PROFESSIONAL JAVA FOR WEB APPLICATIONS (2014)
Part I Creating Enterprise Applications
Chapter 11 Using Logging to Monitor Your Application
IN THIS CHAPTER
· All about logging
· What are the different logging levels?
· What logging facility is right for you?
· How to integrate logging into your application
· Include logging in the Customer Support application
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
You can find the wrox.com code downloads for this chapter at http://www.wrox.com/go/projavaforwebapps on the Download Code tab. The code for this chapter is divided into the following major examples:
· Logging-Integration Project
· Customer-Support-v9 Project
NEW MAVEN DEPENDENCIES FOR THIS CHAPTER
In addition to the Maven dependencies introduced in previous chapters, you also need the following Maven dependencies:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-jcl</artifactId>
<version>2.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-taglib</artifactId>
<version>2.0</version>
<scope>runtime</scope>
</dependency>
UNDERSTANDING THE CONCEPTS OF LOGGING
Imagine a scenario: You have a report of a bug in your application. Given precise replication steps from customer support, you can duplicate the bug every time. The problem is, as soon as you hit a breakpoint in the debugger, the problem goes away. Vanishes without an explanation. This likely (though not certainly) means the problem is related to multithreading, and hitting a breakpoint slows the execution down enough to mask the problem. So how are you supposed to figure out what the problem is? Application logging is critical to successful debugging, troubleshooting, monitoring, and error reporting in your application. In this chapter you explore the concepts of logging; learn about logging façades, APIs, and implementations; and integrate logging into an application.
Why You Should Log
As a personal choice, we tend not to use debuggers beyond getting a stack trace or the value of a variable or two. One reason is that it is easy to get lost in details of complicated data structures and control flow; we find stepping through a program less productive than thinking harder and adding output statements and self-checking code at critical places. Clicking over statements takes longer than scanning the output of judiciously-placed displays. It takes less time to decide where to put print statements than to single-step to the critical section of code, even assuming we know where that is. More important, debugging statements stay with the program; debugger sessions are transient.
Kernighan, Brian W. and Rob Pike. The Practice of Programming. Reading: Addison Wesley Longman, Inc., 1999. 119.
There are many reasons you should log. The preceding quote highlights some important points about logging — and about the drawbacks of debuggers. It should be noted that much time has passed since that book was published, and debuggers have come a long way. The ease of firing up a debugger in an IDE and stepping through an application’s execution cannot be understated in today’s world. In many ways the Java debugger is the best around, and debugger integration in today’s Java IDEs makes inspection and even modification of static, instance, and stack variables a simple matter. In most Java IDEs, you can evaluate an arbitrary expression at run time when stopped at a breakpoint, and you can change, recompile, and reload code without restarting the Java virtual machine.
But even with all that, debugging is not enough. The hypothetical presented earlier is one of many examples in which a debugger gets in the way. In addition, sometimes a debugger is simply not available. Consider a situation in which a customer issue cannot be replicated in a development environment, or even a quality assurance environment. In most cases, attaching a debugger to your customer’s running production application is simply not an option.
Let’s face it: Bugs are not planned. You write your application to be perfect, but bugs surface anyway. They always will. There are many techniques you can employ and tools you can use to detect and minimize bugs in your code, but you will never avoid them completely. So, it makes sense that you should plan to troubleshoot a bug without a debugger.
Debugging your application is not the only reason you should log, though. Often you need to be notified of important events such as errors, changes in application configuration, unexpected behavior, component startup or shutdown, user logins, data changes, and more. You may also want to simply monitor your application to make sure it is working and undergoing activity of some sort. All of these needs — and more — demonstrate why you should log.
In the earliest days of Java (java.util.logging wasn’t part of the framework until Java 1.4), many developers used System.err.println() and System.out.println() to “log” errors and interesting information. Even today, many applications and even libraries are still filled with statements such as these. These streams can be redirected to separate files, which does have some usefulness, but their lack of granularity and “always on” disposition causes logs to fill up quickly and hinders the performance of the application. Ideally, you want something that is easily customizable, can be configured to display a little or a lot of information, can display different information depending on the package or class, and (most important) does not hinder performance.
What Content You Might Want to See in Logs
Given the ideal logging system described previously — customizable, configurable, variable by package or class, and performs well — think about all the information you would want to put in a log file. You can probably think of a number of things, and really the possibilities are technically endless, but here are some basic ideas to get you started:
· When an application crashes or exits unexpectedly, it is essential to log in as much detail as possible, everything that led up to the crash. This may include messages, stack traces, thread dumps, and even heap dumps. JVM crashes are not easy events to log. Most of the time the very nature of the crash prevents logging facilities from working. Because of this, most JVMs have tools built in to note when these events occur. For example, the Oracle and OpenJDK JVMs have the command line option-XX:+HeapDumpOnOutOfMemoryError that makes Java generate a heap dump when the JVM runs out of memory. Consult your JVM manufacturer’s documentation for more information.
· When errors occur, you should log any information you have about that error (type, message, stack trace, and what the application was doing when the error occurred). Then, with all that important data stored in a log somewhere, you can display to users only a minimal error message telling them that something went wrong without divulging details that could compromise your system (such as file paths or SQL queries).
· Sometimes issues arise that aren’t quite errors and don’t stop an action from continuing but should probably be brought to somebody’s attention at a later time. These issues indicate a potential, but not definite, problem with your application. You should log these types of situations, including a detailed message and what the application was doing. Sometimes, a stack trace is also applicable to these situations. You might consider these “warnings.”
· There are certain important events that you might want to see in your logs. Logging things such as the creation of entities, the starting of components, a successful user login, or the execution of tasks help you know that your system is working properly.
· When you want to track down a problem, you want to see detailed information about the execution of methods and routines, often including the value of applicable variables. However, you probably don’t want to see this data all the time, and creating that much data could hinder performance.
· In the toughest debugging scenarios, you may need to see when any method is entered or exited, as well as the parameter values and return value for each method. In any loops that are executing, you might require data from each iteration. This, of course, is a ton of information in a high-load scenario, so you definitely don’t want it on all the time, and probably not for all methods, even when you do turn it on. In fact, sometimes you may even want to limit this type of logging detail to a specific user or other criteria.
