addScore method modifies the collection and, therefore, should use a write lock, while the getHighScores method only reads the collection and should use a read lock.
D and E are correct. The addScore method modifies the collection and, therefore, should use a write lock, while the getHighScores method only reads the collection and should use a read lock.
![]() A, B, C, and F are incorrect, they will not behave correctly. (Objective 11.2)
A, B, C, and F are incorrect, they will not behave correctly. (Objective 11.2)
9. ![]() D is correct. A lock counts the number of times it has been locked. Calling lock increments the count, and calling unlock decrements the count. If a call to unlock decreases the count below zero, an exception is thrown.
D is correct. A lock counts the number of times it has been locked. Calling lock increments the count, and calling unlock decrements the count. If a call to unlock decreases the count below zero, an exception is thrown.
![]() A, B, and C are incorrect based on the above. (OCP Objective 11.2)
A, B, and C are incorrect based on the above. (OCP Objective 11.2)
10. ![]() B is correct. Executor is the super-interface for ExecutorService. You use Executors to easily obtain ExecutorService instances with predefined threading behavior. If the Executorinterface does not produce ExecutorService instances with the behaviors that you desire, you can always look into using java.util.concurrent.AbstractExecutorService or java.util.concurrent.ThreadPoolExecutor directly.
B is correct. Executor is the super-interface for ExecutorService. You use Executors to easily obtain ExecutorService instances with predefined threading behavior. If the Executorinterface does not produce ExecutorService instances with the behaviors that you desire, you can always look into using java.util.concurrent.AbstractExecutorService or java.util.concurrent.ThreadPoolExecutor directly.
![]() A, C,and D are incorrect based on the above. (OCP Objective 11.3)
A, C,and D are incorrect based on the above. (OCP Objective 11.3)
11. ![]() C is correct. When you submit a Callable to an ExecutorService for execution, you will receive a Future as the result. You can use the Future to check on the status of the Callable’s execution, or just use the get method to block until the result is available.
C is correct. When you submit a Callable to an ExecutorService for execution, you will receive a Future as the result. You can use the Future to check on the status of the Callable’s execution, or just use the get method to block until the result is available.
![]() A, B, and D are incorrect based on the above. (OCP Objective 11.3)
A, B, and D are incorrect based on the above. (OCP Objective 11.3)
12. ![]() B and H are correct. Runnable and Callable serve similar purposes. Runnable has been available in Java since version 1. Callable was introduced in Java 5 and serves as a more flexible alternative to Runnable. A Callable allows a generic return type and permits thrown exceptions, while a Runnable does not.
B and H are correct. Runnable and Callable serve similar purposes. Runnable has been available in Java since version 1. Callable was introduced in Java 5 and serves as a more flexible alternative to Runnable. A Callable allows a generic return type and permits thrown exceptions, while a Runnable does not.
![]() A, C, D, E, F, and G are incorrect statements. (Objective 11.3)
A, C, D, E, F, and G are incorrect statements. (Objective 11.3)
13. ![]() D is correct. The invokeAll method is a var args method that will fork all Fork-Join tasks, except one that will be invoked directly.
D is correct. The invokeAll method is a var args method that will fork all Fork-Join tasks, except one that will be invoked directly.
![]() A, B, and C are incorrect; they would not correctly complete the Fork-Join process. (OCP Objective 11.4)
A, B, and C are incorrect; they would not correctly complete the Fork-Join process. (OCP Objective 11.4)
14. ![]() A and E are correct. When creating multiple ForkJoinTask instances, all tasks except one should be forked first so that they can be picked up by other Fork-Join worker threads. The final task should then be executed within the same thread (typically by calling compute()) before calling join on all the forked tasks to await their results. In many cases, calling the methods in the wrong order will not result in any compiler errors, so care must be taken to call the methods in the correct order.
A and E are correct. When creating multiple ForkJoinTask instances, all tasks except one should be forked first so that they can be picked up by other Fork-Join worker threads. The final task should then be executed within the same thread (typically by calling compute()) before calling join on all the forked tasks to await their results. In many cases, calling the methods in the wrong order will not result in any compiler errors, so care must be taken to call the methods in the correct order.
![]() B, C, D, and F are incorrect based on the above. (OCP Objective 11.4)
B, C, D, and F are incorrect based on the above. (OCP Objective 11.4)
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.