· Often you need to audit activities in your application. If your field is security, healthcare, or legal, the law sometimes mandates keeping a record of who did what and when! At some point, you will likely need a mechanism for keeping track of these things. Make no mistake: This is just another form of logging. There may be unique features to this type of logging, and it may have to be separate from any other logging, but it is still just logging.
This is by no means an exhaustive list. The needs of every developer and project are different, and it’s likely you have already thought of something not on this list. However, these key concepts are common to almost all applications, and you should keep them in mind both when writing your application and when designing your logging system.
How Logs Are Written
An important thing to keep in mind is that a “log” is not necessarily a file in and of itself. Often when you think of logging, you naturally think of a file. After all, at some point your log contents will probably end up in a file somewhere. But this does not mean that your log contents are written directly to a flat file to later be read manually in eye-bleeding sessions. (Although you could certainly do that if you prefer.) Logs can be written any number of ways to any number of media. Sometimes, logs are written to multiple locations simultaneously, or written to a primary media falling over to a backup media if the primary media fails. Sometimes logs are written asynchronously so that your application can continue processing while the logged information is queued waiting to be written. In some circumstances, logging must even be transaction-safe so that the action stops if logging fails. All these things, and your application’s business needs, affect how logs are written.
Generally speaking, there are some common mechanisms that people use for storing application logs. You may want to use one or more of these, or come up with something on your own.
The Console
A time-tested mechanism, console logging is effectively equivalent to using System.out.println(). Although you can gain many advantages using a logging system, the output of the log is the same place: stdout. The thing about console logging is that, unless the process’s standard output redirects using operating system facilities (which often happens), the contents of the console are gone after the application exits or the data falls off the end of the console buffer. However, console logging can be extraordinarily useful during development cycles and when other mechanisms fail. It is nearly always configured as at least a failover logging mechanism for most applications.
Flat Files
Another traditional logging method, flat files are perhaps the easiest media to write logs to and the most difficult media to read logs from. The primary advantage flat files have over console logging is that they are persistent by nature (until you delete them), but that’s about where the advantages end.
Typically, flat-file logging consists of a single line in the file per log entry, but because log messages sometimes take up multiple lines (like stack traces), it can be difficult to apply this pattern programmatically. Standard flat-file logs are decently easy to read with the human eye, but nearly impossible to filter or sift through. There are some variations of flat-file logging that, in some cases, improve on this problem slightly:
· XML logging persists each log event using a standardized XML syntax. The primary advantage of this is that it’s both human readable AND machine readable, meaning programs can be written to read log contents and display them programmatically with filtering capabilities. However, XML is an extremely bloated format and can often triple or quadruple the size of your logs (or worse!).
· JSON logging is similar to XML except that it stores log contents in the JavaScript Object Notation format. This means much less bloat than XML, but on the other hand makes it slightly harder for humans to read.
· On Linux operating systems, syslog is a facility that all processes can write to. The specifics of this are outside the scope of this book, but essentially log events are written to flat files managed by the operating system logging tool and stored in a central location in a standardized format. Windows offers a similar functionality through the Windows Event Log, and that data is stored in XML and comes with a log viewer built in to the operating system.
The concept of rolling files can be applied to all these patterns (and, in the case of syslog and Event Log, is applied automatically). When a logging system is set up to use rolling files, it periodically changes the file it is logging to. Sometimes this rolling is time-based — Tomcat, for example, gets a fresh set of log files every day — whereas other times, when a log file reaches a certain size, log files get backed up to an indexed filename and a new log file starts.
Sockets
A less common method for logging, sockets are nonetheless quite useful in some situations. Log events are translated into some network-communicable form and then sent over the network to some other location. Sometimes the receiving application is on the same machine; sometimes it is on a different machine on the same network; and sometimes it is on a different network (even the other side of the world). In nearly all cases, the other end of the socket connection is a dedicated logging server whose sole purpose is receiving and persisting logs in some way.
SMTP and SMS
Although sending an e-mail for logging events may sound strange, think about how badly you want to know when an error occurs in your application. E-mail and SMS log notifications are rarely sent for typical run-of-the-mill logging events. In every case that this author has seen, e-mail and SMS were reserved for severe application errors only, such as exceptions that caused the abortion of a system action or caused a component to fail to start. This notifies the system administrator that a problem needs to be looked at right away.
Databases
It is very common today for applications to log to a database of some type and for obvious reasons. Databases are efficient, transaction safe means of storage that are extremely easy to query and filter data from. If you are logging audit data, chances are you will have to use a database to store those logs. The disadvantages to logging to a database may also be obvious. The first is speed: Writing data to an indexed table with the overhead of the network stack and a database is much slower (on a small scale) than writing to a flat file. But then there’s the issue of database size: Many databases have limits on how much data they can hold and, even when those limits are lifted, performance suffers drastically. Inserts can take large fractions of seconds or more. For many, this is an unreasonable price to pay for logging that can be easily filtered.
Enter NoSQL databases, which lack many of the problems that relational databases present to logging systems. These databases store data in a nonrelational manner, which removes much of the overhead and enables well-performing storage of many hundreds of gigabytes or even terabytes of data. One of the most popular databases to use for such a task is MongoDB, a NoSQL document database. This database stores data in the Binary JSON (BSON) format, which is an extremely compressed and efficient means of storage.
MongoDB sacrifices read performance — it can be quite slow when filtering large datasets — and exchanges it for write performance. Inserting data into MongoDB can be orders of magnitude faster than popular relational database systems when database size exceeds several gigabytes. This is a huge plus for logging systems, which you want to impact application performance as little as possible. MongoDB, like most other document databases, is not fully ACID-compliant, but if you structure your documents correctly, you can reduce the chances of losing data to about the same as with an ACID RDBMS.
USING LOGGING LEVELS AND CATEGORIES
In the previous section, you explored some of the concepts of logging, including an overview of the various types of information you might want to see in your application logs. As you explored this topic, it probably became clear to you very quickly that there are different types or severity of logging events, and that not all types are logged all the time. This is commonly known as the concept of logging levels. Sometimes, levels are not enough. Often you need the finest logging details from only specific parts of your application, not from the entire thing. If you could just categorize your logging events, your logging data would become even more useful. In this section, you investigate logging levels and categories. You also look at the concept of log sifting and how it relates to and differs from log categorization.
Why Are There Different Logging Levels?
Chances are you have already answered this question. So far in this chapter, you’ve identified a lot of information that should be included in logs; some of it indicative of serious errors, and other types represent extremely fine and numerous debugging detail. If you had all this detail turned on all the time, your logs could grow by megabytes per second. (Trust me, I’ve seen it happen.) Not only would this seriously hinder the performance of the application, but also your logs would become essentially useless. When you have multiple megabytes of log data to sort through for a single second of application execution, you might as well not have any logs.
Levels indicate the severity or relative importance of a logged event. The word “relative” is used here because that’s exactly what it is: One logging level is either more or less important than another logging level. The name of a logging level itself does not define the actual importance of the message it conveys; it just defines the importance of the message as compared to some other message. In some systems, logging levels are merely integers and nothing more. In other systems, logging levels are assigned a name to provide some semblance of semantic usefulness. There is no agreed-upon standard for the number, order, or name of logging levels. Nearly every system you use can define these differently, and it’s up to you to determine what works best for you.
Logging Levels Defined
Although there is not an agreed-upon standard, some common patterns appear in most logging systems written for Java applications. Logging levels are typically named to give them some high-level meaning, and in most systems anywhere from six to ten distinct levels exist. Table 11-1 lists the most common types in order from most severe to most trivial and the equivalent constant as defined in java.util.logging.Level.
TABLE 11.1: Common Logging Levels
|
GENERIC NAME |
LevelCONSTANT |
SEMANTIC MEANING |
|
Fatal Error / Crash |
No equivalent |
Indicates an error of the severest form. Usually these errors result in a crash or at least premature termination of the application. |
|
Error |
SEVERE |
Indicates that a serious problem has occurred |
|
Warning |
WARNING |
Indicates that some event has occurred that may or may not be a problem and probably needs to be looked at |
|
Information |
INFO |
As the name implies, this indicates informational items that could be useful for application monitoring and debugging. |
|
Configuration Details |
CONFIG |
Events with this level typically contain details about configuration information. You often see this at application or component startup. |
|
Debug |
FINE |
Indicates debugging information and often includes the values of variables |
|
Trace Level 1 |
FINER |
These levels represent different levels of application tracing. Many logging frameworks define only a single trace level. One possible way to use these levels separately would be to utilize FINER for logging executed SQL statements and FINEST for logging entry into and exiting from method calls. |
It’s important to note that these examples are based off of one specific logging system: java.util.logging built in to the Java SE APIs. But there are many different logging systems both inside and outside of Java programming, and each defines its own slightly different set of levels. Some systems (such as java.util.logging) enable you to extend and define more levels. Other systems do not.
As an example of a different set of levels, consider the logging levels available in the Apache HTTPD 2.2 server logs: emerg, alert, crit, error, warn, notice, info, and debug. (Version 2.4 adds 8 more levels: trace1 through trace8). The disproportionate number of levels for unusual activity as opposed to debugging highlights a fundamental difference in this system: It was considered more important here to differentiate many different types of errors than many different types of debug information. (Though, that has changed in later versions.) Likewise, your needs may vary based on the use case for your application.
How Logging Categories Work
The concept of a logging category is slightly more abstract than logging level. In nearly all cases in Java (including all of the examples you see in this chapter), logging categories are represented by named logger instances, and each logger can have a different level assigned to it. Through this pattern, two different classes could have two different loggers, and you could set one to log trace data and the other to log warnings only. In fact, that’s exactly how categories are used in most cases: At development time, each class gets its own logger, usually named after the fully qualified class name. Depending on the logging system, a logger hierarchy is usually established so that loggers with undefined level assignments inherit the level from some parent logger.
How Log Sifting Works
Log sifting is conceptually similar to log categorization but serves a slightly different purpose. Using log sifting, different types or originations of events get logged to different locations (different files, different database tables or documents, and so on). In some ways this is the same idea as categories, except that categories typically define a different logging level as opposed to a different logging destination. Many logging frameworks enable you to sift logs by actually using the category, thus knocking out two problems with one feature. Others provide you with the ability to sift using categories and other attributes of a log event (usually determined in a filter of some type). In Java, all major logging frameworks permit sifting based on at least the logging category, if not more attributes of each log event. You explore the topic of sifting more in both of the next two sections.
CHOOSING A LOGGING FRAMEWORK
After you understand the logging needs of your application, your next task is to choose a logging framework. This might not mean using a third-party framework — it might mean creating your own. However, in almost all cases you can find existing, industry-tested logging frameworks that you can configure to meet your needs, which means creating your own is simply an unnecessary task. In this section you examine two important guidelines to keep in mind and then take a look at some existing logging frameworks.
API versus Implementation
Consider this scenario: You’ve written a large, enterprise application with many thousands of classes. Most of these classes (the ones that aren’t POJOs) use logging. After careful research, you chose and integrate an industry-standard logging system into your application. A week after going live, your system’s engineering team informs you that the syslog output you’ve chosen is not adequate, and that it needs database logging. Unfortunately, the logging system you’ve chosen doesn’t support database logging. What can you do? You could extend the logging system, but there’s a perfectly good logging system out there that already supports database logging, and you’d rather use that. However, if you did that you’d need to change thousands of classes to use a different logging system. The effort could take weeks and cost your company tens of thousands of dollars.
The underlying problem in this scenario is that the logging API you are using is tightly coupled with an underlying implementation. You can’t swap out the implementation without changing everywhere in your code where logging is used. You could have avoided this problem if you had simply written a simple logging API to hide the underlying framework from your uses of logging in the code. Then, all you’d have had to do to swap out the framework is change a handful of classes in your API; the rest of your application could continue using your API for logging as it always had. Thankfully, this is not a new concept in the world of logging frameworks, and chances are you won’t even have to write the API yourself.
The standard java.util.logging framework built in to the Java platform is one example of the separation of logging API from implementation. The java.util.logging.LogManager class is responsible for creating and returning Logger instances when requested and delegates to a default implementation. Developers can extend LogManager and specify a system property to provide an alternative implementation of the standard logging API.
The standard implementation has handlers that can write to the files, streams, sockets, console, and even memory. You might wonder, then, why you can’t just use the standard logging facility. The simple answer is, “You can.” In many cases and for many applications, the built-in logging system is completely adequate. However, it has a key drawback that makes it downright difficult if not impossible to use in web applications: It loads its configuration from a system property instead of the classpath. Because of this, two web applications deployed in the same container instance cannot have different logging configurations unless the container has extended the base logging implementation. Tomcat does do this, but not all containers do, so relying on this isn’t portable. Instead, it’s better to find some other solution that combines separate APIs and implementations.
Performance
Obviously, performance is a huge consideration no matter what part of an application you work on, and logging is no different. Think for just a second, however, about the process of writing to files, sockets, or databases, or sending e-mails. These tasks spend considerable time blocking while input/output operations complete, and blocking is a time-intensive situation. There is simply no way around it: Logging messages takes time, and the vast majority of that time is out of your hands and in that of the operating system — meaning you can’t speed it up through software alone.
But, really, if you have a message that you feel is important enough to log, chances are you won’t care that it adds a few milliseconds to an activity. So why does performance matter? The key is it doesn’t matter (much) when you are logging; it matters (drastically) when you are not logging. You are likely to fill up your code with trace, debug, and informational statements that you won’t want to see most of the time. You essentially want these operations to do absolutely nothing unless you have that level of detail enabled.
The following are the critical situations in which performance can make or break a logging framework:
· Calling a debug method when debug logging is disabled shouldn’t add milliseconds to an action — it should add nanoseconds or less.
· With a well-performing logging system, you should fill your code to the brim with logging statements, turn all logging off, and notice no perceivable difference in application response time. This is the key performance indicator that you should look for when choosing a logging system.
Sure, good performance when you turn on logging is admirable and desirable, but it is meaningless if performance is bad when logging is turned off.
A Quick Look at Apache Commons Logging and SLF4J
Apache Commons Logging (http://commons.apache.org/proper/commons-logging/) and Simple Logging Façade for Java (http://www.slf4j.org/) are both Open Source, ultra-thin logging APIs. Neither API contains any implementation code. Instead, developers are expected to pick a logging framework to sit under the API. In a Maven project, the Commons Logging or SLF4J APIs are often given compile scope, whereas the implementation is given runtime scope, thereby completely preventing the application from using the underlying implementation directly.
Though both APIs have several classes, there are only two classes in each API that you will ever use directly. In Commons Logging, the LogFactory class has two static getLog methods that return named Logs. The Log class has methods for logging debug, info, warning, error, and other messages. SLF4J is very similar. The static getLogger methods on its LoggerFactory class return Loggers, which have methods for logging various message levels. The SLF4J API is a bit more flexible because its Logger class supports markers, format-syntax Strings, and arguments for each logging method. You learn more about this later in this section.
Both of these APIs are heavily used in libraries and are the two most popular for this purpose. Application code is not the only code that needs logging. Often libraries that applications use, especially complex libraries such as Spring Framework or Hibernate, need to log messages as well. This logging helps you, the consumer of the library, understand what is happening and track down problems when things go wrong. However, because libraries do not run but instead are coded against, they have no way of knowing (nor do they care) how logging actually takes place.
Enter the Commons Logging and SLF4J APIs. Both logging APIs ship with absolutely no implementation; instead, they come with adapters to multiple logging frameworks. At run time, they discover the logging framework in use (by convention or configuration) and activate the appropriate adapter to translate logging events from the API to the implementation. Commons Logging provides adapters for Avalon, java.util.logging, Log4j 1.2, and LogKit logging. SLF4J provides adapters for (ironically) Commons Logging,java.util.logging, and Log4j 1.2 logging. When the APIs do not provide adapters to support a particular logging framework, often the logging frameworks provide adapters. Logback, for example, is a popular implementation to use with SLF4J and provides the SLF4J adapter binding. In the worst-case scenario, both APIs make writing custom adapters easy.
For years, Log4j was the most popular logging framework to use either standalone or underneath Commons Logging or SLF4J. (It was most commonly used with Commons Logging.) However, Log4j had some drawbacks, and in particular suffered from a very narrow interface (no markers, no message formatting, no message arguments) and performance issues. Dissatisfaction with various APIs and frameworks led to the creation of SLF4J (an improvement on Commons Logging), and later Logback (an improvement on Log4j). Logback boasted an extremely useful interface, a strongly performing implementation, and a battery of tests to demonstrate its stability and performance. It didn’t take long for work to begin on Log4j 2, the successor to Log4j whose goal was to improve the interface and performance of the original Log4j framework.
Introducing Log4j 2
Log4j 2 (http://logging.apache.org/log4j/2.x/), which was released in February 2014, is a vast improvement over Log4j. It includes significant performance improvements, a greatly expanded interface, and plenty of tests to back it all up. In addition, the API and implementation have been completely separated. The API specifies an interface for developers to log to and also provides hooks for creating an underlying implementation.
Of course, there’s also the default implementation, but developers of applications and other logging frameworks are free to use the API hooks to adapt the API to sit on top of other logging implementations. Because there are so many logging frameworks out there and Log4j 2 is still very new, you should still use Commons Logging or SLF4J as your logging API when writing a new library. This is because you have no way of knowing what logging frameworks consumers of your library will use, and there is a better chance those logging frameworks will have adapters for Commons Logging or SLF4J than for Log4j 2. However, when writing an application you call the shots. Writing directly against the Log4j 2 API provides more flexibility and could also help performance somewhat, depending on your use of it, and you won’t lose the ability to swap out the underlying implementation if you ever need to.
NOTE Log4j 2 includes several performance metrics on its website. The most important metric — performance when logging is turned off — is impressive: on midline hardware, 3 nanoseconds for calls to isDebugEnabled, and 4 nanoseconds for calls to debug when debug is turned off. That’s 4 billionths of a second sacrificed to put helpful message logging in your application. To put this in perspective, with all debug logging disabled, your application would have to execute 250,000 debug methods to add 1 millisecond in execution time, or 250,000,000 debug methods per second to double execution time.
All this performance is actually roughly the same as Logback performance. Where Log4j 2 really excels is with log filters. In a multithreaded application, tests show Log4j 2 beats Logback by an order of magnitude or more when filter processing is active.
For the rest of this book, you will log against the Log4j 2 API with the Log4j 2 core implementation underneath it. (In a real-world scenario, you should evaluate the needs of your project and determine which API and implementation work best for you.) You have undoubtedly noticed that this chapter has added five Log4j 2 Maven dependencies. Here is an explanation of each:
· log4j-api provides the API for logging. This is the only Log4j dependency that is in compile scope in your application because it contains the only classes you should code against.
· log4j-core contains the standard Log4j 2 implementation. As you explore Log4j 2 configuration throughout the rest of this chapter, it is the implementation you are configuring, not the API. The API requires no configuration.
· log4j-jcl is an adapter to support the Commons Logging API. Several libraries you use in the rest of this book log against the Commons Logging API, and this adapter causes Commons Logging to use Log4j 2 as its implementation.
· log4j-slf4j-impl is an SLF4J implementation adapter. Several libraries used throughout the rest of this book log against the SLF4J API, and this adapter causes SLF4J to use Log4j 2 as its implementation.
· log4j-taglib is an adapter that includes a JSP Tag Library for logging within your JSPs. Like the previous three dependencies, this dependency is in runtime scope for the purposes of writing your application code because you do not need to compile against it. However, if you were to configure a build to compile your JSPs, you would need this dependency to have compile scope for the JSP compilation process.
The Log4j 2 implementation has several key concepts that you should understand. Although the API exposes some of these concepts in a generic sense (this is noted where applicable), it is the integration with the implementation that makes the features possible.
WHY NOT USE COMMONS LOGGING OR SLF4J?
At this point, you may be thinking back to the scenario presented earlier where you need to quickly swap out your logging implementation. While the Log4j 2 API certainly makes this possible, it does not make it easy. The API is, undoubtedly, written with the implementation in mind. So why don’t you use Commons Logging or SLF4J in front of Log4j 2?
Neither the Commons Logging API nor the SLF4J API is as complete and feature-rich as the Log4j 2 API. Choosing Commons Logging or SLF4J means giving up some features, such as fatal logging, any-level logging, custom level logging, easy method entry and exit logging, and message formatting with arguments. Using a logging façade is a much more important thing to do in an independent library than in an application. If you are willing to sacrifice some Log4j 2 features, you can certainly choose SLF4J or Commons Logging over the Log4j 2 API. On the other hand, if you want to utilize all Log4j 2 features and also use a logging façade, you could create your own façade to match the Log4j 2 API. That choice is left up to you. For this book, you will use the Log4j 2 API directly.
Configuration
The Log4j 2 implementation is completely self-configuring. At the most, the only thing you must do to use Log4j 2 is place logging statements in your code. By default, Log4j 2 can configure itself to log errors and higher and to write log messages to the console. It does this only if all the following steps have failed to locate an explicit configuration:
1. Inspect the log4j.configurationFile system property, and load the configuration from that file if it exists.
2. Look for a file named either log4j2-test.json or log4j2-test.jsn on the classpath, and load the configuration from that file if it exists.
3. Look for a file named log4j2-test.xml on the classpath and load the configuration from that file if it exists.
4. Look for a file named either log4j2.json or log4j2.jsn on the classpath, and load the configuration from that file if it exists.
5. Look for a file named log4j2.xml on the classpath, and load the configuration from that file if it exists.
The purpose of the separate -test files having higher priority is simple: This covers the cases in which unit (or other) tests are executing, and both files are on the classpath. In the next section you explore Log4j 2 configuration by integrating it into a web application.
Levels
In the org.apache.logging.log4j.Level class, Log4j 2 defines six logging levels and two special-meaning levels, listed in order of their priority (most severe to least severe): OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE, ALL. Note that OFF and ALL are not levels you would actually log against; instead, you would assign these levels to a particular org.apache.logging.log4j.Logger or org.apache.logging.log4j.core.Appender, OFF meaning “do not log anything” and ALL meaning “log everything.” Level is, by necessity, exposed through the API, but how it is used to control the logging of messages is configured through the implementation.
Originally, Level was an enum, meaning it could not be extended. Shortly before Log4j 2 was released, Level was changed from an enum to a final class with a private constructor and a factory method forName (String name, int intLevel). This method returns the existing Level if it exists and creates a new Level if it does not. The enum org.apache.logging.log4j.spi.StandardLevel helps map custom Levels you create to standard levels when logging to bridge APIs like SLF4J. There is always exactly one instance of a Level of any given name. This means you can easily create your own custom Levels using the following technique and you can compare a value to a Level using the == operator instead of equals.
public final class CustomLevels
{
public static final Level CONFIG = Level.forName("CONFIG", 350);
public static final Level NOTICE = Level.forName("NOTICE", 450);
public static final Level DIAG = Level.forName("DIAG", 550);
}
Loggers
Loggers and categories are synonymous in Log4j 2, and you must deal with the Logger class in every class you log in. You obtain a Logger by calling one of the getLogger methods of org.apache.logging.log4j.LogManager. When you have a Logger instance you can log errors, warnings, and other messages. Loggers have names in Log4j 2, just like they do in most APIs and implementations. The Logger name defines the logging category, and by convention that name is the fully qualified class name of the class using the Logger (each class has its own Logger instance).
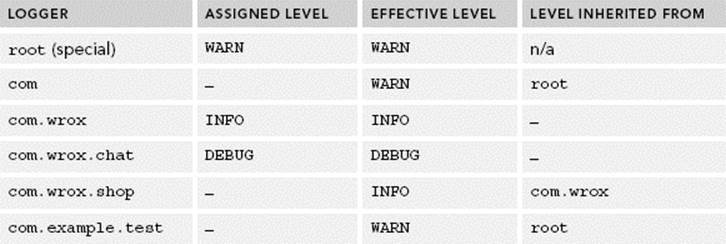
Multiple calls to getLogger with the same name or class result in the exact same instance of Logger, not in multiple instances with the same name (in other words, Loggers are cached). Any two Loggers can have different Level settings and be assigned to zero or moreAppenders. Logger names in Log4j 2 follow a dot-separated hierarchy, with more specific Loggers inheriting the Level and Appenders of ancestor Loggers. This is demonstrated in Table 11-2. This table deals only with Levels, but the inheritance rules are essentially the same for Appenders. The Assigned Level column represents Levels that you might assign in your Log4j configuration.
TABLE 11.2: Inheritance Hierarchy for Log4j 2 Loggers
Appenders
Appenders are responsible for actually writing log contents to their destination. Appenders have essentially the same inheritance rules as Levels when assigned to Loggers, with the exception that the inheritance also has an additivity property that determines whether anAppender adds to or overrides other inherited Appenders.
For example, if the root logger is assigned to a console Appender and com.wrox is assigned to a file Appender, log messages written to com.wrox, com.wrox.chat, and others go to both the console and the file, whereas log messages written to root or com.example.test go only to the console. However, if you set the additivity property to false for com.wrox, messages written to com.wrox, com.wrox.chat, and others go only to the file. (They stop at that Appender.) If com.wrox’s additivity property is still false and com.wrox.shop has a syslog Appenderwith additivity set to true (default), messages written to com.wrox.shop go to syslog and the file, but not to the console.
Layouts
Appenders often use Layouts to determine how to format their output. The most common type of Layout is a pattern-based Layout that defines a series of tokens replaced at write-time with data from a logging message. There are also HTML, XML, syslog, and serialized layouts, to name a few examples. You explore the PatternLayout more in the next section.
Filters
Log4j 2 Filters, not to be confused with Servlet filters, provide a mechanism whereby log messages can be examined to determine if or how they should be written. The result of a Filter evaluation is either ACCEPT, DENY, or NEUTRAL, just like with network firewalls.ACCEPT indicates that the message should be written and all other Filters should be ignored. If a Filter evaluation results in ACCEPT, even the message Level is ignored, and the message is logged even if its Level is not high enough. DENY is the opposite: This means that the message is immediately rejected, and the following filters do not get the opportunity to evaluate the message. NEUTRAL indicates that the Filter neither accepts nor denies the message, and other Filters may evaluate it further.
In a Log4j 2 configuration, Filters can be attached to four different stages of the architecture: the context configuration, the Logger configuration, the Appender reference, or the Appender configuration. When a message is logged, its first stop is any context-wide Filters in the order they were declared. This happens before the Level is evaluated. Assuming the context Filters say NEUTRAL, the message then goes to have its Level evaluated. If it passes the Level test, its next stop is the Logger configuration Filters. After this come theAppender reference Filters, which determine whether the Logger should route the message to a particular Appender. (This can be used to sift messages into different files or database tables, for example.) Finally, Filters on individual Appenders determine whether theAppender should write the message.
Filters can act on all sorts of information. A common pattern is to include Marker objects with logging messages and have Filters examine those Marker objects. (This is especially useful for sifting.) Filters can also look at the contents of a message, the message type, exceptions attached to a message, and data stored in the currently running Thread, just to name a few things. For that matter, Filters can use something as unrelated to the current message as the system time to determine how to act on a message. You’ll see an example for configuring a Filter in the next section.
INTEGRATING LOGGING INTO YOUR APPLICATION
Using and configuring Log4j is a fairly simple task. As described in the last section, you can get away with as little as simply putting logging statements in your application:
private static final Logger log = LogManager.getLogger();
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
if(request.getParameter("action") == null)
log.error("No action specified.");
}
Log4j 2 can configure itself with the default configuration and start writing logging messages to the console. Of course, this default configuration is likely not sufficient for you. Chances are you’re going to need more than just errors logged (you’ll probably want warnings and possibly informational messages), and you’ll likely want the logs to go somewhere other than the console. You can easily achieve both with a configuration file.
NOTE If you are used to configuring previous versions of Log4j, you should keep two important things in mind. First, Log4j 2 does not support configuration through Java properties files anymore. You must use either XML or JSON. Second, Log4j 2’s XML schema is not the same as Log4j’s XML schema. If you have existing log4j.xml files in any of your applications, you cannot simply rename those files to log4j2.xml. You must adopt the new configuration schema.
Creating the Log4j 2 Configuration Files
Remember that Log4j 2 looks for two different configuration files (log4j2 and log4j2-test), and that it supports three different extensions for those files (.xml, .json, and .jsn). The .json and .jsn extensions are both for JSON-format configurations. JSON configurations are much more easily read and written with code than XML configurations, so if you want to programmatically create Log4j 2 configurations, JSON is probably the way to go. If you’re creating your configuration by hand, XML is an easier choice, so that’s what you use here. You can follow along in the Logging-Integration project available for download on the wrox.com code download site.
The project is simple, containing a single servlet with some methods that execute correctly and others that do not. The first thing you must do is create the appropriate configuration files. When you create the standard configuration file, this also affects how logging behaves when unit tests run. Because the standard configuration file instructs Log4j 2 to log to a file and you probably don’t want that when running unit tests, you should first create a log4j2-test.xml file in the resources directory of your project’s test folder:
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="WARN">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout
pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</appenders>
<loggers>
<root level="debug">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
NOTE There is no official XML schema for the Log4j configuration files. The XML that you can use is flexible and also varies depending on which extensions and plugins are on the classpath, thus the configuration file cannot be strictly validated against a schema. You can learn more about which XML elements and attributes are valid in the Log4j Configuration Documentation.
This configuration file is nearly identical to the implicit default configuration. The only differences here are that the configuration status Logger Level changed from OFF to WARN and the root Logger Level changed from ERROR to DEBUG, both of which are more appropriate for testing situations.
You are already familiar with the root Logger (the ancestor of all Loggers in Log4j 2), but you may wonder what the configuration status Logger is. Log4j, too, needs to log messages when things aren’t quite working right. It does this through a special Logger called theStatusLogger. This Logger’s sole purpose is to log events occurring within the logging system itself. As an example, say you create a socket Appender that cannot connect to its destination server. In this case it would log this failure using the StatusLogger. The default setting for the StatusLogger, OFF, suppresses all these messages from the logging system. Here, that Level has been changed to WARN (by changing the <configuration> element’s status attribute).
Now that you have an adequate test configuration, create a log4j2.xml file in the resources directory of your project’s production source folder:
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="WARN">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout
pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
<RollingFile name="WroxFileAppender" fileName="../logs/application.log"
filePattern="../logs/application-%d{MM-dd-yyyy}-%i.log">
<PatternLayout>
<pattern>%d{HH:mm:ss.SSS} [%t] %X{id} %X{username} %-5level
%c{36} %l: %msg%n</pattern>
</PatternLayout>
<Policies>
<SizeBasedTriggeringPolicy size="10 MB" />
</Policies>
<DefaultRolloverStrategy min="1" max="4" />
</RollingFile>
</appenders>
<loggers>
<root level="warn">
<appender-ref ref="Console" />
</root>
<logger name="com.wrox" level="info" additivity="false">
<appender-ref ref="WroxFileAppender" />
<appender-ref ref="Console">
<MarkerFilter marker="WROX_CONSOLE" onMatch="NEUTRAL"
onMismatch="DENY" />
</appender-ref>
</logger>
<logger name="org.apache" level="info">
<appender-ref ref="WroxFileAppender" />
</logger>
</loggers>
</configuration>
There’s some new and interesting stuff here. First, the rolling file Appender is configured to write to application.log in the Tomcat logs directory. (This assumes that your IDE starts Tomcat from the bin directory, which is typical; in a real-world scenario, you want to make these paths configurable.) Although Log4j 2 has a simpler file Appender that writes to a file, this Appender can roll the log in one or more scenarios, such as the log reaching a certain size, the date changing, the application starting, or any combination of those three. In this case, the Appender is configured to roll the log file every time it reaches 10 megabytes and to keep no more than four backed up logs.
NOTE If, when running the application, you can’t find the application.log file in Tomcat’s logs directory, try changing the relative path to an absolute path of a directory on your system and then restart the application.
The PatternLayout has many patterns that can log event information, and you can learn about them all (and other layouts) in the Log4j Layout Documentation. In this case, the file Appender pattern has substituted %c for %logger (the former is shorthand for the latter) and added %l, which prints the class, method, file, and line number where the logging message occurred. It has also added %X{id} (a fish tag) and %X{username}, which are properties on the ThreadContext — you learn about these next. You’ll also notice that the pattern for the file Appender, in addition to actually being a different pattern, is configured using a different XML format than the console Appender. You can specify properties of Appenders, Filters, Loggers, and so on as tag attributes or as nested tags. The two approaches are interchangeable.
Finally, the new Logger configurations in this file say that all Loggers in the com.wrox and org.apache hierarchies have the level of INFO and that the Loggers in com.wrox are not additive — they do not inherit the console Appender and only log to the file Appender. However, notice the com.wrox <appender-ref> element for the console Appender has a nested <MarkerFilter> element with it. This filter says that Loggers in the com.wrox hierarchy can log to the console Appender, but only for events containing a Marker named WROX_CONSOLE. You can learn about the various Filters available in the Log4j Filter Documentation. The following incomplete configuration shows all of the valid locations for Filter configuration elements (shown in bold):
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
...
<FilterName ... /><!-- This is a context-wide filter -->
<appenders>
<AppenderName name="someAppender">
<FilterName ... /><!-- This is an appender filter -->
...
</AppenderName>
...
</appenders>
<loggers>
<logger name="someLogger" level="info">
<FilterName ... /><!-- This is a logger filter -->
...
<appender-ref ref="someAppender">
<FilterName ... /><!-- This is an appender reference filter -->
...
</appender-ref>
...
</logger>
...
</loggers>
</configuration>
This book cannot show you all the possible ways to configure Log4j, as there are many. If you want more information, a good place to start is the Log4j Manual.
Utilizing Fish Tagging with a Web Filter
When using any logging framework, you should fish tag requests so that you can group together logging messages belonging to the same request and analyze them. The org.apache.logging.log4j.ThreadContext stores properties in the current thread until theThreadContext is cleared. Any events logged in the same thread between when a property is added to the ThreadContext and when it is removed can be associated with that property. If there are many concurrent web requests executing, unique fish tags for each request enable you to identify all the messages logged during that particular request.
A fish tag is typically something strongly unique, such as a UUID. The ThreadContext can store anything else useful for distinguishing logging events, such as the username of the user who is logged in. The following LoggingFilter adds the fish tag (id) and session username (username) to the ThreadContext at the beginning of the request and clears the ThreadContext as the request completes. The pattern discussed previously then prints these properties with %X{id} and %X{username}. Because the filter supports multiple dispatcher types and may execute multiple times in a single request, it only sets the fish tag and username properties if they have not already been set, and it only clears the ThreadContext for the same invocation that set the fish tag and username properties:
@WebFilter(urlPatterns = "/*", dispatcherTypes = {
DispatcherType.REQUEST, DispatcherType.ERROR, DispatcherType.FORWARD,
DispatcherType.INCLUDE, DispatcherType.ASYNC
})
public class LoggingFilter implements Filter
{
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
boolean clear = false;
if(!ThreadContext.containsKey("id")) {
clear = true;
ThreadContext.put("id", UUID.randomUUID().toString());
HttpSession session = ((HttpServletRequest)request).getSession(false);
if(session != null)
ThreadContext.put("username",
(String)session.getAttribute("username"));
}
try {
chain.doFilter(request, response);
} finally {
if(clear)
ThreadContext.clear();
}
}
...
}
WARNING Recall the lessons you learned in Chapter 9 about asynchronous request handling. If you set values on the ThreadContext at the beginning of an asynchronous request, those values will be cleared before the request completes. For this reason, you must be very careful whenever you use the ThreadContext with asynchronous requests. The Web Applications and JSPs section of the Log4j 2 manual online includes helpful information about using all aspects of Log4j with asynchronous contexts.
Writing Logging Statements in Java Code
Using Log4j 2 Logger instances is extremely straightforward. Overloaded methods exist for each of the logging Levels, and these enable you to specify Strings, Objects, or Messages as messages, provide one or more parameters to substitute in a String message, provideThrowables whose stack traces should be logged, and provide Markers to flag an event. Take a look at Listing 11-1, which uses a Logger to log activity in the ActionServlet. A singleton Logger is created for all instances of the Servlet. Then methods like info, warn, and errorwrite log messages. The special methods entry and exit log at the TRACE level and are shorthand for tracing program execution through method calls and returns. Many more methods are available on this Logger interface, and you should read its API documentation to learn more.
NOTE LogManager’s no-argument getLogger method returns a Logger whose name is equal to the fully-qualified class name of the class calling getLogger. In the case of Listing 11-1, that name is com.wrox.ActionServlet. You could also use the getLoggermethod that accepts a Class argument, which would return a Logger named after that Class. If you want to use something other than class names as Logger names, you could use the getLogger method that accepts a String argument — the name of theLogger.
LISTING 11-1: ActionServlet.java
@WebServlet(name = "actionServlet", urlPatterns = "/files")
public class ActionServlet extends HttpServlet
{
private static final Logger log = LogManager.getLogger();
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String action = request.getParameter("action");
if(action != null) {
log.info("Received request with action {}.", action);
String contents = null;
switch(action) {
case "readFoo":
contents = this.readFile("../foo.bar", true);
break;
case "readLicense":
contents = this.readFile("../LICENSE", false);
break;
default:
contents = "Bad action " + action + " specified.";
log.warn("Action {} not supported.", action);
}
if(contents != null)
response.getWriter().write(contents);
} else {
log.error("No action specified.");
response.getWriter().write("No action specified.");
}
}
protected String readFile(String fileName, boolean deleteWhenDone) {
log.entry(fileName, deleteWhenDone);
try {
byte[] data = Files.readAllBytes(new File(fileName).toPath());
log.info("Successfully read file {}.", fileName);
return log.exit(new String(data));
} catch(IOException e) {
log.error(MarkerManager.getMarker("WROX_CONSOLE"),
"Failed to read file {}.", fileName, e);
return null;
}
}
}
Now compile and start up the application and go to http://localhost:8080/logging-integration/files in your browser. The application.log file should appear in the Tomcat logs directory and have an error in it. Adding ?action=badAction to the URL and reloading the log file reveals a new informational message and warning in the file. Changing the action to readLicense reads the Tomcat license file back to the browser. Only informational messages appear in the log this time. Finally, change the action to readFoo and an error, complete with exception stack trace, appears in the log file. This time the error also appeared in the console (debugger) output because it included the Marker named WROX_CONSOLE. Notice the fish tag for each message logged and how it is the same for multiple messages logged in the same request. You should experiment with the Log4j configuration file and change the level and additivity attributes to see how the data logged changes.
NOTE The relative file name used to access the Tomcat license file only works if your IDE starts Tomcat from Tomcat’s bin directory, which is typical. If your IDE starts Tomcat from some other directory, you may need to change the path to this file to get it to work.
Using the Log Tag Library in JSPs
As mentioned earlier, Log4j 2 comes with a tag library that enables you to log messages in JSPs without using scripting. This book won’t go into a lot of detail on this subject because, generally speaking, there is much less need for logging in the presentation layer. In fact, as long as your JSPs don’t have any business logic in them, you’ll never need to log in them. With that said, you can include the tag library with the following taglib directive:
<%@ taglib prefix="log" uri="http://logging.apache.org/log4j/tld/log" %>
The Logging-Integration project has a logging.jsp file in the web root that demonstrates how to use these logging tags:
<log:entry />
<!DOCTYPE html>
<html>
<head>
<title>Test Logging</title>
</head>
<body>
<log:info message="JSP body displaying." />
Messages have been logged.
<log:info>JSP body complete.</log:info>
</body>
</html>
<log:exit />
Each JSP in your application that uses one or more log tags automatically has a unique Logger created for it. You can override this Logger using the <log:setLogger> tag or the logger attribute on most of the other tags. Try out the JSP logging by starting the application and going to http://localhost:8080/logging-integration/logging.jsp in your browser. Depending on the logging level you have configured, you see different messages appear in the log.
Logging in the Customer Support Application
The Customer-Support-v9 project on the wrox.com code download site has had all uses of System.out, System.err, and Throwable.printStackTrace() removed from its code and replaced with Log4j 2 logging. In addition, more logging statements were added throughout the application. Finally, the LoggingFilter was copied from the previous example and added to the beginning of the filter chain in the Configurator so that all requests are fish tagged.
You should download and review these changes, but they are not detailed here because it’s redundant to what you’ve already learned. The default logging level for all Loggers in the com.wrox hierarchy is set to INFO and the only INFO event so far is when a user logs in. Most other logging events are DEBUG, TRACE, WARN, or ERROR. Because of this, you won’t see much in the support.log file when you run the Customer Support application. Rest assured, this will change in Part II when you start using Spring Framework.
SUMMARY
In this chapter you learned the fundamentals of application logging and why logging in your applications is so important. You investigated several common logging patterns and explored the concepts of categories and logging levels. You also learned about the importance of separating a logging API from its underlying implementation, saving you headaches down the road. You were introduced to several popular logging APIs and implementations, such as Apache Commons Logging, SLF4J, Logback, Log4j 1.x, and Log4j 2. Finally, you learned details for using and configuring Log4j 2 and experimented with integrating it into a web application. Throughout the rest of the book, logging is quietly present in every chapter. Each project you work on contains a Log4j 2 configuration and logging statements. This way, you can get into the habit of consistently logging whenever you program.
This wraps up Part I, where you learned about various aspects of web application development using Java SE, Java EE, Servlets, JSPs, filters, WebSockets, application servers, web containers, and more. By now, you should have a firm grasp on the basics, and you should be able to write fairly complex applications. In Part II you start growing your enterprise development skillset as you learn about Spring Framework and how it supplements, enhances, and — in some cases — supplants parts of the Java Platform, Enterprise Edition.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.